
Abstract
Collecting representative data on sensitive issues has long been problematic and challenging in public health prevalence investigation (e.g. non-suicidal self-injury), medical research (e.g. drug habits), social issue studies (e.g. history of child abuse), and their interdisciplinary studies (e.g. premarital sexual intercourse). Alternative data collection techniques that can be adopted to study sensitive questions validly become more important and necessary. As an alternative to the famous Warner randomized response model, non-randomized response triangular model has recently been developed to encourage participants to provide truthful responses in surveys involving sensitive questions. Unfortunately, both randomized and non-randomized response models could underestimate the proportion of subjects with the sensitive characteristic as some respondents do not believe that these techniques can protect their anonymity. As a result, some authors hypothesized that lack of trust and noncompliance should be highest among those who have the most to lose and the least to use for the anonymity provided by using these techniques. Some researchers noticed the existence of noncompliance and proposed new models to measure noncompliance in order to get reliable information. However, all proposed methods were based on randomized response models which require randomizing devices, restrict the survey to only face-to-face interview and are lack of reproductivity. Taking the noncompliance into consideration, we introduce new non-randomized response techniques in which no covariate is required. Asymptotic properties of the proposed estimates for sensitive characteristic as well as noncompliance probabilities are developed. Our proposed techniques are empirically shown to yield accurate estimates for both sensitive and noncompliance probabilities. A real example about premarital sex among university students is used to demonstrate our methodologies.
1 Introduction
The growing high demand of health and medical interest in sensitive attribute (e.g. drug and alcohol use/abuse, embezzlement, high-risk sexual practices, religious preferences, sexual tendencies, racial attitudes) makes data collection and analysis of sensitive question important and necessary since efficient strategies can be well developed to satisfy the need of our society. Gaining valid answers to sensitive questions, however, has long been an age-old problem in survey research as false replies might be caused by self-protection, or refusal of participation might be caused by embarrassing nature of the questions. Most seriously, both response and non-response biases limit the ability to draw valid inference about the target population.
Various techniques have been developed to maximize cooperation, minimize the respondent’s feeling of jeopardy, and guarantee anonymity. Three major techniques for these purposes include the randomized response technique (RRT), 1 unmatched count technique (UCT), 2 and non-randomized response technique (NRRT). 3 The crux of the original Warner RRT and all its variations4–6 is that the real status of respondent’s answer is hidden by a deliberate contamination of the data via a randomizing device. However, as pointed out by Böckenholt and Van der Heijden, 7 RRTs are not often applied since: (i) their efficiency is low; (ii) they may not be easily followed by every respondent despite their privacy protection mechanisms; and (iii) aggregate-level estimate is not linked to individual-level covariates. To address the efficiency and aggregation issues, a class of so-called item randomized-response (IRR) models (in which a person parameter is estimated based on multiple measures of the sensitive behavior under study) was introduced. Nonetheless, drawbacks such as higher cost and lack of reproductivity induced by the introduction of the randomizing device still exist. Unlike RRTs, UCTs and NRRTs protect respondents’ privacy by a deliberate contamination of the data via one or more innocuous/non-sensitive items/questions. A fatal drawback of UCT and its refinement that their advocators usually overlook is that the privacy is no longer protected if respondents in the so-called sensitive question group wish to answer all sensitive and non-sensitive questions affirmatively. If this issue occurs to many respondents, then the validity of the survey measurement may be compromised. Increasing the number of non-sensitive items may be a possible solution; however, the resultant estimator will be statistically inefficient.
The NRRT is first introduced by Tian et al. 3 and Yu et al. 8 Basically, there are two NRRTs, namely the triangular and crosswise models. In particular, the NRRT based on triangular model outperforms the other techniques as it (i) extends the applicability of RRT which is always restricted by its usage of randomizing device; (ii) is shown to be generally more efficient than its crosswise model which is in fact the non-randomized version of the well-known Warner’s RR model; (iii) never reveals the true status of those participants who possess the sensitive characteristic, which UCT may not guarantee; and (iv) belongs to the class of the admissible design defined by Nayak. 9 The NRRTs have received increased attention recently.10,11 Due to the aforementioned advantages, we will focus our discussion solely on the non-randomized response triangular model (NRRTM) in this article.
