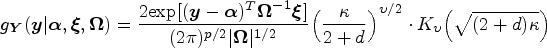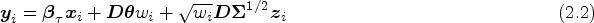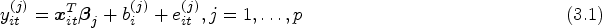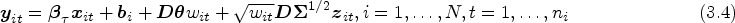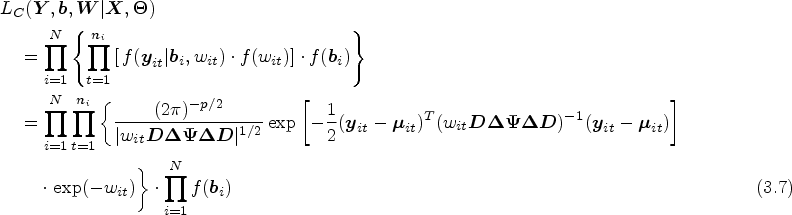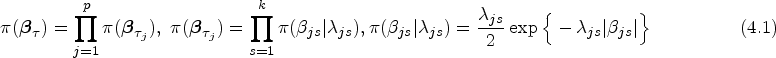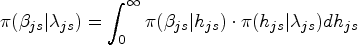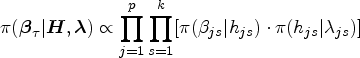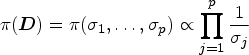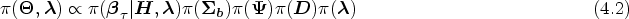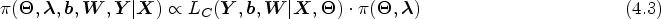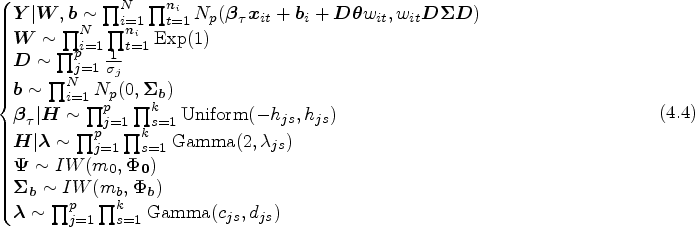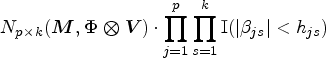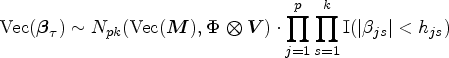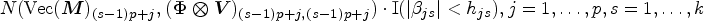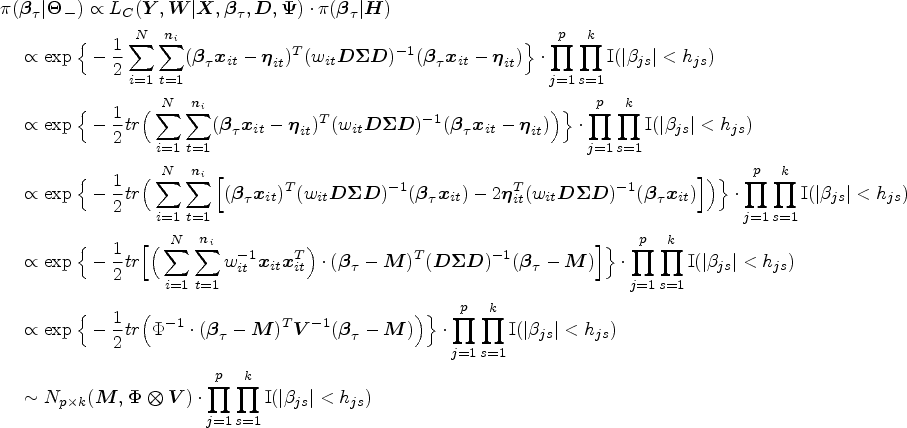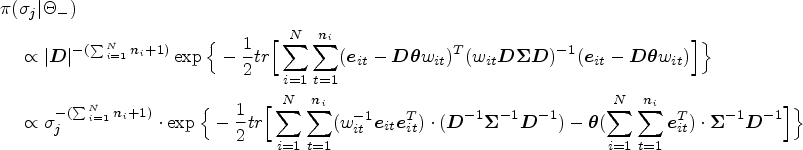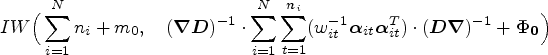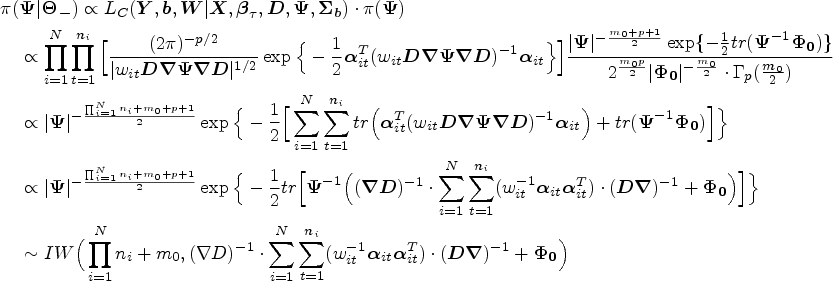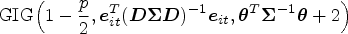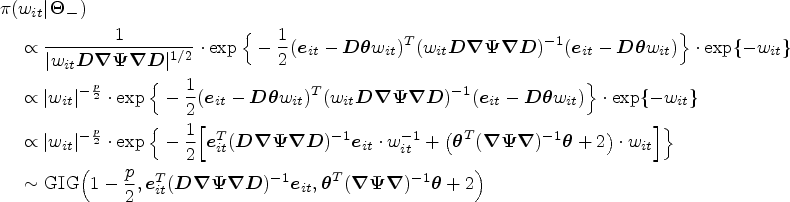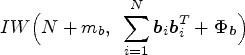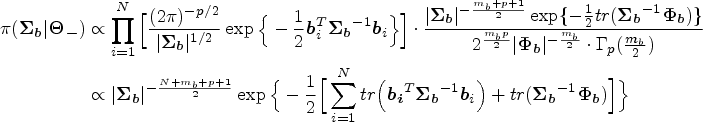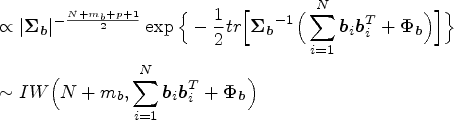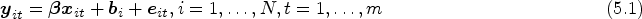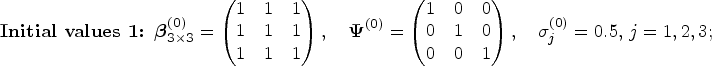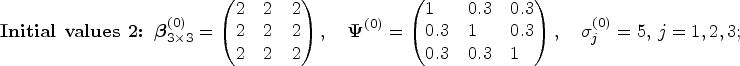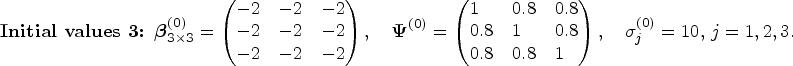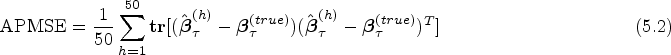Bayesian analysis of joint quantile regression for multi-response longitudinal data with application to primary biliary cirrhosis sequential cohort study
Available accessResearch articleFirst published online July, 2024
Bayesian analysis of joint quantile regression for multi-response longitudinal data with application to primary biliary cirrhosis sequential cohort study
This article proposes a Bayesian approach for jointly estimating marginal conditional quantiles of multi-response longitudinal data with multivariate mixed effects model. The multivariate asymmetric Laplace distribution is employed to construct the working likelihood of the considered model. Penalization priors on regression parameters are incorporated into the working likelihood to conduct Bayesian high-dimensional inference. Markov chain Monte Carlo algorithm is used to obtain the fully conditional posterior distributions of all parameters and latent variables. Monte Carlo simulations are conducted to evaluate the sample performance of the proposed joint quantile regression approach. Finally, we analyze a longitudinal medical dataset of the primary biliary cirrhosis sequential cohort study to illustrate the real application of the proposed modeling method.
Longitudinal data or repeated measurement data frequently occur in studies of various disciplines such as medicine, biology, sociology, and economics. There are many tools available for modeling longitudinal data (e.g. latent growth models, cross-lagged regression models, and hierarchical linear models) that are helpful for revealing how attributes of individuals change over time. In longitudinal data modeling, mixed effects model is one of the most powerful statistical tools for depicting the relationship between the outcome variable and a group of predictors. The most appealing feature of mixed effects models is that observations among different individuals are independent, while observations (recorded over time) within the same subject are correlated. A pioneering study on mixed effects models with longitudinal data can be found by Laird and Ware.1 For general references about longitudinal data and mixed effects models, one can refer to Diggle et al.,2 Hedeker and Gibbons,3 Wu and Zhang,4 Wu,5 and Demidenko.6 Among them, Wu and Zhang4discussed various nonparametric longitudinal data models, while Wu5 presented a thorough discussion about linear effects models with complex data. Further, Demidenko6 reviewed the theory and applications for mixed effects models with R.
Only one response is considered in most of the literatures on longitudinal data analysis. Classical linear mixed effects model is generally used to model single-response longitudinal data sets in which the response variable linearly depends on a set of covariates. In real-world applications, however, we often suffer from multiple-response longitudinal data structure in which responses on two or more characteristics are repeatedly recorded over time for an individual. We need to model the correlations among multiple or multivariate response variables via a set of common covariates with repeated measurements over time. It is noteworthy that multiple responses are not independent but statistically dependent. Therefore, separate analysis for each response would totally ignore the relationships among multiple responses and lead to unstable estimation results. Under such circumstances, a joint or simultaneous modeling approach of multi-response longitudinal data would be highly desirable. For example, in a longitudinal data analysis of the PBCseq (primary biliary cirrhosis sequential) cohort study, orthotopic liver transplantation can be treated as a potentially life-saving alternative for patients with advanced or end-stage primary biliary cirrhosis (PBC). Serum bilirubin and serum albumin are two of the primary indicators for evaluating and monitoring the absence of liver diseases. It is generally believed that there exist some relationships between serum bilirubin and serum albumin levels, and thus a joint analysis of the longitudinally collected serum bilirubin and serum albumin has received increasing attention in diagnosing liver diseases. We will analyze this multi-response longitudinal data set using the proposed joint QR (quantile regression) approach in Section 6.
