
Abstract
The erosion of professional ethics in medicine has severe consequences for patients and society. Existing approaches often rely on retrospective analysis and lack the precision and timeliness needed to effectively identify and mitigate risks. Although patient online reviews offer a unique opportunity to proactively detect ethical issues by providing candid, unsolicited feedback on healthcare experiences, few studies have empirically established the link between patient reviews and ethical breaches in medicine. This research introduces a novel machine learning framework to derive text-based indicators of physicians’ professional ethics using online patient reviews. Our approach leverages large language models to extract ethics-related comments and employs few-shot contrastive learning to train multilabel classifiers. Empirical validation studies suggest that the ethical indicators can help predict a wide range of adverse outcomes including drug-related deaths, disciplinary actions, malpractice claims, and rent-seeking behaviors. Our framework offers promising avenues for proactively managing ethical risks in healthcare and other professional services.
Introduction
Professional ethics are of the utmost importance to healthcare providers. While adherence to professional ethics is often assumed in most OM literature (Li et al., 2016; Wang et al., 2019), recent empirical studies show that breaches of medical ethics are not uncommon and can adversely affect patients (Zhao et al., 2022). In addition, the erosion of medical ethics has serious societal consequences. Between 2000 and 2020, over 270,000 people died of prescription opioid overdoses in the USA, and much of the blame has been attributed to the unchecked financial quid pro quo between pharmaceutical manufacturers and doctors who overprescribe drugs (Kornfield et al., 2022). These rent-seeking behaviors by doctors put their financial interests ahead of their patients’ well-being. Yet, because of the long-standing culture of medical autonomy and self-regulation, early identification and intervention of ethical violations have been difficult (DuBois et al., 2019; Ham and Alberti, 2002).
As patients increasingly rely on online reviews to make informed decisions about providers, researchers have a unique opportunity to explore the extent to which these reviews offer meaningful information about professional ethics. While previous research has primarily focused on the relationship between numerical star ratings and healthcare quality (Gao et al., 2015; Lantzy and Anderson, 2020; Lu and Rui, 2018; Saifee et al., 2020), the predictive utility of text comments left by patients remains largely unexplored, even though they may provide more in-depth and candid evaluations. Recent studies have highlighted the operational value of social media information in nonmedical contexts (Cui et al., 2018; Yan and Pedraza-Martinez, 2019) and demonstrated how text data can be used for risk assessment (Wu, 2023). However, identifying meaningful signals from noisy reviews poses several challenges, such as dealing with colloquial language, ensuring model interpretability, and addressing the sparsity of relevant information. Given these considerations, our work focuses on two research questions: 1. How can we effectively extract information from online patient reviews about physicians’ potential professional ethical issues? 2. What is the predictive value of the information for various ethics-related outcomes?
We propose a new natural language processing (NLP) approach to measure providers’ adherence to professional ethics using online patient reviews. Drawing upon established frameworks in medical ethics literature, we identify 10 key dimensions that capture potential violations across the principles of deontology, utilitarianism, and emotivism (Lucey and Souba, 2010; Mandal et al., 2016; Rosenstein and O’Daniel, 2008). Deontology emphasizes adherence to codes or principles; utilitarianism focuses on outcomes that yield the highest net benefit; and emotivism views moral statements as expressions of personal emotions, not objective truths. Together, they inform guidelines that prioritize patient health and well-being while preserving the integrity of the medical profession. We collect a large dataset of patient reviews covering healthcare providers in the USA. Leveraging this unique data source, we develop a few-shot learning pipeline that fine-tunes a large language model (LLM) to accurately extract sentences within the reviews that pertain to these ethical dimensions. The extracted sentences serve as ethical indicators and provide quantitative measures of professional ethics adherence.
We conduct several validation studies to illustrate the practical relevance of these ethical indicators. First, we show that patient comments regarding controlled substance prescription are correlated with future drug-related deaths at aggregate local levels. Second, these indicators can predict physician sanctions by licensing boards. Third, they predict the type of injury and indemnity payments for malpractice claims. Fourth, they can help predict rent-seeking behaviors, such as healthcare providers accepting payments from pharmaceutical companies in exchange for prescribing drugs. Lastly, we extend our validation with a national clinical quality measure, revealing that while ethical indicators can predict physician quality, clinical quality alone does not predict future sanctions. Furthermore, we employ Explainable AI (XAI) methods to gain insights into our predictive algorithm and quantify the importance of each indicator. Finally, we discuss our framework's implications for the medical profession, healthcare managers, policymakers, and other professional service contexts.
Our study's primary contribution lies in bridging the literature on the operational value of social media data (Cui et al., 2018) and ethical risk management in healthcare. Specifically, we respond to the calls for proactive risk management (NEJM Catalyst, 2018) and the development of new measures that capture the interpersonal and dynamic processes (D. S. Kc et al., 2020) in healthcare. By highlighting the value of social media data on detecting ethical lapses in medical practice—as manifested in the opioid epidemic and troubling cases of patient abuse (Kornfield et al., 2022; Whitaker, 2023)—we provide potential means to address isolated incidents before they escalate to more serious issues. This contrasts with prior healthcare operations studies that focus on singular interventions for specific problems (Bastani et al., 2019; Bobroske et al., 2022; Kc et al., 2022).
From a technical perspective, we develop an integrated machine learning framework grounded in theories. Our approach combines several methodological innovations to address the challenges in this task. Anchoring our framework in established moral philosophies enhances validity and credibility. To tackle data sparsity and class imbalance, we integrate active search strategies with contrastive learning techniques. We harness LLMs to bridge the gap between abstract ethical principles and colloquial patient language, enabling feature extraction aligned with ethical frameworks without extensive manual annotation. Importantly, we go beyond classification performance improvements by validating the predictive power of indicators against a spectrum of real-world outcomes and employing explainable AI methods to provide actionable insights. Our framework offers a promising avenue for managing similar issues across other professional services contexts.
Our third contribution lies in demonstrating the practical relevance of ethical theories to patient-centered healthcare quality. Whereas prior research focused on clinical outcomes and patient satisfaction (Nair et al., 2013), we argue that adherence to ethical principles is a crucial yet often overlooked dimension of patient-centered care. Ethical violations, unlike typical quality issues, often involve deliberate misconduct and tend to be low-probability but high-consequence events, aligning them more with risk management than quality control. By operationalizing ethical constructs into measurable indicators that predict tangible outcomes, we establish a direct connection between ethical principles and operational realities. This approach elevates the concept of professional ethics from abstract ideals into actionable elements of patient-centered care (Chandrasekaran et al., 2012).
Literature and Theoretical Background
Professional Ethics in Healthcare
Professional ethics refers to the values and principles that guide conducts in occupations characterized by high levels of autonomy and specialized knowledge (Chadwick, 2016). In healthcare, this autonomy is particularly pronounced, as workers exercise considerable discretion in their work (Kc et al., 2020). This high level of autonomy, combined with the high-stakes nature of healthcare, necessitates a strong ethical framework. Consequently, professional ethics in healthcare becomes a critical issue with far-reaching implications for patient outcomes, public trust, and the overall efficiency of the system. A recent Gallup (2023) survey ranks medical professionals at the top among all professions in terms of perceived honesty and ethics, which highlights the exceptional ethical expectations placed on them.
However, despite this high level of trust, significant ethical challenges persist. The US healthcare system faces alarming rates of medical errors due to negligence (Bastani et al., 2019). A study reveals that nearly 20% of doctors have encountered impaired or incompetent colleagues over three years, yet many instances went unreported (Roland et al., 2011). Some medical systems failed to take appropriate action against egregious cases of sexually abusive doctors (Whitaker, 2023). Financial relationships between physicians and pharmaceutical companies have driven wasteful spending and contributed to the opioid epidemic (Kornfield et al., 2022). Conventional methods in ethical monitoring, such as whistleblowing (Blenkinsopp et al., 2019), auditing (Busch, 2012), and training programs (Jimenez and Foster, 1998) have shown limitations in effectively addressing ethical breaches. These approaches often rely on retrospective analysis of historical data and manual review processes, which can lack precision and timeliness needed to identify and mitigate ethical issues due to lengthy investigation processes, limited resources, and fragmented reporting systems (Kumaraswamy et al., 2022).
The healthcare operations management literature has focused primarily on clinical outcomes, measured through objective metrics like patient outcomes and guideline adherence (Chandrasekaran et al., 2012; Nair et al., 2013), and experiential aspects, assessed through patient satisfaction surveys (Peng et al., 2020). While several studies have examined the effects of process and policy changes on specific ethical issues such as opioid overuse and upcoding (Bastani et al., 2019; Bobroske et al., 2022; Kc et al., 2022), they tend to focus narrowly on the causal effects of singular interventions on singular problems. As a result, there is a lack of a comprehensive framework for assessing the broad spectrum of ethical risks. This gap is crucial given that ethical breaches, unlike quality problems, range from intentional misconduct to unintentional negligence and are more subjective in nature (Kaptein, 2008). Moreover, ethical breaches often result in low-frequency but high-impact events. Consequently, addressing these issues require shifting from traditional quality management to a new risk management paradigm.
Quantifying Ethical Risks Using Social Media Data
Conceptual Framework: Patient-Centered Risk Perception and Unstructured Data Assessment
Risk management in healthcare refers to systems and processes designed to detect, monitor, assess, mitigate, and prevent risks to patients (NEJM Catalyst, 2018). Conceptually, we situate our work through the lens of two key dimensions of operations risk management: risk perception and risk assessment (Cohen and Kunreuther, 2007).
Risk perception focuses on how different stakeholders understand, view, and act on risks. In the context of data science models for risk perception, this translates to selecting data sources that represent different stakeholder perspectives. We categorize existing work into provider-centered (or more broadly, business-centered) and patient-centered (or customer-centered) approaches. Provider-centered risk perception relies on healthcare organization data through formal channels, with most work focused on detecting fraud and misconduct (Bauder and Khoshgoftaar, 2018; Ekin et al., 2021; Herland et al., 2018; Kumaraswamy et al., 2022). However, these approaches have limitations, as they can be neutralized by organizational cultures where providers address issues independently rather than through official channels (Blenkinsopp et al., 2019). In contrast, patient-centered risk perception focuses on the experiences and perceptions of healthcare consumers, often expressed through unofficial channels such as social media. The literature on online patient reviews has shown mixed results regarding their usefulness in assessing quality and risk. Some studies (Gao et al., 2015; Lantzy and Anderson, 2020; Lu and Rui, 2018) find that online ratings can provide valuable insights into patient experiences. Others caution that reviews may not accurately reflect all aspects of care, particularly for services with credence attributes (Saifee et al., 2020).
Risk assessment involves evaluating the likelihood and consequences of risks using data, expert judgments, and probabilistic methods. These models can be categorized into those using structured data such as sales, inventory, and electronic health records (Ekin et al., 2021; Herland et al., 2018; Markou and Corsten, 2021), and those that rely on unstructured data such as text (Abrahams et al., 2015; Liu et al., 2023; Wu, 2023). Structured data is easier to integrate into existing ERP and business intelligence systems (Araz et al., 2020), thus enabling more precise risk assessment. Conversely, unstructured data captures specifics of risk scenarios that might not be evident in structured data, thus enabling greater granularity of risk assessment (Wu, 2023). Text analytics can add significant value to predictive models for ethical and compliance monitoring, as it combines two important mechanisms of leveraging big data (Cohen, 2018). Crucially, in our context, unstructured data can contain subtle indicators of professional misconduct that are often difficult to reflect in existing structured data collection systems.
Our work belongs to the quadrant of patient-centered risk perception using unstructured text data for risk assessment (Table 1). Among this quadrant, the conceptual novelty of our work lies in leveraging unstructured online patient reviews to quantify ethical risks in healthcare, a hitherto overlooked link. Given conflicting evidence on the value of patient reviews and anecdotal reports of patients inadvertently rewarding unethical practices (e.g., giving high ratings to those who are willing to write opioid prescriptions) (Macy, 2018), it is imperative to empirically test this link. By mining reviews for ethics-related comments and evaluate their predictive power for multiple outcomes, our approach aligns with emerging trends in healthcare risk management that shift from reactive strategies towards more proactive methods that consider risk across the entire ecosystem (NEJM Catalyst, 2018).
Key literature and positioning of our approach.
