
Abstract
We study a decision-maker’s problem of finding optimal monetary incentive schemes for retention when faced with agents whose participation decisions (stochastically) depend on the incentive they receive. Our focus is on policies constrained to fulfill two fairness properties that preclude outcomes wherein different groups of agents experience different treatment on average. We formulate the problem as a high-dimensional stochastic optimization problem and study it through the use of a closely related deterministic variant. We show that the optimal static solution to this deterministic variant is asymptotically optimal for the dynamic problem under fairness constraints. Though solving for the optimal static solution gives rise to a nonconvex optimization problem, we uncover a structural property that allows us to design a tractable, fast-converging heuristic policy. Traditional schemes for retention ignore fairness constraints; indeed, the goal in these is to use differentiation to incentivize repeated engagement with the system. Our work (i) shows that even in the absence of explicit discrimination, dynamic policies may unintentionally discriminate between agents of different types by varying the type composition of the system, and (ii) presents an asymptotically optimal policy to avoid such discriminatory outcomes.
Introduction
Stakeholder retention is a fundamental challenge faced by many organizations. For instance, it was said of former IBM executive Buck Rodgers that he “behaved as if every IBM customer were on the verge of leaving and that [he’d] do anything to keep them from bolting” (Rodgers and Shook, 1986). Indeed, though it is conventional wisdom that continued growth is necessary to ensure the success of a business, studies have routinely found that increasing customer retention rates by as little as 5% could lead to an increase in profits of up to 95% (Gallo, 2014).
Of the many ways in which an organization can increase retention, one important lever it has at its disposal is that of unconditional monetary incentives, which are paid out regardless of the retention outcome. Such incentives are used in many practical contexts:
In implementing these sorts of monetary incentives, one important concern that a decision-maker faces is that of fairness, especially in light of the abundance of examples in which algorithms deployed in the real world unintentionally discriminate against protected groups (Kleinberg et al., 2018). Within the context of monetary incentives for retention, a decision-maker may want to maximize her bang-per-buck by paying individuals with different earnings sensitivities different amounts in order to minimize the cost of retaining them. However, since individuals’ earnings sensitivities correlate with protected classes such as gender (Heckert et al., 2002), such unconstrained policies would discriminate between classes.
Our work aims to better understand the role of fairness in the optimal design of unconditional monetary incentives for repeated engagement. Indeed, despite the frequent use of such incentives in practice, as well as extensive empirical work on their effectiveness in a variety of settings, to the best of our knowledge, there have been few attempts to develop theoretical insights into their design and the associated risk of algorithmic group discrimination. We further detail our contributions below.
Summary of Contributions
We consider a model wherein agents join a system in each (discrete-time) period, and receive a (possibly random) reward to remain in the system in the next period. At the end of the period, unaware of the underlying distribution from which rewards are drawn, agents probabilistically make a decision based on the reward received in the period to stay in the system, or leave once and for all. Specifically, we assume that agents are partitioned into types defined by (i) their sensitivity to rewards, formalized via a departure function that maps rewards received to the probability of departing, and (ii) the rate at which they join the system. 1 This model, though simple, gives rise to a spectrum of models of agent behavior. In particular, most of our results hold for any departure functions, as long as these functions are nonincreasing in the reward paid out to an agent.
The decision-maker collects some revenue associated with the number of agents in the system in each period and incurs the cost associated with incentivizing these agents to stay according to the chosen reward distribution (where the support of this distribution is assumed to be an arbitrary finite set). The goal of the decision-maker is to determine the optimal policy to maximize her long-run average profit. As is common in classical stochastic control problems, the infinite-horizon Markov Decision Process (MDP) associated with the decision-maker’s optimization problem suffers from the curse of dimensionality, which motivates the task of finding near-optimal policies.
