
Abstract
Cell and gene therapy (CGT) manufacturing has outpaced traditional chemistry, manufacturing, and controls frameworks, leaving a “black box” in vector quality control (QC). Legacy assays such as Sanger and short-read next-generation sequencing often fail to resolve complex structures including adeno-associated virus (AAV) inverted terminal repeats, lentiviral recombination, and mRNA poly(A) tails. Oxford Nanopore Technologies enables long-read, native single-molecule sequencing to access these attributes directly. This review summarizes nanopore sequencing across the CGT lifecycle. For plasmid DNA, it confirms full-length circular identity and reveals structural heterogeneity missed by restriction mapping. For viral vectors (AAV and lentivirus), it functions as an integrity assay to distinguish full genomes from truncations and to detect sequence-resolved impurities, including reverse-packaged plasmid backbones. For mRNA therapeutics, direct RNA sequencing profiles poly(A) tail length distributions and base modifications (e.g., m1Ψ) in a single assay. We also discuss adaptive sampling for impurity enrichment and native epigenetic profiling of bacterial methylation. Finally, we assess limitations in accuracy and compliance and outline the regulatory path toward moving long-read sequencing from an orthogonal tool to a validated lot-release method. Overall, nanopore sequencing supports risk-based, high-resolution QC while reducing analytical turnaround time.
Keywords
INTRODUCTION
The landscape of cell and gene therapy (CGT) is undergoing rapid expansion. In recent years, over 100 gene, cell, and RNA therapies have been approved worldwide, with more than 3,700 candidates in clinical or preclinical development.1,2 This momentum, driven by clinical successes such as adeno-associated virus (AAV)-based gene therapies and CAR-T cell immunotherapies, marks a shift toward precision medicine.3,4 Viral vectors—specifically AAV and lentivirus—currently dominate delivery platforms, accounting for ∼75% of gene therapy programs. 5 In parallel, the widespread deployment of mRNA vaccines has validated the scalability and efficacy of RNA-based modalities.6–8 However, this clinical progress has outpaced the capabilities of traditional chemistry, manufacturing, and controls (CMC) frameworks.9–12 Gene therapy vectors are complex biological assemblies, and ensuring their quality, purity, and consistency remains a significant challenge, often described as the manufacturing “black box.”13–16
Traditional quality control (QC) methods, while established, struggle to resolve the structural complexities of these vectors. Sanger sequencing, the legacy standard for identity testing, frequently fails at highly repetitive or guanine-cytosine (GC)-rich regions. 17 For instance, the inverted terminal repeats (ITRs) of AAV—≈145 bp GC-rich palindromic hairpins essential for viral replication—are notoriously difficult to sequence due to polymerase slippage and secondary structure formation.13,17 Similarly, next-generation sequencing (NGS) platforms, such as Illumina, offer high throughput but are limited by short-read lengths. The fragmentation required for short-read libraries destroys long-range phasing information, making it difficult to resolve repetitive elements or distinguish between independent vector genomes and concatemers.18–20 Furthermore, polymerase chain reaction (PCR) amplification in standard NGS workflows introduces bias, potentially obscuring GC-rich regions or structural variants.18,21,22
Quantitative assays face similar limitations. While qPCR is widely used for titration, it is sensitive to primer design and matrix inhibitors, often yielding variable results. 23 Droplet digital PCR (ddPCR) improves precision by enabling absolute quantification,24,25 yet it remains a targeted method; it confirms the presence of specific amplicons but cannot detect unexpected genomic contaminants or characterize the integrity of the full vector genome. 26 Consequently, conventional QC strategies often rely on a labor-intensive patchwork of indirect assays—combining Sanger sequencing, qPCR, and gel electrophoresis. This fragmented approach increases operational complexity and costs while failing to resolve critical quality attributes (CQAs), such as truncated genomes, reverse-packaged plasmid backbones, 14 or epigenetic modifications.27–29
To address these gaps, long-read sequencing has emerged as a critical tool for vector characterization. It is important to situate Oxford Nanopore Technologies (ONT) within this broader landscape, particularly alongside PacBio single molecule real-time (SMRT) sequencing. PacBio HiFi reads, generated via circular consensus sequencing, offer exceptional per-read accuracy (>Q30), making them highly advantageous for confident single-nucleotide variant (SNV) and indel calling. 30 HiFi sequencing has been successfully applied to profile heterogeneous rAAV populations and detect nonvector DNA impurities. 31 However, HiFi workflows typically require SMRTbell library construction and may be less adaptable to rapid, real-time “in-house” QC iterations compared with nanopore workflows. 32
In contrast, ONT nanopore sequencing offers a distinct advantage: the ability to sequence native DNA and RNA molecules in real time without PCR amplification or extensive library manipulation. Mechanistically, nanopore sequencing operates by unwinding and translocating a single-stranded nucleic acid through a nanometer-scale protein pore embedded in an electrically resistant synthetic membrane. As a motor protein regulates the translocation speed, the passing nucleotides cause characteristic disruptions in a steady ionic current. These electrical signals are then decoded in real time into sequence and epigenetic data by deep-learning algorithms. This capability positions the technology as a rapid, highly informative orthogonal characterization tool that can streamline the QC workflow, complementing rather than entirely replacing multiple orthogonal tests. This “native-state” sensing allows for the direct detection of base modifications (e.g., methylation) and the interrogation of RNA features such as poly(A) tail length and secondary structure—capabilities that are challenging for other platforms. 32 Furthermore, nanopore sequencing provides scalable read lengths, enabling the analysis of ultra-long molecules that span entire plasmids or complex vector genomes end-to-end. 33 Recent advancements in pore chemistry (e.g., R10.4.1) and AI-driven basecalling have significantly reduced error rates, with raw single-molecule read accuracies reaching Q20–Q25 (∼99.0–99.5%), thereby increasing the utility of ONT for detailed sequence verification. However, it must be emphasized that nanopore sequencing is currently in its early developmental stages for CMC applications and is not yet an established, fully validated standalone lot-release platform.
Therefore, the most robust CMC strategy is likely a hybrid, risk-centric framework rather than a single-platform solution. Short reads remain valuable for deep variant surveillance; HiFi reads serve as high-accuracy validators; and nanopore sequencing acts as a “molecular microscope” for resolving long-range structural integrity, repetitive elements (ITRs/long terminal repeats [LTRs]), and native epigenetic signatures 34 (Fig. 1).
