
Abstract
Epidemiologists often wish to estimate quantities that are easy to communicate and correspond to the results of realistic public health interventions. Methods from causal inference can answer these questions. We adopt the language of potential outcomes under Rubin’s original Bayesian framework and show that the parametric g-formula is easily amenable to a Bayesian approach. We show that the frequentist properties of the Bayesian g-formula suggest it improves the accuracy of estimates of causal effects in small samples or when data are sparse. We demonstrate an approach to estimate the effect of environmental tobacco smoke on body mass index among children aged 4–9 years who were enrolled in a longitudinal birth cohort in New York, USA. We provide an algorithm and supply SAS and Stan code that can be adopted to implement this computational approach more generally.
1 Introduction
Epidemiologists often wish to estimate quantities that are easy to communicate and correspond to the results of realistic public health interventions, such as changes to treatment guidelines or policy. Recent developments in the field of causal inference have shown that, under stated assumptions, observational data can be used to estimate such quantities. 1 Robins’ generalized computation algorithm formula (the g-formula) is one example of an approach from that field. 2 Using a parametric version of the g-formula, we can easily compare risks or rates of a health outcome in a population of interest under different exposure distributions. 3
One assumption of the parametric g-formula is that we have accurately modeled the association between the outcome of interest and both the exposures of interest and potential confounders. For example, if the rate for a particular outcome varies in a linear–quadratic function with exposure, then our model could capture that by including both a linear and a quadratic term for exposure. This assumption can be approximately satisfied by modeling the association using flexible models that incorporate nonlinear functions and interaction terms. In particular settings, such as the study of complex exposure mixtures, complex longitudinal data, or small data sets, this may result in the model smoothing over strata in which we have little or no data, resulting in highly unstable estimates.
Numerous statistical approaches have arisen for stabilizing model estimates in such scenarios. Of note, Bayesian approaches have shown promise for dealing with sparsely identified models through the use of parameter prior distributions to stabilize estimates that would be highly variable in an unpenalized maximum likelihood procedure.4,5 Further, even a set of default shrinkage priors can improve parameter estimation in multivariable regression models. For example in Stein’s paradox (see, for example, Efron and Morris’s description 6 ), the maximum likelihood estimator of a set of regression parameters will always be inferior to a well-chosen shrinkage estimator whenever the number of parameters exceeds two. The parametric g-formula is computationally intensive and requires modeling a large joint parameter space that includes the outcome of interest, confounders, and possibly exposure. When exposure and confounders are time varying, the modeling requirements increase. When models are specified (approximately) correctly, the parametric g-formula is a powerful inferential tool with applications in many fields of knowledge generation such as public health, environmental health, and medicine. A significant drawback of the parametric g-formula in the frequentist construction is that it relies on inadmissible estimators (i.e. we can always find a better estimator 7 ) of a large number of model parameters, the maximum likelihood estimates.
The primary objective of the current manuscript is to outline a foundational framework for Bayesian causal inference in epidemiologic studies that can be adapted for situations in which frequentist estimators may not be ideal. Such situations arise in cases of sparse data due to small sample size, when the number of parameters approaches sample size, when meaningful prior information is available, when covariates are highly correlated, 4 or when accounting for measurement error. 8 In particular, we focus on the case of small samples when the nuisance parameters of the parametric g-formula may be highly unstable, leading to poor finite-sample characteristics of the parameters of interest. We hypothesize that, in the vein of Stein’s paradox, a Bayesian approach with default shrinkage priors can result in estimates of marginal, population parameters that can improve on our predictions of the outcome of public health actions or interventions. This work extends current work in Bayesian, causal inference9–13 by taking a more general approach to the Bayesian g-formula.
Our work also builds on non-Bayesian approaches to estimating parameters of the g-formula, such as those given by Taubman et al, 14 Ahern et al., 15 Westreich et al., 16 and Keil et al. 3 In particular, the algorithm given in Section 3 is a Bayesian analog of the algorithm given by Taubman et al., 14 whereby we estimate the distribution of potential outcomes under exposure using the empirical distribution of predicted outcomes under hypothetical interventions on exposures. We show, using simulations, that finite sample characteristics of the g-formula can be improved by adopting a Bayesian framework. Thus, provided that causal assumptions are met, our Bayesian approach may provide more accurate predictions of potential public health interventions than other approaches. For example, in a recent example of the non-Bayesian g-formula, Keil and Richardson 17 estimated the potential impact of interventions on arsenic exposure in a cohort of copper smelters. In that example, the authors addressed the effects of airborne arsenic exposure on lung cancer and heart disease mortality. The latter effect estimate was estimated imprecisely, in part due to the highly variable baseline risk of heart disease mortality. Our approach could be applied directly to improve such an analysis by providing shrinkage priors or by leveraging the numerous studies done of nonairborne arsenic exposure and heart disease, which could, for example, provide a reasonable prior range for the estimate of association between arsenic and heart disease mortality. We also show here that the Bayesian Lasso is a viable approach to variance reduction. We are not aware of alternative approaches that can directly leverage prior information or shrinkage estimators while still providing impact estimates for hypothetical exposures. Such estimates are essential in deriving exposures standards in occupational and environmental settings, where precise estimates of risk are necessary to address the cost–benefit between exposure control measures and population health.
