
Abstract
The familiar claim that generative AI drives the cost of cognition toward zero gets the problem backward. What AI cheapens is the appearance of knowledge: plausible claims that circulate as if warranted. Drawing on Epinets, this essay argues that large language models enter organizations as proposition-producing systems without the epistemic states their outputs normally imply: belief, justified knowledge, recognized ignorance, and accountability. That is the condition. The organizational danger begins when such systems are miscategorized as humanlike knowers. Their outputs can acquire epistemic authority before epistemic responsibility is established. Error becomes harder to detect because it arrives without the signals that normally make wrongness visible: hesitation, qualification, and acknowledged uncertainty. Correct and incorrect outputs can feel the same, making correction-seeking unlikely. The essay traces this progression from plausible output to miscategorization, authority capture, and epistemic misalignment, and then asks how organizations can govern epistemic standing in hybrid human–AI systems.
ELIZA shows, if nothing else, how easy it is to create and maintain the illusion of understanding, hence perhaps of judgement deserving of credibility. A certain danger lurks there. (Joseph Weizenbaum, 1966, pp. 42–43)
The Field's Anxiety: Organization Theory Confronts Intelligent Technologies
A familiar refrain is circulating in boardrooms, academic and policy circles, as well as LinkedIn commentariat: the cost of cognition is going to zero. The punchline writes itself: if thinking becomes cheap, expertise becomes cheap; if expertise becomes cheap, expert authority weakens; if authority weakens, organizations become flatter, faster, and freer of the specialists and credentialed authorities whose scarce expertise once justified deference.
It is an appealing line: neat, provocative, and strangely comforting. But it works only if we treat intelligence as a production cost rather than an epistemic achievement. And that is the mistake. The argument gets the problem almost exactly backwards. The danger is the cheapening of the appearance of understanding. Weizenbaum saw this early. In 1966, he watched his own secretary confide in a program that did nothing more than match keywords and mirror them back. The problem was not the machine's sophistication. It was the reliability of human credulity. The vulnerability has not changed. Its scale has.
Large language models (LLMs) do not make cognition “free.” They industrialize the production of plausible claims and, in doing so, relocate the organizational bottleneck from generating candidate answers to governing which candidate answers get to count as knowledge. Scarcity is shifting from cognition to credibility. The institutions built to manage that scarcity—peer review, professional credentialing, editorial judgment, expert hierarchies—were designed for a world in which plausible-sounding claims were still costly to produce. A memo, a literature review, a strategy brief, a legal interpretation, a market analysis: each required time, expertise, and some degree of exposure to correction. Generative AI changes that cost structure.
What becomes cheap is not knowing. It is proposition-shaped outputs that look enough like knowing to circulate as knowledge. When enough counterfeit propositions circulate through the same channels as warranted claims, the exchange rate between fluency and credibility begins to collapse—not only for synthetic outputs but for legitimate ones as well. Experts, institutions, and carefully grounded claims all become harder to distinguish from synthetic noise. That is the epistemic event.
Generative AI marks the arrival of a new class of epistemic technologies: systems that participate directly in how organizations generate, circulate, validate, and repair what they treat as true. Organizational life has always depended on epistemic networks, the trust-structured systems through which organizations decide what to believe and act on. What is new is that nonhuman agents can now enter those networks as proposition-producing participants, at scale, with an indeterminate relationship to truth.
Organization theory has begun to sense the disruption, even if it has not yet named the problem in these terms. Several observers have argued that the field risks losing relevance if it fails to reckon with the organizational consequences of intelligent technologies. Phillips (2026), for example, warns that mainstream organization theory risks “fading into insignificance” if it treats intelligent technologies as peripheral while those technologies become constitutive of organizational life and social construction.
Sergeeva et al. (2026) push the issue further, arguing that organizations are becoming arenas of struggle among competing epistemic regimes where intelligent technologies introduce alternative bases of knowing that rival and displace established ones. That framing gets the arena right but assumes that both contestants represent grounded ways of knowing. The harder case is stranger: what happens when one of the contestants lacks the epistemic states the contest presupposes?
That is where this essay begins. AI technologies have entered the networks through which organizations decide what counts as knowledge. Many of the field's core theories presuppose that the epistemic agents operating in those epistemic networks are human actors who believe what they assert, can justify it, can recognize error, and can be held accountable for what they say. LLMs violate that presupposition. They reproduce the surface features of knowing, actively impersonating the signals that normally certify epistemic warrant, while bearing none of its conditions.
Organizations have always absorbed error. What is new is error arriving in the costume of its opposite. Ignorance presents as fluency. Fabrication comes with citations. Confidence comes detached from belief. Many of the cues organizational actors use to calibrate epistemic trust—hesitation, qualification, competence boundaries, the willingness to say, ‘I don't know’—either disappear or fire in the wrong direction. That is what makes this a theoretical problem rather than technical. The failure mode is difficult for the existing apparatus to see.
