
Abstract
Accurate estimates of the under-five mortality rate in a developing world context are a key barometer of the health of a nation. This paper describes a new model to analyze survey data on mortality in this context. We are interested in both spatial and temporal description, that is wishing to estimate under-five mortality rate across regions and years and to investigate the association between the under-five mortality rate and spatially varying covariate surfaces. We illustrate the methodology by producing yearly estimates for subnational areas in Kenya over the period 1980–2014 using data from the Demographic and Health Surveys, which use stratified cluster sampling. We use a binomial likelihood with fixed effects for the urban/rural strata and random effects for the clustering to account for the complex survey design. Smoothing is carried out using Bayesian hierarchical models with continuous spatial and temporally discrete components. A key component of the model is an offset to adjust for bias due to the effects of HIV epidemics. Substantively, there has been a sharp decline in Kenya in the under-five mortality rate in the period 1980–2014, but large variability in estimated subnational rates remains. A priority for future research is understanding this variability. In exploratory work, we examine whether a variety of spatial covariate surfaces can explain the variability in under-five mortality rate. Temperature, precipitation, a measure of malaria infection prevalence, and a measure of nearness to cities were candidates for inclusion in the covariate model, but the interplay between space, time, and covariates is complex.
1 Introduction
Currently, UNICEF estimates the under-five mortality rate (U5MR) at the national level (which is known as Admin 0), using the Bayesian B-spline bias-reduction (B3) method.1,2 However, subnational variation is of great interest and has been highlighted as such in the Sustainable Development Goals (SDGs). SDG 3.2 states, By 2030, end preventable deaths of newborns and children under 5 years of age, with all countries aiming to reduce neonatal mortality to at least as low as 12 per 1,000 live births and under-5 mortality to at least as low as 25 per 1,000 live births.
From https://sustainabledevelopment.un.org/post2015/transformingourworld, with reference to review processes, paragraph 74.g states, They will be rigorous and based on evidence, informed by country-led evaluations and data which is high-quality, accessible, timely, reliable and disaggregated by income, sex, age, race, ethnicity, migration status, disability and geographic location and other characteristics relevant in national contexts.
In much of the developing world, there is limited or deficient vital registration, and estimates of U5MR are based mostly on survey and census data. In this paper, we carry out detailed analyses of such data from Kenya. Many health policies and interventions in Kenya are implemented at the Admin 1 level, which consists of 47 counties, 3 and hence it is the spatial aggregation that provides our target of inference. To estimate U5MR, we use data from the Demographic and Health Surveys (DHS). The DHS Program began in 1984 and has carried out more than 300 surveys in over 90 countries. Typically stratified, cluster sampling is carried out with information collected on population, health, HIV, and nutrition. We have also carried out a detailed analysis for Malawi, using the methodology developed in this paper, but due to space limitations, we focus on Kenya, with results for Malawi being relegated to the Supplementary Materials.
We briefly review previous approaches to producing subnational U5MR estimates. Adopting demographic notation, we define
In other contexts, methods for small area estimation 11 using spatial smoothing models have been proposed by a number of authors including Congdon and Lloyd, 12 You and Zhou, 13 Porter et al., 14 Chen et al., 15 Vandendijck et al., 16 and Watjou et al. 17 Notably, these approaches all utilize spatial models at the area level, whereas the model we propose models space continuously.
Burke et al. 18 followed a different approach to modeling U5MR across sub-Saharan Africa. Kernel density estimation (KDE) is carried out with surfaces produced at a geographical scale of approximately 10 km × 10 km. This approach follows Larmarange and Bendaud 19 who used the same method in the context of HIV prevalence estimation. Inference, including producing uncertainty surfaces, is difficult to obtain with KDE and the approach has been found to be inferior, when considering prediction at unsampled locations, to Bayesian geostatistical modeling. 20
More recently, Golding et al. 21 carried out subnational estimation of U5MR for sub-Saharan Africa, with a continuously indexed spatial model. Four separate models were fitted to the age groups 0–1 months, 1–11 months, 12–35 months, 36–59 months, with the subsequent estimates being combined to give the U5MR. This combination is done by taking draws from the posteriors assuming they are independent, which is not correct, since they are based on the same children. Data from a variety of sources are included in the analysis including both full birth history (FBH) and summary birth history (SBH) data. FBH data include information for all children on the times of birth and death, if the latter occurs before the time of the survey, and these are the data we utilize from the DHS. SBH data consist of the number of children ever born, and the number who have died, along with the age of the mother. The FBH data are modeled as binomial with no explicit correction for the survey design. The SBH data are also assumed to be binomially distributed, with an artificial response and denominator created through an elaborate procedure with a heuristic justification. A space–time smoothing model is specified via the stochastic partial differential equations (SPDEs) formulation of Lindgren et al. 22 The same space–time covariance parameters are assumed for the whole of Africa. Covariates are also modeled, and we give further details of the approach followed in Section 4. There is no adjustment for mothers lost to HIV, which can lead to serious underestimation in countries (such as Kenya and Malawi) with HIV epidemics. Estimates in each spatial grid cell are adjusted so that the national total agrees with the Global Burden of Disease (GBD) estimates. The most recent GBD 23 produced national estimates for 195 countries and territories over the period 1970–2016. Some of the constituent data in the study of Golding et al. 21 do not contain GPS locations, but rather the administrative region within which the clusters were sampled. In this case, Golding et al. (Supplementary Materials, Section 8) 21 assign the data to a set of points selected within the area, where the points are obtained through k-means clustering. This approach is, at best, an approximation, since one needs to take a mixture over the likelihoods at each potential location, see Wilson and Wakefield. 24
In this paper we develop a new continuous space/discrete time model that acknowledges the complex design by including urban/rural stratum effects. It was necessary to develop this model, because the approach of Mercer et al. 6 requires design-based (weighted) estimates of the U5MR, with an associated standard error, for each time period and area, and as the time intervals become small, and/or the number of areas become large, the estimates and standard errors become unstable. In particular, for the Kenya data, it was not possible to implement the Mercer et al. 6 method on a yearly scale with 47 counties. The rest of this paper is structured as follows. In Section 2 we describe the data that we use for analysis. Section 3 develops the method and gives the results for constructing the space–time child mortality surface, while Section 4 considers covariate modeling. Section 5 concludes the paper with a discussion of ways in which we would like to extend the model.
2 Data
2.1 Survey data
To estimate child mortality in Kenya, we use data from three DHS conducted in 2003, 2008–2009, and 2014. Both the 2003 and 2008–2009 Kenya DHS were designed to give reliable estimates for the eight provinces, and for urban and rural regions separately. To this end, the sample was stratified by eight provinces crossed with an urban/rural designation to yield 15 strata (Nairobi is solely urban). In each of these surveys the first sampling stage selected 400 enumeration areas (EAs) from a sampling frame constructed from the 1999 Census. In the second stage for both the 2003 and 2008–2009 surveys, 10,000 households were selected within the sampled EAs. The 2014 Kenya DHS was designed to make estimates of demographic indicators at the 47 county levels, so it was stratified by the 47 counties crossed with urban/rural indicators. This yields 92 strata since Nairobi and Mombasa are both entirely urban. The first sampling stage of the 2014 survey produced 1584 EAs that gave data that could be used, across the 92 strata, using a sampling frame developed from the 2009 Census. In the second stage, 40,300 households were sampled from the selected EAs. All households within the same EA are aggregated to a single point location. Figure 1 shows the cluster locations for the three surveys along with the boundaries of the 47 counties. For confidentiality reasons, the GPS coordinates of the cluster centers are randomly displaced. Urban/rural cluster locations are displaced by up to 2 km/5 km; the locations of a further 1% random sample of rural clusters are displaced by up to 10 km. We see that the distribution of the sampling locations is far from uniform, reflecting population density. Reported response rates for households and women are high. Such data are potentially subject to various biases, e.g. recall bias, as the birth histories may go back many years if the woman surveyed is old. Though we have data from only three survey waves, the retrospective birth history gives us data on births over the period 1980–2014.