For multi-response or multivariate longitudinal data, the modeling and inference methods are more complex. There have been extensive literatures about multivariate longitudinal data modeling methods. For example, Shah et al.7 proposed a random-effects model for multiple longitudinal data with possibly missing data. Sammel et al.8 studied multivariate linear mixed models for multiple outcomes. Lin9 considered a mixed-effects regression model for longitudinal multivariate ordinal data. Blozis et al.10 considered a nonlinear latent curve model for multivariate longitudinal data. Alfo and Maruotti11 studied a hierarchical model for time dependent multivariate longitudinal data. Bandyopadhyay et al.12 presented a review of multivariate longitudinal data analysis. Gebregziabher et al.13 studied the joint modeling of multiple longitudinal outcomes using multivariate generalized linear mixed models. Laffont et al.14 studied the multivariate longitudinal ordinal data with mixed-effects models. Grimm15 applied the multivariate longitudinal data method to study the developmental relationship between depression and academic achievement. Wang et al.16 considered an extension of the multivariate-t linear mixed models for multiple longitudinal data with censored responses and heavy tails. Luwanda and Mwambi17 discussed a nonlinear mixed-effects model for multivariate longitudinal data. Rajeswaran et al.18 considered a joint modeling of multivariate longitudinal data and competing risks. Lin et al.19 discussed the multivariate longitudinal data analysis with censored and intermittent missing responses, Hui et al.20 studied a sparse pairwise likelihood estimation for multivariate longitudinal mixed models. Jiang et al.21 considered an optimal design for multivariate logistic mixed models with longitudinal data. Wang22 discussed Bayesian analysis of multivariate linear mixed models with censored and intermittent missing responses. Taavoni et al.23 developed multivariate-t semiparametric mixed-effects models for longitudinal data with multiple characteristics. Tian and Qiu24 studied multivariate single index modeling of longitudinal data with multiple responses.
It is noteworthy that most of the existing methods for multivariate longitudinal data are based on modeling the average effects of response variables conditionally on a set of covariates. These modeling methods only provide the mean regression analysis for multivariate longitudinal outcomes and usually require the normality assumption for the outcomes variables. In many real-world applications, we often encounter multivariate longitudinal outcomes which are non-Gaussian distributed. Traditional linear mixed models for handling multivariate longitudinal outcomes do not provide a powerful inference for such data. QR modeling, as a popular alternative to the traditional mean regression modeling, can be employed to assess the relationship between a set of predictors and a specific quantile of the response (see, Koenker25 and Koenker et al.26). Quantiles generally produce a more complete picture of conditional distribution of the response than the mean, and perform more robust for non-normal data. There are many literatures in which QR approach is developed to model longitudinal data. Koenker27 considered QR for longitudinal data analysis. Geraci and Bottai28 studied QR for longitudinal data using the asymmetric Laplace distribution. Liu and Bottai29 proposed the QR mixed-effects models with longitudinal data. Tian et al.30 considered Bayesian joint QR for mixed-effects models with censoring and errors in covariates. Aghamohammadi and Mohammadi31 considered Bayesian penalized QR for longitudinal data analysis. Alhamzawi and Ali32 studied Bayesian QR for ordinal longitudinal data. Tian et al.33 considered likelihood-based QR mixed-effects models for longitudinal data with multiple features via MCEM (Monte Carlo expectation-maximization) algorithm.
Although there are many literatures about QR methods for modeling longitudinal data, most of them only consider the single-response longitudinal data structure. There are shattered work on QR approach for multi-response longitudinal data, even for multi-response regression setting with cross-sectional data. This is mainly because quantiles for multivariate outcomes are not uniquely defined. There is no unique definition of quantiles in higher dimension due to the lack of a natural ordering in Euclidean space of higher dimension framework. However, a few attempts have been made for multivariate QR analyses. Waldmann and Kneib34 considered the Bayesian bivariate QR. For QR modeling of multi-response longitudinal data analysis, Kulkarni et al.35 studied a joint QR model for multiple longitudinal outcomes, Ghasemzadeh et al.36 considered a Bayesian QR for joint modeling of longitudinal mixed ordinal and continuous data, Biswas and Das37 investigated a Bayesian QR approach for multivariate semi-continuous longitudinal data analysis. However, the aforementioned approaches only consider QR estimation at the same quantile for different responses. Recently, new research has gradually emerged on the subject of joint modeling on multivariate response QR for different quantiles. For example, Petrella and Raponi38 proposed the joint estimation approach of conditional quantiles for multivariate linear regression models, Tian et al.39 provided Bayesian joint inference for multivariate QR models.
In this article, we investigate a joint QR modeling approach for multi-response longitudinal data. In Section 2, we present the multi-response linear regression model and the joint QR working likelihood. Section 3 provides model specification of the proposed multi-response longitudinal mixed-effect model. In Section 4, we develop a MCMC (Markov chain Monte Carlo) algorithm for Bayesian joint QR modeling approach. Section 5 provides Monte Carlo simulations to examine the performance of the proposed estimation procedure. We illustrate our methodologies based on a real data set in Section 6. Conclusions are presented in Section 7.
For the convenience of the following description, we provide an unified statement for all formula notations in the following text. Lowercase letters stand for the scalars, boldface lowercase letters stand for vectors and boldface capital letters stand for matrices.
Preliminaries
Consider the following multi-response regression model
where is a p-variate response vector for the -th individual, is a vector of regressors, is a matrix of unknown parameters with , and denotes a vector of error terms.
For model (2.1), we assume that the -level quantile of the -th component in is a function of the -dimensional covariate which can be specified as for , where the is the -th quantile coefficients vector corresponding to the -th response. Denoting is a matrix of parameters with . Based on the common method for univariate QR model, one can estimate each marginally by minimizing the objective function , where denotes the -level univariate quantile check function. It can be noticed, however, that the estimators from the above objective functions totally ignore the dependence among the components in multivariate response . An alterative is to study the joint estimation of the conditional quantiles by incorporating the correlations into the components of the multivariate response . And for that, a MAL (multivariate asymmetric Laplace) distribution can be imposed on the error term of model (2.1) to specify the joint quantiles of conditionally on convarate . The pdf (probability density function) of the -variate random vector for the three-parameter MAL distribution is given as
where , , and are the shift and shape parameters, respectively, is the positive definite matrix of scale parameters, and denotes the modified Bessel function of the third kind with index parameter . One can refer to Kotz et al.,40 Kollo and Srivastava,41 Visk,42 and Hurlimann43 for more disscussion on the MAL distribution. Letting with , and , one can reparameterize the distribution for or the conditional distribution for in model (2.1), where has generic element , is a positive matrix such that , and being a correlation matrix and with . The unknown parameters include , , and (i.e. ).
Petrella and Raponi38 showed that the -th marginal distribution of under the assumption of MAL distribution is an univariate asymmetric Laplace distribution . Besides, the correlations among the components of multivariate response are included in the matrix (or ). It is noticed that the density of MAL distribution is too complex for conducting statistical inference. To make statistical inference simpler, a hierarchical representation of the response can be given as follows:
where follow the -variate standard normal distribution , are latent variables which follow the standard exponential distribution , and are independent of . Conditioning on , follow the multivariate normal distribution with the mean and variance–covariane matrix . In the following sections, we will investigate Bayesian joint QR approach for the multivariate longitudinal mixed effect model and its application.
Model specification
The multi-response longitudinal mixed-effect model
Suppose a data set comes from a unbalanced longitudinal study with subjects and each subject has repeated measurements over time. Each measurement has characteristic responses for each subject. Let be the observation vector of the responses for the -th individual measured at the -th time (). The multi-response mixed-effects models with a random intercept can be expressed as follows:
where is the -th observation of the -th individual for -th variate response, is a vector of covariates, is a unknown parameter vector of fixed effects for the -th response, is the -th random intercept term specific to subject , is the error term.
where , , and . The random effect is simply supposed to follow -variate normal distribution for each subject, in which is a variance–covariance matrix. Random effects in model (3.2) accounts for the longitudinal association of data from the same individual across time. The diagonal elements of quantify the variability between subjects, and the off-diagonal elements of measure the overall association between responses.
In the framework of QR modeling, we specify the -th marginal quantile of response conditionally on and in model (3.1) as follows:
Model (3.3) considers the marginal quantile of response and totally ignores the dependences among the components of . In order to implement the joint QR analysis, based on the preliminaries in Section 2, a multivariate distribution is specified on the error term of model (3.2). Similarly to model (2.5), go a step further, we obtain the hierarchical representation of model (3.2) conditionally on the random effects as follows:
where , follow the -variate standard normal distribution , follow the standard exponential distribution and are independent of . For model (3.4), conditioning on latent variable and random effect , follows the multivariate normal distribution with the mean and variance–covariane matrix , namely
The complete joint hierarchical likelihood
Denote , , , and . In model (3.4), the random effect and are unobserved latent variables. Hence, the observed log-likelihood function is
where , , , is the pdf of conditionally on and .
It is difficult to maximize the above marginal log-likelihood (3.6). We address this problem using the MCMC algorithm in Bayesian framework. We firstly present the joint hierarchical working likelihood of the complete data for model (3.4) as follows:
where .
Bayesian estimation approach
Prior specifications
To select important covariates for improving prediction accuracy, various regularized penalization methods are used to conduct variable selection. Commonly used penalty functions mainly include LASSO (least absolute shrinkage and selection operator) penalty, ridge penalty, SCAD (smoothly clipped absolute deviation) penalty as well as bridge penalty. More discussion on LASSO penalty and Bayesian LASSO can be found by Tibshirani,44 Zou,45 Park and Casella,46 Leng,47 etc. This article considers Bayesian adaptive LASSO regularization of regression parameters in model (3.2). In order to do this, we impose the Laplace priors for regression parameters as follows:
where are tuning parameters.
However, the prior in (4.1) is analytically intractable to calculate the desirable posterior quantities. Using the mixture representation approach by Mallick and Yi (2018), we decompose the prior of as the following uniform–gamma mixture representation,
where
The joint prior of can be represented as
where .
The prior of is set as inverse Wishart distribution: .
The prior of is set as inverse Wishart distribution: .
The prior of is assumed to be the following informative prior
The prior of is set as , where
Hence, the joint hierarchical prior of all parameters is
The fully conditional posteriors and Gibbs sampling algorithm
Incorporating joint prior (4.2) into the joint working likelihood (3.7) results in the joint posterior density of all parameters as follows:
Gibbs sampler procedures are employed to carry MCMC algorithm. The hierarchical expression of posterior distributions of all unknown parameters and latent variables can be presented as follows:
Let denote the remaining parameters subset apart from the present sample parameter. The full conditional posterior distributions of unknown parameters and latent variables can be presented as follows, respectively.
Sample from the truncated matrix normal distribution
In terms of the properties of matrix normal distribution, we have
Specially, we can marginally sample the component of via the following truncated normal distribution:
The theoretical posterior distribution of is derived as follows:
where denotes a matrix normal distribution with parameters , , , and , , , and .
Sample from the following posterior distribution:
where .
Noting that is not a standard distribution, we can sample using the MH (Metropolis-Hastings) algorithm by the following steps:
Generate a random number from the truncated normal distribution which is specified as the proposal distribution in the MH algorithm, where denotes the hyperparameter of variance and is the sampling interval of the truncated normal distribution. The pdf of the proposal distribution is denoted as .
Generate a random number from the standard uniform distribution .
Compute the acceptance probability
If , then accept the proposal , otherwise reject the proposal and let .
Sample from the following inverse Wishart distribution:
The theoretical posterior distribution of is as follows:
where .
