
Abstract
Extreme learning machines have gained a lot of attention by the machine learning community because of its interesting properties and computational advantages. With the increase in collection of information nowadays, many sources of data have missing information making statistical analysis harder or unfeasible. In this paper, we present a new model, coined spatial extreme learning machine, that combine spatial modeling with extreme learning machines keeping the nice properties of both methodologies and making it very flexible and robust. As explained throughout the text, the spatial extreme learning machines have many advantages in comparison with the traditional extreme learning machines. By a simulation study and a real data analysis we present how the spatial extreme learning machine can be used to improve imputation of missing data and uncertainty prediction estimation.
Keywords
1 Introduction
Artificial neural networks (ANNs) are nonlinear structures inspired by the functioning of the human brain: receive stimuli, compile these stimuli, and transmit a response based on learning. The method is represented by neurons, layers, and synapses and involves several techniques of treatment and definition of parameters. When the relationship between observations and covariates is complex, ANNs are an appropriate tool to learn the underlying information by creating a system that captures the patterns available in the data. For more details, Prieto et al. 1 provides a comprehensive overview about ANN applications and capabilities.
Specifically, feedforward neural networks (FNNs) have shown to be efficient to find solutions in problems with complex nonlinear mapping between the inputs and response and, also, provide alternative models for phenomena that are hard to be handled by parametric techniques. Multiple layers networks have been used to model complex data; however, it has been shown in theory that single-layer feedforward neural networks (SLFNNs) can approximate any continuous function. 2 Although SLFNNs success and applicability it is well known that (1) the traditional backpropagation algorithm can stop in local minima providing undesired results, (2) the network can provide overfit to the data by the training algorithm, and (3) gradient-based learning is computationally costly in most applications. 3 To overcome some of these limitations extreme learning machines (ELMs) 3 were proposed as a much more computationally efficient alternative to train SLFNNs providing results as good as traditional SLFNN.
Huang et al. 3 showed that it is not necessary to estimate all parameters in a SLFNN, instead the hidden layer linear coefficients can be randomly chosen without losing the capacity of making prediction (generalization performance). This property is essential to make ELM extremely efficient to be fitted. Also, it guarantees that ELMs will overcome some of the drawbacks presented in the traditional SLFNN. Comparison between ELM and a variety of machine learning methods was performed to check its generalization capabilities.4–6 Recently, Lin et al. 7 showed that ELMs still suffer from generalization problem and an l2 regularization can improve the generalization capability of the method. For a detailed review about ELM, see Huang et al. 8
Bayesian ELM was introduced by Soria-Olivas et al. 9 The method has direct advantages when compared with other ELM approaches: (1) introduction of prior knowledge in the network, (2) automatic production of credible intervals, and (3) straightforward regularization. Further, Luo et al. 10 presented a sparse Bayesian approach that tunes some of the weights to zero allowing for automatic selection of the number of neurons in the model avoiding overfitting.
Application of machine intelligence in the medical and the biomedical areas is a new trend for large data applications. For example, most of the diagnosis techniques in medical field are systematized as intelligent data classification approaches. Recently, ELMs have been used to solve problem in many medical situations.11–15
Spatial models have been used in the biomedical field from many years now to improve modeling.16–21 Spatial regressions are alternative models to facilitate interpretation and to better assess uncertainty. 22 The intrinsic conditional autoregressive model (ICAR) 23 is commonly used as the distribution of the random effects to capture the spatial association in the data and improve fitting.
With the ease and increase of data collection nowadays, several data sources are becoming available for the medical area. However, in many situations the collected data may present underreported values 24 or missing information which make statistical analysis biased, unappropriated, or harder, especially in the spatial setup. Borrowing strength from spatial modeling and ELM we introduce a hierarchical model to perform imputation over the missing data. The integrated nested Laplace approximation (INLA) 25 became popular because of its modeling flexibility and computational efficiency under the Bayesian paradigm. Keeping the computational efficiency of ELMs under the Bayesian framework, we propose a very flexible hierarchical structure that is capable of automatically dealing with complex relationship between the covariates and the response for spatially dependent data and, thus, improve prediction estimates and better estimate uncertainty. As a good side effect, to the best of our knowledge, this is the first time an implementation of ELM and INLA is presented in the literature.
