
Abstract
In sparse penalized regressions, candidate covariates of different units need to be standardized beforehand so that the coefficient sizes are directly comparable and reflect their relative impacts, which leads to fairer variable selection. However, when covariates of mixed data types (e.g. continuous, binary or categorical) exist in the same dataset, the commonly used standardization methods may lead to different selection probabilities even when the covariates have the same impact on or level of association with the outcome. In this paper, we propose a novel standardization method that targets at generating comparable selection probabilities in sparse penalized regressions for continuous, binary or categorical covariates with the same impact. We illustrate the advantages of the proposed method in simulation studies, and apply it to the National Ambulatory Medical Care Survey data to select factors related to the opioid prescription in the US.
Keywords
Introduction
Impacts of covariates on the outcome are often measured by the corresponding coefficients in various regressions. Take linear regression as example, the impact of a covariate is often interpreted as the average or expected change in the outcome when the covariate changes by one unit or from the reference category to another category while holding all the other covariates constant. For continuous covariate, the coefficient size depends on its unit, where larger units lead to larger coefficients even when the impacts on or associations with the outcome remain the same. This creates difficulty in comparing the effect sizes of continuous covariates with different units. For instance, how to determine which factor has a bigger impact on the risk of diabetes, weight in pounds or BMI in kg/m
Sparse penalized regressions are often used to conduct simultaneous variable selection and coefficient estimation, where the coefficients are estimated by optimizing the penalized log-likelihood and are shrunk towards zero by the exerted penalty. However, one issue in performing the sparse penalized regressions in practice is that the covariates with higher probabilities of nonzero coefficient estimates do not necessarily have larger impacts on the outcome, especially when covariates are measured on different units or of different types. Therefore, in order to reduce the interference from different units or data types to the variable selection in sparse penalized regressions, it is important to standardize the covariates so that the standardized coefficients can reflect the covariate impacts. Consequently, penalized regression model applied on the standardized covariates would select covariates of larger impacts or stronger associations with higher chances, regardless of their units or data types.
It is a common practice to standardize covariates before carrying out sparse penalized regressions. In fact, the R package
However, none of the standardization methods mentioned above specifically targets data with both continuous and categorical variables, and covariates essentially remain in different types, even after standardization since they still differ in ways beyond the first and second moments, especially for categorical data which is defined by much higher moments. 7 As a result, standardized coefficients cannot reflect the covariate impacts, and the selection probabilities do not necessarily align with covariate impacts. For example, some standardization methods would favor continuous variables, while others prefer categorical variables, in terms of selection probabilities. In the present study, we propose a novel standardization method that aims at generating comparable selection probabilities for covariates of different types in the sparse penalized regression models. The strategy is to eliminate the essential difference across covariates of different types by dichotomizing continuous and multi-category covariates to binary variables, and leaving binary covariates unchanged, then scaling all binary covariates by their sample standard deviations, respectively. More details are given in the method section 2.1. Moreover, as there has always been controversial of using dichotomization,8–10 we would like to emphasize that in the proposed standardization method, dichotomization serves as a tool to generate comparable coefficient sizes and fairer selection probabilities, not for the purpose of coefficient estimates or interpretations. When coefficient estimation is of concern, we recommend to fit the model using the original forms (before standardization) of the covariates, which are selected from the sparse penalized model applied on standardized inputs. We will address the issue in more details in the discussion section 5.
The remainder of the paper is organized as follows. In Section 2., we summarize the commonly implemented standardization approaches and detail the steps of the proposed standardization, followed by two theoretical results of the standardized coefficient estimates in the lasso logistic regressions. Next in Section 3., we conduct two sets of simulations to examine and compare how different standardization approaches perform with regard to generating comparable coefficient sizes and selection rates. Then in Section 4., we apply the group-lasso logistic regression on the 2016 National Ambulatory Medical Care Survey 11 (NACMS) data standardized by different standardization methods, screening for the important factors that drive opioid prescription in the US. Lastly in Section 5., we provide further discussions on the strengths and limitations of the proposed approach.
