
Abstract
This article describes a mathematical model for the design of supply chain network for a company that sells its products through a set of retail stores that integrates both the movement of fresh products and the returns from the customers. Specifically, the company faces a situation where, given the location and demand from the set of retail stores, it wishes to decide where to locate the warehouses (or distribution centres) and test centres and the routes to be used in transporting the fresh products from warehouses to stores, returned products from stores to test centres and finally, re-stockable returned products from test centres to warehouses. This is formulated as a binary integer linear programming problem. The problem is solved using LINGO and then, an analysis is performed to determine the sensitivity of the optimal solution to different parameters, including sales volumes, return rates, costs of operation and transportation and the various prices.
Keywords
Introduction
The performance of any supply chain at best is as good as its design. While the performance of a well-designed supply chain network may be better or worse depending on the operating decisions made, a poorly designed network will never be able to overcome the limitations of its inferior design and deliver superlative performance (Meepetchdee & Shah, 2007). Supply chain network design, in turn, depends on a host of factors, both internal to the company—like its choice of products, markets and competitive strategy, its cost structure emanating from its choice of technology and production and logistical processes and even its existing network—and external like the demand of its products and its geographical distribution, location of suppliers, tariffs, tax incentives, actions of competitors and perhaps, even disaster risks (Abe & Ye, 2013). As most of these factors are dynamic in their nature, supply chain designs need to be reviewed and modified whenever required, though not very frequently as, by its very nature, it is a strategic decision.
Supply chain network design includes determining the different types of facilities and their roles; location, number and capacities of each type of facility and the quantity of the flow between them (Amiri, 2006). It is a complex, strategic decision problem, often involving multiple and conflicting objectives such as profit (or cost), service level, responsiveness and so on. The importance of supply chain network design can be gauged from the large body of research work incorporating mathematical programming, simulation, multi-objective decision making, empirical studies and other methodologies, as well as the review papers like the ones by Akcali, Cetinkaya and Uster (2009), Carter and Ellram (1998), Fleischmann, Bloemhof-Ruwaard, Dekker, van der Laan, van Nunen and van Wassenhove (1997), Melo, Nickel and Saldanha-da-Gama (2009), Snyder (2006) and Srivastava (2007).
Supply chain networks are often designed considering only the forward logistics, wherein all processes involved in the movement of goods from suppliers through manufacturers, distributors and retailers to the end customers are analyzed. But in many supply chains, physical goods as well as their value do not get fully consumed once they reach the end customer. Coordination between the forward movement and the successive processes after the product return may be imperative to capture the value still present in the returned product/other associated resources. While liberal customer return policies may emphasize customer satisfaction (Lee et al., 2012), ‘…used products are sold on secondary markets, outdated products are upgraded to meet latest standards again, failed components are repaired to serve as spare parts, unsold (and returned) stock is salvaged, reusable packaging is returned and refilled, and used products are recycled into raw materials again’ (Wadhwa & Madaan, 2007) to enhance the value of the output produced by the supply chain. ‘Reverse logistics’ includes the new set of processes that aim at capturing economic as well as environmental values from the products/resources taken back from customer, thus broadening the scope and the span of supply chain networks.
The strategic importance of warehouse location and the design of the supply chain network is well recognized in most industries. In some of these industries, the return rate is also considerably high. A survey by the Reverse Logistics Executive Council found that in the United States (US), return rates varied significantly across industries and for many industries, it was vital to manage the reverse flow (Rogers & Tibben-Lembke, 1999). The return rates were as high as 50 per cent for magazine publishing, 20–30 per cent for book publishing and greeting cards and 10–20 per cent for computer manufacturers.
This article is organized in seven sections. After this brief introduction, we carry out a review of literature on integrated forward and reverse logistics network design in the second section. In the third section, we formally define the problem and the assumptions made. The mathematical formulation of the problem is presented in the fourth section where we formulate the decision problem as an integer linear programming (ILP) problem. We next present a small application and its solution in the fifth section. The sixth section discusses the solution and its sensitivity to some of the key parameters. Finally, in the last section, we present conclusion and the limitations of our model.
Review of Literature
An early usage of the term ‘reverse logistics’ is found in Stock (1992) in which, although the usage of the term in the context of waste disposal and management of hazardous materials is highlighted, the perspective is broadened to include ‘all issues relating to logistics activities carried out in source reduction, recycling, substitution, reuse of materials and disposal’. As the use of reverse logistics concept was found to be much broader than in the context of environmental management, the definitions were also gradually widened to include flows of new products returned for commercial reasons, returns of, say, packaging materials to manufacturers or to parties other than producers, including specialized recovery companies. Fleischmann (2000) defined reverse logistics as ‘the process of planning, implementing, and controlling the efficient, effective inbound flow and storage of secondary goods and related information opposite to the traditional supply chain direction for the purpose of recovering value or proper disposal’.
Rogers, Melamed and Lembke (2012) present an excellent review of published research on modelling and analysis of reverse logistics as well as a summary of modelling opportunities in this area. They mention that both analytical and simulation models have been used in the literature in all areas of reverse logistics, like reverse logistics network design, returned product route planning and scheduling, central return processing optimization, secondary market optimization and product disposition revenue maximization. An understanding of the various processes involved in the reverse logistics of a retailer is presented by Hsu, Alexander and Zhu (2009), while Stock and Mulki (2009) do the same for manufacturers, wholesalers/distributors and retailers.
Many authors have used facility location models based on mixed integer linear programming (MILP) for network designing and combinatorial optimization theory. Kroon and Vrijens (1995) discuss the design of an integrated network for reusable containers based on MILP. They address the role of different actors, the economics of the system, the cost allocation to the different actors, the amount of containers needed and the locations of the depots for the containers. Barros, Dekker and Scholten (1998) present a case study addressing the design of an integrated logistics network for recycling sand resulting from the processing of construction waste in the Netherlands. They develop a capacitated facility location model based on MILP in which they evaluate multiple scenarios and finally select the solution with the best worst-case behaviour. Jayaraman, Guide Jr and Srivastava (1999) present an analysis of logistics network based on mixed integer programming (MIP) of re-manufacturing facilities for electronic equipment. Similarly, Krikke, Kooi and Schurr (1999) develop a mixed integer programme to design an un-capacitated reverse logistics network. Louwers, Kip, Peeters, Souren and Flapper (1999) discuss a reverse open-loop network model with continuous potential locations using non-linear programming for carpet waste. Lieckens and Vandaele (2007) combine MILP with a queuing model to design a reverse logistics network.
Jayaraman, Patterson and Rolland (2003) discuss a model for reverse distribution network and solve it with a heuristic solution methodology. Min et al. (2006) proposes a deterministic model to design a reverse logistics network involving products returned due to either defects or changes in customers’ needs/preferences. Srivastava (2008) developed reverse logistics network design model based on maximizing profits for various scenarios in practical settings using a hierarchical optimization model.
Khajavi, Seyed-Hosseini and Makui (2011) develop an MIP-based model to optimize a multistage capacitated supply chain integrating both forward and reverse logistics. Ozceylan and Paksoy (2013) present an MIP model for a closed-loop supply chain network that includes both forward and reverse flows with multi-periods and multiple components. However, their model assumes known capacities for different facilities as well as disassembly and refurbishing as the only disposal of product returns.
Most authors have chosen to minimize cost as part of their formulation and only a few have formulated the problem to maximize profit. Tan and Kumar (2006) developed a system dynamic model to maximize profit from the reverse logistics operations of a computer manufacturer. Lee et al. (2012) supported the assertion of Guide et al. (2006) that maximization of profit is a better objective than minimization of cost and chose to maximize profit in their non-linear mixed integer programme formulation. Das (2012) also developed an MIP model that integrated the output from a recovery model into a new product model to achieve coordination between two separate markets of new products and recoverables. We have formulated the integrated forward and reverse logistics in our model as a binary ILP problem.
Problem Description and Assumptions
We consider a company that sells products like garments, or shoes or sports goods through its chain of retail stores all across India. Though there could be a large variety of products, these could be aggregated for transportation and storage purposes and the aggregated demand could be expressed in common units like kilogram (kg) or truckload. It supplies the retail stores from multiple warehouses (or distribution centres, DCs) through frequent deliveries. The company has an idea of the average sales volume (in aggregate units) per period and the average return rate at each of these stores. The company buys the products from manufacturers who deliver the products at the warehouses as specified by the company. We consider the supply chain from the warehouses onwards. It is possible that the company produces some of the products itself and is one of the manufacturers. All products returned by the customers (reverse logistics) are first collected at the retail stores and transported to a test centre at which their mode of disposal is decided and a fraction of the returned products, with some additional processing or packaging—if required—is then sent back to a warehouse for onward transmission to a retail store.
To begin with, only the locations of the retail stores are known. The company needs to decide the number and the locations of its warehouses and test centres. A warehouse will be used for storing and transporting products to retail stores, whereas a test centre will be used for testing the returned products. The supply chain network will also specify which warehouse or warehouses will meet the demand for each retail store, that is, the flow of products from warehouses to retail stores. Similarly, the design of the supply chain network must also specify the flow (of product returns) from retail stores to test centres as well as from test centres back to warehouses.