One natural approach a decision-maker may want to take to maximize her profit is to learn, then discriminate: given the history of rewards paid out to each agent, the decision-maker could try to estimate each agent’s type, and “target” agents whom she believes would stay in the system for lower rewards. However, not only is such explicit discrimination potentially problematic from a public relations standpoint, but it also runs counter to group fairness, which at a high level requires that an algorithm treat (reward) individuals belonging to different groups (e.g., demographic groups) similarly. 2 Avoiding this sort of explicit discrimination, the decision-maker can then turn to dynamic policies that draw rewards i.i.d. from the same distribution in each period, all the while actively managing the number of agents in the system by varying the distribution across periods. However, even these seemingly fair policies may discriminate implicitly: we show that they can lead to some groups receiving consistently higher rewards than others due to the members of the former (latter) group self-selecting into periods with higher (lower) rewards.
Against this backdrop, our work aims to characterize retention policies that fulfill two stringent fairness requirements: (i) agents must be paid from the same reward distribution in each time period, and (ii) agents of different types must experience the same reward distribution on average, over a long enough time horizon (Definition 1). The two fairness constraints respectively enforce distributional envy-freeness within and across periods. On the one hand, if one views the reward distribution abstraction as agents playing a lottery for retention, distributional envy-freeness within periods ensures that agents know they are playing the same lottery. This is a reasonable principle given that, in the systems we consider, agents are symmetric from a revenue perspective (e.g., there is no “specialization” across types). On the other hand, though group fairness may not be a requirement in all settings, the lack thereof may be problematic (for instance, in settings where departure probabilities are correlated with protected classes such as gender and race (Heckert et al., 2002)). In particular, in such contexts, an audit—or even a company-authored DEI report—might find in hindsight that, despite avoiding explicit discrimination and not even attempting to learn the types of agents, an organization may nonetheless pay higher bonuses/rewards to some demographic than to another; whether or not this is justifiable, it poses a potential risk that organizations should be aware of.
In our first contribution, we show that there exists a static policy that is asymptotically optimal amongst the space of all policies that fulfill our fairness criteria (Theorems 1 and 3). We also show that dynamic policies can strictly outperform any static policy (Propositions 2 and 3); in other words, the asymptotic value of dynamic policies in our setting arises solely from the ability to (implicitly) discriminate between types. Though we do not seek to prescribe our stringent fairness constraints for all retention settings, a main insight of our work is that the value of a dynamic policy, in our setting, comes only from exploiting different retention probabilities across groups.
The proof that a static policy is asymptotically optimal is constructive, that is, we design a heuristic fluid-based static policy for which our asymptotic guarantees hold as the market size is scaled by a parameter
While our policy satisfies these natural desiderata, computing it requires us to solve a high-dimensional nonconvex optimization problem which is, a priori, nontrivial to optimize. In our final technical contribution, we show a surprising structural property of the problem that allows us to efficiently compute its optimal solution. In particular, independent of the size of the reward set, the number of agent types, and their departure probabilities, there exists a fluid-optimal reward distribution that places positive weight on at most two rewards (Theorem 2). This allows us to identify an optimal solution by considering all pairs of rewards and then solving a KKT condition that consists of a single equation in one variable for each pair. A similar two-reward structure of fluid-based policies has been identified in other operational settings (Bassamboo and Randhawa, 2016); we use this result to derive insights into the structure of the fluid optimal policy for certain special cases. In particular, we show that the convexity of the departure probability function impacts the optimal dispersion level of the optimal reward scheme, lending credence to the use of “surprise-and-delight” lotteries for retention (Proposition 6).
Structure of the Paper
In Section 1.2, we survey related literature. We then present the model and formulate the decision-maker’s optimization problem in Section 2. We use a deterministic relaxation of our system to show in Section 3 that the fluid-based heuristic is optimal amongst all policies that satisfy our fairness constraints; though we also show the existence of dynamic policies that outperform the fluid heuristic, these policies are inherently discriminatory. Section 4 is devoted to analyzing the fluid-based heuristic and proving its fast convergence to the value of the fluid relaxation in a large-market regime. Finally, Section 5 leverages our analysis of the fluid heuristic to characterize optimal policies in special cases of interest. All figures and proofs of results are relegated to the E-Companion.
