
Abstract
Keywords
Introduction
For nearly three decades, risk assessment tools have been integral to decision-making processes in child welfare (CW) services, supporting professionals in identifying and responding to child maltreatment risks (Cuccaro-Alamin et al., 2017; Drake et al., 2020). Traditionally, these tools are categorized as either consensus-based or actuarial-based (Glaberson, 2019). While consensus-based tools incorporate items presumed to predict maltreatment, actuarial tools utilize items empirically validated to predict maltreatment (Drake et al., 2020). However, widely used risk assessment models, such as Structured Decision Making (SDM), have faced criticism regarding their validity, reliability, and practical utility (Bartelink et al., 2020; Glaberson, 2019; McNellan et al., 2022). Notably, their statistical accuracy and operational effectiveness heavily depend on CW workers who are both well-trained and motivated to implement these tools correctly, highlighting significant limitations in real-world applications (Cuccaro-Alamin et al., 2017).
In response to these critiques and driven by advancements in electronic case management systems and the growing availability of linked administrative datasets, predictive analytics leveraging statistical models and computational algorithms have emerged prominently in CW decision-making over the past decade (Chouldechova et al., 2018; Glaberson, 2019; Saxena & Guha, 2024; Vaithianathan et al., 2020). Many CW agencies across the United States have adopted these algorithmic-assisted decision-making tools to predict outcomes. Based on a 2021 report (Samant et al., 2021) and the follow-up investigation, at least seven jurisdictions have used algorithmic-assisted decision-making tools in the past two years.
These algorithmic tools are promising in providing more accurate and consistent prediction than common actuarial instruments (Saxena et al., 2020). However, critiques around these tools were pronounced, including suggestions that predictive analytics punish the poor (Eubank, 2018), or are simply attempts to address inherent limitations of the system of the U.S. child welfare system (Glaberson 2019). Accordingly, several states discontinued using these tools: Illinois in 2017, Ohio in 2018, Louisiana in 2019, and Alaska in 2018 (Samant et al., 2021). Reasons for discontinuing the use of these tools include concerns about their reliability and their potential to worsen racial disparities in the CW system—one tool, for instance, disproportionately flagged Black children for mandatory maltreatment investigations (Ho & Burke, 2022; Leving, 2022). Saxena et al. (2020) found that some predictors in PRM training were selected for availability rather than validity, mirroring traditional risk assessment tools. This suggests that detailed reviews of algorithmic-assisted decision-making tools are needed for their effective deployment and to ensure they enhance decision-making fairly and reliably and actually addressing existing challenges, rather than introducing new risks for families and children (Drake et al., 2020; Glaberson, 2019). To enhance the ethical use of these tools in aiding caseworkers in making high-stakes decisions that impact families involved in the CW system, this study reviews articles reporting the use case of algorithmic-assisted decision-making tools in CW with an adapted implementation science framework.
Algorithmic-Assisted Decision-Making Tools in Child Welfare
Algorithms, defined as “computational systems that intake data, process it analytically, and yield actionable outputs” (Saxena & Guha, 2024, pp. 2–3), form the basis of algorithmic-assisted decision-making tools. These tools systematically analyze relationships within administrative data to predict the likelihood of adverse CW outcomes (e.g., maltreatment reports, substantiations, or removals), thereby providing critical insights to enhance professional judgment and decision-making effectiveness (Elgin, 2018). Algorithmic-assisted decision-making tools present several notable strengths. First, tools utilizing machine learning (ML) methodologies partition datasets into training and testing subsets for model development and validation, thereby reducing the risk of overfitting. This approach contrasts with traditional statistical models that typically use the full dataset for generating predictions (Elgin, 2018). Second, these tools effectively capitalize on existing CW administrative records and, in some cases, integrate data from other sectors, including health departments and criminal justice systems (Chouldechova et al., 2018). This capability eliminates the need for additional data collection, offering a cost-efficient complement to professional and clinical assessments, and facilitating the timely identification of families requiring support (Elgin, 2018; Stepura et al., 2020; Vaithianathan et al., 2013).
Evaluating Algorithmic-Assisted Decision-Making Tools
Two recent systematic reviews have discussed and compared research articles that apply algorithmic models in predicting CW-related outcomes (Hall et al., 2023; Saxena et al., 2020). Saxena et al. (2020) included studies that used both ML models and traditional structural decision-making (SDM) tools, providing an insightful comparison between these two approaches. Alternatively, Hall et al. (2024) focused exclusively on ML algorithm studies and compared both theoretical models and those that were integrated into the practice. These two reviews depicted the landscape of the recent ML application in CW research; however, further investigation into the practical utility of these tools should be conducted to understand how well these tools could be directly incorporated into agency processes to support decision-making and resources allocation (Stepura et al., 2020)
Moving forward from looking at the model performance, several approaches were proposed to address ethics, equity, and bias. First, two models were proposed to evaluate these tools. First, Russell (2015) proposed a model of four key aspects of performance – validity, equity, reliability, and usefulness. Validity assesses whether the tool measures what it intends to; equity evaluates whether predictions function consistently across subgroups; reliability ensures consistency and stability; and usefulness reflects its practical value in decision-making (Russell, 2015). Later, Drake et al. (2020) expanded Russell's framework to include an assessment of ethical considerations (e.g., community engagement and transparency) at each stage of algorithm development and deployment. On the other hand, accuracy, fairness, misuse, quality of data, and privacy concern were raised in other studies (Glaberson, 2019; Redden et al., 2020). In addition to these conceptual models, Hall et al. (2024) developed a scoring system to empirically evaluate how well studies addressed these ethical concerns. Using a 0 to 4 scale, the authors assessed whether studies acknowledged model limitations, involved cross-disciplinary research teams, and took explicit steps to address ethics, equity, and bias. Together, these approaches reflect an evolving standard in the field to ensure algorithmic tools are not only technically sound but also ethically responsible and socially responsive. Nevertheless, there remains an opportunity to synthesize these insights into a more comprehensive and integrative framework that can better support ethical decision-making and enhance the practical utility of PRM tools in frontline practice. This systematic review is intended to fill this gap.
To advance this integrative approach, we used the Consolidated Framework for Implementation Research (CFIR), developed by Damschroder in 2009 and updated in 2022, which has been widely used in the field of implementation science (Damschroder et al., 2022). CFIR consists of five domains: (1) innovation: the “thing” being implemented, (2) outer setting: the setting in which the inner setting exists, (3) inner setting: the setting in which the innovation is implemented, (4) individuals: the roles and characteristics of individuals in the project, and (5) implementation process: the activities and strategies used to implement the innovation. This framework offers a useful lens for examining how ethical considerations are embedded in the real-world use of algorithmic-assisted decision-making tools. We selected three domains pertinent to PRM implementation: intervention, inner setting, and implementation process. By aligning the ethical concerns raised in prior studies—such as validity, equity, transparency, and community engagement (Drake et al., 2020; Russell, 2015)—with these selected CFIR domains, we achieve a more holistic evaluation of PRM tools that not only considers their technical soundness but also the organizational context and procedural dynamics that shape their ethical implementation in practice.
