
Abstract
In clinical and observational studies, secondary outcomes are frequently collected alongside the primary outcome for each subject, yet their potential to improve the analysis efficiency remains underutilized. Moreover, missing data, commonly encountered in practice, can introduce bias to estimates if not appropriately addressed. This article presents an innovative approach that enhances the empirical likelihood-based information borrowing method by integrating missing-data techniques, ensuring robust data integration. We introduce a plug-in inverse probability weighting estimator to handle missingness in the primary analysis, demonstrating its equivalence to the standard joint estimator under mild conditions. To address potential bias from missing secondary outcomes, we propose a uniform mapping strategy, imputing incomplete secondary outcomes into a unified space. Extensive simulations highlight the effectiveness of our method, showing consistent, efficient, and robust estimators under various scenarios involving missing data and/or misspecified secondary models. Finally, we apply our proposal to the Uniform Data Set from the National Alzheimer’s Coordinating Center, exemplifying its practical application.
Introduction
Clinical trials and observational studies often collect secondary outcomes alongside the primary outcome. These secondary outcomes can be highly associated with the primary outcome and therefore contain information that could improve the primary model efficiency. In our study, we use the Uniform Data Set from the National Alzheimer’s Coordinating Center (NACC) to explore risk factors on the development of short-term dementia. Thus, the primary outcome of clinical interest here is a cross-sectional variable such as three-year dementia status. Along with the primary outcome, some secondary outcomes are also collected during the study. For example, one of the diagnosis tools, the Mini Mental State Examination (MMSE), is implemented to gather information on overall cognitive ability and monitor the progression.1,2 Additionally, the clinical dementia rating scale is another informative secondary outcome that is used in the definition of dementia status. 3 Typically, secondary outcomes are analyzed separately or only baseline observations are used for the primary regression analysis. These approaches fail to fully consider the high association between the outcomes or incorporate information contained in these secondary outcomes that are longitudinally measured. Efficient integration of secondary outcomes into the primary model fitting is desired to further boost the statistical performance of estimating risk factors on the primary outcome. However, naive solutions such as including both baseline variables and secondary outcomes as covariates could be inappropriate or misleading. Since both primary and secondary outcomes might be affected by risk factors in a similar manner. Thus, adding secondary outcomes to the primary model can dilute or even eliminate all effects from the baseline, which can render the primary model less clinically interpretable. This phenomenon is known as collider bias in causal inference. So far, few work on how to integrate secondary outcomes into the primary outcome analysis in an effective and robust manner in the literature exists. One of our study goals is to fill this gap and proposes novel approaches that effectively integrate secondary outcomes into the primary analysis to enhance the estimation efficiency.
Here, we consider auxiliary information collected within the same study, which is distinct from the information obtained from external independent studies. While there are several information borrowing techniques developed for independent studies, such as constrained maximum likelihood using summary information from independent studies,4,5 calibration estimation utilizing some shared effects across studies, 6 and Bayesian integration introducing external information via prior distributions, 7 there is relatively few work concerning within-study auxiliary information. Recently, Chen et al. 8 proposed an empirical likelihood-based method for incorporating secondary outcomes to improve estimation precision of the primary analysis. However, this work only applies to cases where the primary data are fully observed or missing completely at random (MCAR) that is easily to be violated in real practice including our data application. 9 These existing methods cannot be directly applicable to our setting due to bias susceptibility. Thus, our another study goal is to develop novel approaches to reduce the bias due to missingness in primary or secondary outcomes.
In the NACC, patients were followed approximately annually, and the diagnosis of dementia was in accordance with published research criteria (e.g. the Diagnostic and Statistical Manual 4th edition). The primary outcome of interest, three-year dementia, could be missing due to subjects being lost to follow-up, missing a visit, or refusing to provide a response, which is commonly encountered in reality. Ignoring or improperly handling missing data could lead to less efficient or even biased inference when the data are not MCAR. 9 To address these issues, we extend the empirical likelihood-based information borrowing method proposed by Chen et al. 8 with the adoption of the inverse probability weighting (IPW) technique 10 and the uniform mapping strategy. Specifically, we incorporate the IPW to adjust for missing data in the primary model, and propose the uniform mapping strategy to facilitate unbiased information borrowing by homogenizing incomplete secondary outcomes. By doing so, we obtain an efficiency-improved and robust parameter estimator when the data are missing at random (MAR). 9 This approach is particularly relevant for our study given the complex features and missingness of the NACC data.
