
Abstract
Mass media have long provided general publics with science news. New media such as Twitter have entered this system and provide an additional platform for the dissemination of science information. Based on automated collection and analysis of >900 news articles and 70,000 tweets, this study explores the online communication of current science news. Topic modeling (latent Dirichlet allocation) was used to extract five broad themes of science reporting: space missions, the US government shutdown, cancer research, Nobel Prizes, and climate change. Using content and network analysis, Twitter was found to extend public science communication by providing additional voices and contextualizations of science issues. It serves a recommender role by linking to web resources, connecting users, and directing users’ attention. This article suggests that microblogging adds a new and relevant layer to the public communication of science.
Keywords
1. Introduction
Mass media and the Internet are the main sources of science information and research-based knowledge for a general public (Brossard, 2013; Horrigan, 2006; National Science Board, 2014; Wade and Schramm, 1969). Science news outlets thus constitute an important interface between the scientific community and a broader public. Twitter, the dominant microblogging platform (see Van Dijck, 2011), functions as an “ambient news network” (Hermida, 2014). It potentially complements traditional science communication by affording new ways to disseminate, consume, and discuss scientific issues and findings. Despite initial dismissal of microblogging as just another way of spreading trivialities, Twitter does seem to provide useful functionalities that have promoted its diffusion (Arcenaux and Schmitz Weiss, 2010); currently, 23% of online American adults use Twitter (Duggan et al., 2015).
The communication of scientific knowledge in a networked public sphere is part of larger structural changes in how modern complex societies produce information, knowledge, and culture (see Benkler, 2006; Han, 2010; Weinberger, 2012). Effective public engagement in science requires mediated forms of communication where differences in expert knowledge, values, and goals can be articulated and discussed (Nisbet and Scheufele, 2009)—traditional media, however, have by design largely supported a unidirectional form of science communication. Recent studies that took new media into account explored the communication of single science topics such as climate change (Veltri and Atanasova, 2015), nanotechnology (Veltri, 2013), human genome research (Gerhards and Schäfer, 2010), or food contamination (Shan et al., 2014). The question of how Internet-enabled services affect science communication—from websites promoting scientific knowledgeability (Eveland and Dunwoody, 1998) to blogs and videos (Ranger and Bultitude, 2014) to Google and Wikipedia (Segev and Sharon, 2016)—deserves continued attention due to accelerated media change (see Brossard, 2013).
2. The flow of knowledge in mediated social systems
Producing science news
The flow of knowledge from a semi-public scientific community to a broader general public is generally mediated by dedicated science reporters (Trench, 2007). They pick up scholarly output and produce news. Turning research results into valuable information is vital for the public understanding of science as well as the democratic decision-making processes in public policy (e.g. Kennedy, 2010). Still, this normative role of mass media need not degrade popular science to a mere derivative of “real” science as the production of knowledge is always subject to various social influences (see Hilgartner, 1990). Science reporting is a form of specialist journalism where formal training in the science fields reported on is less important than journalistic professionalism and news values (Hansen, 1994). In new media such as blogs, professionals and amateur enthusiasts are driven more by personal motivations (Ranger and Bultitude, 2014).
Given the vital societal role of science news, it is noteworthy that scientists often regard traditional science reporting as poor (Ashwell, 2014)—this opens up opportunities for new media. Or as Edward J. Robinson (1963) concluded more than 50 years ago, “the mass media should not be expected to carry the whole burden of reporting science news” (p. 313). He suggests, “supplementary media and techniques such as the use of company publications, speeches to civic groups, open houses, etc.” (p. 313). Does Twitter serve as a supplementary medium for science news today?
The integration of new media in science communication
The technologies and platforms that enable online public communication—natively web based or adapted from offline—also structure the production, representation and distribution of scientific knowledge (also see Schäfer, 2014). Negatively expressed, new media such as Twitter interfere with the traditional model of scientific and journalistic knowledge production and representation. The positive formulation is that new media can enhance the communication processes shown in Figure 1 and eventually transform science communication as new communication models, and nontraditional actors gain relevance (Bucchi, 2013). New media as platforms constitute a technical frame for communication that is interpreted and put into practice by various users, including journalists and scientist. As Figure 1 shows, their practical uses may materialize in several forms: conversation, dialogue, collaboration, and exchange (two-way communication); self-communication, status updating, and monitoring (one-to-many communication); and information sharing, news sharing, and marketing (many-to-many communication; Van Dijck, 2011: 337).