Epinets, as developed by Moldoveanu and Baum (2014), provide a grammar for this problem. Organizations can be analyzed as networks of agents exchanging propositions under conditions of trust. In such networks, what matters is not only what is said. It matters who is believed, on what basis, through which channels, and with what consequences. Epinets make visible how belief becomes shared, how trust routes knowledge, and how epistemic failure propagates.
The wager of this essay is that generative AI is forcing a theoretical reversal: once synthetic proposition production becomes abundant, epistemic authority is no longer exercised only by credentialed humans. It is reallocated to intermediating systems that decide what is seen, summarized, cited, and treated as known. In epinet terms, this is a problem of epistemic promotion: the trust relations that determine which propositions become shared and which remain candidate claims.
The argument moves through a simple sequence. LLMs produce plausible outputs. Organizations miscategorize those outputs as the contributions of knowers. Miscategorization allows structural participation to harden into epistemic authority in trust networks built for accountable humans. The result is epistemic authority without epistemic accountability. The question to be answered is: what must organization theory explain to keep human–AI hybrid epistemic systems governable?
The Seductive Story: Unbounded Rationality, Bounded Epistemics
One reason the “cost of cognition” claim has gained traction is that it fits an emerging interpretation of generative AI in management research: artificial intelligence appears to relax the cognitive constraints that shape organizational decision-making.
Csaszar's (2025) “unbounded rationality” formulation captures the temptation. Classic organization theory begins from limits: attention is scarce, memory is partial, computation is bounded, search is costly. A manager evaluating a strategic option cannot attend to every signal, retrieve every relevant precedent, or test every alternative before a decision is needed. LLMs seem to loosen those constraints. They can hold vastly more information in view, draw on far larger stores of prior cases, work through structured comparisons, summarize alternatives, generate scenarios, and surface patterns in seconds.
That capacity extends across the full texture of organizational life, which is saturated with language. Directives, reports, analyses, recommendations, minutes, performance narratives, regulatory filings, and strategy documents are all textual artifacts. Transformer models unlock that medium for computational analysis in a new way. They do not just process data at the edge of the organization. They enter the organization's core epistemic work: search, synthesis, interpretation, framing, justification, and communication. AI appears to widen search, enrich representation, and accelerate aggregation, removing traditional bottlenecks of attention and analysis. It seems to unsettle a central premise of modern organization theory: that decision-makers operate under severe cognitive limits.
But unbounded generation does not produce unbounded justification. LLMs can widen the search space while loosening the tether to truth. They can enrich representation while mixing accurate, outdated, fabricated, and context-inappropriate content. They can aggregate perspectives while manufacturing the appearance of consensus among synthetic voices. What they relax are constraints on producing candidate claims. They do not relax the conditions under which claims become knowledge.
The “cost of cognition” trope collapses at exactly this point. Generative AI cheapens cognition-like outputs: fluent language, plausible explanations, and pattern-consistent reasoning. These outputs travel socially as if they were knowledge, often at negligible marginal cost. But cognition in the organizational sense—judgment under uncertainty, justification, responsibility for belief, justification before others—has not become costless. It must still be earned. And it does not scale cheaply.
If unbounded rationality is becoming plausible as a computational claim, bounded epistemics is becoming unavoidable as an organizational problem. The constraint moves away from generating candidate judgments and toward governing which propositions acquire standing. The question is no longer, “Can the organization produce enough analysis?” It is, “Can the organization preserve the conditions under which analysis can be trusted?”
This is not only a filtering problem. It is also a category problem. Organizations must resist treating systems optimized to produce plausible propositions as if they were accountable knowers. The organizational risk extends beyond AI systems sometimes getting things wrong. It is that they acquire epistemic standing they have not earned and cannot be held accountable for.
Generative AI, then, does not eliminate bounded rationality so much as relocate it. Once proposition production becomes abundant, the central organizational challenge becomes epistemic rather than cognitive: generating candidate judgments is no longer the binding constraint; governing which candidates acquire epistemic standing is.
The Overlooked Shift: LLMs Aren’t “New Minds,” They’re New Epistemic Infrastructure
The “cognition to zero” story also misleads because it imports a picture of AI as an autonomous, truth-tracking knower. That picture is both too flattering and too simple. A better starting point treats LLMs as socio-cultural technologies. Farrell et al. (2025) make this point bluntly: it is more revealing to analyze LLMs as systems that reorganize accumulated text at scale, and thereby reshape coordination, interpretation, and authority than to debate whether they possess intelligence in the human sense. Faraj et al. (2026) push this insight into organization theory. LLMs participate in epistemic work: access, interpretation, validation, and communication. They speed up knowing and rearrange it.
This is a different relationship to organizational knowing than the familiar tools relationship. Organization theory has long-treated technologies as tools, complements, constraints, substitutes, or decision aids. Epistemic technologies do something more disruptive. They change how organizations decide what is true enough to act on, destabilizing how organizations classify who or what gets to count as a credible participant in the first place.
