
Abstract
Individualized learning in higher education involves systems that modify instructional sequences to the knowledge and learning behavior of individual students. The conventional fixed curricula do not take into account dynamism of learning over time thus resulting in ineffective development and poor performance. This research presents a framework of the adaptive path generation of learning based on Deep Knowledge Tracing (DKT) and Deep Reinforcement Learning (DQN) to simulate student mastery and provide the best module order. DKT model is an LSTM network that predicts the probability of mastery, based on the learning interactions in sequential form. A DQN agent makes use of these representations and designs the optimization of the learning path as a Markov Decision Process (MDP) in order to select specific modules to maximize the long-term learning gain. Multi-institutional student datasets were used to evaluate the framework based on mastery prediction, convergence, learning gain, engagement, efficiency and generalization measures. Results show the DKT model achieved 87.6% accuracy, AUC-ROC 0.7343, RMSE 0.1569, and stable convergence across 42 epochs. The DQN agent increased cumulative reward from 53.94 to 57.68, reaching 70.01 and converging by episode 742. Adaptive learning paths improved learning gain by 23.59%, reduced learning steps by 36.44%, increased average mastery from 0.68 to 0.84, and enhanced weak concept recovery to 86.5%. Engagement improved, with time spent rising from 45% to 68%, revisit rate from 12% to 32%, and dropout reduced from 18% to 5%. Cross-institution evaluation confirmed strong generalization with consistent learning gain improvements. These findings demonstrate that the framework delivers personalized, scalable learning for tutoring systems and modern education platforms, supporting diverse student populations in higher education settings. The dataset includes approximately 300 students, multiple simulated institutions, and diverse learning modules which were created from more than 9000 interaction sessions.
Introduction
Over the past few years, higher education has undergone tremendous change following the dynamism in the development of digital technologies, online learning systems, and intelligent tutoring systems. 1 The developments have made educational institutions provide flexible and scalable learning opportunities to a large and diversified student population. 2 The learners however vary greatly in terms of their background, cognitive capacity, pace of learning, and mode of engagement. 3 Conventional curriculum designs have a predetermined strictly linear developmental pattern, and the developmental background of different students is assumed to be equal. 4 This fixed method is likely to result in the ineffective learning experience of certain students who may lack the ability to grasp new material that requires knowledge of topics which have already been covered, whereas others are likely to feel bored by reading the same content again. 5 These restrictions lead to a decrease in the level of engagement, frustration, and high rates of dropouts in institutions of higher learning. 6 Adaptive learning systems have also become the solution to these challenges. 7 The systems use student interaction data, performance, and behavioral trends to dynamically modify the instructional content to the needs of individual learners. 8 Adaptive learning systems improve student interaction, learning efficiency, and mastery-oriented progression by offering individualized suggestions. 9 With the growing inclusion of technology-based instruction models into the higher education frameworks, there is a move towards smart adaptive structures that can constantly track the knowledge development of the students and provide them with tailored learning platforms that can maximize academic performance and ultimate outcomes of learning. 10 The static nature of traditional educational programs prevents them from meeting the unique learning requirements of students which leads to inefficient learning results and student disengagement and higher dropout rates. The systems function under the assumption that all learners will progress through the same learning path despite their different backgrounds and learning speed and level of participation. Adaptive learning systems use student behavior data to create personalized learning paths which help them overcome their learning challenges. The integration of Knowledge Tracing with Reinforcement Learning creates a complete system that uses KT to track student knowledge development while RL works to improve module recommendation decision processes. This combination enables educational institutions to create personalized learning paths which use actual performance data to improve student learning results and engagement in contemporary learning environments. 11
Recent developments in AI, especially the use of DL models, have made such modeling of complex student learning behavior and prediction of the progression of knowledge far easier. 12 Knowledge Tracing (KT) is a basic methodology, which estimates the level of student mastery over time through the analysis of sequential learning dynamics, including quiz questions, assignment submissions, and module completions. 13 Classical KT methods, including Bayesian Knowledge Tracing, are based on probabilistic models and in most cases fail to model complex time dependence found in real world learning data. 14 In order to address these shortcomings, DKT was proposed, and LSTM networks were used to better model sequential learning patterns. 15 DKT allows the system to develop temporal association of previous and ongoing learning tasks that would give the correct prognosis of student mastery chances of various knowledge components. 16 This is because it allows the educational systems to have a constantly updated record of the knowledge state of each student. Nevertheless, though DKT is very effective in forecasting mastery levels, it does not directly give instructions on the best next learning activity. 17 Stated differently, DKT is based on a predictive model and not a decision-making system. Consequently, there is an essential gap between the estimation of knowledge and the optimization of instruction, 18 showing that clever decision-making processes are urgently required to help with the use of predictions of the knowledge states to construct the optimal personal learning trajectories. 19
RL, is an effective framework of computation that provides solutions to problems of sequential decision making, thus it is very applicable in adaptive learning. 15 By interacting with the environment and providing feedback in the form of incentives, RL can assist an intelligent agent in learning the optimal choice policies. 20 Going by the adaptive learning, the environment state can be defined as the knowledge state of the student, whereas learning modules are the actions. 21 The RL agent is trained to real-life higher education systems. Assistive technologies enable students with different disabilities to access educational materials because these technologies provide solutions to their unique learning requirements. The innovations create inclusive learning environments because they improve accessibility and student engagement and academic participation of students. Traditional fixed curricula assume that all students learn at the same pace which prevents students from developing personalized knowledge and limits their ability to learn at their own pace. Students tend to lose interest which leads to poor educational results. Recent deep learning-based knowledge tracing approaches have improved mastery prediction; however, they lack decision-making capabilities for optimal content sequencing. The combination of Deep Knowledge Tracing with Deep Reinforcement Learning creates a system that delivers accurate knowledge assessment and personalized learning path development for smart tutoring systems.
Research objectives
The development of an intelligent adaptive learning framework for the creation of personalized learning paths is the main objective of this project. The specific objectives are: (1) Evaluate consecutive student interaction data to learn about the learning behavior and knowledge development. (2) Use Deep Knowledge Tracing (DKT) to selectively forecast mastery by students over time. (3) Reduce the formulation of adaptive module recommendation as a reinforcement learning problem of optimal path selection. (4) Deploy Deep Q-Network (DQN) agent to suggest dynamically learning modules depending on the knowledge state of the students. (5) Determine the effectiveness, influence of engagement, learning performance and overall generalization of the framework over various institutions.
Research contributions
The proposed research is a combination adaptive learning model that offers combination of DKT and DRL to generate personal learning paths. A DKT model that operates using LSTM is aimed at predicting the degree of mastery of students according to the learning sequence, optimization of the learning path is modeled as a MDP and solved with the assistance of a DQN agent. The framework introduces new state representations, which are more mastery-oriented, to supplement the policy reinforcement and policy stability learning performance. The experimental outcomes have shown a great improvement in learning outcome, engagement, and efficiency when compared to non-experimental curricula and control adaptive approaches. Moreover, the model is tested on various institutional datasets and its soundness, scalability and the ability to generalize are evidenced. The suggested solution is an effective and scalable method of intelligent tutoring systems, online learning platforms, and higher education setting.
The remainder of this work is structured as follows. The literature on adaptive learning systems, knowledge tracing, and reinforcement learning in learning environments is covered in Literature Review. The proposed adaptive learning structure and its system architecture are offered in Methodology. Experimental Setup records the dataset, preprocessing steps, and features engineering methods applied to process student interaction data. Methodology describes the proposed methodology that includes Deep Knowledge Tracing model, reinforcement learning environment, state representation, and adaptive learning path generation process. In Result and Discussion, the authors show the results and discussion of the experiment, which includes mastery prediction performance, improvement of learning gains, enhancement of engagement, analysis of efficiency, and the multi-institution generalization. The report concludes in Conclusion and Future work, which also outlines future research directions for improving adaptive learning systems and enabling widespread implementation in the real world.
Literature review
The purpose of adaptive learning systems is to tailor the course material to the individual characteristics, performance, and degree of knowledge of the students. Past adaptive learning methods were based on rule logic and fixed sequence of curriculums, which were not responsive to learner improvements and cognitive status. Adaptive learning has been greatly improved in recent developments in artificial intelligence, knowledge tracing, and reinforcement learning. Recent studies show that assistive technologies now include screen readers and speech recognition and adaptive interfaces for supporting students with disabilities in educational settings. However educational institutions face difficulties establishing scalable systems that provide personalized learning experiences while implementing their programs in various teaching environments.
Adaptive learning systems
Early adaptive learning systems put emphasis on structured curriculum and pre-determined recommendation strategies. Rincon-Flores et al. established that adaptive learning strategies enhance academic performance and student engagement because educational content is customized on the basis of learner progress. On the same note, Contrino et al. created an adaptive learning system, which increased the outcome of student performance and satisfaction both in online and traditional forms of learning, a fact that underscores the power of personalized learning structures. Artificial intelligence has been adopted in recent studies to improve adaptive learning systems. Song et al. presented a dynamic feedback-based learning optimization model, which used machine learning to modify learning trajectories through student interactions. Similarly, Sajja et al. proposed an intelligent assistant, which is an AI-based tool that can provide customized suggestions in tertiary learning institutions. Suryanarayana et al. have also established that the educational management systems based on AI enhance the efficiency of learning, scalability, and sustainability of the learning process based on the automated adaptive learning processes. Ma et al. introduced a recommendation approach based on the personalized learning path that incorporates several algorithms to enhance the learning results. Nevertheless, their model did not provide real-time adaptation and dynamic optimization that is needed in continuing learning settings.
Knowledge tracing models
Knowledge tracing is a very important aspect of adaptive learning systems, which allows predicting the state of knowledge of a learner throughout the learning process. Conventional knowledge tracing methods like BKT offered probabilistic models but could not model sophisticated patterns of learning. Knowledge tracing models based on deep learning have contributed to a high accuracy in estimating student knowledge. A DKT model was proposed by Tong et al. based on neural networks to predict the knowledge of students and their cognitive load, enhancing the recommendations of the learning path. On the same note, Fang et al. came up with an adaptive knowledge tracing model to simulate student learning activity with behavioral interaction data. Fu et al. combined reinforcement learning and dynamic knowledge tracing to maximize individualized learning directions. Their model showed better efficiency of learning, but did not have strong state representation and generalization across institutions. Despite its ability to enhance the estimation of student knowledge, these models will have issues with the state representation, scalability, and flexibility in a dynamic learning context.
Reinforcement learning in adaptive learning
Adaptive learning path optimization via RL has proven to be effective due to its capability to perform sequential decision making based on student performance. A dynamic programming algorithm was proposed by Lou et al., which employed cognitive graphs to produce dynamic Learning Paths; however, Lou et al.’s model did not use deep knowledge tracing in order to estimate an accurate student state. Another model was documented by Lin et al., employing a hierarchical reinforcement learning model using knowledge tracing to recommend Learning Paths that meet multiple objectives; meanwhile, Lin et al.’s model continued to exhibit issues of scalability when applied to very large Educational Systems. Pögelt et al. used reinforcement learning to suggest Mathematical Problems based on intended learning outcomes. The use of reinforcement learn RL for Learning Path Optimization by Fu et al. further validated the successful use of RL for dynamically adapting content sequences based upon current student performance; however, continued to experience unresolved challenges with training stability, generalization and real-time adaptation.
Multi-institution adaptive learning and evaluation
Recent studies have stressed the assessment of adaptive learning systems for different types of educational settings to ensure their robustness and ability to scale across many different submissions. The authors, Suryanarayana et al. make an argument about the significance of AI-powered education management systems in large-scale learning environments. In addition, both authors, Song et al. and Contrino et al. show significant improvements in student performance and engagement from adaptive learning systems across multiple learning environments; however, these were only single-institution datasets that don’t provide enough evidence for generalizability. Fu et al. and Lin et al. have been working on optimizing learning pathways using reinforcement learning and knowledge tracing but do not provide sufficient evaluation of their models from many different institutions and types of learning contexts.
Research gap
Although adaptive learning systems have made tremendous advancements, there are still a number of key limitations: (1) Most of the existing adaptive learning models lack a detailed state of student knowledge, especially the temporal learning behavior, interaction of behaviors, and cognitive development which lessens the precision of learning direction suggestions. (2) The majority of the existing systems employ either the knowledge tracing method or the reinforcement learning method separately, but not both in one tool of precise student modeling and the best decision-making. (3) A number of adaptive learning models have been tested on small or single-source datasets which limits their capability to be effective in generalization across a variety of educational resources and large-scale learning platforms. (4) Numerous currently used adaptive systems are based on fixed or semi-adaptive recommendation policies and do not have full autonomous schemes to constantly revise learning trajectories basing on instantaneous student performance. (5) The vast majority of adaptive learning frameworks are experimented in a controlled or single-institution environment which restricts their strength, scalability, and generalizability in real-world, multi-institutional educational scenarios.
The limitations of the current adaptive learning systems are prevented with the proposed model, which adds a single framework that combines Deep Knowledge Tracing and Reinforcement Learning to obtain precise student modeling and dynamic learning path optimization. Deep Knowledge Tracing component provides learning pattern over time and generates accurate representations of the knowledge state, which improves insight into the mastery of students. The Reinforcement Learning agent utilizes these states of knowledge to continually propose the best learning modules, with regard to real-time performance, to ensure completely adaptive and personalized learning trajectories. The model is also tested using a variety of institutional datasets to determine strength, scale, and generalization in a variety of learning settings. All of these factors work together to make this integrated method more effective in learning and more accurate in providing recommendations. It also provides a scalable solution that can be applied to intelligent tutoring systems in higher education and the real world. The proposed framework directly solves these identified gaps through its implementation of DKT model, which accurately estimates temporal mastery, and DQN agent, which uses the estimates to improve its learning path selection. The system uses knowledge modeling to create a smooth transition process that leads to adaptive recommendation.
Methodology
The primary objective of the study is to provide a framework for constructing adaptive learning paths for college students by combining KT and RL to support individualized learning procedures that maximize efficiency, engagement, and mastery. First, the data of student learning interaction is obtained based on a large-scale educational dataset of module attempt, quiz results, time and session counts. The raw data are preprocessed, such as missing value management, normalization and sequence generation to generate learning trajectories in a temporal order. In order to convert raw performance metrics into mastery indicators, feature engineering maps modules to concepts, aggregates interaction statistics, smooths the learning trends, and converts raw performance metrics into mastery indicators. The predicted sequences are inputted into a DKT model to approximate the student mastery probabilities within modules, reflecting as the tight state vectors to be represented as state vectors by the RL agent. To simulate the adaptive learning setting, a DQN is used to model the Markov Decision Process, where the agent chooses the next module based on the level of knowledge of a student, and rewards are determined by the learning gained, the improvement of the mastery, and the variety of exercises. The study uses technology as its main method to create assistive solutions which help disabled students learn more effectively. The methodology uses adaptive systems together with user-centered design principles to create solutions which can be used by all people. The framework is additionally tested in a multi-institutional simulation to test generalization and its functionality is measured in terms of KT accuracy, learning gain, engagement, RL reward, as well as cross-domain adaptability. The general design of the suggested adaptive learning path generation system that will combine Deep Knowledge Tracing and Deep Reinforcement Learning to individualize the recommendations of modules to follow and to evaluate in a multi-institution setup is presented in Figure 1. The proposed adaptive learning framework’s overall block diagram.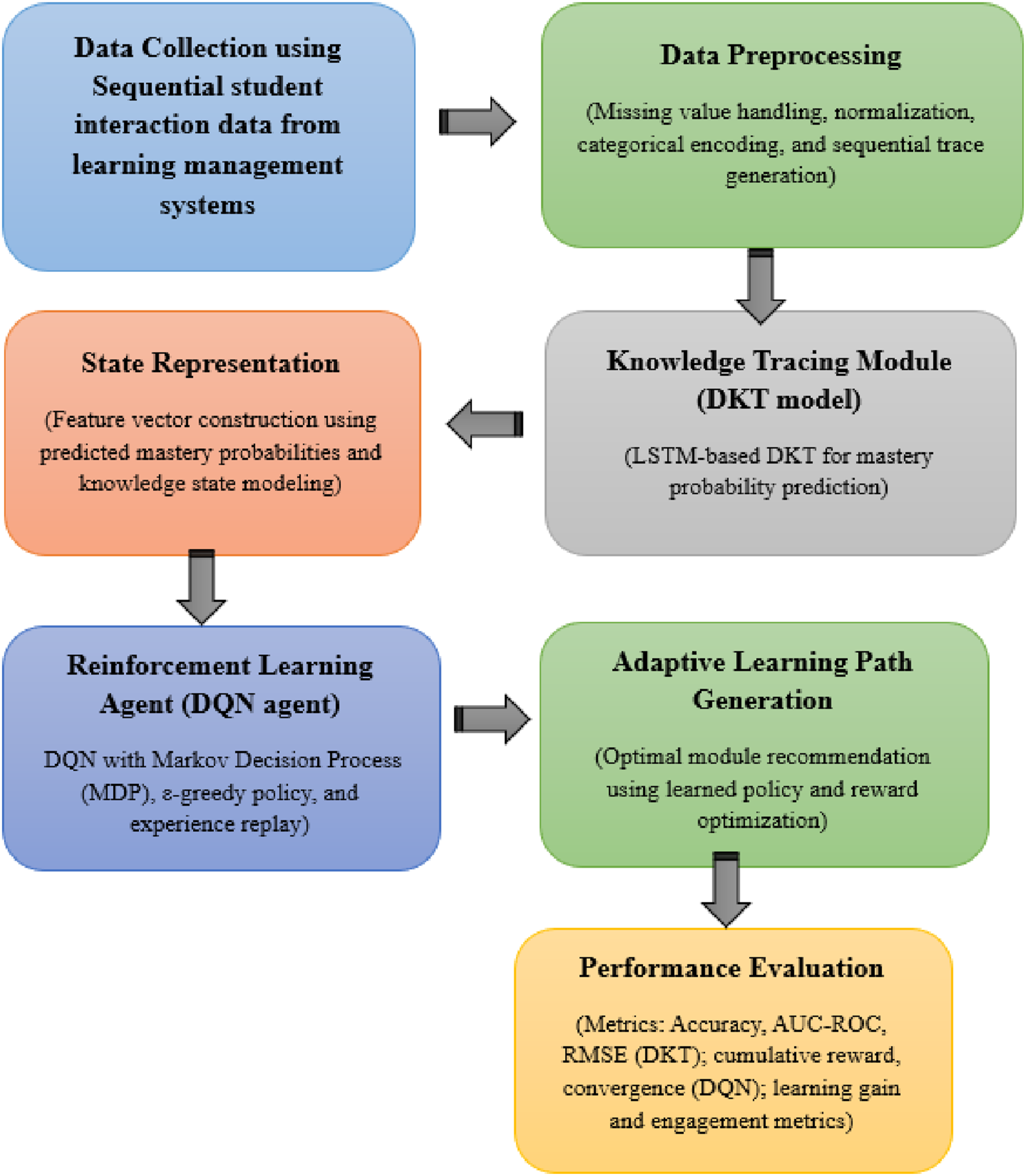
Feature engineering
In order to convert unstructured student interaction data into meaningful representations appropriate for KT and RL models, feature engineering is essential. The objective of this stage is to extract informative features that accurately reflect student learning behavior, conceptual understanding, engagement level, and mastery progression over time. Since KT models require sequential learning inputs and RL models require structured state representations, feature engineering ensures that student interactions are represented as continuous, interpretable, and temporally consistent feature vectors. The Exponential Moving Average (EMA) method is used to smooth student interaction data because it helps to stabilize their temporal behavioral patterns by decreasing their short-term measurement fluctuations and their measurement noise. The EMA method gives more importance to current data while preserving the effect of earlier data which allows it to show how student learning patterns develop over time. This situation becomes critical because educational settings that use sequential learning methods experience sudden performance changes which do not show actual learning patterns. The EMA method produces stable feature values through its smoothing process which improves the quality of input data used in the knowledge tracing model and enhances the precision of subsequent reinforcement learning outcomes.
