
Abstract
This paper introduces the Corpus of the Canon of Western Literature (Version 1.0), accompanied by a demonstration of its potential uses. The canon of western literature has been an important construct in the study of literature, long standing and long contested. It has been argued to represent many of the greatest works produced in the history of western literature. This corpus operationalizes the western canon based on Harold Bloom’s The Western Canon: The Books and School of the Ages (1994). The paper describes the development of the corpus, its organization and source material. Corpus procedures are applied to the corpus, such as word frequency analysis, lemmatization and keyness, to demonstrate its potential uses in culturomics and corpus stylistics, two interdisciplinary fields between the traditional and digital humanities, and the linguistic and literary approaches to literature. Culturomics is the study of culture and social psychology via the investigation of corpora of literature as cultural artefacts, while corpus stylistics is the application of corpus linguistics to traditional literary scholarship. The corpus introduced in this paper is open source and freely available.
1 Introduction
A relatively recent paper in Science, introducing the Google Books corpus with approximately 4% of books ever published, termed a new field of study: culturomics (Michel et al., 2011). As originally framed, culturomics was the use of the Google Books corpus to investigate the culture and social psychology of different times and places, with the corpus considered as a collection of cultural artefacts. While culturomics is a new term, widely cited (Acerbi et al., 2013; Greenfield, 2013; Pechenick et al., 2015), using corpora for cultural studies is something corpus linguists have been doing for some time (e.g. Baker, 2003). Parallel to the rise of culturomics has been the related field of corpus stylistics. Corpus stylistics is the study of literary style via computational tools applied to machine readable literary works. It combines the science of linguistics with literary studies and, like culturomics, is one of the growing interdisciplinary fields between the traditional and digital humanities.
This paper introduces the Corpus of the Canon of Western Literature (Version 1.0), with a demonstration of its potential in culturomics and corpus stylistics. The canon of western literature has been an important construct in the study of literature, long standing and long contested (Beach et al., 2016; Guillory, 2013). Speaking broadly, traditional-minded literature scholars have held the works of the canon to be the greatest literature in the history of the West (Adler and Weismann, 2000; Bloom, 1994). By ‘greatest’, they tend to mean that such literature exhibits qualities such as aesthetic beauty, profound ideas, themes, notable characters and language, and impressive artistic skill. Canonical works are also those that have influenced other literature; for example, by exhibiting intertextuality and impacting culture, e.g. Aristotle’s Politics or Christendom. The Corpus of the Canon of Western Literature (henceforth CCWL) is an attempt to operationalize the construct of the western canon as defined by Bloom (1994). The paper first describes the development and organization of the CCWL. Next, to demonstrate its applications to culturomics and stylistics, some standard corpus procedures are reported, such as lemmatization, keyness, standardized type–token ratios (a measure of vocabulary range), as well as word and sentence length estimates across genres, authors and texts.
2 Corpus linguistics, culturomics and stylistics
Culturomics, as introduced by Michel et al. (2011), argued that the 5,195,769 texts in the Google Books corpus opened a new field of study in the digital humanities: the tracking of cultural trends and social psychology through linguistic artefacts in big data. In their introductory paper, they demonstrate how the relative frequencies of n-grams (words and phrases) map onto cultural phenomena. For example, the names for inventions in their corpus show that from the 1800s onward the cultural adoption of technology has become more rapid. The frequency of reference to an invention first mentioned in the early 1800s peaked around 66 years later in the corpus, yet by the 1900s peak frequency occurred within 27 years. Other demonstrations of culturomics in their paper include the tracking of censorship, evidenced by declining mentions of Jewish artists during Nazi Germany, the spread of scientific concepts such as evolution throughout modernity, and political concepts such as feminism, which has been taken up more rapidly in English books than French. Given the limitations of the Google Books corpus, for example prolific but unread authors affect frequency but not culture (Pechenick et al., 2015), culturomics has expanded to other corpora. Samothrakis and Fasli (2015), for example, built a corpus from the digital repository Project Gutenberg consisting of 3403 public domain literary texts. They found that the frequency and dispersion of words associated with lexical domains such as anger, fear, joy and surprise help predict publication periods of texts as these words tap into the changing cultural milieus of different historical periods (see also Hughes et al., 2012).
Corpus stylistics is concerned with how the literary style of an author, text or genre is reflected in language, yet like culturomics it is also interested in broader issues of how literature reflects culture, how ideas and themes pattern in texts, and how literature creates psychological effects in readers and characters (McIntyre, 2015). Even though corpus linguistics is advancing toward ever increasing complex quantitative research designs, the basic toolkit of the field has provided much insight into literature. Stubbs (2005: 14), for example, shows that the application of what he calls ‘very simple frequency stuff’ such as word lists and collocations capture important themes and style markers in Conrad’s Heart of Darkness. Amongst the most frequent words are seem, like and looked, as well as something, somebody, sometimes, somewhere, somehow, which Stubbs (2005) argues reflect the vagueness and sense of the inscrutable that has long been noted as a stylistic marker of Conrad’s novella (Leavis, 2011 [1948]).
Mahlberg and McIntyre (2011: 216) view corpus stylistics as ‘an approach that can link in with the concerns in literary stylistics and criticism’, rather than as field of study that competes with traditional literary studies (see also McIntyre, 2015). They demonstrate this in a corpus stylistic study of Fleming’s Casino Royale where, similar to Stubbs (2005), frequency information functions as evidence for arguments about theme, style and characterization. Beside raw frequency, they employ corpus linguistics procedures such as lemmatization and keyword analysis, which identify lexis associated with core themes (e.g. cards, casinos, spies), characters (Bond, Le Chiffre, Vesper) and the male viewpoint (e.g. the subjective pronoun he). Mahlberg and McIntyre (2011: 221) report that a key semantic domain in Fleming’s work is physicality, since there is high frequency of lemmas associated with the body. Further, the representation of the body is constructed differently according to gender. A collocational analysis of the n-gram his body (i.e. Bond’s) compared to the central female character Vesper reveals Bond’s collocates emphasize his ability to separate his physical self from his mental and emotional self, while Vesper’s body is presented either sexually, collocating with words such as morals, bed, sheet, sensual, conquest, or from Bond’s point of view as unemotional, cold, arrogant, remote.