Method
Standardization
In this section, we explain the Z-score, Gelman, Bring and Min–max standardization methods through a simple example. Though coefficient interpretation is not our goal, it’s presented here to illustrate the connections among different standardization methods and to explain why the standardized coefficients are not comparable in some cases. Suppose a data set has two covariates and one outcome variable. One covariate is age (
When variables age and gender are in their original forms without any standardization, the interpretation of coefficient
Next we fit a logistic regression on the Z-score standardized covariates, age and gender are now on the same unit of one standard deviation and the corresponding coefficients are denoted as
The standardized coefficients calculated by the Bring
5
method inherit the same interpretation and comparability issues as Z-score, but the Bring method makes a numerical improvement by using the partial standard deviation in the standardization, instead of the marginal standard deviation. The partial standard deviation is more appropriate than the marginal standard deviation because the former calculates the spread of the variable of interest conditioning on the values of other covariates, while the latter considers the spread of a variable for all observations in the sample. The partial standard deviation of variable
In order to overcome the interpretation issue of Z-score standardization in the presence of binary covariates, Gelman
4
suggested to scale the continuous variables by twice their standard deviations and leave the binary and multi-category variables unmodified. The rationale goes as follows, although it’s not reasonable to have one standard deviation (0.5) change in gender, it makes sense to have two standard deviations (
Min–max standardization is popular in image processing, it does not modify the categorical variables, but linearly transforms continuous variable
So far, all the standardization approaches mentioned above improve, but not address the comparability issue among coefficients of covariates of different types, which further leads to different selection probabilities in sparse penalized regressions even when the covariates have the same impact. To overcome this problem, we propose an alternative standardization method. Recall that we assume the relationship between the outcome and the observed covariate is in fact driven by the outcome’s relationship with a latent variable, and the covariate impact is measured by the corresponding latent effect size. The relationships between the latent covariates and the outcome are not necessarily linear, for example, it can be a polynomial function, step function, zero below a threshold then continuous after the threshold, etc. The observed covariates are generated from the latent continuous covariates by some mechanisms, for instance, the observed continuous covariate is the same as the latent continuous variable, the observed binary or multi-category covariate is categorized from the latent variable where categories correspond to non-overlapping regions of that latent variable. However, in practice, the latent variables are not observed and the mechanisms from the latent variables to observed covariates are often unknown, so it’s impossible to convert the observed variables back to the latent continuous variables. Nevertheless, we can always convert observed continuous covariates and multi-category covariates to binary variables, so that all the covariates are of binary types. And the coefficients of all binary covariates, which are essentially the differences between the average outcomes in two classes decided by the covariate values, would be comparable and reflect the covariate impacts to a certain degree. Furthermore, the comparability among coefficients would help sparse penalized regressions penalize covariate coefficients according to their relative impacts, leading to selection probabilities in agreement with impact sizes across continuous and categorical covariates. In summary, we propose to dichotomize the observed continuous and multi-category covariates using data-driven cutoff points and leave observed binary covariates unchanged, then standardize all binary variables by their standard deviations. More details are given in Section 2.2.
In the situations where data has no binary variables among the candidate covariates, there is no need to convert all continuous and categorical covariates into binary. Instead, we can convert the continuous covariates into the categorical variables with the fewest categories. For example, if the simplest categorical covariate has three levels—normal/overweight/obese, we would convert all continuous covariates (e.g. age) and categorical covariates with more than three levels (e.g. race) into three levels using the adaptive procedure with either random or empirical thresholds. The proposed standardization is not simply dichotomization. It is to eliminate the essential difference across covariates of different types by transforming all covariates into the same format, which is usually the simplest format, for example, the categorical variable with the fewest categories. However, if a data has only continuous covariates, no transformation is needed and we can directly standardize the continuous covariates using the Z-score method.
Steps of applying the proposed standardization
There are four steps to implement the proposed standardization, detailed as follows.
Identify the cutoff points using the Dichotomize continuous covariates to binary variables. The value of a continuous covariate is set to one if it’s less than the covariate’s Regroup multi-category covariates to binary variables. For each multi-category covariate with Standardize binary covariates by their standard deviations. Follow the same logic as in the Z-score standardization, dividing the binary covariate by one standard deviation can inflate the covariate values and deflate the coefficient estimate when the binary has extreme probability, hence achieving more comparable coefficient estimates among binary covariates of varying probabilities.
Group lasso logistic regression
There have been various types of sparse penalized regression models proposed in the last two decades, for instances, lasso regression, 12 elastic-net regression, 13 etc. In the present study, we take a group-lasso logistic regression 14 as an example to illustrate how different standardization methods affect variable selection in the sparse penalized regressions, especially when different types of variables (i.e. continuous, binary or categorical) coexist in a dataset.
Let
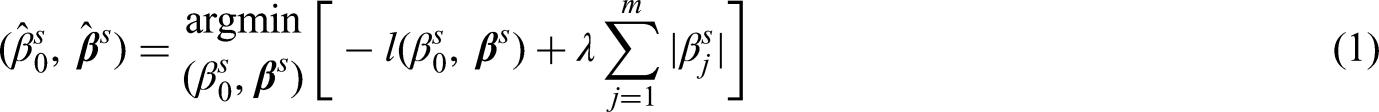
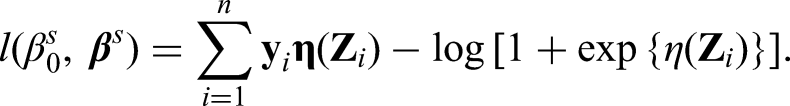
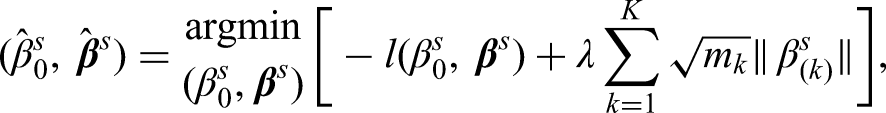
We provide two lemmas to theoretically justify that the proposed standardization will achieve fairer selection rates. Recall the assumption that each observed covariate is generated from a latent continuous covariate and that the covariate impacts to the outcome are reflected by the latent coefficients. Lemma 1 states that under certain conditions, applying the proposed standardization on covariates of different types will produce standardized coefficients that reflect the covariate impacts. Moreover, Lemma 2 states that under the same conditions, covariates with equal impacts have the same asymptotic probability of being selected in the lasso penalized logistic regression. Overall, Lemmas 1 and 2 together imply that applying the proposed standardization on covariates in logistic regression with lasso penalty will make fairer variable selection. The conclusion applies to group-lasso logistic regression and can be generalized to other types of linear regressions. The technique proofs of Lemmas 1 and 2 are provided in the Supplemental Material.
