
Abstract
Spatial data are often aggregated from a finer (smaller) to a coarser (larger) geographical level. The process of data aggregation induces a scaling effect which smoothes the variation in the data. To address the scaling problem, multiscale models that link the convolution models at different scale levels via the shared random effect have been proposed. One of the main goals in aggregated health data is to investigate the relationship between predictors and an outcome at different geographical levels. In this paper, we extend multiscale models to examine whether a predictor effect at a finer level hold true at a coarser level. To adjust for predictor uncertainty due to aggregation, we applied measurement error models in the framework of multiscale approach. To assess the benefit of using multiscale measurement error models, we compare the performance of multiscale models with and without measurement error in both real and simulated data. We found that ignoring the measurement error in multiscale models underestimates the regression coefficient, while it overestimates the variance of the spatially structured random effect. On the other hand, accounting for the measurement error in multiscale models provides a better model fit and unbiased parameter estimates.
1 Introduction
It is of interest to model the relationship between spatially referenced health outcomes and predictors by taking into account the spatial uncertainty in the data. Spatial data are often observed in the form of aggregated counts at census tract, county, and state levels. These aggregations essentially smooth the data, that is to say that the variability in the data will be reduced and hence there will be loss of information. Using appropriate spatial statistical methods can help to alleviate the loss of information. Much work has been done to handle the variability in the outcome using spatially structured and unstructured random effects. 1 In addition, multiscale modeling has been used to model the aggregation of outcomes from one level to another level. 2 However, less emphasis has been given to modeling the uncertainty in outcomes when aggregation of predictors from one level (e.g., county) to another level (e.g., state) is considered. Since we cannot directly measure the predictor (e.g., income) at coarser levels, it is often approximated by aggregating the observed values of the predictor obtained from the individuals at the finest level. Hence, using the aggregated predictor as a proxy (surrogate) measure for the true unobserved predictor might induce measurement error (ME), i.e., predictor uncertainty due to aggregation.
Researchers usually model classical ME as follows. The true covariate is measured with additive error, i.e., W = X + U, where W is the error-prone covariate, X is the true unobserved covariate, and U is the ME structure. 3 Since we cannot observe the true covariate X, we cannot fit directly the regression of Y on X. Hence, the aim of the classical ME modeling is to obtain unbiased estimates of parameters of the regression of Y on X indirectly by fitting Y on W after adjusting for ME. 3 If we regress Y directly on W without accounting for the ME, it leads to biased estimates and loss of power for detecting relationships between variables. There are different methods that are applicable for ME analysis: regression calibration, simulation extrapolation (SIMEX), using instrumental variables (IVs), etc. In regression calibration, the main idea is to replace X by the regression of X on W and then doing a standard regression analysis. This is a simple, effective, and widely used method. 4 Although regression calibration is often useful for generalized linear models, it can be rather poor for highly non-linear models. 3
Alternatively, a computationally intensive and simulation-based method, known as SIMEX, has been considered to adjust for ME. 5 Like regression calibration, it is simple, general, and approximate method. SIMEX involves the following steps: (1) simulation: the error-contaminated covariate (W) is simulated with additional independent MEs, (2) estimation: the parameter of interest is estimated from each of the simulated contaminated data sets, (3) replication: steps (1) and (2) are replicated a large number of times, and the mean values of the parameter estimates are computed for each level of contamination, and (4) extrapolation: the SIMEX estimate is obtained by extrapolating to the ideal case of no ME.6,7 Both regression calibration and SIMEX rely on knowing the ME variance or estimating it with validation data. When we do not have such information, IV (T), which is related to X, can be used to estimate the ME variance. 3 Note that the IV must be independent of all the variability remaining after adjusting for X, i.e., T must be uncorrelated with the ME U and Y − E(Y − X). In this paper, we use an IV to account for the ME in the framework of multiscale modeling for multiple spatial scale data.
Multiscale modeling has been used to incorporate finer scale information to the coarser level in different fields such as computer vision, signal and image processing, mathematics, and statistics.8–11 In spatial epidemiology, a multiscale model that factorizes the likelihood into the individual components of local information has been used. 12 This approach, however, lacks a spatial component that addresses spatial correlation between neighbors. Recently, a joint shared multiscale convolution model that shares the correlated random effect between the scale levels has been proposed. 13 They have shown that jointly modeling the data at different scale levels provide a better description of risk variation than a separable model. Furthermore, 14 multiscale models have been used to investigate the impact of income on low birth weight (LBW) incidence in the state of Georgia (GA) with two levels: county and public health (PH) district levels. Using the shared multiscale model, they found that income has a negative impact on LBW incidence at both levels. However, income can be inaccurately reported. Hence, an ME model is needed to account for the predictor uncertainty.
The ME U is usually assumed to be normally distributed with mean zero and constant variance. However, the ME could be spatially dependent.15,16 Furthermore, ME has been considered 17 as a spatial misalignment problem to study the relationship between levels of particulate matter (PM) and birth weight. The misalignment occurs due to the difference in spatial location of the monitoring station and residence location. In addition, county-level data and interpolated county-level measures have been used to estimate the spatial misalignment error. 18 On the other hand, an intrinsic conditional autoregressive structure (ICAR) for the ME with a constant variance or heterogeneous variance that places more uncertainty on the residences farther away from the monitoring station has also been proposed. 19 They used a Berkson ME that assumes the true unobserved covariate depends on the observed surrogate measurement (X = W + U) and implemented their method to investigate the association between a continuous birth weight outcome and maternal PM exposure. Here, we assume a proper conditional autoregressive (PCAR) structure and estimate the classical ME using an IV for multiple scale data. In contrast to ICAR, A PCAR assumption helps to quantify the correlation component between the neighbors. We considered the classical ME rather than the Berkson ME because income is measured at an individual level, 3 a point that will be elaborated further in Section 2.
In this paper, we assume that the ME could be induced from the following situations: (1) households might report their income inaccurately. Hence, income could be measured with error and (2) the aggregation of income from one scale level to another scale level might cause ME. The true income at the county and PH levels cannot be measured directly. We averaged the household income within the county to obtain the proxy (surrogate) estimate of the true unobserved income at each county. Similarly, we averaged the income of the counties within the PH district to obtain the proxy estimate of the true unobserved income for each PH district. Thus, we can assume an ME model to adjust for income uncertainty due to aggregation.
The structure of the paper is as follows. Section 2 is dedicated to the Georgia very LBW (VLBW) incidence that will be implemented using the methods in Section 3. Section 4 presents a simulation study, and simulation results followed by Section 5 that will be devoted to the application of the VLBW incidence in Georgia. Finally, discussion and concluding remarks will be drawn in Section 6.
2 VLBW in Georgia
The data are available from the state of Georgia via the Georgia Division of Public Health OASIS system (http://oasis.state.da.us) at both counties and PH levels. In Georgia, there are 159 counties nested within 18 PH districts. On average nine counties are nested within each PH district. We choose to examine the association between the VLBWs rate (the number of VLBW divided by the total number of births for each county) and the median household income in the state of Georgia as it has reasonably large set of spatial units at each scale level. VLBW is a birth weight of liveborn infants less than 1500 g. The predictors’ median household income of the residents of a given area and the percentage of persons in poverty are available through the Area Health Resource File dataset. The number of VLBWs and the total births at the PH level are obtained by summing up the number of VLBWs and the total births of the counties within a given PH district, whereas the income and percentage of poverty at the PH level are obtained by averaging the income and % of poverty of the counties within the given PH district, respectively. We selected the recent data in 2007.
The relation between VLBW and socio-economic predictors at the small area level (such a median income or % under the poverty line) has been well established.20–23 However, these relations could be affected by inaccuracy in determination of the true predictor, and hence attenuation could occur, thereby affecting the strength and reliability of the estimated relation. We use classical ME if the error-prone covariate is necessarily measured uniquely to an individual, whereas we choose Berkson ME if all individual in a group given the same value of the error-contaminated covariate, such as maternal exposure to air pollution.
