
Abstract
For time-to-event data, the study sample is commonly selected using the nested case–control design in which controls are selected at the event time of each case. An alternative sampling strategy is to sample all controls at the same (pre-specified) time, which can either be at the last event time or further out in time. Such controls are the long-term survivors and may therefore constitute a more ‘extreme’ comparison group and be more informative than controls from the nested case–control design. We investigate this potential information gain by comparing the power of various ‘extreme’ case–control designs with that of the nested case–control design using simulation studies. We derive an expression for the theoretical average information in a nested and extreme case–control pair for the situation of a single binary exposure. Comparisons reveal that the efficiency of the extreme case–control design increases when the controls are sampled further out in time. In an application to a study of dementia, we identified Apolipoprotein E as a risk factor using a 1:1 extreme case–control design, which provided a hazard ratio estimate with a smaller standard error than that of a 2:1 nested case–control design.
1 Introduction
Large biobanks are valuable sources of information for genetic and molecular epidemiology. However, the amount of stored biological material is often limited and analysing it is costly. Thus, researchers are frequently forced to use case–control studies of limited size, and since the magnitude of genetic associations are often moderate, many studies have low power. This may lead to the use of non-standard sampling designs that are perceived to boost the statistical power in a specific study. One example of such a non-standard design can be found in Sboner et al. 1 In that study, men who died from prostate cancer within 10 years of diagnosis were defined as cases, and were compared to controls who were event free at least 10 years after diagnosis. The design was motivated by a conjecture that the efficiency of finding biomarkers predicting lethal prostate cancer was maximised by contrasting these two ‘extreme’ groups. The assumption was that there was underlying information in the time from diagnosis to death from prostate cancer, which seems reasonable and is intuitively appealing. However, the authors analysed the study with a logistic regression model that did not explicitly incorporate this information. In recent decades, there have also been other published studies that used a similar design, where the data also were analysed with logistic regression.2–4
We will refer to the design used in Sboner et al. 1 as an extreme case–control (ECC) design, which we define more generally as a study that samples controls from individuals who are event-free at a pre-specified time which is either at the event time of the last case, or at a later point in time. Salim et al. 5 suggested an alternative to logistic regression for the analysis of ECC data, proposing a method where the sampling design is taken into account in the analysis step. They considered an unconditional likelihood approach for frequency-matched controls, and a conditional approach for individually matched controls. Although the contribution of time to the sampling process is taken into account, the authors did not find any power advantage over analysis with simple logistic regression. However, their simulation studies were under-powered in many settings and they only considered a constant baseline hazard.
The nested case–control (NCC) design (incidence density sampling) 6 is the most common sampling design for time-to-event data and is known to be close to fully efficient with four or more controls per case. 7 The purpose of this paper is to investigate how the power of the ECC design, in particular its performance relative to the NCC design, depends on the underlying baseline hazard and the extent of the delay in sampling controls. We investigated the power of these two designs in simulation studies, and in order to understand the observed differences in power, we developed an analytical expression for the average observed information in an ECC case–control pair in a simple setting and compared it to the average observed information in an NCC pair.
2 Statistical methods
Consider a cohort of size N followed prospectively in time for an event of interest. Let τ be the end of follow-up and let ti be the follow-up time for subject i, where ti denotes the event-time for the cases and the censoring time for the non-cases. We assume that the event times follow the Cox proportional hazards model
2.1 ECC design
Assume subjects with event times smaller than τ0 are regarded as cases and that the controls are required to be event free at time
Data with

Here

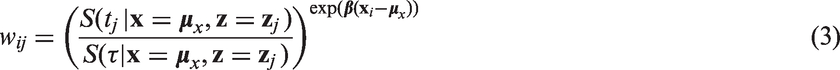
The regression coefficient
As noted above, both weighted Cox regression and logistic regression are valid methods of analysis for ECC data. However, the two regression models have different target parameters, the hazard ratio and odds ratio, respectively. In addition, the weighted Cox regression is only valid for rare events, while logistic regression is always a valid estimator of the odds ratio.
2.2 NCC design
In a NCC design, the m controls sampled for each case are required to be event-free at the event-time of the case, and may also be matched on additional factors. The traditional way of analysing NCC data is by stratified Cox regression, or equivalently conditional logistic regression, each of which maximises the following (partial) likelihood when all confounders have been matched

The regression coefficients are interpreted as log-hazard ratios and the partial likelihood has the usual likelihood properties. 8
3 Simulation study
Sboner et al. 1 wrote that the efficiency of finding signature genes predicting prostate cancer was maximised by comparing cases with the ‘extreme’ controls which were required to be event-free 10 years after diagnosis. Those controls were ‘long-term survivors’ and the underlying assumption was that there was information in the follow-up time. The expression for wij above facilitates an investigation of how this information is reflected in the power of the ECC designs with different baseline hazards and different τ (minimum survival time of a control), for a given τ0 (time of last event).