Further, the company has shortlisted some cities (and sites within the cities) for possible location of its warehouses. Similarly, it has also prepared a second shortlist of candidate locations for its test centres, some or many of which may be common to the first shortlist of locations for warehouses. Obviously, a common location for both warehouse and test centre may save on the transportation cost from the test centre to the warehouse, while it has also been found that ‘DCs do not work well managing both forward and reverse distribution at the same location’ (Rogers et al., 2012) as the returned product almost always gets a lower priority. Since we are designing the supply chain network, we are not assuming any capacity constraints, either for a warehouse or for a test centre. Rather the cost of operating a warehouse, as that of a test centre, is made dependent on the capacity required to handle the flow of products through it.
There are seven types of costs which affect the company’s decision in selecting the locations of its test centres and warehouses. These are:
Fixed cost of operating a warehouse. Variable cost of operating a warehouse. Fixed cost of operating a test centre. Variable cost of operating a test centre. Transportation cost of products from a warehouse to a retail store. Transportation cost of product returns from a retail store to a test centre. Transportation cost of re-stockable product returns from a test centre to a warehouse.
The company can reduce its transportation costs by operating more warehouses and test centres; but then its costs of operating the warehouses and the test centres would rise. This trade-off between transportation costs on one hand, and the operating costs (fixed and variable costs) on the other, would be important in the final design of the supply chain network. In fact, since we assume different procurement prices at each warehouse and different secondary price at each test centre, we formulate our decision problem as one of maximizing profit rather than one of minimizing cost.
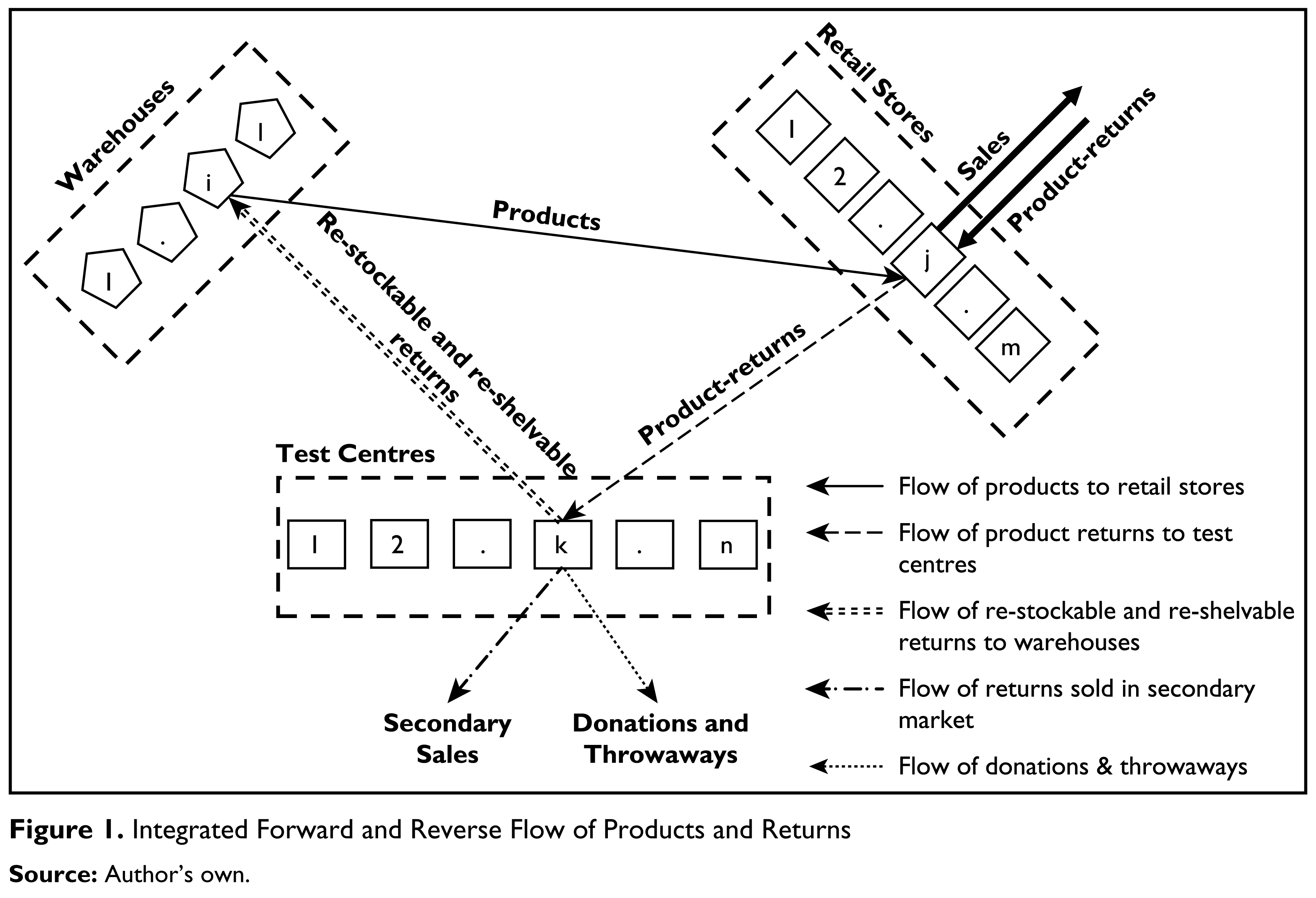
Figure 1 presents a diagrammatic representation of different flows in the supply chain network. In our design, each retail store will be fully served by a single warehouse. Similarly, each retail store will send back its product returns to a single test centre. We assume that products are returned by customers only at the retail stores. This is a realistic assumption because the customer would be inclined to return the products to the closest retail store to get a refund or to purchase another product. From the retail stores, returned products are taken to test centres. At a test centre, products are tested, and on the basis of the test results, the mode of disposal is decided. A particular returned product may be found to be fit for:
Re-stocking and re-shelving. Reselling to secondary markets. Donations. Throwaway.
Returns segregated for re-stocking and re-shelving are sent to a warehouse after repackaging them, if necessary, while those identified for reselling to secondary markets are sold to the secondary sellers at the test centre itself. The company also donates and throws away the identified product returns from the test centre itself. So, we are not considering any transportation cost for reselling to secondary markets, nor are we considering any cost for donations and throwaways.
We know the average aggregate sales of the products and the average return rate in each retail store, unit transportation cost between a retail store and each of the candidate warehouse or test centre and between a test centre and a warehouse. We also know the fixed and the variable cost of operating each candidate warehouse and test centre. The supply chain network design will determine which candidate warehouse and which candidate test centre should be operated and the flows between the chosen warehouses, the test centres and the retail stores.
Model Formulation
We use the following parameters and variables for defining our formulation:
Parameters
i = Index of candidate sites for warehouses (or DCs) that would send products to retail stores.
l = Total number of candidate sites for warehouses.
j = Index of retail stores that sell products to customers.
m = Total number of retail stores.
k = Index of candidate sites for test centres that would test the product returns, decide the mode of disposal and send re-stockable returns to warehouses.
For the ith warehouse:
PPi = Procurement price per unit of fresh products at the ith candidate warehouse site. f WHi = Fixed cost of operating the ith candidate warehouse site per period. vWHi = Variable cost of operating the ith candidate warehouse site per unit per period.
For the jth retail store:
SPj = Selling price per unit of fresh products at the jth retail store. Sj = Sales of the product (in units and net of returns) at the jth retail store per period. ρj = Total returns as a proportion of sales (in units) at the jth retail store.
For the kth test centre:
DPk = Secondary market selling price (discounted price) of returned products per unit at the kth candidate test centre site. f TCk = Fixed cost of operating the kth candidate test centre site per period. vTCk = Variable cost of operating the kth candidate test centre site per unit per period.
Other parameters and movement costs:
μ = Re-stockable returns as a proportion of total returns. ν = Secondary saleable returns as a proportion of total returns. C1ij = Transportation cost per unit of the product from the ith candidate warehouse site to the jth retail store. C2jk = Transportation cost per unit of total returns from the jth retail store to the kth candidate test centre site. C3ki = Transportation cost per unit of re-stockable returns from the kth candidate test centre site to the ith candidate warehouse site. M = A large number. λ = A small number greater than zero.
