
Abstract
Multiple-period cluster randomised trials, such as stepped wedge or cluster cross-over trials, are being conducted with increasing frequency. In the design and analysis of these trials, it is necessary to specify the form of the within-cluster correlation structure, and a common assumption is that the correlation between the outcomes of any pair of subjects within a cluster is identical. More complex models that allow for correlations within a cluster to decay over time have recently been suggested. However, most software packages cannot fit these models. As a result, practitioners may choose a simpler model. We analytically examine the impact of incorrectly omitting a decay in correlation on the variance of the treatment effect estimator and show that misspecification of the within-cluster correlation structure can lead to incorrect conclusions regarding estimated treatment effects for stepped wedge and cluster crossover trials.
Keywords
1 Introduction
It is now well recognised that the correlation between subjects from the same cluster must be accounted for in the analysis of data from cluster randomised trials.1,6 The standard error of the estimated treatment effect depends on the variance components, and failure to properly account for within-cluster correlation structure may lead to confidence intervals for the treatment effect estimate that are of incorrect width. When cluster randomised trials are conducted over multiple periods, the entire within-cluster correlation structure, which incorporates correlations between observations taken in the same and different trial periods, must be considered.
A simplifying assumption that can be made for the within-cluster correlation structure for multiple-period cluster randomised trials is that correlations between subjects’ outcomes do not depend on the timing of measurements: the correlation between outcomes from any pair of subjects from the same cluster is identical. In a recent systematic review, the majority of stepped wedge cluster randomised trials with protocols published between 1987 and 2014 were found to have made this assumption for power calculations. 7 In the broader context of multiple-period cluster randomised trials, this assumption may be made less frequently, see e.g. Feldman and McKinlay 4 and Murray et al. 8 for earlier papers discussing alternative models. The underlying statistical model for outcomes incorporates this assumption through the inclusion of a cluster-level random intercept. Recommended practice requires the inclusion of fixed effects for periods. 9 In the stepped wedge context, this model is usually referred to as the Hussey and Hughes model. 10 More recently, in the context of stepped wedge trials, several authors have relaxed the assumption of constant correlation within clusters, considering in detail particular variants of the general model presented in Feldman and McKinlay. 4 Girling and Hemming 5 and Hooper et al. 11 incorporated a random interaction between period and cluster, thus allowing the correlation between subjects within a cluster from the same period to differ from the correlation between subjects in the same cluster measured in different periods. There are thus two intra-cluster correlations associated with this model: within-period intra-cluster correlations and between-period intra-cluster correlations. More complex within-cluster correlation structures were introduced by Kasza et al., 12 allowing for the correlation between the outcomes of any pair of subjects in the same cluster but in different periods to diminish as the time between periods increases. The statistical models allowing for this correlation decay include a structured covariance matrix for the cluster-period random interaction, and imply that the between-period intra-cluster correlation depends on the distance between the periods in which observations being compared were measured.
While the impact of ignoring clustering on inference for the treatment effect in single-period cluster randomised trials has previously been considered, e.g. Moerbeek et al., 13 the impact of within-cluster correlation structure misspecification on analysis, and planning, of multiple-period cluster randomised trials has not. We investigate the impact of within-cluster correlation structure misspecification on the estimation of variance components, and on the estimation of a treatment effect and its associated standard error. The impact of misspecification of the correlation structure at the planning stage of a multiple-period cluster randomised trial, when the values of the various within-cluster correlations are assumed to be known without error, has previously been considered (see e.g. Kasza et al. 12 ) Here our interest is on the impact of the misspecification of that structure when fitting a model to a dataset. Moerbeek 14 has considered estimators of variance components when random intercepts for clusters or for periods within clusters are incorrectly excluded from the outcome model: we extend this work to cross-classified data structures and a model that allows for a decay in correlations over time and discuss the implications of variance component mis-estimation and misspecification on estimating treatment effects and planning cluster randomised trials.
