
Abstract
In discrete choice experiments, patients are presented with sets of health states described by various attributes and asked to make choices from among them. Discrete choice experiments allow health care researchers to study the preferences of individual patients by eliciting trade-offs between different aspects of health-related quality of life. However, many discrete choice experiments yield data with incomplete ranking information and sparsity due to the limited number of choice sets presented to each patient, making it challenging to estimate patient preferences. Moreover, methods to identify outliers in discrete choice data are lacking. We develop a Bayesian hierarchical random effects rank-ordered multinomial logit model for discrete choice data. Missing ranks are accounted for by marginalizing over all possible permutations of unranked alternatives to estimate individual patient preferences, which are modeled as a function of patient covariates. We provide a Bayesian version of relative attribute importance, and adapt the use of the conditional predictive ordinate to identify outlying choice sets and outlying individuals with unusual preferences compared to the population. The model is applied to data from a study using a discrete choice experiment to estimate individual patient preferences for health states related to prostate cancer treatment.
Keywords
1 Introduction
Discrete choice experiments (DCEs) have been increasingly used in health applications to characterize the preferences of individual patients for various health care interventions and services.1,2 In a typical health care DCE, patients are presented with sets of health states described by various attributes and asked to make choices from among them. 3 For example, a patient might be asked to choose between a health state with long life expectancy and poor quality of life and a health state with shorter life expectancy and high quality of life. By asking individuals to make choices between health states, they are forced to make trade-offs that reveal information about their preferences for different aspects of health-related quality of life.
Historically, in a DCE, patients provided their most preferred health state or a full ranking of a set of possible health states. However, continued research in discrete choice experiments has led to the development of best–worst designs in which patients provide only their most preferred and least preferred choices.4,5 While reducing patient burden compared to full rankings, best–worst discrete choice experiments pose new statistical challenges. In such data, incomplete ranking information occurs when choosing best and worst from among four or more health states, and patient-level data are often insufficient to estimate individual-level preferences using maximum likelihood methods as it is not uncommon to obtain estimates of the coefficients in the wrong direction with sparse data.6,7
A number of models have been developed for discrete choice data. The multinomial logit models the probability of observing best choices, 8 while the rank-ordered logit models the probability of full rankings. 9 Mixed logit models include random effects that vary across individuals to account for heterogeneity in preferences.10,11 More recently, Allenby et al. developed a Bayesian hierarchical model for best choices with random effects and individual-level covariates 6 and Hernandez-Alava et al. introduced a model for ranked and partially ranked data that includes random effects, and estimated the random effects using Monte Carlo maximum likelihood methods. 12 Although the model introduced by Hernandez-Alava et al. accommodates partially ranked data, it is not uncommon to obtain coefficient estimates in the wrong direction when using maximum likelihood estimation with sparse data. 7 Moreover, their model does not include individual-specific covariates although inference on covariate effects is often of interest and it has been shown that including covariates can improve preference estimates for the mixed logit.6,13–15
In many studies, a key purpose of the DCE is to obtain an individual’s ranking of various attributes relative to each other. The concept of relative attribute importance is widely used in the marketing research literature to provide rankings of features of consumer products.16–18 Recently, this concept has been extended into the health care domain.19–21 In this context, the purpose of the DCE is to obtain an individual’s ranking of various attributes of health care or health-related quality of life, so that this information can be used as part of the health care decision-making process. For example, how a prostate cancer patient values full sexual functioning, long lifespan and no urinary incontinence relative to each other may inform which treatment options are a better match for the patient. While discrete choice data are now routinely analyzed using Bayesian hierarchical models with random effects to accommodate preference heterogeneity,6,11,22,23 methods to compute relative attribute importance for such models are not fully developed.
Methods to identify outliers for such models are also lacking. Using the means of the individual-specific parameter distributions, Campbell et al. 24 classified individuals in the upper and lower percentiles as outliers. Farrel et al. 25 proposed a graphical method to identify outliers by plotting standardized random effects against their expected values for a Bayesian hierarchical logistic regression model. Several approaches for outlier detection in Bayesian models have been explored. For example, using the posterior distribution of the residuals of a regression model, Chaloner and Brant 26 and Chaloner27,28 define an outlier as an observation with a large random error and calculate the posterior probabilities that observations are outlying. Other approaches for outlier detection are based on the predictive distribution. The conditional predictive ordinate (CPO), first suggested by Geisser, 29 is a diagnostic measure used to detect observations discrepant with the proposed model.29–34 To our knowledge, CPO has not been used to identify outlying random effects.
In this paper, we develop a Bayesian hierarchical model for best–worst discrete choice data. Our model extends previous approaches. Incomplete rankings are handled by marginalizing over all possible permutations of unranked health states in a model that includes random effects to model individual-specific preferences. Bayesian methods are used to overcome the problem of sparse data to obtain estimates of individual preferences. To enable analysis of how patient characteristics are related to preferences, we model individual-specific preferences as a function of individual-specific covariates. We also define Bayesian versions of relative attribute importance for individuals and for the population that handle random effects and covariates. To identify outliers in DCEs, we adapt the CPO in two ways: we adapt it to include random effects to identify patients who are unusual in their preferences for specific attributes or combinations of attributes, and we adapt it to handle vector outcomes to identify choice sets that are outlying with respect to individual preferences.
The paper is organized as follows. Section 2 describes the motivating dataset and defines terms used throughout the remainder of the paper. Section 3 presents the Bayesian hierarchical model for best–worst choice data with random effects and patient covariates. Section 4 defines measures of relative importance, while Section 5 presents CPO-based measures for outlier detection. Section 6 demonstrates application of our methods to data from the PROSPECT study. This is followed by a discussion in Section 7.
2 Motivating example: the PROSPECT study
The methods are motivated by the PROSPECT (PROState cancer PrEferenCes for Treatment) study, which used a DCE to understand patient preferences for aspects of health-related quality of life associated with prostate cancer treatment outcomes. 35 The 121 patients were men with negative prostate biopsies.