Decision Variables

Intermediate or Structural Variables

The Optimizing Model
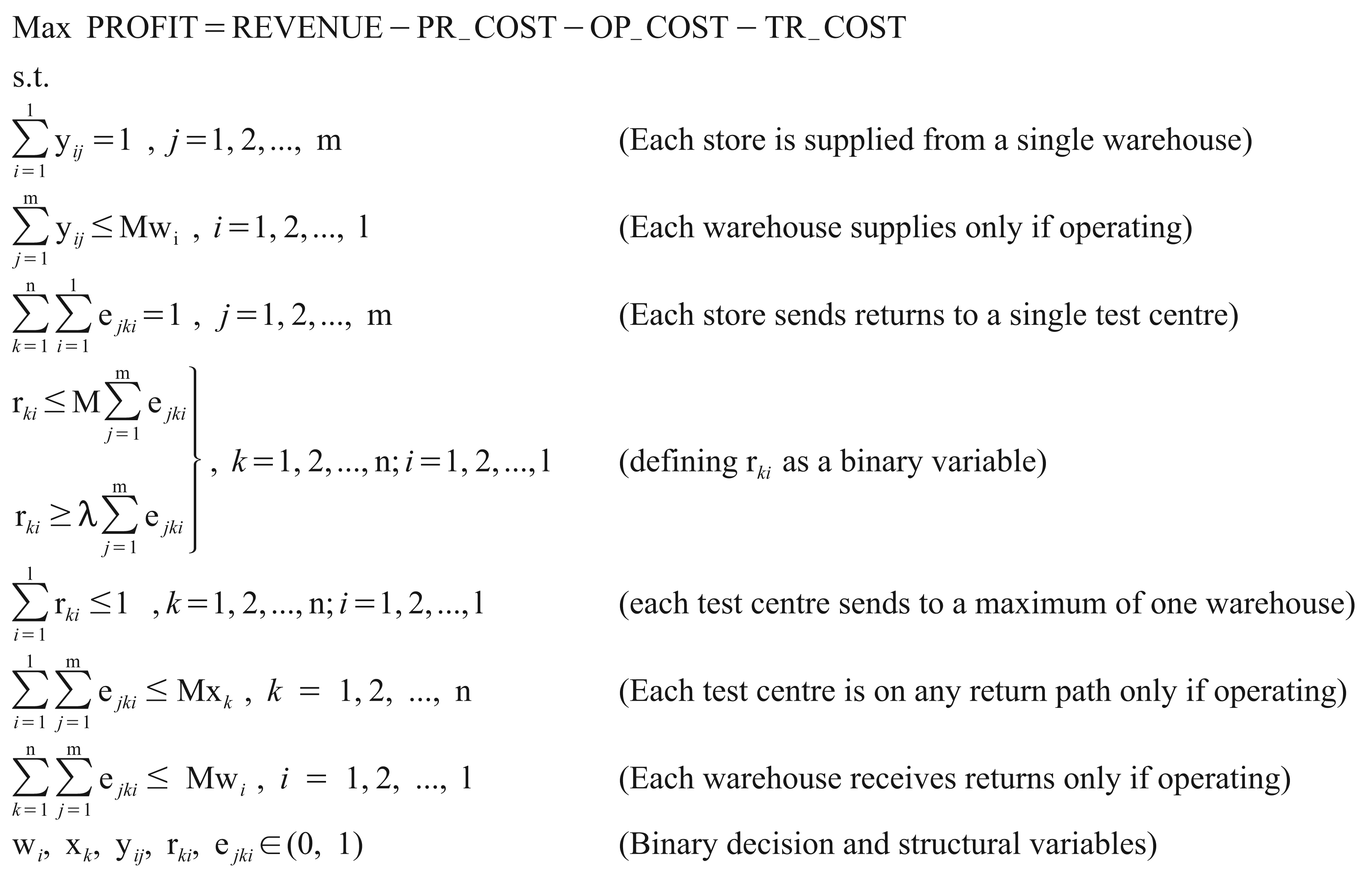
We have formulated the above integrated logistics problem as a binary ILP. The ILP maximizes the profit per period which is obtained by subtracting the total supply chain cost from the revenue per period. The revenue per period is from sale of products at the retail stores and from sale of returned products in the secondary market. Similarly, the supply chain cost per period is the sum of procurement cost, operating cost and the transportation cost per period.
The procurement cost of fresh products from manufacturers and vendors is for quantity net of re-stockable returns. The operating cost is the sum of the fixed and the variable cost of operating the warehouses and the test centres, respectively and the transportation cost is the sum of three transportation costs, namely, from warehouses to stores, from stores to test centres and from test centres to warehouses, respectively.
While yij and ejki are binary decision variables representing whether the forward path from warehouse i to store j and from store j to warehouse i via test centre k are used or not, we have also introduced a binary structural variable rki to represent if test centre k should send product returns to warehouse i or not. This is required to represent the constraint that each test centre sends returns to a maximum of one warehouse. This constraint, as well as the ones representing that each store is supplied from a single warehouse and that each store sends returns to a single test centre are introduced from considerations of effectiveness and convenience, particularly because no capacity limitations have been assumed for any facility.
It may appear that we could use binary decision variables, pjk and rki, to represent, respectively, if the route from the jth store to the kth test centre and the route from the kth test centre to the ith warehouse is used or not. However, this results in a quadratic objective function. By defining decision variables over the complete return path, ejki, we could formulate this as a binary ILP, however at the cost of additional variables. This trade-off between a simpler objective function and fewer variables could be used differently in bigger problems. Of course, pjk and rki values can always be obtained from the ejki values by summing over the appropriate indices.
Application and Results
We apply the formulated problem to a smaller version of a realistic situation to demonstrate the appropriateness of the formulation as well as to interpret the results and study the sensitivity of the designed supply chain network to the parameters identified so that any conclusions derived therefrom can be used in designing as well as modifying similar supply chain networks.
In this application, we consider a company having 10 retail stores in different parts of the country selling the product. The stores get their supplies from warehouses (or DCs) and any returns from the customers are sent by the stores to test centres. The company has shortlisted six possible locations for the warehouses and another six candidate locations for test centres. Some of the candidate test centres are at the same locations as the candidate warehouse locations (three in number), while three additional locations are shortlisted only for possible test centre locations. In this conceptualization, we face a network facilities location problem where the nodes and the arcs are well defined. What is required is to choose some nodes and some arcs in such a way that the supply chain conditions for forward and backward logistics are satisfied and the profit per period is maximized. The parameters chosen for this problem are shown in the Appendix. When this problem is solved using LINGO, we find the solution as given in Table 1.
Optimal Solution—Forward and Return Paths
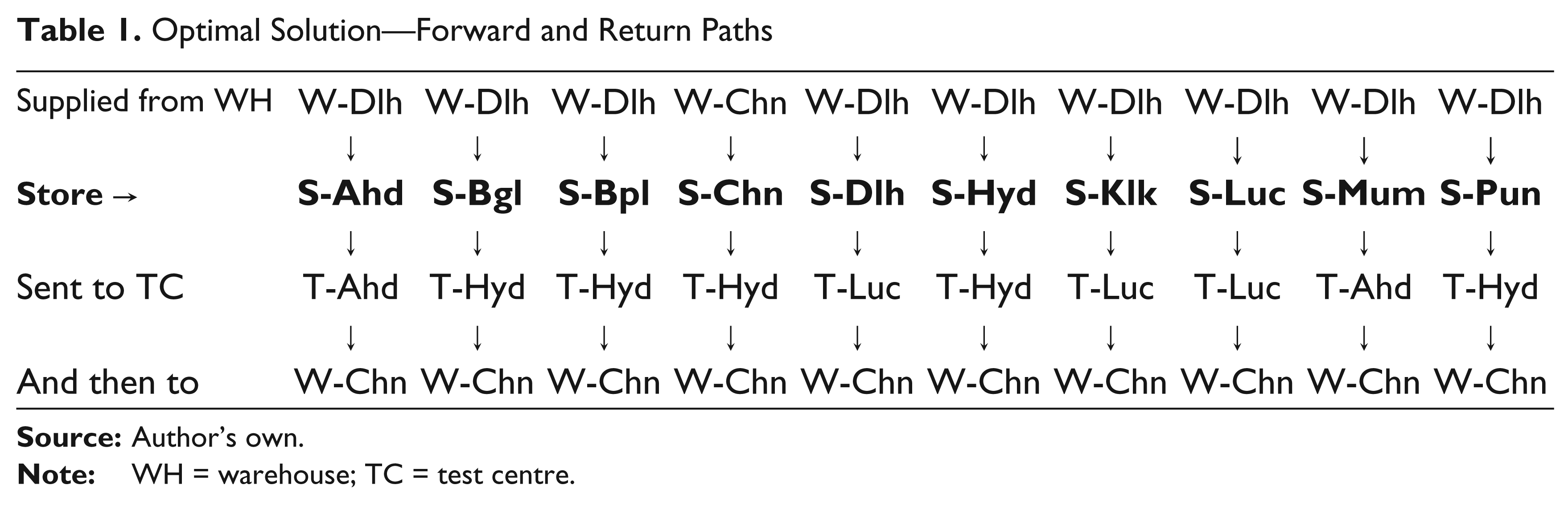
According to the LINGO solution, the company should operate only two warehouses—W-Dlh and W-Chn—and three test centres, T-Ahd, T-Hyd and T-Luc. The table shows the forward path to each store and the return path from each store. For example, store S-Ahd is supplied from W-Dlh and sends the product returns to T-Ahd, which then sends the re-stockable returns to W-Chn. The LINGO solution also reports the revenues, costs and profit per period as shown in Table 2.