Suppose continuous variables
Suppose continuous variables
We conduct two sets of simulation studies to compare the performance of the five standardization approaches discussed in Section 2.1., as well as the method of using covariates in their observed forms without standardization. In both simulations, we first generate latent continuous variables from multi-variate normal distribution, then create the response variable using logit link and latent variables with equal latent coefficients. This is a very special case of our hypothetical latent variables where all latent variables have the same distribution and the same effect size on the outcome, therefore, the impacts of all the covariates are the same. Next we construct the observed covariates by converting the latent variables to continuous, binary and multi-category forms. Last we standardize the observed covariates and fit logistic regression models without (simulation I) or with (simulation II) penalty. The first simulation assesses the statement in Lemma 1 and examines whether relationships among latent coefficients are retained after standardization, and the second simulation assesses the statement in Lemma 2 and shows how standardization affects variable selection in sparse penalized regressions. We use R package
Simulation I: recover covariate impacts with standardization
In simulation I, we examine whether the standardized coefficients mimic relationships among latent coefficients, which would indicate that the standardization is able to recover the relative impacts of the latent covariates on the outcome, that is, the covariates with larger latent coefficients would have larger standardized coefficients, representing more impacts or stronger associations, regardless of the types of observed covariates. We employ linear functions for the relationships between latent covariates and the logit outcome, and set the sizes of all latent coefficients to the same value. The observed covariates are generated from latent covariates to different types (continuous, binary and categorical). If we fit a regression model directly on the observed covariates, the sizes of the fitted coefficients are not equal. A good standardization method would maintain the equality among standardized coefficients, reflecting the equal relationship among the covariate impacts. Therefore, in the simulation we inspect if standardized coefficients remain equal for each standardization method.