The rest of the article is organized as follows. In Section 2, ELMs are presented. Section 3.1 presents an overview about the INLA methodology. The widely applicable information criterion (WAIC) to perform model comparison is presented in Section 3.2. In Section 4 we introduce the proposed model to create spatial ELMs. In Section 5 we study the performance of the model in comparison with the traditional ELM and variants to perform accurate prediction. Section 6 presents a real data example on how to perform prediction using the presented methodology. Section 7 concludes with a discussion.
2 ELMs
ANNs are models inspired in the human brain to allow machines to perform specific tasks resembling the behavior of biological networks. Many architectures for ANNs have been proposed: FNNs, recurrent neural networks, Hopfield networks, Boltzmann networks, and others.
Suppose we observe a sample of
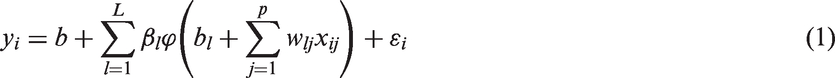
In Figure 1 we have a graphical representation of (1) for the ith individual. We can see that in the first layer the bl and wlj coefficients are combined with the nonlinear function Representation of a SLFNN.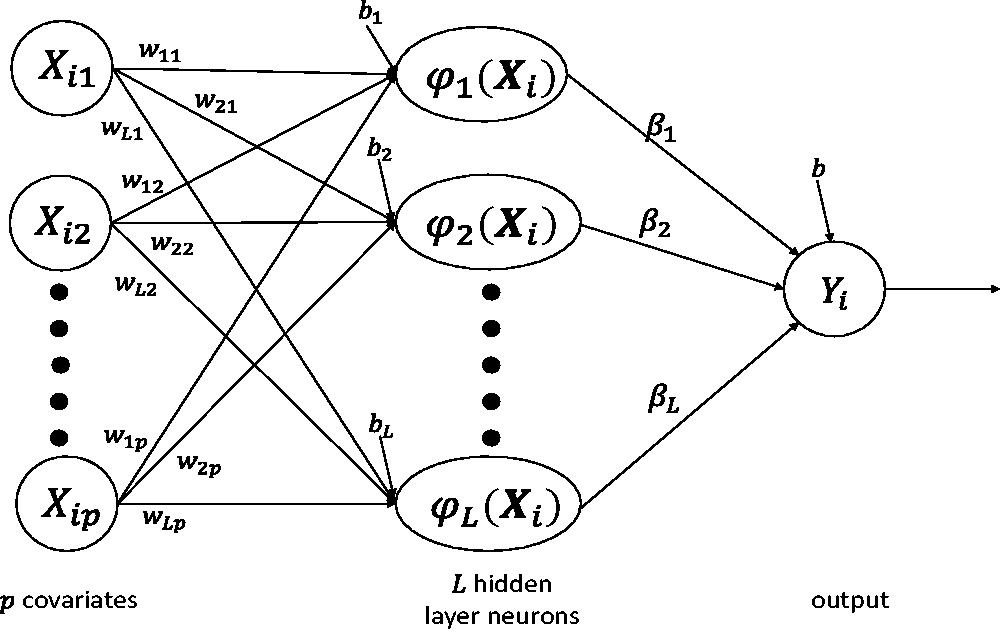
The universal approximation theorem 26 guarantees that under mild constraints a SLFNN with L neurons can approximate any continuous function arbitrarily well. To improve the computational cost of the SLFNNs, the ELMs randomly preassign values for all bl and wlj (named random feature map) and then solve a linear equation to estimate b and βl. This prespecification step greatly speeds up the fitting of the ELM in comparison with the traditional SLFNNs. A fundamental result showed by Huang et al. 3 is that even with the random feature map preselected the ELMs still have the universal approximation property and it is not sensitive to the fixed values. However, the choice of an optimum L that guarantee both good fitting and capacity of generalization (good prediction) is not a trivial task and is usually done by model selection criteria or cross validation.