Most of the existing models for sensitive attributes assume that respondents will provide true answers and comply with the survey design. However, it has been reported in various experimental studies that some respondents still chose those answers which could demonstrate their positive image even being told that answers could not leak their privacy.12,13 This kind of noncompliance could, however, lead to severe response bias. For instance, Edgell et al. 12 reported that about 25% of the respondents did not follow the instructions when answering a question on homosexual experience and the parameter of interest was underestimated due to noncompliance. In another study (see Section 5 for detail) of premarital sex among college students in Changchun of Jilin Province, China, the NRRTM reported that around 19% of the respondents have ever had premarital sexual intercourse, which is fairly consistent with the result reported in a recent cross-sectional study using anonymous self-questionnaire among Beijing college students. 14 On the other hand, China Health and Family Life Survey (CHFLS), a national probability survey of sexual behavior conducted between 1999 and 2000, reported that almost 36% of never-married adults aged 20–34 have ever had sex. 15 The striking difference between the two proportions could be partly attributed to different (i) target populations (i.e. college students vs. never-married adults aged 20–34); (ii) scales (i.e. regional vs. national); (iii) periods (i.e. 2012 vs. 2000) and (iv) survey techniques (i.e. NRRT vs. interview). Here, we hypothesize that the true proportion of college students having premarital sex is substantially underestimated by noncompliance. Indeed, after incorporating noncompliance into our NRRTM, the proportion is estimated to be 32%. Obviously, one must take the noncompliance into consideration to draw reliable conclusion.
Recently, some researchers have taken the noncompliance in surveys into account in order to draw accurate and reasonable statistical inference. For instance, by introducing mixture components in their proposed IRR models, Böckenholt and Van der Heijden 7 developed mixture versions of the IRR models that allow for respondents who do not follow the randomized response instructions. Cruyff et al. 16 developed a log-linear model which includes a so-called self protection (SP) parameter that accounts for self-protective response behavior for randomized response data (e.g. Böckenholt and Van der Heijden, 7 Böckenholt et al., 17 and Cruyff et al. 16 ). These models focus on the multiple sensitive questions and relate the estimates with the individual covariates. However, randomizing devices are still required in these models and they cause the non-reproductivity issue (i.e. the same respondent may provide different answers for different trials as the answers partly depend on the outcomes of the randomizing device). Besides, the usage of randomizing device also increases the cost and restricts the survey to face-to-face interview. As a result, simple models for measuring the noncompliance are very necessary and important in practice. Two new NRRTMs with their point estimates and confidence intervals are proposed under noncompliance in Section 2. Their sample size formulae are also developed in Section 3. In Section 4, a simulation study is conducted to evaluate the performance of the two models. The aforementioned premarital sex study is adopted to demonstrate our methods in Section 5. A brief conclusion is presented in Section 6.
2 NRRTMs with noncompliance
2.1 The original NRRTM
Traditional NRRT design for sensitive question.

2.2 The dual non-randomized response triangular model (DNRRTM)
The corresponding cell probabilities in the first group under DNRRTM (and ANRRTM).

DNRRTM, dual non-randomized response triangular model; ANRRTM, alternating non-randomized response triangular model.
The corresponding cell probabilities in the second group under DNRRTM.

DNRRTM, dual non-randomized response triangular model.
Similar to the NRRTM, π =
Suppose there are r1 (r2) among n1 (n2) respondents who put a circle on the triangle formed by the three solid dots in the first (second) group. The likelihood function based on the data becomes
Let E( Theorem 1 suggests that To our best knowledge, existing papers only proposed Wald-type confidence intervals which in practice yield lower bound less than zero or upper bound greater than one if the true value of π is close to zero or one. Furthermore, the Wald-type confidence interval constructions are based on normal approximation, which is questionable when the sample size is small to moderate. The bootstrap approach here can be used to obtain reliable confidence interval for π while the resultant confidence interval is guaranteed to lie within the interval [0, 1]. Using 
Theorem 1
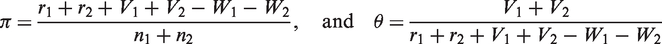
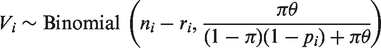
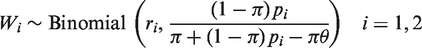
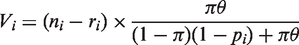
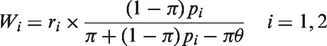
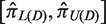
2.3 The alternating non-randomized response triangular model
The corresponding cell probabilities in the second group under ANRRTM.

ANRRTM, alternating non-randomized response triangular model.
Suppose there are r1 (r2) among n1 (n2) respondents who put a circle in the triangle in the first (second) group. The likelihood based on the observed data is given by
Let E( Similarly, when π or θ are not in the interval [0, 1] we employ the EM algorithm to obtain reliable estimates. Let the number of respondents who are supposed to tick triangle but eventually tick circle be Vi in the The M-step finds the maximum likelihood estimates of π and θ based on the complete data, i.e.