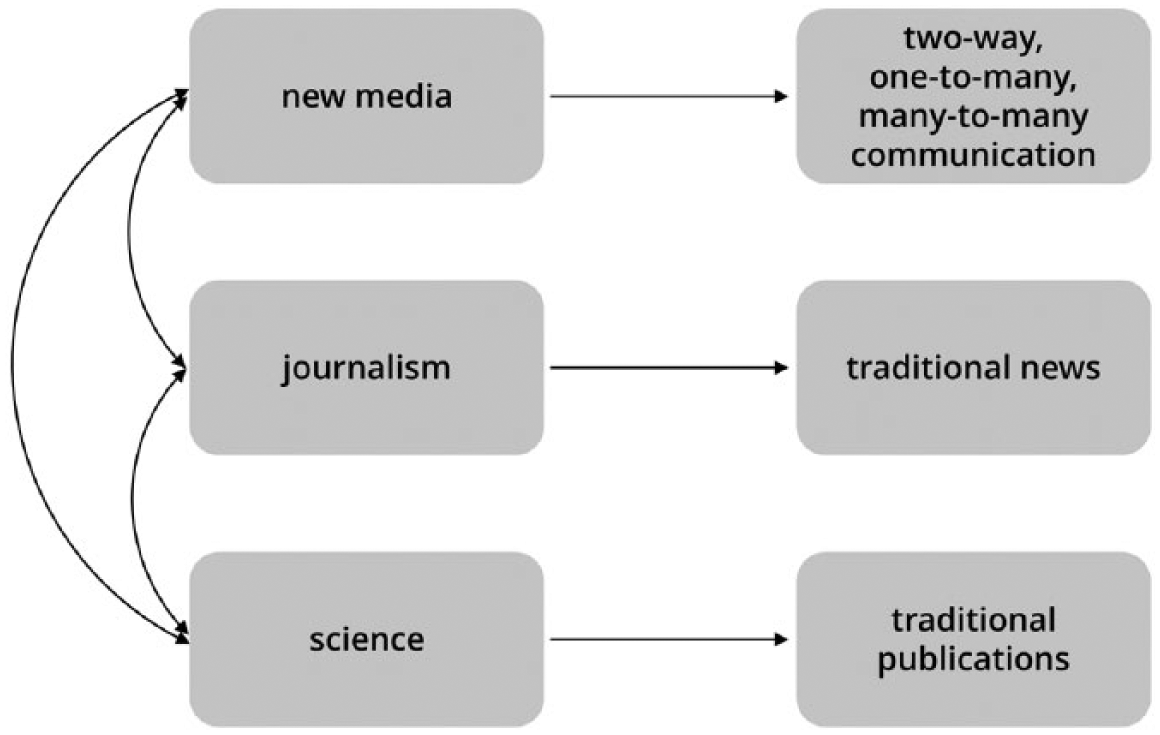
Science, journalism, and new media as connected fields of communication.
Essentially, new media are remediatizing the “science-media interface” (Peters et al., 2008) and the science–public interface. For instance, science is affected in that researchers have new possibilities of staying up to date or collaborating (e.g. Bik and Goldstein, 2013; Meyer and Schroeder, 2009). Traditional scholarly output such as journal articles is now complemented by forms of self-publishing, multi-media content, and data (e.g. Rzepa, 2011). New media can link interested amateurs with science projects to foster citizen science (e.g. Silvertown, 2009). Future developments may even lead to an increased merging of the production and the publication subsystem including general publics—a development discussed under the label of “open science” (Neuberger, 2014: 337). Journalists can use new media as sources for investigation and interact with scientists in perhaps more informal and immediate ways (e.g. Fahy and Nisbet, 2011). The traditional formats of news such as newspaper articles can be tied to commenting features or news organizations can distribute their content via application programming interfaces (APIs) for reuse on different platforms (see Aitamurto and Lewis, 2013).
The simplistic idea that scientists transmit their “superior knowledge” to the public via mass media has faded (Schäfer, 2011); the notion of completed facts being unidirectionally transferred to the public needed revision even before interactive online media emerged (Bucchi, 1998, 2004; Hilgartner, 1990; Weinberger, 2012). New models, therefore, incorporate the evident mutual interrelations of science, the media, and the public (Schäfer, 2011: 400–401), but new media have not been systematically integrated into theories of science communication and public engagement with science. New media afford the possibility for public discussions, new voices, and new contexts (see Atton and Wickenden, 2005; Batts et al., 2008; Shan et al., 2014), but research has also shown that online sources’ actors and frames hardly differ from those of print media (Gerhards and Schäfer, 2010). It is thus argued that the comparison of old and new forms of science communication deserves continued attention from social science research.
Twitter, the de facto standard platform for microblogging, has shifted from being primarily a social communication tool to a global news and information following tool (Van Dijck, 2011). On the basis of graph analysis, recent in-house research from Twitter unsurprisingly concluded that the platform is both an information network and a social network (Myers et al., 2014). Another large-scale study showed that the trending topics are mostly news in nature and point to the potential of Twitter to rapidly diffuse such content via retweets and the large implied audiences (Kwak et al., 2010). Traditional news outlets can drive traffic to their own media products through strategic use of Twitter (Hong, 2012). Beyond reposting prominent messages, ordinary users also extend news on Twitter by commenting on current issues (Subasic and Berendt, 2011) and may form conversational clusters around current issues (Smith et al., 2014).
Twitter has been of interest to science communication scholars (Puschmann, 2014). For example, Shan et al.’s (2014) content analysis of the 2008 Irish dioxin crisis showed that “Twitter mainly functioned as a news information disseminator” (p. 924). Their study investigated 175 social media documents (68 tweets) and compared them with 141 newspaper articles (Shan et al., 2014). In terms of topic contextualization, they find that social media emphasize global reaction, the government’s handling, and public perception more (Shan et al., 2014: 921). Veltri (2013) collected 24,634 tweets on nanotechnology and found that communication is not conversational but rather dominated by very few “power users” while issue framing is congruent with newspaper reports.
The diverse features of new media have the potential to make them relevant during the entire process of information diffusion—from first exposure to potential attitude changes. The popularization of (science) issues depends on broadcasting functionalities afforded by new media such as Twitter, while the high trust put in interpersonal relationships maintained on such platforms supports their perpetuation (see Karnowski, 2011). This means that the multi-step flow of communication (Katz and Lazarsfeld, 1955) can be contained in a single medium. While the roles of sources, opinion leaders, and audience are dynamic in the new media environment, empirical findings show that mainstream news organizations can hold considerable influence across a variety of topics (Cha et al., 2010).