Attributes and attribute levels from the PROSPECT Study.
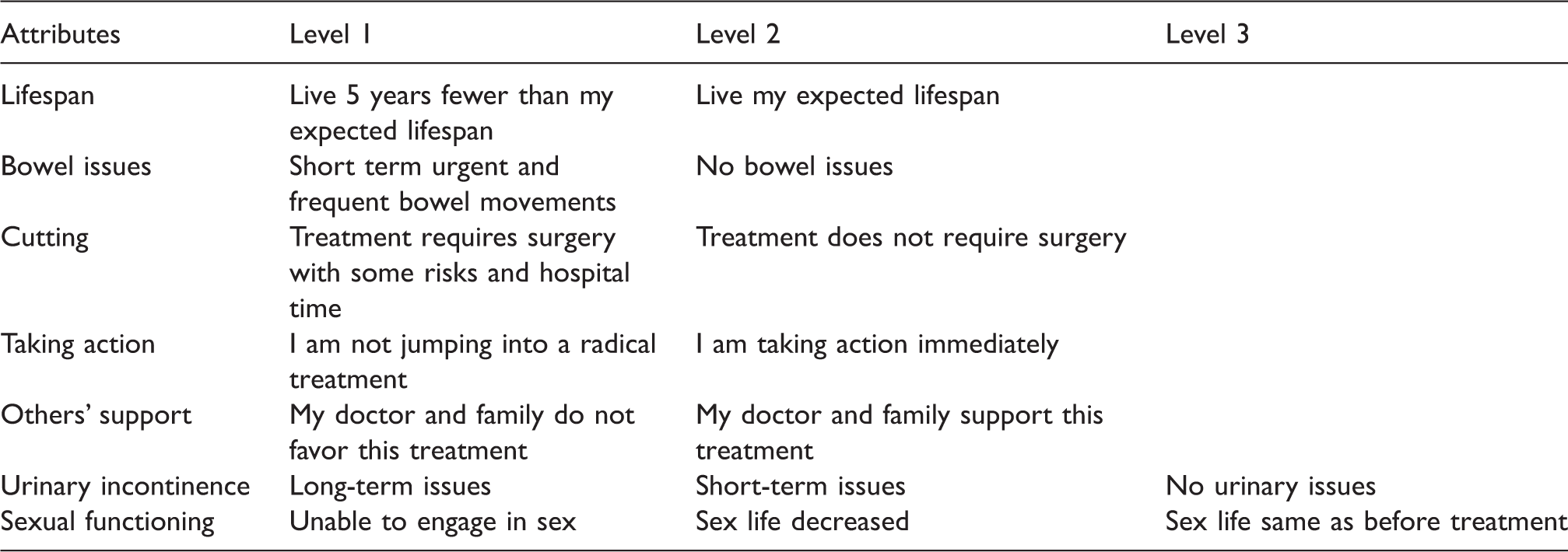
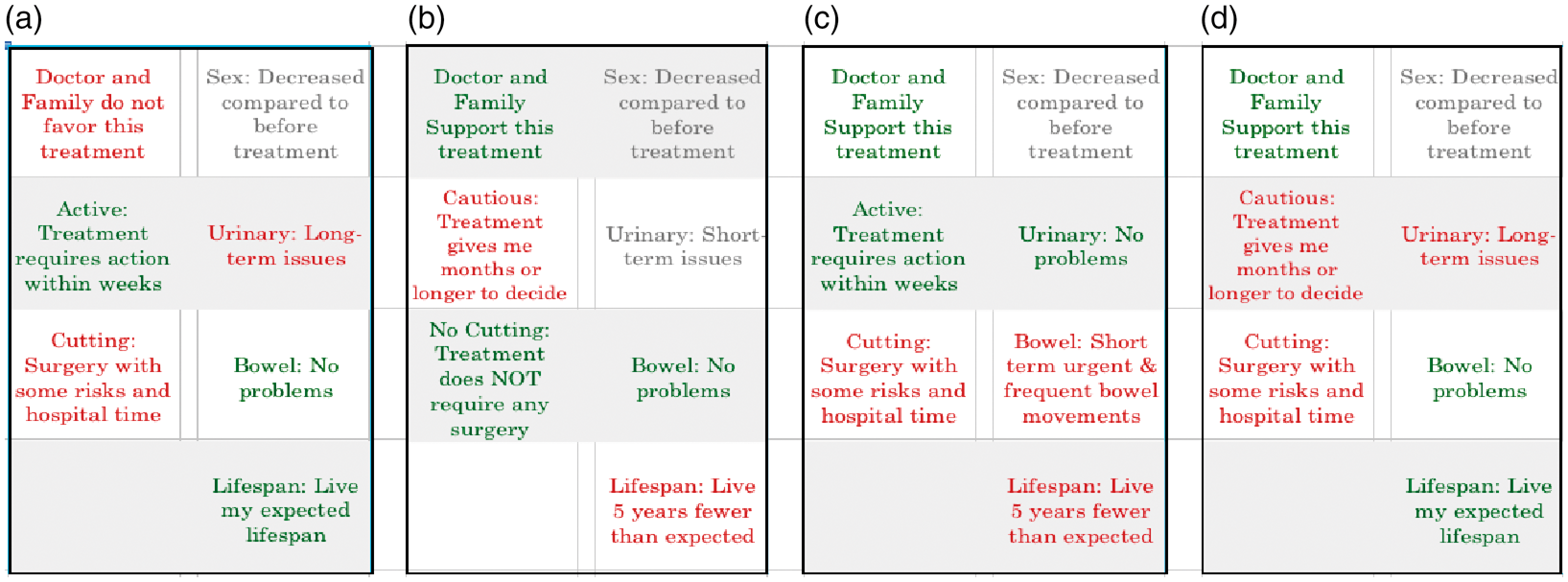
Example of a choice set from the PROSPECT study. Patients choose their most and least preferred health state from among the four health states.
