
Abstract
In medical statistics, when the effect of a binary risk factor on a binary response is of interest, relative risk is often the preferred measure due to its direct interpretation. However, statistical inference on this quantity is not as straightforward as for other measures of association, especially when further explanatory variables have to be taken into account. Starting from a review of available methods for inference on relative risk, this paper deals with small and moderate sample size settings for which we show that classical approaches can be problematic. For this reason, we propose the use of improved estimation procedures, aiming at mean or median bias reduction of the maximum likelihood estimator. In particular, these methods are developed for a new alternative specification of a model recently proposed by Richardson et al, where higher computational stability of the estimation methods is achieved. A real-data example and extensive simulation studies show that the proposed methods perform remarkably better than the standard ones.
Introduction
Many statistical studies investigate the influence of a group of explanatory variables on a binary response of interest. This necessity has led to the development of an enormous literature on the topic, with methodologies that differ mainly according to whether the final goal of the study is inference or prediction.1,2 While, for prediction, the interpretability of the model usually fades into the background, when the main aim is inference the possibility of clear communication of the results is crucial and, in this context, logistic regression is by far the most popular statistical model.
Among the several reasons for the success of logistic regression there is the fact that, unlike some other models that are discussed in this paper, the maximum likelihood estimator can be obtained with standard optimization techniques without imposing any constraint on the parameter space. In addition, several results are available to allow the data analyst to perform valid statistical inference in non-standard regimes such as in situations of small or moderate sample size,3,4 but also in the opposite case, where the number of predictors and observations is huge. 5 Despite the above-mentioned advantages, a possible drawback of logistic regression is that the effects of the explanatory variables are parametrized in terms of log-odds ratios and the results can be sometimes difficult to communicate to a non-technical audience. 6 Even though modelling odds ratios are, in some cases, an obligated choice, as in case-control studies, see, for example, Rothman et al., 7 there are many situations where other measures of association, such as the relative risk or the risk difference, can be directly estimated and give more interpretable results. 8 In this paper, we focus on the relative risk and on some of the difficulties that this parametrization poses to statistical inference.
To estimate the relative risk several approaches are available in the literature.6,9 The majority of them have been designed to overcome the well-known numerical instability of log-binomial regression. 10 Indeed, even though this model represents a natural way to parametrize relative risk using a generalized linear model, its parameter space is constrained and this can lead to serious computational problems. 11 For what concerns point estimation, some of these difficulties have been addressed by Donoghoe and Marschner, 10 who implemented a number of strategies to maximize the log-likelihood function of the model. At the same time, statistical inference based on the maximum likelihood estimator can still be challenging when the estimate lies on the boundary of the parameter space, due to the non-invertibility of the estimated Fisher information. This limitation motivated a growing interest in the study and development of different estimation strategies. In particular, Zou 12 and Lumley et al. 6 showed that consistent and asymptotically normal estimators of the relative risk can be obtained by replacing the binomial likelihood with the Poisson or the Gaussian ones. These strategies are particular instances of estimation based on unbiased estimating equations. Since in these cases, the second Bartlett’s identity usually does not hold, the asymptotic variance of the estimators has to be obtained by using a sandwich estimator. 13 A possible drawback of the unbiased estimating equations approach is that fitted probabilities greater than one can easily occur. As argued by many authors, usually this is not problematic in practical situations, since the focus is mainly on parameter estimation. 6 However, as we illustrate in Section 2, in small sample regimes, the presence of estimated probabilities outside the admissible range can have a strong impact on inference since it can lead to negative estimated variances for some parameters.
Finally, when the main interest is on the effect of a binary exposure and its interactions with the other explanatory variables, an alternative and particularly attractive approach was proposed by Richardson et al. 9 The novelty of their proposal stands on a different parameter specification, where the interest component is the log-relative risk and the nuisance part is the log-odds product. In this way, the two components of the parameter of the model are variation independent, that is, the parameter space for each component does not depend on the value of the other. As a consequence, the computation of the maximum likelihood estimates and their standard errors is simplified. Moreover, since the model of Richardson et al. 9 gives a genuine likelihood, the predicted probabilities are always positive and smaller than one.
