
Abstract
Recently, various methods have been developed to estimate the sample mean and standard deviation when only the sample size, and other selected sample summaries are reported. In this paper, we provide a unified approach to optimal estimation that can be easily adopted when only some summary statistics are reported. We show that the proposed estimators have the lowest variance among linear unbiased estimators. We also show that in the most commonly reported cases, that is, when only a three-number or five-number summary is reported, the newly proposed estimators match the previously developed estimators. Finally, we demonstrate the performance of the estimators numerically.
Introduction
When a study deals with a continuous outcome variable, one needs an estimate of the underlying standard deviation (
However, other summaries are also possible; for example, Bowley’s “seven-figure summary,” including the minimum, first deciles, first quartile, median, third quartile, last decile, and maximum.
20
In general, estimators for the sample mean and sample SD are developed separately and independently of each other. Moreover, the estimators are developed differently for each different scenario; see, for example, Shi et al.
13
In this paper, we propose a unified approach to optimal estimation of the mean and standard deviation. Our method provides unbiased estimators and has the smallest variance (amongst all linear unbiased estimators). The method is robust and can be easily modified when only some summary measures are reported.
Derivation of best estimators
Suppose a study reports
Let us assume that these reported statistics are derived from a distribution with location parameter
Let us denote the


Set




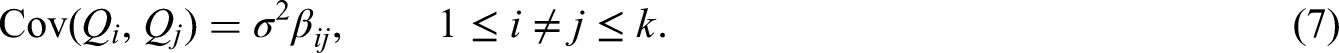
To obtain values of
Next, we give the formulas for the best linear unbiased estimators.
The best (i.e. with minimum variance) linear unbiased estimators of


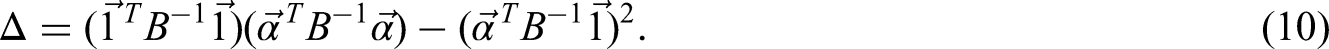
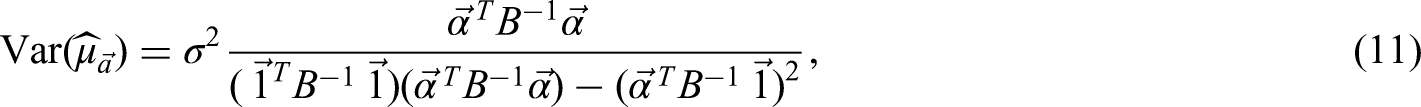
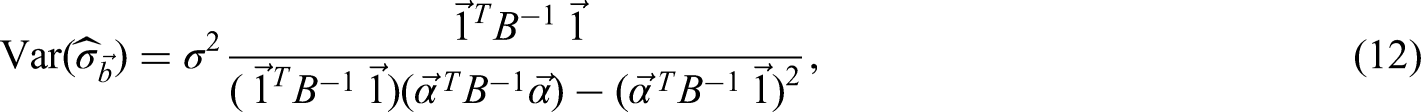
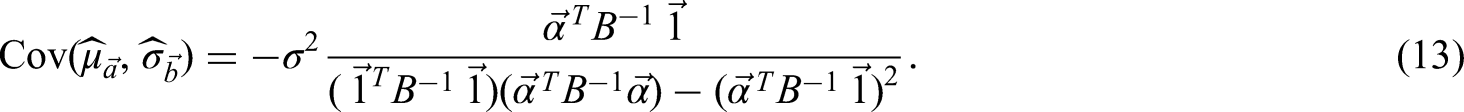
We use the Lagrangian method and present the detailed proof in Appendix 6. with an alternative proof in Appendix 7. □
If the distribution is symmetric and the reported summaries are symmetric, the best (i.e., with minimum variance) linear unbiased estimators of


It follows from Theorem 2.1 with the details presented in Appendix 6. □
In order to use the best linear estimators
Let
Explicit integral formulas are given in Appendix 5.. Those formulas can be used in a software package like R or Matlab, which can also be used to invert the matrix
Scenario 1
For illustration, we simplify formulas (14) and (15) for Scenario 1. Assume that the summary statistics consist of the minimum (
Due to the symmetry of the distribution



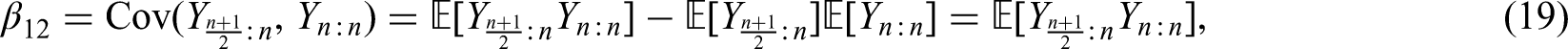
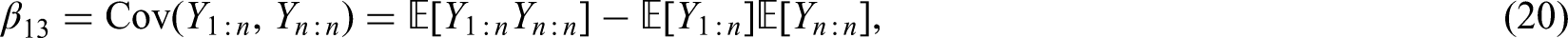

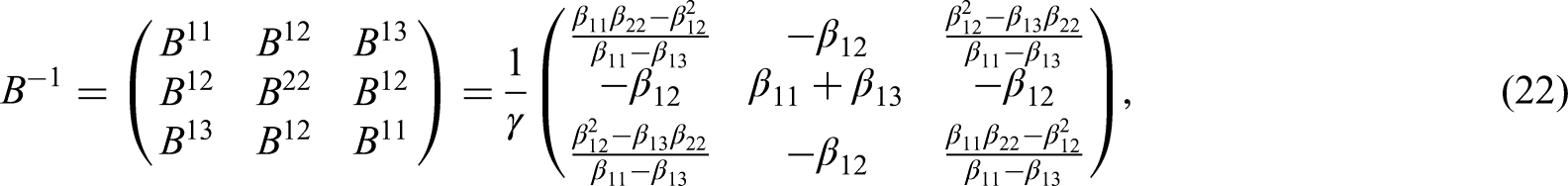
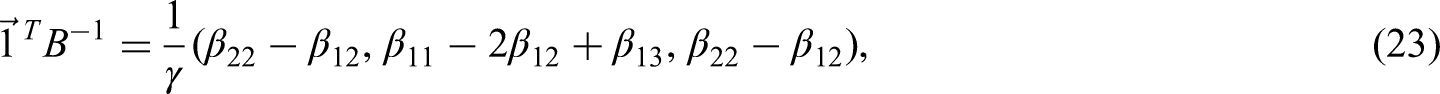
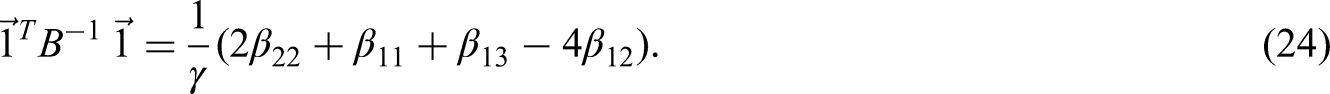
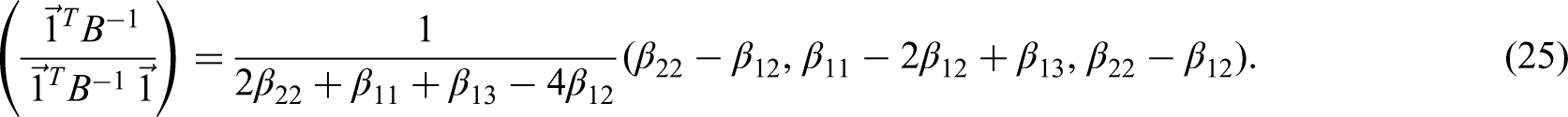
Similarly, to find the optimal estimator for

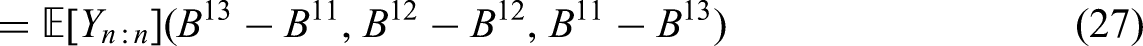