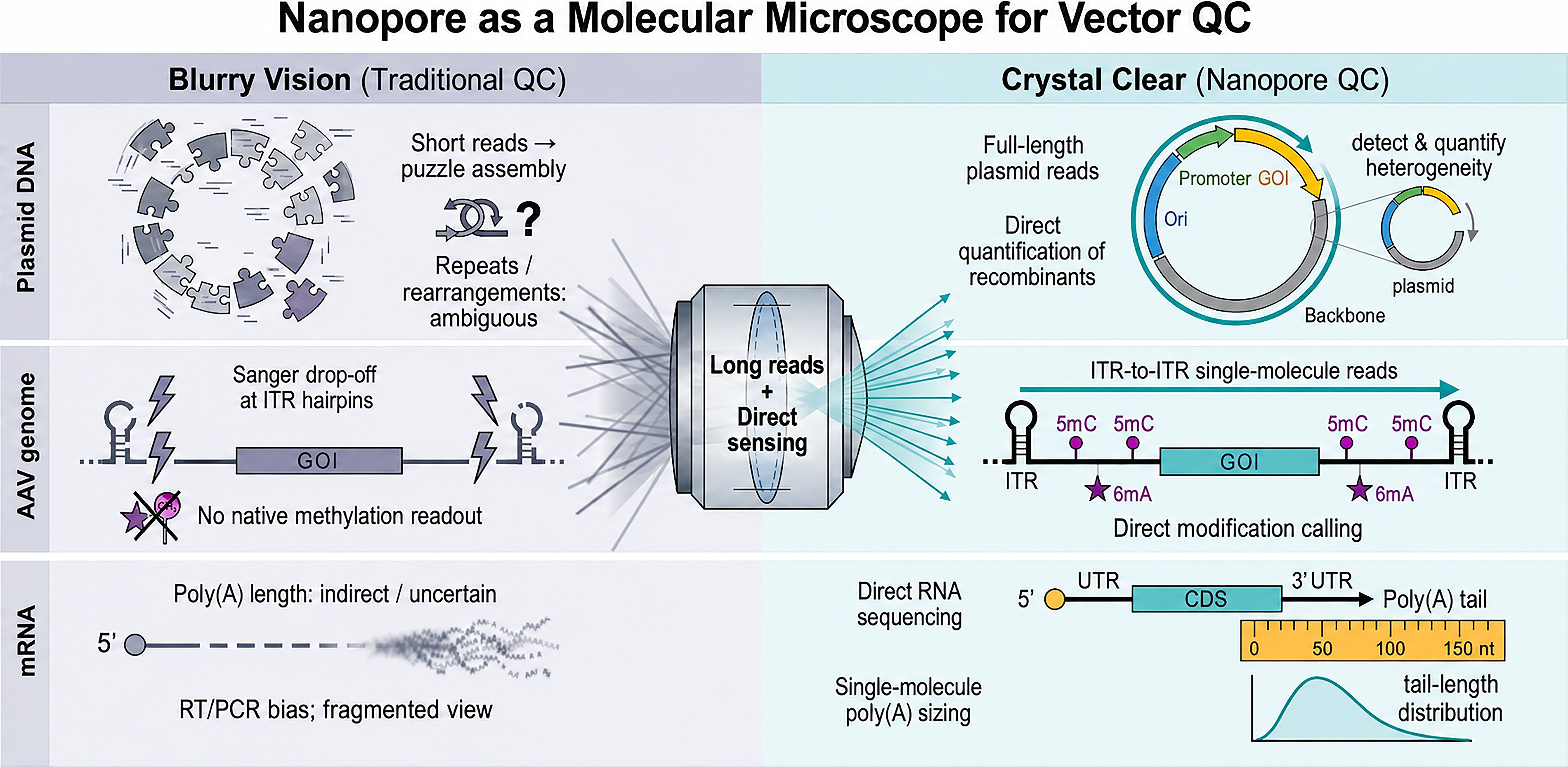
Nanopore sequencing as a “molecular microscope” for gene therapy vector quality control. Traditional QC methods provide a fragmented or incomplete view of complex vector molecules (left, “Blurry Vision”), exemplified by Sanger drop-off at AAV ITR hairpins, short-read sequencing that breaks long plasmids into ambiguous assemblies, and the inability to directly sense native base modifications. In contrast, nanopore sequencing enables end-to-end single-molecule resolution (right, “Crystal Clear”), including full-length circular plasmid reads, ITR-to-ITR AAV genome profiling with direct modification detection, and direct RNA sequencing of mRNA with single-molecule poly(A) tail length measurements. AAV, adeno-associated virus; ITR, inverted terminal repeat; QC, quality control.
In this review, we examine the specific application of ONT nanopore sequencing across the CGT manufacturing workflow. We detail how this technology is being applied to: (1) plasmid DNA, to verify full circular sequences and resolve recombination events; (2) viral vectors, to illuminate genome truncations, ITR stability, and packaged impurities; and (3) mRNA therapeutics, to measure poly(A) tails and base modifications directly (Fig. 2). We also explore advanced capabilities such as adaptive sampling for impurity enrichment and discuss the current regulatory outlook for integrating these long-read metrics into routine QC.
A comprehensive workflow for gene therapy quality control enabled by nanopore sequencing. Nanopore sequencing serves as a versatile tool across three critical manufacturing stages: (
THE FOUNDATION: PLASMID DNA (PDNA) QC
Plasmid DNA serves as the fundamental starting material for the majority of gene therapies, functioning either as the template for viral vector production or as the active drug substance in DNA vaccines.35–37 Ensuring the sequence fidelity and structural homogeneity of pDNA is therefore critical. Traditional verification methods, primarily restriction digest mapping and Sanger sequencing, rely on fragmenting the molecule. This approach often fails to detect subtle rearrangements or characterize complex secondary structures.35,36 Nanopore sequencing addresses these limitations by enabling full-length plasmid sequencing—reading the linearized or circular molecule in a single continuous pass.38–41
Sequence identity and consensus accuracy
A key advantage of the nanopore platform is the ability to confirm plasmid identity without assembly. A single read, typically 5–15 kb, can span the plasmid from origin to terminus.39,41 This capability is particularly valuable for synthetic biology and vector manufacturing, where confirming the exact arrangement of modular components is essential.6,38,40
However, single-molecule raw read accuracy has historically been a concern for SNV detection. To address this, workflows utilizing rolling circle amplification (RCA) have been developed (often termed NPlasmid-seq). By amplifying the plasmid into long concatemers containing multiple tandem repeats of the monomer, a single nanopore read can capture dozens of passes over the same sequence.13,42,43 Aligning these repeats yields a high-fidelity consensus sequence that eliminates random stochastic errors, often achieving consensus accuracies >Q30 (>99.9%)—comparable to or exceeding Sanger sequencing for plasmid verification.43,44 This approach effectively marries the read-length benefits of ONT with the high accuracy required for Good Manufacturing Practice (GMP) release testing.
Furthermore, systematic errors in nanopore basecalling often arise from bacterial methylation patterns. Plasmids propagated in standard Escherichia coli strains carry Dam (6-methyladenine) and Dcm (5-methylcytosine) modifications, which alter the ionic current signal and can confuse standard basecallers. 18 Modern “methylation-aware” polishing tools (e.g., Medaka and Nanopolish) or models trained on modified bases can correct these systematic artifacts, ensuring that the final consensus sequence is error-free even in the presence of native bacterial methylation.28,45
Resolving structural heterogeneity and inverted repeats
A major blind spot in short-read QC is structural heterogeneity. Plasmids often exist as a population containing monomeric, multimeric, and recombined forms—variants that may be low-abundance but biologically significant.
Multimerization: Homologous recombination during bacterial replication can produce head-to-tail dimers or trimers.46–49 Nanopore reads can traverse these concatemer junctions directly, providing a “species census” of the plasmid population (monomer vs. multimer) that agarose gels may not fully resolve.
26
ITR Instability: For AAV vectors, the ITRs are notoriously unstable in E. coli, prone to deletions that render the resulting virus replication-incompetent.27,50 These 145-bp GC-rich hairpins act as strong blocks to Sanger sequencing polymerases and are often bridged (missing) in short-read assemblies.
51
Nanopore sequencing is currently the only accessible technology capable of reading through intact ITR hairpins natively.
