
Abstract
Objective
To assess the ability of a cleft-specific multi-site learning health network registry to describe variations in cleft outcomes by cleft phenotypes, ages, and treatment centers. Observed variations were assessed for coherence with prior study findings.
Design
Cross-sectional analysis of prospectively collected data from 2019–2022.
Setting
Six cleft treatment centers collected data systematically during routine clinic appointments according to a standardized protocol.
Participants
714 English-speaking children and adolescents with non-syndromic cleft lip/palate.
Intervention
Routine multidisciplinary care and systematic outcomes measurement by cleft teams.
Outcome Measures
Speech outcomes included articulatory accuracy measured by Percent Consonants Correct (PCC), velopharyngeal function measured by Velopharyngeal Competence (VPC) Rating Scale (VPC-R), intelligibility measured by caregiver-reported Intelligibility in Context Scale (ICS), and two CLEFT-Q™ surveys, in which patients rate their own speech function and level of speech distress.
Results
12year-olds exhibited high median PCC scores (91–100%), high frequency of velopharyngeal competency (62.50–100%), and high median Speech Function (80–91) relative to younger peers parsed by phenotype. Patients with bilateral cleft lip, alveolus, and palate reported low PCC scores (51–91%) relative to peers at some ages and low frequency of velopharyngeal competency (26.67%) at 5 years. ICS scores ranged from 3.93–5.0 for all ages and phenotypes. Speech Function and Speech Distress were similar across phenotypes.
Conclusions
This exploration of speech outcomes demonstrates the current ability of the cleft-specific registry to support cleft research efforts as a source of “real-world” data. Further work is focused on developing robust methodology for hypothesis-driven research and causal inference.
Keywords
Introduction
Throughout their young lives, children with cleft lip/palate may experience challenges in eating, speaking, breathing, and hearing, and they may carry the visible stigma of looking “different,” even when appropriate and timely treatment is provided. Such treatment consists of complex protocols of operative and non-operative interventions, delivered in stages across two decades of the child's life, and best coordinated by an interdisciplinary team. Unfortunately, the study of cleft care is limited by the small size of this population, its heterogeneity, and the decades of follow-up time required to adequately study their long-term outcomes. Pioneering studies, such as those from the Eurocleft,1,2 Scandcleft,3,4 Americleft,5,6 CSAG,7,8 CleftCareUK,9–11 UK Cleft Collective,12,13 and TOPS 14 projects as well as work by Klintö et al.15–17 demonstrate the power of multi-center collaboration to generate impactful scientific evidence and improve care for cleft patients. These projects also demonstrate the magnitude of time and resources required to answer a single question about cleft care through traditional study designs.
While the most robust research data arguably comes from randomized controlled trials, experimental research designs may be unfeasible for studying long-term outcomes of cleft lip/palate care. A more practical solution may be longitudinal outcome studies that take advantage of multi-center, “real-world data.”18–20 In recent years, the importance of utilizing “real-world data” (RWD) to produce “real-world evidence” (RWE) has been emphatically stressed by the FDA, 20 the NIH, 21 and respected research groups.22–30 Sources of RWD include electronic health records, administrative databases, and clinical registries. Each of these data sources has strengths and weaknesses, and their suitability may vary based on the specific research question. Of these potential data sources, condition-specific registry data are arguably the most suitable for addressing questions about clinical care; however, because registry data are usually not collected with a specific research question in mind, there exists a critical need to evaluate the type and quality of scientific evidence that a RWD registry can support.
Several cleft-specific registries exist internationally, including the Swedish Cleft Lip and Palate Registry15,31–33 and those organized by European Registration Network (ERN) CRANIO, 34 CRANE, 35 and Cleft Outcomes Registry/Research Network (CORNET), 36 among others. Several of these registries collect speech outcomes data by recalling patients for research-specific visits. For the purposes of this study, we adhere to a more restricted definition of “real-world data” as structured outcomes data and other variables that are prospectively measured and recorded according to recommended guidelines during routine clinical encounters, rather than as part of a more rigid research protocol. Specifically, the data presented here derive from the Allied Cleft & Craniofacial Quality-Improvement and Research Network (ACCQUIREnet). 37 This is a North American collaborative learning health network of multidisciplinary cleft/craniofacial teams that have adopted and implemented data standards for prospective data collection. Uniquely, ACCQUIREnet is the first scalable network of its kind in the Americas to integrate systematic cleft-specific data-collection into the clinical workflow of participating centers. This exploratory pilot study evaluates the potential of ACCQUIREnet's cleft-specific RWD to meaningfully describe outcomes of cleft care, focusing on speech outcomes as proof-of-concept. Rigorous conventional research has demonstrated impaired articulation, velopharyngeal function, and intelligibility in patients with cleft lip and palate, especially bilateral,38–43 while speech of patients with less-severe clefts tends to be less affected.4,38,44 Meanwhile, speech is likely to be impaired in younger patients with clefts.4,8,13,17,40,45,46 Here, the ACCQUIREnet registry data were assessed for coherence with these previous findings. Registry data were also evaluated as proof-of-concept for their capacity to support future inter-center comparisons. In this study we expected that the registry data could describe speech outcomes (1) by cleft phenotype, (2) by age or stage in treatment, and (3) by treatment center.
Methods
Network, Data-Collection Protocol, and Registry Details
ACCQUIREnet 37 is a collaborative learning health network that includes (at the time of this writing) 11 multidisciplinary cleft/craniofacial teams in North America in various stages of onboarding. This study analyzed data collected by the first six teams, which were located in urban cities throughout the Northeast, Southeast, and Midwest United States. Their combined data did not constitute a specific regional catchment area, but rather reflected the state of cleft care at these individual treatment centers and across the ACCQUIREnet community. Geostatistical data was not routinely collected in the database during this study, however, ACCQUIREnet ultimately intends to capture such information for the purpose of future geostatistical modeling.
The outcomes data and other variables collected by ACCQUIREnet were defined by data standards codebook version 2020–08–14, which was a superset of the International Consortium for Health Outcome Measurement (ICHOM) Standard Set for the Comprehensive Appraisal of Cleft Care,37,47,48 version 5. As previously described, the outcomes in the Standard Set included clinician-reported, patient-reported, and family-reported outcome measures across many outcome domains (e.g., speech, hearing, dental, surgical, psychosocial, etc.). 48 Each team collected data prospectively, with required time points in early infancy, childhood (3y and 5y), adolescence (8y, 12y, and 15y), and young adulthood (up to 22y). Data were collected during routine clinical encounters. There were no project-specific recalls of patients simply for data collection. Clinician-reported outcomes were measured by the appropriate clinical discipline (in this study, speech-language pathologists). Patient-reported outcome measures and family-reported outcome measures were collected using iPad® computers (Apple Inc., Cupertino, CA) during the clinical encounter. 49 Data were stored in a standardized database using Research Electronic Data Capture (REDCap™) (Vanderbilt University, Nashville, TN).50,51
All patients with orofacial clefts and English-speaking families were eligible for inclusion in the ACCQUIREnet registry, from which this study derived its data. Centers in the network obtained signed English consent from parents/patients for participation and data collection. One center joined the network using a quality-improvement exemption from its local Institutional Review Board (IRB) such that no signed consent was necessary; in this case, data were reported to the coordinating center in de-identified fashion, as specified by the data-transfer agreement. The study protocol was reviewed and approved by the IRB (Pro00104806), and the project was registered with clinicaltrials.gov as a prospective cohort study (NCT02702869).
Study Design and Population
This exploration was a cross-sectional study of speech outcomes data collected by six multidisciplinary cleft teams (designated centers A through F) between 2019 and 2022. Inclusion criteria were that patients had an isolated cleft lip and/or palate, no known syndrome or genetic anomaly, were aged 3–15y at time of data collection, spoke English, and had English-speaking parents. Cleft phenotypes were categorized into the following groups: unilateral or bilateral cleft lip with/without cleft alveolus (CL ± A); unilateral cleft lip, alveolus, and palate (uCLAP); bilateral cleft lip, alveolus, and palate (bCLAP); and cleft palate (CP). 52 Patients with CL ± A were expected to have largely unaffected speech and were included in this study to contextualize speech data from patients more affected by their clefts.