3
As we mentioned, we are interested in studying the impact of income, which could be reported inaccurately, on VLBW incidence. Since income is measured uniquely at the household (individual level), the classical ME is an appropriate choice. Hence, we employed the classical ME in the multiscale modeling framework using an IV. Since % of poverty is highly correlated with income (
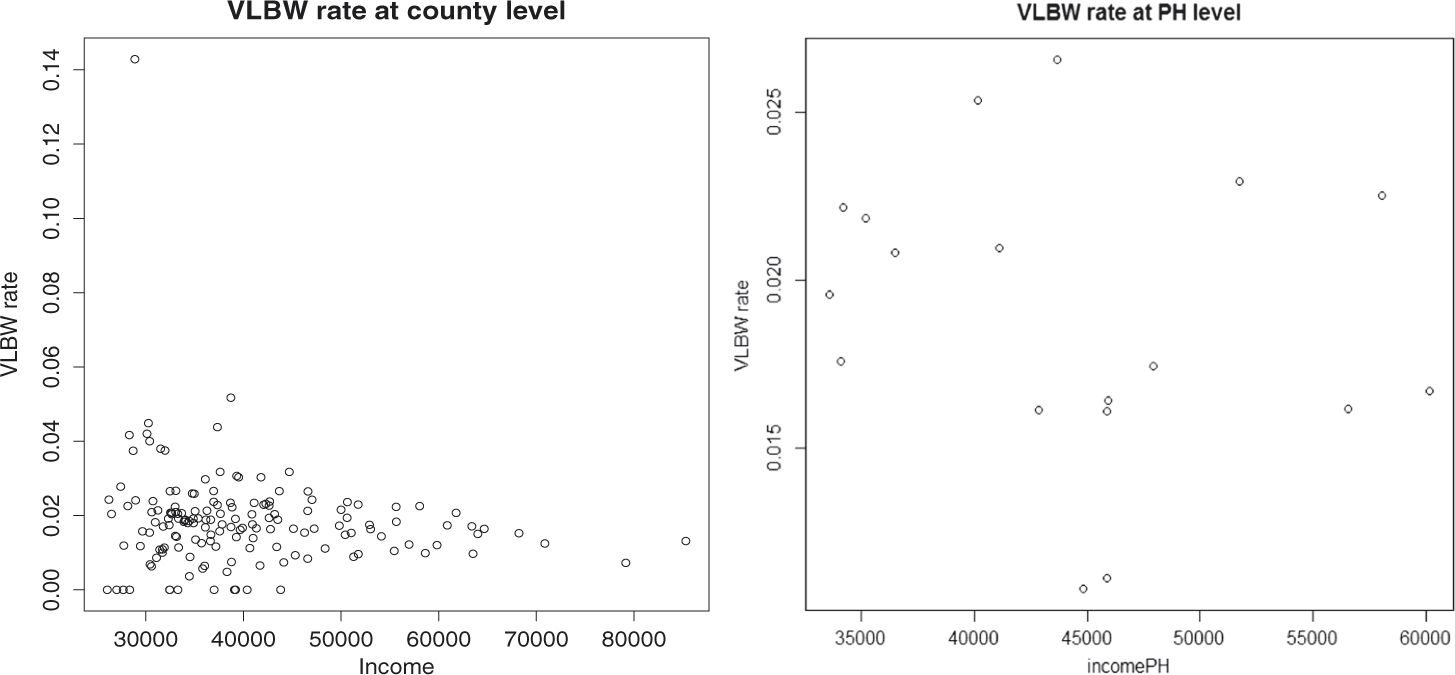
The spatial pattern of the observed VLBW rate (incidence) and the median household income at both the county and PH levels is shown in Figure 1. We can see that there is an inverse relationship between income and VLBW incidence (Figure 2). There are high VLBW incidences at the central and southwest of the GA state, whereas the associated median household income is relatively low in those areas. Furthermore, the observed income has a spatial structure. We describe this spatial dependency of the error-contaminated income (W) through the PCAR structure (see Model 1; Section 3.1). In practice, the ME could be spatially dependent. For example, the error associated with household-reported income could be high for areas which have wealthy residents, whereas it could be low for areas which have poor residents. The analysis of this data set accounting for both ME and scale effect is deferred to Section 4.
Observed very low birth weight (VLBW) incidence at the county and PH levels (top figure) and median household income at the county and PH levels (bottom figure). In this figure as well as in the subsequent figures, the second bracketed values are the number of regions in each risk category. The relationship between income and VLBW rate at the county and PH levels.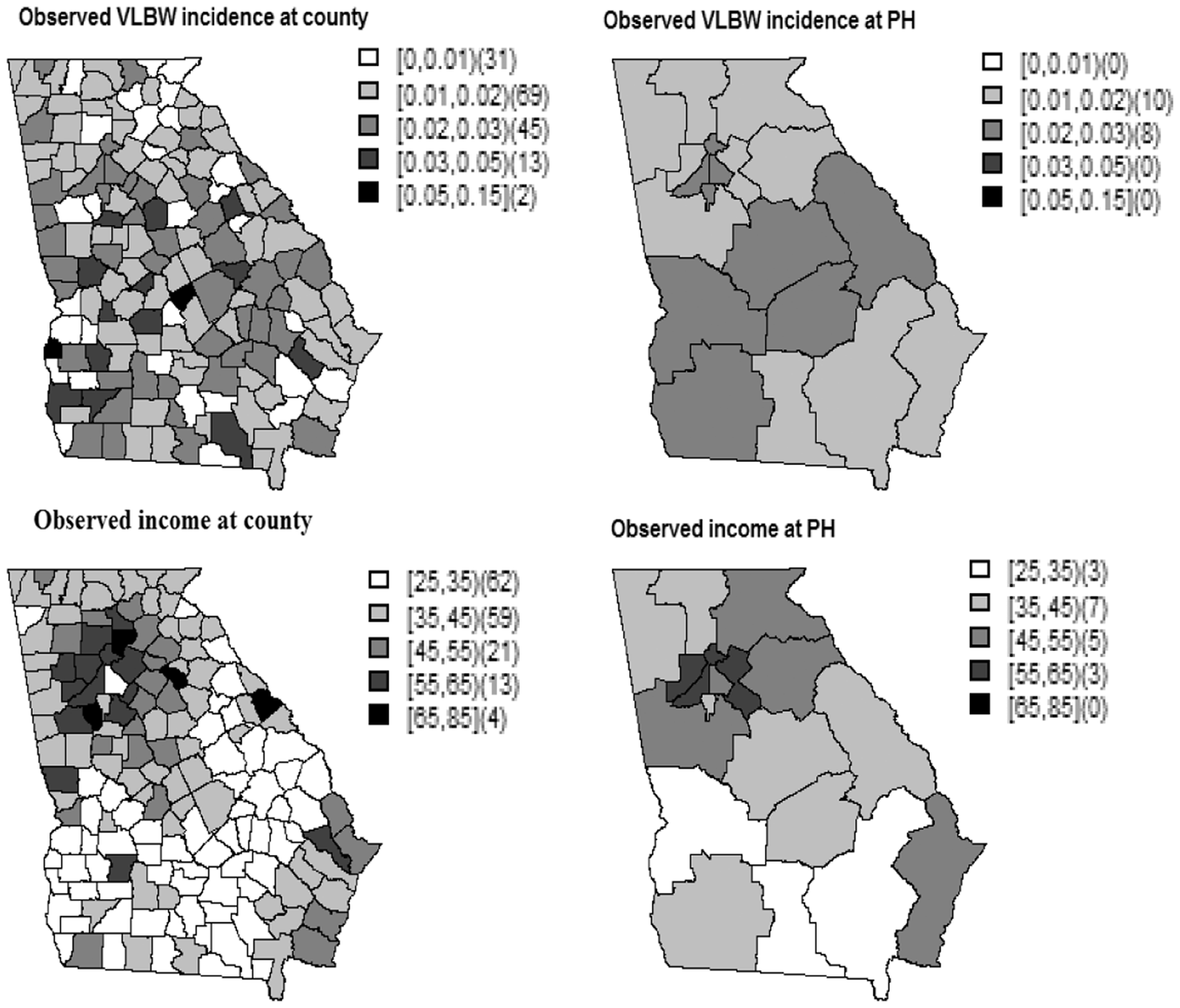
3 Multiscale ME models
The goal of this paper is to model explicitly the spatially dependent predictor using ME in the multiscale modeling framework. Suppose
The ME variance can be estimated using replicate measurements or validation data. However, it is not always possible to get replication measurements or validation data. In such cases, an IV, T, can be used to estimate the regression model parameters.
3
In this paper, we use an IV to estimate the parameters. Hence, the regression of
3.1 Model 1
We demonstrate here the spatial multiscale ME model for binomial data obtained from two scale levels, i.e., k = 1, 2. Let
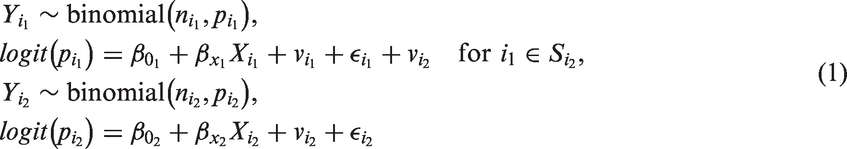

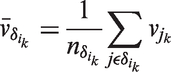
We have seen that the shared correlated random effect handles the scaling effect. To accommodate for the ME, we used a PCAR structure. The PCAR formulation for the error-contaminated covariate
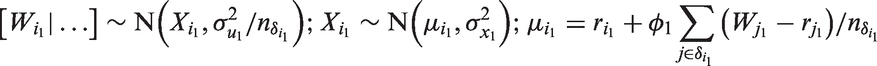
Similarly, PCAR for the ME at the unit level is expressed as
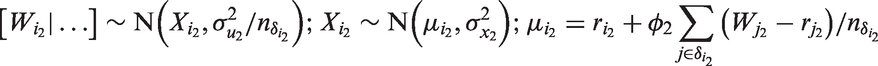
3.2 Model 2
Model 1 assumes a spatially dependent ME. In the literature, the ME is often assumed to be normally distributed.