In the PROSPECT study, patients were presented with choice sets comprised of four hypothetical health states that could result from various cancer treatments, and asked to choose their most and least preferred health state from each set, leaving two health states unranked. Sixteen health states were selected by investigators for creation of choice sets. These sixteen health states described by their attribute levels are presented in Table 6, Appendix 1. The first four choice sets were the same for all patients and consisted of health states {1,3,9,15}, {2,4,10,14}, {5,6,11,12} and {7,8,13,16}. An algorithm was used to create the remaining choice sets for each patient. The algorithm composed subsequent choice sets in a manner that achieved an implicit ranking of the 16 states using the minimum of choice sets. As a result, the number of choice sets as well as the choice sets presented to each patient differed. The number of choice sets per patient ranged from 10 to 17.
3 Bayesian hierarchical model for best–worst choice data
Our model includes a probability model for best–worst choice data with incomplete rankings, a hierarchical prior distribution, and individual-specific covariates predicting an individual’s preference scores for attributes.
3.1 Probability model
Let
Let
We use a linear predictor
36
to relate choices to the attribute levels of health states. Let
Suppose that individual i provides only a most preferred health state for choice set t. Then the probability that individual i chooses the jth health state as the best state in choice set t is

Patient i is presented with Ti choice sets, each of size Jit = 4. Eliciting the best and worst choices from a choice set of size 4 yields a partial ranking of the choice set. Two possible full rankings are consistent with each partial ranking. For example, the full rankings
Let 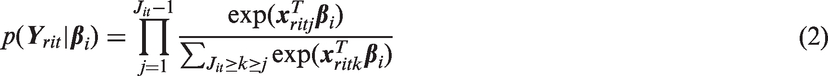
Because the set of Rit full rankings consistent with 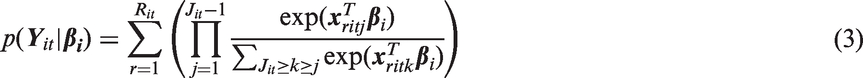
If a patient is asked to provide their most preferred and least preferred health states from a choice set t containing fewer than four alternatives or if choice set t is fully ranked, then equation (3) simplifies to equation (2). Moreover, if we observe only best choices, then equation (3) simplifies to equation (1).
Let 
3.2 Hierarchical prior distributions
Let 



4 Relative attribute importance
An attribute may be represented using two, three or more levels. When using dummy variable coding, this yields one, two or more coefficients where the coefficient for the reference level is defined to be zero. In market research, the difference between the estimated maximum and minimum attribute-level coefficients has been used as a measure of attribute importance.16–18 Relative attribute importance is calculated by normalizing attribute importance measures to sum to one, so that the relative importance of an attribute is a proportional contribution to the importance of all attributes jointly.
39
Although model coefficients can be estimated using maximum likelihood or Bayesian methods,
18
current methods only provide point estimates of relative importance. We extend current measures by defining relative attribute importance as a function of the random effects
Let 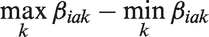
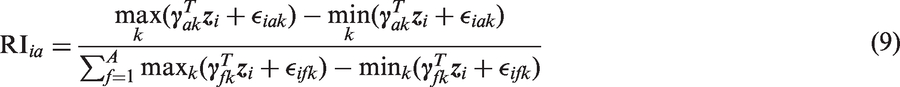
We can define the average relative importance (ARI) of attribute a for the population as the arithmetic average of equation (9) over all patients

For a specific set of patient covariates 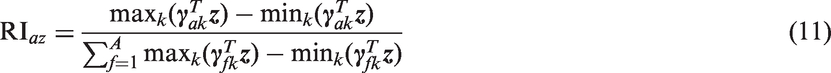
Equation (11) differs from equation (10) in that relative importance is calculated from population parameters, rather than as an average of the individual preference scores.
The posterior means and standard deviations of equations (9) to (11) are estimated as the means and standard deviations of the MCMC samples of relative importance scores, calculated using randomly sampled draws from the posterior distributions of the relevant parameters.
