
Abstract
We present a novel model, SCP1, of monkey sequence learning that takes the processes of stimulus recognition and motor planning seriously in addressing a robust dataset on list learning obtained through the Simultaneous Chaining Paradigm (SCP). Strikingly, SCP violates stimulus-response (S-R) mappings in that after several different lists are learned, monkeys are able to conserve this learning on a new list which is “conserved” in the sense that the jth element is specified as the jth element of any one of the previously learned lists. We demonstrate list acquisition as a result of multiple concurrent learning processes that together contribute to competent performance. In addition to reproducing behavioral results, we offer observations linking the work to macaque neurophysiology.
Keywords
1. Introduction
We present a neuro-computational model of primate sequential learning and test it against a thorough behavioral dataset from the Simultaneous Chaining Paradigm (SCP). But first, some comparison with other models. Competitive Queuing (CQ) models represent temporal knowledge through the activation induced by a sequence node across a layer of planning neurons, each of which corresponds to an individual action (Bullock & Rhodes, 2003; Hartley & Houghton, 1996). The sequence can then be “read out” in order of greatest activity by a third layer of competition nodes that implement a Winner-Take-All (WTA) dynamic with the added feature that inhibition-of-return inhibits previously selected items to avoid repetition of earlier actions (see Figure 1, left). Such models have been widely applied and have been integrated with explicit “rank ordering” modules to model more complex sequential performances where items repeat within a sequence (Davelaar, 2007; (Silver, Grossberg, Bullock, Histed, & Miller, 2012).
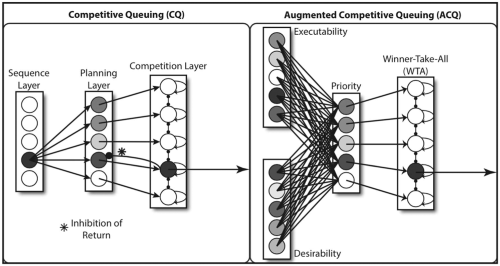
(Left) Competitive Queuing (CQ), highlighting (*) one case of inhibition of return. (Right) A partial view of the Augmented Competitive Queuing (ACQ) schema for opportunistic action sequencing, in which priority for the next action is given to the currently executable action which is most desirable with respect to the current goal (see text for details).
Complementing such execution of stored sequences. the Augmented Competitive Queuing (ACQ) model (Bonaiuto & Arbib, 2010) combines reinforcement learning mechanisms and action recognition modules to support opportunistic scheduling of behavior. ACQ associates with each action in the repertoire desirability (reward predictive) signals learned through temporal-difference reinforcement learning (Sutton & Barto, 1998), and executability (likelihood of successful execution) signals related to the affordances for that action which are learned through cumulative (context-based) success or failure. The desirability and executability of an action within a context are then combined to represent an action’s behavioral priority, and so behavior can more quickly converge on stable sequences of actions to achieve some goal (Figure 1 right).
The DAJ model (Dominey, Arbib, & Joseph, 1995) modeled sequential saccade-generation tasks (though the model is generic as to the nature of the elements of the sequence). Recurrent loops based on prefrontal cortical organization in relation to basal ganglia generate a “reservoir” of “meaningless” sequences as deterministic state transitions between context states. A cue for a given sequence initiates the same reservoir sequence in prefrontal cortex on each occasion. Learning associates successive predetermined prefrontal context state with successive actions as read out through the basal ganglia.
The model we present here borrows notions from the above models, for example, by applying internal context states which can learn and retrieve associations with unique items, as in (Dominey et al., 1995). However, it departs importantly from the latter by its ability to generalize across different lists in the manner described below. The competition for expression among action plans occurs in spatially structured maps for action correlated with relevant environmental properties (Cisek, 2007; Zelinsky & Bisley, 2015).
We now turn to an analysis of the main behavioral dataset we will use to explore issues in sequential learning thus far neglected in modeling.
2. Behavioral data for the SCP
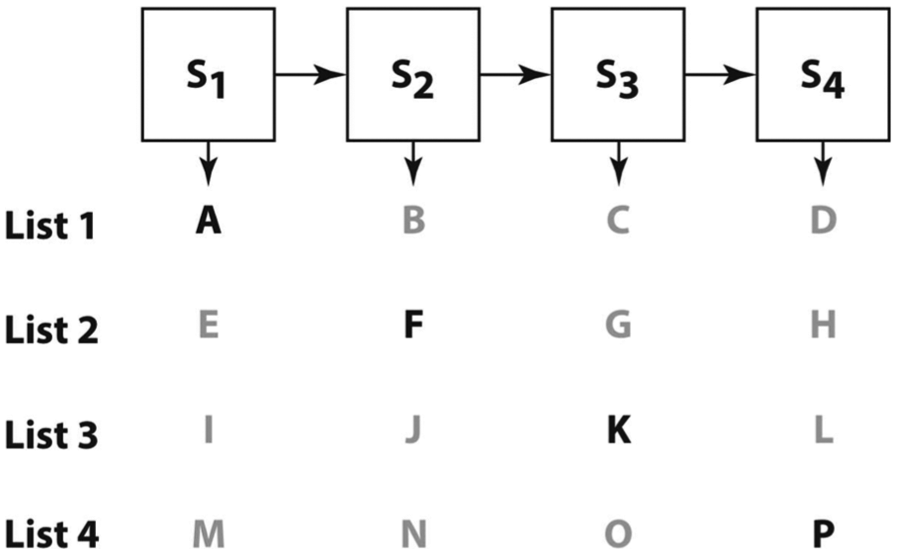
The SCP (Terrace, 2005) probed monkeys’ skill at list learning (see Figure 2) and the extent to which they (i) can learn the serial structure of individual lists, (ii) can gradually become more competent at the task, (iii) are sensitive to the serial structure of learned lists, and (iv) are sensitive to observation of others’ actions. The model presented here (SCP1) accounts for (i)–(iii); we develop an extended model (SCP2) to address (iv) in (Gasser & Arbib, 2017). SCP violates stimulus-response (S-R) mappings in that after several different lists are learned, monkeys are able to conserve this learning on a new list (a conserved list) in which the jth element can be specified as the jth element of any one of the previously learned lists. Explaining this ability was a key challenge for the present modeling effort.