Even though solving many difficulties regarding inference on relative risk, classical likelihood inference under the model developed by Richardson et al. 9 still presents two main issues. First, it may be subject to a significant bias, especially with small sample sizes or a large number of explanatory variables. Second, as it happens for logistic regression, 14 infinite maximum likelihood estimates can occur. To reduce both problems, in this paper, we propose the use of mean or median bias reduction techniques developed by Firth 15 and Kenne Pagui et al., 16 respectively. These methods allow to improve the finite sample properties of the maximum likelihood estimator by reducing its mean or median bias. In addition, as a useful side effect, they solve infinite estimate problems in many practical situations. 17 Recent applications of bias reduction methods to other models of interest in medical statistics can be found in Kyriakou et al., 18 Kenne Pagui and Colosimo, 19 and in Kenne Pagui et al., 20 while some preliminary simulation results are available 21 for the model of Richardson et al. 9
However, as numerically illustrated in Section 7, direct application of mean and median bias reduction to the model of Richardson et al. 9 may still be affected by convergence issues. For this reason, we propose to apply mean and median bias reduction to a new alternative specification of the nuisance parameter. This parametrization maintains the property of variation independence but leads to easier implementation and higher computational stability of improved estimation methods. An R 22 implementation of the proposed models is given in the brrr function available on GitHub (https://github.com/Francesco16p/brrr).
The rest of the article is organized as follows. Section 2 introduces some of the problems regarding relative risk inference with a real-data example. Section 3 briefly reviews some approaches to inference on relative risk with a particular emphasis on the proposal of Richardson et al. 9 Section 4 introduces the new alternative parametrization for the model of Richardson et al. 9 and Section 5 describes the mean and median bias reduction methods developed by Firth 15 and Kenne Pagui et al. 16 Section 6 revisits the motivating example by applying the improved estimation methods to the model developed in Section 4. In Section 7, the performance of the bias-reduced estimators is evaluated through two simulation studies, with the second considering models with many nuisance parameters. Section 8 concludes the paper with a short discussion.
Motivating example
As a motivating example, we consider data from a clinical study conducted by Goorin et al. 23 and available in Table 1 of Kolassa and Tanner. 3 The aim of the investigators was to identify significant prognostic variables to predict the probability of recovery, after three years, for 46 patients which were treated for nonmetastatic osteogenic sarcoma. Along with the health status, three other explanatory variables are available: sex, presence of lymphocytic infiltration (LI) and presence of any osteoid pathology (AOP).
Even in the more standard case in which one wants to make inference by assuming a logistic regression model, the moderate sample size and the presence of separation in the data represent two serious challenges. These problems led Hirji et al.
24
and Kolassa and Tanner
3
to develop methods for small sample confidence regions. Here, we focus on the different problems of making inferences on the effect of LI controlled for the other explanatory variables and parametrized in terms of log-relative risk. Table 1 reports maximum likelihood estimates of the parameters obtained by assuming a log-binomial regression, a Poisson regression with robust estimation of standard errors and the model of Richardson et al.
9
Poisson regression and the model of Richardson et al.
9
give similar point estimates for the log-relative risk associated with LI, while the estimate for the log-binomial regression is smaller in absolute value. For what concerns uncertainty evaluation, the R package logbin
10
does not provide any estimate for the standard errors since the maximum likelihood estimate lies on the boundary of the parameter space. The other two methods give similar values for the standard error of the estimated log-relative risk associated with LI. However, both of them present some weaknesses. The sandwich estimate
25
for the Poisson regression makes use of the probabilities predicted by the model, which turn out to be
Estimates of the log-relative risk associated with LI and of the other model parameters for the motivating example in Section 2.