5 Outlier statistics for choice sets and preferences
We use the conditional predictive ordinate (CPO)29–34 to identify outliers in discrete choice data. In general, suppose we have a set of observations 

We can use CPO to identify outlying choice sets as follows. If we let
Gelfand et al.,
40
Dey et al.,
33
Gelfand,
41
Pettit,
34
and Weiss42,43 observed that

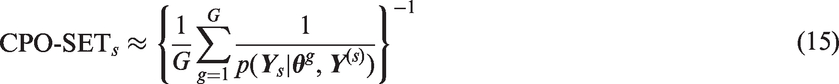
We also use CPO to identify patients with outlying preferences with respect to the population. To do so, we define several varieties of the conditional predictive ordinate for preferences. Suppose we want to identify patients with outlying preferences on a single attribute variable h. Let 
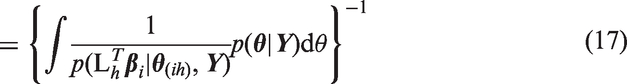
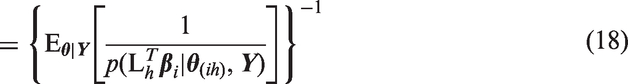
More generally, suppose we want to identify patients with outlying preferences on a combination of attribute variables. For example, in our application, urinary functioning and sexual functioning are represented by two attribute variables and thus two components 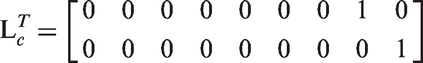
Then the CPO for individual i and combination of attribute preferences c, which we could here denote as CPO-BVP (bivariate preference), is defined using equation (18)
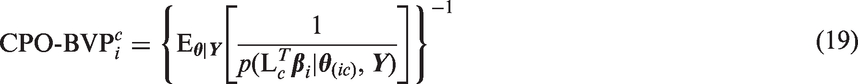
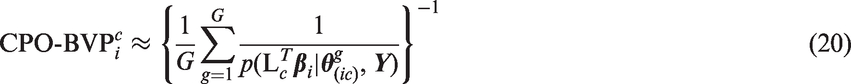
We can also compute a more global outlier statistic for preferences. Identifying patients with outlying preferences on all attributes is a special case in which
6 Results
We fit the Bayesian hierarchical model of Section 3 to data from the 121 patients in the PROSPECT study. Dummy variables for three patient covariates were included in the model. These were: age (≥ 65 years vs. age < 65 years), race (black vs. white, other race vs. white), and partnered (vs. unpartnered). We chose a proper prior distribution
44
for
Posterior means (standard deviations) of the components of the vector of population mean preferences
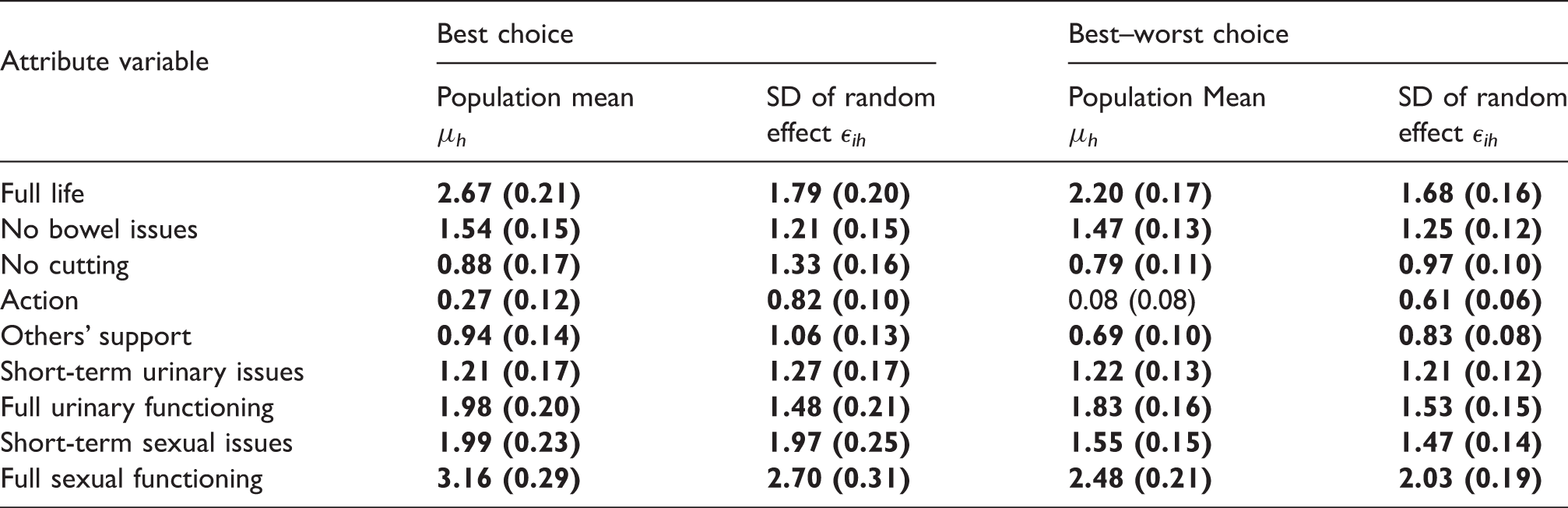
Note: Values in bold denote that the posterior probability that the parameter is greater than zero is greater than 95% or less than 5%.
Posterior means (standard deviations) of the elements of the correlation matrix of the residual effect
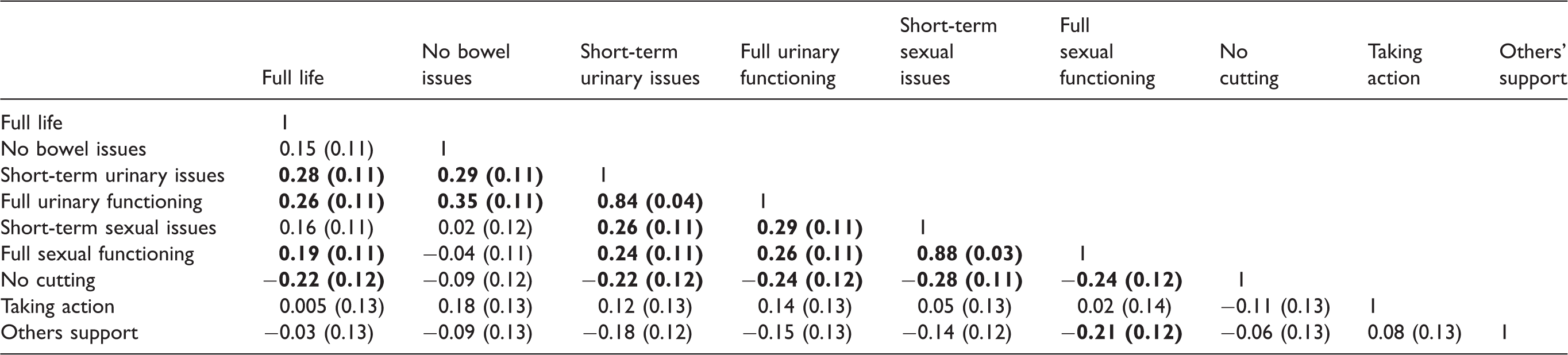
Note: Values in bold denote that the posterior probability that the parameter is greater than zero is greater than 95% or less than 5%.
