
Abstract
Master protocol designs are often proposed to improve the efficiency of drug development with multiple subgroups. In the basket trial design, different subgroups can have similar biological pathogenesis pathways. Hence, a target therapy can result in similar responses. A good information sharing strategy between different subgroups can potentially improve the efficiency of evaluating treatment efficacy. In traditional hierarchical models, based on the exchangeability assumption, all subgroups are placed into the same sharing pool for cross subgroup information sharing. However, due to the heterogeneity between subgroups, there can be large differences in drug efficacy. Under such cases, strong borrowing across all subgroups is not suitable and no borrowing can be inefficient, because the treatment effect is analyzed in each subgroup separately. We propose a Bayesian cluster hierarchical model (BCHM) to improve the operating characteristics of estimating the treatment effect in multiple subgroups in basket trials. Bayesian nonparametric method is applied to dynamically calculate the number of clusters by conducting a multiple cluster classification based on subgroup outcomes. A hierarchical model is used to compute the posterior probability of the treatment effect, with the borrowing strength determined by the Bayesian nonparametric clustering and the similarities between subgroups. We apply the BCHM to clinical trials with binary endpoints. For treatment effect estimation, the BCHM yields lower mean squared error values, when compared to the independent analyses. In scenarios with a heterogeneous treatment effect, the BCHM provides lower mean squared error values compared to traditional hierarchical models. In addition, we can construct a loss function to optimize the design parameters. BCHM provides a balanced approach and smart borrowing, which yields better results in assessing the treatment effect in different scenarios compared to other conventional methods.
Keywords
1 Introduction
Recently, rapid advances in cancer biology, genomics, and immunology have greatly inspired the development of new cancer therapies. Traditional treatment assignment and clinical trial design in oncology is based on tumor histopathology. With the momentous development of genome sequencing technologies, the study of genomic alterations in different types of tumors reveals two facts. First, genetically, the tumor from the same organ or tissues can be heterogeneous, and secondly, the genomic alterations from tumors in different organs can be the same. Moreover, such genomic alterations have considerable impact on the prognosis and treatment of cancer patients. As a result, these discoveries can change the traditional histopathology-based cancer treatments. For instance, BRAF mutation is common in melanoma 1 ; it can also be found in colon cancer, 2 lung cancer, 3 thyroid cancer, 4 and brain tumors. 5 Similarly, the HER2 test is extensively applied in breast cancer, 6 but it can also be associated with lung cancer, 7 among others.
Fast progress in cancer drug development can result in serious challenges for oncology clinical trial designs. 8 It can take 15 years for an oncology drug to complete the entire phase I–II–III paradigm. 9 The number of adult patients diagnosed with cancer in the United States each year is nearly 1.7 million, and only 3%–5% of these patients are enrolled in clinical trials, which is an insufficient number to provide statistically impactful results from such studies. 10 To improve the efficiency of oncology clinical trials and accelerate cancer drug development, “master protocol” clinical trial designs have been advocated in recent years.10,11 In a master protocol design, investigators study multiple therapies and/or multiple disease types defined by both pathological and molecular criteria. Most importantly, the master protocol design conducts multiple studies in a parallel fashion to accelerate new cancer therapy developments. There are three common master protocol clinical trial designs: umbrella,12,13 basket,14–16 and platform.8,17,18 Some successfully conducted clinical trials classified as based on a master protocol design include the following: BATTLE,19,20 I-SPY 2, 21 Lung-Map, 22 NCI-MATCH, 23 and SHIVA. 24
In a master protocol-based clinical trial design, therapies are studied in parallel with different diseases or different molecular subgroups. In many situations, subgroups share some common features. For instance, subgroups of tumors with the same molecular signature on different organs can be treated with the same therapy. Such common features between different subgroups provide the basis for information sharing. However, the biological pathways are not thoroughly understood in many situations. Some subgroups share the same biological pathways, and the exchangeability between them should be high. On the other hand, in some situations, the performance of therapies in diseases with the same molecular signatures, but on different organs, can be quite different; exchangeability between those subgroups cannot be assumed. Because the number of patients in each subgroup of a master protocol trial is often small, information borrowing between subgroups when high exchangeability occurs is desired to gain efficiency in evaluating the treatment effect. Conversely, information borrowing across non-exchangeable subgroups is not recommended. In this paper, we will use the basket trial design as a primary example in which a single targeted treatment is given to patients in different disease site subgroups that have the same molecular characterization. Our goal is to identify the most meaningful way to conduct information borrowing to enhance the efficiency of evaluating the treatment effect.
Hierarchical models are frequently applied for information borrowing between subgroups.25–27 However, in a traditional hierarchical model, all subgroups are placed into the same borrowing pool, without consideration for different exchangeabilities that could occur between them. Placing subgroups with low exchangeability into the same pool can lead to increased type I errors or decreased power. 28 To avoid this issue, classifying all subgroups into one or more exchangeable clusters and conducting cluster-based information borrowing become desirable. Some cluster-based hierarchical models are studied to allow information borrowing within the exchangeable clusters.29,30 However, in these methods, the number of clusters for all subgroups in the model are pre-specified, which makes the model less flexible for general application. For instance, in Chen and Lee, 29 the number of clusters can only be one or two. When the number of subgroups is large and contains differing responses, there are likely to be more than two clusters.
In this study, we propose a Bayesian cluster hierarchical model (BCHM) in which the number of clusters is dynamically determined by the clinical trial outcomes, and the information borrowing is conducted based on the similarities between subgroups. The BCHM method is based on the Dirichlet process (DP) to dynamically determine the exchangeable clusters. Bayesian hierarchical models are applied for information sharing between subgroups, based on the clustering results from the DP.
BCHM can be applied to both analysis and design of a clinical trial. For the analysis, this design can enhance the estimation of the subgroup response. BCHM can also provide better operating characteristics when designing master protocols. In addition, we apply the decision theoretical method to optimize the design parameters to obtain desirable operating characteristics.
This paper is divided into the following sections: In Section 2, the Bayesian nonparametric method for dynamic clustering is introduced. In Section 3, BCHM is applied to the estimation of subgroup response. The results are compared among BCHM and other methods, including independent, traditional hierarchical, simple pooling, and the “oracle” method. In Section 4, we use BCHM for clinical trial design, comparing the operating characteristics with other methods. In Section 5, sensitivity analysis is conducted. In Section 6, we illustrate application of BCHM in a real trial. In the last section (Section 7), we give further discussion regarding BCHM, followed by concluding remarks.
2 Multiple clustering Bayesian nonparametric method
2.1 Dirichlet process for multiple clustering
The DP is a stochastic process applied for modeling data in Bayesian nonparametric data analysis. Different basis functions can be applied to the models to enhance flexibility. In this study, a DP-based Bayesian nonparametric method is applied to perform clustering classification. We implement the code based on the Gaussian basis function and the Chinese Restaurant Process (CRP). The DP method is thoroughly described by Dey et al.,
31
Blei et al.,
32
Gershman and Blei,
33
and Müller and Rodriguez.