Cluster locations in the three DHS that we consider, with boundaries of the 47 counties.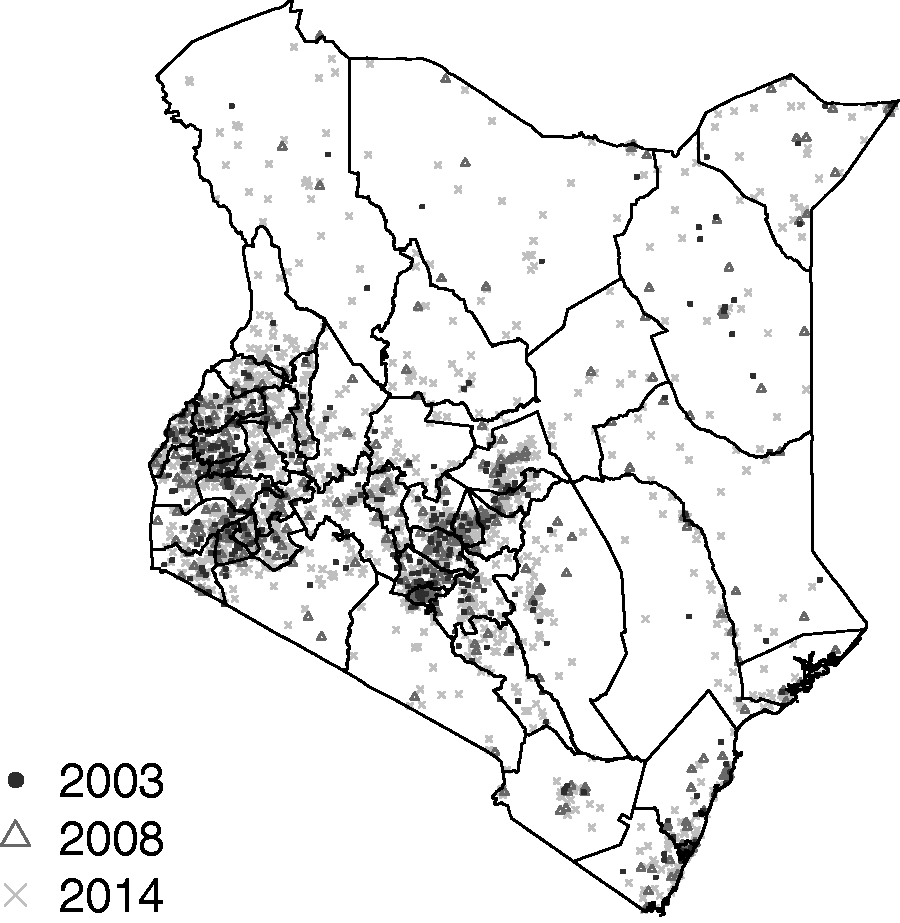
To estimate U5MR we use the portion of the survey devoted to retrospective birth histories. Women who slept in the house the night before, and are aged 15–49 are asked to enumerate all births with dates of birth, and for children who have died, dates of death. Birth histories are converted into person months for each child in the dataset. Using a discrete hazards model, each person month yields a Bernoulli (binary) random variable, survived/dead. Hence, we implement a discrete time event history analysis. It is important to note that each unique case can result in at most one death. We would like to investigate temporal trends in U5MR (at the yearly scale) and the subnational variability in these trends across the 47 counties. Kenya provides a good test example due to the large number of clusters (1584) sampled in the 2014 DHS. The Supplementary Materials contain extensive details on the numbers of deaths by period and county.
2.2 HIV adjustment
Kenya has had a relatively high prevalence of HIV, and this can lead to serious bias in estimates of U5MR, particularly before antiretroviral therapy (ART) treatment became widely available. Pretreatment HIV-positive women had a high risk of dying, and such women who had given birth were therefore less likely to appear in surveys. The children of HIV-positive women are also more likely to die before age 5 compared to those born to HIV-negative women, and therefore we expect to underestimate U5MR if we do not adjust for the missing women, i.e. the missing data are nonignorable.
Estimates of bias may be obtained using the cohort component projection model of Walker et al.
25
Under this model, for a particular survey, year, and province (of which there are eight), the number of births is estimated, and these are attributed to HIV-negative and HIV-positive women, using estimates of the number of women in need of services to prevent mother-to-child transmission. The children born are then further subdivided into those that will and those that will not become infected with HIV, and survival probabilities of these children are then estimated to produce a bias ratio. Let

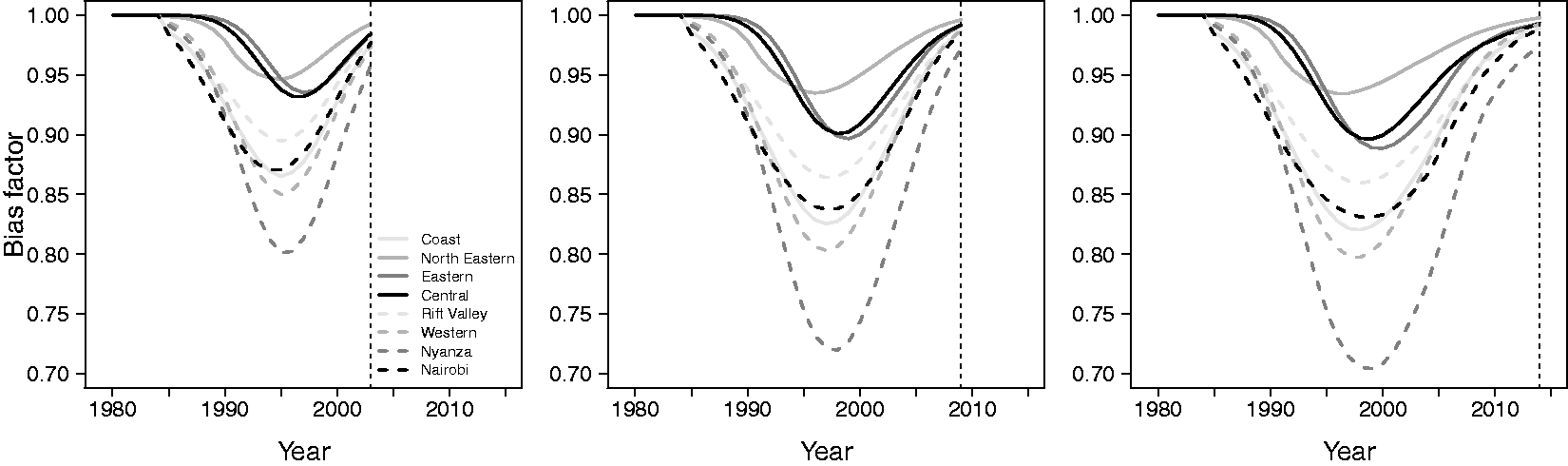
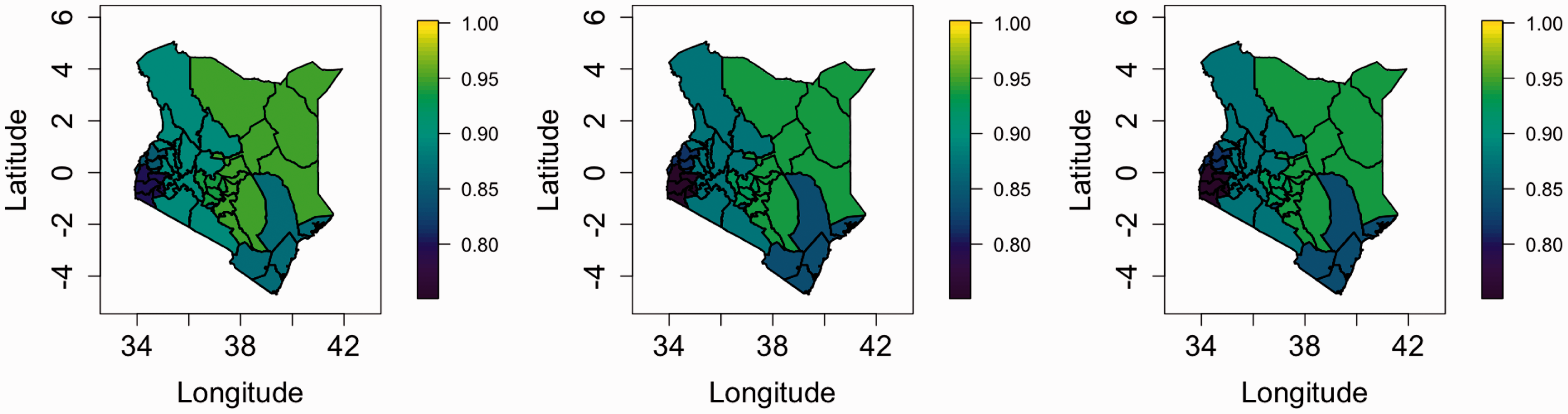
Figure 2 shows the bias ratios plotted against year for each of the three surveys, and for the eight provinces of Kenya for which we have available data; we would prefer to have estimates at the 47 county levels, but the constituent data are not available. The 47 counties are nested within the eight provinces, which eases the application of the adjustment. We see that the ratios of reported to true rates decrease as the HIV epidemic takes hold and then increase with the uptake of ART. Figure 3 shows maps of the ratios in 1995 (as an example year), and large between-province differences are apparent. The ratios will clearly make a significant impact on our estimates and are included in an offset in the model we describe in Section 3. A current weakness of our approach is that we do not account for the uncertainty in the manner by which the ratios were estimated.
HIV adjustment ratios of reported U5MRs to “true” U5MRs, that is (1), by survey, over time (left is 2003, middle is 2008–2009, right is 2014), and in eight provinces. Ratios were calculated using the method of Walker et al.
25
Maps of HIV adjustment ratios of reported U5MRs to “true” U5MRs, that is (1), by survey, in 1995. The three columns represent the adjustments from the 2003, 2008–2009, 2014 surveys. Ratios were obtained using the method of Walker et al.
