
Abstract
A standard model is a theoretical framework that synthesizes observables into a quantitative consensus. Have researchers made progress toward this kind of synthesis for children’s early language learning? Many computational models of early vocabulary learning assume that individual words are learned through an accumulation of environmental input. This assumption is also implicit in empirical work that emphasizes links between language input and learning outcomes. However, models have typically focused on average performance, whereas empirical work has focused on variability. To model individual variability, we relate the tradition of research on accumulator models to item response theory models from psychometrics. This formal connection reveals that currently available data sets do not allow researchers to test the resulting models fully, illustrating a critical need for theory to contribute to shaping new data collection and creating and testing an eventual standard model.
Early language learning is a key challenge for cognitive science: How do speechless, wordless infants become children who can use language expressively and creatively? The field of early language is often portrayed as mired in controversies around issues of innateness. However, we see a new synthesis emerging from theoretical and empirical work on the growth of vocabulary. Our goal here is to present this synthesis as the beginnings of a standard model 1 of early language learning: a baseline theory that is accepted widely in its outlines and that should guide future work even though it is incomplete and its assumptions still require rigorous evaluation.
In physics, the Standard Model is a widely accepted theory from the 1970s that describes all known elementary particles along with three of the four known fundamental forces in the universe. Although incomplete and even incorrect in places, physics’ Standard Model nonetheless explains a wide variety of empirical phenomena, allowing scientists to model physical interactions with great precision and accuracy and to design tests that inform theory revision. Psychology, in general, has been criticized for lacking such formal theories that inform and drive empirical research (Muthukrishna & Henrich, 2019).
Is it possible to build a standard model for the field of language acquisition? Computational models are one potential source of unifying theory, and perhaps the only way to fully specify and quantitatively compare theories. Although models of language learning vary widely, many presuppose a common framework (Fig. 1a). Its core principle is that language input accumulates via repeated exposure and that this results in learning. Although there is evidence for other factors