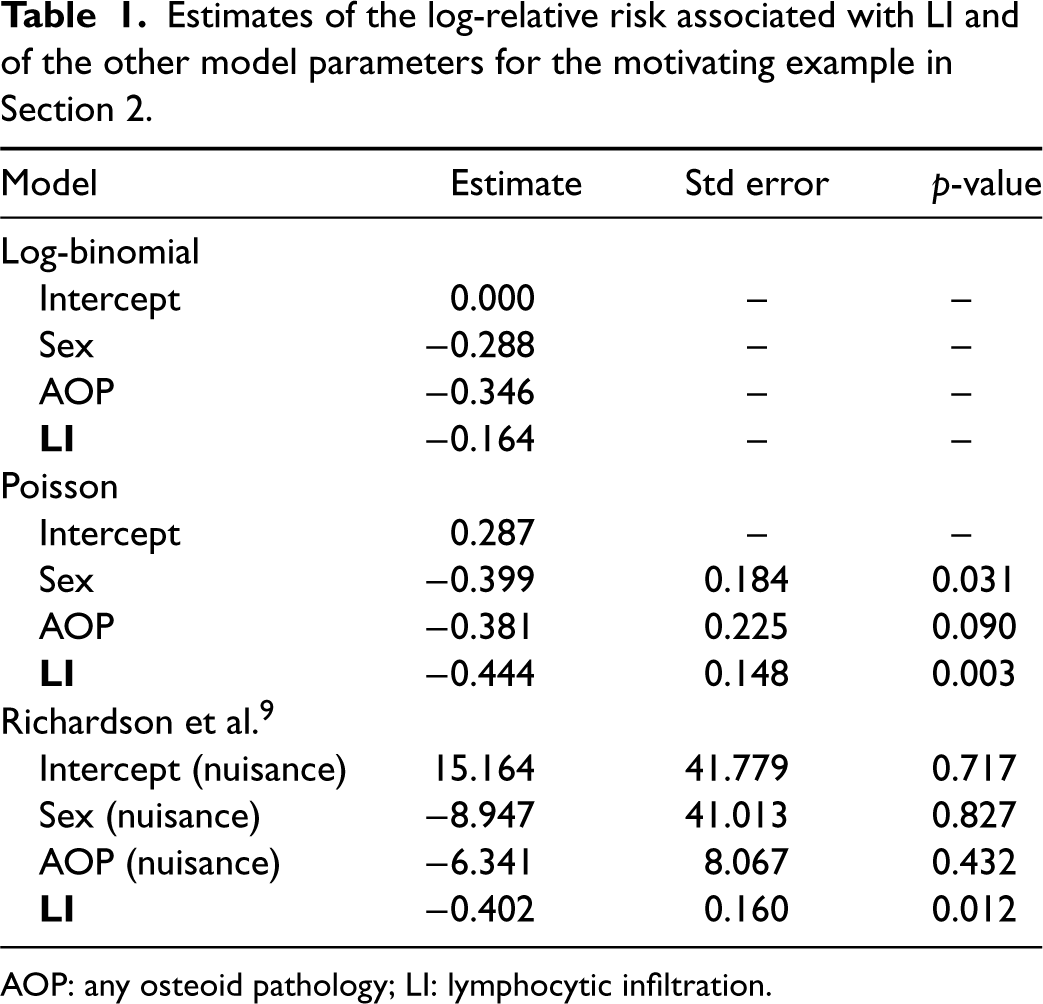
Estimates of the log-relative risk associated with LI and of the other model parameters for the motivating example in Section 2.
AOP: any osteoid pathology; LI: lymphocytic infiltration.
Let 
Inference on 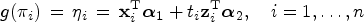
With the former, 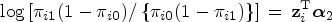
On the other hand, log-binomial regression assumes
Outside the generalized linear models’ framework, Richardson et al.
9
developed a new method to make inference directly on 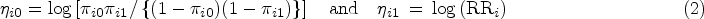
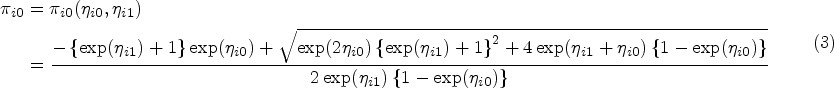
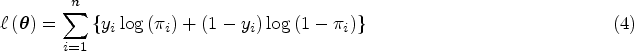
In Section 3, we highlighted the fact that (3) is not defined when 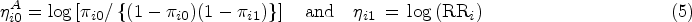
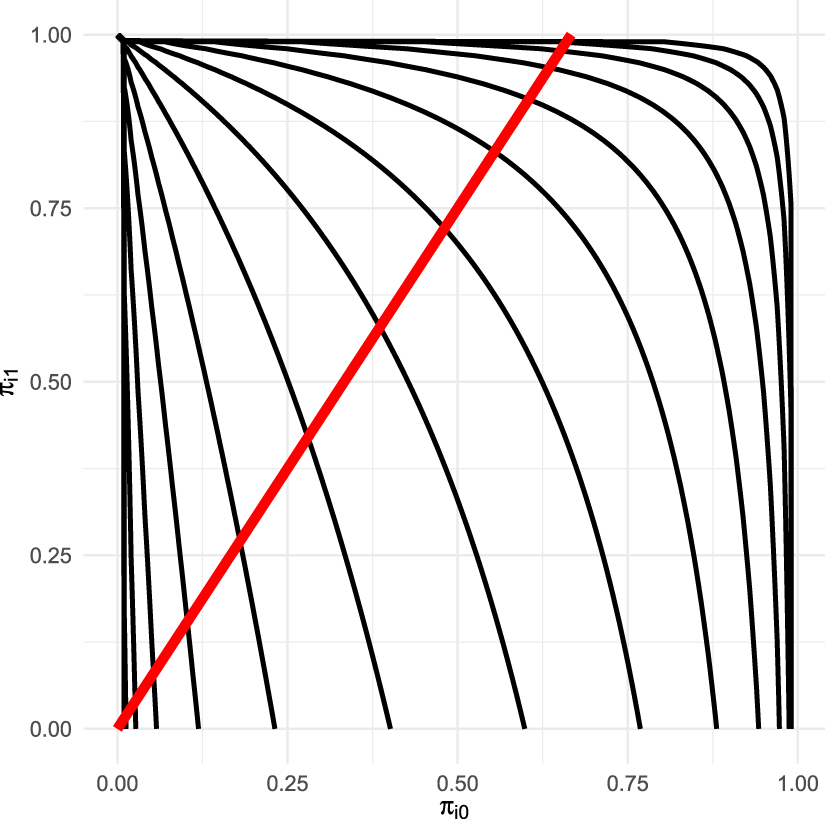
Contour plot of
In this alternative parametrization, the probabilities assumed by the model are equal to 
The log-likelihood function for 
Even adopting the alternative parametrization (5), maximum likelihood estimation may be improved by using bias reduction methods, which are illustrated in the following section for a general statistical model.