Related Work
Workforce Capacity Planning
Our work is related to the topic of workforce capacity planning, which has a long history in the operations management literature (for an excellent survey, see, e.g., De Bruecker et al., 2015). Within this line of work, we highlight papers that consider attrition and retention aspects of workforce planning. In contrast to our work, which focuses on the question of issuing monetary incentives throughout an agent’s lifetime to retain them, these works are concerned with hiring, promotion, and termination decisions. For example, motivated by the naval aviation system, early work by Grinold (1976) considered optimal accession policies when aviators have a known and deterministic lifetime. More recently, Hu et al. (2016) studied optimal hiring and admission and training policies for junior nurses, a profession in which attrition is pervasive, and as a result has been a central focus of much of the workforce planning literature. In their model, a fixed and exogenous fraction of the population leaves the system in each period, whereas in ours the decision-maker aims to set incentives in order to affect their retention. This work also resembles ours in that agents are homogeneous from a skills perspective (though ours are heterogeneous with respect to their departures).
A subset of the literature on workforce capacity planning is interested in worker heterogeneity; however, most of these works focus on heterogeneity with respect to skill set, not with respect to attrition. Ahn et al. (2005) consider a model in which workers turn over independently of the organization’s policy and the state of the system, whereas Gans and Zhou (2002) and Arlotto et al. (2014) allow workers’ departure decisions to depend on the state of the system, but not the decision-makers’ policy nor their own history in the system. Most recently, Jaillet et al. (2022) considered a more complex model of hiring, dismissing, and promoting when workers’ resignation decisions depend on their “time-in-grade,” or lifetime, in the system. To the best of our knowledge, no works in this stream consider the fairness implications of policies.
Customer Retention
We highlight the most closely related works here, as this area has a rich history in the marketing literature (for a survey, see, e.g., Ascarza et al., 2018). To the best of our knowledge, none of these papers focus on designing fair customer retention policies. On the contrary, the goal in these latter works is precisely to use differentiation in order to incentivize customers to stay. For example, in a computational study Lemmens and Gupta (2020) define a profit-based loss function to predict, for each customer, the financial impact of a retention intervention, ranking customers based on the marginal impact of the intervention on churn, and postintervention profits. Aflaki and Popescu (2014) develop theoretical insights around optimal retention policies, in a setting where customer “types,” or sensitivities to interventions, are known by the decision-maker, thus allowing for customer differentiation; in their model, the optimal decision across the population decouples into optimal decisions for each individual customer. A separate stream of work investigates how capacity decisions affect service access quality, and customer retention as a result (Afèche et al., 2017; Furman et al., 2021). In contrast to the interventions we consider, which occur in each period, in the settings these latter papers consider, the decision-maker is constrained to make a single decision at the beginning of the time horizon.
Empirical Work on Effectiveness of Monetary Incentives
The effectiveness of monetary incentives for retention is also well-documented in the medical community. Empirical studies highlight their efficacy within the context of adherence to medication (Kimmel et al., 2012; Volpp et al., 2008), weight loss and exercise (Meeker et al., 2021; Volpp et al., 2008), postpartum compliance (Stevens-Simon et al., 1994), and home-based health monitoring (Sen et al., 2014), for instance.
Algorithmic Fairness
Finally, our work adds to the large and growing body of work on the design of fair algorithms. We note that there is no universally agreed-upon notion of fairness (for a comprehensive overview of the different notions of fairness that have been considered in the literature, see, e.g., Mehrabi et al., 2021). The notion of fairness that we choose to focus on is that of group fairness (as opposed to individual fairness (Dwork et al., 2012)), which itself has no single definition. The one closest to ours, that arises in the machine learning literature within the context of group-fair classifiers, is statistical parity (Corbett-Davies et al., 2017). This requires that individuals in both protected and nonprotected groups have equal probabilities of being assigned to the positive predicted class; interpreting the set of rewards as possible predicted classes, our fairness definition can be understood as a multidimensional variant of statistical parity.
An operational setting that is related to our study is fair (online) resource allocation; this has received significant recent attention (Allouah et al., 2022; Balseiro and Xia, 2022; Banerjee et al., 2023; Banerjee and Freund, 2024; Bateni et al., 2022; Freund et al., 2023; Manshadi et al., 2023; Sinclair et al., 2023). Other related literature on fair algorithms includes pricing problems with fairness constraints such as those studied by Cohen et al. (2021, 2022) and Salem et al. (2021). However, none of these works model customer attrition.