For the ith observation randomly preassign values for bl and wlj, generated say by a N(0, 1), thus
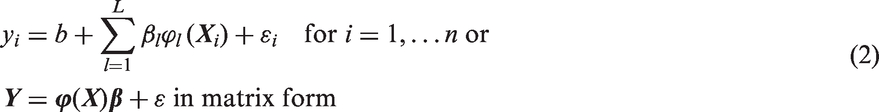
Since
Overfitting may be a problem in either SLFNN or ELM
7
and regularized ELM can be used to reduce this problem. Using a l2 regularization, the problem is equivalent to a ridge regression and is solved by minimizing the following objective function
3 Bayesian inference
3.1 INLA
Suppose the following hierarchical representation
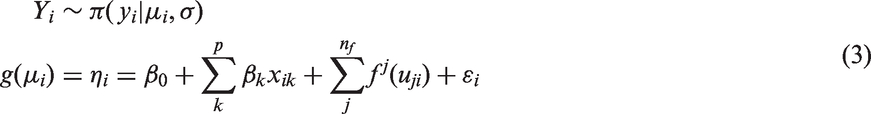
The INLA approach 25 performs efficient Bayesian inference over a broad class of models. The methodology relies on the latent Gaussian models structure. This is a subclass of structured additive models that can be seen as the hierarchical representation in equation (3).
Let
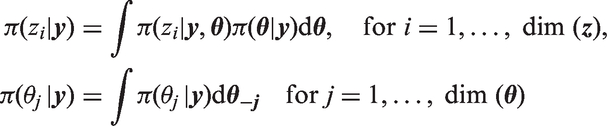
To perform the approximation of the full conditionals
3.2 Model assessment
3.2.1 Model comparison
Recently, Gelman et al. 27 studied and compared a variety of model comparison criterion. Although their conclusion is that “the current state of the art of measurement of predictive model fit remains unsatisfying,” they indicate the WAIC 28 as one of the best current alternatives to perform model selection.
The WAIC is a fully Bayesian approach for estimating the out-of-sample expectation. The idea is to compute the log pointwise posterior predictive density (lppd) given by
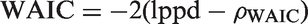
Thus, smaller values indicate better fit to the data.
3.2.2 Model prediction
To assess the predictive power of the models we define the following steps:
A random validation sample All proposed models are fitted with remaining values (data with validation sample removed). Using the mean posterior parameter estimates of each fitted model, the mean of the absolute prediction error (MAPE) is computed using the validation sample Steps 1–3 are repeated R times, where R is the number of simulations.
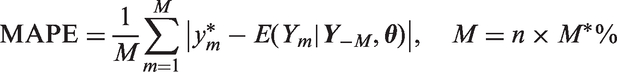
4 Spatial extreme learning machines (SPELMs)
Many biomedical problems are known to have spatial dependence. Inclusion of spatial random effects is common to improve fit and to better quantify uncertainty.29–33 With the increase of data collection in recent years, missing data have become a common problem in datasets. Missing information can make traditional modeling unfeasible or very hard.
To impute data over missing values or to perform prediction, we propose a hierarchical Bayesian model that captures spatial dependence, allows for a flexible relationship between inputs and response, has generalization capability and better quantify prediction uncertainty. The model is coined as SPELMs. Let
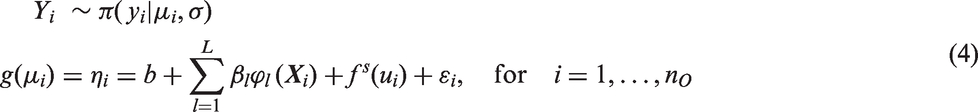
The predictive posterior distribution of
As will be shown, the SPELMs have better point estimates of the missing value, a more parsimonious choice for the number of neurons L and better capability in controlling the prediction uncertainty when compared to the ELM.
5 Simulation study
To determine the prediction capability of ELM, SPELM, and related models, we perform a simulation study using death from lung cancer in 2010 in the municipalities of the state of Minas Gerais, Brazil. The data are freely available for download at https://mortalidade.inca.gov.br/. The Brazilian cancer control is very efficient and data are available even for small municipalities.