We simulated cohorts of size 50,000 where the underlying baseline hazard was either constant
The covariates
In the ‘extreme design’, subjects with
For each case, we sampled controls corresponding to
The ECC data were analysed with the weighted method, equation (1) and logistic regression. The NCC data were analysed with a stratified Cox regression, equation (4). The simulations were conducted 500 times and the power was estimated as the proportion of times the 95% confidence interval for the hazard ratio did not include one. All simulations were carried out using R version 3.3.2. 9
Figure 1 displays the power for the analyses with the weakest confounding by z (g = 0.5) and one control per case. The power increases over time for the extreme designs, except for Power of ECC at τ0, 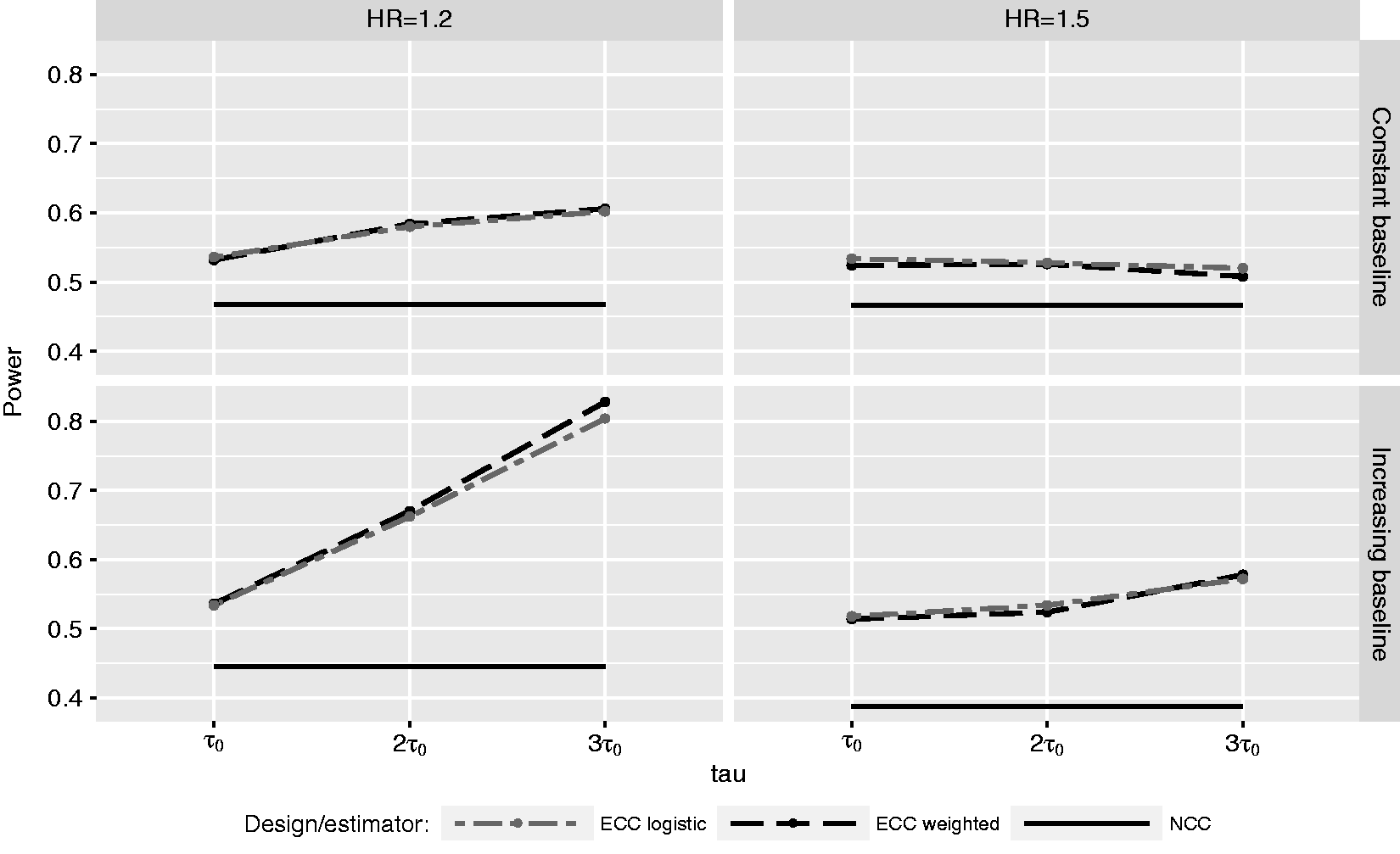