Optimal Solution—Revenue, Costs and Profit
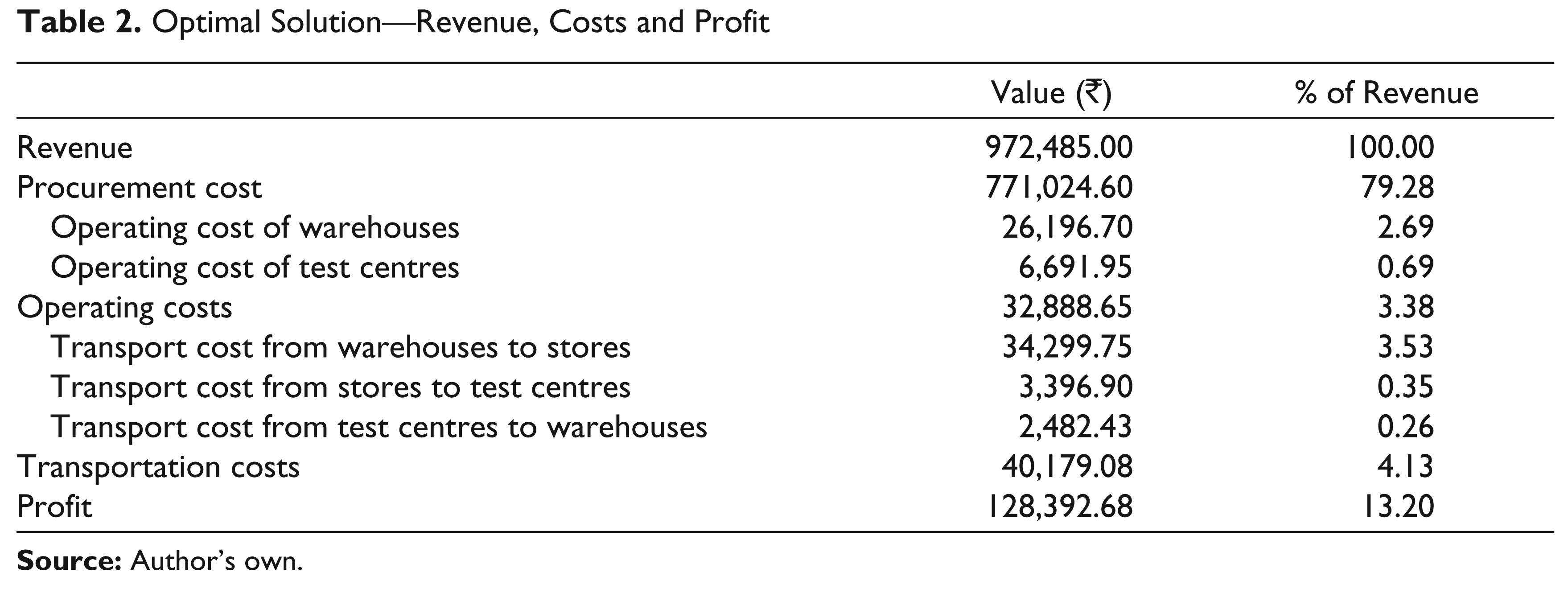
Interestingly, all the product returns are sent back to only one warehouse, namely, W-Chn, although another warehouse, W-Dlh, is also operating. W-Dlh receives only fresh products from the manufacturers and sends these to all stores but to S-Chn.
Discussion and Sensitivity Analysis
We now study the sensitivity of the optimal solution to some of the parameter values assumed in our problem. The initial set of parameter values and the optimal solution presented in the previous section is taken as the baseline for all such analysis in this section.
The observation mentioned at the end of the previous section may be intriguing at first sight but a closer look highlights that it is attempting to take advantage of a lower procurement price at W-Dlh vis-à-vis W-Chn, which overrides the saving in transportation cost that could be obtained by sending the re-stockable returns from each of the test centre to a warehouse with the least transportation cost.
Effect of Changing ‘Fraction’
This raises another important issue for consideration: would it be fair to send all re-stockable returns to one and all fresh products to another warehouse, as suggested by the previous optimal solution? In case the management of the company decides not to send more than a pre-decided maximum ‘Fraction’ of re-stockable returns to any warehouse, this can be achieved by adding the following simple constraint for each warehouse:
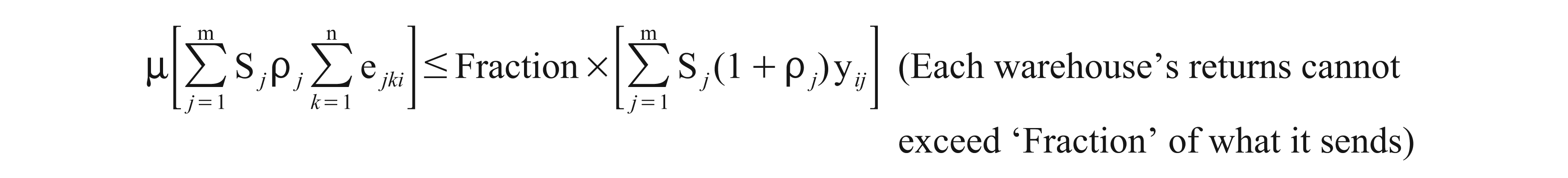
Table 3 shows the revenue per period for the optimal solution under different values of the ‘Fraction’ as well as the various costs—procurement cost, total operating costs (of both warehouses and test centres) and total transportation costs (for both forward and reverse logistics)—and the profit per period as a percentage of the revenue. It also shows the candidate warehouse and test centre locations where these facilities need to be operating using only the binary values of the decision variables wi and xk.
Sensitivity to the Maximum ‘Fraction’ of Re-stockable Returns to a Warehouse
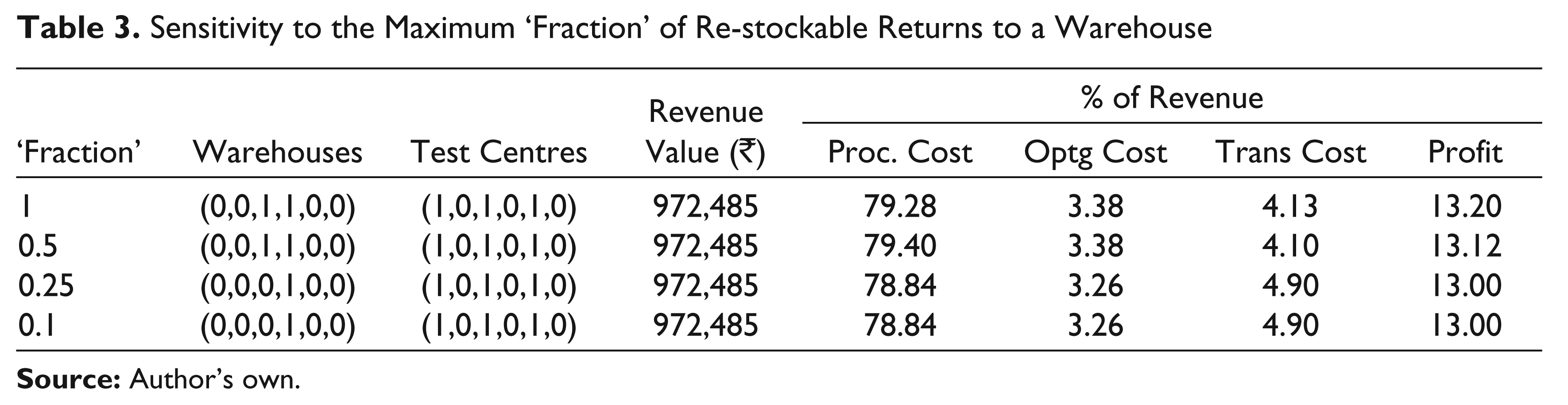
As the ‘Fraction’ allowed is reduced, at first the procurement cost increases slightly as the constraint on returns distributes the returns to more warehouses (among the operating warehouses) and increases the consequent procurement cost. As the ‘Fraction’ is reduced further, the number of operating warehouses reduces with consequent higher flows through the retained warehouses to accommodate the reduced ‘Fraction’ allowed of returns. All through these reductions in ‘Fraction’, the profit margin falls, first as procurement costs increase and then as both procurement and transportation costs increase. There is no effect on the test centres and that on the warehouses is that of closing down an operating warehouse, thus showing the robustness of the optimal solution to changes in ‘Fraction’.