The structure of the article is as follows. In Section 2, we present our proposed method. In Section 3, we perform empirical simulations to verify the consistency, high efficiency, and robustness of our method. In Section 4, we apply our method to the NACC study for illustration. Finally, the conclusions with some discussion are summarized in Section 5. All technical details, regularity conditions, and proofs are presented in the Supplemental Material.
Method
For subject
Empirical likelihood weighting
Suppose the regression parameter vector of the mean model between
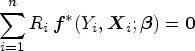
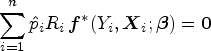
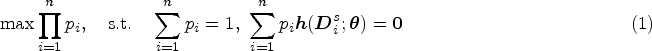
The work by Chen et al.
8
has two limitations. First, it assumes that the primary data are either fully observed or MCAR, which is too idealistic in practice. Second, it takes for granted the assumption that there exist a value
When dealing with MAR primary outcome, various standard approaches such as the IPW and imputation techniques have been widely applied in the literature.14–16 In this article, we focus on the IPW for illustration and rigorous theoretical investigation. Other extensions are discussed in Section 5. We assume that there is a correctly specified model for the observation indicator of the primary outcome,
Joint estimation
In order to properly use the IPW technique in the context of information borrowing, let us first consider the estimator by solving
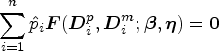
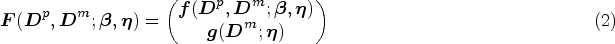
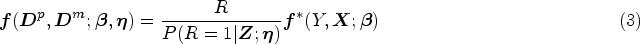
Under some regularity conditions, suppose there exists a parameter
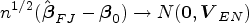
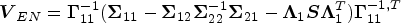
Let
Despite its theoretical advance, the joint estimation may suffer from high estimation complexity as the dimension of the parameters increases. To relieve this issue, alternatively, we consider a two-stage estimation: in the first step, obtain an estimator
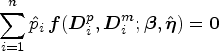
Under some regularity conditions, suppose there exists a parameter
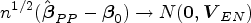
In terms of efficiency, we realize that
If the primary outcome is MAR and all secondary outcomes are fully observed, we have (a)
The above results hold when all secondary outcomes are observed across times and subjects. When some secondary outcomes are missing, we may consider imputing secondary outcomes before estimation. By doing so, we are back to the case with “observed” data. We refer readers to next subsection for more details. For completeness, we also consider the method of full estimating equations and plug-in estimation (FP), where we plug the estimator
To address this issue, we propose using multiple imputations to create complete data. Distinct from imputations in the literature that aims at recovery of the true model, the goal here is to find a unified
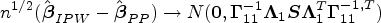
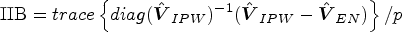
Simulation
In this section, we examine the numerical performance of our proposed estimator under a variety of scenarios. For each scenario, we consider the sample size
For each subject
The generating model for secondary outcomes is
Next, we add dropouts for the binary vector
For the primary, missing data, and secondary analysis, we consider the logistic regression, the marginal model of weighted GEE (WGEE), 18 and the over-identified estimating functions suggested by Chen et al., 8 respectively. The specification of these estimating functions is presented in the Supplemental Material. In order to evaluate the estimation performance, summary statistics including bias, relative bias (RB), Monte Carlo standard deviation (SD), standard error (SE), relative efficiency (RE), and coverage probability (CP) are reported based on 1000 Monte Carlo replications. In the following, we first examine the cases with fully observed secondary outcomes to investigate the equivalence of the FJ and PP estimators and the robustness to secondary model misspecification. We proceed to examine the cases with missing secondary outcomes.
Equivalence of the FJ and PP estimators
As shown in Table 1, the estimation results of the FJ and PP estimators are comparable under finite samples. Compared to the complete case analysis that does not adjust for the missing data, the bias of the PP estimator is significantly reduced. This confirms that the FJ and PP methods are effective ways to handle missing data. Among these four parameters, the estimate for
Estimation results to evaluate equivalence of the FJ and PP estimators. All secondary outcomes are observed. All statistics except RE are multiplied by 100.
