
Abstract
Understanding the world involves extracting the regularities that define the interaction of the behaving organism within this world, and computing the statistical structure characterizing these regularities. This can be based on contingencies of phenomena at various scales ranging from correlations between sensory signals (e.g., motor-proprioceptive loops) to high-level conceptual links (e.g., vocabulary grounding). Multiple cortical areas contain neurons whose receptive fields are tuned for signals co-occurring in multiple modalities. Moreover, the hierarchical organization of the cortex, described within the Convergence Divergence Zone framework, defines an ideal architecture to extract and make use of contingency at increasing levels of complexity. We present an artificial neural network model of the early cortical amodal computations, which we have demonstrated on the humanoid robot iCub. This model explains and predicts findings in neurophysiology and neuropsychology along with being an efficient tool to control the robot. In particular, through exploratory use of the body, the system learns a form of body schema in terms of specific modalities (e.g., arm proprioception, gaze proprioception, vision) and their multimodal contingencies. Once multimodal contingencies have been learned, the system is capable of generating and exploiting internal representations or mental images based on inputs in one of these multiple dimensions. The system thus provides insight on a possible neural substrate for mental imagery within the context of multimodal convergence.
1 Introduction
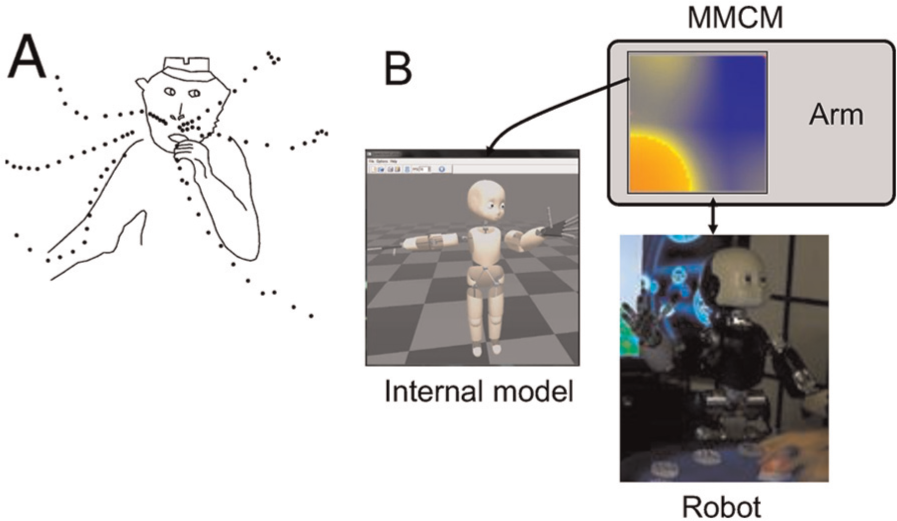
In order to operate successfully in the world, a behaving animal should master its sensorimotor system (i.e., its own physical plant, kinematics, dynamics etc.) and its interaction capabilities in the surrounding world. This can be considered to correspond to Ulrich Neisser’s characterization of the ecological self (Neisser, 1997). We argue that in higher mammals the connectivity of the cerebral cortex provides the substrate for constructing such representations. The cerebral cortex is composed of interconnected areas (Brodmann, 1909; Felleman & Van Essen, 1991), which can be considered a multi-layered sheet-like layout of neurons. It is traditionally considered that the cortex forms a hierarchy, with the sensory areas communicating with thalamus at the bottom and the zones responsible for amodal and complex cognitive functions being higher in the hierarchy. Although the cortex is clearly not a hierarchy in the strict mathematical sense (Ercsey-Ravasz & Toroczkai, 2010; Markov et al., 2010; Vezoli et al., 2010), there is a hierarchical flavour in its global organization. Areas close to the sensory periphery merge into amodal zones, which provide feedback downstream and continue to merge to compute even more amodal representations higher in the stream. This functional framework has been characterized in the idea of Convergence Divergence Zones (CDZ; Damasio & Damasio, 1994). In a nutshell, this theory holds that particular cortical areas could act as pools of pointers to other areas, therefore linking several cortical networks together. These zones would be responsible for linking together representations of various sensory modalities belonging to the same concept. A concrete example is that seeing a photo of a very dirty and wet dog could give you a sensation of its smell. The olfactive representation of the odour associated with the dog in the picture could be activated because those two modalities (olfactive and visual) are linked in some high-level conceptual convergence zone. Of course, this example is an oversimplification and CDZs are dealing with much more distributed and functional linking of concepts. However, the main idea underlying the convergence theory is present: CDZs merge networks of lower-level cortical areas into higher-level amodal constructs and in this way solve the binding problem by allowing the extraction of units and regularities from the complex and not segmented raw sensor information. Along with the feedforward convergent stream, the divergent feedback process is also important. As Meyer and Damasio (2009) emphasize, it is likely that the ‘grandmother neuron’ does not exist. Instead, there is a neuron high in the hierarchy, which becomes activated by a whole cascade of lower areas inputs (convergence) and in return activates all those areas, which finally triggers a pattern on the early sensory maps (divergence). The mental imagery of a concept would therefore be the result of a sensory area’s activity, induced by the cascade of feedback signals coming from an amodal representation high in the hierarchy. Evidence of this bidirectional stream is found in many cases of illusions or disabled patients’ symptoms, and they involve every sense (Meyer & Damasio, 2009). In the end, the CDZ framework appears to be a generic potential explanation of cortical computations that is formalized enough to be modelled and tested. Despite the apparent power of this theory, it has not being intensely investigated for application to artificial cognition, in either robots or agents. Moll and Miikkulainen (Moll, Miikulainen, & Abbey, 1994; Moll & Miikkulainen, 1997) used the CDV framework as the basis for a neuromimetic model of episodic memory, which, however, lacks the topographical organization property that the cortex beholds. In the current research, we propose a simple yet powerful implementation of the CDZ framework based on self-organizing maps [SOMs (Kohonen, 1990), which we call Multi-Modal Convergence Maps (MMCMs)]. We demonstrate how MMCM has been successfully applied to encode the sensorimotor experience of a robot and how in return this knowledge has been used to control the robot behaviour. Five levels of amodality will be presented through specific experiments, namely the encoding of motor primitives, building of peripersonal space, motor imagery of the self-body, mental imagery from language input, and visual-proprioceptive interaction. As much as possible, we ground these robotic experiments with similar neurophysiology studies that have been conducted in the monkey in order to discuss the CDZ and MMCM as plausible models of the aspects of cortical computations.
2 Multi-modal convergence maps: the model
The CDZ Framework (Damasio, 1989; Damasio & Damasio, 1994) makes use of a standard and generic computational mechanism within the cortex: integration of multiple modalities within a single area. From this integration derives a memory capability allowing multimodal traces to be recalled using a partial cue (unimodal stimulation for example). The original model formalization was performed by Moll and Miikkulainen (1997) and is quite similar to Minerva2 (Hintzman, 1984), apart the fact that the former uses a neural network while Minerva2 uses ‘brute force’ storage of all the episodic traces. Both models enter the category of Mixture of Experts models (Jacobs, Jordan, Nowlan, & Hinton, 1991; Jordan & Jacobs, 1994) in which a pool of computational units (experts) are trained to respond to specific input patterns. When a partial or noisy input signal is presented, all the experts examine it and respond with their level of confidence (activation) about this input being their own pattern (receptive field) or not. By a linear combination of their responses and their specific pattern, the missing or wrong information can be filled in. Another model that can be considered a special type of Mixture of Experts is the SOM from Kohonen (1990). While the formalisms are different, the core principle is the same: a pool of neurons is trained so that each of them tunes its receptive field (prototypical vector) in order to be mostly activated by a specific input vector. An interesting characteristic of SOMs is that they provide a model of the organization of cortical connectivity, which through learning induces a topographical mapping between the input vector and the neural map. As a result of this spatial topography, two similar inputs will produce two similar map activations. The MMCM model described applies the SOM learning algorithm to model the CDZ framework.