Sample from the generalized inverse Gaussian distribution
The theoretical posterior distribution of is derived as follows:
Sample from the Gamma distribution:
Sample from the left-truncated exponential distribution , using the inversion method, which can be conducted by the following two steps:
Generate
Generate
Sample from the following inverse Wishart distribution
The theoretical derivation of the posterior distribution of is as follows:
Sample from normal distribution , where , and , .
For carrying out a Bayesian analysis, an efficient MCMC algorithm is used to sample , and from the above conditional posterior distributions. In particular, for correlation matrix , we draw its sample from the posterior inverse Wishart distribution, and then standardize it as the correlation coefficient matrix.
Simulation studies
In this section, we investigate the performance of the proposed Bayesian procedures by conducting some Monte Carlo simulations. We repeatedly generate 50 data sets from the following three-variate longitudinal mixed model
where and equal cluster sizes are considered to illustrate the finite-sample performance. In model (5.1), the elements of are independently generated from the standard normal distribution, random effects is drawn from three-variate normal distribution with zero mean and covariance matrix of dimension . is constructed by simulating from a Wishart distribution with four degrees of freedom and a diagonal scale matrix with element 0.1.
In model (5.1), the true parameter matrix is set as the following cases:
Model 1: Dense case:
Model 2: Sparse case:
Model 3: Extremely sparse case:
We set elements of matrices and as , and . Three cases of quantile levels, that is, , , and , are considered for the three models. Two different distributions for the error term in model (5.1) are considered as follows. Case I: A multivariate normal distribution (MN) with zero mean and a variance–covariance matrix equal to ; Case II: A multivariate student t distribution with three degrees of freedom (Mt3), non-centrality parameter and scale parameter equal to . An illustration of convergence diagnosis of the MCMC algorithm is shown in Section 5.1. The substantive calculations of the considered three models are implemented in Section 5.2. Section 5.3 provides some additional simulations.
Simulation studies in Section 5 and real-world data analysis in Section 6 are conducted on a Dell desktop [OptiPlex 7050, Intel(R) Core(TM) i7-7700U CPU] via statistical software R3.5.2. All codes of simulations and computations in this article can be requested on the first author. In addition, about the computation time, we conduct a test by taking the setting of , , and as an example. The computing times of the proposed joint QR approach for accomplishing one replication are 2.85 min for Model 1, 2.84 min for Model 2, and 2.89 min for Model 3, respectively.
Convergence diagnosis
To guide the MCMC convergence, we carry out a few test runs under different initial values using the joint QR approach based on the settings of Model 2, and (Case II) and . The hyperparameters of the priors discussed in Section 4 are set as follows: , . We consider three groups of initial values for parameters , and as follows:
Initial values of other parameters were simply set as , , , , , and .
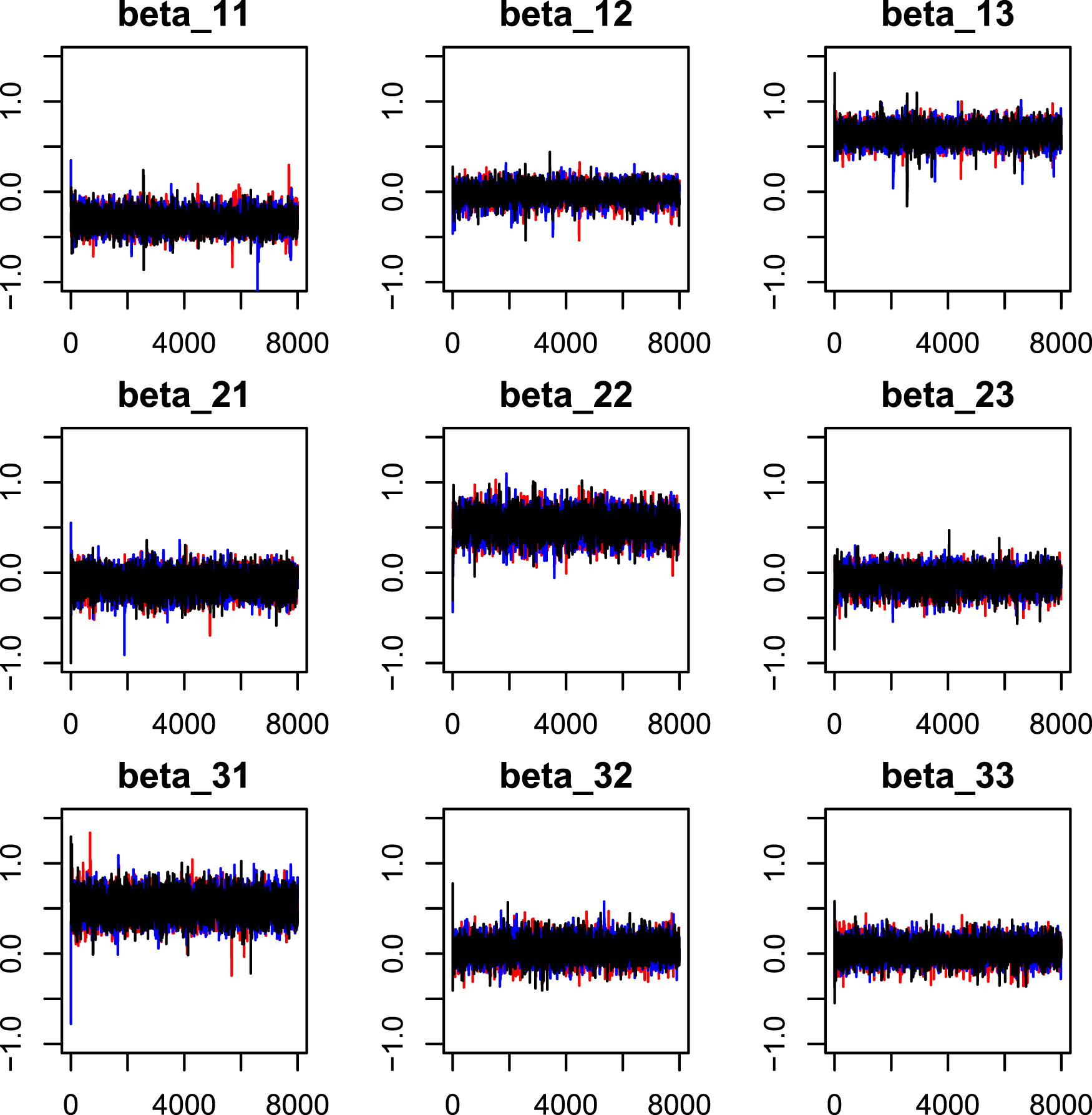
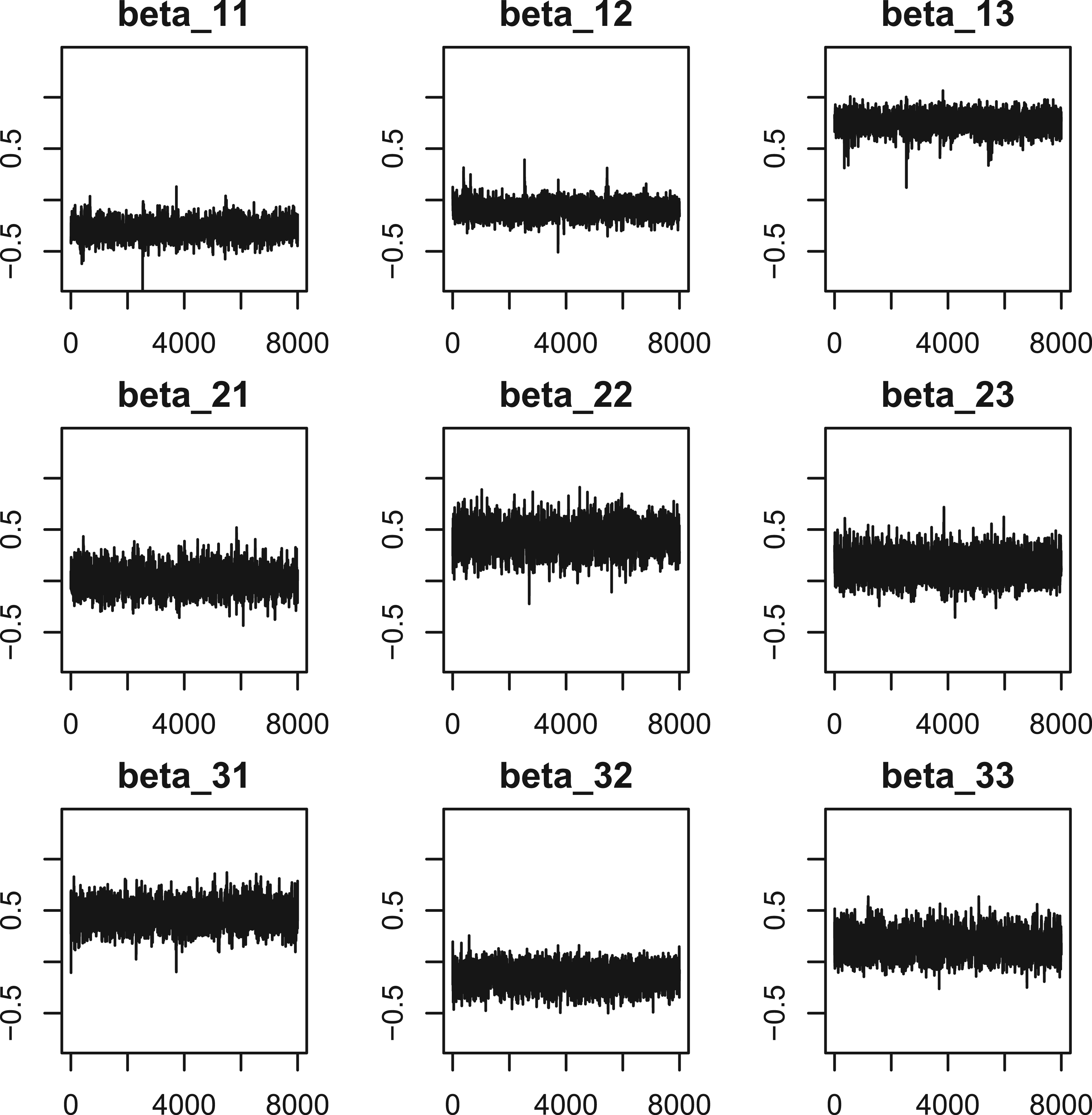
To be conservative, for each simulation, we run the Gibbs sampling algorithm 8000 iterations to assess the convergence of the MCMC algorithm. The MCMC trace plots under three initial values are displayed in Figures 1 and 2. It can be seen in Figure 1, three MCMC chains of regression coefficients starting from the above three initial values are mixed rapidly which shows a sufficient convergence of the algorithm. Figure 2 presents the trace plots of all 8000 posterior iterations of one MCMC chain for all regression coefficients under the setting of Initial values 1, which reconfirm that the MCMC chains rapidly converge to their stationary distributions. We also depict the autocorrelation function (ACF) plots in Figure 3 by discarding the first 2000 burn-in iterations to check the autocorrelation between stationary posterior samples under the setting of Initial values 1.
