
Abstract
Objective
Cleft lip and cleft palate are common craniofacial abnormalities, causing significant functional, esthetic, and psychosocial issues if not treated early. Artificial intelligence (AI) is increasingly explored in cleft lip and/or palate (CL/P); however, the quality, consistency, and clinical readiness of the available evidence remain unclear. This study systematically reviewed the existing literature on AI applications in CL/P care and performed an exploratory meta-analysis.
Design
A comprehensive search was performed on PubMed, WOS, Scopus, and IEEE Xplore until November 2025, following the PECO question: “In patients with CL/P (P), how do AI approaches (E), compared with conventional diagnostic methods or human intelligence (C), perform in terms of diagnostic accuracy, predictive performance, or treatment outcomes (O)?”. Studies applying AI to human CL/P data for diagnostic, predictive, or treatment purposes were included. Risk of bias was assessed using appropriate checklists (eg, QUADAS-2). Due to study heterogeneity, random-effects meta-analyses were limited to subgroups evaluating CL/P detection on panoramic radiographs and prediction of orthognathic surgery using lateral cephalograms.
Results
The search identified 548 articles; after screening and full-text review, 52 studies were included. These studies addressed diagnosis, prediction, and treatment planning. Meta-analysis of CL/P detection indicated pooled sensitivity, specificity, and accuracy of 87%, 89%, and 90%. Prediction of orthognathic surgery showed sensitivity and specificity of 87% and 86%.
Conclusion
AI is increasingly applied in CL/P management, suggesting high accuracy and consistency in diagnosis, prediction, and treatment evaluation, often approaching expert-level performance.
Keywords
Introduction
Cleft lip and/or palate (CL/P) causes many functional, esthetic, and psychosocial challenges for children born with it. Orofacial clefts include a range of anomalies, including cleft lip (CL), cleft palate (CP), and cleft lip and palate (CLP), which may happen alone or as part of a syndrome. Most patients are nonsyndromic, accounting for approximately 70% to 80% of CL/CLP and 50% of CP. 1 CL arises from incomplete fusion of the frontonasal and maxillary processes in the 4th to 5th week during intrauterine life, while CP results from failed fusion of the palatal shelves between the 8th and 12th weeks. CLP involves varying degrees of lip and palatal separation. 1 This disease affects about 1 in every 500 to 1000 live births globally (≈1 in 700 newborns), with the highest prevalence among Asian populations, followed by Caucasian and African people. Unilateral clefts, particularly on the left side, are more prevalent than bilateral cases and occur more frequently in males (2:1 ratio). 2
CL/P has a multifunctional etiology, including complex interactions between genetic predisposition and environmental influences such as maternal smoking, alcohol use, and nutritional deficiencies. CL/P is frequently associated with dental anomalies and skeletal and soft-tissue deformities, including missing or malformed teeth and restricted maxillary growth due to scar tissue formation. 2 These structural and functional impairments can negatively affect oral health, speech, and facial growth, as well as the psychological wellbeing and the patients’ quality of life. CL/P management involves a multidisciplinary team, including surgeons, dentists, orthodontists, speech therapists, geneticists, pediatricians, and other specialists, and often requires long-term follow up, as additional surgeries may be needed to address post-treatment complications.3,4
The progress of artificial intelligence (AI) has had a significant impact on pediatric care. It has become a highly valuable tool in dentistry and craniofacial research because of its capacity to process large datasets and identify complicated patterns beyond human capability.5,6 By using advanced Machine Learning (ML) algorithms such as neural networks, decision trees, random forests, and so on, AI systems can analyze various forms of clinical, imaging, and genetic data to perform diagnosis, outcome prediction, and treatment planning. 7 In patients with CL/P, AI has been employed for prenatal detection, etiological investigation, landmark identification on radiographic and 3-dimensional (3D) images, and prediction of surgical needs. 1 These applications enhance diagnostic accuracy, reduce human expert error, and provide clinicians with evidence-based insights. Ultimately, it improves personalized care and clinical decision making.
Despite its growing potential, the application of AI in CL/P care remains relatively novel, and the available literature is limited. 2 Therefore, a systematic review and meta-analysis were conducted to map the past literature, synthesize current knowledge on AI applications in prediction, diagnosis, and treatment, assess its impact on clinical practice, and identify gaps and opportunities for future research.
This systematic review and meta-analysis aim to evaluate the use of AI and ML in patients with CLP, focusing on their performance compared to conventional diagnostic methods or human expertise in terms of detection and diagnostic accuracy, predictive ability, and treatment outcomes.
Methods and Materials
Protocol and Registration
This systematic review follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA), as well as its extension for Diagnostic Test Accuracy (PRISMA-DTA) guidelines. 8 Its protocol was registered at PROSPERO (CRD420251181349).
Eligibility Criteria
We address the following PECO question: in patients with cleft lip and/or palate (P), how do AI or ML approaches (E), compared with conventional diagnostic methods or human intelligence (C), perform in terms of diagnostic accuracy, predictive performance, or treatment-related outcomes (O)?
Inclusion criteria:
Original studies investigating the application of AI or ML methods in CLP care, including detection, diagnosis, and assessment of treatment outcomes. Studies reporting quantifiable performance metrics using AI or ML techniques in patients with CL/P. Diagnostic accuracy studies, prediction model studies, retrospective cross-sectional studies, and cohorts that employed AI or neural network approaches in CL/P populations.
Exclusion criteria:
Studies not specifically focusing on CL/P cases. Studies whose full text could not be retrieved. Studies lacking a clearly defined study population or an insufficient description of the data source. Review articles, editorials, commentaries, and preprints.
Information Sources and Search
A comprehensive search was performed across PubMed, Web of Science, Scopus, and IEEE Xplore up to October 2025. The search was conducted using Medical Subject Headings (MeSH) and adapted keywords. Search queries are mentioned in Supplemental Table S1. Relevant articles were selected for further review, and a manual search of the reference lists of the included studies was performed to identify any additional eligible papers.
Study Selection
EndNote 21.5 (Clarivate, Philadelphia, USA) was used for reference management. After removing duplicates, all titles and abstracts were screened and triplicated by three reviewers (NA, FM, and SM). Then, three researchers (NA, FM, and SA) independently assessed all full texts of included studies. At each stage, any discrepancies were addressed through discussion with a fourth reviewer (AE).
Data Extractions
Five reviewers (SM, SA, FM, MK, and NA) independently collected data from included studies. Afterward, a fourth reviewer (AE) read the extracted data to check for discrepancies. Collected data items included bibliographic details (author name and publication year), study objective, datasets, image modality or sample type, task of the ML, AI model or algorithm architecture, and results.