The primary substantive interest of this work lies in assessing the role of science tweets: Has the emergence of Twitter as a new media representative extended science communication? Do topic contextualizations between traditional online news outlets and microblogs diverge? Does Twitter add anything to science news beyond disseminating the reports of established media outlets? An a priori confinement to nanotechnology or climate change, for example, is inept for such questions as the interest does not lie in the single issue but potentially generalizable platform differences. Research question 1 thus involves the identification of popular science topics and the comparison of two platforms regarding their contextualization operationalized as co-occurring terms:
RQ1. Content of news and tweets. How does the contextualization of science topics differ between online news and microblogs?
Given that traditional news have received much more attention from science communication research than new media—apart from blogs perhaps—a closer look at the science information sharing practices of Twitter users is warranted. The focus here lies on the structure of science tweets (e.g. references to other users or the use of web links) as well as the topology of the network produced by users’ communicative behavior.
RQ2. Structure of tweets. How are science news topics communicated on Twitter?
Both research questions are used to explore the “science news Twitterverse” and draw conclusions about the affordances of microblogs in science coverage.
3. Methods and data
Linking news and tweets via automated topic extraction
In contrast to numerous empirical studies on media representations which selected scientific issues a priori (see Schäfer, 2007: 63–75)—nanotechnology appears to be particularly popular (e.g. Retzbach and Maier, 2014; Veltri, 2013)—the approach here was to dynamically detect current and prevalent public science topics (Figure 2).
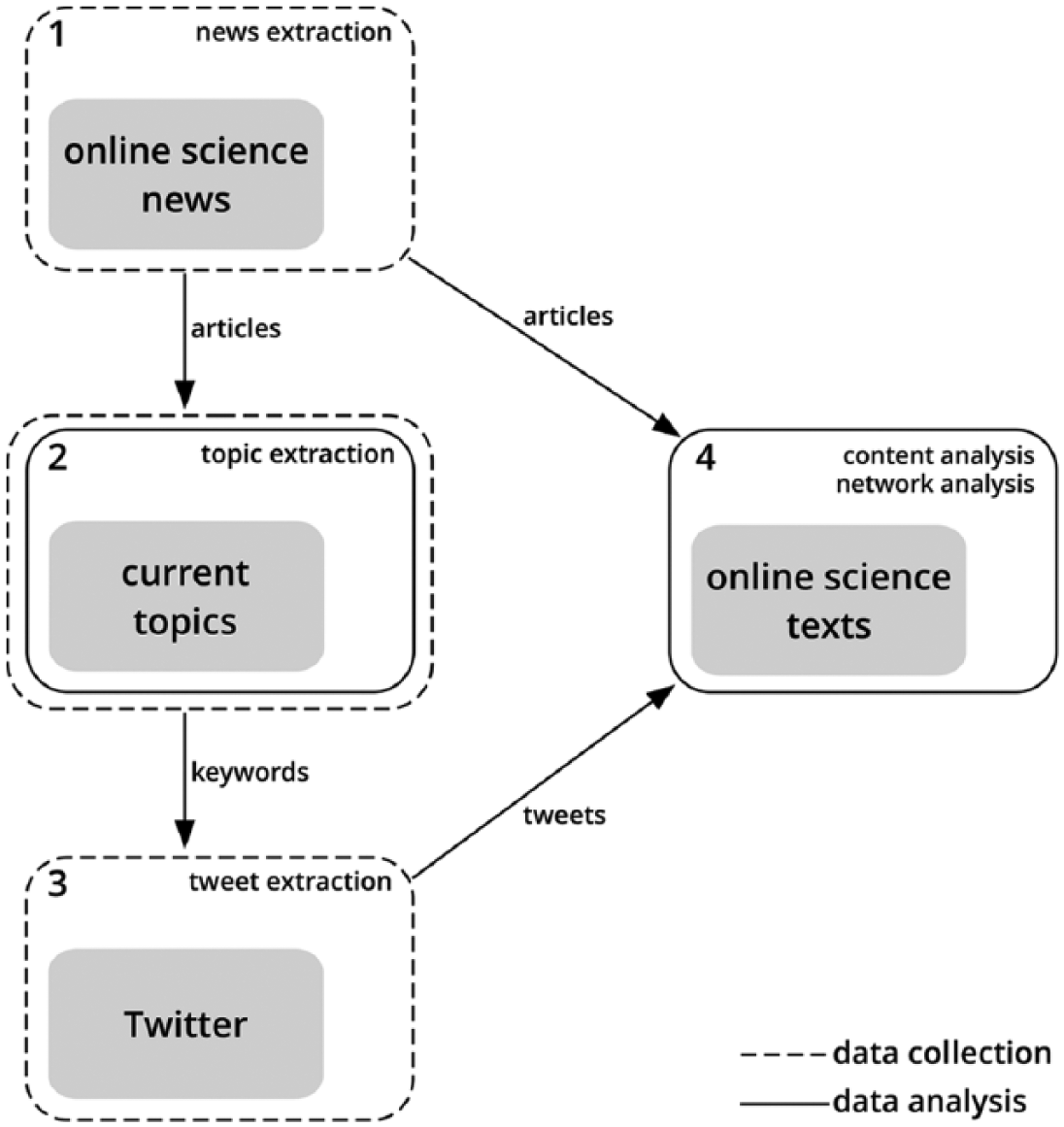
Study overview.