MCMC chains starting from different initial values of the proposed joint QR. Note: The red line denotes the first setting of initial values; the blue line denotes the second setting; and the black line denotes the third setting. MCMC: Markov chain Monte Carlo; QR: quantile regression.
Markov chain Monte Carlo (MCMC) trace plots.
Autocorrelation function (ACF) plots.
Substantive simulations
Parameters estimation and variable selection using the proposed Bayesian joint QR approach are conducted for dense Model 1 and sparse Models 2 and 3. The initial values of all parameters are set as the case of Initial values 1. The hyperparameters of priors are taken as the same values in Section 5.1. To illustrate the superiority of the joint QR approach, we also provide the estimation results of the single QR approach for each response for the aim of comparison. Fifty repeated simulations are conducted by running the Gibbs sampling algorithm for each model and each quantile combination. For each case, we run iterations of Gibbs sampling algorithm for all parameters and latent variables, the first 2000 burn-in iterations are discarded and the remaining 6000 stationary iterations are retained to conduct posterior inference. Based on repeated simulations, the averaged estimation biases (Bias) and root mean square error (RMSE) of regression parameters for different settings are reported in Tables 1 to 3. A total of credible intervals for the regression coefficients are omitted here. For sparse models, we select the important covariates based on the sizes of estimated values of regression coefficients compared with a predetermined threshold value. Covariates with the absolute values of coefficients are greater than the threshold value are specified as important or “significant” predictors. The threshold value in simulations is consistently taken as 0.1 for all cases. Variable selection results based on various settings are reported in Tables 4 to 6, where“NC” denotes the average correctly identified number of important covariates, “NIC” denotes the average wrongly identified number of unimportant covariates. The averaged posterior mean square error (APMSE) of the identified model for 50 simulations is given by
where is the -th estimated value.
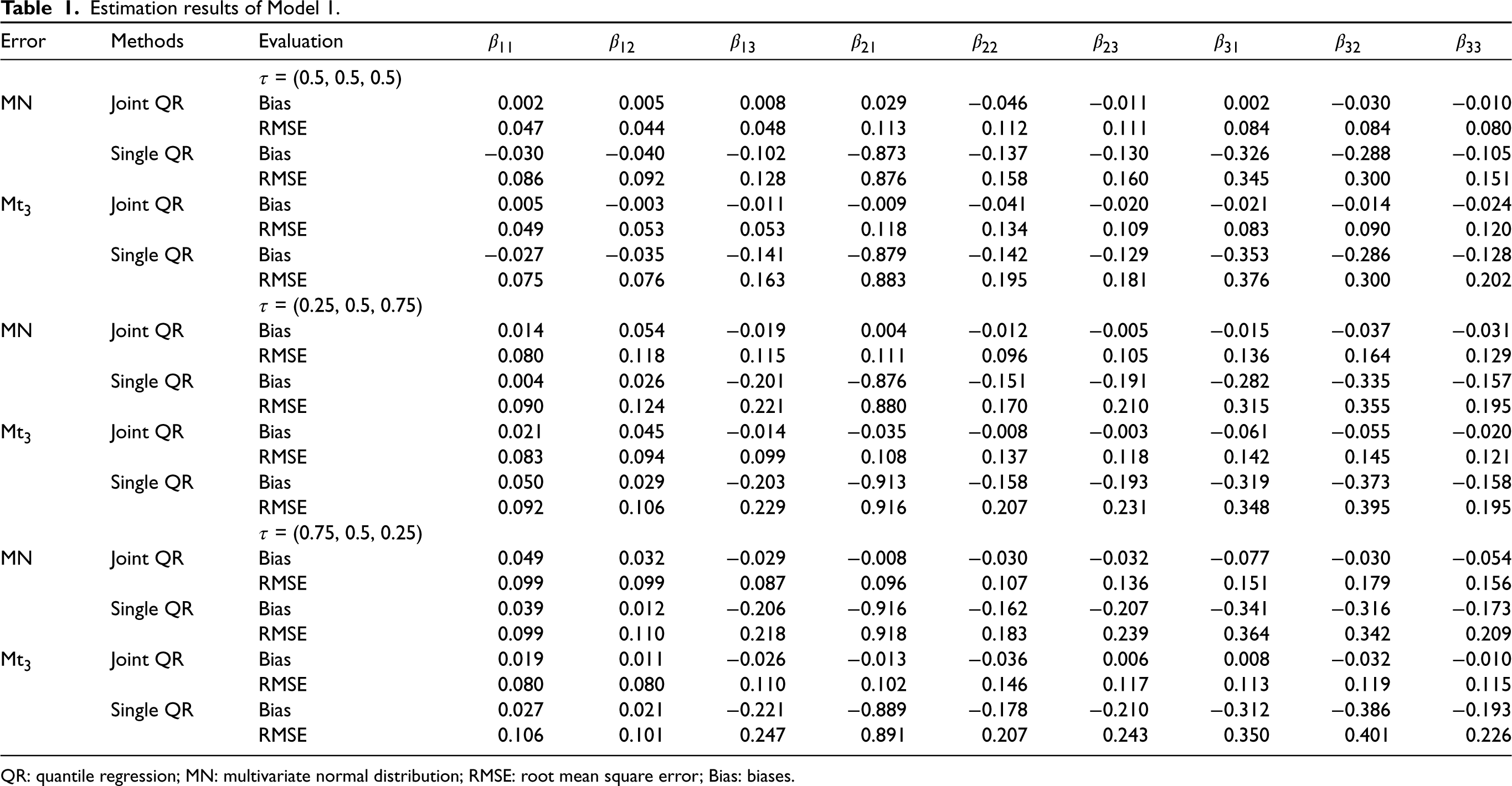
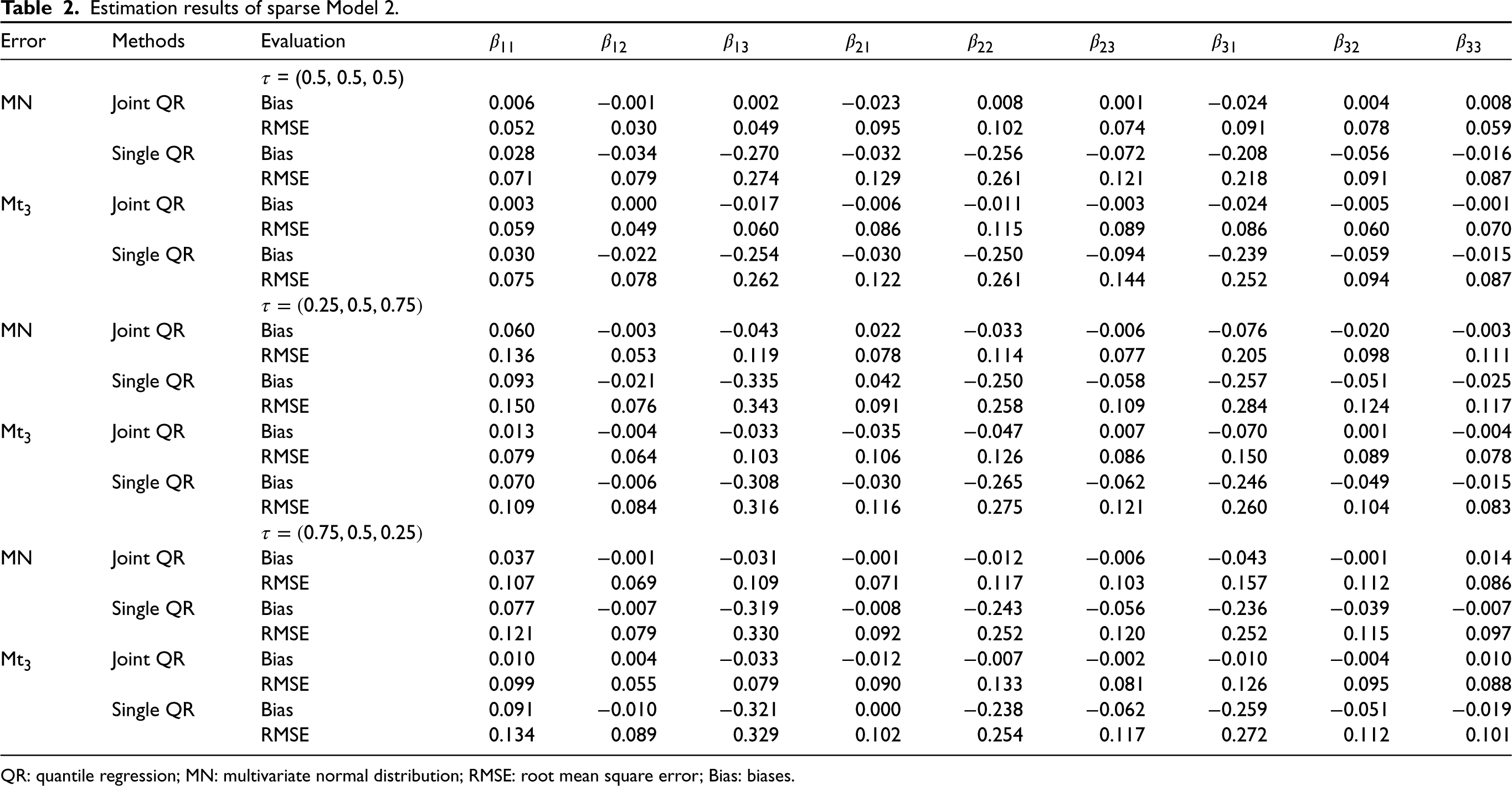
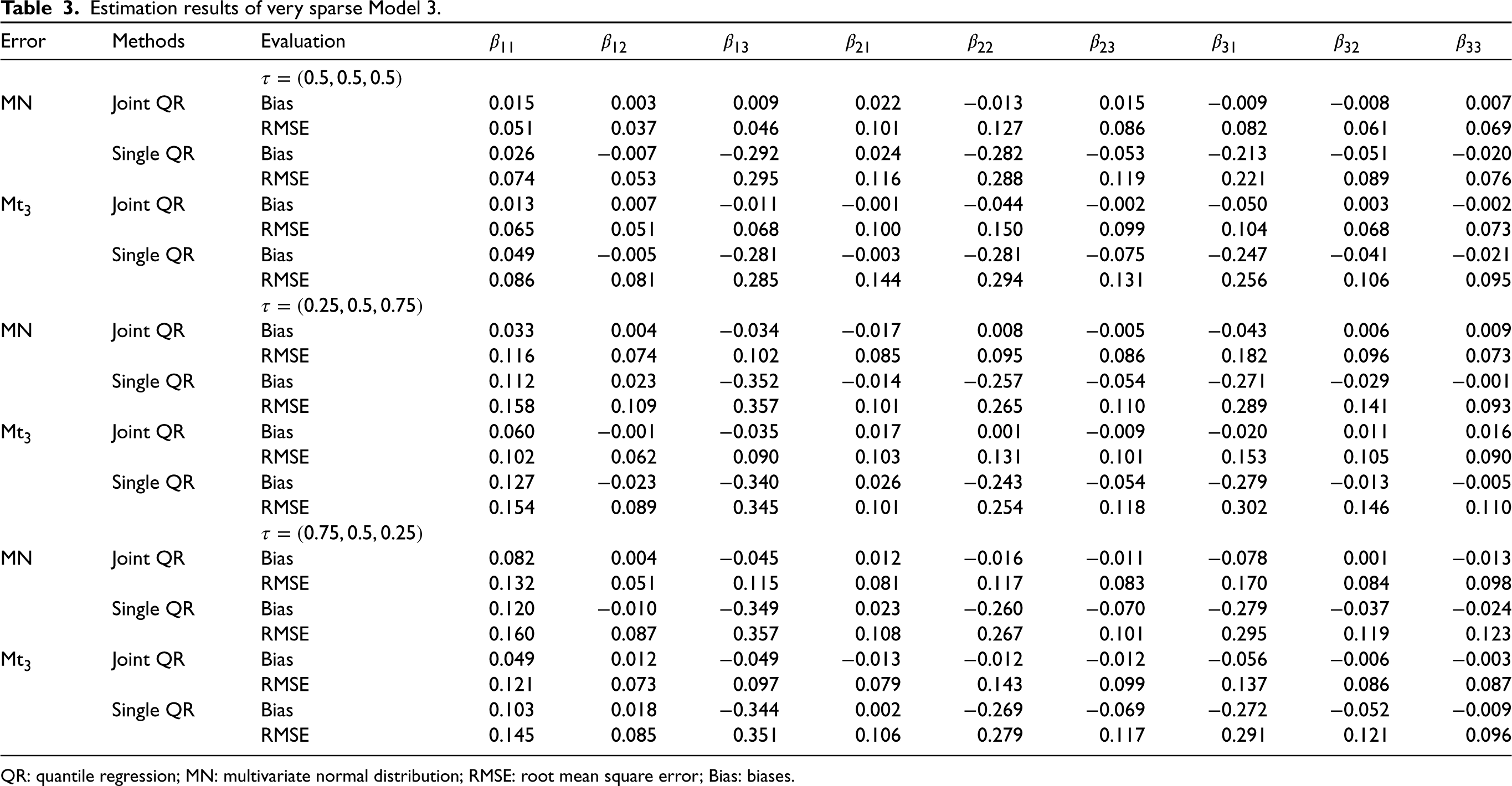
From Tables 1 to 3, we find that the joint QR modeling approach totally performs superior to the single QR approach. Although both two approaches yield unbiased estimates, the former apparently produces more accurate estimates with smaller RMSEs for all considered settings. For variable selection, we observe that both joint and single QR approaches yield the same NC values for the dense Model 1 (see Table 4) except that our approach produces smaller APMSE values. For Models 2 and 3, the joint QR approach obviously gives significantly smaller APMSE and NIC values than those of the single QR approach for the settings under consideration (see Tables 5 and 6). Simulation results show that the joint QR approach is more efficient than the single QR approach for both dense models and sparse models for different quantile combinations and error distributions.