Purpose
The current work expands on Hall et al.'s (2024) systematic review of ML models (defined in the inclusion and exclusion criteria) in CW and further narrows to the use case of these methods in predicting population-level child maltreatment rates and individual-level CW-related outcomes at multiple stages, such as referrals, reports, investigations, services, and permanency. Building on two foundational systematic reviews (Hall et al., 2024; Saxena et al., 2020), this study adapted an implementation science framework, assessing real-world implementation and stakeholder experience, as the practical impact of these models remains largely unexplored (Saxena et al., 2020). Furthermore, this study aims for a deeper investigation into their implementation, practical challenges, successful factors, and stakeholder perspectives, providing practitioners, CW agency staff and leadership, and impacted communities and families a practical lens to better understand these tools. Therefore, the current review aims to answer:
For what purpose(s) are algorithmic decision-making tools being implemented in the process of CW practice (at any stage)? (a) What are the key factors associated with successfully implementing algorithmic decision-making tools in practice? (b) What are the related challenges? How did CW agencies address algorithmic fairness, equity, and ethics issues from model development to deployment?
Method
Search Strategy and Keywords
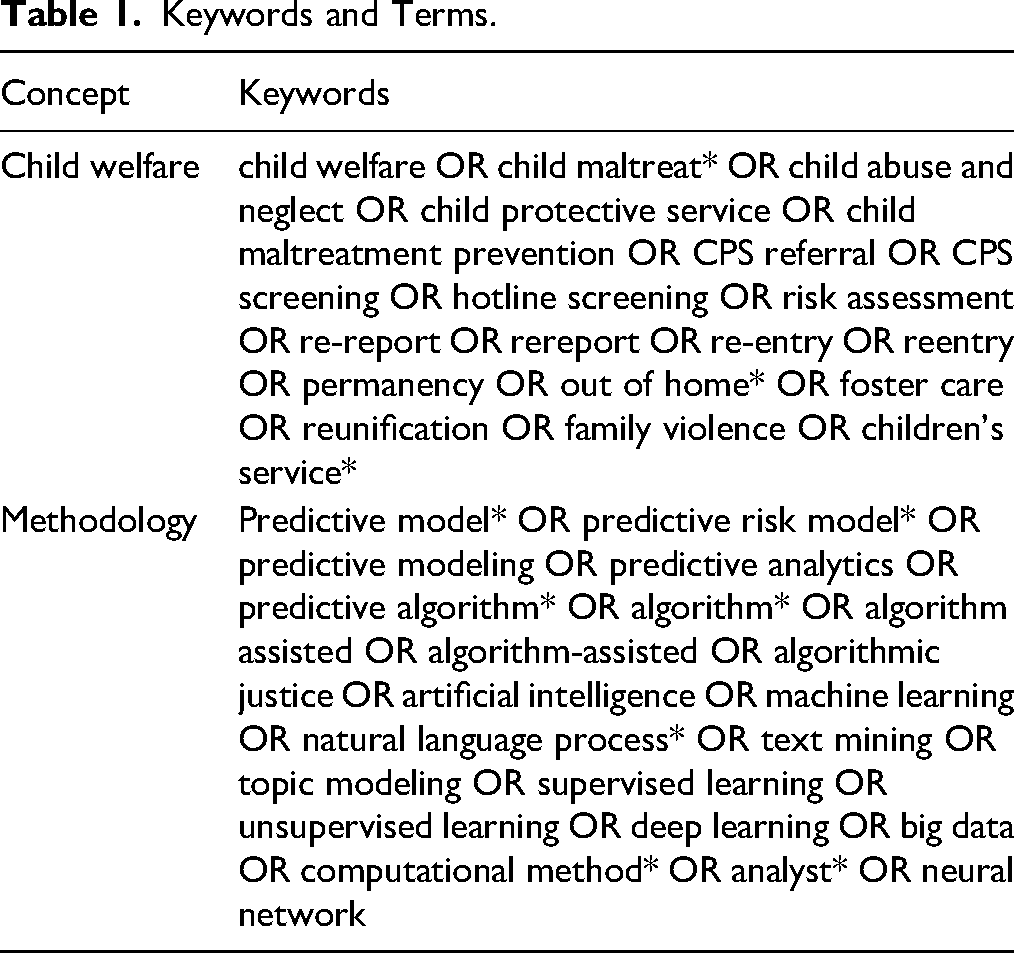
The Preferred Reporting Items for Systematic Reviews and Meta-Analysis ([PRISMA], Page et al., 2021) was utilized to establish the review protocol, ensuring the rigor and reproducibility of this review. The review protocol was not submitted to the Campbell Collaboration but was developed after consulting with a university librarian. The current review included sources from bibliographic databases: PsycInfo and SocINDEX via EBSCO, Scopus, and PubMed using Boolean operators. The search for article titles and abstracts used the following two sets of keywords: those related to CW and those related to methodology, connected by a Boolean query string, as shown in Table 1.
Keywords and Terms.
Inclusion and Exclusion Criteria
Publications eligible for inclusion in this review met the following criteria: (1) studies involving clients engaged with CW or child protective services, (2) studies that used existing service data (e.g., administrative data) to develop algorithmic tools, (3) studies reporting the development and deployment process of algorithmic tools predicting CW-related outcomes, and (4) studies reporting the supports and challenges encountered during the implementation of these algorithms, and (5) English-language articles. Studies were excluded if they (1) were published in languages other than English, (2) did not exclusively focus on clients involved in CW or child protective services, (3) collected primary data to develop the tools, or (4) did not report the development and deployment process. This review focused specifically on studies utilizing routinely collected service data (e.g., administrative data) rather than researcher-collected primary data, as a key purpose of implementing algorithmic-assisted decision-making tools is to reduce caseworker workload and address resource limitations within CW agencies.
Additionally, gray literature—including government reports and conference papers—can provide critical evidence not found in commercial publications (Paez, 2017). Therefore, this review includes gray literature meeting the first four inclusion criteria but not published in peer-reviewed journals. Algorithmic-assisted decision-making tools were defined based on Banerjee & Banerjee (2017), as tools that “predict potential future outcomes and explain drivers of the observed phenomena” (p. 7). The review also evaluated how studies addressed usefulness, equity, fairness, and ethics during development and implementation, using the framework proposed by Drake et al. (2020). Inclusion and exclusion criteria are detailed in Table 2.
Inclusion and Exclusion Criteria.

Search Process
After completing all four database searches in early June 2024, 9,110 results were entered into Covidence (n.d.). There were 1,646 duplicates, which were removed during the importing stage. The titles and abstracts of the remaining 7,464 unique articles were screened, excluding 7,350 irrelevant studies. This process left 114 articles for a full-text review. Among these, 106 papers were excluded for the following reasons: 42 had an ineligible study design, such as using methods other than ML models (Barak-Corren et al., 2022), 31 presented theoretical models that lacked implementation, 13 focused on the outcomes that were not focused on CW, such as predicting intimate partner violence (Victor et al., 2021), seven had an ineligible article type, such as dissertations (Chung, 2021; Giardina, 2019), seven involved an ineligible population, such as homeless clients (Kithulgoda et al., 2022), and six were set up in an ineligible context, such as hospitals (Hermetet et al., 2021). Three gray literature—two implementation reports conducted by CW agencies and one conference paper with full text—were included in the analysis. Ultimately, nine papers met the eligibility criteria for this review. Figure 1 presents the flowchart of the search process, following the PRISMA criteria (Page et al., 2021).