34
We use a DP mixture model to do the data analysis, and the subsequent posterior inference is performed based on a hierarchical model

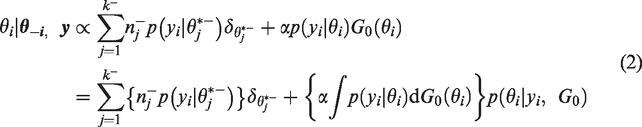
The posterior probability of data
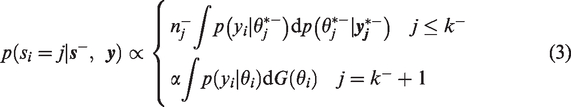
We use the Gaussian distribution as the kernel of the basis function for the DP process, and a CRP is used for clustering. Due to the conjugate prior
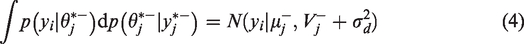
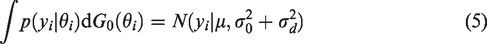
We use the CRP method to sample the data points into clusters. In the CRP method, customers enter into the restaurant with an infinite count of tables and sit at different tables with different probability values. With probability proportional to α, the customer will sit at a new table in which
For the clinical trials with continuous outcomes, we can apply this model to perform the data clustering. The continuous outcome data can be directly incorporated into the model with
The equivalent size of each cluster is expanded to
2.2 DP sampling and clustering matrix
The DP sampling results contain the clustering distribution through the classification space. The probability of two subgroups i and j classified into the same cluster is denoted as
A series of clustering configurations are obtained from the DP sampling. This is a dynamic process which could result in different cluster configurations in
2.3 Hierarchical model for information sharing
A hierarchical model is applied to share information between different subgroups. In this study, we use the hierarchical model for subgroup information borrowing. For a specific subgroup i, we consider borrowing information from all subgroups
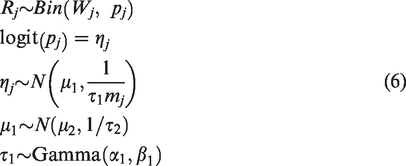
The inference of each subgroup is based on the posterior response distribution
2.4 Parameter selection
In this study, we choose the non-informative prior with
2.5 A clustering example
In this example, there are five subgroups in the trial. The number of responses and patients of subgroups are (1/10, 1/5, 4/10, 3/5, 7/10). We set
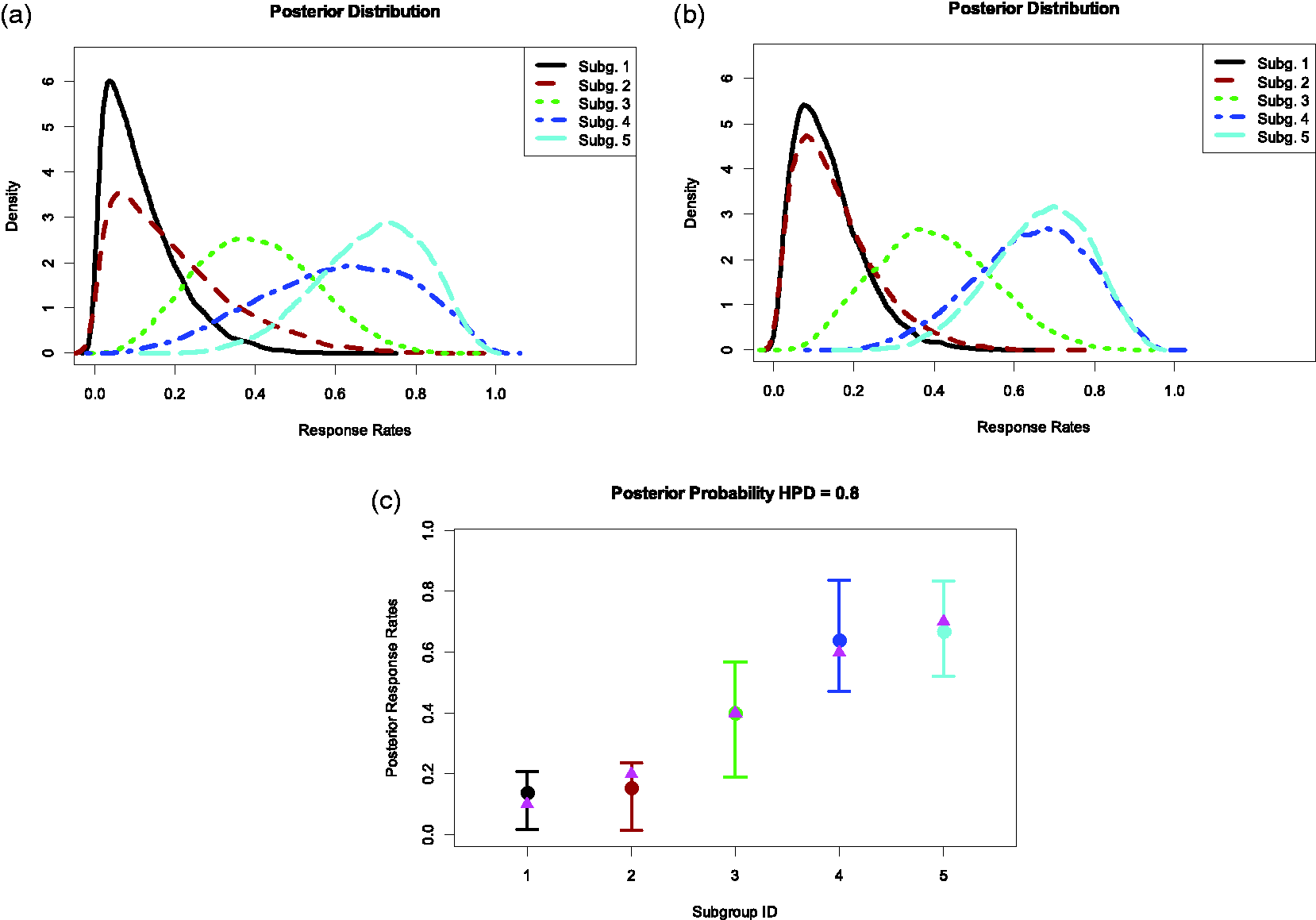
Example of the clustering five subgroups by applying BCHM. The number of responses and patients of subgroups are (1/10, 1/5, 4/10, 3/5, 7/10).
3 BCHM for subgroup response estimation in simulations
In this section, we apply BCHM to the data with clustering structure and compare the subgroup response estimation results from other methods. To mimic the design with multiple subgroups, each with low number of patients, we use the following setting. In the trial, there are 10 subgroups separated into two clusters (high response and low response clusters) and each subgroup has 15 patients. The true response rate of the low response cluster and the high response clusters are 0.2 and 0.5, respectively. Two thousand simulated trials are used in this evaluation. The posterior mean, standard deviation (SD), and the mean squared error (MSE) values of each subgroup are calculated using different methods.