31
This capability allows for the quantification of ITR integrity. Rather than a binary “present/absent” check, nanopore sequencing can quantify the ratio of plasmids with full-length ITRs versus those with truncations (e.g., “70 bp deleted mutant”). 21 Such quantitative insights enable process engineers to optimize bacterial strains (e.g., using recombination-deficient lines) and culture conditions to minimize the propagation of defective plasmids. 51
Contamination profiling: a sequence-resolved taxonomy
Beyond the target plasmid, pDNA preparations must be assessed for composition-level impurities. Nanopore sequencing enables a comprehensive impurity profile that integrates with downstream vector QC:
Cross-Plasmid Carryover: In facilities handling multiple vectors, cross-contamination between helper, packaging, and transfer plasmids is a risk. Nanopore sequencing can identify trace levels of contaminating plasmids by mapping reads against a facility’s plasmid database, preventing the propagation of incorrect genetic elements into the viral vector production stage.52,53 Host Genomic DNA: Residual E. coli genomic DNA is a safety-relevant process impurity. While qPCR provides total mass quantitation, nanopore sequencing offers a “taxonomy of impurities,” identifying the specific genomic origins of contaminants.54–56 This can reveal if specific genomic loci (e.g., mobile elements or transposons) are preferentially co-purifying with the product.
In summary, nanopore sequencing elevates plasmid QC from a patchwork of fragmented assays to a holistic molecular analysis. It concurrently verifies sequence identity, 34 quantifies structural heterogeneity at repetitive elements, and screens for sequence-resolved impurities. As workflows standardize, many groups are shifting to ONT for primary plasmid validation, reserving Sanger sequencing only for targeted confirmation of specific loci. 57 However, it is important to note that while nanopore sequencing excels at sequence verification, orthogonal methods (e.g., capillary gel electrophoresis) remain essential for assessing plasmid topology (supercoiled fraction), which is typically lost during library linearization.
THE DELIVERY VEHICLES: VIRAL VECTOR CHARACTERIZATION
Recombinant AAV: Integrity, ITRs, and contaminants
Recombinant AAV (rAAV) vectors serve as the primary delivery vehicle for in vivo gene therapy due to their favorable safety profile. However, an AAV vector batch is a heterogeneous mixture: capsids may contain full genomes, truncated partial genomes, concatemers, or be entirely empty. 1 Furthermore, unintended DNA species—such as residual plasmid sequences or host–cell chromatin—can be co-packaged during production. 3
Traditional analytical methods provide only partial visibility into this complexity. While techniques, such as analytical ultracentrifugation (AUC) or charge detection mass spectrometry, effectively separate empty from full capsids, they cannot distinguish whether a “full” capsid contains an intact genome or foreign DNA of a similar size. Similarly, PCR-based methods (qPCR/ddPCR) rely on targeted amplification. While dual-probe ddPCR strategies can estimate genome integrity by comparing 5′- and 3′-end signals, 6 these indirect measures fail to characterize the specific nature of internal deletions or identify unexpected sequences. 13 Long-read sequencing addresses these limitations by enabling the sequencing of whole vector genomes from ITR to ITR.
Evolution of long-read AAV profiling
The utility of long-read sequencing for AAV characterization was first established using PacBio SMRT sequencing. In a seminal 2018 study and subsequent optimizations, Tai et al. introduced “AAV Genome Population sequencing (AAV-GPseq),” revealing that vector preparations appearing homogeneous by gel electrophoresis often contained <50% true full-length genomes and demonstrated how vector design influences truncation heterogeneity.27,58 They also identified “reverse-packaged” genomes containing plasmid backbones and host–vector chimeras.
While early SMRT protocols required high DNA input, recent advancements in ONT have improved throughput and accessibility. A 2025 study by Dunker-Seidler et al. utilizing the PromethION platform with R10.4.1 chemistry demonstrated comprehensive profiling of a clinical rAAV9 batch. 21 The study reported that modern nanopore chemistry yielded length profiling and structural resolution comparable to PacBio HiFi. While raw single-molecule accuracy (approx. Q23) is lower than HiFi (>Q30), it proved sufficient for differentiating viral species while requiring significantly lower DNA input. The authors concluded that nanopore sequencing effectively identifies product-related impurities and provides a complete distribution of vector genome lengths. 21
Resolving ITRs
A critical advantage of nanopore sequencing is the ability to resolve ITRs. The ∼145 bp AAV ITR forms a stable GC-rich hairpin that inhibits standard polymerases, making it historically difficult to sequence via Sanger or Illumina methods without extensive protocol modifications.
Nanopore sequencing can read through native ITR hairpins, enabling the end-to-end verification of vector genomes.
59
This capability allows for the direct detection of:
ITR Truncations: Identifying genomes lacking one ITR, a phenomenon often associated with packaging genomes exceeding the ∼5.2 kb limit.
31
Replication Errors: Detecting point mutations or duplications within the ITR “T-tract” or stem regions.
32
Sequence Integrity: Validating read-through across difficult upstream motifs, such as GC-rich insulator sequences, which often cause drop-outs in short-read data.
51
Genome length distribution and truncation analysis
Nanopore sequencing provides a direct readout of the physical length of every encapsidated molecule. These data can be visualized as a length histogram (Fig. 3A), revealing subpopulations of truncated species (e.g., “half-genomes” or snapback genomes) that may be missed by bulk sizing methods. Quantifying the “full-length genome fraction” is essential for predicting potency, as partial genomes generally fail to express the transgene, and for safety, as they may integrate aberrantly. This sequence-based metric is increasingly serving as an informative orthogonal tool to cross-reference statistical models derived from ddPCR. Furthermore, the technology holds promise for orthogonal titer estimation. While currently widely used for relative abundance, the incorporation of well-characterized molecular spike-in standards allows nanopore sequencing to assist in estimating physical titer, serving as a supportive quantitative tool alongside ddPCR results. This emerging capability supports the industry’s shift toward multiattribute methods (MAMs), potentially enabling the simultaneous reporting of genome integrity, identity, and relative titer estimation from a single dataset.