25
3 Constructing a space–time surface
3.1 The space–time model
Survey data come from and describe a finite population. The DHS provides sampling weights for each individual that account for the selection probability and nonresponse. Skinner and Wakefield 26 reviewed the design and analysis of survey data. The design-based (or randomization) approach to inference is to place inference in the context of repeated sampling from the fixed finite population. The word fixed is key here, the data are not viewed as random, rather the indices of the units (households, in this context) within the population that are sampled are the random variables. Weighted (often referred to as direct) estimators 27 provide a design-consistent approach to estimation, but the sparsity of data in both time and space is problematic since a greater proportion of cells with zero deaths in some age groups occur when we drill down to finer spatiotemporal units. Even with small numbers of deaths, variance estimates are unstable. The Supplementary Materials contain information on the standard errors of the direct estimates, by county, as a function of time period. This is a small area estimation problem and at the scale for which inference is desired, smoothing in space and time is required.
As an alternative to design-based inference, a more traditional statistical approach may be employed in which a probability model for the observations is assumed, and the mean model contains terms that reflect the design, with a carefully chosen variance model. This approach is known as model-based inference; Wakefield et al. 28 compared the two approaches via simulation in a spatial context. In general, when a model-based approach is followed, the design must be acknowledged when inference is performed, otherwise biased estimates with an incorrect measure of uncertainty will be produced. As an extreme example, in the DHS, sampling is stratified by urban/rural and if in a particular county (which has both urban and rural clusters) only urban clusters were selected then ignoring this aspect will lead to bias in the estimation of the county-level estimate, if U5MR is associated with urban/rural.
As in Mercer et al.
6
we assume a discrete hazards model, with six hazards for each of the (monthly) age bands: [0,1), [1,12), [12,24), [24,36), [36,48), [48,60). Detailed argument in, for example, Allison
29
shows that the contributions for a generic child correspond to the product of up to 60 Bernoulli likelihoods with
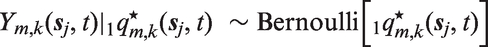
Notice that the potentially HIV biased outcomes are Bernoulli with probability of death given by the biased hazards
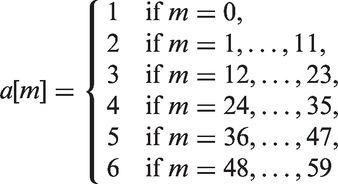
Then the latent logistic model we use is
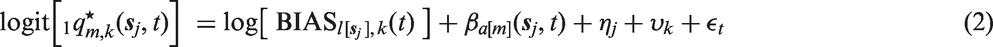
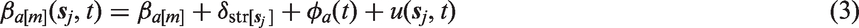
This form consists of a collection of terms that are used for prediction,
A separable spatiotemporal process has a covariance function that is a combination of a spatial dependence structure,
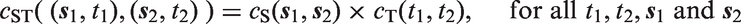
The multiplicative structure is beneficial because it is easy to construct valid spatiotemporal covariance functions by combining valid spatial and temporal covariance functions. We want the spatial component of the separable spatiotemporal effect to have a Matérn covariance function
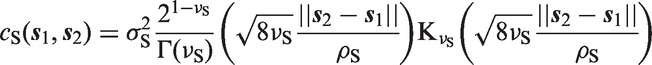

The hazard for each age group is expected to vary spatially, but due to data sparsity the data will not support separate spatial main effects for each of the six age bands. A parsimonious model would include a shared spatial main effect for all age groups, but since a spatiotemporal interaction is necessary to account for the yearly changes in the spatial pattern, we do not include a separate spatial main effect. It is too expensive to apply the necessary temporal sum-to-zero constraints that would be required to give identifiable spatial main effects alongside a spatiotemporal interaction. Therefore, the shared spatiotemporal interaction is handled with a separable spatiotemporal model that combines an AR(1) structure with the Matérn covariance function, with the smoothness parameter fixed. The resulting spatiotemporal covariance function can be explained through a constructive example which gives some intuition on the space–time interaction. A stable AR(1) process with marginal variance 1 can be generated by
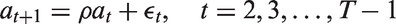
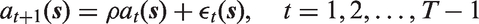
The joint identifiability of the three temporal trends and the spatiotemporal interaction can be achieved through integrate-to-zero constraints for each year. This integration is carried out with respect to the spatially varying population density
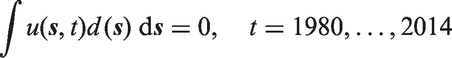
This spatiotemporal effect on a temporal resolution of 35 years is too computationally expensive to include in the SPDE implementation of the Bayesian model, but since we want the spatiotemporal process to change gradually in time, it is possible to use an approximation that changes piecewise linearly in time; a similar approach was taken in Blangiardo and Cameletti (Chapter 8).
30
We decrease the resolution of the spatiotemporal process to eight time steps by defining
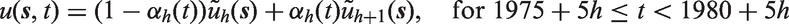
Each of the precisions for the independent and identically distributed effects,
For predictions, the cluster, survey, and temporal independent and identically distributed effects in equation (2) are not included so that the only contribution is
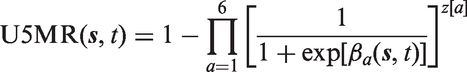
The data and the fitted model are on a continuous spatial scale, but the aim is to produce values on a discrete scale using the 47 administrative regions. To construct the predictive spatial surfaces over time we use the posterior of the spatially–temporally varying U5MR and the population density
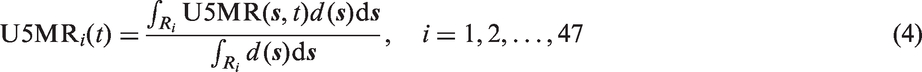
3.2 Constructing a space–time surface result
We begin by reporting inference on some of the key components of the model, before reporting on substantive summaries. We also fitted a model with no HIV bias adjustment, and the left panel of Figure 4 shows the posterior medians of the RW2 fits for each of the [0,1), [1,12), [12,60) age groups (specifically, Median RW2 model temporal trends (left) HIV adjusted time trends (right) for the three age bands. Both with 95% pointwise credible intervals. The trends are on the odds ratio scale.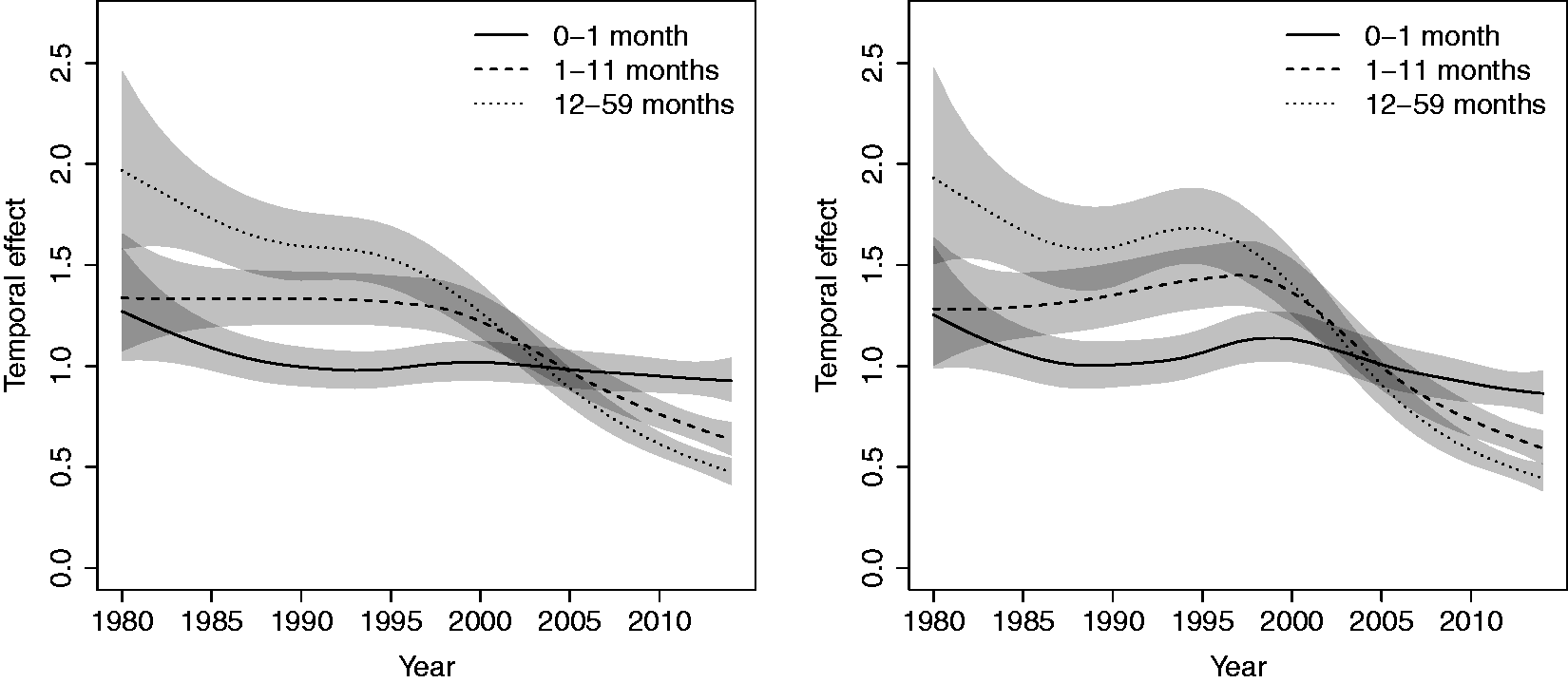
Posterior quantiles for model parameters.