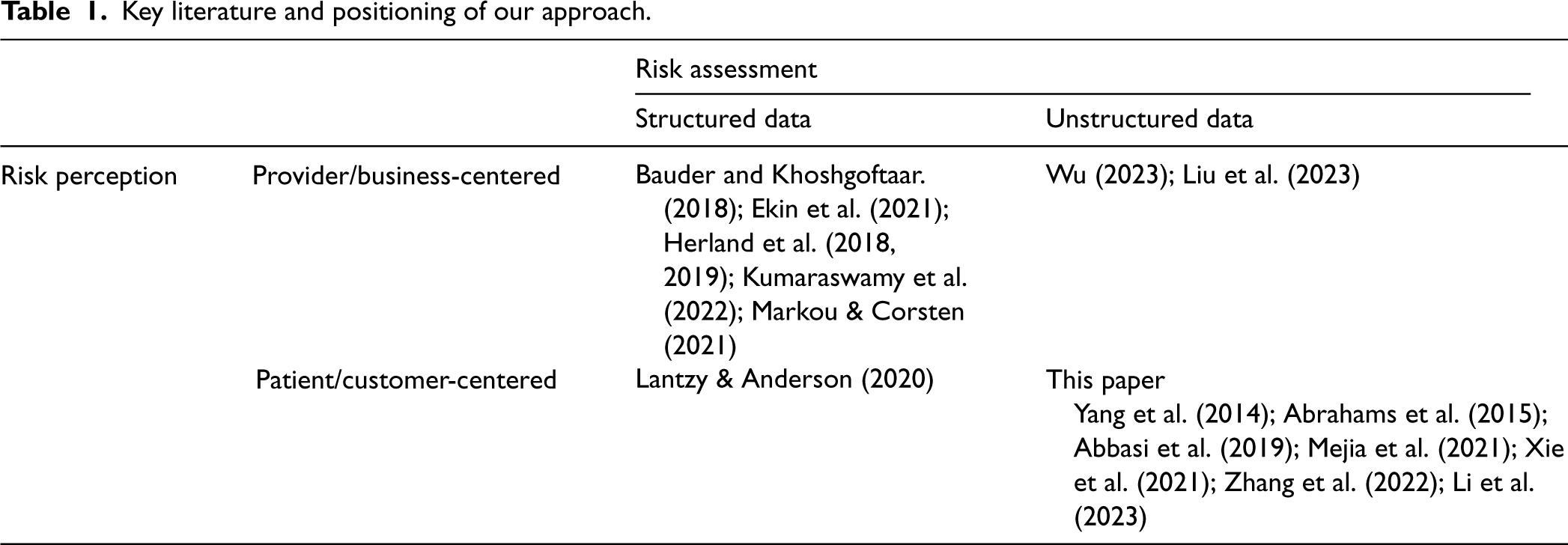
Key literature and positioning of our approach.
The patient-centered, unstructured data approach outlined in our conceptual framework introduces unique challenges. First, extracting features anchored in ethical theories is crucial for model interpretability and actionable insights. This approach enhances conceptual validity by aligning measurements with established moral values, lending credibility when engaging with interdisciplinary audiences, practitioners, or policymakers. Anchoring features in ethical theories ensures that quantified risks reflect principled moral reasoning rather than mere statistical artifacts. Second, the heterogeneous and nuanced expressions of ethical concerns in patient reviews require advanced natural language understanding (NLU) capabilities. The model must bridge the gap between abstract ethical principles and diverse, colloquial patient expressions to accurately map narratives onto ethical constructs. Third, the unstructured nature of text data results in sparsity within the input space, while the infrequency of ethical complaints leads to imbalanced output labels. This combination of sparse inputs and skewed outputs presents challenges for model training. An integrated approach is needed to handle both dispersed signals and uneven class distribution while balancing the identification of rare ethical violations against overfitting risks. Fourth, demonstrating real-world relevance requires evidence that patient reviews can predict multiple ethics-related outcomes while providing interpretable insights. Ethical violations in healthcare can lead to diverse adverse consequences, e.g., patient harm, legal liabilities, emotional distress, and financial losses. In this high-stakes context, the principles of Explainable AI, i.e., the models are understandable, justifiable, and actionable, are crucial (De Bock et al., 2023).
We compare our study with the literature along these dimensions (see Table EC.1). 1 Most studies (except Zhang et al., 2022) do not have a theoretical foundation underpinning their model architectures. Regarding NLU models, prior work has employed lexicon-based approaches (Abbasi et al., 2019; Abrahams et al., 2015; Yang et al., 2014), static word embeddings (Wu, 2023; Xie et al., 2021; Zhang et al., 2022), topic models (Ko et al., 2019), and LSTM (Liu et al., 2023). While effective in their domains, these models have limitations in our context. Lexicon-based methods struggle with diverse patient language; static embeddings fail to capture context; and topic models lack granularity for specific ethical issues. Deep learning models like LSTMs require large, labeled datasets, but obtaining these is difficult given the sparsity of ethical concerns. To address sparsity, some studies use heuristics (Abbasi et al., 2019; Xie et al., 2021), data augmentation (Li et al., 2023), or undersampling (Zhang et al., 2022). However, while some approaches handle imbalanced target classes, acquiring sufficient training data remains challenging due to sparse ethical expressions. In terms of real-world relevance and interpretability, while existing studies demonstrate superior classification performance against benchmarks, most either lack real-world outcome prediction beyond test-set documents or focus on a single outcome type.
Our study contributes novel solutions to address these limitations. First, we ground the measurement of professional ethics in the “big three” ethical theories. 2 Integrating them into the same measurement framework allows us to compare and contrast their practical utility in assessing risks. Second, we leverage the representational power of LLMs to understand the semantics of ethical concerns expressed in patient's words, going beyond the limitations of NLU techniques employed in most extant studies. Third, facing more extreme sparsity issues, we devise a two-pronged solution: active search to efficiently discover sparse signals, and contrastive learning to further amplify these signals. This combination of techniques is novel in the literature. Finally, our work goes beyond simply demonstrating superior classification performance. We validate the predictive power of ethical indicators against a much broader set of real-world outcomes compared to existing work and provide rich interpretable insights using XAI methods.
Theoretical Background: The Three Lenses of Ethical Theory
We draw upon three ethical theories to construct a set of professional ethics measures anchored in the patient experience. Table 2 presents a summary of these measures and example reviews.
Examples of ethical indicators based on three ethical theories.
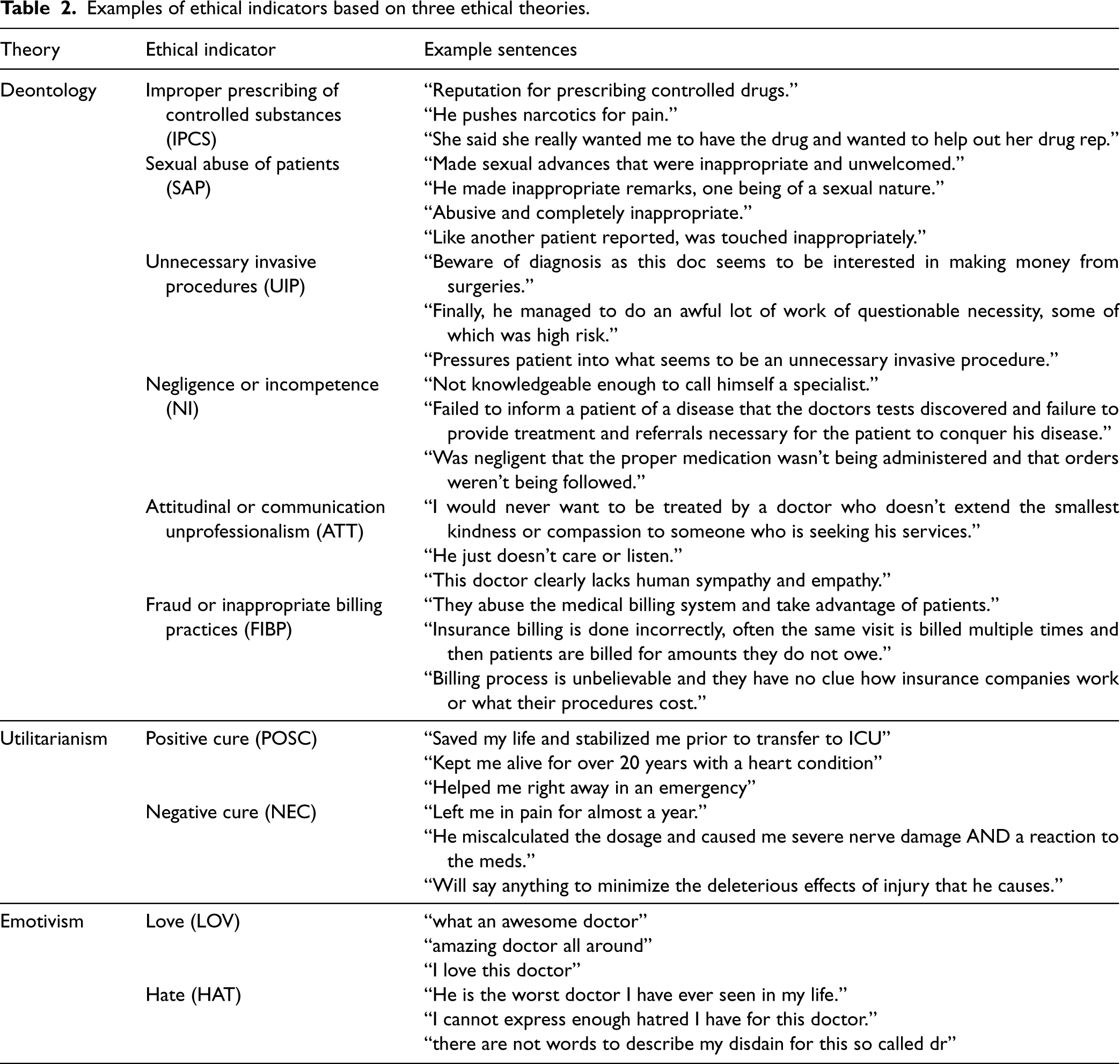
Examples of ethical indicators based on three ethical theories.
The first theoretical lens, deontology, concerns the ethics of duty, that is, what one person should or should not do in relation to another (Garbutt and Davies, 2011). This theory is rooted in the belief that any act can be judged on its own merit, rather than outcome (Gal et al., 2022). A basic criterion for such assessment is whether the act conforms to a moral norm. In healthcare, deontology is strongly reflected in professional codes of conduct (Fineschi et al., 1997). These codes of conduct often outline the moral and legal obligations that healthcare professionals have to their patients. They also prohibit specific violations and behaviors that are deemed unacceptable by the medical community, legal system, and society. Accordingly, we develop six deontological measures. While different medical specialty associations define different codes, the literature suggests that the three most commonly reported violations are improper prescribing of controlled substances (IPCS), sexual abuse of patients (SAP), and unnecessary invasive procedures (UIP) (DuBois et al., 2019). These serious violations can have severe consequences for patients, including opioid addiction and overdose deaths, as well as physical, emotional, and financial harm. Additionally, a national study indicates that other three common reasons for disciplinary action by medical boards are negligence or incompetence (NI), attitudinal or communication unprofessionalism (ATT), fraud or inappropriate billing practices (FIBP) (Papadakis et al., 2005). Table EC.1 provides references to repercussions associated with these deontological indicators.
The second theoretical lens, utilitarianism, holds the best action is the one that promotes overall better consequences. In healthcare, utilitarianism reflects the outcome of the treatment from the patient's perspective, which may include the impact that a diagnosis or treatment has on the patient's overall well-being and quality of life. In other words, outcomes determine the morality of the intervention (Mandal et al., 2016). This lens can be used as an indicator of physician professional ethics, as it reflects the extent to which doctors are fulfilling their ethical obligations to provide the best possible care. We thus develop two utilitarianism measures: positive care (POSC) and negative care (NEC). They capture the degree to which patients believe that their conditions have improved or deteriorated from treatment.
The third theoretical lens, emotivism, holds that moral judgments express positive or negative feelings rather than relying on reasoning or objective evaluation (Bandman, 2003). In healthcare, emotivism reflects how patients feel about their providers and treatments. Though seemingly more subjective than other lenses, emotivism is crucial in patient-centered healthcare as it acknowledges the importance of emotional reactions to healthcare experiences (Husted and Husted, 2005). Patient satisfaction and emotional well-being are important quality indicators (Manary et al., 2013) and can impact clinical outcomes (Robertson et al., 2012). Emotions and sentiments are particularly important on social media channels for providing operational feedback (Cui et al., 2018; Gour et al., 2022). Patients’ emotions expressed in reviews, even when nonspecific, can still be related to the professional ethics of doctors. For example, patients’ expressions of frustration and complaints may indicate a disregard of respect and empathy. Based on this theory, we develop two measures: love (LOV) and hate (HAT), measuring the degree of positive and negative feelings toward providers respectively. 3
Our primary data source is a set of patient reviews from Vitals (http://www.vitals.com), a popular online platform for healthcare provider information. We used a custom web crawler to extract 1,167,455 reviews from July 2005 to December 2014. These reviews cover 449,116 unique providers across various medical specialties. The dataset provides broad coverage of all 50 US states and Washington, D.C. Each review entry contains three key components: an ordinal star rating (1–5 stars), physician metadata (e.g., years of experience, specialty, and gender), and free-text comments explaining the ratings. The textual component averages 52 words per review. We present detailed summary statistics of the patient review data in Table EC.4. The credibility of the data source stems from Vitals’ quality control measures. These include mandatory board certification for listed physicians and a rigorous review authentication process. Vitals also imposes a 30-day cooldown period between submissions from the same reviewer. Anonymity on the platform may reduce social desirability bias and encourage candid feedback.