Based on Kleinberg and Lawrence (2001), Weber and Monge (2011) identified three relatively distinct roles in the flow of online news: sources, authorities, and hubs. The selection of news sites considered in the present study thus aimed to reflect this spectrum. The dedicated online science sections of the following sites were used: Reuters and Associated Press (AP; sources), The New York Times and BBC (authorities), and The Huffington Post and Yahoo (hubs). These news platforms represent traditional media (see Gerhards and Schäfer, 2010), whereas Twitter represents new media.
The research questions of this study posed a methodological challenge regarding the collection and analysis of web content (see Weare and Lin, 2000): How can science texts be sampled on different platforms? To further complicate the issue, the theoretical interest required that the data were not restricted to a single theme (such as climate change). This study provides an innovative solution to building a corpus of science news articles and corresponding tweets by dynamically linking the two platforms with an integrated data collection and data analysis step (Figure 2, step 2).
The first step (news extraction) in Figure 2 used rich site summary (RSS) feeds of the science sections of the news sites to gather the URLs of the all newly published articles. A script then followed these links and extracted the text body of the articles. In step 2 (topic extraction), three topics per day were automatically detected. These current news topics were represented by two keywords each (e.g. “space station”) that were then used in step 3 (tweet extraction) as search terms (e.g. “space and station”) in the Twitter API. This generated corresponding Twitter data that included the publication time, user name, retweet status, and tweet content. The automated data collection process (steps 1–3) and the content analysis (step 4) were performed in the programming language and software environment R (see Jackman, 2006). Network analysis (step 4) was conducted in the software package Gephi.
The method by which the topics of science texts were detected was latent Dirichlet allocation (LDA; Blei et al., 2003). This topic modeling approach differs substantially from communication research’s traditional content analyses in that it is automated and unsupervised (Grimmer and Stewart, 2013): There is no training data, no human coding, and no codebook. In essence, an algorithm detects words that are likely to appear together based on distributional assumptions. The only inputs for this generative approach are the number of topics to detect and a (large) text corpus (Mohr and Bogdanov, 2013; Weng et al., 2010). This method conceptualizes documents as a probabilistic mixture of latent topics, that is, a collection of related words—each topic contributes manifest words to the document (Blei, 2012). Each document exhibits multiple topics, and LDA retrospectively determines out of which pool of words, that is, topic space, a term was most likely selected (Blei et al., 2003). This automated coding results in meaningful and plausible readings of texts with high levels of “substantive interpretability” (DiMaggio et al., 2013: 578). The method is key to linking online news articles with tweets (Figure 2): Even if corpus size were not an issue, near-simultaneous data collection of corresponding tweets would not have been feasible using manual topic extraction.
Comparing topic contexts across traditional and new media
As a precondition for RQ1, mallet LDA topic models (Mimno, 2015) were run on both the news article corpus and the dependent Twitter corpus. The number of topics, which necessarily needed to be specified, was set to 35, and the five terms with the highest weights were used as indicators of broad themes (see section “Five broad science topics in the news: Space missions, US government shutdown, cancer, Nobel Prizes, and climate change”). This strategy of using automatic LDA and then interpreting the high-level classes was shown to yield very good results, comparable to interhuman agreement in manual coding (see Razavi et al., 2013). These analyses used a random subsample of 10,000 tweets because system memory limitations did not allow for the complete corpus to be processed; all news articles were used. To then analyze the contextualizations of these topics (RQ1), a bag-of-words approach (see Grimmer and Stewart, 2014) was employed with lower case conversion and whitespace, number, punctuation, and stopword removal (see Feinerer et al., 2008). The corpora were transformed to term–document matrices for co-occurrence analysis (Scharkow, 2012). The co-occurrences between representative terms of each broad theme and terms from the rest of the corpus revealed how Twitter and traditional news outlets contextualized current science topics. The resulting terms and coefficients were qualitatively interpreted using domain knowledge from web searches (see Mohr and Bogdanov, 2013).
Tweet structure and mention network analysis
RQ2 was addressed by analyzing the structure of tweets as well as the mention network. The prevalence of internal (mentions and retweets) and external (use of URLs) references in the science tweet sample was compared to a baseline. A mention of another Twitter user in a tweet could occur due to conversational interactions, (modified) sharing of others’ tweets, or referencing someone as a source. Every mention thus produced a connection (edge) between two Twitter user accounts (nodes). To further investigate the communication of science topics on Twitter, these user relations were extracted and visualized as a network. Only those users in the data who had at least one mention tie were used. The mention network extracted from the Twitter data comprised 37,190 edges between 41,228 nodes. Network metrics and visual interpretation were used to analyze components (subsets of the total network) and the indegree distribution (the number of received mentions; see Easley and Kleinberg, 2010).
Five weeks of science news content
Data were collected during a period of 35 consecutive days (5 weeks), from 23 September 2013 to 27 October 2013. A total of 55,697 unique Twitter users created 72,469 tweets matching the news topic search terms. A total of 965 articles were obtained from the science news RSS feeds of the six online news platforms (AP, Reuters, The New York Times, BBC, The Huffington Post, and Yahoo).