The novelty of this work is based on four points: (1) we derive a Bayesian g-formula approach in the potential outcomes framework, (2) we show that the Bayesian g-formula is possible using off-the-shelf MCMC software, (3) we provide an example showing that the approach is naturally “modular” and can be used to incorporate existing Bayesian solutions to problematic data, and (4) we demonstrate that the Bayesian g-formula has desirable frequentist properties under some choices of default shrinkage priors. This last point indicates that the Bayesian g-formula may have useful practical applications in scenarios when the frequentist g-formula may typically be used.
In Section 2, we define notation and demonstrate the Bayesian g-formula in time-fixed data, and we discuss some potential settings of interest. We outline an algorithm in Section 3 that can be used to develop software for this approach in a general Markov chain Monte Carlo estimation framework. This algorithm builds on non-Bayesian approaches to estimating parameters of the g-formula, such as those given by Taubman et al., 14 Ahern et al., 15 Westreich et al., 16 and Keil et al. 3 In particular, we focus on the use of Bayesian methodology to improve on the finite sample performance of the g-formula.
In Section 4, we assess the ability to improve parameter estimation using default shrinkage priors by simulation. In Section 5, we demonstrate our approach using a longitudinal study of environmental tobacco smoke exposure and childhood body mass index (BMI) and extend our approach to nonnormal shrinkage priors using a version of the Bayesian least absolute shrinkage and selection operator (LASSO). 18 We close in Section 6 with a discussion of the assumptions underlying our approach and speculate about future extensions. In Appendix 1, we derive our approach for both the time-fixed and longitudinal settings and we supply code in Section 8 to implement our approach for SAS and Stan programming languages.
2 The Bayesian g-formula
2.1 The parametric g-formula
To simplify our presentation, in this section we nest our example in the context of an observed set of time-fixed variables,
In this setting, we are interested in the marginal distribution of the potential outcome
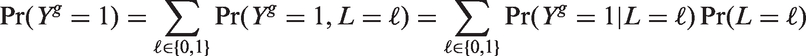
To facilitate the expression of these quantities in a Bayesian framework, we adopt a more general notation and instead express the distribution of the potential outcome as

The parametric g-formula extends the g-formula given in equation (1) by characterizing the conditional components
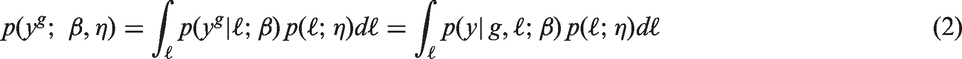
The utility of the g-formula becomes apparent when one considers that the functional form of the relationship between X and Y may be a complicated nonlinear function in nonbinary data, possibly with high-order interaction terms. Note that, under such a scenario, the counterfactual distribution
The parameters β or η may not be stably estimated when L or X is of high dimension relative to the sample size, when estimating effects in small samples, or when there is high correlation between elements of the data (i.e. due to variance inflation or finite sample bias). In such settings, common approaches are to create a more parsimonious model, apply some penalization term/regularizing, or adopt a Bayesian framework to stabilize estimates using prior knowledge. We adopt an approach that recasts the parametric g-formula within a Bayesian framework as a way to embrace the interpretability of the g-formula approach while employing the variance reduction properties of Bayesian inference. We focus on shrinkage estimation, in which we allow the possible introduction of some bias in exchange for higher precision and an overall reduction in mean-squared error (MSE).
2.2 A Bayesian approach
Following Rubin
22
and Saarela et al.,
12
we consider a Bayesian version of the potential outcome distribution, the posterior predictive distribution
Our quantity of interest is the posterior predictive distribution of the potential outcome under the intervention g, which is defined as
The posterior predictive distribution of the potential outcome under intervention g is given in our example as
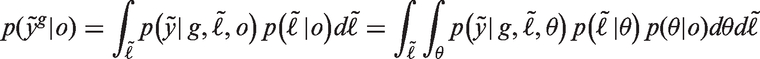
Under counterfactual consistency and the assumptions of conditional exchangeability, positivity, and parameter variation independence (detailed in Appendix 1),
Given a likelihood
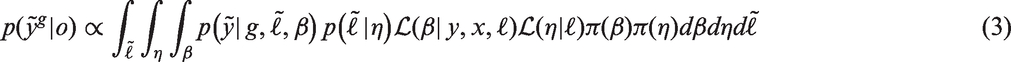
To conceptualize the computation,
3 Bayesian g-formula algorithm
Here we present an algorithm for estimation using the Bayesian g-formula to numerically approximate equation (3), as well as quantities derived from a comparison of
Generalizing our approach to the longitudinal setting requires choosing some time scale, such as time on study, calendar time, or age, and we denote specific points on that time scale as t, which we assume to be fine, yet discrete. We denote the value of the exposure at time t as X(t) and let the history of exposure up to and including time t be
We let
After we have selected an appropriate target population (defined by Specify a model for each component of Specify a time-averaged model (or set of time-specific models) for
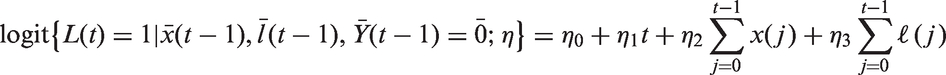
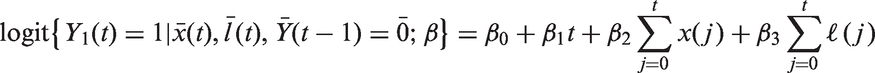
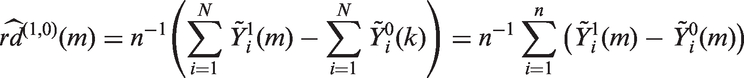
4 Simulation study
We examine the impact of null-shrinkage priors in a Bayesian g-formula approach using two simple simulation studies in scenarios in which shrinkage parameters might typically be used. Our first simulation is in a time-fixed setting in which we have measured an exposure and a confounder that are highly correlated. Such settings are common in environmental epidemiology, such as in the air pollution literature where the effects of one pollutant might be difficult to estimate precisely due to high correlation with another pollutant from a similar source. Our second simulation deals with a simple, time-varying data scenario in small samples.
