
Abstract
Objective
To assess the quality, reliability, readability, and similarity of the data that a recently created NLP-based artificial intelligence model ChatGPT 4 provides to users in Cleft Lip and Palate (CLP)-related information.
Design
In the evaluation of the responses provided by the OpenAI ChatGPT to the CLP-related 50 questions, several tools were utilized, including the Ensuring Quality Information for Patients (EQIP) tool, Reliability Scoring System (Adapted from DISCERN), Flesh Reading Ease Formula (FRES) and Flesch-Kinkaid Reading Grade Level (FKRGL) formulas, Global Quality Scale (GQS), and Similarity Index with plagiarism-detection tool. Jamovi (The Jamovi Project, 2022, version 2.3; Sydney, Australia) software was used for all statistical analyses.
Results
Based on the reliability and GQS values, ChatGPT demonstrated high reliability and good quality attributable to CLP. Furthermore, according to the FRES results, ChatGPT's readability is difficult, and the similarity index values of this software exhibit an acceptable level of similarity ratio. There is no significant difference in EQIP, Reliability Score System, FRES, FKGRL, GQS, and Similarity Index values among the two categories.
Conclusion
OpenAI ChatGPT provides a highly reliable, high-quality, but challenging to read, and acceptable similarity rate in providing information related to CLP. Ensuring that information obtained through these models is verified and assessed by a qualified medical expert is crucial.
Introduction
Cleft lip and palate (CLP), whose etiology is generally multifactorial and may include a combination of genetic, environmental, and nutritional factors, is a type of congenital craniofacial deformation and is seen in approximately 1–2 out of every 1000 live births worldwide. The diagnosis and treatment of individuals with CLP require a long process involving various disciplines such as plastic surgery, orthodontics, and speech therapy from birth. This situation leads patients and their relatives to seek information about the process from experts in their respective fields. Since it is not always possible to be in constant contact with doctors or simply out of curiosity, patients and their families may use internet-based information.1-6 Recently, artificial intelligence-based language models have gained popularity as a valuable tool for acquiring information from internet sources, following websites, and social media tools like YouTubeTM, and Instagram.
The field of computer science known as “Natural Language Processing,” or NLP, focuses on the comprehension and creation of natural language. 7 It makes use of a collection of methods and algorithms made to comprehend and react to naturally spoken or written content. These algorithms include automatic summarization, speech recognition, text classification, phrase parsing, sentiment analysis, and vocabulary construction. NLP is widely utilized nowadays, particularly in fields like social media analysis, search engines, translation software, and digital assistants. 8 Large Language Models (LLM) such as Google Bard, Microsoft Bing, Claude, and ChatGPT are advanced language models trained on extensive datasets, applicable for various NLP tasks. 9
One of the most well-known models, GPT, is a pre-trained language model which has transformer architecture, an artificial neural network that models relationships between words in order to understand word sequences and generate new text based on patterns learned from extensive language datasets. The capacity to learn from large language datasets and generate high-quality text renders GPT a valuable asset for diverse natural language processing tasks.9,10 This model can generate precise, prompt answers regarding users’ inquiries and summarize lengthy texts using grammatically comprehensible features for non-experts. 8 Recently, the advent of multimodal algorithms has facilitated the interpretation of images and video meanings.11,12 However, caution is advised when utilizing language models like GPT for medical information. Due to limitations in the accuracy and currency of information, expertise levels, personalized recommendations, and ethical and security concerns, GPT and similar models cannot supplant consultations with medical professionals for healthcare decision-making or treatment option evaluations. These models should only supplement professional medical advice. Ensuring that information obtained through these models is verified and assessed by a qualified medical expert is crucial.13-15
These NLP models are quickly becoming common in modern society and have the ability to provide patients with CLP and their families with information through interactive dialogues about topics of interest. However, it is crucial to scrutinize the accuracy and reliability of the responses received. In light of the beforementioned data, the current study's aim is to assess the quality, reliability, readability, and similarity of the data that a recently created NLP-based artificial intelligence model provides to users in CLP-related information.
