
Abstract
The increasing popularity of noninferiority trials reflects the ongoing efforts to replace existing treatments (reference treatments) with new treatments (experimental treatments) that retain a substantial fraction of the effect of the reference treatments. The adoption of any new treatment has to be vindicated by a demonstration of benefits that outweigh a possible clinically insignificant reduction in the reference treatment efficacy. Statistical methods have been developed to analyze data collected from noninferiority trials. However, these methods focus on cases with only one reference treatment. In this paper, we provide the statistical inferential procedures for situations with multiple reference treatments. The computation of the corresponding critical values for simultaneous testings of noninferiority of several new treatments to multiple reference treatments in the presence of a placebo is provided. Furthermore, for a prespecified level of test power, a technique to determine the optimal sample size before the onset of a noninferiority trial is derived. A clinical example is given to illustrate our proposed procedure.
Keywords
1 Introduction
Noninferiority (NI) trials are becoming more common, especially in cancer and cardiovascular research.1,2 They are instruments to assert the effectiveness of a new treatment compared to a reference treatment (also called a standard treatment or active control). NI trials verify that the former retains a substantial fraction of the effect of the latter. The adoption of a new treatment has to be justified by the demonstration of benefits that outweigh a possible clinically insignificant reduction in treatment efficacy. 3 Typical benefits associated with the adoption of a viable alternative to a reference treatment include the alleviation of side effects, the lowering of costs, and/or the introduction of less complicated treatment regimens. For instance, Beck et al. 4 conducted an NI trial for patients with opioid use disorder and found that slow-release oral morphine may be used as a substitute for methadone, which has side effects that influence compliance, resulting in inadequate treatment retention. Economic constraints and affordability may also be legitimate reasons for an NI trial. An excellent example is the exploration of less effective, but relatively inexpensive treatments for mother-to-child transmission of HIV in developing countries. 5 Another justification for conducting an NI trial is the simplification of a complicated treatment regimen. For example, Burger et al. 6 pointed out in their report of an NI study that patients suffering colorectal cancer are relieved of the requirement for central access if they are given oral therapy instead of an infusional regimen.
Given the controversies surrounding NI trials, extreme caution is advocated for the planning and implementation of these studies. The purpose of each NI trial should be clearly identified, to avoid committing excessive tests of “me too” drugs. 2 A typical concern in an NI study is the specification of the NI margin, that is the maximum tolerable reduction in efficacy compared to the reference treatment. The NI margin normally represents a small proportion of the effect size of the reference treatment and its formulation depends heavily on previous clinical studies of the efficacy of the reference treatment.7–9 As argued by Fleming et al., 9 with evidence provided by numerous examples, there are various reasons for a biased estimation of the effect size of the reference treatment. Hence, the task of formulating the NI margin should be done with extreme caution.
To ensure the validity of NI trials, both the US Food and Drug administration (FDA) and the European Medicines Agency (EMA) have published technical guidelines for the design and implementation of clinical studies.10,11 According to these two sets of guidelines, to secure validity, the design of an NI trial is required to have assay sensitivity, which refers to the ability of a trial to differentiate between an effective and an ineffective drug. To establish assay sensitivity, it is necessary to verify that the reference treatment has the expected effect of a size similar to those reported in previous placebo-controlled studies. This effect size is also useful as a yardstick for the formulation of the NI margin (e.g. 10% of the effect size of the reference treatment).
Even though the effect size of the reference treatment can be estimated from previous studies, Fleming et al. 9 have pointed out that for various reasons the estimation may be biased. In fact, Vieta and Cruz 12 noticed that the placebo effect may not be stable over time in some depression, mania, and schizophrenia studies. Hence, it is suggested that the placebo be included in an NI trial provided that there is a lack of serious harmful consequences for patients.11,13 In such cases, the resulting NI trial has three arms, consisting of an experimental treatment (new treatment), a reference treatment, and a placebo, denoted by E, R, and P, respectively, hereafter. For a three-arm trial, with the inclusion of the placebo, assay sensitivity can be established in a more direct fashion, increasing the validity of an NI trial.
There has been a lot of research on the statistical methods of a three-arm NI trial (see, for example, Röhmel and Pigeot 14 and Kwong et al. 15 and references therein). These methods can be grouped into two families. The first is the fraction method family, which formulates the NI margin as a fraction of the trial sensitivity (see, for example Pigeot et al., 16 Hasler et al., 17 and Hasler 18 ). The second family of methods expresses the NI margin in terms of the difference of the effects of E and R (see, for example, Hida and Tango, 19 Kwong et al., 15 and Stucke and Kieser 20 ). According to Stucke and Kieser, 20 the difference method is adopted more frequently in NI trials and hence we mainly discuss this approach in this paper.