26
This assumption could be used when the ME does not have a spatial structure. Hence, in this model, we assumed the ME follows a normal distribution. The model formulation for aggregated data at the unit and subunit levels is similar with Model 1 in equation (1) except now
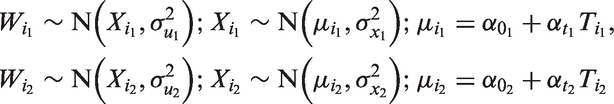
We assumed similar prior distributions for the model parameters as in Model 1.
3.3 Model 3
Models 1 and 2 address both the scaling effect and the ME simultaneously. In this section, our interest is to address only the scaling effect. This approach could help us to investigate the effect of ignoring ME in the framework of multiscale modeling. The multiscale model that accounts for the scaling effect alone but not for the ME is defined as
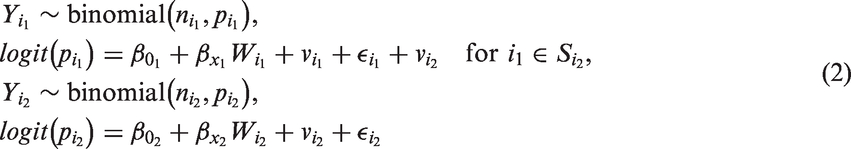
Here also, we assumed similar prior distributions for the model parameters as in Model 1.
3.4 Model 4
In the previous section, we have seen models (Models 1 and 2) that address both the scaling effect and the ME. Also, we described a model (Model 3) that accommodates the scaling effect but not the ME. To assess the impact of ignoring both the scale effect and the ME, we describe here the simple naive approach. The model is of the form
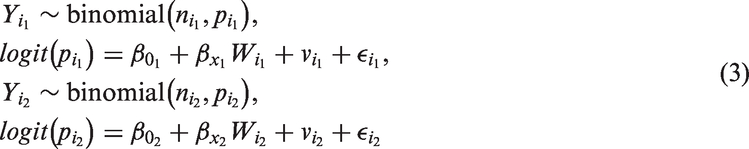
Note that there is no random effect that introduces linkage between the two levels, and hence it ignores the scale effect. Furthermore, we are using the error-contaminated covariate
3.5 Model assessment and selection
We compared the performance of the models using different criteria and prediction accuracy measurements. For the model selection, we employed a deviance information criterion
27
(DIC) and a Watanabe–Akaike information criterion (WAIC).
28
The DIC is a combination of the deviance and the effective number of parameters (PD) that penalizes for model complexity, while the WAIC is an approximation to cross-validation. In addition, the DIC is not a fully Bayesian method as it is based on a point estimate,29,30 whereas the WAIC is a fully Bayesian technique and uses a posterior distribution. To measure the predictive ability of the models, we implemented the mean square prediction error (MSPE) and mean absolute prediction error (MAPE) given by
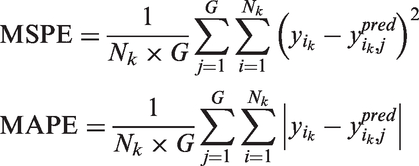