The simulation setup is as follows.
Generate three latent continuous covariates Generate the binary outcome Generate the observed covariates Standardize the observed data
The setup is repeated 2000 times, and the results are reported in Table 1. There are three main columns indicating the
Average standardized coefficient sizes (empirical standard deviation) of
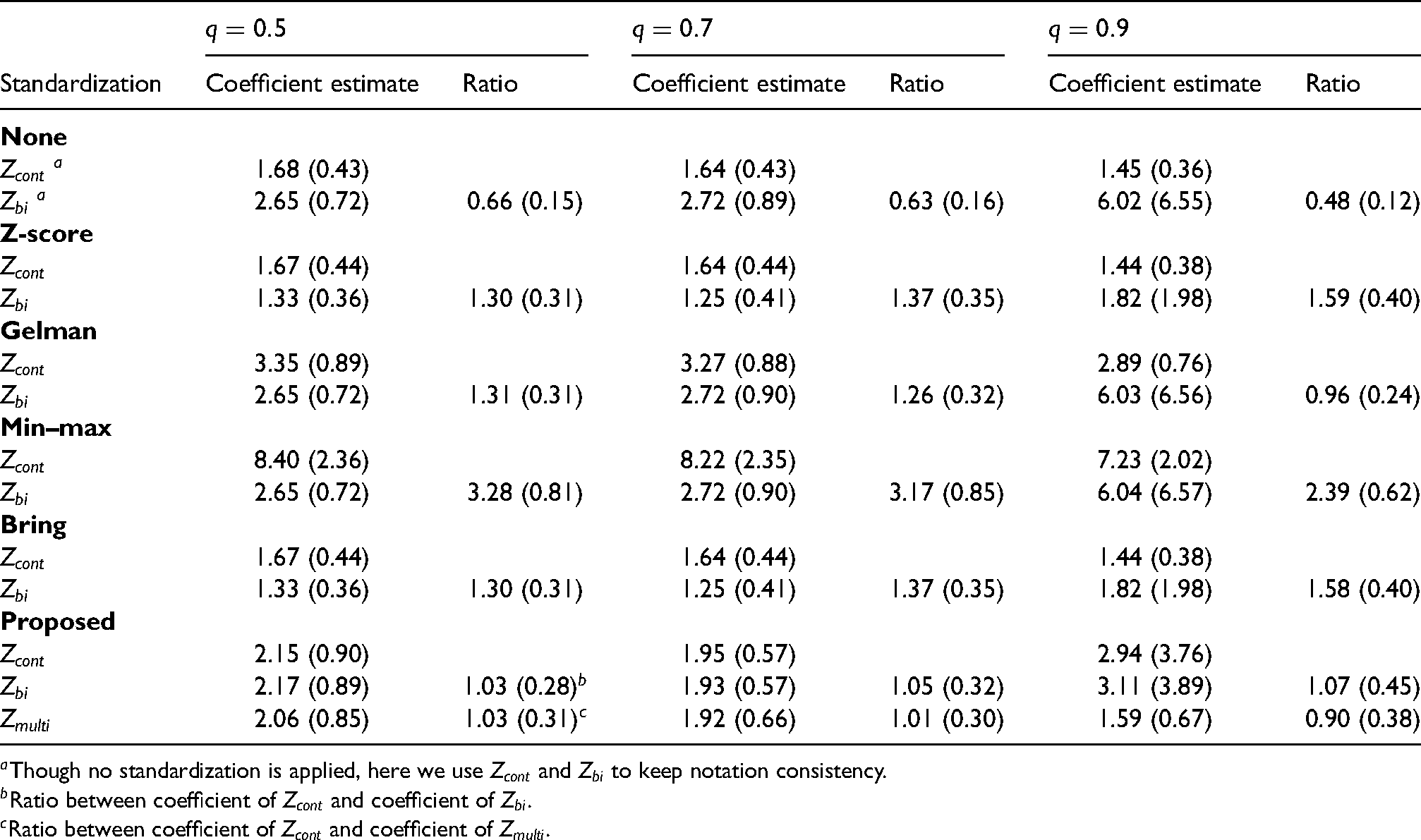
We expect the appropriately standardized coefficients of
In simulation II, for each standardization method, we examine how the capacity of recovering covariate impacts affects the selection probabilities of covariates of different types in the sparse penalized regressions. In the simulation outcome generation model, there are 12 latent continuous covariates in total. The first six are important covariates assigned with nonzero and equal coefficient size (i.e. equal impact), and the last six are noise covariates assigned with zero coefficient size. Next we transform latent variables to observed covariates in different types (i.e. continuous, binary and categorical). Then we perform group-lasso logistic regression on the standardized versions of the observed data. We expect that a good standardization method would lead to comparable selection probabilities for covariates with equal impacts.
The simulation setup is as follows.
Generate 12 latent continuous variables Generate the binary outcome Generate the observed covariates:
Standardize the observed data
We experiment the simulation setup with two latent distributions, symmetric normal distribution and skewed gamma distribution (shape = 2, scale = 2) , in order to examine how the distribution skewness affects the standardization performance. Additionally, with both distributions, we also inspect the situation where latent variables are correlated with correlation equal to 0.1. Under each scenario, the above simulation setup is repeated 2000 times, and the results are reported in Tables 2 and 3. One thing worth noting is that when applying the proposed standardization, by the criterion described in Section 2.2., we set the cutoff