The World Cancer Report 2014 34 states that cancer is one of the most important health-related problems in developing countries. The National Cancer Institute José de Alencar da Silva is responsible by the register of cancer incidence, cancer deaths, and many other statistics related to the disease in Brazil. Lung cancer is a type of cancer that has one of the highest incidence in the world porpulation and understanding its causes is essential to perform prevention as well as control of its occurence and mortality. 35
Demographic information of each municipality is obtained by the 2010 Brazilian CENSUS and the following factors are used as explanatory variables: life expectancy, Gini coefficient, human development index, average income, and percent of urban areas. These variables were selected to be the same as in the real application (Section 6).
Besides having data available for all municipalities of Minas Gerais, as can be seen in Figure 2 the incidence of lung cancer somehow resembles the incidence of HIV (Section 6) where data are not fully collected. Figure 2 presents the standard incidence ratio for both lung cancer and HIV in Minas Gerais municipalities. From this figure it is also clear to verify the strong spatial association in both scenarios.
Map of the standardized incidence ratio of lung cancer and HIV, respectively, in the state of Minas Gerais. (a) Lung Cancer and (b) HIV.
To perform prediction over missing counts we study four models as variations of equation (4) given by
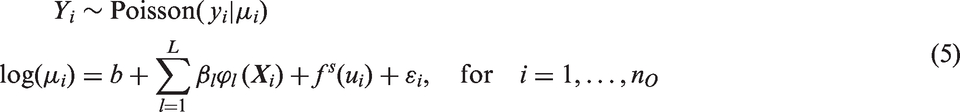
Model (1) is the traditional ELM (no random effects, no
To check the models’ imputation capacity we break the simulation in two parts: (1) we use the complete data to train the model and select the number of neurons to avoid overfitting for the data improving generalization. To do so, we allow the number of neurons to vary from 2 to 30 and the cost parameter