Posterior means (standard deviations) of the elements of the matrix of regression coefficients
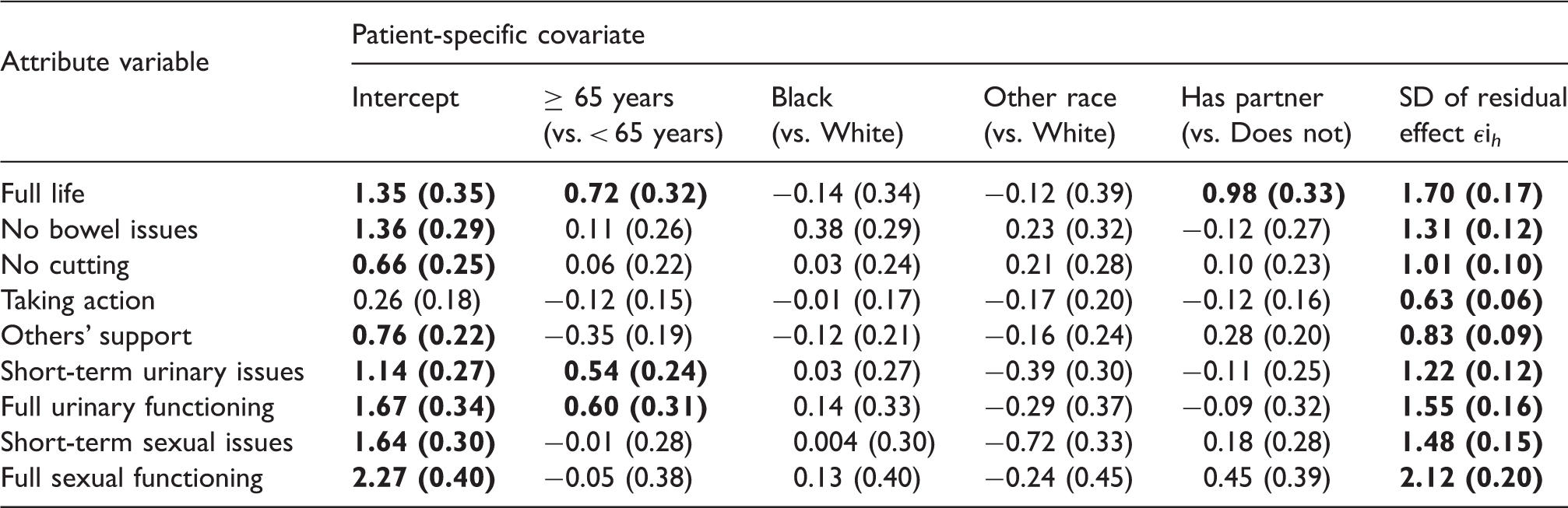
Note: Values in bold denote that the posterior probability that the parameter is greater than zero is greater than 95% or less than 5%.
Figure 2 presents the posterior mean average relative importance scores for each health state attribute for the population and the posterior mean relative importance scores for 14 sample patients. To select the 14 patients in Figure 2, patients were sorted by decreasing the relative importance score on full lifespan and every 10th ranked patient was selected. This figure shows the heterogeneity of preferences for health state attributes in the sample. Greater heterogeneity in preference for full lifespan and lower heterogeneity in preference for taking action were apparent.
Posterior mean relative attribute importance scores for each health state attribute for 14 men and for the population.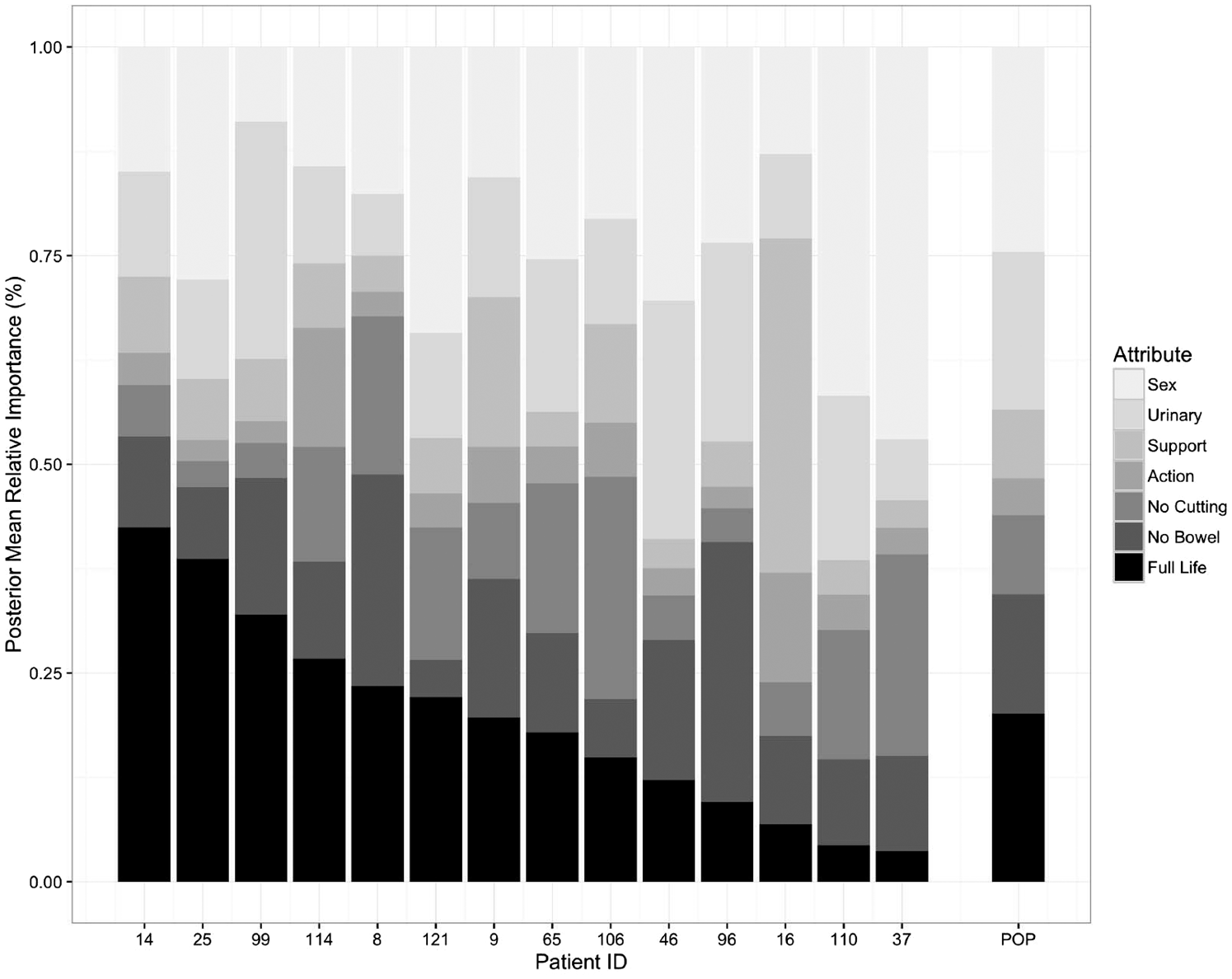
Posterior mean (standard deviation) of relative attribute importance scores for three men and for the population.