For both simulations, we are primarily interested in
For the standard g-formula, the risk difference and its standard error were estimated using a nonparametric bootstrap. For each of the M iterations, we created S = 1000 bootstrap samples of each of the M simulated datasets and calculated a risk difference using the Monte Carlo approach we described previously,
3
which involves taking D draws from each bootstrap sample, where we set D = 2000. The risk difference for each of the M iterations was taken to be the mean risk difference across the S samples, and the standard error was calculated as the sample standard deviation for these S samples. Thus, for each analysis, the standard g-formula required simulation across
For the Bayesian g-formula, we analyzed each dataset using the MCMC procedure of SAS 9.4. Each analysis was performed using C = 10,000 iterations after a burn-in of B = 1000 iterations. We estimated
We calculated 95% confidence/credible intervals for each analysis by as the 2.5th and 97.5th percentiles of the bootstrap/MCMC estimates. Confidence/credible interval coverage was calculated as the proportion of all datasets for which the 95% confidence/credible intervals contained the true risk difference. We also compared the standard deviation of the bias across the M samples for each approach as a measure of precision. MSE, our primary metric of comparison, was calculated as the average across the M iterations of the squared bias plus the variance. We also calculated the mean-squared (in-sample) prediction error (MSPE) as the mean of the squared difference between individual predictions of
For computational considerations, all simulations are performed on samples of 100 or fewer units. Data-generating mechanisms were designed to maximize precision of the parameter of interest in such small data situations. We expect that the choice between the Bayesian g-formula and the standard g-formula will be driven by the sparsity of data, which occurs even in large samples as the number of parameters grows. We expect that general statements about bias–variance trade-off from our simulation results will apply to larger sample sizes in more realistic scenarios, though the (unknown) ideal amount of shrinkage that minimizes MSE will vary according to the data, the model, and the parameter of interest.
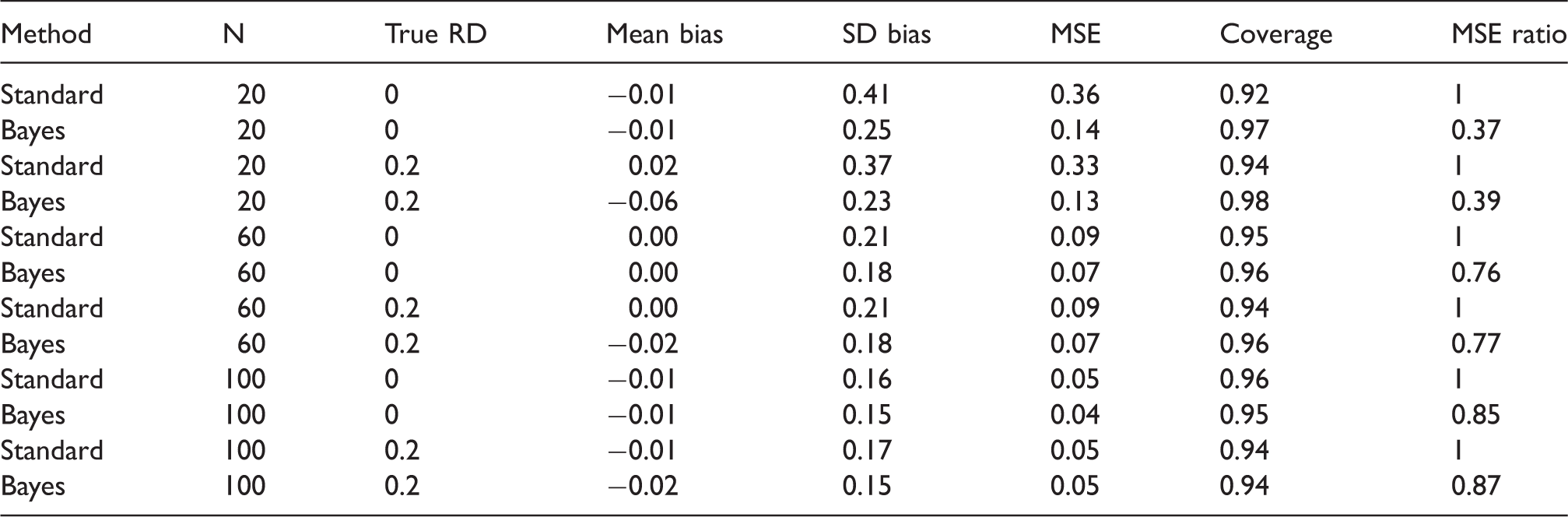
4.1 Time-fixed example
We simulate a simple dataset to represent a scenario in which two highly correlated measured variables may be independently associated with an outcome, and we are interested in the independent effect of a single exposure X. The simulated data consist of a binary outcome Y, a binary exposure X, and a binary covariate L, where X and L are correlated with coefficient ρXL.