The WAIC criterion varies with the number of neurons and cost parameter. To continue the analysis, the cost is fixed at C = 10 which provided the best results for all fitted models under the WAIC criterion for these data. Figure 3 shows the WAIC variation by the number of neurons. As it can be seen, the selected number of neurons is L = 25, L = 15, and L = 15 for the ELM, ELM-IID, and SPELM, respectively. This shows that the ELM-IID and the SPELM are more parsimonious in the number of neurons, being able to achieve the same learning with less neurons. Moreover, the SPELMs (Figure 3(c)) have a better fit for the data and the competitors’ models, since its WAIC have lower values than the other models. For the SPGLM there is no C nor L, so the model was fitted once with a WAICSPGLM = 2190.17 which is little higher than the WAICSPELM = 2186.33.
(a) WAIC estimates by neurons for the ELM model, (b) WAIC estimates by neurons for the ELM-IID model, and (c) WAIC estimates by neurons for the SPELM model.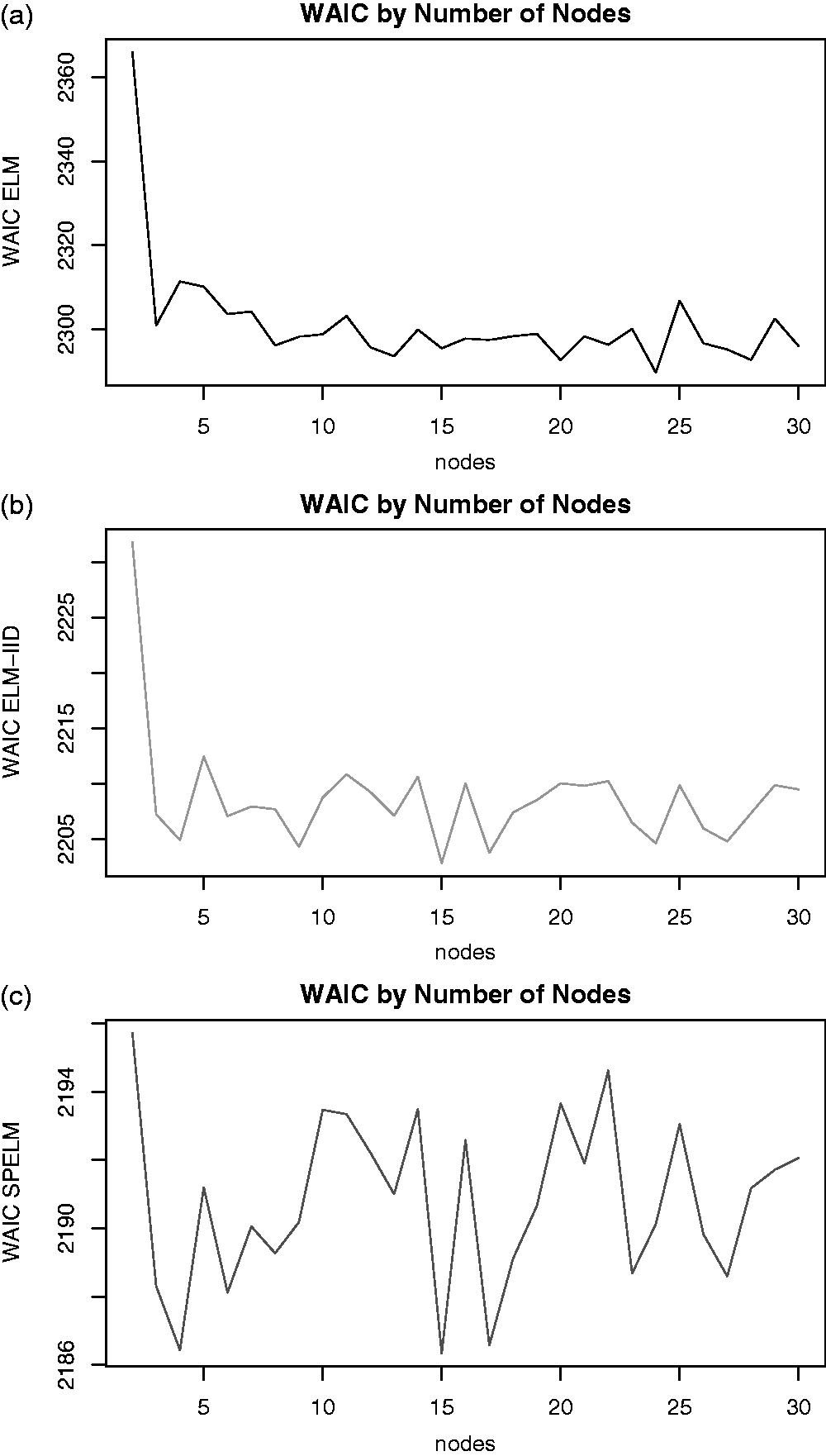
After selecting the best models fitting model in stage (1), we move to stage (2) to study the prediction potential of each model. Figure 4 shows the box plots of the MAPE for the 500 Monte Carlo replicates for the ELM, ELM-IDD, SPGLM, and SPELM. As can be seen, for all fitted models, the median of the prediction error increases as the missing percentage also increases. However, the SPELMs uniformly have better performance in the pointwise estimation than the other methods. Thus, including a spatial effect improve the prediction capacity of the ELM model. Note that the SPGLM is very competitive; however, in the SPELM, there is no restriction about the functional relationship between the mean and the covariates. This fact makes the model more robust since it can simply adapt even when this relationship is complex and far from linear.