Material and Methods
Determination of CLP-Related Questions and Acquisition of Answers
The study's flowchart is displayed in Figure 1. As this study does not involve any materials obtained from humans or animals, it did not require ethical approval. In this study, the ChatGPT-4 (OpenAI, 2021) large language model was employed to acquire information provided by an NLP-based artificial intelligence model in the field of CLP. The objective was to evaluate the information supplied by the NLP-based model to patients with CLP or their relatives in the form of directed questions and human-like dialogue, leveraging the model's capacity to answer directed questions and engage in human-like conversations.
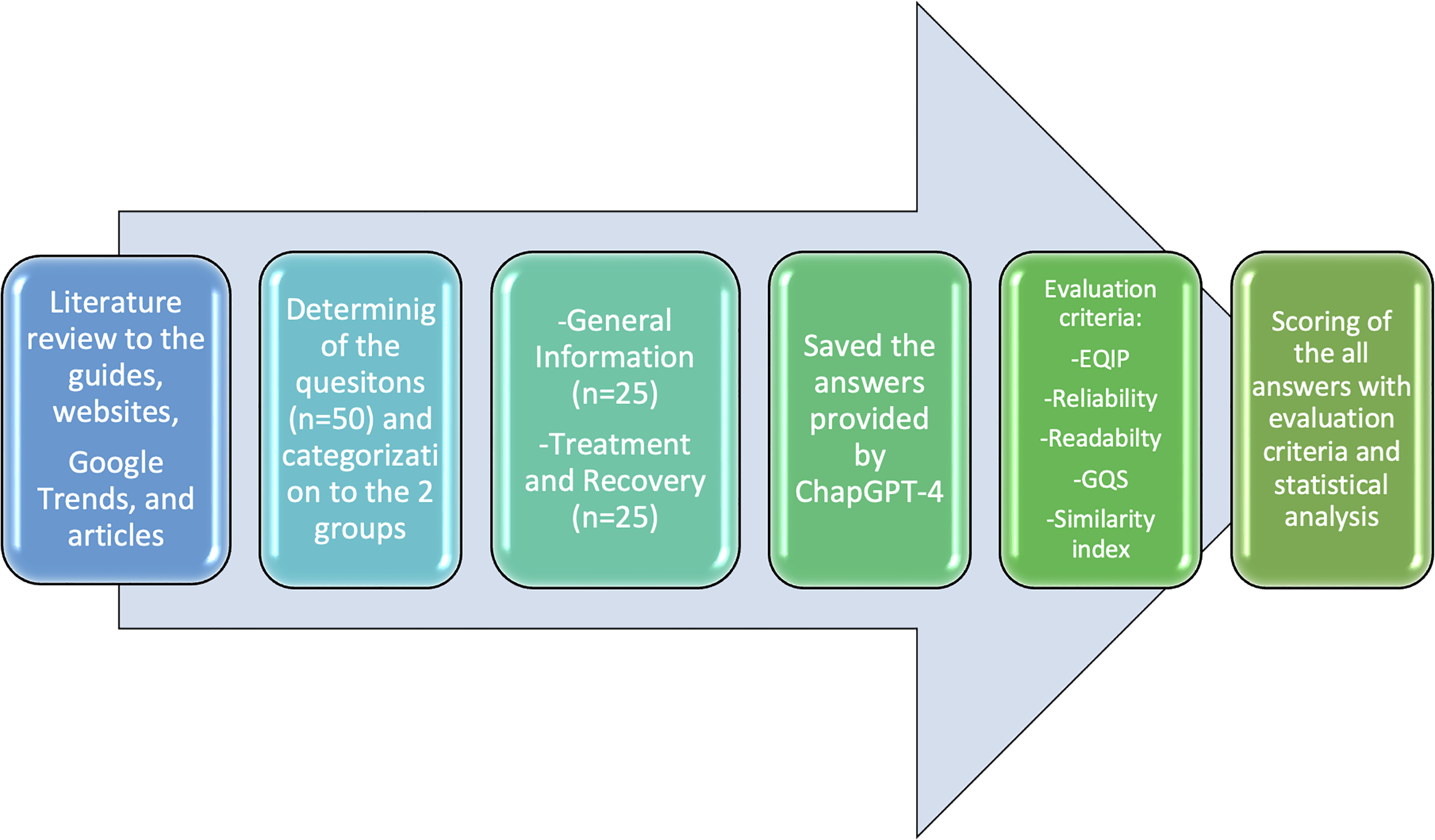
The flowchart of the study.