2.1 Formalize multi-modality
The convergence zone principle is to store references to multiple lower-level activity patterns in one place. It can be seen as a sort of hub, a map of pointers or more generally as an associative memory. The input patterns are divided into multiple independent units (vectors or maps) depending on the modality they represent, which is something the standard SOM does not take into account. The initial convergence zone model (Moll & Miikkulainen, 1997) lacks the self-organizing and topographical property inherent to cortical maps. The MMCMs are designed to cope with both of these requirements in a unified model merging the SOM and convergence-divergence zone principles. In a nutshell, it can be seen as an SOM using multiple modalities, each of whose contribution to the network activity can be tuned. A schematic overview of a simple MMCM is presented in Figure 1, which describes in a simplified way the flow of information through the network.
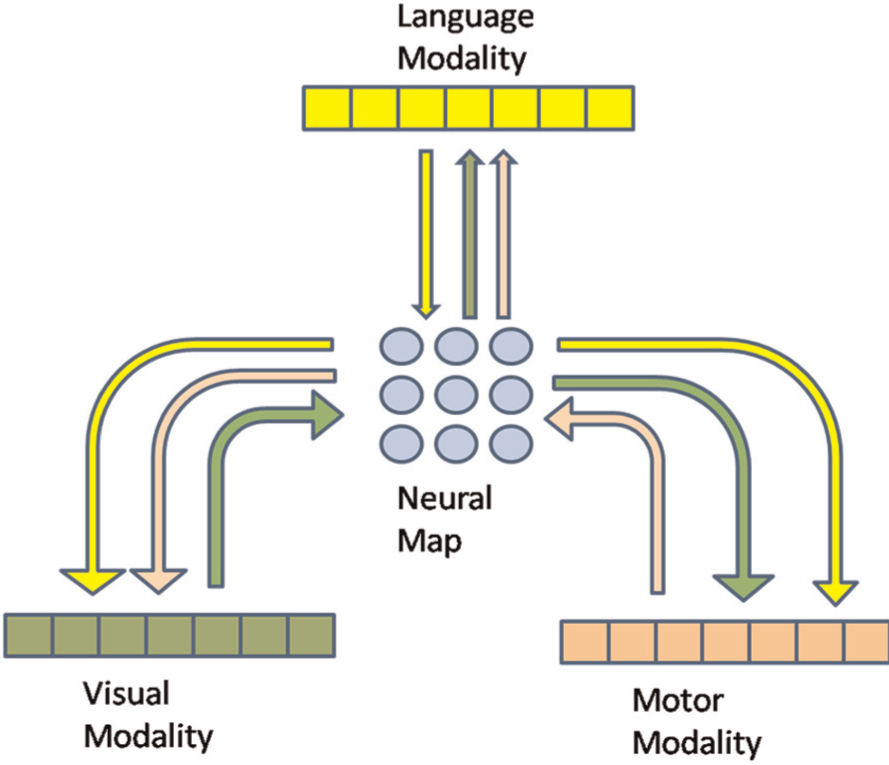
Schematic representation of a Multi-Modal Convergence Map (MMCM) linking three modalities. Each modality is assigned a colour, the arrows of the respective colours represent the possible interaction between modalities created by the convergence map.
Each modality is taken into account during the map activity calculation according to Equations 1 and 2, with Pim being the ith component of the input vector perceived by modality m and Im the influence factor of the modality m. The modality influence is a number in [0,1], which represents how much a modality contributes to the map activity, in comparison with the others. In our implementation, the ‘map’ is in fact a cube and neurons are distributed along three dimensions, which means that Axyz represents the activity of the (x,y) neuron of the layer z. This third dimension is inspired by the three-dimensional structure of cortex, the third dimension of the cortical map corresponding to the laminar structure (Brodmann, 1909). The idea is that cortex is a 3D object. Two dimensions define the cortical sheet, and the third dimension is tangential to the sheet, corresponding to the layered structure. While this has not been extensively examined, we can consider that adding a dimension allows a higher storage capacity by providing more non-linear transformations to be represented while keeping the topographical properties of such representations.
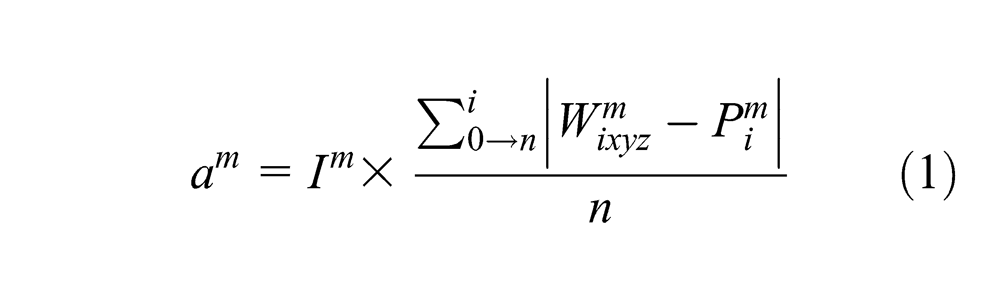
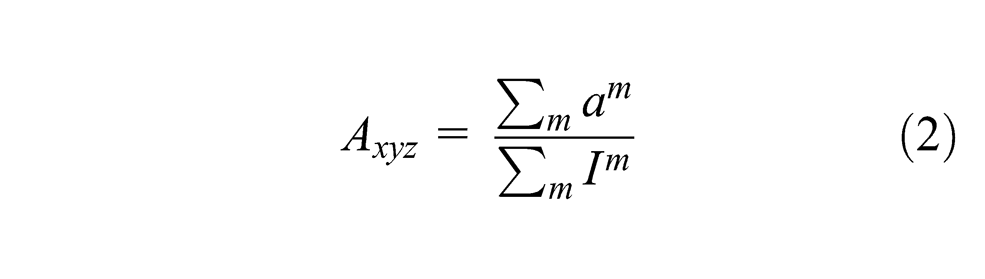
To ground the discussion in a concrete example, consider that a robot is looking at its hand, which is changing postures, and listening to an observer say the names of these postures (i.e., rock, paper, scissors). If we take the map from Figure 1, at each step, three vectors are obtained from the robot sensors: the image (visual modality), the joint encoders (motor modality, similar to proprioception) and the words recognized by the spoken interaction (language modality). All the respective modalities inputs are activated according to these vectors, and then the map activity is calculated. The most activated neuron of the map (i.e., the winner) is recorded and its weights give the prediction for each modality. If the learning mode is on, the weights of each neuron in the map are adjusted according to the Equations 3, 4 and 5.