Outcomes were measured prospectively and longitudinally during routine clinic visits with the team at ages 3y, 5y, 8y, 12y, and 15y. For patients with multiple (longitudinal) measurements, only the most recent measurement was considered in this analysis, and the patient was categorized as that age. Patients were not necessarily consecutive at each treating center and were simply considered representative of each phenotype and age.
Outcomes Measures
The primary outcomes considered in this study included clinician-reported, patient-reported, and family-reported measures of speech function and related distress, as described below:
Percent Consonants Correct (PCC) is a clinician-reported measure of articulatory accuracy assessed by listening to the patient produce target sounds. 53 PCC is a continuous variable on a scale of 0–100%, with higher scores indicating better articulation. For this study, PCC was measured in live sessions at ages 3y, 5y, 8y, and 12y by speech-language therapists with training in perceptual assessment of cleft palate speech. 48 Most centers evaluated PCC in the context of single-words using a standardized word sample, such as the Goldman-Fristoe (GFTA-3), 54 but at the time that these data were collected, Center C evaluated PCC in the context of whole sentences. Passive articulatory errors were not scored as incorrect if oral placement was correct.
The velopharyngeal competence rating (VPC-R) is a clinician-reported measure that grades the functionality of a patient's velopharyngeal mechanism by considering oral pressure during appropriately-articulated oral pressure consonants, overall resonance, and nasal air emission. 55 VPC-R is a 3-level ordinal scale (0, 1, 2), in which the velopharyngeal mechanism is rated as competent (0), marginally incompetent (1), or incompetent (2). Notably, the scale's chosen terms “competence” and “incompetence” here describe the overall function of the velopharyngeal mechanism rather than denoting specific etiology (which may be structural or neuromuscular). In this study, VPC-R was measured by experienced speech-language pathologists at ages 3y, 5y, 8y, and 12y. 48 The clinicians formed a perceptual impression of the patient's velopharyngeal competence throughout the entirety of the live clinical speech assessment, which included the standardized speech sample at single-word level and in connected speech. Although patients with CL ± A are not typically at risk of velopharyngeal incompetence (due to an intact palate), their VPC-R scores were included in this analysis as a reference cohort for speech not impacted by cleft palate.
The Intelligibility in Context Scale (ICS) is a caregiver-reported measure of the patient's ability to be understood by others (family, friends, teacher, etc) in activities of daily life.56,57 The ICS is structured as a series of 5-point Likert-type questions, and the total score is the average of the prior responses, treated as a continuous variable ranging from 1–5. Higher scores indicate more functionally intelligible speech. In this study, ICS was measured at ages 5y, 8y, and 12y of age. 48
The CLEFT-Q™ Speech Function scale is a patient-reported measure that quantifies the frequency of experiencing difficulty with speech tasks.58–60 This is a continuous variable on a scale of 0 to 100. The higher the score, the easier the patient perceives speaking to be. In this study, this outcome was measured at ages 8y, 12y, and 15y of age. 48
The CLEFT-Q™ Speech Distress or Speaking-Related Distress scale is a patient-reported measure that quantifies the frequency of a patient's negative feelings towards his or her speech.58–60 This is a continuous variable on a scale of 0 to 100. The higher the score, the higher the degree of well-being (i.e., less distress) that the patient experiences during speaking. In this study, this outcome was measured at ages 8y, 12y, and 15y. 48
Data Analysis
Data from the six sites were aggregated into a single de-identified sample. Patients were stratified by age, phenotype, and treatment center. Parametric estimates for these cross-sections are summarized in Supplemental Tables 2 and 3, including the median scores and interquartile ranges of PCC, ICS, CLEFT-Q Speech Function, and CLEFT-Q Speech Distress scores as well as the frequency of each ordinal VPC-R score. Figures 1–5 show relationships graphically using box-and-whisker plots for the continuous variables and stacked bar charts for the categorical VPC-R. Further statistical significance testing was not pursued because of the exploratory, descriptive intent of this study. Statistics and figures were generated using Python 3.8.12 61 and matplotlib 3.5.2 62
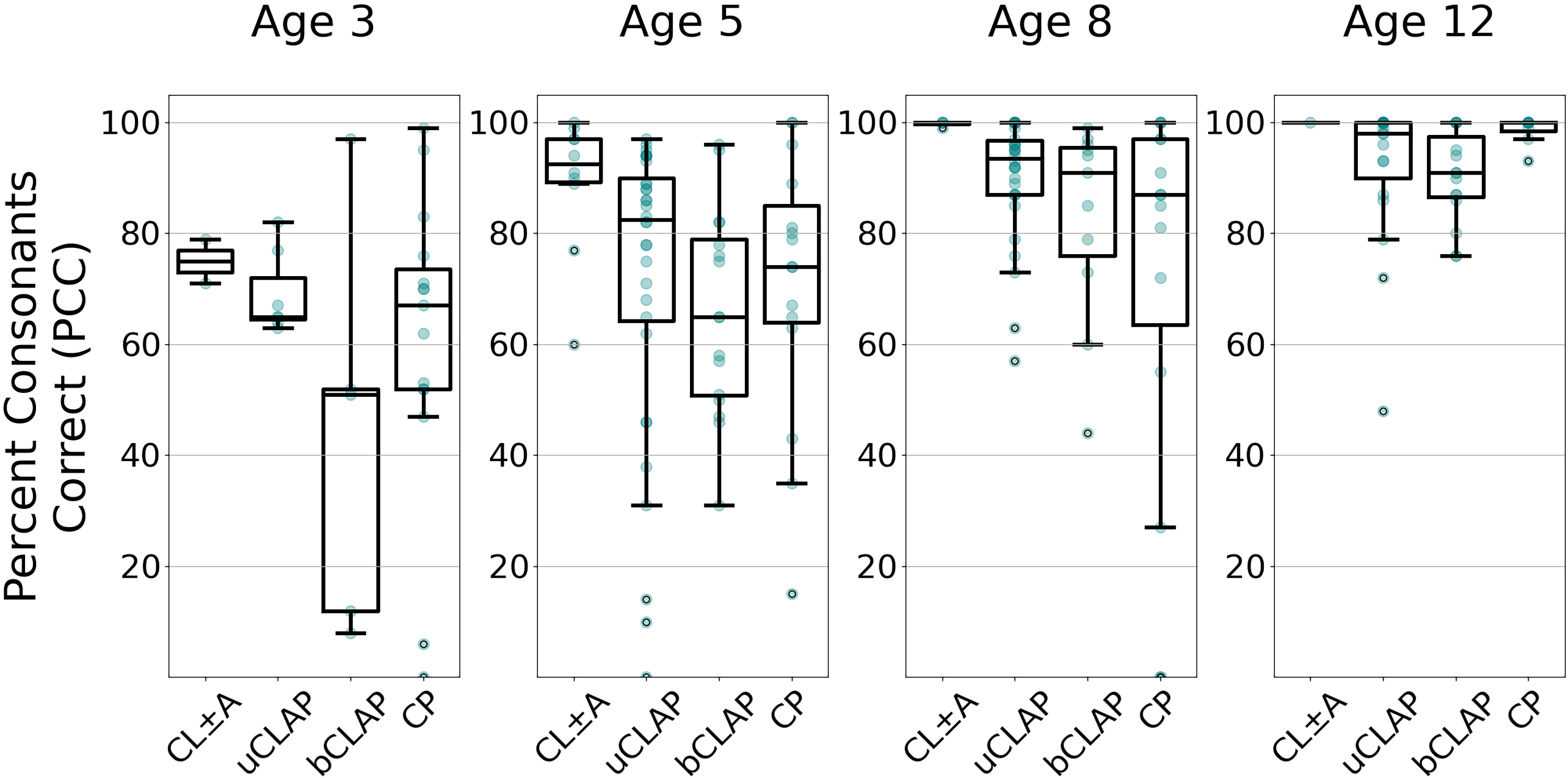
Articulation outcomes according to percent consonants correct (PCC) by age and phenotype. Patients are separated by age into four subplots. Within each, phenotypes are separated along the horizontal axis and PCC scores are shown along the vertical axis. Phenotype abbreviations from left to right: cleft lip with or without cleft alveolus; unilateral cleft lip, alveolus, and palate; bilateral cleft lip, alveolus, and palate; and isolated cleft palate. Sample sizes (grouped by age) from left to right: (n = 2, 7, 65, 15); (n = 10, 32, 16, 15); (n = 4, 30, 11, 15); (n = 1, 19, 15, 8).