Not only do the above studies indicate the wide range of research applications for literary corpora once they are built, but also how the basic toolkit of corpus linguistics can produce insights into literature, culture and social psychology (Greenfield, 2013). The following sections describe a newly built literary corpus and, by way of introduction, apply some of the above procedures in the context of culturomics and corpus stylistics.
3 The canon of western literature
Unlike the corpora in the previous section, the corpus introduced in this paper represents a specific literary and cultural construct, i.e. it is a specialized corpus, and this construct is the canon of western literature (Bloom, 1994). The canon of western literature has been an influential idea in literary studies. It has been argued to consist of the core literary tradition of the west. Canonical literature has been defined as texts with great aesthetic beauty and important influence in shaping other literature, as well as western thought and culture in general. Leavis (2011 [1948]) argued it represents a ‘Great Tradition’ in which previous great works shape the style and form of the literature that follows. Adler and Weismann (2000) use a similar phrase: the ‘Great Conversation’. They conceive of the canon as an intertextual conversation between authors across centuries, where ideas, styles, characters, philosophies and science are discussed, refined, rejected and renewed. The canon has an overall coherence, they believe, as literature that does not participate in this ‘Great Conversation’, either explicitly or implicitly via literary criticism, falls outside canonical literature. Bloom (1994), author of the influential The Western Canon: The Books and School of the Ages, presents a similar definition, though he largely excludes scientific treatises as he argues that aesthetic beauty is a key inclusion criterion. Bloom (1994) is one of the staunchest current defenders of the western canon, and also offers one of the most cited taxonomies of canonical authors and texts.
The challenges and critiques of the canon are well known, part of the general culture wars of recent academia (Gorak, 2013), and include that the canon overwhelmingly represents white male authors, characters and viewpoints, suppresses the voices of women, the cultures of minorities, the spiritual beliefs of those not consistent with an era’s reigning (and often brutally enforced) theology, etc. The canonicity of any text is debatable, and overrepresented is literature related to the Greco-Roman tradition, which partly reflects 19th century models of liberal arts education (Towheed and Owens, 2011). Further, there is a debate over who gets to choose the works in the canon, as scholars who have proposed lists of canonical literature tend to be much like the authors they include, i.e. white, male, English speakers of European heritage. The current paper’s introduction of a corpus of the canon of western literature is not meant as a defence of the construct itself. Rather, the corpus is presented as an object of study for the empirical investigation of what has been held up to be literature of great importance to western culture (cf. Google Books).
4 The development and structure of the corpus of the canon of western literature
The corpus introduced here operationalizes the construct of the canon of western literature based on Bloom’s (1994) description of the canon, chosen because he is a major contemporary literary scholar who specializes in canonical literature, because his work is highly cited and influential, and because his list can be operationalized since he offers an explicit taxonomy of thousands of texts and authors in Appendix A of his book. The structure of Bloom’s (1994) canon has guided the structure of the CCWL. He organizes canonical literature into four chronological ages: 1. The theocratic age (2000 BCE to 1321 CE); 2. The aristocratic age (1321 CE to 1832 CE); 3. The democratic age (1832 CE to 1900 CE); 4. The chaotic age (20th Century). The names of the ages, Bloom (1994) suggests, reflect important cultural or stylistic underpinnings of the literature in each era such as a heightened religiosity (the first literary age) or a lack of cultural coherence (the final age). He subdivides the four ages into different cultures/societies. For example, nested within the theocratic age are the Ancient Greeks and the Romans, while nested in the democratic age are works from Great Britain and the United States.
The majority of texts in the canon are from the British Isles or the United States and originally written in English. Indeed, one might suggest that Bloom’s (1994) western canon is more specifically a western canon of the English-speaking peoples. Hundreds of literary works not originally in English, from Homer to Proust, are listed by Bloom (1994), and these have been included in the CCWL in translation. While Bloom (1994) might hold that the works should be read in the original languages (though this is not clear), others, such as Adler and Weisman (2000), argue that translations still represent the ‘Great Conversation’, and so it was decided they have a place in the corpus. Of course, the style of the translator and era of translation influence these texts, but the CCWL has been designed for researchers to ignore translated texts if desired.
The development of the CCWL proceeded as follows. Every text listed in Bloom’s (1994) Appendix A was searched for in Project Gutenberg (www.gutenberg.org/), a digital repository of public domain literature. Project Gutenberg texts are not copyrighted and are available freely for research. Each text contains a licence statement, and scholars who use this corpus should read the licence, as countries vary on copyright. The CCWL is freely available under the standard licencing of Project Gutenberg upon request from the author or via the download link in the notes section of this paper. 1 The corpus was tagged and cleaned to minimize non-target text. Licence statements were put behind the XML tags <License>; footnotes, endnotes, indexes, introductions, appendices and contents pages were tagged <notes>. Texts were also tagged for the genres <fiction>, <non-fiction>, <play>, <poetry>, <prose>, <scripture>, <mixed genres>. When possible, regex scripts were written to remove noise such as line break characters, page numbers, etc. Plays presented a particular challenge as Gutenberg editions standardly have a period immediately after a line-initial speaking character’s name. This skews estimates of mean sentence length, and such repetition affects type–token ratios (TTRs). To minimize this, all plays (and works such as Plato’s Dialogues) had the speaker’s names put behind <character> tags. All files were Utf-8 encoded, which provides a standard and compact formatting for all characters in text files.