Additional simulations
We implement additional simulations to assess the performances of other settings in this subsection. In the following, the specifics of the settings are indicated. All other conditions are identical to Section 5.2.
Model 4 (high correlation case): , , , and
where and is a variance-covariance matrix with off-diagonal elements 0.5.
Model 5 (high-dimensional case): , , the submatrix consisting of the first three columns of is in Model 4, other elements are zero. , where is an identity matrix.
Model 6 (ultra high-dimensional case): , , the submatrix consisting of the first three columns of is in Model 4, other elements are zero. , where is an identity matrix.
Under the same initial values, priors and Gibbs sampling algorithm in Section 5.2, we implement the simulation tests for Models 4 to 6 for the joint QR approach. Compared with Models 2 and 3, the performance of the proposed approach is equally good in Model 4, unsatisfactory in Model 5, and breaking down in Model 6. The computation results for Models 4 to 6 are omitted here. For high-dimensional and ultra-high-dimensional cases of Models 5 and 6, we can incorporate Bayesian feature screening algorithm into the joint QR approach to improve the unsatisfactory endings. However, we do not discuss this issue here.
Estimation results of Model 1.
Error
Methods
Evaluation
= (0.5, 0.5, 0.5)
MN
Joint QR
Bias
0.002
0.005
0.008
0.029
−0.046
−0.011
0.002
−0.030
−0.010
RMSE
0.047
0.044
0.048
0.113
0.112
0.111
0.084
0.084
0.080
Single QR
Bias
−0.030
−0.040
−0.102
−0.873
−0.137
−0.130
−0.326
−0.288
−0.105
RMSE
0.086
0.092
0.128
0.876
0.158
0.160
0.345
0.300
0.151
Mt3
Joint QR
Bias
0.005
−0.003
−0.011
−0.009
−0.041
−0.020
−0.021
−0.014
−0.024
RMSE
0.049
0.053
0.053
0.118
0.134
0.109
0.083
0.090
0.120
Single QR
Bias
−0.027
−0.035
−0.141
−0.879
−0.142
−0.129
−0.353
−0.286
−0.128
RMSE
0.075
0.076
0.163
0.883
0.195
0.181
0.376
0.300
0.202
= (0.25, 0.5, 0.75)
MN
Joint QR
Bias
0.014
0.054
−0.019
0.004
−0.012
−0.005
−0.015
−0.037
−0.031
RMSE
0.080
0.118
0.115
0.111
0.096
0.105
0.136
0.164
0.129
Single QR
Bias
0.004
0.026
−0.201
−0.876
−0.151
−0.191
−0.282
−0.335
−0.157
RMSE
0.090
0.124
0.221
0.880
0.170
0.210
0.315
0.355
0.195
Mt3
Joint QR
Bias
0.021
0.045
−0.014
−0.035
−0.008
−0.003
−0.061
−0.055
−0.020
RMSE
0.083
0.094
0.099
0.108
0.137
0.118
0.142
0.145
0.121
Single QR
Bias
0.050
0.029
−0.203
−0.913
−0.158
−0.193
−0.319
−0.373
−0.158
RMSE
0.092
0.106
0.229
0.916
0.207
0.231
0.348
0.395
0.195
= (0.75, 0.5, 0.25)
MN
Joint QR
Bias
0.049
0.032
−0.029
−0.008
−0.030
−0.032
−0.077
−0.030
−0.054
RMSE
0.099
0.099
0.087
0.096
0.107
0.136
0.151
0.179
0.156
Single QR
Bias
0.039
0.012
−0.206
−0.916
−0.162
−0.207
−0.341
−0.316
−0.173
RMSE
0.099
0.110
0.218
0.918
0.183
0.239
0.364
0.342
0.209
Mt3
Joint QR
Bias
0.019
0.011
−0.026
−0.013
−0.036
0.006
0.008
−0.032
−0.010
RMSE
0.080
0.080
0.110
0.102
0.146
0.117
0.113
0.119
0.115
Single QR
Bias
0.027
0.021
−0.221
−0.889
−0.178
−0.210
−0.312
−0.386
−0.193
RMSE
0.106
0.101
0.247
0.891
0.207
0.243
0.350
0.401
0.226
QR: quantile regression; MN: multivariate normal distribution; RMSE: root mean square error; Bias: biases.
Estimation results of sparse Model 2.
Error
Methods
Evaluation
= (0.5, 0.5, 0.5)
MN
Joint QR
Bias
0.006
−0.001
0.002
−0.023
0.008
0.001
−0.024
0.004
0.008
RMSE
0.052
0.030
0.049
0.095
0.102
0.074
0.091
0.078
0.059
Single QR
Bias
0.028
−0.034
−0.270
−0.032
−0.256
−0.072
−0.208
−0.056
−0.016
RMSE
0.071
0.079
0.274
0.129
0.261
0.121
0.218
0.091
0.087
Mt3
Joint QR
Bias
0.003
0.000
−0.017
−0.006
−0.011
−0.003
−0.024
−0.005
−0.001
RMSE
0.059
0.049
0.060
0.086
0.115
0.089
0.086
0.060
0.070
Single QR
Bias
0.030
−0.022
−0.254
−0.030
−0.250
−0.094
−0.239
−0.059
−0.015
RMSE
0.075
0.078
0.262
0.122
0.261
0.144
0.252
0.094
0.087
MN
Joint QR
Bias
0.060
−0.003
−0.043
0.022
−0.033
−0.006
−0.076
−0.020
−0.003
RMSE
0.136
0.053
0.119
0.078
0.114
0.077
0.205
0.098
0.111
Single QR
Bias
0.093
−0.021
−0.335
0.042
−0.250
−0.058
−0.257
−0.051
−0.025
RMSE
0.150
0.076
0.343
0.091
0.258
0.109
0.284
0.124
0.117
Mt3
Joint QR
Bias
0.013
−0.004
−0.033
−0.035
−0.047
0.007
−0.070
0.001
−0.004
RMSE
0.079
0.064
0.103
0.106
0.126
0.086
0.150
0.089
0.078
Single QR
Bias
0.070
−0.006
−0.308
−0.030
−0.265
−0.062
−0.246
−0.049
−0.015
RMSE
0.109
0.084
0.316
0.116
0.275
0.121
0.260
0.104
0.083
MN
Joint QR
Bias
0.037
−0.001
−0.031
−0.001
−0.012
−0.006
−0.043
−0.001
0.014
RMSE
0.107
0.069
0.109
0.071
0.117
0.103
0.157
0.112
0.086
Single QR
Bias
0.077
−0.007
−0.319
−0.008
−0.243
−0.056
−0.236
−0.039
−0.007
RMSE
0.121
0.079
0.330
0.092
0.252
0.120
0.252
0.115
0.097
Mt3
Joint QR
Bias
0.010
0.004
−0.033
−0.012
−0.007
−0.002
−0.010
−0.004
0.010
RMSE
0.099
0.055
0.079
0.090
0.133
0.081
0.126
0.095
0.088
Single QR
Bias
0.091
−0.010
−0.321
0.000
−0.238
−0.062
−0.259
−0.051
−0.019
RMSE
0.134
0.089
0.329
0.102
0.254
0.117
0.272
0.112
0.101
QR: quantile regression; MN: multivariate normal distribution; RMSE: root mean square error; Bias: biases.
Estimation results of very sparse Model 3.