With the strongest confounding by z (g = 1), the overall picture is similar (Figure 2) but the power advantage of the ‘extreme’ design is somewhat higher at Power of ECC at τ0, 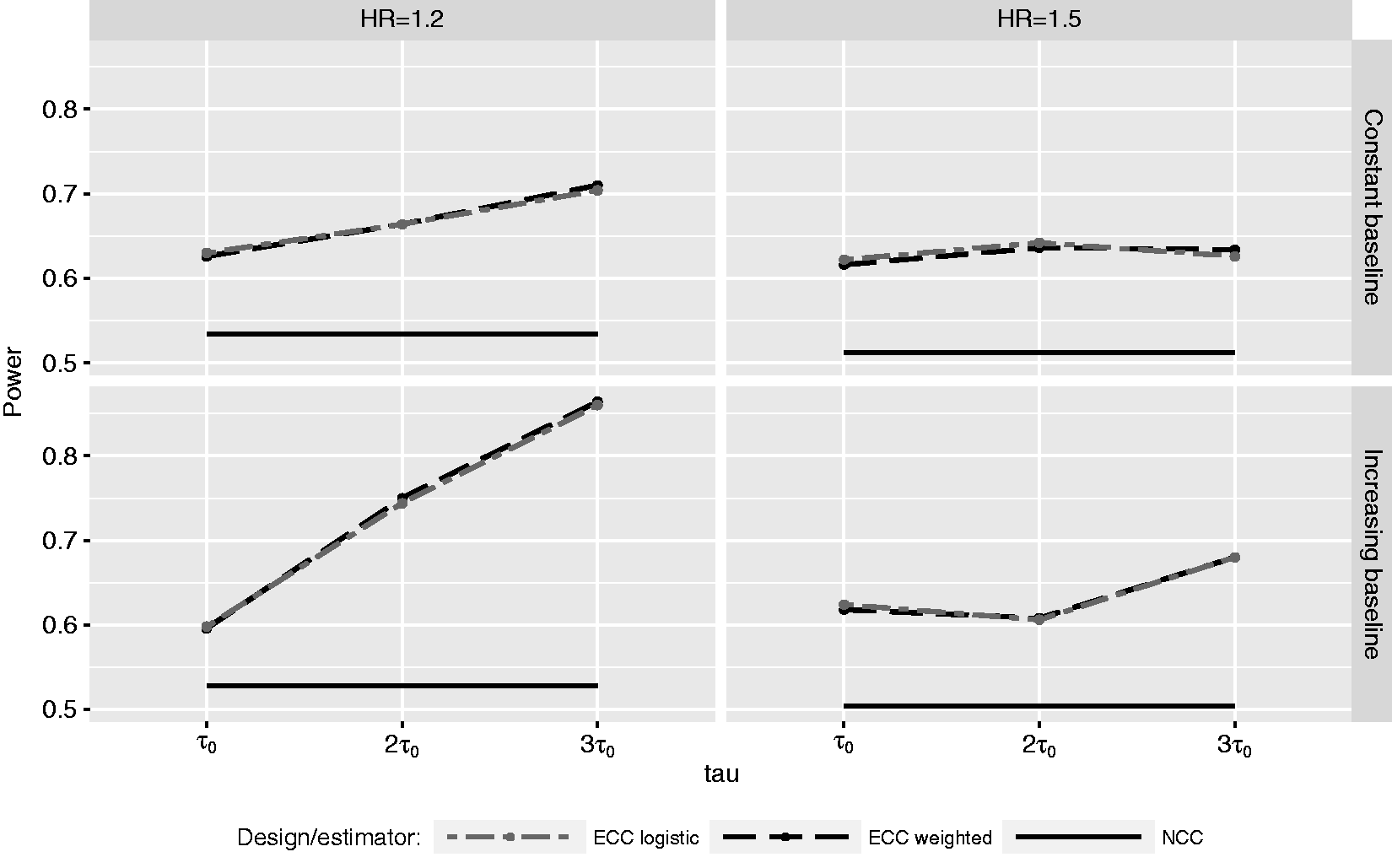
Simulation results for one control per case, constant baseline hazard and weakest confounding by z.
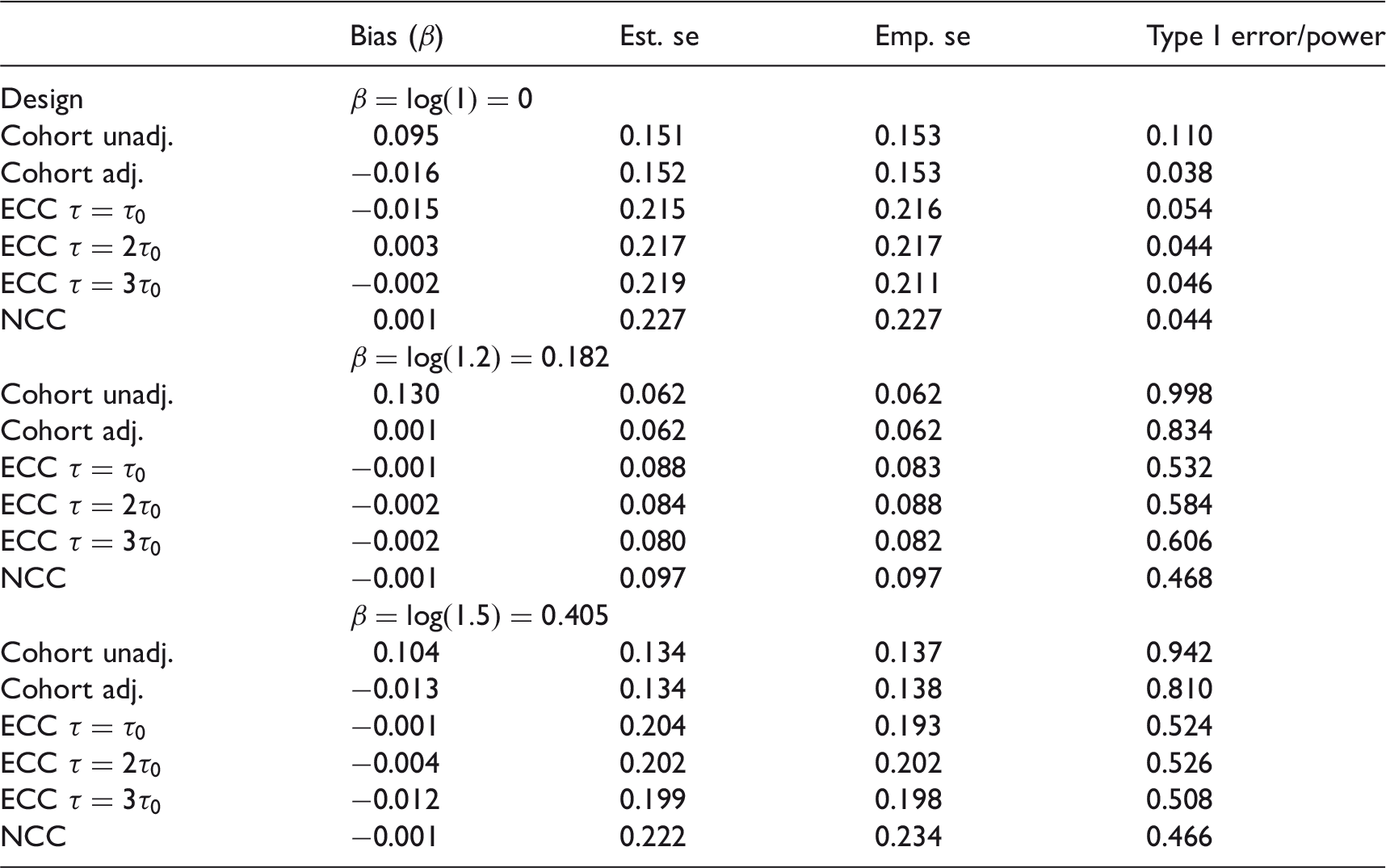
Bias: mean of estimates – true value; Est. se: mean of estimated standard error; Emp. se: standard deviation of estimates; Type I error/power: proportion of estimates within 95% confidence interval; Cohort unadj./adj.: Cox regression of full cohort not adjusted/adjusted for z; ECC: extreme case–control data; NCC: nested case–control data.
4 Variance comparison
To understand the contributions to the higher power of the ECC design, we compared the variance estimators from the two designs by using the information matrix. For simplicity, we consider a binary exposure and a 