Sensitivity to Changes in Demands
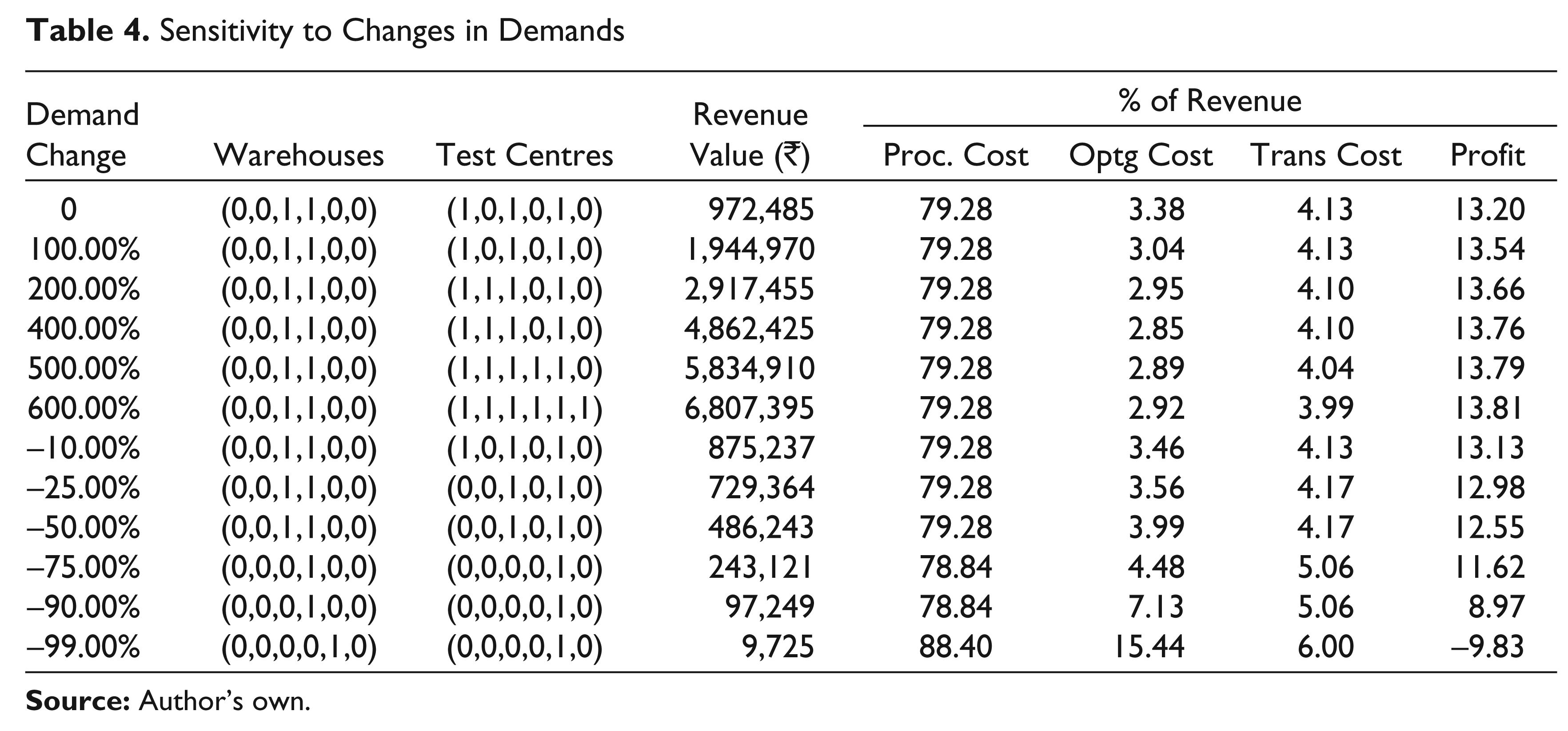
Effect of Changes in Demand
Table 4 studies the sensitivity of the optimal solution to changes in demand from the retail stores. If the demand changes by as much as +100 per cent or –50 per cent, there is no change in the warehouse or test centre locations. As the demand increases by more than +200 per cent, more test centres become viable and as demand falls by more than 50 per cent, only some of the operating test centres and warehouses are retained. In the extreme case when demand falls by more than –99 per cent, does a new warehouse location become better suited than of the existing ones—again highlighting the relative robustness of the optimal solution to moderate changes in demands.
Sensitivity to Changes in Selling Price
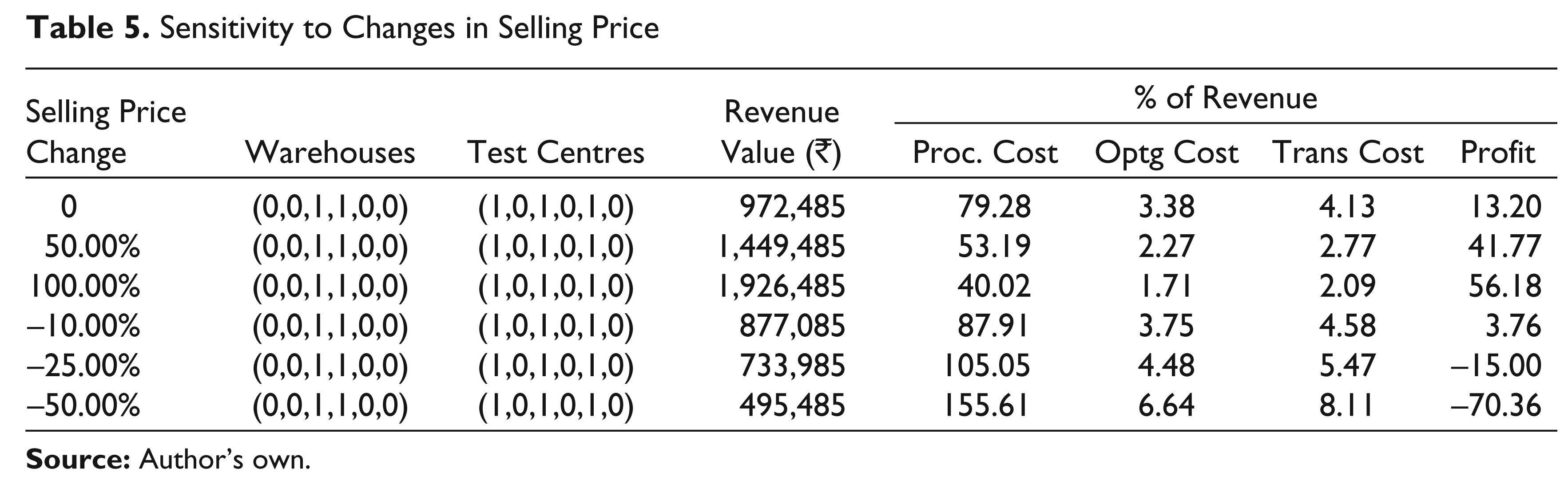
Effect of Changes in Selling Price
In our model, we have made a reasonable assumption that the selling prices across all retail stores are equal even though the procurement prices at different warehouses (including freight inwards) are different. Table 5 shows the optimal solution for different changes in the selling price. If the selling price alone changes by as much as +100 per cent or –50 per cent, there is no change in the optimal location of warehouses and test centres. Of course, the profitability of the supply chain is highly sensitive to selling price changes—for example, a 50 per cent increase in the selling price causes a more than 200 per cent increase in profit margin.
Effect of Changes in Procurement Prices
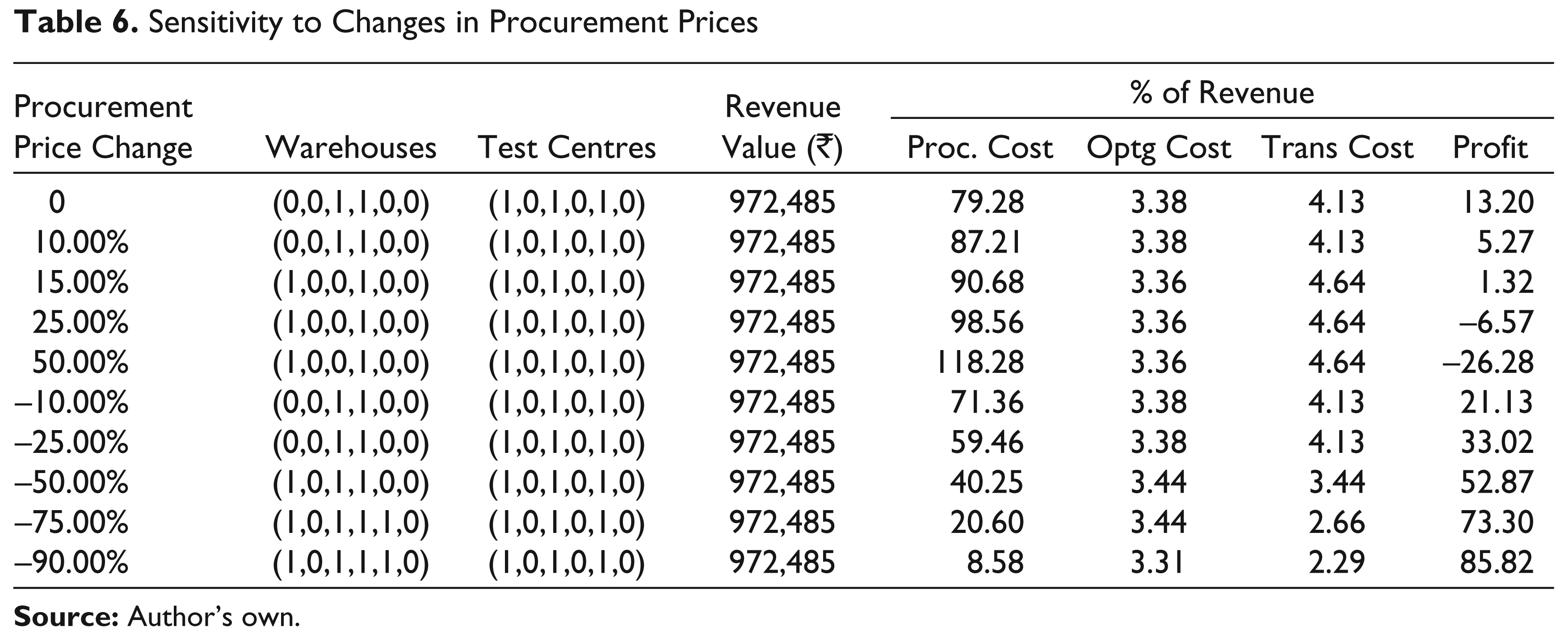
Table 6, which captures the effect of procurement price changes, shows that additional warehouses would be needed if the procurement prices fell by 50 per cent or more. This may be because, with a constant percentage decline in procurement prices, the procurement prices at different warehouses would tend to equalize and warehouse location would largely be decided by the trade-off between the operating and transportation costs alone.