In determining the CLP-related questions, potential questions that non-experts in the field, as well as individuals affected by the condition and their families, might direct toward the software were investigated. In order to gather information, the keywords “cleft lip and palate guide for parents” were typed into Google search engine (1998, USA). From the search results, guidelines for patients and their families were identified. Two researchers reached a consensus on selecting five guidelines (The Children's Hospital at Montefiore, Boston Children's Hospital, Cleft Lip and Palate Association, Weill Cornell Medicine Pediatrics, and Washington University School of Medicine in St.Louis) that were compatible with existing literature and then used these selectec guidelines as references for creating questions. Among the most frequently encountered topics in CLP resources were definition, etiology, symptoms, treatment procedures and timing, surgical operations, the impact of nutrition on individuals and their quality of life, and topics related to enhancing oral hygiene and dental health. The two researchers identified fifty questions that could be directed by individuals with CLP and their families and transferred them to a Word file format (Figure 2), considering the contents to more comprehensively assess the software's effectiveness in different fields. The questions were categorized based on content, resulting in two distinct categories: “General Information About CLP” and “Treatment and Recovery of CLP”. Under the “General Information About CLP” category, there are questions related to the definition, etiology, prevalence, feeding of infants with CLP, quality of life, and oral hygiene and dental health. All questions were directed to the program by a single researcher with the ‘NewChat’ for each question. The obtained answers were saved to a Microsoft Office Word (Microsoft Office 365, Microsoft Inc., Redmond, WA, USA) file without any alterations made and evaluated by the same researcher on the same day.

CLP-related questions asked to ChatGPT in the study.
Evaluation Criteria
In the evaluation of the responses provided by the software to the 50 questions, several tools were utilized, including the Ensuring Quality Information for Patients (EQIP) tool, Reliability Scoring System (Adapted from DISCERN), Flesh Reading Ease Formula (FRES) and Flesch-Kinkaid Reading Grade Level (FKRGL) formulas, Global Quality Scale (GQS), and Similarity Index with plagiarism-detection tool. EQIP was specifically utilized to evaluate the reliability and validity of the responses provided by the software due to its applicability to any type of written material in the healthcare field. Developed by Moult et al., this tool consists of a total of 20 questions. 16 The first 14 questions of the form are related to the general nature of the text, while the remaining questions are related to the content of the information provided on a disease, test, procedure, condition, or medication. There are four possible answers for each question: “yes,” “partially,” “no,” and “not applicable.” The scoring is presented as a percentage and varies between 0–100 after being calculated using the formula provided below.
In addition to the EQIP tool, the Reliability Scoring System Adapted from DISCERN was used to evaluate the reliability and quality of the answers provided by the software. The Reliability Scoring System primarily assesses the information on healthcare-related websites based on its readability, source credibility, and quality of the information provided to the reader. 17 Each aspect is evaluated on a scale of 1 to 5, with 5 being the highest score possible (Figure 3).