The models were applied in real and simulated data (see Sections 4 and 5) using the mix of Gibbs and Metropolis–Hastings algorithms of Markov chain Monte Carlo (MCMC) via R2WinBUGS package (see online Supplementary Appendix).
4 Simulation study
The aim of the simulation study is the following: (1) to investigate the impact of ignoring ME and scaling effect for multiscale spatial data, (2) to study the benefit of accounting for ME and scaling effect, and (3) to compare the performance of using a normal distribution and a PCAR for spatially dependent ME. We considered two scenarios: (1) we assumed an independent ME and (2) a spatially structured ME. We describe each scenario in the next section.
4.1 Scenario 1: An independent ME
Many studies assume independent ME in predictors. This is less reasonable for spatial data. In such cases, we can still use Model 1 that assumes a spatially dependent ME because Generated true covariate (X), error-prone covariate (W), instrumental variable (T), and measurement error (U) for the counties of Georgia (scenario 1).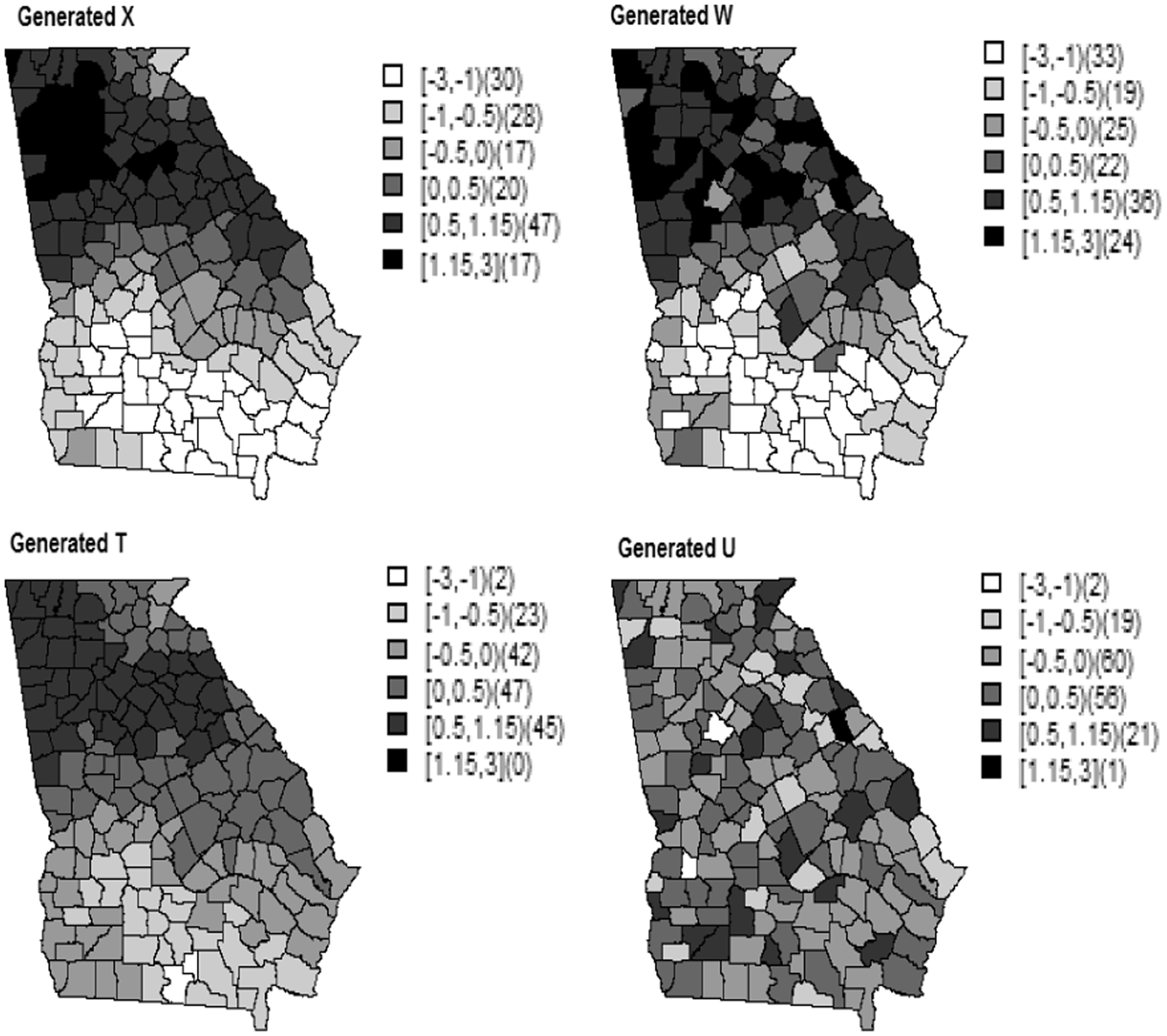
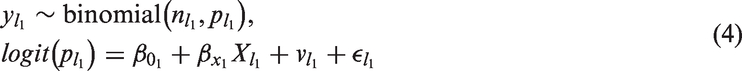
To obtain
4.2 Scenario 2: A spatially structured ME
Since we are interested in modeling ME for spatial data, it is more reasonable to assume a spatial dependent ME. Here, we investigate the misspecification of the ME, i.e., the impact of assuming an independent ME for data simulated using a spatially structured ME. Hence, we simulated the ME Generated true covariate (X), error-prone covariate (W), instrumental variable (T), and measurement error (U) for the counties of Georgia (scenario 2).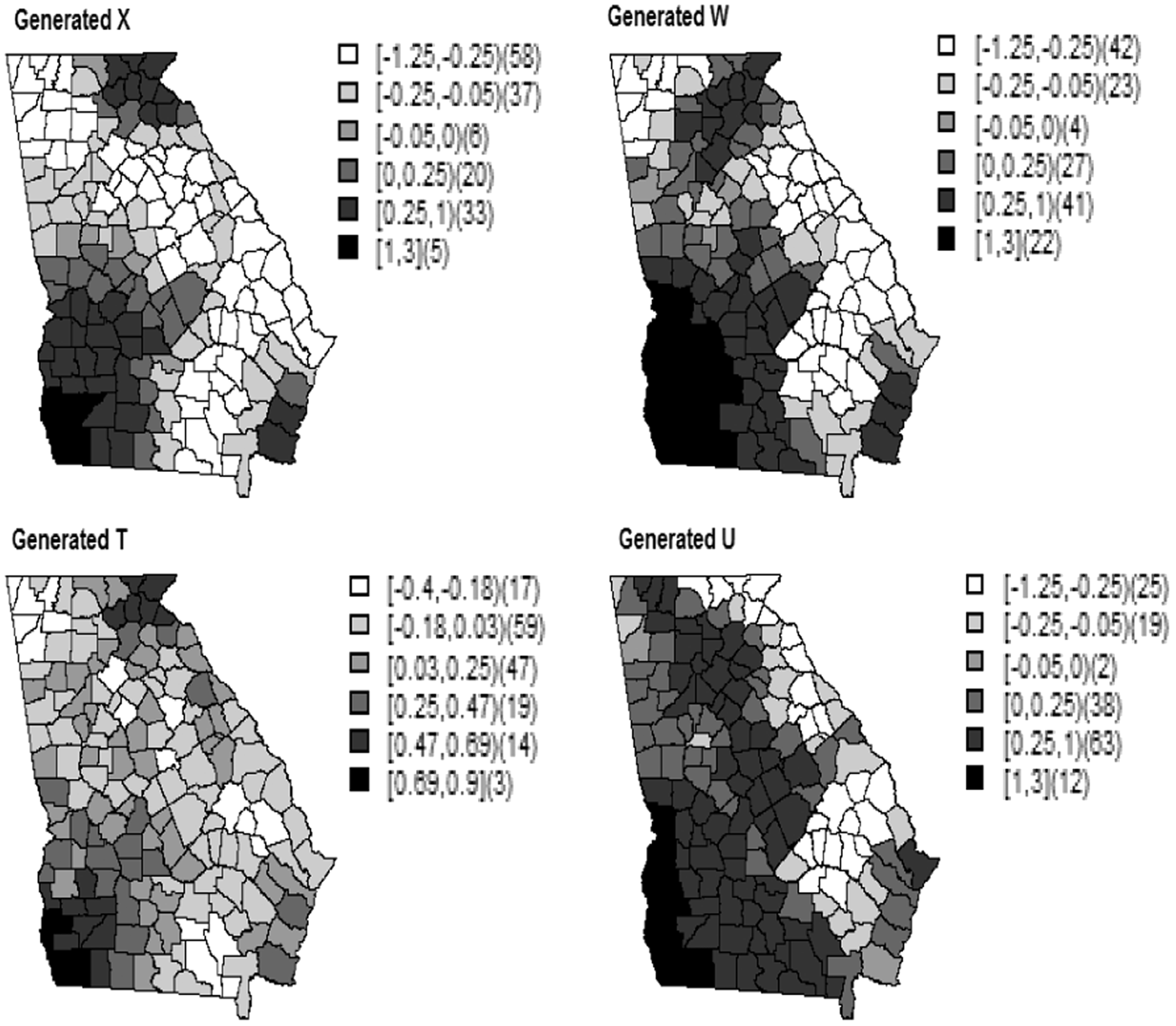
4.3 Simulation results
4.3.1 Scenario 1: An independent ME
Simulation results for data generated within the Georgia state map.
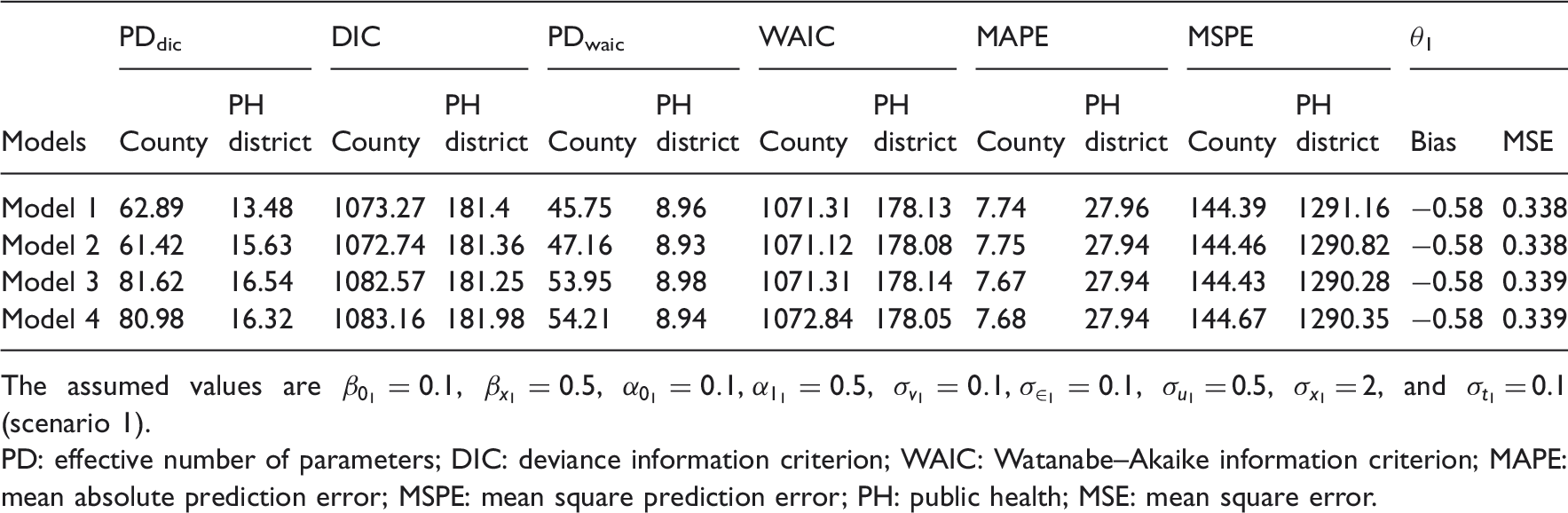
The assumed values are
PD: effective number of parameters; DIC: deviance information criterion; WAIC: Watanabe–Akaike information criterion; MAPE: mean absolute prediction error; MSPE: mean square prediction error; PH: public health; MSE: mean square error.
Summary of the estimated values and MSE of the parameters for the data generated within the Georgia state map (scenario 1).
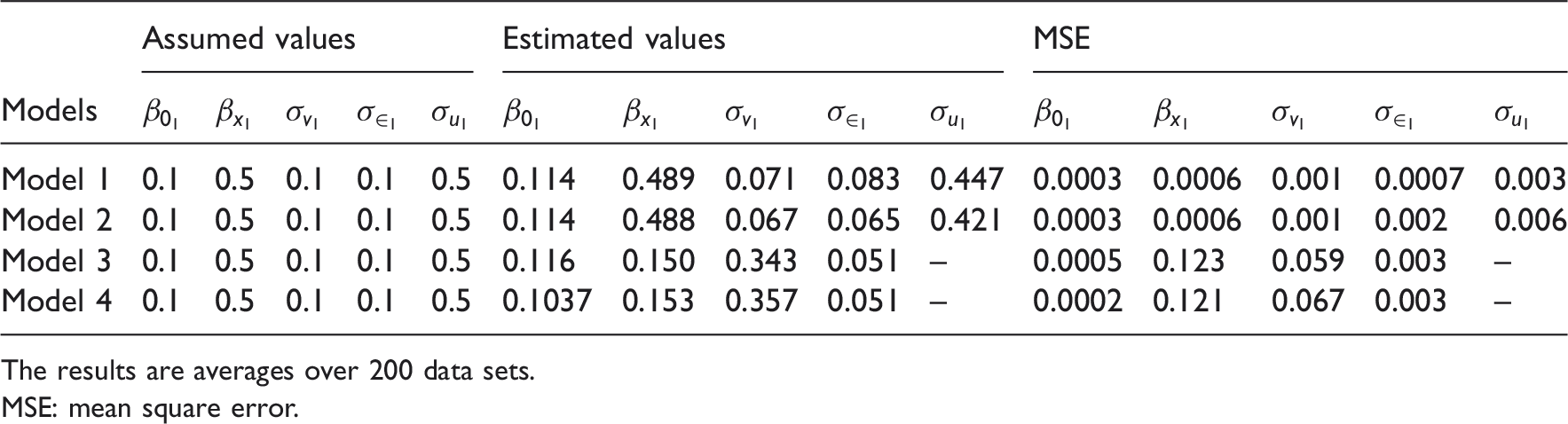
The results are averages over 200 data sets.
MSE: mean square error.
Simulation study.