In summary,
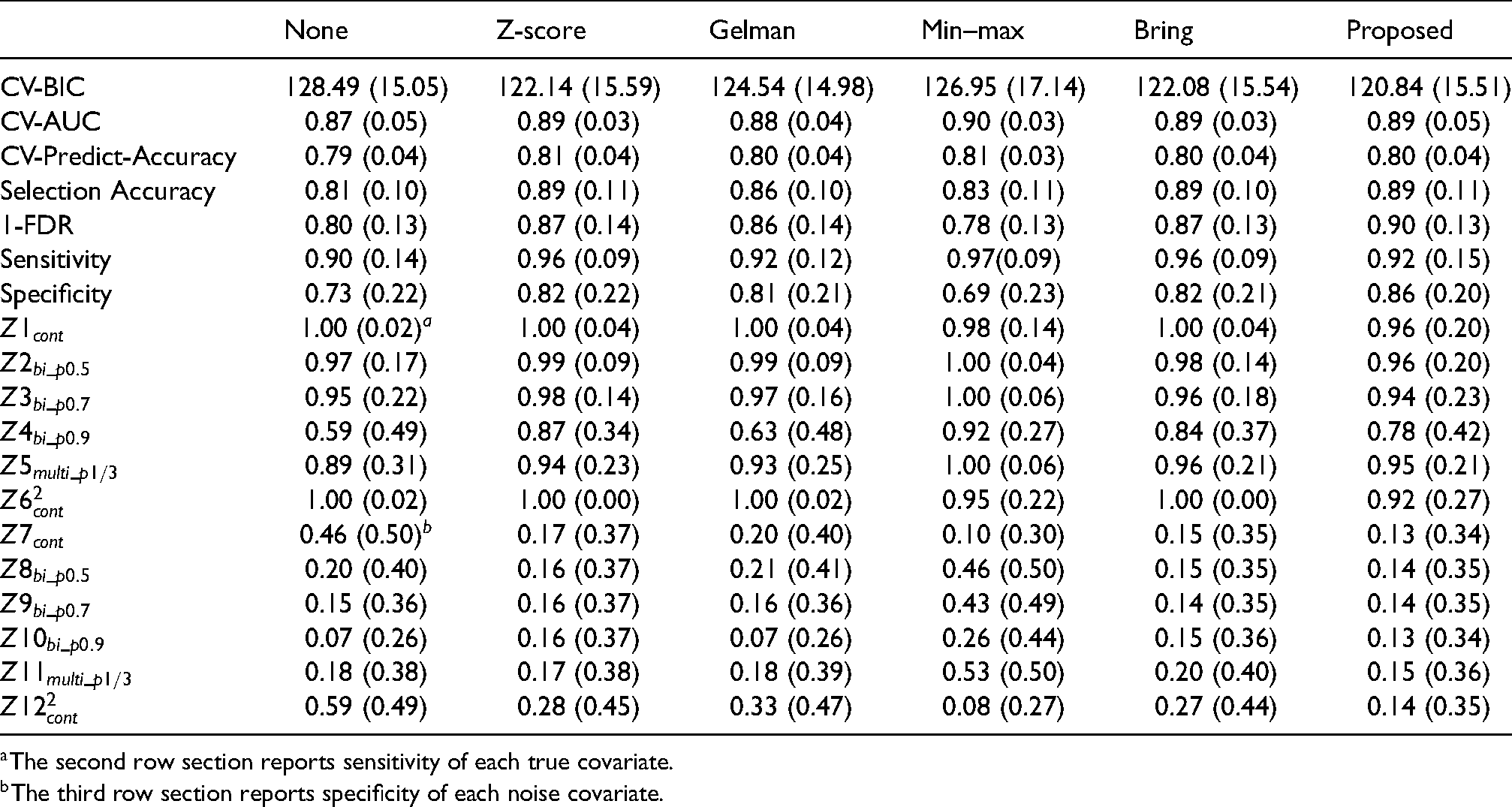
Performance of variable selection using different standardization methods when effects/associations are of the same size (coefficient size of the latent continuous covariates is two for Z1 to Z6 and coefficient size of the latent continuous covariates is zero for Z7 to Z12)
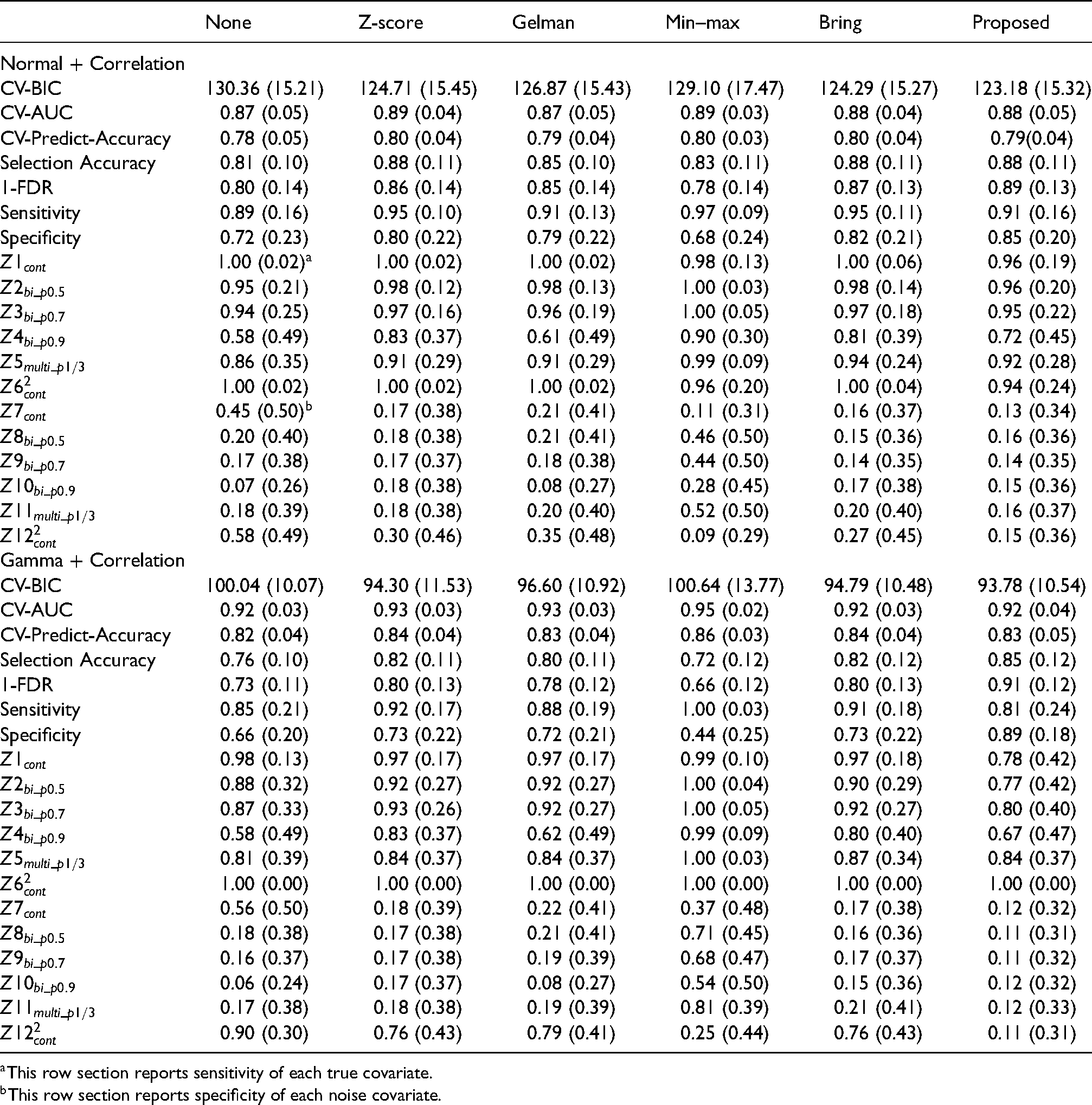
Performance of variable selection using different standardization methods in the presence of correlated covariates (the correlations between the latent covariates are 0.1)
In Tables 2 and 3, the columns display the results of different standardization methods. When conducting the group-lasso regression, the default sequence of candidate penalty
There are some patterns observed from Table 2. Without any standardization, the continuous variables are favored with higher selection rates, regardless the relationship being linear or quadratic, compared to binary and multi-category variables. Among the categorical covariates, binary variables of probability 0.5 or 0.7 have higher selection rates than multi-category covariates. The selection rate decreases when the probability of binary variable gets more extreme. Similar behaviors are also observed when using Z-score, Gelman and Bring standardization approaches. Notice that the aforementioned four standardization methods do not eliminate the essential difference between a variable being continuous and a variable being binary, so those detected patterns are likely due to Lasso’s beta-min condition, 7 which establishes a lower bound for the amount of signal, such as signal-to-noise ratio (SNR), required for feature recovery. As a result, Gaussian variables have a higher probability of being selected than binary variables because they demand lower thresholds. Meanwhile, binary variables with more extreme probabilities require higher signal thresholds, therefore are less likely to be selected. Although Min-Max standardization produces large coefficient estimates for continuous covariates (from simulation I), the continuous variable is disfavored with smaller selection rate compared with the binary and multi-category variables. Above all, the proposed standardization produces similar selection rates across