The Simultaneous Chaining Paradigm (SCP). Subjects must learn to press items on the screen in a pre-specified order. It is the sequences of images, not positions, that must be learned—each item can appear in nine possible positions on the screen, but these positions vary randomly between trials, thus removing sensorimotor associations that might facilitate learning. The lettering is included for the reader, not for the monkey. For the current model, we only consider lists up to 4 items long (see text for details; adapted from Terrace (2005]
Items (photographs) are presented simultaneously on a touch-screen monitor for the duration of a trial, and a pre-specified order of selecting the items must be discovered through trial-and-error. The locations of the items on the touch-screen monitor are randomized between trials, while the desired order of item-touching is preserved. In other words, the monkey must learn a sequence of images even though their position will vary from trial to trial.
During training, the animal is incrementally shaped on the list, first mastering smaller sub-sequences before more items are presented on the screen, until the full list is learned—giving implicit order information, at least at this stage of learning. Once performance criteria are met for the current increment—typically, consecutive blocks of trials below a certain error rate, which may vary between experiments—a new item is appended to the end of the list, as follows:
List 1, Increment 1: A
List 1, Increment 2: A-B
List 1, Increment 3: A-B-C
List 1, Increment 4: A-B-C-D
The configuration on the monitor does not change during a single trial. Following selection of each correct item—other than the last—the only feedback the animal receives is a briefly highlighted outline of the item selected, while incorrect selections are immediately followed by a “time-out” (Swartz, Chen, & Terrace, 1991) during which an overhead light goes out, eventually followed by a new arrangement of the current set of items (i.e. new trial). Food delivery (reward) follows successful completion of the current full increment. Repeat selections of an item are tolerated, but are not “correct.”
Having introduced the experimental paradigm, we briefly report the major behavioral findings as culled from the literature.
2.1. Monkeys learn the SCP through explicit shaping
Monkeys do indeed master the SCP task following incremental shaping. In the original study (Swartz et al., 1991), four lists of four items were learned, with 3-item, and especially 2-item increments often learned in the fewest possible number of trials to meet the criterion of two consecutive blocks of 60 trials at >75% accuracy. The four-item increments—that is, the whole list—often required many more total trials to reach criterion, upward of more than 1000, though substantial variation did exist.
To test the effect of the incremental shaping, experimentally naïve monkeys—subjects not familiar with the SCP task prior to the testing—were tasked to begin with increments of three items immediately. It was shown that, even here, monkeys were still able to eventually reach a criterion of single session accuracy of >65% (Terrace, Son, & Brannon, 2003), though it required substantially more training than the baseline established in previous experiments. It has not been demonstrated, so far as we are aware, that naïve animals can learn 4-item-long lists without at least some incremental shaping. Interestingly, monkeys are able to eventually learn lists up to seven items long (Terrace et al., 2003), with no studies that we know of testing macaques beyond this limit. The monkeys had extensive task experience prior to testing (on the order of having mastered ∼20 separate lists), and required substantial time—upward of 30 sessions of 60 trials per session—to achieve criterion levels (>65% accuracy in a session). However, we will focus on 4-item-long lists for which the data provide further tests of the model.
2.2. Monkeys can learn the SCP without explicit shaping
For monkeys with enough training, shaping periods could be foregone and new lists learned with all four list items presented simultaneously from the start (Swartz, Chen, & Terrace, 2000). The subjects responded poorly at first, though eventually criterion levels (>75% accuracy) were achieved. The total number of trials to reach criterion varied between lists and between subjects, but this task was substantially more difficult than learning lists in the incremental shaping method.
2.3. Monkeys can develop serial expertise
Over time, monkeys accumulate “expertise” for the SCP task. In both the incremental shaping method, and in the “simultaneous” list presentation method—for example, new 4-item-long lists presented in absence of any incremental shaping—accuracy improved over time, suggesting list learning strategies were being extracted by the monkey (Swartz et al., 1991).
2.4. Monkeys are sensitive to manipulations of serial structure
Various manipulations of the lists’ serial structure were performed to probe mechanisms the monkeys employed to solve and execute the lists.
Conserved lists are lists composed entirely of items already encountered. Each item is from a different list previously performed at criterion level and, crucially, serial position is conserved in the new list (i.e. if item X was “third” in its original list, then it is also “third” in the new list). That way, learned associations between the items in these lists and their putative serial position are maintained, which was hypothesized to facilitate reproducing these lists (Chen, Swartz, & Terrace, 1997).
Monkeys perform these lists at levels comparable to lists they have upward already been extensively trained on (Chen et al., 1997)—achieving performance of 97% correct (29/30) over the first 30 trials—suggesting little need for trial-and-error learning or otherwise adapting to the novel combination of familiar items (Figure 3). In fact, for the most part, these lists require the minimum total trials necessary to reach criterion performance rates.
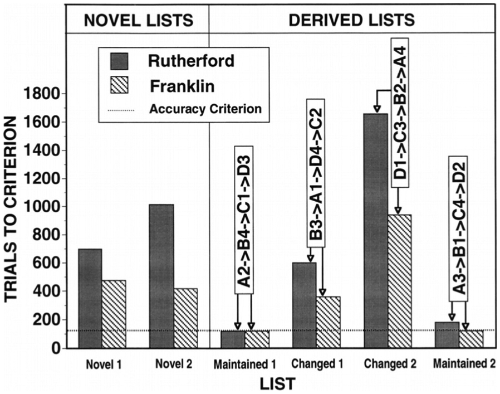
Results from derived list manipulations. The figure shows the results for two monkeys (dark and hashed bars, respectively) for three different manipulations, each with two instances of lists. On the left are novel “control” lists, showing the trials-to-criterion for each list, for each monkey. On the right are what Chen and colleagues refer to as changed and maintained lists—what we refer to in the text as scrambled and conserved lists, respectively: Here Aj refers to the first element of known list j; Bk refers to the second element of list k, and so on. The “maintained” lists conserve the learned serial structure, while the “changed” lists scramble these associations. The control lists are learned moderately quickly. The maintained (conserved) lists are performed at criterion levels in the fewest possible trials for three of the four lists, demonstrating impressive transfer effects. The changed lists, though variable, seem to be the most difficult lists to learn and reproduce. The list that takes longest here seems to be the most scrambled (D-C-B-A) and thus with the most to “unlearn.” (Adapted from Chen et al. (1997)
Crucially, this result rules out “chaining” models based on associations between each item of a list and its successor. It thus provided a major stimulus for the modeling presented below.
Scrambled lists, like conserved lists, are composed of items encountered in previous lists, but the previous serial positions are scrambled. (Note: the scrambling here is a scrambling of the order in which images are to be touched by the monkey. Recall that for each list, the positions of these images on the screen is randomized between successive trials.) These lists may take longer to reach criterion levels as novel lists composed of elements with no previous associations (Chen et al., 1997) (and see Figure 3). Previous associations were predictive of the errors the monkeys would make: items previously learned to be first in a list were selected as such, even following many successive errors, suggesting the monkeys required substantial time to un-learn these associations.