In the independent method, the data of each subgroup is analyzed independently. In the BCHM method, we use the following parameters:
Mean, SD, and MSE as the results of data analysis by different methods in the mixture, null, and alternative scenarios with 10 subgroups with 15 patients in each.
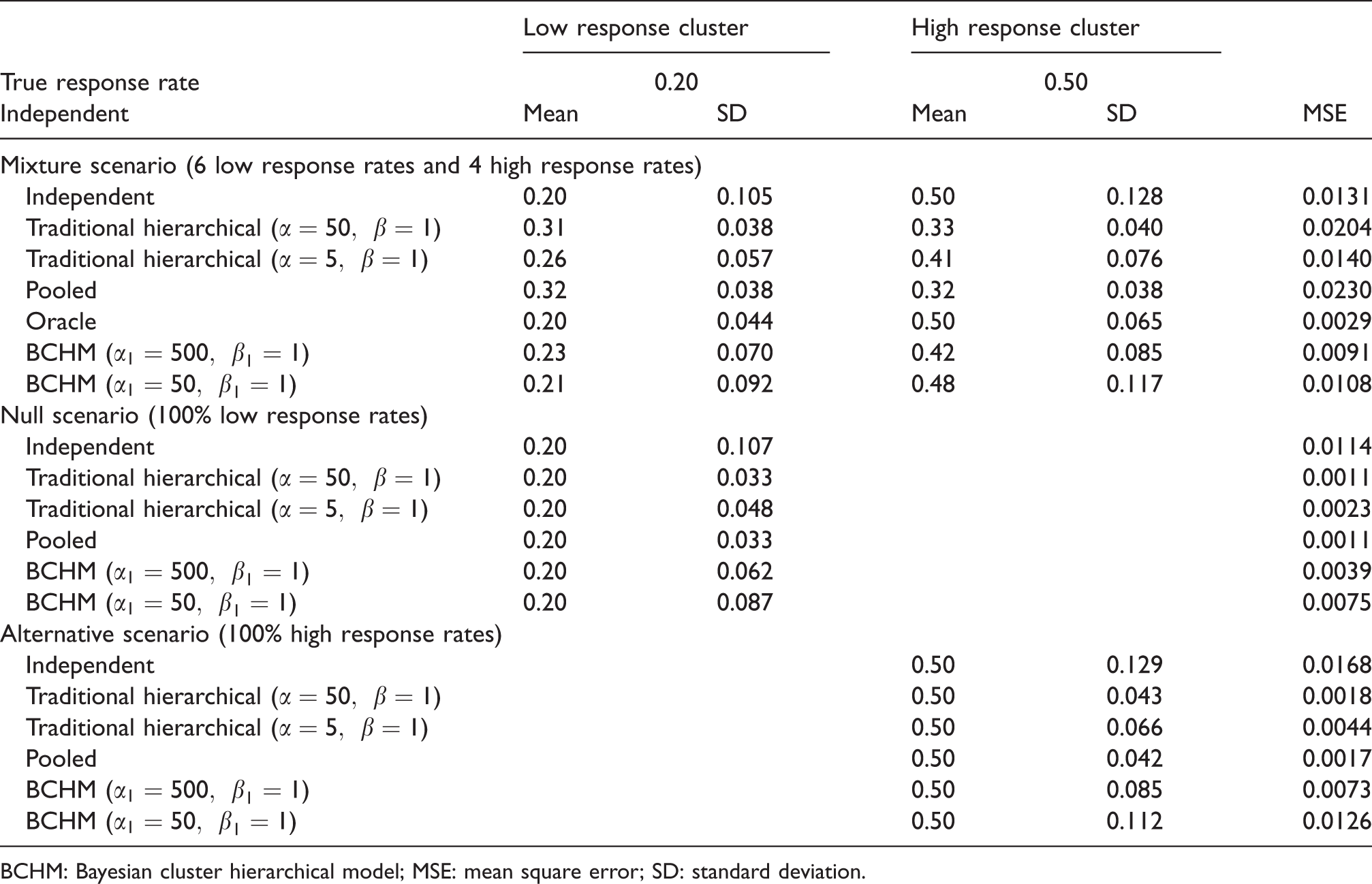
BCHM: Bayesian cluster hierarchical model; MSE: mean square error; SD: standard deviation.
Table 1 shows the results of three scenarios: the mixture scenario, the null scenario, and the alternative scenario. In the mixture scenario, the low response cluster and the high response cluster have six and four subgroups, respectively. The oracle method assumes that we know the true clustering structure, hence, we can correctly classify subgroups into the low or high response clusters, respectively. The oracle method results in the accurate estimation of the mean response rate and yields the smallest and theoretical limit of MSE. For the independent method, the average posterior mean values of the response rates are the same as their corresponding true means (0.2 and 0.5, respectively). However, the SD of the estimated response rate is the largest among all methods. For the traditional hierarchical model, moderate borrowing results in smaller SD but larger MSE, while weak borrowing results in a larger SD but smaller MSE.
The average posterior means of the response rates for both moderate and weak borrowing are considerably different from their true means. When subgroups are substantially different in their response rates, global borrowing causes bias on estimating the true response rate in each subgroup. The pooled method produces results with the strongest borrowing under the traditional hierarchical model, but yields the largest MSE for all of the methods. In contrast, BCHM gives the posterior mean response rate estimates, which are closer to the true response rates because borrowing only occurs within exchangeable clusters. Strong borrowing under BCHM results in smaller SD and MSE, while moderate borrowing produces more accurate posterior mean estimates of the true response rates. In general, BCHM provides lower MSE values compared to the results from the independent, traditional hierarchical, and the pooled methods. The cluster borrowing by BCHM improves the accuracy and efficiency of the data analysis. In the mixture scenario, BCHM provides the best subgroup estimation analysis results compared to the results of the independent, traditional hierarchical, and pooled methods.
In the null and alternative scenarios, the response rates of all subgroups are identical. Hence, the pooled method is the oracle method. All methods provide accurate estimation of the mean response rate. The stronger borrowing under the traditional hierarchical method, the smaller SD, and MSE are reached. Strong borrowing under BCHM gives a little larger SD and MSE, but they are considerably smaller compared to that of the independent method.