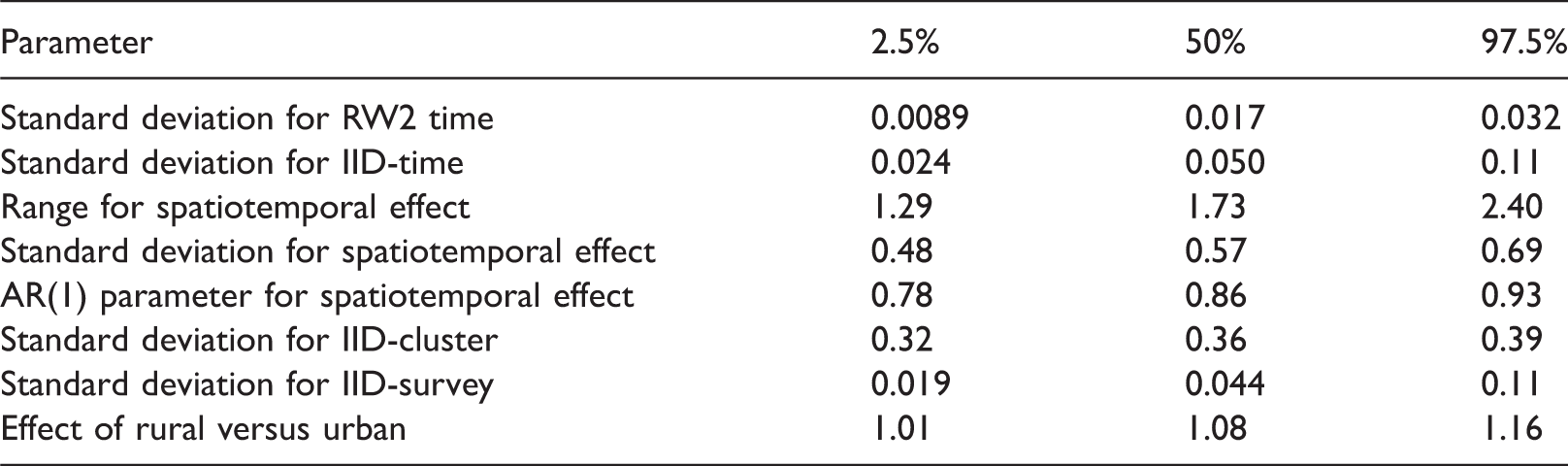
IID: independent and identically distributed; RW2: random walk of order 2.
Figure 5 shows a comparison between the modeled U5MR and weighted estimates at the 47 county levels and aggregated over five years (aggregation over years is required, otherwise the weighted estimates are unstable). The weighted estimates in a particular area and time period are based on data from all surveys that were collected in those areas/time periods; the way we combine the data from different surveys and make the HIV adjustment is described in the Supplementary Materials. We see some attenuation of the modeled estimates due to shrinkage, as expected. In the Supplementary Materials we include more detailed plots and show the uncertainty in the modeled and weighted estimators. These plots show that, again as expected, the modeled estimates have much greater precision.
Modeled estimates versus weighted (direct) estimates on the logit scale.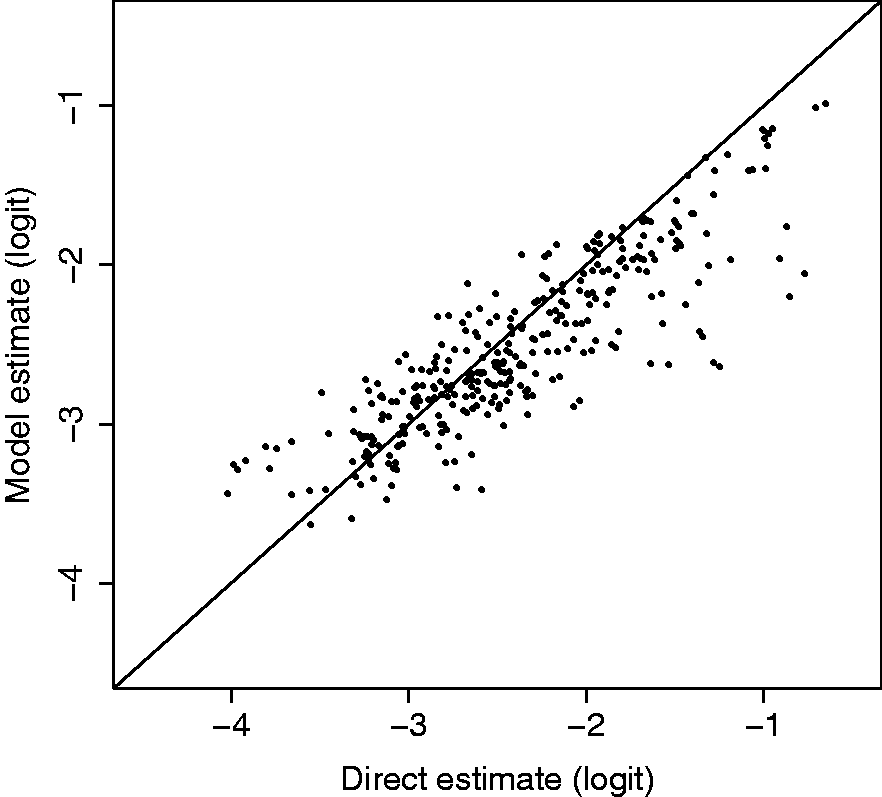
As mentioned in Section 1, we wish to make inference at the spatial level at which policy interventions occur. For Kenya, this is at the 47 county levels, and Figure 6 shows a sequence of nine maps of U5MR for the years Maps of the posterior median estimates of U5MR at the county level, with uncertainty represented by hatching. Top row: 1980, 1985, 1990. Middle row: 1995, 2000, 2005. Bottom row: 2010, 2015, 2020.
Figure 7 shows the posterior medians of the spatiotemporal terms Maps of the spatiotemporal odds surface, 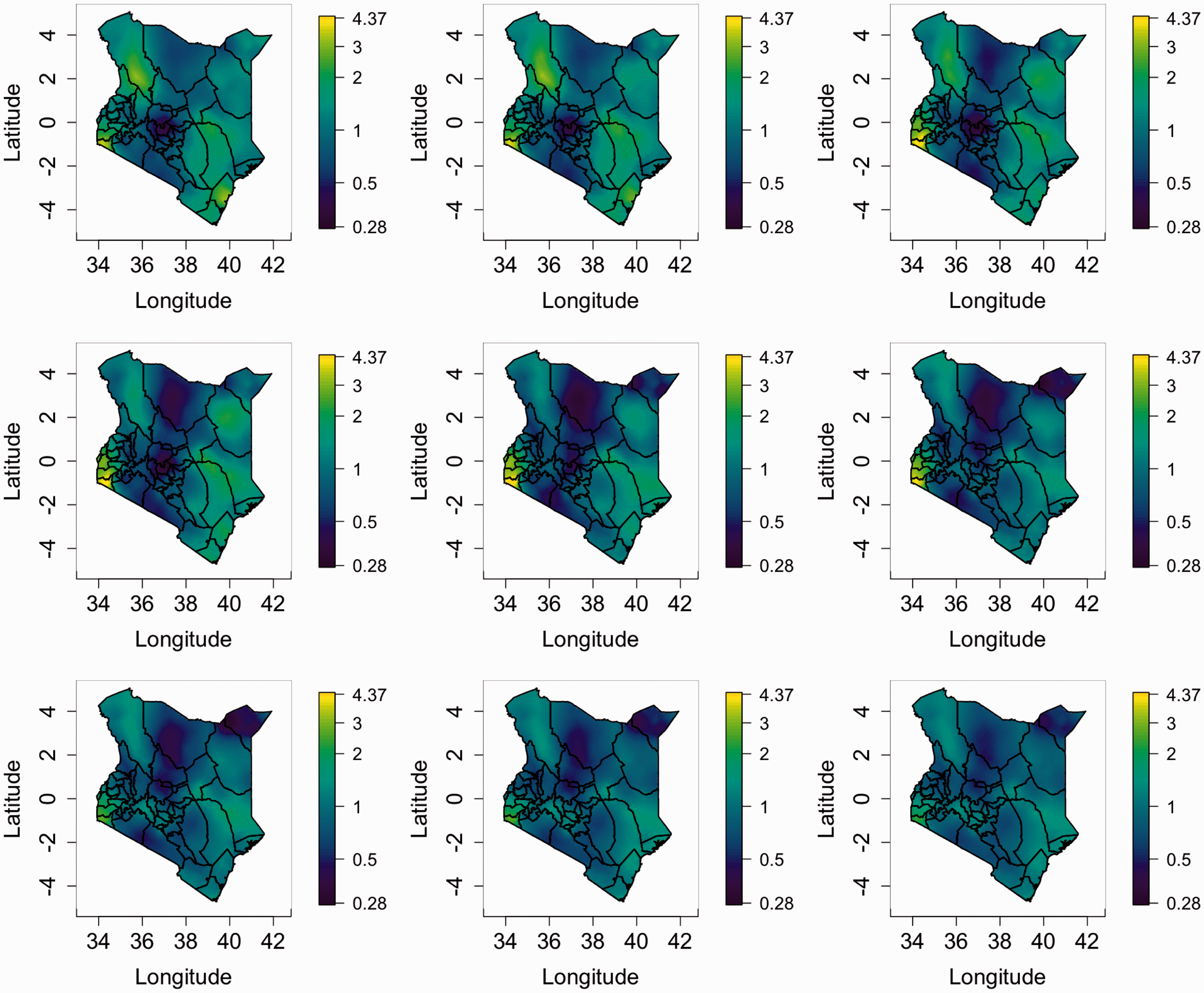
While it might appear that the spatiotemporal variability is decreasing over time it should be emphasized that there is still strong variability present across the map in recent periods and also in the future. To illustrate this we computed the 95 and 5% quantiles of the posterior medians across pixel values for each of the nine maps. Figure 8 summarizes the spatial heterogeneity over time. In 1980, the 95% quantile was 2.2 and the 5% quantile was 0.63 leading to a ratio of 3.4. While the 5% quantile decreases until 2005 and then increases again, the 95% quantile decreases almost constantly. The ratio of 95–5% points increases until 1995 with a value of 4.4 and then decreases. However, in 2010 the ratio is still 3.5, with ratios of 3.0 and 2.6 in the (predicted) years of 2015 and 2020, respectively. In summary, there remains strong subnational heterogeneity in U5MR in Kenya; further discussion will be given in Section 3.3.
