
Abstract
Background
Pediatric electromyographic prostheses have limited accessibility due to factors including device weight, training challenges, and aesthetics. When prescribed, high rejection rates still remain. In an effort to reduce rejection, a video game training platform was developed to improve training outcomes. Utilizing this platform shifts training to a low stress virtual environment and can include structured and free-play modes. Due to the unique nature of the interface, validating the level’s effectiveness in reaching a training goal can be difficult by traditional observation methods. Level design and the challenges of learning the interface have pressed for new methods to validate the training prior to deployment. This research seeks to determine if machine learning agents can be used to validate design decisions in a training game for teaching children to utilize electromyographic prostheses, to ensure the game is a more accurate measure of participant abilities and to avoid negative training.
Methods
This research explores integration of a customized AI training program to aid in improvement of game design and efficacy. The Program for Autonomous Unity Learning (PAUL) is a machine learning agent that uses reinforcement learning to optimize its path through a prescribed obstacle course by determining the best electromyographic biosensing input level and timing for each obstacle in the character’s path.
Results
Training reward value begins approaching the end of its improvement at around 1 million steps. The average reward was approximately 140 out of a possible maximum score of 150 or approximately 96.67% of optimal play.
Conclusion
PAUL can determine whether obstacles within the game are technically possible for completion by players. Through this method, the game becomes more accurate as a measure of participant evaluation. Future uses of PAUL include validation of other training games developed to ensure games are playable.
Background
This research uses myoelectric arms for the pediatric limb different population developed with rapid manufacturing techniques to develop custom solutions. The prostheses use a single surface electromyography (EMG) sensor to actuate multiple gestures. EMG control systems provide a method of collecting and evaluating electrical signals that are produced from muscle contractions. Myoelectric prostheses function upon receiving EMG signals on the surface of the skin using electrodes, which translates into a function the arm performs (Su et al., 2007). This assumption that specific electrical signals given off from flexion will be similar in value is referred to as a pattern classification based system (Jiang, 2020). This assumption thus allows for a consistent flex to be correlated to one gesture (Jiang, 2020). Learning to use prostheses may pose difficult for users, especially those that are born with a congenital limb difference. This technology leverages serious video games to optimize muscle contraction necessary for the use of the myoelectric prostheses in a virtual training environment.
One such training game, Runner, uses a Bluetooth based EMG controller to correlate electrical signals into actions within the video game. This controller is designed to be analogous to the prosthesis in both signal input and flexion control scheme. In the game, any flexion performed by the player will respond to the character jumping at a corresponding height. For example, when a player performs a hard flex, the character performs a high jump. The thresholds in the game needed to perform an action correspond to the thresholds required for prosthesis function. The implementation of an analogous system was accomplished to introduce users to the EMG system prior to exposure to the device. Early functionality failures in prosthesis may lead to higher rejection rates however failures within games are considered part of the experience. The desired outcome is for players to experience failure in the games but find success upon reception of the arms, improving rejection rates. The games have an additional benefit of improving muscle strength and endurance prior to control of the prosthesis, another significant factor leading to rejection (Smith et al., 2018). Training games combine incentives and obstacles to engage players in an endless running style game.
The training game described in this study utilizes a free-play and ring challenge mode (McLinden et al., 2023). Assessment of game performance can be difficult, particularly in games with a free-play mode. In endless runner games, such as Runner, free-play mode is characterized by random obstacles to traverse. Other training environments developed are even more freeform in regards to when a flexion can occur and allow for more variation in flexion based on the player’s desired action. This is by design as providing a variety of opportunities within the game for user enjoyment is important in engaging the user, enticing them to continue play (Cairns et al., 2014). As a solution to the validation and assessment challenges, a fixed hoop jumping course was developed for the endless runner game, to act as a pre- and post-test for free-play mode in training sessions.
An artificial intelligence (AI) powered agent was developed to play the game and evaluate variables largely to advance efforts for pre-qualification and validation of level designs. Such variables that we sought to evaluate and improve following this development include errors in level design that impede player progress, and errors that would encourage action that would result in negative training. Following the necessary adjustments to game design, future work with the AI agent includes the development and addition of in-game non-playable characters to play against. This paper highlights the process and results of developing an agent, using Unity ML-Agents, and determining how it could further progress the prostheses training game program to lead to better assessment overall (Juliani et al., 2020).
