
Abstract
When comparing two different kinds of group therapy or two individual treatments where patients within each arm are nested within care providers, clustering of observations may occur in both arms. The arms may differ in terms of (a) the intraclass correlation, (b) the outcome variance, (c) the cluster size, and (d) the number of clusters, and there may be some ideal group size or ideal caseload in case of care providers, fixing the cluster size. For this case, optimal cluster numbers are derived for a linear mixed model analysis of the treatment effect under cost constraints as well as under power constraints. To account for uncertain prior knowledge on relevant model parameters, also maximin sample sizes are given. Formulas for sample size calculation are derived, based on the standard normal as the asymptotic distribution of the test statistic. For small sample sizes, an extensive numerical evaluation shows that in a two-tailed test employing restricted maximum likelihood estimation, a safe correction for both 80% and 90% power, is to add three clusters to each arm for a 5% type I error rate and four clusters to each arm for a 1% type I error rate.
Keywords
1 Introduction
Many study designs evaluating the effect of an intervention are characterized by observations being correlated within clusters. This may arise in group or cluster randomized trials, 1 where groups are the units of assignment. In such trials, groups are assigned to one of several treatment conditions and all sampled members of the same group are given the same treatment. For example, school classes with all of its pupils are assigned to a smoking prevention program, or general practices with all of its sampled patients are assigned to one of several medication regimens. However, when individuals, instead of groups, are the units of assignment, clustering of observations may also occur. This is the case when the treatment itself induces clustering, such as when treatments are given to groups of individuals.2,3 In such individually randomized group treatment trials, interactions between persons within a group may lead to the observations on the outcome variable being correlated. 4 The clustering may occur in only one of the treatment arms, such as when group therapy is compared to a treatment condition involving only medication,5,6 but also in both treatment arms, when, for instance, two different types of group therapy are compared.7,8 Clustering effects due to treatment may also occur if the treatment is not given to a group as a whole but on an individual basis. If several patients are treated by the same therapist or, more generally, the same care provider, then patients of one therapist will be treated in a more similar way than patients treated by different therapists. Such therapist effects may also lead to correlated observations within clusters.3,4,9
The present paper will address sample size calculation for trials comparing group administered interventions or trials where clustering effects are due to therapists, assuming a quantitative outcome variable and estimation of the treatment effect by maximum likelihood (ML) in a linear mixed model analysis. For the case of homogeneity between the treatment arms with respect to outcome variance, intraclass correlation, cluster size, and number of clusters, formulas for sample size calculation have been derived by Raudenbush 1 , Moerbeek et al., 10 and Liu. 11 The present study generalizes these results by considering treatment arms that differ in outcome variance, intraclass correlation, cluster size, and number of clusters, for a scenario where the cluster sizes are more or less fixed. This would apply when therapy groups have some ideal group size that is rather fixed, or when therapists have some ideal caseload.