Module-to-concept mapping
The learning modules are linked to one or several underlying concepts which depict certain knowledge elements. This mapping also allows the system to follow conceptual level mastery and not just at module level, which increases generalization and interpretability. Let the set of concepts be defined as Equation (1),
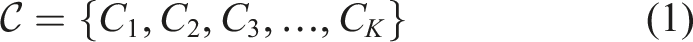
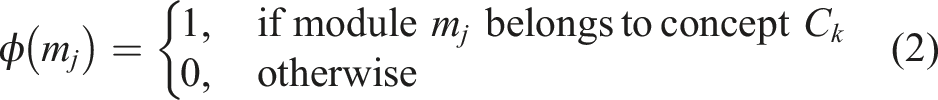
The Knowledge Tracing model can determine the likelihood of mastery at the concept level by mapping, which can be used to give more accurate adaptive learning advice. Concept-based tracking also enables the Reinforcement Learning agent to specify modules that can fill special gaps in knowledge.
Feature aggregation across learning sessions
Students have the ability to engage in several sessions with the same module, thus feature aggregation is conducted to generalize learning behavior and minimize noise due to individual session variability. Aggregated feature values are calculated as the mean interaction feature values of all sessions that a student
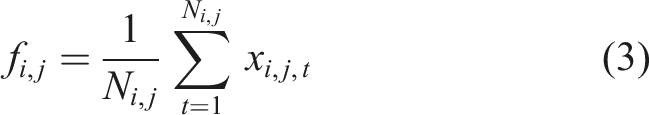
Mean quiz score, mean assignment score, mean time spent, mean attention score and mean attempts completed are aggregated to show the overall student learning performance. This averaging is highly useful in limiting the impact of short-term variations, and gives a consistent, dependable overview of student behavior. Such aggregated indicators, in turn, assist the Knowledge Tracing and Reinforcement Learning models in gaining a better insight into long-term learning dynamics and predicting mastery more accurately and make adaptive learning directions more likely to succeed.
Learning trend smoothing using exponential moving average (EMA)
The student learning process tends to have peaks and lows because of short-term changes in engagement or performance. To ensure that the underlying learning trend is captured and reduce noise, EMA smoothing is used in features involving performance. The EMA is defined as Equation (4),
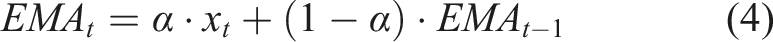
Mastery indicator conversion
In order to quantitatively encode student learning performance information, the raw performance scores are transformed into continuous mastery indicators with a range of 0 to 1. This makes it interpretable probabilistically and compatible with neural network models. The mastery indicator is defined as Equation (5),


Engagement feature construction
Student engagement plays a significant role in learning outcomes. Therefore, engagement-related features are combined to create composite engagement indicators. The engagement score is defined as Equation (7),
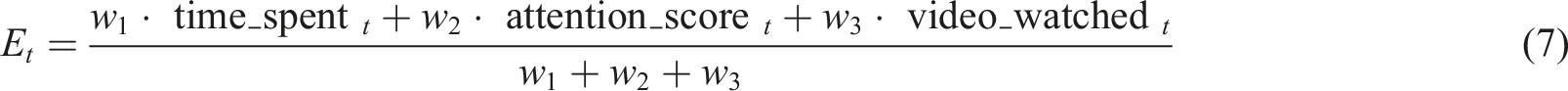
Feature vector construction
After feature extraction and transformation, each student interaction is represented as a feature vector Equation (8),
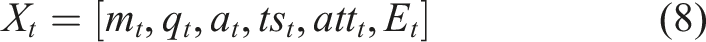
These designed feature vectors offer a well-structured and holistic representation of student state of knowledge, performance, progression and behavioral pattern. They are fed into the Knowledge Tracing model to get precise estimation of mastery and to the Reinforcement Learning agent to minimize adaptive optimization of the learning path. This feature engineering procedure enhances the general precision, stability and readability of the adaptive learning model, which allows making learning suggestions more meaningful and individual.
Knowledge tracing (KT)
To appropriately model student development of learning and dynamically forecast mastery levels, the present study will apply the DKT framework, which is offered on a LSTM neural network. Knowledge Tracing is sequential prediction task that predicts how the student knowledge state changes with time given access to the historical sequences of interaction. As opposed to the conventional models like BKT, which make the assumption of independent knowledge components and fixed transition probabilities, DKT uses deep neural networks to bring complex, nonlinear, and long-term causes and effects in learning behavior. The LSTM architecture is also an appropriate choice due to the presence of an internal memory state that can be used to memorize previous learning activities that will enable the model to make accurate estimates of mastery progression between modules. The ability is necessary in adaptive learning systems as it gives the system a consistent depiction of what the student has learned which can be used by the reinforcement learning agent to create individualized learning paths. The LSTM-based knowledge tracing model receives input through an embedding layer which transforms categorical module identifiers into dense vector representations. The system encodes module IDs through index encoding which subsequently links to a continuous embedding vector of low-dimensionality. The embedding establishes hidden connections between learning modules which enable the model to apply its knowledge to related concepts. The embedding vectors are learned jointly during model training, allowing the representation to adapt based on student interaction patterns. The method eliminates one-hot encoding sparsity problems while it enhances the capacity to model sequential knowledge through greater efficiency and expressiveness.
At each time step
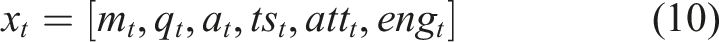

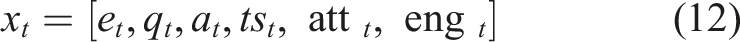
For each student
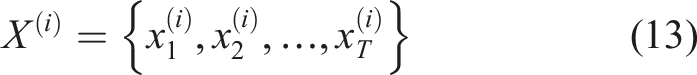
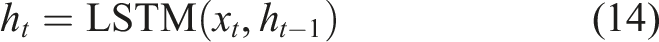
The forget gate can decide on whether the information that comes out of the last cell state is to be retained or discarded. This mechanism allows the model to remove outdated or irrelevant knowledge and preserve useful learning patterns. The forget gate is mathematically represented in Equation (15):
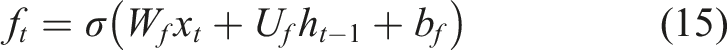
The input gate regulates the amount of fresh data that should be added to the cell state from the current input. By evaluating the significance of recently observed student learning characteristics, it controls the updating process. The input gate is defined in Equation (16):
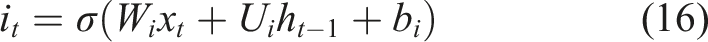
The weight matrices related to the hidden state are represented by
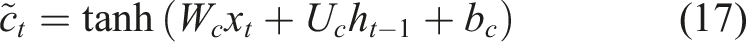
The new candidate memory and the previously held memory are combined to update the cell state. The input gate decides what should be added, and the forget gate decides what should be kept. This update mechanism is defined in Equation (18):
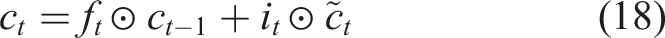
The output gate controls the amount of information that should be revealed to the hidden state from the updated cell state. As a result, in the current time step, the model may generate a suitable knowledge representation. Equation (19) defines the output gate:
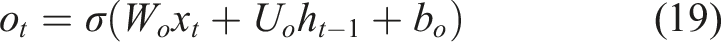

Such gating processes allow the model to store relevant knowledge, drop obsolete information, and store long-term learning dependencies, and makes student knowledge representation more accurate and adaptive learning path recommendation more effective. The hidden state

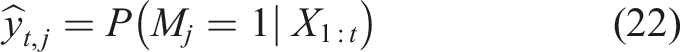
Based on these predictions, the student knowledge state is represented as a knowledge state vector defined as equation (23), DKT architecture for Student Mastery Prediction.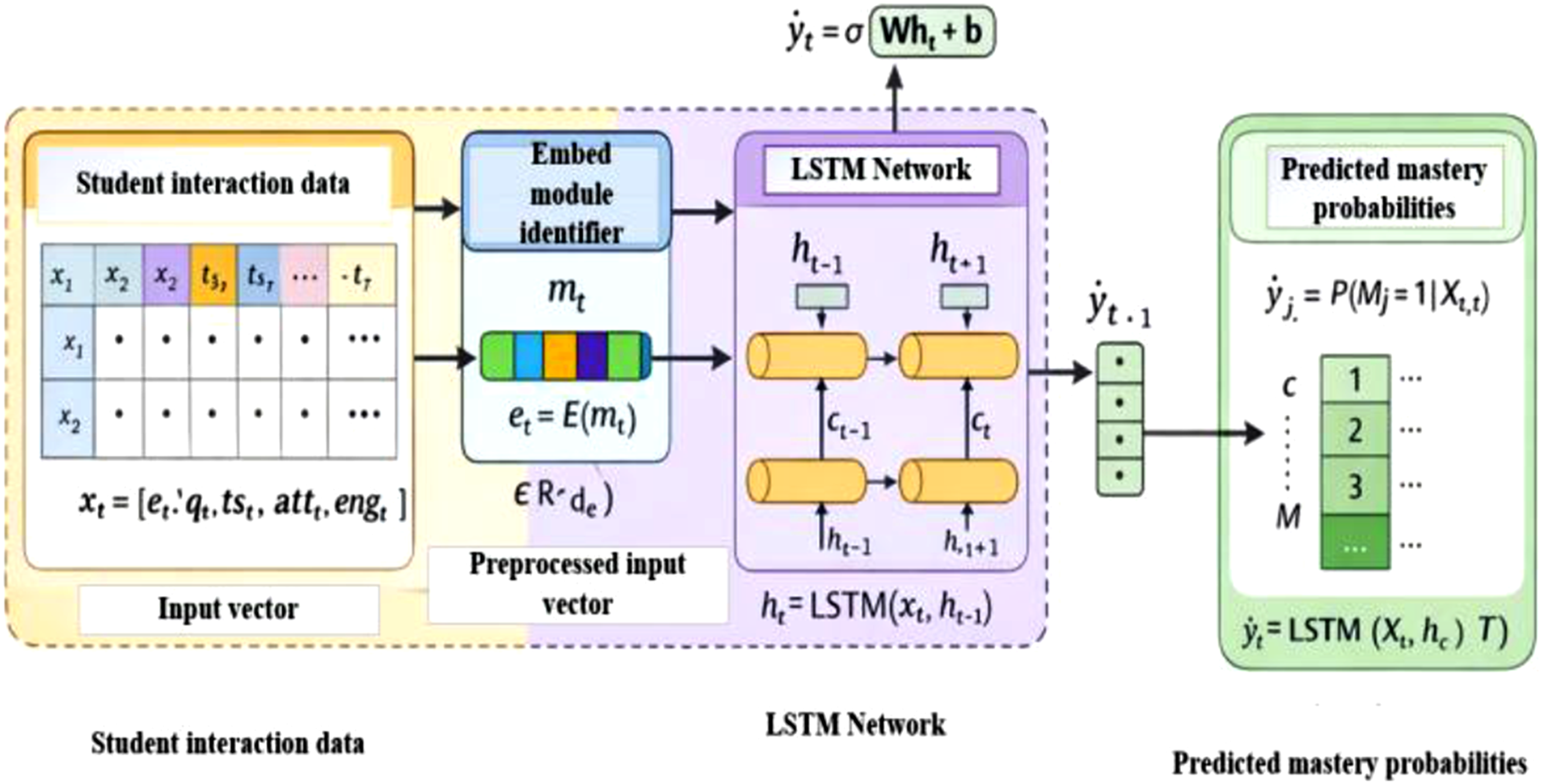
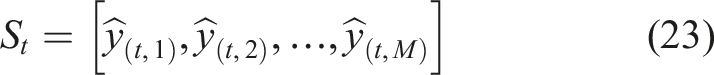
The LSTM model uses a hidden state size that enables optimal performance through its advanced ability to learn and its capacity to generalize. The study needs a moderate hidden dimension to capture complex temporal dependencies between student learning sequences while maintaining research efficiency and computational effectiveness. The embedding dimensionality is designed to transform sparse interaction inputs into dense representations, enabling the model to effectively learn relationships between learning activities. The system captures short-term performance signals and long-term knowledge progression through its design, which creates a reliable student learning behavior representation that enables accurate mastery prediction.
There are a number of properties of knowledge state vectors. The first one is its dimension, which is
The DKT model is used to forecast the likelihood of the student passing through the next learning unit on the basis of the present level of knowledge. This is a prediction that is referred to as equation (24),
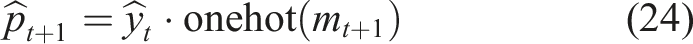
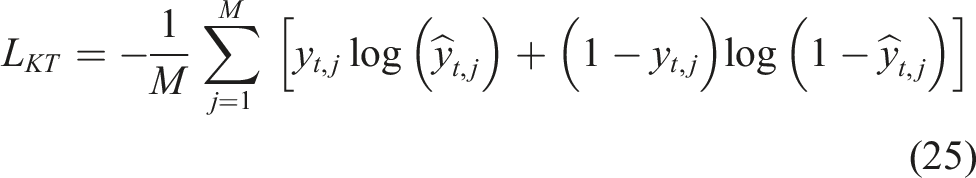
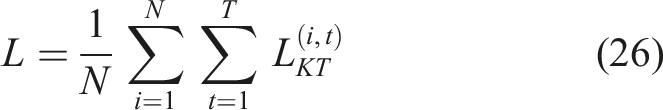
The Adam optimizer, which effectively updates parameters using gradient-based optimization and adaptive learning rates, is used to optimize the model’s parameters. The parameter update rule is defined as equation (27),

To achieve a stable convergence and effective learning of the DKT model, the model was trained with hyperparameters that were carefully chosen. Learning rate (
The DKT model training procedure entails sequential learning of student interaction information. First, the input sequence
The DKT model produces a sequence of knowledge state vectors of the learning of the student over time after training. This is defined as equation (28),
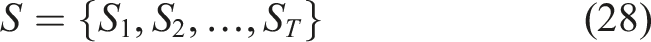
Here,
The final output of the trained DKT model is a mastery matrix defined as equation (29),

Each element of the matrix is defined as equation (30),
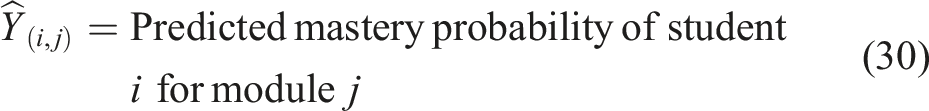
The LSTM-based DKT model uses temporal student interaction data to train its system. The network receives learning sequences from each student in a chronological manner which processes input xt at time step t and previous hidden state ht−1 to create an updated state ht. The system tracks Knowledge development through different time periods. The model produces mastery probability outputs
The mastery measurement that the DKT model yields is pivotal in the adaptive learning path development since it provides a profound explanation of student proficiency in all the modules. This is a vector that allows identifying weak and strong modules, after which the system can suggest individualized learning material depending on the needs of particular students. It also facilitates optimization of learning paths whereby it helps in selecting relevant modules and facilitating the adaptive adjustment of difficulty based on the capability of the student. Moreover, the mastery vector is used to represent the state of the RL agent, and this is intelligent in making decisions to reach a sequence of modules to recommend. DKT has a number of benefits compared to the traditional knowledge modeling methods, such as superior prediction accuracy, ability to model nonlinear and temporal learning behavior, better personalization, and lifelong mastery estimation. Also, the model is very scalable and can be deployed to massive educational data. The knowledge state vector S t, the mastery possibility matrix Y ˆ, and the chronological learning description of student activities are the ultimate outcomes of the knowledge tracing phase. These outputs are a holistic and dynamic account of the progress of student learning and are fundamental contributions to the Reinforcement Learning agent of adaptive learning path optimization. Student Mastery Prediction DKT procedure is represented in algorithm 1.

The Deep Knowledge Tracing (DKT) model operates by representing student knowledge as a continuous changing hidden state which develops over time. The LSTM stores a hidden state
State representation
The knowledge state vector undergoes PCA dimensionality reduction because its high dimensionality needs to be solved through this method which also achieves better computational performance. The process eliminates duplicate content from the learning patterns yet vital patterns needed for learning remain intact, which leads to faster learning progress and steadier results from the reinforcement learning agent. The trained DKT model outputs a mastery prediction matrix
Initial knowledge state representation
At each time step
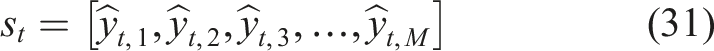
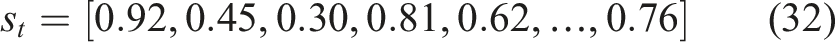
The value of 0.92 is strong mastery in module 1, the value of 0.45 is moderate mastery in module 2, the value of 0.30 is weak mastery in module 3, and the value of 0.76 is good mastery in the final module This vector is a comprehensive and quantitative description of the learning status of the student in all the modules. When applied in real world adaptive learning systems, M may be very large, which leads to a high dimensional knowledge state vector. With such high dimensionality, computing complexity is escalated, and convergence rate of reinforcement learning is decreased, as well as there is a risk of overfitting. It also decreases the efficiency of the RL agent in learning and raises memory demands. In an attempt to overcome these difficulties, dimensionality reduction is utilized to reduce the knowledge state vector to a reduced dimensional representation without any loss of vital student knowledge information, which yields better training efficiency, scalability, and system performance in general.