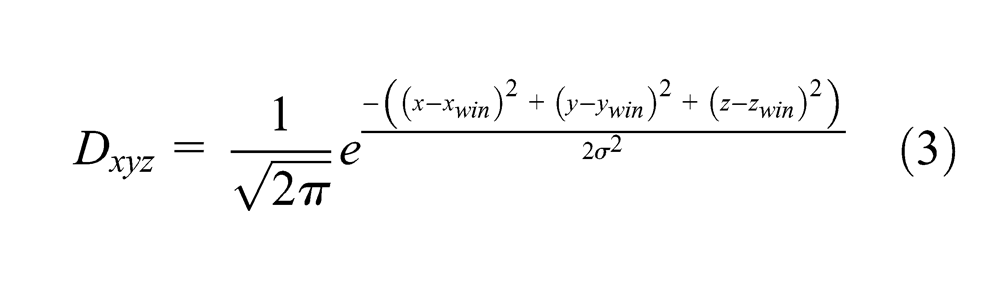
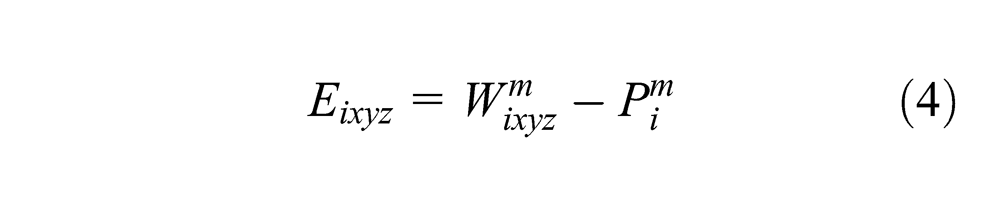
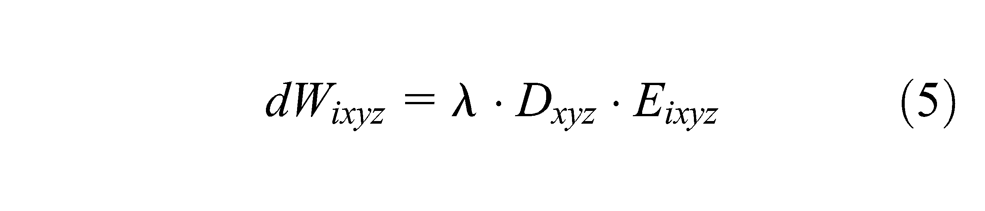
To summarize the equations, the winner weights are modified to better match all the input vectors so that next time those inputs are presented this neuron activity will be higher. The other neurons of the maps also learn with a rate depending on the distance separating them from the winner on the map.
Through learning, the receptive fields of neurons will shape the map so that different regions will encode for different contingencies of sensorimotor modalities. It means that the same part of the map will be activated by the word ‘rock’, by the proprioception and the vision of a hand closed, while two other regions of the map will encode the concepts of ‘paper’ and ‘scissor’. Neurons between those regions encode interpolation points between those concepts, allowing representation of a motor trajectory, which takes the hand smoothly from one posture to the other.
2.2 Bi-directionality allows prediction and mental imagery
Once the map has been trained, it can be used to predict the activation of one modality given the other(s). The model implementation allows changing the influences of different modalities at runtime, for example to take only the speech modality into account. The activity of the map will reflect the speech modality, but neurons also possess weights to the visual and motor modalities, which are used to predict an image and a motor command. This prediction mechanism using these influences is flexible and allows weighting the contribution of each modality to the final prediction of the system. An additional important aspect of the maps is that they encode a concept both in their connection weights, but also in terms of the position of neurons on the topography. The position of the winner neuron can be considered a 3D vector (x,y,z), which compresses the information of all the modalities connected to the map. Consider a modality that is a 300×300 image. The map will compress this image into a three-component vector that will be ready to be used as an input modality for a higher-level map. One of the strength of the CDZ framework is the hierarchical organization of maps allowing high data compression and cascaded retrieval of vivid memories. The MMCM implementation gives the possibility to link several maps together within hierarchical models, each map possessing a specific hierarchical modality that can be used both to send feedforward information and to receive feedback from higher-level areas. The communication between maps is achieved using YARP (Yet Another Robot Platform; Fitzpatrick, Metta, & Natale, 2007), which allows the possibility of running multiple maps in parallel on a cluster of computers, intrinsically solving the computational power requirements to run large hierarchies. It also provides easy interfacing with many devices like robots, Kinects and eye trackers.
2.3 Hierarchical coding
A crucial aspect of the proposed framework is that modality specific maps can be used as input to amodal, hierarchically organized maps. From a technical perspective, this type of representation is inherent to the model, as follows. In the same way that data from a sensor can be used as input to a map, the contents of another map can be vectorized and then serve as input to a hierarchical map. For example, in the experiment on vision and mental imagery below (Section 3.3), we will describe a hierarchical configuration where proprioception for the arm, torso and head, respectively, and vision are each represented first in modal maps, and these maps then are merged into an MMCM. The arm, torso and head are represented in 50×50 maps, each taking as input the robot encoders (left_arm, degrees of freedom, DoF=16; head, DoF=6 and torso, DoF=3). Vision is represented in a 50×50 map, with input coming from the iCub left eye camera. The camera input is down-sampled, grey-scaled and cropped to a fovea area and rescaled to a 15×15 matrix, which is then linearized into a 225-element vector. The four modal maps are trained, and when they become stable, their inputs to the MMCM are activated and this multimodal map is trained. The result of such a multimodal configuration is that input from one dimension can propagate to the amodal MMCM and from there back to a different dimension, thus allowing a form of cross-modal interaction whereby input in one modality (e.g., proprioception of the hand/arm) can generate a ‘mental image’ in another modality (e.g., vision of the hand in that proprioceptive posture). It is worth noting that in addition to this potent mechanism for imagery, the hierarchical coding also allows for a significant form of dimensionality reduction in coding. In this example, the sum of the input dimensions for the pure modal maps is: 16 (arm)+6 (head)+3 (torso)+15×15 (vision)=250. The amodal map is connected to those maps using their hierarchical modalities (which is a vector of three component) so four sub-maps×3=12. Thus there is a form of dimensionality reduction from 250 to 12.
3 Experiments
This section will focus on applying the MMCM model to the early cognition of a humanoid robot, the iCub, on various levels of complexity. The iCub platform (Metta, Sandini, Vernon, Natale, & Nori, 2008) provides 53 DoF that we can both sense (proprioception) and control (motor commands). Those DoF include two arms and hands with fingers, a torso a head and two coupled eyes. Each eye mounts a 640×480 RGB camera that we can use to retrieve the vision modality. The arms are covered with skin, which can detect contact as an array of tactile sensors therefore allowing the use of the tactile sense in addition to all the modalities already mentioned.
3.1 Experiment 1 – encoding motor primitives
The first level of the perception action loop requires only the ability to feel a limb and to move that limb, namely proprioception and motor control. Both of those signals pass via the thalamus and project to the motor cortex, which has been demonstrated to be organized in a somatotopic representation of the body (the homunculus). Graziano, Taylor, Moore, and Cooke (2002b) investigated the nature of information encoded by neurons of the motor cortex in the monkey, and demonstrated that a long-lasting (500 ms) stimulation of specific regions of the cortex evoked specific postures of one or more body part. Stimulation in such zones resulted in smooth trajectories that took the arm to a given location in space, independently of the initial posture of the arm. This is illustrated in Figure 2A. In this sense, the motor cortex can be seen as a map-like collection of body postures whose stimulation leads to an appropriate sequence of motor commands resulting in the monkey finally adopting this posture.