4 BCHM for clinical trial design
In this section, we illustrate how BCHM can be used for designing clinical trials. We assume that a targeted therapy is applied to treat patients in several different subgroups. The primary endpoint is the response rate. In the null case, the treatment does not work in all or most of subgroups. In the alternative case, the treatment works in all or most of subgroups. We assume that the null and alternative response rates are 0.1 and 0.3, respectively. We consider all possible cases that may fall broadly into one of the following five scenarios: global null, global alternative, equal mixture, mostly alternative, and mostly null with the proportions of the null and alternative cases listed in the online Appendix Table A1. In the global null scenario, the true response rates of all subgroups are 0.1 (low response subgroup). Similarly, in the global alternative scenario, the true response rates of all subgroups are 0.3 (high response subgroups). In the equal mixture scenario, the true response rates in half subgroups are 0.1 (low response subgroups) and in the other half are 0.3 (high response subgroups). In the mostly null scenarios and mostly alternative scenarios, the true response rates of subgroups are (80% 0.1 and 20% 0.3) and (20% 0.1 and 80% 0.3), respectively.
4.1 Loss function and parameter optimization for clinical trial
Loss functions are applied to optimize the design parameters for controlling type I errors and maintaining the desirable power in a wide range of mixed scenarios of different treatment effects among the various subgroups. The five scenarios for the loss function calculation are listed in online Appendix Table A1. The loss function combining all scenarios is