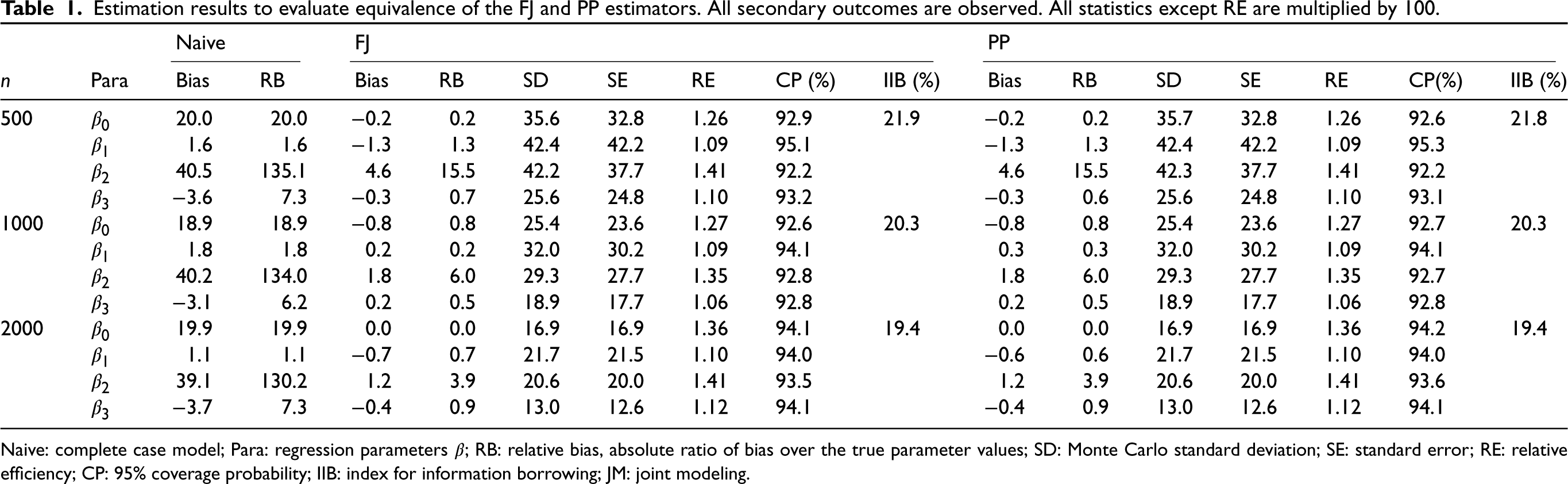
Estimation results to evaluate equivalence of the FJ and PP estimators. All secondary outcomes are observed. All statistics except RE are multiplied by 100.
Naive: complete case model; Para: regression parameters
Now we examine the robustness of our proposed method to the model misspecification in the secondary analysis. Recall that the generating model for secondary outcomes takes the form
The results are summarized in Table 2. Again, the estimator is consistent to the true value, and the SE and CP are close to the SD and nominal level, respectively. Next, we look at the precision improvement. In the first case, the IIB becomes smaller, which is about 0.15, compared with the benchmark. This is mainly because the RE of
Estimation results to evaluate robustness to secondary model misspecification. All secondary outcomes are observed. All statistics except RE are multiplied by 100.