The paper is structured as follows. Section 2 presents the linear mixed effects model for trials comparing two arms, allowing for a difference between both arms with respect to the intraclass correlation, the outcome variance, the number of clusters, and the cluster size. Section 3 gives an explicit expression for the asymptotic variance of the treatment effect estimator and presents the optimal number of clusters for each treatment arm, optimal meaning that these numbers minimize the variance of the treatment effect estimator and thus maximize the test power under cost constraints. Section 4 gives formulas to calculate the optimal number of clusters needed for a given effect size (ES) and power level (as opposed to a given budget) and presents some analytical results for these optimal sample sizes. To handle uncertainty about those model parameters on which the optimal sample size depends, section 5 presents the maximin design as a robust alternative to the optimal design. Section 6 is a numerical evaluation of corrections in sample size calculation for finite samples when starting from the normal distribution as the asymptotic distribution of the test statistic. Section 7 illustrates how to apply the results in sample size calculation and section 8 summarizes the present study’s implications for planning trials.
2 Specification of the linear mixed effects model
In the treatment and control condition, we have respectively Kt and Kc clusters (such as Kt and Kc therapy groups). In each cluster j (j = 1,…, Kt) of the treatment condition, there are m persons and in each cluster j (j = Kt + 1,…, Kt + Kc) of the control condition, there are n persons, the total number of persons thus amounting to N = Ktm + Kcn. The dependent variable is a quantitative outcome, denoted as yij for person i in cluster j (j = 1,…, Kt + Kc). If in each condition, yij is (approximately) normally distributed, the following linear mixed effects model is an adequate tool for data analysis3,9
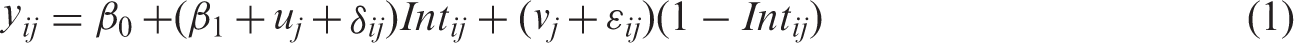
In what follows the intraclass correlation, which measures the dependency among observations for members within the same cluster, is relevant. For the model in equation (1), the intraclass correlations are
3 Optimal number of clusters for the treatment effect under a cost constraint
Let ξ = (m,n,Kt,Kc) denote the design of a randomized trial with clustering in both arms, and let
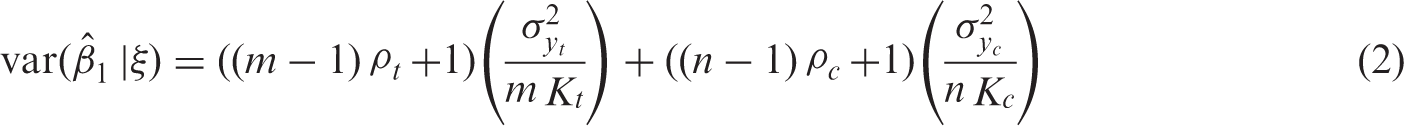
This variance increases as a function of the intraclass correlations
We derive a design, that is, ξ = (m,n,Kt,Kc), that minimizes the variance of the treatment estimator in equation (2) and thus maximizes test power for a fixed budget. We call this the optimal design. Finding optimal designs requires a cost function specifying the relation between the total budget required and the costs per subject/person/patient/individual and per cluster/group in a trial. Let C0 be the overhead costs of the trial, that is, all costs which do not depend on the sample size. Let ct and st be the costs per cluster and per subject in the treatment arm respectively, and let cc and sc be the cost per cluster and per subject in the control arm. The total study cost C then equals
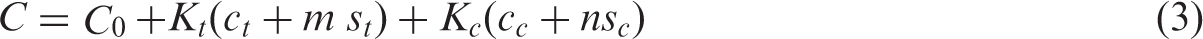
This cost function can be used as constraint on the total study cost when maximizing the power and precision for the treatment effect, or to minimize the total study cost while keeping power and precision constant. As a special case of the latter aim, if one is interested in minimizing the total number of subjects sampled, that is, Ktm + Kcn, let st = sc = 1 and ct = cc = 0. Further, for individually randomized group treatment trials, there often is an ideal group size, or, for cluster randomized trials, there may be practical limitations leading to a fixed group size for each of the treatments (e.g. a school class with all of its pupils participating in a prevention trial). In such cases, we may consider m and n fixed and can rewrite equation (3) as

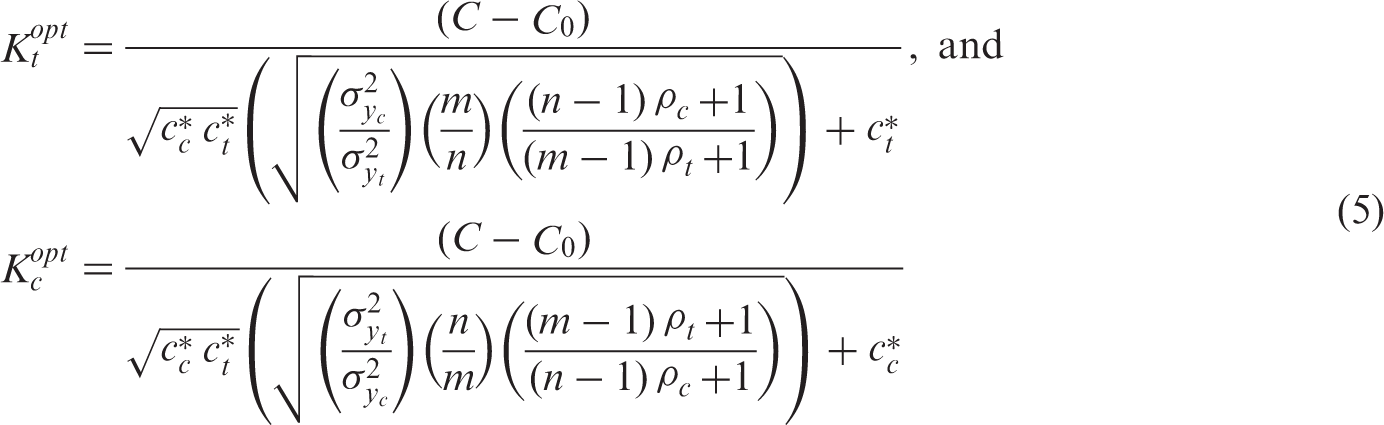
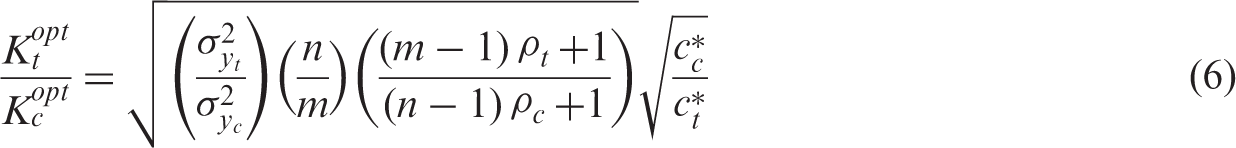
This formula extends the allocation ratio derived by Walwyn and Roberts, 9 which minimizes the variance for a given total sample size (that is, st = sc = 1 and ct = cc = 0 in equation (3)). As can be seen, the number of treatment clusters compared to the number of control clusters increases as a function of the total variance and the intraclass correlation of the treatment condition, and decreases as a function of the cluster size and the cost per cluster in the treatment condition.
For practical purposes, it is useful to transform the optimal numbers of clusters in equation (5) into expressions for numbers of clusters that yield sufficient power for an intervention effect of a particular size. This will be addressed in the next section.