The data are simulated as follows:
Select L = 1 if
We repeated each of these simulations for values of the correlation coefficient equal to (0.4, 0.8, 0.9). Each analysis was repeated under a true risk difference of 0 and 0.2.
In a time-fixed setting, the standard g-formula requires only a single model to predict the outcome (if we take
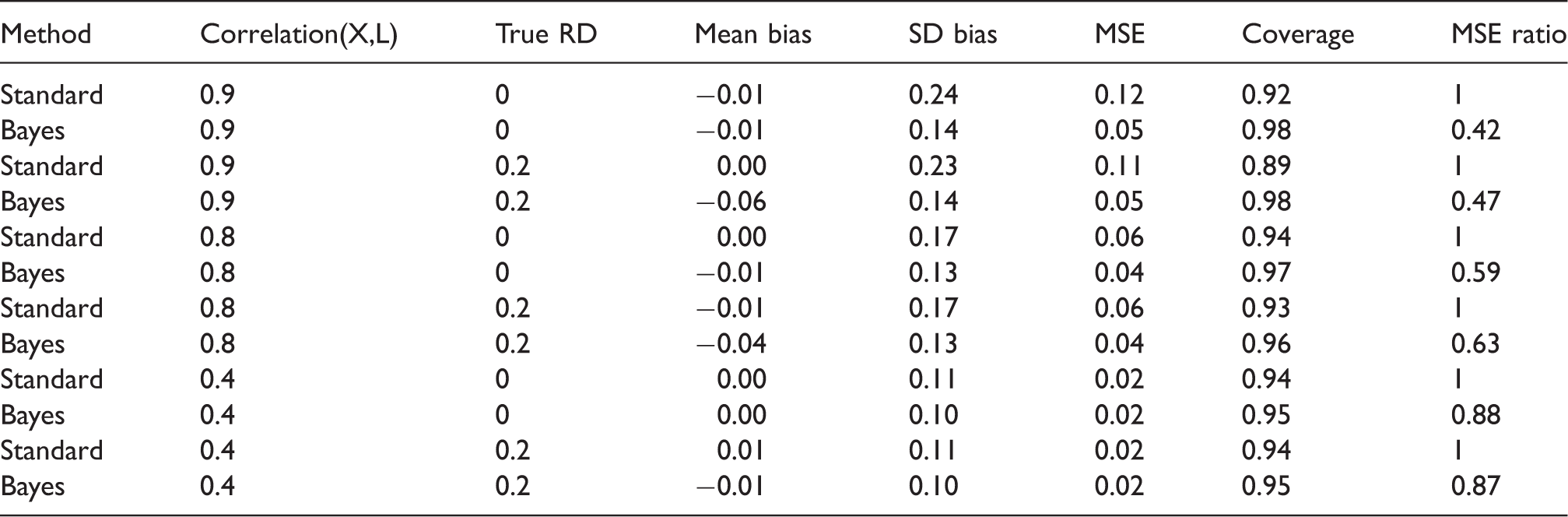
As expected, the bias was larger for the Bayesian g-formula than for the standard g-formula (Table 1). The sample variance was higher for the standard g-formula estimator, however. With respect to MSE, the Bayesian g-formula under moderately informative priors outperformed the standard g-formula at correlation coefficients of 0.8 and 0.9, and 0.4. Credible interval coverage was, in general, conservative, while confidence interval coverage in the standard g-formula was anticonservative at higher values of the correlation coefficient. Overly precise, null-centered prior information can lead to overshrinkage when the true risk difference is nonnull, in which the MSE starts to increase as one posits increased precision (decreased variance) for the prior distributions of β for the Bayesian g-formula. For example, the minimum MSE for a risk difference of 0.2 occurred at a prior variance of 0.3. At prior variances larger than 0.3, the MSE increases due to larger posterior variance of the risk difference. At prior variances smaller than 0.3, the MSE increases due to larger bias in the posterior mean of the risk difference. When the true risk difference is null, decreasing prior variance leads to vanishing MSE because null values for individual coefficients in the Bayesian g-formula imply a null value for the posterior risk difference (Figure 1).