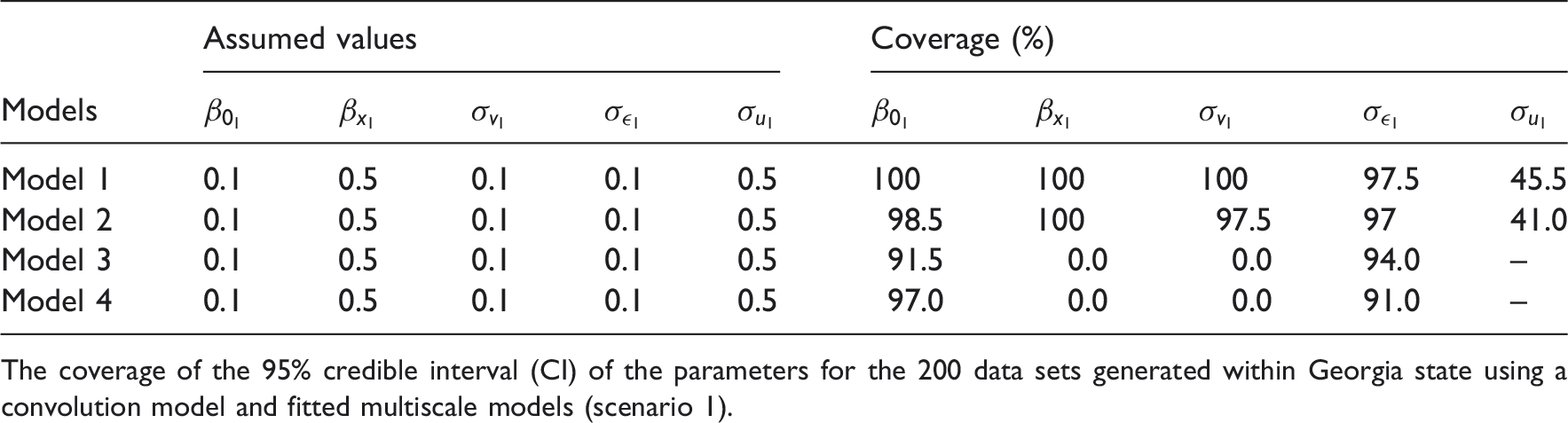
The coverage of the 95% credible interval (CI) of the parameters for the 200 data sets generated within Georgia state using a convolution model and fitted multiscale models (scenario 1).
Simulation results for data generated within the Georgia state map.
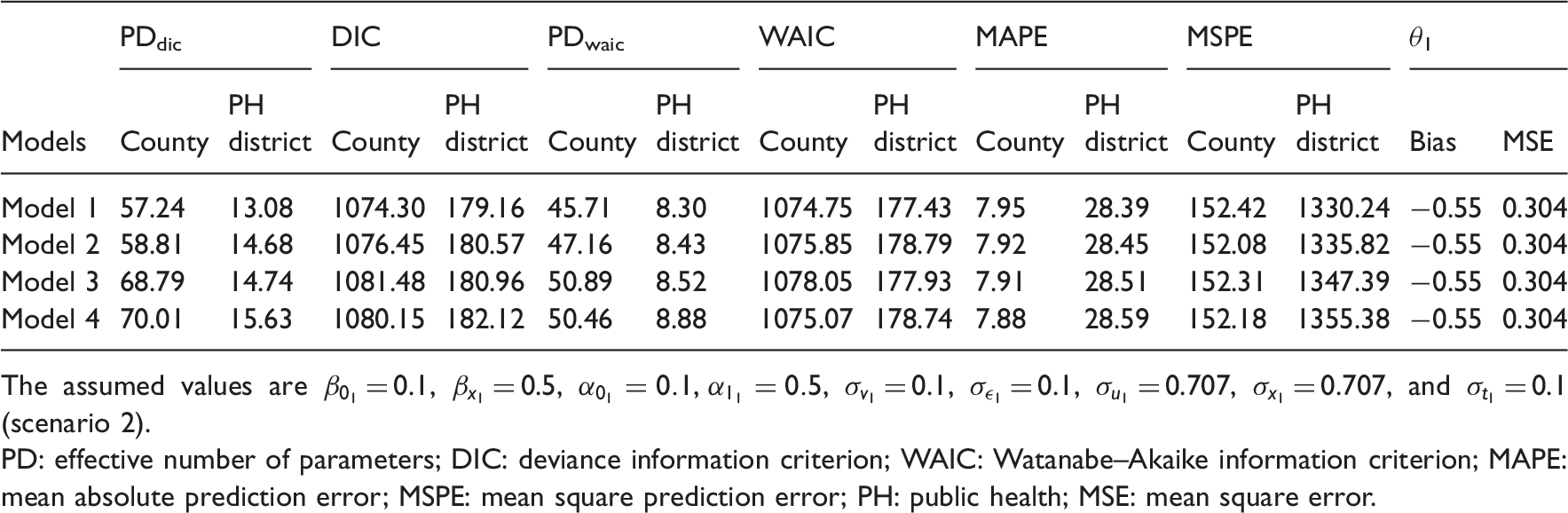
The assumed values are
PD: effective number of parameters; DIC: deviance information criterion; WAIC: Watanabe–Akaike information criterion; MAPE: mean absolute prediction error; MSPE: mean square prediction error; PH: public health; MSE: mean square error.
Summary of the estimated values and MSE of the parameters for the data generated within the Georgia state map (scenario 2).
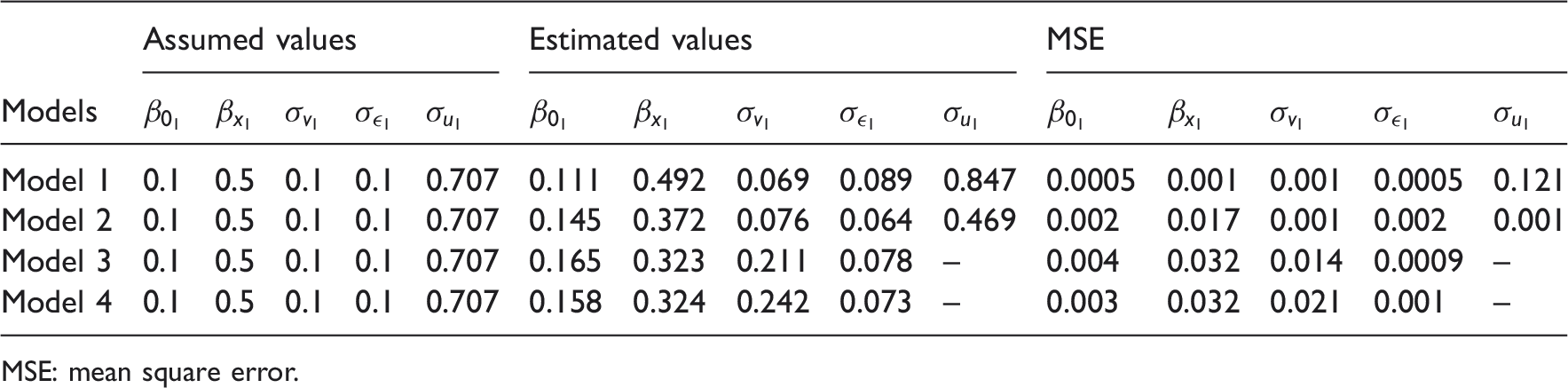
MSE: mean square error.
Furthermore, the coverage of the 95% CI for regression coefficient
To investigate how well the models recover the risk variation, we compared the generated risks and the risks obtained from the models as shown in Figures 5 and 6, respectively. We can see that all the models recover well the generated risk variation. There is a slight difference between the models in terms of recovering the risk variation.
Simulation study. Generated risks at each county ( Simulation study. Average of the risks obtained from the models fitted to the 200 data sets generated within the Georgia state (scenario 1).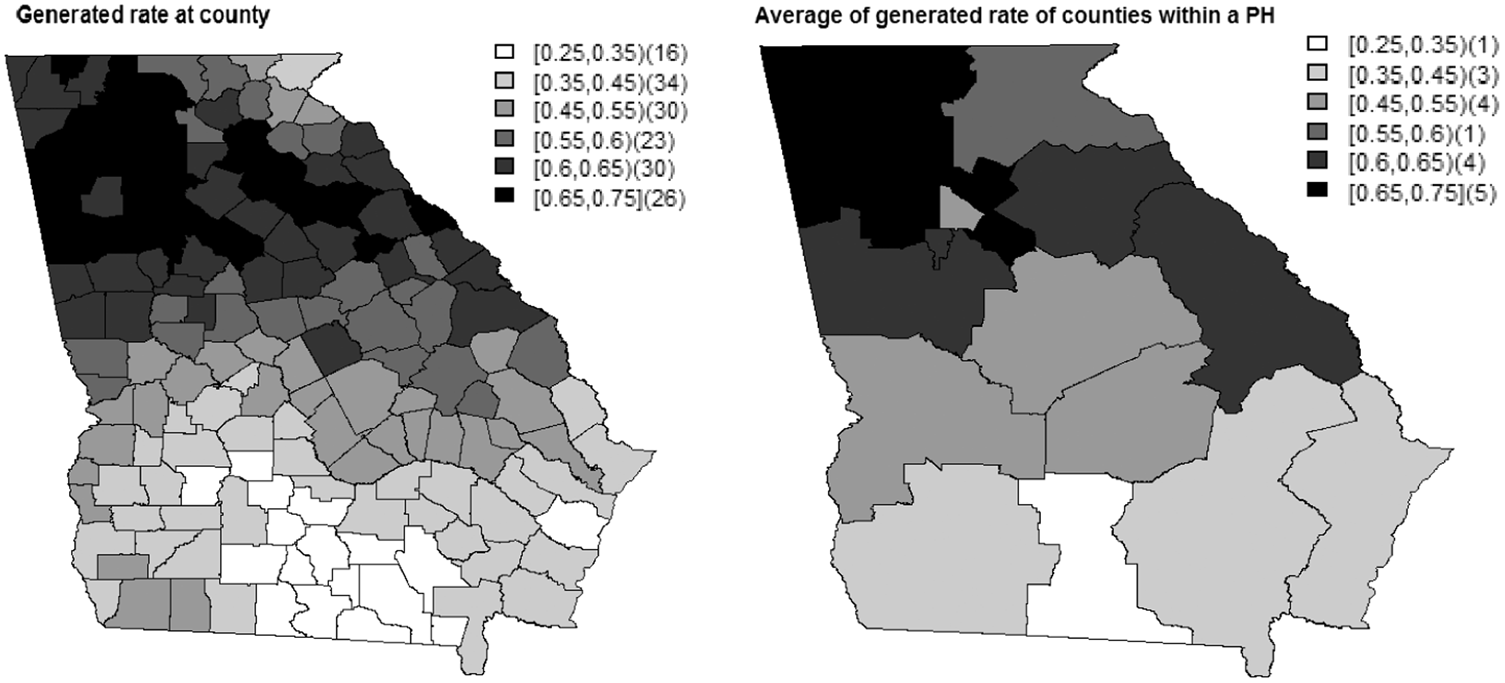
4.3.2 Scenario 2: A spatial structured ME
Simulation study.