Let 

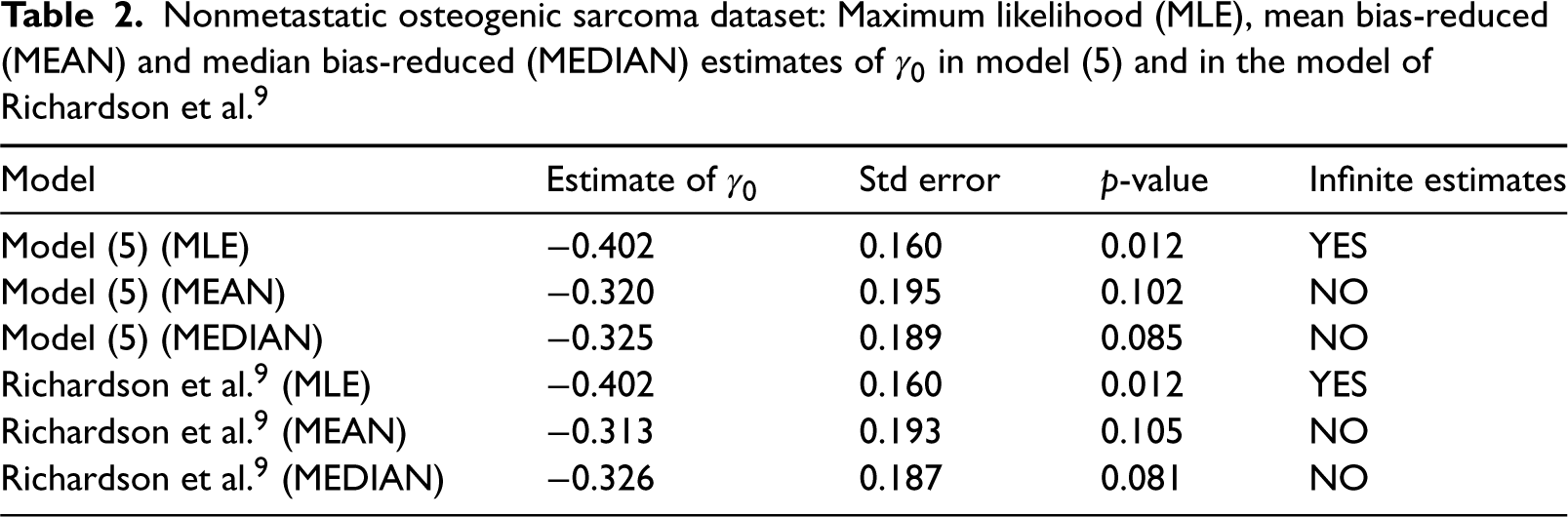
Consider again the nonmetastatic osteogenic sarcoma dataset of Section 2. Here, we apply the mean and median bias-reduced estimators to model (5) and to the one of Richardson et al.