covariates of different types, though the selection rate of binary covariate still goes down with extreme probability 0.9. Since the proposed standardization actually convert observed covariates of different types into binary variables of similar probabilities, according to Lasso’s beta-min condition, they have similar signal thresholds. The simulation result of the proposed method corroborates the statement in Lemma 2.
Table 3 displays the simulation results of different latent distributions with correlation structures. According to the irrepresentable theorem, 17 the selection consistency would be compromised if the true covariates are highly correlated with the noise variables, and we do observe that performance measurements, especially the overall sensitivity, in Table 3 are worse than those reported in Table 2. In spite of the correlation structure, patterns observed in Table 2 still apply to data in Table 3.
Opioid abuse has been the number one reason of death due to drug overdose in the US. According to the Center for Disease Control (CDC), 18 nearly 70% of the drug overdose deaths in 2018 involved an opioid, and 32% of those opioid overdose deaths was attributable to prescription opioid. In the 12-month period that ended in April 2021, 19 the overdose death toll reached a record high number in the US, more than 100,000 Americans died of overdoses, more than the toll of car crashes and gun fatalities combined. Thus, it is of great importance to study the pattern and identify the factors associated with opioid prescription, which would further serve as evidences to inform and reinforce interventions seeking to reduce unnecessary opioid prescriptions. The National Ambulatory Medical Care Survey (NAMCS) is jointly conducted by the CDC and the National Center of Health Statistics yearly since 1973, it examines office visits from a sample of office-based physicians across the US. The data includes visits information, prescription medications, patient and physician characteristics. We apply penalized logistic regression model on the NAMCS data to explore factors related to opioid prescription in US, as well as illustrate and compare the performance of all six standardization methods (None, Z-score, Gelman, Min–max, Bring, and Proposed).