Final state representation using PCA
In this study, PCA is used to project the state of high-dimensional knowledge using a lower-dimensional representation. The transformed state vector becomes as shown in equation (33),


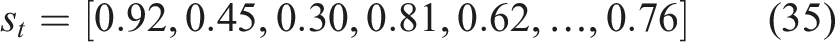
Reduced state vector:
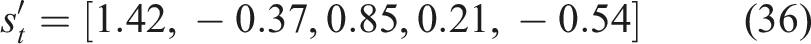
The transformed features represent the latent knowledge elements, such as the learning proficiency, understanding of concepts, consistency, retention ability, and focus of learning weaknesses.
The agent of reinforcement learning uses the final reduced state s
The proposed state representation has shown a solitary and precise modeling of student knowledge because it models mastery probabilities of learning modules. PCA dimensionality reduces learning patterns without losing important patterns, whereas enhancing computing efficiency and convergence of reinforcement learning. This organized form will allow the RL agent to produce high-quality personalized recommendations based on the strengths and weaknesses of the students. The scalable structure can also be used to support large populations of students, modules, and interactions, which means that the framework can be used with real-world adaptive learning systems and large-scale educational systems.
The final state used by the RL agent is defined as equation (37),
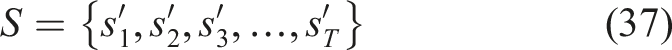
Reinforcement learning (RL) environment
The recommendation process is also developed to be optimal in an adaptive and personalized way with an underlying MDP formulation. The MDP framework has a mathematical basis to model sequential decision-making, where a smart agent engages the learning system and the choice of the best learning modules by the student depending on the current state of knowledge development. By suggesting the best module at each stage, the RL agent aims to maximize cumulative learning improvement. The tuple (
State definition
The state represents the student’s current knowledge level across all modules. At time step
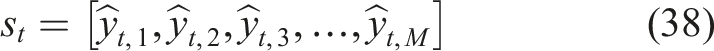
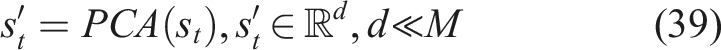
The RL agent uses this state representation as input for decision-making, capturing the student’s learning progress.
Action space
The action represents the selection of the next learning module to recommend. At each time step
State transition
After the agent selects an action
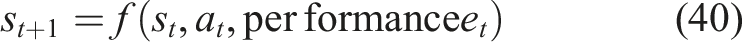
This transition reflects how student knowledge evolves after completing the recommended module.
Reward function
Repetitive or ineffective recommendations are discouraged by the reward function, which is intended to promote meaningful learning progress. The reward at time step
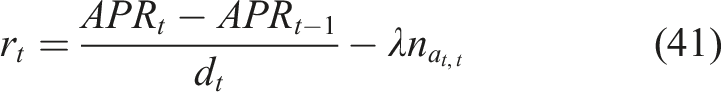
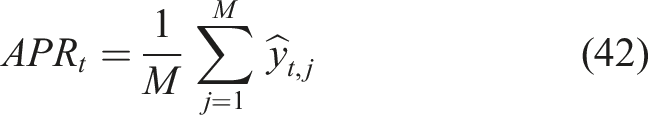

Episode definition
An episode represents one complete learning session for a student equation (44),
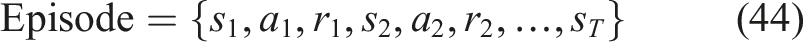
Policy function
The RL agent adheres to a policy,
Exploration and exploitation strategy
In RL, balancing exploration and exploitation is essential for optimal adaptive learning path generation. While exploitation concentrates on choosing modules that have historically yielded significant learning gains, exploration enables the agent to suggest novel or infrequently chosen modules to determine their potential impact on enhancing student understanding. The suggested framework employs an epsilon-greedy approach in which the agent investigates alternative modules with probability ϵ and chooses the most well-known module with probability (1-ϵ). In the course of training, the rate of exploration decreases gradually and the agent approaches an optimal policy that is the most effective at learning, and makes individualized suggestions on the modules.
The RL environment aims at learning an optimal recommendation policy that enhances mastery by students and reduces the learning time. The RL agent chooses suitable modules depending on the knowledge level of the student and prevents the duplication of the advice by the reward and penalties system. The system creates individual learning paths through the adjustment of personal learning behavior and history of progression. This guarantees effective learning of knowledge, quicker mastery of knowledge and maximum educational development according to the needs of the students. The RL environment generates the best module suggestions to each student based on their level of knowledge and learning advancement. It creates individualized adaptive learning pathways which enhance mastery levels and reduce redundancy and inefficiencies. As a result of constant communication and feedback of rewards, the system determines the most efficient order of modules. These outputs facilitate intelligent and data-driven learning paths to improve the learning efficiency and promote personalized learning.
RL algorithm: Deep Q-Network (DQN)
The study uses the DQN algorithm, a value-based RL technique that blends Q-learning with deep neural networks, to optimize adaptive learning path construction. The DQN agent’s goal is to discover an ideal policy that, given each student’s present knowledge state, chooses the best learning module for them. DQN can handle high-dimensional state spaces like mastery vectors obtained from the Knowledge Tracing model because it approximates the action-value function using a neural network, in contrast to standard Q-learning, which employs tabular representations. The Q-function, which calculates the expected cumulative reward of acting
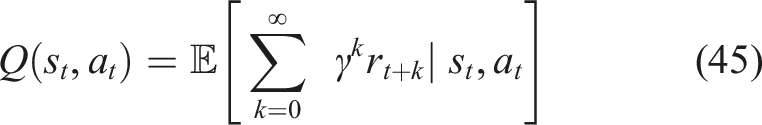
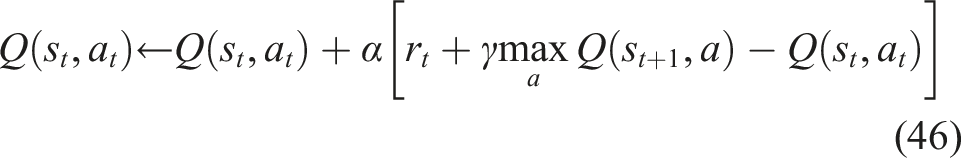
The MSE Eqn. is the loss function that is utilized to train the neural network equation (47).
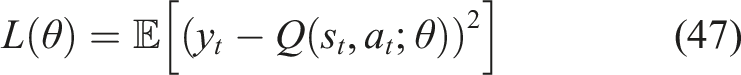
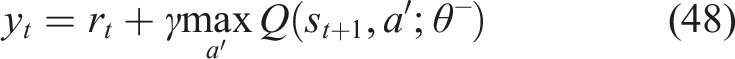
The RL agent can predict the expected cumulative reward associated with recommending each learning module thanks to the DQN’s use of a fully connected feed-forward neural network to approximate the action-value function. The representation of the student’s knowledge state is mapped by this neural network to matching Q-values for every action that could be taken.
The input to the neural network is the student knowledge state vector obtained from the Knowledge Tracing model, represented as
The hidden layers consist of fully connected dense layers that transform the input knowledge state vector into higher-level feature representations. The hidden layer operation is defined as equation (49),
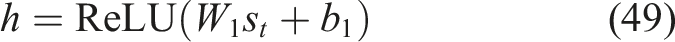
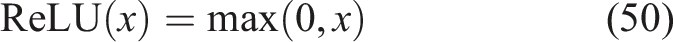
The ReLU activation introduces nonlinearity, allowing the network to learn complex patterns and interactions between student knowledge components and module effectiveness. Additional hidden layers may be used to improve representation learning and enhance model performance.
The output layer produces the Q-values corresponding to all possible learning module recommendations. It is defined as equation (51),
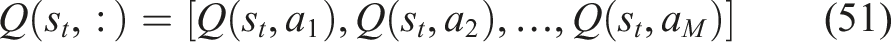
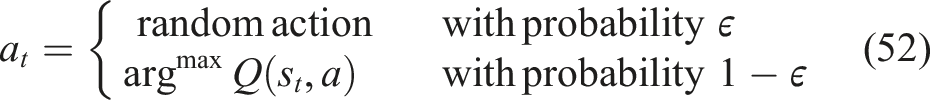
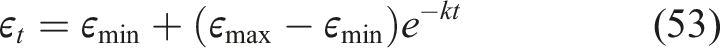
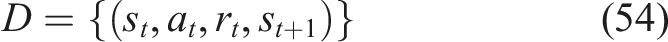
Instead of learning from consecutive samples, the agent randomly samples mini-batches, DQN architecture for adaptive path generation.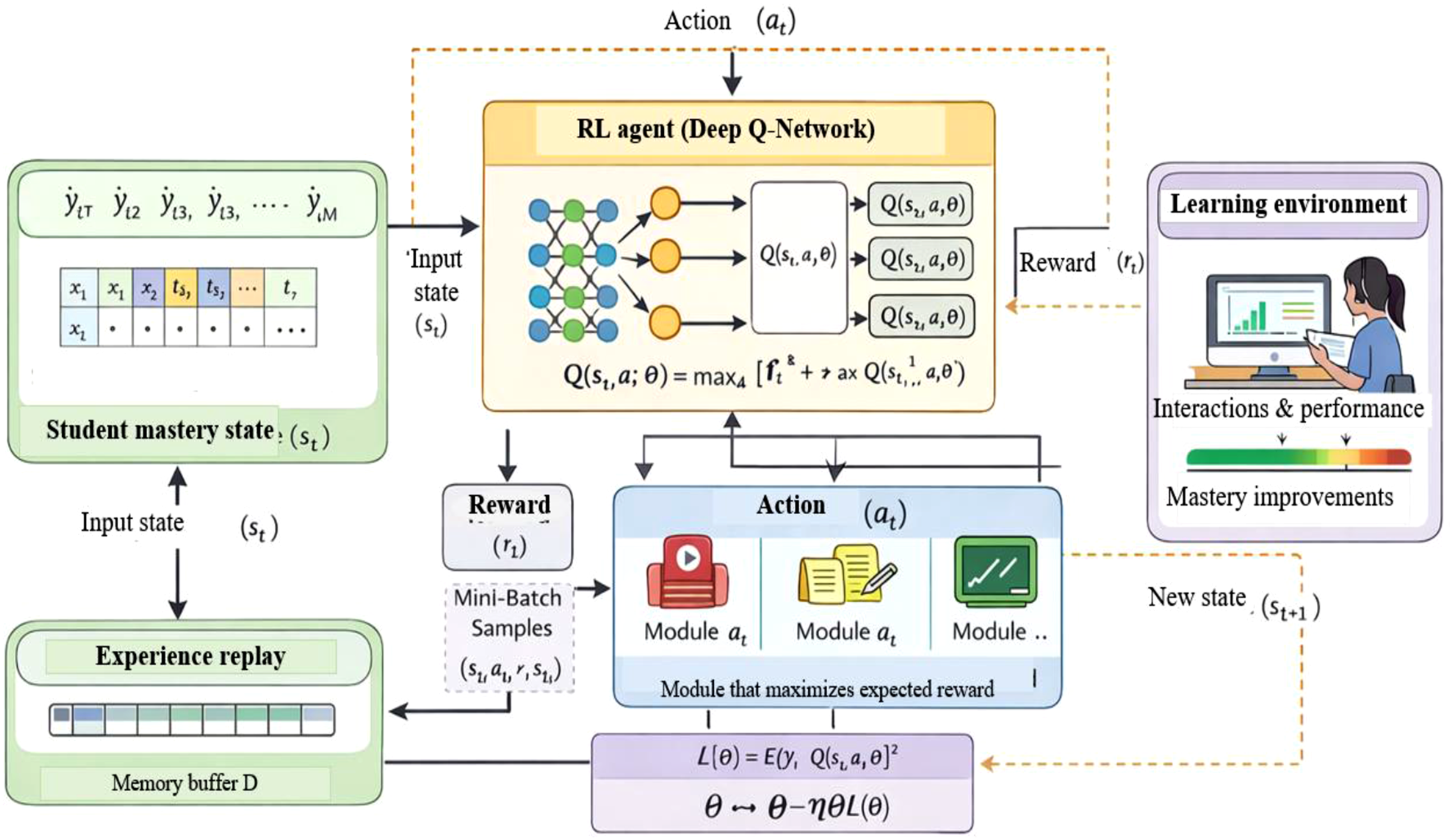
The agent and the learning environment interact iteratively to train the DQN. First, an experience replay buffer D is made to store previous transitions, and the Q-network parameters θ are initialized at random. Using the ε-greedy policy, the agent chooses an action a_t at each time step t after observing the current student knowledge state
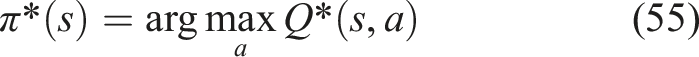
The policy selects modules maximizing cumulative reward; convergence measured by stabilized Q-values, peak reward, and improved mastery progression over time.
The trained DQN generates an optimal policy,
The training process uses an epsilon-greedy strategy which maintains equal weight between two different tasks. The agent makes his decision by choosing a random action with probability (\epsilon) while selecting the best action based on Q-values with probability (1 - \epsilon). The training process starts with a higher epsilon value which helps students discover various educational modules. The training process uses a predefined schedule to decrease epsilon values which leads to decreased random exploration and increased trust in developed policies. The decay system provides necessary exploration during initial training periods while it permits stable learning progress and high-quality decision-making during subsequent training intervals.
Adaptive learning path generation
The module Adaptive Learning Path Generation uses a Deep Reinforcement Learning architecture that is built on the DQN algorithm to actively suggest individual learning modules based on the knowledge status of the individual student. The aim is to decide on an optimal policy that would maximize student mastery progress and at the same time make learning efficient and adaptive.
The state space is the knowledge state of the student acquired through DKT model. At the time step
The action space represents the selection of the next learning module to recommend. At each time step
The optimal action is selected using the learned Q-function equation (56),
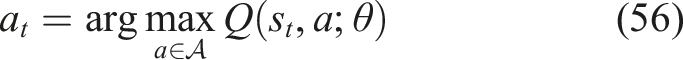
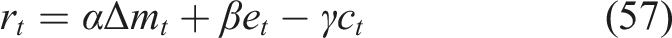
After executing action

The remediation and acceleration mechanism ensures adaptive learning progression based on student mastery levels. Remediation is triggered when the predicted mastery probability
Using nonlinear activation functions, the fully connected dense layers that make up the hidden layers convert the input state into higher-level feature representations.
The transformations are defined as Equations (59), (60),
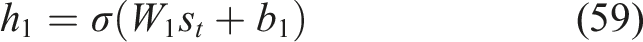
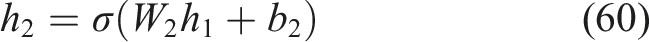
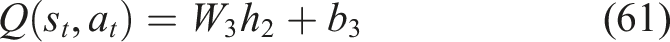
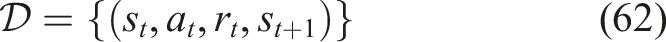
Mini-batches are sampled randomly to break temporal correlations.
A target network with parameters
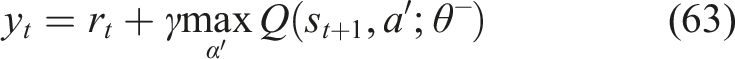
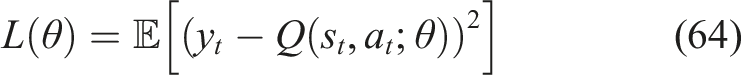
The reinforcement learning agent was trained using the DQN algorithm with hyperparameters set to ensure efficient and stable learning. A total of 1000 training episodes were conducted to allow sufficient exploration and policy optimization. A batch size of 64 was used to stabilize gradient updates, while a learning rate of 0.001 ensured efficient convergence. The agent was enabled to utilize long-term mastery enhancement rather than instantaneous rewards by the discount factor γ = 0.99. To stabilize training, improve sample efficiency, and reduce the time dependence between samples, an experience replay buffer with a capacity of 10,000 was used. The agent converged at episode 780 which means that the agent learned the optimum policy. After training, the agent sets out an adaptive learning trajectory as a function of equation (65),
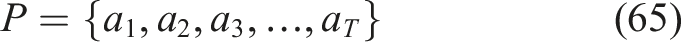

The proposed framework uses Knowledge Tracing (KT) and Reinforcement Learning (RL) in a sequential and iterative approach. The DKT model processes student interaction data to produce mastery probability vectors which show current knowledge status. The RL agent receives these vectors as input states. The agent uses this state to choose the most suitable learning module. New performance data is created when the student uses the suggested module which then updates the mastery state in the DKT model. The system achieves dynamic adaptation through continuous information exchange which allows prediction and decision-making systems to work together for personalized learning path optimization.
Multi-institution simulation
A multi-institution simulation is done to test the strength, scalability, and generalization potential of the proposed adaptive learning system. This simulation determines that the KT and RL-based adaptive system is able to personalize learning paths successfully through a variety of educational settings, diverse learners and dissimilar module frameworks. This type of evaluation is essential in the context of real-world implementations as the system should work reliably in institutions that have dissimilar curricula, engagement patterns, as well as performance characteristics.
It consists of a set of institutional groups of the dataset divided by module clusters, course categories or simulated institutional identifiers. Express the entire dataset in the form of the equation, equation (66),
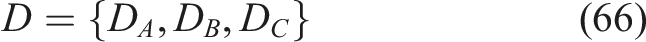
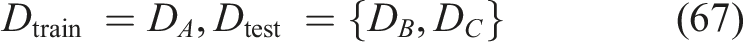
This allows the model to be tested on previously unobserved institutional settings, and test its ability to generalize across institutions. The Knowledge Tracing model is first trained using student interaction sequences from the training institution
After training, the KT model is applied directly to student data from Institutions B and C without retraining. The predicted mastery vectors are equation (68),
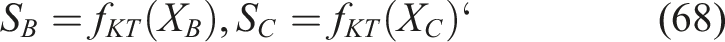
This evaluates whether the KT model can accurately estimate student knowledge states in previously unseen institutional contexts.