Alternatively, we apply the bootstrap approach for confidence interval construction to guarantee the CI to fall into the interval [0,1]. Using the obtained 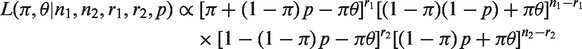
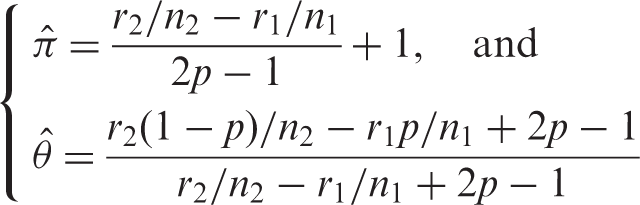
Theorem 2
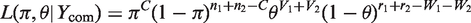
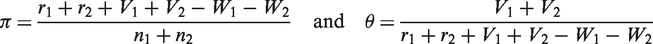
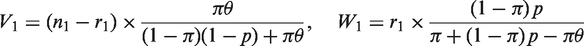
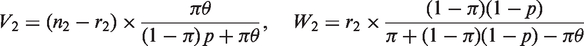
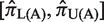
3 Sample size determination
Sample size determination has become an important topic in surveys with sensitive questions. Accurate sample size formula is necessary since validity of statistical inferences from research studies heavily relies on this. Besides, sample size is important for both economic and ethical reasons. To test whether the population proportion is identical to a pre-specified value 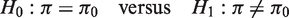
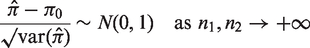
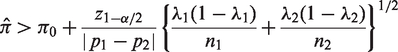
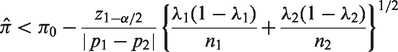
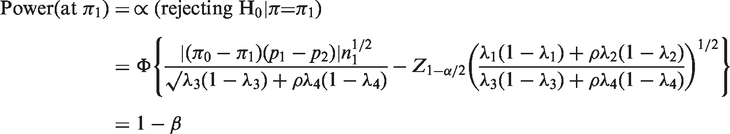
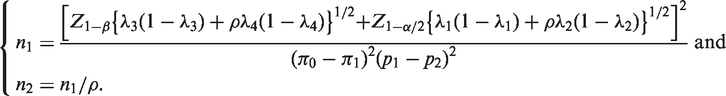
Similarly, the sample sizes based on ANRRTM can be obtained by
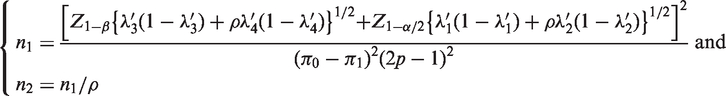
4 Simulation studies
In Section 2, we propose two NRRTs (i.e. DNRRTM and ANRRTM) which take the noncompliance into consideration. To investigate their performance, we consider biases of their estimates, the confidence widths and coverage probabilities.
Estimates and confidence intervals using NRRT and DNRRTM for

NRRT, non-randomized response technique; DNRRTM, dual non-randomized response triangular model.
Estimates and confidence intervals using NRRT and DNRRTM for
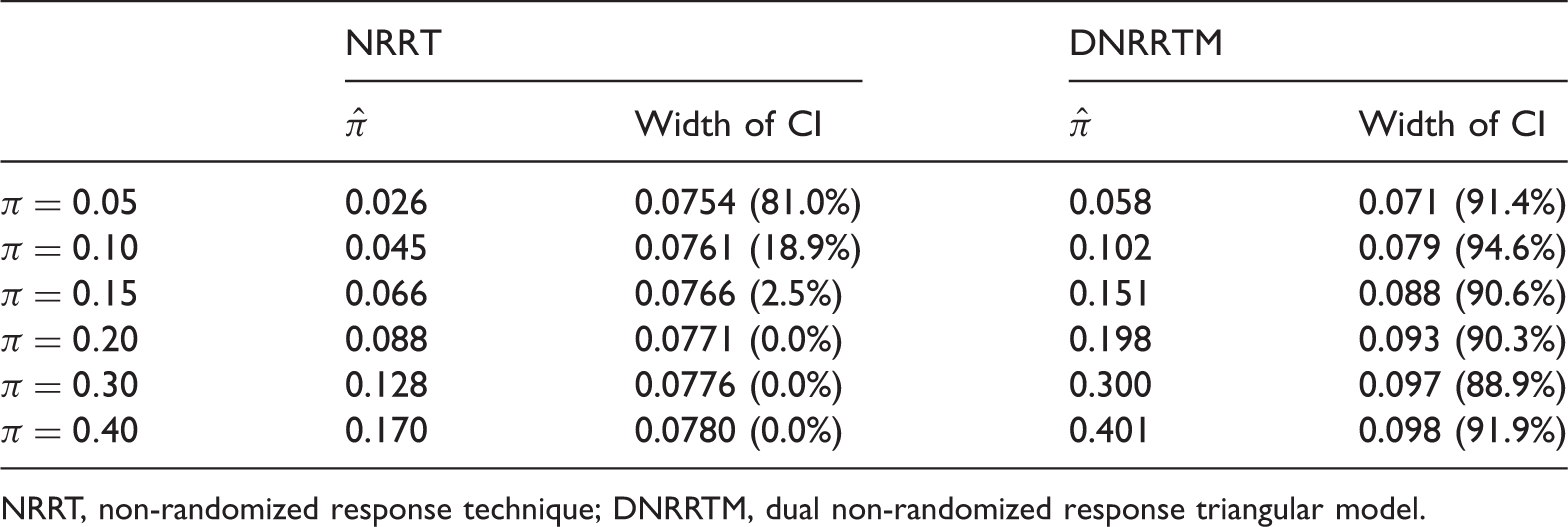
NRRT, non-randomized response technique; DNRRTM, dual non-randomized response triangular model.