Mean-squared error for the risk difference as a function of correlation between X and L and of the prior variance on regression coefficients (log-odds ratios) for simulation given in Section 4.1. Simulation scenario 1: Two correlated exposures, one time-fixed confounder model intercept priors were vague ( MSE: mean-squared error.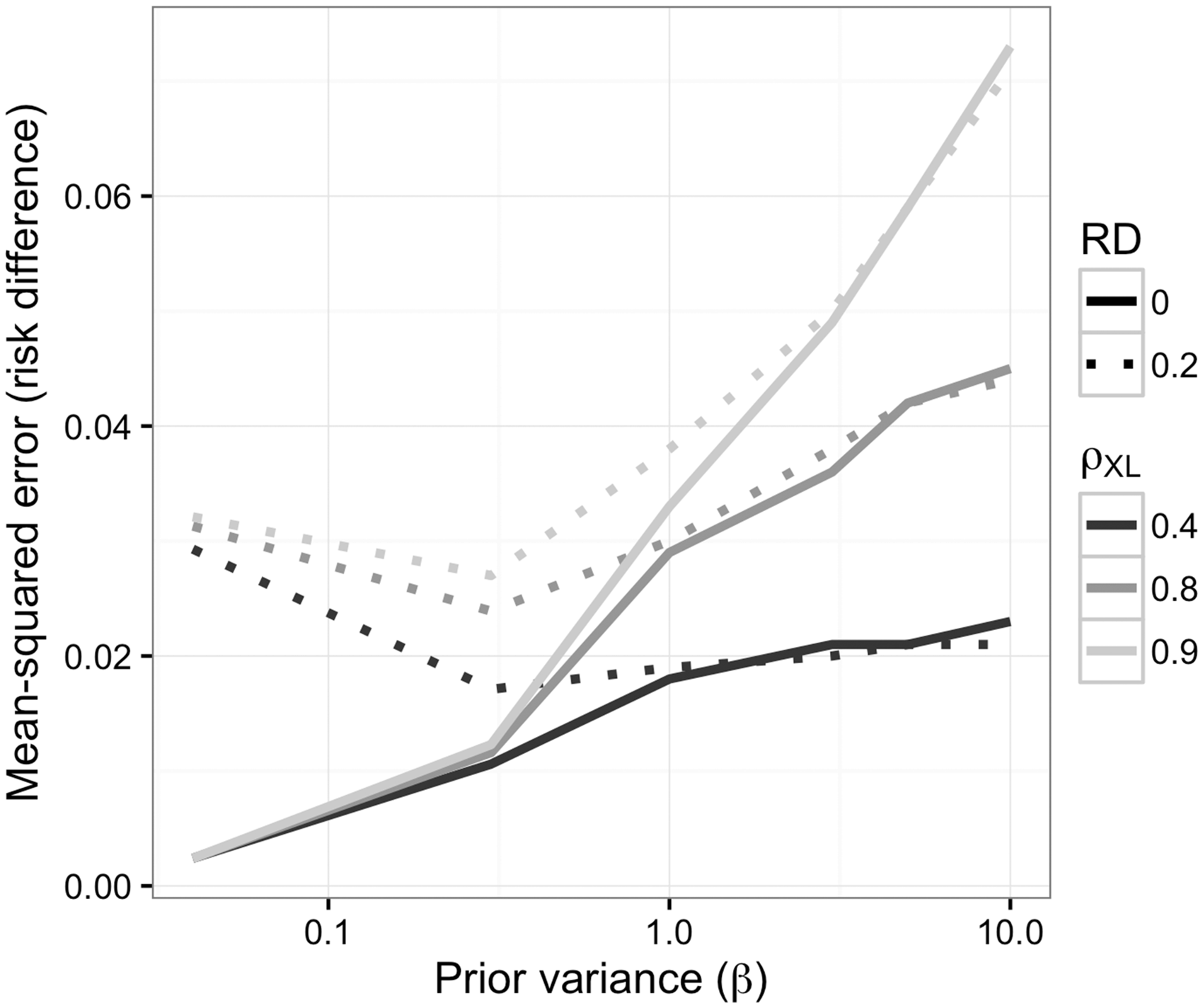
4.2 Time-varying example
We simulate a simple dataset with a time-varying exposure. The data, collected at two time points,
The data are simulated as follows:
In a time-varying setting, the parametric g-formula requires a model to predict L(1) and Y(1). For both the standard and the Bayesian g-formula, we use the correct model (i.e. the logistic model implied by the data-generating mechanism) to predict L(1) (with coefficients η) and we predict Y(1) using a logistic model with terms for
As in our time-fixed simulations, under moderately informative, null priors, the bias was larger and the sample variance was smaller for the Bayesian g-formula than for the standard g-formula. In the samples we examined, the Bayesian g-formula outperformed the standard g-formula with respect to MSE (Table 2). As in the previous example, at increasingly higher precision of prior information, the MSE for the Bayesian g-formula can increase as a result of overshrinkage (Figure 2). Unlike the simulation shown in Figure 1, there is no inflection point for which a decrease or increase in prior variance will lead to an increase in the MSE. This is likely due to the small number of values we used for the prior variance, and we speculate that MSE reaches a minimum at some prior variance between 0.04 and 0.3.