Left plot: 5% and 95% quantiles of pixel map of the posterior medians of the spatiotemporal effect. Right plot: ratio of 95% to 5% quantiles. The values are computed for years 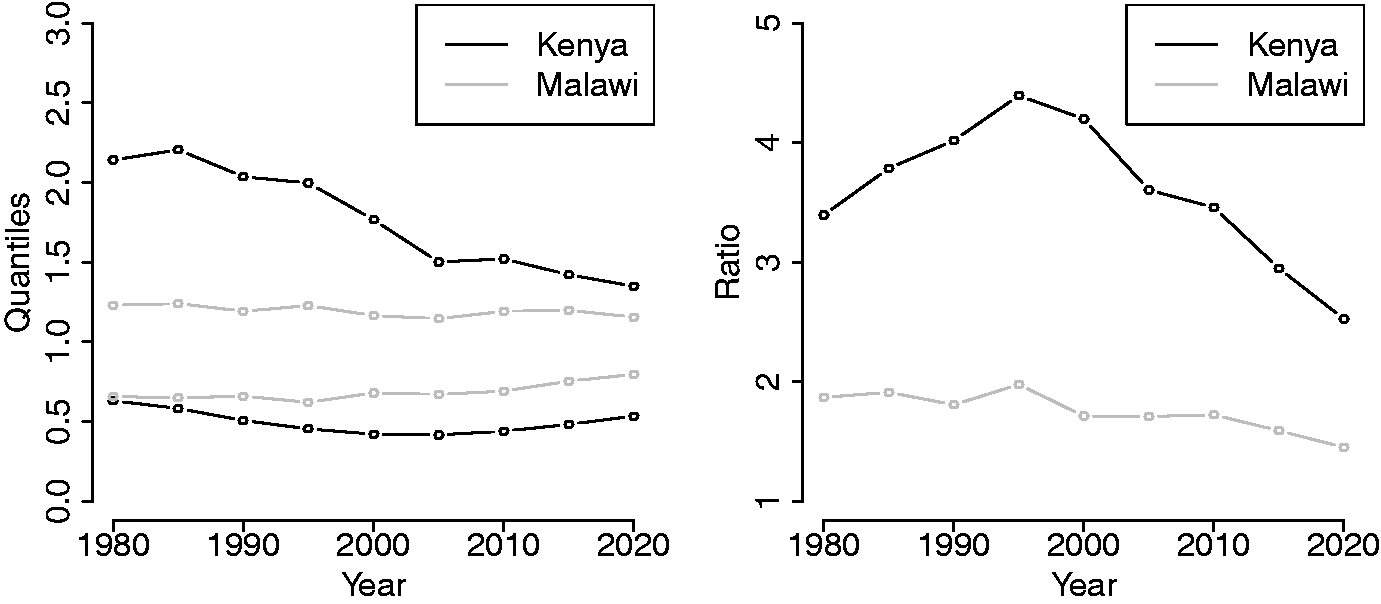
The Millennium Development Goals aimed for a drop of 67% in U5MR between 1990 and 2015. In the left-hand panel of Figure 9 we map the posterior median of the percentage drop at the county level. Counties in the central part of Kenya experienced very small decreases only. In the right-hand panel we plot the posterior probability that each county achieved this aim and we see that very few attained a 67% drop. Over the country as a whole, the posterior median drop was 55% with 95% credible interval of (45%, 61%), and a 0% probability that the 67% drop was achieved.
Left plot: Posterior median of 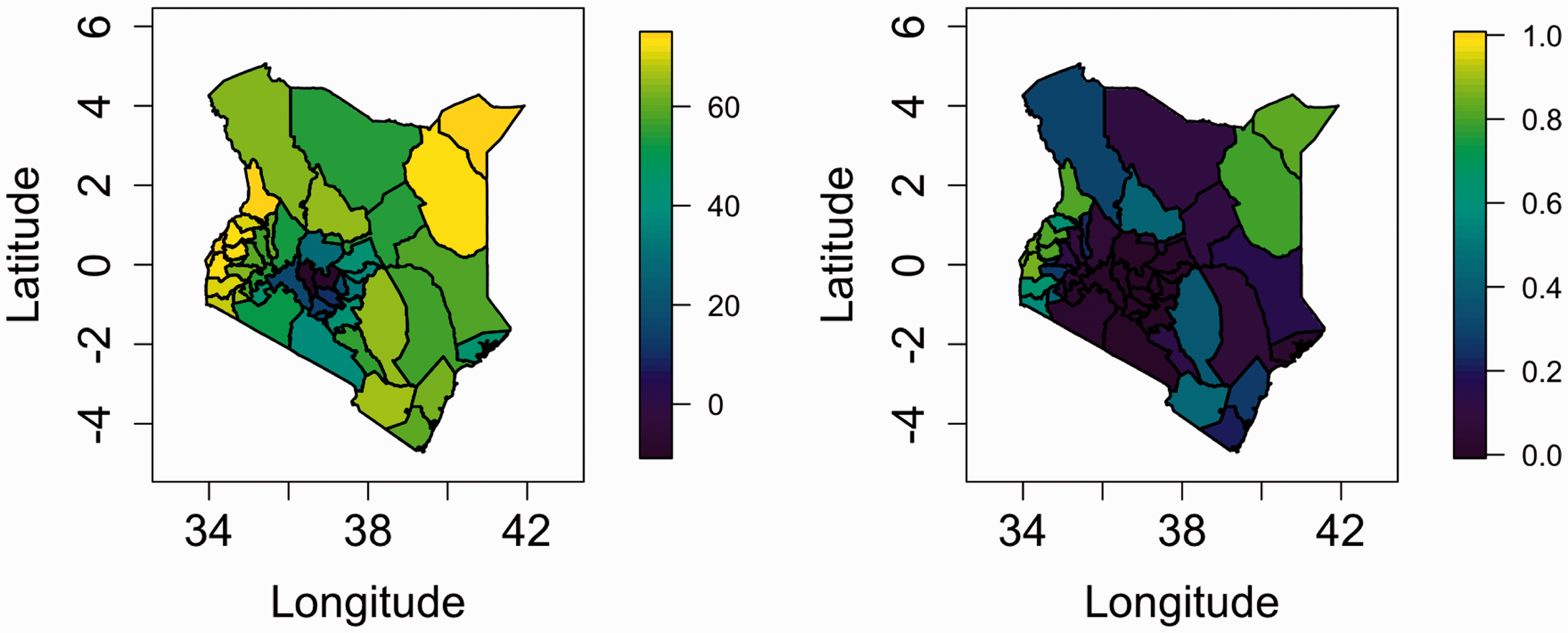
To examine the accuracy of the space–time smoothing model, we held out some of the data and then predicted the U5MR at these left-out points, using weighted and smoothed estimates. Specifically, we calculated estimates of U5MR for all counties and periods from the model using all the 2003 and 2008–2009 DHS, along with 397 clusters from the 2014 DHS. We then calculated weighted estimates of U5MR using the remaining 1187 clusters, and these are treated as the target, since they are based on a relatively large sample. Due to stability of the weighted estimates we look only at the periods 1990–1994, 1995–1999, 2000–2004, 2005–2009, and 2010–2014, and form estimates for each of the 47 counties in these periods. For county i and period p, we let
We also calculate predictions using a model that is the discrete spatial analog of the continuously indexed spatial model described in Section 3.1. Hence, the likelihood is a product of Bernoulli’s with a HIV adjustment; six age-specific intercepts; independent and identically distributed random effects for cluster, survey, and time; a fixed effect for urban/rural; three RW2 models for yearly time for the three age bins; and a space–time interaction model that replaces the SPDE (continuous space) model with an ICAR model. With respect to the latter, we therefore have an ICAR spatial model
37
at the first time point and this then contributes to the next time point, via an AR(1) model, with the addition of a new ICAR contribution. This space–time interaction model is defined on eight rather than 35 time steps, as in Section 3.1. The estimators from this model will be denoted

Mean-squared errors

3.3 Analyzing multiple countries
The spatiotemporal model can be applied separately to multiple countries to obtain estimates for each country and to perform within-country and between-country comparisons. We demonstrate by using Malawi and its four DHS from 2000, 2004, 2010, and 2015. The details are given in the Supplementary Material, and show that, as for Kenya, the MSEs of the estimates from the continuously indexed spatial model are considerably lower than for the direct estimates; there is also a modest improvement over the BYM formulation. The spatiotemporal component can be used to examine the temporal evolution of spatial inequality across and between countries. We compute the 5 and 95% quantiles of the posterior medians of the spatiotemporal effects at the pixels within Malawi. Figure 8 demonstrates that Kenya has stronger spatial inequality than Malawi and that there is larger temporal change in the spatial inequality for Kenya than for Malawi.