Despite having analyzed about 75 times more Twitter documents than news documents, the tweet corpus was only 1.45 times larger with respect to characters (8.3 and 5.7 million, respectively). The average day yielded 28 articles. The average number of tweets returned per day was 2070, the theoretical maximum being 4500 due to API limitations. Using all six news platforms, a clear weekly reoccurring pattern was evident with a peak around Thursdays and lows on Sundays and Mondays. The news platforms The Huffington Post and Yahoo (type hub) were most active. The news wires AP and Reuters (type source) each had several days without any articles—as did BBC (type authority). The other authority, The New York Times, matched the overall mean of about 4.5 science articles per day. The mean document length was about 18 words for tweets (skewed toward the platform’s limit of 140 characters) and 980 words for news articles. Because automatic tweet extraction could fail due to unknown character encodings, the script had to be restarted on 9 days.
4. Results
Five broad science topics in the news: Space missions, US government shutdown, cancer, Nobel Prizes, and climate change
Before analyzing any differences between news and tweets, it is necessary to know which science topics were covered during the time of data collection. Using the news article corpus, an LDA model was run, and the top words were interpreted to find general topics (see Razavi et al., 2013; Weng et al., 2010). The same was done for the Twitter corpus; since by design the sample of tweets depended entirely on the news, this yielded very similar results. The five main terms were discovered in the combined online science texts. These were space, government, cancer, Nobel Prizes, and climate. Other high-weight terms clearly assignable to one of the main five terms were also included in the co-occurrence analysis to achieve a more precise outline of each theme (Table 1, first column).
Science topic contextualizations for news articles and tweets.
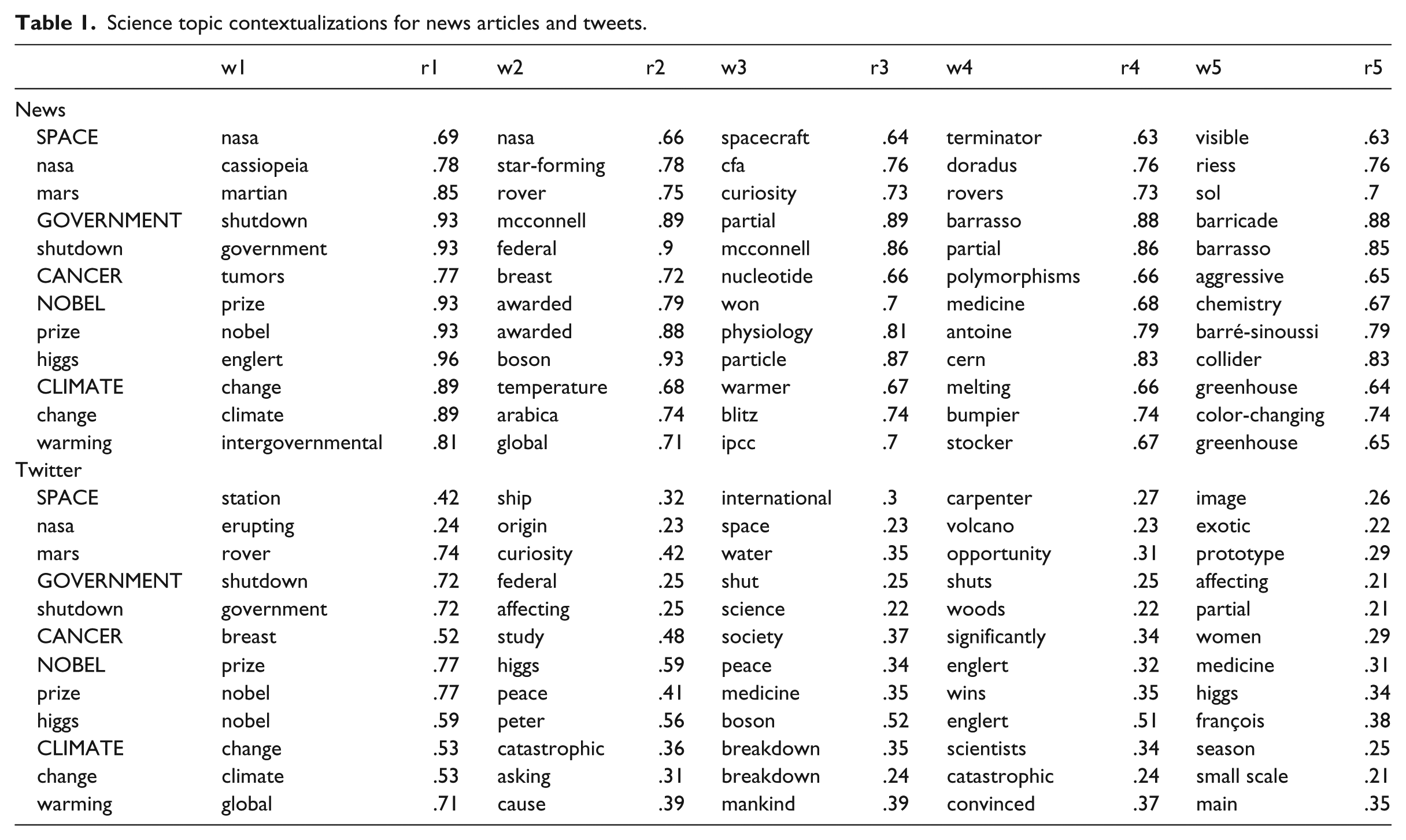
In sum, science reporting from major English-language news sites during the fall of 2013 predominantly featured NASA space missions, the US government shutdown, cancer, Nobel Prizes, and climate change. These foci of science reporting reflect organizational selection processes based on news values such as relevance, reference to elite people, or negativity (Galtung and Ruge, 1965). The first criterion, perceived relevance to the reader, has specifically been shown to guide science news selection (Hansen, 1994). The five themes also show that news organizations collapse science, medicine, and technology into their science sections (see Lewenstein, 1995: 344).