Our focus in this paper is the misspecification of mixed-model ANOVAs: we do not consider models that incorporate random coefficients, for example for time or treatment. Such more complex models have been considered by other authors, e.g. Hemming et al. 15 and Murray et al. 8 Models of the type that we consider are frequently used within the stepped wedge and cluster cross-over literature in particular, and thus an investigation of the properties of these models is needed to allow a more in-depth understanding of these designs.
In Section 2, we consider the estimation of variance components using ANOVA formulas for two-way cross classified mixed models with and without random interaction terms. In Section 3, we investigate the impact of omitting a decay in correlation on the estimation of variance components and on the variance of the treatment effect in multiple-period parallel cluster randomised trials with post-baseline measurements only, cluster cross-over and stepped wedge designs. We provide an R Shiny app2 to allow users to investigate the impact of correlation structure misspecification for scenarios corresponding to various parameter configurations, available at https://monash-biostat.shinyapps.io/MisspecCorrStruct. Code for local implementation of the app can be downloaded from https://github.com/jkasza/MisspecCorrStruct. In addition to the designs considered in this paper, the R Shiny app allows for parallel designs with baseline measurements, and for users to upload design matrices.
2 Mixed effects models and ANOVA estimators
In order to investigate the impact of within-cluster correlation structure misspecification on the estimation of variance components, we consider three models for a continuous outcome Ykti, where in each cluster Model 1. This is the two-way crossed classification model with fixed period effects and no interaction between period and cluster:
Model 2. This model is the two-way crossed classification model with fixed period effects and an interaction between period and cluster:
with
again
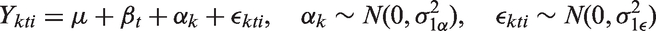
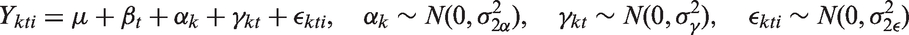
Model 3. This extends Model 2 and supposes that within each cluster, the dependence between random effects for each period decays over time:
Models 1–3 are appropriate for repeated cross-sectional designs, where measurements are taken from distinct sets of subjects in each period. Inclusion of subject-specific random intercepts allows for closed or open cohort designs, as described by Copas et al., 3 where some or all subjects may contribute measurements in multiple periods.
Mean squares and ANOVA estimators for the variance components of the two-way crossed classification models with and without interactions.
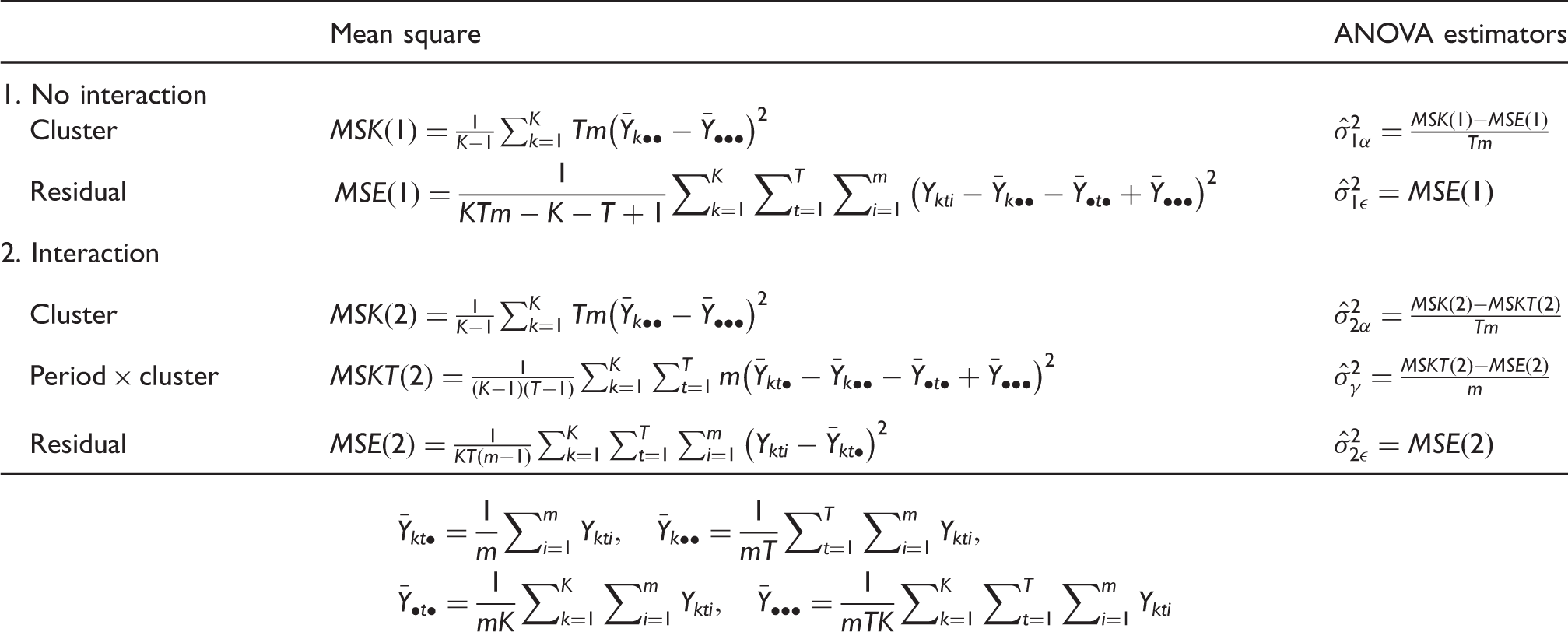
3 Implications of correlation structure misspecification