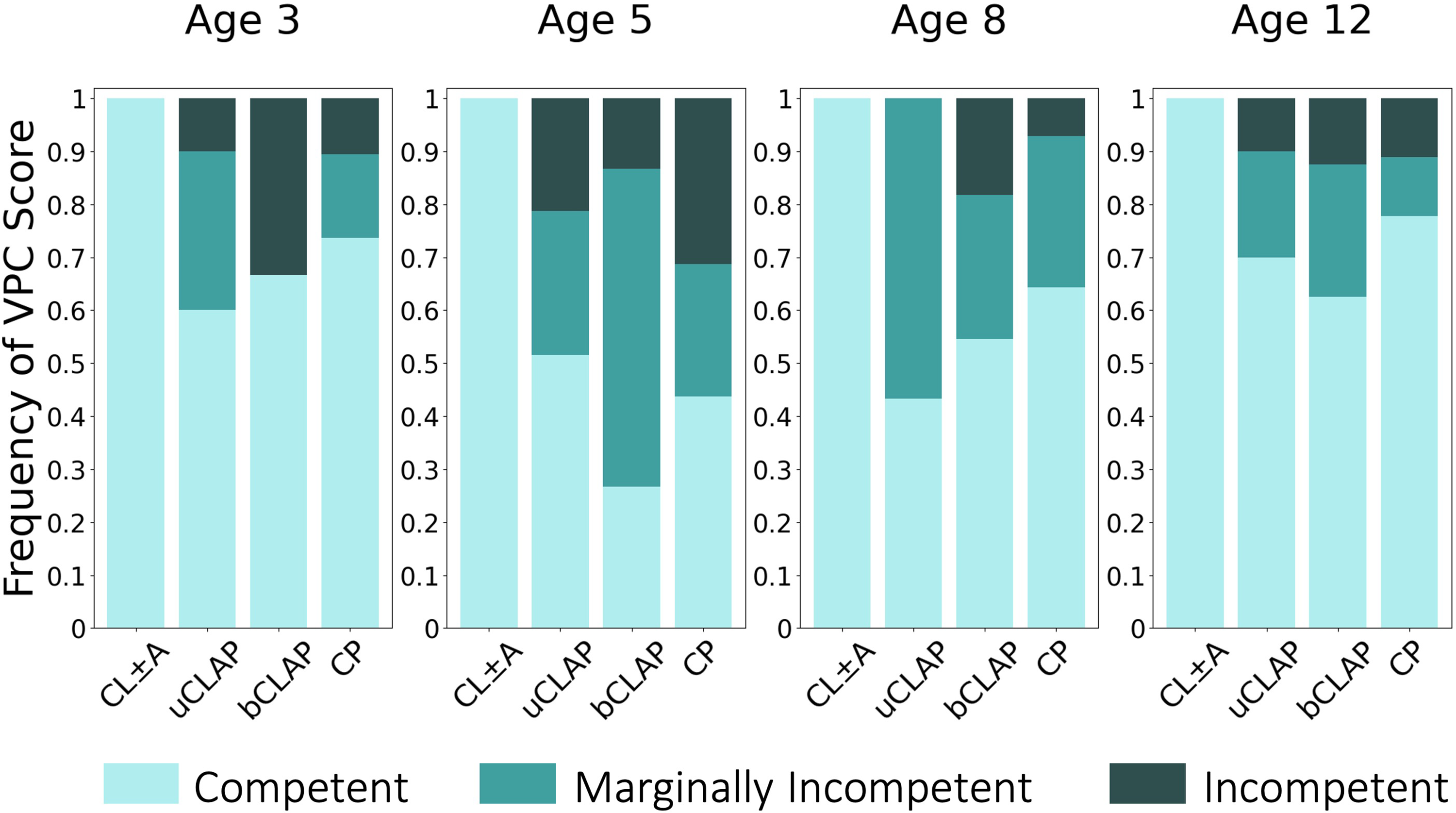
Velopharyngeal competence rating (VPC-R) scores, stratified by age and phenotype. Again, patients are stratified by age into 4 subplots and along the horizontal axis by phenotype. Vertically, bars are normalized to 1.0, with height of the bar representing the percentage of patients receiving a given score. Darker shades represent more dysfunctional VPC scores. Phenotype abbreviations from left to right: cleft lip with or without cleft alveolus; unilateral cleft lip, alveolus, and palate; bilateral cleft lip, alveolus, and palate; and isolated cleft palate. Sample sizes (grouped by age) from left to right: (n = 2, 10, 6, 19); (n = 10, 33, 15, 16); (n = 4, 30, 11, 14); (n = 1, 20, 16, 9).
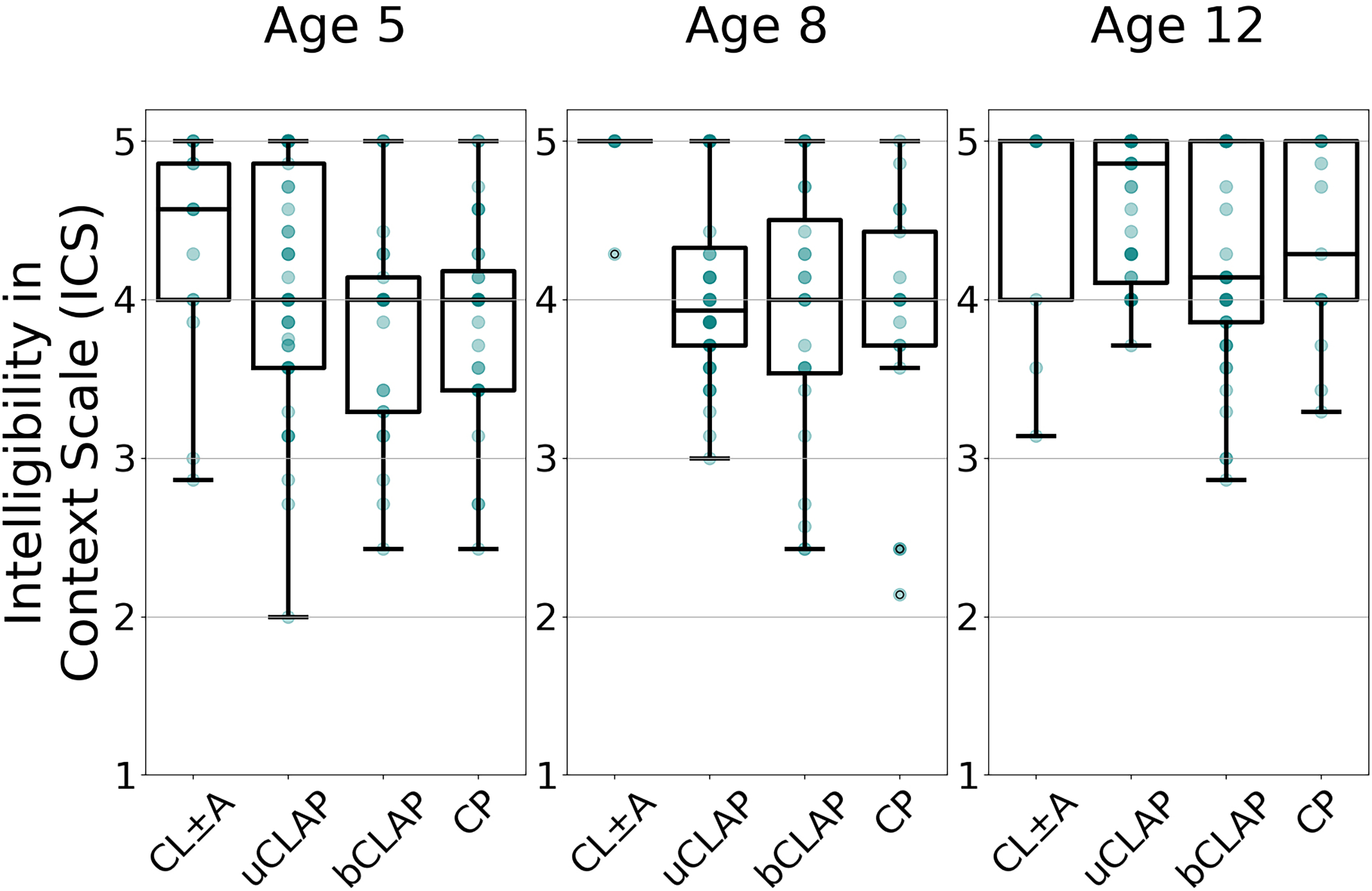
Intelligibility outcomes according to intelligibility-in-context scale (ICS), stratified by age and phenotype. Patients are stratified by age into 3 subplots and along the horizontal axis by phenotype. The vertical axis shows ICS scores. Phenotype abbreviations from left to right: cleft lip with or without cleft alveolus; unilateral cleft lip, alveolus, and palate; bilateral cleft lip, alveolus, and palate; and isolated cleft palate. Sample sizes (grouped by age) from left to right: (n = 14, 45, 25, 32); (n = 6, 44, 24, 17); (n = 9, 48, 41, 13).