relating input quality to learning, or uptake (e.g., lexical diversity: Jones & Rowland, 2017; referential transparency: Cartmill et al., 2013), a framework focusing on input quantity underpins much of the broader policy discussion of links between environmental stimulation and individual variability in children’s outcomes (e.g., Hart & Risley, 1995). Moreover, this framework corresponds nicely with a group of computational models that we refer to jointly as “accumulator models,” which make distributional assumptions about the difficulty of words and are sometimes fit to words’ average age of acquisition, but not to data from individual children (Hidaka, 2013; McMurray, 2007; Mollica & Piantadosi, 2017).
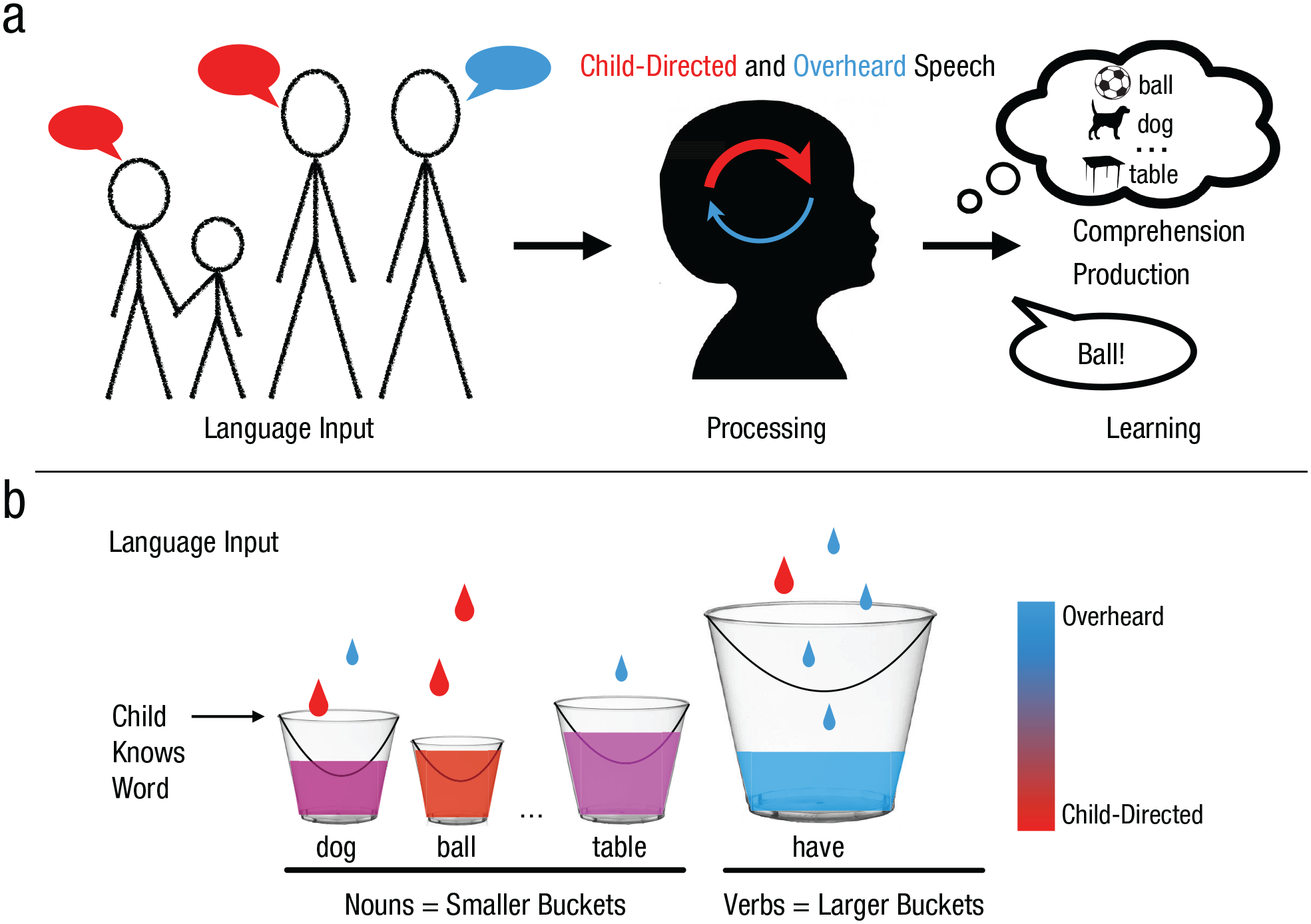
Conceptualizing early language learning. The standard model described in the literature (a) assumes that child-directed speech (represented in red) is more valuable than overheard speech (represented in blue). This descriptive theory can be instantiated in an accumulator model (b), visualized as a set of buckets, each representing knowledge about a particular word. Each token (i.e., instance) of a word is a drop in the corresponding bucket. Some words are more difficult than others (i.e., have larger buckets). When a bucket is full, the corresponding word is learned. Child-directed tokens (represented in red) may be more valuable (i.e., are larger drops) than overheard tokens (represented in blue) for a variety of potential reasons. For example, overheard tokens are more likely to be ignored, and child-directed tokens are more likely to be of greater interest, or are heard in more informative contexts.
Our aim here is to make an explicit connection between accumulator models and the broader, but less formal, discussion of the role of language input in learning. We use item response theory (IRT) from psychometric testing as a framework for connecting empirical data about language input with accumulator models. Sitting at a level of analysis between generic regressions and cognitive-process models, data-analytic cognitive models offer a way to implement researchers’ theories and evaluate them quantitatively, with parameters mapping to both real-world, measurable units (e.g., words heard per hour) and psychological constructs (e.g., a child’s ability to process language).
Discussions of language input typically focus on variation between children. In contrast, models of acquisition (ours included) typically focus on average patterns of acquisition (but see Jones & Rowland, 2017). By connecting such models with psychometric models that are intended to capture variation, we hope to bring individual variability back to the center of language-learning theory.