9
The specification of the two models is 
In this section, we present results from two simulation studies providing empirical evidence that mean and median bias reduction largely improve on maximum likelihood both in terms of finite sample properties and in terms of computational stability. The simulation experiment of Section 7.1 corresponds to a standard setting with a fixed number of covariates and increasing sample size. Section 7.2 illustrates the results of simulation experiments with many nuisance parameters. In each simulation, we assume that the model is correctly specified. This results in simulating from model (5) and from the one of Richardson et al. 9 separately. For this reason, the results for the two models are in general not directly comparable. In the following, we minimize this discrepancy by imposing the nuisance parameters in (5) to be related to those in (2) so that the probabilities in the two simulations are approximately the same. This approximation is reported in Appendix A.2.
Setting 1: Fixed number of explanatory variables
In this first scenario, we assume
For each model, the three estimators are evaluated in terms of estimated bias (BIAS), empirical probability of underestimation (PU), root mean squared error (RMSE) and empirical coverage of the 95% Wald-type confidence intervals (WALD). The values of PU and WALD are reported in percentages. For model (5), Figure 2 shows that the median bias-reduced estimator
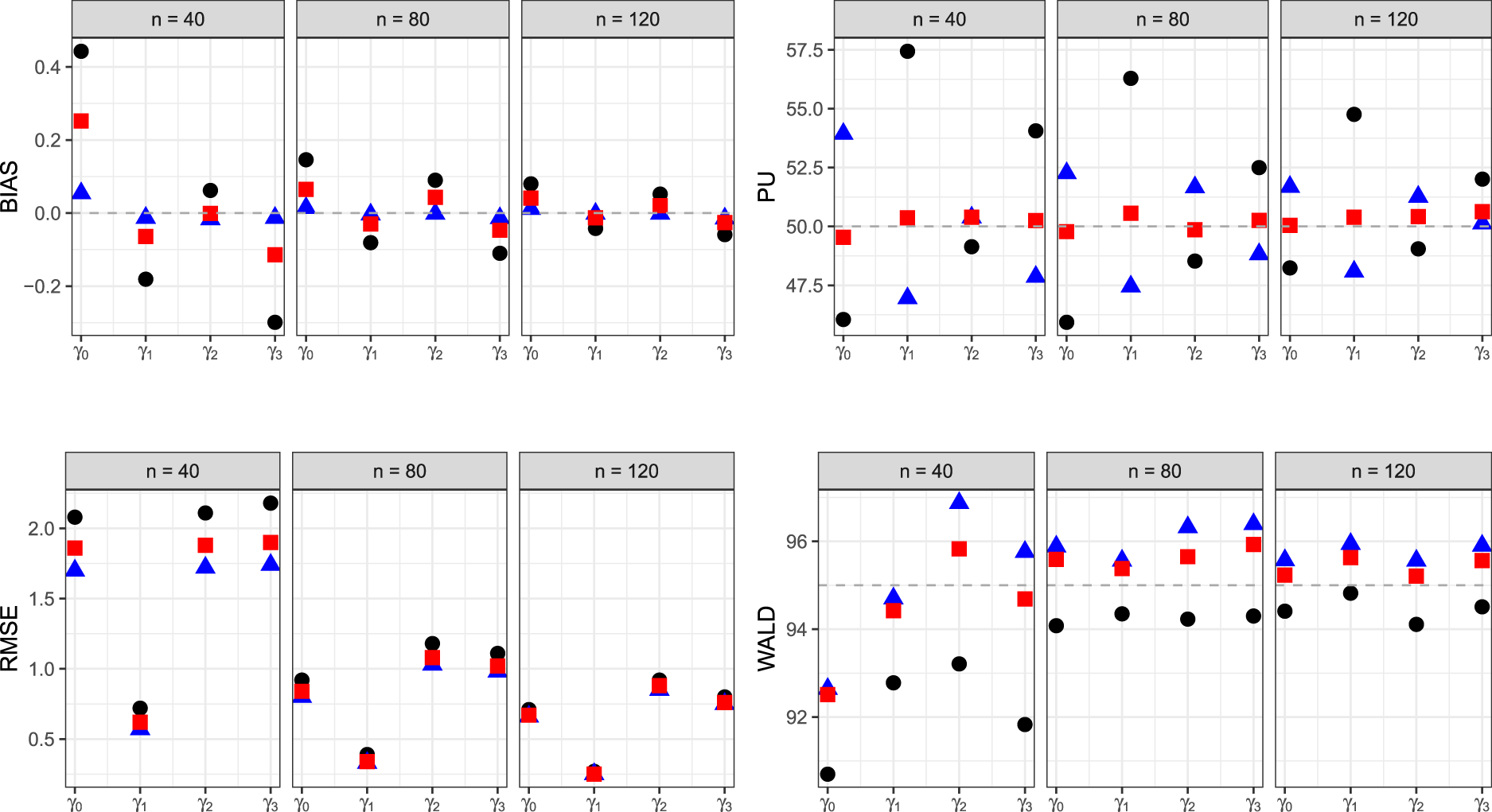
Finite sample properties of maximum likelihood (circle), mean bias-reduced estimator (triangle) and median bias-reduced estimator (square) of
We now focus on the computational stability of the proposed methods. Table 3 reports the number of failed convergences of the maximum likelihood estimators and the bias-reduced ones in the two models. When
Number of failed convergences for each estimator in the simulation study of Section 7.1.