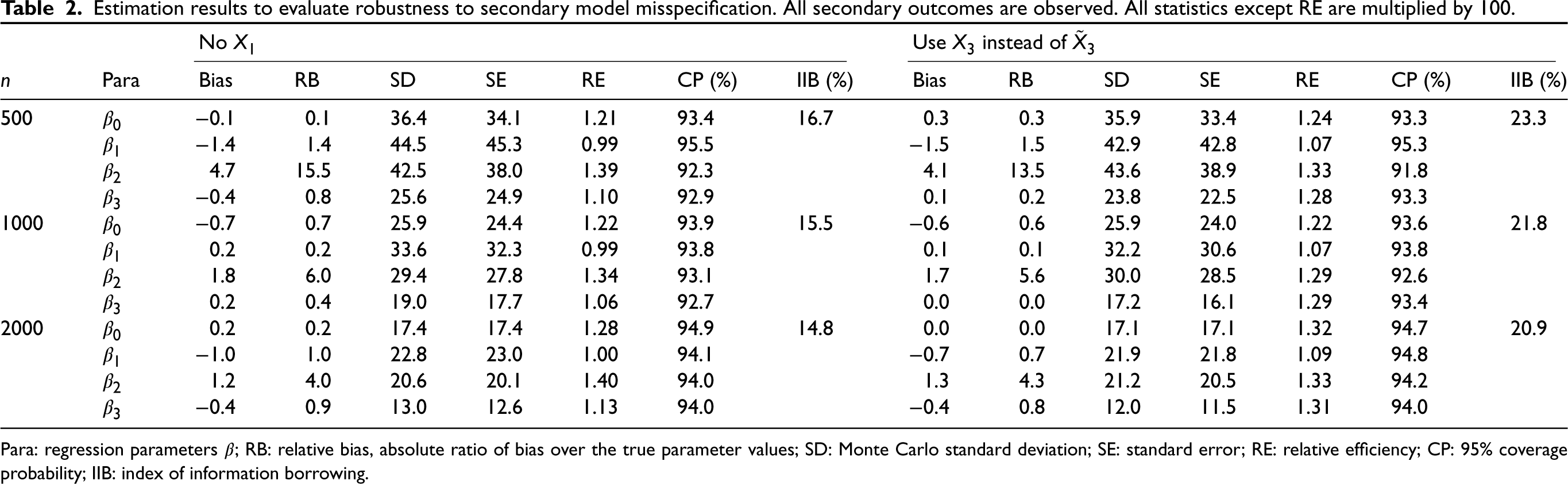
Estimation results to evaluate robustness to secondary model misspecification. All secondary outcomes are observed. All statistics except RE are multiplied by 100.
Para: regression parameters
In the previous cases, we assumed secondary outcomes are completely observed. Now we relax this assumption and allow missing data to occur in secondary outcomes, which is commonly encountered in practice. Here, we consider two scenarios. The first one is the case where the secondary outcome has exactly the same missing pattern as the primary outcome. In other words, the secondary outcome is missing simultaneously along with the primary one. The second scenario is to consider primary and secondary outcomes with different missing patterns. For subject
The simulation results are summarized in Table 3. As discussed, the classic ELW method may introduce bias when there is no unified
Estimation results for the scenarios with missing secondary outcomes. All statistics except RE are multiplied by 100.
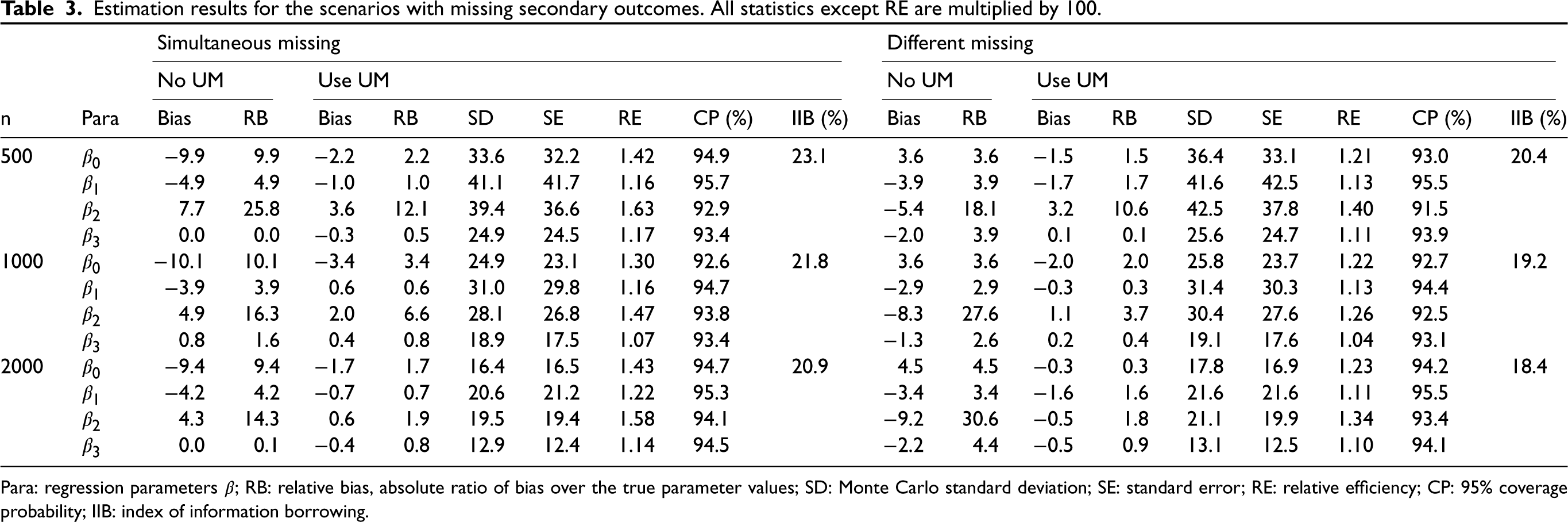
Estimation results for the scenarios with missing secondary outcomes. All statistics except RE are multiplied by 100.