3.1 Expected values of variance component estimators
Expected values of variance component estimators in Table 1 for outcomes distributed according to the two-way crossed classification model without and with an interaction between cluster and period, and correlation decay models.

Table 2 indicates that applying the no interaction estimators to data without an interaction or the interaction estimators to data with an interaction results in unbiased estimation of variance components. When the interaction estimators are applied to data without an interaction, the expected values of the subject-level error and the cluster-level random effect variances are unbiased, and the expected value of the cluster-period level random effect variance is zero. These are standard results: the ANOVA estimators for the variance components are unbiased 16 and overspecification does not result in bias. However, as is expected, when the assumed correlation structure omits a decay in the correlation between cluster-period level random effects over time, the expected values of the variance components compensate for that misspecification. As observed in Moerbeek, 14 where the misspecification of two-way nested models by omission of a level of clustering was considered, when the cluster-period level is omitted (i.e. Model 1 is fitted to data generated according to Model 2), the variation due to the cluster-period level is spread across the subject-level and cluster-level variance component estimates. When T is large, most of the cluster-period-level variability will be added to the subject-level error variance.
When applied to the model with a correlation decay, the expected values of no interaction and interaction variance component estimators depend on the decay parameter r, and the design parameters T, K, and m. When r = 1, there is no decay in the correlation, the correlation decay model collapses to the model with no interaction, and the no interaction and interaction estimators are thus unbiased for the correlation decay variance components.
3.2 Correlation structure misspecification and treatment effect variance estimation
To investigate the impact of correlation structure misspecification on the treatment effect estimator variance, we include
In this section, we seek to determine for which trial designs and values of T, K, m and r the variance components estimated using the two-way crossed with or without interaction ANOVA formulas sufficiently capture the correlation structure of the correlation decay model when estimating the variance of the treatment effect estimator. We compare the value of var
To allow for comparability between Models 1 to 3, we set
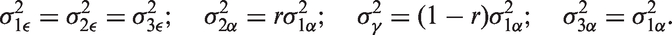
Within-period and between-period intra-cluster correlations (ICCs) for the three considered models, setting

ICC: intra-cluster correlation.