The applications of AI have evolved to include different industries, such as that of video games and healthcare. Advancement of AI has progressed to include subsections that aid in automation, allowing for data driven for a range of scenarios. This background seeks to address the current applications of AI within games and its potential for interplay in prosthesis training.
Artificial Intelligence for Games
AI in computer settings began developing in the early 1950s, with the primary goal revolving around replicating the human brain to create a computer based intelligence system (European Commission. Joint Research Centre., 2020). One of the earliest learning systems, the Turing machine, was characterized by its memory capabilities, allowing it to improve its program over time (French, 2000). To solve computational problems, the machine registers written input generated from its respective tape (French, 2000) (Hopcraft, 1984). Subsequent actions were then generated based on the read symbols, a notion that served as the basis for AI (French, 2000) (Hopcraft, 1984). As more computer intelligence systems were developed, the Turing test was created in order to test the efficacy of developed AI systems. The test, often referred to as the Imitation Game, involves a human, a computer, and an examiner (Moor, 1976). The examiner’s task is to distinguish between the responses of the human and a machine generating a human-like response (Moor, 1976) (French, 2000). If the examiner is unable to decipher between the two, the machine is deemed intelligent (French, 2000).
It was not until the late 1980s, however, that AI began being implemented in computer game settings(Anderson, 2003). Early games such as Pong, Space Invaders, and Pac-Man included computation alongside randomization of in-game movements in their programming (Chan et al., 2020). These features laid the groundwork for current developments in more sophisticated applications of AI. Later games incorporated AI in their environments which included the development of non-playable characters (NPCs) and the implementation of artificial neural networks (ANN). These new features ensured players could overcome appropriate challenges throughout (Johnson & Wiles, 2001). AI has and will continue to make significant advancements in the video game industry.
Video games can utilize AI to improve player satisfaction, create a more realistic experience, and make game development autonomous (Rath & Preethi, 2021). A large application of AI in video games involves the concept of replay-ability- the suitability to be played multiple times. If a game is exceedingly predictable, a player may lose interest and will not want to continue playing the game due to the absence of challenges (Alvarez, 2013). AI may help retain user interest by creating more challenging opponents. An additional and newer application of AI in the gaming industry is its usage in goal testing. AI can be used to play a game with programmed test goals where the results can be used to improve user experience (Ariyurek et al., 2019). The RiverGame testing tool automates game testing by reporting metrics, checking whether programmed sounds play as intended, and detecting animation problems (Paduraru et al., 2022). Implementing AI tools provides a resource to identify user interface or level design issues and may save developer time. One paper discusses the development of reinforcement trained “automatic players” or RL agents that play through a game and can provide insight into the difficulty of each of the level’s parameters (Gutiérrez-Sánchez et al., 2021). Another study found that RL agents outperformed human game testers, as the agent could cover and play multiple paths of the game that humans were not able to (Ariyurek, 2022). Reinforcement trained agents are useful in playtesting as they are able to highlight various glitches with high coverage levels (Sestini et al., 2022). As AI tools develop, there will be more advancements in gamified testing.
Artificial Intelligence for Prosthesis Use
Gamified training is a tool used to shift aspects of a video game, such as power-ups or points, into more serious real-world applications (Willwacher & Korn, 2021). For this work, a machine learning agent was integrated into an endless runner game called Runner which contains obstacles and power-ups the user must avoid or collect (McLinden et al., 2023). Past work revolving around Runner proved it effective for training muscles with an EMG game controller in preparation for their bionic arms (McLinden et al., 2023). The goal of this agent is to eliminate time spent on the tedious tasks for improving game design and aid in precise evaluations for factors that improve game play.
Further research shows that technologies such as AI can be used to control prosthesis arms through EMG patterns (Kristoffersen et al., 2021). Specifically, ANN involves recognizing physical movements through patterns from EMG signals with an overall success rate of 88.4% (Ahsan et al., 2011). With ANN, pattern recognition can classify motions effectively with a faster computation time (Ahsan et al., 2011). The use of AI in prosthesis training is important for future developments and can begin a new generation of prosthesis acceptance (Luu et al., 2022). Different types of AI used for testing game usability can continue to improve future training platforms.