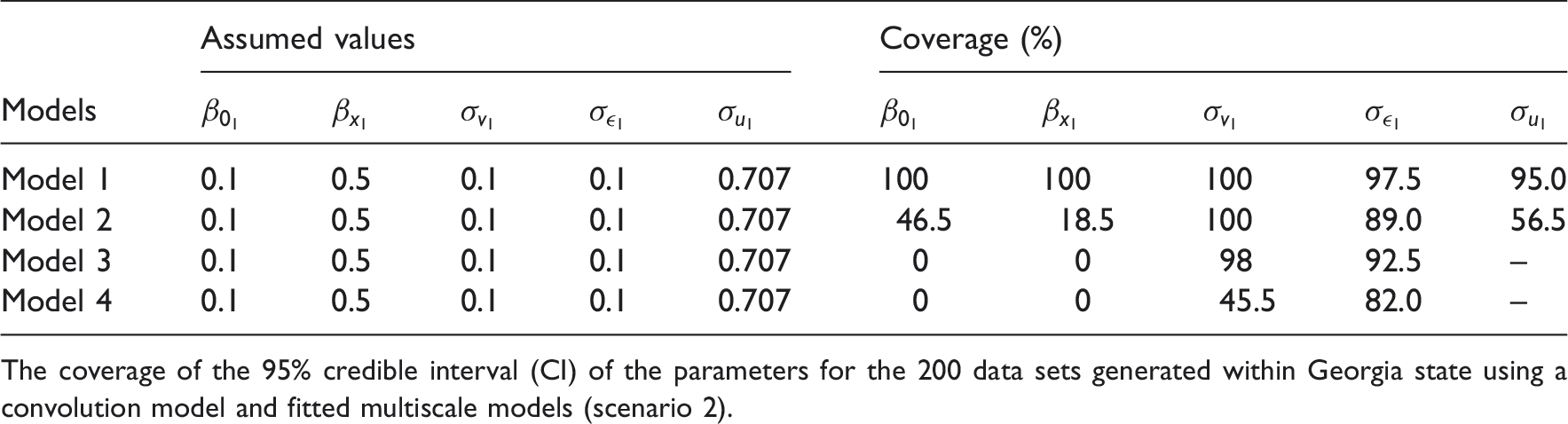
The coverage of the 95% credible interval (CI) of the parameters for the 200 data sets generated within Georgia state using a convolution model and fitted multiscale models (scenario 2).
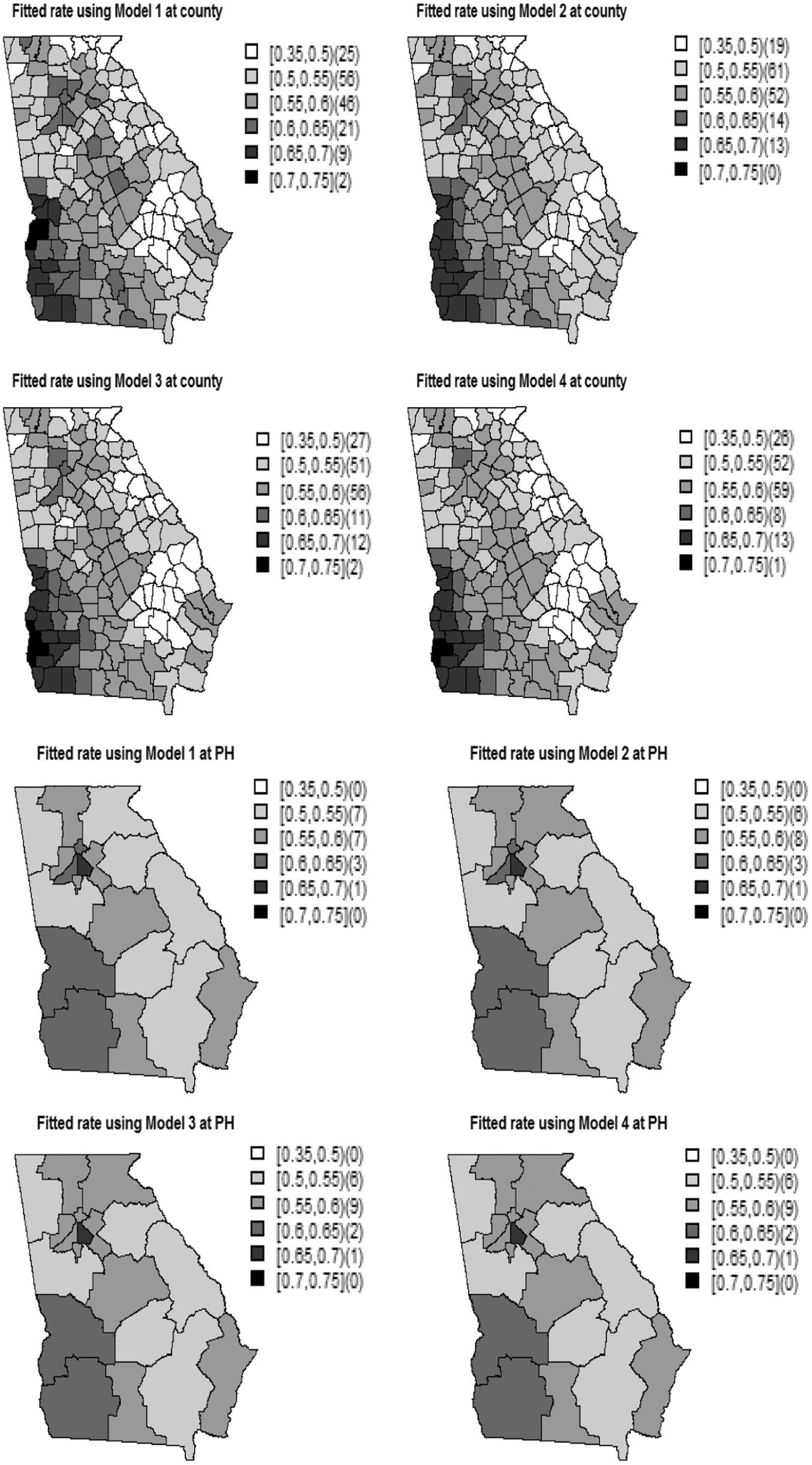
Figures 7 and 8 show the simulated risk, and the estimated risks are obtained from Models 1–4, respectively. We can see that Model 1 recovers the risk variation at the county and PH levels slightly better than the other models. For example, both the simulated and the estimated risks obtained from Model 1 are relatively low to the northeast of Georgia at the PH district, whereas the other models provide a relatively higher risk in those areas.