We consider three types of multiple-period cluster randomised trials: parallel and cluster cross-over designs over T periods, where
For each design type and combination of The ratio of the variances of the treatment effect estimator obtained under the one-way layout and under the decaying structure (Model 1 versus Model 3), when the correct model has the decaying within-cluster correlation structure for a range of decay parameters r, and numbers of periods T, with number of subjects per period, m = 100, The ratio of the variances of the treatment effect estimator obtained under the two-way nested layout and under the decaying structure (Model 2 versus Model 3), when the correct model has the decaying within-cluster correlation structure for a range of decay parameters r, and numbers of periods T, with number of subjects per period, m = 100, 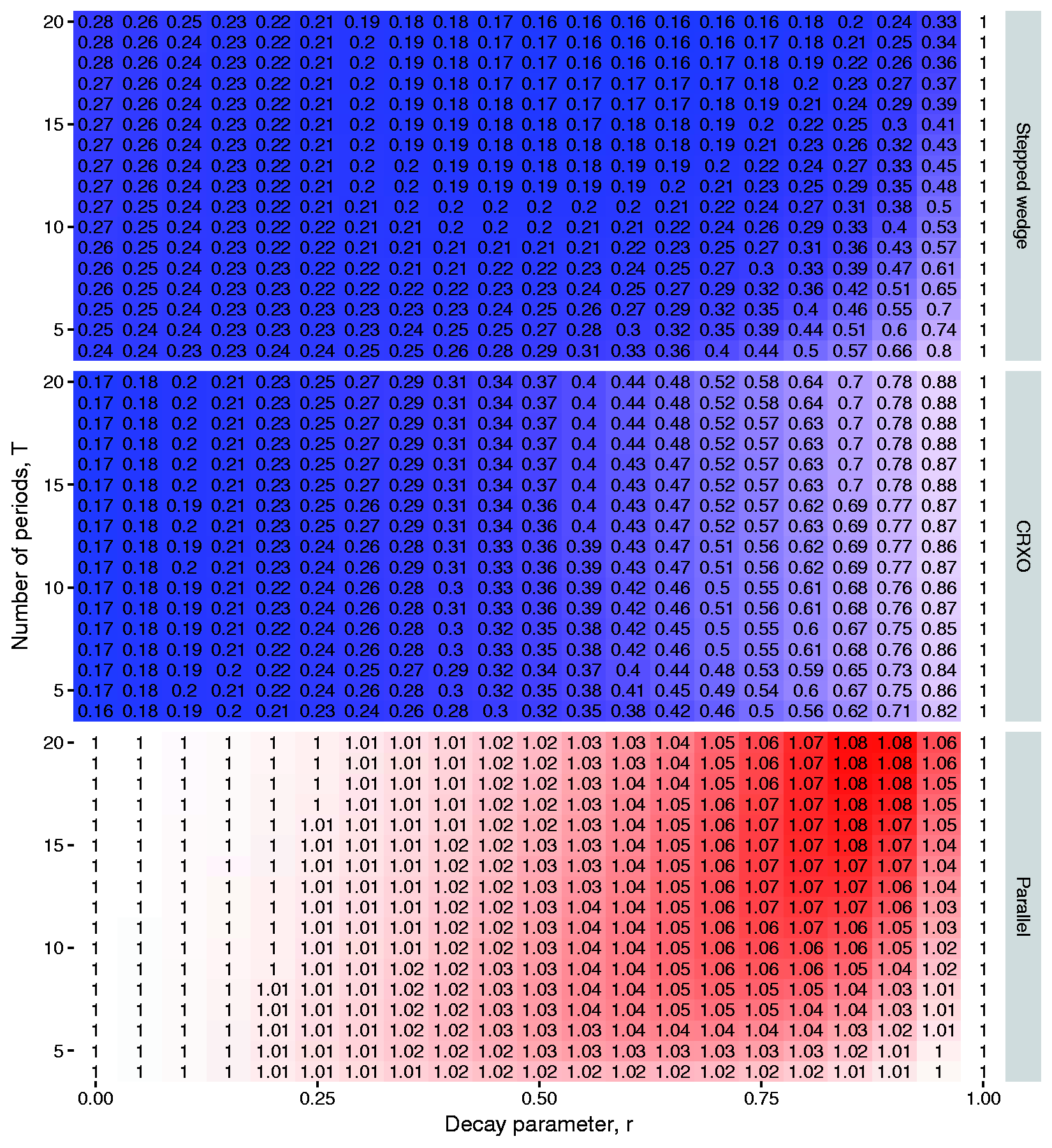
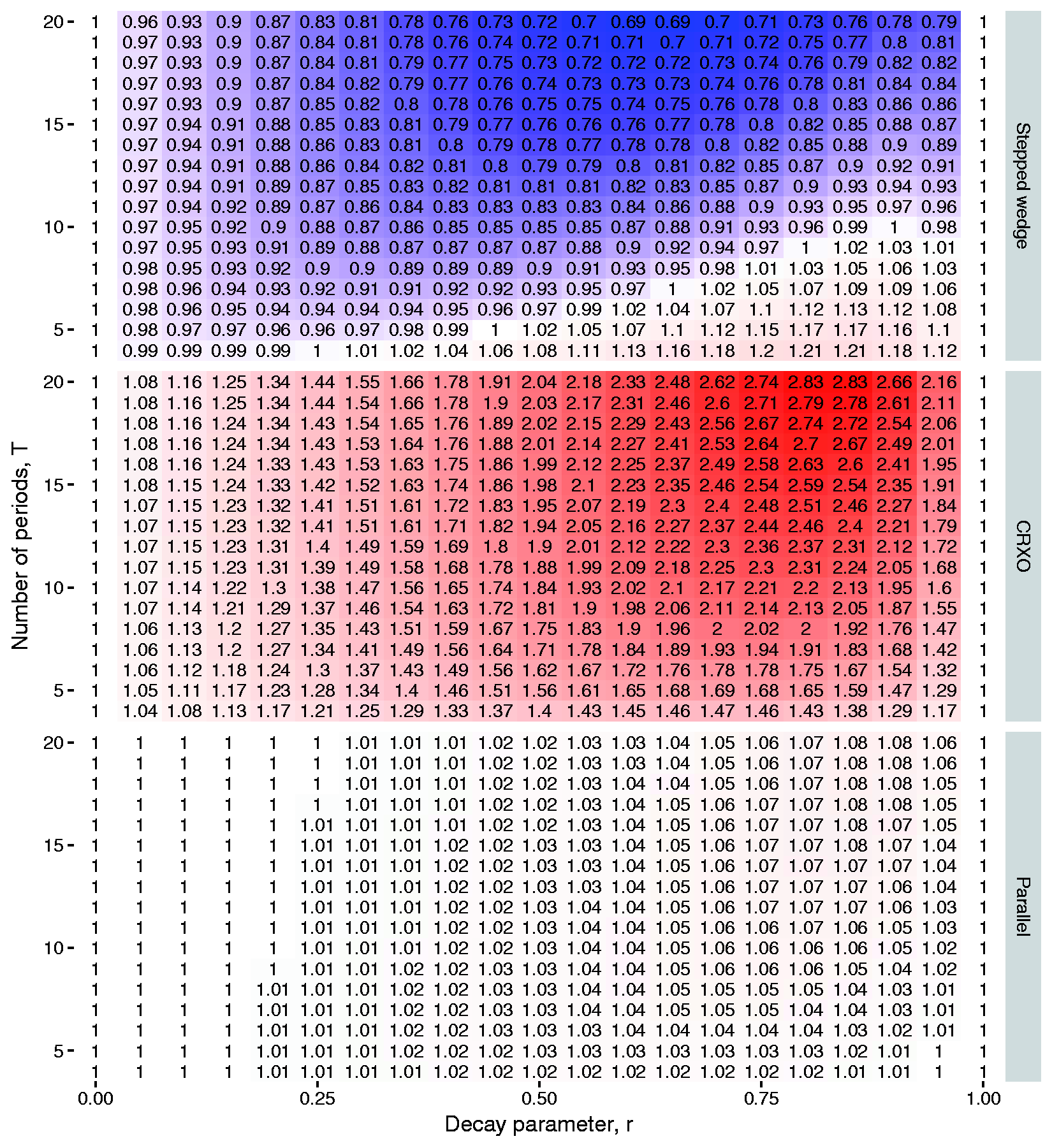
Figures 1 and 2 both confirm that when r = 1 (implying no decay in the correlation between subjects in the same cluster over time),
4 Discussion
The results in Section 3 have implications for both inferences on the treatment effect and for trial planning, but the implications depend on the study design. The impact of correlation structure misspecification is much less for the parallel design than for the SW and CRXO design. In the SW and CRXO designs, treatment varies at the cluster-period level, and within-cluster between-period comparisons are required to estimate the treatment effect: these comparisons rely on the correlations between subjects in the same cluster in different periods, so misspecification of the structure of the within-cluster covariance matrix has a greater impact for these designs than for the parallel design. We did not consider parallel designs with pre-intervention baseline measurements, although users can investigate the impact of misspecification for such designs in our online app. Whether results for parallel designs with baseline measurements more closely resemble those for parallel designs or stepped wedge designs will depend on the proportion of the