Error
Methods
Evaluation
MN
Joint QR
Bias
0.015
0.003
0.009
0.022
−0.013
0.015
−0.009
−0.008
0.007
RMSE
0.051
0.037
0.046
0.101
0.127
0.086
0.082
0.061
0.069
Single QR
Bias
0.026
−0.007
−0.292
0.024
−0.282
−0.053
−0.213
−0.051
−0.020
RMSE
0.074
0.053
0.295
0.116
0.288
0.119
0.221
0.089
0.076
Mt3
Joint QR
Bias
0.013
0.007
−0.011
−0.001
−0.044
−0.002
−0.050
0.003
−0.002
RMSE
0.065
0.051
0.068
0.100
0.150
0.099
0.104
0.068
0.073
Single QR
Bias
0.049
−0.005
−0.281
−0.003
−0.281
−0.075
−0.247
−0.041
−0.021
RMSE
0.086
0.081
0.285
0.144
0.294
0.131
0.256
0.106
0.095
MN
Joint QR
Bias
0.033
0.004
−0.034
−0.017
0.008
−0.005
−0.043
0.006
0.009
RMSE
0.116
0.074
0.102
0.085
0.095
0.086
0.182
0.096
0.073
Single QR
Bias
0.112
0.023
−0.352
−0.014
−0.257
−0.054
−0.271
−0.029
−0.001
RMSE
0.158
0.109
0.357
0.101
0.265
0.110
0.289
0.141
0.093
Mt3
Joint QR
Bias
0.060
−0.001
−0.035
0.017
0.001
−0.009
−0.020
0.011
0.016
RMSE
0.102
0.062
0.090
0.103
0.131
0.101
0.153
0.105
0.090
Single QR
Bias
0.127
−0.023
−0.340
0.026
−0.243
−0.054
−0.279
−0.013
−0.005
RMSE
0.154
0.089
0.345
0.101
0.254
0.118
0.302
0.146
0.110
MN
Joint QR
Bias
0.082
0.004
−0.045
0.012
−0.016
−0.011
−0.078
0.001
−0.013
RMSE
0.132
0.051
0.115
0.081
0.117
0.083
0.170
0.084
0.098
Single QR
Bias
0.120
−0.010
−0.349
0.023
−0.260
−0.070
−0.279
−0.037
−0.024
RMSE
0.160
0.087
0.357
0.108
0.267
0.101
0.295
0.119
0.123
Mt3
Joint QR
Bias
0.049
0.012
−0.049
−0.013
−0.012
−0.012
−0.056
−0.006
−0.003
RMSE
0.121
0.073
0.097
0.079
0.143
0.099
0.137
0.086
0.087
Single QR
Bias
0.103
0.018
−0.344
0.002
−0.269
−0.069
−0.272
−0.052
−0.009
RMSE
0.145
0.085
0.351
0.106
0.279
0.117
0.291
0.121
0.096
QR: quantile regression; MN: multivariate normal distribution; RMSE: root mean square error; Bias: biases.
Variable selection results of dense Model 1.
Quantiles
Error
Methods
APMSE
NC
NIC
(0.50, 0.50, 0.50)
MN
Joint QR
0.063 (0.035)
9
0
Single QR
1.081 (0.196)
9
0
Mt3
Joint QR
0.079 (0.051)
9
0
Single QR
1.158 (0.231)
8.94
0
(0.25, 0.50, 0.75)
MN
Joint QR
0.125 (0.062)
9
0
Single QR
1.182 (0.240)
8.96
0
Mt3
Joint QR
0.123 (0.073)
8.98
0
Single QR
1.320 (0.266)
8.96
0
(0.75, 0.50, 0.25)
MN
Joint QR
0.143 (0.084)
9
0
Single QR
1.294 (0.243)
8.96
0
Mt3
Joint QR
0.108 (0.058)
9
0
Single QR
1.310 (0.244)
8.96
0
QR: quantile regression; MN: multivariate normal distribution; APMSE: averaged posterior mean square error; NC: average correctly identified number of important covariates; NIC: average wrongly identified number of unimportant covariates.
Variable selection results of sparse Model 2.
Quantiles
Error
Methods
APMSE
NC
NIC
(0.50, 0.50, 0.50)
MN
Joint QR
0.048 (0.035)
4
0.64
Single QR
0.248 (0.048)
4
1.52
Mt3
Joint QR
0.053 (0.038)
4
0.76
Single QR
0.263 (0.068)
4
1.64
(0.25, 0.50, 0.75)
MN
Joint QR
0.123 (0.088)
3.96
1.12
Single QR
0.341 (0.121)
3.90
1.78
Mt3
Joint QR
0.090 (0.058)
4
1.04
Single QR
0.306 (0.066)
4
1.58
(0.75, 0.50, 0.25)
MN
Joint QR
0.100 (0.062)
4
1.16
Single QR
0.301 (0.092)
4
1.56
Mt3
Joint QR
0.082 (0.060)
4
0.70
Single QR
0.318 (0.062)
3.98
1.62
QR: quantile regression; MN: multivariate normal distribution; APMSE: averaged posterior mean square error; NC: average correctly identified number of important covariates; NIC: average wrongly identified number of unimportant covariates.
Variable selection results of very sparse Model 3.
Quantiles
Error
Methods
APMSE
NC
NIC
(0.50, 0.50, 0.50)
MN
Joint QR
0.137 (0.061)
4
3
Single QR
0.367 (0.064)
4
4.26
Mt3
Joint QR
0.175 (0.073)
4
3.62
Single QR
0.432 (0.094)
4
5.62
(0.25, 0.50, 0.75)
MN
Joint QR
0.238 (0.092)
4
4.66
Single QR
0.524 (0.134)
3.96
6.54
Mt3
Joint QR
0.234 (0.094)
4
5.14
Single QR
0.539 (0.118)
3.94
7.26
(0.75, 0.50, 0.25)
MN
Joint QR
0.231 (0.090)
3.98
4.70
Single QR
0.522 (0.149)
3.92
6.34
Mt3
Joint QR
0.249 (0.106)
3.98
5.42
Single QR
0.546 (0.140)
3.92
7.30
QR: quantile regression; MN: multivariate normal distribution; APMSE: averaged posterior mean square error; NC: average correctly identified number of important covariates; NIC: average wrongly identified number of unimportant covariates.
Multivariate longitudinal analysis of PBCseq cohort study
In this section, we analyze a subset of longitudinal data on PBCseq cohort study using the proposed annroach. A total of 312 patients were recruited from the Mayo Clinic between January 1974 and May 1984, and participated in either of two double-blind, placebo-controlled, randomized trials with D-penicillamine for treating primary biliary cirrhosis until April 1988. A clinical laboratory database which comprised ID number, time-dependent variables (age and total number of follow-up days), categorical variables (sex, drug, and status), and two continuous measurement variables (natural logarithm scale of bili and albumin), was established on each patient who was collected repeatedly and prospectively at yearly intervals under standardized forms, definitions, and study protocols. In the second paragraph of Section 1, we have alluded that serum bilirubin and serum albumin are two of the primary indicators to help evaluate and track the absence of liver diseases. An extremely higher or lower level than the standards that bilirubin is excreted in bile and urine can indicate certain diseases. Also, extreme higher or lower circulating serum albumin levels are harmful to human body. Additionally, there exist some relationship between serum bilirubin and serum albumin levels. Fukui et al.48 showed that the serum bilirubin level is associated with microalbuminuria and subclinical atherosclerosis in patients with type 2 diabetes. A separate analysis for those two markers may lose important information about evolutional relationships among multiple responses. Thus, a joint analysis of the longitudinally collected serum bilirubin and serum albumin may be more appropriate in diagnosing liver diseases. The PBCseq data set is available from “mixAK” package of R49 and has been analyzed by Wang50 and Taavoni et al.,23 etc. Wang50 analyzed this data set using a mixture of multivariate linear mixed models with heterogeneity, Taavoni et al.23 analyzed the data set using multivariate semiparametric mixed-effects model with multiple characteristics.
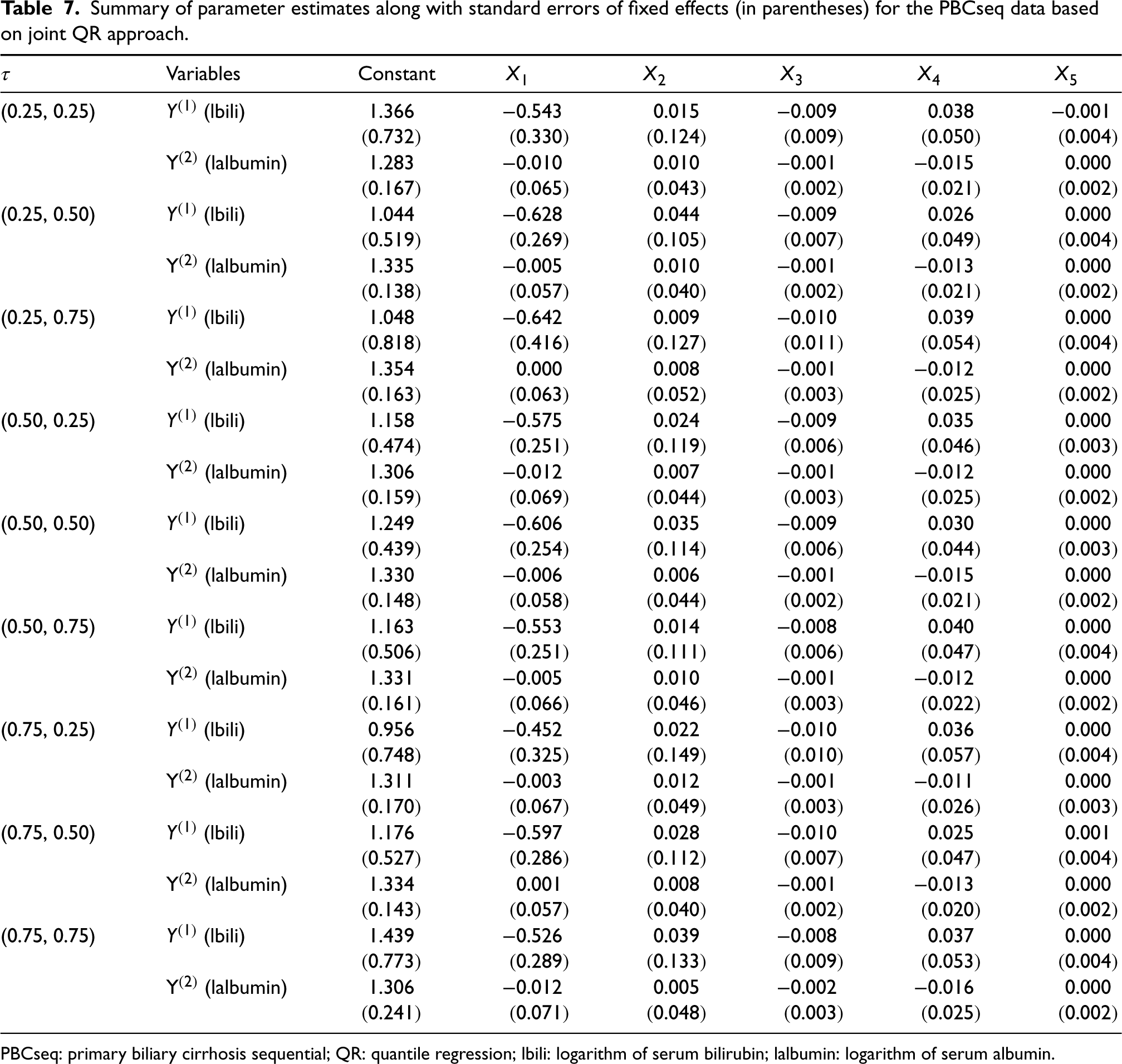
Summary of parameter estimates along with standard errors of fixed effects (in parentheses) for the PBCseq data based on joint QR approach.