Novel devices, such as the prosthesis described in this paper, may benefit from consideration in how to best increase user satisfaction in case of challenges with the original manufacturer being able to support repairs. Software as a medical device and software in a medical device both have unique considerations for regular updates, modernization with changing operating systems, and security path necessities (Svensson et al., 2018). Computer engineering research has shifted in recent years to explore AI’s potential for generating solutions (Monperrus, 2019), (Rivera et al., 2023). Deep learning, a specialized application of AI has proven useful in the repair of program errors, a highly time consuming activity (Gupta et al., 2017). One such example lies in DeepFix, a neural network that is capable of predicting errors and generating the amended commands (Gupta et al., 2017). Though current work is limited by sequence length and the complexities of such programming errors (Gupta et al., 2017), current progress suggests that AI has potential to streamline solution generation for programming languages. Other work in the field should consider utilization of AI to reduce time and increase consumer convenience for coding repairs and updates. AI enhancements will undoubtedly lead to a higher priority and focus across personalized medicine.
Machine Learning (Technical Components and Applications)
Artificial intelligence can be utilized in various applications, with machine learning (ML) being of major note. ML involves the adaptation of the agent to tasks by gathering information from prior experience (Alvarez, 2013) (Geisler, 2004). A predominant branch of ML algorithms are ANNs, which emulate the layers, nodes, and connections of the human brain. Input, such as unprocessed data, passes through the network and makes adjustments to make more precise predictions (Skinner & Walmsley, 2019). AI algorithms such as ANNs allow for a better player experience, by creating balance and offering more interaction features, and can be used to train the gaming system.
A tailored approach to ML includes reinforcement learning and deep learning. Reinforcement learning is a method in which the agent is not told what actions to take, but rather discovers the next steps through a trial and error process (Kaelbling et al., 1996). It is based on a reward system in which the agent must discover the actions that will maximize the rewards through repeated exposures to the given environment, as visualized in Figure 1. The ML-Agent considers all possible outcomes and chooses the one that gives the largest benefit based on its previous experiences. Both the ML-Agent and the player choose the best option based on the desirability of the positions (Sutton & Barto, 1998). AI has a largely untapped potential to improve various applications of computer engineering, including video games. ML-Agents in particular have been used previously for testing games due to their reinforcement learning strategy. One study examined the capabilities of their developed framework, Wuji, which leverages deep reinforcement learning for automatic bug detection (Zheng et al., 2019). The explorative nature of the agent was capable of finding such errors in simple and commercial games (Zheng et al., 2019). Taking a similar approach, this paper seeks to evaluate the effectiveness of a machine learning agent in assessing errors and improving game play within the novel training game, Runner. Methodology for the reinforcement learning algorithm, PAUL.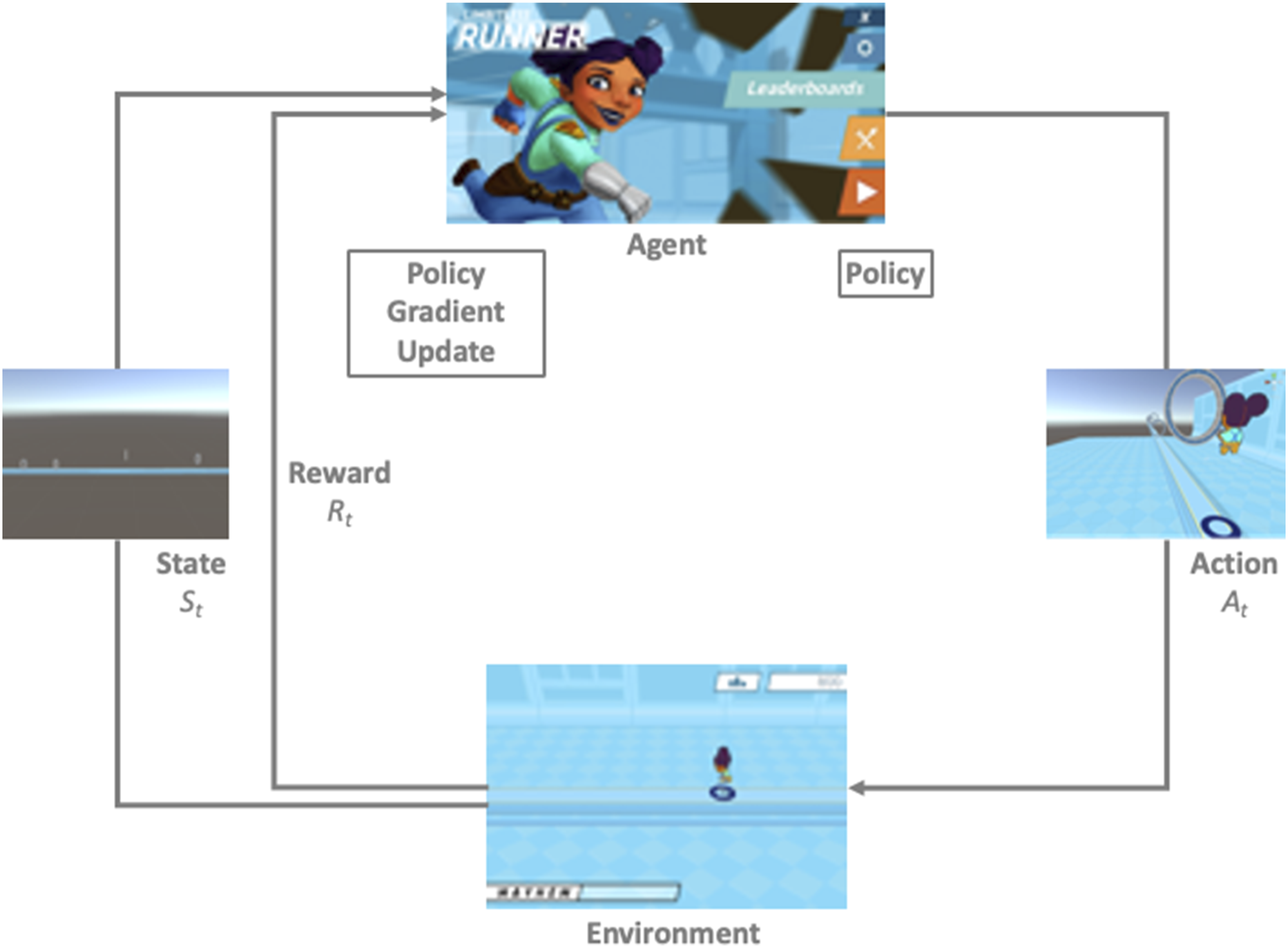