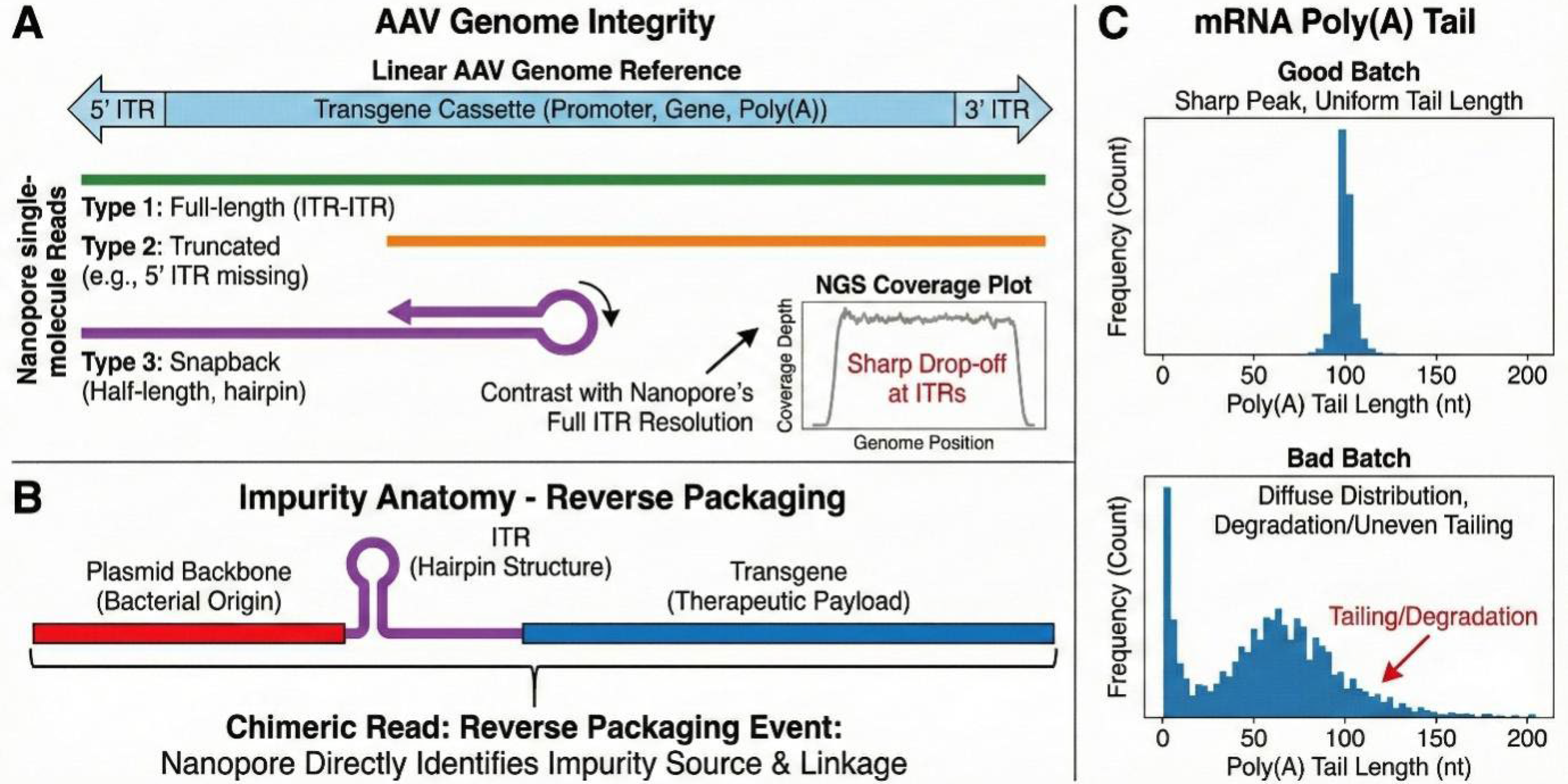
Resolving structural heterogeneity and sequence-resolved impurities at single-molecule resolution. (
Limitations in aav characterization
Despite these capabilities, it is critical to state that nanopore sequencing is not a validated approach for the absolute quantification of truncated AAV genomes. Even with the inclusion of molecular spike-in DNA, quantitative biases can arise from differential extraction efficiencies between full and partial capsids, adapter ligation biases during library preparation, and the preferential pore loading of shorter DNA fragments. Consequently, while it provides unparalleled structural insight, nanopore sequencing remains an orthogonal characterization tool. Established methods such as AUC or capillary electrophoresis (CE) remain indispensable for quantitative evaluation.
Sequence-resolved impurity profiling
Perhaps the most significant safety application of nanopore sequencing is the identification of packaged contaminants. During production, helper plasmids, transfer plasmids, and host genomic DNA co-exist with the vector; fragments of these can be inadvertently packaged.
13
Reverse Packaging: Long-read data have confirmed the “reverse packaging” mechanism, where the viral packaging machinery extends beyond the ITR into the plasmid backbone, encapsidating antibiotic resistance genes or bacterial origins of replication
21
(Fig. 3B). Crucially, resolving these backbone-ITR linkages typically necessitates ligation-based library preparation to preserve molecular connectivity, as transposase-based methods may fragment these diagnostic junctions. Host–Vector Chimeras: Studies have detected human genomic sequences fused to vector ends, constituting 1–2% of genomes in some preparations.
27
Unlike bulk residual DNA assays, sequencing identifies the source of the contamination. Random versus Hotspot Encapsidation: Recent GMP-grade analyses suggest that while some impurities are stochastic (“random origin”), others may be driven by specific sequence elements.
60
Because encapsidated DNA is protected from nuclease treatments (e.g., benzonase) used during purification, characterization and upstream process control are the primary mitigation strategies. The detection of plasmid backbone carryover has specifically driven the industry adoption of minicircle DNA and other backbone-free technologies to minimize the risk of packaging extraneous bacterial sequences. 61
Lentiviral vectors: LTR stability and carryover
Lentiviral vectors (LVs), widely utilized for ex vivo therapies such as chimeric antigen receptor T-cel cell manufacturing, present a distinct set of QC challenges compared with AAV. These vectors package a ∼9–10 kb RNA genome within an enveloped particle.62,63 A critical structural feature is the LTR at both ends, which is essential for integration but also acts as a hotspot for homologous recombination.
Genome integrity and cryptic splicing
During vector production, recombination between the identical 5′ and 3′ LTRs in the transfer plasmid can lead to deletion of the internal transgene cassette. Furthermore, the lentiviral RNA genome is prone to aberrant processing events, such as cryptic splicing or premature termination, which result in truncated, nonfunctional transcripts being packaged into virions.
Nanopore sequencing offers a direct method to assess the structural integrity of the packaged RNA. A recent benchmarking study by Zeglinski et al. established an optimized long-read QC workflow, comparing nanopore direct RNA sequencing (dRNA-seq) against nanopore cDNA and PacBio cDNA methods. 64 The study found that ONT dRNA-seq provided superior coverage of the vector genome without the internal priming biases observed in cDNA approaches, which often skew read distribution toward the 3′ end. 64
Crucially, this “native RNA” approach enabled the robust identification of cryptic splice sites and cryptic poly(A) motifs that drove premature truncation of the vector genome. 64 The authors demonstrated that protocol refinements, such as artificial polyadenylation [to capture truncations lacking natural poly(A) tails], allowed for the quantification of full-length versus defective species. These insights directly informed vector design: by mutating identified cryptic motifs, the fraction of full-length, functional vector RNA was significantly increased. 64
Impurity profiling: Plasmid DNA, host DNA, and nonvector RNA
Unlike AAV, where nonvector DNA is encapsidated within the protein shell, LVs are enveloped particles that primarily package RNA. However, the packaged cargo is not restricted to the therapeutic vector genome. Recent long-read sequencing studies have revealed that substantial amounts of nonvector RNA—including host cell-derived transcripts and RNAs from packaging plasmids—can be inadvertently packaged into lentiviral particles. 65 In addition to these RNA impurities, residual plasmid DNA from the transient transfection process can co-purify with the product. Regulatory guidelines strictly limit residual host–cell and plasmid DNA levels (typically <10 ng/dose), necessitating sensitive detection methods.
Nanopore sequencing is highly sensitive for characterizing these DNA impurities. Because viral preparations are often dominated by host nucleic acids, adaptive sampling (or “ReadUntil”) can be deployed to selectively enrich for low-abundance contaminants. A proof-of-concept study demonstrated an ∼8-fold enrichment of viral sequences from a complex human background by actively rejecting host DNA reads in real-time. 66 Conversely, this technique can be inverted to enrich for plasmid backbone sequences, providing a sequence-resolved profile of residual DNA that persists despite DNase treatment.
Limitations in lentiviral profiling
As with AAV vectors, the application of nanopore sequencing to lentiviral QC is subject to significant quantitative limitations. The accurate quantification of intact versus defective lentiviral RNA genomes is hindered by the inherent fragility of long RNA molecules (∼9–10 kb), which are prone to degradation during extraction and handling. This makes it challenging to distinguish true biological premature truncations from in vitro degradation artifacts. Furthermore, if cDNA-based workflows are utilized to mitigate input limitations, biases from internal priming and template switching during reverse transcription (RT) can distort the relative abundance of viral transcript forms and create artificial recombinants. Therefore, nanopore sequencing currently serves as an advanced characterization tool rather than a validated quantitative assay for LVs.
Safety: Replication-competent lentivirus
A primary safety concern for LVs is the potential generation of replication-competent lentivirus (RCL) via recombination between the transfer vector and packaging plasmids. 67 Traditional RCL testing relies on culture-based assays that can take weeks to complete. 68 Nanopore sequencing offers a potential molecular alternative: by generating long reads that span the entire vector construct, it can distinguish between safe, self-inactivating vectors and recombination events that restore functional gag-pol-env sequences. 69 While currently supportive, this molecular assurance provides a level of resolution—distinguishing true recombinants from random noise—that short-read methods cannot achieve.