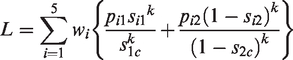
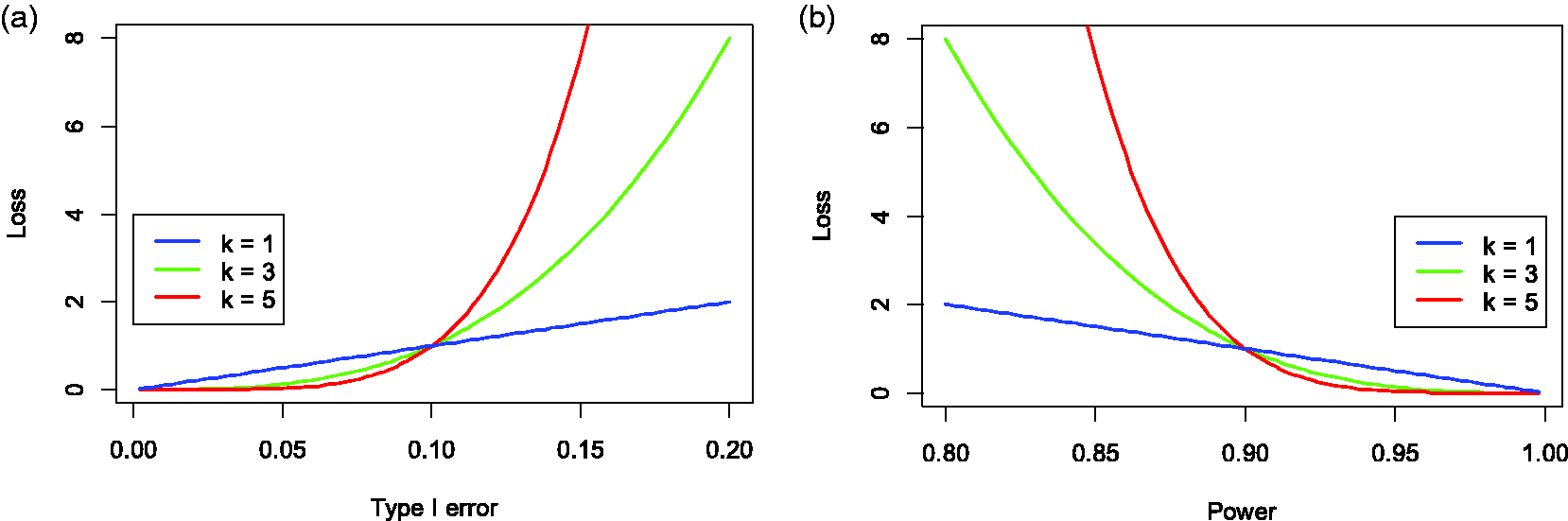
Shapes of loss functions with different exponential factors (
We assume that the trial has 10 subgroups, with 25 patients enrolled in each subgroup. To apply BCHM, we need to specify the design parameters. First, we set
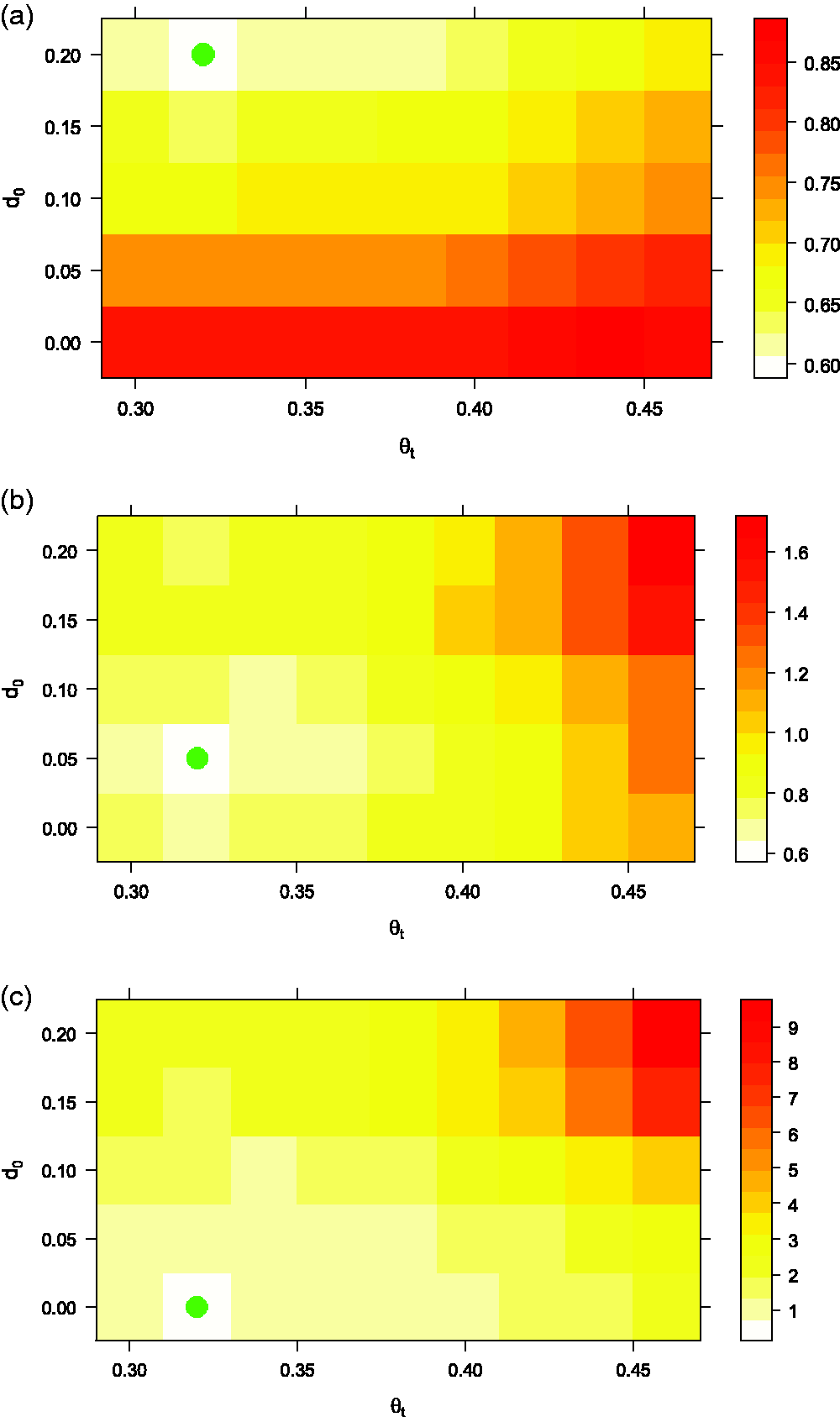
Heat map of the loss function distribution by varying
4.2 Rejection rates of the Bayesian cluster hierarchical model
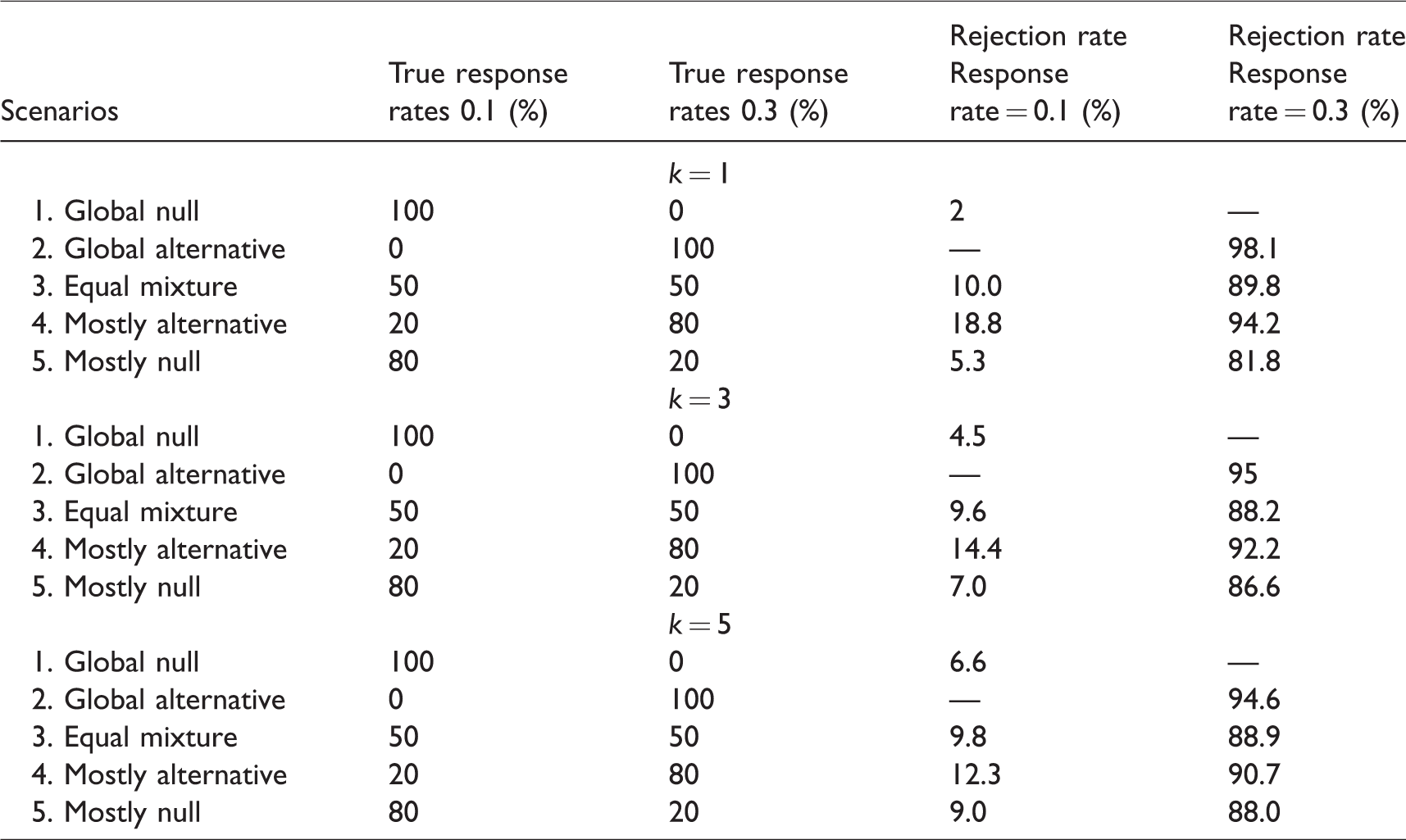
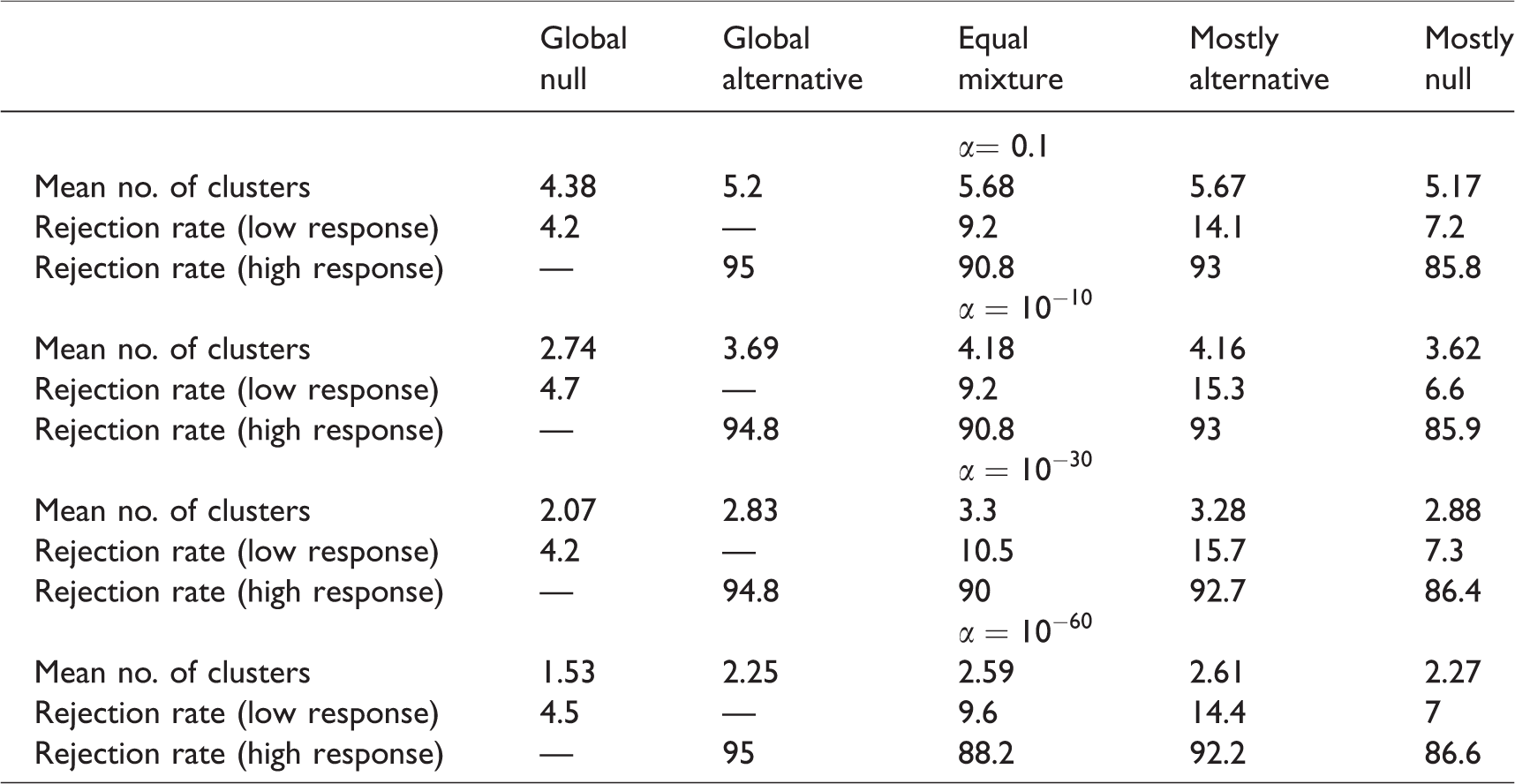
With the design parameters in Section 4.1, we study the rejection rates of BCHM for various scenarios with different exponential factors. Table 2 shows the results of 2000 simulation runs. From the results, under the global null and global alternative scenarios, all settings well preserve a 10% type I error rate and 90% power. For the equal mixture setting, all methods have a type I error rate no larger than 10% and power just a little lower than 90%. With k = 1, in the mostly alternative scenario and the mostly null scenario, 20% of subgroups’ operating characteristics (18.8% and 81.8%) are much worse than the pre-specified type I error rate (10%) and power value (90%). As the value of k increases, in the mostly alternative scenario and the mostly null scenario, 20% of the subgroups’ operating characteristics improve (lower type I error and higher power), while 80% of the subgroups’ operating characteristics worsen (lower power and higher type I error). Such a trend suggests a large value of k is not desirable. Based on these results, k = 3 is selected for further study of the operating characteristics.