Motor primitive encoding. (A) Trajectories of arm movements in the monkey evoked by stimulation of the ‘mouth’ area in motor cortex, independent of the initial starting position. Reproduced with kind permission from Elsevier (Graziano, 2002a). (B) Schematic of robot iCub with joint proprioception connected to the Multi-Modal Convergence Map (MMCM), and a visualization of the internal model.
As a first experiment with the robot, we used an MMCM with a single modality, the proprioception/motor synergy of the left arm. We considered that the input to the map was the encoders-proprioceptive signal, while the prediction of the map was the motor command sent to the motors, represented as a Cartesian position in the robot’s workspace. For ease of understanding, the map was trained using a set of four different postures, offline. However, we obtained similar results and more complicated map landscapes by performing online learning during continuous motor babbling. The results of the training are shown on Figure 2, which demonstrates that the map converged to represent the input space. Every trained posture is stored in one corner and every neuron of the map represents a linear interpolation between those four postures.
The MMCM software allows us to apply external stimulations to a map, therefore simulating in vivo electrodes, which drag the map activity in direction of the stimulated neuron. Activation of the map both by the proprioceptive input and by an electrode ends in a sequence of motor commands starting from the initial posture to the stimulated one. Such a stimulation in the robot produces the same behaviour as the observed in the cortical stimulations performed in the monkey by Graziano et al. (Graziano & Aflalo, 2007; Graziano et al., 2002b), i.e., a non-jerky motion between the current posture and the one encoded by the stimulated region. On the robot, two mechanisms guarantee the smoothness of the commanded trajectory. First, the motor commands take the form a sequence of the receptive fields of the neurons composing the trajectory on the map (illustrated in Figure 3), as the topographical organization of the map assures us that two neighbouring elements of this sequence will be similar. At a lower level, the motor control of joint-space commands in the robot is achieved using PID controllers that calculate a smooth interpolation between two joint positions. Those controllers can be compared with the spinal cord and central pattern generator (CPG) mechanisms in biological beings. After learning, the map provides a compact way to store body posture for the robot and acts as a tool to command it by external stimulation. However, while in this case the stimulation was manual, it can easily be replaced by a feedback input coming from another map higher in the hierarchy. This is the case in the next experiment, which demonstrates how to build peripersonal space representation by using a collection of postural maps linked through a high-level amodal convergence zone.
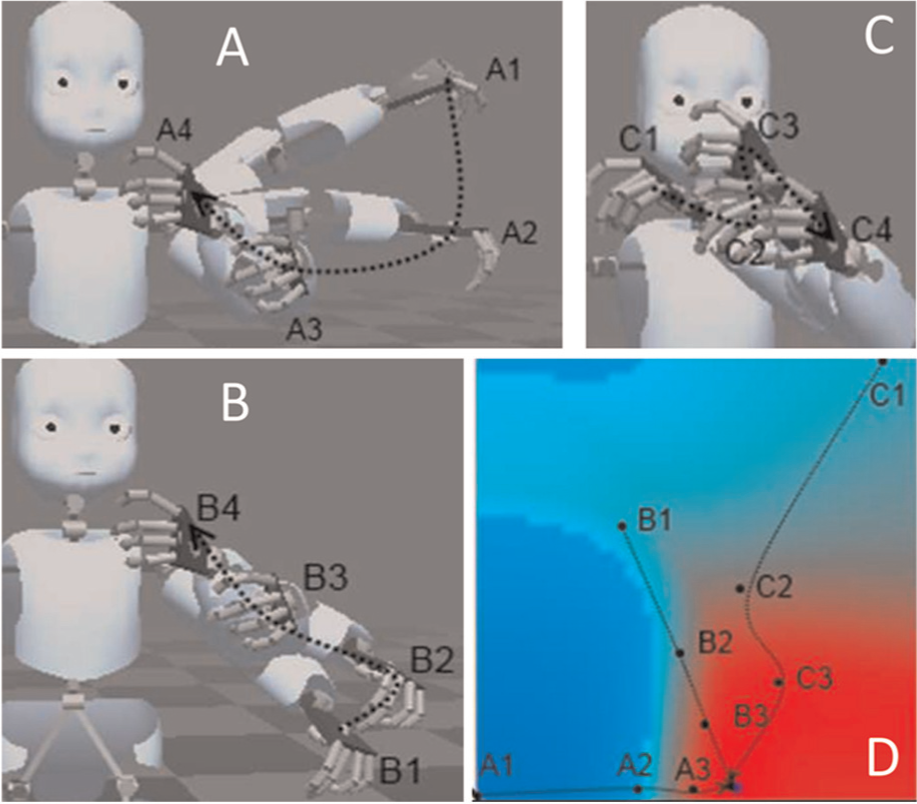
Illustration of the iCub brining its hand to the mouth area based on stimulation of the Multi-Modal Convergence Map (MMCM) of the arm proprioceptive space, independent of the starting position. (A–C) A set of trajectories bringing the hand near the mouth from three initial positions. (D) Activation trajectories on the MMCM. A single map stores the space of body configuration; each neuron of the map encodes a specific body posture, which can be evoked by stimulation. The command to reach this posture is computed by lower-level mechanisms [PID in the robot, spinal cord and central pattern generator (CPG) in living beings].
3.2 Experiment 2 – building peripersonal space (gaze+proprioception)
Peripersonal space is the space that closely surrounds the body, representing a sort of reachability sphere where each contained point is a place we can look at and reach without having to walk. This representation of space is interesting because it is here that the problem of referential change between visual target, gaze target and more generally how to reach a point in space with any part of our body must be solved. Demonstration of the existence of such a representation has been found both in neurophysiology in the monkey (Colby, Duhamel, & Goldberg, 1993; Graziano, Yap, & Gross, 1994) and in neuroimagery in the human (Makin, Holmes, & Zohary, 2007). The cortical areas (anterior intraparietal sulcus, IPS) responsible for encoding the peripersonal space respond at the same time to tactile, visual and proprioceptive modalities with some specific areas (posterior IPS and lateral occipital complex, LOC) devoted more to the visual modality. Neurons within those areas respond to visual targets that are close to the hand, which means that their receptive field is tuned for a gaze directed at the hand. We therefore used this constraint as the main contingency to be extracted by our MMCM model. The generated training data was collected by choosing a random point in the close Cartesian space of the robot, and then commands were issued in order to have the robot looking and reaching this target. We collected the related proprioception (head, torso and arm) and the original Cartesian position issued. We trained the MMCM model depicted in Figure 4, and conducted several external stimulations. First, we disabled the connections between the first-layer maps and the convergence zone and we stimulated them. This demonstrated the same effect as in our first experiment, with the initial-layer maps acting as collections of body parts postures.