Variables
Constant
X1
X2
X3
X4
X5
(0.25, 0.25)
(lbili)
1.366
−0.543
0.015
−0.009
0.038
−0.001
(0.732)
(0.330)
(0.124)
(0.009)
(0.050)
(0.004)
(lalbumin)
1.283
−0.010
0.010
−0.001
−0.015
0.000
(0.167)
(0.065)
(0.043)
(0.002)
(0.021)
(0.002)
(0.25, 0.50)
(lbili)
1.044
−0.628
0.044
−0.009
0.026
0.000
(0.519)
(0.269)
(0.105)
(0.007)
(0.049)
(0.004)
(lalbumin)
1.335
−0.005
0.010
−0.001
−0.013
0.000
(0.138)
(0.057)
(0.040)
(0.002)
(0.021)
(0.002)
(0.25, 0.75)
(lbili)
1.048
−0.642
0.009
−0.010
0.039
0.000
(0.818)
(0.416)
(0.127)
(0.011)
(0.054)
(0.004)
(lalbumin)
1.354
0.000
0.008
−0.001
−0.012
0.000
(0.163)
(0.063)
(0.052)
(0.003)
(0.025)
(0.002)
(0.50, 0.25)
(lbili)
1.158
−0.575
0.024
−0.009
0.035
0.000
(0.474)
(0.251)
(0.119)
(0.006)
(0.046)
(0.003)
(lalbumin)
1.306
−0.012
0.007
−0.001
−0.012
0.000
(0.159)
(0.069)
(0.044)
(0.003)
(0.025)
(0.002)
(0.50, 0.50)
(lbili)
1.249
−0.606
0.035
−0.009
0.030
0.000
(0.439)
(0.254)
(0.114)
(0.006)
(0.044)
(0.003)
(lalbumin)
1.330
−0.006
0.006
−0.001
−0.015
0.000
(0.148)
(0.058)
(0.044)
(0.002)
(0.021)
(0.002)
(0.50, 0.75)
(lbili)
1.163
−0.553
0.014
−0.008
0.040
0.000
(0.506)
(0.251)
(0.111)
(0.006)
(0.047)
(0.004)
(lalbumin)
1.331
−0.005
0.010
−0.001
−0.012
0.000
(0.161)
(0.066)
(0.046)
(0.003)
(0.022)
(0.002)
(0.75, 0.25)
(lbili)
0.956
−0.452
0.022
−0.010
0.036
0.000
(0.748)
(0.325)
(0.149)
(0.010)
(0.057)
(0.004)
(lalbumin)
1.311
−0.003
0.012
−0.001
−0.011
0.000
(0.170)
(0.067)
(0.049)
(0.003)
(0.026)
(0.003)
(0.75, 0.50)
(lbili)
1.176
−0.597
0.028
−0.010
0.025
0.001
(0.527)
(0.286)
(0.112)
(0.007)
(0.047)
(0.004)
(lalbumin)
1.334
0.001
0.008
−0.001
−0.013
0.000
(0.143)
(0.057)
(0.040)
(0.002)
(0.020)
(0.002)
(0.75, 0.75)
(lbili)
1.439
−0.526
0.039
−0.008
0.037
0.000
(0.773)
(0.289)
(0.133)
(0.009)
(0.053)
(0.004)
(lalbumin)
1.306
−0.012
0.005
−0.002
−0.016
0.000
(0.241)
(0.071)
(0.048)
(0.003)
(0.025)
(0.002)
PBCseq: primary biliary cirrhosis sequential; QR: quantile regression; lbili: logarithm of serum bilirubin; lalbumin: logarithm of serum albumin.
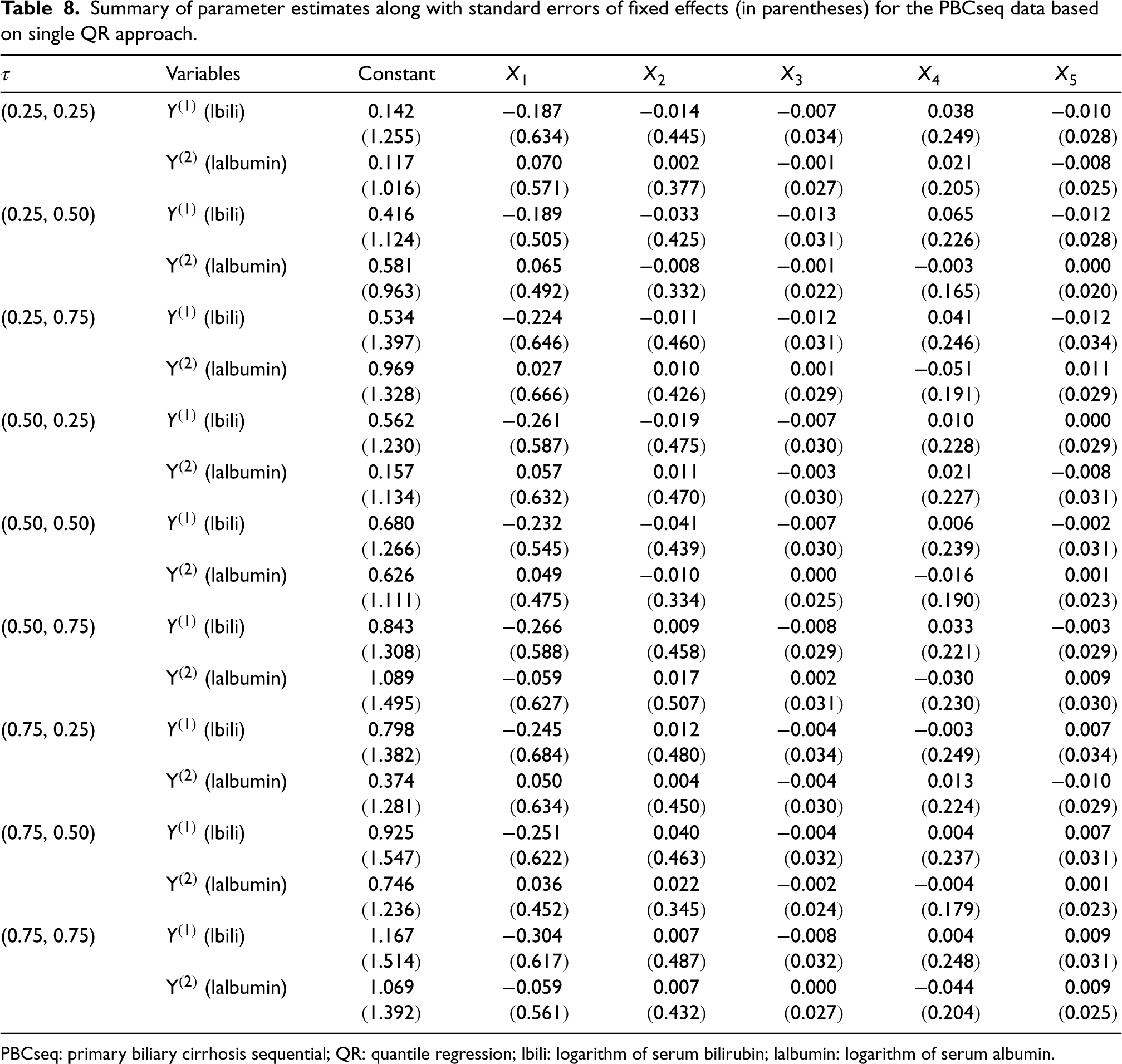
Summary of parameter estimates along with standard errors of fixed effects (in parentheses) for the PBCseq data based on single QR approach.
Variables
Constant
X1
X2
X3
X4
X5
(0.25, 0.25)
(lbili)
0.142
−0.187
−0.014
−0.007
0.038
−0.010
(1.255)
(0.634)
(0.445)
(0.034)
(0.249)
(0.028)
(lalbumin)
0.117
0.070
0.002
−0.001
0.021
−0.008
(1.016)
(0.571)
(0.377)
(0.027)
(0.205)
(0.025)
(0.25, 0.50)
(lbili)
0.416
−0.189
−0.033
−0.013
0.065
−0.012
(1.124)
(0.505)
(0.425)
(0.031)
(0.226)
(0.028)
(lalbumin)
0.581
0.065
−0.008
−0.001
−0.003
0.000
(0.963)
(0.492)
(0.332)
(0.022)
(0.165)
(0.020)
(0.25, 0.75)
(lbili)
0.534
−0.224
−0.011
−0.012
0.041
−0.012
(1.397)
(0.646)
(0.460)
(0.031)
(0.246)
(0.034)
(lalbumin)
0.969
0.027
0.010
0.001
−0.051
0.011
(1.328)
(0.666)
(0.426)
(0.029)
(0.191)
(0.029)
(0.50, 0.25)
(lbili)
0.562
−0.261
−0.019
−0.007
0.010
0.000
(1.230)
(0.587)
(0.475)
(0.030)
(0.228)
(0.029)
(lalbumin)
0.157
0.057
0.011
−0.003
0.021
−0.008
(1.134)
(0.632)
(0.470)
(0.030)
(0.227)
(0.031)
(0.50, 0.50)
(lbili)
0.680
−0.232
−0.041
−0.007
0.006
−0.002
(1.266)
(0.545)
(0.439)
(0.030)
(0.239)
(0.031)
(lalbumin)
0.626
0.049
−0.010
0.000
−0.016
0.001
(1.111)
(0.475)
(0.334)
(0.025)
(0.190)
(0.023)
(0.50, 0.75)
(lbili)
0.843
−0.266
0.009
−0.008
0.033
−0.003
(1.308)
(0.588)
(0.458)
(0.029)
(0.221)
(0.029)
(lalbumin)
1.089
−0.059
0.017
0.002
−0.030
0.009
(1.495)
(0.627)
(0.507)
(0.031)
(0.230)
(0.030)
(0.75, 0.25)
(lbili)
0.798
−0.245
0.012
−0.004
−0.003
0.007
(1.382)
(0.684)
(0.480)
(0.034)
(0.249)
(0.034)
(lalbumin)
0.374
0.050
0.004
−0.004
0.013
−0.010
(1.281)
(0.634)
(0.450)
(0.030)
(0.224)
(0.029)
(0.75, 0.50)
(lbili)
0.925
−0.251
0.040
−0.004
0.004
0.007
(1.547)
(0.622)
(0.463)
(0.032)
(0.237)
(0.031)
(lalbumin)
0.746
0.036
0.022
−0.002
−0.004
0.001
(1.236)
(0.452)
(0.345)
(0.024)
(0.179)
(0.023)
(0.75, 0.75)
(lbili)
1.167
−0.304
0.007
−0.008
0.004
0.009
(1.514)
(0.617)
(0.487)
(0.032)
(0.248)
(0.031)
(lalbumin)
1.069
−0.059
0.007
0.000
−0.044
0.009
(1.392)
(0.561)
(0.432)
(0.027)
(0.204)
(0.025)
PBCseq: primary biliary cirrhosis sequential; QR: quantile regression; lbili: logarithm of serum bilirubin; lalbumin: logarithm of serum albumin.