periods in the design that are dedicated to pre-intervention versus post-intervention measures. If the proportion is very small, the results will more closely resemble the parallel design results; as the proportion increases, the results will more closely resemble the stepped wedge results. In the parallel design without any pre-intervention baseline measurements, treatment varies only at the cluster level. As has been observed by Moerbeek, 14 ignoring a level of clustering lower than that at which the exposure of interest varies has no impact on inference for the effect of that treatment or any treatments that vary at a higher level of the structure. Thus, our results align with those of Moerbeek: 14 misspecifying the cluster-period level correlation structure has minimal impact on the variance of treatment effects at a higher level. Thus, if the study being considered was a parallel cluster randomised design with each subject measured in each period, instead of the repeated cross-sectional design we have considered, misspecifying the within-subject correlation structure (as distinct from the within-cluster correlation structure) would have minimal impact on the variance of the treatment effect estimator, provided that random effects for higher levels of the data hierarchy are included in the model.
When the number of periods in a study is large, including a fixed term for each period as we have done may result in a less efficient estimator for the treatment effect than a model where a linear term for time is included. In practice, including continuous terms for time may lead to more efficient estimation of the treatment effect, which will then lead to additional considerations regarding how random effects for time should be included in the model. Murray et al. 8 considered three models in their investigation of the issue in the context of parallel cluster randomised trials: the first was similar to our Model 2; the second included a random cluster-period interaction but a linear fixed effect for time; and the third included random coefficients for a linear term for time. They concluded that