On the other hand, if the procurement prices increased by, say, 15 per cent, the optimal choice of warehouses would change (although the number of warehouses operating would not change) and the supply chain operations would become less profitable under such circumstances. This could again be because the difference in procurement prices at different warehouse locations becomes larger and warehouse location tends to be made on lower procurement prices than on the trade-off between the operating and transportation costs alone.
However, for small changes in procurement prices up to 10 per cent, the optimal network design would remain unchanged. In either case—that, is for procurement price increases or decreases—the test centre choices are not affected at all.
Sensitivity to Changes in Procurement Prices
Sensitivity to Changes in Discounted Prices
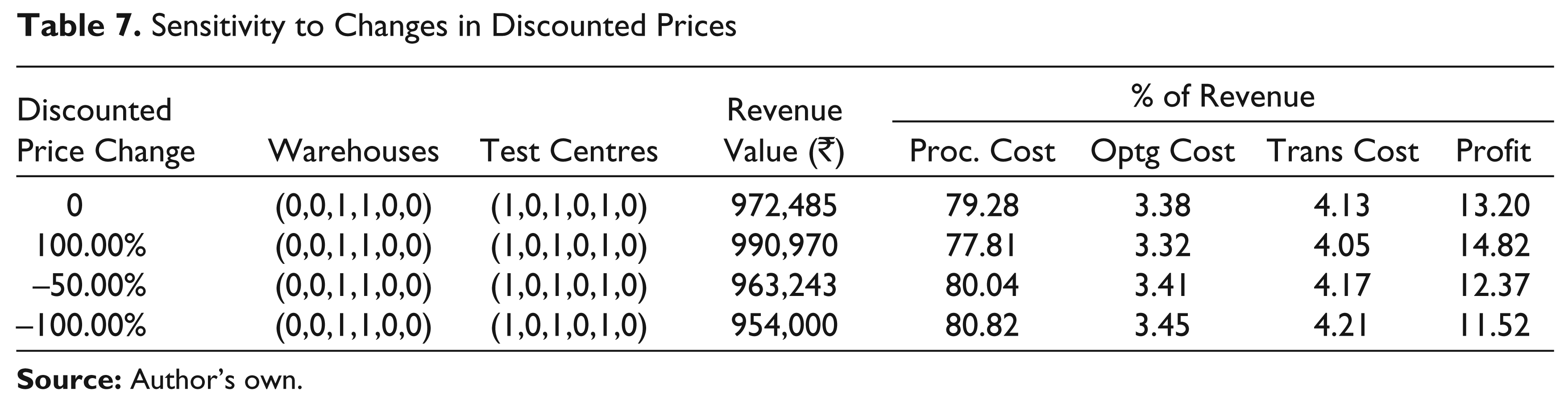
Effect of Changes in Discounted Prices
As the quantities of the returned products sold in the secondary market are relatively small, the network design is not affected at all by changes in discounted prices. This can be seen from Table 7, which shows the optimal solution for different percentages of this change.
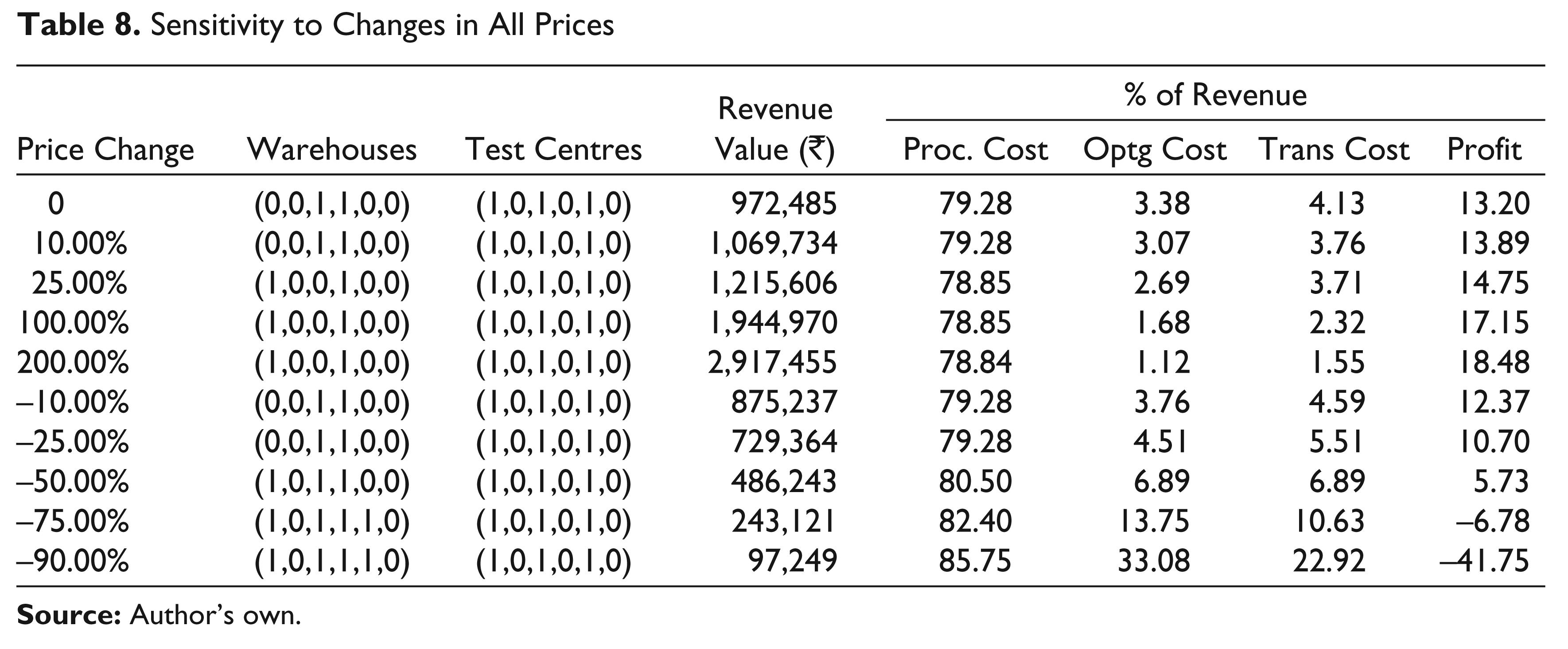
Effect of Changes in All Prices Simultaneously
In case all the three prices changed by an equal percentage, the network design is primarily affected by procurement price changes. This can be seen from Table 8, where the sensitivity of the optimal solution to simultaneous changes in all three prices is presented. A comparison with Table 6 confirms that the changes in network design are driven by the changes in procurement prices alone.
Effect of Changing Return Rate (ρ)
An increase in the return rate increases the secondary sales (for the same primary sales), and so increases the revenue but reduces the profit margin. Table 9 also shows that the locations of warehouses and test centres are not affected if the return rate increased by as much as 100 per cent; however, an increase of 200 per cent would require the operation of an additional warehouse and an additional test centre and yet the supply chain would become unprofitable.
Sensitivity to Changes in All Prices
Sensitivity to Changes in Return Rates (ρ)
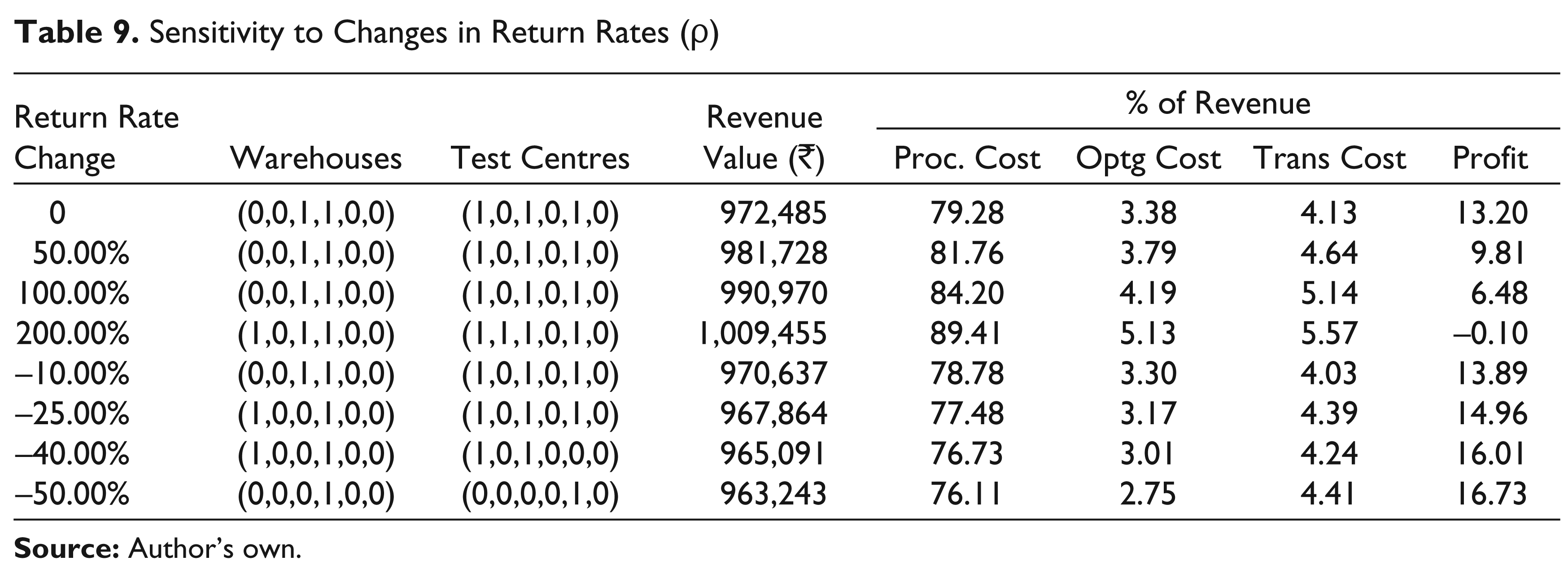
Interestingly, a drop of 25 per cent in the return rate would require the relocation of one warehouse and further drops would require the closing down of, first, test centres and then, warehouses as well. For very small return rates, only one warehouse and one test centre from the baseline network need to operate.