Twitter has been found to reproduce the diversity of news (Bastos and Zago, 2013); therefore, it is consequential that there was simultaneous tweeting on all five broad science news topics, indicating high “transmissibility” of these issues (Milkman and Berger, 2014). The next step then was to evaluate the topic contexts and differences between traditional news outlets and Twitter.
Old and new media contextualizations of popular science (RQ1)
The term co-occurrence analysis to compare the topic contextualizations between news and Twitter used 12 keywords that cover the five broad topics (Table 1). The five upper case terms in Table 1 best represent each topic in a single word, and the lower case terms frequently co-occurred with them and further specify the topic. Thus, Table 1 reveals which words frequently appeared together in a document (news article or tweet, respectively), and this illustrates which issue contexts or subtopics were dominant. For example, in the news corpus, the term “mars” was strongly correlated with “curiosity” (.73); this was the third highest correlation for “mars.” In the Twitter corpus, “mars” was also correlated with “curiosity” (.42), albeit less strongly. Still, it was the second highest correlation for this topic word on Twitter, meaning the comparative interpretations below are based on the type and order of the terms rather than on direct comparisons of coefficients across platforms. In this case, news articles and tweets covered NASA’s Mars rover called Curiosity—a research article released during the study time period reported findings of water in Martian soil detected by Curiosity (Leshin et al., 2013).
The topic of NASA space explorations, in the news articles, was associated with rather specific terms such as Cassiopeia, a supernova remnant of which new images were made by NASA’s X-ray observatory. A star-forming region near the Milky Way named Doradus was also reported on. Tweets, however, seemed more concerned with NASA satellites improving volcano eruption forecasts. The government shutdown topic in the news focused on prominent individuals: John Barrasso and Mitch McConnell are both US senators. The contextualization of the shutdown seemed broader on Twitter. Interestingly, the term “science” in tweets was strongly associated with the government shutdown indicating that the payment default for science programs was discussed (see Maron, 2013). Cancer as a recurring science topic generally dealt with breast cancer on both platforms. In the news, “nucleotide” and “polymorphism” were often mentioned which refer to a DNA sequence variation. Nobel Prizes were again associated with similar terms in news and tweets: the Higgs boson, its place of discovery CERN, medicine, and peace. The Nobel Prize announcements traditionally begin in October, which was during data collection.
Climate, a major topic in science news, was clearly discussed in terms of global warming and climate change. The Intergovernmental Panel on Climate Change (IPCC) had set an upper limit for greenhouse gas emissions in late September 2013. This United Nations panel’s proceedings constituted the context of climate discussions in the news in the fall of 2013 (see Pearce et al., 2014). Simultaneously, Twitter users’ communication was more emotional: associated terms were “catastrophic” and “breakdown.” A very interesting finding is that tweets seemed concerned with the anthropogenic causes of global warming (see Veltri and Atanasova, 2015).
The recommender role of Twitter (RQ2)
The above results illustrated the contextualizations of science topics in Twitter and news. In the following findings on the structure of tweets and the mention network describe how science news topics are communicated on Twitter. Of the tweets collected for this study, 35.7% were retweets, 71.4% included a URL, and 51.5% contained a mention (Figure 3). These structural attributes clearly show that science tweets are rarely intended to be self-contained.
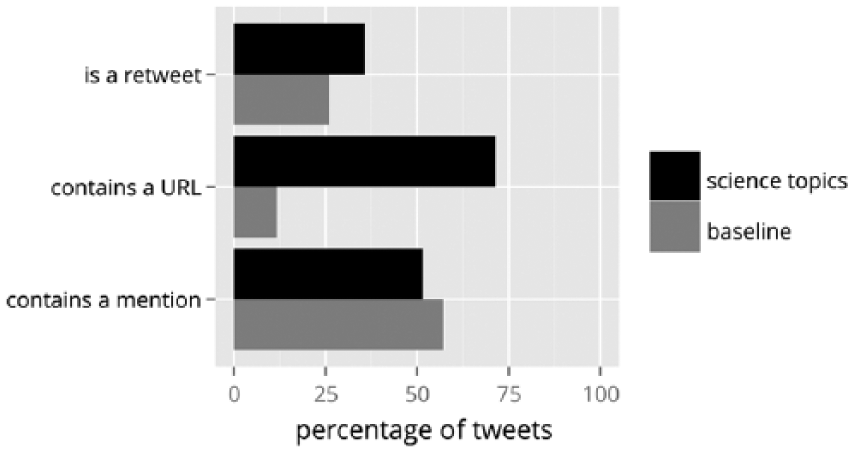
The structure of science tweets.
These values for tweets about science topics are most informative when compared to a baseline, that is, corresponding percentages for random non-topic-restricted tweets (Figure 3). Partly owing to the very large sample size, all deviations from the baseline were statistically highly significant. The proportion of retweets was slightly above the baseline, so disseminating existing science messages to one’s followers is comparably prevalent. Even though retweets are not original content, the practice of retweeting pushes messages to new networks of followers. Roughly half of the science tweets contained a mention to another user in some form (by retweet, reply, or genuine mention), which was just slightly below the general rate. The most remarkable and substantively significant deviation from the baseline was in references to external resources via URLs. This certainly makes sense when thinking about communicating science in microblogs that are limited to 140 characters. Twitter users referenced web resources in 71% of all science tweets compared to a vastly smaller 12% in general tweets.