Text files were kept intact as much as possible; that is, sometimes a single volume in Project Gutenberg contained multiple target texts from an author listed in Bloom (1994). However, when a target text was only available in a collected volume, non-target texts within that file were removed. Files in the corpus were named according to Bloom’s Appendix (i.e. author/title), rather than given codes. This was done in an interdisciplinary sprit, in the hopes that intuitive file names may make the corpus more accessible to non-corpus linguists such as literary scholars. When there were multiple versions of the same text available, it was decided to use the edition that had been most downloaded from Project Gutenberg. This is arbitrary, but it is possible the most downloaded version is more central to the canon than less read editions. Bloom (1994) operates similarly, including only the King James version of the Bible. A supplementary part-of-speech tagged version of the corpus was also developed, with tagging by TagAnt (Anthony, 2015). Checks of random samples suggested that tag accuracy varies, with performance best on prose written after 1800. For example, within Chaucer’s Canterbury Tales the tagger handled some archaic style with 100% accuracy, e.g. Thus _RB can _MD Fortune _NP her _PP wheel _NN govern _VV, while it was inaccurate with other sequences, e.g. He _PP which _WDT that _DT misconceiveth _NN oft _RB misdeemeth _VVZ. An examination of the 100 most frequent NP tags in periods A3, A4 and A5 (see table 1) indicated an error rate of around 6%. Given time and resource constraints in this phase of the project, machine tagging has not been checked by hand by independent raters nor errors corrected.
The corpus of the canon of western literature.

The final corpus contains 805 individual files (many containing multiple works) in a flat structure and, excluding non-target text, approximately 73 million words, which compares favourably to large corpora such as the British National Corpus (BNC) at 100 million. Table 1 shows the organization of the corpus and the sample sizes (excluding license statements and edition notes) for each literary age, society and culture listed in Bloom (1994).
Table 1 indicates significant word count differences exist in the representation of times and places, but this reflects the canon as described by Bloom (1994). Approximately 25% of the corpus is British literature from the democratic age (1832–1900 CE). The sample sizes for other periods and cultures/societies are quite good, nonetheless, with around half of the nested subcorpora around or greater than one million words. Corpora of a million words have been effectively used since the 1960s (e.g. Brown) until the current era (e.g. International Corpus of English). It is worth noting that Bloom (1994) is not strictly chronological in categorization, but considers also literary movement. For example, the romantic poets are nested in the democratic age, as they were a reaction to neoclassicism and a style he considers of the aristocratic age. Not every text listed in Bloom (1994) was obtainable in Project Gutenberg. Literature from the chaotic age has the least coverage, as many of the texts are still under copyright; yet, as Table 1 shows, the age nevertheless has sizeable representation. Gaps in consecutive numbering (e.g. D2–3) indicate no available texts. The exact coverage of the western canon as described by Bloom (1994) can only be approximated. This is for two reasons. One is that Bloom is at times vague about the texts that are canonical; for example, while the specific titles of Dickens are listed, for other authors he simply notes ‘Selected Poems’ or ‘Short Novels’. The second issue relating to coverage is that where Bloom specifies the complete works of an author as canonical, Project Gutenberg did not always have all their work. If we estimate representation by authors, from the theocratic age, the CCWL represents 48 of 63 (76%) canonical authors mentioned by Bloom (1994); from the aristocratic age, 88 of 139 (63%); from the democratic age, 125 of 159 (79%); and finally from the chaotic age, where Bloom (1994) lists a total of 506 authors, only 58 (11%) are represented. Representation bias is thus toward literature before 1900. Bloom (1994: 548) leaves open whether chaotic age texts are technically canon, as he suggests they must also withstand the test of time: ‘I am not as confident about this list… Not all of the works here can prove to be canonical’.
5 Applications to culturomics
This section applies a few standard corpus procedures to the CCWL, and illustrates how the corpus can be used for culturomics. Simple frequency has its interest, but to home in on the lexis of literature lemmatization and keyness procedures often provides more insights (McIntyre, 2015; Stubbs, 2005). Keyness highlights lexis in a corpus that stands out statistically in terms of relative frequency and dispersion compared to a larger reference corpus. Reported in Table 2 are the 20 highest ranked keywords in the CCWL, computed against the BNC. The BNC is a far from perfect reference corpus (no currently available corpus would be) as it is a contemporary, mixed-genre corpus of speech and writing. Nevertheless, it is a well-known British corpus of a size larger than the CCWL, and the comparison for the generation of keywords, while problematic, is not meaningless. Consider that when a school student encounters Shakespeare, the lexis that stands out is that which is distinct from their everyday experience of English: e.g. Shall I compare thee to a summer’s day?
Highest ranked keywords in the corpus of the canon of western literature.