Risk of Bias and Applicability
Five reviewers (NA, SA, SM, FM, and MK) evaluated risk of bias separately utilizing the Quality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) tool for diagnostic accuracy studies, Prediction model Risk Of Bias Assessment Tool (PROBAST) for prediction studies, and JBI Critical Appraisal Tool for Assessment of Risk of Bias for cross-sectional and cohort studies. In case of disagreement or discrepancy between the other reviewers, it was discussed through consensus with a 6th investigator (AE). The QUADAS-2 tool evaluates risk of bias across 4 domains—patient selection, index test, reference standard, and flow/timing—while also considering applicability concerns. Patient selection is judged as high or unclear risk when data splitting methods are poorly described or inappropriate exclusions are made. Index test bias is suggested when model construction lacks sufficient detail, reproducibility is not reported, or robustness is not assessed. Bias related to the reference standard occurs when it is vaguely defined or based on a single examiner. Flow and timing are considered low risk if all data are included in the analysis, each dataset is assessed against a reference standard, and the same standard is consistently applied; however, using multiple reference standards within a single study increases the risk of bias. 9 The PROBAST tool assesses risk of bias and applicability in prediction model studies across 4 domains: participants, predictors, outcome, and analysis. Bias may arise from inappropriate participant selection, poorly defined or measured predictors, unclear or inconsistently assessed outcomes, or inadequate analytical methods. 10 The JBI Critical Appraisal Tools evaluate risk of bias in cross-sectional and cohort studies by examining participant selection, measurement of exposures and outcomes, identification and handling of confounders, and appropriateness of statistical analysis. 11
Meta-Analysis
Studies with homogeneous methodology and similar tasks were chosen to be included in the meta-analyses. Due to the limited number of studies included in each meta-analysis, correlated pooling of sensitivity and specificity using diagnostic odds ratios and SROC curves was not possible. Hence, the authors decided to analyze sensitivity and specificity separately. Random-effect models using restricted maximum likelihood (REML) were used to analyze sensitivity, specificity, and accuracy in diagnosing cleft palate and predicting the need for orthognathic surgery from radiographs. Forest plots were depicted to demonstrate the effect of each study and the global pooling estimation. STATA 17.0 software (StataCorp LP, Lakeway Drive, College Station, TX, USA) was used to perform analyses. P-values less than .05 were considered significant.
Results
Study Selection
An initial search resulted in 548 articles, which were then screened to remove duplicate papers and irrelevant titles. This process yielded 64 articles for a full-text review. After screening the full texts, 12 articles were excluded because of various reasons, such as not focusing on cleft lip or palate and focusing on other orthodontic problems (n = 3), not using machine learning methods (n = 8), or not being able to retrieve the full text (n = 1). Finally, 52 studies were chosen for the systematic review (Figure 1). Six studies were included in the meta-analysis. Other studies were excluded from the meta-analysis due to methodological heterogeneity, including different image modalities and AI tasks.
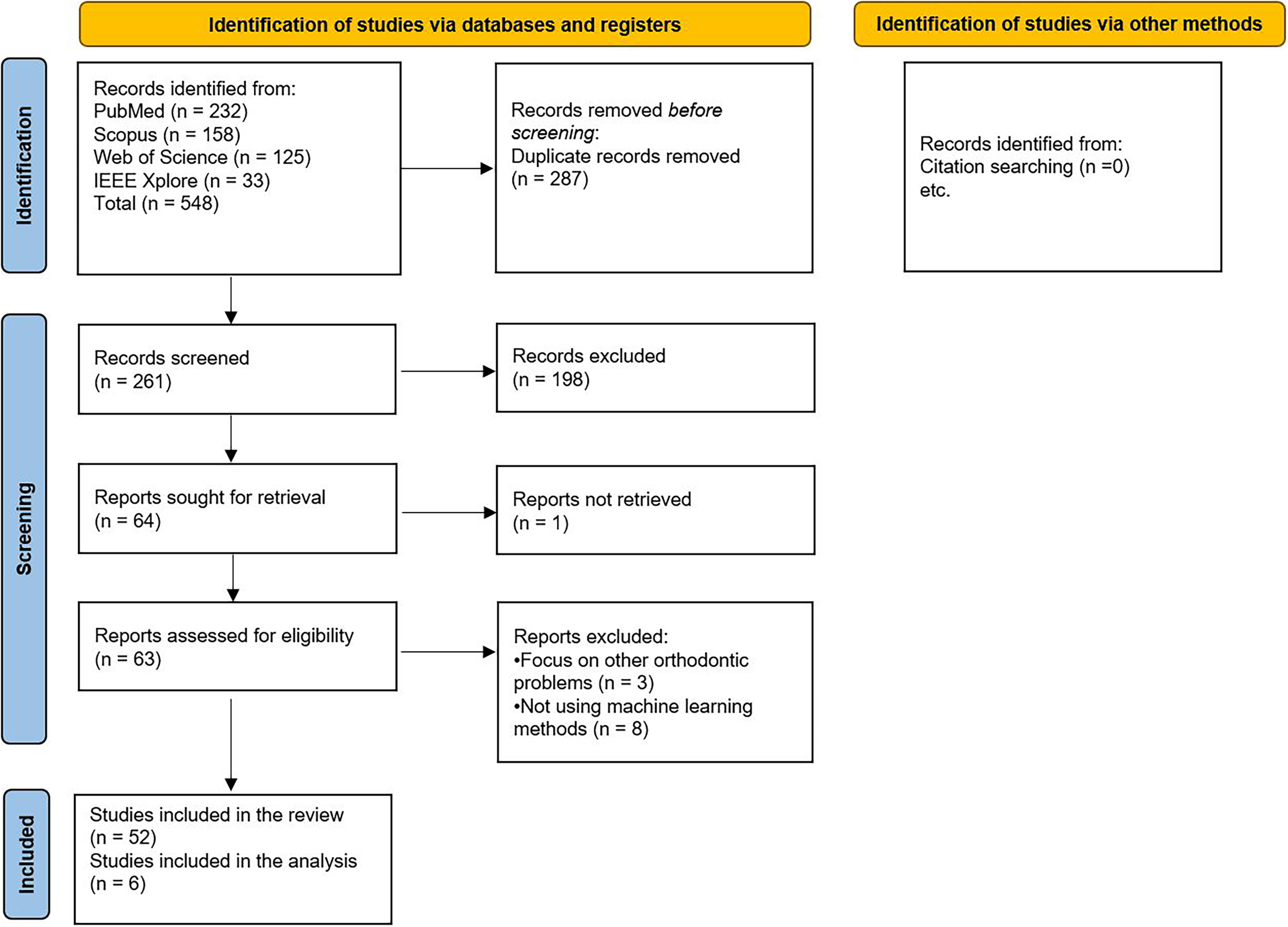
PRISMA Flow Diagram of the Search Strategy.
Study Characteristics
The studies summarized in Tables 1 to 3 addressed CLP across 3 primary domains: (1) diagnosis, detection, and classification; (2) prediction and genetic risk assessment; and (3) surgical outcome assessment and treatment planning (Figure 2). Most included studies relied on imaging data, particularly 2D facial photographs,12–22 radiographs,23–32 and computed tomography and cone beam computed tomography (CT/CBCT) images,3,33–39 while others employed advanced modalities such as 3D intraoral scans,40–43 stereophotogrammetry, 44 and ultrasound.22,37,45,46 A subset of studies also utilized nonimaging data, 47 including genomic,48–55 epigenomic,48,50 lipidomic, 56 and questionnaire-based clinical information4,57 (Figure 3).