To validate our ethical indicators and demonstrate their practical utility, we employ several additional datasets. First, we use state- and county-level drug poisoning mortality data from the Centers for Disease Control and Prevention (CDC). This dataset allows us to quantify opioid-related deaths across all 50 states and Washington, DC from 1999 to 2016 (Giles et al., 2023; Janssen and Zhang, 2023).
Second, we collect physician discipline information from 21 state medical boards’ public websites. We convert these state-specific records into a machine-readable format through extensive data processing. 4 We present detailed characteristics of these disciplinary records in Table EC.5.
Third, we use physicians’ payment-prescription sensitivity as a measurement for rent-seeking behavior (Parsons et al., 2018). This measure reflects the relationship between payments made by pharmaceutical firms to doctors and the value of prescriptions written by those doctors for drugs produced by those firms. To construct this measure, we combine two datasets. The first is ProPublica's Dollars for Docs data, which contains the payments made by these companies to providers in the form of speaking fees, consulting fees, dinner, etc. from August 2013 to December 2016. The data is compiled from publicly available information, including Open Payments data from the Centers for Medicare and Medicaid Services (CMS) and voluntary disclosures from the firms. We then collect the Medicare Part D Prescriber Data provided by CMS to merge with the Dollars for Docs data. The Prescriber Data constitutes detailed records of prescription drugs in the Medicare Part D program. The data contains the National Provider Identifier (NPI) of the healthcare provider, the prescribed drug, the brand names (which we use to identify manufacturers), and the cost incurred under Medicare. Prior literature has shown that this data can be a useful resource for understanding the conflicts of interest that may exist between healthcare providers and the industry (Brennan et al., 2006).
For a given doctor-firm pair, we aggregate the payment amount and prescription cost. The payment data
Fourth, as a measure of more detailed financial and legal repercussions of medical misconduct, we access the Professional Liability Tracking Database from the state of Florida. The database contains 35,632 claims linked to Florida state licenses, and provides more granular information than state medical board sanction records, including injury classifications (permanent, temporary, or emotional) and indemnity payment details. 5 These payments comprise settlements, court-ordered judgments, and associated legal fees covered by insurers, thus allowing us to analyze the spectrum of patient-reported adverse events and their associated costs. Table EC.7 details the claims’ characteristics.
Fifth, to validate our ethical indicators in the context of clinical quality, we utilize measures from the CMS Merit-Based Incentive Payment System (MIPS). Established by the Medicare Access and CHIP Reauthorization Act (MACRA) in 2017, MIPS evaluates clinician performance on a scale from 0 to 100 based on CMS-approved criteria. The criteria encompass preventive care, chronic disease management, care coordination, patient safety, patient engagement, and efficient use of clinical resources. MIPS assesses performance across three domains: quality, promoting interoperability, and improvement activities. Our analysis focuses on the quality component of the MIPS scores from 2018, as it is the first year with stable enrollment following the inaugural year of 2017.
We merge the above datasets (see Figure EC.1) by first matching the doctor records in the review dataset with the Medicare provider data from CMS, using doctors’ full names and the city to locate their NPI. We acknowledge that mapping the review dataset to the NPI can be noisy. Nevertheless, we employ a stringent criterion requiring both name and city matching. For the majority of doctors (65.91%) in the review dataset, we are able to find exact matches. To mitigate the issue of unmatched NPIs, we conducted a robustness test in Section 5.3, which demonstrates that our model's performance remains robust even in the presence of unmatched NPIs. We then merge the Dollars for Docs and Medicare Part D Prescriber data using NPI. For physician disciplinary records, we use NPI when available. In cases where NPI is unavailable, we match records using the physician's name and licensed state. We also utilize state license numbers and other identifying information for manual deduplication when necessary. We standardized names, states, and other entities during the merging process to ensure consistency.
Methods
Overview of Methods
Figure 1 presents our framework's flowchart addressing the challenges laid out in Section 2.2.2. Our approach begins by grounding the analysis in the three theoretical lenses of professional ethics—deontology, utilitarianism, and emotivism—and identifying 10 dimensions that embody these principles (detailed in Section 2.3). To operationalize these dimensions, we first develop a set of generic, representative seed statements that depict the corresponding ethical standards (see Table EC.9). For example, we use “prescribed unnecessary narcotics” for improper prescription of controlled substances (IPCS), and “saved my life” for positive care (POSC).
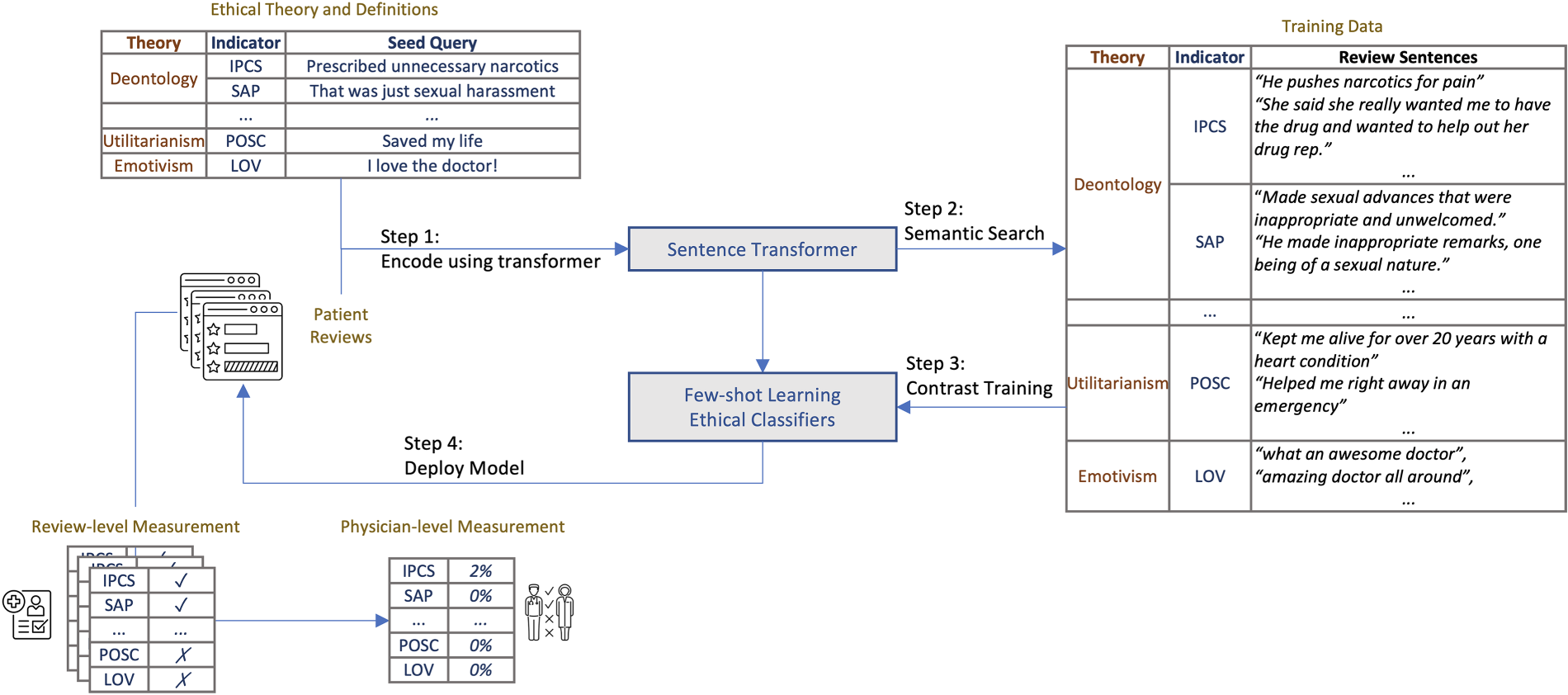
Analysis flowchart.
Our next goal is to construct a training dataset. This task presents a challenge due to the sparsity of ethics-related concepts in the web-scale review corpus. Annotating a random sample as a training set would likely yield very few, if any, review sentences directly related to the ethical indicators. To overcome this challenge, we leverage the representation power and NLU ability of LLMs to conduct a cost-effective active search (Jiang et al., 2019)—a labeling strategy that targets the identification of positive examples within a large unlabeled dataset. Active search is a specialized form of active learning (Saar-Tsechansky and Provost, 2007) designed for highly skewed class distributions. It focuses on the maximization of minority class discovery. Our approach is partly inspired by Coleman et al. (2022), which prioritizes the nearest neighbors of currently labeled examples to enhance efficiency by avoiding exhaustive scans of all unlabeled data. We adapt this idea from image to text domain by using semantic search, an information retrieval technique that identifies relevant documents matching the meaning of a query, to find the nearest neighbors of labeled ethics-related reviews.
Furthermore, we encounter a multiclass few-shot learning problem. Each review sentence may pertain to multiple ethical indicators, with some indicators having a limited number of positive sentences even after employing an active search labeling strategy. Although GPT-style models are technically feasible for such tasks (Brown et al., 2020), their associated cost and latency render them unsuitable for our context. We opt for a contrastive learning approach that can outperform GPT-style models in few-shot classification tasks (Tunstall et al., 2022). Contrastive learning focuses on improving the representation ability of a model, so that they can better distinguish between similar and dissimilar pairs of sentences. After contrastive learning, a classification head is then trained on top of a frozen transformer model (i.e., their parameters are not updated during training). Research has shown that freezing the parameters in a transformer model can improve the robustness of the model, particularly when distribution shift is a concern such as in few-shot learning (Kumar et al., 2021).
Finally, as our eventual goal is to enable regulators and healthcare managers to transform online review data into insights, establishing clear reasonings for decision-making is crucial. Rather than developing an end-to-end model for directly predicting real-world ethical violations from review texts, we first construct review-level measurements and subsequently assess their predictive power in downstream tasks. This approach provides a clearer understanding of the model's mechanisms; it also enables the generation of theoretical and managerial insights into which types of ethical indicators are most indicative of actual behavior. We next describe the implementation of each step in detail.
Step 1: Encode seed sentences in the same semantic space as the patient review text. We employ a sentence-transformer model (all-mpnet-base-v2) (Song et al., 2020), to encode both seed statements and patient reviews. This sentence-transformer model is built upon the MPNet architecture, a pretrained encoder-only LLM that refines the widely-used BERT model (Devlin et al., 2019). It is specifically optimized for semantic textual similarity tasks. While BERT-like encoders excel at various NLP tasks, they often struggle to capture subtle semantic differences in text. Sentence-transformer models are fine-tuned on specialized datasets like human-annotated text similarity corpora to overcome this limitation (Reimers and Gurevych, 2019).
Step 2a: Semantic search. We adopt an active search strategy within the patient review corpus. This addresses the challenge posed by the scarcity of explicit ethical content in these reviews (Jiang et al., 2019). In the first step, we embed all reviews and seed statements into sentence vectors using the sentence-transformer. We then index these vectors using a semantic search engine to facilitate semantic comparison. The search utilizes cosine similarity to measure the closeness between the embedding vectors of our seed sentences and sentences in the patient review corpus. This approach bypasses the limitations of traditional keyword matching by prioritizing semantic relevance over exact term alignment. Given a query, the semantic search engine yields a ranked list of review sentences based on their semantic pertinence to our queries.
For each of the 10 ethical indicators, our initial queries are a set of seed statements that represent unethical or unprofessional physician behaviors (see Table EC.9). Guided by these seed statements, we interactively search all review sentences to find those pertinent to the ethical notions, such as “Dr. wanted to perform unnecessary procedures,” “gross negligence of patient care,” “deliberately misleading and unethical billing practices,” “kept me alive for over 20 years with a heart condition,” or “caused nothing but pain and agony.” This step essentially bridges the linguistic gap between the more professional terminology of the seed statements and the more colloquial language of patient reviews.
Step 2b: Dataset finalization. The construction of the dataset involves a multi-round, iterative active search process. In the first round, the top 100 review sentences most semantically similar to the seed statements are manually annotated for relevance to the corresponding ethical indicator. The sentences deemed relevant are then used as additional queries in the second round of search, along with the original seed statements. This process is repeated for a third round, with the relevant sentences from the second round serving as additional queries. The iterative process allows for the discovery of a wider variety of relevant expressions that patients use to describe ethical concerns, which may not be captured by searching the initial seed statements alone. The result is a collection of 150–300 manually validated sentences for each ethical indicator, totaling 1729 sentences across all indicators. We also add 500 randomly drawn negative examples per ethical indicator from the review corpus to form the final dataset.