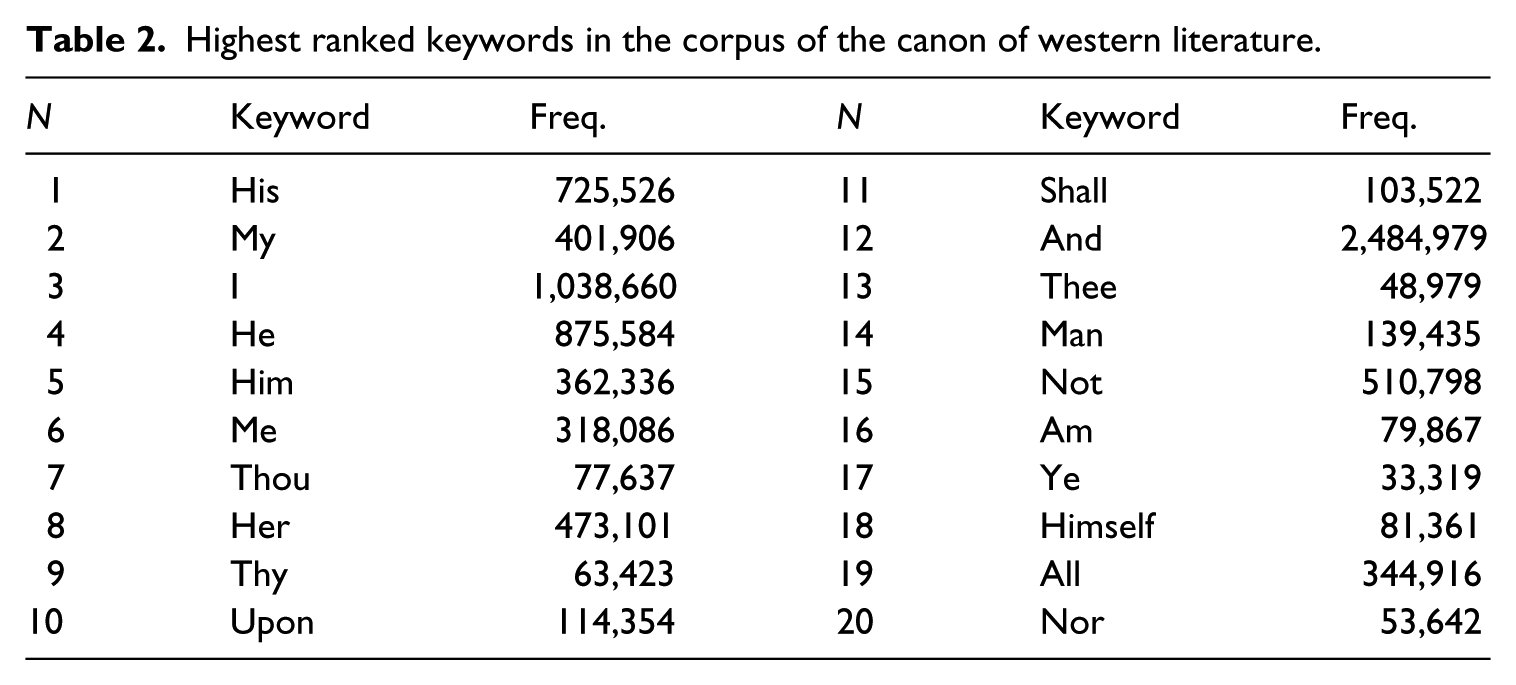
Table 2 shows that pronouns stand out as keywords in the CCWL. This likely reflects a property of literature that Stockwell and Mahlberg (2015) call the textual trace of characterization, i.e. characters display pronominal chains reflecting their participation in a narrative. Note that masculine pronouns are more key than female ones. In the top 20 keywords, five male referents occur, four being pronominal, and one superordinate: man. There is only one female referent, the pronoun her, which is not subjective case; indeed, nominative she is only the 28th keyword of the CCWL, compared to he, ranked 4th. The subject of a clause is typically the agent, one who does, acts, perceives, thinks or senses (Givón, 1993), while the predicate is the part of the clause where propositions prototypically package those who are recipients, instruments, acted upon or thought about (Halliday, 2003). Thus, Table 2 suggests that gender representation in canonical literature is qualitatively and quantitatively distinct. This observation is not necessarily true only of canonical literature, but it demonstrates nonetheless how the CCWL can be used to bolster with supporting empirical evidence long-standing criticisms of the canon, such as that it is dominated by male characters, experience and viewpoints.
As discussed, Mahlberg and McIntyre (2011) effectively used lemmatization to highlight lexis associated with key themes, characters and semantic domains in their study of Casino Royale. A function word stoplist and the Someya (1998) list of 4,762 lemmas were therefore applied to the CCWL using Wordsmith v.6 (Scott, 2016). The Someya (1998) list, derived from modern corpora, lacks coverage of archaisms like in the Chaucer example above, but this seems a relatively minor limitation. Table 3 ranks the 25 most frequent lemmas in the CCWL.
Most frequent lemmas in the corpus of the canon of western literature.