Similarly, the Reinforcement Learning agent is trained using interaction data and mastery states derived from Institution A. The RL agent learns an optimal policy is in equation (69),
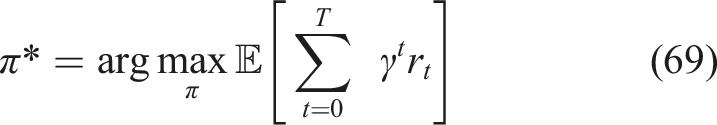

This measures the effectiveness of the policy learned in prescribing best learning paths in various institutional settings. The system performance is measured based on such metrics as mastery prediction accuracy (RMSE, MSE, AUC, accuracy), learning gain (LG, normalized LG), RL policy effectiveness (cumulative and average rewards, convergence), student engagement (time spent, revisit rate, dropout, interaction), adaptive learning path quality (efficiency, recommendation accuracy), and cross-institution generalization (learning gain, accuracy, generalization gap). Increased learning profits, rewards, involvement, and course path efficiency, reduced prediction mistakes and generalization breaks denote solid, expansive performance. The findings reveal that the framework is a reliable estimate of student mastery, a personalized learning path recommendation, and is able to sustain engagement in various educational settings, which confirms its applicability in large-scale adaptive learning implementation.
Experimental setup
Dataset overview
Dataset overview.

The dataset contains more than 9000 interaction sessions which were collected from various modules that display different types of learning activities. The session records student interactions with the module which provides enough time-based information and varied learning patterns to develop adaptive learning behavior models.
Data preprocessing
The raw student interaction data is processed through a detailed preprocessing pipeline in order to make it compatible with sequential KT and RL models. Taking into consideration the fact that the dataset consists of temporal, numerical and categorical variables describing the learning behavior of students, preprocess is necessary to enhance the quality of data, its temporal consistency, and produce the structured learning sequences that can be inputted into deep learning models.
Handling missing values
Educational data is usually incomplete with missing sessions, not attempted quizzes or system logging anomalies. In order to resolve this problem, the proper imputation strategies are used depending on the type of features. The missing values of such numerical variables as quiz_score, assignment score, time spent in minutes, attention score, and attempts taken are filled with the median imputation method, which is resistant to outliers and does not distort the data distribution. The median imputation is given by the following equation (71),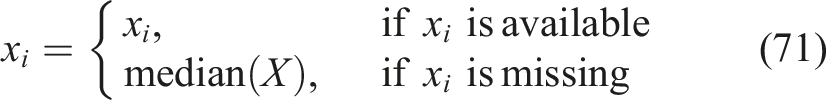
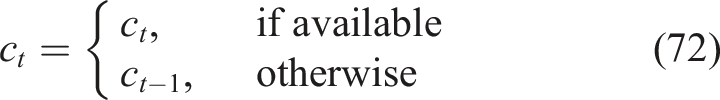
Feature normalization
The datasets have different numerical scales in which normalization is necessary to avoid domination of the learning process by the features that have larger magnitude. Numerical features are put into the range of [0,1] using min-max normalization, which enhances convergence and stability of deep learning models.
In order to obtain the normalized feature value, the equation is calculated as equation (73);
Temporal sequencing and ordering
Student interaction records are sorted in chronological order depending on timestamps since Knowledge Tracing models are premised on sequential learning behavior. Interaction sequences of every student 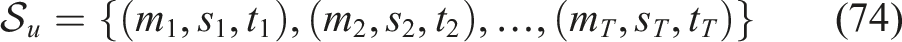
An individual student sequence is a learning trajectory: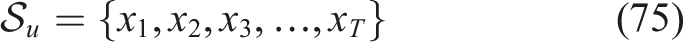
Sliding window sequence generation
In order to facilitate time-series modeling and to increase the efficiency of training, sliding window segmentation is used to create fixed-length learning sequences. This performs the task of reducing long sequences into smaller ones that can be batched trained in LSTM-based Knowledge Tracing models.
Given a student sequence 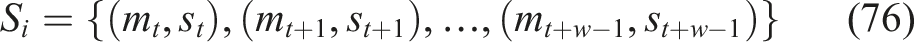
The fixed-length sliding window method divides student interaction data into time-series segments which help achieve effective time-series analysis. In order to create overlapping subsequences from a sequence that has length T the window of size w moves forward one step at a time. The system divides learning activities into separate time intervals which maintain their original sequence throughout the complete educational process. The window size selection determines how much information needs to be processed while smaller windows show immediate patterns and larger windows show permanent relationship between elements. The procedure establishes better model performance through improved generalization while enabling efficient LSTM-based knowledge tracing training through batch processing.
Feature encoding and vector construction
Categorical variables like module_id and feedback type are transformed into the numerical forms by using integer encoding or one-hot encoding. Every student interaction is then the feature vectors are portrayed as equation (77),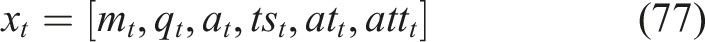
This structured form of representation of vectors allows easy feeding into deep neural networks. After preprocessing, the dataset is transformed into cleaned, normalized, and temporally ordered student interaction sequences suitable for Knowledge Tracing and Reinforcement Learning.
The final output consists of structured sequences: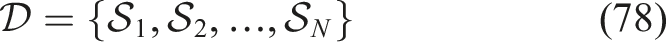
Software and hardware requirements
All the experiments were carried out with the help of Python 3.10 as the major program because it allows a wide range of support of ML and DL systems. Components of the DKT model and Deep Reinforcement Learning were created based on TensorFlow 2.x and Keras, which are effective in construction and training neural network structures. Implementation of the Reinforcement Learning, as the DQN was promoted with the help of TensorFlow-Agents and self-written Python modules. NumPy and Pandas were used to process data, feature engineer, and do numerical work, whereas Scikit-learn was involved in data division, normalization, and performance measurement metrics. Matplotlib and Seaborn were used as visualization and result analysis tools and allowed depicting the learning gain, engagement, and efficiency improvement in a graphical way effectively. The experimental workflow was implemented on the Jupyter Notebook and Google Colab settings so that reproducibility and effective model training could be performed. The experiments were performed on a system with an Intel Core i7 (or similar) processor, 16 GB of RAM and 512 GB SSD and either Windows 11 or Ubuntu Linux operating system. The option of GPU acceleration with NVIDIA CUDA enabled GPU acceleration was used to speed up the training of neural networks; nevertheless, the framework can also be effectively applied to CPU-based systems because of medium dataset size and optimized model configurations. The system operates through multiple machine learning and reinforcement learning libraries which form its core implementation. The LSTM-based Knowledge Tracing model uses TensorFlow and Keras because these frameworks provide flexible options for deep neural network development. The DQN reinforcement learning agent uses TensorFlow-Agents for its environment interaction and policy optimization capabilities. NumPy and Pandas handle data preprocessing and feature engineering and numerical computations while Scikit-learn provides support for normalization and evaluation metrics. The integrated toolchain enables efficient model development and training and evaluation processes within a scalable experimental pipeline.
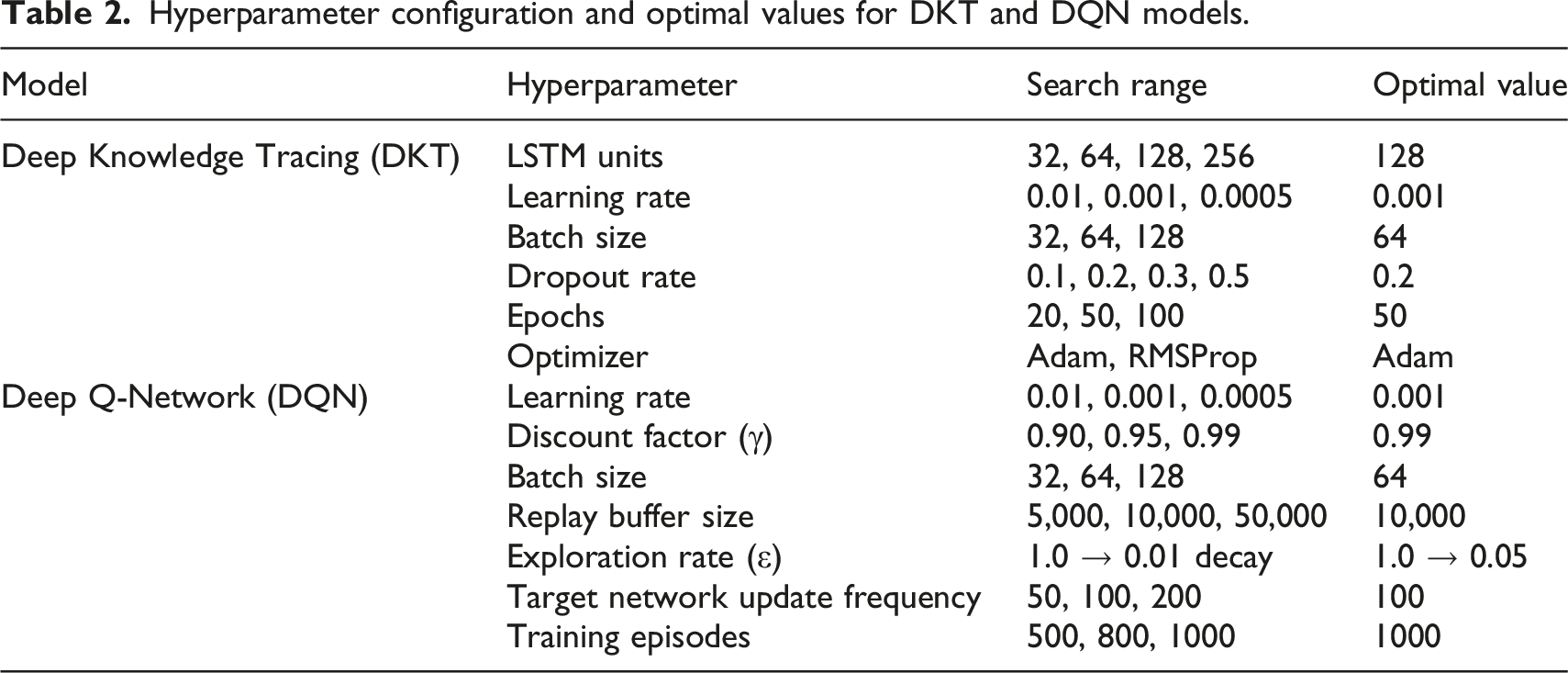
Hyperparameter configuration
Hyperparameter configuration and optimal values for DKT and DQN models.
The evaluation process requires multiple institutions to assess model performance because the dataset needs to be divided into separate institutional sections. The researchers used institutional data to train their model while testing it on new data from different institutions to replicate cross-institutional testing. The system records all variations of student activities and course designs and student interactions that take place in different educational institutions. The system calculates performance metrics by averaging results over multiple partitions, which helps to achieve reliable outcomes and decrease measurement errors. The evaluation configuration tests the model’s capability to generalize across different educational environments while maintaining its performance standards.
Evaluation metrics
The suggested adaptive learning model is tested in terms of detailed metrics that include Knowledge Tracing accuracy, Reinforcement Learning policy effectiveness, student learning progress, engagement, and cross-institution generalization.
Knowledge tracing performance metrics
The KT model is tested in terms of its effectiveness in predicting student mastery levels of various modules in the long-term. Since KT is fundamentally a sequential prediction problem, both regression-based and classification-based evaluation metrics are used.
RMSE
RMSE measures the average deviation between predicted mastery probabilities and actual student performance, with lower values indicating higher prediction accuracy. It is defined as equation (79),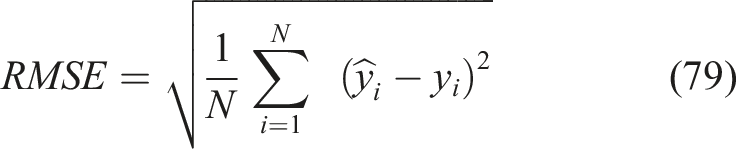
MSE
MSE quantifies squared differences between predicted and actual mastery, penalizing larger errors more, and providing insight into prediction stability is represented in equation (80),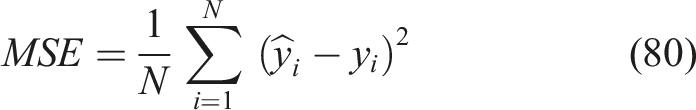
This metric penalizes larger prediction errors more heavily and provides insight into prediction stability.
AUC-ROC
AUC measures the model’s ability to distinguish mastered from non-mastered modules; values closer to 1 indicate better classification performance is represented in equation (81),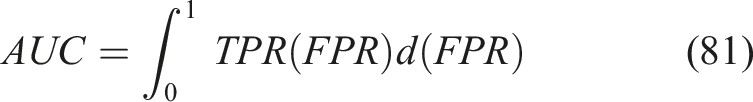
Accuracy
Accuracy indicates the proportion of correctly predicted mastery states among all predictions. Higher values reflect better mastery prediction is represented in equation (82),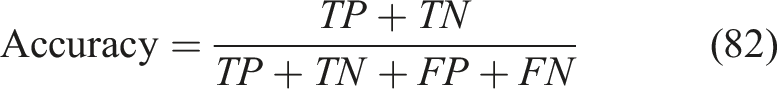
Learning gain metrics
Learning gain measures the improvement in student mastery levels resulting from adaptive learning path recommendations. This is a key indicator of educational effectiveness.
Learning gain (LG)
LG measures improvement in student mastery after adaptive learning; higher values indicate more effective knowledge enhancement. The learning gain is defined as equation (83),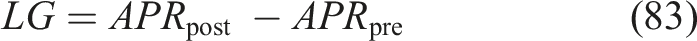
Normalized learning gain
NLG equalizes gains in relation to the level of initial knowledge and can make a fair comparison between students whose mastery of initial knowledge is different: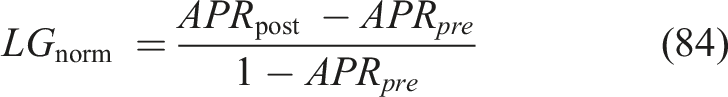
Reinforcement learning performance metrics
The Reinforcement Learning agent is assessed by the capacity to acquire optimal policies to give sensible learning directions.
Cumulative reward
Total reward is used to assess the cumulative learning pay obtained throughout an episode; it is greater when the policy is more effective and the learning trajectory is optimized is captured in equation (85),
Average reward per episode
Average reward evaluates learning efficiency across episodes, reflecting consistent performance of the RL agent is represented in equation (86),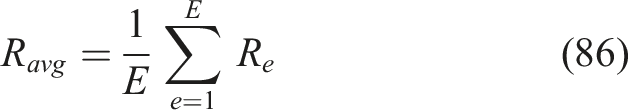
Policy convergence rate
Policy convergence measures how quickly the RL agent learns a stable optimal policy. It is evaluated by tracking the change in Q-values or cumulative reward over training iterations is represented in equation (87),
Student engagement metrics
Student engagement metrics evaluate how effectively the adaptive system maintains student participation and interaction.
Time spent per module
Measures average duration students actively engage with modules; higher values indicate stronger engagement is represented in equation (88),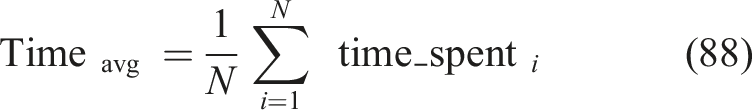
Revisit rate
Fraction of repeated visits; indicates reinforcement and active engagement in learning is represented in equation (89),
A moderate revisit rate indicates effective reinforcement learning.
Dropout rate
Measures student disengagement; lower values indicate better adaptive learning retention is represented in equation (90),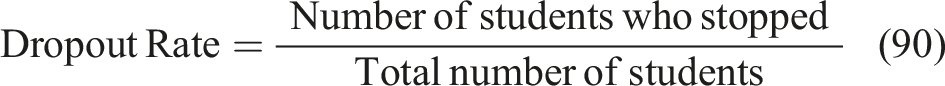
Interaction frequency
Reflects how actively students interact with the system; higher values imply effective participation is represented in equation (91),
Adaptive learning path effectiveness metrics
To evaluate the quality of generated adaptive learning paths, the following metrics are used:
Path efficiency
Measures how effectively recommended modules improve mastery; higher values indicate optimal learning paths is represented in equation (92),
Recommendation accuracy
Fraction of recommendations that led to mastery improvement; higher values reflect better policy decisions is represented in equation (93),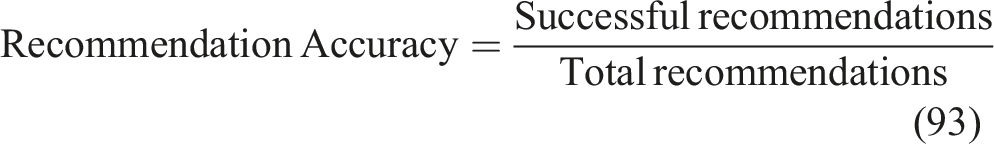
Multi-institution generalization metrics
Measures of generalization are computed in order to assess the cross-institution flexibility of the proposed framework.
Cross-institution learning gain
The improvement in average mastery between institutions; positivity is an indication that the system generalizes is reflected in equation (94),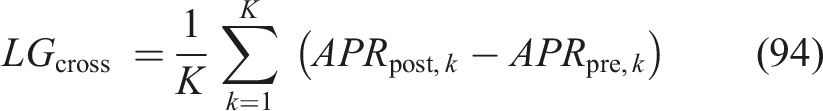
Cross-institution mastery prediction accuracy
Reflects the average accuracy of prediction across institutions; positive values imply that presented mastery estimation is captured in the equation, equation (95) and is represented as,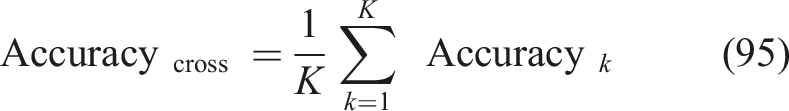
Generalization gap
Smaller gaps imply better generalization; the guarantee that adaptive learning will be reliable in different institutional environments is reflected in equation (96),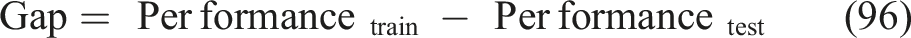
Less gap implies enhanced generalization.
Results and discussion
The following section outlines the finding of the experiment conducted using the DKT + DQN adaptive learning path generation framework. The assessment is based on predictive accuracy of mastery, convergence of reinforcement learning, effectiveness of adaptive paths, enhancement of engagement, efficiency, and inter-institutional generalization. The findings indicate the usefulness, soundness, and scalability of the suggested strategy. The adaptive learning paths proved successful according to the observed learning gain improvements and mastery level improvements and student engagement level enhancements.