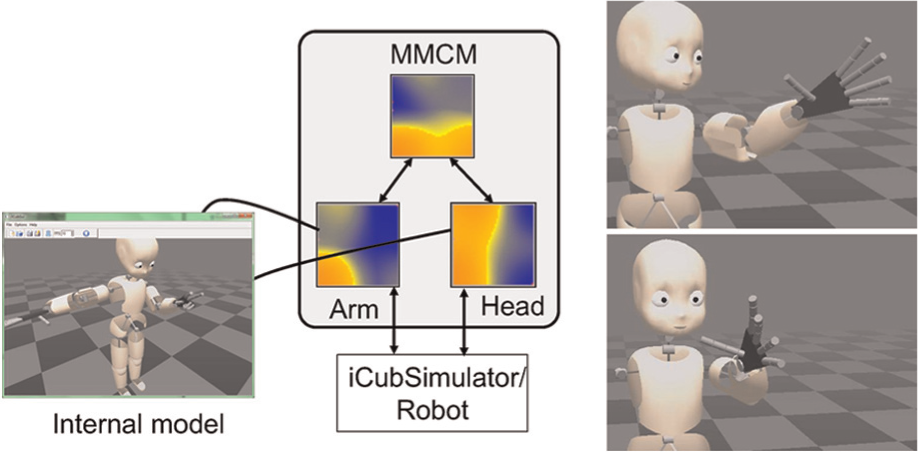
Multi-Modal Convergence Map (MMCM) model computing the peripersonal space of the robot as defined by the eye/head and hand. The first layer of the hierarchy is composed of 2 50×50 maps (head, and arm) converging into an amodal 50×50 map, which can also receive the Cartesian target as an additional modality. Stimulation of the amodal MMCM produces coordinated eye-hand movements.
Then we enabled the convergence to the higher map and again performed stimulations of the initial layer (Figure 4). This created a motion of stimulated part as well as the other part, via the higher-level CDZ. Indeed, in this configuration, one of the initial maps gets its activity changed artificially (e.g., if we stimulate the head map), this activity is processed by the amodal convergence zone, which in turn sends feedback to the other body parts so that they will be more consistent with the head posture. We performed an additional experiment that was to stimulate the convergence map directly, which triggered a motion of all body parts, demonstrating that the convergence map acts as a full body postures’ collection.
In this experiment, we demonstrated the ability of MMCM to model the peripersonal space of the robot. However, what we took as a ‘visual’ input was indeed the head proprioception (which depends directly on the robot gaze). While this assumption was appropriate in order to demonstrate a hierarchical application of the model, it cannot really be considered as involving vision. In the next experiment, we will introduce the cameras images into the model and show that it can cope with true vision.
3.3 Experiment 3 – vision and mental imagery
Cortical representation of the peripersonal space in both monkey and human is realized in areas principally influenced by vision and, others more related to proprioception and tactile inputs. In our previous experiment, we focused on modelling peripersonal space from the proprioceptive side; however, the MMCM model can also deal with vision and images. An image can be linearized as a vector of pixels and then used as a modality for the map. The set-up of this experiment is presented on Figure 5. It adds to the proprioceptive map a visual modality, which is a 50×50 pixels image coming from the left eye camera of the robot, linearized into a 2500-element vector. As for any other modality, the MMCM model is able to become activated by the image but also to produce predictions on what this modality should be like, given all the others.
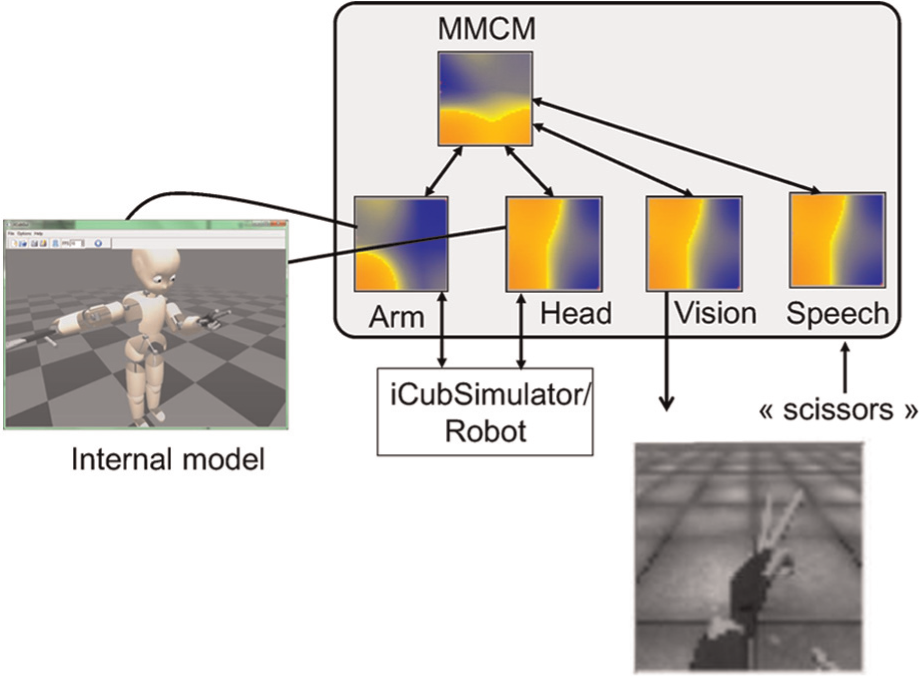
Peripersonal space model merging proprioception, vision and language. Arm and head are 50×50 maps taking as input the robot encoders (left_arm=16 DoF and head=6 DoF); the speech is a 50×50 map fed by a string (converted to a vector of double using the metaphone; Philips, 2000). The vision is coming from the iCub left eye camera, grey-scaled and cropped to a fovea area and rescaled to an experiment dependent resolution (from 15×15 to 320×240). The image of the hand is actually reconstructed from input to the vision map from the stimulated Multi-Modal Convergence Map (MMCM).
While proprioceptive predictions could be sent to the robot motors in order to generate a motion, it is a bit more delicate to make a concrete use of the visual prediction. Those predictions take the form of an image, which the user can visualize and represent what the robot thinks it should perceive. One can compare this with imagining what his arm/hand should look like while having his eyes closed. This corresponds to mental imagery of the system’s own body. A typical example of a mental image produced is illustrated in Figure 5. Such an image can be obtained by disabling the camera and having the robot moving in a configuration or by applying an external stimulation on the amodal map (which in this case both move the robot limbs to the stimulated posture and evoke a mental image). In both cases, the image produced is consistent with the body configuration, with a ‘perfect’ image if the body configuration belongs to the training set, and a blurry one in the case of interpolation.
Figure 6 illustrates the convergence of an amodal map merging proprioception of head, torso, arm and a left eye fovea input in the form of a 15×15 image. The discrete nature of the training set, which alternates from one posture to another, is reflected in the error rate, which is quite discontinuous, particularly in the early phases of learning. Trend curves (illustrated in doted lines) provide more visibility into the progressive reduction in error as learning proceeds.