Para: regression parameters
Dementia is a common syndrome among the elderly, characterized by a decline in memory and cognitive functioning leading to a loss of independent living. With the rapid growth of the elderly population, the number of people living with dementia is expected to reach 65.7 million by 2030 and 115.4 million by 2050 worldwide. 19 To illustrate our method and meet clinical needs, we use the Uniform Data Set from the National Alzheimer’s Coordinating Center (NACC) 20 to investigate baseline risk factors for developing dementia after a three-year follow-up, which holds primary clinical significance. The onset of dementia is a gradual process that unfolds over a relatively extended period. Gaining insight into dementia risk within this timeframe and pinpointing associated risk factors can facilitate early disease detection and enhance healthcare management.21,22
Our analysis focuses on subjects aged 55 or older who have not developed dementia at baseline. To better demonstrate the empirical performance of our method, we randomly select one Alzheimer’s Disease Research Centers, with site ID 8646, and use the subjects enrolled between 2005 and 2014 for our analysis, resulting in a sample size of 733. The summary statistics of subjects in this site and the others are provided in the Supplemental Materials. The baseline risk factors of interest include age, sex (female vs. male), race (non-white vs. white), years of education, body mass index (BMI), depression, and APOE genotype (including allele
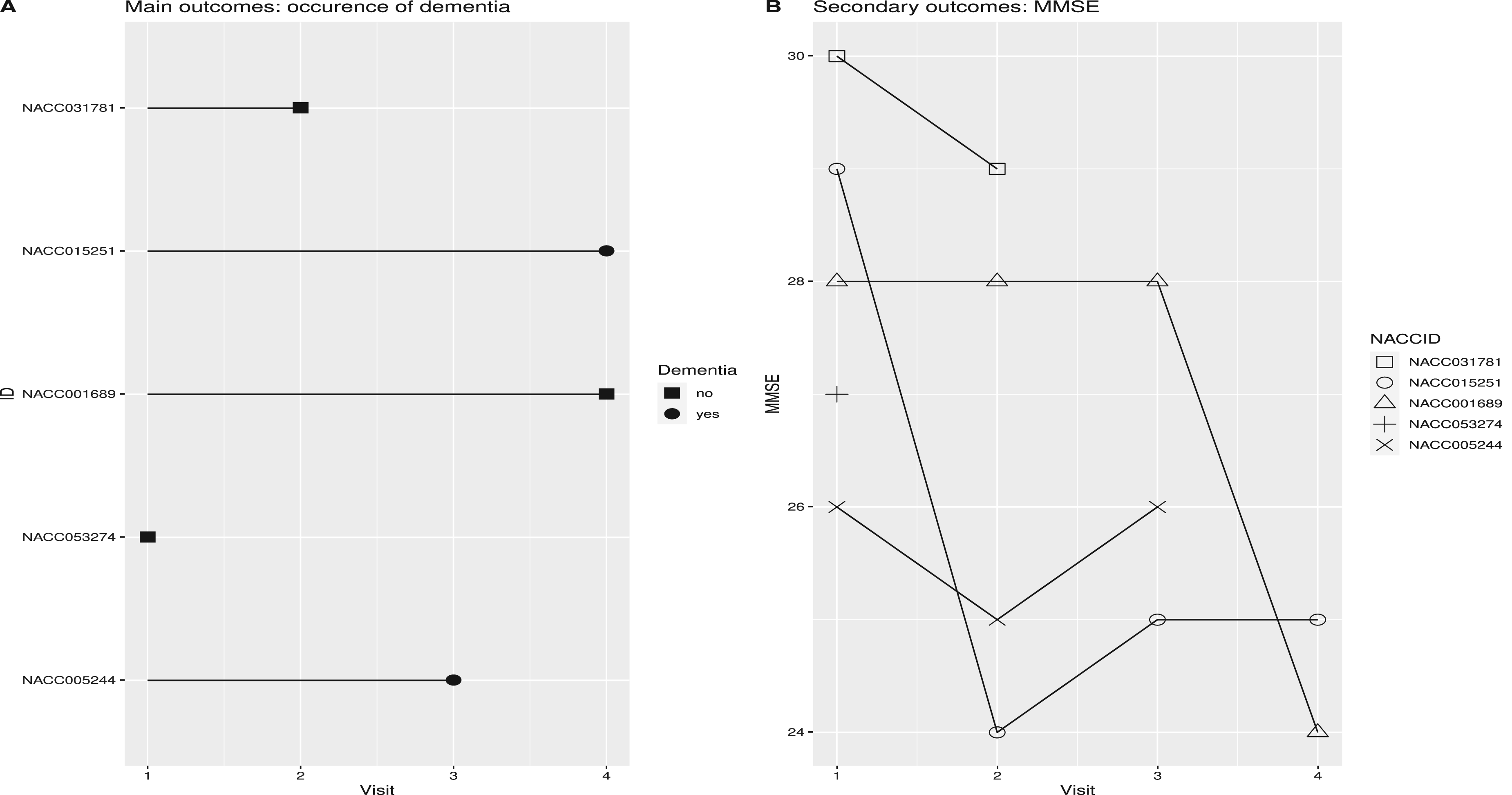
Trajectories of outcomes for five randomly selected subjects from the National Alzheimer’s Coordinating Center (NACC) study (panel A: primary outcomes and panel B: secondary outcomes).