Mean-squared error as a function of sample size and the prior variance on regression coefficients for simulation given in Section 4.2. Simulation scenario 2: One exposure, one time-varying confounder that depends on exposure. Model intercept priors were vague ( MSE: mean-squared error; RD: marginal risk difference comparing ‘always exposed’; SD: standard deviation.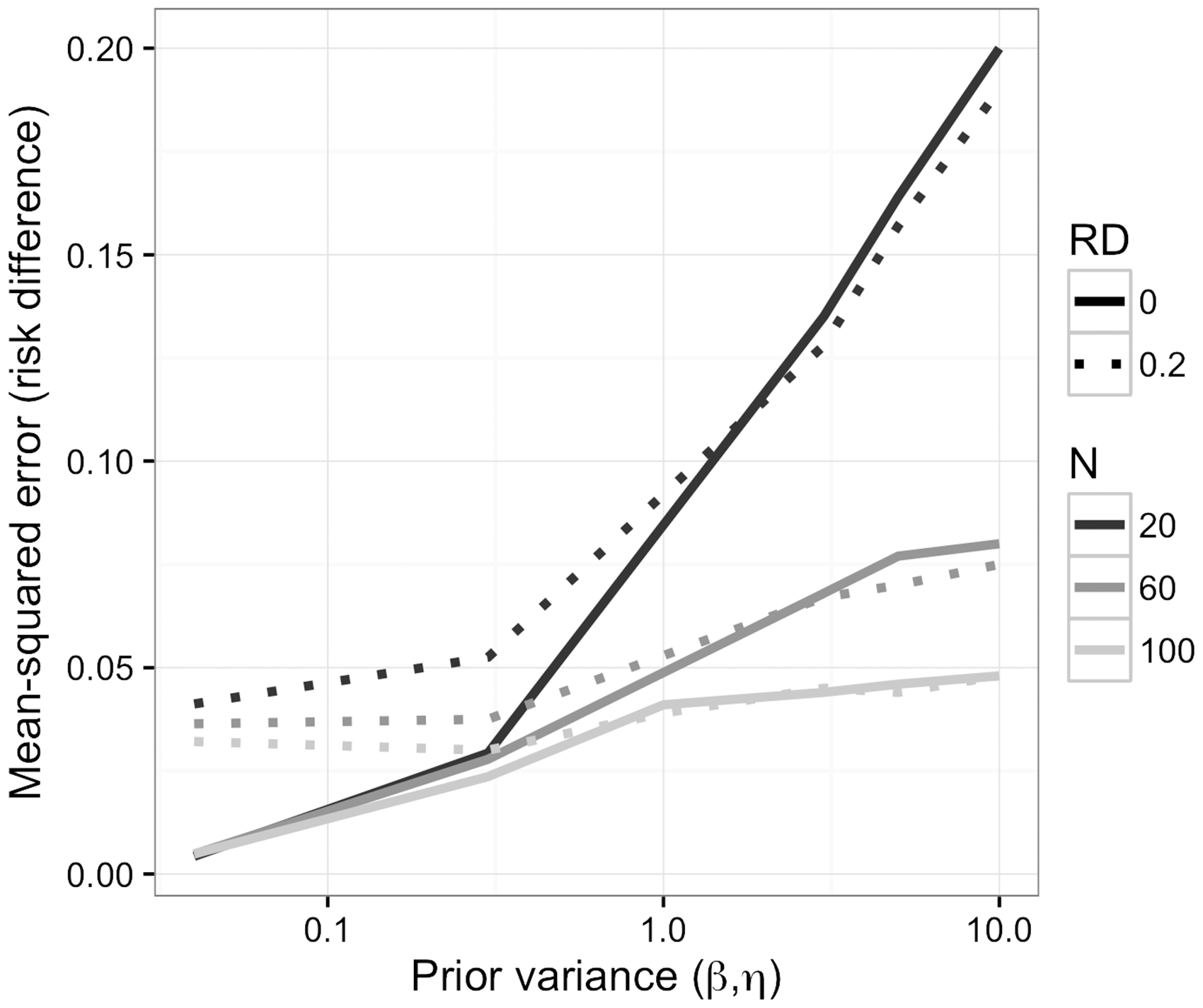
5 Application
We estimated the impact of interventions on environmental tobacco smoke (ETS) on childhood BMI z-scores in a prospective birth cohort. Here we propose to estimate the effects of an intervention that could affect smoking without otherwise influencing BMI (to reiterate, the intervention is assumed to be an instrument for environmental tobacco smoke exposure with respect to BMI). The Mount Sinai Children’s Environmental Health and Disease Prevention Research Center enrolled 479 primiparous women with singleton pregnancies in New York City between 1998 and 2002. The final cohort consists of 404 mother–infant pairs who met previously described inclusion criteria. 27 Children were invited to attend follow-up visits at approximately 4–5.5, 6–6.5, and 7–9 years of age (hereafter referred to as visits 1, 2, and 3, respectively) and 69 children attended all three visits. For simplicity, we assume that loss to follow-up is missing completely at random. Maternal baseline characteristics were ascertained via questionnaire at enrollment. At each follow-up visit, we calculated age- and sex-standardized BMI z-scores and classified children as physically active or inactive as described by Buckley et al. 28
We estimated posterior distributions for the BMI z-score using the Bayesian g-formula approach. Our specific approach involved a pooled-logistic model for physical activity and a pooled-linear model for the BMI z-score. The predictors in the physical activity model included all baseline covariates (maternal age (quadratic polynomial), maternal prepregnancy BMI (quadratic polynomial), maternal height (linear), smoking during pregnancy (yes, no), race (white, black, or other), education (some high school, high school grad, some college, college grad)) as well as time-varying covariates for cumulative number of visits at which physical activity was reported (lagged one visit, range 0–2), cumulative visits at which ETS was reported (lagged one visit, range 0–2), child’s age (months), and product terms for cumulative ETS and all other variables. The model for BMI z-score used identical predictors and additional terms for current ETS, cumulative years of ETS, and current PA.