Wild card lists are formed by taking a learned list and eliminating an item and replacing it with a novel “wild card” item the monkey has no experience with. The monkey must discover that the novel item replaces the missing item (D’Amato & Colombo, 1989). (The design of their task—e.g., lists being upward of 5 items long—and the training undergone by the monkeys, is not the same as the SCP, though the results hold.) In the wild card lists, the monkeys perform at high levels almost immediately by selecting the wild card item in the list position vacated by the missing item.
3. Related neurophysiological data
The results from the SCP are purely behavioral, but neurophysiological investigations of decision-making and sequential behavior in macaques have revealed characteristic patterns of responses that provide some hints of the mechanisms likely to participate in representing decision variables for the monkeys.
First, several nuclei within at least parietal and frontal regions have shown response profiles correlated with “rank,”“ordinality,” and/or “numeric” variables (Nieder & Dehaene, 2009). Multiple cortical regions in macaques can represent serial order for both particular sequences of actions, and for sequences of items toward which actions are targeted (Berdyyeva & Olson, 2009, 2010).Sawamura, Shima, and Tanji (2002, 2010) studied monkeys learning sequences of lever manipulations—for example, twisting a lever—which do not result in great environmental feedback, and showed that disruptions of area 5 of parietal cortex by muscimol impair the temporal organization, not the motor coordination. All this suggests that there are diverse decision-related signals, while further investigation has shown these signals can combine to affect decision-making (Watanabe & Sakagami, 2007), as also suggested above by the ACQ model in which reward-related desirability and affordance/context-based executability combine to give the behavioral priority of each action.
Additionally, neurons within fronto-parietal networks—lateral intra-parietal (LIP) region in particular—have shown response characteristics across a wide variety of task conditions and demands that have led some to regard these networks as implementing “priority maps” crucial for integrating and structuring information for real-world interaction with one’s immediate environment (Bisley & Goldberg, 2010; Gottlieb, 2007).
Networks representing, in parallel, potential motor plans have been described (Cisek & Kalaska, 2002), and it can be observed that when a cue indicates which plan is appropriate for that context, the correlated neural population then wins out. Parallel planning of sequential motor acts has also been described in prefrontal cortex, with the relative activation of a plan at a given time predictive of its order in the sequence (Averbeck, Chafee, Crowe, & Georgopoulos, 2002). Neurons responsive to a single, well-learned sequence of movements (and even sequence sub-sets) have also been isolated in various parts of frontal cortex (Tanji & Shima, 1994). In short, neural recording data suggest that a suite of mechanisms is available to the monkeys during list representation and production. However, it is up to computational modeling to offer precise hypotheses on how such mechanisms may relate to each other, and how learning may rely on one or another mechanism at different times, from initial acquisition to well-rehearsed performance.
4. Model design of the SCP1 model
Chaining models fail to explain the above data for conserved and wild card lists where item-to-item associations disappear, but performance rates are not affected. Indeed, all the models discussed thus far fail to explain the learning required in such a task. We now provide a brief sketch of our new model, which we call SCP1, demonstrating the two key mechanisms for solving this complex sequence learning task.
The model must demonstrate mechanisms to acquire the lists—first through incremental shaping and then without that crutch. We stress that learning and behavior constitute a continuous “information pipeline” from sensory input to motor output. Our two key mechanisms are (a) a learning and decision-making network that represents temporal context and item value together and (b) a mechanism for generating and maintaining precisely those internal context states that correlate with the temporal progression in execution of the learned sequence. We base the primary learning mechanisms of our model on the two complementary and learnable signals from ACQ: reward-related signals (desirability), and context-related signals (executability), which combine to give a behavioral priority signal. Note, though, that in the ACQ model (Bonaiuto & Arbib, 2010), the executability of an action is based on whether or not it can be carried out in the current context, which may change when actions are executed. However, an action in SCP does not change the state of the world (i.e. the array of patterns on the screen). Thus, internal “updating” of the state of execution of a sequence must be maintained, for example, via a CQ-like “inhibition of return” mechanism to ensure that once an image has been touched, it is no longer “executable”—that is, “executability” is now based on an internal memory mechanism, not on a re-assessment of the external environment. Moreover, desirability of an action in ACQ (as in temporal-difference learning more generally, Sutton & Barto, 1998) is based on effective reinforcement, which is larger the closer one is to reaching the goal state in which the reward is achieved. By contrast, in SCP one must delay touching later elements in the list even though they are “executable”—the earlier in the sequence, the more “desirable” the element.
We have already seen that conserved lists cannot be explained by chaining models, but nor can they be explained by a reservoir model like DAJ in which elements of a list are paired with a reservoir sequence specific to that list, thus disavowing the “sequence merging” exhibited by conserved lists in SCP. Thus, while our model also associates temporal context states with a list item, we extend the learning to include generalizing from the variations in visuo-spatial input in such a way that the order of items in different lists come to be learned in relation to a single sequence of temporal context states (details below).
One last comment before turning to a more detailed tour of Figure 4. Any experimental study of learning in monkeys is preceded by a period of shaping in which the monkey learns what the stimuli are and which actions are relevant to gaining a reward in the current set-up. In some sense, testing with increment 1 of the first list is akin to the essential shaping for SCP: the monkey learns to attend only to the images on the screen, and it learns that the only actions which have a chance of yielding any reward are to touch squares on the screen that contain an image. They learn that the actions to be sequenced are of the kind “touch a particular picture no matter where it is located.” By contrast, in the study (Barone & Joseph, 1989) which inspired the DAJ model, the monkeys were shaped to know that the constituent actions were “touch a particular place on the screen.” The power of the present model is that it can learn what actions are appropriate—the basic action is to touch a square on the screen, but the model learns that the target is based on the pattern in the square, not the location of the square per se.