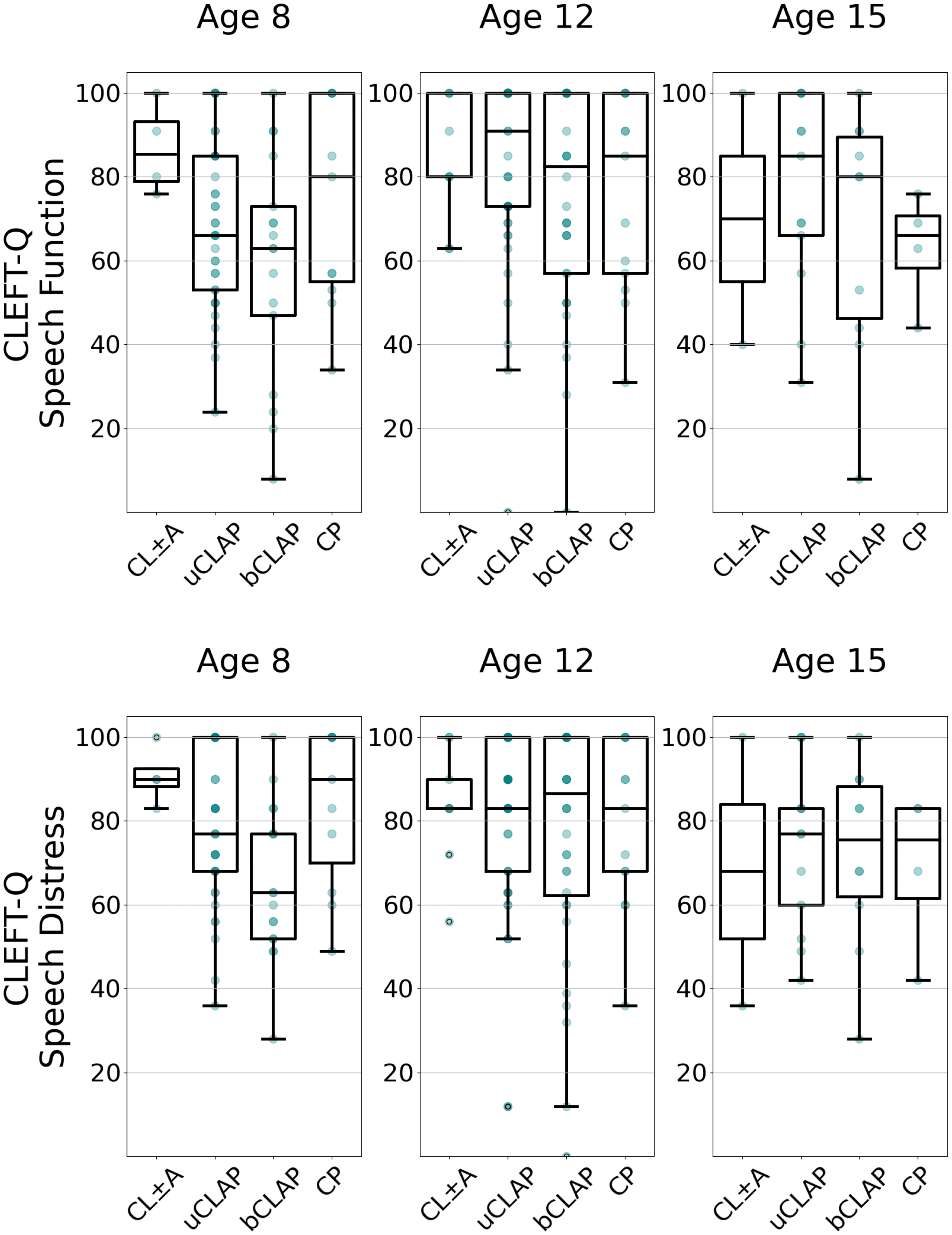
CLEFT-Q™ speech function (top) and speech distress (bottom), stratified by age and phenotype. In each row, patients are stratified by age into 3 subplots and along the horizontal axis by phenotype. Along the top row, the vertical axis shows CLEFT-Q Speech Function scores. Sample sizes (grouped by age) from left to right: (n = 4, 37, 17, 11); (n = 9, 45, 36, 13); (n = 2, 13, 10, 4). Along the bottom row, the vertical axis shows CLEFT-Q Speech Distress. Sample sizes (grouped by age) from left to right: (n = 4, 37, 17, 11); (n = 9, 45, 36, 13); (n = 2, 12, 10, 4). Phenotype abbreviations from left to right: cleft lip with or without cleft alveolus; unilateral cleft lip, alveolus, and palate; bilateral cleft lip, alveolus, and palate; and isolated cleft palate.