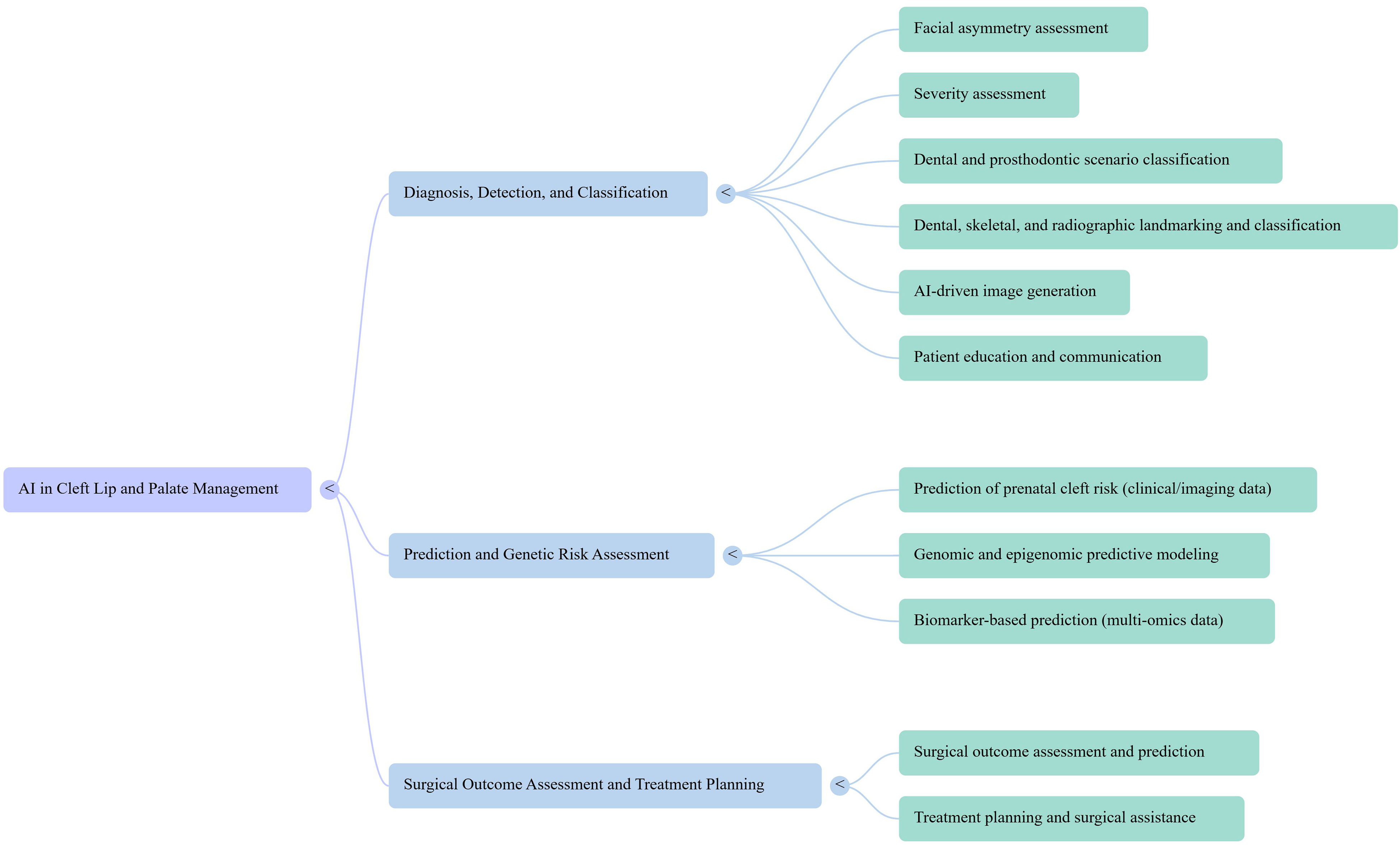
Categorization of the Included Studies.
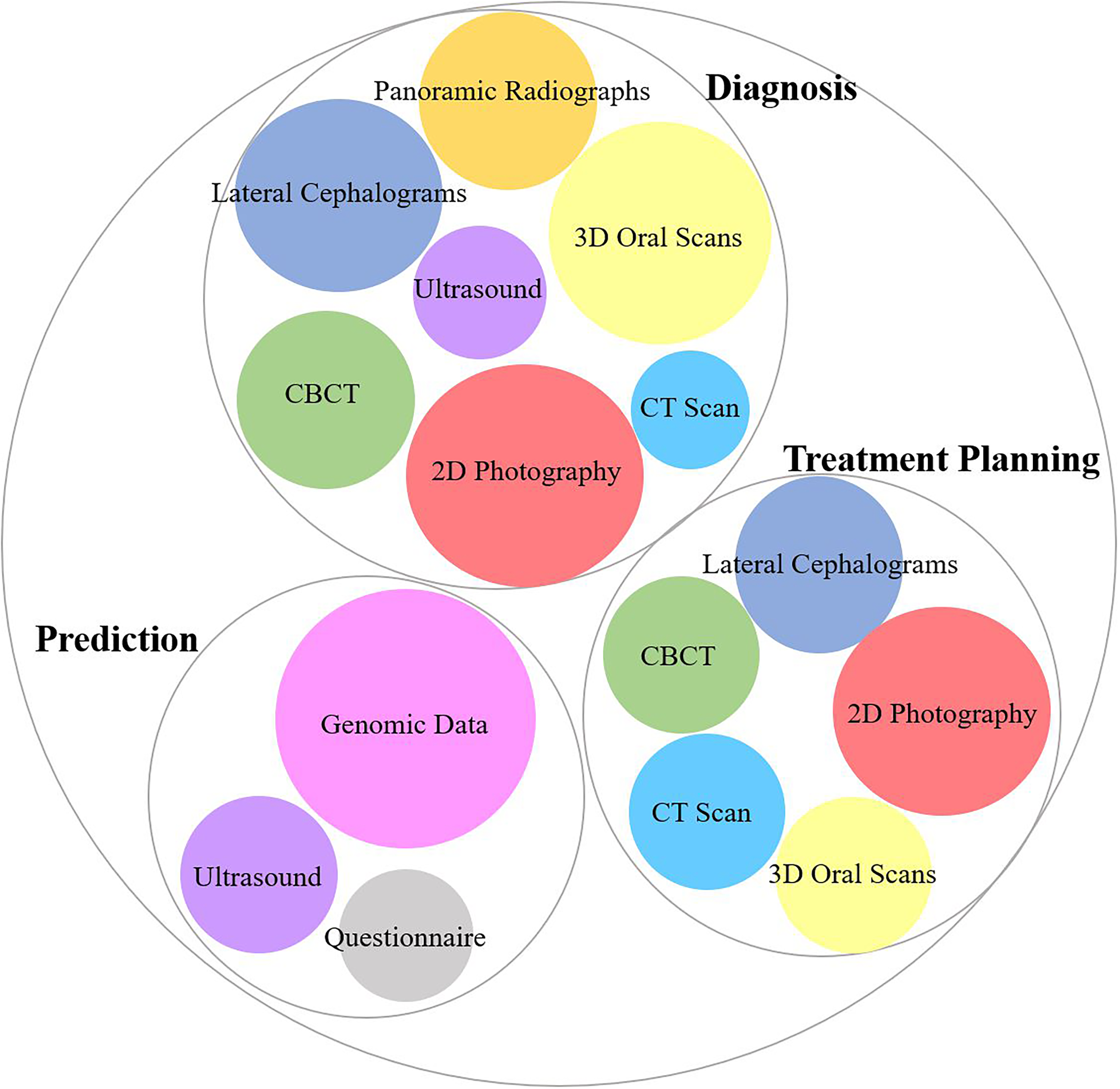
The Data Modalities Used in the Included Studies.