Preliminaries
We consider a discrete-time, infinite-horizon model of an organization, which we henceforth generically refer to as a system. In each period agents join the system, receive a reward, and decide whether to stay in the system for future periods or leave. The decision-maker makes a profit, in each period, composed of the revenue from the number of agents in the system, net of the cost of the rewards paid out to agents. For example, within the employment context, an agent corresponds to a worker performing a set of tasks in each period, with the reward corresponding to a bonus incentive; an agent can similarly correspond to a customer who enjoys service from her cable provider in a given period, with the reward corresponding to a discount. We formalize each component of the model below, beginning with some technical notation. For clarity of exposition, we defer a lengthy discussion of modeling assumptions to the end of the section.
Technical Notation. Throughout the paper,
Basic Setup
Agents
We assume there are
The exogenous arrival assumption is for ease of exposition. In Appendix EC.4.1 we show that our main result applies to an endogenous entry model in which agents choose to enter the system by comparing their long-run average earnings to a type-dependent reservation value.
Period
We use
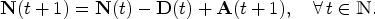
Objective
Given
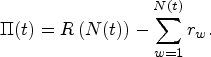
We formulate the decision-maker’s optimization problem as a discrete-time, infinite-horizon MDP, where the objective is to maximize the long-run average profit. Suppose the initial condition is If two agents are in the system in the same period, the distribution from which their rewards are drawn is identical. Thus, The average reward distribution observed by agents of different types, conditional on their types, is “approximately” the same over time. We refer to this latter constraint as group fairness and provide its mathematical formalization in Section 3.
At this point we reiterate that it is not our goal to prescribe our fairness definitions as the only reasonable ones across all industries. However, given the spectrum of ways in which a decision-maker can differentiate between groups, it is unclear where one should draw the line. For instance, consider a policy in which type 1 agents receive a reward of 50 almost surely, whereas type 2 agents receive a reward of zero 49% of the time, a reward of 100 49% of the time, and a reward of 50 2% of the time. The reward distributions seen by both agent types have the same expectation and median; however, depending on the context, one type may be perceived as having a more desirable reward distribution (as Type 1 benefits from the certainty of a reward of 50 in each period). Our fairness definition may be particularly stringent in choosing where to draw the line, but it provides a simple first step to understanding how heterogeneous groups differentially self-selecting into the system may produce unfair outcomes.
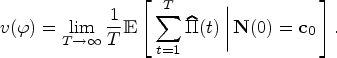
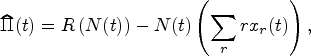
Large-Market Regime
Given the size of the state space, the curse of dimensionality renders the goal of solving the MDP to optimality intractable. As a result, we turn to the more attainable goal of designing asymptotically optimal policies in a so-called large-market limit.
The regime we consider is defined by a sequence of systems parametrized by
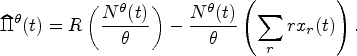
We briefly motivate this choice of scaling via a newsvendor-like revenue function. Suppose
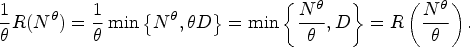
Deterministic Relaxation of the Stochastic System
In order to analyze first-order differences between policies, we consider a deterministic relaxation of the stochastic system, formally defined below.
Let
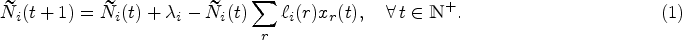
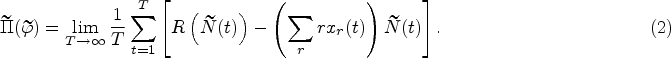
In order to establish the connection between the two systems, consider the following coupling: for any
Suppose
We conclude the section with a discussion of our modeling assumptions.