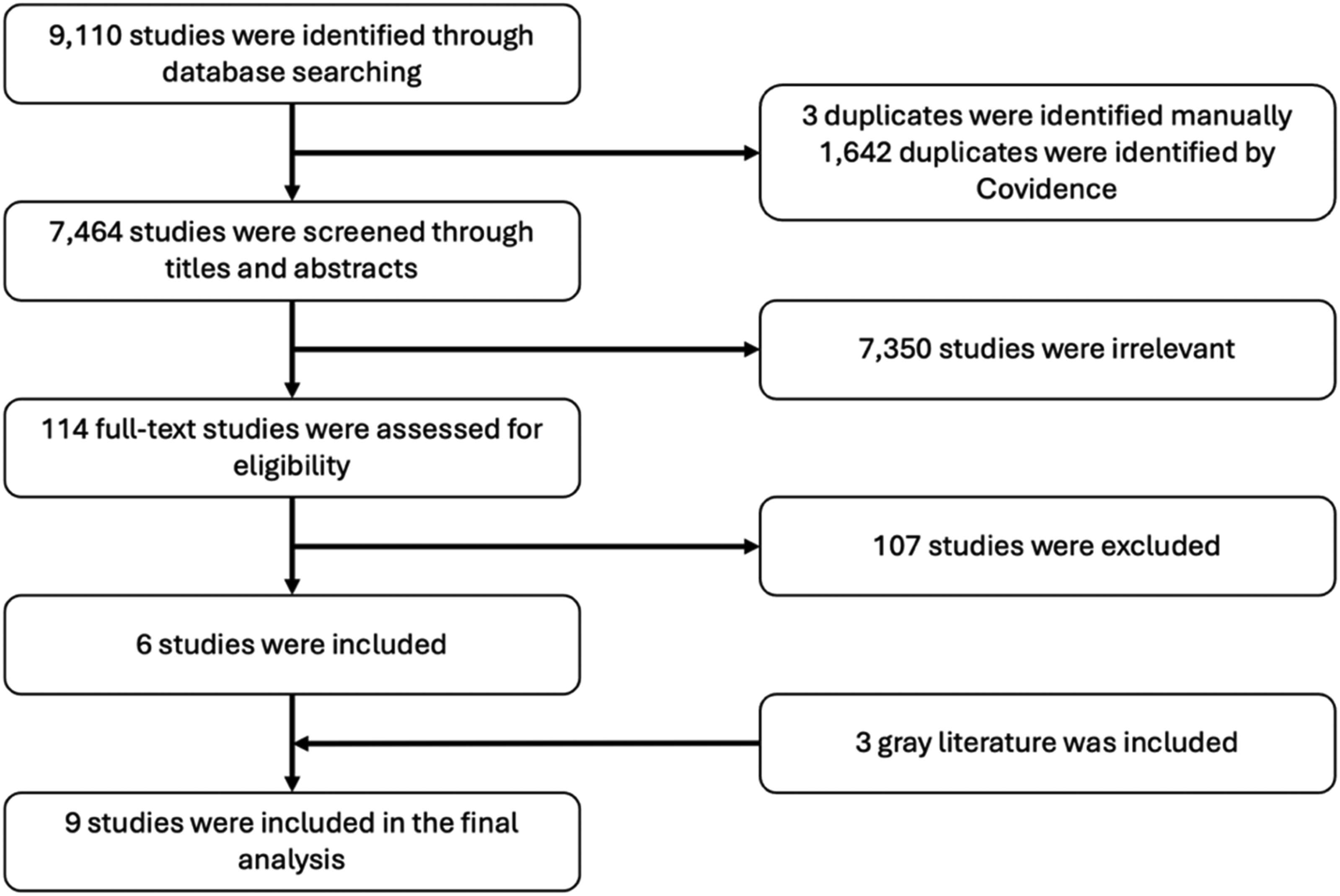
PRISMA flow chart.
The nine eligible articles described algorithmic tool implementations across the globe, with eight in the United States and one in Copenhagen, Denmark (Jørgensen & Nissen, 2022). In the U.S., notable tools include the Allegheny Family Screening Tool (AFST) in Pennsylvania (Chouldechova et al., 2018), Predict-Align-Prevent (PAP) in Richmond, Virginia (Predict-Align-Prevent, 2019), and the Eckerd Rapid Safety Feedback (ERSF) in Washington state (Parker et al., 2022). Other implementations occurred in California (Putnam-Hornstein et al., 2022), Kansas (Moore et al., 2016), New York City (Shroff, 2017), Oregon (Purdy & Glass, 2023), and Wisconsin (Saxena et al., 2021).
Quality Assessment
Quality assessment reviews were conducted for quantitative and qualitative studies, respectively. The three qualitative studies were assessed using the modified Critical Appraisal Skills Programme (CASP) tool (Long et al., 2020), with responses categorized as yes, somewhat, can’t tell, or no. The six quantitative studies were assessed using a modified Critical Review Form for Quantitative Studies (Law et al., 1998), evaluating rigor in study purpose, literature, research design, results, and conclusions and implications. Each question (e.g., Was the sample described in detail?) was rated with yes, no, not addressed, and N/A.
Data Extraction
Data from the final nine studies were organized into a summary table. Table 4 includes authors, data characteristics (source, time frame, unit of analysis), predicted outcome, model type, performance, and analysis methods).
Analysis Framework
Guided by the Consolidated Framework for Implementation Research (CFIR), we examined RQ2: What are the key factors and challenges from development to implementation; and RQ3: how ethical, fairness and equity concerns are embedded within the domains of innovation, inner setting, and implementation processes. Table 3 summarizes the domains that authors selected to answer the research questions of this review. Within the innovation domain, we assessed the design and evidence base behind each tool. In the inner setting domain, we evaluated structural characteristics (e.g., physical, information technology, and work infrastructure), communication processes, resource availability (e.g., funding, space, materials, and equipment), and access to knowledge and information. For the implementation process domain, we focused on needs and context assessment, stakeholder engagement, and mechanisms for reflection and evaluation. Special attention was given to the strategies these studies employed to address ethical, fairness, and equity concerns in the deployment of algorithmic-assisted decision-making tools. Each study will be examined on these aspects with narrative analyses.
Revised CFIR Framework With Ethical Concern(s).

Results
Quality Assessment Results
Qualitative Studies
Jørgensen and Nissen (2022) and Saxena et al. (2021) clearly defined aims, applied suitable methodologies, partnered effectively with CW agencies, and had rigorous data collection and analysis. Ethical considerations varied; Saxena et al. (2021) reported IRB approval explicitly, while Shroff (2017) lacked detail on study design, recruitment, and rigorous analysis. All studies presented clear findings but inconsistently addressed researcher-participant relationships and ethics.