The goal is not to produce the “correct” model, but rather to explore the ways that model assumptions lead to predictions about specific patterns of data. In fact, the greatest value of data-analytic cognitive models is the ability to identify the areas of greatest mismatch between data and model, highlighting areas requiring further investigation (Tauber et al., 2017). Perhaps such iterative work will lead to a true standard model for language learning, one that captures differences not only in quantity, but also in the quality of various activities and sources of input.
Accumulator Models Are a Formalism for Describing Word Learning in Absolute Units
We focus here on word learning as a central component of early language learning and return to connections with morphology and syntax later. 2 Accumulator models assume that experiences with words accumulate in separate registers (depicted as buckets in Fig. 1b). When a register exceeds a particular threshold (i.e., the bucket is full), the word is learned.
Accumulator models have already contributed significantly to theoretical debates. For example, McMurray (2007) elegantly demonstrated that children’s “vocabulary explosion”—an acceleration in the rate of vocabulary growth in the 2nd year—can result from the steady accumulation of words over time at a constant rate. In other words, the nonlinear change in the rate of word learning can arise without changes in the environment or learning mechanism. Other work has examined similar models using empirical rather than theoretical distributions of words (as in McMurray, 2007), developmental change in learning mechanisms, and comparison with children’s aggregate vocabulary growth (Hidaka, 2013; Mitchell & McMurray, 2009; Mollica & Piantadosi, 2017). Although this work is exciting, these models have not yet been developed sufficiently to make direct predictions about learning in individual children (Bergelson, 2020).
One difficulty in connecting such models to data is that the relevant variables are often measured in relative, rather than absolute, units. 3 This practice is common in psychology. For example, measures of intelligence are given on a standardized scale defined by population variability. Yet in the study of early language, researchers have access to absolute units—which is unusual in a psychological domain. One can count how many words a child hears and express this number as a rate that is comparable across studies (words per hour; Bergelson et al., 2019). One can similarly estimate how many words a child knows (e.g., by parents’ reports of vocabulary size; Frank et al., 2021, Chapter 5). These absolute units mean that models can make powerfully general quantitative predictions, which can be tested across different situations and populations. Few data sets have measurements of the relevant variables, however. Thus, in the future, researchers should collect and report data in absolute units, whenever possible.
Accumulator Models Are Presupposed in the Empirical Literature
Since seminal work by Hart and Risley (1995), the connection between children’s language input and the growth of vocabulary has been a topic of intense interest and debate (e.g., Sperry et al., 2019). Numerous studies have found positive associations between the total number of words and the diversity of words heard from caregivers and children’s vocabulary learning (e.g., Hoff, 2003)—as predicted by accumulator models—though the magnitude of these relations has varied across studies (Wang et al., 2020). These correlations are also partially moderated by other factors, including socioeconomic (Hoff, 2003) and genetic (Hayiou-Thomas et al., 2014) variables. Although they are costly and difficult to conduct, randomized interventions are the gold standard for estimating causal effects. When they have been conducted in the field of early language learning, interventions have had modest but reliable effects (e.g., Suskind et al., 2016), thus providing support for a causal connection between input and outcomes.
There are many dimensions of input quality that modulate uptake, including lexical diversity (Jones & Rowland, 2017), referential transparency (Cartmill et al., 2013), and activity context (Roy et al., 2015). A link between input quantity and uptake is a fundamental assumption of all theories of language learning, though. Reasoning from first principles, you cannot learn the word “table” if you do not hear it: Input quantity must to some extent predict learning of individual words.
Words vary in how difficult it is to learn them. For example, the referent of the word “table” is often more apparent than that of the word “tomorrow,” which leads to easier learning. Yet traditional correlational studies typically capture differences in input using only aggregate measures of what a child may experience, asking whether variation in overall amount or quality of input relates to variation in overall vocabulary size.