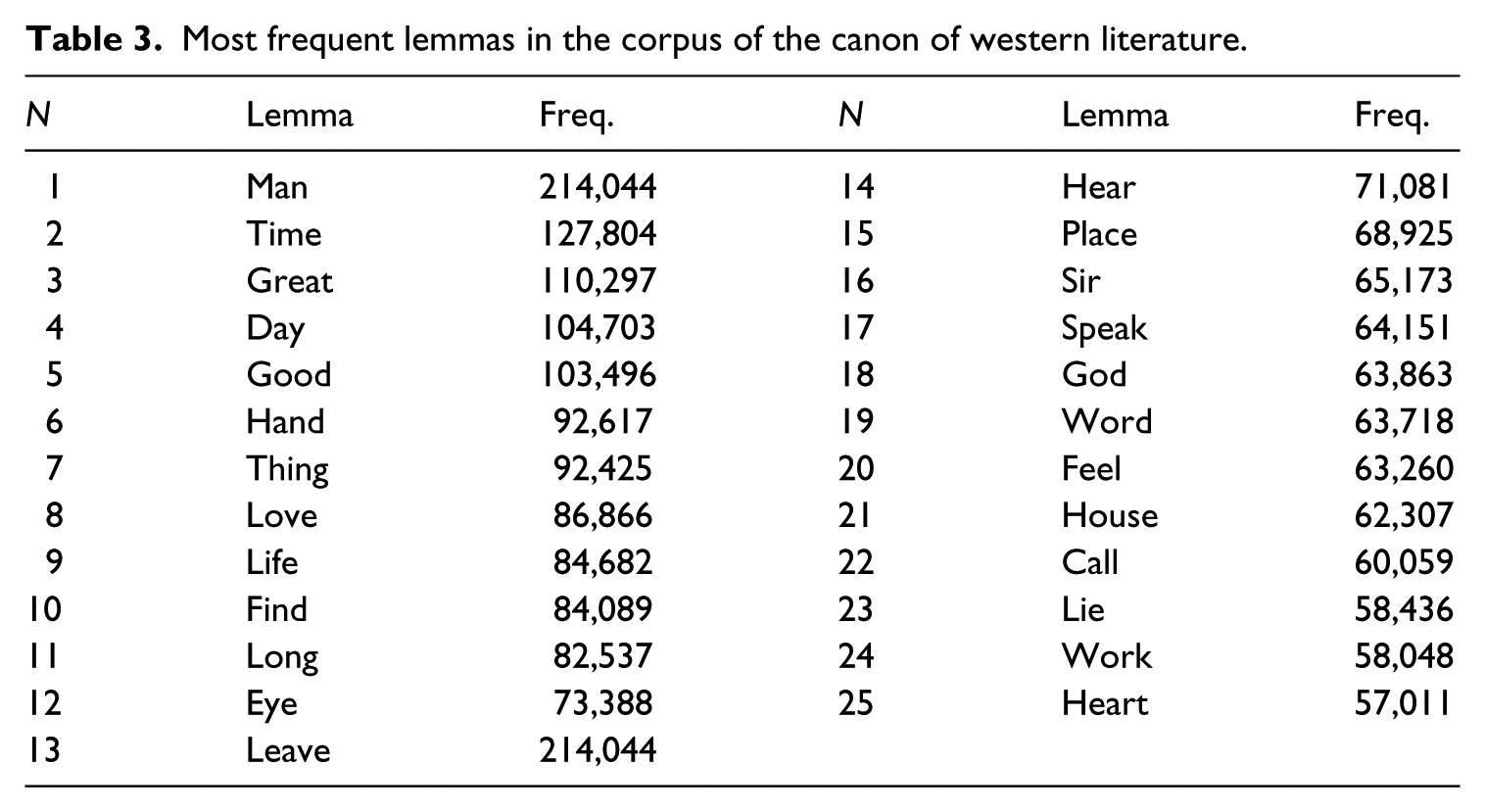
A few interesting observations can be drawn from Table 3. The first is that canonical literature exhibits the Pollyanna Effect (Ingram et al., 2016). The Pollyanna Effect proposes that although human languages tend to have a wider range of words for negative experience, those for positive experience are much more frequent. In the CCWL, the most frequent lemmas reflect recurrent themes of love and life, things that are great and good, and discussions of the heart and God. This positivity bias is more marked than in a general corpus. For example, good occurs 1276 times per million words in the BNC (Leech et al., 2001)., compared to 1430 p/m in the CCWL; great occurs 635 p/m words in the BNC and 1524 p/m in the CCWL; heart 152 p/m in the BNC and 755 p/m in the CCWL; and finally love occurs 150 times p/m in the BNC but 1200 times p/m words in canonical literature. This suggests that even though canonical literature from Homer to Hemmingway addresses death, war, heartache and tragedy, the overall cultural preoccupations of the western canon over history have been largely positive.
The list also shows many lemmas for body parts. Some of these lemmas are physical, such as hand, heart, eye, and others are for bodily sensory experience such as hear, speak, feel. The reason why body part language plays such an important role is perhaps the cognitive poetic one noted by Stockwell and Mahlberg (2015: 132); namely, that effective characterization for mind-modelling requires more description of the body than non-literary language since the author needs to communicate what characters look like, how they move, what they are doing, in order to help readers create a cognitive representation. Table 3 reflects the (not surprising) fact that human experience is a major focus of canonical literature, and that this experience is embodied.
5.1 The decline in influence of the Greco-Romans and the theocratic age
Michel et al. (2011) argue that culturomics can track the rise and fall of the cultural preoccupations of those who produced the texts in a corpus. This section explores two cultural preoccupations of canonical literature, namely religion and the Greco-Romans. Firstly, let us consider religion as a literary theme over time. As was reported in Table 3, God is the 18th most frequent lemma in the CCWL, indicating that religion is a canonical theme. Yet, the focus on religion wanes over time. Lemma lists computed for each age indicate that in the theocratic age religion is a dominant topic, with God as the 2nd most frequent lemma, lord 3rd, and soul 35th. The top four keywords, computed against the rest of the corpus, are God, son, lord and king respectively. Bloom’s (1994) intuitive naming of a theocratic age of canonical literature seems apt. However, in the aristocratic age, God is only the 18th most frequent lemma, lord 15th and soul 81st. By the democratic age, God has slipped to 50th, lord 77th, soul 87th; and by the chaotic age, God is 65th, lord 350th and soul 107th. While the influence and themes of the theocratic age decline, the rise of humanism appears to take its place. For example, even though man is the most frequent lemma in the theocratic age and all others, it is ranked seven places (i.e. eighth) below God as a keyword for the era; however, by the democratic age, God is no longer within even the top 500 keywords. Further, in the democratic and chaotic ages, the top 20 keywords and lemmas contain the following words which theocratic age literature does not: eye, face, stand, sit, cry, feel, walk, laugh – all related to human (bodily) experience. The data suggest a shift of focus in canonical literature across time from the spiritual to the representation of human experience. Arguably, the decline in religion evidenced in canonical literature is a reflection of the decline in its historical centrality to western culture (i.e. a culturomic trend).