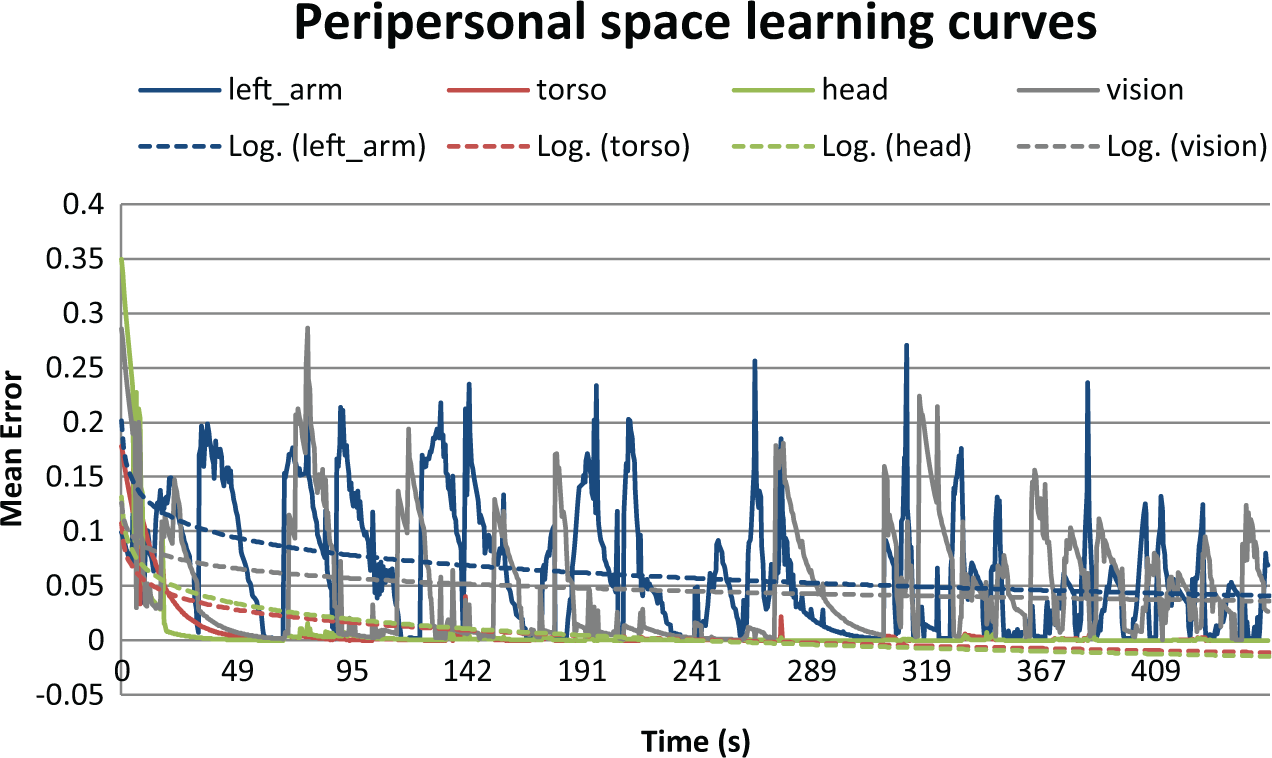
Error rate evolution of a map of peripersonal space while learning body postures. The hierarchical map is of dimension 50×50, with four input modalities: proprioception from the left arm, torso and head; and vision from the left eye. The pure modal signals are encoded in four pre-trained maps running in parallel. The convergence of the modal inputs, to their respective maps, and finally to the Multi-Modal Convergence Map (MMCM) allows a form of data compression (see Section 2.3). In this experiment, learning rate was set to 0.1, sigma was set to 12.25. Training data consist in repeating a 50-s sequence recorded from the robot sensors during moving to different body postures (copycat of the online training process).
It is interesting to note that in Figure 6, the error for the torso and head values converge fairly rapidly, while those for the arm and vision require more learning. We hypothesize that this is related to the higher DoF in the vision and arm proprioception signals. After learning, the system is able to achieve synthetic mental imagery in all four of the trained dimensions, as illustrated for vision in Figure 5.
The body mental imagery has been studied in human with a focus on the self/other distinction (Giraux, Sirigu, Schneider, & Dubernard, 2001) and led to the conclusion that own-body imagery involves motor activation, which is consistent with our model where the own-body motor imagery is achieved through top-down influence of the amodal map encoding the peripersonal space. We can hypothesize that motor imagery for others is activating the same visual area, but the source of this top-down activation is different. While it is not modelled in our current experiment, this idea of the same low-level sensory area used by different higher-level mechanisms is also consistent with the differences between acting and imagining. It is likely that, according to the source of the top-down activation, the motor pattern will be forwarded to the spinal cord or not.
While the MMCM model presented interestingly demonstrates the ability to form mental imagery, it is impossible to restrict the mental imagery process in humans to a simple top-down mechanism between two areas. However, we would like to use it as a proof of concept about the CDZ framework, which states that mental imagery is produced by the activation of primary visual areas activated by a cascade top-down mechanism originating from a more abstract cortical zone. As we will show in the next experiment, this is one way to explain our outstanding ability to form vivid representations of situations described through language.
3.4 Experiment 4 – evoking mental images from language
The objective of this experiment is to demonstrate how language and motor representation could merge in a higher-level area of the cortical hierarchy to form concepts that would ground together a symbolic word and a multi-sensory representation of the experience of this word. We use the same model layout as in the last experiment (Figure 5) and add an additional modality, which represents the spoken language input after early processing. The language input takes the form of a vector where each component encodes one word of the robot vocabulary. The speech recognition is achieved by state of the art language technology, Sphynx-II. The corresponding vector is constructed based on the recognition results and passed to the MMCM as for any other modality. The map is trained by the robot alternating between three hand postures (rock, paper, scissors) and the experimenter describing verbally the posture generated by the robot. Once the training is achieved, the model can be used in several ways. If we disable the top-down connections to the motor maps and say a word then the mental image corresponding to this word is evoked. With the motor connections enabled, the robot will in addition move to the position ordered by the human. Since the MMCM model is bidirectional by nature, we can also request predictions on the language modality based on proprioception. By manually moving the robot motors to the rock, paper or scissor configuration, the model produces the right word representation, which can afterward be sent to some text-to-speech tool. Since the language modality is already quite abstract and not generated through a cascade of maps grounded in the raw sound sensory data, there is no concrete opportunity for tests on interpolation on this experiment. However, the model shows nice noise cancellation properties when asking the robot which is the shape of its hand, as the learnt postures act as attractors. The same phenomenon is predictable in the case we would stimulate it with images. The language label of an object would be stabilized, even with images including some small variations.
3.5 Experiment 5 – influences of proprioception on visual recognition
In this final experiment, we demonstrate an application of MMCM on a real robotic platform, the iCub. The visual–proprioceptive link will allow significant performance enhancement due to the MMCM, both on the iCub simulator and real robot (preliminary results have been presented in Lallée, Metta, Natale, Pattacini, and Dominey (2009)). Our goal was efficiently to grasp objects recognized using vision. One main problem in grasping at this time was the inconsistency between the coordinates of an object obtained through vision and the position of the hand when commanding its Cartesian controller to move to reach this point. Due to minute errors in calibration, those two positions were not identical, therefore resulting in a hand displaced relative to the target of the reach (Figure 7) and the robot failing to grasp. The solution found was to proceed to an initial reach of the object, visually detect the hand and the target, calculate the difference and reduce it by repeating this process in a closed loop. However, the hand is a deformable object: according to its kinematic configuration, it can correspond to a functionally infinite space of different visual appearances, thus rendering the recognition problem non-trivial.

Status of target and hand after the initial grasp of the iCub. The distance between the hand and the ball needs to be reduced using a closed loop (error reducing) control. Visual recognition is achieved using Spikenet. Reproduced with kind permission from Elsevier (Thorpe et al., 2004).
The visual system of the robot is based on a robust pattern matching system, Spikenet (Thorpe, Guyonneau, Guilbaud, Allegraud, & VanRullen, 2004), which means that an object is visually defined as database or set of models (patterns) extracted from images of the object. In order for an object to be recognized, it should be modelled from several viewpoints and in all possible configurations, which results for the hand in the creation of an extensive number of models (Figure 8). Of course, the performance of such a system in term of recognition time depends mainly on the number of models it is asked to check for: in the case of the hand, the system became intractable.