Summary: The molecular microscope for viral vectors
The application of nanopore sequencing to viral vector characterization—whether for AAV or lentivirus—marks a shift from inferential QC to direct molecular observation. We can now interrogate the actual contents of the therapeutic particle: verifying genome length, confirming the integrity of terminal repeats (ITRs/LTRs), and taxonomizing sequence-resolved impurities. 21
This “molecular microscope” capability closes critical gaps left by traditional methods. It resolves the “invisible” heterogeneity of vector preparations, such as determining whether a “full” AAV capsid contains a therapeutic genome or a host–vector chimera. 23 As the technology matures, with reduced costs and validated GMP implementations already emerging, long-read sequencing is poised to evolve from an orthogonal characterization tool into a routine release assay, underpinning the next generation of higher-quality genetic medicines.
THE NEW ERA: mRNA THERAPEUTICS AND VACCINES
Messenger RNA therapeutics—exemplified by the rapid deployment of COVID-19 vaccines—have become a central pillar of the CGT field. Manufacturing typically involves in vitro transcription (IVT) to generate synthetic mRNA incorporating modified nucleotides (e.g., N1-methylpseudouridine, m1Ψ) and a poly(A) tail, followed by formulation into lipid nanoparticles.
Ensuring the quality of these transcripts presents unique CMC challenges. CQAs include the precise sequence identity, the integrity of the 5′ cap and poly(A) tail, and the absence of abortive transcripts or double-stranded RNA (dsRNA) by-products.70–72 Among these, dsRNA by-products from IVT constitute a major immunostimulatory impurity and are routinely monitored and removed during downstream purification.73,74 Traditional analytics—such as CE for sizing and Illumina RNA-seq for identity—struggle to resolve these features simultaneously. CE lacks sequence resolution, while standard NGS requires RT and PCR, which erase base modification signals and bias the readout of homopolymeric poly(A) tails.
dRNA-seq on the nanopore platform offers a solution by translocating native RNA molecules through the sensor. This enables the simultaneous interrogation of sequence, tail length, and chemical modifications on the same single molecule.75,76
Poly(A) tail quality: Length and composition
The poly(A) tail is a determinant of mRNA stability and translational efficiency. Tail heterogeneity or truncation can significantly impact therapeutic potency. Nanopore dRNA-seq enables direct poly(A) tail length profiling at single-molecule resolution.
Length Profiling: Algorithms such as Nanopolish and Tailfindr infer tail length from the raw ionic current dwell time rather than basecalling, which is prone to error in long homopolymers. These inferred lengths correlate well with orthogonal benchmarks, allowing manufacturers to verify that the bulk product meets design specifications (e.g., “100 ± 10 nt”) and to detect subpopulations of truncated tails caused by polymerase slippage or RNase contamination (Fig. 3C). Platform Considerations and Algorithmic Frameworks: The accuracy and reproducibility of poly(A) tail profiling via nanopore dRNA-seq are intrinsically linked to both the sequencing chemistry (e.g., the specific motor protein and buffer conditions defined in commercial kits such as SQK-RNA004) and the bioinformatic algorithms employed. Comprehensive benchmarking and application studies have validated the use of tools, such as Nanopolish polya, for robust tail length estimation across diverse biological samples.
77
For the detailed characterization of nonadenosine residues within the tail—a critical attribute for mRNA stability—specialized frameworks such as Ninetails have been developed to directly parse these heterogeneities from the raw sequencing signal.
78
Tail Composition: Recent studies have revealed that therapeutic mRNA tails may not be pure adenosine homopolymers. “Mixed” tails containing incorporated C, G, or U residues can retard deadenylation and enhance stability. Using frameworks such as Ninetails, dRNA-seq can quantify these nonadenosine residues, establishing tail composition as a measurable quality attribute.
Base modifications and identity
A hallmark of effective mRNA therapies is the substitution of uridine with N1-methylpseudouridine (m1Ψ) to suppress innate immune sensing through Toll-like receptor (TLR) + PKR/OAS–RNase L79–85 and enhance translational efficiency through eIF2α-dependent and independent mechanisms.
86
Standard cDNA sequencing cannot distinguish m1Ψ from U, as both are reverse-transcribed as adenine. Nanopore sensors, however, detect the native physicochemical footprint of the modification.87,88
Detection Mechanism: Modified bases often manifest as systematic basecalling errors or “glitches” at specific positions. Tools such as ELIGOS (Epitranscriptional Landscape Inferring from Glitches of ONT Signals) leverage the increased “Error of Specific Bases” (%ESB) in native RNA relative to an unmodified reference to infer modification sites. Vaccine QC: This capability allows for the direct verification of m1Ψ incorporation rates. For vaccine lots, dRNA-seq can confirm that essentially all uridine positions carry the modification, differentiating the drug substance from potential contaminants or process failures that incorporate unmodified U.
Transcript integrity and by-products
IVT reactions are prone to generating impurities such as abortive (truncated) transcripts or 3′-extended read-through products (e.g., if the DNA template is not fully linearized). Because nanopore sequencing preserves full-length connectivity:
Truncation Analysis: A length histogram of mapped reads can reveal distinct peaks corresponding to abortive species, which might act as dominant-negative inhibitors or immunogenic contaminants.
5′ Capping Efficiency: Distinguishing capped (Cap1) from uncapped (Cap0/OH) species is a critical industrial challenge, as the native ionic current shift caused by the 5′ cap is extremely subtle. In humans, the innate immune sensor IFIT1 specifically binds to and inhibits the translation of mRNAs lacking 2′-O-methylation (Cap0), while fully methylated Cap1 structures evade this recognition.89,90 To address this, specialized library preparation strategies or enzymatic remodeling are required to “amplify” this signal, as standard native protocols often lack the signal-to-noise ratio to distinguish these modifications. Approaches such as enzymatic remodeling—where the cap is specifically cleaved to allow ligation of a distinct sequencing adapter—transform the elusive physicochemical signal into a clear, sequence-based readout. This innovation is crucial for accurately quantifying capping efficiency, a key determinant of translational potency, without identifying false positives from signal noise.91,92 In parallel, orthogonal analytical methods such as CE and liquid chromatography-mass spectrometry continue to be refined, providing complementary approaches for the detailed characterization of capping efficiency and the identification of cap-end impurities under various stress conditions.93,94 Fusion Transcripts: Rare events such as tandem transcription (multimers) are immediately visible as double-length reads, a structural anomaly often invisible to short-read assembly. However, a critical limitation remains regarding dsRNA, a potent immunogenic impurity. Because nanopore dRNA-seq requires the motor protein to translocate a single linear RNA strand, dsRNA by-products are either unwound or fail to enter the pore efficiently. Consequently, dRNA-seq cannot currently serve as a quantification method for dsRNA content, necessitating continued reliance on orthogonal “gold standard” assays such as J2 antibody-based immunoblotting or enzyme-linked immunosorbent assay (ELISA).
Limitations: Throughput and input requirements
Despite its power, dRNA-seq has distinct limitations compared with cDNA-based methods.