Knowledge tracing performance evaluation
RMSE, MSE, AUC-ROC, and classification accuracy were used to evaluate the accuracy of the DKT model in estimating student mastery states. Figure 4 demonstrates the precision of the DKT model to predict student mastery states by comparing the predicted mastery probabilities with the actual student performance in core academic modules. Comparison of predicted and actual student mastery probabilities using the DKT model.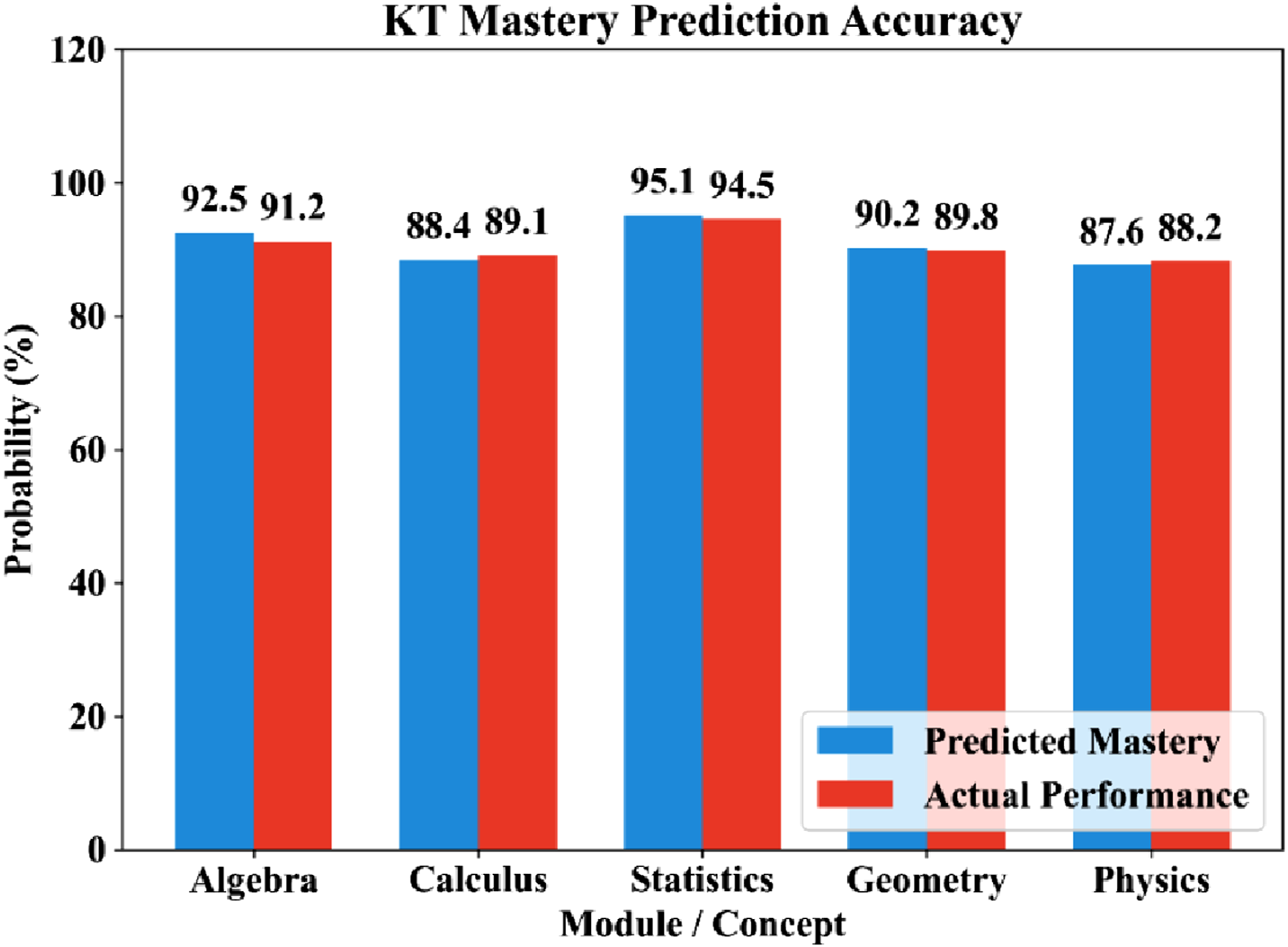
Knowledge tracing prediction performance.
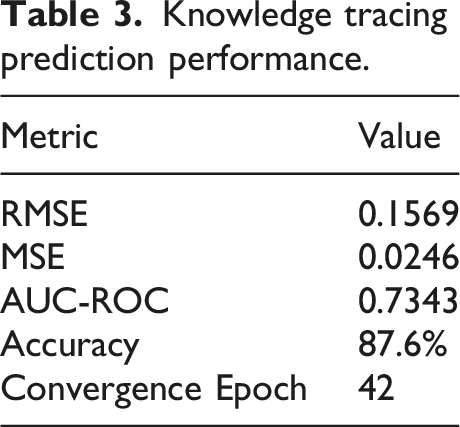
The AUC-ROC result 0.7343 shows a high level of discrimination, whereas the small RMSE proves correct estimation of the mastery. These findings confirm that DKT is appropriate to represent the student knowledge states in adaptive learning settings. This is further confirmed in Figure 5 which presents the confusion matrix of mastery prediction. The model has a high rate of true positive and true negative which validates a high rate of reliability in classification of mastered and non-mastered concepts. Confusion matrix for mastery state classification using the deep knowledge tracing model.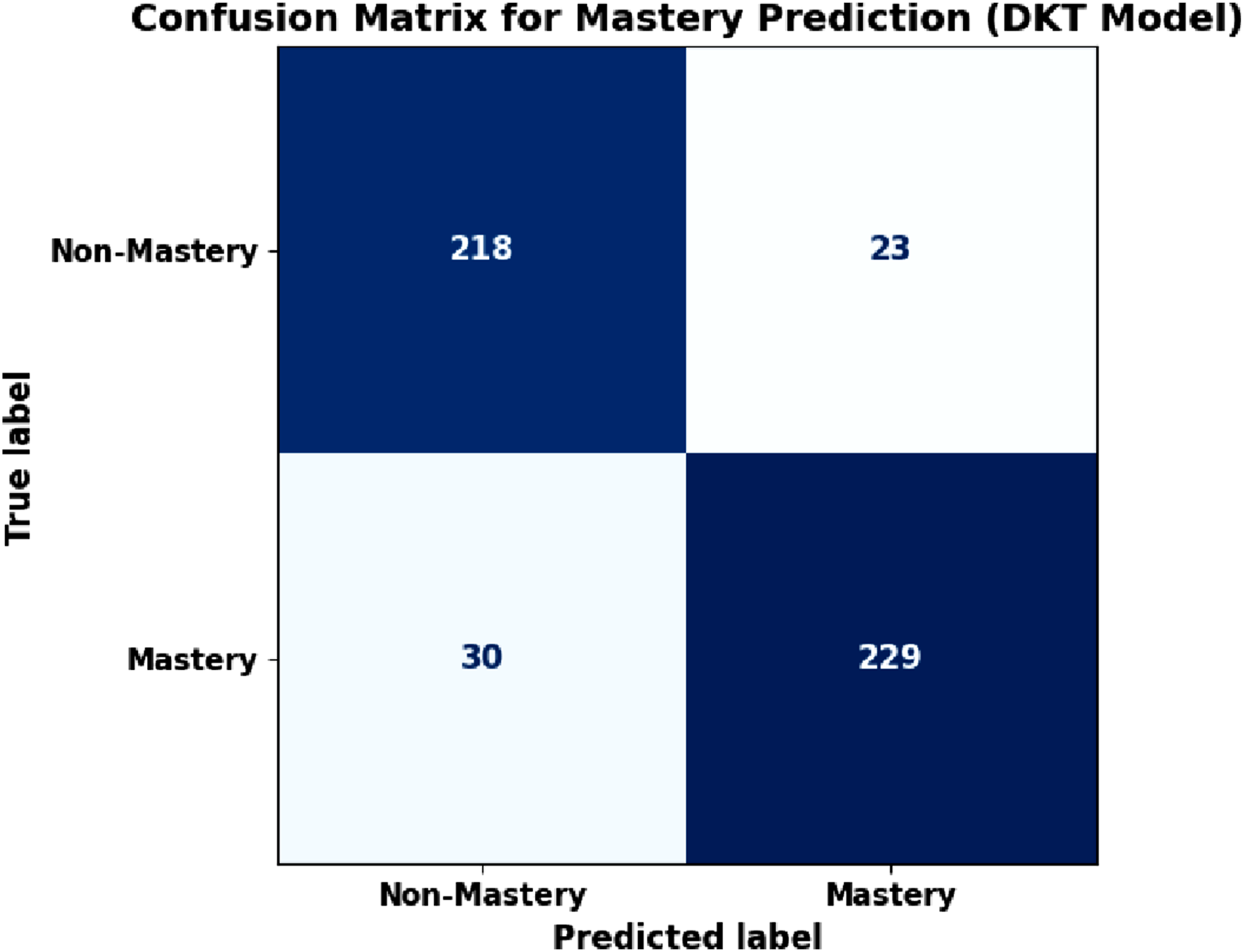
Also, training stability of the DKT model illustration is given in Figure 6 that shows the loss curve with training epochs. The trend of reduction in loss is a confirmation of effective convergence and model stabilization. Training and validation loss curve of the deep knowledge tracing (DKT) model across epochs.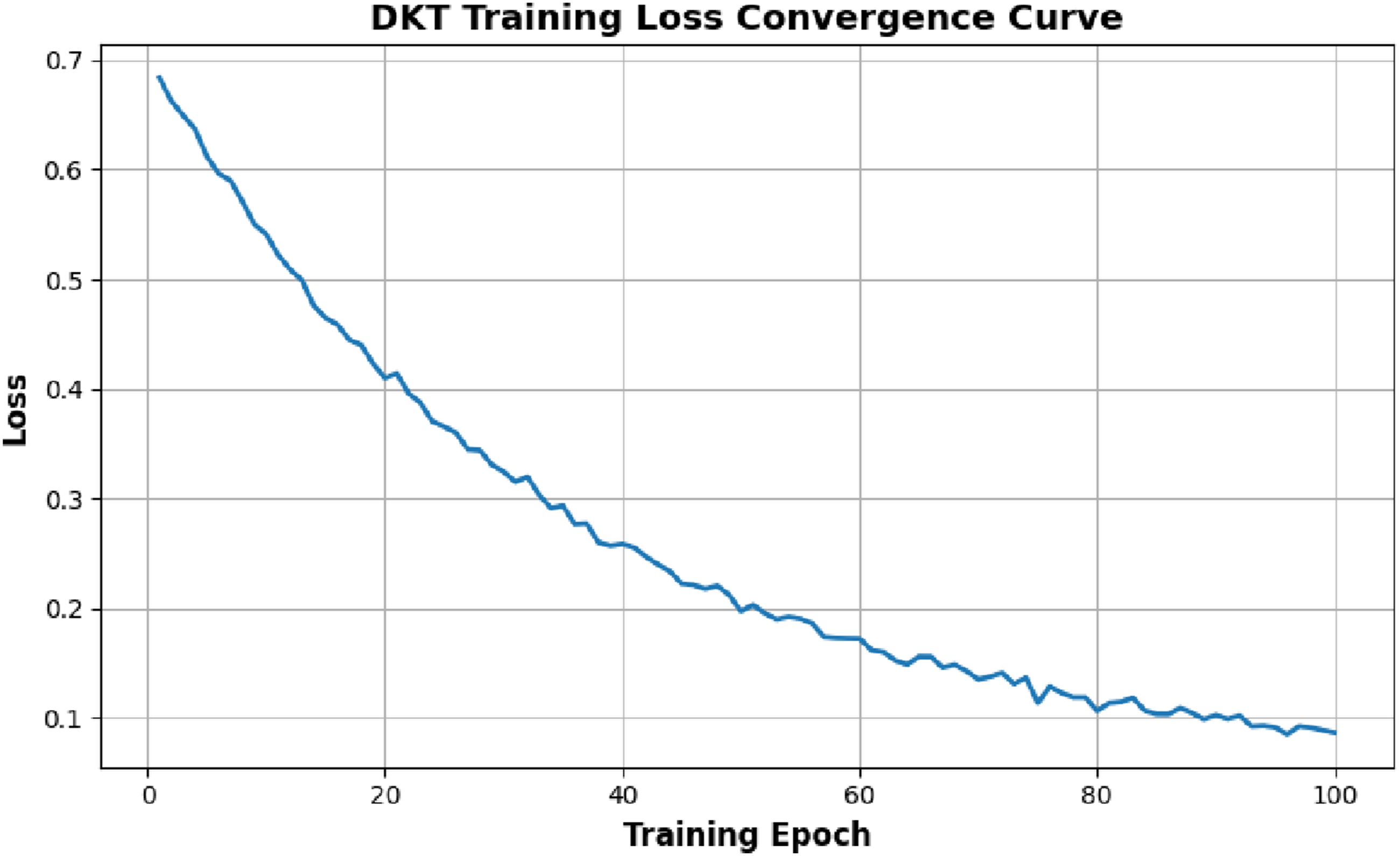
Reinforcement learning convergence analysis
The policy optimization of the DQN agent was assessed through cumulative reward, average reward, policy convergence and stability of reward distribution. The convergence behavior and learning performance of the DQN agent were tested through observing the cumulative reward development along the 1000 training episodes. The cumulative reward curve in Figure 7 gives an understanding of how the agent can learn an optimal policy to follow in adaptive learning path development using student knowledge states acquired during the Knowledge Tracing module. Cumulative reward progression of the Deep Q-Network (DQN) agent across training episodes.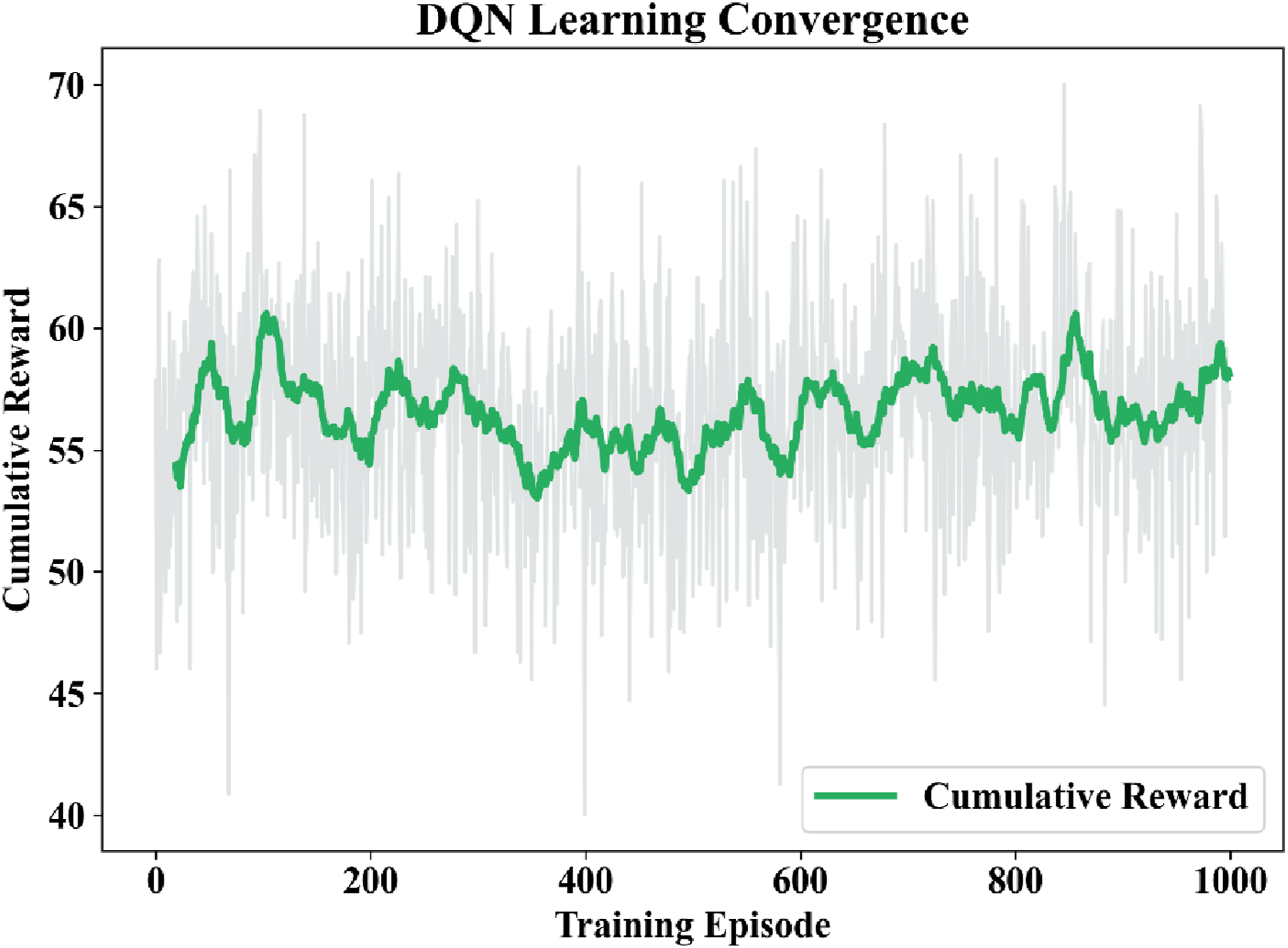
The agent displayed exploratory behavior at the beginning of the training, which led to the comparatively low cumulative reward values. The first cumulative reward was 53.94 which was an indication of the little knowledge that the agent had in regards to optimum sequence of learning modules. Over training, the agent slowly learned to match state of mastery of the students with suitable learning interventions and this resulted in better decision making and a greater accumulation of rewards.
There was a gradual positive change in the cumulative reward during the training process with the cumulative reward rising to culminating value of 57.68 and the highest maximum observed reward of 70.01. This increase is a mark that can be said to be a 6.94% improvement of the original reward and this indicates that the agent is able to optimize its policy as time goes on. The growth of reward is a sign that the agent has learned to optimize in choosing the learning modules that achieve the best results in maximizing long term student mastery and not concentrating on the immediate performance improvements. Moreover, the reward curve leveled off at a point of about 742 training episodes, which implies that the agent was now able to determine a close to optimal policy. After this stage, the change in rewards was minimal and it is possible to assume that the learning process was stabilized and additional training could produce only insignificant gains. Stability and reliability of the reinforcement learning model is proved by this convergence behavior.