Study Characteristics: Diagnosis, Detection, and Classification.

AI: artificial intelligence; ALR: Automated Landmark Recognition; ANB: the anteroposterior relationship between the maxilla and mandible; BCA: bilateral cleft alveoli; CA: cleft alveolus; CBCT: cone-beam computed tomography; CleftGAN: Generative Adversarial Network; CLP: cleft lip and palate; CNN: Convolutional Neural Network; CP: cleft palate; CVA: cervical vertebral anomalies; GCN: Graph Convolutional Neural Network; MaxCNET: Maxume Estimation Network; MDE: mean distance error; MSE: mean squared error; NLA: nasolabial angle; NME: normalized mean error; NSCLP: nonsyndromic cleft lip and/or palate; PCP: percentage of correct predictions; RVE: Relative volume error; SNA: Sella-Nasion to A-point; SNB: Sella-Nasion to B-point; SNP: single nucleotide polymorphism; SVM: Support Vector Machine; U/BCLP: unilateral/bilateral CLP; UCA: unilateral cleft alveoli; VGG: Visual Geometry Group.
Study Characteristics: Prediction and Genetic Risk Assessment.
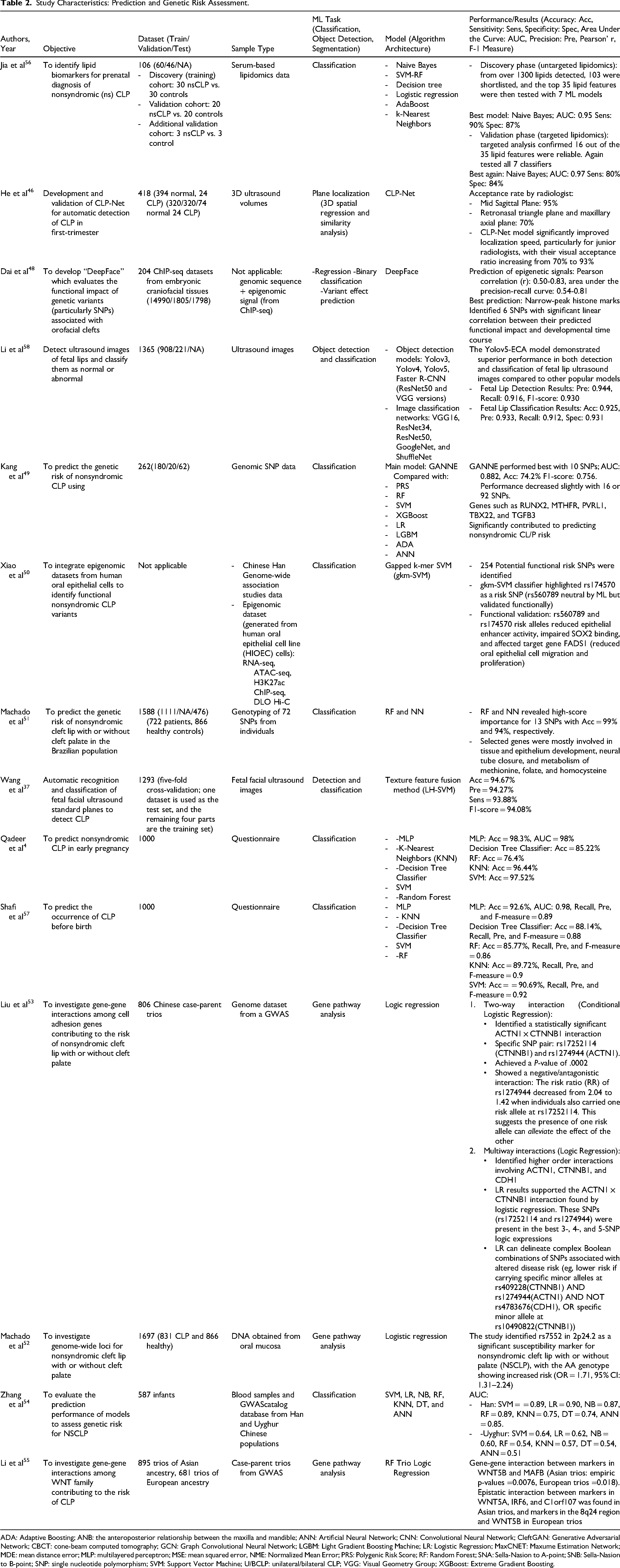
ADA: Adaptive Boosting; ANB: the anteroposterior relationship between the maxilla and mandible; ANN: Artificial Neural Network; CNN: Convolutional Neural Network; CleftGAN: Generative Adversarial Network; CBCT: cone-beam computed tomography; GCN: Graph Convolutional Neural Network; LGBM: Light Gradient Boosting Machine; LR: Logistic Regression; MaxCNET: Maxume Estimation Network; MDE: mean distance error; MLP: multilayered perceptron; MSE: mean squared error, NME: Normalized Mean Error; PRS: Polygenic Risk Score; RF: Random Forest; SNA: Sella-Nasion to A-point; SNB: Sella-Nasion to B-point; SNP: single nucleotide polymorphism; SVM: Support Vector Machine; U/BCLP: unilateral/bilateral CLP; VGG: Visual Geometry Group; XGBoost: Extreme Gradient Boosting.
Study Characteristics: Surgical Planning or Postsurgical Assessment.