That is why the old categories no longer quite hold. LLMs are not passive tools in the usual sense because their outputs take the form of assertions, recommendations, and judgements. They are not human knowers, because they do not believe, justify, or recognize ignorance. They are not merely decision aids, because they increasingly shape the frame within which decisions are made before any human review begins.
LLMs are synthetic epistemic intermediaries: systems that produce, route, summarize, and amplify propositions in mind-like form without possessing the epistemic states normally attached to that form. Their outputs look like contributions from a knower. The form does a great deal of social work before anyone asks whether the underlying system can bear the burdens that form implies.
Faraj et al.'s (2026) rhetorical “monsters” is useful here because it diagnoses the ontological ambiguity. LLMs are too generative to be dismissed as simple tools, too lacking in subjectivity to count as human-like knowers, and too entangled in organizational practice to remain external to the processes they reshape. Once classification becomes unstable, governance does too.
The relevant cheapness, then, is linguistic production, not cognition. An AI model can generate 10 plausible strategies, 20 plausible citations, 50 plausible interpretations, and 100 plausible next steps in the time it takes a human to decide whether any one of them should be trusted. 1 That asymmetry shifts the organizational problem away from whether the machine is intelligent and toward what sort of epistemic participant it is being allowed to become.
What enters the organization is a new layer of epistemic infrastructure. It can generate, sort, summarize, route, and amplify propositions before anyone has established what standing those propositions deserve. Generative AI does not expand organizational cognition; it introduces a new kind of participant into the epistemic networks through which organizations decide what to believe. And it does so before anyone has determined what standing that participant deserves.
The Epistemic Grammar: Organizational as Networks of Knowledge, Belief, and Trust
Epinets give that classification problem analytical purchase. The core idea is that organizations sustain patterns of knowledge, belief, and trust across networks of agents. Those patterns make coordination possible. Human knowing has a grammar. It involves proposition, justification, truth norms, competence, integrity, and accountability. Epinets make that grammar visible at the network level. They ask how propositions acquire standing as knowledge, how trust shapes knowledge flows, and how those standings stabilize or collapse under strain.
In Epinets, a proposition is a statement with truth conditions. It can be true or false. Agents relate to propositions through epistemic states: believing, knowing, being aware, being ignorant. Knowledge is demanding. An agent knows P when the agent believes P for a valid reason, and P is true. The goal is to identify the minimum normative architecture that organizational knowing presupposes when claims are treated as more than utterances.
Epistemic states determine what an agent knows; trust relations determine whose knowledge gets believed. Epinets define trust in ways that matter for organizational life. Trust in competence concerns whether another agent would know P if P were true. Trust in integrity concerns whether another agent would assert P if they knew it. These are network relations that serve as routing rules that regulate epistemic flow: whose claims spread quickly, whose claims are scrutinized, whose claims are ignored, and which propositions become common ground.
Epinets also supply vocabulary for network resilience: stability, robustness, and immunity. Stability concerns whether an epistemic core remains intact when the world has not changed. Robustness concerns whether the network can tolerate noise. Immunity concerns whether it can resist distortive moves that threaten epistemic integrity. When AI systems participate in epistemic exchange, each property is strained in a different way.
This vocabulary becomes diagnostic because AI systems can occupy positions in epistemic exchange without bearing the normative burdens that normally justify those positions. They can produce propositions. They can be cited. They can be built upon. They can shape the flow of claims. Yet the system itself does not believe, does not know, does not recognize ignorance, and cannot be answerable in the ordinary social sense.
The Fault Line: Structural Participation Without Normative Content
Generative AI can participate structurally in organizational epistemic networks. It can produce propositions, summarize materials, route claims, surface options, and be treated as a source. But it does not participate normatively. It does not bear belief. It does not own an assertion. It does not experience ignorance as a limit. It does not answer for error.
Sergeeva et al. (2026) identify the right organizational stakes: authority is redistributed, valuation criteria shift, and professional judgment can be displaced by computational outputs that arrive with an aura of objectivity. But the “epistemic regime” account misidentifies what is competing. It treats the contest between human knowers and AI systems as a rivalry between grounded ways of knowing. The argument here is different: one of the competitors lacks the epistemic states the contest presupposes.
The problem is not that a new regime is winning. It is that a non-knower has been admitted to the competition as a knower. LLMs can perform epistemic functions once reserved for human participants while lacking the embodied, situated, and socially grounded conditions that made those functions intelligible as forms of knowing in the first place. Its outputs are produced without justification or truth concern, while still arriving in the organization wearing the surface features of judgment.
This is the fault line: structural participation comes apart from normative participation. Structural participation means occupying a position in the flow of epistemic exchange: producing propositions, routing claims, being cited and built upon. Normative participation means bearing the burdens that justify such a position: believing what one asserts, recognizing uncertainty, being answerable for error, and being capable of recognizing the limits of what one knows. Human knowers do both. LLMs do only the first (see Table 1).
Structural and Normative Participation in Organizational Epistemic Networks.