In total 10,031 observations (rows) and 177 input variables (columns) are used in the final analysis. Among the 177 input features, three of them are continuous, 139 are binary and 35 are the multi-category type. More than three-fourths of the binary variables have empirical probabilities greater than 0.9 or less than 0.1, and most of the multi-category variables have categories with frequencies less than 0.1. The outcome variable is a binary variable with a value one indicating opioid prescription, and zero otherwise. In addition, each observation has a sampling weight calculated as the product of the patient level weight and the physician level weight that produces nationally representative estimates. We notice that in the real data, (1) there are three data types and the majority are binary and categorical variables; (2) extreme frequencies of categories, such as 0.9 or 0.1, prevail in the binary and categorical variables. Those observations will later be used to justify the choice of the
Weighted group-lasso logistic regression is conducted on the standardized NAMCS data using different standardization methods, the performance is summarized in Figure 1 and Table 4. For each standardization approach, (1) we first construct a sequence of penalty
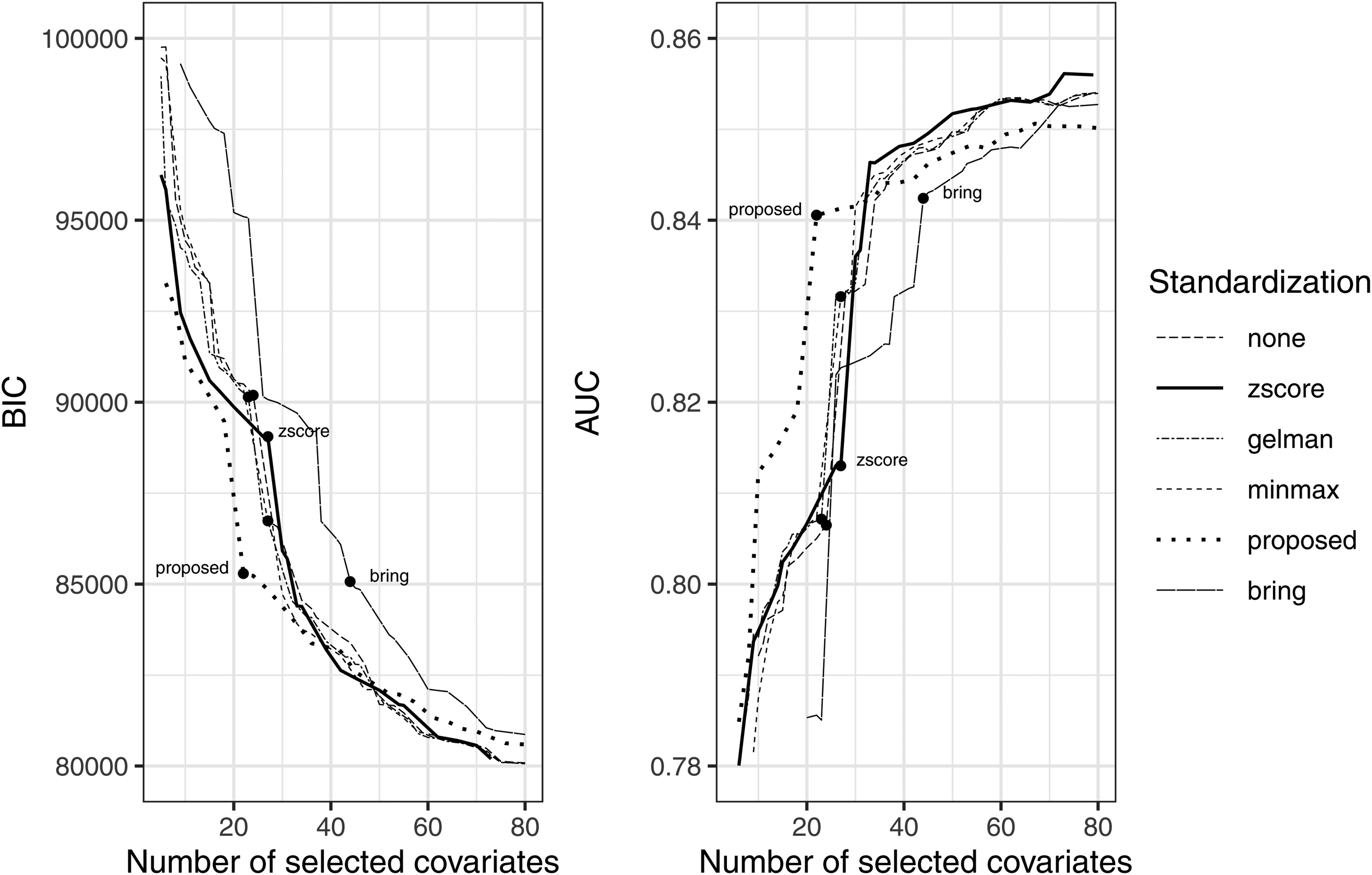
Plots of the BIC and AUC values versus the total number of selected covariates as penalty
NAMCS covariates selected by different standardization methods.