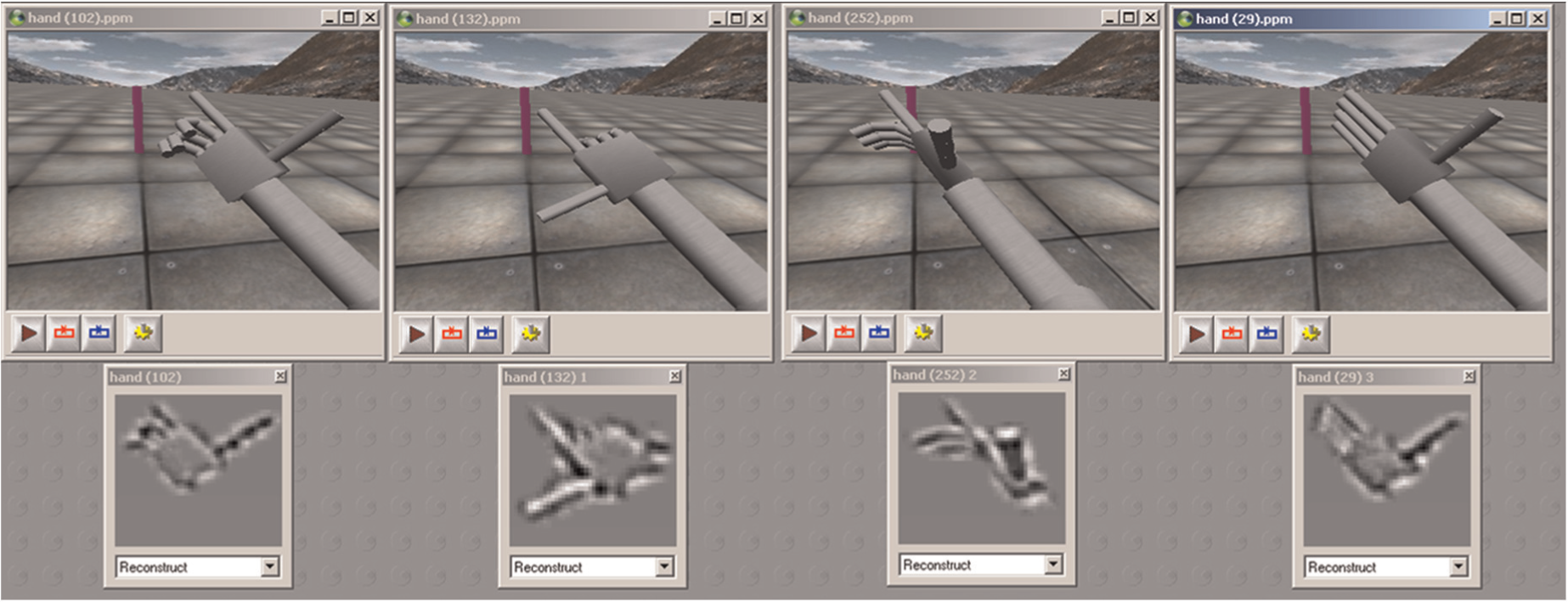
iCub visual models of the hand in a few configurations. The visual pattern changes dramatically from on configuration to the other and a huge amount of models is needed to recognize the hand in every posture. Below each image is the Spikenet template that has been generated to recognize the hand in the corresponding posture.
However, not all the models are relevant in every situation: since the recognized item (the hand) belongs to the robot, it is possible to take advantage of the embodiment information in order to reduce the complexity of the recognition process. Indeed, given a kinematic configuration, or a proprioceptive vector, the model database can be reduced to a subset of relevant models. The MMCM was used to identify this subset: a map linking vision and proprioceptive modalities was built, in the following manner.
The robot gazed forward, and with its hand in its visual field, rotated the hand about the wrist while opening and closing the fist. Proprioceptive signals were collected from the joint angle sensors, and visual signals from the vision recognition system. The vision modality was a vector of M components, M being the size of the full database of hand models. At each time step, the visual modality was obtained by setting the units corresponding to recognized models to 1 and all the other to 0. The proprioceptive modality was a vector of 16 components corresponding to the encoders of the robot arm scaled in [0,1]. The experiment was divided in two phases: 1-Learning, 2-Recognition. During the learning phase, the robot was looking at its hand while moving it in a semi-babbling mode as depicted in Figure 9. The full model database of 112 recognition models was loaded in the vision system, resulting in a slow recognition, and both visual and proprioceptive modalities were feeding the convergence map. The convergence map, MMCM, learned to associate a kinematic arm configuration with its subset of activated models in approximately 8 min of babbling.

iCub robot and simulator learning to visually recognize their hand based on their proprioception.
Once the map has learned, its predictive capabilities can be used. The influence of the vision modality is set to 0 so that the map gets its activation only from the proprioception. At each time step, the proprioception is sensed and the vision vector is predicted therefore producing the subset of models (10%), which should be recognized in this configuration. The visual system restricts the database of recognizable models in this subset in order to allow a faster recognition than if it was using the whole database. The effects of this pre-selection of visual patterns are presented in Figure 10. The effect of this pre-selection is of course dependent of the number of models present within the database, in our conditions.
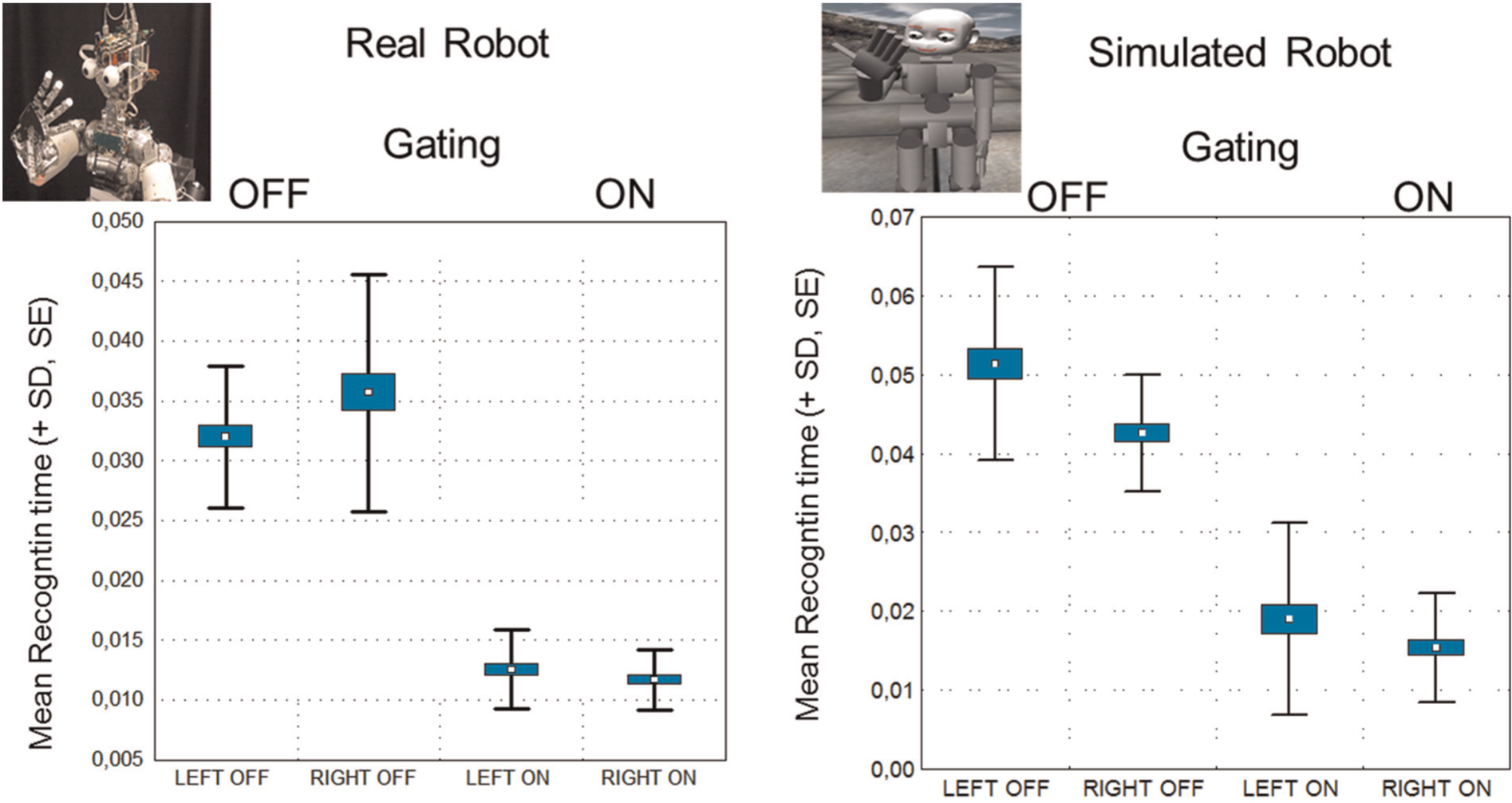
Effects of proprioceptive gating on visual recognition time. Experiment was conducted twice: once on the simulator and once on the real robot, similar highly significant reduction of recognition time was found. Gating is the reduction of the set of recognition candidates, by the predicted candidates from the Multi-Modal Convergence Map (MMCM) based on the proprioceptive position of the hand.