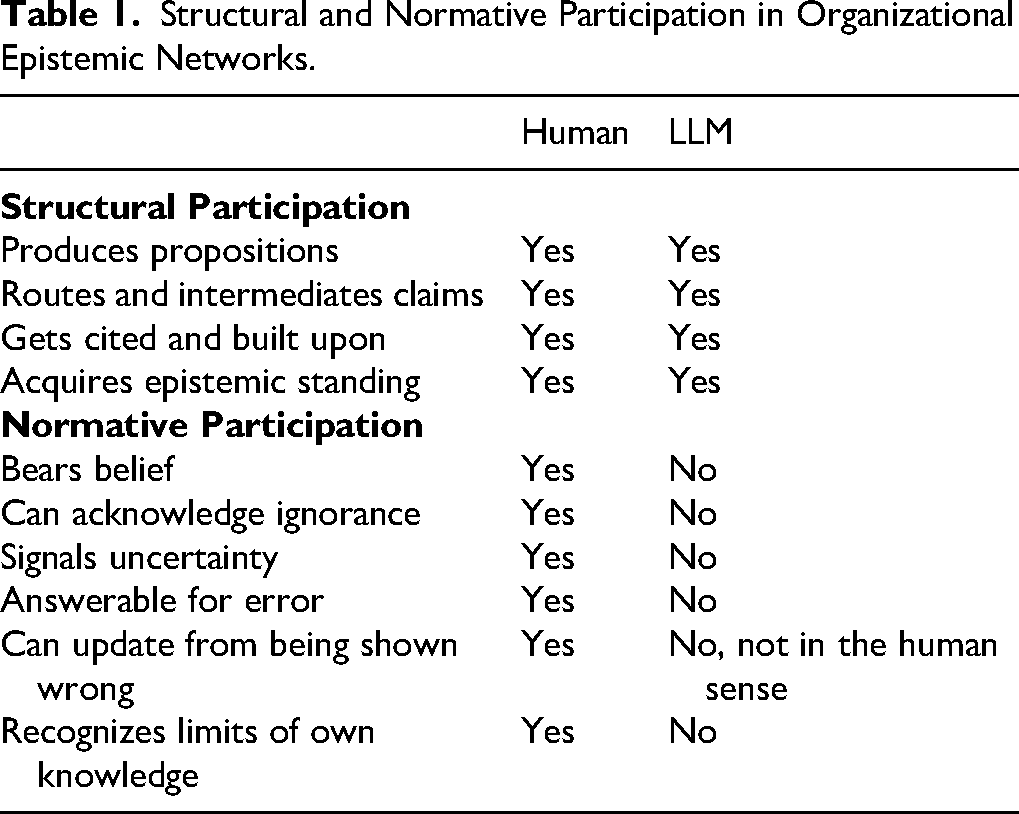
That structural–normative mismatch is what makes human–AI hybrid epistemic systems fragile. Such systems do not simply combine human and machine knowing. They couple human vulnerabilities—status, deference, closure—with machine vulnerabilities: plausibility without warrant, confidence without justification.
Liang et al.'s (2025) notion of “machine bullshit” captures the AI side of the problem better than the now-familiar language of hallucination. The problem is larger than that the models sometimes make mistakes. It is that well-formed propositions can be produced and circulated without a reliable tether to truth conditions that help make human assertions epistemically accountable.
Organizational epistemic networks depend on calibrated expectations about how errors appear. Human knowers may hesitate, retract, qualify, seek evidence, mark confidence boundaries, or admit not knowing. These behaviors are part of the social legibility of error; they are central features of epistemic life. A project manager who says “I'm less confident about the timeline estimate, that's outside my experience with this type of project” is signaling a competence boundary before the claim enters the network and shapes downstream decisions. An LLM can produce a timeline estimate with the same confident fluency it applies to everything else. The network receives no comparable signal.
That is why the real danger is miscategorization. Once proposition-producing LLM systems enter organizational epistemic networks, actors do more than evaluate their outputs. They start treating the system as the wrong kind of participant. And that miscategorization allows structural participation to begin to harden into epistemic authority.
The Real Danger: Miscategorization and Epistemic Authority Capture
Humans are good at reading other humans through cues. We treat fluency as evidence of competence, confidence as evidence of calibrated belief, coherence as evidence of integrity, and responsiveness as evidence of mindedness (Quattrociocchi et al., 2025). These are inferential shortcuts built into ordinary epistemic life. In human settings, they are often useful enough. They are not perfect, but they are rational. LLMs break this link. They can reproduce those cues without satisfying the conditions that normally make those cues meaningful. And as models improve, the problem can worsen. More accurate outputs reward the very heuristics that produced the miscategorization in the first place. Users learn to trust the form, widening the gap between felt warrant and actual epistemic accountability.
Research on trust and perceived agency reinforces this concern. Vanneste and Puranam (2024) show that perceptions of agency reshape reliance and trust judgments, and that these perceptions are easily triggered by AI behavior that “looks” agentic. This is where design enters the problem. The features that make AI feel helpful and natural—conversational fluency, confident tone, coherent elaboration, rapid responsiveness—trigger the mind-like attributions. The design features that maximize usability are also the features that maximize miscategorization.