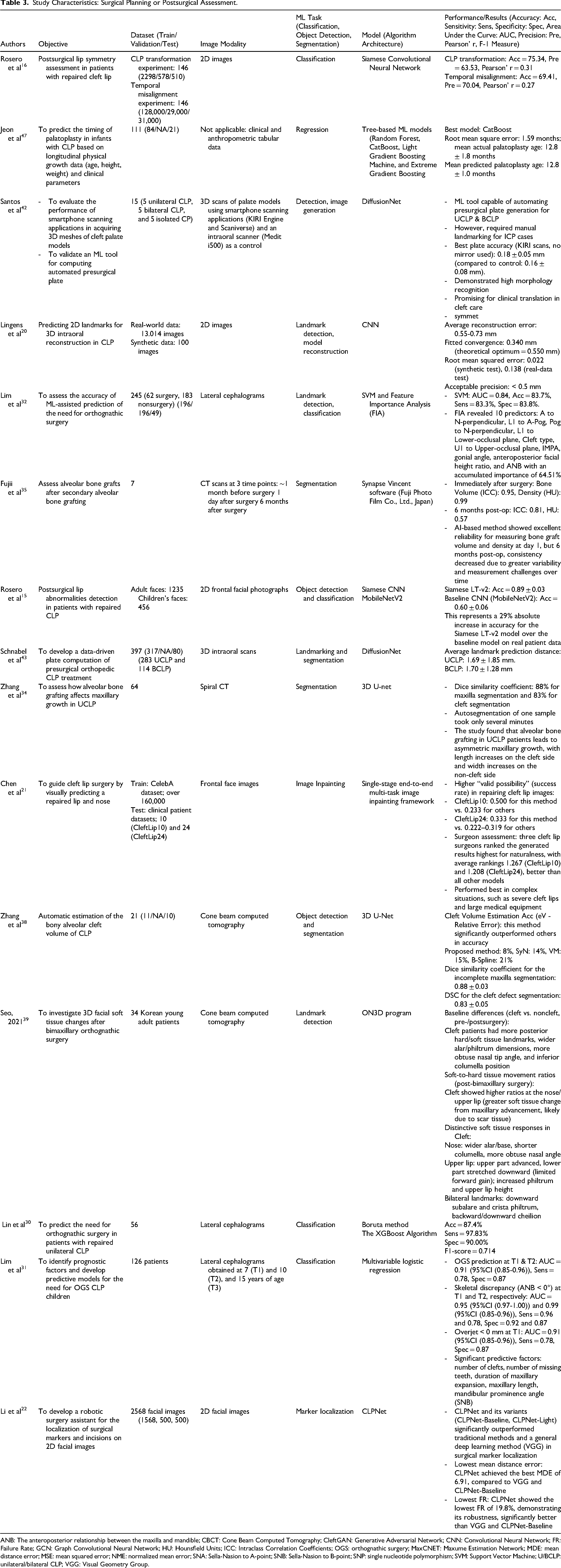
ANB: The anteroposterior relationship between the maxilla and mandible; CBCT: Cone Beam Computed Tomography; CleftGAN: Generative Adversarial Network; CNN: Convolutional Neural Network; FR: Failure Rate; GCN: Graph Convolutional Neural Network; HU: Hounsfield Units; ICC: Intraclass Correlation Coefficients; OGS: orthognathic surgery; MaxCNET: Maxume Estimation Network; MDE: mean distance error; MSE: mean squared error; NME: normalized mean error; SNA: Sella-Nasion to A-point; SNB: Sella-Nasion to B-point; SNP: single nucleotide polymorphism; SVM: Support Vector Machine; U/BCLP: unilateral/bilateral CLP; VGG: Visual Geometry Group.
The included studies encompassed 4 broad categories of AI tasks. First, computer vision tasks were the most prevalent, with classification (n = 29),3,4,13–16,19,23,24,26–32,36,37,41,44,45,48–51,54,56–58 object detection (n = 25),3,13–15,17,18,20,23–29,32,36–42,44,58,59 segmentation (n = 8),3,33–35,38,41,43,59 including 2 studies that combined all three major vision tasks.3,41 Second, generative and reconstructive approaches were investigated in a smaller number of studies (n = 5), including image generation, inpainting, and model reconstruction.12,13,20,21,42 Third, Natural Language Processing (NLP) was applied in 2 studies for medical text simplification and content generation.60,61 Finally, bioinformatics-driven tasks appeared in 6 studies, involving regression-based prediction (n = 4)32,46–48 and gene pathway analysis (n = 3).52,53,55 This distribution demonstrates that while computer vision remains the cornerstone of AI research in craniofacial disorders, emerging applications in generative modeling, NLP, and genomics signal a broadening scope of innovation.
Regarding the number of cases, 13 studies analyzed very large datasets with 1000 samples or more with the largest exceeding 13,000 clinical images.4,15,17,20,22,37,51,52,57,58 Twenty-seven studies reported large datasets between 101 and 999 cases.3,12–14,18,19,23–29,31,32,36,41,43,46–49,53–56 Smaller datasets with 100 cases or fewer were used in approximately 12 studies,21,30,33–35,38–40,42,44,45,59 typically in exploratory or pilot designs. Two studies did not specify a sample size and instead used qualitative sources.60,61 Overall, the included studies exhibited striking variability in sample size, spanning from as few as 7 subjects to more than 13,000 cases, underscoring the heterogeneity in data availability across AI research in craniofacial disorders.
Deep learning approaches were the most frequently applied (n = 21), with CNN-based models being the predominant choice,3,13,15–18,20–22,26,33,36,38,40,46,48,54,59 most often using ResNet 58 and VGG derivatives.19,27,58 GANs (n = 3),12,14,49 transformers, and other advanced architectures (n = 6) were less common but represented recent trends. Classical ML methods (n = 31), including SVMs,4,32,37,50,54,57 random forests,4,47,51,54,55,57 logistic regression,31,52–55 and boosting algorithms, were mainly applied to genetic and tabular datasets.49,56 A smaller number of studies incorporated large language models or commercial AI software (n = 9).
The majority of studies included in this systematic review were undertaken in the United States3,12–18,40,44,48,55,60,61 and China22,33,34,36–38,46,50,53,54,56,58,59 with additional investigations originating from Japan,27–29,31,35 Korea,30,32,39,47,49 the United Kingdom,21,41 and the rest in Switzerland, Egypt, Saudi Arabia, Brazil, Pakistan, India, and Thailand.
Risk of Bias and Applicability
We assessed the included studies using QUADAS-2, PROBAST, and JBI. The results of the risk of bias assessment are presented in Supplemental Figures S3 to S6. Uncertain risk was caused by inconsistent patient enrollment procedures, missing patient data from exclusions, ambiguous index tests, and ambiguous information on reference standards. High risk resulted from failing to guarantee that every patient received a reference standard and from not all patients obtaining the same reference standard. A high-risk applicability was caused by the included patient groups’ misalignment with the particular settings of our review question, as well as variations in the techniques and interpretations of indicator tests, especially with regard to imaging modalities.
QUADAS2
Nine studies had a low risk of bias in all 4 domains (Supplemental Figure S3). Low risk of bias was observed for index tests (n = 17) and reference standards (n = 30). Regarding the patient selection domain, 20 were assessed as low risk of bias, 8 as unclear, and 2 as high risk. Also, the flow and timing domain (n = 19) was mostly graded as low, while 5 articles were graded as unclear and 6 as high risk of bias. Regarding applicability domains, the majority of studies (n = 28) had low risk across all domains, except for 2. One of them had a high risk in both the index test and the reference standard domains. Another was at high risk in the patient selection and reference standard domains.