4 Exploratory covariate modeling
4.1 The covariate model
In this section we carry out an exploratory investigation into whether any of the spatial variability we see in Kenya can be attributed to a variety of covariates that we have acquired. Mosley and Chen 38 attempted to bring together medical and social sciences research, in order to provide a framework for child survival. A key element of this framework is the identification of a set of proximate determinants that directly influence the U5MR. Mosley and Chen 38 listed five categories of proximate determinants: maternal factors (age, parity, birth interval), environmental contamination (air, food/water/fingers, skin/soil/inanimate objects, insect vectors), nutrient deficiency (calories, protein, micronutrients), injury (accidental, intentional), and personal illness control (personal preventive measures, medical treatment). Socioeconomic determinants influence these proximate determinants.
At this point, we comment briefly on the roles and limitations of different kinds of spatial modeling in this context. We can distinguish between individual and ecological modeling. In the former, one may directly estimate the associations with proximate determinants. In an ecological setting, we are in a very different situation as there is no individual adjustment for these determinants, but instead we introduce area (or cluster) level variables which are proxies for proximate or socioeconomic variables. In an ecological study for a complex outcome such as U5MR, one will not have a hope of getting close to mimicking individual-level associations, due to ecological bias, 10 but if the areas are not too large, and if the input variables are well measured, then one may find variables that can aid in predicting area-level U5MR. It is this latter setting that we are in. If we wish to obtain predictions for unobserved locations on the basis of a covariate model, then those covariates must be available at those locations.
In a comprehensive analysis of DHS data from 10 West African countries, Balk et al.
39
carried out individual-level modeling and fitted a range of models that included child and mother demographics; household characteristics; and spatial characteristics that included urban/rural, population density, rainfall, distance to coast, and a farming variable. Models were fitted for both
Before outlining our approach to covariate modeling, we provide a brief literature review of suggestions for building covariate models in the setting considered here. Gething et al.
41
described the use of DHS data to construct surfaces of access to HIV testing in women, stunting in children, anemia prevalence in children, and access to improved sanitation. For each outcome and each country the following procedure was carried out. A collection of 17 covariates were examined. Initially, simple linear regression was used taking three versions (the original, the square, and the square root) of each of the 17 variables. Cross-validation was then used to reduce these to a subset of 17 terms. Two-way interactions for these 17 were added to the collection to give 289 = 17 × 17 additional terms. This complete set was reduced to 20, again via cross-validation. Then the resultant potential
Bhatt et al. 42 used an approach known as stacked generalization 43 in which multiple predicting algorithms are weighted to produce a final prediction. This approach is closely related to the more general super-learner approach. 44 This approach has optimality properties for prediction but has a lack of interpretability, and the model is not suitable for predictions into the future. There is also no way that uncertainty in the estimation procedure can be incorporated into interval estimates for the surface. A similar approach was used by Golding et al. 21
The variables that we selected for examination were access (estimated travel time to cities with at least 50,000 people), 45 aridity,46,47 precipitation, 48 temperature, 48 enhanced vegetation index, 49 and the Plasmodium falciparum parasite rate (PfPR) in children. 50 The rationale for including access is that it is thought to be related to availability of health services and improved public health infrastructure (e.g. clean drinking water). Population density can play a role in the transmission of infectious diseases and is also related to access of resources. 51 The climatic variables (aridity, precipitation, temperature, and vegetation) may affect vector-borne disease transmission and food production, which influences malnutrition. Malaria transmission has been previously shown to explain mortality especially in Eastern Africa. 52
Further details on these covariates can be found in the Supplementary Materials, including the sources and the spatial resolution. For the purposes of exploration, we model access, aridity, temperature, and precipitation as time invariant; plots of these variables can be found in the left column of Figure 10. Data on PfPR, population, and vegetation were obtained for the years 2000–2014 and subsequently averaged within each of the three five-year periods (2000–2004, 2005–2009, and 2010–2014) to obtain values for each period; these data are also displayed in Figure 10.
Left column: maps of time-invariant spatial covariates in Kenya. Columns 2–4 represent five-year maps for PfPR (row 1), population (row 2), and vegetation (row 3). Access, aridity, and population have been log transformed for presentation purposes. The units for population are number of people per 5 km × 5 km area. All time points are on the same scale for each variable.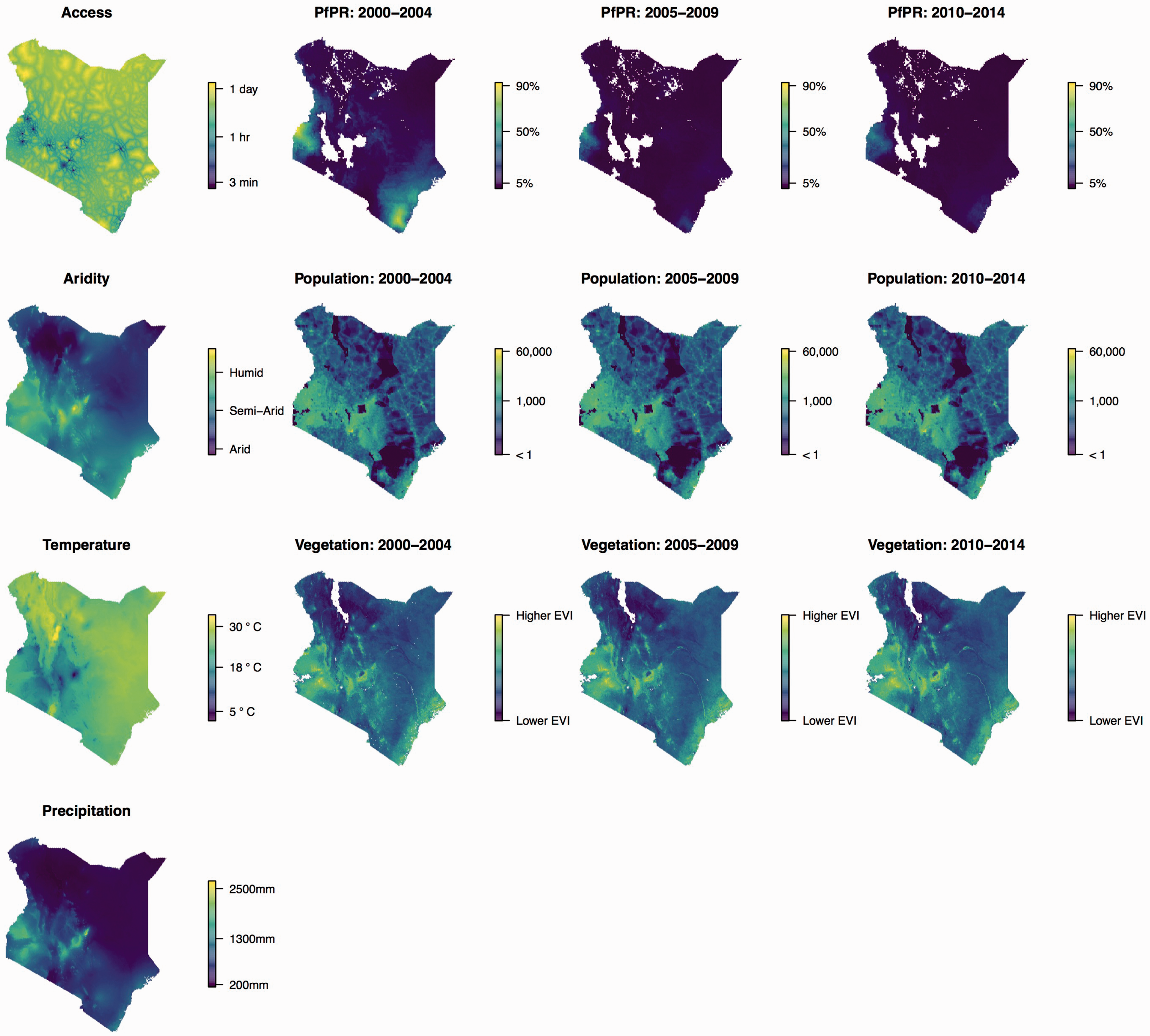
In order to determine which covariates are predictive of U5MR, we will use a simplified version of the model described in Section 3.1, in which we replace the yearly model with a model over five-year periods 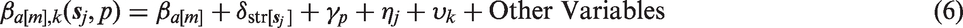
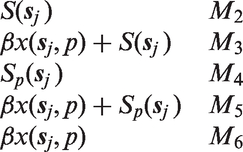
Under Mj we have an estimator of the logit of U5MR for each area i and period p, 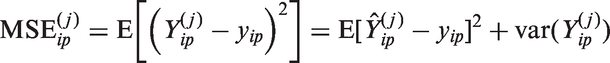
The best approach is that which minimizes the MSE.