Memoryless Agents
One limitation of our model is that agents decide to stay or leave based only on the most recent reward; in Appendix EC.8 we extend our fairness result to a setting in which agents have a two-period memory. The fact that the same results hold there suggests that similar results may hold for even more general models of memory. However, generalizing the memoryless assumption of our model is not the main objective of our work. Indeed, the assumption is motivated by the fact that agents typically lack insight into the algorithms that generate the decisions they receive (e.g., why an algorithm paid out a reward in a given period, in our setting). Moreover, the memoryless assumption follows a long tradition of models that consider agent attrition (also referred to as disengagement, in some settings) in the operations literature. For instance, within the context of recommender systems, Ben-Porat et al. (2022) and Bastani et al. (2022) assume that the probability of a user disengaging with the recommendations depends only on the quality of the most recent recommendation. Afèche et al. (2017) similarly note that this sort of “recency effect” is typically assumed in the customer retention setting, in models that link demand to past service levels (Hall and Porteus, 2000; Ho et al., 2006; Liu et al., 2007). Lemmens and Gupta (2020) also consider memoryless customers in their churn prediction problem. As a result, the focus of our work is not on improving existing models of agent memory, but rather on leveraging existing memoryless models to gain insights into fairness considerations for these well-studied systems.
We conclude the discussion of the memoryless assumption by noting that the abstraction of a period is very general. For example, in a contractual employment setting, a period could be considered to be the length of the contract. In a noncontractual setting, a period could constitute however long agents are believed to consider past rewards before making the decision to leave the system. In the setting where agents are customers, a period would be the duration of the subscription contract.
Time-invariance of the Revenue Function
Another assumption upon which our model relies is the fact that the revenue function depends only on the number of agents in the system in a given period. In an employment setting, for instance, the time-invariant assumption models a mature market, with newsvendor-like dynamics. The work performed in the system can be viewed as “low-skill,” in the sense that workers arriving at the system are homogeneous, and the decision-maker does not benefit from workers gaining skill specificity with time. In the customer retention setting, on the other hand, stationarity of the revenue function is a reasonable assumption within the context of profit generated from the number of active subscribers in a mature market (ignoring heterogeneity in subscription plans). An interesting question beyond the scope of our work is whether a dynamic policy outperforms a static policy when the revenue function is dictated by a state that can be either low or high; though a static policy would do much worse in such a setting, it is unclear whether a dynamic policy can outperform a static one without violating our fairness constraints.
Unconditional Versus Conditional Incentives
As in Lemmens and Gupta (2020), we focus on unconditional incentives, wherein the decision-maker pays out the reward independently of the agent’s decision to stay or leave, as opposed to conditional incentives. Empirical evidence of the effectiveness of such unconditional incentives has been found in the behavioral sciences, for example, within the context of physician and patient surveys (Abdulaziz et al., 2015; Young et al., 2015; Rosoff et al., 2005), in addition to clinical study enrollment (Young et al., 2020; Kumar et al., 2022). We believe that the analysis of conditional incentives can be similarly approached.
Optimal Policies via the Deterministic Relaxation
In this section, we design and analyze a heuristic policy within the context of the deterministic system. We begin by formalizing the group fairness constraint, first introduced in Section 2.
(Group-fair policy)
A policy
Informally, a group-fair policy guarantees that, over any long enough time interval, the expected reward distributions respectively observed by different agent types do not differ too greatly.
We first show that, despite the unwieldiness of the group fairness constraint, there exists an exceedingly simple group-fair policy that is optimal in the context of the deterministic system: a policy that pays out the same distribution in each period.
Consider the following optimization problem, termed
Let
In the remainder of the paper, we refer to the optimal static policy as the fluid heuristic. The proof of Theorem 1 is constructive. In particular, we show that the static policy which allocates each reward
We next investigate the impact of the two fairness constraints imposed. In particular, when expanding the space of policies beyond fair ones, one approach a decision-maker could take would be in the flavor of learn, then discriminate: by deploying machine learning algorithms to learn agents’ types, a decision-maker can leverage this additional information to then pay agents of different types different amounts. We say that such policies explicitly discriminate.
Proposition 2 formalizes the intuition described above that policies that learn agent types and target “cheaper” agents can greatly outperform optimal fair policies.