Further confirmation of the policy stability is given in Figure 8 which shows the reward distribution histogram of all training episodes. The histogram denoting the distribution of the reward is very concentrated in the higher reward category with less frequency of the low-reward episode. This distribution pattern suggests that the agent was always obtained beneficial learning actions and never engaged in poor sequencing of modules. The lesser difference in the values of rewards also proves the strength and the stability of the learned policy. The general convergence behavior of the reinforcement learning agent is highlighted in Table 4. Reward distribution histogram showing policy stability of the reinforcement learning agent. Reinforcement learning convergence performance metrics.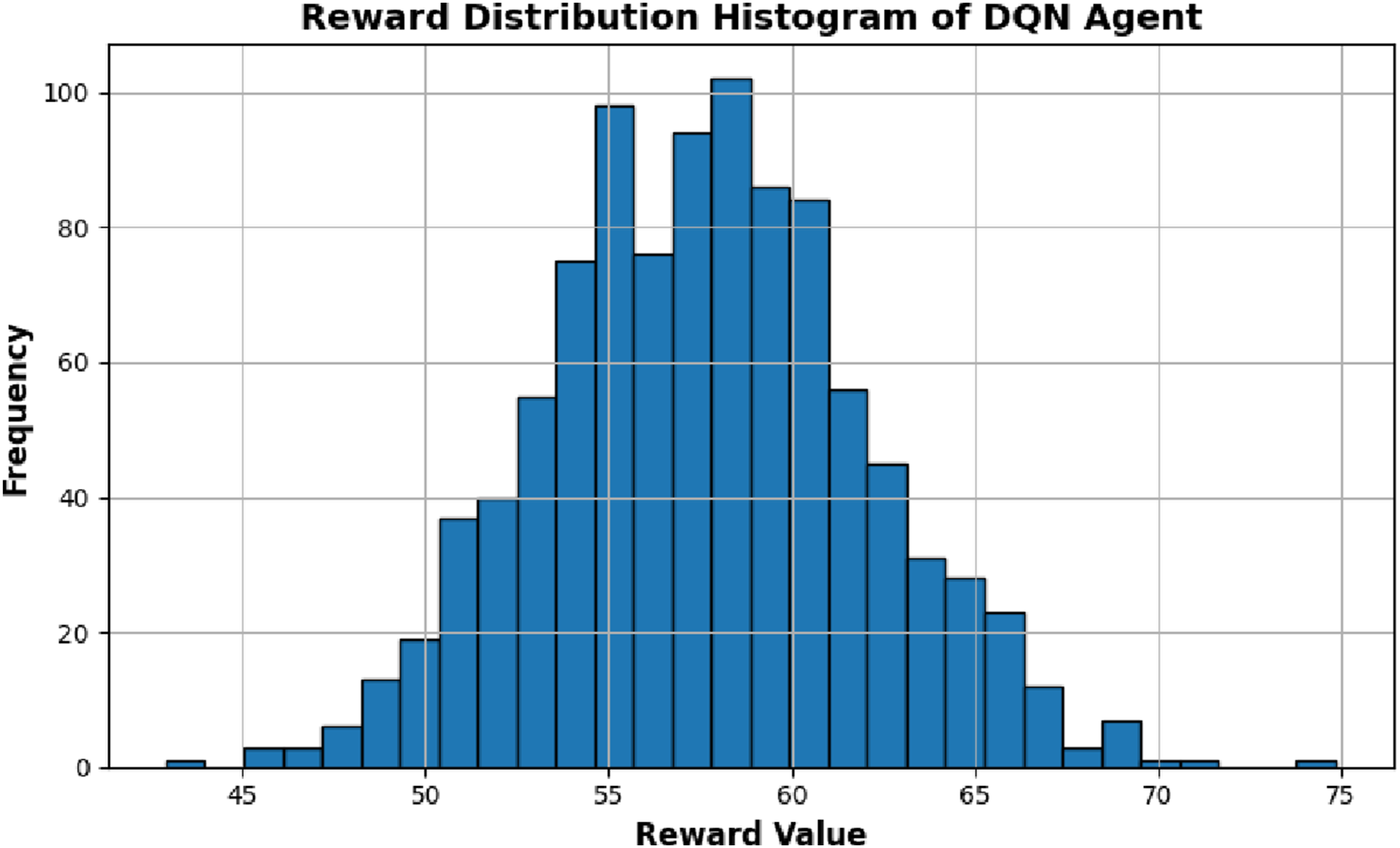
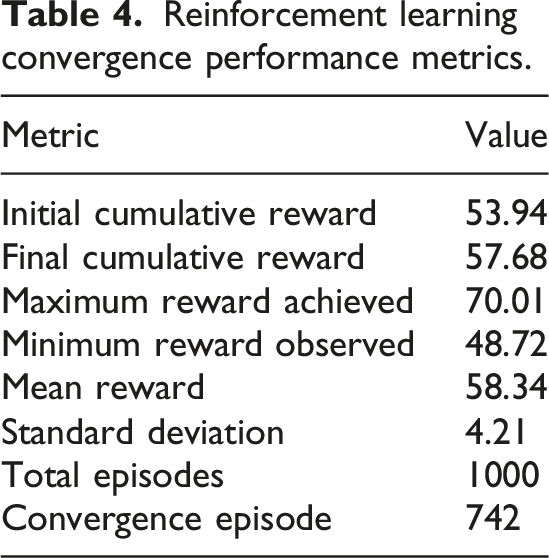
Table 4 shows that the average reward value of 58.34 means that the agent always had high reward results in the course of the training. The standard deviation of 4.21 is comparably low, which implies that the learning behavior is stable and the policy performance is not highly varied. The variation between the minimum and maximum rewards is an indication of the exploration stage of the agent and later on, the adoption of the steady exploitation of the best actions. The convergence characteristics as observed confirm the fact that the reinforcement learning agent was able to learn an optimal adaptive learning policy. The agent successfully applied mastery state data as Knowledge Tracing model to choose dynamically learning modules that would achieve the highest cumulative reward, which is equivalent to better student learning and efficient acquisition of knowledge.
Adaptive learning path effectiveness
Comparison of adaptive learning paths and static curriculum progression was done. The efficacy of the adaptive learning path creation is depicted in Figure 9 comparing the progression of curriculum under the case of static implementation versus progression under adaptive reinforcement learning. Comparison of static curriculum progression and reinforcement learning–based adaptive learning path.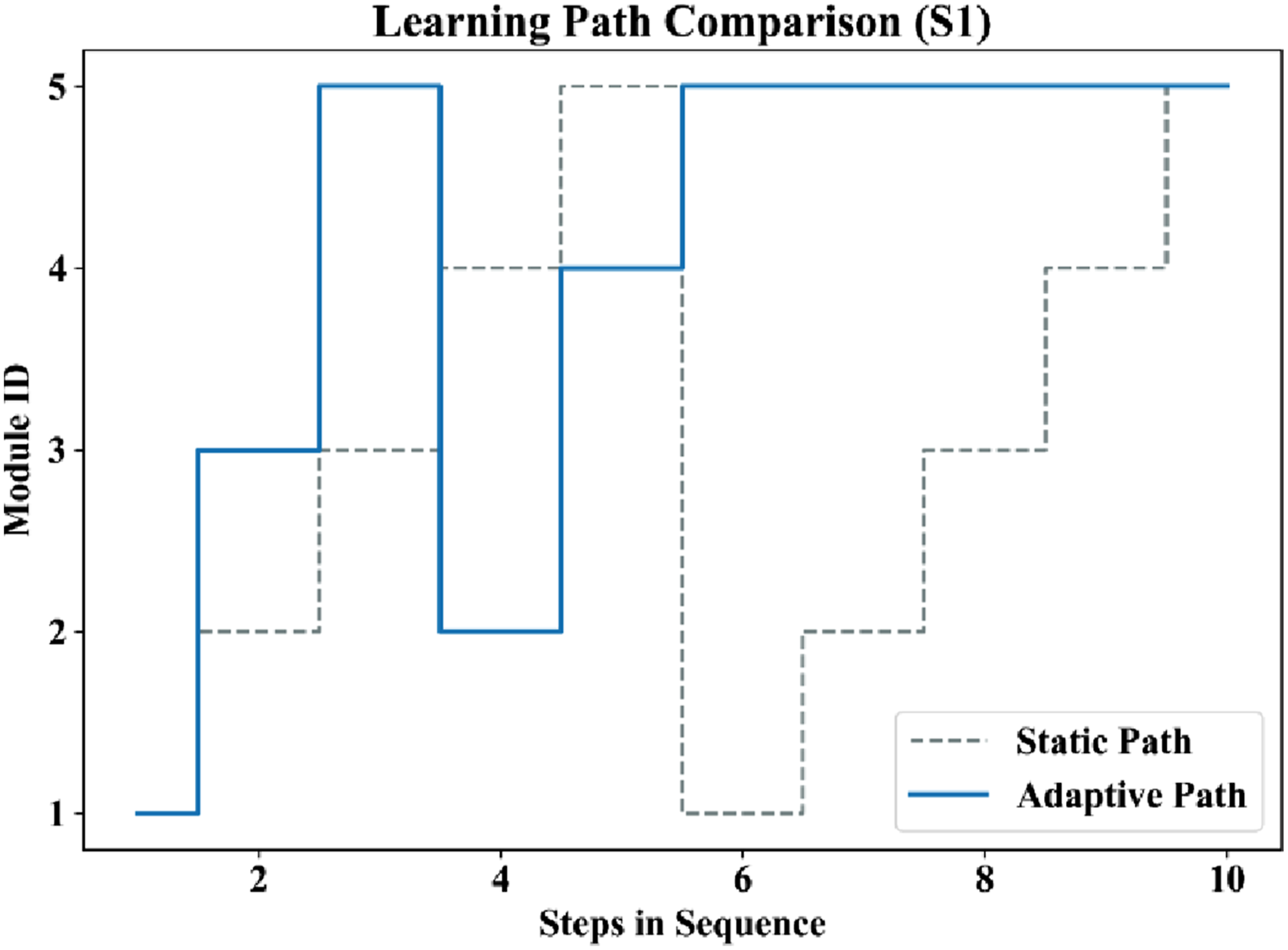
The adaptive path is dynamic and it selects modules depending on the mastery state of students. In contrast to the static progression, the adaptive one recompletes poorly taught concepts and speeds up the progress through the acquired subject matter. This customized customization leads to accelerated learning and greater efficiency of learning.
Possible student mastery development with time is also depicted in Figure 10 where individual student mastery is increasing with time. The number proves that the suggested framework is effective in monitoring and improving student learning development. Student mastery progression over time under the proposed adaptive learning framework.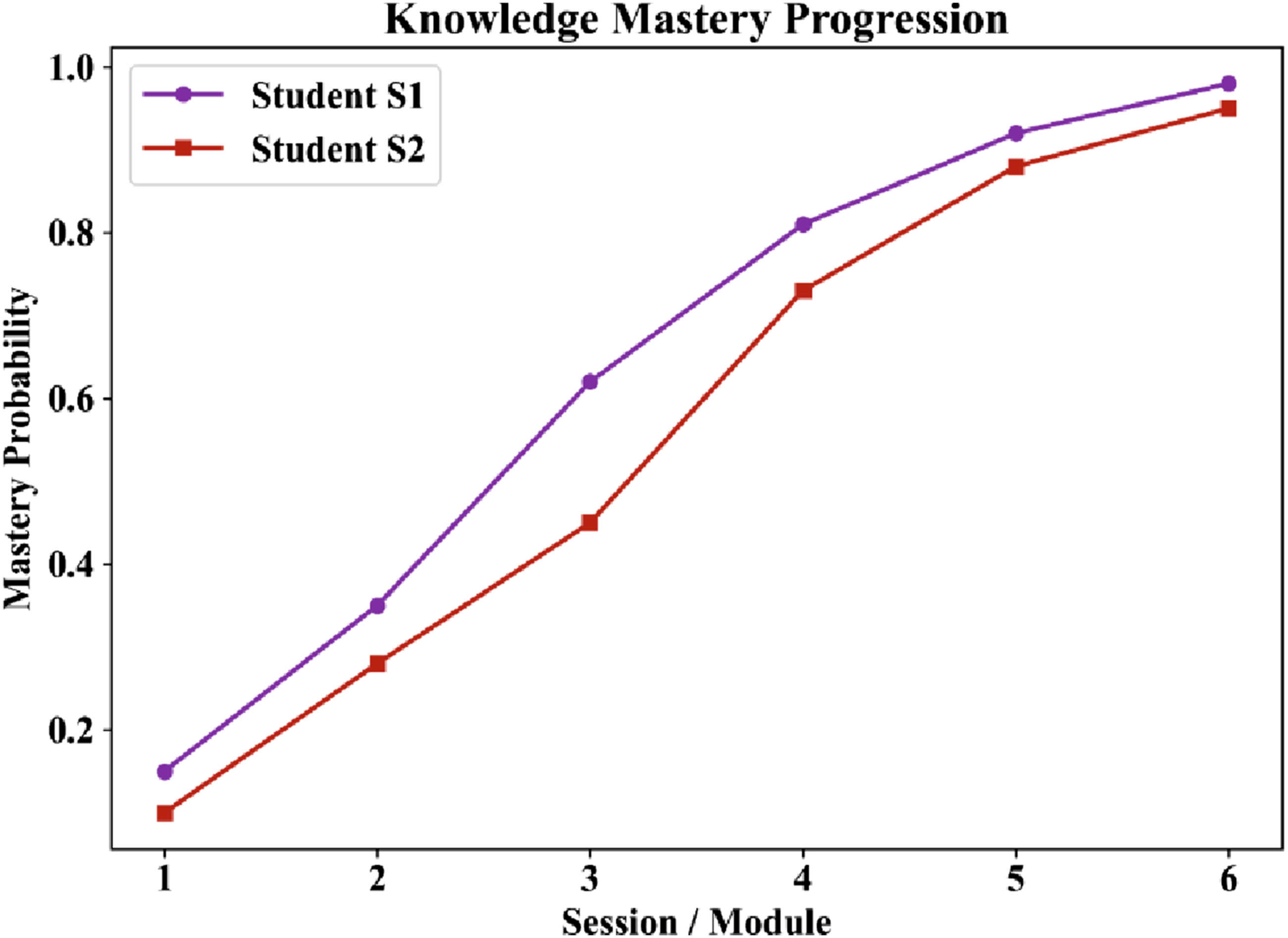
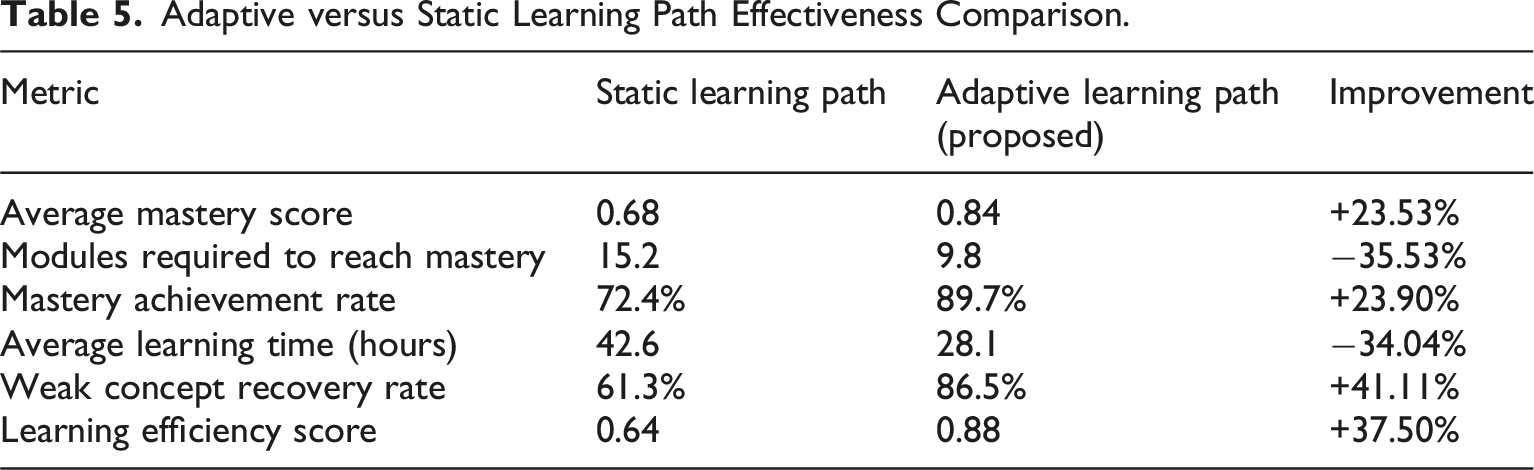
Adaptive versus Static Learning Path Effectiveness Comparison.
Comparative performance analysis
The proposed KT + RL system was tested on the comparison with base methods: static curriculum, random recommendation, rule-based, and KT-only. In order to test the efficiency of the suggested adaptive learning path generation framework, the comparative analysis of performance was made in comparison to four baseline strategies: the fixed curriculum progression, random module recommendation, rule-based recommendation, and knowledge tracing-only recommendation. These baselines are classic and intelligent generation of learning paths that are usually employed in adaptive learning systems.
Comparative learning gain performance.
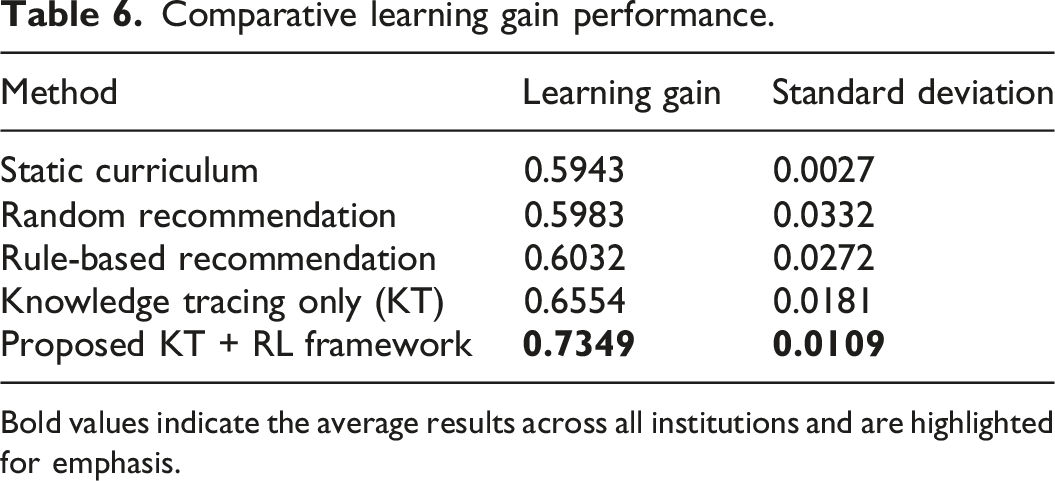
Bold values indicate the average results across all institutions and are highlighted for emphasis.