For the physical activity model, we used moderately informative priors with 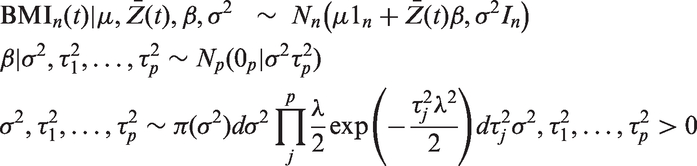
A linear model for the BMI z-score is standard in the literature. We assessed the fit of a linear model for the BMI z-score using the White test for heteroscedasticity,
29
which yielded an Lagrange multiplier statistic of 207 (p = 0.45). A plot of standardized residuals versus the predicted BMI z-score is given in Figure 3. For visits 1, 2, and 3, we estimated the median BMI z-score under the interventions “always exposed to ETS” and “never exposed to ETS,” as well as the difference in the mean BMI z-score under these interventions. We report the median of the posterior distribution of the population mean BMI z-score under each intervention (reported as “mean” or “mean z-score”). We report the 2.5th and 97.5th percentile of the posterior distributions as 95% credible intervals.
Pearson residuals versus predicted BMI z-score from the linear model to predict BMI z-score in the example given in Section 5. Dashed line represents a LOESS line of fit to the data shown in the figure. BMI: body mass index; LOESS: LOcal regrESSion.
Comparing childhood BMI z-scores after potential interventions on environmental tobacco smoke exposure in 69 children, New York, USA, 2004–2008.

BMI: body mass index; CI: confidence interval; CrI: credible interval.
Mean age at visit.
Using a standard linear regression model adjusted for age and all baseline variables, we estimated that the BMI z-score at each visit was 0.15 higher among those actively exposed to ETS than among those not exposed (95% confidence intervals = −0.20, 0.49). After also adjusting for physical activity, this association increased to 0.22 (95% confidence intervals = −0.12, 0.57). The regression results do not correspond to potential interventions, as in the Bayesian g-formula and so the two results are difficult to compare directly. We note that the magnitude of association was smaller in the regression analysis. In the regression models, we can potentially capture an unbiased estimate of the association between BMI and the ETS behavior reported at the current visit. Thus, this regression model does not capture potential cumulative effects of ETS exposure at prior ages. We fit a model using cumulative ETS exposure, but this model may be subject to uncontrolled confounding by physical activity. After adjusting for physical activity, our estimate could be interpreted (under the assumptions outlined in Appendix 1) as a cumulative direct effect of ETS on BMI that does not operate through physical activity. Further, if there is effect measure modification by physical activity on the absolute scale, then the adjusted regression estimates will not have an easily defined interpretation with respect to informing interventions.
While our results should be seen as primarily illustrative, they show that the effects of interventions on childhood risk factors for obesity can be estimated using standard epidemiologic data, provided that the interventions act as instruments for exposure (a “no side effects” or “treatment-version irrelevance” assumption 30 ). Such inference is valuable in placing the results of observational studies in real-world contexts to prioritize public health actions. We could easily compare the benefits of interventions on smoking to the benefits of interventions on physical activity or diet, for example. 14 Such comparisons are difficult with standard regression approaches, even under conditions in which estimators from regression models are unbiased.
One potential weakness of the Bayesian LASSO approach is that we assume that all model coefficients are exchangeable. It is likely that prior BMI is a much stronger predictor of current BMI than the other confounders considered, so future applications of the Bayesian g-formula could implement nonparametric Bayesian approaches that allow coefficients to shrink to different means. To assess whether our results might be sensitive to the shape of the LASSO prior, we estimated the risk difference using null-centered, normal variables (
6 Discussion
From a Bayesian perspective, the g-formula is a natural approach to causal inference. The frequentist version of the g-formula uses the basic rules of probability calculus, along with the language of counterfactuals and explicit identification assumptions, to make inference on the effects of treatment regimes or interventions. Other studies investigating postnatal exposure to environmental tobacco smoke in relation to child body size have also reported positive associations.31–34 For example, in the Menorca subcohort of the Spanish INMA study, children living with one or two smoking parents at age four years had higher BMI z-scores at ages 4–14 years. 33 BMI z-scores were on average 0.21 (−0.05 to 0.48) or 0.27 (−0.07 to 0.61) units higher among children living with one or two smoking parents compared to nonsmoking parents, respectively.
The observed reduction of the MSE makes the Bayesian g-formula attractive for data analysis from a frequentist perspective. Our simulations suggest that, even in a limited longitudinal setting, default shrinkage priors on conditional model coefficients can result in improved frequentist results for marginal, population parameters (for whom the prior is a complex function of the model parameters and target population covariate distribution). Overshrinkage can result in an increase in the MSE, as well. Our example in Section 5 shows that the Bayesian g-formula is useful in the epidemiologic setting that originally motivated the g-formula: longitudinal data in which exposures, covariates, and outcomes vary over time. 3 The approach is useful for making easily interpretable inference, even when data or the relationships between variables are highly complex. Thus, the results are easily communicated with stakeholders, public agencies, and nonstatisticians.