As before, we consider constant and linearly increasing baseline hazards and hazard ratios of {1.2, 1.5}. The baseline exposure prevalence is set at 0.01 and 0.5. In each scenario, we let the event times range from 0+ to τ0 which we fix at a specified decile, α0 of the given survival distribution (assuming no censoring). We chose the first decile, hence Schematic representation of one case–control configuration. Probability distribution function of event times. Te and Tc are a particular event and sampling time, respectively. Cases occur before 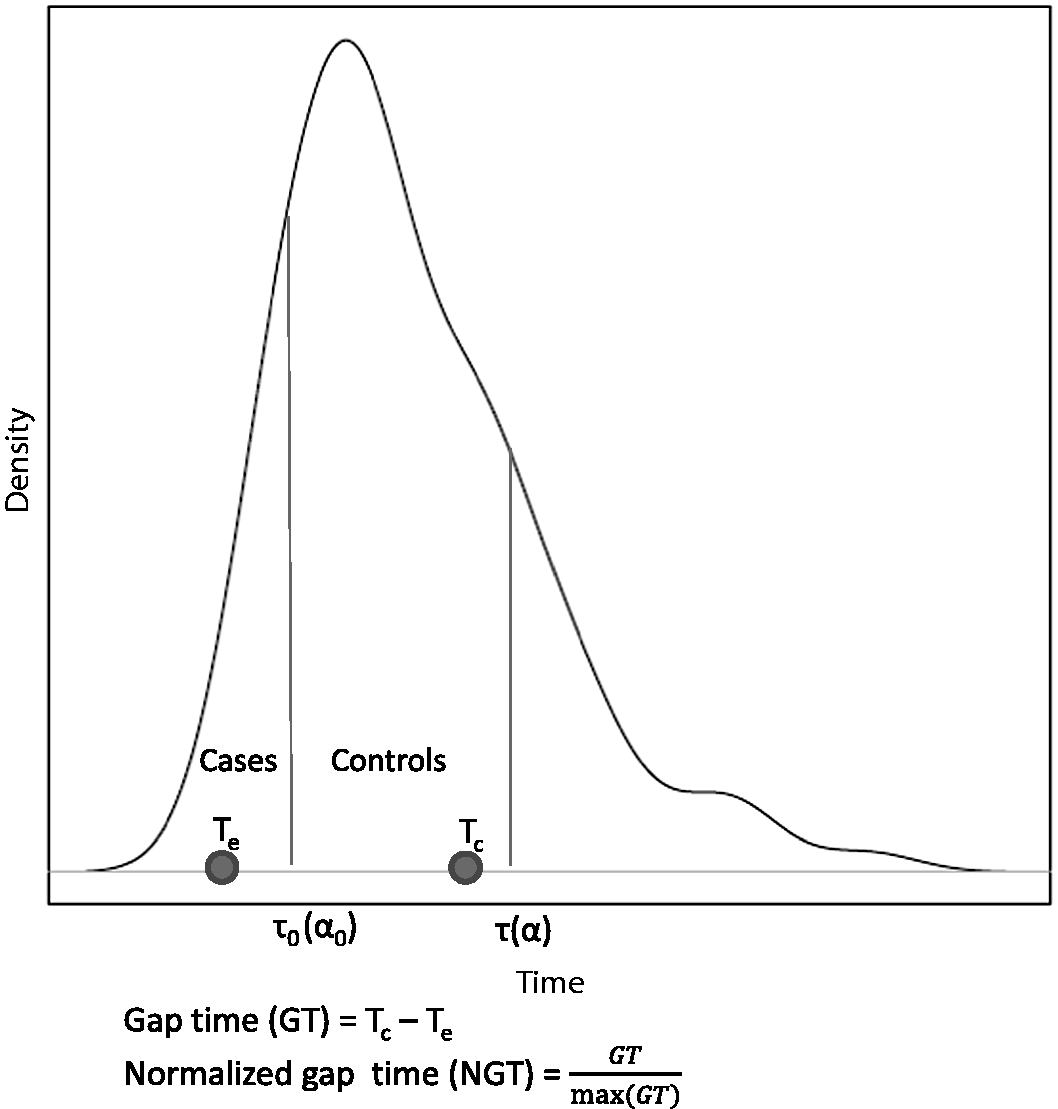
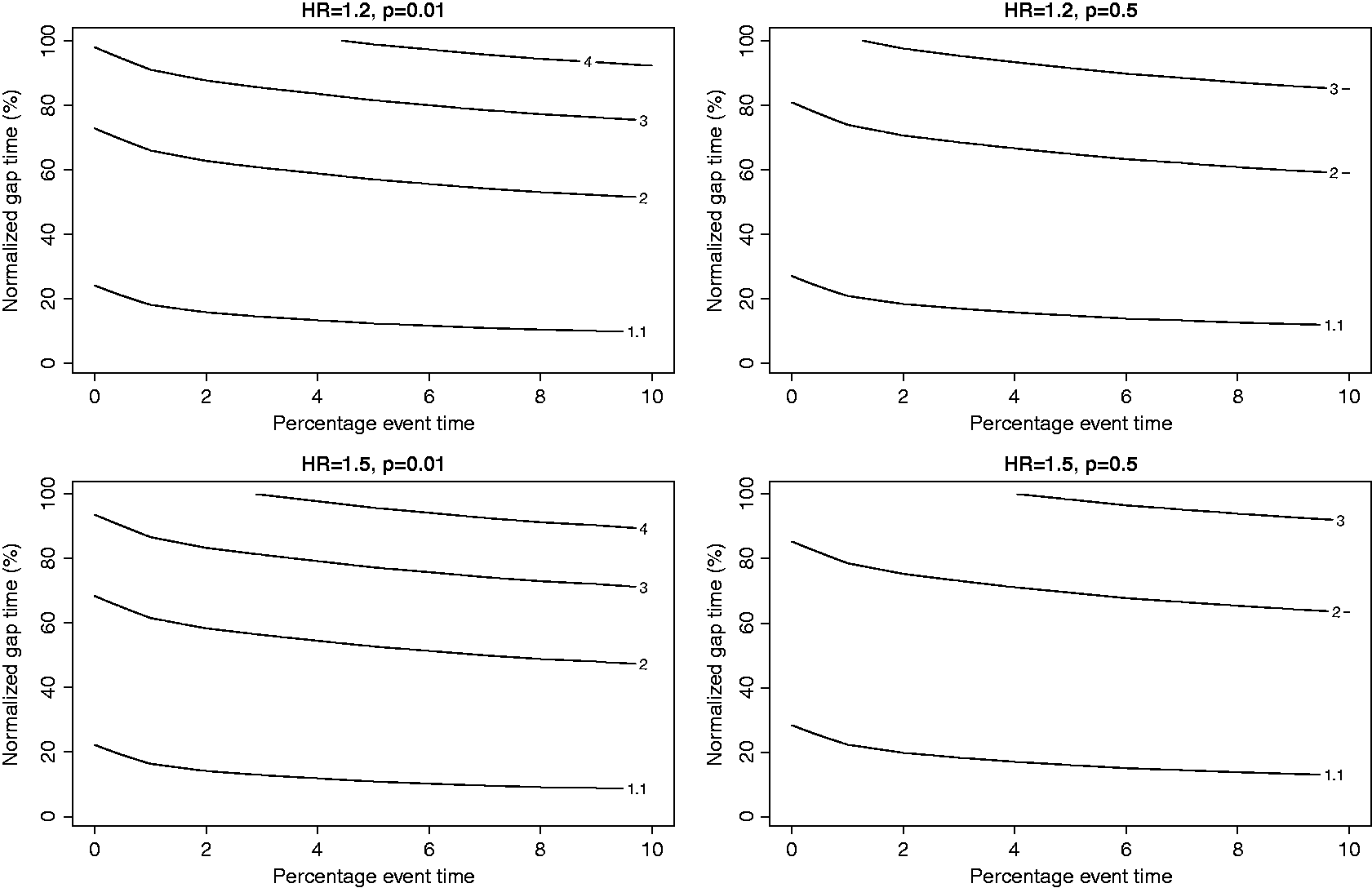
The contour plots of average information in an ECC pair relative to the average information in a NCC pair for four combinations of hazard ratio and baseline exposure prevalence are given in Figure 4 for