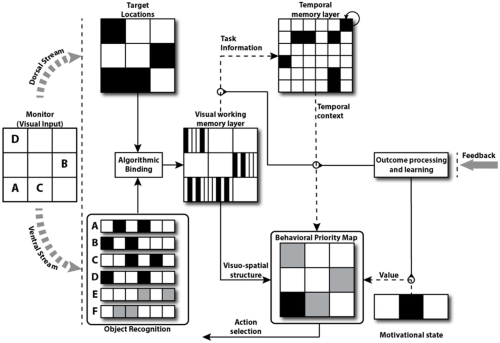
High-level model schematic for SCP1. Visual input in the form of a 3x3 array provides input to the model. (Caution: In Figure 3, A, B, … labeled lists of patterns; here, A. B, stand for individual patterns.) Immediately, two paths process the input: the dorsal path computes a binary representation of target locations that preserves spatial relations between items, while a ventral path visually discriminates the items based on their unique feature-vector representation. However, this visual processing is irrelevant to the success of SCP1; the key is the integrated visuo-spatial information is represented in a visual working memory layer. This layer informs downstream structures of the content and visuo-spatial features of the monitor. The temporal memory layer maintains the internal state of execution for the current list and projects, complementary to the value-based signal provided by the current motivational state (which is held constant in the present version of the model), a temporal context signal that informs the behavioral priority map which (see Figure 12 of the Appendix 1) provides the planning layer for what is essentially a CQ mechanism based on the current disposition of sequence elements. The major representations used in the model are visible, as are the learning pathways (dotted lines) that contribute to model performance. Learning itself is managed by an outcome processing module that manages the feedback of the environment and interacts with relevant learning pathways (circled cross-sections).
We will fill in the details of SCP1 (Figure 4) according to the following outline: The real processing in SCP1 starts with the formation of a visual working memory of the input, associating the recognition of a pattern with its position in the array. The challenge of the model is to convert this representation into a behavioral priority map which indicates the priority for touching squares of the input array as based on list learning. This drives the system for selecting the next response. The crucial intermediary is the temporal memory layer which learns how to provide the right biases for the conversion from visual working memory to the behavioral priority.
4.1. Visual processing
The input to the model is given by a 3x3 array, with the “visual” pattern in each square represented as sparsely coded feature-vectors, “n”-long, with “i” total active units (set equal to 1) for each vector. There is no attempt to capture actual images like those in the squares of Figure 2; our aim is simply to distinguish “visual input” from the neural pattern that constitutes “object recognition.” The visual patterns are randomly arranged on the monitor. (In the implementation, we require that the middle location is unoccupied.)
Dorsal and ventral pathways together build up a visual working memory representation that binds item information (ventral) with spatial information (dorsal). The upper (dorsal) visual pathway of Figure 4 processes the image to establish a binary representation of all occupied target locations (i.e. those locations containing a visual pattern). A second (ventral) pathway decodes each visual feature vector and activates a code for that pattern in the object recognition layer. This mapping is fixed and arbitrary. The visual working memory, yv, preserves the spatial distribution of the items and the rich distributed feature vectors, algorithmically combining both representations: For the 3x3 monitor and feature vectors of length 16, yv is a 9x16 array. The first dimension has 9 elements corresponding to the elements of 3x3 input grid, and the second dimension correspond to the length n of the object recognition feature vectors. It is this layer that projects via modifiable weights
In terms of SCP1, the contents of the visual working memory layer are more important than the way they are obtained. It would be more realistic to imagine a sequential process in which foveation allows object recognition to proceed one or two squares at a time, allowing population of the working memory to combine location with a “recognition code” for a pattern as distinct from its retinal image. Memory load is reduced because new eye movements can serve to refresh the array as the present trial proceeds. However, to reiterate, the exact nature of this prior visual processing is irrelevant to the functioning of SCP1.
4.2. Motor control: selecting the next response
The task of the SCP1 model is to learn how to transform the patterns arrayed on the grid as represented in the visual working memory layer into the array of values (behavioral priorities) represented in the Behavioral Priority Map. Motor control must be able to take the array of values and direct a touch to the patterned squares in their order of priority. Just as we have already noted that it is the entries in the visual working memory layer that are crucial for the operation of SCP1, not the way in which those entries get there, so it is the reading out of entries in order from the Behavioral Priority Map that is crucial not the particular mechanism that converts priority into action. We thus omit details of selection and control from the main text. However, the interested reader will find in Appendix 1 an account of the model employed in our simulation. In this version, a Competition Model (Figure 12) selects the grid element with highest priority and uses this to disinhibit the corresponding element of a 3x3 basal ganglia model; this disinhibition then allows the touch to the corresponding grid element to proceed. This may be seen as akin to a CQ model with inhibition of return (Figure 1 left) with the output neurobiologically elaborated to operate via the basal ganglia.
Appendix 1 also includes a listing (Table 1) of the parameters used in the simulations presented below.
4.3. Temporal memory layer
The crucial challenge for SCP1 is to learn the order of elements in a list even though the positions of those elements vary from trial to trial. In other words, it must convert the array of patterns in visual working memory to a corresponding array of priority values in the behavioral priority map. Note that yv is fixed during the four or so touches required to perform a trial. But now, we need to model how the monkey makes its next choice in the sequence, and how it learns to master a sequence across multiple trials.
We introduce a temporal memory system, ym(t), as a layer of neurons that are first activated by the visual working memory representation, from which a k-WTA process maintains only the k most active units (set equal to 1). Here, t here indexes time steps within a trial. Together, the activation of the temporal memory layer is given by as follows (compare Figure 5). At the beginning of a new trial, when t is reset to 1

Here, Sk is the k-WTA process that maintains activity only in the k most active neurons. The crucial learning element here is Wf. The success of SCP1 hinges on the ability of Wf to ensure that the resultant state can learn biases that influence item selection.
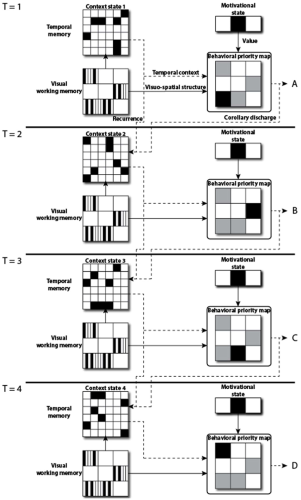
Event-level evolution of decision-related representations. In these four panels, T = 1 corresponds to the initiation of a new trial. Transitions to T= n+ 1 (n = 1, 2, 3) occur if stage n results in a successful selection; otherwise the trial is terminated. At T = 1, visual processing establishes the content of the visual working memory layer, which in turn activates the temporal memory layer and so generates temporal context state 1 (equation (1a)). The temporal memory layer projects this activation to the behavioral priority map concurrently with the visuo-spatial structure provided by visual working memory. (The role of the motivational state in informing the behavioral priority map of the reward-predictive value of each visible item is explained in the section on “Behavioral priority.” For T = 2, following a successful selection recurrent activities induce a new pattern of activation in the temporal memory layer (equation (1b)), now discriminable as context state 2 (and deterministically computed from state 1, as recurrent connectivity is fixed) to provide new input to the behavioral priority map. Similarly for T = 3 and T = 4. Thus, the initial activation of the temporal memory layer by the visual working memory layer selects a trajectory in context space that unfolds predictably, allowing reliable retrieval of temporal context information that, along with reward-predictive considerations, influence downstream decision processes. The dashed lines in the figure denote data streams that change in time, while solid lines indicate data that does not vary over the course of a single trial.