As illustrated in Figure 10, when the ‘gating’ of proprioceptive information into the MMCM was enabled, this resulted in significant reduction in the processing time for visual recognition of the robot hand using the Spikenet recognition system. These results were confirmed statistically with an analysis of variance (ANOVA), main effect for Gating, F(1,39)=418, p<.0001. Thus, the MMCM allows the system to learn the association between hand postures, and the visual representations of these postures, which allows for a preselection of the templates that will be used in visual recognition with the Spikenet software, and a corresponding speed-up in the actual recognition. This experiment provides a quantitative demonstration of how the MMCM can link proprioception to vision, in order to allow the visual system to anticipate the visual image of the hand, based on its sensed proprioceptive configuration.
4 Discussion
The current research extends that of Aflalo and Graziano (2006), which demonstrates how a set of multidimensional movement vectors can be used to create a self-organizing motor map. In their model, each neuron coded a given movement, represented as an 18-dimensional vector. Each vector specified the body parts that were being moved (10 dimensions, one for each body part), the position that the hand reached in Cartesian space (three dimensions) and the ethological category to which the movement belonged (five dimensions corresponding to five categories). Aflalo and Graziano (2006) demonstrated that an SOM generated a topographic representation that has characteristics that are similar in a number of ways to those of motor cortex.
In the current research, we exploited these notions of self-organization of motor representations, but we used a related but more ecological coding, in the context of the spatial control of 16-DoF robot arm, where each dimension corresponded to one controlled DoF in the robot arm. The resulting map demonstrated a topographical representation of the motor space. This was not our particular interest, which was, instead, to determine whether the functional organization of the map, in terms of its motor control capabilities, could be used to control the robot. In particular, we wanted to determine whether the map would produce coherent movement representations similar to those observed in Graziano, Taylor, and Moore (2002a).
We generated a set of ecologically relevant movement postures and then used the resulting vectors to train an SOM. We then stimulated the map, simulating the experiment of Graziano et al (2002a). In particular, we were interested in determining whether one of the principal properties that was observed in the monkey would be observed in our SOM. That is, stimulation in the large arm and hand region evoked complex postures, with smooth trajectories to those postures, independent of the initial configuration of the arm. We then extended this concept to multiple domains, which made possible the notion of mental imagery.
We proposed the MMCMs, an artificial neural network implementation of the CDZ theory. We demonstrated how this theory could be applied concretely to model the early embodied representations of a humanoid robot in a cortico-mimetic fashion. Several case studies inspired by the existing neurology literature have been designed to test the model and we strongly believe that the MMCM can be extended to build much more complex representations and concepts. Promising directions to extend this framework include adding some preprocessing of the input signal with a reservoir as has been done in Morse, Belpaeme, Cangelosi, and Smith (2010) or adapting the recurrent SOM algorithm (Varsta, Heikkonen, Lampinen, & Millán, 2001) to fit within the MMCM framework. One point that our experiment demonstrates is that a sequence (of postures, images, concepts, etc.) can be understood as the path between two points on a cortical map. Any mechanism dragging the peak of activity between two different locations in a high-level cortical area could produce by the divergence effect a complex sequence of sensorimotor behaviours. This high data compression intrinsic to the CDZ theory indeed significantly reduces the complexity of sequence storage outside of the cortex. The cortical hierarchy could be understood as an index of sensory motor concepts that is built and used by other cerebral structures, which is consistent with the work of Doya (1999).
Linking MMCMs, a model of the cortex, with models of other cerebral entities would solve another issue of the current implementation. At the time of writing, a limiting factor of the model is the way to train it. MMCMs are extracting contingency and regularities in co-occurrences of sensory motor signals; we therefore need a behaviour that will produce those contingencies. In some cases, it is trivial: motor babbling produces body configurations in which what the eye sees is always consistent with what the body feels; and the same motor command sent to the speech apparatus will always produce the same sound. However, in more evolved cases like decision making, exploration of the input space should not be purely random, instead some curiosity mechanism based on the prediction error could be a valuable addition to the model so that it will generate its own training data. This is an invitation to introduce models of the basal ganglia with reinforcement learning. For example, a directly applicable mechanism would be intrinsic curiosity developed by Oudeyer and Kaplan (2007) so that the model would select the behaviour that offers the most chance to increase knowledge, the one which is the most likely to reinforce an existing weak contingency relation between sensors.
Finally, we would like to emphasis the kind of computations achieved by the cortex: what if the role of this complex hierarchy of neural maps was to extract contingency? Linking sensorimotor signals that are correlated by direct temporal co-occurrence allows building a probabilistic model of the reality just by applying the Hebbian rule, which is in the end another formulation of Friston’s free energy principle (Friston, 2010).
The MMCM provides an implemented framework (source code available at https://code.google.com/p/mmcm-net/) in which multiple modalities are represented in distinct and also converging maps. Activation in one modality can be used to generate a mental image in the other modalities. We demonstrated concretely how this can be used to increase the performance of the iCub in recognition of its hand in different postures. We demonstrated also how this framework accounts for primate neurophysiology data related to the postural encoding of action (Graziano et al., 2002a). Future work will examine how this system can be used to explain data in primate sensorimotor coordination, and in the use of mental imagery for improving performance in other robot behavioural conditions.
Footnotes
Funding
This work was funded in part by the EU Grant EFAA under FP7-ICT- Challenge 2 ‘Cognitive Systems, Interaction, Robotics’ (Grant Agreement Number 270490) and by the French ANR Comprendre (ANR-08-BLAN-0003).