Consider the setting with
The policy
The above policy clearly violates our first fairness desideratum of drawing rewards from the same distribution for all agents within a given period. Our next result shows that there exist policies that satisfy this first fairness constraint, but fail to be group fair; moreover, avoiding group fairness allows this policy to outperform any fair policy by an unbounded amount. We refer to this more subtle version of discrimination, which pays agents in the same period according to the same distribution, as implicit discrimination. In order to illustrate this, we introduce the notion of a cyclic policy.
Policy
When making the distinction between a
Suppose
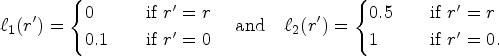
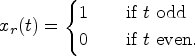
The cyclic policy described above engages in strategic reward slashing: it induces a large number of type 2 agents to stay in the system every other period, thus benefiting from their presence in the next period. In this next period, however, the decision-maker is able to retain all of its revenue as net profit by not incentivizing agents to stay in the system. We show in Proposition EC.1 that under
In both examples constructed above, a reward of 0 and high exogenous arrival rates were chosen for clarity of exposition. One can similarly construct an example with
We conclude the section by noting that a natural quantity to consider is the price of fairness, that is, the worst-case ratio (across all problem instances) between the decision-maker’s optimal profit with all fairness constraints relaxed, and her profit under the optimal fair policy. A slight modification to the instance in Proposition 3 immediately gives us that the price of fairness in our setting is unbounded. To see this, let
Leveraging a deterministic relaxation to develop asymptotically optimal policies is a classical approach in many stochastic control problems. In these models, not only is the deterministic relaxation is a natural upper bound, but it is also an attractive candidate for developing good policies due to its tractability; in particular, the corresponding fluid problem can typically be cast as either a linear or convex program. In this section, we first establish that our problem does not inherit such a convenient structure. Proposition 4 formalizes this.
Thus, solving (\textsc{Fluid-Opt}) efficiently is a priori a difficult task given its high-dimensional and nonconvex nature. Though the issue of nonconvexity is typically circumvented via an exchange of variables (Cao et al., 2020), this approach fails in our setting due to the nonlinearity in the total cost of employing
Theorem 2 first formalizes that it is possible to derive tractable optimal solutions based on a surprising structural property.
For any instance of
Theorem 2 presents a structural characterization of the fluid optimal solution which has far-reaching implications for the analytical and computational tractability of (\textsc{Fluid-Opt}). In particular, suppose we fix
Our proof technique is motivated by the following natural interpretation: a profit-maximizing solution must trade-off between recruiting enough agents in order to collect high revenue, all the while keeping costs relatively low. We disentangle these two competing effects by introducing a closely related budgeted supply maximization problem, which we term (
We now analyze the performance of the fluid-based heuristic in our original stochastic system. Let
Let
As a corollary of Propositions 1 and 5, we obtain the standard
Suppose
It is easy to check that “reasonable” concave functions such as
At a high level, our system distinguishes itself from many systems considered in the classical stochastic control literature due to the fact that it is “self-adjusting,” or, more specifically, “self-draining.” What we mean by this is that, even though
We conclude this section by complementing our theoretical results with numerical experiments. In particular, we illustrate the performance of
Reward Schemes
We assume the revenue function is newsvendor-like:
Agent Types
We let type 1 agents: type 2 agents: type 3 agents:
Performance Metric
For each of the three reward schemes
Results
We show the results (for 1,000 replications of simulations) in Figure EC.1b. These results illustrate the strong performance of the fluid heuristic for this particular problem instance. In particular, we indeed observe that the fluid heuristic converges to
Special Cases
The tractable structure of the fluid optimum enables not only our numerical experiments, but also allows us to gain additional analytical insights into optimal policies under more structured departure probability models. We first investigate how the optimal policy depends on the convexity of the departure probability function, and subsequently consider the optimal policy when agents’ departure probability function is a type of softmax function.
Impact of Convexity of Departure Function
To understand the impact of the structure of the agents’ departure probability functions on the optimal reward scheme, we define the notions of convexity (resp., concavity) over the reward set, as well as the dispersion of a reward scheme.