Recall that yv is constant for the trial. ym remains constant until a selection is made. If the selection is unsuccessful, or if the whole list has been responded to correctly, the trial terminates. Otherwise, ym is updated after a successful selection according to
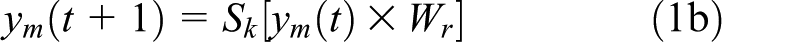
updating the layer via other-excitatory and self-inhibitory projections followed by Sk. Wr is a fixed matrix that provides recurrent connectivity: each unit in the layer is connected with excitatory weights to all other units, with inhibitory self-connectivity. For example, the weights for a 3-unit layer would be
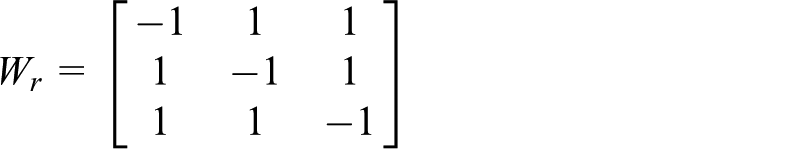
This gives the property that any state of activation, ym(t), will be deterministically followed with ym(t + 1) in such a way that ym(t + 1) ≠ym(t).
In summary, the temporal working memory acts as a reservoir. Wf establishes the initial state (1a) which is then updated each time a selection is made. However, the mapping from visual working memory content

where αf is a learning rate constant, and rp(t) is the value of the primary feedback, namely 1 if rewarded (the sequence is completed successfully) and −0.1 if punished (i.e. the trial is discontinued due to an error).
Over many trials, the model “generalizes” the task demands in part by establishing a consistent mapping to the temporal memory layer which facilitates list acquisition over time. This also gives the property that the model is robust to the list manipulations. Because the temporal memory layer evolves deterministically, successive states allow retrieval of past associations, even if the content of the monitor, and thus the visual working memory, is novel. The added learning process on the “input side” of the temporal memory layer—lacking in the DAJ model—allows us to explain how items not previously presented together are nonetheless easily executed when ordinal positions are conserved.
The temporal memory layer in our model encodes the state of execution, and each state can then be read to bias a particular selection. Neural populations encoding temporal state information can be found in various nuclei in frontal and parietal regions, which are reviewed in the Discussion.
4.4. Behavioral priority
As indicated in the earlier section on “Motor control,” the behavioral priority map is a network of 3x3 layers of neurons, topographically correlated with the monitor and the visual working memory layer. If learning is successful, the behavioral priority signals should encode reward-relevant information for each location on the monitor, such that selecting across the behavioral priority signals immediately gives motor parameters for acting
In order to drive appropriate decisions, the model must retrieve learned associations about each item: temporal context associations c(t) and reward-predictive or “value-based” associations v(t). The behavioral priority matrix p(t) combines these via
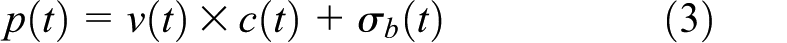
where σb(t) is Gaussian noise injected to provide variability that assists learning.
4.4.1. Temporal context associations
Just as we specified learning for a matrix Wf for the connections from the visual working memory to the temporal memory system, ym(t), so we now specify learning for a matrix Wf for connections from ym(t) to the behavioral priority map. Associations must be established between the evolving temporal context states and the visible items, and these associations must bias selections independent of value-based biases. The temporal context signal c(t) is given by

where ym(t) is the temporal memory state at time t and Wc is the modifiable weight matrix which encodes the temporal context associations. The modifiable weight matrix is adapted according to associative learning

where αc is the context learning rate, and re(t) is the effective reinforcement (not the primary reinforcement), which is equal to 1 unless the selection is incorrect, in which case it is equal to −1. (i.e. state+item associations are positively reinforced unless followed directly by negative feedback.) Weights are re-normalized by decreasing all the weights of non-selections by a factor of ΔWc. The learning is “competitive” in that learning of one state+item association, per selection, comes at the expense of the associations between the current temporal context state and all other items.
4.4.2. Value-based associations
In future modeling, we may want to extend SCP1 to handle different rewards, for example., an animal might act differentially to gain a reward of food versus water. However, no such variation is considered here, and so we simply fix upon a single internal motivational state g with a single, fixed node equal to 1. Value-based associations v are encoded in a modifiable weight matrix that maps to each item, as follows

where Wν, the weight matrix encoding value, is updated according to the difference in expected and actual reward-prediction, based upon temporal-difference reinforcement learning (Sutton & Barto, 1998)
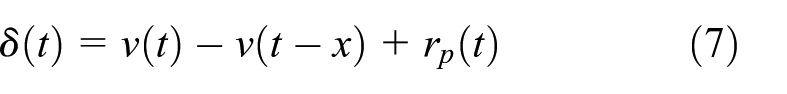
where δ(t) is the reward-prediction error, ν(t) gives the estimated value of the selection made at time t, ν(t − x) gives the estimated value of the selection at t − x (the previous selection, a variable x number of time-steps prior), and rp(t) gives the value of the feedback (described above). Wν is updated according to

where αν is the value learning rate. This retrieves value associations for each visible item that influences decision-making complementary to learned temporal context signals.
5. Simulation results for the SCP1 model
In the SCP experimental results, “repeat” selections were not followed by negative reinforcement (trial termination), but were not rewarded. However, we consider these repeats “wrong” for ease of simulation. (Repeat errors contributed only ∼5% of total errors for our model.) Given random weight initializations and arrangement of items, and so on, we ran 10 simulations of the model to arrive at simulation results we could test for statistical significance. Each simulation ran each of the 7 lists summarized in Figure 6 to criterion; the bars in Figure 6 indicate means, the error bars standard deviation. We compare our results qualitatively to data in the literature, contrasting overall model performance, error rates and error distributions to the literature, as well as contrasting model neural response profiles against known response types as recorded in macaques during structurally similar tasks.