In some NI trials, multiple new treatments are used to compare a reference treatment, especially when the efficacy of different dosage levels of a new drug or different combinations of several new drugs are being examined.21,22 A single-step testing method is given in Kwong et al. 15 However, their procedure is limited to a case with only one reference treatment. For NI trials, it is not uncommon for experimental new treatments to be compared to multiple reference treatments. For instance, in response to the gradual phasing out of chorofluorocarbon (CFC) inhalers, an NI trial was conducted to compare a hydrofluoroalkane propellant (HFA-134a) to two reference treatments for asthma (formoterol CFC aerosol spray and formoterol dry powder inhaler). 23 Another example is an NI trial that compared two experimental treatments for hypertension (40 mg azilsartan medoxomil and 80 mg azilsartan medoxomil) to two reference treatments (320 mg of valsartan and 40 mg olmesartan). 24 The objective of this paper is to extend Kwong et al. 15 method to the case of multiple reference treatments while the familywise error rate (FWE) is controlled at a designated level, denoted as α.
The remainder of this paper proceeds as follows. In Section 2, we provide an overview of the procedure by Kwong et al. 15 for NI trials with a single reference treatment. In Section 3, a detailed description of the testing procedures for multiple reference treatments, focusing on the popular case of two reference treatments, is presented. In addition, selected critical values of the two reference treatment case are tabulated for practical users. Then, the proposed method is demonstrated with a clinical example in Section 4. The test power and the determination of sample size are discussed in Section 5. Finally, we make concluding remarks in Section 6.
2 NI trials with one reference treatment
We first overview the statistical methods given by Kwong et al.
15
; their procedure is denoted by KCHW hereafter. Consider a one-way fixed effect model in an NI trial with k new treatments (E1, … , E
k
), a reference treatment (R), and a placebo (P). The primary endpoints are

Altogether, there are k + 1 null hypotheses to be tested, with k NI tests and one hypothesis for testing assay sensitivity. To test the null hypotheses
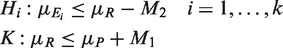
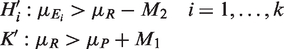
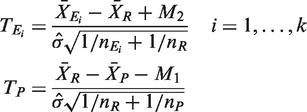
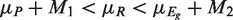
Under H
i
for i = 1,…,k and K, the k + 1 variates
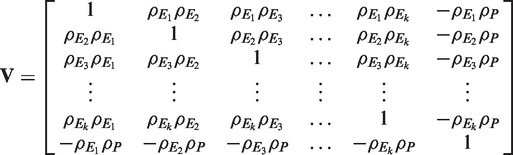
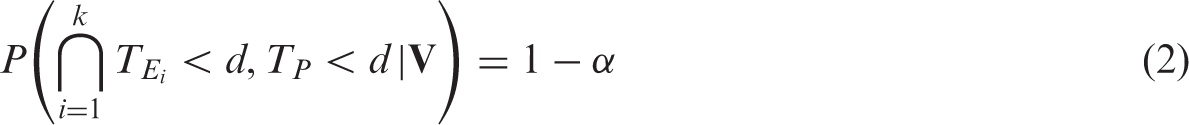
3 NI trials with multiple reference treatments
The generalization of the KCHW procedure to the case with multiple reference treatments in an NI trial is discussed in this section. Instead of having only one reference treatment, assume the existence of s ≥ 1 reference treatments; then model (1) is reformulated as follows
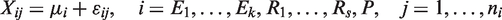
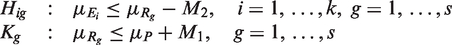
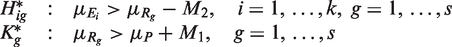
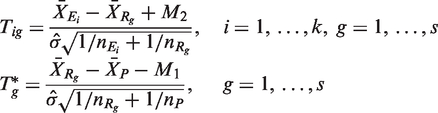
As the efficacy of all of the reference treatments compared to the placebo should be similar in practice, it is reasonable to use a single value of M1 for simplicity. Under H
ig
(i = 1,…,k; g = 1,…,s) and K
g
(g = 1,…,s), the ks + s variates
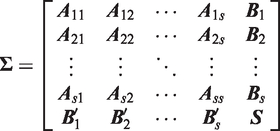
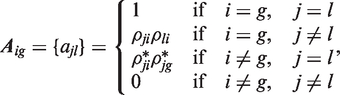