An alternative approach focuses on differences in relations between input and learning at the level of words, not children (Roy et al., 2015). Using regression to predict which words are easier or more difficult to learn, averaging across children (Braginsky et al., 2019 e.g., Goodman et al., 2008), these models show a strong association between word frequency and the average age at which particular words are acquired, especially for object labels. Swingley and Humphrey (2018) extended this regression approach to predict the acquisition of individual words by individual children on the basis of the words’ prevalence in the children’s mother’s speech. These findings provide convergent support for accumulator models and, thereby, provide the conceptual underpinning of the relations between input (frequency for words, quantity for children) and learning.
Connecting Accumulator Models With Psychometric Models
We believe accumulator models can be the basis for an eventual standard model of early language learning. The core of our view is that individual experiences with words lead to their eventual acquisition via accumulation. Although the specific situations in which a word is experienced likely vary along many dimensions that influence learning, in general, the more of these experiences a child receives, the faster the child’s vocabulary grows. However, both children and words vary: Children may learn slower or faster (and perhaps the rate varies with age), and words are more or less difficult to learn. Combining these ideas, our basic hypothesis is that a child’s vocabulary at a particular time should be predicted by the child’s cumulative language exposure and learning rate, combined with the breadth of the sample of words to which the child has been exposed and those words’ individual difficulties.
This hypothesis describes an approach similar to IRT (Embretson & Reise, 2013). IRT is commonly used for estimating the ability of test takers (here, language learners) as assessed with a particular set of test items (particular words). IRT models provide a convenient and broadly used psychometric framework within which to describe and compare different model variants, which in turn represent different sets of theoretical assumptions.
In their formal structure, IRT models describe responses to individual items as a function of both the difficulty of the items (words) and the language abilities of the test takers (children). These latent parameters can be inferred from an observed data set. In the basic Rasch (or 1-parameter logistic) IRT model, a person i responds correctly to item j with probability determined by the person’s ability (θ i ) and the difficulty of item j (dj):
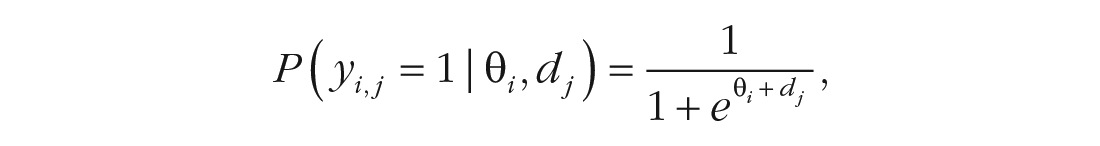
where e is Euler’s number and yi, j = 1 denotes a correct response to item j by person i. These parameters can easily be mapped onto an accumulator model of language learning: Items are words (e.g., dj is the difficulty of word j), and θ i is child i’s estimated latent language ability.
In typical IRT models, both item difficulties and person abilities are standardized (normally distributed and centered on 0) and unit free. In principle, however, these scores can be mapped to measurements of word frequency and rates of children’s experienced input expressed in absolute units (e.g., words heard per hour). This mapping can then provide a quantitative linking hypothesis connecting measurements of input and learning.
The equivalence of accumulator models to IRT carries a variety of benefits. First, IRT extensions can be used to explore different theoretical assumptions. For example, item-level covariates—such as estimates of word frequency (Braginsky et al., 2019)—and person-level covariates—such as age, sex, and socioeconomic status—can be added with the flexibility of standard regression modeling. 4 Further, tools for multivariate IRT allow consideration of whether variation in early language is unidimensional or multifactorial (Frank et al., 2021). Finally, models can be compared using standardized tools, a major benefit over more ad hoc frameworks.