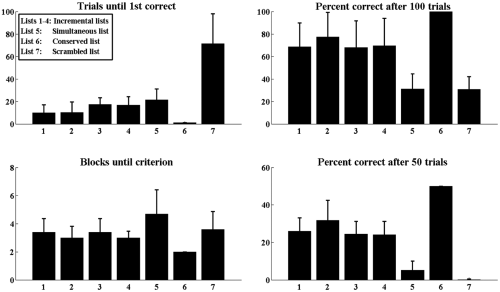
Model behavioral results. Performance measures for the incrementally shaped lists (Lists 1−4) are shown only for the length 4 increment. These lists are easier to learn, on average, than the simultaneous (baseline) list (List 5). Compared to this baseline, conserved lists (List 6) are much easier, requiring virtually no learning to master. Conversely, the scrambled lists (List 7) are substantially more difficult than baseline.
5.1. Learning SCP lists through explicit shaping
The model can indeed acquire SCP lists through incremental shaping. In the simulation, lists are 4 elements long; incremental shaping involves training in which increment k (k = 1, 2, 3, 4) involves reaching the criterion of completion of consecutive blocks of 50 trials above 80% performance prior to training on increment k+1, until the full list was presented. (We also considered alternative criteria, but these did not greatly change the overall behavioral pattern.) In total, we trained four lists of four items each this way. The model was able to learn all four lists in this way, as shown for Lists 1 through 4 in Figure 6. Note the increase in percent correct after 100 trials (two blocks of 50 trials each) as compared to after 50 trials (the first such block).
We also reproduced the finding that monkeys with no prior experience on the task were able to learn lists starting with two or even three items: we re-initialized and re-ran the model with increments starting at “A-B” or “A-B-C.” The condition beginning with “A-B-C” was significantly more difficult to learn compared to beginning with a single item as above, as well as an “A-B” beginning, but each condition can be learned eventually (though the range of parameter values, weight initializations, and so on are more narrow than when beginning with a single item). For the rest of the article, though, we only consider incremental shaping beginning with a single item.
5.2. Learning SCP lists without explicit shaping
Following the learning in (1), a new list of four items was presented simultaneously to the model (i.e. without incremental shaping). See List 5 in Figure 6. The model eventually reached criterion, but on average needed more blocks to reach criterion levels compared to lists 1−4. Figure 6 shows that incremental shaping improves model performance (e.g. percent correct after 50 trials) and learning rates (blocks until criterion). Nonetheless, it is a significant finding that the trained model can indeed reach criterion, although requiring perhaps 50% more trials to do so.
5.3. Sensitivity to list manipulations
Most significantly, the model (unlike S-R, CQ or DAJ models) was able to reproduce the pattern of behavioral results for both conserved lists (Figure 6, item 6)—it performed conserved lists at criterion levels immediately. As a control, we used the list from (2) as a baseline here. Conserved lists were performed at much higher rates than the baseline list from (2) (p < .01). In fact, on average, the total trials required for the conserved list was the minimum necessary to reach criterion.
Conversely, it performed scrambled lists at very low rates (Figure 6, item 7). Across the first 50 trials, the scrambled lists were performed more poorly than baseline (p < .01), as also indicated by the measure of trials until first correct performance (p < .05). On average, however, simultaneous lists (item 5) required more total blocks to reach criterion (p < .01), owing probably to the fact that these items are novel and the weight initializations established weak initial biases.
These results follow from the structure of the temporal memory layer and how its trajectory in state-space is essentially selected upon presentation of visual patterns on the monitor. There exists no sequence-specific privileged starting position—no privileged initial activation state—since variation in monitor configuration projects activity to the temporal memory layer in highly variable ways. Instead, however, the network learns to map the visuo-spatial features to the temporal memory layer. This mapping is, necessarily, arbitrary—it need only do so consistently as a basis for retrieval of the appropriate biases. For conserved lists, the network activates the temporal memory layer in an appropriate initial state despite the features appearing together for the first time. As the temporal memory layer iterates through its state-space, it retrieves the biases previously established, for each state and for each item, and the resultant priority signals drive correct selections (see Figure 7). For scrambled lists, the biases that are retrieved interfere with correct performance and new biases must be learned.
Temporal memory layer retrieval of biases during list manipulations. During the conserved list manipulation, the model must execute a sequence of item selections despite the novel composition on the monitor: the visible items have never appeared together before. The network activates the temporal memory layer into an appropriate initial state from which both the state evolution immediately follows, and the pre-established biases are retrieved according to whether or not the item is currently visible.
Wild card lists consisted of the learned list from (2), with the third item replaced by a novel item (e.g. “ABXD,” where “X” is a novel item not previously encountered by the model). Wild card lists were performed at significantly higher rates (p < .01) than the baseline list from (2) since the introduction of the novel wild card item does not disrupt the temporal memory layer’s state evolution, and so each “familiar” item is strongly associated with a particular context state and not the “open” third list position. Thus, the model essentially selects the novel item by default, though no inference process takes place. We note here, however, that it is possible that such “exclusive inference” processes may underlie at least some cases where monkeys make categorical judgments (Call, 2006; Pan et al., 2014).
5.4. Error rates and distributions
The number of total mean errors made during 4-long increments is greater than for 2- or 3-long increments. Additionally, the total number of errors made during 4-long increments of simultaneous lists are greater than 4-long increments of incrementally shaped lists. By other measures, too, the 4-long simultaneous lists are more difficult than 4-long incrementally shaped lists, including by total number of trials to criterion, total number of blocks to criterion and mean error totals (p < .01).
More precisely, we can examine, for each error made, at what position in the list the error was made, what item was (erroneously) selected, and what type of error that constitutes: repeat (e.g. A-A), forward (e.g. A-C), or backward error (e.g. A-B-A). Forward errors comprise a greater proportion for simultaneous lists, as compared to incrementally shaped lists. However, after the first correct trial, backwards errors comprise only ∼10% of total errors.
Looking at the errors made at positions 3 and 4 (still, for just the 4-long increment) across the incremental and simultaneous lists, we found that making a forward error to item 4 is most common, followed by item 3. Both of these errors reflect reward-predictive influences, since it is this item that is most closely (temporally) associated with reward. Additionally, making errors at position 1 was most common, for both list types.
5.5. Simulated neurophysiological responses and learning-related weight changes
Neurophysiological studies have characterized functional response profiles of neurons involved in many of the information-processing steps in our model. Note, however, that the behavioral data for SCP did not have concurrent neurophysiological data, and so the neurophysiological data with which we now compare our simulated responses are pulled from a multitude of different experimental paradigms. Additionally, we emphasize multiple, concurrent learning processes that contribute to task performance. Learning-related changes are reflected in the re-organization of values in the weight matrices that map activation levels in one layer of neurons to neurons in another layer.