PROBAST
Three studies were rated as low risk in all domains (Supplemental Figure S4). Three studies showed an unclear status in the analysis domain, while 3 others were high risk. Regarding the predictor's domain, only 2 studies were graded as high risk, which were also unclear in the participants and data sources.
JBI
All articles had a low risk of bias (Supplemental Figures S5 and S6).
Risk of bias assessment was not applied to certain studies, such as those evaluating AI-based patient education tools,60,61 image reconstruction/inpainting,12,13 and genomic studies identifying variants.50,52,53 These types of studies do not involve predictive modeling, diagnostic accuracy testing, or clinical interventions; therefore, established RoB tools are not directly applicable. Instead, their findings were integrated narratively into the discussion, emphasizing their contributions, strengths, and limitations in context.
Overall, the evidence base showed moderate confidence, with most studies having low to moderate risk of bias but important limitations in generalizability. Common concerns included unclear patient selection and data source, incomplete reference standards, and inconsistencies in flow and timing.
Qualitative Synthesis
Upon assessing the full text of the included studies, the overall accuracy of AI models for classifying and detecting CL/P and its subtypes ranged from 74.5% to 95%, while segmentation and localization models achieved Dice coefficients of 0.84 to 0.92. Correlation with expert assessments was notably strong (Pearson's r range = 0.89-0.94). Across modalities, AUC values typically ranged from 0.88 to 0.97 for classification tasks; accuracies of greater than 90% were common in both genetic and imaging studies; and F1-scores of 0.75 to 0.94 indicated strong model balance (Tables 1-3).
Meta-Analysis
Meta-analyses were performed as exploratory quantitative summaries of narrowly defined subsets of studies. Supplemental Figure S1 illustrates the forest plots of the pooled accuracy (Supplemental Figure S1-A), sensitivity (Supplemental Figure S1-B), and specificity (Supplemental Figure S1-C) for studies reporting the diagnostic ability of AI to detect unilateral and bilateral CL/P on panoramic radiographs. Using random-effects models, the results showed a pooled accuracy of 90% (95% CI: 0.82-0.97), a pooled sensitivity of 87% (95% CI: 0.75-0.99), and a pooled specificity of 89% (95% CI: 0.77-1.01).
Supplemental Figure S2 illustrates the forest plots of the pooled sensitivity (Supplemental Figure S2-A) and specificity (Supplemental Figure S2-B) for studies predicting the need for orthognathic surgery from lateral cephalograms of patients with CL/P. The results indicated an overall sensitivity of 87% (95% CI: 0.75-0.98), and an overall specificity of 86% (95% CI: 0.83-0.89).
Discussion
This systematic review demonstrated that AI is increasingly being applied in the management of cleft lip and palate, with current applications focused on three main areas: CL/P diagnosis, detection, and classification, CL/P prediction and genetic risk assessment, and CL/P surgical outcome assessment and treatment planning. The findings show that AI works best as a second reader by prioritizing suspicious cases, standardizing radiographic landmarking, reducing operator variability, and facilitating early detection of patients needing orthognathic surgery, while final diagnosis and treatment planning remain clinician-led. The pooled accuracy for both meta-analyses should be interpreted as decision-support performance rather than autonomous decision making.
CL/P Diagnosis, Detection, and Classification
Alam et al 23 demonstrated that AI-assisted (WebCeph software) cephalometric analysis offers accurate evaluation of nasolabial angles and upper lip projection in nonsyndromic patients with CL/P, providing a reproducible and time-efficient alternative to traditional manual measurements. In a subsequent investigation, Alam et al applied AI techniques to assess sagittal skeletal parameters, uncovering significant reductions in Sella-Nasion to A-point, ANB (the anteroposterior relationship between the maxilla and mandible), and Wits indices among cleft subjects, while SNB remained largely unaffected, underscoring the precision of AI-based craniofacial quantification. 24 Kamei et al 26 expanded these findings by implementing CNN-based MobileNet models, which achieved high accuracy in cervical vertebral maturation staging and vertebral anomaly detection, simultaneously revealing delayed skeletal maturation in unilateral cleft patients. Conversely, Tageldin et al 25 reported that fully automated AI landmark identification can produce notable deviations in critical points, particularly subnasale, resulting in meaningful reductions in nasolabial angle measurements, highlighting the necessity for expert validation. Collectively, these studies emphasize that AI markedly improves the speed, consistency, and objectivity of cephalometric and craniovertebral analyses. Comparative evaluation indicates that Kamei et al's CNN models demonstrate superior performance in skeletal assessment, whereas Alam et al's AI platform is more effective for soft tissue and sagittal measurements.23,24,26 Deep neural networks have also been used to automatically identify 21 essential nasolabial landmarks that are required for surgical planning, achieving accuracies close to expert manual annotations. 18 Recently, a 3D graph convolutional network for cephalometric landmarking reported the mean localization error was 1.3 mm, with its performance highly relying on image quality and severity of deformity. 36 Taken together, the evidence supports the integration of AI as a transformative adjunct in orthodontic diagnostics, offering enhanced quantitative precision.
Regarding CLP classification, across the 3 Kuwada et al studies, they reached a high accuracy for DetectNet in the diagnosis of CLP (AUC = 0.95) and classification of unilateral and bilateral clefts (almost the same as human raters) based on panoramic radiographs.27–29 Exploratory meta-analysis of DetectNet suggested a high pooled diagnostic accuracy of 0.90, though notable heterogeneity (I2 = 96.27%), indicates that these estimates are not directly generalizable and reflect variability in datasets. This underscores the need for standardized protocols, larger multicenter datasets, and external validation before these models can be reliably implemented in clinical workflows.27–29 Concurrently, the ViT and Siamese Network integration was used by Nantha et al to classify CLP types, utilizing multimodal ultrasound and speech data, and achieved an overall accuracy of 82.76%, demonstrating particular effectiveness for bilateral CLP cases. 45
Moreover, Zhang et al utilized MaxCNet for cascaded registration on CBCTs for personalized maxilla completion and cleft defect volume estimation. It achieved a dice similarity coefficient of 0.84 ± 0.04 on estimated cleft defects and a relative volume error of 0.09 ± 0.08. 33
Studies have shown that deep learning models have also been useful for detecting facial asymmetries accurately. Wang et al. employed deep learning on CBCT scans to quantify asymmetry in unilateral CP, and found significant hypoplasia on the cleft side. 59 Similarly, Hayajneh et al introduced a rapid ML framework for detecting and rating facial anomalies on 2D images, achieving strong agreement (92%) with human evaluations. 13 Wu et al tested midfacial reference plane methods on 3D meshes, showing that the automated deformation method matched the best manual approaches. 44
AI is also applied to CLP severity measurement, ranging from objective surgical outcome assessment to automated severity scoring. Miranda et al demonstrated the utility of deep learning for 3D clinical image evaluation of cleft-related deformities, reaching an accuracy of 0.81. 3 At the same time, Hayajneh et al introduced a StyleGAN2-based unsupervised anomaly detection model that correlated strongly with human ratings (Pearson's r = 0.89), offering a reliable and scalable tool for real-time clinical measurement. 14
Additionally, 2 studies evaluated the application of AI and large language models for patient education and communication about CLP. A study claims that ChatGPT-4 improves the readability and clarity of patient educational materials to 6th-grade reading levels. 60 Also, according to Mahedia et al's study, ChatGPT can assist patients with CLP in learning by providing information that is generally accurate and simple to comprehend, by having a high readability score (grade 10.87) and no verified references. Due to its limitations, AI should not be utilized in place of therapeutic conversation, but rather in addition to it. 61
Collectively, these AI models demonstrate significant and possibly competitive potential to expert judgment in CLP diagnosis and analysis, although their widespread use will depend on larger, more diverse databases and improved model interpretability for ensuring the clinical reliability.17,18,27,29,36 Models such as DetectNet, MobileNet, and U-Net were the most effective platforms and have become benchmark tools for radiographic and CBCT-based tasks, while GANs and Transformers show potential for esthetic evaluation and multimodal fusion.