constant baseline and in Figure 5 for increasing baseline. The x-axis denotes the percentile of the survival distribution (from zero to Contour plots of relative average information for a constant baseline for combination of hazard ratios and exposure prevalence. X-axis: event times, ranging from 0+ to the first decile. Y-axis: normalised gap time between event time and sampling time in percent with 0 representing control sampled at the event time of the case and 100 the gap time between the first case and the last control sampled at the third quartile of the survival distribution. Contour plots of relative average information for an increasing baseline for combination of hazard ratios and exposure prevalence. X-axis: event times, ranging from 0+ to the first decile. Y-axis: normalised gap time between event time and sampling time in percent with 0 representing control sampled at the event time of the case and 100 the gap time between the first case and the last control sampled at the third quartile of the survival distribution.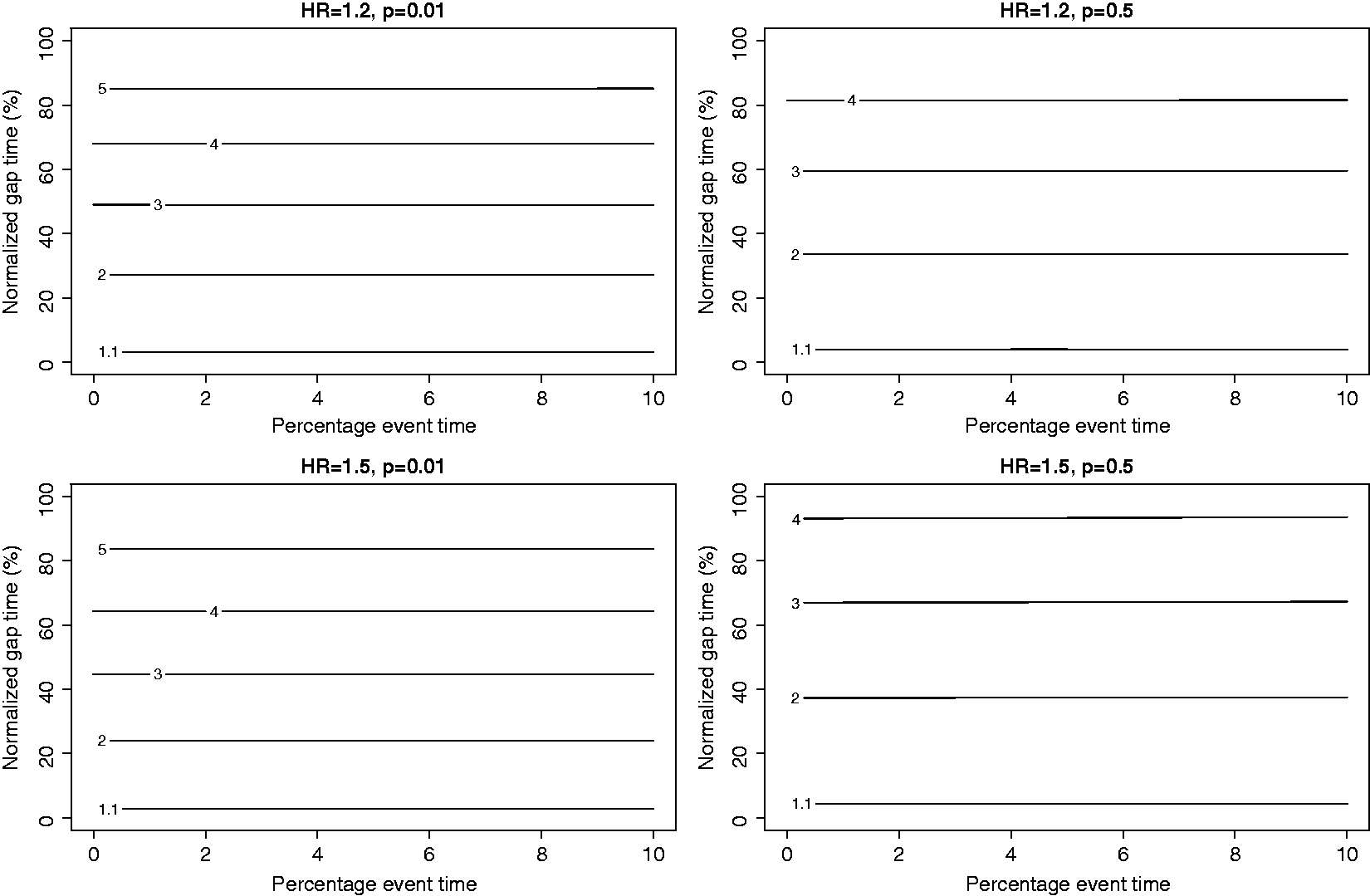
From Figure 4, we see that with a constant baseline hazard, the average information is always higher for the ECC design than for the NCC design. The horizontal contour lines indicate that it is only the time difference between the case and the control that governs the information increase of the ECC design. It is also seen that to obtain the same relative increase in information, a shorter gap time is required for the rare exposure compared to the common exposure. For a rare exposure, the ECC design is relatively more informative for larger hazard ratios, while for a balanced exposure, the relative information is larger for smaller hazard ratios.