Box plot with the mean posterior prediction error of the models for the missing information of 5, 10, and 20%.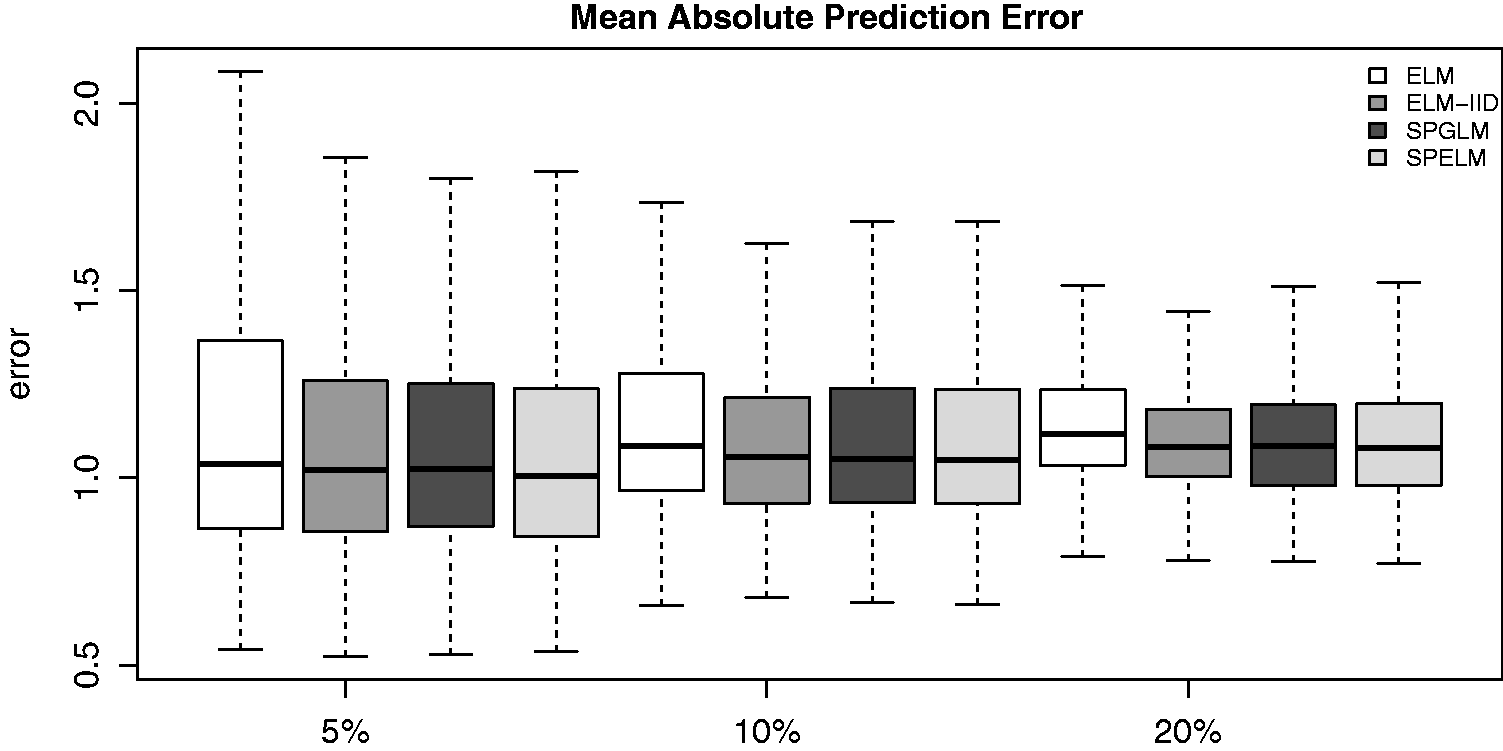
Coverage of the 90% predicted posterior intervals for the fitted models.

ELM: extreme learning machine; ELM-IID: extreme learning machine with overdispersion; SPELM: Spatial extreme learning machine; SPGLM: traditional generalized model with ICAR spatial effects
6 Imputing HIV data
The human immunodeficiency virus (HIV) is a chronic disease with no cure, constituting a serious public health problem. It is estimated that today 35 million people have the disease and that 54% of them are not aware that they carry the virus. 36 An important public health challenge is to understand the complexity and dynamics of the disease in the society, and for public policies to be effective it is necessary that more studies are conducted about the topic. Many spatial studies about HIV have been done to understand its dynamics and enlighten possible improvement in public policies (e.g. Brunello et al., 37 Hixson et al., 38 Thorpe et al., 39 De Araujo Teixeira et al., 40 Magalhães, 41 and others).