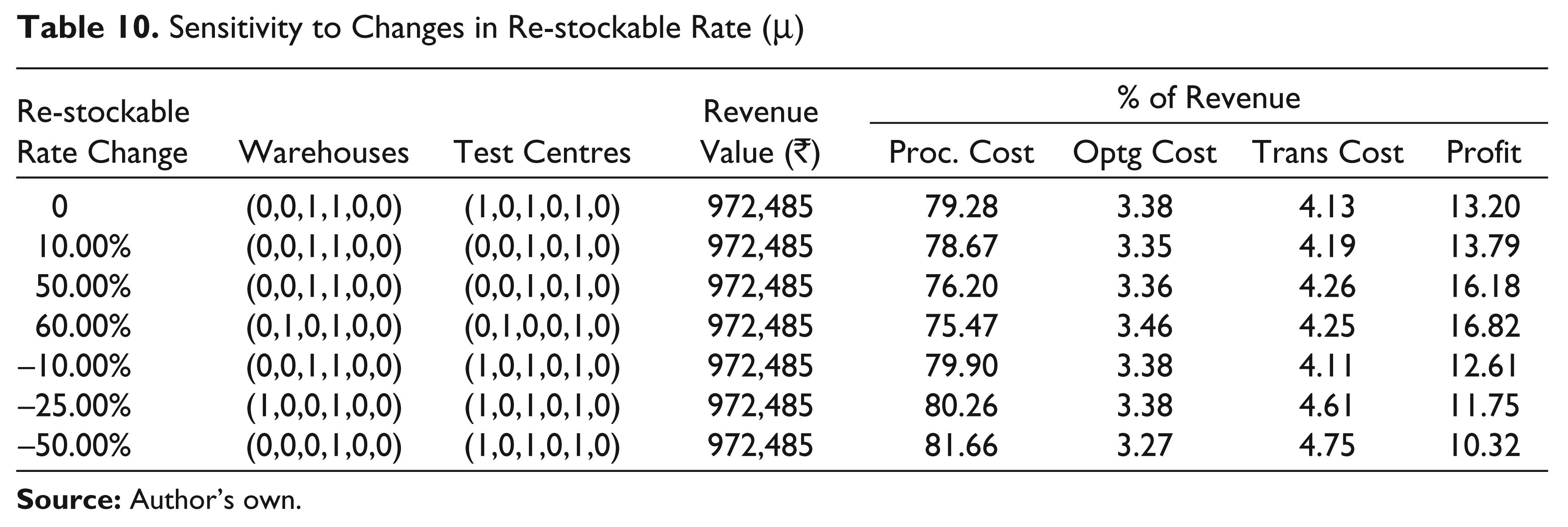
Effect of Changing Re-stockable Rate (μ)
Table 10 reveals that even a small 10 per cent increase in re-stockable rate enables the closure of one test centre, while a moderate increase of 60 per cent causes a relocation of both warehouses and test centres. Similarly, a decrease of 25 per cent in this rate requires a relocation of one warehouse and a decrease of 50 per cent enables the closure of one warehouse. In the baseline model, the re-stockable rate emerges as a key parameter affecting the design of the supply chain network.
Sensitivity to Changes in Re-stockable Rate (μ)
Effect of Changing Fixed Costs (for both warehouses and test centres)
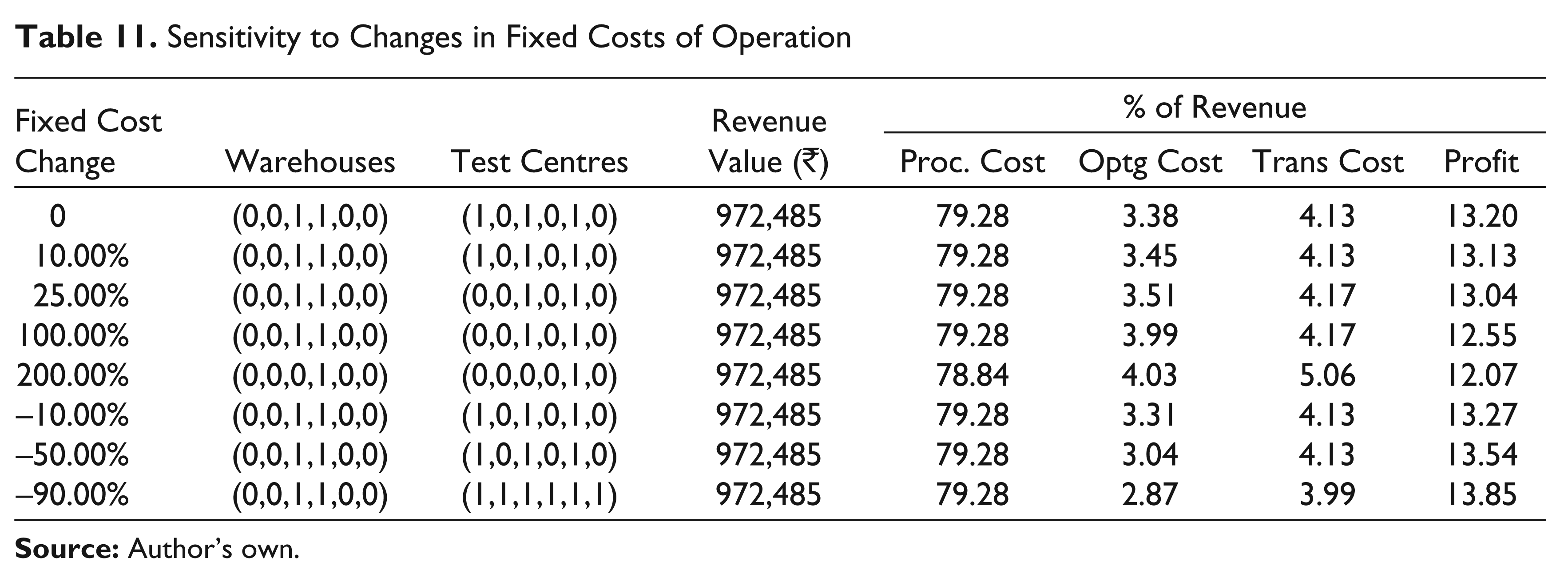
The effect of a change in fixed costs of operating warehouses and test centres is reflected in Table 11, according to which a moderate increase of 25 per cent or 100 per cent would require the closing down of one test centre, while a large increase of 200 per cent would require the closure of all but one warehouse and all but one test centre. The consequent increase in transportation cost is moderated by a reduction in production cost as only the warehouse with the least procurement price is retained. The table also shows that moderate decreases in fixed costs have no effect on the network design, but very large decreases would mandate operation of all test centres to take advantage of lower fixed costs as well as transportation costs. The operation of warehouses, however, is not affected as they continue to exploit the procurement price differentials.