Methods
To optimize existing processes in assessing and resolving errors in game play, this case study features a machine learning agent developed utilizing Unity’s ML-Agents toolkit to evaluate the game design for optimal play and find errors within game design that prevent user progress, or lead to negative learning outcomes.The Unity engine is a platform where individuals can create virtual environments through the software and engage with it through the C# coding language (Juliani et al., 2020). The external plug-in being utilized for this study, Unity ML-Agents, is a toolkit created by Unity that allows developers to create and train their own agent within the engine (Juliani et al., 2020). The Unity ML-Agent can be trained with various parameters, to allow for training specified for its task in an existing game environment. The parameters included hoop height, distance between two hoops, player speed, player height, and if a jump was available. These agents can be trained to complete various tasks within their virtual environment and past experiences can be extracted and implemented into future versions of the agent, increasing potential for future success.
Unity ML-Agents provides users with the agent training environment so that training and evaluation can be focused on (Juliani et al., 2020). Within the environment are the agent component and the academy component, where the agent is the brain of the actions and the academy is the facilitator. The agent tries to make informed decisions to take the best action that will lead to the highest reward, stratified by a point system described later in this study. The academy attempts to be the management system, where it decides the learning process of the agent to lead to optimal outcomes. However, the agent is the source that ultimately makes the decisions, which will either lead to a penalty or a reward, shown in Figure 1.
The Program for Autonomous Unity Learning (PAUL) is a ML-Agent utilizing the Unity ML-Agents Toolkit that returns observations and receives input from an external program applied to the Runner game. PAUL utilizes a Proximal Policy Optimization (PPO) training algorithm. Policy gradient algorithms like PPO have been very prominent in the ML space, as they are good at resolving issues with no clear solution (Schulman et al., 2017). Unlike problems such as solving a maze, every action can be calculated, and by the end, the policy that the agent will follow is optimized by rewards and punishments to collect the most points. For a PPO based agent, the policy becomes a series of probabilities based on observations. PAUL’s PPO policy will assign a probability value to an upcoming jump and as it gets closer in proximity to the hoop. As the probability increases, PAUL will jump in order to maximize points. PPO is currently the most optimized policy gradient algorithm, as it takes significantly less time to reach similar results comparatively. These optimizations come in the form of limiting the amount of change the policy can receive in each step. In this manner, negative progression is limited and prevents the development of a policy where the probabilities of the actions can only cause bad rewards.