Since 1980s, the Ministry of Health annually releases the number of new people infected with HIV for the Brazilian municipalities. Although the number of HIV infection is systematically controlled in Brazil, in practice, smaller municipalities are not able to report the number of new people infected annually, generating missing information in the available data. This missing information makes some statistical analysis harder or impracticable, especially in spatial modeling. Brazilian HIV data are freely available at http://datasus.saude.gov.br/. To make statistical analysis feasible we use the ELM, ELM-IDD, SPGLM, and SPELM to impute the missing HIV data for the state of Minas Gerais in 2010.
Magalhães 41 showed that life expectancy, Gini coefficient, human development index, average income, and percent of urban areas are important covariates to explain the number of HIV new infections by municipalities in the state. These variables cover many social dimensions that are related with the HIV incidence of each municipality, e.g. life expectancy is related with the health structure; Gini coefficient, human development index, and average income are related with the wealth and job opportunity; and percent of urban areas is related with population distribution.
From the 2010 HIV report for the state of Minas Gerais, 81 out of the 853 municipalities (around 10%) of the state were unable to provide information about the number of new cases in its premises. Figure 2(b) shows the relative incidence ratio of HIV in the state. From the figure it is possible to see the missing municipalities and a clear strong spatial association in the map, which indicates that accounting for spatial dependence will improve model fitting and prediction. Following the selection model procedure presented in Section 5 we find that the best combination of the number of neurons and cost for the ELM, ELM-IID, and SPELM models are (L = 28, C = 1), (L = 4, C = 10), and (L = 4, C = 10), respectively. As we can see in Figure 5 the ELM is the only model that does not provide a good fit for the observed data. From the WAIC criterion the SPELM is the one with better fit to the data with WAICSPELM = 1871.97 in comparison against WAICELM = 2085.51, WAICSPGLM = 1886.64, and WAICELM–IID = 1873.53. As observed in Figure 5 the ELM has the worst fit which is captured by its high WAIC.
Fitted values versus observed values for the ELM, ELM-IID, SPGLM, and SPELM, respectively.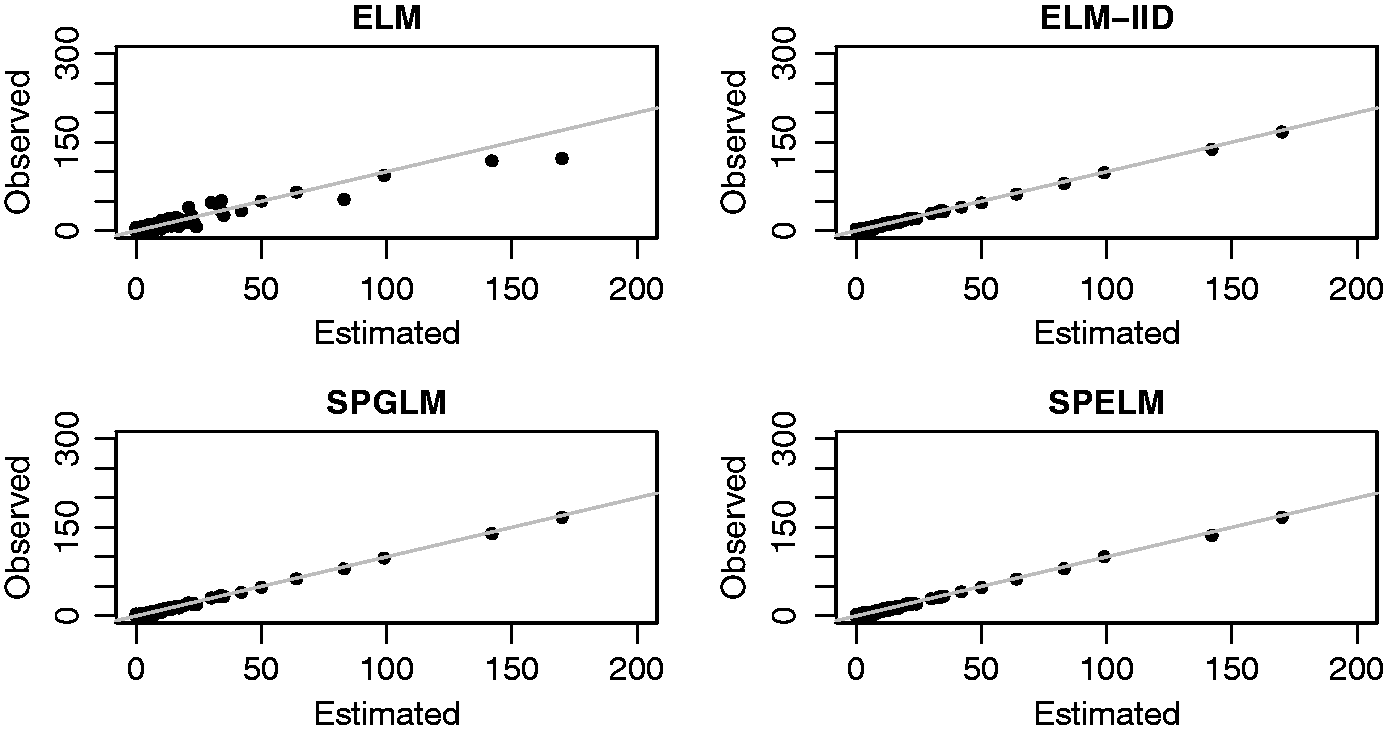
Figure 6 shows the predicted values and standard deviation of the fitted models. From the second column of figure it is clear that the ELMs have very small standard deviation which comprises its credible interval making it too narrow. Figure 6, first column, shows that the SPELM and SPGLM have predicted value that varies smoothly over the region; this is expected because both have an ICAR spatial component that capture the spatial dependence in the data while the other two models do not. Another observation is that Figure 6(a) has more extreme predicted value (low: orange areas; high: dark blue areas) than the competitors, followed by Figure 6(e) model.