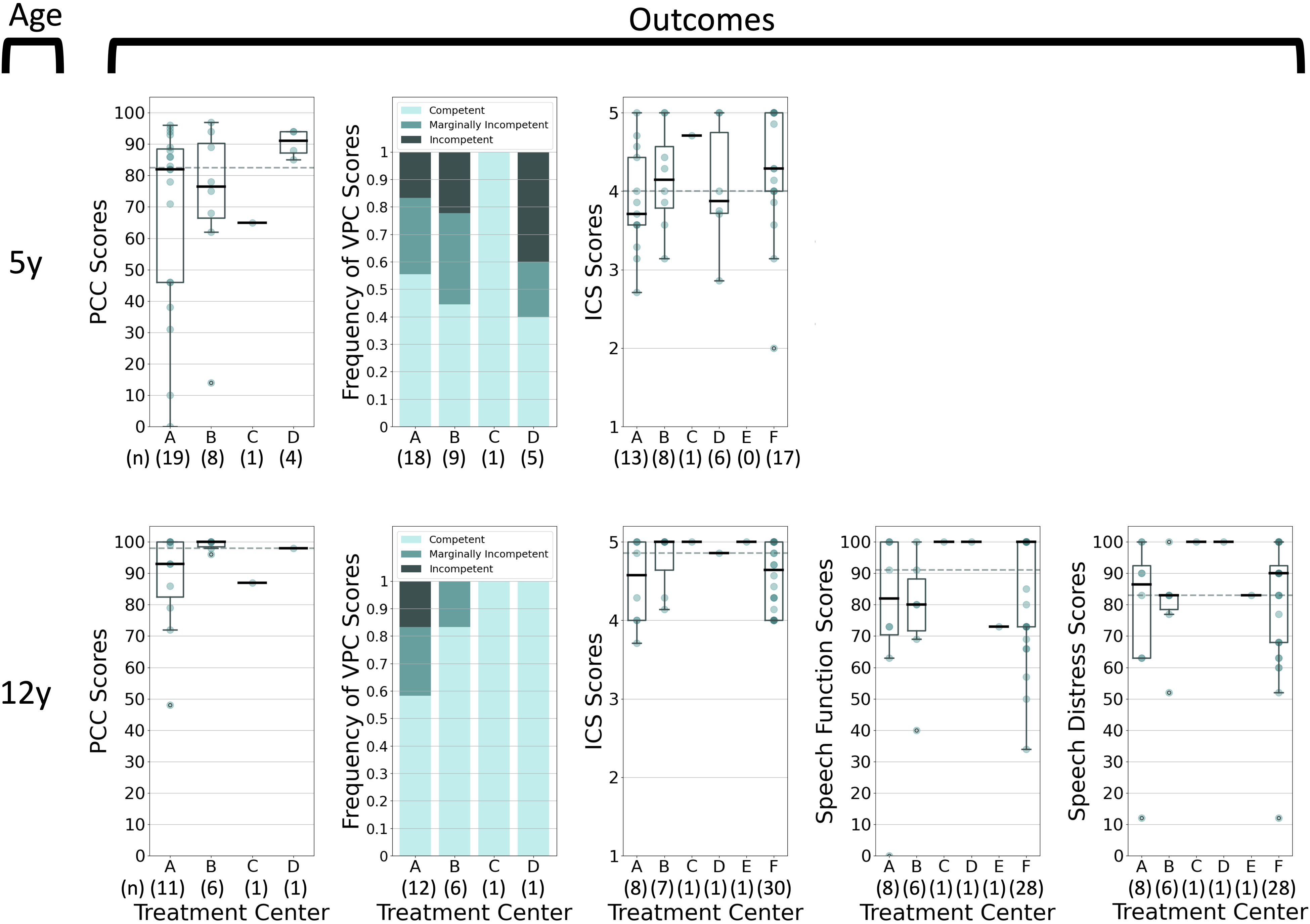
Speech outcomes by treatment center for 5y-old patients (top) and 12y-old patients (bottom) with unilateral cleft lip, alveolus, and palate. From left to right: Percent Consonants Correct (PCC), Velopharyngeal Competence Rating (VPC-R), Intelligibility in Context Scale (ICS), CLEFT-Q™ Speech Function, and CLEFT-Q™ Speech Distress scores stratified by treatment center (A-F). Sample sizes are shown in parentheses below each team label.
Results
Baseline Characteristics
This study consented 813 patients, of which 87.82% (714/813) met inclusion criteria. Twelve were excluded because English was not routinely spoken at home, despite giving consent in English, and an additional 87 were excluded because of a comorbid syndrome affecting speech. Although this study included a large total of patients, stratification by phenotype and exact age in years yielded small sample sizes for all analyses to follow. As summarized in Table 1, 57.56% (411/714) of the sample was male and 39.08% (279/714) came from Center A (because it began data collection first). Regarding phenotype, 8.96% (64/714) of this sample had CL ± A, 43.56% (311/714) had uCLAP, 25.63% (183/714) had bCLAP, and 21.85% (156/714) had CP. These proportions are consistent with prior national 63 and international 64 reports that cleft lip and palate is more prevalent than isolated cleft palate, which is more prevalent than isolated cleft lip. Of the sampled patients, 50.14% (358/714) contributed PCC data, 51.96% (371/714) contributed VPC-R data, 77.31% (552/714) contributed ICS data, and 48.04% (343/714) contributed CLEFT-Q Speech Function and CLEFT-Q Speech Distress data. As not all outcomes were intended to be collected at each age, these statistics underestimate data completion.
Baseline Characteristics of Study Population.
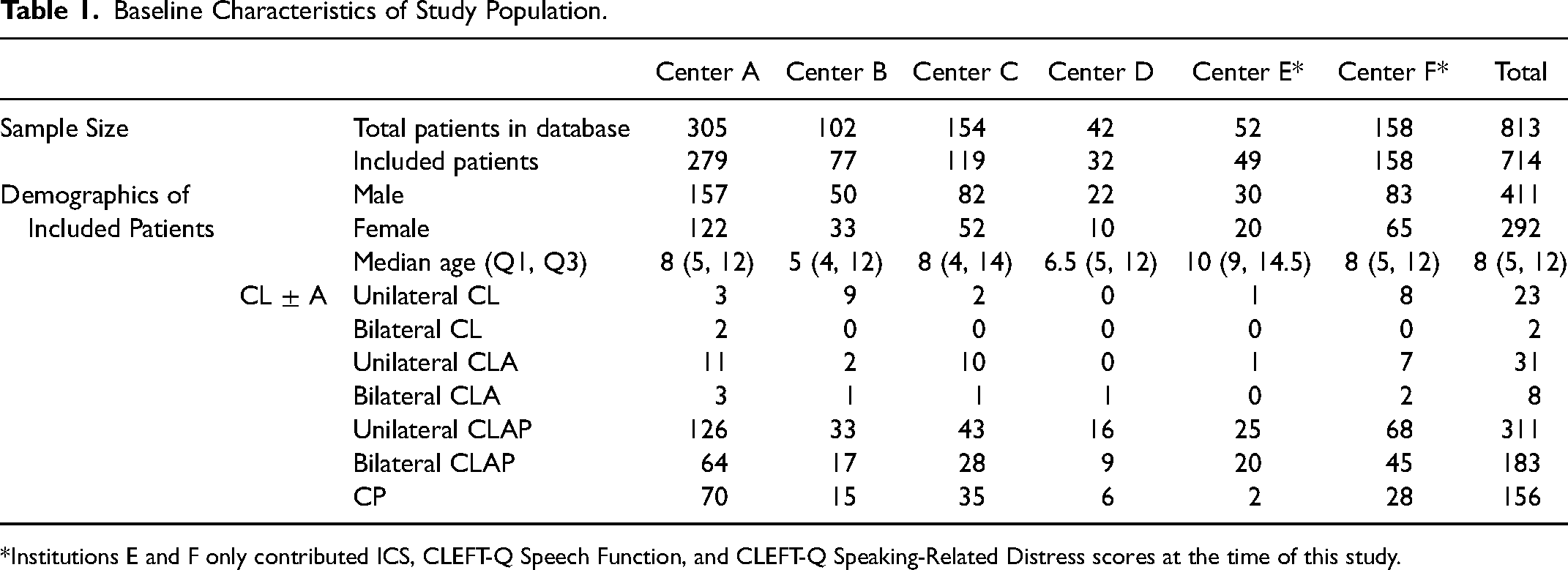
*Institutions E and F only contributed ICS, CLEFT-Q Speech Function, and CLEFT-Q Speaking-Related Distress scores at the time of this study.
Outcomes by Age and Phenotype
Percent Consonants Correct (PCC)
In this sample, older age groups exhibited better articulatory proficiency, as measured by higher median PCC scores, than younger age groups of the same phenotype (Figure 1). The 3y-old cross-sections exhibited the lowest median PCC scores when parsed by phenotype (51–75%). Median PCC scores for 5y- and 8y-olds were 65–92.5% and 87–100%, respectively. The 12y-old cross-sections exhibited the highest median PCC scores parsed by phenotype (91–100%).