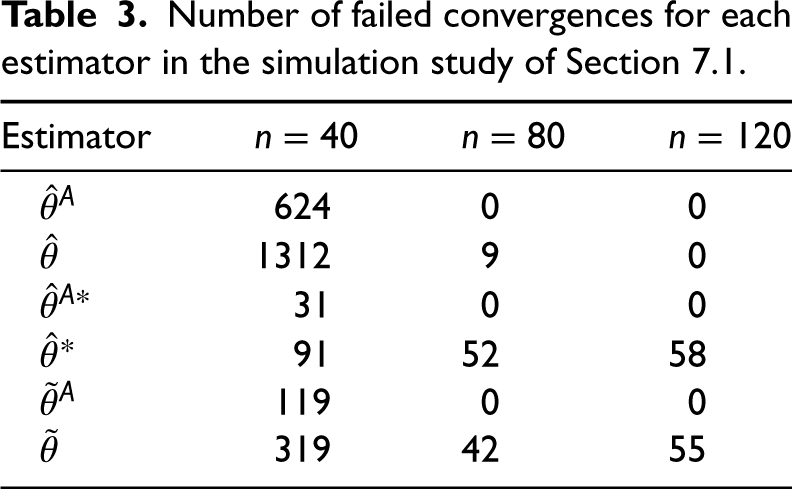
In Section 7.1, the proposed methodologies were evaluated in settings where the number of observations is significantly bigger than the dimension of the parameter space. Indeed, the mean and the median bias reduction methods of Firth
15
and Kenne Pagui et al.
16
are theoretically justified in the standard asymptotic regime where the number of parameters is fixed and the sample size tends to infinity. At the same time, in current applications, it is not uncommon to deal with models where the parameter dimension is of the same order as the sample size. Motivated by this fact, we investigate the behaviour of the proposed methods through a simulation study where the sample size is fixed and the number of parameters in the nuisance part is allowed to increase, see e.g. He et al.
29
In more detail, we consider four different sample sizes, 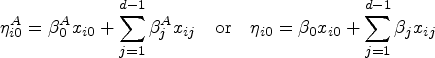
Table 4 reports the number of failed convergences of each method and for every possible combination of
Number of failed convergences for each estimator in the simulation study of Section 7.2.
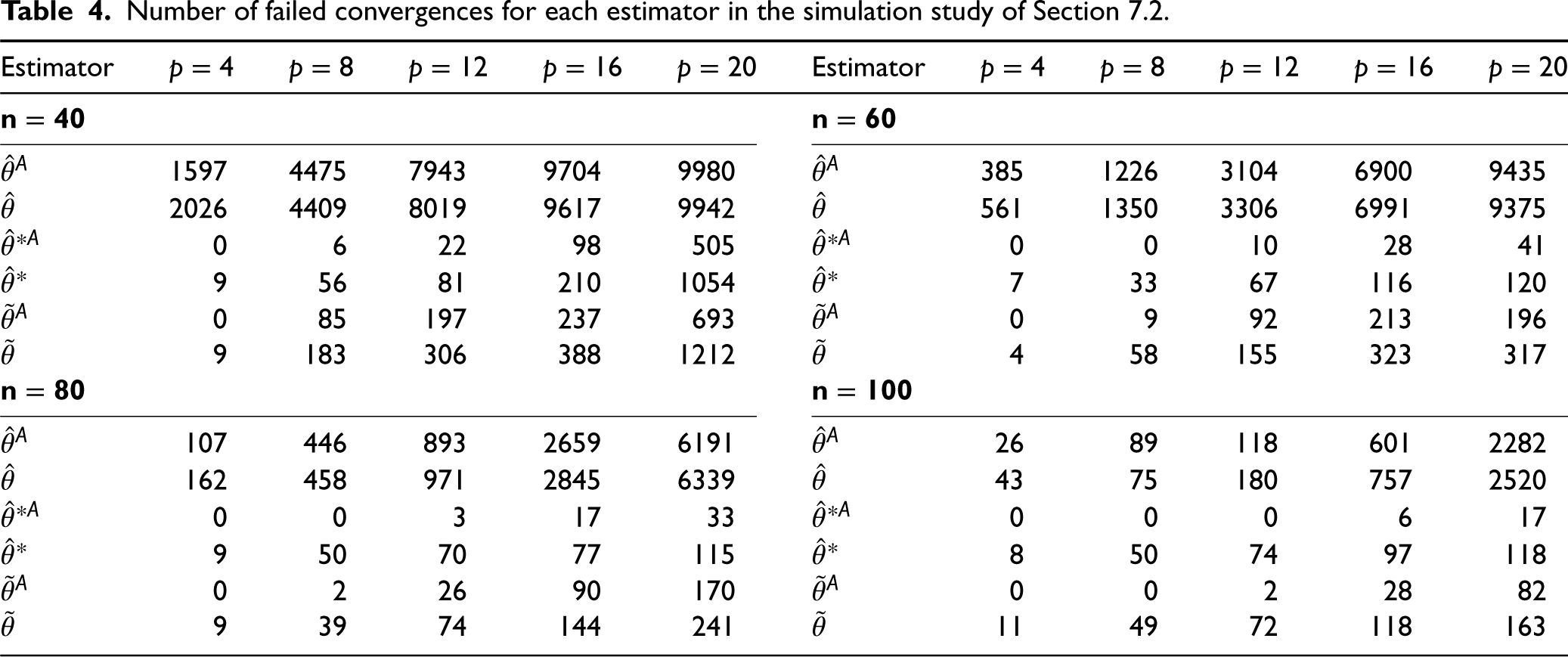
Number of failed convergences for each estimator in the simulation study of Section 7.2.
Finally, Figure 3 reports the finite sample properties of mean and median bias-reduced estimators under model (5). Maximum likelihood is omitted due to the high number of failed convergences. The figure highlights that the bias-reduced estimator of Firth
15
has, in general, the lowest bias while the median bias-reduced estimator of Kenne Pagui et al.
16
presents values of PU closest to Finite sample properties of mean bias-reduced estimator (triangle) and median bias-reduced estimator (square) of 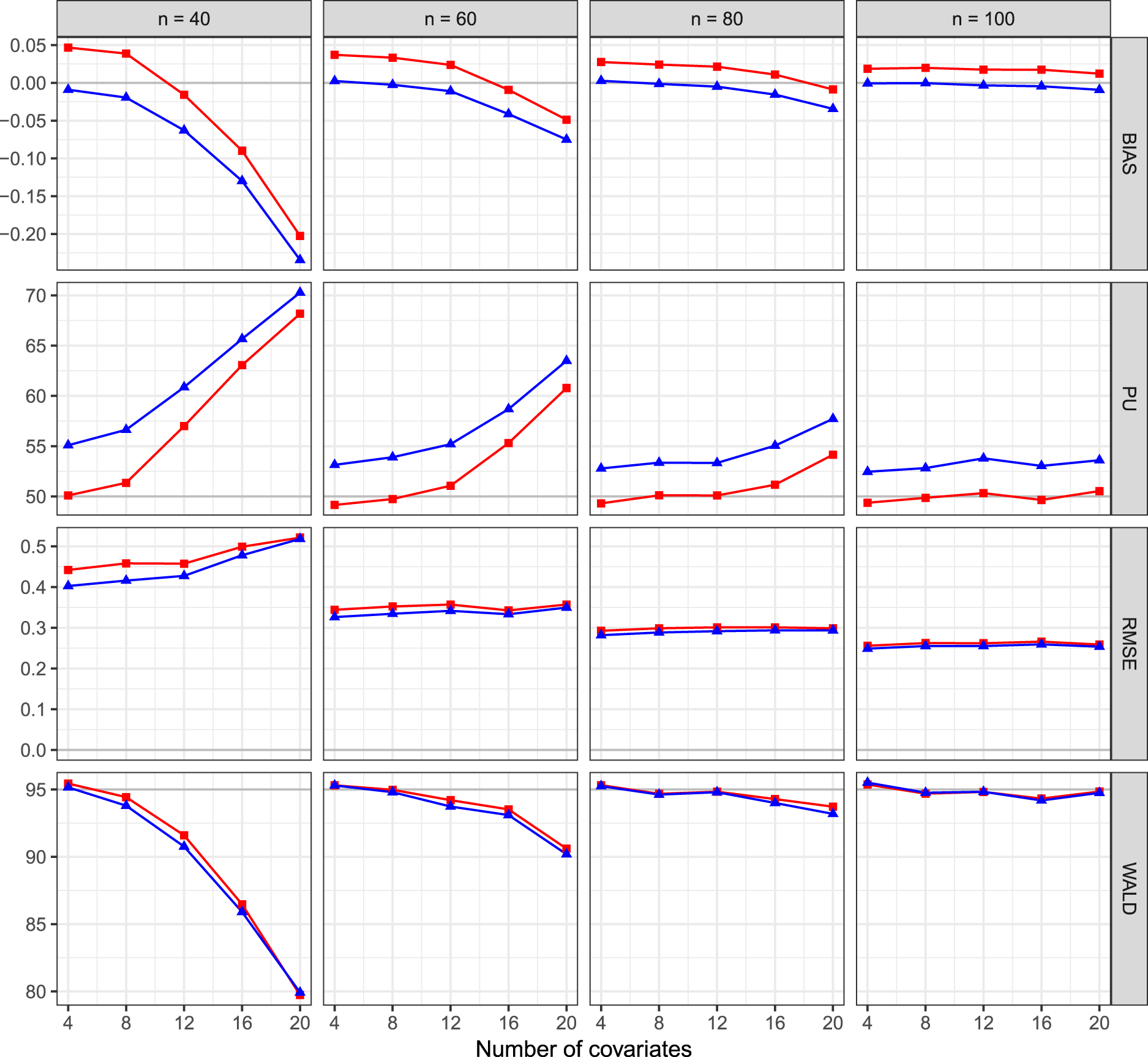