For the increasing hazard ratio (Figure 5), the contour lines are no longer horizontal but have a negative gradient, indicating that the event times also influence the relative information and for larger event times a smaller gap time is required to obtain the same amount of relative information compared to the earlier cases. This seems reasonable since the cases will occur more and more frequently and a specific gap time early in the process is somehow less ‘extreme’ than the same gap time later in the process. Apart from this, the plots display the same features as Figure 4 with respect to exposure prevalence and gap times.
5 Data analysis
As an illustration, we analysed the association between the Apolipoprotein E (APOE)
From Figure 6, we see that the baseline hazard is increasing from approximately year 10 of the follow-up in our data set. For the ECC sampling design, we define a dementia case to be a subject experiencing dementia within 10 years of inclusion in the study (76 cases) and we sample controls from the 153 individuals who are alive and dementia-free 15 years after inclusion, i.e. 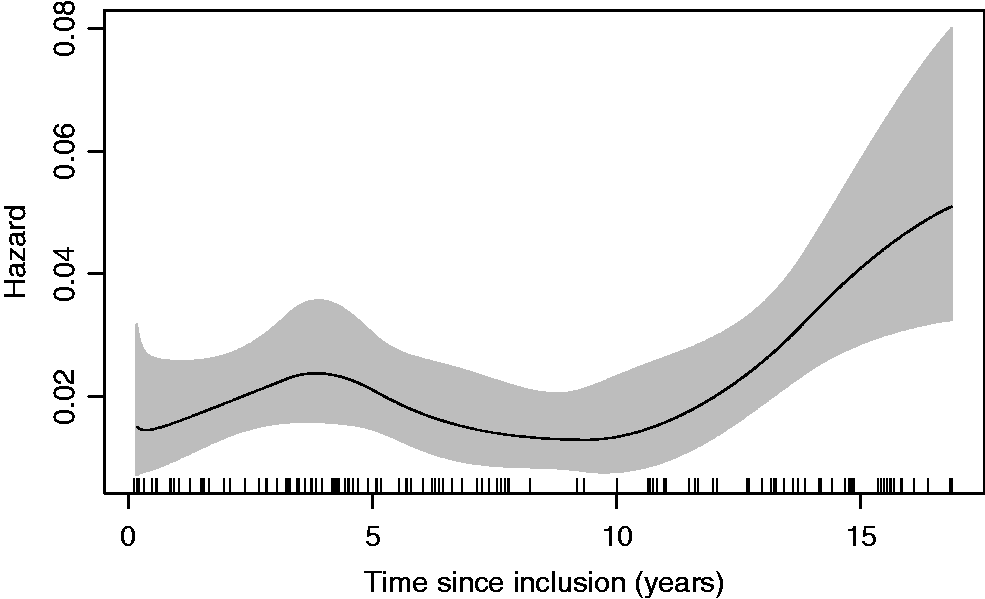
Results from the dementia data.
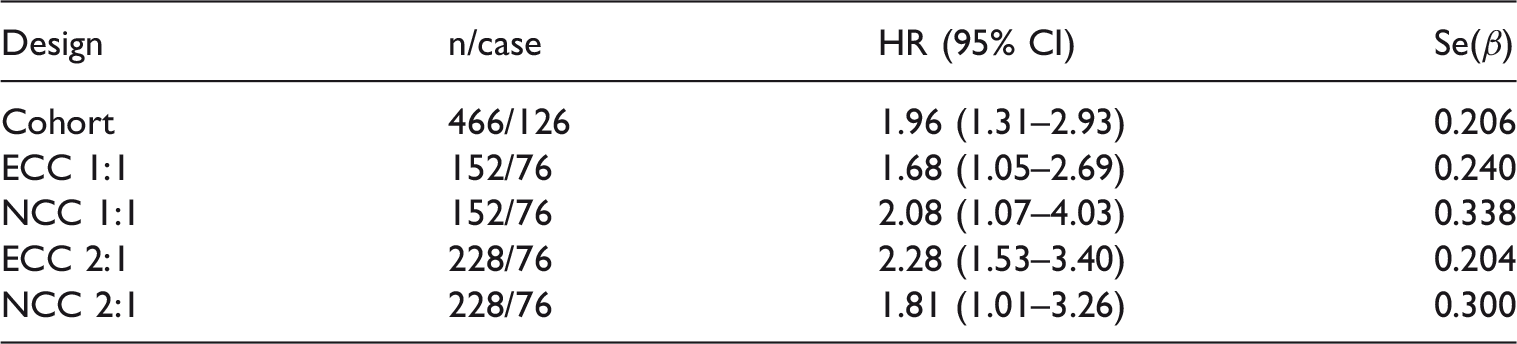
ECC: extreme case–control; NCC: nested case–control.