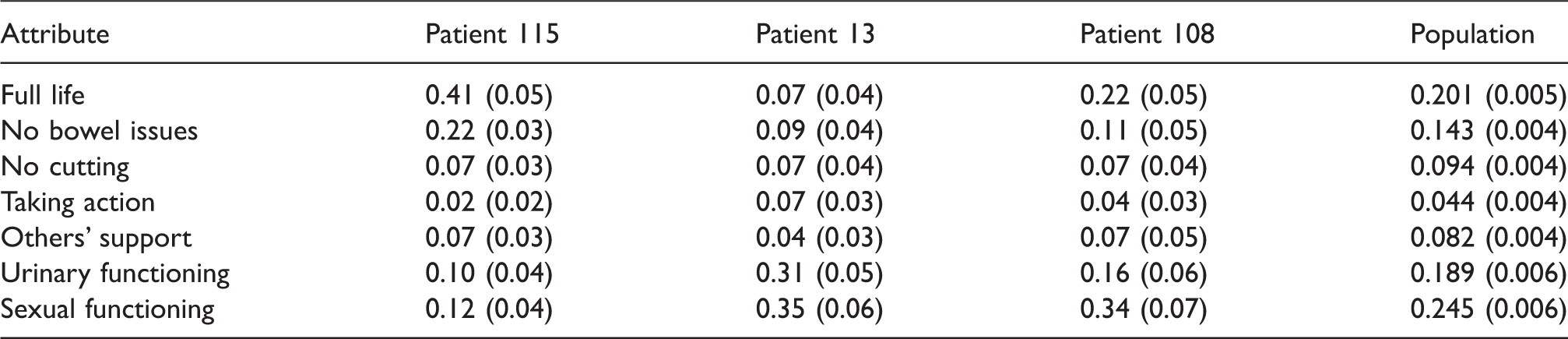
Figure 3 presents boxplots of CPO-MVP values for the set of all attributes, CPO-UVP values for specific attributes, and CPO-BVP values for the two bivariate combinations of attributes for urinary and sexual functioning for the 121 patients. A negative log-transformation was applied to the CPOs to better visualize small values. High values of negative log-transformed CPOs indicate possible outliers (low CPO). Patients 15, 83, and 17 are multivariate outliers on the set of all attribute variables by CPO-MVP. Patient 83 is also outlying on the bivariate CPO for urinary functioning and the bivariate CPO for sexual functioning. Patient 15 had highest negative log-transformed CPO-UVP values on others’ support. Patient 17 is an example of a multivariate outlier that cannot be detected by looking at outliers on specific health state attributes, while patient 54 is an example of a patient with outlying preferences on a single attribute who is not a multivariate outlier.
Plot of the −log(CPO-MVP)s on all health state attributes, the −log(CPO-UVP)s for specific attributes, and the −log(CPO-BVP)s for the bivariate combinations of attributes for urinary and sexual functioning for 121 patients. Patients with values of the outlier statistic in the upper 2.5th percentile are labeled with ID numbers.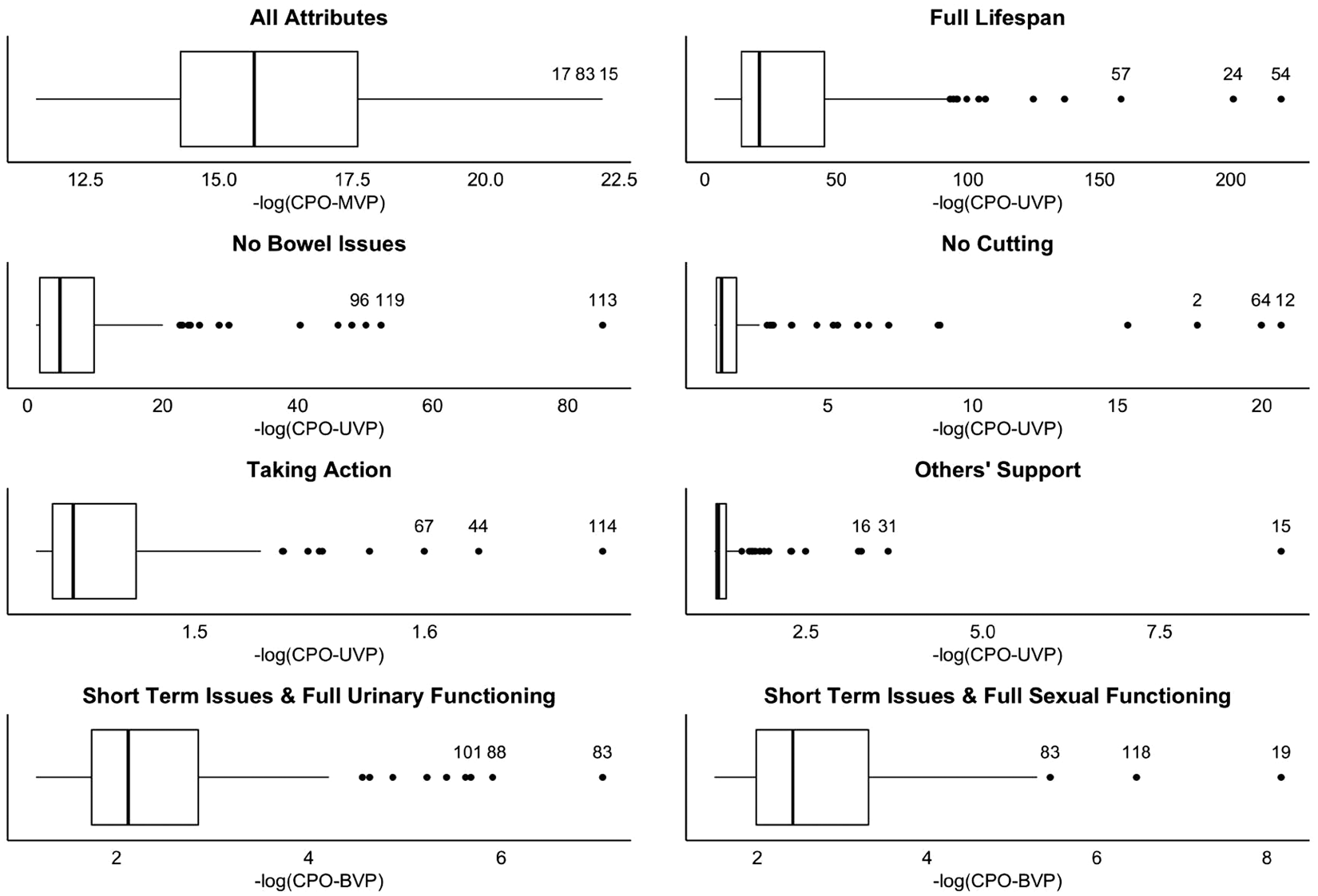
Figure 4 presents the time series of the negative log CPO values for choice sets presented to eight patients. DCEs require patients to evaluate a number of different choice sets and some patients may undergo a learning effect where accuracy in responses improves with time. Conversely, some patients may become fatigued and accuracy of their responses may degrade as the number of questions increases.46,47 By examining these time series, we can gain insight as to an individual’s performance on discrete choice tasks, and observe possible learning effects or fatigue effects, and whether they made choices on specific sets that were inconsistent with their preferences. High values of negative log-transformed CPO indicate possible outlying choice sets. Patient 115 is an example of a patient with consistent responses and no outliers. In contrast, patient 52 shows highly variable responses, which might indicate more difficulty with the choice tasks. Patient 10 has an outlier on the first choice set, which may indicate a cognitive error early in the exercise. Patient 109 shows an upward trend suggesting a possible fatigue effect and an especially inconsistent choice on the second to last choice set. For patient 74, we observe a downward trend suggesting a learning effect where patient performance on choice tasks improves over time.
Plot of the −log(CPO-SET)s calculated for each choice set presented to eight patients.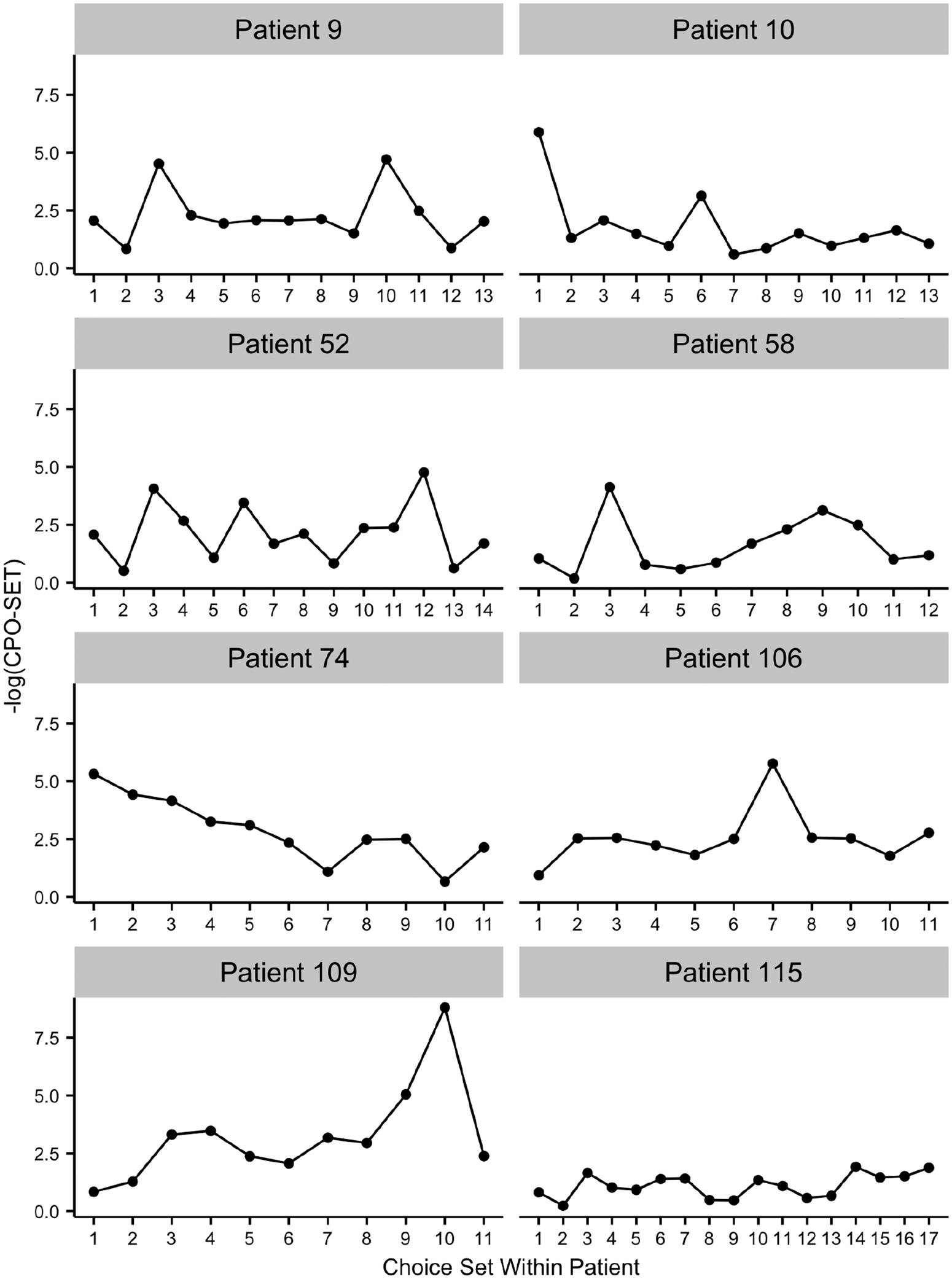
We conducted sensitivity analyses on the prior assumptions
7 Discussion