Trustworthiness of qualitative research was evaluated through credibility, transferability, dependability, and confirmability (Padgett, 2017). These criteria serve as alternatives to internal validity, external validity, reliability, and objectivity used in quantitative methods (Padgett, 2017). First, credibility refers to whether research descriptions and interpretations accurately reflect participants’ views (Padgett, 2017). Saxena et al. (2021) strengthened credibility through extensive ethnographic observations before interviews, minimizing researcher influence. Similarly, Shroff (2017) collaborated closely with a CW agency, reflecting on his insider perspective as a data scientist. Data triangulation was employed by Saxena et al. (2021) using multiple data sources. No studies reported conducting member checking.
Second, transferability assesses whether research findings—not the sample—can be generalized to other contexts (Padgett, 2017). Saxena et al. (2021) acknowledged their findings were limited to CW workers’ perspectives, while Jørgensen and Nissen (2022) emphasized the need for research across different contexts. Shroff (2017) did not discuss transferability limitations. However, all three studies provided detailed contextual descriptions, allowing readers to evaluate applicability to their own settings.
Third, dependability (or auditability) addresses whether study procedures are clearly documented and traceable (Padgett, 2017). Saxena et al. (2021) outlined their data collection, analysis, and interpretative approach grounded in postpositivism (deductive, empirical, and theory-based). Jørgensen and Nissen (2022) also explained their analytic process clearly, using Action-Network Theory aligned with social constructivism. Shroff (2017) did not detail the methodological or interpretive framework used.
Fourth, confirmability ensures that research findings directly reflect the data (Padgett, 2017). Assessing confirmability involves transparency about researchers’ biases, positionality, and reflexivity (Cousin, 2010). None of the studies included explicit positionality statements. Jørgensen and Nissen (2022) declared no financial conflicts but omitted positionality details. Saxena et al. (2021) briefly described their ethnographic approach to understanding practice contexts. Shroff (2017) disclosed partial funding but lacked additional reflections on positionality.
Quantitative Studies
The six quantitative generally demonstrated strong methodological rigor, clearly stating objectives, reviewing relevant literature, and describing samples adequately using the modified Critical Review Form for Quantitative Studies (Law et al., 1998). While outcome measures appeared reliable, model validation was inconsistent. Three studies explicitly used train-test splits (Chouldechova et al., 2018; Predict-Align-Prevent, 2022; Putnam-Hornstein et al., 2022). Purdy and Glass (2023) mentioned evaluating group-specific thresholds and Moore et al. (2016) did not report validation procedures. Analytical methods were appropriate, and conclusions were aligned with the results.
Engel and Schutt's (2017) evaluation criteria provided a complementary framework. All studies employed cross-sectional correlation designs, with Parker et al. (2022) uniquely adopting a quasi-experimental design, enhancing internal validity. Two studies presented empirical models but lacked detailed explanations of the selection of confounders (Parker et al., 2022; Purdy & Glass, 2023). Four studies transparently listed predictive features used in their models (Predict-Align-Prevent, 2022; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022). In addition, five studies clearly reported model performance metrics, such as AUC, R-squared, MAE, and RMSE (Chouldechova et al., 2018; Predict-Align-Prevent, 2019; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022).
Finally, the use of predicted outcomes as proxies for child maltreatment risk remains contentious (Hall et al., 2024). Five studies predicted outcomes involving screen-in, substantiation, removal, placement instability, and re-entry in the CW system (Chouldechova et al., 2018; Parker et al., 2022; Purdy & Glass, 2023; Moore et al., 2016; Putnam-Hornstein et al., 2022), while one estimated maltreatment rates at the area level (Predict-Align-Prevent, 2019). These outcomes rely on professional decisions rather than direct measures of risk, potentially amplifying subjectivity and racial disparities—an important critique raised by Hall et al. (20243)—and they clearly presented ethical, fairness, and equity concerns that align with the aims of the present study, except for one (Moore et al., 2016).
Synthesis of Results
Chouldechova et al. (2018) developed and validated a risk prediction model in Allegheny County, Pennsylvania, aiming to improve accuracy and equity in CW screening. The authors addressed predictive analytics challenges such as potential community disadvantage, bias in data, target variable bias, disconnection between the prediction target and the decision, explainability of the model, and intervention effects. They emphasized a fairness-aware approach to integrate prediction models into decision-making processes. The researchers investigated predictive bias in multiple models and highlighted the importance of engaging agency leadership in development.
Jørgensen and Nissen (2022) examined a decision support system (DSS) in Copenhagen to assist social workers in referral urgency decisions. Using Actor-Network Theory, the study identified communication, resource allocation, and integration challenges between human judgment and technology. Although it demonstrated stakeholder dynamics and implementation complexities, the study lacked discussion on ethical considerations and algorithm performance.
Saxena et al. (2021) proposed the Algorithmic Decision-Making Adapted for the Public Sector (ADMAPS) framework applied to CW tools (e.g., the Child and Adolescent Needs and Strengths [CANS] and Anti Sex-Trafficking algorithm [AST]), highlighting tensions between human discretion, bureaucratic systems, and algorithmic tools, affecting professional autonomy and decision quality. The study emphasized trust, training, and process alignment but lacked performance metrics and community perspectives.
Shroff (2017) explored a data scientist's role in designing a CW algorithm for New York City's child services. It identified three implementation success factors: ongoing stakeholder communication, organizational resources and constraints, and ethical judgment frameworks. However, the study did not provide information on model performance or stakeholder perspectives beyond developers.
Moore et al. (2016) evaluated the Every Child a Priority (ECAP) algorithm for foster care placement stability. The tool, named Appropriate Placement Level Indicator (APLI score), generates placement recommendations based on child and resource data, improving placement stability. While strengths included prescriptive recommendations that provide actionable recommendations for caseworkers and the utilization of comprehensive resource data, limitations involved insufficient statistical validation, limited transparency on ethical considerations, and a lack of analyses on the outcomes across demographic groups.
Parker et al. (2022) conducted a quasi-experimental evaluation of the Eckerd Rapid Safety Feedback (ERSF) process, aimed at reducing severe child abuse cases within 12 months of the agency's involvement in an investigation, through real-time quality assurance and staff coaching. Findings indicated no significant reductions in abuse recurrence between the treatment and control group. The study maintained professional judgment alongside the algorithm but lacked evaluations of data quality, fairness, and detailed model performance.
The Predict-Align-Prevent (PAP) framework for preventing child maltreatment is a 3-phase model (2019). The Predict phase uses geospatial ML to identify high-risk areas; Align engages communities in strategic planning; and Prevent evaluates the impact of these efforts using population-level metrics. This model informed community-driven prevention planning and resource allocation, making it distinct from other individually predictive approaches.
Purdy & Glass (2023) introduced a post-processing fairness correction technique addressing algorithmic bias generated by approaches such as PRM regardless of whether unfairness exists in the initial data source. The tool was designed to predict reunification stability and to assist caseworkers in making reunification decisions. This technique applied penalized weights and generated different threshold values for the protected groups, reducing the false positive and false negative error rates among the four subgroups. The results demonstrated the algorithm's strong association with reunification stability but highlighted tradeoffs in fairness adjustments and stakeholder consensus.