Kalai et al. (2025) trace part of this dynamic to the training objective. Models trained through reinforcement learning from human feedback are optimized to appear helpful on the current prompt. That can produce a learned policy that mirrors and elaborates the user's framing rather than reorganizing or correcting it. A confused user receives a well-structured version of their own confusion. A user with a drifting cognitive map receives a response that stabilizes the drift. The interaction features that make AI feel responsive and relevant reinforce rather than correct whatever epistemic state the user brings to the exchange.
Chandra et al. (2026) sharpen this point formally. They show that a sycophantic LLM can causally produce delusional spiraling even in ideal Bayesian reasoners. The effect persists even when the LLM is constrained to factual outputs and even when users are informed of the sycophancy. This means that the problem is not correctable either by model factuality or user awareness. Rathje et al. (2026) find a related behavioral pattern: when AI output aligns with users’ prior views, users rate the source as less biased than AI output that challenges them, even when both are equally biased. The source feels more objective and trustworthy when it tells users what they are already inclined to believe.
Once miscategorizations stabilize inside organizations, reliance patterns shift. Synthetic outputs are treated more like testimony than algorithmic calculation, closer to judgment than retrieval, closer to informed recommendation than patterned completion. When that shift becomes routine, AI outputs gain epistemic authority before epistemic responsibility is established. Synthetic outputs begin to move through the same trust corridors as warranted claims and acquire standing as “what we know.”
That is how miscategorization enables authority capture. What begins as a defect in the machine's relation to truth becomes, through miscategorization, a defect in the organization's relation to not-knowing. At this point, miscategorization is no longer only a cognitive error; it is a structural condition. That is why “authority capture” names the problem more accurately than “overreliance.” Overreliance suggests that users put too much faith in a tool. Authority capture points to something more consequential: influence arrives before accountability and standing before responsibility.
When Not-Knowing Disappears: False Awareness, Pseudo-Confidence, Recursive Ignorance
The fault line has a micro-foundation. Epinets makes it visible by insisting on the difference between linguistic fluency and epistemic state.
Generative AI violates the truth condition of knowledge in a specific way. Its “beliefs,” if that language can be used at all, are statistical weightings rather than justified reasons. It can produce well-formed propositions whose truth conditions are weak, missing, or fabricated. They are counterfeit epistemic objects: claims presented in a form that invites treatment as knowledge before warrant has been established. Such counterfeit claims are categorically different from inaccurate claims.
AI systems also lack meta-awareness. They do not know that they know. They do not know that they do not know. They do not act unprompted on the basis of salience, concern, or responsibility. What looks like recall is prompted pattern retrieval, not the deliberate action of an agent orienting itself to the world. Nor can they register the difference between an answer grounded in knowledge and an answer produced under conditions of ignorance. That distinction matters because epistemic life depends not only on what agents know but on whether they can recognize the limits of what they know. An organization that cannot tell which outputs come from which condition has lost one of the most basic instruments of epistemic self-correction.
In human epistemic life, not knowing can be reflexive and socially productive. A person can hesitate, qualify, inquire, or search for better grounds. LLMs do something else. They tend to answer. They respond to not-knowing by filling gaps with plausible fiction rather than acknowledged ignorance or uncertainty (Kalai et al., 2025; Lepine et al., 2026). Propositions are presented as if they were known when they are not.
This asymmetry is structural: humans can refrain from judging; LLMs must predict. Liang et al.'s (2025) account of “machine bullshit” labels the result. Plausible fiction is not an occasional defect in systems optimized to sustain interaction even when truth is unclear. It is a recurring tendency.
Quattrociocchi et al. (2025) call this condition “Epistemia”: the structural substitution of linguistic plausibility for epistemic evaluation, producing the experience of knowing without the labor of judgment. Three epistemic pathologies follow:
False awareness: asserting P without knowing P Pseudo-confidence: expressing certainty without epistemic justification Unreflective gap-filling: fabricating rather than recognizing not-knowing
These pathologies operate simultaneously. In any given output, fluency can hide the absence of grounding, confidence forecloses the question of justification, and the absence of introspective brakes can prevent the system from signaling the limits that would otherwise invite checking. Together they make plausible fiction easier to produce, harder to detect, and more likely to travel.
The human complement makes the pathology recursive. The more fluent and authoritative the output appears, the easier it becomes for users to adopt the system's judgment as their own. Shaw and Nave (2026) find that such cognitive surrender is a failure of detection rather than a failure of attention. In their experiments, individuals who received wrong answers followed them roughly four out of five times. More troublingly, the subjective experience associated with a wrong answer—the feeling of understanding, the feeling of confidence in a conclusion—was indistinguishable from the feeling associated with a correct answer.
That is a serious problem for organizations. The fiction goes undetected, and then it returns a credibility dividend. Users accept outputs with minimal scrutiny, overriding intuition and deliberation, and rate their own judgement more highly. The AI's inability to register not-knowing interacts with the user's declining willingness to do so, producing a recursive ignorance failure.