4.2 Exploratory covariate modeling results
The DIC, CPO, and WAIC scores for all possible covariate combinations for models M3, M5, and M6 are reproduced in the Supplementary Materials. There is good agreement between the three different assessments of model fit for M3 and M5. For M3 (“fixed” spatial effect with covariates), the best model was that which included precipitation. For M5 (period-varying spatial effect with covariates), the model that included temperature, PfPR and access performed best. For M6 (covariates only), WAIC and DIC suggested the model that included temperature, precipitation and PfPR, and aridity, while CPO suggested the model with temperature, population, and PfPR.
The MSE and constituent squared bias and variance are shown in Figure 11. We see that M2, M3, and M4 perform better than M1, with M3 performing (marginally) better than the others. In the summary figures we report, we take the version of M6 that was suggested by WAIC and DIC, though results are similar for the CPO version, with the model including aridity having a slightly higher MSE. We see in Figure 12 that the predicted surfaces are almost identical under models M2–M6.
Plot of MSE broken down into Regional predicted U5MR. Top row is the “truth,” i.e. direct estimates based on the 799 test locations in the 2014 survey. Model M1 are the direct estimates based on the other clusters. Model M2 is the fixed spatial only model (no covariates). Model M3 is the fixed spatial model with covariates (precipitation). Model M4 is the time-varying spatial only model (no covariates). Model M5 is the time-varying spatial only model with covariates (access, temperature, and PfPR). Finally, model M6 is the only covariates model (aridity, temperature, precipitation, and PfPR).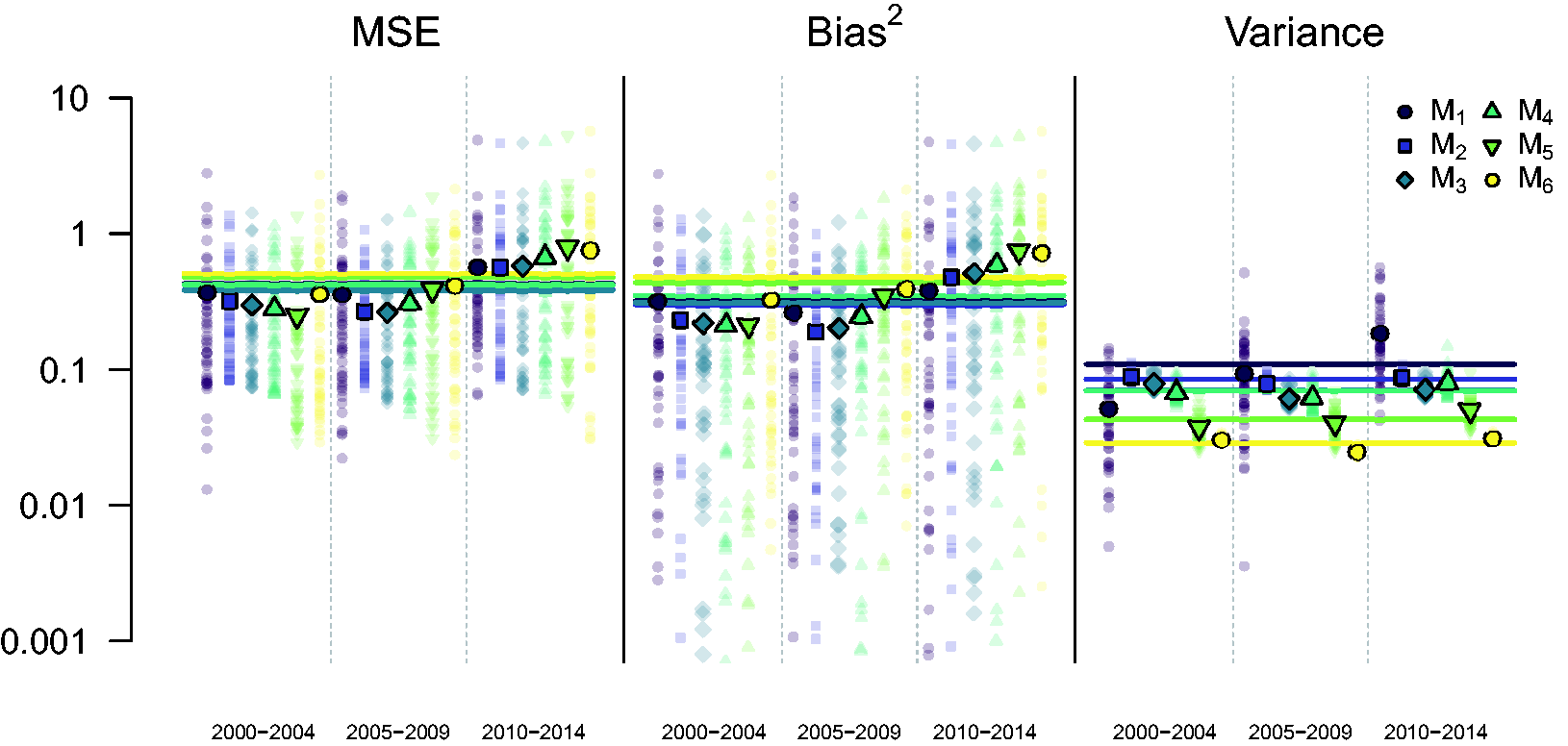
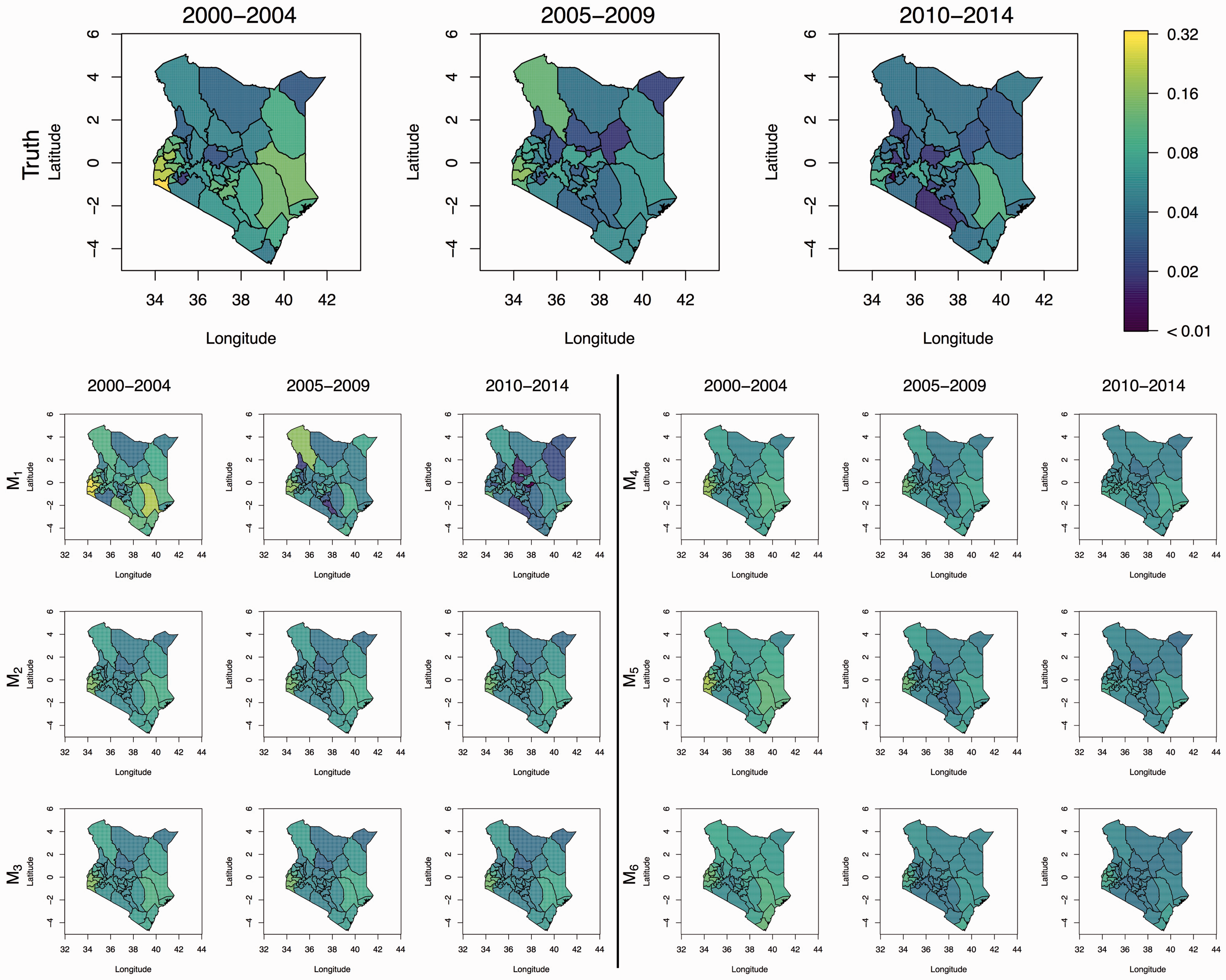
We conclude from this exercise that the covariates we have investigated add little predictive power at the 47 county levels to the space–time models. This is disappointing, and consistent with the results of Golding et al., 21 but we believe that continued examination of spatial covariates is warranted, though the quality and relevance of potential covariates should be critically evaluated.