In our study, another evaluation criterion we used is GQS, which was originally introduced by Bernard et al. to assess the educational quality of videos. 18 The evaluation scale takes into account the quality of content, level of information, flow, and usefulness for patients. Scoring is done on a scale of 1 to 5, with 5 being the highest score. Similarly, in our study using GQS, the written responses provided by the program were evaluated. Accordingly, a score of 1 represents low quality, lack of information, and text content that is not useful for patients, while a score of 5 represents excellent quality and flow with highly useful text content for patients. (Figure 3).
In evaluating the readability level of the answers provided by the software, we utilized the FRES and FKRGL tests developed by Rudolf Flesch and J. Peter Kincaid.19,20 These tests are used to determine the readability and comprehensibility level of an English text. 21 In essence, the formulas of both tests rely on calculating the average number of words per sentence and the average number of syllables per word, with different weights assigned to each of these measures.
The FRES test score indicates that as the score increases, the readability of the text becomes easier, and as the score decreases, it becomes more difficult. Scores ranging from 0–100 define the text's comprehensibility based on educational levels. When the text is scored between 90–100, it indicates that it can be understood by a 5th-grade level individual, whereas a score ranging from 0–10 shows that the readability is challenging and can be better understood by individuals who have graduated from a university. The FKRGL test, like FRES, measures its scoring based on education level. Both tests are based on the premise that longer sentences and words are more complex and require more cognitive effort to read than shorter ones, making them more difficult to read.
The Similarity Index was used to determine the quantitative similarity between the answers provided by the software and the written texts in different databases. The aim was to detect the possible plagiarism rate and the level of originality of the answers. For this purpose, all answers provided by the artificial intelligence model were transferred to the plagiarism detection program (iThenticate, http://www.ithenticate.com) and the similarity rates were calculated as a percentage. The similarity rates were grouped into four categories: 0–10%, 10–20%, 20–40%, and 40–100%. Texts with less than 10% similarity rate were classified as having high originality, those with 10–20% similarity rate as having acceptable similarity, and those with 20–40% similarity rate as having very high similarity. Two researchers with at least 10 years of experience scored the answers provided by the software to 50 questions using the evaluation criteria and tests mentioned above. The readability levels and similarity indices were calculated for all questions.
Statistical Analysis
Descriptive statistics, including mean, median, Standard deviation (SD), maximum, and minimum values, were calculated for the data obtained from the evaluation criteria. The normality assumption of the data was evaluated using skewness, kurtosis coefficients, and the Shapiro-Wilk test. As a result of the evaluation, it was observed that all data exhibited normal distribution. The One-way ANOVA test was applied to detect any statistically significant difference between group means that were formed based on different evaluation criteria and question categories. Pairwise correlations between group data were evaluated using the Pearson correlation coefficient. To determine inter-observer reliability, the same researchers repeated the scoring for all evaluation criteria two weeks later. Inter-observer reliability was calculated with the intraclass correlation coefficient (ICC) with a 95% confidence interval. A p-value of less than 0.05 was considered statistically significant. Jamovi (The Jamovi Project, 2022, version 2.3; Sydney, Australia) software was used for all statistical analyses.
Results
The recent study results revealed that the mean and SD of the whole questions EQIP values were 47.0 ± 7.20, Reliability Scoring Systems values were 4.00 ± 0.495, FRES values were 47.0 ± 9.52, FKGRL values were 11.4 ± 1.85, GQS values were 4.30 ± 0.763, and Similarity Index score values were 9.38 ± 13.4 (Table 1).
Descriptive Statistics of the Answers to all Questions.