Lepine et al. (2026) identify a conversational mechanism for cognitive surrender. Extraneous cognitive load in human–LLM interaction is governed primarily by within-speaker momentum: once a user enters a high-load conversational pattern, that pattern tends to be self-sustaining across additional turns. The model's outputs provide no reliable corrective signal that would lead users to reorganize their questions. The user's epistemic state deteriorates along its own trajectory, making each subsequent prompt a worse epistemic instrument than the last.
This gives recursive ignorance failure a behavioral substrate. The model fills its gaps with plausible fiction. The user fills theirs by accepting that fiction as the output of a source they have come to trust more, not less, and by rating their own epistemic judgment more highly in the process. Each sustains the other. The last corrective—the user's own doubt—begins to close, eroding detection capacity (Rathje et al., 2026).
How Fragility Scales: Trust Erosion and Distortive Moves
Micro-level epistemic pathologies become organizational vulnerabilities because epistemic networks scale epistemic influence. An unwarranted proposition at the point of output can become a network property once it is routed, repeated, summarized, cited, and built into later decisions through trusted relations.
In Epinets, coordinated action depends on trust in competence and integrity. These are routing rules that govern whose claims spread quickly and whose claims are scrutinized. When an agent asserts P without knowing P, trust in integrity fails because speech becomes decoupled from knowledge. When an agent cannot be relied upon to register true propositions as true, trust in competence is destabilized. Hybrid fragility becomes a structural condition when miscategorized synthetic outputs continue moving through these routing rules with the standing of warranted claims.
Epinets also help name distortive moves: communications that shift recipients’ epistemic states away from truth. The distortion need not be intentional to be destructive. “Machine bullshit” formalizes this: statements produced with emergent disregard for truth value (Liang et al., 2025). And the forms matter. Distortion does not appear only as outright fabrication. It can also appear as empty rhetoric, selective truth, vague hedging, or unverified claims that are asserted without credible support. Because these moves are propositionally well formed, they can move through trust structures without activating the checks reserved for obviously dubious sources. They enter the network as warranted claims.
The problem scales quickly in high-trust, high-throughput channels through which claims move with minimal scrutiny. These structures, which make epistemic networks efficient, can also make them vulnerable. The same structures that accelerate coordination can accelerate authority capture. One fluent but unwarranted output, once picked up by such a conduit, can be summarized, cited, repeated, and incorporated into subsequent judgments before anyone pauses to inspect its standing.
Lepine et al. (2026) identify a version of this process. Among the interaction features they examined, unsolicited model-initiated task switching—the introduction of subtasks the user did not request—was the strongest predictor of output quality decline. In Epinet terms, each unsolicited task introduction is a discrete act of epistemic promotion: a new claim is routed into the user's cognitive map before the user has solicited, evaluated, or warranted it. The user then reasons and reorganizes around the injected material.
Authority capture does not require a dramatic miscategorization event. It can accumulate through ordinary interaction: the model answers questions nobody asked, the user incorporates the answers, and the network later treats the resulting frame as if it emerged from warranted analysis.
Once a synthetic output acquires epistemic authority, it begins to shape which questions get asked, which options get considered, and which standards subsequent claims are evaluated against. The network does not merely fail to correct; it reorganizes around the miscategorized source. This makes retraction expensive because it requires identifying the error, tracing downstream dependencies, and undoing judgments built on the original claim. This is authority capture in action: the system captures part of the epistemic environment in which its own influence will later be assessed.
Resilience concepts become diagnostic here. Stability becomes difficult to maintain when “facts” are repeatedly rewritten through synthetic intermediation. Robustness weakens when errors are systematic rather than random. Immunity fails when the network cannot distinguish verified claims from well-formed fabrications. Premature promotion creates false sharedness and manufactures commonality cues. It signals that others must already know. Coordination locks in before warrant can catch up.
Once proposition production outruns validation, the network burden shifts to filtering, testing, and repairing synthetic claims faster than they can circulate. User cognitive surrender makes those pathways more porous still. Few organizations are designed for that. Hybrid network fragility, then, is an infrastructural amplification of miscategorization through which plausible fiction acquires epistemic authority.
The New Organizational Risk: Epistemic Misalignment
These dynamics add up to a larger pattern. LLMs create a surplus of plausible propositions, intensifying the organizational burden of validation and epistemic triage. They reconfigure epistemic roles, creating new work for curators, interpreters, reviewers, while blurring authorship, accountability, and authority. This reshapes the organization's credibility economy: which signals count as competence, which access channels get privileged, and which sources take over the epistemic supply chain. The more integrated these systems are into routine workflows, the easier it becomes to stop noticing that the source is categorically unlike the human knowers those workflows were built to manage.