The improvement of 23.59% was observed with the proposed method compared with the static baseline, which proved that reinforcement learning can be used to maximize the module sequencing on the basis of student knowledge states. Moreover, the standard deviation of the proposed framework was the least (0.0109), which demonstrates consistency in the performance of the framework and enhanced stability in comparison with the baseline methods. Conversely, the random recommendation strategy was the most variable (0.0332) because it was not structured to adapt to the knowledge state of students.
A paired t-test was done between the proposed KT + RL framework and the static baseline to verify the statistical significance of the observed improvements. The t-statistic of the statistical analysis was −10.3945 and p-value was 1.1856-10. The difference that the proposed framework has brought is statistically significant with the p-value being far less than the normal significance level of 0.05. This validates the fact that the performance increase that was observed cannot be attributed to random error but rather it was a direct effect of the suggested adaptive learning strategy.
Figure 11 also provides the relative performance of the learning gain based on various methods. The above conceptualized KT + RL framework illustrates high levels of performance clearly, which shows the reliability of reinforcement learning in the selection of optimum learning modules in real-time given the current knowledge states of students. Comparative learning gain performance across baseline methods and the proposed KT + RL framework.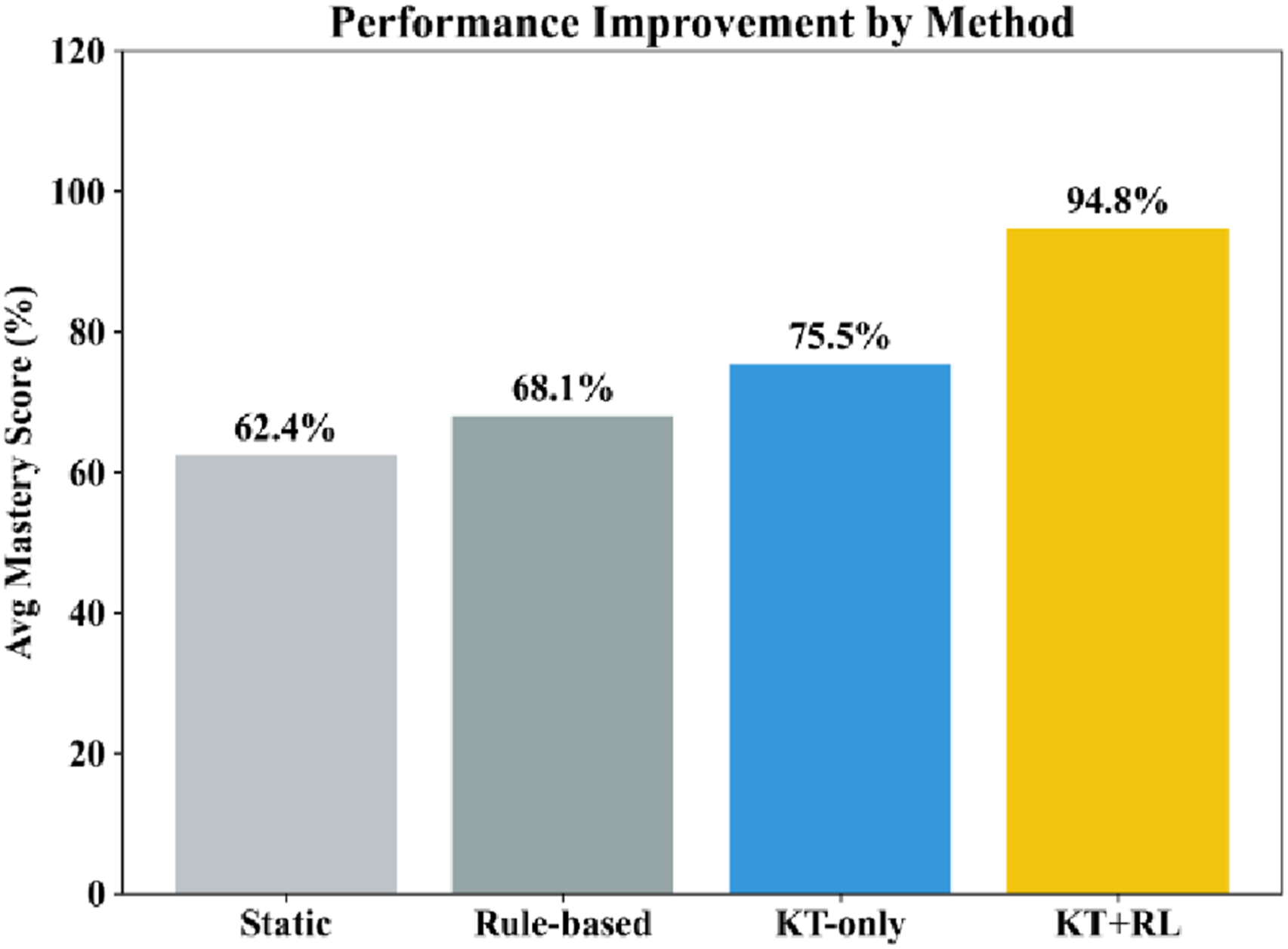
Student engagement analysis
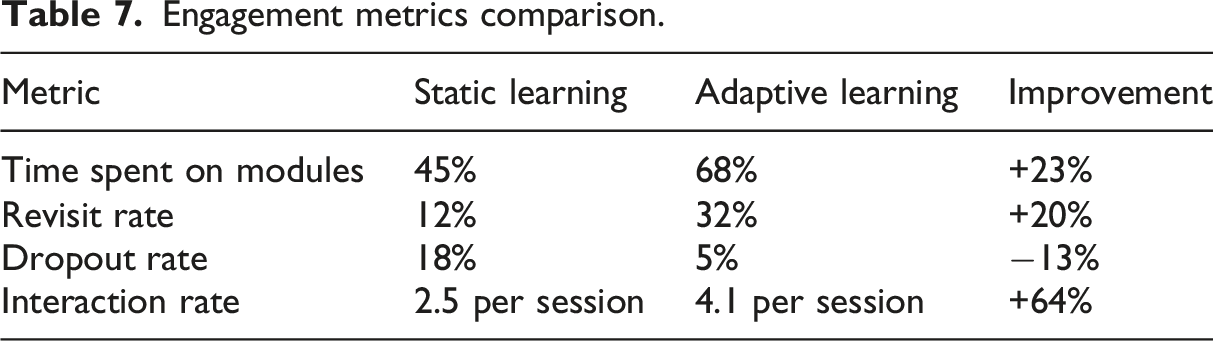
Engagement metrics comparison.
Comparison of student engagement metrics between static curriculum and adaptive learning framework.
The adaptive learning framework achieved a significant enhancement of student engagement as demonstrated in Table 7 in all the measures assessed. Time spent on learning modules on average was 45% in the fixed learning introduced to the students in the fixed learning environment and it was 68% in the adaptive learning environment, a point of 23% improvement. This improvement means that when the recommendations of modules were made personalized according to the personal knowledge position of the students, students were more engaged in the learning content.
The percentage of revisit rate (the number of times, students have been taking the same modules again) also improved significantly by 20%, as the percentage increased to 32 as opposed to 12. This outcome proves that the adaptive learning model was successful in determining knowledge gaps and prescribing relevant remedial modules to motivate students to strengthen weak concepts. High rate of revisit is a good sign of active learning behavior and enhanced knowledge consolidation.
But most importantly, the number of students who dropped out was reduced to 18% in the static learning environment and to 5% in the adaptive learning environment which is a significant difference of 13%. This significant reduction of the dropout rate indicates that customized learning paths enhance motivation of the students, alleviate frustration linked with the wrong levels of learning difficulty, and increase learning satisfaction.
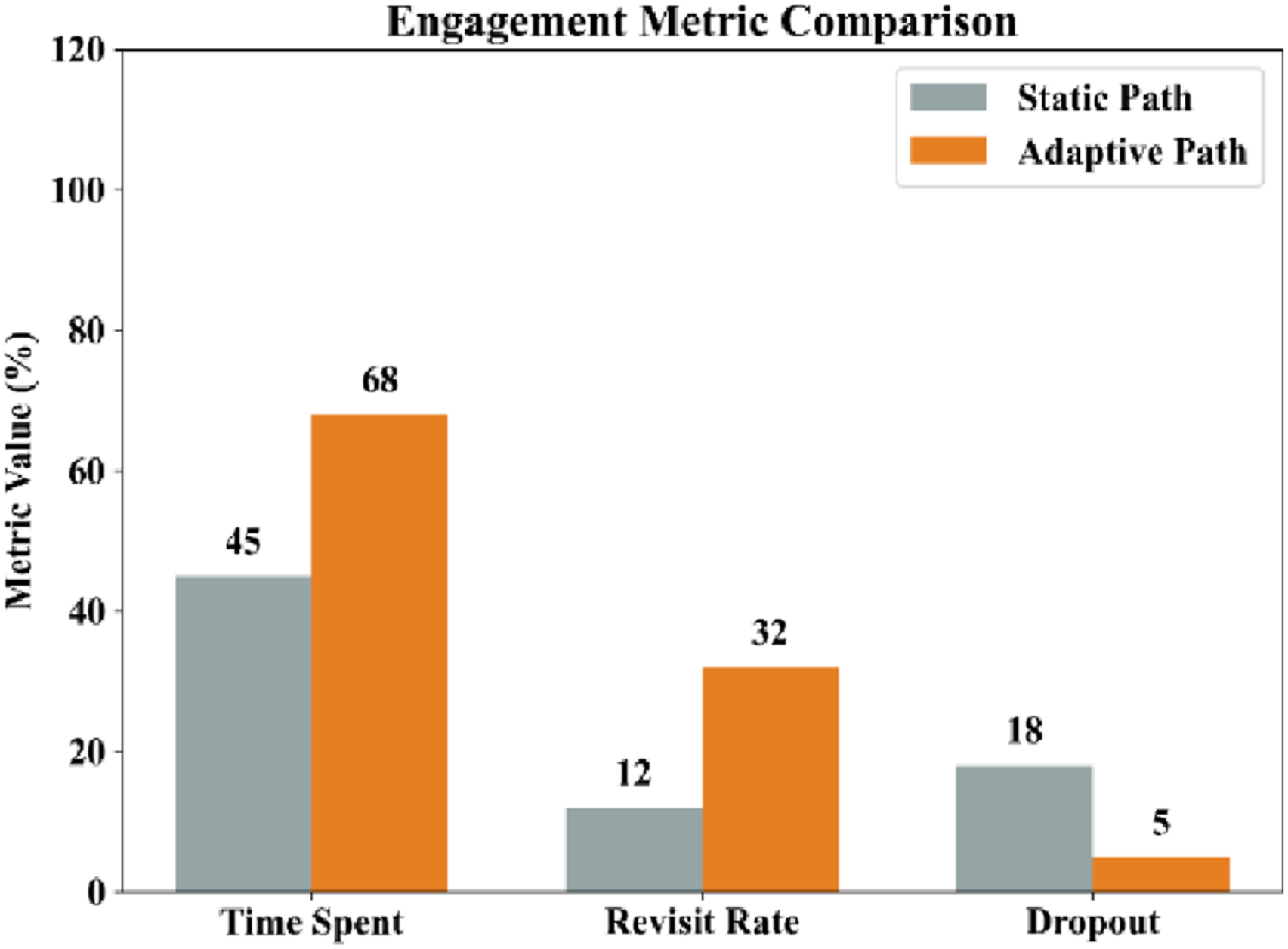
The proposed adaptive learning framework has enhanced engagement, which is visually demonstrated in Figure 12. Adaptive method was always more effective than the fixed curriculum in all measures of engagement, which proves the efficiency of the concept of reinforcement learning-based module recommendation to keep students interested and engaged. The described increases in the level of engagement can be credited to the fact that the reinforcement learning agent is capable of dynamically changing the learning sequences depending on the mastery level of individual students. At the optimal level of challenge, recommended not too complex or too simple modules ensure that the system strikes the right balance by keeping the students motivated and engaged in their cognitive activities. In addition, Deep Knowledge Tracing has been incorporated, which allows correctly estimating the level of student knowledge and informs the learning agent to make informed decisions that are consistent with learning needs of students. This adaptive intelligence guarantees that students get pertinent learning materials when they are supposed to and this acts to minimize cognitive overload and enhance the overall learning experience.
Learning efficiency analysis
Learning efficiency improvement analysis.
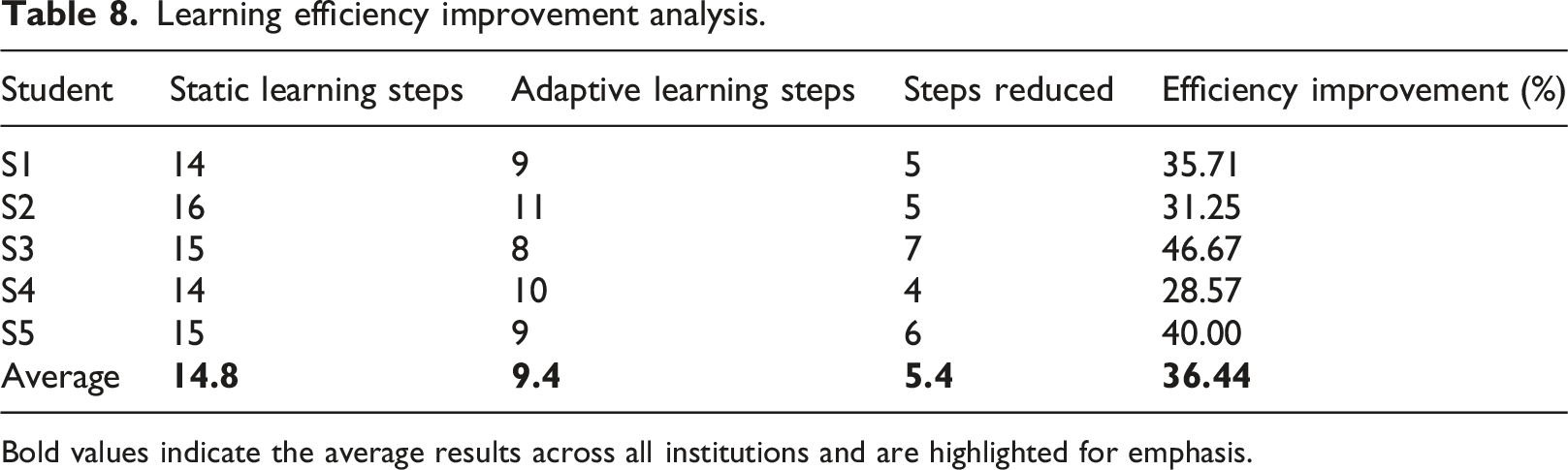
Bold values indicate the average results across all institutions and are highlighted for emphasis.
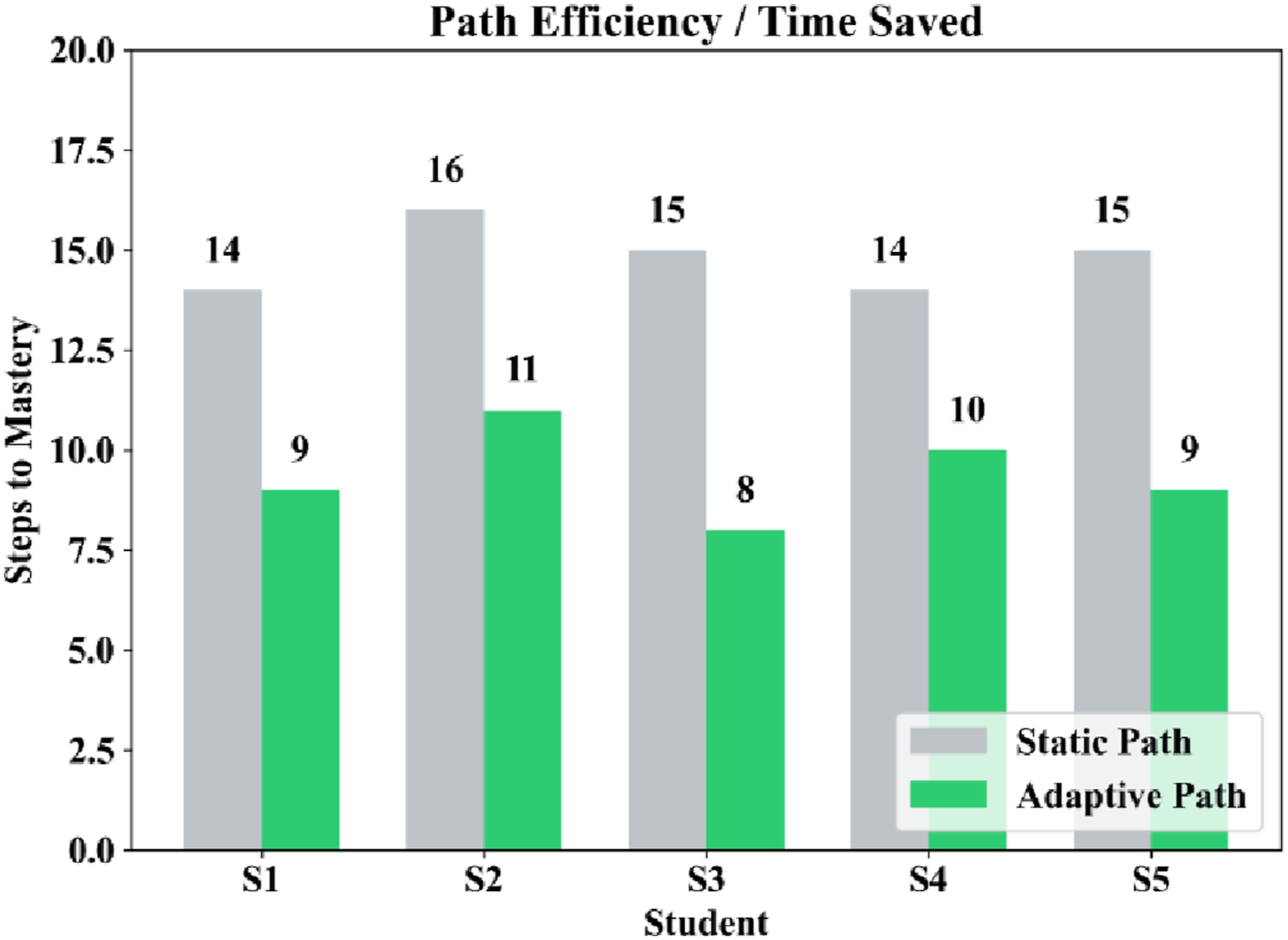
Comparison of learning steps required to achieve mastery between static and adaptive learning paths.