The PPO algorithm was written by the Unity package and is based on a given action frame. The action with the highest probability of happening is selected and its results are evaluated. Each action will receive a score that determines its effectiveness. An actions score will be made based upon a compilation of correlations with the games parameters. For instance, when the agent gets within 2 Unity Units, there would be a high correlation for PAUL to execute a jump command. Eventually the correct action for all of the given scenarios will have significantly higher correlations with the parameters, and the probabilities of these actions will be increased, until they are taken most of the time. The pseudocode is displayed below. 1. Initialize PPOTrainer with configurations, policy, optimizer, and reward tracking. 2. Collect trajectories by interacting with the environment: • Record observations, actions, rewards, and next states. 3. Process trajectories: • Normalize observations. • Calculate value estimates, advantages (using GAE), and discounted returns. • Store processed data in the update buffer. 4. Check if the update buffer has enough data to train. 5. Train the policy: • Shuffle and split data into mini-batches. • Update the policy using the PPO loss for several epochs. • Reset the buffer after training. 6. Log performance metrics and adjust training parameters as needed. 7. Repeat until the stopping condition (e.g., max steps or desired performance) is met.
To begin training, the training function is run and played in Unity, beginning an episode. Episodes refer to a period of time where the AI tests its weight values placed on certain outputs in accordance with observations. To do this, it creates generations, which are multiple versions of the algorithm running concurrently, which independently calculate optimal weights for reception of a reward. For example, if it sees the next hoop is close, it will eventually learn that the jump output is a good option here, as it would consistently yield more points. Reduced distance to the next hoop, will correlate with a higher weight to the jump output. At the end of an episode, the generation takes the top performing agents and brings them to the next episode to continue training. Remaining generation slots are filled with agents whose weights are based on the previous generations success, as well as some randomness. Most of the time the episode ends and then quickly restarts, leading into a newer episode and continuing learning. However, it’s possible to grab the best performing agent from an early episode, and compare it to one from a later episode.
Each agent within a generation operates on steps where the program is constantly trying to calculate the optimal weights for each possible action based on the current observations. For each step of the agent we must: • Provide observations of the game • Read decisions based on observation weights • Optimize weights based on an episode’s rewards
For PAUL, the observations provided are: • The height of the next hoop • How fast the game is currently moving • The horizontal distance between the agent and the next hoop • The player’s current height and the number of jumps remaining
Based on the agent’s personal weights from these observations it will decide whether to either do nothing and continue to run forward, or jump and read a second variable for how high the jump should be. Each agent is evaluating its total rewards for each step across an entire episode and adjusting the decision weights to prioritize rewards over punishments. These rewards and punishments are set by the environment the agent exists in, and determine the path of their training. Intuitively, ML algorithms will be optimizing to get the highest average reward score for the episode, so ensuring that the rewards correlate with optimal gameplay mechanics is very important. Gameplay mechanics can be defined as elements of a game that can receive inputs based on user interactions (Fabricatore, 2007). Runner game mechanics include the hoop users jump through and its associated rewards.
PAUL’s rewards are determined by various gameplay mechanics such as: • +3 if cleanly going through a hoop • -0.5 if hitting any part of the ring on a hoop • -2 if jumping without going through or hitting a hoop • -2 if a hoop goes past without the agent going through or hitting
Eventually over time the agents will slowly determine better timings and values for the jumps to better abide by these rewards. Ideally for PAUL, these rewards push the AI quickly into realizing excess jumping is bad, as well as complete misses of a hoop, causing the eventual push into the agents trying for each hoop, and then steadily the optimization of better timing and jump heights to get more perfect jumps. This behavior was displayed when looking at the data, as the number of jumps quickly decreased to around 50 (the number of hoops within an episode) first before any real score improvements occurred, the score in this case being the number of hoops a player jumped through in an episode, not the reward value.
Results
The results are broken up into two sections, refinements made to the model on early training episodes and the results of the final agent. The early results showed needed changes to both the agent being trained, and the environment the agent was being trained for. The environment changes needed showed real world changes that would improve the training for both the AI agent and human players, and are therefore some of the most valuable results of this work.