We adopt the logistic regression for the primary analysis, regressing the primary outcome on the baseline risk factors of interest listed above. For the missing data analysis, we use the dropout model by Robins et al.
18
as in the simulation. The covariates are risk factors and MMSE at the last visit instead of the baseline measurements because we believe the last measurements are more informative and indeed the model has smaller AIC, indicating a better fit. Analysis reveals that the higher MMSE at the last visit, the more years of education are significant factors for subjects to be observed in follow-up. Additionally, dropout is more likely to occur for individuals with dementia at the last visit (marginally significant), higher age at the last visit, and non-white race. These findings provide evidence supporting that the primary outcome is not MCAR and the detailed results are presented in the Supplemental Materials. For the secondary analysis, we regress MMSE on risk factors at the same visit. Because some time-varying covariates such as BMI are missing simultaneously with the outcome MMSE, we impute them as well. We use the JM imputation for uniform mapping, and we impute the data for 100 times. After imputing data, we conduct the regression with the same working model used in the simulation. We use the JM imputation for uniform mapping, and we impute the data for 100 times. After imputing data, we conduct the regression with the same working model used in the simulation. The p-value for testing whether
The results of the primary analysis using different models are summarized in Table 4. The naive and IPW models produce similar results, with both indicating the significance of covariates APOE, age, depression, and BMI. Specifically, the APOE genotype that carrying
Estimation results for the risk-effect model with three-year dementia as the primary outcome using the NACC study.