(a) and (b) ELM predicted value and posterior standard deviation for the missing municipalities. (c) and (d) ELM-IID predicted value and posterior standard deviation for the missing municipalities. (e) and (f) SPGLM predicted value and posterior standard deviation for the missing municipalities. (g) and (h) SPELM predicted value and posterior standard deviation for the missing municipalities. (a) ELM—prediction, (b) ELM—standard deviation, (c) ELM-IID—prediction, (d) ELM-IID—standard deviation, (e) SPGLM—prediction, (f) SPGLM—standard deviation, (g) SPELM—prediction, and (h) SPELM—standard deviation.
7 Discussion
In this paper a Bayesian SPELM is introduced. The proposed modeling strategy has many advantages: (1) it is simple yet very attractive allowing for the learning capabilities of neural networks while accommodating spatial dependence; (2) combined with INLA keeps the ELM computational efficiency even in a Bayesian framework; (3) by the intrinsic l2 regularization of the method and the approximation theorem guarantee good generalization capacity; (4) easily allows for any likelihood for the response; and (5) extension for more complex models is straightforward, e.g. spatiotemporal.
From our simulation study and real data analysis we can conclude that accounting for spatial dependence make fitting and prediction more reliable and robust to spurious observations, providing more stable results when imputing the missing values. Another advantage is that the SPELM makes no restriction in the functional form of the connection between the covariates and the mean making the model more robust; this is a strong advantage in comparison with the traditional SPGLM that heavily depends on the linearity assumption. It also improves the estimation of uncertainty in prediction. However, although it has some improvement in the uncertainty estimates of the predicted values, from our simulation we can see that the improvement is still not adequate. A possible solution is to choose another likelihood for the response; this might improve model fit and help improve uncertainty estimation. This possibility will be investigated in future studies.
From the practitioners’ point of view, we think that the SPELM is a straightforward and interesting modeling alternative for the biomedical community when a nonlinear or unknown relationship between the explanatory variables and the response is observed, and, moreover, it is an adequate tool to make imputation in areal data problems with missing information.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This works was partially supported by FAPEMIG and CNPq.