Sampled patients with bCLAP had lower median PCC scores at 3y, 5y, and 12y of age compared to age-matched peers with other phenotypes. Across age groups, their median PCC scores ranged from 51–91%. As expected, median PCC was highest for patients with the CL ± A phenotype. 65 Aside from these clear trends, score distributions for each phenotype overlapped considerably within each age group (Figure 1).
Velopharyngeal Competence Rating (VPC-R)
For patients of any phenotype, the velopharyngeal mechanism was perceived as less competent at ages 5y and 8y and more competent at age 12y, as shown in Figure 2. Among 3y-olds with susceptible phenotypes (uCLAP, bCLAP, or CP), the perceived frequency of velopharyngeal competence (VPC-R = 0) was low (60–73.68%). This frequency was lower among 5y-olds (26.67–51.52%) and 8y-olds (43.33–64.29%) but was more frequent among 12y-olds (62.5–77.78%).
As shown in Figure 2, patients with bCLAP exhibited the lowest frequency of velopharyngeal competence (26.67%) among 5y-olds in this sample. Patients with uCLAP exhibited the lowest frequency of velopharyngeal competence (43.33%) among 8y-olds in this sample. At-risk phenotypes otherwise performed similarly within each age group. As expected, the frequency of complete velopharyngeal competence was perceived to be 100% among patients with the CL ± A phenotype for each age group.
Intelligibility in Context Scale (ICS)
Caregiver-reported functional intelligibility, as measured by median ICS score, ranged from 3.93–5.0, indicating that the child is “usually” or “always” understood (Figure 3). ICS scores for patients with bCLAP or CP were stable across age groups (4.0–4.14 and 4.0–4.29, respectively). Scores for patients with CL ± A or uCLAP showed more variation by age group (4.57–5.0 and 3.93–4.86, respectively).
In this sample, patients with uCLAP had a slightly higher median ICS score (4.86) among 12y-olds compared to age-matched peers with bCLAP and isolated CP. ICS was highest for patients with the CL ± A phenotype, but was otherwise similar across phenotypes, as shown in Figure 3.
CLEFT-Q Speech Function
Median CLEFT-Q Speech Function scores were slightly higher among 12y-olds (80–91) than among 8y-olds (63–85.5) in this sample. This was particularly true for patients with uCLAP and bCLAP, as shown in the top half of Figure 4. Sample sizes were particularly limited for this outcome among 15y-old patients.
Phenotypic groups largely reported similar Speech Function, as shown by the overlapping score distributions in the top half of Figure 4. Scores among patients with uCLAP were 66–91, among patients with bCLAP were 63–82.5, among patients with CP were 66–85, and among patients with CL ± A were 70–85.5.
CLEFT-Q Speech Distress
In this sample, median CLEFT-Q Speech Distress scores were higher among 12y-olds with uCLAP (83) and bCLAP (86.5) compared to their 8y-old counterparts. Patients with other phenotypes did not exhibit consistent age-based trends for patients aged 8y to 15y, as shown in the bottom half of Figure 4. Small sample sizes were particularly limited for this outcome among 15y-old patients.
Median CLEFT-Q Speech Distress scores were lower (worse) among patients with uCLAP (77.0) and bCLAP (63.0) compared to peers at age 8y in this sample. Phenotypic groups otherwise reported similar Speech Distress.
Outcomes by Treatment Center
Analysis of results by treatment center was extremely limited by small sample size when also stratifying by age and phenotype. No statistical testing was pursued due to this limitation; however, one example of a graphical inter-center analysis was included here as a proof-of-concept. Figure 5 shows the score distributions of for the most prevalent phenotype (uCLAP) at 5y and 12y – two timepoints at which collection of many outcomes was required. Similar parsing of registry data for other age and phenotypic combinations were possible.
Discussion
This project explored the potential of cleft-specific, multi-center, “real-world data” (RWD) to generate “real-world evidence” (RWE). The data source used was the cleft-specific registry maintained by ACCQUIREnet, 37 a learning health network that implemented the ICHOM Standard Set for the Comprehensive Appraisal of Cleft Care.47,48
ACCQUIREnet is just one of many collaborative efforts to study cleft care. In the UK, nationally organized audits carried out by CSAG and subsequently by Cleft Care UK used multi-center data to identify areas for improvement, motivate change in clinical practice, and study interval improvement after such changes were made.7–11 Doing so required a nationally standardized process of data collection, external funding, and considerable investment from clinicians and patients. ACCQUIREnet aims to create a similar cycle of self-reported outcomes research and iterative improvements. Unlike its counterparts, ACCQUIREnet must approach this aim through a minimalistic infrastructure that fits within the workflow of routine clinic visits and requires minimal, if any, outside funding to sustain itself. Prior work by Bittar et al. reported a development cost of $7707 and an average time cost per clinician of 21 min per week to implement ACCQUIREnet's data collection protocol. 49 Using RWD to achieve this minimalism, ACCQUIREnet continuously accumulates data that may eventually be used to answer multiple research questions simultaneously without the additional expense of building a new research infrastructure for each project. This example may be of particular interest to cleft centers and research entities operating with limited funding and resources.
While long-term objectives for the network are to conduct robust, prospective cohort studies and embedded pragmatic clinical trials, this present pilot study was limited to cross-sectional description of speech outcome measures, as an early proof-of-concept. Generally, the results of the study were consistent with clinical knowledge of cleft speech sound disorders and corroborate previous research findings3,4,15,17(p5),38,66 about speech in children with cleft lip/palate. The remainder of this discussion will focus on the utility of RWD to generate RWE and will comment on interesting findings.
RWD Permitted Isolation of Cohorts
The essential condition of any clinical outcomes research project is the accurate identification of the population of interest. Because the data source used here was a condition-specific registry, cleft phenotype and relevant comorbid conditions were explicitly recorded. This exemplified one advantage of a cleft-specific registry over other sources of RWD, such as an electronic health record (EHR) or administrative database.
At the time of this writing, years of multi-center collaborative data collection yielded only modest sample sizes for cross-sections made based on specific age and phenotypic groupings. However, the broad inclusion of patients into the ACCQUIREnet registry and the specificity of its baseline data has made the network's data compatible with nearly any external data source compliant with the ICHOM standard set or collecting a subset of these measures. For example, ACCQUIREnet contributed data to two projects in collaboration with the ERN CRANIO database, a large and well-respected source of RWD based out of Europe.67,68 In future studies, this external collaboration can be used to power larger outcomes studies or to conduct international inter-center comparison studies.
RWD Permitted Speech Analysis by Age
The registry can group patients into any number of age ranges (e.g., 3–6y, 7–10y, 10–12y, etc.) to best suit a particular research question. This analysis isolated patients of particular ages, using the time points recommended by ICHOM (i.e., 3y, 5y, 8y, 12y, and 15y of age). 48 Importantly, no statistical testing was performed in this project. Therefore, conclusions could not be drawn from any variation described here. However, interesting age-related patterns were noted in the speech outcomes.