Simulation study. Generated risks at each county ( Simulation study. Average of the risks obtained from the models fitted to the 200 data sets generated within the Georgia state (scenario 2).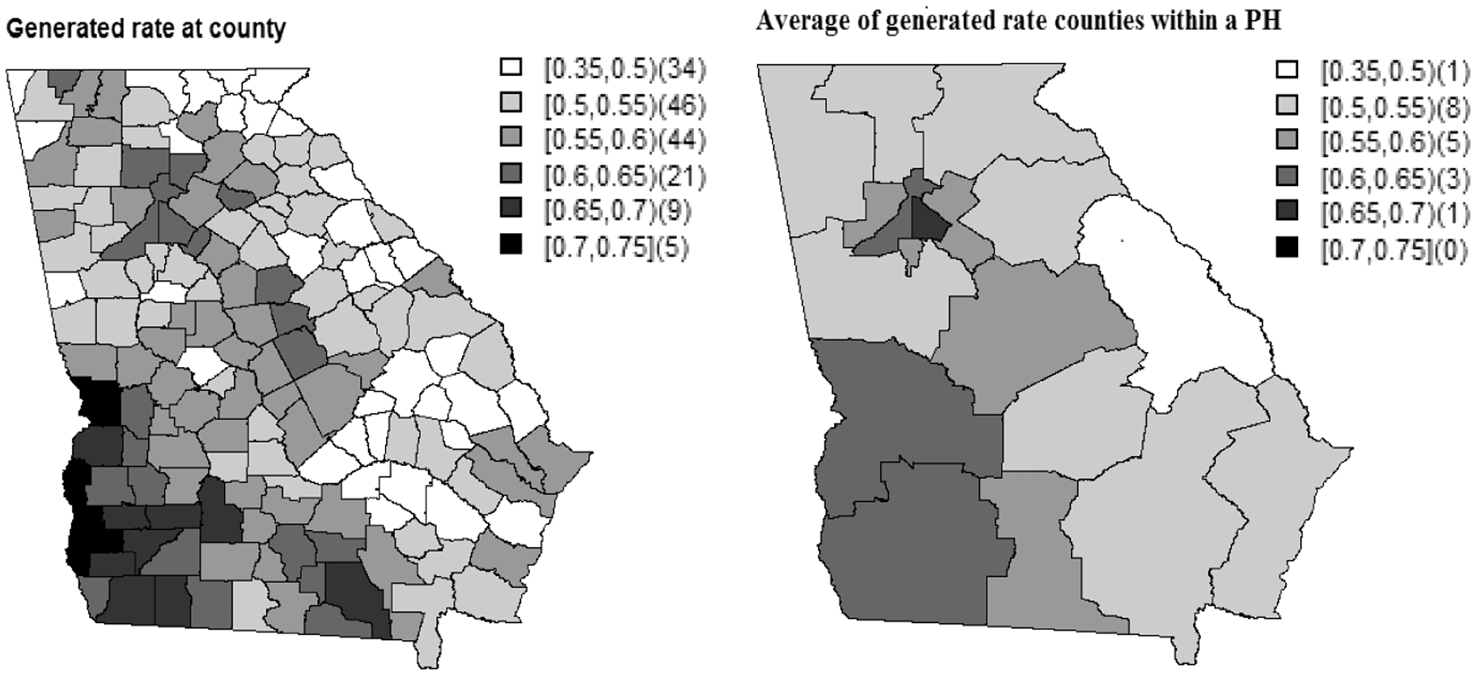
5 Application to Georgia VLBW incidence
Model fit and predictive accuracy results for Georgia VLBW data.
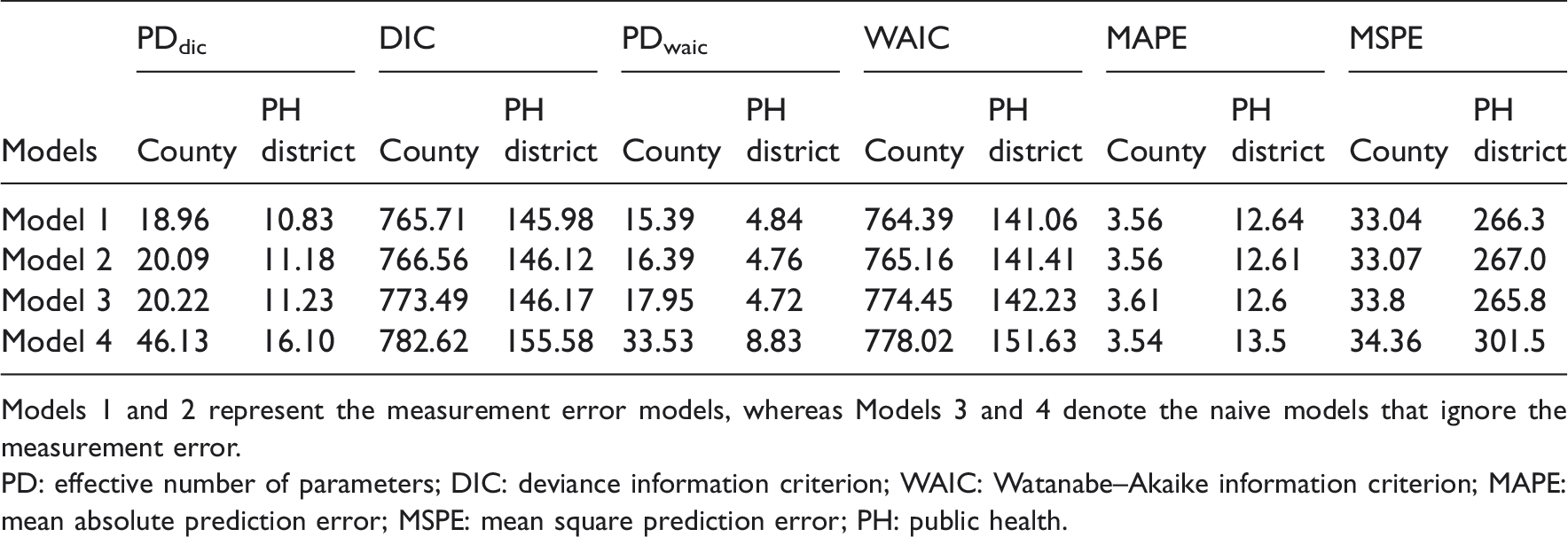
Models 1 and 2 represent the measurement error models, whereas Models 3 and 4 denote the naive models that ignore the measurement error.
PD: effective number of parameters; DIC: deviance information criterion; WAIC: Watanabe–Akaike information criterion; MAPE: mean absolute prediction error; MSPE: mean square prediction error; PH: public health.
Georgia VLBW incidence data.

Posterior mean estimates and standard error. Models 1 and 2 represent the measurement error models, whereas Models 3 and 4 denote the naive models that ignore the measurement error.
SD: standard deviation.
Shows the parameter is significant.
If we consider the absolute value of the estimate of the regression coefficient
One way to assess whether a given covariate can be used as an IV (T) to the true unobserved covariate (X) is that T and X should be significantly related.
3
Since the % of poverty is significantly associated with income Pearson residuals versus the standardized instrumental variable poverty at the county and PH levels for Model 1 (top figure) and Model 2 (bottom figure).
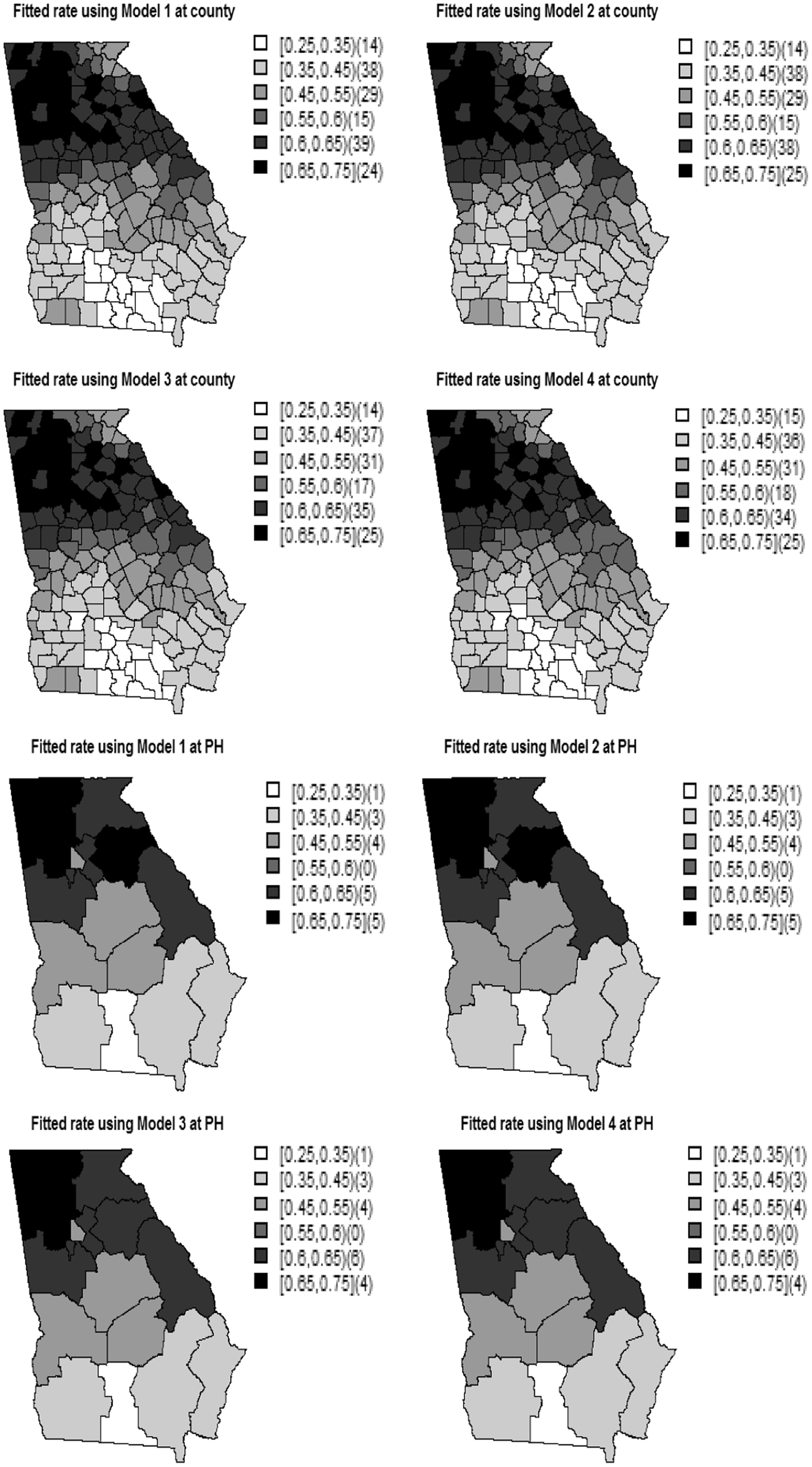
To compare the models in terms of explaining the disease risk variation, we computed the VLBW incidence as shown in Figure 10. We can see that there is a higher risk of VLBW incidence to the central and southwest GA as compared to the other regions.