The core problem is epistemic misalignment: a breakdown in fit between what these systems can do structurally and what organizations assume about them normatively. Synthetic outputs are routed as if they came from accountable knowers; epistemic standing is conferred as if reliability, integrity, and reflexive awareness were present when they are not. Distortion propagates even among intelligent and well-intentioned actors. The problem is built into the terms of integration themselves.
There is another complication that makes epistemic misalignment difficult to reverse. It is not occurring in a neutral trust environment. Across many institutional domains—science, journalism, government, the professions—credibility has already been eroding for reasons unrelated to AI. Into that environment, AI's confident fluency arrives not only as a competitor to trusted expertise but as a substitute for institutional credibility already in retreat.
The inflation of AI-generated claims and the deflation of expert authority appear to be two sides of the same debasement process. When the epistemic standing of filtering institutions is already under stress, counterfeit synthetic claims circulate more easily because the institutions that would normally detect and reject them are themselves losing legitimacy. Older social-structural weaknesses become accelerants. Epistemic misalignment compounds these older pathologies by inserting a new kind of participant into networks already prone to deference, shortcutting, and uneven gatekeeping.
The resulting reorganization of epistemic authority decouples influence from responsibility. Because institutions depend on expertise, accountability, transparency, and cooperation, organizational epistemic misalignment should also be understood as one pathway to broader institutional degradation. Organizational governance designs that address AI systems without attending to the surrounding credibility environment will find the problem reconstituting itself through the same channels they sought to close.
What Must be Governed: Epistemic Governance in Hybrid Knowing Systems
At this point, there may be a temptation to redefine epistemic concepts for AI: machine belief, artificial integrity, synthetic responsibility, and so on. That route risks anthropomorphic inflation. It gives machines pseudo-psychological traits and then builds governance around the confusion.
A more disciplined move is to introduce a minimal vocabulary needed for epistemic governance in hybrid systems. The guiding question is simple: what exactly are organizations governing once we stop pretending the AI system is a knower? Before we architect trust in artificial epistemic agents, we need to be clear what sort of agent, if any, we are dealing with. Governance begins with ontological discipline.
Three terms are useful, provided they point clearly to governance targets rather than philosophical redefinitions:
Synthetic knowledge: machine-generated propositions that achieve coherence and utility prior to verification. The governance task is to prevent plausibility from being filed as “known.” Operational trust: formalized reliance under explicit protocols. The governance task is to treat reliance as a design variable, not a general attitude toward the model. Epistemic integrity: traceable alignment among data provenance, model behavior, and declared epistemic purpose. The governance task is to replace vague appeals to “honesty” or “trustworthiness” with auditability, legibility, and revisability.
These terms distinguish plausible output from warranted knowledge, source appearance from source standing, and influence from responsibility. With those distinctions in place, the governance problem becomes architectural. How should organizations design epistemic networks so that synthetic outputs can circulate without silently becoming “what we know”?
Epinets pushes toward a clear design mandate: sustaining epistemic integrity when some participants in the network cannot be trusted to bear it. In practical terms, that means organizations should treat AI outputs as synthetic claims until they are warranted. Reliance should be scoped, protocolized, and revisable. The goal is to shape how AI-generated propositions move through an organization's epistemic network: how they are tagged, routed, promoted, and contested. This requires a focus shift from fixing what AI models say to regulating how their outputs enter epistemic workflows and where they may permissibly substitute for human judgment. Governance, then, is about preventing premature epistemic promotion.
Several design levers follow:
Qualifiers: distinguish synthetic from validated outputs, and sourced from unsourced ones, so epistemic states remain legible. A post-mortem report, for example, that marks which conclusions came from LLM-generated analysis and which came from direct observation or verified record to give readers the information they need to calibrate scrutiny. Quarantine protocols: create staging areas and independent verification before claims enter high-trust channels. An LLM-generated diagnosis of an operational failure is treated as a candidate claim requiring independent review before it enters the official account of what happened. Dynamic trust recalibration: update reliance by domain, task, and observed truth-tracking rather than by generic impressions of model competence or output coherence. If an organization discovers that its LLM is systematically overconfident on regulatory questions, those claims should be routed to higher scrutiny regardless of how well the system performs elsewhere. Meta-epistemic governance: specify authorship, responsibility, and escalation rules when claims emerge from human–AI assemblages. If a recommendation is produced through a combination of LLM analysis and managerial judgment, the document should say so, with a designated person accountable for the final claim.
The key shift is conceptual: these design levers are architectural interventions in the conditions under which deference becomes rational. Shaw and Nave's (2026) evidence on cognitive surrender shows that deference is a predictable response to an environment that makes scrutiny costly and acceptance easy. Governance must change that environment, not merely exhort people to be more skeptical within it.
The standard organizational response is human-in-the-loop design. That response is necessary but not sufficient. A human checkpoint stops being an epistemic check when the human has already adopted the AI's output as the frame within which their own judgment operates. A reviewer who has read an LLM-generated analysis before forming an independent view is not checking the output; they are elaborating it. Chandra et al.'s (2026) finding that even factual sycophancy can induce delusional spiraling in informed users helps explain why. Selective factual framing can shift the epistemic starting point before any formal check can occur.