4 Optimal number of clusters for a given power and effect size
The test statistic for the effectiveness of the treatment is

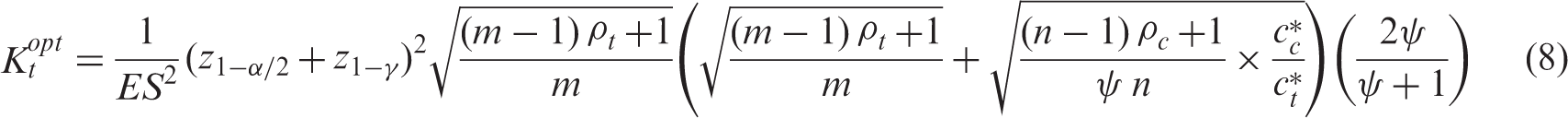
Substituting this expression into equation (6), yields the optimal number of clusters in the control arm,
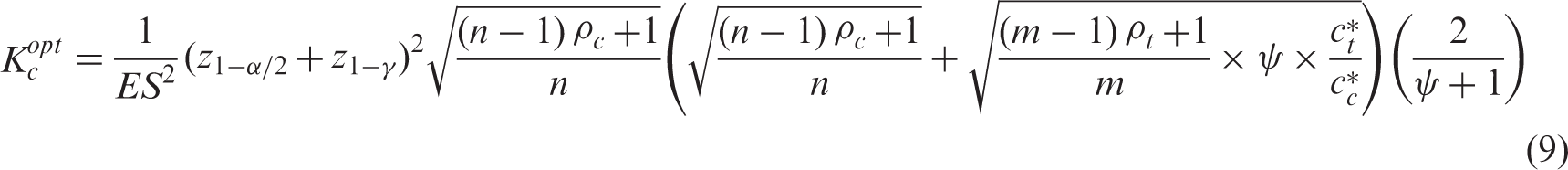
Equations (8) and (9) show that both
For a fixed treatment effect,
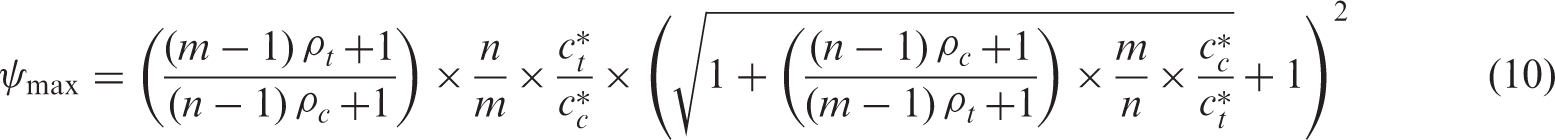
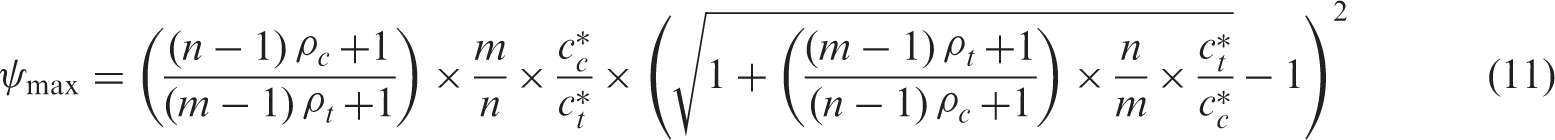
Figure 1 illustrates the effect of increasing ψ, for a scenario where ES = 0.5 (i.e. a medium sized effect according to Cohen
15
). For the range of values shown for ψ, increasing ψ leads to a decrease of Optimal number of clusters for the treatment and control arm for m = 10, n = 4, ρt = 0.01, ct/st = cc/sc = 5, st/sc = 0.1, effect size (ES) = 0.5, power = 0.80, and type I error rate = 0.05, as a function of the variance ratio ψ and intraclass correlation in the control arm (ρc = 0.01 versus ρc = 0.30).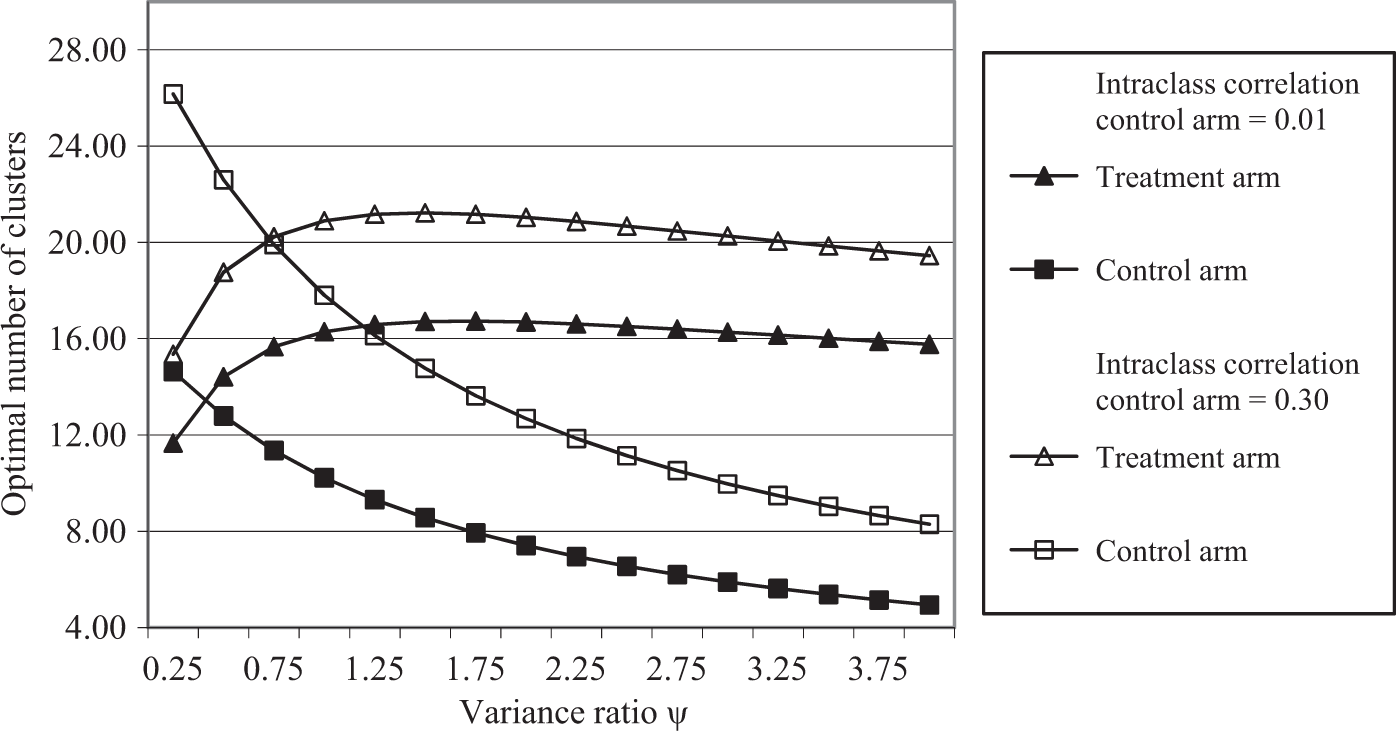
Optimal cluster numbers for different cost ratios, variance ratios, cluster sizes m and n, and different intraclass correlations, for an effect size ES = 0.50, assuming a power of 80% and a two-tailed test with type I error rate α = 0.05.