6 Discussion
We have investigated the power of the ECC design and compared it to the NCC design. Our main conclusions are that an ECC design may be more powerful than the NCC design, with the gain increasing with increasing time gap between the sampling of cases and controls. In the dementia analysis, the standard error of the hazard ratio in the 1:1 ECC design was smaller than the corresponding standard error for the 2:1 NCC design. Secondly, our investigations confirmed the findings of Salim et al. 5 that there is almost no gain in power using the estimators they suggest compared to a simple logistic regression. However, an important advantage of using the weighted Cox regression is that we can estimate hazard ratios instead of odds ratios. The size of the hazard ratio does not depend on the follow-up time τ0, and it therefore provides a parameter estimate that is comparable with other studies and will lend itself to future meta analyses. The drawback is, of course, that the estimation is somewhat more complicated since the likelihood must be optimized numerically.
In this paper, we show that there can be substantial power gains when the controls are sampled after τ0. This contrasts with previously reported minor differences, 5 which may have been due to a lack of power especially for the smallest β (where we found the largest power gain). In addition, we found the largest gain for an increasing baseline hazard which has not been investigated previously.
The contour plots in Figures 4 and 5 showed that for the same percentage event time and normalized gap time, the relative information gain from ECC is larger under constant hazards. This may seem surprising at first, especially since our simulation studies demonstrated greater power gain under an increasing baseline hazard. These seemingly contrasting results can be explained by the fact that in the simulation studies, the threshold for early cases (τ0) under a constant baseline hazard was much earlier than the threshold for early cases under the increasing baseline hazard (Supplementary Figure 5). Since we choose the gap time in the simulation studies as multiples of τ0, this results in wider gap times for simulations where τ0 is larger, in this case under the increasing hazards. Hence, the power gain we observe in the simulation studies under the increasing baseline hazard is primarily due to larger gap times, which is consistent with our observations from the relative information plots.
In practice, sampling controls at specific percentiles of the survival distribution may be difficult due to censoring. We therefore chose to use the one, two and three times τ0 ‘rule’ for sampling controls in the simulations and we refer to such controls as ‘extreme’. It is, however, important to think about where/when τ0 and τ are defined, because depending on where we fix τ0 in the survival process, a time point that is a factor of two and three times larger might or might not be an ‘extreme’ survival time. Additionally, it is important to keep in mind the duality of
Some caution is required regarding the weighted estimator. Firstly, the weights given in equation (2) are only valid when censoring does not depend on covariates, so further work is needed to derive weights that could account for this type of dependent censoring. Secondly, we assume time-constant coefficients, so if this assumption does not hold, there is no clear interpretation of the estimate of β, in contrast to a cohort analysis where it is the weighted average of the time-varying coefficients. 17
We have motivated the use of ECC for situations where limited and expensive material (e.g. from a biobank) is to be used so that selecting the most informative cases and controls can be important in order to make efficient use of valuable resources. 18 However, in studies of rare diseases, the main limitation is slow accrual of cases, so that (i) sampling only the earliest cases may be too costly in terms of power, and (ii) by the time sufficient cases have been identified, extending the follow-up to obtain more extreme controls too costly in terms of time. In such situations, an NCC design may be the best choice.
In summary, we have shown that ‘extreme’ case–control designs may be more powerful than the NCC design. We have also shown that with regard to power, a simple logistic regression analysis is no less powerful than the somewhat more complicated weighted Cox regression. Thus, the purpose of the study becomes important when choosing the method of analysis: if the only motivation is discovery, for example identification of significant molecular or genetic markers, the logistic model is adequate. However, if the effect sizes are of interest, the weighted Cox regression is a better choice since the estimated hazard ratios enable comparison with other work and a contribution to meta-analyses.
Supplemental Material
Supplemental material for Is the matched extreme case–control design more powerful than the nested case–control design?
Supplemental Material for Is the matched extreme case–control design more powerful than the nested case–control design? by NC Støer, A Salim, K Bokenberger, I Karlsson and M Reilly in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Swedish Cancer Society [Grant number CAN 2009/1175 and CAN 2015/493].
Supplemental material
Supplemental material for this article is available online.
Appendix 1
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.