CL/P Prediction and Genetic Risk Assessment
AI is carefully establishing itself in prenatal diagnosis of CL/P, but still seems to be learning the ropes. For example, a model that worked only on 2D images of fetal lips reached approximately 92% accuracy in distinguishing normal from abnormal lips, despite the variable and noisy characteristics of ultrasound data. 58 He et al developed CLP-Net, a reinforcement-learning framework that autonomously navigates 3D first-trimester ultrasound volumes to locate the mid-sagittal, retronasal-triangle, and maxillary-axial planes used for CLP screening. By integrating spatial-anatomical feedback during training, the model mimicked expert decision-making and produced planes consistently judged acceptable by clinicians. 46 In contrast, Wang et al employed a more conventional pipeline, extracting texture-based descriptors (Local Binary Patterns and Histograms of Oriented Gradients) from mid-gestation 2D fetal facial ultrasound images and classifying them via a support vector machine. Their approach demonstrated that carefully engineered features can still perform reliably even with limited data. Collectively, these studies illustrate the methodological transition from handcrafted texture analysis to autonomous, anatomy-aware learning systems that promise greater standardization and reproducibility in prenatal imaging. 37 That said, all of these approaches share familiar struggles: too few abnormal cases to learn from, and differences in ultrasound quality from one clinic to another. So yes, AI is starting to make cleft prediction faster and more consistent, but for now, it's still a tool to support clinicians, not to replace them.37,46
Shafi et al and Qadeer et al used ML to predict nonsyndromic CLP risk in embryos based on maternal and environmental questionnaire data from Pakistan. Shafi et al reached 92.6% accuracy with a Multilayer Perceptron model, while Qadeer et al. improved performance to 98.3% by applying SMOTE (Synthetic Minority Oversampling Technique) to expand the dataset. Both studies emphasized that accurate prediction models could guide preventive measures (including regularly visiting doctors and avoiding nonprescribed drugs) for expecting mothers and healthcare providers.4,57
Three studies explored the application of ML methods for SNP-based genetic risk prediction of nonsyndromic CLP; however, they revealed controversies regarding overfitting, population specificity, and clinical applicability, with each stating the need for further cross-ethnic validation before translation into genetic counseling or personalized prevention.49,51,54
Zhang et al evaluated 43 previously reported SNPs from DNA extracted from blood samples in Han and Uyghur Chinese infants, finding that Logistic Regression outperformed other ML methods, while underscoring the influence of folic acid and vitamin A genes such as MTHFR and RBP4. The predictive power of this study varied by ethnicity, raising concerns about its generalizability across populations. 54 Machado et al examined 72 SNPs in a Brazilian cohort and reported a high predictive accuracy (up to 99% with random forest), identifying a 13-SNP panel as most informative; however, they noted that ancestry-specific effects limited extrapolation to other populations and called for validation before clinical use. 51 Kang et al, working with a Korean cohort, introduced a novel genetic-algorithm-optimized neural networks ensemble (GANNE), which achieved a high accuracy (AUC 88.2% with a 10-SNP model). This article emphasized the need for larger datasets and external validation to ensure clinical utility. 49
Three studies assessed gene-gene interaction analysis combined with ML techniques. Li et al examined gene-gene (GxG) interaction among WNT pathway genes and Genome-Wide Association Studies (GWAS)-identified regions (MAFB, IRF6) in Asian and European case-parent trios. They reported robust evidence of G × G interaction between markers in WNT5B and MAFB in both ancestral groups. 55 Liu et al focused on G × G interactions within the cell adhesion gene pathway (ACTN1, CTNNB1, and CDH1) in Chinese case-parent trios. Logistic Regression confirmed a significant 2-way ACTN1 × CTNNB1 interaction, also evidence for higher-order interactions involving CDH1. 53 Machado et al investigated 5 GWAS-reported loci in a large Brazilian case-control population, identifying rs7552 (in FAM49A on 2p24.2) as a risk marker and confirming several highly significant SNP-SNP interactions involving rs7552. 52 The main controversy in GxG interaction studies comes from distinguishing true interactions from false positives due to Linkage Disequilibrium, and in validating results across different populations.
In admixed groups, replication is challenging where risk alleles may be population-specific, so all detected interactions need independent confirmation and functional validation before being considered biologically meaningful in CLP. Collectively, Multilayer Perceptron, GANNE, Random Forest, Naive Bayes, and YOLOv5-based models showed the best performance for genetic risk prediction, questionnaire-based screening, and prenatal ultrasound detection.