5 Discussion
In this paper we have developed a continuous space/discrete time model for investigating the dynamics of U5MR in a developing world setting. We have illustrated that the model improves on the use of weighted estimates and can provide reliable inference at the required geographical scale. As a further illustration of the model’s applicability we have included in the Supplementary Materials a parallel analysis of data in Malawi, and find similar behavior of the model, and in particular its superiority (in terms of MSE) to the use of weighted estimates. The potential for between-country comparisons based on the estimated model components is an advantage of the modeling framework that we have described in the paper. In particular, spatial inequality can be examined via the estimated spatiotemporal component, differences in temporal change from the estimated RW2 component, unexplained variation from the nugget variance, etc. Figure 8 gives a hint of the between-country comparisons that can be made, here showing the across-country spatial inequality for both Kenya and Malawi.
However, there are a number of aspects that we aim to improve upon in future work. An adjustment for HIV epidemics is crucial, given the extent of the epidemic in Kenya (and in many other countries), and we would like to acknowledge the uncertainty in the bias correction, and also obtain corrections at a finer geographical granularity. A source of potential bias that we want to investigate is migration, since earlier births in particular may have occurred at different locations to those at which the survey was carried out.
The age pattern of human mortality between ages 0 and 5 years follows a regular, decreasing pattern across a wide range of overall levels. Net of level, this age pattern can be characterized by the ratio of mortality at each age compared to a reference age. Our model has six age-specific intercepts and a random walk of second order to model the time trend, with one each for [0,1) and [1,12) months and then a third for the remaining period of [12,60) months. An alternative might be to use a Lee–Carter 56 like approach that includes one component representing the average shape of the age profile, and a second component representing a time varying trend, which is multiplied by the age-specific mortality change from the average age profile. For applications of this model in a similar context, see for example Sharrow et al. 57 and Alexander et al. 58 One computational challenge of the Lee–Carter approach is the multiplicative structure of two random effects which is hard to incorporate into INLA.
Our models estimate mortality in six independent age groups, and it is possible that the age pattern that results from combining the estimates from the six models does not follow any of the regularly observed age patterns of human child mortality. In our analysis, this was not a problem (see Supplementary Materials), but we are currently working on a flexible model of the age pattern of mortality that can enforce this constraint.
We would like to include other data sources, for both Kenya and other countries. Early DHS do not contain the GPS coordinates of the sampled clusters, but rather the administrative areas within which sampling took place. We plan to extend methods presented in Wilson and Wakefield 24 to model the location of the unknown sampling point. As described in Section 1, we have utilized so-called FBH data in which the birth and death times of each child are available. SBH consist of only the number of children ever born and the number who died, by age of mother. These data are easier to collect and are available in a large number of surveys and censuses. The incorporation of such data into a model-based framework is a priority for future work.
In this work we have used a continuous spatial model, whereas our major interest was to inspect results on the discrete scale for the 47 administrative regions. To this end, we may view the continuous spatial prior as a means by which we induce a prior for the collection of 47 discrete areas. Our model can produce estimates at much finer geographical scales, but an important question is how reliable would estimates be at such scales? One way of answering this is by comparison with direct estimates, but at a fine scale, such estimates have large variance. Without such a comparison, using estimates at a fine scale is inherently hazardous, and we would only carry out such an endeavor in exploratory analyses.
To produce estimates at the 47 area levels, we integrated over the spatial field and included the population density to produce the results at the county level. An obvious question that arises is: what advantages are there with this approach as compared to using a discrete spatial model, such as the ICAR model, 37 directly? One advantage of the continuous model is that we get a smoothed estimated field giving an indication of the U5MR at a finer resolution, though as just pointed out, caution in such surfaces is required. Other advantages of the continuous spatial model are the ability to avoid ecological bias when modeling covariates, and its ability to naturally incorporate data measured at different spatial resolutions, in particular the model can account for boundary changes in a very clean way.
Another advantage of our model is that when using a continuous random field we do not need to specify a neighborhood structure. The 47 administrative regions of Kenya vary widely in shape and size, and therefore in the number of neighbors, so that it is not clear how to define a sensible neighborhood dependence structure. Part of our future research will continue to investigate how discrete spatial models would perform in this setting. In this context, we are particularly interested in the performance of the recently proposed model of Riebler et al. 59 and in a comparison of the results to the continuous model presented here. It would also be interesting to compare the spatial model that we have developed with other possibilities including lattice kriging, 60 fixed rank kriging, 61 and predictive processes. 62 See Bradley et al. 63 and Heaton et al. 64 for recent reviews and comparisons of these approaches (and others), with an emphasis on big data. Multiscale models have also been recently proposed. 65
There are several limitations to the covariate modeling carried out in Section 4. For one, we use geographically referenced covariates rather than household or individual-level variables since we were interested in predicting U5MR at locations without outcome data, and so we restricted ourselves to covariates that were available at the pixel level for the whole of Kenya. Therefore, we do not directly model several variables that are known to have an impact on childhood mortality such as characteristics of the child/birth (e.g. gender, single versus multiple birth, birth order) maternal demographics (e.g. age, education), biological factors (e.g. vaccination rates, disease prevalence), and household characteristics (e.g. toilet facilities, access to water). We also assumed a common covariate model for all age hazards when there is evidence 39 that both the covariates and the strengths of the association depend on the age of the child. In future work, we will carry out individual-level modeling and refine the model. It will not be possible to use such a model for prediction, but it will be of great interest to see if spatial characteristics can improve on a model that includes child, mother, and household variables, for different ages.
Though spatial surfaces do exist for some of the above variables (e.g. measles vaccination coverage) 66 or surfaces could be developed based on DHS data, 41 there is greater uncertainty associated with these variables, which can lead to misleading inference. 67 We therefore limited the number of heavily modeled covariates in our model. Additionally, many of these factors are associated with variables already included in our model.
The computations were run on a computing server with 32 Intel Xeon 2.7 GHz CPUs available. The full Bayesian model required around 14 h for estimation and 19.5 h for predictions. An empirical Bayes version of the model required around 2.5 h for estimation and 10 h for predictions. Code to run the models described here can be found at http://faculty.washington.edu/jonno/u5mr.html.
Supplemental Material
Supplemental material for Estimating under-five mortality in space and time in a developing world context
Supplemental material for Estimating under-five mortality in space and time in a developing world context by Jon Wakefield, Geir-Arne Fuglstad, Andrea Riebler, Jessica Godwin, Katie Wilson and Samuel J Clark in Statistical Methods in Medical Research
Footnotes
Acknowledgements
We would like to thank Zehang Li, Yuan Hsiao, Bryan Martin, Danzhen Yu, Lucia Hug, Leontine Alkema, Jon Pedersen, Patrick Gerland, Trevor Croft, Bruno Masquelier, Kenneth Hill, David Sharrow, Roy Burstein, Simon Hay, and Jonathan Muir for providing data and helpful comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Wakefield and Wilson were supported by grant R01CA095994 from the National Institutes of Health, Fuglstad and Riebler by project number 240873/F20 from the Research Council of Norway, Godwin by R01AI029168 from the National Institutes of Health and Clark by R01HD086227 from the National Institutes of Health.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.