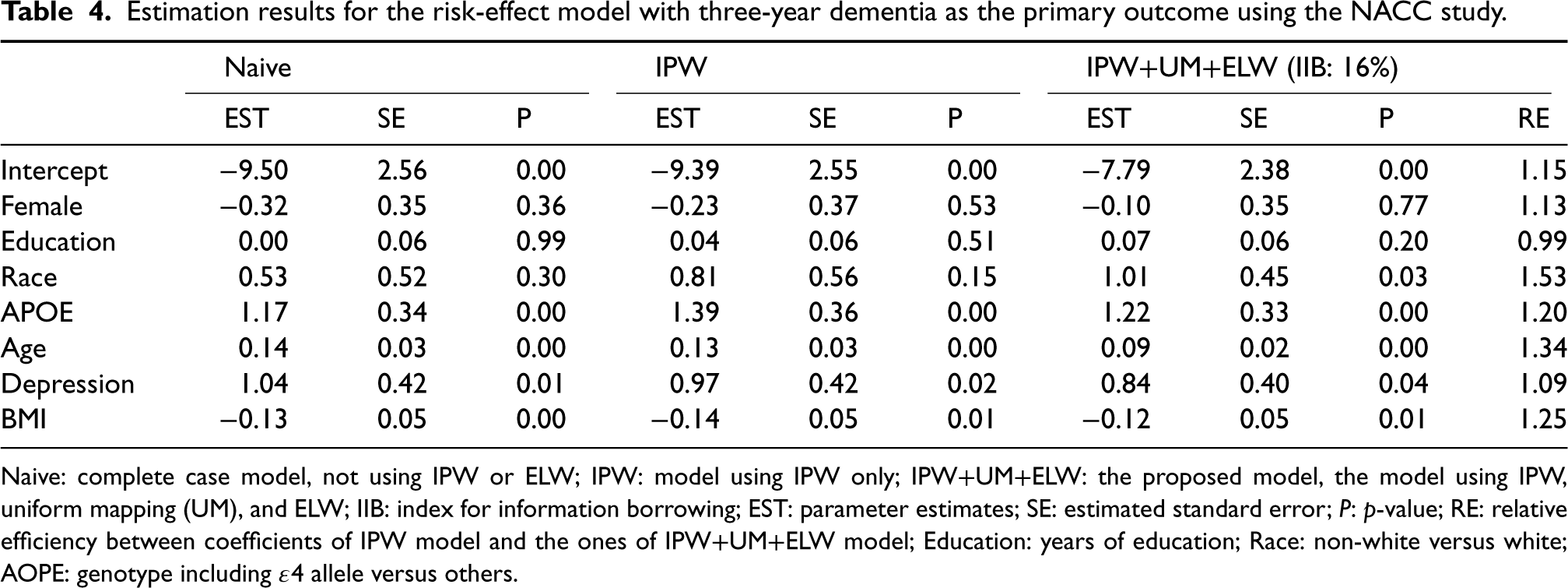
Naive: complete case model, not using IPW or ELW; IPW: model using IPW only; IPW
For more in-depth investigation, we also consider another longitudinal continuous variable, the global score from the Clinical Dementia Rating (CDR) Dementia Staging Instrument, as the secondary outcome, and the post-hoc analysis results are presented in the Supplemental Material due to space limitations and relatively weaker efficiency improvement. In practice, we recommend researchers to consider different variables as the secondary outcome for sensitivity analysis and explore their potentials for efficiency gain. How to synthesize information from multiple secondary outcomes simultaneously into the primary analysis to further improve the efficiency and robustness is one of our ongoing work. 28 Furthermore, we have not explicitly considered competing risk events, such as deaths, due to the relatively low death rate within our cohort over the three-year period (2%). Under such scenario, any impact on our results is expected to be minimal and negligible, rendering them robust and valid, which are further verified by our post-hoc empirical studies. However, informative censoring resulting from deaths warrants further investigation as part of our model extensions, a direction we intend to explore in our future work.
In this work, we generalize an existing data borrowing method and propose an extension into the context of missing data with improved efficiency and robustness. We adopt the IPW technique to ensure the unbiasedness of the primary outcome analysis and further propose a uniform mapping strategy to take care of secondary outcomes analysis by employing multiple imputations to facilitate homogeneous secondary outcomes in the sense that it is governed by a unified
It’s worth noting that there are alternative techniques for leveraging information from secondary outcomes, such as structural equation modeling (SEM), although they are not applied in our current context. SEM is a statistical method used to explore complex (causal and directional) relationships among variables, both observed and latent, requiring the specification of a path diagram and a model between primary and secondary outcomes. However, our method pursues a distinct objective aiming to improve the efficiency of our primary outcome analysis. Also, we do not necessitate the specification of directional relationships between primary and secondary outcomes, which could be challenging to disentangle in various circumstances. Therefore, our method offers broader applicability, robustness, and generalization. It’s worth emphasizing that our approach can be integrated into SEM to enhance causal inference within that specific framework, a direction we plan to delve into further in our future research.