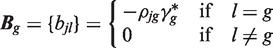
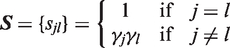
To control the FWE at level α, the critical value c for testing all of the hypotheses can be determined by solving the equation
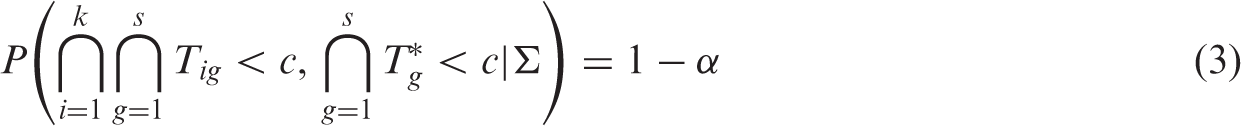
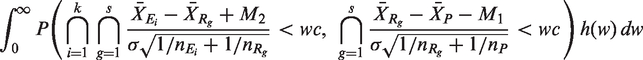
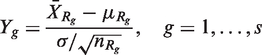
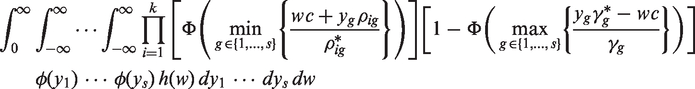
For ease of illustration, let the NI trial have two experimental treatments, two reference treatments, and a placebo, i.e. k = s = 2. The test statistics
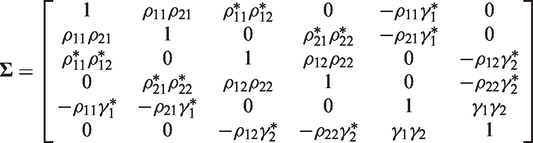
Critical values c (where

The NI null hypothesis H
ig
is rejected if in the corresponding test T
ig
> c, whereas the assay sensitivity hypothesis K
g
is rejected when in the corresponding test
A less stringent approach, of course, is to declare NI of E r to R w when both H rw and K w are rejected, without the requirement for the other sensitivity hypotheses to be rejected at the same time. Nevertheless, we prefer the more conservative approach, as it strengthens our confidence in the validity of the NI trial. However, it is worth pointing out that if both H rw and K w are rejected, and some of the remaining sensitivity hypotheses yield insignificant results, we should scrutinize the reasons underlying the inability of the trial to claim significance for any of the sensitivity hypotheses. For instance, if one of the reference treatments has a very small sample size, the test power may be too small to declare a significant result. In such cases, further investigation of possible NI of E r to R w should be conducted.
The purpose of the proposed method is to identify those experimental treatments that are NI to a particular reference treatment. Once these NI treatments have been found, additional hypothesis testing could be conducted to compare their efficacy.
4 Example
One quarter of the adults in the world are affected by hypertension. 26 The drug class of angiotensin II receptor blockers (ARBs) has long been identified as an effective treatment for hypertension. 27 Two reference drugs, olmesartan and valsartan, are among the most commonly used ARBs. Another newly developed drug, azilsartan, is a potent and highly selective ARB with estimated bioavailability of 60% and an elimination half-life of 12 h. 24 Azilsartan is in general well tolerated and patients are likely to persist with long-term treatment as there are few adverse events associated with it. 28 In addition, there are concerns that olmesartan may increase cardiovascular risk. 29
Changes from baseline in 24-h mean ambulatory systolic BP (mm Hg).

Test statistics with

Significance at
With the given sample sizes and FWE α = 0.05, the exact value of the critical value c computed using our algorithm is 2.347. As the sample sizes are not very different, the approximation method suggested in Section 3 can be used. As
5 Sample size determination
In designing a clinical trial, it is crucial to determine the minimum number of patients required for each treatment group to achieve a certain level of test power. As explained in the earlier sections, the objective of an NI study is to identify at least one experimental treatment that is noninferior to one of the reference treatments and at the same time, to establish assay sensitivity of all of the existing reference treatments. To evaluate the sample size requirement, the modified version of the any-pair power (APP) defined in Kwong et al.