The topology of the reference network extracted from the tweets featured several distinct characteristics. The distribution of received mentions (indegree) was L shaped, meaning the vast majority of users received very few mentions, whereas a small number of users were mentioned very frequently. A generalized linear model estimation showed a close fit to a power law distribution with an exponent of 2.28 (see Easley and Kleinberg, 2010: 543–555). The largest connected component, that is, the subset of Twitter users who are directly or indirectly connected through mentions, comprised 38.7% of all network nodes (Figure 4). The size of this component was exponentially larger than any of the remaining 8135 components—the second largest contained only 1.5% of the nodes. The Twitter accounts of the six news platforms were all part of the giant component, where for example, The Huffington Post employed multiple specialized accounts. Simply put, those users in the giant component were part of the science news conversation. Due to the imperfections of topic modeling, the many smaller components mostly revolved around other topics in the collected tweets such as “cancer” as an astrological sign rather than the disease.
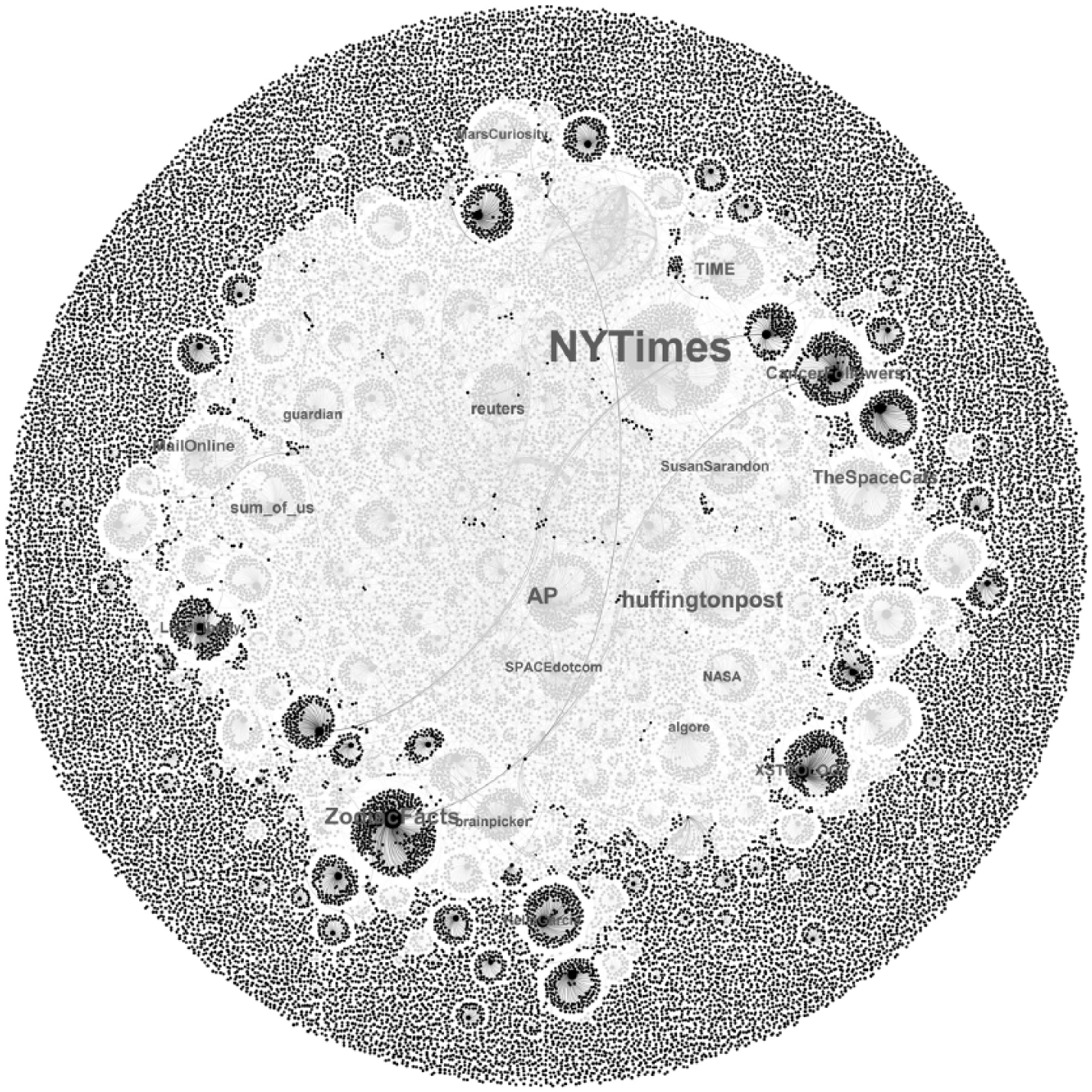
Twitter mention network.
Most mentioned overall was The New York Times Twitter account (NYTimes). Looking further at the giant component (Figure 4), many other news outlets besides the six used for sampling news articles were also present (e.g. TIME, guardian). Celebrity activists (Al Gore, Susan Sarandon), a scholarly blogger (brainpicker), and specialist accounts (MarsCuriosity, SPACEdotcom) complemented the high-indegree list. The rest of the giant component was made up of thousands of users, both organizational and individual, referencing and retweeting each other in tweets that mostly contained an external web link. The most mentioned accounts provided a kind of anchor for the practice of tweeting about a science topic with references to them as information sources.