CL/P Surgical Outcome Assessment and Treatment Planning
Rosero et al developed a deep learning Siamese CNN model to automatically evaluate how well lip symmetry was restored after CL surgery. Trained on simulated images of healthy faces, the model could assess surgical success without using anatomical landmarks, reaching approximately 75% accuracy and showing a 0.31 correlation with surgeons’ esthetic evaluations. 16 In related work, Rosero et al combined a Siamese CNN and a Transformer network (Siamese LT-v2) to detect residual lip irregularities following surgery. By comparing each patient's real lip image with a “normalized” version generated by the model, they achieved 89% accuracy in identifying abnormal outcomes, which was 29% improved compared to the baseline network (MobileNetV2). 15 Taken together, Rosero et al focused on measuring how symmetrical the lips are right after surgery, looked at how natural the lips appear later on, and whether further corrective surgery might be needed.15,16
Four studies explored how AI can be applied to evaluate surgical bone graft outcomes in patients with CL/P, each using a different approach. Seo et al. analyzed soft-tissue changes after orthognathic surgery and found that the ratio of soft-to-hard-tissue movement was higher around the nose and lips in patients with cleft, suggesting a distinct pattern of soft-tissue response compared with noncleft individuals. 39 Fujii et al focused on automatic bone segmentation and evaluation of secondary alveolar bone grafting (SABG) outcomes. They reported that AI-based analysis significantly improved the speed and accuracy of bone volume and density measurements compared with manual methods, achieving excellent interobserver reliability within a much shorter processing time. 35 In a similar direction, Zhang et al applied deep learning to automatically reconstruct the alveolar cleft and measure maxillary growth before and 1 year after bone grafting. Their results showed a significant reduction in the dimensional difference between the cleft and noncleft sides, along with improved maxillary growth on the cleft side after SABG. 34 In another study, they refined a 3D U-Net model combined with nonrigid CT registration and confirmed that AI can accurately quantify jaw growth and postsurgical changes with high efficiency and minimal error. 38 Taken together, Fujii and Zhang et al focused mainly on bone outcomes, showing that AI provides an effective tool for the quantitative evaluation of grafted bone and maxillary development, while Seo et al emphasized esthetic and soft-tissue outcomes.34,35,38,39
Studies have also investigated the use of AI for predicting the need for orthognathic surgery. Lim et al developed a deep learning CNN model to automatically locate important cephalometric landmarks in patients with CLP. Trained on real patient images, the model showed high precision, identifying most landmarks within 2 mm of expert measurements in 90% of cases, making cephalometric analysis and diagnosing the need for orthognathic surgery faster and more consistent. 31 In comparison, Lin et al used Boruta and XGBoost algorithms to predict which patients would later require orthognathic surgery. By analyzing longitudinal cephalometric data, their model achieved 87.4% accuracy using only 4 key measurements (ANB, PP-FH, Combination Factor, and Facial Convexity Angle). Together, they show how AI can enhance both the assessment and prediction of the need for orthognathic surgery in patients with CLP, with pooled meta-analytic sensitivity and specificity of 87% and 86%.30,32
Regarding the application of advanced computational tools on the workflow of surgical treatments, Li et al and Chen et al focused on preoperative surgical planning from patient 2D images, offering a guidance image for CL surgery; achieving demonstrable superiority in their tasks compared to state-of-the-art methods or baselines.21,22 In contrast, Lingens et al aimed to enhance treatment planning by demonstrating rapid 3D intraoral reconstruction from a single smartphone image. Using real and synthetic datasets, they trained a CNN to predict 2D landmarks and generate 3D models. The method performed well on synthetic data but was less accurate on real images due to a domain gap, suggesting that larger real datasets could greatly improve performance and support low-cost, noninvasive clinical applications. 20
Santos et al and Schnabel et al tackled the 3D digital workflow for orthopedic plates. Santos et al explored the use of smartphone scanning apps to create 3D models of newborn palates for fabricating presurgical orthopedic (PSO) plates. The results indicated that the KIRI Engine app, particularly for unilateral CLP models, achieved accuracy comparable to professional intraoral scanners. 42 Schnabel et al presented a fully automated, data-driven pipeline using a DiffusionNet to design PSO plates from 3D intraoral scans. The results were highly positive, with the pipeline producing accurately fitting plates in under 3 min, and were qualitatively and quantitatively similar to those based on manual expert annotations. 43 Overall, Siamese CNN, DiffusionNet, 3D U-Net, and XGBoost were the most effective platforms for surgical planning and prediction.
Augmented reality (AR) is also a promising adjunct in cleft surgery that can improve surgical marking and intraoperative guidance by projecting patient-specific landmarks and preoperative plans directly onto the surgical field. 62 Recent studies have shown that AR-guided marking improves precision and supports better symmetry in cleft lip repair. 63 Portable smartphone- or projector-based AR systems may be especially valuable in low- and middle-income countries, where access to advanced surgical planning tools is limited, by providing low-cost support for accurate and standardized treatment. Although challenges such as cost and technical training remain, AR represents an important future direction for improving accessibility and precision in cleft surgical care. 64
Recent advancements in deep learning have substantially advanced the diagnosis, detection, classification, and treatment planning of CLP. The overall findings reinforce a practical shift toward using AI for triage, workflow efficiency, and long-term monitoring, especially in landmark identification, graft evaluation, and presurgical planning. 65 Similar to recent orthodontic reviews, AI has improved time efficiency and reproducibility, even though it does not outperform experts.65,66 Moreover, similar to radiology, dermatology, and ophthalmology, AI performs best in image-based detection and classification tasks. 67
A limitation of this research is the predominance of small, single-center datasets and the lack of external validation across diverse populations, imaging modalities, and clinical settings, which restricts the generalizability and real-world applicability of current AI models. This also raises the possibility of overfitting, where models perform well during internal testing but fail to remain accurate in real practice. Therefore, larger multicenter datasets and independent validation cohorts are needed before AI models can be reliably brought into clinical care. Future AI development can shift from single-task models, such as landmark detection, toward multimodal systems integrating genetic, imaging, and clinical parameters, such as CBCT, cephalometrics, intraoral scans, and clinical history. This shift can enhance prediction accuracy, enable personalized treatment planning, and support evidence-based decision making in CL/P management.
Conclusion
In conclusion, AI is increasingly being applied in the management of CLP, with current applications focused mainly on 3 domains: (1) CL/P diagnosis, detection, and classification; (2) CL/P prediction and genetic risk assessment; and (3) CL/P surgical outcome assessment and treatment planning. Across these areas, AI has demonstrated reliable accuracy and consistency in anatomical landmarking, radiographic analysis, image-based classification, and pre- and postoperative evaluation, which approached or, sometimes, matched expert-level performance.
Supplemental Material
sj-docx-1-cpc-10.1177_10556656261460187 - Supplemental material for Artificial Intelligence Applications in Cleft Lip and Palate Diagnosis, Prediction, and Treatment: A Systematic Review and Meta-Analysis
Supplemental material, sj-docx-1-cpc-10.1177_10556656261460187 for Artificial Intelligence Applications in Cleft Lip and Palate Diagnosis, Prediction, and Treatment: A Systematic Review and Meta-Analysis by Nozhan Azimi, DDS, Sahar Akbari Iraj, DDS, MSc, Fateme Mazaheri, DDS, MSc, Sarina Maddahi, DDS, MSc, Mohammad Mahdi Khanmohammadi, DDS, Ali Azadi, DDS, and Asghar Ebadifar, DDS, MSc in The Cleft Palate Craniofacial Journal
Footnotes
Author Contributions
NA: Conceptualization, Methodology, Investigation, Writing—Original Draft, Writing—Review & Editing, Project administration.
SA: Investigation, Writing—Original Draft, Writing—Review & Editing.
FM: Investigation, Writing—Original Draft, Writing—Review & Editing.
SM: Investigation, Writing—Original Draft, Writing—Review & Editing.
MK: Investigation, Writing—Original Draft, Writing—Review & Editing.
AA: Investigation, Formal analysis.
AE: Investigation, Writing—Review & Editing, Supervision, Project administration.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data supporting the findings of this study are available within the paper and upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.