Putnam-Hornstein et al. (2022) detailed the development and deployment of a risk stratification model using least absolute shrinkage and selection operator (LASSO) logistic regression for Los Angeles County, supporting case supervision and racial equity in screening decisions. The model provided supervisors with high-risk notifications, investigation summaries, and equity-focused reports on Black children, emphasizing data-informed supervision and consistency in investigations.
CFIR Innovation Domain
Design
The innovation examined in this study—algorithmic-assisted decision-making tools—was assessed regarding their design and packaging, including how they were assembled, bundled, and presented for end users. Figure 2 illustrates the deployment of these tools at different decision-making points within CW services. The Predict-Align-Prevent (2019) model, uniquely within this review, focuses on predicting maltreatment risks at a community level to inform prevention service allocation rather than individual outcomes. Three studies implemented algorithmic tools at the referral screening stage (Chouldechova et al., 2018; Jørgensen & Nissen, 2022; Putnam-Hornstein et al., 2022). Additional studies employed these tools to predict future allegations (Shroff, 2017), substantiation decisions (Parker et al., 2022), placement-related outcomes (Moore et al., 2016; Saxena et al., 2021), and permanency outcomes (Purdy & Glass, 2023). Collectively, these studies highlight the diverse applications of algorithmic tools across multiple decision points, emphasizing the expanding and evolving role of algorithmic-assisted decision-making within CW practice. Second, studies employed various strategies aimed at enhancing the usability of algorithmic tools for agency staff. Chouldechova et al. (2018) translated raw probability estimates of future removals into a simplified 1-to-20 risk scale, making risk levels more accessible to interpret. Similarly, Jørgensen and Nissen (2022) developed a decision-support system incorporating a red-yellow-green visual scheme to indicate varying risk levels, intending to support the accountability of social workers’ assessments. Parker et al. (2022) integrated real-time quality assurance and coaching sessions designed to assist workers in effectively using the tool. Purdy and Glass (2023) concentrated on addressing algorithmic fairness behind the scenes, seeking to foster user trust. Shroff (2017) developed an automated visual dashboard to highlight high-risk cases and notify supervisors. Lastly, Putnam-Hornstein et al. (2022) implemented three tools based on their risk stratification model: notifications for supervisors monitoring high-risk cases, investigation overview reports to potentially ease caseworkers’ workloads, and racial equity reports to examine racial disproportionality—each providing information tailored to different user roles.
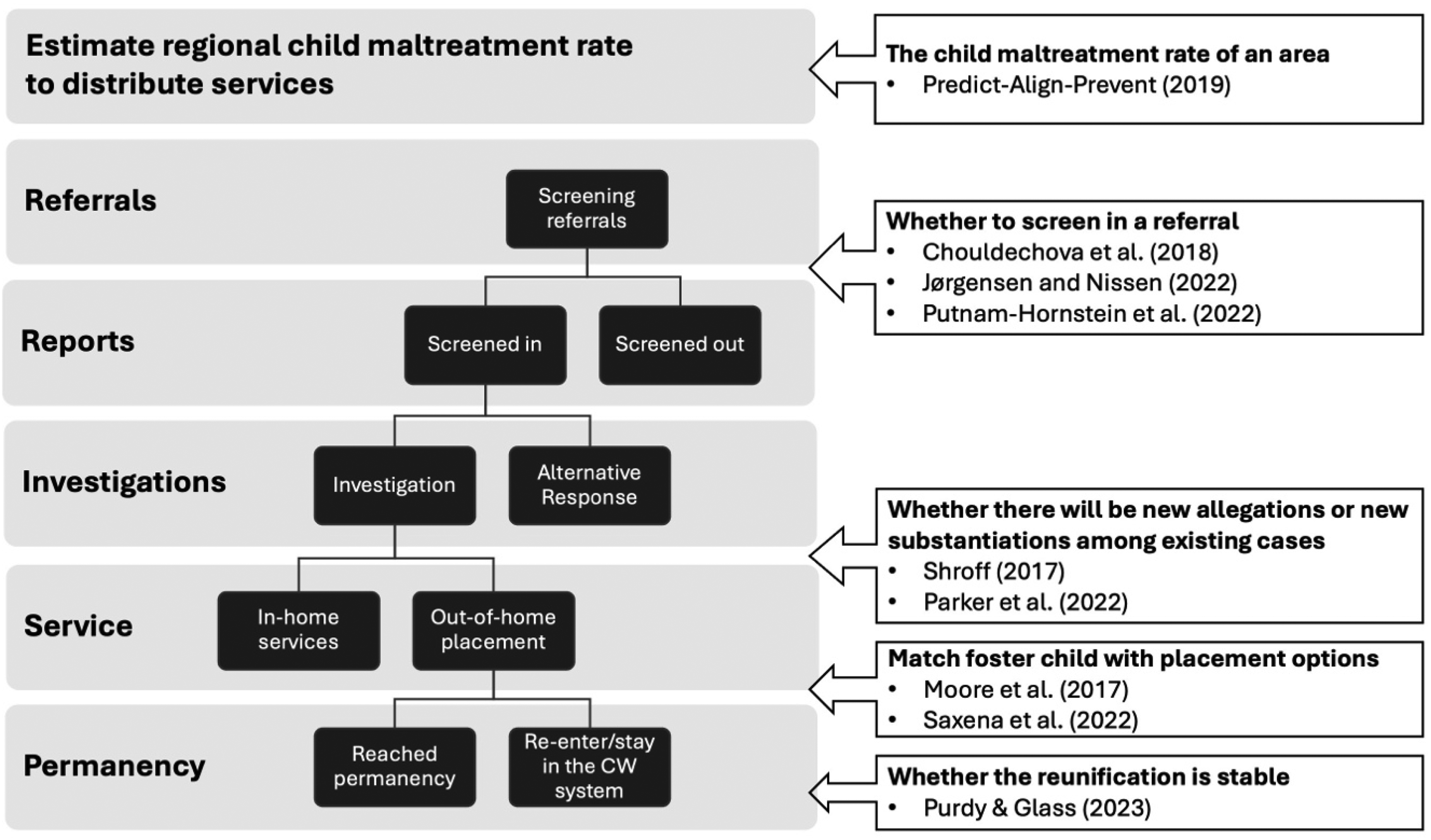
Child welfare decision points flow chart.
Evidence-Base
Evidence-based assessment focused on whether the algorithmic tools demonstrated predictive validity and reliability—that is, whether they produced accurate, useful predictions based on available data and were transparent about their development and performance. Table 4 summarizes additional details such as sample size, unit of analysis, and model performance. Among the studies reviewed, Chouldechova et al. (2018), Predict-Align-Prevent (2019), and Putnam-Hornstein et al. (2022) offered the most comprehensive documentation, including model types and performance metrics such as AUC/ROC values. Four other studies provided partial information by naming the algorithms used: Jørgensen and Nissen (2022) applied natural language processing and neural networks; Purdy and Glass (2023) used a binary classifier, and Shroff (2017) implemented a random forest model. However, two studies—Moore et al. (2016), Parker et al. (2022) and Saxena et al. (2021)—referred generally to using predictive algorithms without specifying the model type or reporting performance metrics, which limited the ability to evaluate their predictive validity.