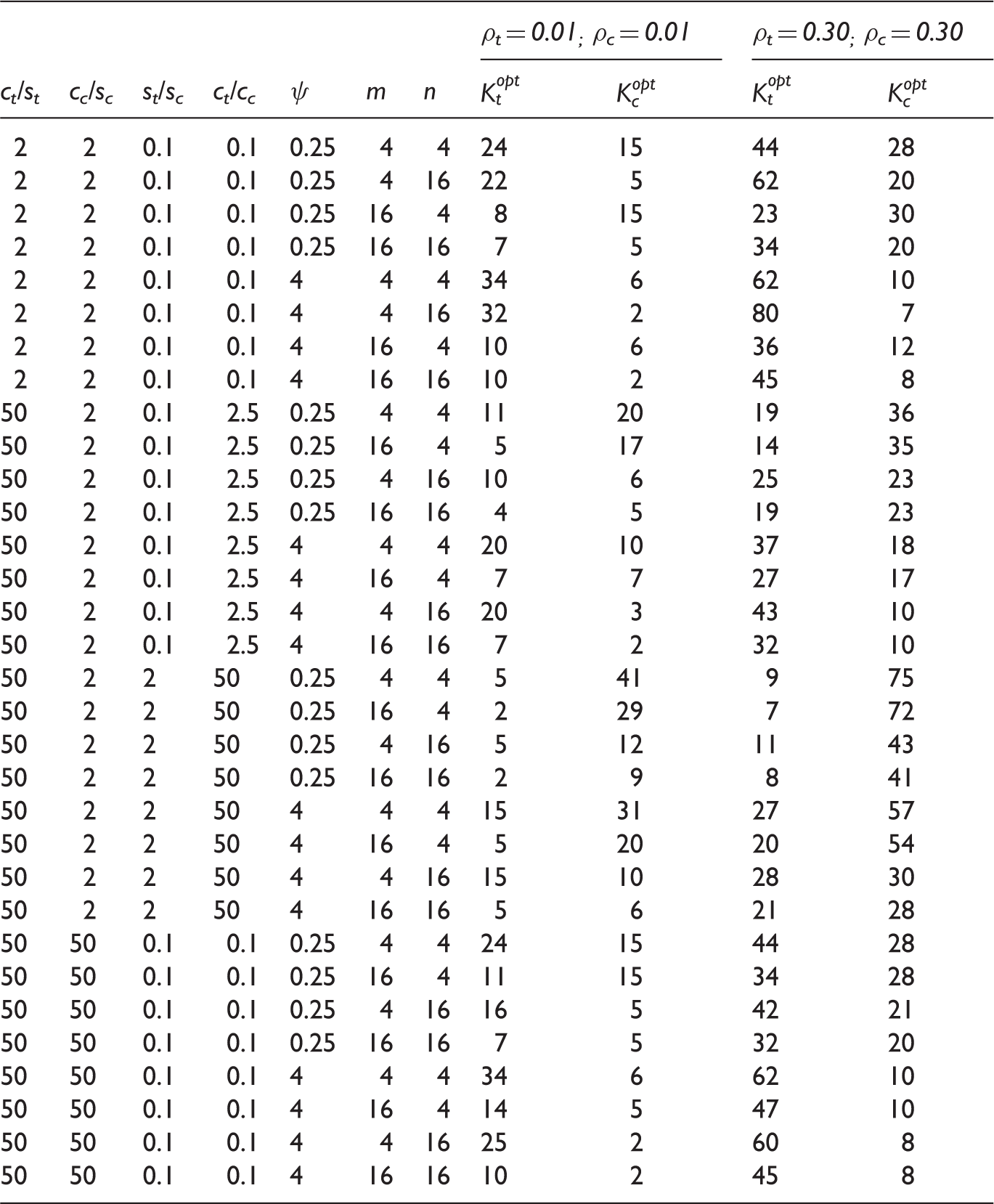
Table 1 furthermore illustrates that the optimal number of clusters for one of the arms may become larger than feasible. In these cases, the number of clusters in this arm could be reduced to the largest number that is feasible, and the number of clusters in the other arm then needs to be increased such that the power level is maintained according to equations (2) and (7). This would then be the most cost-efficient feasible design.
Calculation of optimal designs yielding sufficient power requires knowledge of relevant model parameters such as the intraclass correlations ρt and ρc and the variance ratio ψ. Since there will rarely be precise knowledge on these parameters, in the next section, we will discuss the maximin design as a possible solution.
5 Uncertainty on model parameters: Maximin designs
To calculate the optimal cluster numbers by equations (8) and (9), we need to specify the values of the intraclass correlations ρt and ρc and the value of ψ, on which we may have no precise prior knowledge. A rather straightforward solution is the maximin strategy. 20 The maximin strategy consists of the following two steps: (1) for each design determine the minimum efficiency of the treatment effect estimator across the range of plausible values for the intraclass correlations and variance ratio ψ, and (2) choose that design, which, given the budget, maximizes this minimum efficiency. This design optimizes a worst case scenario and is known as the maximin design. Since efficiency is the inverse of the variance of the treatment estimator, the maximin strategy implies choosing that design which minimizes the maximum variance of the treatment effect estimator. This is practically useful because, in sample size calculation, choosing values for the intraclass correlations and the variance ratio which maximize the variance of the treatment estimator, will guarantee a desired power level also for all other values of these parameters within their plausible ranges. The maximin design is obtained by filling in these worst case intraclass correlations and variance ratio in equations (8) and (9), and thereby guarantees the power level under the worst case scenario at the lowest costs.
Taking the derivative of equation (2) with respect to ρt and ρc shows that the variance of the treatment effect estimator increases as a function of both ρt and ρc. The maximin design therefore should be based on the upper boundaries of the plausible ranges for these parameters. Keeping the total outcome variance, that is 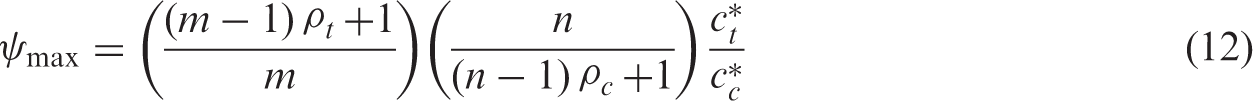
If the range of plausible values for ψ comprises equation (12), then this value should be chosen, if the range is below the value in equation (12), then the upper boundary of the range should be chosen, and if the range is above the value in equation (12), then the lower boundary of the range should be chosen. These choices give the maximum variance of the treatment estimator in equation (2), and therefore yield safe sample sizes by equations (8) and (9).