The aim of this work was to develop methods for accurate estimation of the log-relative risk in challenging contexts, such as in situations of small sample size or when infinite maximum likelihood estimates may occur. This goal is reached by implementing the mean and median bias reduction techniques developed by Firth 15 and Kenne Pagui et al. 16 to model (5), proposed in Section 4 as an improvement of the model of Richardson et al. 9 in order to gain computational stability of the estimation method.
The simulation study in Section 7.1 confirms that, when both maximum likelihood and bias-reduced estimators exist with high probability, mean and median bias reduction are highly preferable to maximum likelihood in terms of finite sample properties. In particular, the median bias-reduced estimator presents a remarkable centring around the true value of the parameter in both parametrizations and a bias which is much lower than the one of the maximum likelihood estimator. On the contrary, the method of Firth 15 is the most effective in reducing the mean bias of the maximum likelihood estimator. In general, this results also in a good centring of the estimator around the true value of the parameter on interest. Even though not supported by the theory yet, a similar behaviour seems to hold also in the challenging setting with many nuisance parameters described in Section 7.2.
Moreover, both Sections 6 and 7 show that bias reduction methods are also effective in preventing non-finite estimates and, in general, they provide estimators which are more computationally stable. When the sample size increases, this property gets a little lost if we adopt the parametrization proposed by Richardson et al. 9 This is probably due to the fact that the estimation algorithms are quite sensitive