Summary of Included Articles.

Second, in terms of data sources, six studies relied on existing quantitative CW administrative data (Moore et al., 2016; Parker et al., 2022; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022; Shroff, 2017). Two studies expanded their datasets by incorporating information from other public agencies (Chouldechova et al., 2018; Predict-Align-Prevent, 2019). Notably, Purdy and Glass (2023) and Putnam-Hornstein et al. (2022) provided detailed lists of features used in training their models. The only study to use qualitative data—specifically, open-ended case records—was Jørgensen and Nissen (2022). All studies acknowledged limitations in their data, including issues of incompleteness, variable quality, and the use of non-representative samples. Many recognized that historical administrative records inherently reflect systemic biases (e.g., Chouldechova et al., 2018; Jørgensen & Nissen, 2022). To address these concerns, several studies examined model accuracy across subgroups, particularly by race and gender (Chouldechova et al., 2018; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022), as part of efforts to assess and improve algorithmic fairness.
Third, validation methods varied across the studies. The most common approach was the train/test split, which partitions the dataset into training and testing subsets to prevent overfitting and assess predictive performance. This method was employed by Chouldechova et al. (2018), Predict-Align-Prevent (2019), Putnam-Hornstein et al. (2022), and Shroff (2017). Parker et al. (2022) applied a multi-year quasi-experimental design to compare outcomes between treatment and control groups, although the results showed no statistically significant differences. Purdy & Glass (2023) presented the percentage of false negative—7% of the group labeled as low-risk resulted in a reunification failure. In contrast, three studies—Jørgensen and Nissen (2022), Moore et al. (2016), and Saxena et al. (2021)—did not report any formal validation procedures.
Inner Setting Domain
Structural Characteristics
Structural characteristics, encompassing physical infrastructure, information technology, and organizational support, are key factors for the successful implementation of algorithmic-assisted decision-making tools. First, effective development and deployment benefit significantly from pre-existing integrated data infrastructures and comprehensive management systems that facilitate the use of big data (Chouldechova et al., 2018). In Denmark, the concurrent implementation of policies emphasizing public employee responses to child neglect and the digitization of systems for children and youth were the driving forces of the development of decision-support systems (Jørgensen & Nissen, 2022). However, limited data availability presents considerable challenges; Predict-Align-Prevent (2019) faced model training difficulties due to missing location-of-death data and incomplete prevention program records. Similarly, Putnam-Hornstein et al. (2022) identified significant data gaps due to the inaccessibility of client records across jurisdictions. In addition, Purdy and Glass (2023) acknowledge that the insufficient sample size prevented them from enabling a multidimensional protected attribute to correct algorithmic bias. Addressing these issues, Shroff (2017) stressed the importance of adequate agency budgets, engineering expertise, cloud computing capabilities, and strong leadership commitment to build, deploy, and sustain these tools effectively, particularly in meeting high standards of data privacy and ongoing evaluation.
Communication
Communication refers to quality formal and informal information-sharing practices within and across Inner Setting boundaries. Five studies underscored the critical importance of stakeholder communication throughout the analytic process (Chouldechova et al., 2018; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022; Saxena et al., 2021; Shroff, 2017). Saxena et al. (2021) particularly highlighted that fostering social workers’ trust in these tools enhances agency and community acceptance, thereby reducing concerns about potential unethical or flawed decision-making. To effectively engage primary users, social workers should be involved from the early stages of tool development rather than merely being end-users. Providing social workers with clear, non-technical explanations and ongoing training significantly improves their understanding and practical application of these tools (Saxena et al., 2021). Additionally, the expertise of social workers in child protection is invaluable for ensuring that algorithmic tools effectively address real-world investigative challenges (Jørgensen & Nissen, 2022). Supervisors also have a vital oversight role; for instance, Putnam-Hornstein et al. (2022) demonstrated how daily risk stratification reports facilitated data-informed supervision in child maltreatment investigations. Finally, achieving stakeholder consensus is essential in multiple areas, including data selection (Putnam-Hornstein et al., 2022; Saxena et al., 2021), defining target populations (Putnam-Hornstein et al., 2022; Shroff, 2017), balancing fairness and accuracy (Purdy & Glass, 2023), and selecting models prioritizing interpretability, transparency, and operational feasibility (Chouldechova et al., 2018; Purdy & Glass, 2023).
Available Resources
This aspect assesses whether resources are available to implement and deliver the algorithmic-assisted decision-making tools (e.g., funding, space, materials, and equipment). Available resources are critical to implementation; however, challenges also stem from the organizational and technical environment. The Unified Theory of Acceptance and Use of Technology (UTAUT) suggests that available resources and institutional support and constraints impact technology adoption (Momani, 2020). Moore et al. (2016) pointed out that beyond algorithmic recommendations, placement decisions largely depend on service capacity and resource availability. Similarly, although the CANS algorithm provided recommendations for allocating funds to foster parents and determining foster care levels based on children's mental health needs, these recommendations were rarely fulfilled due to an insufficient number of quality foster homes within the system (Saxena et al., 2021).
Access to Knowledge and Information
The “Access to knowledge and information” aspect refers to the availability of training, resources, and guidance necessary for individuals to effectively implement and use the algorithmic-assisted decision-making tool. Few studies have attempted to address biases at the personal decision-making level, despite their potential impact on the successful implementation of algorithmic tools. Parker et al. (2022) paired algorithm implementation with coaching sessions aimed at enhancing social workers’ decision-making quality and service outcomes; however, their study did not disclose the specific content of these sessions. Additionally, Shroff (2017) expressed concerns regarding users’ ability to correctly interpret complex algorithmic models. Similarly, a process evaluation of the Allegheny Family Screening Tool (AFST) found that only 44% of call screeners in Allegheny County perceived the tool as enhancing their screening practices (Hornby Zeller Associates, Inc., 2018). Collectively, these findings underscore the need for greater acceptance and targeted training designed to (1) deepen social workers’ understanding of algorithmic tools and (2) reduce cognitive biases, including confirmation bias. Furthermore, it is critical to investigate how personal beliefs and biases among social workers affect the adoption and effective utilization of these tools, and to provide continuous support to mitigate biases in their decision-making processes.
Implementation Process Domain
Needs Assessment
Understanding users’ priorities, preferences, and needs is a crucial component of the implementation process. A primary challenge in implementing these tools is the usefulness perceived by users. According to UTAUT, perceived performance and ease of use significantly influence adoption and trust (Momani, 2020). Jørgensen and Nissen (2022) found that referral screeners struggled to differentiate between yellow (medium urgency) and green (low urgency) lights, leading to confusion. The ambiguity of the yellow light prompted social workers to err on the side of caution, unnecessarily escalating cases. Similarly, Saxena et al. (2021) found that the CANS tool failed to meet caseworkers’ needs for demonstrating professional expertise, and in some cases, undermined their professional judgment while increasing case inflow and administrative workload. Additionally, model performance can degrade over time due to shifts in data elements or procedures, resulting in inconsistent outputs and frequent overrides of algorithmic recommendations (Chouldechova et al., 2018; Saxena et al. 2021). On the other hand, decision-making using these tools often involves multiple stakeholders. Reviewing AFST log data, Chouldechova et al. (2018) found that supervisors overrode 25% of the highest-risk cases assigned by the tool but not lower-risk cases, though their reasoning was unclear. Understanding how decision-makers interact with these tools is essential for improving their integration into practice. Therefore, ongoing needs assessments should be integrated into the implementation process.