Let us consider the intertextual question of the influence of classical literature on the western canon. A long-standing claim has been that the influence of the Greco-Romans has been unparalleled in terms of style, themes, philosophy, characters etc. (Highet, 2015 [1953]: 19). To compute literary connections to the classics, the Greco-Roman subcorpora of the CCWL were queried: approximately 3,567,232 words of texts nested within A3: The Ancient Greeks, A4: The Hellenistic Greeks, and A5: The Romans. To create a metric for tracking classical reference in subsequent literary eras, the 50 highest ranked keywords (computed against remaining eras) and the 100 most frequent proper nouns were extracted (from the Part of Speech tagged version, with tag accuracy checked by hand) and used as batch searches in Wordsmith 6 (Scott, 2016). The cutoff ranks are arbitrary (Mahlberg and McIntyre, 2011), but the procedure produced a list of characters, places and historical figures central to Greco-Roman literature, as reflected in the sample in Table 4.
Highest ranked keywords and proper nouns in Greco-Roman literature.
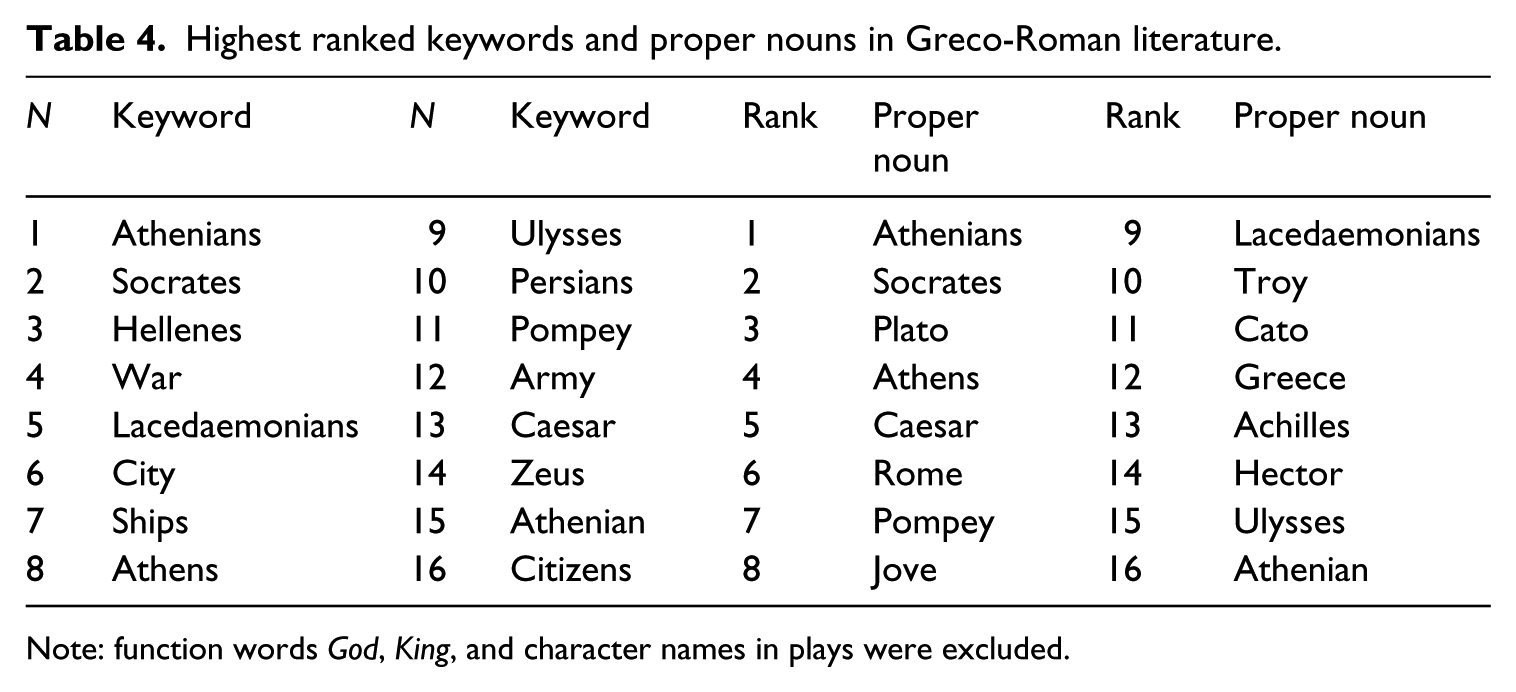
Note: function words God, King, and character names in plays were excluded.
The keywords and proper nouns in Table 4 capture important classical characters (Achilles), places (Rome), gods (Zeus), people (Socrates), as well as characteristics of the Greco-Romans such as the emphasis on the city, ships and citizens, and the valour of the army and war. Reported in Table 5, normalized per million words, are the keywords and proper nouns from Greco-Roman literature tracked across the literary ages.
Frequencies (per million) of Greco-Roman lexis across time in canonical literature.

Table 5 suggests a general decline of the literary influence of the classics, or at least, with their literary preoccupations. Greco-Roman keywords steadily decline till the modern era, as do literary references to Greco-Roman characters, people and places. However, note how references to proper nouns from the classical period spike in the literature of the aristocratic age. This age, which in Bloom’s (1994) estimation spans 1321 to 1832 AD, represents the late middle ages, Renaissance and the reestablishment of democracy. One of the defining characters of this period of western history was looking back to the classical world (Pitts and Versluys, 2014).