We developed a Bayesian hierarchical model for best–worst discrete choice data that accounts for incomplete rankings and includes patient covariates. The model can handle sparse data and is particularly useful when discrete choice experiments involve relatively few choice sets per patient. Although our application had choice sets of size 4, the model can be applied to studies with larger choice sets.
The main goal of our discrete choice experiment was to identify health state attributes that are most important to individual patients to guide that individual’s treatment; thus, we presented Bayesian versions of a commonly used measure of relative attribute importance. The estimates of relative attribute importance include posterior standard deviations that reflect uncertainty; in the literature, many studies only provide point estimates which may give false confidence about how the patient ranks the attributes. Our method for computing relative attribute importance is not specific to best–worst DCE and can be applied to other DCE designs. The concept of relative attribute importance is akin to the concept of variable importance in regression and prediction modeling. We have not explored other possible measures of variable importance that might be applied to DCE. The measurement of relative variable importance is an active area of research.48–53
We have shown how the conditional predictive ordinate can be adapted to identify outlying choice sets and outlying patients with unusual preferences in discrete choice data. Our CPO for identifying preference outliers finds outliers in the random effects. Random effects are a common feature of Bayesian models, and this new application of the CPO could have broader application in Bayesian modeling. The method is quite flexible and general, and can even identify outliers on sets of multiple random effects. We have shown how the method can be applied to identify outliers on categorical attributes modeled using two coefficients. The CPO for identifying outlying choice sets utilizes a vector outcome and is also an important extension of the CPO that could be used in other applications.
Our application includes two attributes, sexual functioning and urinary functioning, whose attribute levels are naturally ordered; the levels of sexual functioning are none, decreased and full, and the levels of urinary functioning are long-term issues, short-term issues, and full functioning. One approach to estimate the corresponding coefficients would be to impose order constraints, such that the coefficient for decreased functioning must be less than or equal to the coefficient for full functioning. This could be accomplished by specifying a truncated multivariate prior density on the vector of random effects and the vector of population effects. 40 However, we obtained satisfactory results without imposing such constraints.