Input Material: Direct RNA sequencing typically requires significantly higher mass input (often 500 ng–1 µg) compared with PCR-amplified cDNA protocols. This can be prohibitive for scarce samples or early-stage process development. Throughput and Yield: The data yield per flow cell for dRNA-seq is generally lower than for DNA sequencing due to the slower translocation speed and motor protein dynamics. Accuracy: While improving, the raw single-read accuracy of native RNA (typically ∼96–98%) remains lower than that of DNA (Q20–Q25 or ∼99.5%). Therefore, dRNA-seq is best used as a characterization tool (confirming structure/modifications) rather than for detecting ultra-low frequency SNVs, where deep Illumina sequencing remains superior. Additionally, the platform recognizes an “analyte blind spot”: dsRNA. While it excels at profiling intrinsic attributes such as poly(A) tails and modifications, it does not currently offer a validated workflow to quantify double-stranded impurities. For this specific CQA, traditional immunochemical methods remain indispensable. Concurrently, the standardization and sensitivity of these orthogonal methods, such as antibody-based sandwich ELISA or dot blot assays using the J2 antibody, continue to be refined to meet the stringent requirements of mRNA vaccine QC.95,96 These efforts are supported by a deeper understanding of dsRNA formation mechanisms, including aberrant RNA-dependent RNA polymerase activity during IVT, and the development of robust purification strategies such as selective binding with chaotropic agents or affinity chromatography to minimize this critical impurity.97,98
In summary, nanopore sequencing enables a comprehensive “characterization study” on every mRNA batch. By verifying sequence, tail length, and modification status in a single assay, it aligns closely with quality by design (QbD) principles. As throughput scales, it is foreseeable that metrics such as “poly(A) tail length distribution” derived from sequencing could evolve from informational characterization to formal release specifications.
ADVANCED CAPABILITIES: EPIGENETICS AND ADAPTIVE SAMPLING
Beyond primary sequence verification, modern gene therapy products possess critical epigenetic attributes that influence safety and potency. Nanopore sequencing’s ability to directly sense nucleotide modifications allows manufacturers to explore these advanced quality layers. Furthermore, its real-time data streaming enables adaptive sampling—the selective enrichment of rare targets in complex backgrounds. Here, we discuss the detection of bacterial DNA methylation signatures and their implications for immunogenicity.
Epigenetic signatures: Dam/Dcm patterns and CpG motifs
Plasmid DNA produced in E. coli carries distinct bacterial epigenetic marks: N6-methyladenine at GATC sites (Dam methylation) and 5-methylcytosine at CCWGG sites (Dcm methylation).99–101 In contrast, mammalian DNA is characterized by 5-methylcytosine at CpG dinucleotides. Crucially, bacterial plasmids typically lack CpG methylation.
Immunological implications
The host immune system relies on these methylation differences to distinguish self from nonself. Unmethylated CpG motifs—abundant in bacterial backbones—act as potent pathogen-associated molecular patterns. They bind to TLR9, triggering innate immune signaling and nuclear factor kappa B activation. While this adjuvant effect is beneficial for DNA vaccines, it is often detrimental for gene therapy, where it can lead to inflammation or transgene silencing.102–105 Consequently, manufacturers may employ strategies such as CpG-free plasmid design or in vitro CpG methylation to “mask” the vector from TLR9 surveillance.106,107
Direct methylation sensing
Historically, verifying methylation status required laborious indirect methods such as bisulfite sequencing or methylation-sensitive restriction digestion. Nanopore sequencing transforms this by detecting modifications natively.28,108–110 The passage of a modified base (e.g., 6 mA or 5 mC) through the pore induces a characteristic shift in ionic current compared with its canonical counterpart (Fig. 4B). Advanced basecalling models (e.g., in Dorado or Megalodon) can now reliably call 5 mC and 6 mA sites across the entire plasmid topology.
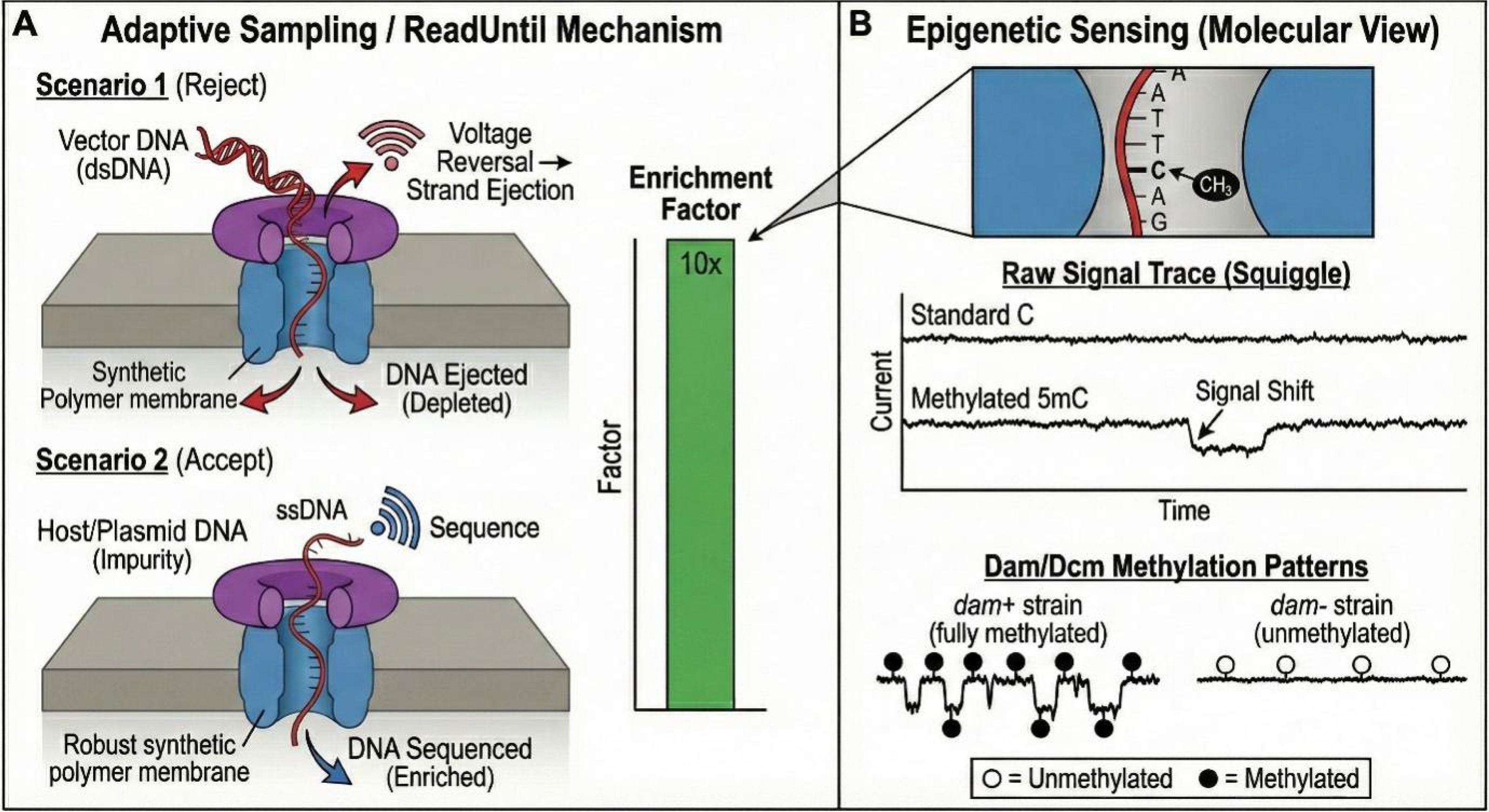
Mechanistic basis of nanopore sequencing: motor protein control and single-molecule sensing. (
Applications in QC
This capability supports several emerging QC applications:
Strain Validation (Dam−/Dcm−): To reduce bacterial signatures, plasmids are often propagated in methylase-deficient strains. Nanopore sequencing can quantitatively confirm the phenotype of the production host. A plasmid from a functional Dam−/Dcm− strain will show background-level signals at GATC/CCWGG motifs, whereas contamination with a standard strain will reveal near-100% methylation at these sites.99–101 Verification of In Vitro Methylation: For processes utilizing CpG methyltransferase (M.SssI) to dampen immunogenicity, nanopore sequencing provides a site-specific readout of enzymatic efficiency. It can determine, for example, that “95% of CpG sites are methylated,” highlighting any protected regions that remain unmethylated and potentially immunogenic.