We concentrate on modeling the dependence of the longitudinal profiles of two markers with the natural logarithm of serum bilirubin (lbili) and the natural logarithm of serum albumin (lalbumin), on time (visited years) and other covariates of interest (e.g. sex, drug, and age). We conduct the joint QR analysis for the longitudinal PBCseq data set on responses of lbili and lalbumin by establishing model (3.1). Denote , where is the bivariate response for the -th patient, and represent lbili and lalbumin levels, and is a vector of regressors, denotes the gender indicator (0 = male and 1 = female), denotes the drug treatment indicator (0 = patient treated with placebo and 1 = patient treated with D-penicillamine), denotes the age at entry in years, denotes time (visited years), and . Thus, the parameter matrix of fixed effects is denoted as
Nine quantile combinations, that is, , , , , , , , , and , are considered for the response . The priors and initial values are set as the same setting in Section 5. We run iterations of Gibbs sampling algorithm for each quantile combination, the first 2000 burn-in iterations are removed and the remaining 6000 stationary iterations are retained to conduct posterior inference. Estimation results including average estimation values and standard errors of the considered nine quantile combinations are reported in Table 7. For the aim of comparison, we also provide the estimation results of single QR approach in Table 8.
Compared Table 7 with Table 8, we again conclude that the proposed joint QR approach has better estimation results with apparently smaller standard errors for almost all parameters. In addition, from Table 7, we find that five covaraites have not exactly the same impacts on two responses for each quantile combination. The impacts of five covariates on two responses also totally vary with the quantile combinations. Further, at all quantile levels under consideration, covariates (gender) and (age) have simultaneous negative effects on responses (lbili) and (lalbumin), and covariates (drug) have simultaneous positive effects on two responses. Yet, has a clearly bigger impact on response than while has a slightly bigger impact on response than . Whereas, covariates (visited years) has positive effects on response and negative effects on response for all quantiles. Specially, we find has almost no impact on responses and for all considered quantiles since the coefficients are approximately estimated as zeros. Some useful conclusions can be drawn based on the above quantitative analysis. lbili and lalbumin becomes slightly smaller as the ages of patients increase. Female patients () have faster change for lbili and lalbumin than male patients (). Patients treated with D-penicillamine () have bigger change for lbili and lalbumin than patients treated with placebo (). Generally, in the diagnosis of clinical liver disease patients, the increase of serum bilirubin and the decrease of serum albumin indicate liver cell damage. Hence, conclusions suggest elderly female patients with liver disease more should receive medication intervention of D-penicillamine to more effectively reduce the risk of liver disease development.
Concluding remarks
We investigated the Bayesian joint QR modeling of multi-response mixed-effects model with longitudinal data in this paper. A MAL distribution was imposed on the errors of the considered model to build the working likelihood of Bayesian joint inference. For implementing the efficient Bayesian inference, the location-scale mixture reparameterization of the working likelihood and LASSO-type penalization priors of regression coefficients were employed to construct the Bayesian joint hierarchical QR model. The conditional posterior distributions of parameters and latent variables based on MCMC algorithm were derived. Monte Carlo simulation examples were presented to illustrate the proposed joint QR approach. Simulation results showed that the proposed joint QR approach has more satisfactory performance than the single QR approach. Finally, we analyzed a real-world data set of a longitudinal PBCseq cohort study using the proposed joint modeling approach. The proposed joint QR approach can be extended to more complex longitudinal data models and applications.
Footnotes
Acknowledgements
The authors thank editors and two referees for their constructive comments and suggestions which have greatly improved the paper. The work of Tian Yu-Zhu was jointly supported by grants from the National Natural Science Foundation of China (Grant 12061065) and Funds for Innovative Fundamental Research Group Project of Gansu Province of China (Grant 23JRRA684). The work of Tang Man-Lai is partially supported by the Research Matching Grant (700006) from the Research Grants Council of the Hong Kong Special Administration Region and FDS Grant (UGC/FDS14/P05/20) from the Big Data Intelligence Center in The Hang Seng University of Hong Kong.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
ORCID iD
Catherine Wong
Supplemental material
Supplemental material for this article is available online.
References
1.
LairdNMWareH. Random-effect models for longitudinal data. Biometrics1982; 38: 963–974.
2.
DigglePHeagertyPLiangkY, et al. Analysis of longitudinal data. USA: Oxford University Press, 2002.
3.
HedekerDGibbonsRD. Longitudinal data analysis. Wiley, New Jersey: Blackwell Publishing Ltd, 2006.
4.
WuHZhangJT. Nonparametric regression methods for longitudinal data analysis: mixed-effects modeling approaches. New York: Wiley, 2006.
DemidenkoE. Mixed Models: Theory and Applications with R. (2nd ed). Hoboken Wiley, 2013.
7.
ShahALairdNSchoenfeldD. A random-effects model for multiple characteristics with possibly missing data. J Am Stat Assoc1997; 438: 775–779.
8.
SammelMLinXRyanL. Multivariate linear mixed models for multiple outcomes. Stat Med1999; 18: 2479–2492.
9.
LinTI. A mixed-effects regression model for longitudinal multivariate ordinal data. Int Biometric Soc2006; 62: 261–268.
10.
BlozisSACongerKJHarringJR. Nonlinear latent curve models for multivariate longitudinal data. Int J Behav Dev2007; 31: 340–346.
11.
AlfoMMaruottiA. A hierarchical model for time dependent multivariate longitudinal data. Berlin, Heidelberg: Springer, 2010.
12.
BandyopadhyaySGanguliBChatterjeeA. A review of multivariate longitudinal data analysis. Stat Methods Med Res2011; 20: 299–330.
13.
GebregziabherMZhaoYDismukeCE, etc. Joint modeling of multiple longitudinal cost outcomes using multivariate generalized linear mixed models. Health Serv Outc Res Methodol2013; 13: 39–57.
14.
LaffontCMVandemeulebroeckeMConcordetD. Multivariate analysis of longitudinal ordinal data with mixed effects models, with application to clinical outcomes in osteoarthritis. J Am Stat Assoc2014; 109: 955–966.
15.
GrimmKJ. Multivariate longitudinal methods for studying developmental relationships between depression and academic achievement. Int J Behav Dev2015; 31: 328–339.
16.
WangWLLinTILachosVH. Extending multivariate-t linear mixed models for multiple longitudinal data with censored responses and heavy tails. Stat Methods Med Res2015; 27: 48–64.
17.
LuwandaAGMwambiHG. A nonlinear mixed-effects model for multivariate longitudinal data with partially observed outcomes with application to HIV disease dynamics. J Appl Stat2017; 44: 441–456.
18.
RajeswaranJBlackstoneEHBarnardJ. Joint modeling of multivariate longitudinal data and competing risks using multiphase sub-models. Stat Biosci2018; 10: 651–685.
19.
LinTILachosVHWangWL. Multivariate longitudinal data analysis with censored and intermittent missing responses. Stat Med2018; 37: 2822–2835.
20.
HuiFKCMuellerSWelshAH. Sparse pairwise likelihood estimation for multivariate longitudinal mixed models. J Am Stat Assoc2018; 113: 1759–1769.
21.
JiangHYYueRXZhouXD. Optimal designs for multivariate logistic mixed models with longitudinal data. Commun Stat-Theory Method2019; 48: 850–864.
22.
WangWL. Bayesian analysis of multivariate linear mixed models with censored and intermittent missing responses. Stat Med2020; 39: 2518–2535.
23.
TaavoniMArashiMWangWL, et al. Multivariate semiparametric mixed-effects model for longitudinal data with multiple characteristics. J Stat Comput Simul2021; 91: 260–281.
24.
TianZQiuP. Multivariate single index modeling of longitudinal data with multiple responses. Stat Med2023; 42: 2982–2998.
25.
KoenkerR. Quantile regression. Cambridge: Cambridge University Press, 2005.
26.
KoenkerRChernozhukovVHeX, et al. Handbook of Quantile Regression. Florida CRC Press, 2017.
TianYZWangLYTangML, et al. Likelihood-based quantile mixed effects models for longitudinal data with multiple features via MCEM algorithm. Commun Stat-Simul Comput2020; 49: 317–334.
34.
WaldmannEKneibT. Bayesian bivariate quantile regression. Stat Model2014; 15: 326–344.
35.
KulkarniHBiswasJDasK. A joint quantile regression model for multiple longitudinal outcomes. AStA-Adv Stat Anal2019; 103: 453–473.
36.
GhasemzadehSGanjaliMBaghfalakiT. Bayesian quantile regression for joint modeling of longitudinal mixed ordinal and continuous data. Commun Stat Simul Comput2020; 49: 375–395.
37.
BiswasJDasK. A Bayesian quantile regression approach to multivariate semi-continuous longitudinal data. Comput Stat2021; 36: 241–260.
38.
PetrellaLRaponiV. Joint estimation of conditional quantiles in multivariate linear regression models with an application to financial distress. J Multivar Anal2019; 173: 70–84.
39.
TianYZTangMLTianMZ. Bayesian joint inference for multivariate quantile regression model with penalty. Comput Stat2021; 36: 2967–2994.
KolloTSrivastavaMS. Estimation and testing of parameters in multivariate Laplace distribution. Commun Stat-Theory Method2005; 33: 2363–2387.
42.
ViskH. On the parameter estimation of the asymmetric multivariate Laplace distribution. Commun Stat-Theory Method2009; 38: 461–470.
43.
HurlimannW. A moment method for the multivariate asymmetric Laplace distribution. Stat Probab Lett2013; 83: 1247–1253.
44.
TibshiraniRJ. Regression shrinkage and selection via the LASSO. J R Stat Soc (Ser B)1996; 73: 273–282.
45.
ZouH. The adaptive LASSO and its oracle properties. J Am Stat Assoc2006; 101: 1418–1429.
46.
ParkTCasellaG. The Bayesian LASSO. J Am Stat Assoc2008; 103: 681–686.
47.
LengCTranMNNottD. Bayesian adaptive LASSO. Ann Inst Stat Math2014; 66: 221–244.
48.
FukuiMTanakaMShiraishiE, et al. Relationship between serum bilirubin and albuminuria in patients with type 2 diabetes. Kidney Int2008; 74: 1197–1201.
49.
KomarekAKomarkovaL. Capabilities of R package mixAK for clustering based on multivariate continuous and discrete longitudinal data. J Stat Softw2014; 59: 1–38.
50.
WangWL. Mixture of multivariate linear mixed models for multi-outcome longitudinal data with heterogeneity. Stat Sin2017; 27: 733–760.