Rejection rates of Bayesian cluster hierarchical model for various scenarios with different exponential factors.
4.3 Operating characteristics and comparison among different methods
We applied the BCHM method on different scenarios with the optimized parameters from the above subsection with
Operating characteristics of different methods (loss function k = 3.0).
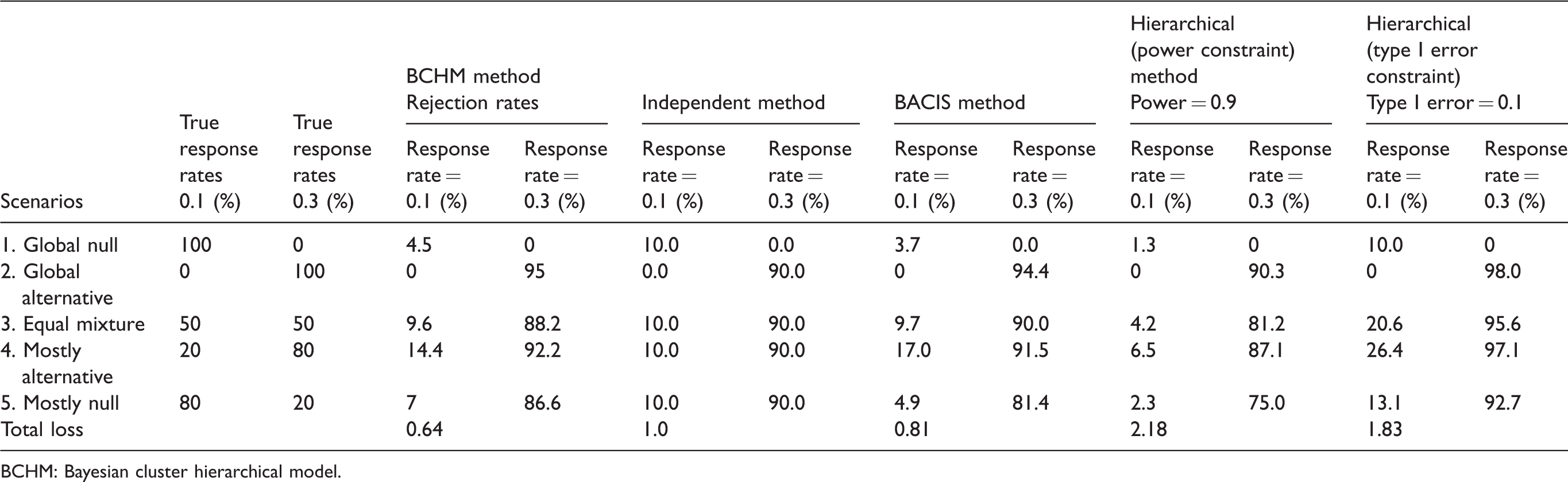
BCHM: Bayesian cluster hierarchical model.
We also studied the distribution of the number of clusters produced by BCHM in different scenarios, which are plotted in Figures 4 (25 patients in each subgroup) and 5 (50 patients in each subgroup). With the global null and the global alternative scenarios, the true response rates in all subgroups are the same. Thus, we observe a low number of clusters, as expected. The global alternative scenario has a higher response rate (0.3) with a larger variance than the global null scenario (response rate = 0.1). As a result, the number of clusters for the global alternative is higher than those from the global null. In the other three scenarios, the true response rates come from two clusters (0.1 and 0.3); therefore, more clusters are observed. With larger number of patients (50 in Figure 5), the number of clusters are reduced compared with those from the lower number of patients (25 in Figure 4). A larger number of patients in each subgroup leads to lower variance therein, as well as a smaller number of identified clusters.