106
Refining Basecalling Accuracy: Interestingly, the systematic basecalling errors caused by modifications—once considered a liability—are now leveraged for detection. Because specific modifications consistently perturb the signal, methylation-aware polishing tools can simultaneously correct the primary sequence consensus (restoring accuracy to >99.9%) and map the modification landscape.28,45,108–112
Regulatory outlook
While epigenetic profiling is not yet a mandatory release test, it represents a deep level of product understanding consistent with QbD principles. As the industry moves toward highly engineered vectors, the ability to demonstrate that a product is not only genetically correct but also “epigenetically optimized” (e.g., devoid of bacterial methylation patterns) offers a compelling safety argument to regulators.
Adaptive sampling: Targeted sequencing in complex samples
Beyond passive data collection, nanopore sequencing introduces a capability unique to real-time electronic sensing: adaptive sampling (also known as “ReadUntil”). This feature allows the sequencing device to actively select or reject individual DNA molecules based on their sequence identity as they transit the pore, effectively performing “software-defined enrichment” without the need for primers, baits, or complex library preparation.60,113,114
Mechanism and scalability
Adaptive sampling operates by analyzing the initial segment (approximately 400 bases) of a DNA strand. This sequence is aligned in real-time to a user-defined digital reference. If the strand matches a target of interest (enrichment mode), sequencing continues; if it does not (or matches a “blocklist” in depletion mode), the software reverses the voltage across that specific pore, ejecting the strand and freeing the channel to capture a new molecule (Fig. 4A). 115
Recent advancements have scaled this capability to high-throughput platforms. Munro et al. demonstrated barcode-aware adaptive sampling on PromethION flow cells, successfully targeting unique gene panels across three multiplexed human genomes simultaneously. They achieved 7–15× enrichment of target regions. Crucially, the study highlighted a dual utility: while targets were enriched, the “rejected” reads were not discarded but used to generate accurate copy number variation profiles, validating the method’s ability to provide both targeted depth and genome-wide structural context in a single run. 116
Applications in gene therapy QC
This “search-and-sequence” capability addresses specific CMC challenges where the signal of interest is obscured by a high-background matrix.
Biodistribution and integration site analysis (enrichment mode)
In biodistribution studies or patient monitoring, vector genomes are rare events within a vast background of host DNA. Sequencing total DNA is inefficient and costly.
Strategy: By setting the vector genome as the target, the system selectively sequences vector-positive strands while ejecting the overwhelming majority of host DNA. Precedent: This approach has been validated in clinical metagenomics, where pathogen DNA was enriched ∼8-fold in clinical bronchoalveolar lavage fluid samples by depleting human host reads.
117
Applied to gene therapy, this could enable the detection of rare integration events or low-copy persistence in patient biopsies without PCR bias.
Impurity clearance and contaminant screening (depletion mode)
For purified vector preparations, the analytical goal is often the inverse: detecting rare impurities (host DNA, residual plasmids) amid a dominant population of the vector product.
Strategy: Manufacturers can define the vector genome as the “depletion target.” The sequencer actively rejects the main product (AAV or lentivirus reads), dedicating its sequencing capacity to “everything else.” Outcome: This effectively enriches for nonvector contaminants, increasing the sensitivity for detecting residual E. coli genomic fragments or plasmid backbones that might otherwise fall below the limit of detection in a standard run. This method transforms the sequencer into a broad-spectrum impurity detector that requires no prior knowledge of the contaminant’s identity.
Flexibility and limitations
The primary advantage of adaptive sampling is its agility: targets are defined digitally in a .bed or .fasta file, allowing for immediate assay reconfiguration. If an unexpected signal (e.g., a strange plasmid fragment) is observed during a run, the targeting parameters can be updated on the fly to enrich that specific sequence for detailed characterization.
However, current limitations exist. The enrichment factor typically plateaus at 5–10-fold. While this is lower than hybridization-based capture methods (which can reach >100×), the speed and simplicity of the workflow make it superior for rapid QC. Additionally, the rejection process introduces “pore dead time,” slightly reducing the total data yield. Nevertheless, for regulatory applications—such as screening for replication-competent viruses (RCL/RCA) or proving the absence of specific transforming sequences—a 10-fold increase in effective coverage can be the deciding factor in detecting a trace safety risk.
In summary, adaptive sampling shifts nanopore sequencing from a passive observation tool to an active interrogation system. It allows QC laboratories to “tune” the sequencer to focus on the most CQAs—whether that is the product itself or the impurities hiding in its shadow.
CURRENT LIMITATIONS AND REGULATORY OUTLOOK
While nanopore sequencing has matured into a robust research tool, its integration into regulated QC environments faces distinct hurdles (summarized in Table 1). Transitioning from a “discovery” mode to a “release testing” mode requires addressing challenges in accuracy, data infrastructure, and regulatory validation.
High-impact CQA matrix for gene therapy vectors and mRNA therapeutics: Nanopore utility and current limitations

CQA, critical quality attribute; DS, drug substance; FL, full-length single-molecule reads; IMP, sequence-resolved impurities; LC-MS, liquid chromatography-mass spectrometry; LNP, lipid nanoparticle; MOD, base modifications; RCL, replication-competent lentivirus; SIN, self-inactivating; SNV, single-nucleotide variant; SV, structural variant; TAIL, poly(A) tail length.
Accuracy and error profiles
Historically, the primary critique of nanopore data was its raw read accuracy, particularly regarding homopolymer insertions/deletions (indels). Early pore chemistries (R9 series) hovered around 90–95% accuracy, insufficient for detecting SNVs without deep coverage.118,119
However, the introduction of R10.4.1 pores combined with transformer-based basecallers (e.g., Dorado) has significantly closed this gap. The R10.4.1 dual-reader head measures a longer nucleotide context, reducing homopolymer errors. 118 A 2025 GMP-grade study by Dunker-Seidler et al. reported that false indel errors in raw simplex reads dropped from ∼1.4% (V9 chemistry) to ∼0.55% (V14 chemistry). This improvement is critical for AAV QC, as it allows for the differentiation between genuine mutations in the poly-T tracts of ITRs and sequencing artifacts. 118
Despite these gains, caution is warranted for low-frequency variant calling. Distinguishing a true variant present at 1% abundance from a systematic sequencing error remains challenging without high depth or replicate sequencing.120,121 For applications requiring near-perfect single-molecule accuracy, duplex sequencing (reading both strands of a DNA molecule connected by a hairpin) offers raw accuracies >Q30 (99.9%), though at the cost of reduced throughput compared with standard protocols.
Bioinformatics: The GMP compliance gap
Perhaps the most significant barrier to routine adoption is not wet-lab chemistry, but software compliance.
Locked Workflows: Academic pipelines often rely on a constellation of open-source tools (e.g., Minimap2 and Samtools) that change frequently. In a GMP environment, software must be rigorously “locked” (version-controlled) and validated to ensure process stability.