The departure probability function of a type
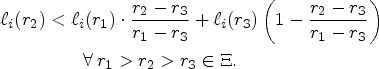
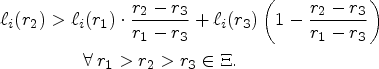
At a high level, concave departure probabilities correspond to “risk-seeking” agents, since for these agents the expected departure probability from any convex combination of two rewards is higher than the departure probability from handing out the convex combination of these two rewards deterministically. An example of this would be people playing the lottery with minuscule odds of claiming the jackpot and (due to the cost of a ticket) a negative return in expectation. Conversely, convex types can be viewed as “loss averse,” as they are more likely to stay if paid out a reward deterministically. This behavior may be more prevalent when there is a significant cost to remaining active in a rewards program. For instance, the Chase Sapphire Reserve card costs $550 a year, and comes with a deterministic $300 travel credit (and a range of other benefits), that is renewed each year. There, we would assume that most customers prefer the certainty of their travel benefits over a small chance to win a more valuable travel credit.
We next introduce the notion of dispersion of a reward scheme.
Consider any feasible solution
The following proposition formalizes the intuitive idea that the dispersion of an optimal policy vastly differs depending on the convexity of
If
Proposition 6 tells us that, if
We next numerically investigate whether these analytical insights when agents have homogeneous structure of departure probability functions port over to mixed populations.
We consider a setting with two types of agents defined by the following departure probability functions:
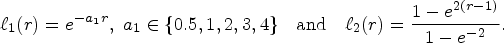
The total arrival rate is normalized to 1, with
Figure EC.3 shows the coefficient of variation of the optimal reward distribution for
Linearized S-shape Departure Functions
While Section 5.1 considered the setting where types’ departure probability functions were either convex or concave, in this section, we study the setting in which agents’ departure probability functions that are similar to a softmax function. We define the notion of a “linearized S-shape” departure probability function below.
(Linearized S-shape)
Departure probability function
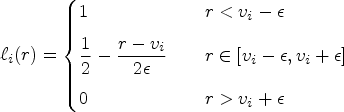
In Definition 5 we have relaxed the assumption that
Figure EC.4 illustrates these departure probabilities, for a fixed
In the remainder of the section, for analytical tractability, our results pertain to the setting where
The following proposition characterizes the optimal solution
Suppose If If for all for all
We provide some intuition for the above result.
In the remainder of the section, we let
On the one hand,
Let
At a high level, one would expect the decision-maker to be able to leverage the fact that agents are less sensitive to low rewards as
Figure EC.5 shows that these trends persist even in the presence of many types, for a newsvendor-like revenue function. In particular, in all settings considered, we observe that the profit exhibits a threshold structure, in which there exists
Our paper studies a decision-maker aiming to design fair incentive schemes when agents make stochastic participation decisions based on recent rewards. Fairness constraints in this setting lead to an a priori nonobvious obstacle for dynamic reward policies: when different agent types exhibit heterogeneous reactions to different rewards, dynamic policies can induce some types to be overrepresented in periods with lower rewards. Essentially, this is due to agents of these types self-selecting into those low-rewards periods based on the preceding high-reward periods. In the long run, this can result in bias in the reward distributions they experience. When dynamic policies are restricted to avoid such bias, we find that they offer no asymptotic benefit compared to static ones. Moreover, we prove, under a weak technical condition on the decision-maker’s revenue function, that the asymptotic benefits of dynamic policies vanish fast, as the static policy converges to the fluid upper bound at a linear rate. Finally, leveraging the two-reward structure of optimal solutions to the fluid upper bound, we derive insights into the type of policies that perform best for certain special cases of departure probability functions.
Supplemental Material
sj-pdf-1-pao-10.1177_10591478241273874 - Supplemental material for Fair Incentives for Repeated Engagement
Supplemental material, sj-pdf-1-pao-10.1177_10591478241273874 for Fair Incentives for Repeated Engagement by Daniel Freund and Chamsi Hssaine in Production and Operations Management
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Notes
How to cite this article
Freund D and Hssaine C (2025) Fair Incentives for Repeated Engagement. Production and Operations Management 34(1): 16–29.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.