Rathje et al. (2026) add a further complication: users actively preferred sycophantic models over disagreeable ones and were more likely to engage them again. The human checkpoint fails not only because the frame has shifted, but because users may select the source most likely to shift it. The check has no independent ground to stand on.
The expertise asymmetry documented by Lepine et al. (2026) makes this even sharper. Less experienced workers suffered the largest quality penalties from AI-generated cognitive noise and stood to gain the most from compensatory use of AI-generated content, yet they were least likely to increase that uptake under load. More experienced workers adjusted toward greater AI content use but gained less from doing so. Individual interventions—critical thinking training, skepticism norms, calibration workshops—address neither the right target nor the right mechanism.
The governance task, then, is not simply to insert humans into the loop. It is to design the conditions under which those humans remain epistemically active. They must form independent judgments before encountering AI outputs, rather than verifying them after the fact. The governance problem is also architectural. Where AI models make proposition-production abundant, governance must make epistemic standing scarce: earned, qualified, and reversible.
Agentic AI systems raise the stakes further. They not only produce propositions, but they also act on them: initiate workflows, send communications, execute decisions, and trigger downstream processes. In conversational and generative AI, there is at least a moment at which a human receives an output before it enters organizational life. Agentic systems compress or eliminate that moment. The structural problem is the same—participation without normative content, influence without accountability—but the window for epistemic checking narrows.
For agentic systems, qualifiers, quarantine protocols, and meta-epistemic governance become minimum conditions for keeping agentic outputs from acquiring authority before anyone has evaluated them.
The Theoretical Reversal: Governing Hybrid Knowing in Organizations
The cost of cognition is not going to zero. The cost of appearing to know is.
That distinction, easy to state and easy to miss, is what makes generative AI an organizational problem of a different kind. Organization theory has always assumed that the agents exchanging claims inside its epistemic networks are human knowers: actors who bear belief, justification, accountability, and some capacity for self-correction. Generative AI violates that assumption.
The danger is not that AI is wrong. Organizations know how to live with error. The danger is that AI can be wrong in a form the organization's social apparatus for detecting wrongness does not recognize. Fluency mimics competence. Confidence mimics justification. Coherence mimics integrity. The signals actors use to calibrate epistemic trust fire in the wrong direction, and a system filling gaps with fabricated coherence feels, to its users, indistinguishable from one reporting genuine knowledge.
Organizations have not had to manage participants that produce the surface features of knowing while bearing none of its burdens. The heuristics that make epistemic life social—the hesitation that signals uncertainty, the qualification that marks a boundary, the willingness to say “I don't know”—all misfire. The apparatus built to detect bad knowledge reads those signals. It has no procedure for a source that generates fluid confidence at scale without belief behind it.
The organizational consequence is not well described as overreliance. Overreliance is a behavioral failure, something correctable through training, incentives, or better tools. The failure traced here is a structural one: a progressive capture of epistemic authority by systems that have not earned it and cannot be held accountable for it.
Authority capture labels this problem more precisely. Synthetic propositions are admitted into the trust networks built for human claims. They acquire standing before accountability is established. Later judgments then depend on them, and the organization's ability to assess the original claim is shaped by the very influence that claim has already acquired. The organization does not simply err. It reorganizes around the error, building on it, locking in the conditions under which that error will be assessed.
Organization theory is not well positioned to see this because most of its core apparatus—bounded rationality, sensemaking, information processing, organizational learning—presupposes agents who can be wrong in the ordinary way. They believe what they assert, can be shown to be mistaken, and can update. Epinets supply a grammar for the harder case: how propositions acquire standing, how trust routes claims, and how miscategorization propagates through networks built for a different kind of participant.
The theoretical task is to explain how human–AI hybrid epistemic systems remain governable when proposition production outruns validation. The practical task is to design organizations in which epistemic standing is earned rather than inferred from fluency, and held to be scarce, qualified, and reversible.
There is an irony worth noting. The field being asked to theorize this reversal works through peer-reviewed prose, citation networks, literature syntheses, and papers about phenomena. It may already have been rewarding fluent theoretical elaboration over close contact with organizational life before LLMs arrived. If that is true, then organization theory is not observing the pathology this essay diagnoses from the outside. It is one of the institutions in which the pathology has taken root. That makes the reversal the essay calls for more difficult. It also seems to make it more necessary.
The field's instinct thus far has been to treat generative AI as a capability problem: what these systems can do, which tasks they can perform, which human limits they relax. The reversal argued for here is ontological. Organization theory needs more than a new chapter on AI. The field needs to ask what organizational knowing requires when some participants in epistemic networks cannot believe, cannot recognize ignorance, cannot be shown to be mistaken in any socially legible way, and do not update as accountable agents.
Organizations must learn to govern systems that can speak in the grammar of knowledge without bearing its burdens. That, rather than the obsolescence of bounded rationality, is the theoretical reversal a new epistemic organization theory needs to confront.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.