As indicated in Table 8, the suggested adaptive learning model decreased the number of learning steps towards mastery in all students. With the static curriculum, the average number of learning steps needed to reach the status of mastery was 14.8, and with adaptive learning framework, the average number of required learning steps dropped to 9.4. This is an average of 5.4 steps per student and a total of 36.44% has been saved in efficiency. Student S3 showed the greatest improvement in efficiency with a reduction of 7 learning steps, which is equivalent to 46.67% improvement. In the same manner, students S1 and S5 made 5 and 6 step improvements, which translates to efficiency increase of 35.71 and 40.00, respectively. The smallest improvement that was observed, in the case of student S4, was still a significant decrease of 4 steps, which is a 28.57% efficiency gain.
Figure 13 illustrates graphically the difference in mastery of the learning steps necessary to the learning path used in the static and adaptive learning in learning. Adaptive learning framework made significantly fewer steps in all students, which proved the efficacy of reinforcement learning to improve learning sequences.
The intelligent decision-making ability of the reinforcement learning agent can be credited with the efficiency improvement. With the help of the correct representations of knowledge states that the Deep Knowledge Tracing model provides, the agent chooses the modules that should be recommended and that directly relate to the knowledge gaps in students. This will help to avoid wastage of time by a student in concepts which he/she has already mastered and direct any learning activity towards areas that one needs improvement. In addition, the adaptive framework promotes the remediation as well as acceleration. Students with poor mastery in some of the concepts are directed to the relevant remedial modules, whereas high mastery students are given an opportunity to skip unnecessary material. This interactive adjustment reduces unnecessary learning processes and speeds up the process of mastering. The shorter number of learning steps also translates to the shorter learning time, increased student productivity, and the higher learning experience. Institutionally, this efficiency increase will facilitate the more efficient use of learning resources and allow deploying it on a large scale among a large number of students.
Multi-institution generalization performance
Multi-institution learning gain comparison.
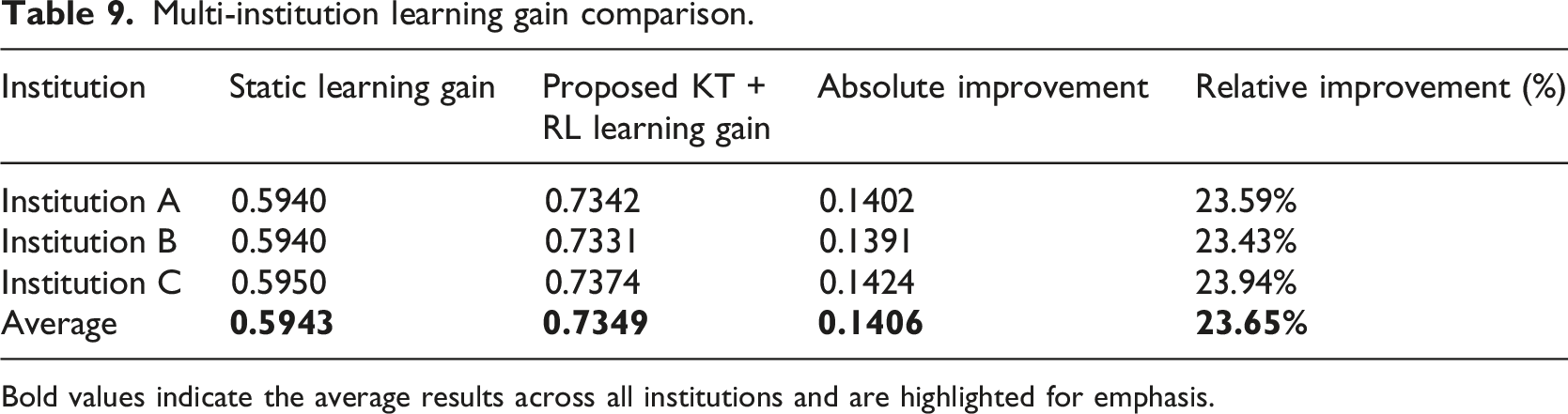
Bold values indicate the average results across all institutions and are highlighted for emphasis.
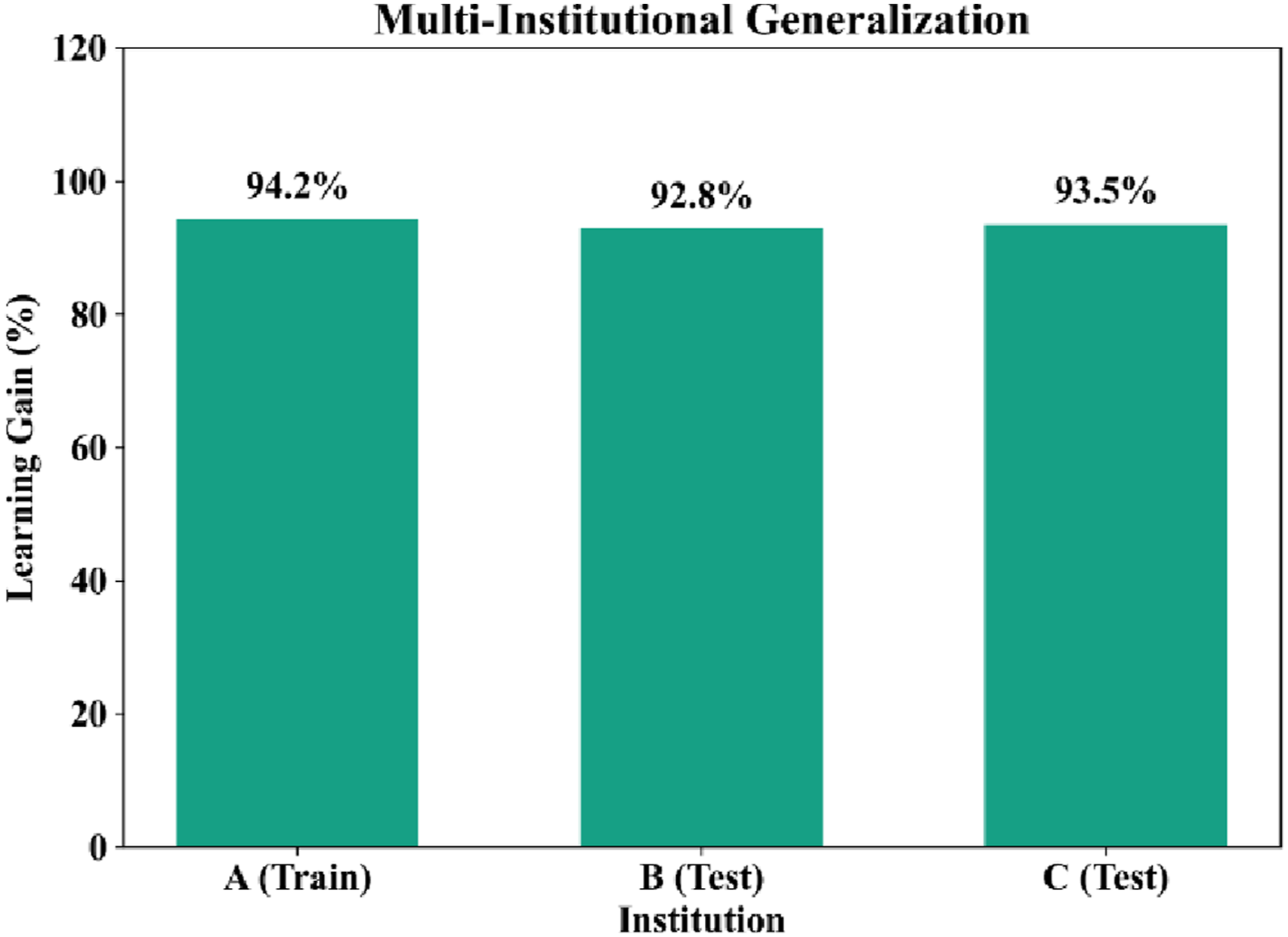
Cross-institution generalization performance of the proposed adaptive learning framework.
The proposed Knowledge Tracing and Reinforcement Learning (KT + RL) framework was found to be performing better than the static learning system in all the three institutions (Table 9). The learning gain in institution A was between 0.5940 and 0.7342 which is a relative improvement of 23.59. Likewise, Institution B showed the improvement of 23.43% and Institution C had the best improvement of 23.94 thereby going up to 0.7374 than 0.5950. The proposed framework had an average learning gain of 0.7349 and 0.5943 of the static baselines (with an average relative improvement of 23.65%). This generalizability of performance in different institutions implies that the suggested adaptive learning framework is successful in generalizing performance in diverse academic settings.
Figure 14 demonstrates how effective the adaptive learning model has been at all the different institutions as demonstrated through much higher learning gains than the static curriculum. Also, the very little difference in the percentages of improvements across the various institutions further confirms the reliability and stability of the proposed adaptive learning model.
There are two primary reasons for the adaptive learning model’s apparent strong generalizability. First, using the deep knowledge tracing (DKT) model allows for an accurate inference of common learning patterns and the progression of knowledge of students as they move from one education system to another (or across institutions). Secondly, the reinforcement learning agent learns the best policies to obtain mastery of skills based on student mastery states (not on how students were taught at different institutions). This allows for the creation of an optimal learning policy for students regardless of the environment in which they are learning.
The cross-institutional consistency of the proposed framework is evidence that it does not exhibit overfitting to a specific dataset, and the proposed framework can be successfully implemented across a variety of higher education settings. In order to be implemented in the real world, an ability to generalize from one university to another is very important because of scalability and ability to implement across many types of institutions, courses, and student populations.
Overall performance summary of the proposed adaptive learning framework.
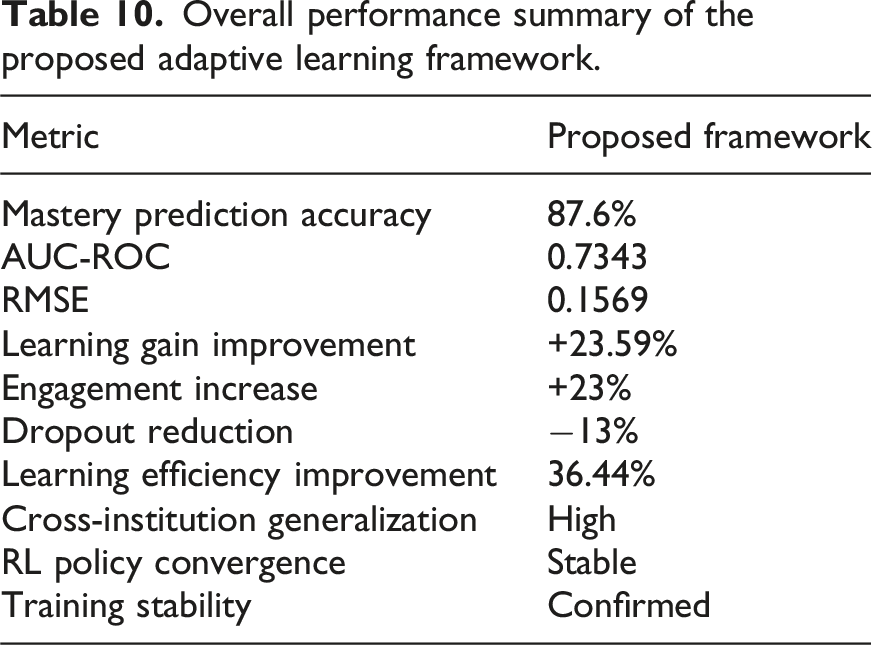
The proposed framework performs better than fixed learning paths in all measures considered. A combination of DKT and DQN allows creating a personalized, efficient and scalable adaptive learning trajectory, enhancing engagement, decreasing dropout rates and extrapolating across institutions. Besides, the consistency of performance, computational cost across institutional datasets was also consistent, and training convergence was reached within similar epochs and did not grow exponentially with the processing time. The complexity of the model is proportional to the number of students and interactions of the learning process, which ensures its feasibility at large scales, meaning the possibility of cross-institutional implementation. The state representation and fixed capacity neural architecture ensure that uncontrolled parameter growth when expanding to other institutions, which also favors scalability.
Discussion
The experiment findings are clear evidence that the adaptive learning framework that combines DKT and DQN has a great impact on the effectiveness of personalized learning systems. The smart adaptive decision-making and correct modeling of student knowledge allow generating optimal learning paths leading to quantifiable changes in learning outcomes, engagement, and efficiency. The accuracy of the Knowledge Tracing component is one of the major strengths of the proposed framework. The DKT model had a mastery prediction accuracy of 87.6, AUC-ROC of 0.7343 and RMSE of 0.1569, which means that it has good predictive properties and can be used to estimate student states of knowledge. These findings ascertain that the DKT model, built on LSTM, is an effective way of capturing the temporal dynamics of student learning behavior and the changes in knowledge with time. Mastery estimation is vital because it gives the state representation in which reinforcement learning is effective.
The RL component showed effective and constant optimization of policies. The accumulated reward has been on the rise, and the distribution of the reward is constant. DQN agent has managed to converge after about 742-780 training episodes. This verifies that the agent was exposed to an optimum policy of selecting a module, which results in the maximization of the long-term learning. The optimization mechanism that is reward-based is what allows the agent to respond dynamically to the progress of the students and thus have an efficient and individualized instruction. One of the most important findings of the present research is a significant enhancement in the learning gain of the proposed framework. The KT + RL model has a learning gain of 0.7349 which is a 23.59% improvement over the score of the static curriculum baseline. This difference was statistically significant (p < 0.05), which proves that adaptive reinforcement learning-based module sequencing has calculable advantages over the standard fixed learning sequences. The ablation experiments also confirmed the significance of combining the two elements, and reinforced the fact that, although Knowledge Tracing can give precise mastery prediction, Reinforcement Learning is the key to the optimization of the learning sequence.
The proposed framework also led to significant improvement on student engagement in addition to improving the learning outcomes. The time used in learning activities was raised to 68 out of 45% and the rate of revisit improved to 32 out of 12%, showing that there was better active engagement and knowledge reinforcement. Moreover, the dropout rate was lowered significantly (18% to 5%), which proved that individual adaptive learning increases student motivation and retention. A lot of efficiency was also realized in the proposed framework. The adaptive learning methodology minimized the number of instructions needed to master the learning by about 35% implying that the learning was quicker. This efficiency level improves the cognitive load and learning time of students and optimizes the level of knowledge acquisition.
Notably, the multi-institution assessment reflected the strength and applicability of the suggested framework. The model has shown a high ability to generalize, with all the institutions having learning gains of more than 23%. This validates the fact that the framework is not based on institution-related features and can be effectively implemented in a variety of educational settings. In general, Knowledge Tracing and Reinforcement Learning have synergistic value in integration. Knowledge Tracing allows to model student knowledge states correctly, and Reinforcement Learning allows choice of learning routes based on student knowledge states. This integration allows the creation of smart adaptive learning systems that would be able to provide personalized, efficient, and scalable learning.
Conclusion and future work
This research presented a learning path generation framework that is intelligent and based on DKT and DQN to optimize the optimization of personalized learning in higher education. The main goal was to create a data-driven framework that can precisely model the knowledge of students and dynamically suggest the best learning modules to achieve the maximum mastery and the best efficiency in learning. Deep Knowledge Tracing component effectively promoted the knowledge evolution of the students based on the data of temporal learning interaction. The DKT model was associated with highly positive predictive power, which had a mastery prediction accuracy of 87.6%, AUC-ROC of 0.7343, and a RMSE of 0.1569. The findings prove that the LSTM-based architecture is useful in capturing the sequential learning patterns and accurate student knowledge state representations. On these knowledge representations, the Deep Reinforcement Learning component maximized selection of modules by applying a reward-based learning approach. The Deep Q-Network agent was able to converge as well as learn optimal policies in module recommendation. Adaptive learning model recorded a 23.59 % learning gain over traditional static plot of curriculum progression, which indicated the feasibility of reinforcement learning in streamlining individualized learning paths. Besides, increasing the learning outcomes, the suggested framework considerably positively increased the engagement and the efficiency of learning among the students. The adaptive approach gave a boost in the level of engagement, dropout rates reduced, and the number of steps needed to master the learning process decreased by around 35%.
These results show how personalized adaptive learning is effective in enhancing the performance and learning experience of students. Moreover, the multi-institution test assured the strength and extrapolation ability of the offered framework. The model was constantly found to be very successful in various types of institutional data which confirms that it can be scaled and used in a wide variety of educational settings. In general, Knowledge Tracing and Reinforcement Learning integration offers a highly intelligent and efficient adaptive learning path generation solution. The suggested structure would allow proper modeling of students, optimal learning paths, and scaling to be used in the higher education systems. In the future, researchers could look into more intricate reinforcement learning approaches (e.g., PPO, Actor-Critic) that would enhance how policies are created. They could also look into adding additional types of behavioral variables for students, enabling online utilization of Learning Management Systems (LMS), performing multi-objective optimization, employing explainable artificial intelligence (AI), leveraging larger, varied datasets; and utilizing multimodal data (i.e., video interactions and eye-tracking) so that models are created based on a broader understanding of the student. The adaptive learning framework we developed can be applied to intelligent tutoring systems and personalized recommendation platforms which deliver educational solutions based on data-driven methods to meet the needs of individual learners. Assistive technologies create major benefits for inclusive education because they improve accessibility and enable students with disabilities to learn and participate in school activities. Future work should focus on scalable, intelligent, and personalized assistive systems for broader educational impact.
Footnotes
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
All authors have reviewed and approved the manuscript and consent to its publication.
Author Contribution
Long Jishuang: Conceptualization, methodology, software development, data curation, formal analysis, writing – original draft preparation, visualization. Kamisah Osman: Supervision, conceptualization, validation, writing – review and editing, project administration. Faridah Mydin Kutty: Methodological guidance, validation, writing – review and editing, academic supervision. All authors have read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.