To address potential underreporting of ethical concerns, especially for sensitive issues like sexual misconduct, our data collection strategy captures a diverse set of training sentences covering a wide range of misconduct behaviors. For instance, we include sentences such as “made me uncomfortable by stating inappropriate comments and touching,” and “inappropriate behavior, made me feel uncomfortable as a female patient” to capture subtle forms of sexual misconduct. As a result, the incidence rate of sexual misconduct indicators (SAP) is of similar magnitude (0.18%) as fraud and improper billing (FIBP) 0.22%, improper prescription of controlled substance (IPCS) 0.19%, hate (HAT) 0.19%, or negative care (NEC) 0.20% in the sanctioned cases (see Table EC.4). This suggests our data collection strategy effectively captures a representative distribution of ethical violations, even for sensitive issues prone to underreporting.
Training and Deploying Classifiers
Step 3: Few-shot learning using contrastive training. To construct a classifier for ethical indicators, we turn to few-shot learning, a methodology that trains language models for classification tasks using a relatively small number of labeled examples. This approach has been effective in various natural language processing applications, such as text classification and question answering (Brown et al., 2020). Specifically, we employ the SetFit method. SetFit conducts contrastive fine-tuning of pretrained sentence embeddings, and is shown to be more efficient than traditional fine-tuning and GPT-style in-context learning methods (Tunstall et al., 2022).
SetFit employs a two-stage training approach for the development of a professional ethics indicator classifier. Initially, the sentence-transformer (ST) is fine-tuned using 80% of the curated dataset from step 2. This contrastive fine-tuning process enhances the embedding model's discriminative capabilities between different ethical classes. Subsequently, to avoid overfitting and maintain the stability of the embeddings, the transformer is frozen while a classification head is trained on these embeddings. Classifier performance is assessed using the remaining 20% of the data as a hold-out set.
Specifically, in the contrastive fine-tuning phase, given a small set of K labeled examples
After the ST is fine-tuned contrastively, the original labeled training data
The trained model is made accessible on the HuggingFace platform. 6 For training, we set epochs to 4 and use an Adam optimizer with a 2e−05 learning rate. A learning rate scheduler is employed for linear rate increases during the warmup phase. To prevent overfitting, the model incorporates a weight decay of 0.01 as a form of L2 regularization. Full hyperparameter details are available in Table EC.10.
Step 4: Deploy the classifiers for downstream tasks. Once the multiclass professional ethics indicator classifier is trained, it is deployed on all review sentences. Each sentence in the text is then labeled as either related to one of the 10 ethical indicators or not. Depending on the downstream task, the ethical indicators are aggregated either at the physician level or at the state/county-year level.
To improve the prediction accuracy of physician sanction status and payment-prescription sensitivity, we turn to XGBoost, a machine learning technique that aggregates the predictions of multiple decision trees (Chen and Guestrin, 2016). In economics and operations management, XGBoost has been used to predict police misconduct (Chalfin et al., 2016) and has demonstrated superior performance compared to other tree-based algorithms and machine learning approaches (Krauss et al., 2017; Mohri et al., 2018). Other benchmark techniques, e.g., random forests, decision trees, logistic regression, linear regression, and ridge regression, are also tested (see Section EC.3 for more details).
We split our data into an 80% training sample and a 20% test sample and use five-fold cross-validation to fine-tune the hyperparameters of machine learning models. To mitigate the effects of this rarity of sanctions, we adopt class weighting and the Synthetic Minority Over-sampling Technique (SMOTE). To measure the performance of classification tasks, we report the out-of-sample receiver operating characteristic (ROC) curve's area under the curve (AUC), precision, recall, and F1 score. Measures for regression tasks, for example, MSE, RMSE, and MAE, are also computed.
We use a common XAI method, SHapley Additive exPlanations (SHAP) (Lundberg and Lee, 2017) to interpret the trained XGBoost models. SHAP values are assigned to each feature based on the classic Shapley value from game theory. The values allow us to rank ethical indicators based on their predictive power. SHAP uses the conditional expectation
Results
Measurement: Search and Classification Performance
We benchmark the encoder's search performance against human annotation following the information retrieval literature. We compare the all-mpnet-base-v2 sentence-transformer, applied herein, against two other encoding models. The first, TF-IDF, assigns weights to words based on their frequency within a specific document relative to their frequency across an entire corpus. This provides a sparse vector representation for each review sentence. The second, word2vec, employs a single-hidden-layer neural network to derive word associations from the review corpus. Its outputs are static word embeddings that encapsulate semantic relationships between words (Mikolov et al., 2013). We train a 400-dimensional word2vec model on the review corpus for five epochs; the hyperparameters are set to default in the gensim package (Rehurek and Sojka, 2011). We represent each review sentence using the mean pooling of its word2vec word embeddings.
Given the three encoders, we process all reviews and seed statements, and retrieve the top 20 sentences ranked by each encoder. We subsequently shuffle these sentences randomly and request that two human annotators assess the relevance between each query and the corresponding sentences. The annotators use a 1–3 scoring system and take into account the general context and the specific definition of each ethical indicator. We use Normalized Discounted Cumulative Gain (NDCG) to evaluate the ranking efficacy of three encoder models. 7 We find that the sentence-transformer outperforms both TF-IDF and word2vec across all ethical indicators as measured by its concordance to the human annotators and the NDCG scores (Table EC.11). The sentence-transformer's superior performance may be ascribed to its refinement through human-annotated paraphrase pairs and similarity data, which more closely resonates with the task at hand. The only cases when the benchmark models show comparative performance to the sentence-transformer are emotivism categories (love and hate). This result may stem from the less intricate nature of emotivism than deontology and utilitarianism indicators, where the need to comprehend contextual meanings is more challenging for simpler models.
We find that when processing indicators like improper prescription of controlled substances (IPCS), word2vec captures general prescription and controlled substances elements but struggles with the nuances. For example, it often provides irrelevant results such as strict prescription practices or patients being treated as addicts. A word2vec IPCS search yields matches like “He believes that controlled substances should never ever be prescribed,” which does not accurately reflect IPCS. Similarly, for sexual misconduct indicators, alternative methods find it challenging to distinguish between patients recounting past abuse experiences and actual complaints of physician misconduct. A notable misalignment can be seen in sentences like “what she didn't bother to find out was that I was a victim of sexual abuse” being erroneously matched to the sexual abuse by physicians (SAP) category. These patterns are consistently observed across various ethical indicators. They indicate the limitations of simpler encoding models in representing complex ethical notions.
In terms of classification performance, our few-shot learning model consistently achieves impressive results across all indicators (average ROC AUC 0.98, minimum ROC AUC 0.94, maximum ROC AUC 1.0, average PR AUC 0.92, minimum PR AUC 0.79, maximum PR AUC 0.99, see Figure 2). 8 This model's high performance is also evident through various evaluation metrics such as precision, recall, and F1 score (Table 3). The ROC curves demonstrate the model's strong ability to distinguish between various cases of ethical notions and negative examples (Figure 2). The precision, recall, and F1 scores provide a more detailed view of the model's performance. Given these strong metrics, we conclude that the model can accurately identify ethics-related comments with a high degree of accuracy.
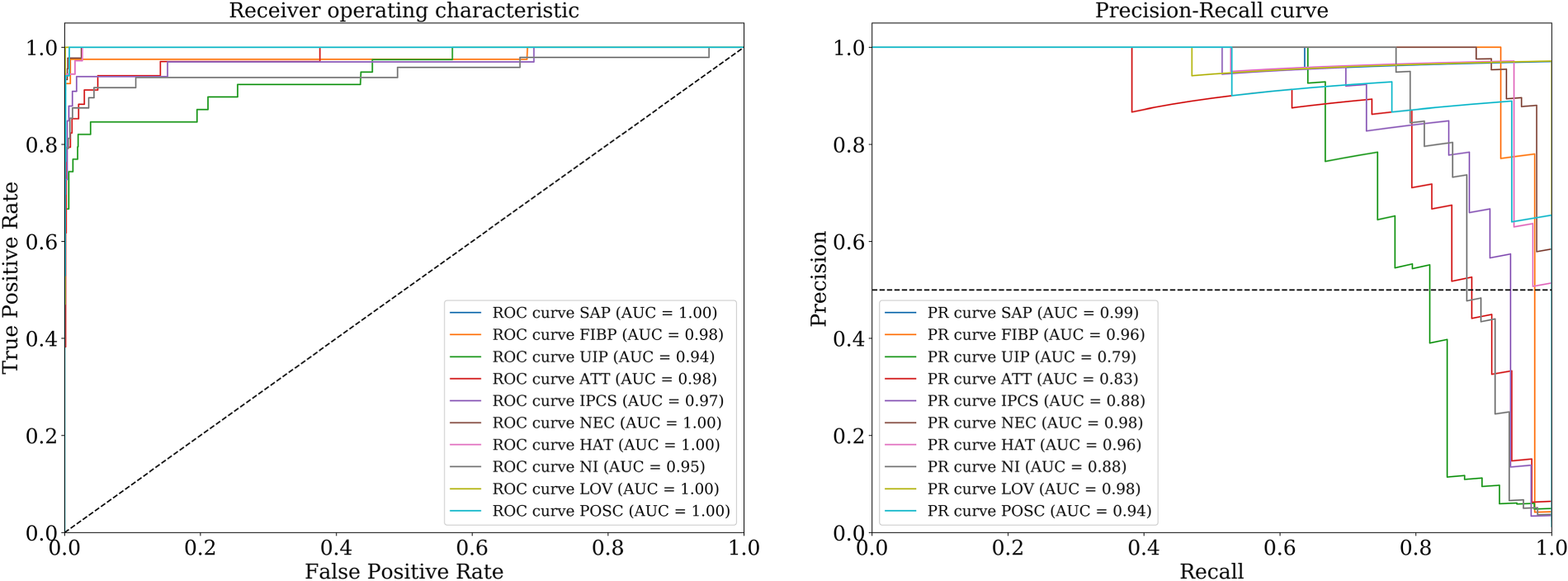
ROC and PR curves for 10 professional ethics indicators.
Performance of the few-shot learning model in extracting ethical indicators.
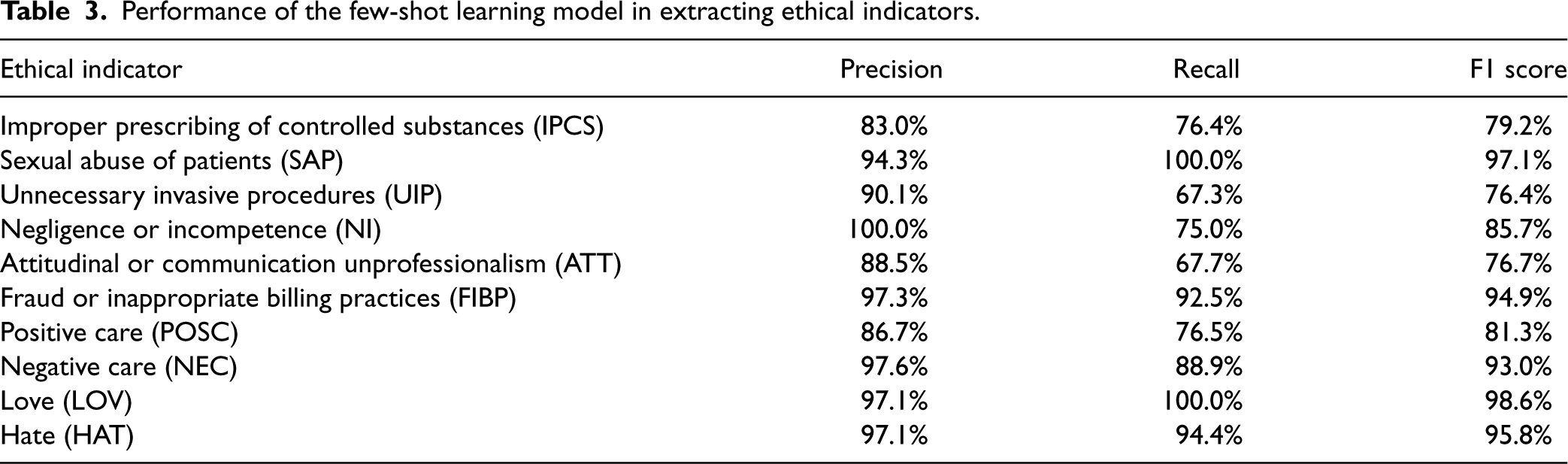
To benchmark our classifier, we compare it against several other models (details in Table EC.12). These benchmarks span a range of text classification techniques: a naive BERT multiclass single-label classifier, a BERT-based embedding with an RNN for a single-label classification head, a word2vec embedding with a single-class XGBoost classifier, and a TF-IDF vector-based single-class XGBoost classifier. The results demonstrate that our few-shot learning approach achieves superior or comparable results in all dimensions. Another advantage of our model is its ability to quickly adapt to new data and improve its performance over time (Tunstall et al., 2022). By actively selecting and labeling a small number of examples, our model is able to learn and make accurate predictions on new data more efficiently than a traditional model. This makes it an especially useful tool for identifying and addressing new forms of ethical violations if the need arises.