incorrectly omitting a random coefficient for time led to an inflation of Type I error rates. We have not investigated scenarios where a linear term for time and random coefficients for time are incorrectly excluded or included, given our focus on the impact of omitting a decay in the within-cluster correlation structure. Given the lack of closed-form estimators for the decaying correlation model, it is difficult to determine how inference for the treatment effect would be impacted were a decaying correlation structure incorrectly included in a model instead of a random coefficient for time (or vice-versa). Further work comparing these two models is required.
Summary of the implications for the width of the confidence interval of the treatment effect when Model 3 is correct, but Model 1 or Model 2 is incorrectly assumed, for parallel, CRXO and stepped wedge designs.

We have assumed balanced data for our derivations and comparative studies. When data are not balanced, formulae for variance components do not have closed forms, and as pointed out by Moerbeek, 14 it is difficult to determine the impact of within-cluster correlation structure misspecification on the estimation of variance components without undertaking numerical simulation. In some of the results in Figures 1 and 2, cluster randomised trials with small numbers of clusters were considered. Although our conclusions would not change were trials with larger numbers of clusters considered, we caution against cluster randomised trials with small numbers of clusters for reasons as described in Taljaard et al. 17
By casting multiple period cluster randomised designs as classical experimental designs and applying ANOVA-based calculations, we have derived results concerning model misspecification using models often applied in practice. Further, we have provided a web-based application to allow researchers to investigate the impact of model misspecification for their particular multiple-period cluster randomised trials.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Health and Medical Research Council of Australia Project Grant ID 1108283.