Comparing Model Variants as a Method for Evaluating Theories
IRT accumulator models can be fit to data, which allows different theoretical assumptions to be compared empirically. To illustrate this point, we ask the following: Is a 2-year-old language learner different from a 1-year-old language learner, aside from having twice as much experience with each word? Is the amount of language experience the only developmental change one should account for (as assumed by the simplest version of an accumulator model), or are there other age-related changes that distinguish younger and older children’s learning?
We fit multilevel logistic regression IRT models (De Boeck et al., 2011) to data from Wordbank (Frank et al., 2021), a repository of data from the MacArthur-Bates Communicative Development Inventory (CDI), a reliable and valid parental report instrument containing a vocabulary checklist of 680 words. 5 Data on words produced by 5,429 monolingual, English-learning children (16 to 30 months old) were used.
In each model, we estimated parameters for each child’s linguistic ability and each word’s difficulty. Each word’s frequency was the key parameter controlling its accumulation—hence, an item-level covariate of difficulty. To characterize individual children’s environments, we followed previous work (Braginsky et al., 2019; Goodman et al., 2008) and estimated average word frequencies using the American English corpora in the Child Language Data Exchange System (CHILDES; MacWhinney, 2000), retrieved via the childes-db R package (Sanchez et al., 2019). Our average child received 1,200 words per hour, 12 hours per day, for a total of 438,300 tokens per month, of which 285,200 tokens (65.1%) were words on the CDI (see the Supplemental Material available online).
In our simple accumulator model, the expected total number of tokens per word given a child’s age was included as a covariate. We also included an interaction between word frequency and lexical category (Braginsky et al., 2019; Goodman et al., 2008). A second model included age as a person-level covariate, word frequency and lexical class as separate item-level covariates, and an interaction of the latter two.
Multiple model-selection techniques indicated that this second model offered a better fit to the data, thus providing some support for age-related changes in the accumulation mechanism. Curves predicting acquisition as a function of age, separately for different lexical classes and prevalence levels (Fig. 2, left) showed the expected results that nouns were learned more rapidly than verbs and that frequent nouns were