Experimental design for DCEs is an area of active research54,55; however, there is little consensus on the optimal design of choice experiments, including how to generate choice sets.56,57 A recent report described alternative approaches to experimental design for DCEs, 54 but did not recommend any specific approach as best practice. The choice of alternatives for each choice set and the choice sets presented to each patient are important with regard to statistical efficiency. Random selection of profiles to choice sets may result in choice sets for which little information is gained on relative preferences because the attributes are not varied sufficiently. In addition, increasing the number of choice sets presented to patients can increase cognitive burden, jeopardizing the quality of patient responses. When creating a DCE, a trade-off is made between maximizing statistical efficiency and maximizing respondent efficiency (measurement error related to the quality of responses). A direction for future research would be to formally evaluate the impact of the experimental design on estimation of preferences.
Our DCE uses factors with different numbers of levels. Studies have shown that there is a positive association between the number of attribute levels and attribute importance scores.58,59 Designing a study with the same number of attribute levels for each attribute may not be acceptable for some applications. In our study, all of our attributes have either two or three levels. We think it reasonable that a priori important variables, such as urinary and sexual functioning, would be modeled using more levels. We fit the model after collapsing the two highest categories of urinary functioning and sexual functioning into a single category and obtained similar posterior means. Hence, we surmise that the different numbers of levels did not appreciably affect our results.
The development of best–worst discrete choice designs reduces patient burden compared to full rankings while posing new statistical challenges. By accounting for missing ranking information, patient covariates, and the sparse nature of the individual-level data in a Bayesian framework, our model extends current methods and provides individual-level preference estimates. Our CPO measures provide some of the first diagnostic techniques for discrete choice models. Our model coupled with our measures of relative importance and outlyingness, provides practical methodology for discrete choice modeling applications, in which parameter estimation at the individual-level is desirable, but observed data at the individual-level are limited.
Footnotes
Acknowledgements
We mourn the passing of our esteemed colleague Ely Dahan, who passed away before this work could be published, and are deeply grateful for his contributions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Saigal, Dahan, and Crespi were supported by grant from the National Cancer Institute (grant no. 5R01CA134997-02). Crespi was also supported by NIH/NCI P30 CA16042. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Cancer Institute or the National Institutes of Health.