Our approach has much in common with recent examples of Bayesian causal inference and Bayesian predictive inference. Namely, Arjas and coauthors developed an approach analogous to the Bayesian g-formula under a causal framework that does not utilize potential outcomes (described in a general setting in Arjas and Parner 9 and under a Bayesian framework in Chapter 7 of Berzuini et al., 35 with a practical example given in Arjas and Saarela 36 and Saarela et al. 37 ). Robins and Greenland 38 refer to the approach that does not utilize the language of potential outcomes as an “agnostic” causal model. In contrast, our approach is derived under the original causal framework of Rubin, 22 which bases causal inference on the concept of potential outcomes. The approach of Chib 10 is identical to the g-formula in the time-fixed setting. A previous example by Wang et al. 13 used the Bayesian g-formula to estimate the effect of a change in ventilation practices on survival in patients with acute lung injury. Notably, none of the examples mentioned focused on Bayesian inference as a way to improve the frequentist performance of causal inference methods. Using our general framework, we build on these applications by integrating the Bayesian Lasso, which demonstrates the potential utility of our approach to use other shrinkage or dimension reduction procedures to improve causal inference. The modularity of our approach allows for the straightforward incorporation of other Bayesian regression solutions to problems such as inference with highly correlated covariates 4 or accounting for measurement error. 8
As we show, Bayesian causal inference can be framed as a prediction problem. De Los Campos et al. 39 previously used a Bayesian LASSO approach to predict quantitative traits in wheat and mice based on genetic markers. In contrast to their approach, our work frames prediction in terms of causal inference, where the goal is not simply to predict observed outcomes, but to predict such outcomes had we been able to change an exposure or treatment. Interestingly, De Los Campos et al. 39 showed that the Bayesian LASSO can be used when the number of parameters exceeds the sample size, a canonical problem in high-dimensional data. Our approach could be used to extend these results to make causal contrasts in higher dimensional problems.
A characteristic feature of our approach is that we do not place priors directly on the quantity of interest. Thus, the bias–variance trade-off of the Bayesian g-formula is not targeted toward the causal estimand. Similar claims can be made about frequentist parametric g-formula. Recent likelihood-based approaches, such as targeted maximum likelihood (minimum loss) estimation (TMLE), remedy this feature of standard causal inference approaches by “targeting” the estimator at the parameter of interest, rather than the nuisance parameters that go into predicting the outcome or the treatment/exposure. 40 TMLE is typically combined with SuperLearner, which is an ensemble learning approach that averages predictions across many (possibly semiparametric or nonparametric) models. 41 More generally, TMLE falls under the heading of “double-robust” methods, which are consistent if either the outcome model or the treatment/exposure model is correct. Such methods are typically based on restricted-moment models developed in the semiparametric literature, 42 which do not imply a full likelihood and thus are not easily incorporated into a Bayesian framework. Graham et al. 43 used an approach on Bootstrap methods, which has approximate Bayesian inference for the posterior predictive distribution of causal effects. Because such an approach is outside of a formal Bayesian framework, it is difficult to ascertain whether it could easily incorporate other aspects of a formal Bayesian analysis that accounts for problems such as measurement error or missing data. However, it is more robust to model misspecification than our approach. We address this shortcoming by ensuring that the posterior is flexibly parameterized, which allows for a variety of model forms. Thus, the Bayesian g-formula can be cast as one alternative to double-robust estimation as a way to reduce model specification assumptions. Bayesian model averaging 44 may be an additional way to incorporate robustness to model misspecification in our framework.
In more general settings with higher dimensional data, the need for flexibility grows even further as approximating correct model specification is more difficult. Other causal approaches, such as the use of inverse probability weighting to estimate the parameters of a marginal structural model, can marginalize over some of these parameters. However, such an approach necessitates modeling the (possibly longitudinal) exposure mechanism and a marginal model for the outcome, and thus does not completely absolve one from the modeling task. In some settings, such as studies of occupational exposures where time-varying confounders may have deterministic relationships with the exposure of interest, such alternative approaches may not be possible.
45
Using multiple causal approaches with different modeling assumptions to answer the same question can help triangulate the effects of interventions. Further work is needed regarding how to select model forms for
One potential concern in using the g-formula is the g-null paradox, in which model misspecification leads to hypothesis tests that inevitably reject the null hypothesis as sample size increases, even when the causal null hypothesis is true. 47 Part of this paradox is explained by considering that some choices of model form can rule out the null hypothesis a priori because no parameter values in the model parameter space are consistent with the causal null hypothesis—we say that such models are “incompatible.” Similar concerns may arise with prior specifications that rule out the null. Allowing for flexible models increases the parameter space but may necessitate the use of shrinkage priors, which may reduce concern over this paradox in the Bayesian setting, provided that the prior parameter space includes the “g-null” hypothesis. In the Bayesian setting, presence of the g-null paradox can be assessed by examining whether the prior predictive distribution of the potential outcomes (which is a function both of the priors, the intervention, the model, and the target population) rules out the g-null hypothesis. In general, we recommend examining the prior predictive distribution of the marginal parameter of interest to conceptualize how the joint function of the regression priors might influence the marginal parameter of interest in possibly unexpected ways.
We demonstrated that hierarchical modeling is feasible in the Bayesian g-formula, which suggests multiple future directions. Our example leveraged the naturally modular aspect of Bayesian modeling: once a probability model can be used to describe a process (e.g. measurement error, missing data), it is relatively straightforward to include that model as part of a Bayesian hierarchical model. This modular aspect of the Bayesian g-formula opens up many possibilities for improving causal inference in real-world data where some variables are not measured, and those that are measured may be recorded with error.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Institutes of Health Grant # 5T32ES007018-38; The Mount Sinai Children’s Environmental Health Study was supported by NIEHS/EPA Children’s Center grants ES09584 and R827039, The New York Community Trust, and ATSDR/CDC/ATPM.