Motivated by our application, we currently consider the primary outcome is cross-sectional and secondary outcomes are longitudinal. Of note, our method can be flexibly extended to other contexts beyond our current contexts. For instance, the IPW method can be applied to longitudinal data, such as WGEE. 18 Our method can also handle cross-sectional secondary outcomes by constructing an over-identified estimating equation based on them. 8 Besides, there are other ways to handle missing data in the primary analysis, such as imputation and the EM algorithm. How to combine these methods with ELW and uniform mapping effectively and efficiently is of great interest. Additionally, we aim to explore borrowing information from multiple secondary outcomes to further improve our method’s effectiveness. Furthermore, our current focus in data application lies on examining the main effects of the risk factors. However, it would be intriguing to explore their interactions within the model and devise information criteria for selecting interaction terms, thereby potentially enhancing the informativeness of our findings. These topics will be investigated in future studies.
While our work mainly assumes fully observed covariates, we acknowledge that in practice, the covariates are often missing simultaneously with the outcomes. Nevertheless, our proposed method remains valid when the outcomes are MAR, and we can easily extend our method to impute the missing covariates along with the outcomes. In some cases, the uniform mapping may introduce variability to the estimator, resulting in reduced efficiency compared to the ELW estimator not involving the uniform mapping. Thus, the uniform mapping strategy can be viewed as a remedy to the secondary analysis when a unified
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241254195 - Supplemental material for Robust integration of secondary outcomes information into primary outcome analysis in the presence of missing data
Supplemental material, sj-pdf-1-smm-10.1177_09622802241254195 for Robust integration of secondary outcomes information into primary outcome analysis in the presence of missing data by Daxuan Deng, Vernon M Chinchilli, Hao Feng, Chixiang Chen and Ming Wang in Statistical Methods in Medical Research
Footnotes
Acknowledgements
Wang’s work was supported by the start-up funding from Department of Population and Quantitative Health Sciences at Case Western Reserve University. The contents of this article are solely the responsibility of the authors, and do not represent the official views of NIH.
This article was prepared using the NACC database, which is funded by the National Institute of Aging (NIA) of the NIH Grant U24 AG072122. NACC data. NACC data are contributed by the NIA-funded ADRCs: P30 AG062429 (PI James Brewer, MD, PhD), P30 AG066468 (PI Oscar Lopez, MD), P30 AG062421 (PI Bradley Hyman, MD, PhD), P30 AG066509 (PI Thomas Grabowski, MD), P30 AG066514 (PI Mary Sano, PhD), P30 AG066530 (PI Helena Chui, MD), P30 AG066507 (PI Marilyn Albert, PhD), P30 AG066444 (PI John Morris, MD), P30 AG066518 (PI Jeffrey Kaye, MD), P30 AG066512 (PI Thomas Wisniewski, MD), P30 AG066462 (PI Scott Small, MD), P30 AG072979 (PI David Wolk, MD), P30 AG072972 (PI Charles DeCarli, MD), P30 AG072976 (PI Andrew Saykin, PsyD), P30 AG072975 (PI David Bennett, MD), P30 AG072978 (PI Neil Kowall, MD), P30 AG072977 (PI Robert Vassar, PhD), P30 AG066519 (PI Frank LaFerla, PhD), P30 AG062677 (PI Ronald Petersen, MD, PhD), P30 AG079280 (PI Eric Reiman, MD), P30 AG062422 (PI Gil Rabinovici, MD), P30 AG066511 (PI Allan Levey, MD, PhD), P30 AG072946 (PI Linda Van Eldik, PhD), P30 AG062715 (PI Sanjay Asthana, MD, FRCP), P30 AG072973 (PI Russell Swerdlow, MD), P30 AG066506 (PI Todd Golde, MD, PhD), P30 AG066508 (PI Stephen Strittmatter, MD, PhD), P30 AG066515 (PI Victor Henderson, MD, MS), P30 AG072947 (PI Suzanne Craft, PhD), P30 AG072931 (PI Henry Paulson, MD, PhD), P30 AG066546 (PI Sudha Seshadri, MD), P20 AG068024 (PI Erik Roberson, MD, PhD), P20 AG068053 (PI Justin Miller, PhD), P20 AG068077 (PI Gary Rosenberg, MD), P20 AG068082 (PI Angela Jefferson, PhD), P30 AG072958 (PI Heather Whitson, MD), and P30 AG072959 (PI James Leverenz, MD).
Author contributions
All authors have made important contributions and have approved this work.
Data availability
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.