This network analysis supports the idea that Twitter enables different types of users to become part of a greater conversation (i.e. the giant component) by spreading or commenting on news (see Murthy, 2012: 1064; Pearce et al., 2014). The highly skewed distribution of mentions, however, demonstrates that established organizations, most notably The New York Times, are able to retain their dominant position as trusted news sources.
5. Discussion
Main findings and implications
This research was designed to explore the “science news Twitterverse.” The study makes an important step past hashtag-coordinated or expert-constricted Twitter activity by dynamically linking tweets and news articles with automated topic extraction. Based on content analysis of science tweets, instances were highlighted where the discussion of a current science topic on Twitter (most notably, climate change) differed considerably from the dominant contextualization provided by news platforms during the period of study. Other topics exhibited virtually no differences—or at least they were not detected with the methods employed—which highlights the need to differentiate between different science issues (see Schäfer, 2009). The structure of tweets as well as the network topology of mentions showed that Twitter directs attention to science news and comments, thereby fulfilling a recommender role. Mentions are also a way of crediting sources and signaling credibility by referencing authorities.
Network visualization further revealed that frequently mentioned users are not only established institutions such as the news platforms themselves but also additional actors, from activist collectives (e.g. YourAnonNews) to influential individuals (e.g. brainpicker) who contribute new voices. Figure 4 reveals that these new actors produce local hub-and-spoke networks that are very similar to those around traditional news outlets. Some conversational patterns emerge in the network but a pronounced and unidirectional focus on big traditional players such as The New York Times is evident. This finding is in line with research that has found Twitter discussions to rely heavily on professional sources of information (Veltri and Atanasova, 2015). Overall, the network extracted from the science tweets features properties of two ideal-type structures: “community clusters” (Smith et al., 2014: 35) and “broadcast network” (p. 41). This means that multiple hubs—primarily news outlets—provide different sources and perspectives on a current issue, while many users retweet the central actors’ messages. The majority of these users are connected only to one of the central hubs, but there are also smaller groups of interconnected users who comment and discuss the science topics. In summary, these findings demonstrate that microblogging on Twitter extends public science communication by providing additional voices and contexts as well as recommending content and directing attention.
This extension of science communication may allow publics to share and find information essential for the interpretation of scientific developments and how they relate to their social realities. Vital to the understanding and judgment of new knowledge are the context and method of its creation (Kua et al., 2004)—yet science reporting frequently omits such information in an attempt to minimize complexity (Pellechia, 1997). While a 140-character tweet cannot fill this void, microblogging does generate an additional layer of science communication with new sources, voices, and interpretations. This is in line with others who have observed that news reporting and tweeting have become intertwined by means of (science) communication (Bastos and Zago, 2013; Subasic and Berendt, 2011). Twitter may be seen as a platform where both the public’s understanding of science and scientists’ understanding of the public are made visible.
Gerhards and Schäfer (2010) demonstrated that “internet communication does not differ significantly from the offline debate in the print media” (p. 143). This study, however, does not draw the analytical line between offline and online but rather differentiates between traditional and new forms of communication that both happen online. Twitter did differ considerably in terms of topic contextualization, particularly for the climate change theme, and let new voices surface. Robinson’s (1963) “supplementary media” (p. 313) have found their feet alongside traditional formats.
Limitations and future research
The public agenda as reflected in new media is not identical to that of traditional news, with influences in either direction (Neuman et al., 2014). In this article, the media agenda was taken as a pragmatic starting point for data collection (Figure 2). This implies an important limitation of this study: Topics emerging first or exclusively on Twitter could not be detected (see Rogstad, 2016).
Quantitative and automated content analyses were crucial for the analysis, yet this introduced the problem of ambiguity. Human reading of random tweets containing the search term “cancer” revealed that several users were talking about astrology rather than the disease. In spite of this, tweets containing the word “cancer” dominantly discuss medical issues (Table 1). The topic models were not able to generate perfect keywords; therefore, part of the collected tweets deal with non-science-related issues. Furthermore, in qualitatively interpreting the output of the co-occurrence analysis, domain knowledge is crucial. For example, the term “curiosity” is highly correlated with “mars”—one needs to know that Curiosity is NASA’s robotic rover. If unknown, most terms can be quickly researched, for example, IPCC, which was correlated to “warming.” Regarding the network analysis, it must be acknowledged that the topology of the mention network cannot definitively show conversational interactions—future research should, therefore, combine network analysis with more in-depth content analysis.
The broadening of science communication research attempted in this study was achieved by allowing several topics to emerge rather than defining one at the outset. Another path to achieving higher levels of generalizability is to include more new media sources. As only Twitter was considered here, future studies may look to simultaneously collect content from social networking sites, blogs, and other web sources on several topics—an agenda that will need to be accompanied by advances in digital social research methods. In order to further characterize the layer of communication that Twitter has added to public engagement with science, future research could apply methods to automatically trace the external links included in the majority of tweets. What types of resources are referenced (news media, social media, academic literature, etc.) and what kinds of information do they offer? In general, research should continue to analyze the affordances of the web as a knowledge creation and sharing infrastructure.
Footnotes
Acknowledgements
The author(s) would like to thank Sulkhan Metreveli, Michael Latzer, Mike Schäfer, Simone Reiser, and two anonymous reviewers for their suggestions.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.