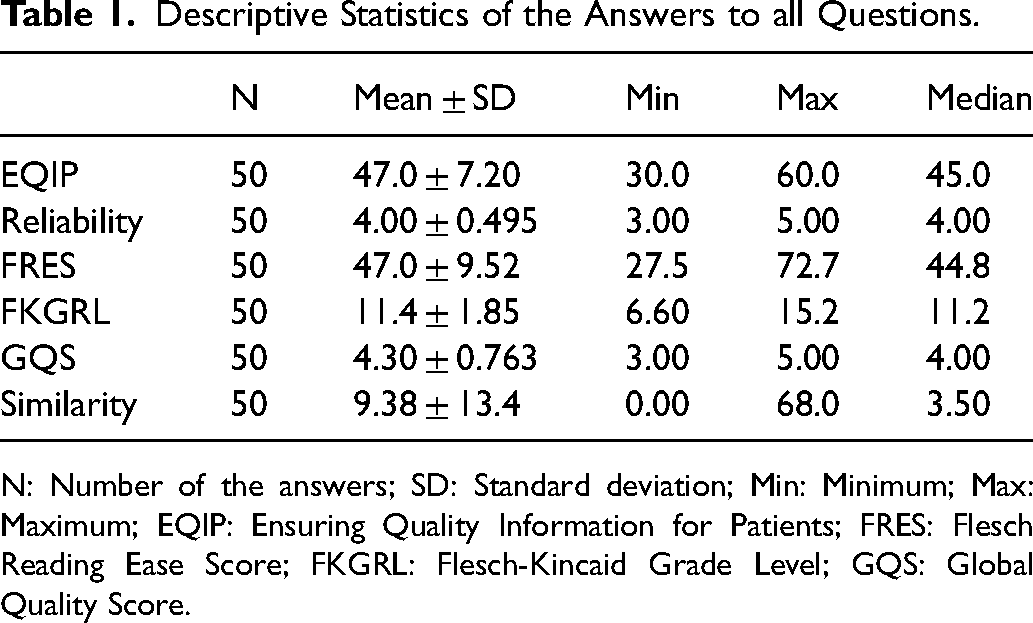
N: Number of the answers; SD: Standard deviation; Min: Minimum; Max: Maximum; EQIP: Ensuring Quality Information for Patients; FRES: Flesch Reading Ease Score; FKGRL: Flesch-Kincaid Grade Level; GQS: Global Quality Score.
Table 2 was shown the descriptive statistics of two categories’ EQIP, Reliability Scoring System, FRES, FKGRL, GQS, and Similarity Index values. In the ‘General Information About CLP’ category, EQIP tool mean and SD values were found 46.1 ± 8.54, Reliability Scoring Systems values were found 3.96 ± 0.455, FRES values were found 47.7 ± 9.67, FKGRL values were found 11.6 ± 1.81, GQS values were found 4.12 ± 0.781, and Similarity Index score values were found 9.72 ± 14.7. Answers to the ‘Treatment and Recovery of CLP’ category mean and SD values of the EQIP tool were 47.8 ± 5.61, Reliability Scoring Systems were 4.04 ± 0.539, FRES values were 46.3 ± 9.51, FKGRL values were 11.2 ± 1.91, GQS were 4.48 ± 0.714, and Similarity Index was 9.04 ± 12.4 (Table 2). There was no statistical differences were found between the ‘General Information About CLP’ and ‘Treatment and Recovery of CLP’ categories in EQIP, Reliability Scoring System, FRES, FKGRL, GQS, and Similarity Index values.
Descriptive Statistics and Post hoc Comparisons of all Categories.