6 Stylistics with the CCWL
The above has largely used the CCWL for culturomics, so let us conclude this paper with some uses of the corpus for stylistics. This section reports on: 1. The authors/texts in canonical literature with the most sesquipedalian style, which is a long word that refers to the overuse of long words; 2. Those with a preference for longer/shorter sentences; 3. Those with larger/smaller vocabulary ranges (measured by standardized type–token ratios). These may not be profound questions, but they are reflections of style that the CCWL can help us put on record. Since genre affects style, Tolstoy’s sentence length in Anna Karenina, for example, is likely not comparable to his plays; the following reports genre estimates separately for texts tagged <poetry>, <prose>, <play>. Estimates have been computed by Wordsmith (Scott, 2016), excluding notes, licence statements and character names in plays. Table 6 reports the longest and shortest mean word lengths by author/text across genres.
Mean word lengths in the corpus of the canon of western literature (CCWL).

Table 6 indicates that mean word length varies across genres. Plays use shorter words on average compared to poetry or prose, likely a stylistic marker of direct speech which correlates with high frequency, shorter words (Greenbaum and Nelson, 1995). Gibbon’s Decline and Fall of the Roman Empire uses the longest words, on average, of any author, which perhaps reflects a conscious (or unconscious) Latinate prose style related to his subject matter. Nietzsche also favours long words, which may partly be the influence of translation from German (see also Goethe’s and Wagner’s plays), a language with less analytic word building processes than English (Wierzbicka, 1997). However, it also seems to be a style associated with philosophy since J.S. Mill and Carlyle also have some of the longest average word lengths in the canon. Table 6 reflects authorial style more specifically; for example, the different plays of Synge are recurrent in the list of shortest mean words lengths, as are volumes of poems by Frost and Robinson. The Adventures of Huckleberry Finn uses the shortest words in prose, a style likely reflecting a conscious attempt by Twain at authenticity in the representation of the thoughts/conversations of central characters who would have used shorter, high frequency words: i.e. Huck Finn is a child, Jim is a slave deprived of education (Wood, 2012). The style associates with children’s literature more generally, as Stevenson, Morris and Grimm’s Fairy Tales also make the list of shortest mean word lengths. Further, there is also perhaps reflection of the preferred styles of different literary ages, as the majority of authors with a preference for short words across genres are generally more modern rather than (neo) classical.
In corpus stylistics, sentence length has been correlated with the style of a range of authors, from the short declarative sentences of Hemmingway (Toolan, 2009) to the long verbose sentences of Joyce (O’Halloran, 2007). Table 7 reports the authors/texts in the CCWL with the longest and shortest average sentence lengths.
Mean sentence lengths in the corpus of the canon of western literature (CCWL).

In Table 7, again one can see both styles of authors and genres reflected in sentence length. Plays have a much shorter mean sentence length than prose, though not it seems in the era of Shakespeare and Marlowe, where the style was not intended to represent actual speech. This is unlike modern playwrights, who use the shortest sentences, an imitation of spoken utterances which tend to be shorter and lack the syntactic complexity of writing (Greenbaum and Nelson, 1995). Ibsen’s style of realism, with its truncated utterances to produce melancholic effects, is reflected in the fact that he has multiple plays within the 10 texts with the shortest mean sentence length in the corpus. Poetry has generally longer sentences than prose, which one suspects reflects that a unit of scansion is more often offset from other text lines by a comma, or (semi)colon, as in Milton (Fish, 2001), rather than sentence punctuation. Table 7 also suggests that long sentences pattern with the Greco-Roman or Aristocratic Ages. As the previous section indicated, the two periods appear to be intertextually and culturally related. Note that Ulysses had one of the shortest sentence lengths in the CCWL, despite having one of the longest sentences in the history of literature. The estimate here, however, accords with previous reported estimates (Borja, 2014), and the novel did have the second highest standard deviation in the corpus.
Scholars have often used the literary output of authors to estimate their vocabulary size, Shakespeare being one frequently studied case (Craig, 2011). A common procedure for the estimate is the type–token ratio, which calculates how many different types of words there are in a text (i.e. lemmas) relative to how many actual words there are in the text (i.e. tokens). If an author’s work has higher number of types to the overall number of tokens, this indicates it contains a wider vocabulary range (Holmes, 1994). Since text length affects the type–token ratio (Baker, 2004), i.e. texts with more words will have more words that occur only once, Table 8 reports a standardized TTR based on averages per 1000 words for the authors/texts in the CCWL.
Vocabulary range in the corpus of the canon of western literature (CCWL).