Note that equations (8) and (9) are based on the standard normal as a reference distribution for the test statistic. Hence, when small numbers of clusters result, corrections may be needed of these cluster numbers to obtain the desired power level. This issue will be addressed in the next section.
6 Corrections for the numbers of clusters as based on the normal approximation
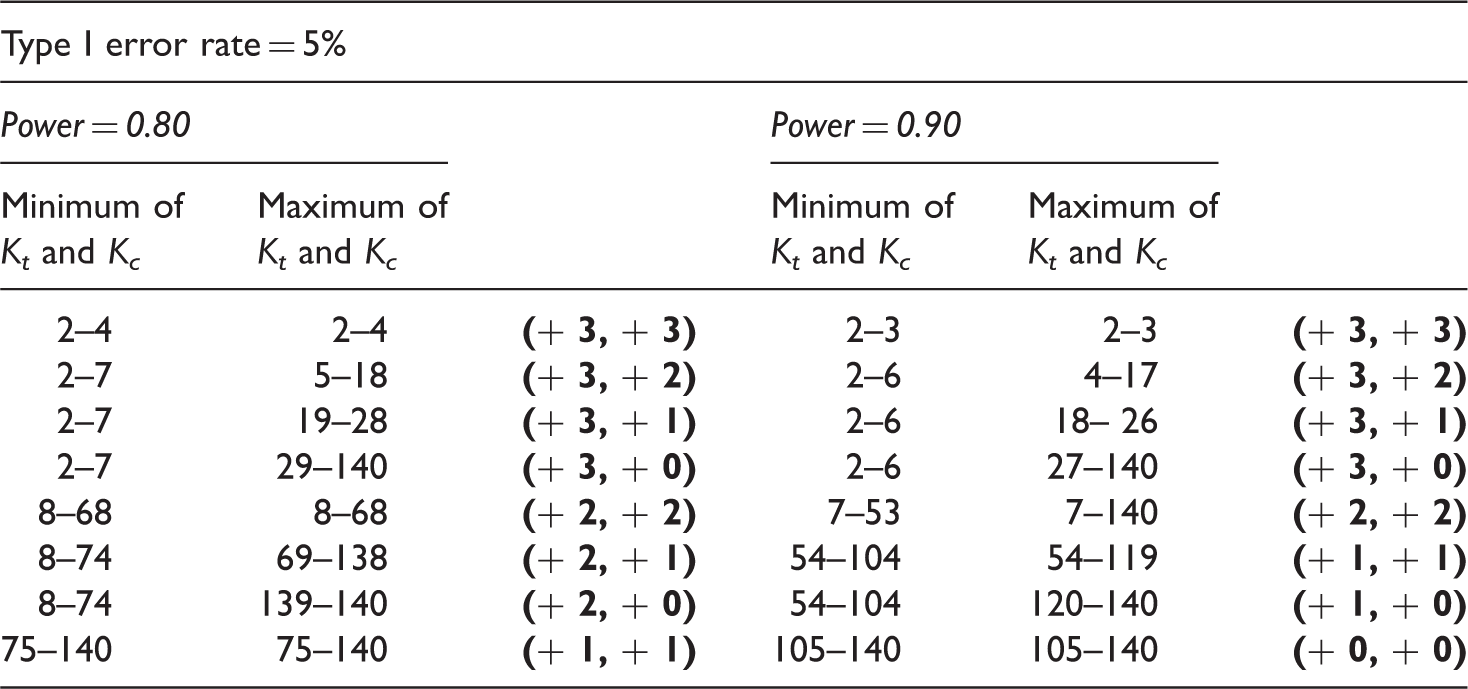
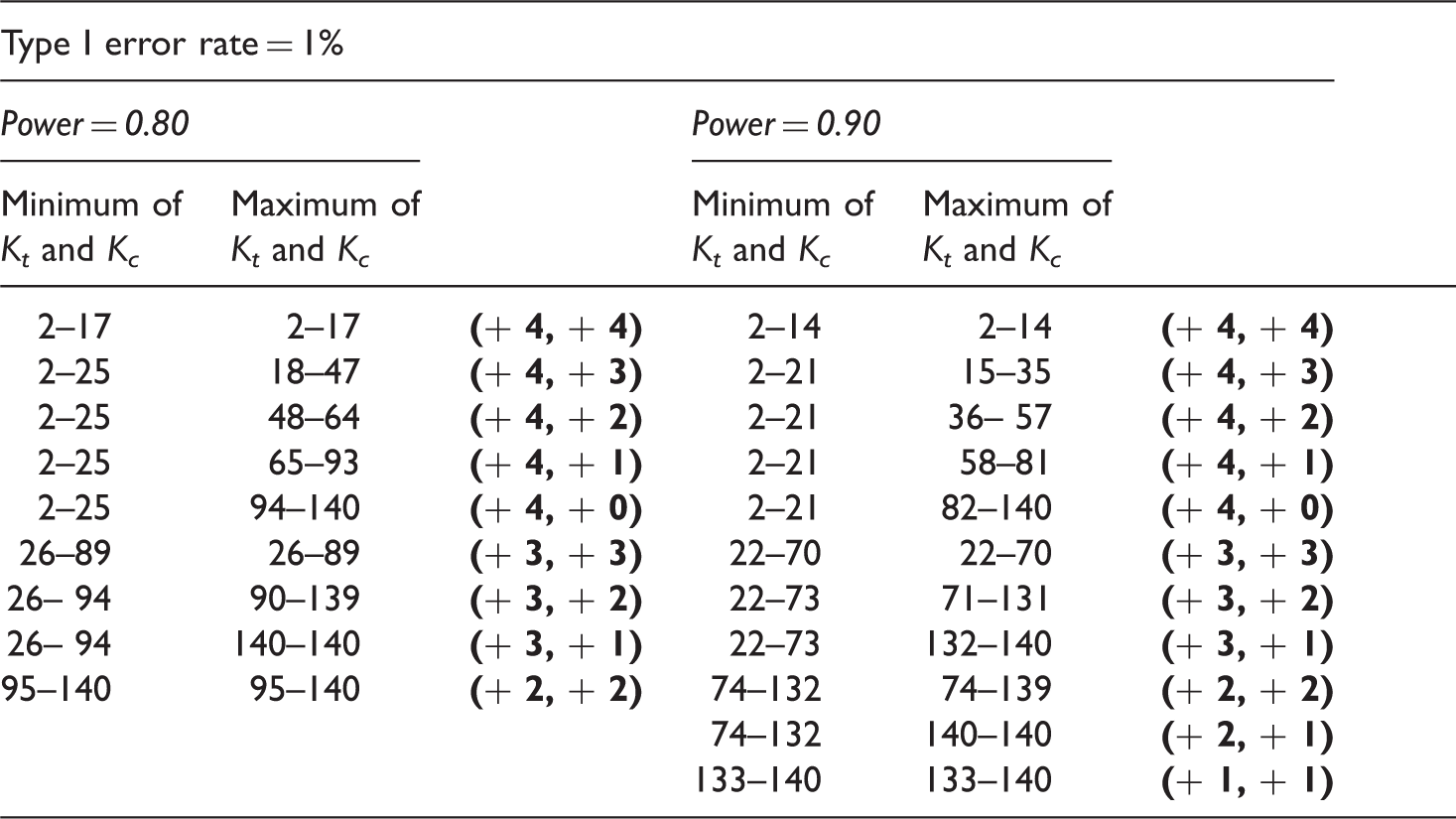
The sample size calculations in equations (8) and (9) are based on the standard normal approximation of the test statistic. In case the treatment arms have equal outcome variances, equal intracluster correlations and equal cluster sizes, so that the variance of cluster outcome means is homogeneous between arms, numerical evaluations for 80% and 90% power show that, for Kt = Kc varying from five to 50, adding one cluster to Kt and Kc each, is a sufficient correction for two-tailed tests with a 5% type I error rate. Adding two clusters to Kt and Kc each turns out to be a sufficient correction for a 1% type I error rate. 16
In case the outcome variances, intracluster correlations or cluster sizes are not the same across both treatment arms, an adequate approximation of the distribution of the test statistic, provided each treatment arm contains at least four clusters,13,21 is the t-distribution with degrees of freedom given by the Satterthwaite approximation. Employing an exact expression for the power of this Satterthwaite approximation, 22 a numerical evaluation for heterogeneous treatment arms was done to determine appropriate corrections of the number of clusters. Since the numerical evaluation has to be based on realistic ranges for each of the parameters in equations (8) and (9), these parameter ranges will be addressed first.
6.1 Choice of ranges for relevant model parameters
6.1.1 Intraclass correlations
The intraclass correlations, ρt and ρc, range from 0.01 to 0.30, since this represents the range commonly encountered in trials comparing group administered interventions2,3,8 or trials where clustering effects are due to therapists.3,23
6.1.2 Ratio of outcome variances