Prediction of State-Level and County-Level Drug Poisoning Mortality
To illustrate the aggregate-level predictive power of our ethical indicators, we conduct a panel-data regression analysis to predict state-level drug poisoning deaths using improper prescription of controlled substances (IPCS) as our main independent variable. We merge state-level drug poisoning data from the CDC with our aggregated, state-level IPCS measures to obtain a matched panel of 50 states and Washington DC across 7 years (2008–2014). We use feasible generalized least squares (FGLS) to estimate the relationship between IPCS and drug poisoning deaths, adjusting for heteroskedasticity. We include year and state fixed-effects to account for time-invariant and state-invariant factors, and use the one-year lag of IPCS to mitigate simultaneity concerns. We also control for state-level per-capita income, population, and a time trend. The results (Table 4) show the IPCS coefficients are highly significant and consistent across models, with the lagged model indicating one more IPCS-related comment is associated with about twoo more drug poisoning deaths, representing a strikingly strong predictive relationship.
Results of IPCS and drug poisoning mortality.
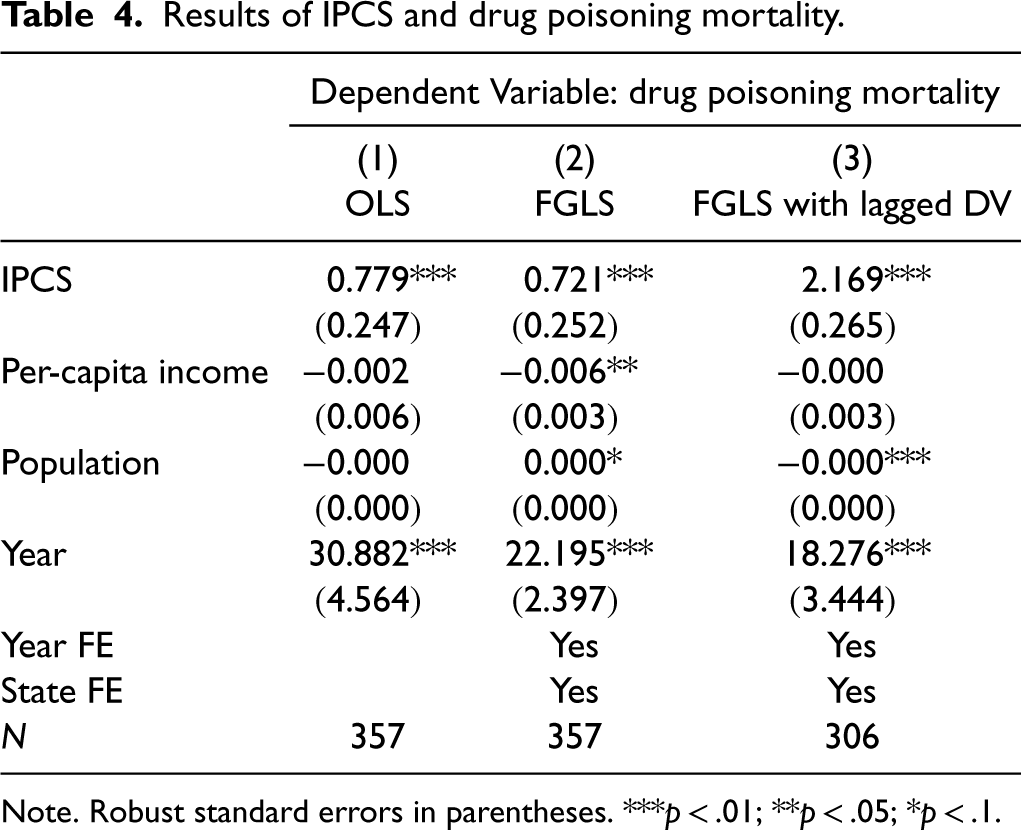
Results of IPCS and drug poisoning mortality.
Note. Robust standard errors in parentheses. ***p < .01; **p < .05; *p < .1.
We further validate these findings using a county-level analysis covering 1908 counties from 2005 to 2014 (Table EC.3). The results remain qualitatively the same, with 10 more IPCS-related comments associated with 3.5 more drug poisoning deaths at the county-year level.
Next, we investigate the predictive power of the ethical indicators along with star ratings and physician metadata in identifying provider sanctions across all sample periods. Employing a range of machine learning algorithms, including XGBoost, Logistic Regression, Random Forest, and Decision Tree, we assess their performance using the ROC AUC. The results in Figure 3 demonstrate strong predictive capabilities across all models, with ROC AUCs ranging from 0.76 to 0.90. This consistent performance highlights the robustness of the ethical indicators in identifying instances of sanctions. Among the evaluated models, XGBoost exhibits the best performance with an AUC of 0.90. Consequently, we employ XGBoost for the subsequent analysis of predicting sanctions after 2016, that is, for cases beyond our review sample period.
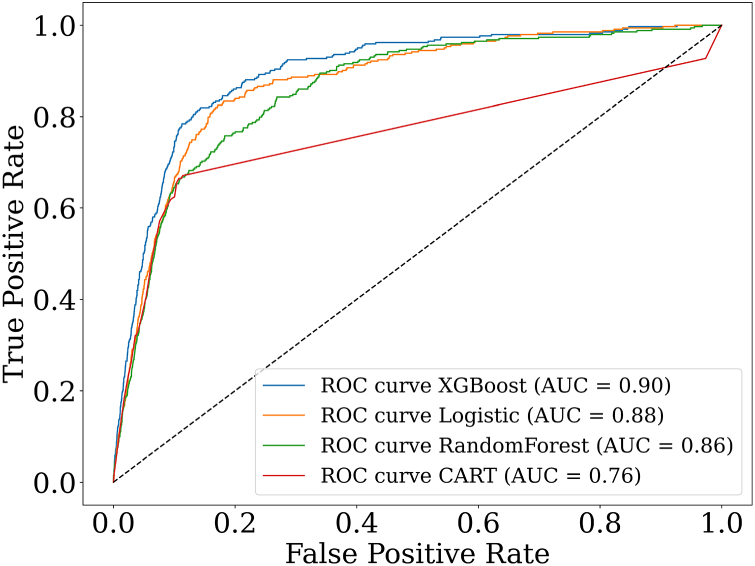
ROC curves for predicting physician sanctions.
We use the Global SHAP graphs to highlight the importance of individual ethical indicators in the XGBoost model's predictions. Sentences related to improper prescribing of controlled substances, fraud/billing problems, sexual misconduct, and neglect and incompetence are highly influential in predicting physician sanctions. Improper prescribing of controlled substances (IPCS) emerges as one of the most significant predictors of sanctions, both overall and specifically for cases after 2016 (Figure 4).
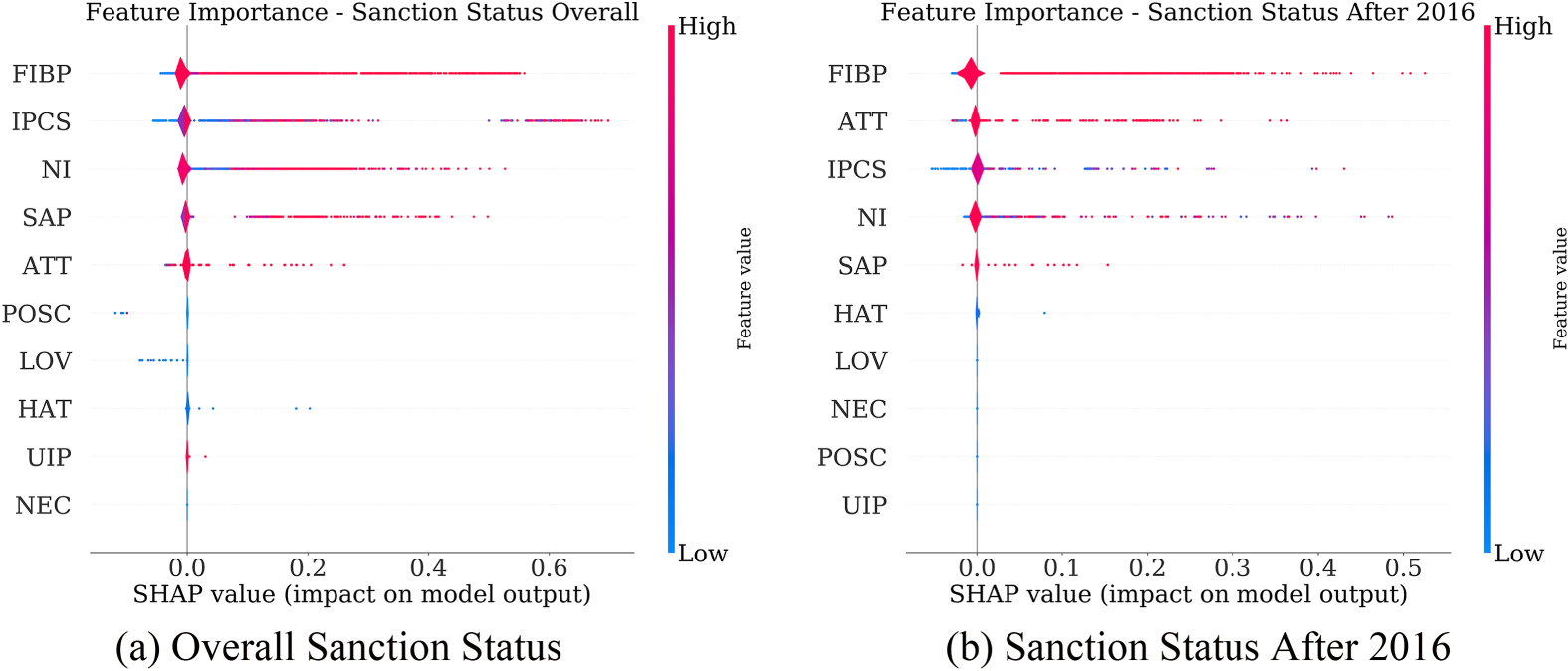
SHAP variable importance plots for predicting physician sanctions (global interpretability).
To illustrate the impact of ethical complaints on the likelihood of an individual physician being sanctioned, we provide examples of local SHAP plots. Figure 5(a) illustrates the case of a physician with a base log odds of approximately −4.76. The presence of improper prescription practice complaints has the most substantial effect on increasing the sanctioned odds above the baseline, with an increase of 0.8 in the log odds (from approximately −4.76 to −3.97).