Figure 1 plots the BIC and AUC of the logistic model as more variables are selected by the penalized model using a sequence of decreasing
In Table 4, we list the number of selected continuous, selected binary and selected multi-category variables, as well as the performance of logistic model using selected variables for each standardization method. There are some common patterns observed in both the simulation II and real data results: (1) With no standardization, continuous variables are more likely to be selected than with other standardization approaches. In real data, all three continuous variables are selected when no standardization is applied, while the other five standardization methods only have one or two continuous variable selected; (2) Z-score and Bring standardization approaches display similar behaviors. Binary variables with percentages of one close to 0.9 or 0.1 have higher chance of being selected in those two approaches compared with using the other methods. In real data, considering the fact that the majority binary variables have proportions of one greater than 0.9 or less than 0.1, 21, and 26 binary variables are selected in Z-score and Bring standardized data respectively, larger than the selection number of other methods; (3) Multi-category variables have the highest selection rates in Min–max and Bring methods. In real data, 11 and 16 multi-category variables are selected when Min–max and Bring standardization approaches are used, more than the numbers selected by other methods.
In addition, we have compared the covariates selected by different standardization methods with the 71 characteristics associated with opioid prescriptions proposed in St Clair et al., 20 which identifies the characteristics based on the literature review, clinical relevance, and results from a random forest procedure on the 2015 NAMCS data (the present paper uses 2016 NAMCS data), and there are quite a few factors selected by both studies. Despite that the proposed method selects the least number of covariates, its selection set has more common covariates with St Clair et al. 20 —16 common factors compared with 13 by None, Z-score, Gelman, Min–max methods and 19 by Bring method. It’s not surprising that Bring has more common factors with the reference study, but its selection performance is not necessarily better than the proposed methods, taking into account that Bring acutally selects twice as many factors as the proposed method. There are seven factors selected by all methods and the reference literature: number of medications other than the opioid prescribed to the patient, whether the patient’s injury occurs within 72 h prior to the visit, whether the patient has Arthritis, whether the doctor is the primary care provider to the patient, tobacco use of the patient, number of visits in the last 12 months of the patient, and depression of the patient.
In the present study, we propose an alternative standardization method that aims to fairly select covariates of different types (i.e. continuous, binary, or categorical) in sparse penalized models. In the presence of covariates of different types in the same data set, we dichotomize continuous and multi-category variables to binary forms using a predefined percentile, then scale all binary covariates by their standard deviations. Our simulations show that the covariates with the same impact or association have comparable selection rates regardless of their data types by implementing the proposed standardization. In real data example, model using the proposed standardization has better BIC and AUC with the least number of predictors selected, compared to other standardization approaches.
Though dichotomization is common in clinical, epidemiology and social science research, the practice has always been controversial. Quite a few papers8–10 criticized the practice of categorizing continuous covariates. However, most of the concerns focus on coefficient estimation and prediction accuracy. For instance, dichotomizing the continuous predictor when the underlying relationship with the outcome is continuous will lead to loss of power and loss of precision. And coefficient estimation can vary by the choice of cutoff points and sample data, sometimes the cutpoints are manipulated to generate over-optimistic P-values. We agree with those concerns, but would like to emphasize the important differences of the dichotomization implementation in the proposed method. First, the objectives are different. We focus on the variable selection instead of coefficient estimation. The cutoff point is not chosen to best discern outcome, alternatively, the choice is made to have the empirical probabilities consistent across the newly constructed (by dichotomization) binary variables and the observed binary variables. If coefficient estimation and prediction accuracy are of concern, one can always refit a model using the selected predictors in their original forms. Second, the assumptions are different. We assume that every observed covariate is generated from a latent continuous variable. That is, the observed continuous covariate is the same as the latent continuous variable, while the observed binary and multi-category covariates are categorized from latent continuous variables with unknown thresholds. Under such assumption, the standardization step of dichotomizing the observed continuous covariate aligns with the generation mechanism of the observed binary and multi-category covariates, which leads to the standardized coefficients reflective of the relationships between latent covariates and the outcome.
Various lasso extensions have been proposed to improve variable selection consistency. For example, the adaptive lasso
21
and the lasso with nonconvex penalty,
22
which maneuvers the penalties to achieve consistent variable selection. The block randomized adaptive iterative lasso (B-RAIL)
7
reduces the influence of variation across mixed data types on the variable selection by alternating the algorithm. Compared with them, the present study tackles the variable selection from the perspective of data standardization, instead of model modification. Meanwhile, we admit that there are some limitations of the proposed standardization. For example, when regrouping the multi-category variable to binary form, we cannot guarantee the newly generated binary variable has percentage of one exactly equal to the specified value
Supplemental Material
sj-pdf-1-smm-10.1177_09622802221129042 - Supplemental material for Standardization of continuous and categorical covariates in sparse penalized regressions
Supplemental material, sj-pdf-1-smm-10.1177_09622802221129042 for Standardization of continuous and categorical covariates in sparse penalized regressions by Xiang Li, Yong Ma and Qing Pan in Statistical Methods in Medical Research
Footnotes
Acknowledgements
We gratefully acknowledge the computing resources provided on the High Performance Computing Cluster 23 operated by Research Technology Services at the George Washington University.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work received funding support from the US Food and Drug Administration, Center for Drug Evaluation and Research, the Regulatory Science and Review Enhancement program. This manuscript reflects the views of the authors and should not be construed to represent the views or policies of the Food and Drug Administration.
Supplemental material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.