Estimates and confidence intervals using NRRT and ANRRTM for
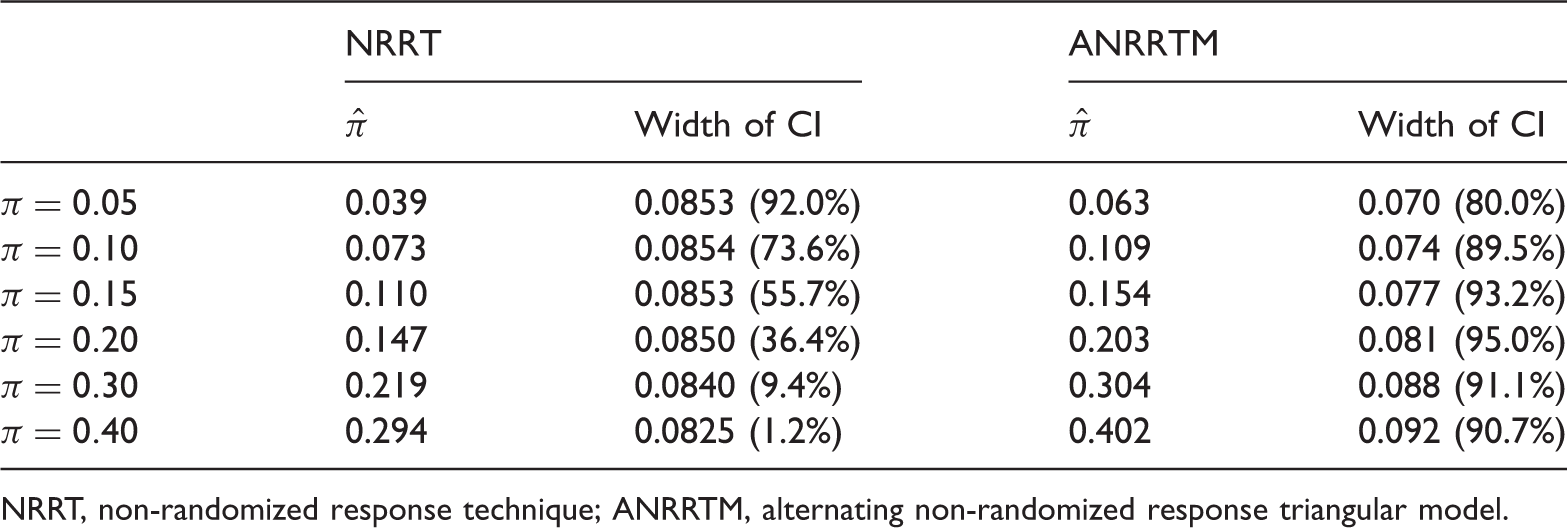
NRRT, non-randomized response technique; ANRRTM, alternating non-randomized response triangular model.