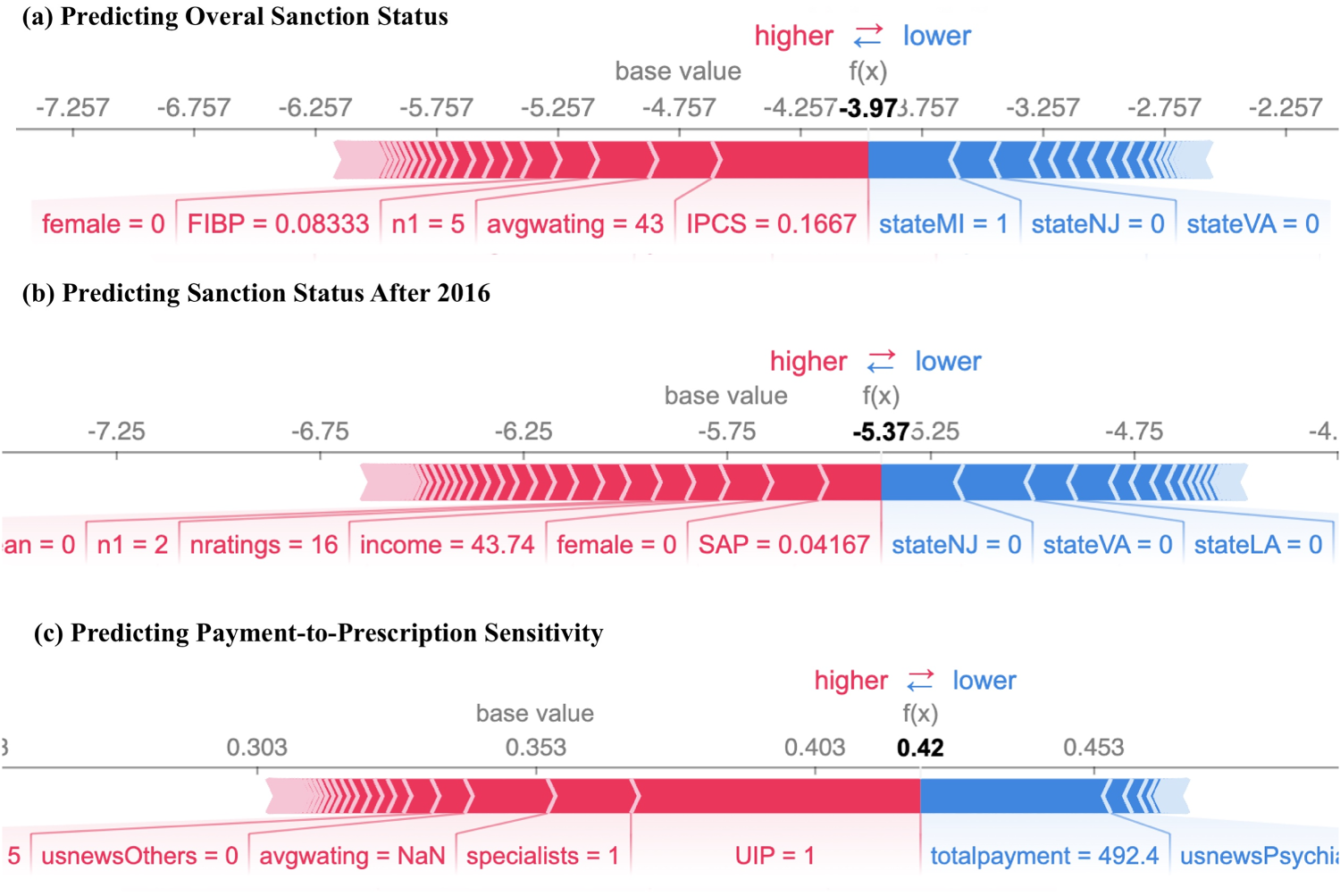
SHAP variable importance plots (local interpretability).
To further validate the predictive power of our ethical indicators, we conduct an analysis to predict sanction actions after 2016 using review data before 2015. The results show that the model achieves an out-of-sample AUC of 0.90 for sanctions after 2016 (Figure EC.2), indicating that it is effective at predicting future sanctions. The XGBoost model shows the highest accuracy. Figure 4(b) reveals that improper prescribing of controlled substances is again one of the most important factors for predicting future sanctions after 2016. Figure 5(b) illustrates a physician with reviews complaining about sexual misconduct, which significantly increases their sanctioned log-odds. Together, the SHAP plots point to the importance of addressing the issue of improper prescribing of controlled substances (IPCS) and the effectiveness of our model in identifying and capturing such trends. Additionally, reviews related to sexual misconduct (SAP), and fraud or improper billing practices (FIBP), are also associated with a higher likelihood of future sanction.
The heightened importance of IPCS in predicting future sanctions aligns with the increased scrutiny during the ongoing opioid crisis. The widespread abuse of prescription opioids has led to stricter regulations and oversight of prescription practices (Barre et al., 2019; DuBois et al. 2016). This increased focus on preventing prescription drug abuse and improving patient safety (Degenhardt et al., 2019; Rutkow et al., 2015) may result in more severe penalties for physicians who engage in inappropriate prescription practices, such as prescribing outside the scope of professional practice, failing to properly monitor patients for signs of addiction, or prescribing excessive amounts of controlled substances.
Prediction of Future Injuries and Professional Liability
We utilize Florida's Professional Liability Tracking Database to demonstrate how ethical indicators can predict specific consequences of unethical behaviors in healthcare, including psychological, physical, legal, and financial outcomes. We select medical malpractice claims submitted after 2016 to evaluate the predictability of our ethical indicators generated from patient reviews before 2015. Using a multinomial logistic regression model, we examine the relationship between the type of injury (categorized as emotional only, temporary, or permanent) and these ethical indicators. The results in Table 5 reveal significant correlations between ethical indicators and specific injury types. The sexual misconduct indicator (SAP) substantially increases the likelihood of emotional-only injuries, with an odds ratio of 2.35. The unnecessary invasive procedures (UIP) indicator also shows a large effect, increasing the odds of such injuries by over 50%. In contrast, the negative care indicator (NEC) demonstrates a stronger association with physical injuries: it increases the odds of temporary injuries by 63% and permanent injuries by 25%. These findings highlight the predictive specificity of our ethical indicators. For example, while sexual misconduct is more strongly associated with emotional harm, negative care incidents (as indicated by reports of pain and suffering) are more likely to predict future physical injuries.
Ethical indicators and injury types from Florida Claims Data after 2016.
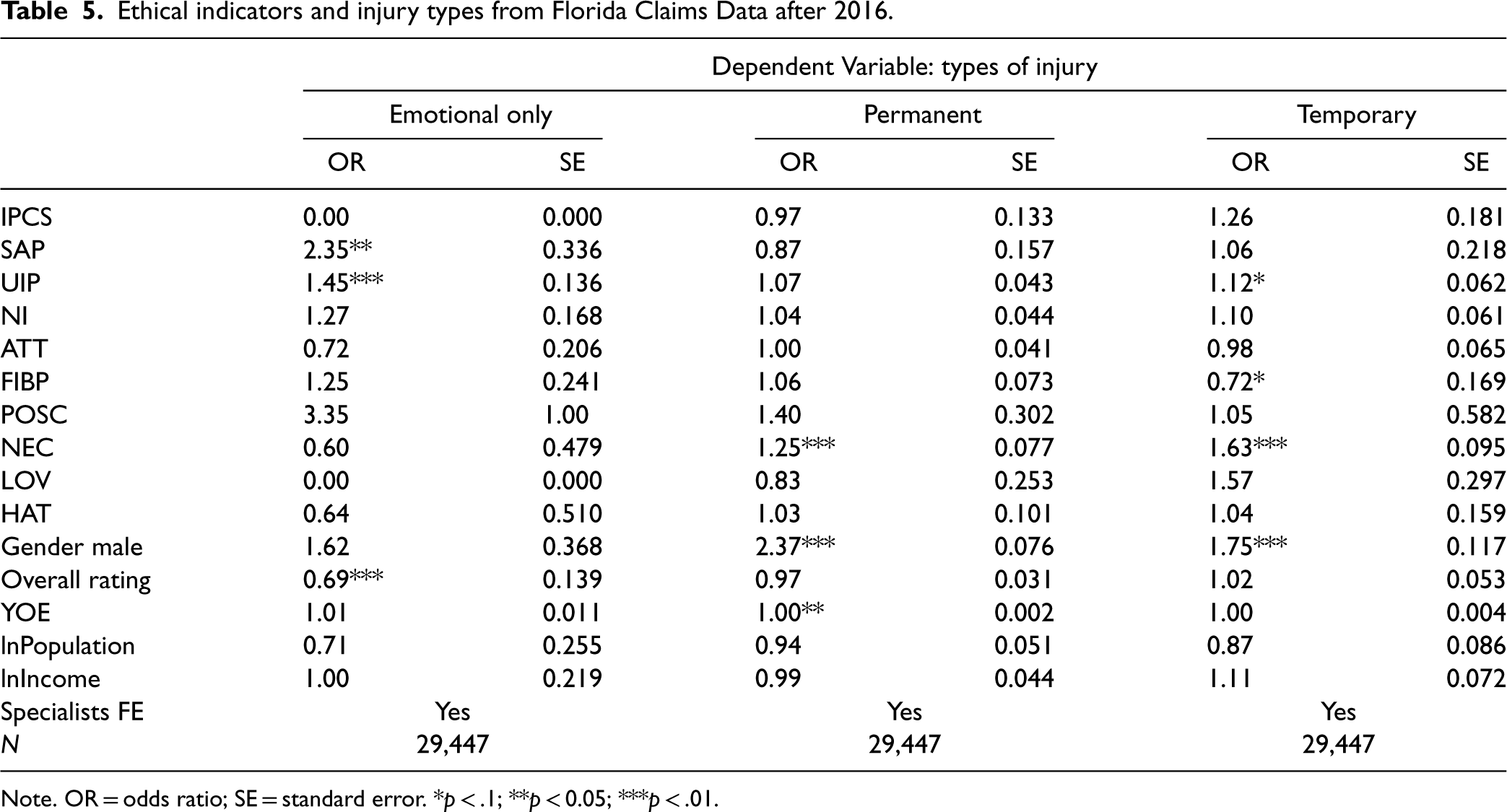
Ethical indicators and injury types from Florida Claims Data after 2016.
Note. OR = odds ratio; SE = standard error. *p < .1; **p < 0.05; ***p < .01.
We further examine the relationship between ethical indicators and indemnity payments using ln(Indemnity) (Table 6). We find that most indicators, particularly improper prescription of controlled substances (IPCS) and negative care (NEC), significantly predict indemnity amounts. When all ethical indicators are included in the same model, the negative care (NEC) and neglect and incompetence (NI) indicators remain significant predictors, with coefficients indicating 78% and 17% increases in the amount paid, respectively.
Ethical indicators and indemnity payment amount from Florida Claims Data after 2016.
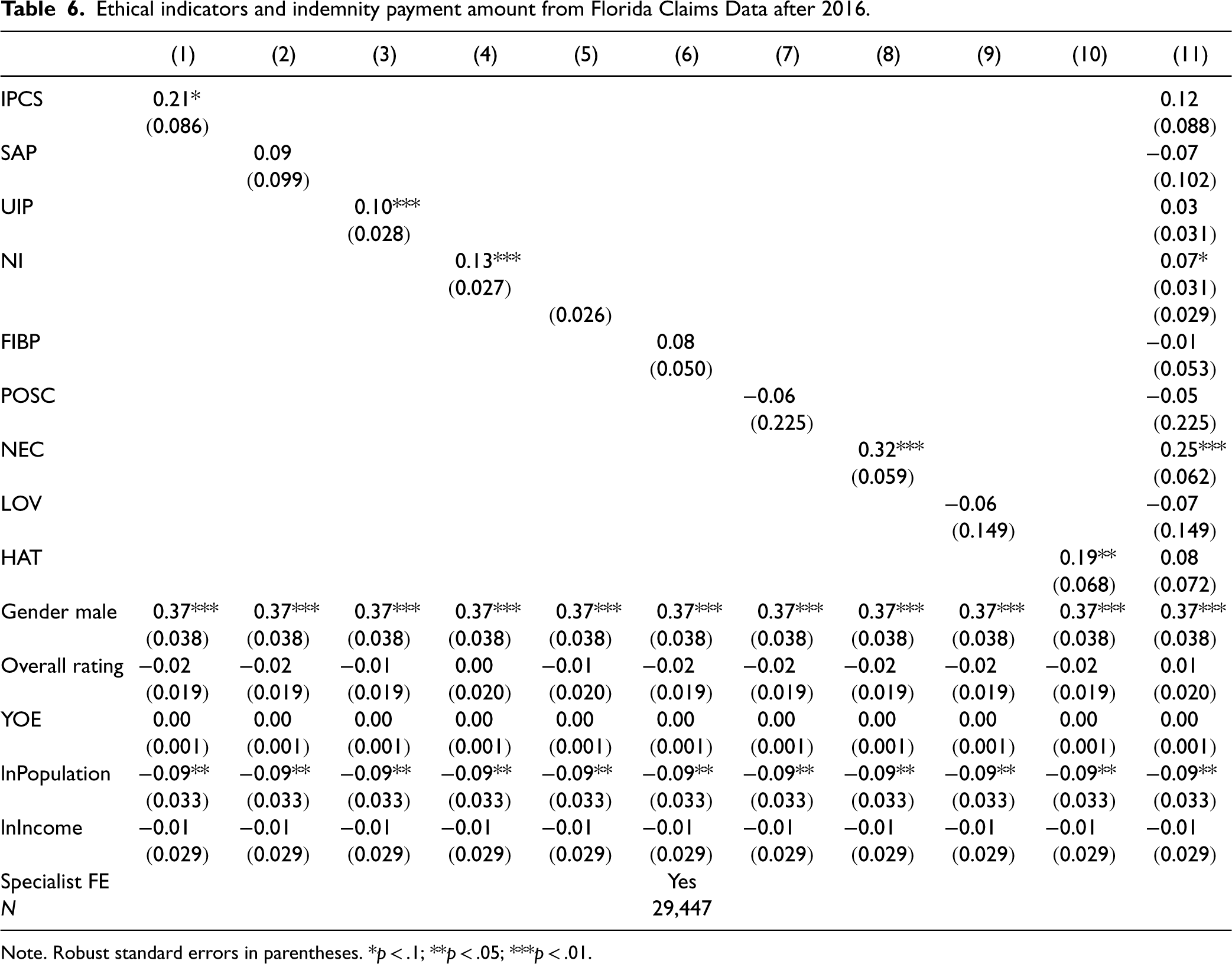
Note. Robust standard errors in parentheses. *p < .1; **p < .05; ***p < .01.