learned earlier than less common ones; frequency had little effect on acquisition of verbs and function words. Moreover, the model displayed expected item-level acquisition trajectories (Fig. 2, right): For example, “ball” was learned earlier than “dog,” and “go” was easier than “have.” The model also generated per-child CDI learning curves (see the Supplemental Material, Fig. S4), which could, for example, be used to generate predicted acquisition curves for children receiving much more (or less) monthly input. By combining the CHILDES frequencies of non-CDI words with the lexical-class parameters, one could also predict the total size of individual children’s vocabulary. More generally, this simulation showcases the use of large-scale data sets to test hypotheses about the nature of learning mechanisms and provides evidence of age-linked changes in the word-learning process.
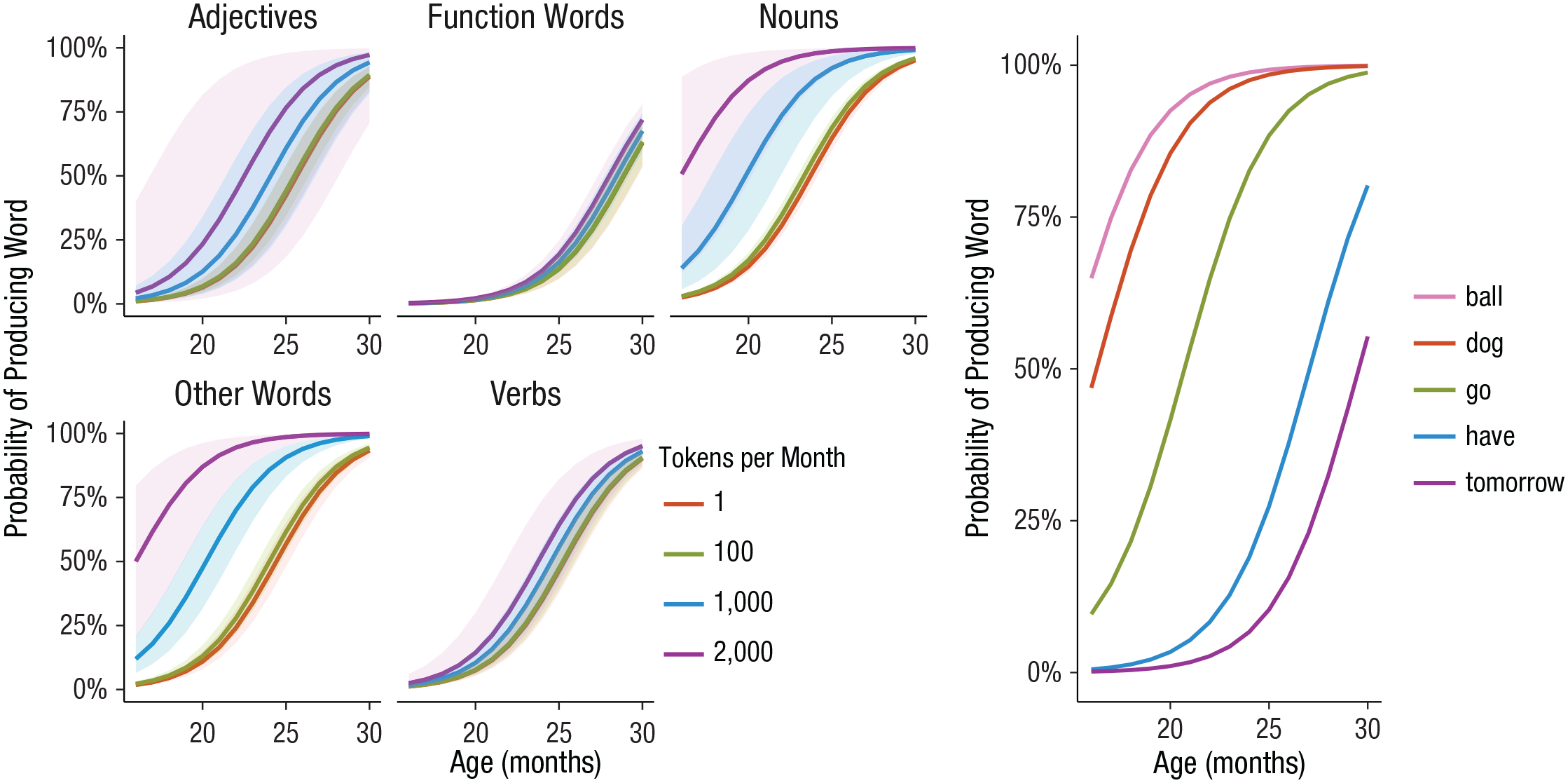
Predicted acquisition curves derived from a fitted age-dependent accumulator model (see the text). The graphs on the left show curves for five lexical classes as a function of age, separately for words with different levels of expected token frequency per month. The graph on the right shows curves for a sample of specific words. The shaded bands represent 95% confidence intervals.
Onward Toward a Standard Model
The goal of any computational theory is to derive the predictions arising from a specific set of assumptions. Often, however, it is the failure of such a model to predict observed patterns of data that is most useful, as these failures point the way forward toward future refinements. We discuss three potential future directions for data-analytic accumulator models of early language learning.
Leveraged learning and the role of processing
As our results show, older children accumulate language from their input faster than younger children do. Why? Perhaps older children are simply better at remembering words, so that the drops in their buckets are bigger. Or they might leverage their knowledge of language to learn faster than younger children (Mitchell & McMurray, 2009). They could do this by reasoning about new words by exclusion (e.g., assuming new words have new meanings; Markman & Wachtel, 1988). Or maybe their increasing fluency with the words they know helps them learn new words. A surprising proportion of variance in the rate of vocabulary growth is accounted for by the speed with which children process familiar words (e.g., Marchman et al., 2016). These theoretical proposals yield predictions that could be tested using the models we have described.