For example, as age of the cross-sections increased from 3y to 12y, perception of articulatory proficiency measured by clinician-reported PCC also appeared to increase within this sample, reaching a plateau at age 8y or 12y, (depending on the phenotype). An improvement in articulation was expected as patients aged, developed, and received speech interventions.46,69 Moreover, these results appeared to be consistent with previously reported articulation outcomes for select ages and phenotypes. The Scandcleft trials reported PCC scores ranging from 78–85% among 5y-old patients with uCLAP. 45 Klintö et al. reported an age-adjusted mean PCC of 93.9% for the same age/phenotypic group. 17
Variation in VPC across age also fit into the expected pattern based on prior findings. A study by the Scandcleft project reported the frequency of velopharyngeal competence to be 35–61% among 5y-olds with uCLAP, 55 while Lohmander et al. reported the frequency to be 82% at 16y. 46 ACCQUIREnet's data also demonstrated a low frequency of competence among 5y-olds, with scores trending in the more favorable direction among 12y-olds. Adding to this picture, ACCQUIREnet's data suggested that VPC may have been perceived to be more competent in these 3y-olds than in these 5y- and 8y-olds. The possible worsening of velopharyngeal function around age 5y corresponded with a known period of rapid midfacial growth 70 that may have worsened underlying velopharyngeal dysfunction. This apparent worsening of VPC may also have been due to better articulatory precision, increased participation, and longer utterances among 5y- and 8y-olds in the speech evaluation. These factors may have made velopharyngeal pathology easier to detect compared to 3y-old patients. Once concern for velopharyngeal incompetence was identified, a treatment plan was made with the speech-language pathologist(s) and surgeons on the child's cleft team. Recommended treatments included speech-language therapy and/or surgical intervention, which were often underway prior to age 12y. The high frequency of velopharyngeal competence seen in this 12y-old cross-section may have reflected these interventions as well as better effort from older patients participating in speech testing.
To better understand these patterns in VPC scores, this study would have needed to consider pre- and post-surgical status, the patient's participation in speech therapy sessions, and their PCC score. The registry could have theoretically tested for the impact of surgical intervention vs nonsurgical management because it collected data on the number of surgical interventions a patient received for velopharyngeal insufficiency. However, in this study, the recording of surgical interventions into the database took place outside clinical workflow, and these data were often missing from the registry. At that time, there was also no information in the registry about the quantity or quality of speech therapy a patient had received. To control for this intervention or to explicitly study its impact, this registry would have required additional details from speech therapy sessions or been paired with another data source such as a health record or school system record. Although valuable to future projects, information from speech therapy sessions will be challenging to collect as these encounters often occur outside of the clinic.4,42,45 Improving these friction points will be the focus of future projects.
While literature regarding the speech of younger patients with clefts reported lower ratings of intelligibility, 13 speech has reportedly been entirely intelligible among patients as young as 10y with a history of cleft. 46 ICS scores recorded here were within one standard deviation of the scale's normative mean (4.4), 57 however, a clear improvement with age was not evident among patients with bCLAP or CP. This lack of clear pattern may have been attributable to the small sample size of patients with CP contributing ICS scores. It was also possible that patients with bCLAP did not experience this improved intelligibility with older age as strongly as the other phenotypes did.
Preliminary analysis of CLEFT-Q Speech Function and Speech Distress may have suggested some minor variation by age. Because these outcomes were not measured before age 8y, fewer CLEFT-Q Speech Function and Speech Distress scores had been collected compared to the quantity of clinician- or caregiver-reported scores that had been collected. With time, this registry will have the volume of patient-reported data to see age-based trends more clearly and to support robust statistical analysis.
In general, it was possible that the various attributes of speech, as captured by each outcome measure, may have been positively correlated with age. As the network continues to collect longitudinal data on these same patients over time, future prospective studies should test the hypothesis of an age-based improvement in speech outcomes within the same patient. The specific mechanisms of any age-based improvement should also be explored: i.e., there are many reasons that may explain this, including normal development (and elimination of age-appropriate developmental speech errors), the salutary effect of speech therapy, and structural changes from operative and orthodontic intervention.
RWD Permitted Speech Analysis by Phenotype
Again, the lack of statistical testing performed precluded conclusive evidence of phenotype-based patterns. Nonetheless, some patterns documented in prior literature could also be appreciated in the ACCQUIREnet data. Work by Klintö et al. suggested inferior PCC scores and velopharyngeal function in patients with bCLAP compared to other phentoypes. 38 Butterworth et al. found that the likelihood of achieving normal speech, according to the UK National Speech Standards, was lower for 5y-old patients with CLAP compared to those with isolated CP. 40 Work by Baillie and Sell showed no phenotype-based differences in VPC but did note cleft-specific articulatory errors to be more common in patients with bCLAP. 42 CLEFT-Q Speech Function and Speech Distress both demonstrated an inverse relationship with cleft severity as represented by Veau type in field test data. 71
Of course, phenotypes with less palatal disruption appeared to have better articulation, functional intelligibility, and velopharyngeal function, as measured by PCC, ICS, and VPC, when compared to phenotypes with more palatal disruption. Although not explicitly explored in this study, the relationship between anatomy at birth and speech outcomes may have also been influenced by the width of the cleft before surgical repair72–74 or by the prevalence of unrepaired fistulas73,75,76 in these phenotypes. These additional factors may help explain why patients born with the uCLAP phenotype performed better (both in the literature,38,40,71 and in this dataset) than patients born with the bCLAP phenotype. The registry included information on fistula presence and location but did not include initial cleft width or history of pre-surgical infant orthopedics, such as nasoalveolar molding. For this reason, future research studying the impact of cleft width on speech outcomes will need to pair this registry with an outside data source.
RWD Showed Potential for Future Speech Analysis by Treatment Center
Outcomes of patients treated by the six centers were comparable using ACCQUIREnet data, as evidence by Figure 5. The network limited such an inter-center analysis to cross-sections based on both age and phenotype, which minimized confounding at the cost of reduced sample size. Thus, we have refrained from commenting on any patterns in Figure 5. Although these early findings were too small to permit robust statistical analysis, they served as a proof-of-concept for inter-center comparisons made possible with registry data. The theoretical power of such analyses to motivate change and improve care has been well established in work by Klintö et al.,15,17 CSAG,7,8 Cleft Care UK,9–11,75 and Eurocleft,1,2 among others.
Because this proof-of-concept was not intended to draw conclusions about inter-center differences, we did not isolate patients whose care started and remained at each institution. Future comparative studies to evaluate treatment protocols will necessarily exclude patients transferred from outside clinics. In future inter-center comparisons, we also intend to compare case-mix-adjusted observed:expected ratios of performance, similar to how the American College of Surgeons (ACS) National Surgical Quality-Improvement Program (NSQIP) provides “performance reports” back to participating centers. Case-mix adjustment is important to account for different phenotypic presentations at each center. For now, we have simply presented crude measurements stratified by age and phenotype but not adjusted for severity or other clinically relevant factors.
Limitations of RWD
Evaluating the quality of evidence supported by a registry of real-world patient data would not be complete without a discussion of the registry's inherent limitations. First, the usefulness of any source of RWD depends on the accuracy, precision, and completeness of the data. In this project, the outcome measures chosen were those recommended in the ICHOM Standard Set, 47 each of which has been validated and used in other cleft speech studies. Nevertheless, it is always possible that an instrument may be employed differently (or incorrectly) at a particular center. Indeed, we did discover that this was the case for the PCC outcome measure: As ICHOM did not specify in the Standard Set any recommendations or requirements for the source of words to be used in assessment of the PCC, variation was discovered in implementation, with five centers (A, B, D, E, F) using single-word testing and one center (C) using sentence-level testing. In any multi-center project, it is critical to routinely examine data-collection processes and quality to make iterative improvements in these processes. Upon identification of this variation in PCC measurement, the ACCQUIREnet speech working group agreed to adopt the standard of single-word-level testing using the GFTA-3 54 as the word bank. Furthermore, the ACCQUIREnet speech working group discovered some challenges using the subjective VPC-R measure. They advised the network to consider coordinated training for clinicians administering both PCC and VPC-R to ensure that these scales are applied in the same way across centers. Americleft is an excellent model to follow in how it offers training for Cleft Audit Protocol for Speech-Augmented Americleft Modification (CAPS-A-AM).5,6,77 Any differences in method of PCC or VPC-R assessment were noted as a potential source of measurement error or confounding; however, this should not invalidate the gross findings of this exploratory project. Going forward, the network will place renewed emphasis on training, surveillance/audits, and a feedback loop for iterative improvement (thus, “learning health network”).