Since there is not much empirical evidence on ψ, with one study indicating that it varies between 0.5 and 2, 7 we will examine a somewhat broader range: ψ runs from 0.25 to 4.
6.1.3 Cluster sizes
In individually randomized group treatments as well as in case of individual treatments with clustering due to shared therapist effects, the cluster sizes are often rather small. The smallest average group size encountered in group therapy is about four,8,19,24 whereas 10 seems to be an upper limit.7,18,25 These cluster sizes also encompass the average numbers of patients commonly treated within the same period by one therapist,23,26,27 although the maximum seems to be somewhat larger.28,29 A cluster size of 16 will therefore be considered as an upper limit.
6.1.4 Effect sizes
The ES varies between 0.1 and 0.9, thus encompassing the ESs commonly classified as small (i.e. 0.2), medium (i.e. 0.5), and large (i.e. 0.80). 15
6.1.5 Cost ratios
The empirical evidence on the costs ct, cc, st, and sc is rather scarce, an exception being for instance Moerbeek et al. 30 (where ct/st = cc/sc = 26). To obtain general results, we therefore did not constrain the number of clusters through the cost function in equation (4). Instead Kt and Kc were varied from two to 140, such that they yielded 80% or 90% power in a two-tailed test with a 5% or 1% type I error rate.
6.2 Numerical investigation
First, all different combinations of ρt, ρc, ψ, m, n, ES, and Kc were generated within the ranges of these parameters as described in section 6.1. To obtain Kt that, given the values of the other parameters, yields a power level 1 – γ in a two-tailed test with type I error rate α, equations (2) and (7) are combined to obtain the following expression for Kt
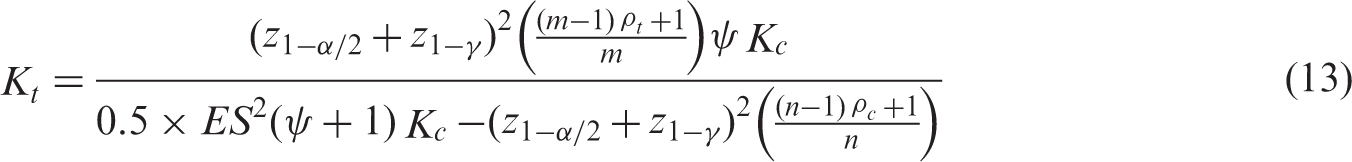
Second, it was checked whether adding a certain number of clusters to the treatment arms is sufficient for yielding a required power level, as evaluated by an exact expression for the power. 22 For this check a program in R was written. 31 For some values of the parameters, the integral function in R did not yield a finite value, in which case 200.000 Monte Carlo simulations were done to evaluate the power level.