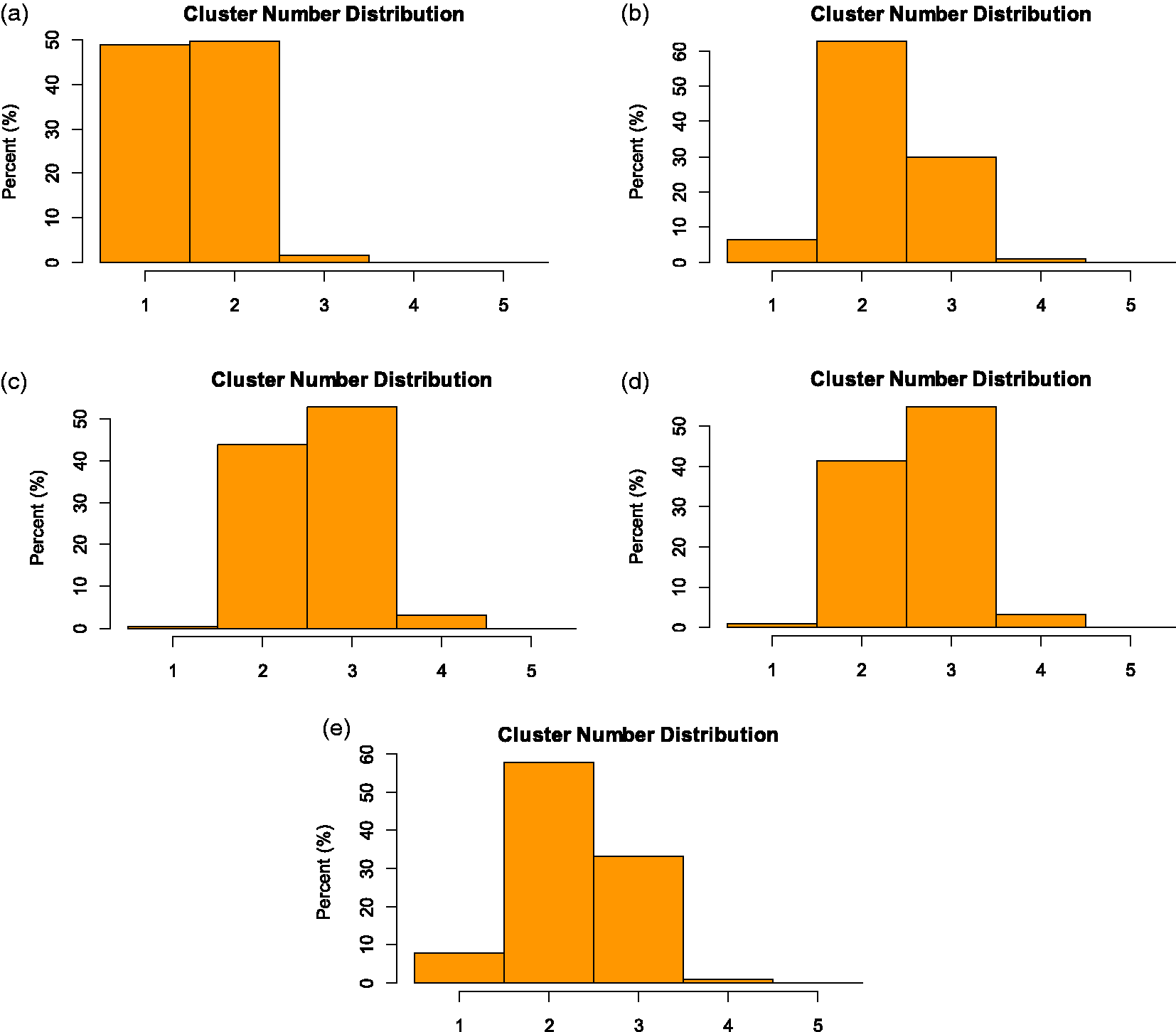
Distribution of cluster number in five different scenarios by applying Bayesian cluster hierarchical model with 25 patients per subgroup: (a) Global null (ANC = 1.53). (b) Global alternative (ANC = 2.25). (c) Equal mixture (ANC = 2.59). (d) Mostly alternative (ANC = 2.61). (e) Mostly null (ANC = 2.27).
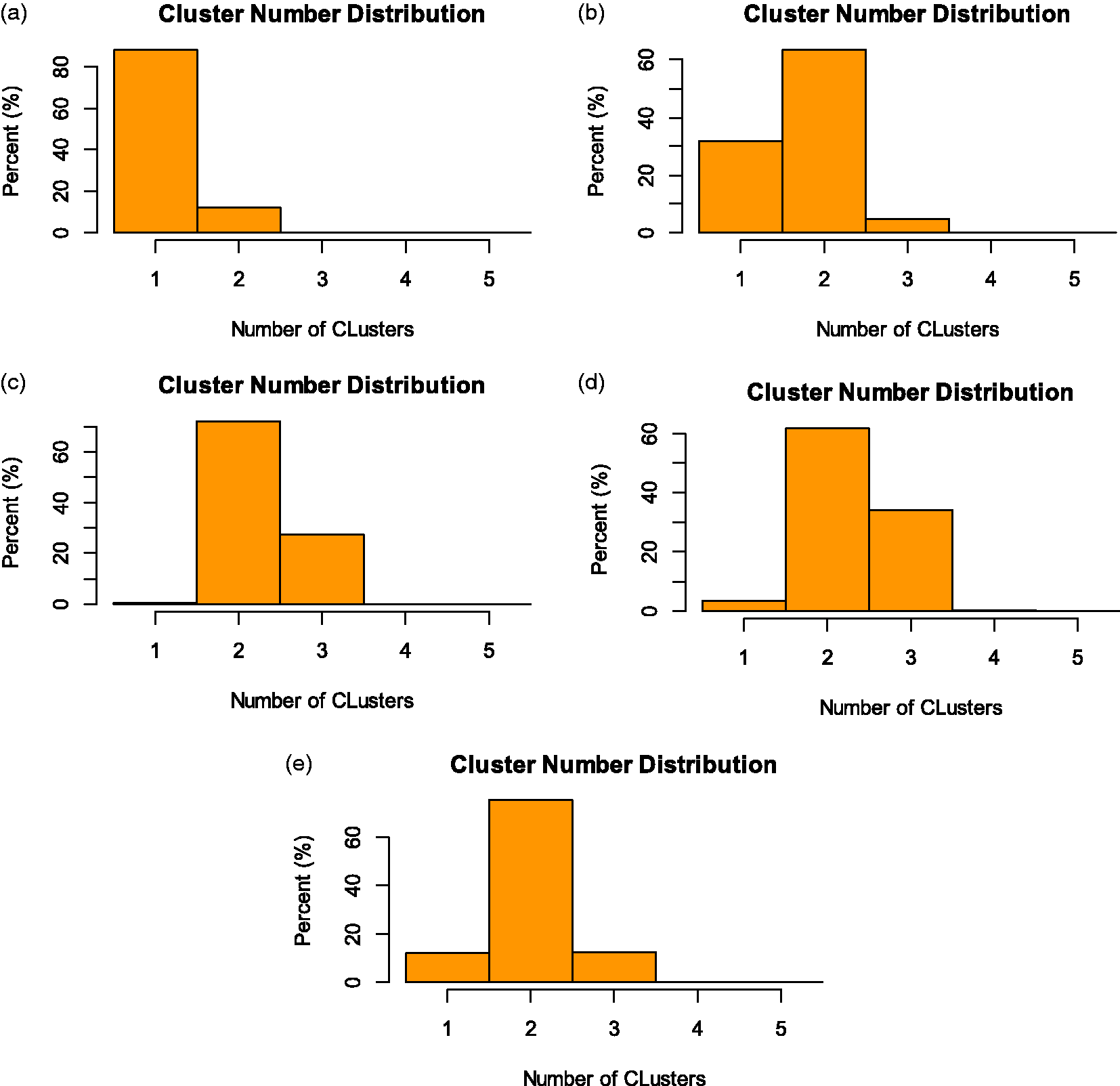
Distribution of cluster number in different scenarios by applying Bayesian cluster hierarchical model with 50 patients per subgroup: (a) Global null (ANC = 1.12). (b) Global alternative (ANC = 1.73). (c) Equal mixture (ANC = 2.27). (d) Mostly alternative (ANC = 2.31). (e) Mostly null (ANC = 2.00).