To examine the relationship between physician rent-seeking behaviors and ethical indicators, we conduct two regression analyses. The first analysis employs an OLS regression model with payment-prescription sensitivity as the dependent variable. The second analysis uses logistic regression, where the dependent variable is an indicator for physicians with a sensitivity above the sample median (0.315). 9 The empirical results in Table 7 present a clear pattern: Indicators for improper prescription of controlled substances (IPCS) and fraudulent billing practices (FIBP) show significant associations with the dependent variables in both models, suggesting reviews about these behaviors correlate with higher payment-prescription sensitivity. Unnecessary invasive procedures (UIP) are significant in the OLS model, implying that physicians who perform more of these procedures may also exhibit rent-seeking behaviors. The significant coefficients of IPCS, FIBP, and UIP affirm the validity of the indicators as financial incentives from pharmaceutical companies are likely to influence these behaviors. In contrast, the effects of other indicators such as sexual abuse of patients (SAP) and attitudinal or communication unprofessionalism (ATT) are not significant.
Ethical indicators and rent-seeking behaviors.
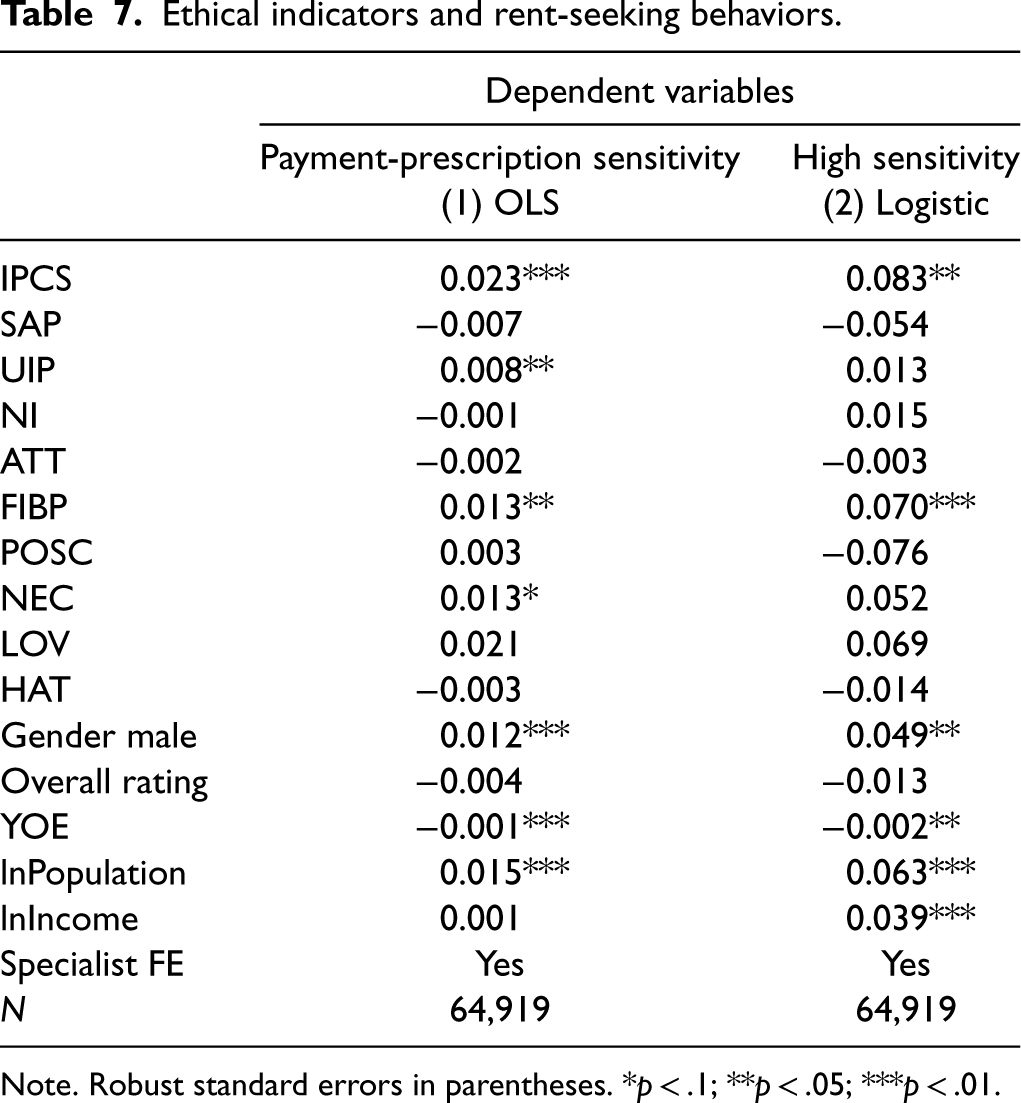
Ethical indicators and rent-seeking behaviors.
Note. Robust standard errors in parentheses. *p < .1; **p < .05; ***p < .01.
We next compare several prediction models using the payment-prescription sensitivity as the target variable. Table EC.14 demonstrates comparable performance among the models, with XGBoost showing a slight advantage. The out-of-sample R2s of the models are relatively low, with the highest equal to 0.119. This indicates that subtler individual behaviors are more difficult to predict using online review data. The SHAP plot (Figure EC.4) highlights the influence of various features in the XGBoost model. Interestingly, while the more direct indicators like UIP, IPCS, and FIBP are, as expected, strong predictors due to their financial implications, nonfinancial indicators such as ATT (attitudinal or communication unprofessionalism) and HAT (hate) are also important. This finding suggests that, when predicting rent-seeking behaviors, the model benefits from a broader spectrum of indicators.
We employ the 2018 CMS MIPS quality score to evaluate the ethical indicators’ association with provider quality. Again, we employ both an OLS and logistic regression, where the latter predicts physicians with quality scores above 90%. Our analyses reveal that most ethical indicators significantly predict future clinical quality, as detailed in Table 8. Notably, indicators for unnecessary invasive procedures (UIP) and fraud and improper billing practices (FIBP) correspond to the largest decreases in quality scores, reducing them by 0.90% and 0.88% respectively out of a total 100%. Additionally, overall rating scores (1–5) are also significant predictors, with each additional rating point correlating to a 1% increase in the MIPS quality score. However, emotivism indicators show no significant association with the MIPS quality score. The lack of correlation between emotive measures from patient reviews and MIPS quality scores likely stems from the subjective nature of these indicators, which often focus more on personal experiences and perceptions than on measurable clinical quality.
Ethical indicators and CMS MIPS quality measure.
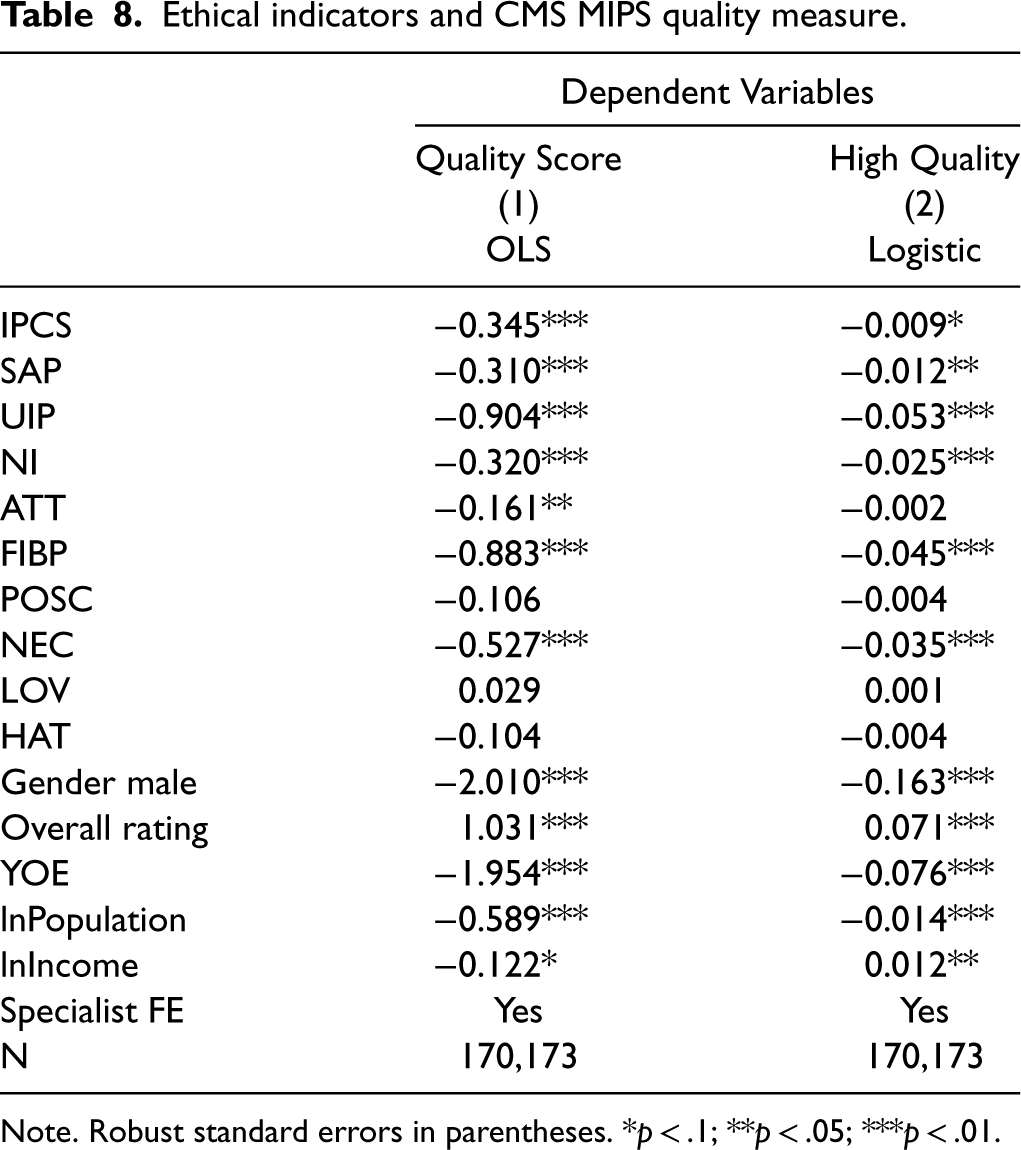
Ethical indicators and CMS MIPS quality measure.
Note. Robust standard errors in parentheses. *p < .1; **p < .05; ***p < .01.
Furthermore, we investigate whether the quality score in 2018 could predict future sanction post-2018. The analysis yields a ROC AUC of 0.55 (Figure EC.5), which is only marginally better than a random guess (0.5). This suggests that, while our ethical indicators can predict the physician's quality, relying solely on quality scores is insufficient in forecasting future medical misconduct.
In summary, our ethical indicators demonstrate strong predictive power across a wide range of external validations, as summarized in Table 9. Collectively, these findings attest to the robustness and versatility of our approach.
Summary of external validations and prediction performances.