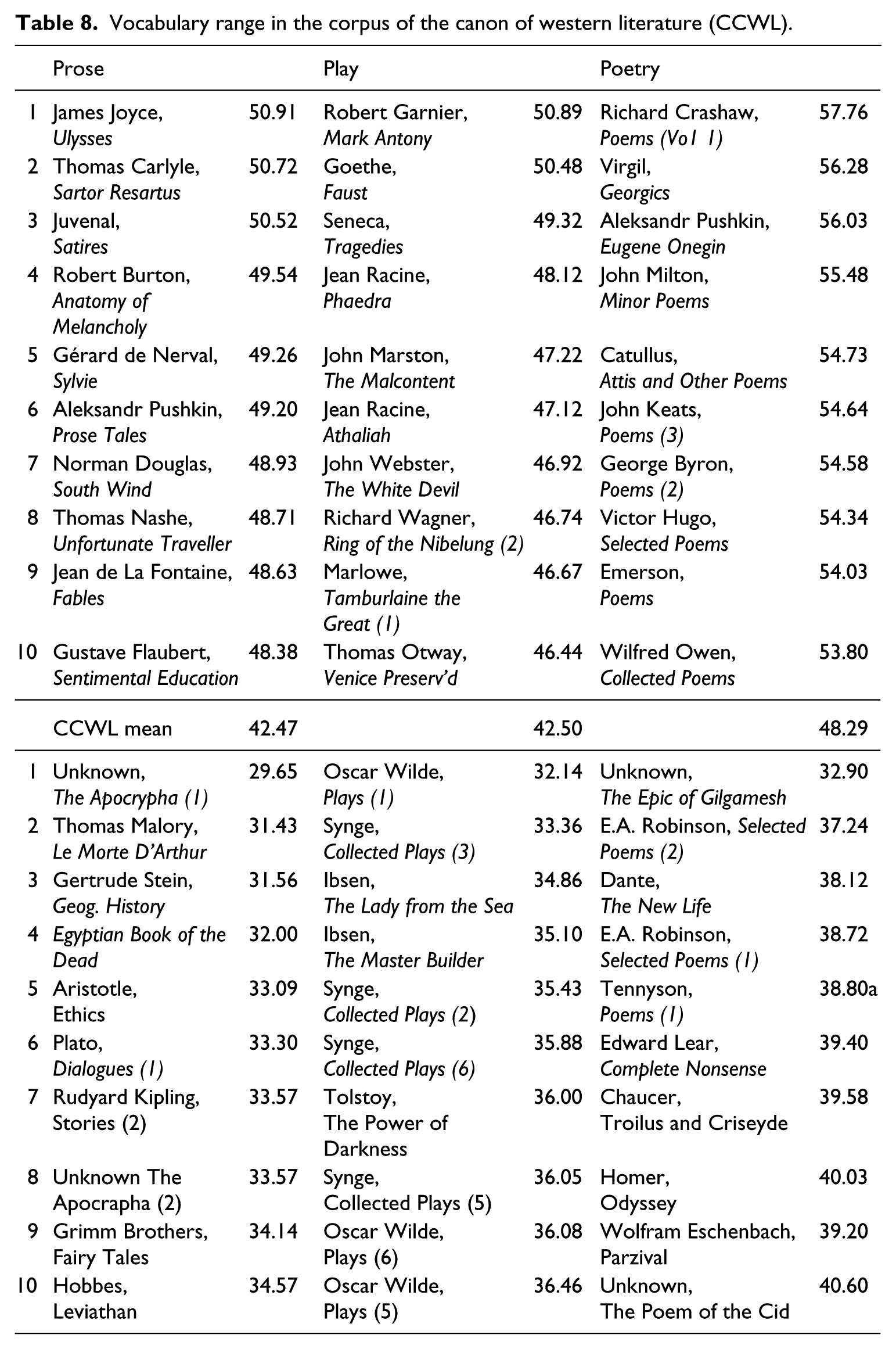
While Ulysses has one of the shorter average sentence lengths in canonical literature, Table 8 indicates the novel has the highest standardised type token ratio (STTR) of any prose work in the corpus. The finding is consistent with previous stylistic work that has emphasized Joyce’s lexical complexity (O’Halloran, 2007). Generally, poets seem to have the widest vocabulary range in the canon. There are several reasons for this. One is that poetry relies more heavily than other literature on the artistic choices made in relation to vocabulary, so rather than frequent words that come to mind easily, poets select words that are less common. Further, a poem is usually short, and the demands of the form sacrifice function words. A collection of poems also might not deal with same characters, places and things, thus decreasing STTR. Lexical range appears to be an element of the style of Ibsen, Synge and Oscar Wilde, at least in his plays, while authors such as Pushkin have a high STTR regardless of the form they are working in. Children’s literature and religious prose, which had shorter words and sentences, tends to have a higher rate of lexical repetition.
The previous data have indicated that there is variation style according to genre and author across the three metrics of word length, sentence length and vocabulary range. However, some authors, e.g. Defoe, Joyce and Coleridge, appear multiple times across the measures, suggesting there may be a relationship across these elements of style. A Pearson’s product moment was therefore computed for all texts in the CCWL, finding the following general correlations: word and sentence length (r=.39, p<.01), word length and STTR (r=.45, p<.01), STTR and sentence length (r= .07, p<.01). In other words, canonical literature with longer sentences has a moderate tendency to also have longer words; higher vocabulary ranges tend to pattern with an increased use of longer words, and there is a weak but significant relationship between larger vocabulary ranges and longer sentences.
7 Conclusion
This paper has introduced the Corpus of the Canon of Western Literature (Version 1), a corpus of approximately 73 million words that represents the construct of the western canon according to Bloom (1994). Future releases of the CCWL aim to add more markup to the files, such as date of publication, more genre categories and, when required, the translators and original languages. Further markup will help researchers disambiguate how such variables affect canonical literature. A few limitations of the corpus and its analysis presented above are worth closing with. One general limitation on the corpus is the issue of translation for non-English texts. In translation, there is often a blend of the language and style of an era with that of the source material, the King James Bible being a good example. Also, as noted, the CCWL does not have complete representation of the western canon described in Bloom (1994). The open source nature of this corpus, however, allows for the CCWL to be updated (by anyone) with other editions, perhaps beyond Project Gutenberg, to improve coverage and quality. While much time and effort has been expended to try to reduce noise and thus provide other researchers with accurate numbers and a useful corpus, noise still remains. It also should be noted that different corpus tools can produce variable estimates of word count, sentence length etc. Future releases will further reduce transcription errors, unwanted characters and any other non-target text that may still remain. While the culturomic and stylistic analysis above has been introductory, future research can use this corpus for much more complex quantifications of style and culture, for example which authors in the canon cluster together according to intertextuality or other style metrics? Are there differences in country of origin in literary preoccupations? Do male and female canonical authors (of which there are only approximately 7% for the latter) differ in their construction of themes, characters and narrative ideas? How have what Adler and Weismann (2000) termed the ‘great ideas’ contained in the western canon spread throughout literature across time and place? The canon of western literature has been an important and contested idea in literary studies, and the corpus introduced in this paper is hoped to be of use to scholars interested in culturomics and stylistics.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.