to the correction that has to be imposed when the linear predictor associated with the nuisance parameter is close to zero. On the contrary, this problem is not present in the alternative parametrization proposed in this paper, making the latter particularly attractive for practical purposes.
We conclude by highlighting aspects that may be relevant for future work. First, the methods developed in this paper concern estimation of log-relative risk with one binary exposure. Extensions that allow continuous or categorical exposures as in Yin et al.
30
are feasible in principle, but not straightforward, and additional work in this direction is needed. A further point deserving consideration is possible model misspecification and its consequences, in particular for what concerns the nuisance component. Ideally, the behaviour of estimators of
Supplemental Material
sj-zip-1-smm-10.1177_09622802231167436 - Supplemental material for Improved and computationally stable estimation of relative risk regression with one binary exposure
Supplemental material, sj-zip-1-smm-10.1177_09622802231167436 for Improved and computationally stable estimation of relative risk regression with one binary exposure by Francesco Pozza, Euloge Clovis Kenne Pagui and Alessandra Salvan in Statistical Methods in Medical Research
Supplemental Material
sj-pdf-2-smm-10.1177_09622802231167436 - Supplemental material for Improved and computationally stable estimation of relative risk regression with one binary exposure
Supplemental material, sj-pdf-2-smm-10.1177_09622802231167436 for Improved and computationally stable estimation of relative risk regression with one binary exposure by Francesco Pozza, Euloge Clovis Kenne Pagui and Alessandra Salvan in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.