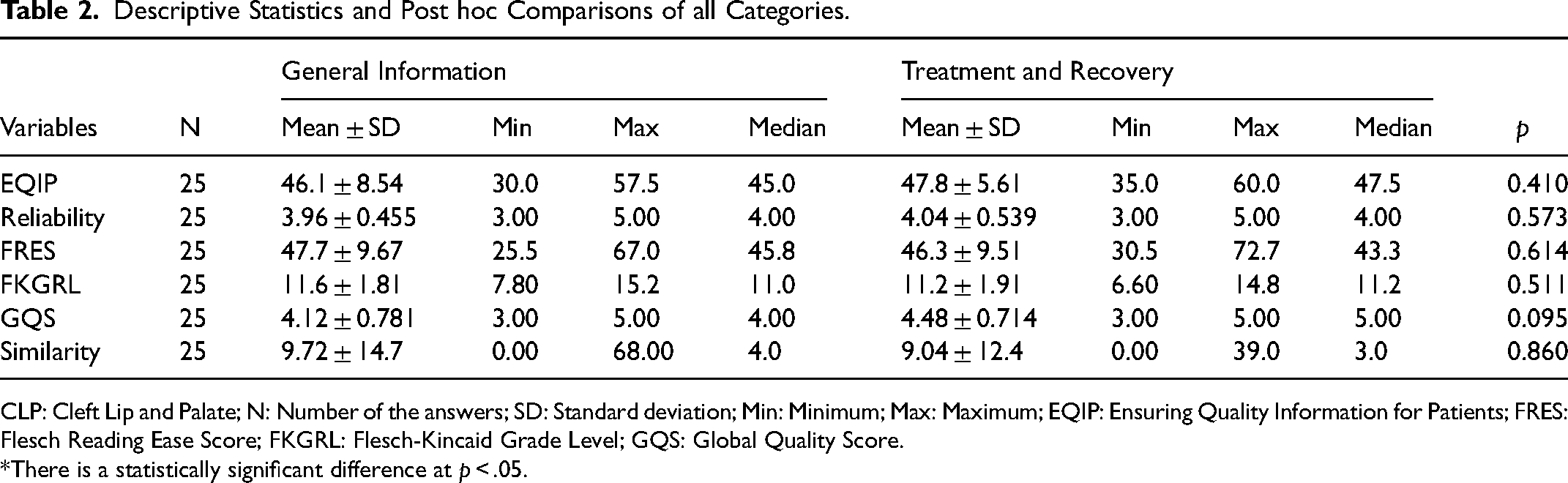
CLP: Cleft Lip and Palate; N: Number of the answers; SD: Standard deviation; Min: Minimum; Max: Maximum; EQIP: Ensuring Quality Information for Patients; FRES: Flesch Reading Ease Score; FKGRL: Flesch-Kincaid Grade Level; GQS: Global Quality Score.
*There is a statistically significant difference at p < .05.
The correlation between the evaluating criteria was shown in Table 3. There was a correlation between the EQIP-Reliability scores, and FRES-FKGRL scores (p < .001, and p < .001 respectively) (Table 3). Also, the intraobserver reliability was assessed by ICC analysis and it revealed that a strong positive correlation was found.
Correlation Between the Evaluating Criteria.
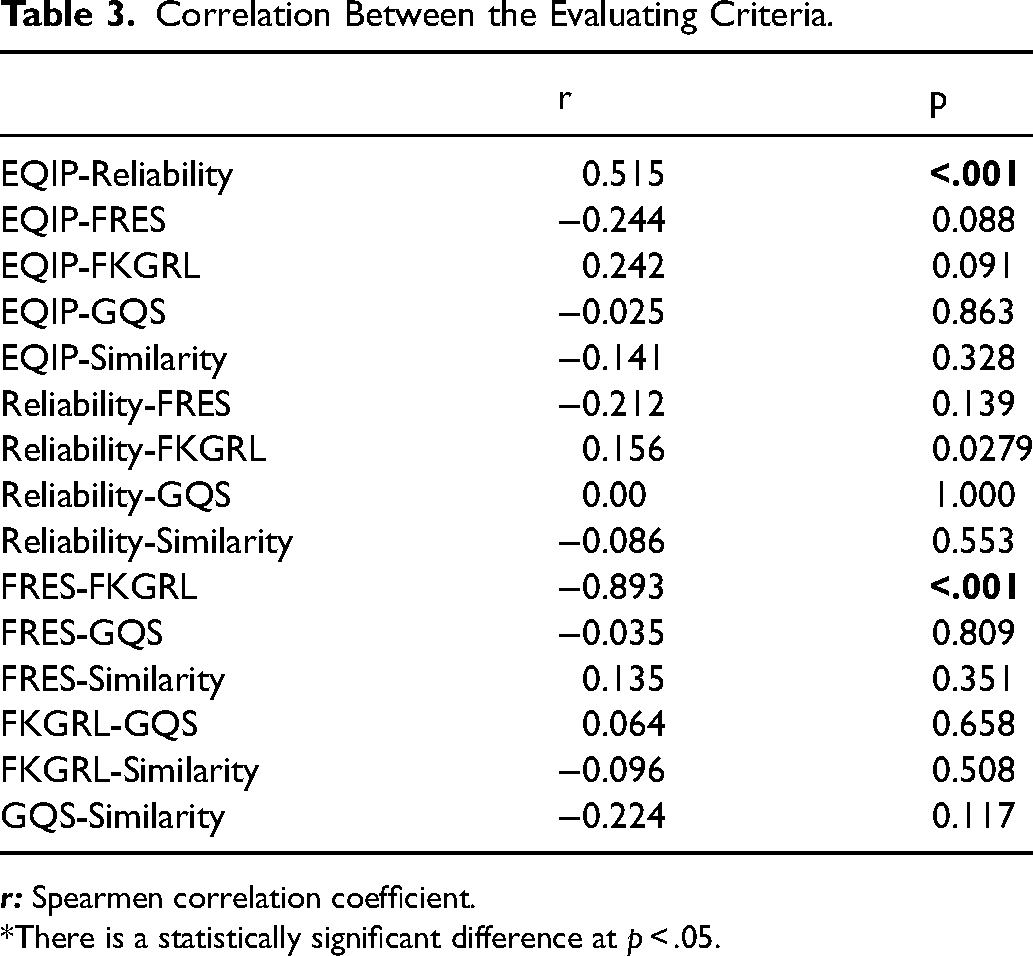
*There is a statistically significant difference at p < .05.
Discussion
In this study, the quality, reliability, readability, and similarity index of the NLP model named ChatGPT were evaluated. Based on the reliability and GQS values, ChatGPT demonstrated high reliability and good quality attributable to CLP. Furthermore, according to the FRES results, ChatGPT's readability is difficult, and the similarity index values of this software exhibit an acceptable level of similarity ratio. CLP questions asked by ChatGPT were divided into two categories. There was no significant difference in EQIP, Reliability Score System, FRES, FKGRL, GQS, and Similarity Index values among the two categories.
The technology of NLP enables computers to understand human language and interact with humans in a natural and intuitive manner. NLP-based models are capable of comprehending, interpreting, and generating human language. 