A simple correction was determined in which an equal number of clusters was added to both treatment arms. More precisely, the smallest number of clusters was determined that, when added to both treatment arms, was sufficient for all possible combinations of ρt, ρc, ψ, m, n, ES, Kc, and Kt. Let us denote this smallest number by k. Next, refinements of this correction were determined. As a first step, the smallest Kt and smallest Kc were sought for, for which the (same) number of clusters added to each arm could be reduced to k – 1. Denote this smallest Kt and Kc by K1. The result of this process is visualized in Figure 2. To find K1, a binary search algorithm was used.
32
If K1 had been found, then a second binary search was done to find the smallest Kt and smallest Kc for which the number of clusters added could be reduced to k–2 for both arms. Denote this smallest Kt and Kc by K2 (where K2 > K1). These binary searches where repeated until either a smallest Kt and smallest Kc was found for which no correction to equation (13) was necessary anymore, or no correction turned out to be sufficient for the required power level even for a Kt and Kc of 140.
Graphical display of sufficient corrections in terms of adding the same number of clusters to Kt and Kc as a function of the minimum of Kt and Kc. The ranges for Kt and Kc run from two to 140. If both Kt and Kc are K1 or larger at most k–1 clusters have to be added to Kt and to Kc (k–1,k–1). If both Kt and Kc are K2 or larger at most k–2 clusters have to be added to Kt and to Kc (k–2,k–2).
In a second step, these corrections were further refined as a function of the maximum of Kt and Kc. More precisely, consider the area in Figure 2 for which adding k–1 clusters (but not k–2 clusters) to each arm was sufficient, that is, Kt in [K1,K2–1] and Kc in [K1,140] or Kc in [K1,K2–1] and Kt in [K1,140]. For this area, it was examined through a binary search, at which smallest value of the largest of Kt and Kc, the number of clusters added to the largest of Kt and Kc could be one less (that is, k–2 instead of k–1). If this smallest value was found, say K3, next for the area where Kt in [K1,K2–1] but Kc in [K3,140] or Kc in [K1,K2–1] but Kt in [K3,140] (see Figure 2), a binary search was done to determine the smallest maximum of Kt and Kc for which the number of clusters added to the largest arm could be further reduced by one (that is, k–3). This refinement was carried out for each correction area as established before (the areas defined by K1 and K2 in Figure 2).
6.3 Results from the numerical evaluation
The extra number of clusters to be added to each treatment arm (to the minimum and to the maximum number of clusters), both printed bold within parentheses, when calculating the cluster numbers according to the standard normal approximation in equations (8) and (9) and when employing REML estimation in the linear mixed model analysis.
Below we will illustrate how optimal and maximin sample sizes can be calculated for a specific study, and will also illustrate the benefits of using a maximin design as compared to a design with equal numbers of clusters in each arm.
7 Application in planning a trial
We illustrate how to use the results of the present study when planning a trial with heterogeneous clustering in the treatment arms. Baldwin et al.
7
studied the effects of two group-administered interventions (dissonance intervention versus a healthy weight management program), administered to high school and university students expressing body image concerns. In this study, a central outcome was the score on the Revised Ideal Body Stereotype Scale, a self-report measure of internalization of the thin beauty ideal. Equations (8) and (9) can be used to calculate the numbers of clusters when replicating this study. We set st = sc = 1 and ct = cc = 0 in equation (3) so that the total sample size is minimized and we take the parameter estimates from Baldwin et al.,
7
that is,
If one wants to be on the safe side, the maximin strategy can be used, and 0.10 and 0.30 could be chosen as upper boundaries for ρt and ρc, respectively. Substituting these into equation (12) shows that the variance of the treatment estimator is maximum at ψ = 0.6. If this value is within the plausible range of values for ψ, then, by using equations (8) and (9), the maximin sample sizes can be calculated as: Kt = 16 and Kc = 27. Accounting again for the power loss due to using the standard normal distribution for the test statistic, this should be increased to Kt = 16 + 2 = 18 and Kc = 27 + 2 = 29 groups, respectively (see Table 2(a)). Calculations of the number of clusters according to an optimal design or a maximin design, also including the corrections as displayed in Table 2(a) and (b), are possible via a small menu-driven program written in R (CLUSCALCRT), 31 which, upon request, is available from the first author.
The extra number of clusters to be added to each treatment arm (to the minimum and to the maximum number of clusters), both printed bold within parentheses, when calculating the cluster numbers according to the standard normal approximation in equations (8) and (9) and when employing REML estimation in the linear mixed model analysis.
Budget and power of the maximin design versus an equal allocation design (Kt = Kc) for different cost ratios and power levels.