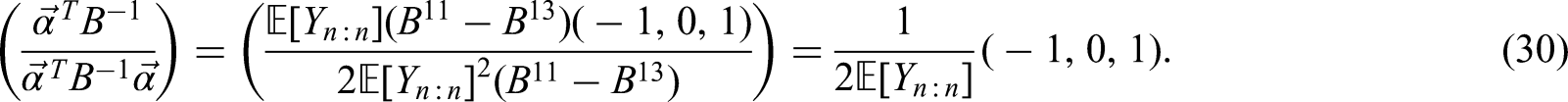
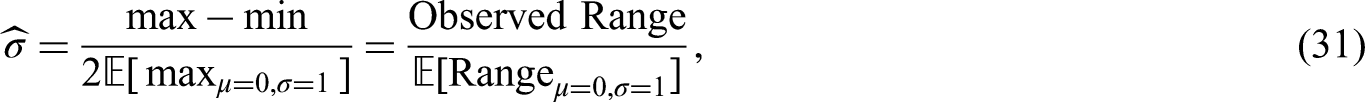
Assume that the summary statistics consist of the first quartile, the median and the third quartile. In the framework of this paper, the situation is analogs to Scenario 1. Thus, the best estimator for

The optimal estimator for
Finally, assume that the summary statistics consist of the minimum, the first quartile, the median, the third quartile, and the maximum. As
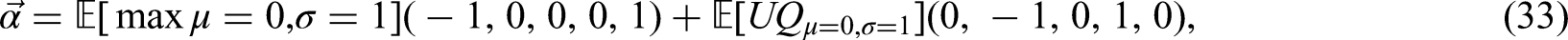
Design of simulation studies
For illustration purposes, we consider the following seven scenarios for reported summary statistics:
min, median, max, 25% median, 75%, min, 25%, median, 75%, max, 10%, median, 90%, 10%, 25%, median, 75%, 90%, min, 10%, median, 90%, max, min, 10%, 25%, median, 75%, 90%, max.
We consider the following four distributions: normal, logistic, Gumbel, and Student’s
The numerical simulations confirm that the estimators (8) and (9) are unbiased. Regardless of the scenario, distribution, or the sample size, the bias is generally between
As expected, the MSE decreases with sample size.
There is also a difference between various scenarios. A scenario which reports more statistics gives a smaller MSE. In particular, from the seven scenarios we considered, Scenario 7 has the lowest MSE and Scenario 3 has MSE lower than either Scenario 1 or Scenario 2. This is easy to see from the optimality of the estimators. For example, the optimal estimator in Scenario 1 is also an estimator for Scenario 3 by simply ignoring the reported values of interquartile ranges. Thus, the optimal estimator for Scenario 3 will always have a strictly smaller MSE. This is seen in Figure 1.