22 Chatbots and ChatGPT are increasingly popular tools for conveying health information to patients. These tools employ NLP algorithms to understand user input and provide relevant information in response.23-26 One of the main advantages of using chatbots or ChatGPT to obtain information about CLP is accessibility. Patients can access these tools from any device with an internet connection, making them convenient and available 24/7. This can be particularly beneficial for patients living in peripheral regions or with limited access to healthcare providers. 26 Moreover, LLM can be adapted to provide personalized responses based on the user's specific needs and questions. This can help patients receive accurate and relevant information tailored to their individual conditions.
This study employed the EQIP quality criteria form, a 20-item scale applicable to any written material in the healthcare field, to assess the reliability and validity of the responses provided by ChatGPT. Evaluation results showed that both researchers generally answered “yes” to the first six questions. These questions are reader-oriented, and the high frequency of “yes” answers indicates that the software is more readable. However, the tendency to answer “partially” or “no” to the question with a score in the EQIP scale, “Is it composed of short sentences of 15 words or less?” supports the feature of ChatGPT's low readability according to the FRES formula results. Additionally, a correlation was found between the EQIP scale and FRES formula results. Items 15 to 20 of the EQIP quality criteria form are the sections that need to be answered if any treatment or procedure is mentioned. Therefore, despite the EQIP score of “Treatment and Recovery of CLP” category being higher than the “General Information About CLP” category, it was concluded that this difference was not statistically significant.