Estimates and confidence intervals using NRRT and ANRRTM for
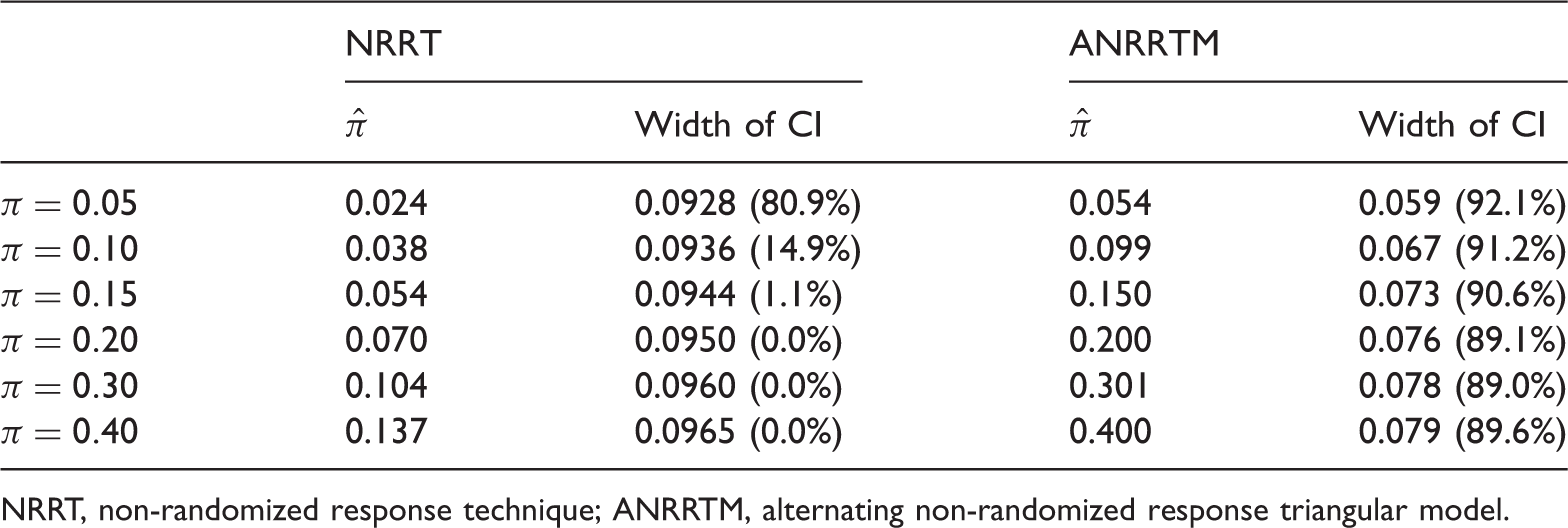
NRRT, non-randomized response technique; ANRRTM, alternating non-randomized response triangular model.
According to Tables 5 and 7, NRRT yields severely biased estimates and extremely low coverage probabilities even for small proportion of noncompliance (i.e.
5 Real example: pre-marital sex experience
The risk of transmission of HIV and other sexually transmitted diseases is higher in sexual relationships with multiple partners and without the use of condoms. Premarital sex often involves multiple partners, and extramarital sex, by definition, implies multi-partner relationships. Avoidance of multi-partner sexual relationships, use of condoms and sexual abstinence are usually advocated for prevention of spread of HIV and other sexually transmitted diseases. In some Asian countries, premarital sexual activity has long been considered as taboo and becomes a sensitive issue in which we can hardly get reliable answer by direct asking. To investigate the proportion of college students (in Changchun City of Jilin) who have ever had premarital sex experience, we apply the proposed DNRRTM and ANRRTM to estimate the desired proportion. In both surveys, the sensitive variable (i.e. Y) represents whether an interviewee has had premarital sex intercourse (i.e. Y = 1 if yes; = 0 otherwise). Under the DNRRTM, the non-sensitive variable (i.e. P) in the first group represents whether the last digit of an interviewee’s phone number is odd (i.e. P = 1 if yes; =0 otherwise) while in the second group the non-sensitive variable (i.e. Q) represents whether the interviewee was born in the first nine months of a year (i.e. Q = 1 if yes; =0 otherwise). At the end of the study, we observed n1 = 97, r1 = 60, n2 = 76, r2 = 60,
Under the ANRRTM, the non-sensitive variable (i.e. P) in the first group represents whether the interviewee was born in the first nine months of a year (i.e. P = 1 if yes; =0 otherwise). At the end of the study, we observed n1 = 76, r1 = 60,
6 Conclusion
In this article, we consider two design techniques which incorporate the cheating behavior (i.e. noncompliance) into the NRRTM. They are namely the DNRRTM and ANRRTM. The fundamental difference between the two noncompliance non-randomized response models is the number of innocuous questions being introduced in the design. According to our simulation results, both proposed models are superior to the existing NRRTM in the sense that they generally yield unbiased estimates and guarantee the coverage probabilities close to the pre-specified coverage level. On the other hand, the existing NRRTM could produce severely biased estimates and confidence intervals with zero coverage probability. In practice, the ANRRTM is highly recommended as it introduces only one innocuous question in the questionnaire.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.