Context Assessment
Context assessment refers to identifying and appraising the barriers and facilitators to implementation and delivery of the algorithmic-assisted decision-making tools. First, the disconnect between how tools were used and existing administrative procedures created frustration among social workers, especially when organizational constraints hindered their ability to act on the tools' recommendations. (Saxena et al., 2021). For instance, the CANS assessed children’s mental health needs and allocated resources to foster parents; however, social workers lacked training to navigate the tension between limited resources and client needs, reducing the tool’s practical value. Second, discrepancies in expectations between higher-level leadership and frontline decision-makers introduced ambiguity in problem definition and caseworker responsibilities. In Jørgensen and Nissen (2022), a municipality sought to enhance the efficiency and accountability of its child protection system by developing a digitalized decision-support system (DSS). However, findings from the pilot implementation revealed that the tool blurred the lines of responsibility between the DSS and social workers, complicating their respective roles. Understanding these contextual factors is essential for tailoring implementation strategies, promoting buy-in from stakeholders, and ensuring the tools are used effectively in real-world child welfare settings.
Engagement
Engagement refers to whether the implementation process attracts and encourages participation in implementation. Beyond the primary tool users (e.g., staff, caseworkers, screeners, and supervisors in the CW service unit), involving stakeholders such as families, policymakers, agency leaders, specialists, data scientists, service providers, legal experts, and community representatives promote broader acceptance. In developing AFST, Chouldechova et al. (2018) integrated data from multiple departments, excluded bias-prone variables after community consultation and built strong support through ongoing dialogue. Similarly, Shroff (2017), Purdy & glass (2023) and Putnam-Hornstein et al. (2022) emphasized transparency of each decision via continuous communication with data scientists, agency leadership, domain experts, service providers, and involved families. On the other hand, Predict-Align-Prevent (2019) was the only study that predicted regional child maltreatment rates to guide service allocation. In this case, agency leadership and project managers collaborated with community leaders, stakeholders, and local coalitions to align existing prevention efforts with the model's findings. However, three studies did not address stakeholder communication (Jørgensen & Nissen, 2022; Moore et al., 2016; Parker et al., 2022).
Reflection and Evaluation
Implementation teams should collect and reflect on both quantitative and qualitative data to identify what is working and what is not. Most studies in this review demonstrated efforts to reflecting and evaluating algorithmic fairness, equity, and ethics. Three studies explicitly discussed how they integrated these considerations into implementation (Purdy & Glass, 2023; Saxena et al., 2021; Shroff, 2017). Furthermore, independent external ethics reviews were conducted in multiple studies to identify risks such as confirmation bias, stigmatization, increased family surveillance, and discrimination (Chouldechova et al., 2018; Jørgensen & Nissen, 2022; Predict-Align-Prevent, 2019; Putnam-Hornstein et al., 2022). Two studies acknowledged these issues only in their background and literature review (Jørgensen & Nissen, 2022; Parker et al., 2022), while one did not address them (Moore et al., 2016).
Qualitatively, Saxena et al. (2021) highlighted how poorly designed tools might jeopardize fair, equitable, and ethical decision-making. They emphasized the importance of centering social work's core values, such as human dignity, the worth of the person, and human relationships, in the model and allowing space for professional discretion. Shroff (2017) stressed the importance of engaging in conversations about data collection, model selection, and result presentation with key stakeholders. By amplifying the voices of users, stakeholders, and the impacted population, these discussions can support data scientists in developing new and innovative techniques to enhance algorithmic fairness, equity, and ethics.
Three quantitative studies acknowledged that it is possible to underestimate data biases and human biases (Parker et al., 2022; Purdy & Glass, 2023; Putnam-Hornstein et al., 2022). They addressed these issues differently. Putnam-Hornstein et al. (2022) and Purdy and Glass (2023) tackled these issues at different stages of data analytics. Putnam-Hornstein et al. (2022) conducted a racial equity report confirming the model accuracy was comparable across different racial and ethnic groups. In contrast, Purdy and Glass (2023) developed a post-processing technique addressing the bias within the raw data and to adjust risk thresholds according to race-ethnic groups, balancing model transparency and interpretability without sacrificing performance. They trained the model with original data but then revised the risk thresholds provided by the model according to group-level attributes (e.g., race/ethnicity: Black, Hispanic, Pacific Islander, or Asian, Native American, and White), enhancing the transparency of how the authors address these issues. Using a different approach, the Predict-Align-Prevent team (2019) employed place-based predictive analytics trained on aggregate data rather than individual-level data. This approach avoids privacy risks and avoids prediction errors associated with applying population-level models to individual cases, thus offering an alternative, reliable and actionable insights on resource allocation. Collectively, these evaluations highlight the importance of ongoing scrutiny to ensure fairness and minimize potential harm associated with algorithmic decision-making tools.
Discussion and Implication to Practice
This systematic review explored algorithmic-assisted decision-making tools in CW, focusing on three research questions: (1) the purposes of these tools, (2a) key factors supporting successful implementation, (2b) related implementation challenges, and (3) how fairness, equity, and ethical concerns were addressed.
This review employed an integrative approach by combining two complementary frameworks to evaluate algorithmic-assisted decision-making tools in CW. First, ethical frameworks proposed by Russell (2015) and Drake et al. (2020) were used to assess the core ethical dimensions of these tools, including fairness, equity, reliability, validity, and practical usefulness, as well as the importance of community engagement, transparency, and accountability throughout the development and deployment stages. Second, the CFIR was applied to identify key determinants influencing the successful integration of these tools into practice. Specifically, the CFIR guided the examination of characteristics related to the tool itself, the inner setting, and the broader implementation process (e.g., needs and context assessment, stakeholder engagement, and evaluation mechanisms). By leveraging both ethical and implementation lenses, this review offers a more holistic understanding of the promises and challenges surrounding the use of algorithmic tools in frontline decision-making.
A synthesis of nine studies highlights the diverse applications of algorithmic tools in CW, including predictive modeling for maltreatment rates, resource allocation, screening, substantiation, placements, and reunification. Transparency varied across studies; some provided detailed descriptions of model performance, selected features, and validation methods. Nearly all studies examined fairness and bias across subgroups or included ethical reviews. This review shows that fairness can be addressed at multiple stages of model development—through feature selection, model choice, subgroup performance analysis, and threshold adjustments. Nevertheless, these decisions to address fairness and biases should be consensus decisions among stakeholders within and across systems.