In addition, we perform extensive simulations with different response rate distributions and sample sizes to check the robustness of the method. Because of the page limitation, we place the simulation results and discussions in the online Appendix. Generally speaking, these simulation scenarios have complex response rates distributions and are more challenging. However, under these scenarios, the BCHM still yields robust results. Readers who are interested in these simulation details can find them in the online Appendix.
5 Sensitivity analysis
In the CRP, the value of
Number of clusters and rejection rates of Bayesian cluster hierarchical model by varying different
The value of the
The equal mixture scenario is applied in the sensitivity analysis and the average number of clusters is expected to be two in the cluster analysis. Both
6 Clinical trial application
In this section, we apply the BCHM method on data collected from a phase II trial conducted by Chugh et al. for testing the efficacy of imatinib in 10 different subtypes of advanced sarcoma. 36 The trial includes 10 subgroups: angiosarcoma, Ewing sarcoma, fibrosarcoma, leiomyosarcoma, liposarcoma, malignant fibrous histiocytoma, osteosarcoma, malignant peripheral nerve sheath tumor, rhabdomyosarcoma, and synovial subtypes. The number of responses and the total number of patients in these subgroups are 2/15, 0/3, 1/12, 6/28, 7/29, 3/29, 5/26, 1/5, 0/2, and 3/20, respectively. Chugh et al. 36 used a traditional hierarchical Bayesian model and information was shared between all subgroups, despite the wide observed response rates of these 10 subgroups (from 0% to 24.1%).
We use the parameters of
We also compared the results between the BCHM method and BACIS method. With the BACIS method, only subgroups 4 and 5 are classified into the high response cluster, while subgroups 7 and 8 are classified into the low response cluster. The probability of response rates greater than 15% from BACIS are (0.259, 0.113, 0.203,
7 Discussion and summary
In this study, we develop and investigate the application of BCHM on both subgroup estimation analysis and clinical trial design. The current setting is based on binary outcomes. However, from the derivation in Section 2, this method can also be applied to the subgroup analyses and clinical trial designs with continuous outcomes. In the clustering step, we can directly apply the DP method with continuous outcomes. In the hierarchical model for information borrowing step, we can modify the model described by equation (6) to accommodate continuous outcomes.
The early stopping interim-analyses are not included in the simulations of our study. However, using BCHM, early stopping can be easily implemented based on the Bayesian posterior probability. The computation results of BCHM include the response posterior distributions of all subgroups. Based on the posterior distribution of each subgroup, we can calibrate the threshold values for efficacy and futility early stoppings. When early stopping is implemented in the trial design, non-performing subgroups can be terminated early, such that subsequent patients with similar characteristics will not be treated with an inefficacious therapy, and thus saving cost. Subgroups with superior performance can graduate early and reach the next stage of evaluation that much quicker. A decision theoretic approach is applied to find the optimal design parameters to control the type I and type II error rates by minimizing the loss function. In equation (7), equal weights are employed to five potential scenarios ranging from global null, mostly null, equal mixture, mostly alternative, to global alternative. These weights can be changed depending on the setting of the drug development to further tailor the error rate control to tackle various challenges. For example, finding effective drug for lowering blood pressure is relatively easy compared with finding effective drug for treating pancreatic cancer; thus, different weights can be constructed accordingly.
The subgroup clustering results produced by BCHM also provide useful information for clinicians to understand the biological pathways between biomarkers and/or patient characteristics and therapies. The subgroup clustering provides quantifiable information to study interactions between biomarkers/patient characteristics and therapies, despite that the information is not directly obtained from biological experiments.
Another extension for the BCHM method is to conduct the subgroup clustering by incorporating the biomarker information. In the current setting, only the response rates of subgroups are taken into account for the subgroup clustering. The BCHM can be extended to high-dimensional data incorporating patients’ surrogate endpoint biomarkers as measures of treatment efficacy. Thus the BCHM may be utilized for the clustering and information borrowing between patients based on the surrogate endpoint biomarkers. The challenge for the biomarker-based clustering is how to identify the relative importance of different biomarkers on the treatment effects and incorporate this information into the model. Another way is to include the biomarkers as the covariates which are used to adjust the treatment effect by applying regression models. The likelihood terms in the MCMC calculation can be modified correspondingly. Some progress has been made in this topic, for instance, longitudinal biomarker information are incorporated into the patients clustering models for information borrowing between subgroups. 30 Future research is warranted to identify and use biomarkers to improve the performance of clustered Bayesian hierarchical model.
In the current borrowing model, the magnitude of borrowing is determined by the prior values of
In addition to adaptively selecting the value of prior
In this study, we combine the nonparametric Bayesian method for subgroup clustering, the decision theoretic method for parameter optimization, and the hierarchical model for information borrowing. Simulations show that BCHM is better than other competing methods in both the estimation of subgroup treatment effect and the clinical trial design. BCHM provides a balanced approach and smart borrowing, which yields better results in evaluating the treatment effect in different scenarios compared to other conventional methods. An R-package BCHM is available at the CRAN repository (https://cran.r-project.org/) to facilitate its implementation.
Supplemental Material
SMM910186 Supplemental Material - Supplemental material for Bayesian cluster hierarchical model for subgroup borrowing in the design and analysis of basket trials with binary endpoints
Supplemental material, SMM910186 Supplemental Material for Bayesian cluster hierarchical model for subgroup borrowing in the design and analysis of basket trials with binary endpoints by Nan Chen and J Jack Lee in Statistical Methods in Medical Research
Footnotes
Acknowledgements
We thank Peter Mueller for helpful discussion and Jessica Swann for editorial assistance.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by grants CA016672, 1P50CA221703 from the National Cancer Institute and RP160668 from the Cancer Prevention and Research Institute of Texas (CPRIT).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.