122
21 CFR Part 11 Compliance: Regulatory standards require electronic records to ensure data integrity through audit trails and user access controls. While ONT offers the “Epi2me” platform, developing a fully compliant, end-to-end bioinformatic pipeline that integrates seamlessly with Laboratory Information Management Systems remains a burden often shouldered by the manufacturer.123–128 AI/ML Algorithm Validation: The “Deterministic Paradox”: A more fundamental challenge lies in validating the basecalling algorithms themselves. GMP regulations rely on “deterministic” processes—where the same input invariably yields the same output. However, modern nanopore basecallers (e.g., Dorado) utilize deep neural networks that are inherently probabilistic. Although models are “locked” during deployment, their “black box” nature complicates root-cause analysis for out-of-specification investigations. To address this, manufacturers should reference the U.S. Food and Drug Administration (FDA)’s framework for Software as a Medical Device and adopt a Predetermined Change Control Plan. This shifts validation to a lifecycle model, ensuring that model updates are prespecified and verified against synthetic “ground truth” datasets without compromising the assay’s validated state.
129
Standardization: The Sequencing Quality Control Consortium (SEQC2), involving FDA scientists, is working to establish best practices and reference standards. Standardizing metrics—such as defining exactly how “genome integrity” is calculated—is a prerequisite for cross-industry comparability.
130
Implementation logistics: cost and turnaround
Unlike traditional assays, implementing nanopore sequencing shifts the resource burden from capital equipment to data infrastructure.
Capital Expenditure (CapEx): ONT devices (e.g., GridION and PromethION) function on a low-CapEx model, costing significantly less than high-throughput short-read sequencers (e.g., Illumina NovaSeq) or long-read competitors (e.g., PacBio Revio). This lowers the barrier to entry for smaller QC labs. Operational Costs (OpEx) and Throughput: The cost per sample for ONT is competitive for low-to-medium batch sizes but may be higher than Illumina for ultra-high-throughput applications. However, for gene therapy lots (where sample volume is low but value is high), the cost is negligible compared with the value of the data. Turnaround Time: ONT excels in speed. A typical library-to-report workflow can be completed in <24 h. In contrast, outsourced Sanger sequencing or culture-based biosafety assays can take weeks. The “Hidden” Cost: The primary logistical challenge is IT infrastructure. Storing and processing terabytes of raw “pod5” signal data requires high-performance computing and long-term cold storage strategies that many QC labs historically did not need for simple PCR or ELISA data.
Regulatory recognition and the path forward
As of 2025, no gene therapy product lists nanopore sequencing as a sole release test in public filings. However, regulators are increasingly encouraging its use for characterization and comparability (see Supplementary Table S1 for a detailed mapping of CQAs to regulatory guidelines). 15
The FDA and European Medicines Agency have acknowledged the utility of NGS for investigating vector integrity. The likely regulatory trajectory will follow a phased adoption15,131:
Phase 1 (Current): Orthogonal Characterization. Used to troubleshoot “out-of-spec” results from legacy assays (e.g., identifying a mystery peak in CE). Phase 2 (Near-term): Supportive Evidence in Filings. Data are included in IND/BLA submissions to demonstrate deep process understanding (e.g., “We confirmed the absence of plasmid backbone using long-read sequencing”). Phase 3 (Future): Validated Release Assay. Replacing specific tests (e.g., using sequencing to replace gel electrophoresis for sizing and PCR for identity) once method validation guidelines (ICH Q2) are formally adapted for NGS.131–133
In conclusion, while limitations in single-molecule accuracy and software compliance persist, they are being rapidly eroded by technological updates. The industry is moving toward a consensus that the depth of insight provided by nanopore sequencing—resolving the “black box” of vector integrity—outweighs the logistical challenges of adoption.
CONCLUSION
Nanopore sequencing has matured from a specialized research capability into a high-resolution analytical platform capable of addressing the most persistent challenges in gene therapy QC. By enabling the end-to-end reading of single molecules, this technology resolves structural and chemical attributes—from plasmid recombination events to mRNA poly(A) tail dynamics—that were previously inferred via indirect surrogate assays. 134 The applications reviewed here demonstrate that ONT offers a unified mechanism to interrogate CQAs across the entire manufacturing lifecycle.
For plasmid DNA, long reads provide a definitive check on the structural homogeneity of the starting material. By capturing full circular sequences, nanopore sequencing detects subtle recombination events in repetitive regions that short-read methods bridge and Sanger sequencing fails to resolve.17,51 This capability allows manufacturers to validate upstream constructs with a level of confidence that mitigates the risk of propagating defective elements into downstream viral production. 15
In the context of viral vectors, specifically AAV and lentivirus, the technology serves as a primary integrity assay. It reveals the true distribution of full versus truncated genomes and identifies sequence-resolved impurities, such as reverse-packaged plasmid backbones or host–vector chimeras, which are invisible to standard titration methods. This sequence-level visibility is equally critical for mRNA therapeutics, where direct RNA sequencing simultaneously profiles poly(A) tail length, capping efficiency, and base modification status (e.g., m1Ψ incorporation) on single molecules, streamlining a battery of physicochemical tests into a single workflow. 60
Furthermore, advanced capabilities such as epigenetic profiling and adaptive sampling are expanding the boundaries of CMC characterization. The ability to map bacterial methylation patterns allows for a deeper assessment of immunogenic risk, 43 while software-driven enrichment enables the detection of ultra-rare contaminants in complex biological matrices without the bias of PCR amplification. 28
Looking forward, we anticipate a gradual shift where long-read sequencing evolves from an orthogonal characterization tool toward a more integrated role in the CMC framework, potentially supporting lot release testing once quantification biases are addressed and fully validated. While challenges remain—specifically regarding the validation of bioinformatic pipelines and the standardization of accuracy metrics for regulatory filings 28 —the trajectory is clear. The transition from fragmented, attribute-specific assays to holistic, single-molecule profiling represents a fundamental advancement in how we define “purity” and “identity” in genetic medicine. This trajectory parallels the broader shift in mRNA analytics toward MAMs, where orthogonal physicochemical assays—often including chromatographic platforms such as HPLC and increasingly at-/on-line monitoring—are being consolidated into standardized QC workflows. 135
Ultimately, the adoption of nanopore sequencing is driven by the imperative of patient safety. By identifying subtle vector defects and rare impurities early in the manufacturing process, developers can ensure that the increasing complexity of gene therapies is matched by an equally sophisticated QC framework. 23 As the technology overcomes current quantitative limitations, achieves greater regulatory familiarity, and demonstrates operational robustness, it is poised to become a vital orthogonal standard for characterizing the next generation of genetic medicines.
AUTHORS’ CONTRIBUTIONS
X.-B.Z. and J.-P.Z. conceived the study, obtained funding, and supervised the overall work. X.Y. drafted the article. All authors read and approved the article prior to submission.
Footnotes
AUTHOR DISCLOSURE
The authors declare no conflict of interest.
FUNDING INFORMATION
This work was supported by the National Key Research and Development Program of China (grant nos. 2019YFA0110803 and 2021YFA1100900), the National Natural Science Foundation of China (grant nos. 82570286, 92568302, 82402188, 81870149, 82070115, 81890990, and 81730006), the Chinese Academy of Medical Sciences (CAMS) Innovation Fund for Medical Sciences (CIFMS) (grant nos. 2024-I2M-3-018, 2024-I2M-ZH-015, 2023-I2M-2-007, 2022-I2M-2-003, 2022-I2M-2-001, 2021-I2M-1-041, 2021-I2M-1-040, and 2021-I2M-1-001), the Haihe Laboratory of Cell Ecosystem Innovation Fund (grant nos. 24HHXBSS00005 and HH22KYZX0022), China Foundation For Youth Entrepreneurship and Employment-Incaier Public Welfare Fund (HH25KYHX0009), Postdoctoral Fellowship Program of CPSF (grant no. GZC20240154), and Fundamental Research Funds for the Central Universities (grant no. 3332024074).