Refinements to the Model
While running the PAUL agent, some results did not match the desired outcomes of the players, and changes needed to be made to the rules to enforce the correct behaviors. One such error occurred when the character would jump through the hoops. Rather than figuring out the correct amount of power for each hoop PAUL would jump with the same power for each hoop and adjust the distance they needed to start the jump from each time. This would not resemble what a human player would do when playing the game, so it is important to devise ways to adapt the algorithm to simulate user decisions. An important limitation to note is the absence of a direct metric to measure deviance from normal player behaviors. However, observed real-time human interactions with the game were used to determine a baseline level of normalcy. The goal of PAUL was to eventually mimic these human-like tendencies in its game playthrough. As trained versions of PAUL were created these were compared to desired outcomes for patients to see if PAUL was performing well. In some cases this led to needed changes in the training parameters, while other issues identified game design flaws. This required the addition of a preferred jump zone that the jumps needed to occur within and punishing jumps that occurred too early.
Many other refinements had to be done by adding more rewards and punishments to the policy until the AI reaches the desired output. Specifically, the addition of punishments for over and under jumping can adjust the speed and the time of jump for each hoop. Another refinement included considering the speed of the player character and the AI’s ability to complete the obstacle.
In the early versions of, PAUL jumped much more often than necessary. The policy was adjusted to punish jumps that did not clear a hoop. PAUL then learned to minimize the number of jumps while playing the game. The AI made a correlation to see that less jumps resulted in a higher score. Since there are fifty hoops per episode, many of PAUL’s attempts to jump were unsuccessful, resulting in large penalties. An additional behavior of note was that PAUL adapted to jump through hoops on the downswing. This allowed for the AI to have more time to prepare for the next jump, increasing the overall score. The ideal jump would be for the apex of the arc to be hit inside the hoop.
As PAUL learned to jump through hoops over millions of episodes, it became apparent from watching the resulting AI agent running the track that there were errors in the design of the track itself. There were points where multiple hoops aligned together were designed to elicit three small hops, but PAUL found that making one very high jump and coming down through all the hoops at once, was a better strategy. A similar issue occurred with two very high hoops in row, PAUL was unable to make this large jump. This issue was solved with randomizing the order in which hoops arrived and constraining them to not repeat the same heights in a row.
Final Agents