A second source of measurement error occurs when an outcome instrument does not perfectly capture the construct that it is meant to capture. As all outcomes instruments are abstractions of reality, the measurement is always an approximation of “the Truth” — the important question is how close the instrument can get to the truth. An example from our project is that PCC and VPC-R are generic speech outcome measures. While they have been used successfully by many groups in studying cleft speech, it is true that they do not differentiate between cleft-related and non-cleft-related findings (e.g., developmental errors). An argument could be made to prefer a cleft-specific system of speech evaluation, such as CAPS-A-AM 78 or GOS.SP.ASS. 79 Presently, ACCQUIREnet includes only PCC and VPC-R as clinician-reported instruments, although it is considering optional extension to include CAPS-A-AM at sites where their speech-language pathologists have been trained by Americleft. 5 When conducting a study using RWD, the researcher is limited to the outcomes instruments adopted by that network.
While imperfect, the generic speech measures permit evaluation in any language and may aid the network in addressing the current restriction of data collection to English-speaking patients only. Inclusion of patients and families who speak predominantly other languages has always been a planned milestone for ACCQUIREnet. Presently, Spanish translations and consent forms are under IRB review with plans to launch this year. Other languages are being considered. Thus, future datasets may permit cross-linguistic analysis and more equitable study inclusion criteria.
Because this was an early explorational project, sample size was limited. We therefore restricted our analysis to descriptive reports and refrained from statistical testing. Any patterns in the data that seem apparent will need to be confirmed in future research powered for statistical testing.
Missing data are another reason why sample size may be limited and are commonly encountered in research using RWD from registries and databases. This problem can exist in clinical trials also, which may necessitate trimming, censoring, and other adjustments in analysis. While statistical methods do exist to deal with missing data, the ideal should remain to collect complete data sets for each patient. When using RWD, care must be taken to thoughtfully assess missing data and respond accordingly in order to limit the impact of this variation on the study's outcome of interest. In this study, restricting data collection to clinic appointments may have selected disproportionately for patients requiring more follow-up or those with easier access to the team (e.g., those who lived closer) or other confounding factors (e.g., parents’ ability to take time off of work for team visits). This may have introduced a selection bias. The reason why data were missing was not always clear, either: Did the patient stop filling out surveys early? Did the clinical appointment get cancelled? Were a patient's speech abilities bad enough to preclude a thorough assessment of PCC and VPC-R? Data completeness was investigated by the leading site in a foundational work published by Bittar et al. in 2018, which found the completion rate of clinician-reported measures to be 91% and the completion rate of patient-reported measures to be 97%. 49 Although that foundational work did not include all sites that reported data here, ACCQUIREnet aims to uphold a similar standard of completeness at all centers. Future work will more rigorously investigate data completion and evaluate for non-responder bias at all centers.
Future Directions for RWD and RWE
While these limitations do present challenges that must be considered, the numerous strengths of RWD support its role in cleft research. The ACCQUIREnet registry offers large quantities of standardized, prospectively collected RWD on outcomes for patients with a variety of cleft phenotypes and ages. These data are suitable for many observational study designs, including prospective cohort studies modeled using a target-trial framework. Observational study designs are a cost-effective means of studying outcomes. They can also be used to generate hypotheses for future controlled trials and to assess the practicality of a controlled trial design, as described by the FDA in its Real-World Evidence program. 20 Experimental study designs can be crafted more thoughtfully when informed by preliminary exploration of outcomes using RWD like this. Such exploration can make hypotheses more specific, methodology more informed, and studies more successful.
In addition to powering large observational studies, real-world data can also be used to identify baseline characteristics, early trends in performance, and prognostic indicators, as outlined by the FDA. 20 This database allows easy research access to standardized information on patient age, sex, cleft phenotype, comorbidities, race and ethnicity, and medical history, all of which are easily extracted from the registry and can be analyzed with minimal processing. To study more specific information, such as cleft width, access to speech therapy, or specifics regarding surgical intervention, future studies will either need to supplement this registry with an outside data source such as health records (which capture data in a non-standardized fashion that is not easily extracted or analyzed) or expand the variables defined within the network codebook and data-collection platform.
Finally, RWD pairs well with the concept of a learning health network. ACCQUIREnet's detection of inconsistent PCC and VPC-R implementation is evidence of this. A learning health network is well-poised to respond to changing needs once they are detected and to study its own evolution. When a standardized training system for PCC and VPC-R has been implemented, the network will also be able to detect interval improvement in its process metrics regarding data collection and utility. This capacity for agile, continuous learning sets the network apart from other cleft-specific data sources and study designs.
Conclusions
RWD from a cleft-specific, multi-center learning health network proved useful in describing speech outcomes across these centers. The findings of this early explorational project using RWD corroborated prior results from rigorous outcomes studies and other registries, suggesting that RWD may be a useful source of outcomes data for future pragmatic clinical trials. Analysis suggested multiple age- and phenotype-based variation that may be investigated by hypothesis-driven study designs. This study also identified the opportunity for coordinated training to improve consistency in outcomes measurement across sites. Going forward, ACCQUIREnet's focus will be on developing the necessary robust statistical methods for conducting observational and quasi-experimental studies using real-world data. This ever-growing source of RWD may support innumerable research and quality improvement initiatives both within the network and in collaboration with outside groups.
Supplemental Material
sj-docx-1-cpc-10.1177_10556656231207469 - Supplemental material for Using “Real-World Data” to Study Cleft Lip/Palate Care: An Exploration of Speech Outcomes from a Multi-Center US Learning Health Network
Supplemental material, sj-docx-1-cpc-10.1177_10556656231207469 for Using “Real-World Data” to Study Cleft Lip/Palate Care: An Exploration of Speech Outcomes from a Multi-Center US Learning Health Network by Kristina Dunworth, Banafsheh Sharif-Askary, Lynn Grames, Carlee Jones, Jennifer Kern, Jillian Nyswonger-Sugg, Arthur Suárez, Karen Thompson, Jessica Ching, Brent Golden, Corinne Merrill, Phuong Nguyen, Kamlesh Patel, Carolyn R. Rogers-Vizena, S. Alex Rottgers, Gary B. Skolnick and Alexander C. Allori in The Cleft Palate Craniofacial Journal
Supplemental Material
sj-docx-2-cpc-10.1177_10556656231207469 - Supplemental material for Using “Real-World Data” to Study Cleft Lip/Palate Care: An Exploration of Speech Outcomes from a Multi-Center US Learning Health Network
Supplemental material, sj-docx-2-cpc-10.1177_10556656231207469 for Using “Real-World Data” to Study Cleft Lip/Palate Care: An Exploration of Speech Outcomes from a Multi-Center US Learning Health Network by Kristina Dunworth, Banafsheh Sharif-Askary, Lynn Grames, Carlee Jones, Jennifer Kern, Jillian Nyswonger-Sugg, Arthur Suárez, Karen Thompson, Jessica Ching, Brent Golden, Corinne Merrill, Phuong Nguyen, Kamlesh Patel, Carolyn R. Rogers-Vizena, S. Alex Rottgers, Gary B. Skolnick and Alexander C. Allori in The Cleft Palate Craniofacial Journal
Footnotes
Acknowledgments and Declarations
We extend our gratitude to the dedicated clinicians, academicians, and project teams who helped to develop the ICHOM Standard Set and the various outcomes measurement instruments that it utilizes. Use of the CLEFT-Q™ and FACE-Q™ Questionnaires, 56 authored by Dr. Anne Klassen and Dr. Karen Wong, was made under license from McMaster University. Study data were collected and managed using REDCap™ electronic data capture tools,46,47 hosted at each institution. REDCap™ (Research Electronic Data Capture) is a secure, web-based software platform designed to support data capture for research studies. It provides the following: (1) an intuitive interface for validated data capture; (2) audit trails for tracking data manipulation and export procedures; (3) automated export procedures for seamless data downloads to common statistical packages; and (4) procedures for data integration and interoperability with external sources.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.