Probability of VLBW outcome obtained from Models 1–4 at the county level (top figure) and at the public health (PH) district level (bottom figure).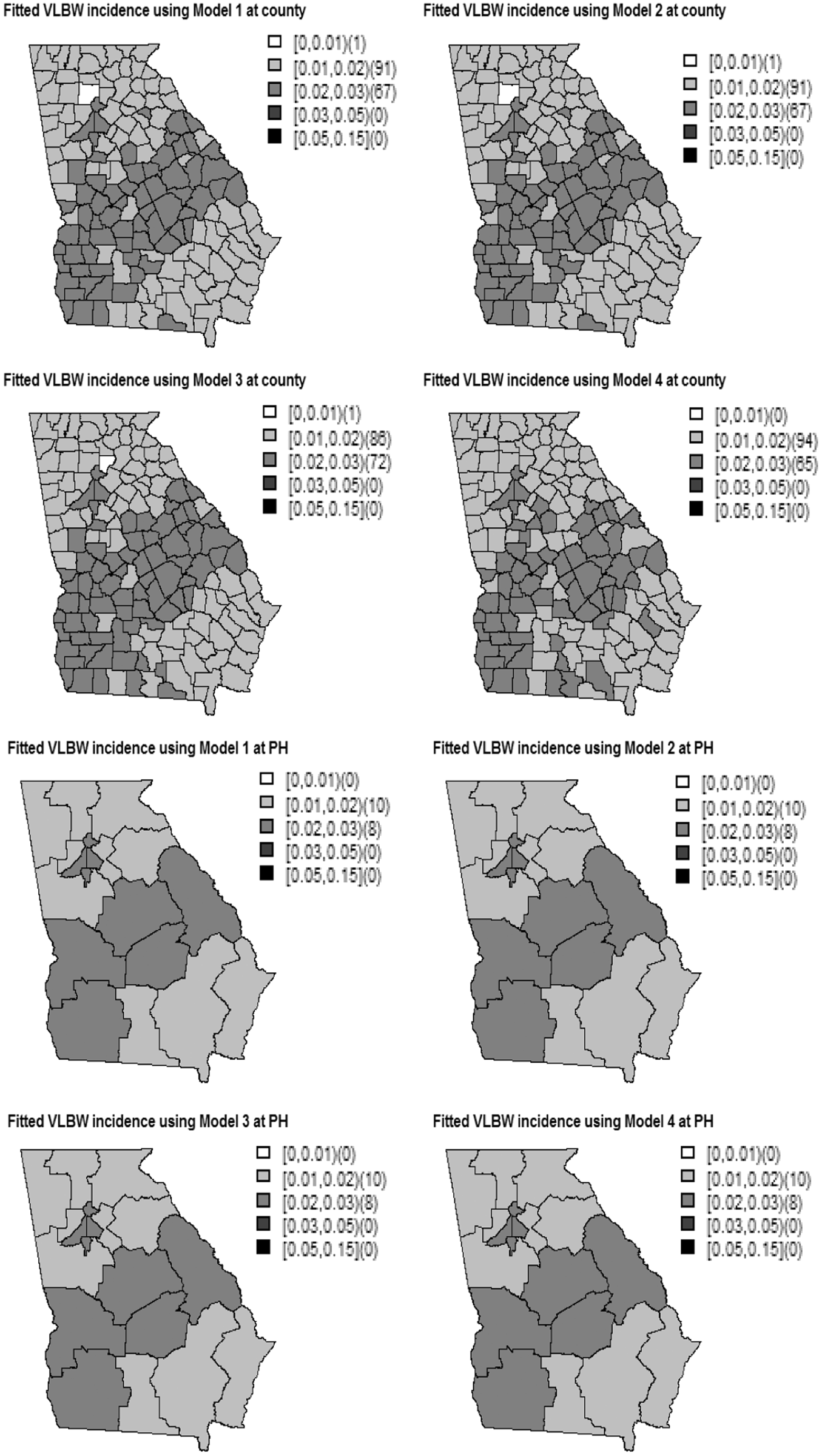
6 Discussion and conclusion
In this paper, our goal was to account for both ME and scale effect in our model-building for hierarchical multiscale spatial data, and we achieved this goal using multiscale classical ME models. We compared four models: the first two models (Models 1 and 2) accommodate the ME and the scale effect simultaneously. The third model (Model 3) only handles the scale effect. The fourth model (Model 4) ignores both the scale effect and the ME. The difference between the first two models (Models 1 and 2) is that Model 1 assumes a spatially dependent ME, whereas Model 2 assumes an independent ME. We evaluated the performance of the models in real and simulated data and found that accounting for both the ME and the scale effect improves the model fit as well as the prediction accuracy as compared to the model that ignores the ME and the scale effect (Model 4). Furthermore, the models that adjust for both the ME and the scale effect explain the risk variation better than the model that ignores both the ME and the scale effect. As it is the case for univariate data, we found that ignoring the ME for multiple scale data also underestimates the regression coefficient of the true unobserved covariate
When the outcome Y and the true unobserved covariate X share the same spatial variance components, it has been shown that ignoring the ME results in attenuated estimate of the regression coefficient and an inflated estimate of the spatial variance component. However, when the variance component of Y and X differ, no analytical expressions are available.
26
Note that our approach is different from the approach in Li et al.
26
because we assumed a PCAR for W, which is the proxy of X, whereas they
26
assumed the same variance component as in Y, i.e.,
Although we did not see a significant improvement in model fit and prediction accuracy for the VLBW incidence in Georgia, we found that the model that assumes a spatially dependent ME (Model 1) is slightly better than the model that assumes a spatially unstructured ME (Model 2). We also conducted a focused simulation study and obtained that Model 1 provides slightly better model fit and prediction accuracy than Model 2. Furthermore, Model 1 explains the risk variation slightly better than Models 2–4. Moreover, Model 1 provides more unbiased and precise estimates for the regression coefficient
There are several advantages of jointly modeling the risk variation at different geographical levels using a shared multiscale model after adjusting for ME. It results in a consistent negative effect of income on VLBW at both the county and PH levels. Accounting for the scale effect alone or ignoring both the ME and the scale effect, however, leads to inconsistent effect of income on VLBW incidence at the county and PH levels: While there is a significant negative effect of income on VLBW at the county level, we found insignificant income effect on VLBW at the PH level. Using Model 4, we obtained a negative effect of income on VLBW at the county level, whereas we obtained an insignificant positive effect of income on VLBW at the PH level. On the other hand, accounting for ME and scale effect provides unbiased estimate of the regression coefficient.
The models presented here only focus on the association between a response and an error-contaminated covariate. However, in the case of error-free covariates, our method could be extended as described in Section 3. Furthermore, we used a shared correlated random effect to jointly model the risk variation at different scale levels. Instead of sharing the correlated component, it is also possible to share the uncorrelated component or both the correlated and the uncorrelated random effects. In addition, we did not quantify the scale effect, and it can be done by assuming a multivariate PCAR or a multivariate normal distribution when the uncorrelated component is shared between the scale levels. In this paper, we conducted a focused simulation study to compare the models. An extensive simulation study that shows the importance of using a spatially structured ME remains our further research.
In summary, accounting for ME and scale effect due to data aggregation leads to a better description of disease risk variation than ignoring them. Moreover, the model fit and prediction accuracy obtained from the models that account for these two issues simultaneously are better than the parsimonious models. Ignoring the ME for multiscale data results in attenuation of bias and inconsistent estimate of the covariate effect at different scale levels. The methods proposed here are useful in health application and can be easily applied by health practitioners in standard software such as WinBUGS. Finally, we conclude that jointly modeling the disease risks at different geographical levels as well incorporating the ME for spatially aggregated data provides an accurate risk estimate that can be used for planning purpose.
Footnotes
Acknowledgements
The authors would like to acknowledge support from the National Institutes of Health via grant R01CA172805. The third author also acknowledges support from the IAP Research Network P7/06 of the Belgian State (Belgian Science Policy).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.