After all the refinements were made to the policy and the environment, PAUL ran for 4 million iterations. The resulting agent is capable of running the hoop challenge mode of Runner at a very high level of efficiency, often hitting a “perfect run” though the course. As can be seen in Figure 2, PAUL hit a plateau between its 1 millionth and 2 millionth episode. Reward earned over number of runs. Over time the reward optimizes and plateaus to a single value.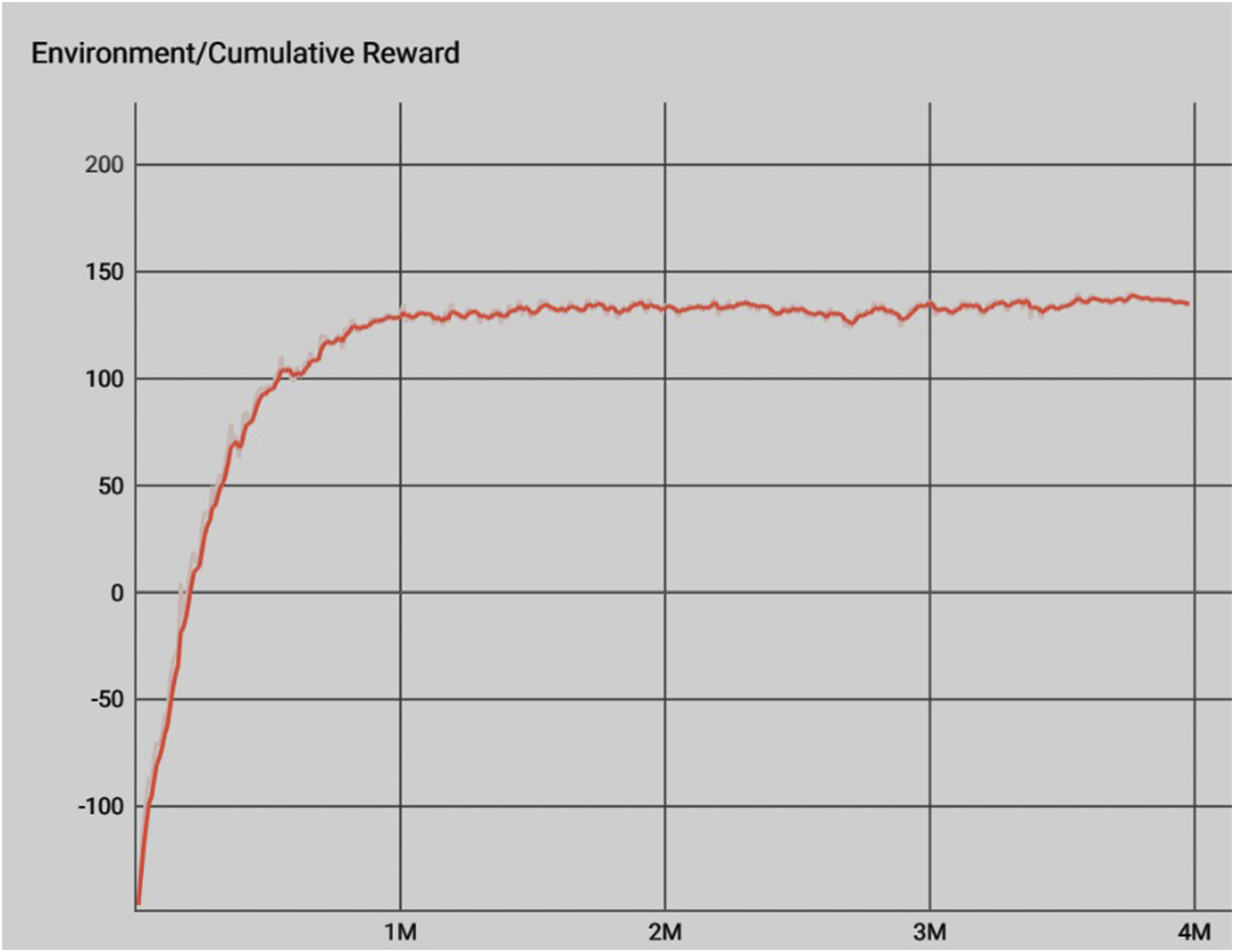
Throughout testing, PAUL will compile data to determine possible jumps and correct them. Since PAUL will eventually refine itself to become near perfect on the obstacle course, by simply observing its behavior researchers can modify values such as distance between obstacles, height of obstacles, or even height of an obstacle based on how much time it has to react based upon the previous obstacles jump. If PAUL would be able to get perfect scores on a course with modified values, developers will know that the course is possible. With the new information, values can be adjusted to make the game more difficult if needed, and re-run training to determine if it is still entirely possible.
Discussion
During the simulation period, PAUL’s algorithm would jump through a maximum of fifty hoops at each episode and learn from itself after each one. Using a PPO algorithm, PAUL slowly became more adept at making the appropriate jumps to complete the course with the highest score.
PAUL was able to identify impossible jumps and show the developers situations that should not be included in level design. These resulted in environmental changes needing to be made to help train the AI alongside improvements that enabled better training and assessing humans. The result is more appropriate spacing between obstacles. Doing so allows for any course from Runner to now become possible to complete. This also helped identify the need for a randomization mechanic for hoop jumping. This will make the game more dynamic and be better for training the agent as the agent did not just learn the set track, but had to understand what a good jump was for each hoop height. Lastly, the AI can output its ideal jumping power for a hoop of any height, taking into account the height of the jump and the speed of the player. This will be applied to the free-play mode in the future as the game constantly increases in speed over time and adds more obstacles for the player.
Limitations and Suggestions for Future Further Research
The base model of PAUL runs efficiently through the whole game. However, the ML-Agent may have applications beyond game testing for bugs. Future work may include the usage of PAUL as a non-playable character, namely as a ghost racer that can effectively compete against the player. The most current version of PAUL, which has been optimized across multiple episodes, would be virtually perfect in its approach to the game, likely deterring users from continuing to play. An early version of PAUL would likely allow for a greater sense of competition and enjoyment. The Unity ML-Agents package also includes imitation learning. In this case, the AI is trained based on human inputs to the game. Ideally, agents could be trained with the skill level of the player on their first clinical visit, and they could compete with that agent, until their next visit. They could also be assessed based on how much improvement they have compared to their own AI agent.