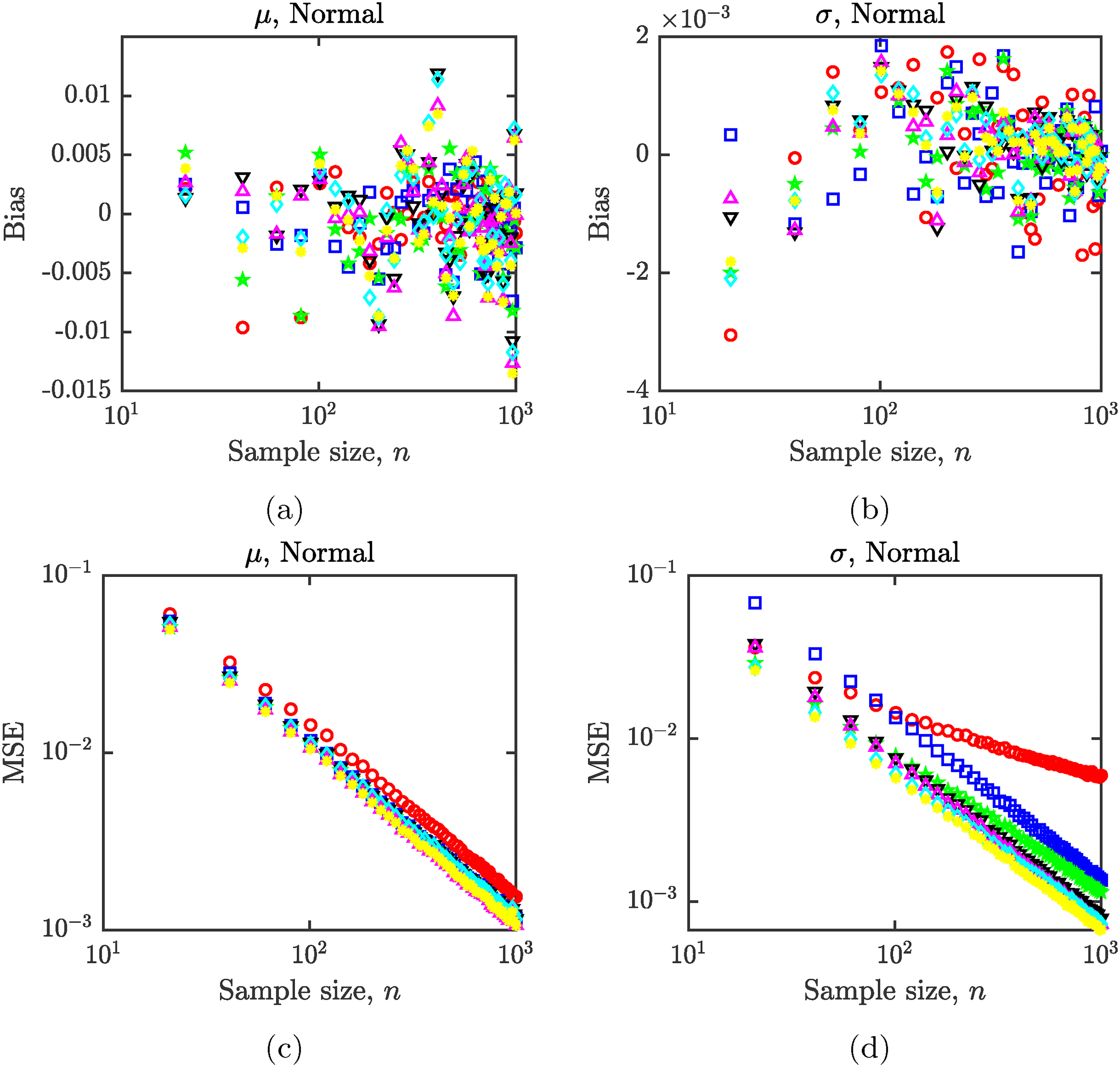
Bias (top row) and MSE (bottom row) for estimating
An interesting observation is that when one scenario does not include all statistics reported by the other, the relationship between them depends on
In this section, we illustrate the use of the proposed method to estimate the mean and SD when only summary statistics are reported. We note that the performance of the methods (for the normal distribution) have already been illustrated before.11,13,14 Here, we use publicly available data from the Centers for Disease Control and Prevention on COVID-19 vaccination status in the US.
22
For each US state (and territory), CDC provides 74 different statistics such as total doses delivered, doses delivered per 100K population, percentage of population with at least one dose, percentage fully vaccinated, etc. Data is also categorized by age (total or 18+) and vaccine (total, Pfitzer, Moderna, Janssen, unknown). When the data deals with absolute counts, it generally follows what seems to be a Gamma distribution with a skewness typically two or more. When data deals with percentages or with counts per 100K population, it generally follows an approximately normal distribution truncated between 0% and 100% or between 0 and the appropriate number of doses. The skewness is then around 0 or negative as the peak often occurs near the upper bound. This can be seen in Figure 2. For each of the provided statistics, we extracted the summaries for each scenario and used (8) and (9) to estimate the location parameter