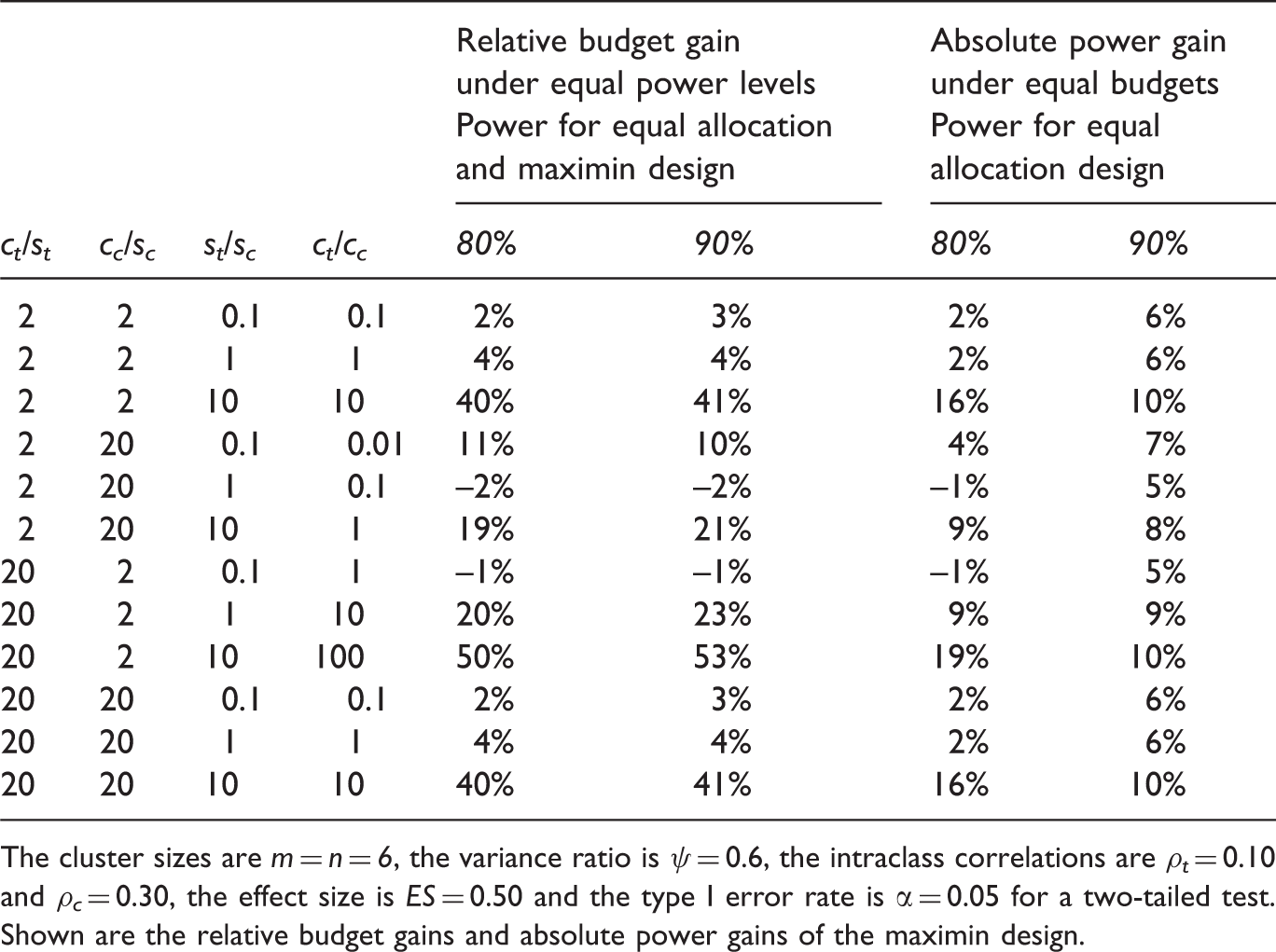
The cluster sizes are m = n = 6, the variance ratio is ψ = 0.6, the intraclass correlations are ρt = 0.10 and ρc = 0.30, the effect size is ES = 0.50 and the type I error rate is α = 0.05 for a two-tailed test. Shown are the relative budget gains and absolute power gains of the maximin design.
8 Conclusions and discussion
Clustering may occur when comparing group administered treatments, such as group wise psychotherapy where group members influence each other, or when comparing individual treatments where individuals are nested within care providers, such as psychotherapists, and provider effects occur. Starting from a priori fixed and constant cluster sizes and employing a flexible cost function, we derived the numbers of clusters that minimize the variance of the treatment effect estimator. This generalizes previous studies in that allowance is made for between-arm differences in the intraclass correlation, outcome variance, cluster size, number of clusters, and costs. The optimal number of clusters for a treatment arm may vary to a large extent (from two to more than 70) and the optimal allocation of clusters to the treatment arms may clearly deviate from a 50-50 allocation. Calculating optimal sample sizes requires prior knowledge on the intraclass correlations in both arms and on the between-arm ratio of outcome variances, which often may not be very precise. To accommodate this, a maximin strategy for calculating sample sizes was presented. Maximin sample sizes guarantee a desired power level at the lowest costs for all parameter values in their plausible ranges. Since the power of any design, including an optimal or a maximin design, also depends on the ES of interest, expressions were furthermore given for calculating the number of clusters needed for a certain power level and ES. As these equations were based on the normal approximation of the test statistic, a numerical study was done which showed that for both 80% and 90% power, increasing the number of clusters in each arm by either three or four clusters was sufficient to obtain the required power level for type I error rates of 5% and 1%, respectively.
For some care providers, such as nurse practitioners or general practitioners, the intervention often involves a single or a few meetings of limited duration, implying that the average number of patients per care provider may be much larger than considered in the present numerical study (see e.g. Roberts and Roberts, 3 Roth et al. 33 ). Additional numerical evaluations with larger average cluster sizes could be done to examine whether similar corrections result in this case.
The methodology of the present paper could also be applied to designs where the number of clusters are fixed. That is, it is also possible to derive the optimal cluster sizes, for fixed numbers of clusters in the treatment and control arm, by minimizing the variance of the treatment effect estimator for a given budget. However, it may not be possible to find optimal cluster sizes needed for achieving a certain power level, as the variance of the treatment effect estimator does not become arbitrarily small as m and n approach infinity, except if both intraclass correlations are zero (see equation 2). Stated otherwise, given fixed numbers of clusters in the treatment and control arm, there may be no optimal m and n realizing a desired power level for a particular ES.
Since the sample size formulas assume constant cluster sizes, whereas varying cluster sizes, due to dropout or naturally varying group sizes, is the more common case, one relevant extension of the paper is examining the effect of varying cluster sizes on the design efficiency and deriving a correction for the potential efficiency loss in a cost-efficient way when planning sample sizes. Van Breukelen et al. 34 have shown that in many cases adding about 10% of the clusters to both arms compensates the efficiency loss due to varying cluster sizes, but this result applies to arms that are homogeneous in their intraclass correlation, outcome variance, number of clusters and average cluster size. Formulating correction guidelines for the efficiency loss for designs where there is between-arms heterogeneity in these features requires deriving the efficiency loss for the asymptotic case and evaluating the adequacy of this asymptotic result for finite samples through an extensive Monte Carlo simulation study. This extension will be addressed in an upcoming paper.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Conflict of interest
None declared.