PAUL will also be expanded to run on the free-play mode of the game. In this mode there are no hoops to jump through, but even more obstacles to overcome, including treadmills, crates, low ceilings, gaps in the floor, and more. Some items are power-ups that would further complicate training, but learning to use all of the available resources would increase the enjoyment and engagement of the game. Furthermore, introducing a difficulty slider will allow players to adjust the distance between obstacles to alter the challenge level to their liking. This would be beneficial in managing boredom or frustration while playing. If a new user is adjusting to the equipment, such as the EMG controller, the game should not be difficult to play. However, with the increase in game speed, there may be an impossible jump, where there is no way for the player to jump through the hoop. Ideally, an AI can be utilized to make a function which allows every jump possible to limit the amount of frustration, as a difficult jump is much more manageable than an impossible jump. The AI would essentially be used to make the game more player-friendly so that users have an enjoyable experience throughout.
Another future objective is to compare the agent’s data against human data, which would show if there were discrepancies between the players and the agent. This can determine whether the AI is finding optimizations that a human would not. If this is the case, more significant signposting could be done to help human players build these skills.
PAUL may also have implications towards future work in the investigation of flexion. Especially in the context of prostheses training, the degree of muscular flexion serves as an additional variable alongside the timing behind initiation of an action. With the usage of PAUL these variables can become an accurate measurement of training progression, while also contributing to a more refined gameplay and higher user satisfaction. Specifically, when playing through the game, users will find that the jumps required to score points are feasible. This leads to greater motivation for the user to score higher and desire to continue playing the game due to increased enjoyability. The magnitude of a flexion can complicate game play, as it may or may not lead to a successful attempt in clearing obstacles. With additional developments, PAUL can be reconfigured to focus on generating “perfect jumps”, providing us with valuable insight into another facet of game design.
Conclusion
It is clear that PAUL can be used to test any configuration from prebuilt courses to fully randomly generated courses for Runner. The agent can determine if the hoops are well placed and can output appropriate jump values for comparison to the human players. Though PAUL is capable of ascertaining the feasibility of obstacle placements, future work will take imperfect reaction times into consideration as well to diminish potential user frustration. Such adjustments to level design aims to encourage users to play for longer periods and provide increased training for muscular discretization in tandem. This can be fixed by using values from an earlier stage of PAUL, such as when training first started, where the algorithm is beginning to comprehend how the game works. The base model of PAUL runs efficiently through the whole game. However, future work includes maximization of efficiency and productivity to learn from the game. Additionally, analysis of the difference between the behavior of PAUL and a human player may provide information on how to improve this model. An assessment of player performance also needs to be completed to test the effectiveness of reaching training goals. Training an ML-Agent to successfully play a training game is also an interesting way to test the validity of the training game. If the agent can not be trained to use the environment, it is possible that the environment will need to be changed, and that these changes will lead to better outcomes for human players as well.
Footnotes
Acknowledgements
The researchers appreciate the philanthropic support for undergraduate research from the Paul B. Hunter & Constance D. Hunter Charitable Foundation, the Don & Lorraine Freeberg Foundation, and the Albert E. & Birdie W. Einstein Foundation. The authors declare no competing interests, and want to disclose that Limbitless Solutions has received a Unity for Humanity Grant for an unrelated training game, along with financial support from Autodesk (3D design software company), Adobe, Microsoft, and Stratasys (3D printer manufacturer).
Author Contributions
Peter Smith: Writing—Original Draft, Visualization, Conceptualization, Methodology, Software, Supervision. Matt Dombrowski: Software, Supervision. Viviana Rivera: Writing—Original Draft, Visualization, Data curation. Maanya Pradeep: Writing—Original Draft, Visualization. Eric Gass: Investigation, Conceptualization. John Sparkman: Software, Supervision. Albert Manero: Project Administration, Supervision, Funding Acquisition.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Limbitless Solutions® program has received financial and in-kind support from Unity, however this grant did not power the presented research. Unity had no direction in the choice to publish the study. The Limbitless Solutions games team receives funding from Unity for other projects generated in facility.
Data Availability Statement
Data supporting this study is available upon request.