Sensitivity to Changes in Fixed Costs of Operation
Sensitivity to Changes in Variable Costs of Operation
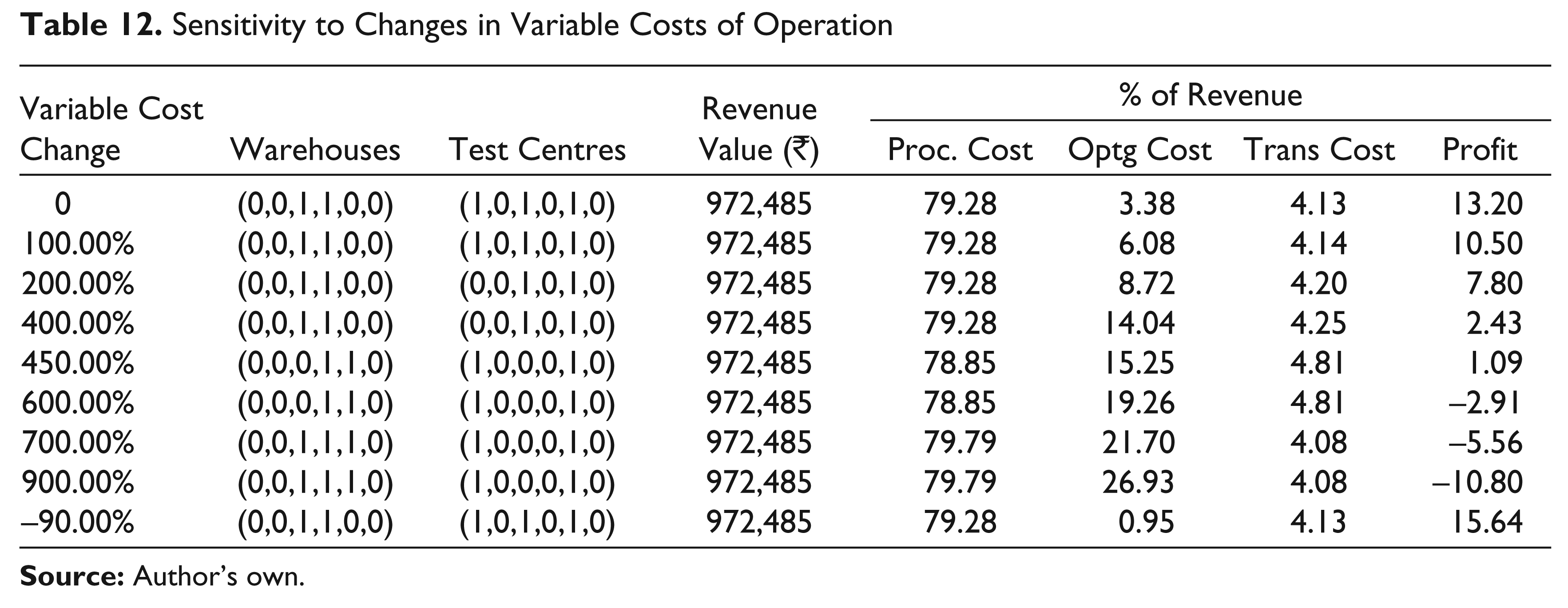
Effect of Changing Variable Costs (for both warehouses and test centres)
In case the variable costs of operating warehouses and test centres change rather than the fixed costs, the network designs should be according to the Table 12. Moderate increases up to 100 per cent have no effect, while a 200 per cent or 400 per cent increase would require the closure of one test centre. Surprisingly, an increase of, say, 450 per cent or 600 per cent requires the relocation of one warehouse and one test centre as such large increases change the warehouse location preference, which is based on the sum of procurement price and the variable cost at the respective warehouse. Still higher increases in variable costs tend to stabilize the network design. As variable cost differentials are not very large to begin with, reductions in variable costs have no effect on the network design.
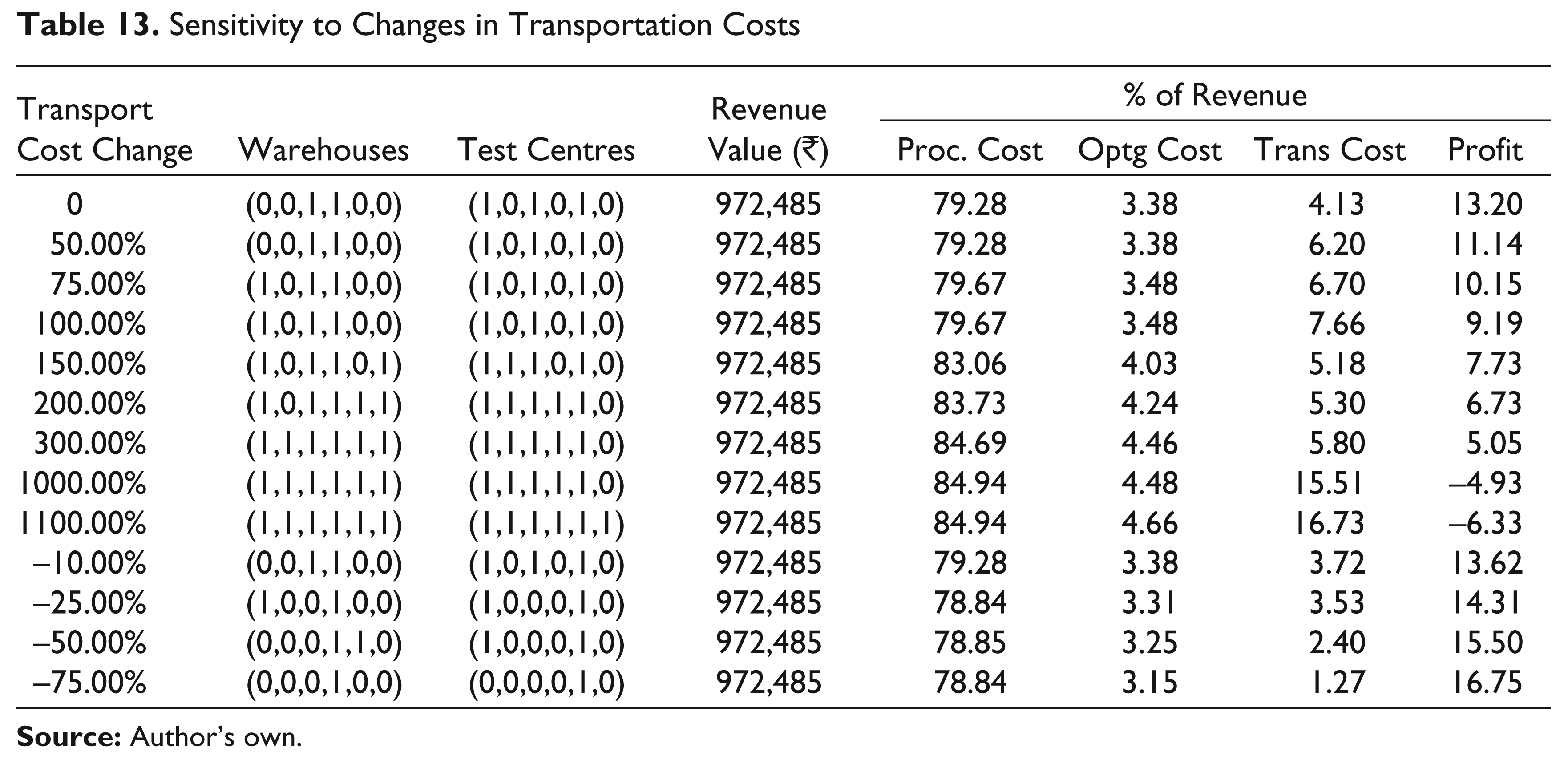
Effect of Changing Transportation Costs
Table 13 shows that as transportation costs increase, additional warehouses are first introduced—for example, a third warehouse is introduced when the transportation costs increase by 75 per cent—followed by further additions of both test centres and warehouses. For very high increases in transportation costs, as expected, all warehouses and test centres need to operate.
A small decrease—say of 10 per cent—in transportation costs has no effect on the optimal design of the supply chain network, but a moderate decrease of 25 per cent causes a relocation of a warehouse and closure of a test centre. As transportation costs reduce, warehouse locations are influenced more by lower procurement prices. Further decreases may require relocations of warehouses and eventually, when transportation costs have declined by 75 per cent, only one warehouse and one test centre would be needed. Substantial decreases in transportation costs and similar increases in fixed costs of operation are nothing but two sides of the same coin and have similar effects.
Conclusion
As pointed out in the review of literature, some authors have modelled integrated reverse logistics network design problem as an MILP or as an MIP—whereas we have used binary ILP. The formulation is simpler and ILP software is relatively easy to obtain, particularly for not very large problems. In spite of this simplification, the formulation retains the flexibility to handle different types of products and their supply chains through adjustments of the parameter values. Such adjustments could easily handle products with different characteristics—commodity products, niche products, high and low-value products, etc.
Sensitivity to Changes in Transportation Costs
Extensive sensitivity analysis of our model reveals the relative robustness of the optimal design to small and even moderate changes in most parameter values. Surprisingly, we found greater sensitivity to procurement price changes vis-à-vis changes in selling prices or discounted prices, and also relatively high sensitivity to the re-stockable rate. The model also revealed its ability to change procurement decisions even within the framework of existing warehouses and test centres.
In a complex decision problem with a large number of parameters, it is not always straightforward to find the effect of a change in some parameter value. Modelling has a normative as well as a descriptive role in such situations. For example, our baseline decision problem involved the establishment of two warehouses, but all product returns were routed to only one of the two warehouses, whereas all retail stores, except a local one, were required to get their supplies from the other warehouse. The role of procurement price differences was thus clearly brought to light by the model.
The model formulated here could be easily adapted to situations where the selling price at each retail store is different or the procurement price at each warehouse (including freight inward) is a constant or variations thereof. In some cases, there could be some costs involved in donation to charities or throwaways, and minor changes in the model could easily accommodate such changes. We have considered the supply chain from warehouse onwards. It could be expanded to include other echelons in the supply chain like manufacturers and even their suppliers. However, we have taken the average sales per period in a retail store as known and as a constant. In reality, it is stochastic and so could be the prices used in the model. For some products with large uncertainty in demand and prices, this could be a limitation in the use of deterministic models.
In this article, we have modelled an efficient supply chain, where the effect of time on the performance of the supply chain has been ignored. It is possible to include opportunity costs in the objective function to reflect the effect of time on ordering and delivery; such a model could then handle both efficient and responsive supply chains. Often, the size of such decision problems is very large and it may be difficult to obtain the optimal solution. Development of good heuristics to solve large problems should prove immensely useful to practitioners.
Footnotes
Appendix
Parameters:
μ = 0.45; ν = 0.25