In this study, the Reliability Scoring System, adapted from GQS and DISCERN, was used to evaluate the quality and reliability of the training data. According to the evaluations, ChatGPT's responses were found to be highly reliable and of good quality, with a correlation detected between these two parameters. Korkmaz and Buyuk assessed the reliability of YouTube videos related to CLP in their study and stated that YouTube is not a completely reliable source for patients. 6 The difference in these results can be attributed to the fact that YouTube and ChatGPT are different platforms. While YouTube is mostly based on video sources, ChatGPT is a platform that relies on human feedback and hosts more data.
Alfonso et al. evaluated American Cleft Palate-Craniofacial Association-approved websites that provide information on CLP in terms of content and readability. 5 According to the results of this study, the evaluated websites exceed the sixth-grade reading level recommended by the AMA. Antonarakis and Kiliaridis assessed the readability of websites related to CLP in their study and reported that these websites varied in terms of content provided for families, and their readability was at the eighth and ninth-grade levels according to the American education system. 1 According to the results of our study, the readability level of responses provided by ChatGPT was determined to be at the college level. ChatGPT can adjust the conducted dialogue according to the user's instructions and can be used with more academic or more casual language features thanks to its prompt feature. With this feature, ChatGPT can address individuals with different educational levels, which makes it different from websites that provide information about CLP. Also, national and international cleft organizations have a crucial role in regulating the use of AI tools in disseminating CLP-related information. They could establish guidelines to ensure the reliability and accuracy of the AI-generated information, perform periodic assessments and accreditations, and also organize awareness campaigns about these tools’ potential benefits and limitations.
According to the results of the plagiarism check software, the similarity index of the questions directed to ChatGPT ranged from 0% to 38%, with an average of 11.3% ± 9.26%. Based on these findings, it is believed that ChatGPT has an acceptable similarity rate. In a study conducted by Khalil and Er, the originality of 50 articles on the ChatGPT program was evaluated using plagiarism check software, and it was reported that the program has an acceptable similarity rate, which is similar to our study's results. 27 In addition, our study also found that the similarity indices of the “General Information About CLP” category was higher than the “Treatment and Recovery of CLP” category, but there was no statistically significant difference between them.
Limitations
This study and the chosen language model have some limitations. Firstly, ChatGPT's training data consists of text-based information from before September 2021 on the Internet and does not contain up-to-date information. Also, while ChatGPT can interact with the context of the text, it does not have a deep understanding of the meaning beyond the text. This contextual understanding relies on patterns and probabilities derived from training data rather than a more comprehensive understanding of the world. These models lack the mechanism to recognize or verify the accuracy of false or fake information. Hence, when users seek information from ChatGPT or similar systems, it is crucial for them to verify the obtained information, check the sources, and employ critical thinking skills. Finally, these systems cannot experience human emotions, intuitions, or empathy in the same way. While artificial language models have the potential to bridge the gap between machine and human language, users must constantly question the accuracy and reliability of their knowledge and advice. Bearing these limitations in mind, users should view this technology as a complementary resource for information and support, particularly for medical topics, and consult professional and expert opinions to supplement the information provided by ChatGPT. This tool can be incorporated into routine clinical practice to supplement the information given by clinicians, patients with CLP, and their families to gather more knowledge about this situation.
Conclusion
In conclusion, the ChatGPT which was used in our study provides a highly reliable, high-quality, but challenging to read, and acceptable similarity rate in providing information related to CLP. Language models enable artificial intelligence applications to interact more efficiently and fluently with humans by effectively communicating in natural language. The development and use of such models allow for the increasing effectiveness of AI and NLP technologies and their greater involvement in people's daily lives and work.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.