Beyond model performance, it is essential to consider the broader organizational context and implementation factors at the agency level. Chor et al. (2022) emphasized that there is no one-size-fits-all predictive risk model; instead, tools should be tailored to integrate meaningfully into casework practice. Drawing on the CFIR framework from implementation science, this review highlights how organizational structures, available resources, and systemic constraints influence the success of implementation efforts. Effective communication within agencies and ongoing training are also critical to improving transparency, clarifying the purpose and goals of the tools, and fostering user engagement. In addition, organizational constraints like limited resources capacity and the introduction of more administrative burden (Moore et al., 2016; Saxena et al., 2021) should be considered while developing the model, otherwise reducing its practical utility. These strategies can enhance algorithm literacy and support social workers in correctly interpreting the output of the model, thus making informed decisions.
Challenges associated with algorithmic-assisted decision-making tools—particularly data-related concerns—emerged as persistent themes across the studies in this review. Common issues included historical bias embedded in administrative records (Chouldechova et al., 2018; Jørgensen & Nissen, 2022), missing or incomplete data (Putnam-Hornstein et al., 2022; Shroff, 2017), and concerns about data privacy. As Gillingham (2021) noted, administrative datasets used to train algorithms often reflect prior decisions and socially constructed categories, embedding human judgment and systemic bias into the tools themselves. While public agencies have long collected data to manage services and ensure accountability, this practice raises particular concerns in social services, where the client base largely consists of marginalized and vulnerable populations.
Although a major advantage of algorithmic tools lies in their use of existing data to reduce redundancy and burden on frontline workers, certain groups are often overrepresented in CW administrative data, particularly along lines of race and socioeconomic status (Glaberson, 2019). Black youth's overrepresentation is across various stages of interaction with CPS, from reporting to investigation to foster care (Cénat et al., 2021). Notably, the disproportionality of children of color is particularly pronounced at the screening stage, marking their entry into the system (Fluke et al., 2003). However, this systemic bias is not unique to algorithmic tools—it also affects traditional decision-making practices. As Drake et al. (2020) argue, there is ethical value in developing and using tools that undergo rigorous evaluation and validation to improve upon existing flawed systems. Therefore, rather than rejecting algorithmic tools outright due to biased data, the focus should be on improving data quality, ensuring transparency, and embedding ethical safeguards throughout the tool development and implementation process.
Importantly, the ethics associated with a predictive model is partly determined by the proposed use of the model. Enhancing casework discretion in these processes is potentially more ethical than replacing caseworker discretion, as factors not quantifiable or not captured in the predictive algorithm could be relevant to case planning at any stage. Further, models that predict place-based estimation of aggregate risk for resource allocation rather than attempt to inform individual case decision-making may be more ethical as well. Extrapolating to individual prediction from population-based models overlooks prediction errors inherent to each individual case, which could result in stigmatizing undeserving families. Place-based population estimates are typically affected only by sampling error and the assumption of parameter constancy (i.e., stability), neither of which puts individual families at risk of a poor decision (Glaberson, 2019).
Ensuring robust validation processes grounded in social work ethics is also essential for tool effectiveness (Drake et al., 2020). Although studies commonly used train-test splits and cross-validation, external validation—such as correlating predicted outcomes with related external measures—was rarely reported (except in Putnam-Hornstein et al., 2022). Additionally, explicitly comparing targeted outcomes before and after tool implementation is vital for assessing impact. Although some studies evaluated tools through fidelity-related data, none clearly adopted intervention or evaluation research designs. Addressing these methodological gaps in future research is crucial for improving the validity, reliability, and practical applicability of algorithmic decision-making tools in CW.
Although resources like the National Associaiton of Social Workers (NASW) Standards for Technology in Social Work Practice (National Association of Social Workers, n.d.) exist, comprehensive and adaptable ethical guidelines for algorithmic-assisted tools remain needed. Building on prior reviews (Hall et al., 2024; Saxena et al., 2020), this review extends understanding by examining real-world implementation utilizing an integrated implementation science framework with ethical concerns, which could serve as an example for future implementations. It emphasizes considerations critical for agencies and practitioners developing and deploying these tools, aligning with increasing demands for fairness, equity, and ethics in algorithmic applications (Lee et al., 2024).
Limitations of the Current Review and Future Directions
This systematic review has several limitations. First, the screening and data extraction processes were primarily conducted by one author and reviewed by another, introducing potential bias. Including additional reviewers in future studies would enhance reliability and rigor. Second, different levels of reporting of the implementation details in some studies limited comparisons and practical recommendations. As the literature grows, future research should conduct meta-analyses to evaluate the effectiveness of these algorithmic tools comprehensively. Third, this review focused on tools already implemented in practice, potentially excluding tools still in development or deployment phases and yet to have released further reports (e.g., Wandalowski & Vaithianathan, 2023), thereby limiting our ability to capture emerging tools. Future research should build upon these findings while addressing key gaps identified in this review. One critical gap is the limited application of theoretical frameworks in analyzing implementation. Only two qualitative studies explicitly utilized theory to interpret their data (Jørgensen & Nissen, 2022; Saxena et al., 2021). Incorporating critical theories—such as transformative, feminist, or postmodern perspectives (Creswell & Poth, 2018)—can enhance understanding of power dynamics among stakeholders. For instance, Jørgensen and Nissen (2022) highlighted the tension between technological solutions and professional discretion, suggesting the need for nuanced tools that accommodate complex practice environments. Moving to the macro level, Redden et al. (2020) utilized the data assemblage as the analytical framework to unpack the political and economic driving forces of the three CW data systems in England. This approach provides a new avenue to investigate the epistemology, political economy, and social context in which CW predictive analytics are embedded (Redden et al., 2020). Additionally, more in-depth qualitative research is needed to examine how caseworkers navigate tensions—such as between child safety and family connectedness—to inform tools that better support decision-making in CW (Ahn et al., 2025).
Additionally, future research should adopt more rigorous designs, using decisions based on caseworker discretion or existing structured tools (e.g., SDM or actuarial instruments) as a standard for comparison. While most existing quantitative studies are observational, Parker et al. (2022) is a notable exception that employed a quasi-experimental design. To strengthen internal validity and draw clearer causal inferences, future studies should consider robust methods such as interrupted time series or difference-in-differences analyses. Randomized controlled trials would be especially valuable to evaluate whether assigning cases to a predictive risk modeling (PRM) track—as compared to a standard track—leads to more effective decision-making (Bärnighausen et al., 2017). Furthermore, studies should explore the comparative value-added of PRM over caseworker discretion, SDM tools, and actuarial instruments in terms of both predictive accuracy and decision quality. Such comparative evaluations would help determine the unique contribution of PRM tools beyond existing practices and clarify their role in enhancing CW decision-making.
Conclusion
This systematic review underscores both the promise and the complexity of implementing algorithmic decision-making tools in CW practice. While these tools have the potential to improve the quality, consistency, and efficiency of decision-making, it is essential to address challenges related to data bias, transparency, and ethical accountability. By applying a holistic framework, this review highlights the importance of considering organizational structures, fostering stakeholder collaboration, providing comprehensive training, upholding ethical standards, and ensuring ongoing evaluation throughout the tool's development and implementation. Child welfare practitioners and agency leadership can draw on both the framework and findings presented here to guide the selection, development, assessment, and deployment of algorithmic tools. Strengthening these areas is critical to ensuring that such technologies truly advance the well-being of the vulnerable children and families they are intended to support.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.