A theory for understanding language acquisition in diverse contexts
Our framework formalizes an implicit assumption: namely, that children learn the same way in all circumstances. Yet this assumption could very well be false. For example, some children might learn more from overheard speech, and others might learn more from child-directed speech (Sperry et al., 2019), or children may learn more from words spoken in some types of activity contexts than in others (e.g., book reading vs. play). The kinds of data necessary to test the assumption of uniformity across contexts directly are only now being collected, for example, in studies that rigorously track learning outcomes and the amount of language input in diverse populations (e.g., comparisons between children in low-income, rural, indigenous communities and those in higher-income Western contexts; Casillas et al., 2020). To accurately estimate the relative value of tokens of overheard versus child-directed speech, or of book reading versus free play, it will be necessary to have accurate measurement over long periods (given the variability in children’s experience) of (a) how much children experience each context (say, hours per month) and (b) the amount of speech of each type is heard in each context (we elaborate on one such extension in the Supplemental Material, pp. 5–7).
Beyond vocabulary
We have described a model of the accumulation of words. Yet language is a rich, complex system in which words are inflected morphologically and arranged syntactically to express compositional meanings. In early generative views, syntax and morphology were conceptualized as distinct and unconnected from the lexicon, but this conception has not been borne out empirically. Instead, evidence has shown again and again that the language system is “tightly woven,” with extremely tight correlations between the acquisition of words, morphology, and syntax (Frank et al., 2021). Theoretically, accumulator models are generic models of skill acquisition, and could thus model more than word learning. If language learning is a form of skill acquisition (Chater & Christiansen, 2018), such connections among different aspects of language learning could lead the way toward extensions of the standard model to the accumulation of broader units of language-like constructions (e.g., multiword phrases).
Conclusions
An implicit theory drives research and policy making on early language acquisition: Early language accumulates through discrete experiences with individual words. The more experiences a child has, the faster the words are learned. This implicit theory can be expressed within a family of computational models that make quantitative predictions for individual children based on environmental sources of variation, thus enabling the theory to be used to make quantitative predictions (see Haines et al., 2021). By situating these models in a common psychometric framework, we have shown how computational modeling can be used to connect theoretical assumptions to data from large-scale data sets. This modeling framework synthesizes measures of language input and vocabulary growth, making it possible to formalize, test, and iteratively improve understanding of language learning. Moreover, this formalization identifies a specific gap in current empirical approaches that needs to be filled in: Measurements must be reported in absolute units (e.g., words per hour rather than standardized scores) to allow integrated modeling across studies. Perhaps one day soon, these developments together will lead to a true Standard Model of early language learning.
Recommended Reading
Bergelson, E., Casillas, M., Soderstrom, M., Seidl, A., Warlaumont, A. S., & Amatuni, A. (2019). (See References). A large-scale analysis of multiple language-input corpora of the type that will be needed to help constrain the standard model, along with discussion of demographic variation in input.
Frank, M. C., Braginsky, M., Yurovsky, D., & Marchman, V. A. (2021). (See References). A book examining the influence of many child- and word-level factors on early language learning, along with an introduction to the use of psychometric models on data from the MacArthur-Bates Communicative Development Inventory.
McMurray, B. (2007). (See References). A short introduction to the idea of accumulator models and a demonstration of how they can inform theories of language learning.
Swingley, D., & Humphrey, C. (2018). (See References). An example of how statistical models can be used to infer the relative importance of different language-input factors in predicting children’s learning of individual words.
Supplemental Material
sj-pdf-1-cdp-10.1177_09637214211057836 – Supplemental material for Toward a “Standard Model” of Early Language Learning
Supplemental material, sj-pdf-1-cdp-10.1177_09637214211057836 for Toward a “Standard Model” of Early Language Learning by George Kachergis, Virginia A. Marchman and Michael C. Frank in Current Directions in Psychological Science
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.