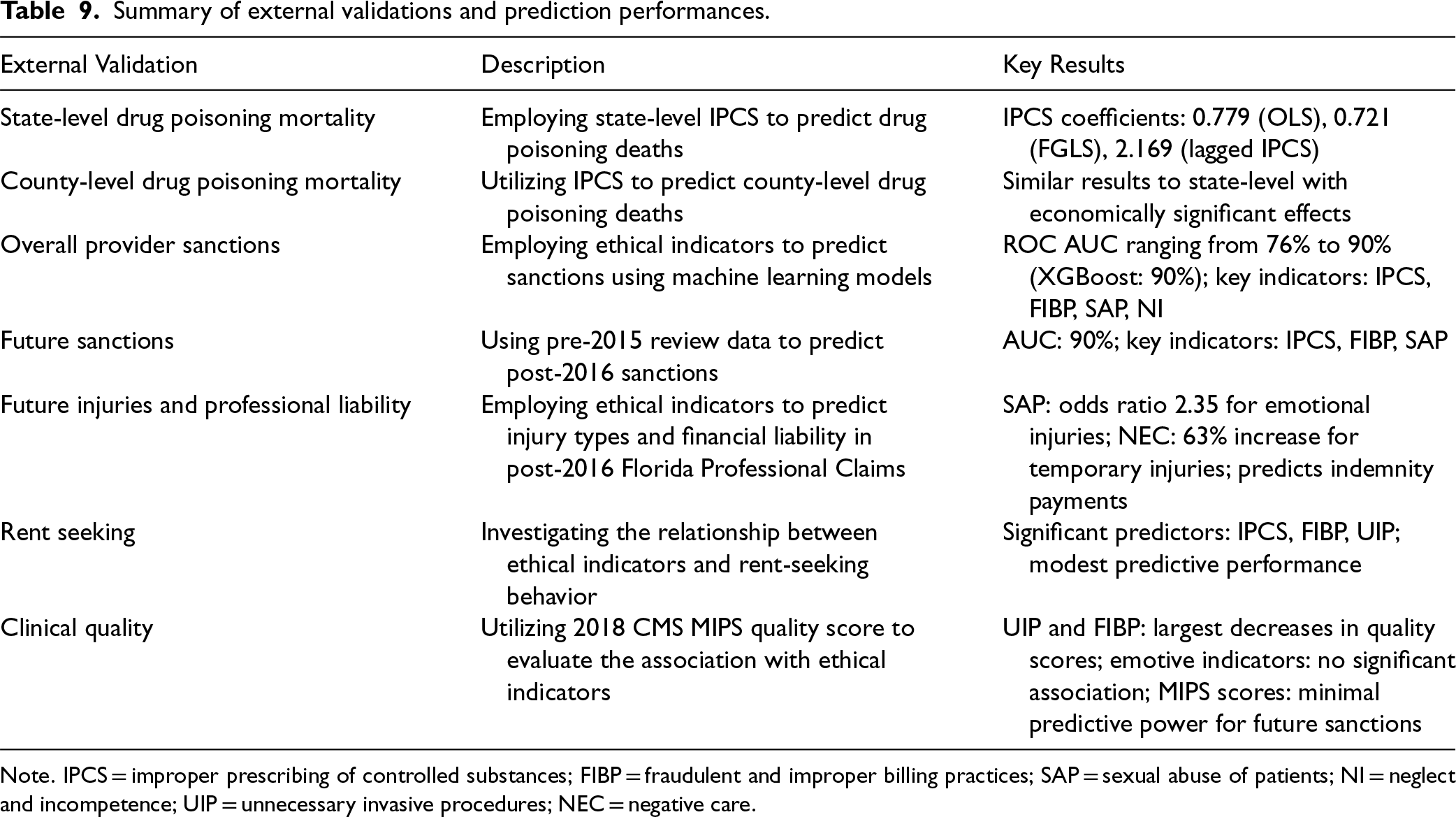
Note. IPCS = improper prescribing of controlled substances; FIBP = fraudulent and improper billing practices; SAP = sexual abuse of patients; NI = neglect and incompetence; UIP = unnecessary invasive procedures; NEC = negative care.
We conduct five robustness tests. First, to ensure that unmatched NPI data does not skew our model's performance, we implement a propensity score trimming approach. We train a logistic regression classifier to predict the likelihood of missing NPI and generate propensity scores for each physician. By sorting matched physicians by these scores and removing the bottom 10%, that is, physicians who are least likely to have missing NPI, this approach yields comparable characteristics between “trimmed matched” and unmatched groups. The model trained on the trimmed matched set exhibits negligible performance differences compared to the models trained on the entire matched set. Second, we evaluate the sanction prediction model's performance across different states using state-specific review data. This allows us to assess if the influence of diverse state-specific factors such as regulatory, cultural, societal, and demographic factors impact model training and prediction. We find that the model has relatively satisfactory performance despite geographic variations. Third, we stratify the sanction prediction model by the number of reviews a physician receives and find consistent performance across different review count categories. The model shows a decline in precision for physicians with only one review. Still, the model's ability to correctly rule out sanctions (TNR) and identify true instances of sanctions (TPR) remains relatively stable. Fourth, we show our sanction model strikes a balance between precision (avoiding false positives) in the very high-risk group, recall (identifying true positive cases) in high and medium-risk groups, and specificity/TNR (correctly identifying true negative cases) in the low-risk group. Fifth and finally, we assess the impact of training data size on model accuracy. We find consistent performance across different subsets, even with as little as 25% of the review data. Precision appears to be most sensitive to the amount of training data used. The details of the tests are reported in Section EC.2.
Discussion and Conclusion
Implications for Literature
Our research aims to identify potential medical ethics violations by considering patient reviews as a primary source of information. Based on a comprehensive review of the literature, we develop a set of ethical indicators grounded on three ethics theories. To support our analyses, we merge data from multiple sources, including patient reviews, physician sanction data, financial relationships with pharmaceutical companies, drug poisoning mortality, malpractice claims, as well as national quality measures. We design and validate a machine learning framework capable of predicting state and county-level poisoning mortality, physician sanction status, malpractice injury payments, payment-prescription sensitivity, and clinical quality.
Our results provide compelling evidence for the power of patient-generated content in identifying ethical risks. Our findings add to the ongoing debate in the literature regarding the value of online reviews in healthcare. By demonstrating that textual content from patient reviews contains valuable information beyond star ratings, our work suggests that these reviews can serve as an early warning system for ethical breaches, thereby broadening their utility in operations management.
Moreover, our analysis sheds light on the relative importance of different ethical theories in identifying unethical behavior in healthcare. The SHAP analysis (Figure 4) and regression models (Tables 5 to 8) consistently reveal that deontological indicators are the strongest predictors of various outcomes. The insight contributes to the ongoing discourse in the ethics literature about the practical applicability of different ethical frameworks in professional settings (Beauchamp, 2003; Mandal et al., 2016), offering support for the high relevance of duty-based ethical considerations. In contrast, we show that emotivism has the least predictive power. This finding diverges from previous social media research, which often suggests emotions as a key factor in shaping behavior. Our results also underscore the multifaceted nature of ethical risks. The model's ability to predict a range of outcomes highlights the interconnectedness of different types of ethical violations. Relatedly, the results imply that ethical lapses in one area may be indicative of broader behavioral patterns, a perspective that has been underexplored in the literature.
Furthermore, our findings have implications for the literature on professional compliance and regulation. The ability to predict ethical violations using patient-generated content suggests a potential shift in the dynamics of professional oversight. It indicates that patients, through their collective feedback, can play a more significant role in identifying misconduct. Their voice can complement traditional regulatory mechanisms. This opens up new avenues for research on the role of patient feedback in professional governance.
Managerial and Policy Implications
From a risk management perspective, preventing medical malpractices and unethical physician behavior is less costly, both economically and socially, than addressing their aftermath. While our model relies on reviews written after incidents occur, it enables faster detection of patterns compared to many traditional regulatory mechanisms, which often lag significantly behind violations. Unethical behaviors rarely occur in isolation—early identification through patient reviews can help detect concerning patterns before they escalate into more serious violations or harm additional patients. To this end, our model provides a foundation for early warning and prevention systems for such adverse incidents. The economic implications could be significant. Take malpractice for example, over the period of 2010 to 2019, $42 billion was paid to victims of medical malpractice in the USA (Justpoint, 2021), with the average settlement amount ranging from $425,000 to $1 million (Medscape, 2013). Another example is the opioid crisis which is in part due to unethical prescription practices. The economic cost of opioid use disorder was estimated to be $471 billion in the USA (Luo, 2021). Early-prevention systems can identify practitioners at risk of malpractice, allowing for more proactive strategies and avoiding costly legal and financial consequences. When integrated with complaint records and internal reports, the system becomes invaluable in risk management and resource allocation. For example, it enables hospitals to direct resources towards areas with higher risks of ethical violations or invest in training programs aimed at preventing such issues.
Likewise, our approach leads to management strategies that can reduce the impact of unethical practices. The strategies can work through three avenues. First, early detection of ethical lapses can not only mitigate their negative impacts but also enhances patient trust and satisfaction, ultimately leading to cost reductions. Policymakers can incentivize the adoption of such models through grants or recognition programs for institutions that actively contribute to model development or maintenance of review platforms. Second, drawing from the economic theory of crime (Becker, 1968), it is important to communicate to providers the concrete benefits of ethical compliance and the repercussions of violations. More targeted educational campaigns or mandatory training programs can be informed by a predictive model's findings. Lastly, our approach serves as a promising tool for empowering victims of unethical practices, which often remain underreported due to power dynamics or fear of reprisal (Roland et al., 2011). Policymakers can promote the use of online review platforms as legitimate channels for patient feedback while ensuring that these platforms are safeguarded against retaliation. Given the importance of deontological indicators, these platforms could prompt patients to share specific instances of adherence or violations of code of ethics. Integrating this data into healthcare oversight mechanisms increases visibility and scrutiny of violations. This could catalyze a shift towards improved compliance and stronger patient advocacy.
Generalizability to Other Sectors
Professional services, such as law, education, management consulting, and banking, are vital to modern societies and economies. Like healthcare, these fields involve high levels of customer contact and delivery specificity, where each case or problem is unique; they are also characterized by fluid operational processes, where professionals exercise judgment in determining outcomes and means (Harvey et al., 2016). Given the similarities in the nature of these services and the importance of ethical conduct across all professional domains, it is natural to consider the broader applicability of our approach: can our approach be extended to these other professional services sectors?
On the one hand, the lenses of different ethics theories can still be relevant in other sectors. For example, consider the case of the FTX scandal in finance (Oliver, 2023): it is reported that Sam Bankman-Fried claimed a utilitarian viewpoint: “the only moral rule that mattered was doing whatever would maximise utility”—which clearly clashed with deontological principles and led to grave consequences. Second, the design pattern of our approach can serve as a strong foundation, being grounded in theory, mining specific indicators from large corpora, and using them as features for downstream models. On the other hand, understanding the contextual details of different sectors is crucial (Joglekar et al., 2016). Other sectors take feedback through different channels, such as client surveys or complaint registries (e.g., the CFPB). Integrating feedback from diverse sources requires additional attention. Moreover, the ethical perspectives pertinent to different professions may vary. For instance, in law, ethical indicators might emphasize fairness in representation and confidentiality, while in banking, the focus could shift to transparency and fiduciary responsibilities. Finally, careful validation should be conducted in other sectors. For instance, in legal services, validation might involve disciplinary actions from bar associations, while in financial services, it could include reports from regulatory authorities such as the SEC. In sum, extending our approach to other sectors holds promise, but will likely require adaptations to their ethical requirements, feedback mechanisms, and relevant validations.
Limitations and Future Research
Our study has several limitations. First, the model developed in this research is based on reviews from a specific time period in the USA. As social media discussions evolve, the model may need updating to maintain relevance. Furthermore, our sample may not be representative of the broader patient population due to the digital divide, potentially underrepresenting less technologically savvy groups (Hao, 2015). Additionally, while our method focuses on discovering more negative aspects from reviews, which partly mitigates the issue of fake reviews, we cannot validate the authenticity of every review. Despite this, our approach is also applicable to reviews from authenticated sources like insurers and providers, and future research may explore additional validation techniques through automated algorithms or cross-referencing with other data sources. Second, although the active search strategy can handle skewed class distributions, it may miss rarer yet important ethical violations. In this vein, our approach could benefit from more granular, domain-specific theories, especially on how utilitarianism and emotivism principles are applicable in guiding patient–provider interactions. Additionally, information retrieval methods enhanced with domain knowledge may be considered (Tamine and Goeuriot, 2021). Third and most important, it is imperative to acknowledge the limitations and risks of our ethical indicators and predictive models. Drawing from Harcourt's (2007) critique of actuarial methods in criminal law, several cautions apply to our work. For one, merely predicting unethical behavior may not reduce such behavior—predictions require appropriate regulations and enforcement mechanisms to drive meaningful change. For another, the use of machine learning models in the field of ethics has raised complex questions about the role of technical knowledge in shaping justice, an issue that has garnered increasing attention in the broader scientific community (Christian, 2020) but out of the scope of this paper.
Despite these limitations, our work represents a meaningful proof-of-concept in discovering ethical violations and mitigating their societal costs. Future studies that aim to confirm and build on our findings may incorporate other forms of text data, such as interviews with providers, patient surveys, or expand to ethical violations of other forms. When applied responsibly, research in this area has the power to significantly improve patient outcomes, prevent harm, and increase public trust in the healthcare system.
Supplemental Material
sj-docx-1-pao-10.1177_10591478251318885 - Supplemental material for Analyzing Professional Ethics of Physicians Using Online Patient Reviews: A Machine Learning Approach
Supplemental material, sj-docx-1-pao-10.1177_10591478251318885 for Analyzing Professional Ethics of Physicians Using Online Patient Reviews: A Machine Learning Approach by Kanix Wang, Feng Mai, Zhe Shan, Dawei (David) Zhang and Xiaosong (David) Peng in Production and Operations Management
Footnotes
Acknowledgments
The authors are grateful to the Special Issue editors, the senior editor, and anonymous reviewers for their constructive comments. They also extend thanks to the participants of the 2020 Conference on Health IT & Analytics (CHITA 2020) for the valuable feedback received.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Notes
How to cite this article
Wang K, Mai F, Shan Z, Zhang D and Peng X (2025) Analyzing Professional Ethics of Physicians Using Online Patient Reviews: A Machine Learning Approach. Production and Operations Management xx(x): 1–22.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.