15
for one reference treatment is now extended to NI trials with multiple reference treatments as follows
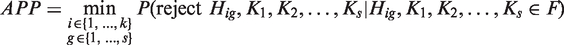
For i = 1,2,…,k and g = 1,2,…,s, assume that an NI trial is designed to detect the differences
Without loss of generality, we assume that only H11 and K1,…,K
s
are false, as the test statistic T
ig
for i = 1,…,k; g = 1,…,s has the same marginal probability distribution as under the balanced design trial. For a given design configuration (n
E
, n
R
, n
P
), with given values of k and s, and critical value c with a specified δ1 and δ2, the power of the test is
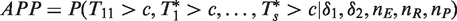
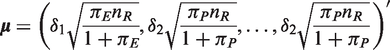
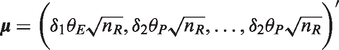
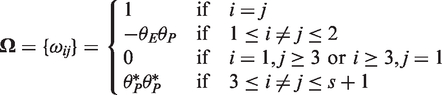
Then, transform 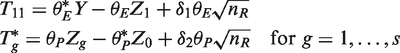
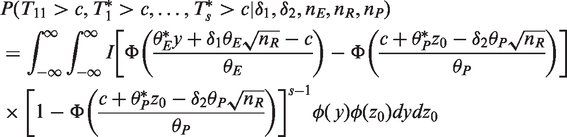
Let the optimal sample size allocation for a balanced design have a ratio 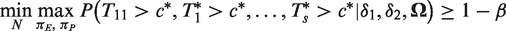
As the analytical determination of the optimal design configuration Obtain the initial conservative total sample size, N
′
under the assumption that For a given N′, search for Set N′ = N′ – 1 and repeat step (b) if Optimal design configurations
Based on the above algorithm, selected sample size requirements for the optimal designs for given power levels 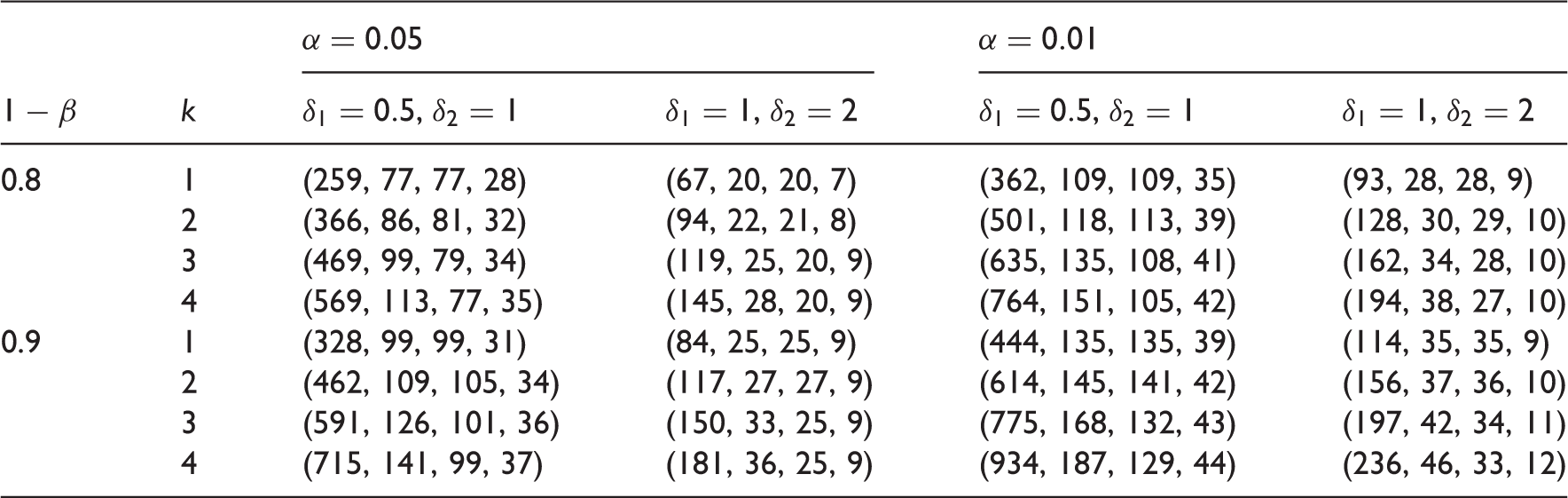
6 Conclusion
The number of NI trials has increased rapidly in the past decade, and more sophisticated statistical methods are emerging to deal with various complex setups. In this paper, we develop a testing procedure for three-arm NI trials that have multiple reference treatments. Given that both researchers and government regulators continue to urge caution in the implementation of NI trials, we adopt a conservative approach that requires the NI declaration of a new treatment to be accompanied by the establishment of assay sensitivity for all of the reference treatments. The implementation of our proposed method is facilitated by the inclusion of critical values for the popular case of two reference treatments in the trial. The computation of power is also given to enable the determination of sample size before the onset of the trial. As pointed out by Kwong et al., 15 if ethical considerations militate against the allocation of many patients to a placebo, it is also straightforward to incorporate this constraint into the proposed algorithm when computing the optimal sample size. This paper concentrates on developing a single-step procedure for NI trials with multiple standard treatments. A stepwise testing procedure could be explored in the future, although the framework and procedures will be far more complex. In addition, the model that is presented in this paper assumes that treatments are having homogeneous variances. Though more complicated, an extension of this paper to models with heterogeneous variances could be developed using the idea given in Huang et al. 30
Footnotes
Acknowledgements
We are grateful to the referee for many valuable suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research of Huang and Wen were supported by the Ministry of Science and Technology of Taiwan (MOST 102-2118-M-006-003-MY2). Cheung's research was funded by the Research Grants Council of the Hong Kong Special Administrative Region (CUHK14300814).