The temporal memory layer in our model is not an a priori rank-order module, and so must learn to generalize across instances of trials, and lists, in such a way that any past associations can be retrieved in future trials. This requires the model to map the visuo-spatial features from the monitor to a subset of neurons in the temporal memory layer—which effectively selects a trajectory in state-space. At first, the mapping is inconsistent. Over exposure to many trials, increments, and lists this mapping generalizes to select an arbitrary temporal memory state as the initial state of the network. By the fourth and final list, the model consistently selects the same initial state for the temporal memory layer, resulting in predictable state evolution of the layer such that strong associations can be established, and existing associations can be retrieved (Figure 8).
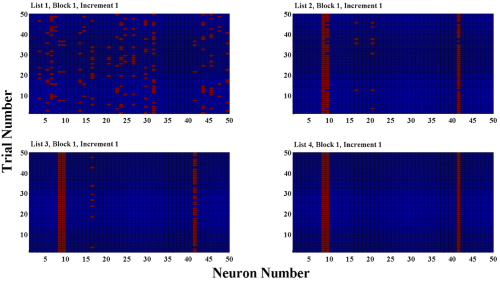
Stabilization in temporal memory layer across training. The model learns to generalize the mapping from visuo-spatial features to the temporal memory layer across training. For the first set of 50 trials (top left; trials are rows, from bottom—first trial—to top—last trial of block—while the columns are temporal memory layer neurons: red = active, blue = quiescent), the initial activation in the temporal memory layer is sporadic, as indicated by a pseudo-random distribution of activation over time. This suggests that as the visual pattern is randomly displayed on the monitor, it interferes with a consistent mapping to the temporal memory layer. For the first set of 50 trials for lists 2 and 3 (top right, bottom left) the mapping appears much more consistent, though there is some variation, owing at this point to the novel combinations of visual features (i.e. a new list means a new set of visual patterns). By the first set of 50 trials for the final, fourth list, the network appears to have successfully generalized the mapping, as the initial activation pattern in the temporal memory layer is fully consistent. This is important for, for example, conserved lists to be able to retrieve the appropriate biases.
The overall activation of neurons in the temporal memory layer can be seen in the top panel of Figure 9, which clearly show how following efferent feedback from item selections, the layer updates and settles into a new state, as indicated by a new pattern of activity across its surface (though note that the distributed code across the surface is rendered as a single curve in Figure 9). The biases that are retrieved from each state influence the behavioral priority signal represented in the planning layer (behavioral priority) neurons, also shown. The Appendix 1 describes the submodel which converts behavioral priority into action. Specifically, behavioral priority neurons inform competition layer neurons, which themselves drive a final layer of neurons above threshold—the accumulator neurons. The activations of these neurons participating in competitive decision-making resemble response profiles characterized in the literature. We discuss some of these data in the Discussion.
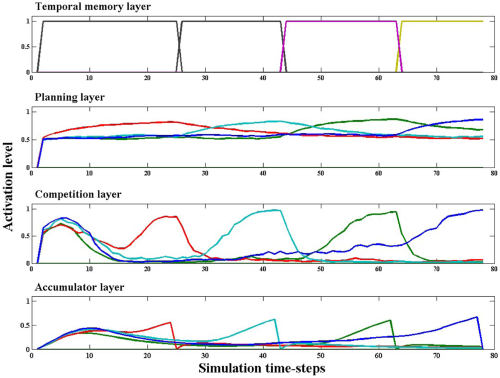
Sample activation profiles during a correct trial. Here, we see the four phases of activity as the monkey touches successive targets during a correct trial. The temporal memory layer neurons encode the state of execution through binary activation levels. (Recall that the representation here is distributed, but the “profile” view here only renders a single curve.) These states retrieve, during each of the four phases, the temporal context biases that integrate with value-based signals to drive planning layer neurons. In the next three panels, we use color coding to show how activity levels favor one pattern during each phase. The planning layer (= Behavioral Priority Map) neurons encode the behavioral priority for each visual pattern. The last two traces correspond to the output submodel described in the appendix 1 which converts a small advantage in the behavioral priority map into a decisive action. The competition layer neurons integrate planning layer, inhibitory layer (not shown) and self-excitatory signals to compete for expression. The instantaneous firing rates are shown for each. Finally, the accumulator neurons are driven by corresponding competition layer neurons above threshold, and initiate disinhibition in the basal ganglia gating system. The membrane potentials of accumulator layer neurons are shown here.
6. Predictions
The primary claim of the model is that the strict temporal organization must be learned, and not just item-by-item associations. Another claim of our model is that decision-making does not occur, at least not exclusively, in amodal networks. Instead, decision-related variables (contextual, motivational, etc.) are represented together with visuo-spatial and motoric parameters (Cisek, 2007). Above, in Figure 9, we displayed the neural response profiles of a subset of the neurons comprising our behavioral priority map. Alternatively, we can visualize these responses within a structure topographically correlated with the touch-screen monitor to show how these responses additionally encode parameters for motor control—as opposed to, as in the case of amodal decision networks, needing then to retrieve these motor parameters from other networks (Figure 10). Figure 10 shows activations of the planning layer neurons at the time of item selections, where warm colors correlate with stronger activation and cool colors with weak activation. Figure 11 collapses the 2-D structure from Figure 10 and adds a time dimension. We predict that neurons in posterior parietal cortex and dorsal premotor cortex—each involved in managing reaching movements (e.g. parietal reach region and dorsal premotor cortex)—would encode reaching parameters together with decision-related variables in behavioral maps.

Priority map activation over course of trial. The priority map in our model provides a topographic structure, correlated to the visuo-spatial organization provided by the monitor, to the competition network that ultimately makes item selections. Areas of warm, bright colors indicate strong activation, and show not only what item selection was made, but also what that selection involves in actual execution.
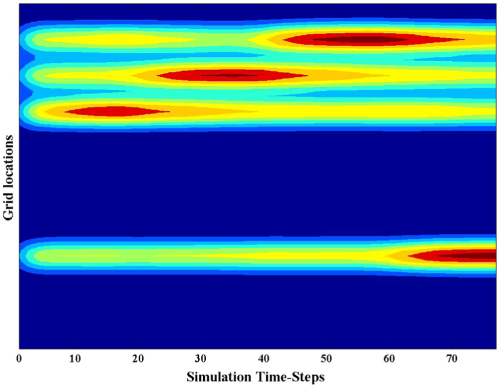
Time-course of activations in the behavioral priority map. The competition network is topographically correlated with the touch-screen monitor. We see here, by rendering the 2-D surface of the planning layer neurons as a 1-D layer (y-axis), how the time-course (x-axis) of activation varies spatially and temporally, and how the strength of activation (warm colors = more activation, cool colors = less activation) correlates with time of selection. Note: this visualization applies a Gaussian filter across the map for ease of viewing.