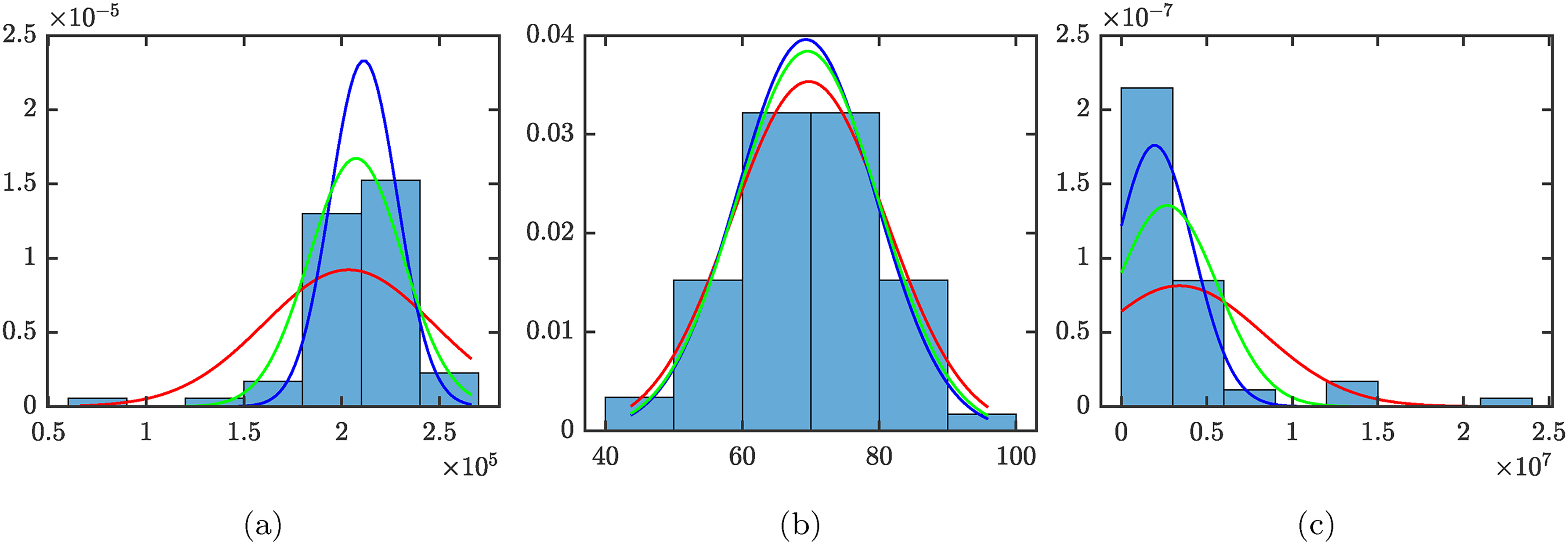
Representative histograms of the data sample from the CDC vaccination data
22
and p.d.f.s of normal distributions obtained by estimating the mean and standard deviation (red: Scenario 1, blue: Scenario 2, green: Scenario 3). (a) The number of doses administered in each state per 100K of 65+ residents; (b) percentage of people 18+ in each state that are fully vaccinated; and (c) number of people 18+ in each state that are fully vaccinated. The skewness from left to right is
The mean and SD of sample of size

For normal estimates, as expected, the estimates of the mean and SD are very good for data that are close to normal. Moreover, the relative error of estimates of the mean are very low for all scenarios whenever the skewness is around
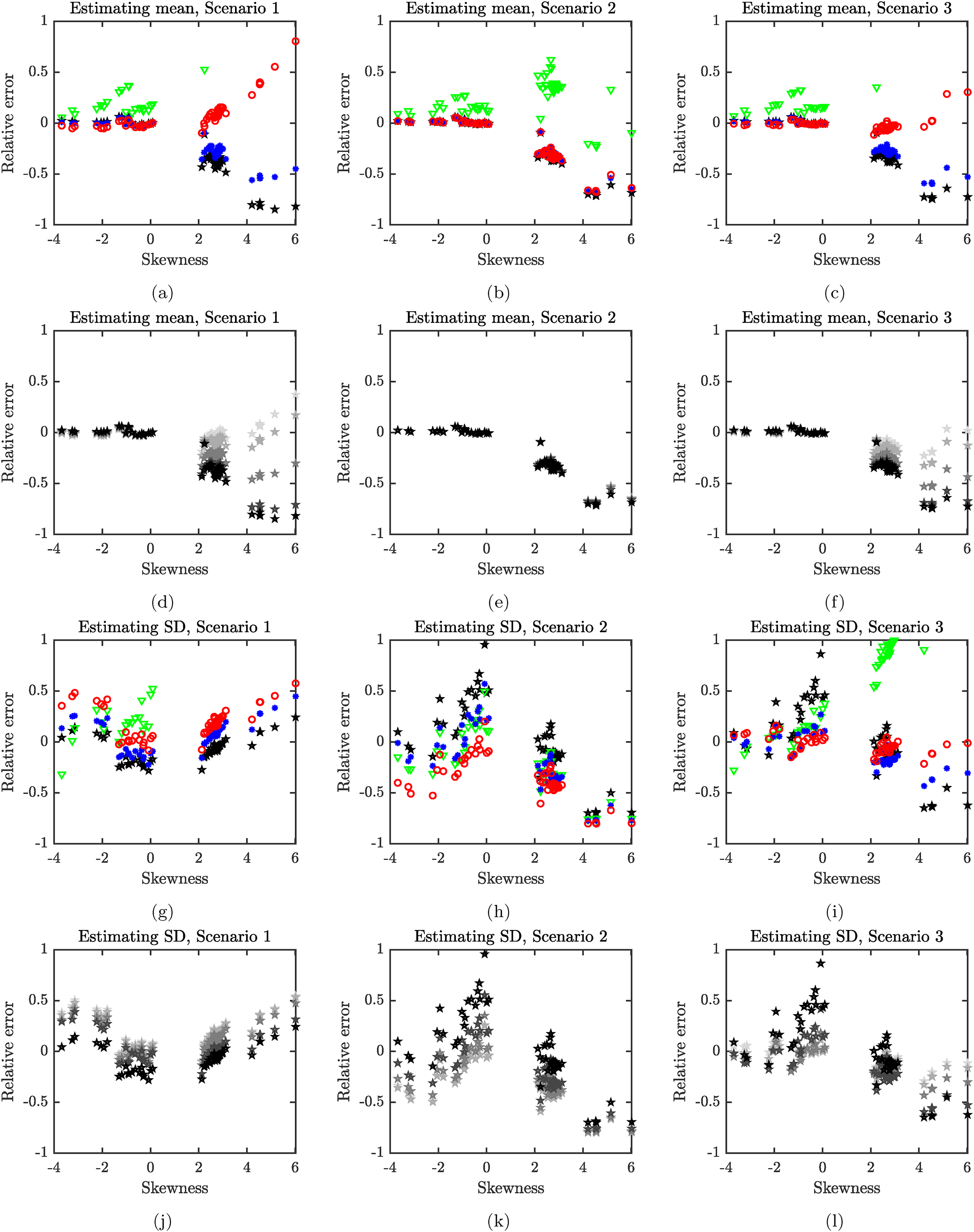
Relative error as it depends on the skewness of data. We estimate the mean and the standard deviation from the CDC vaccination data
22
as if the underlying distribution is assumed to be normal (red circle), logistic (blue stars), Gumbel (green triangles), or Student’s
For our particular data sets, the estimates of the mean using logistic or Student’s
We proposed a general method to estimate the location parameter
The proposed method has several advantages. First, it can be easily adapted to whatever summaries are reported without the need of extra theoretical derivations. In fact, the reported summaries do not even have to be symmetric. Second, the proposed method automatically gives the standard error. Finally, the method works for a general family of location-scale distributions, not only for normally distributed data. This includes the logistic, Laplace, Student’s
When data are skewed, investigators typically report the sample median and other sample quantiles, and so it is important to develop methods for this situation. Unfortunately, there is still a lack of literature on this subject with Shi et al.
23
and McGrath et al.
24
being notable exceptions. While the proposed method can handle non-normal data, the problem with a practical application of our method is that one needs to make a priori assumptions about the underlying data distribution. If the data distribution is not known, McGrath et al.
24
offer a promising approach of using the Box-Cox transformation to modify data summaries before estimating
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The research was funded by the Natural Sciences and Engineering Research Council of Canada RGPIN-2020-06733 (N.B.) and RGPIN/3670-2016 (S.D.W.). The funding agency had no input in study design, analysis and interpretation of data, in the writing of the report, nor in the decision to submit the article for publication.
Appendix A. Formulas
Appendix B. Proofs of the main theorems
Let
So, let us take the linear estimators of
Now, let us minimize the trace, that is, the sum of variances (after dropping the multiple
Appendix C. Estimation with change of optimality criterion
Here we present an alternative proof of Theorem 2.1.
Suppose we define a new parameter