7. Discussion
We have demonstrated how our model can master a complex list learning task by leveraging multiple, concurrent learning processes, while other models appear insufficient in explaining the range of behavioral results obtained. We additionally have shown how decision-making networks based on competitive interactions between action plans may be situated in topographically structured maps to facilitate fluid interaction with one’s immediate environment. Of course, our model is necessarily simplified in its implementation, but provides nonetheless a framework for modeling more complex sequential behaviors and the learning that support those behaviors that are not buttressed by, for example, S-R associations and explicit environmental feedback following one’s actions.
Our temporal memory system is not an a priori ordinal representation module. While it is a deterministic system and provides sufficient cues for list learning, it contains both no single “initial or pre-established biases mapping states to actions.” Instead, both initial state and biases must be learned in time, and in a sense this pattern of learning—and the activations that causally influence the decision processes—is arbitrary, since each simulation can, and does, result in different activation patterns within the context layer that nonetheless result in highly competent performance. Thus, the expert animal presumably has access to these representations and has appropriate associative biases, but we instead suppose a naïve animal may not spontaneously understand the task. In the single-unit recording studies cited above, too, the monkeys undergo considerable training—upward of many months—prior to any neural recording sessions, and so have time for systems to adapt themselves to task conditions. Thus, for our model, the monkey must slowly learn that leveraging higher-order contextual representations contribute to reward, while other equally probable sensory variables may not.
Our model contrasts temporal context signals with reward-modulated value signals—each an essential and necessary component of most decision-making. For instance, multiple brain regions, including lateral prefrontal cortex (LPFC) (Kennerley & Wallis, 2009, Watanabe & Sakagami, 2007), orbitofrontal cortex (OFC) (Wallis, 2007) and many more are implicated, and their signals are known to be modulated by diverse aspects of “reward.” Such reward-modulated responses can be contrasted with neurons representing cognitive variables like “rank” and “numerosity” that are not greatly modulated by explicit reward-based/value-based considerations, and so are viewed as distinct (Berdyyeva & Olson, 2009, 2011). Thus, it appears that in the service of complex, extended tasks, representations of reward expectation and representations specific to the structure of the task (temporal, spatial, etc.) can be maintained in separable populations of neurons, only to be eventually combined to affect response selection, as demonstrated by Watanabe and Sakagami (2007).
This more-or-less fits the paradigm from ACQ that affordance-based signals identify the executability of different actions and then combine with reward-based signals that identify the desirability of those actions. The resultant integrated signal is the behavioral priority from which decision-making is based. We merely extend the notion of affordance-based executability to encompass not just externally driven representations but also internally driven and maintained signals like temporal context, discussed above, which then also combine with reward-related information to inform decision-making.
Our model leverages multiple, concurrent learning processes to master the Simultaneous Chaining Paradigm, though it is worth pointing out that multiple other learning processes are neglected in this iteration of the model. The monkeys tested by Terrace and colleagues mastered numerous lists, and during learning were exposed to upward of a hundred or more visual patterns. So far as we can tell, no real attempt was made to study the perceptual discrimination abilities of the monkeys and how visual interference possibly contributed to error rates. Additionally, Terrace et al. (2003) reported an increase in task expertise over the course of many trials, as indicated by a reduction in un-informative errors and in the number of total trials required to reach criterion levels. We have shown partial results that support generalization, but note that a full accounting of the development of task expertise is lacking in our model. Our generalization involves learning to span the space of visual features, applying the learning encountered across a subset of features to the full set—thus, later lists become less difficult to master. However, more sophisticated “meta-learning” is also possible, as in the models of Schweighofer and Doya (2003). There, the reinforcement learning formalisms provide a set of parameters—learning rates, time-discounting, and so on—that can be controlled through learning, and which provide a more adaptive learning framework.
7.1. Social learning
In the companion article (Gasser & Arbib, 2017), we offer an explicit extension (SCP2) of this article’s SCP1 model which is able to support observational facilitation of list learning in macaques as investigated by Subiaul, Cantlon, Holloway, and Terrace (2004).
In closing, we note two further challenges that should be addressed in further tests of SCP1, and/or in the development of extended or competing models but which are outside the scope of the present effort.
7.2. Pair subset testing
In several of the papers by the Terrace group (Jensen, Altschul, Danly, & Terrace, 2013; Terrace et al., 2003), SCP learning is followed by presentation of stimulus pairs. These may be viewed as two-item conserved lists. Not only do subjects reliably perform above chance on these pairwise presentations, they also show a reliable symbolic distance effect ((D’Amato & Colombo, 1990); in the SCP context, see Terrace et al., 2003, Figure 4). These symbolic distances are reliably observed even when the two list items were drawn from two separate lists, and Jensen et al. (2013) show that this symbolic distance effect for response accuracy can be described in terms of a simple logistic model, with response accuracy growing as a log-odds function of the symbolic distance. A next step for SCP1 would be to test whether it can predict this log-odds function. However, in this article, our emphasis has been on finding a possible mechanism that explains the phenomena of conserved and wild card lists.
7.3. List linking
An exciting challenge for future modeling is to assess how learning long lists might be improved by chunking the problem as a splicing of sublists. For example, Treichler et al (2003) trained three 5-items lists and, with training on just “connecting pairs,” were able to yield practicable serial learning of a 15-item list. A later attempt (Treichler, Raghanti, & Van Tilburg, 2007) to use the same strategy to yield a 45-item list was not altogether successful.
Footnotes
Appendix 1
In the core of the SCP1 model, the representations are basically reset at the beginning of each trial and then, within the trial, each time an action is taken. In this appendix, we make explicit the dynamic interactions whereby the current state of the Behavioral Priority Map is converted into the selection of which square to touch. Thus, we move from discrete state neurons occasionally reset to hold a static representation awhile to leaky-integrator neurons whose competition and cooperation plays out on a finer time scale.
We first model a competitive neural network composed of leaky-integrator style membrane potentials and sigmoidal firing rates to arrive at an item selection. Motor output then involves disinhibiting a particular unit (corresponding to the selection of a tile on the touch-screen monitor) through a basal ganglia-based gating mechanism which we describe in the second subsection below.
This appendix provides a set of parameter values (Table 1) used in the simulations reported here.
Acknowledgements
We thank Reviewer 1 for comments that greatly enriched the suggestions for future work in the Discussion section.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based in part on work supported by the National Science Foundation under Grant No. BCS-1343544 “INSPIRE Track 1: Action, Vision and Language, and their Brain Mechanisms in Evolutionary Relationship” (Michael A. Arbib, Principal Investigator).