
Abstract
The foraging task is a commonly studied scenario for distributed swarm robotic systems. The robots switch searching and resting behavior in a distributed manner to perform foraging quickly and energy efficiently. It is known that robots that are resting can act as a potential labor pool in addition to saving energy. Because they function as a potential labor pool, resting robots can help with foraging if needed. In this study, we consider the group foraging task, which requires two or more robots to transport a food item. In a group foraging task, resting robots can help with the transportation of a heavy food item in response to the recruitment of other robots. Until now, the efficacy of the resting behavior as a potential labor pool has been suggested, but the environments in which this function is dominant is still unknown. In this study, we propose a state-transition model for robots that includes the resting behavior and investigate the performance through multi-agent simulation. By comparing models with and without the resting behavior, we found that the function of the resting behavior as a potential labor pool is dominant in cases when the food items are heavy or the population is small.
1. Introduction
A swarm robotic system (SRS) is composed of a swarm of robots that perform a given task faster than a single robot by actuating in different places simultaneously. Therefore, SRSs are expected to be used for several practical tasks such as warehousing (Digani et al., 2013), agriculture (Barrientos et al., 2011), and rescue activities (Kantor et al., 2006). In the design of a robot controller in a swarm, autonomous distributed control has attracted increasing attention in recent years (Bayindir, 2016). In autonomous distributed control, there is no central integrator, and each robot can access only local information. These limitations provide the robotic system with scalability, flexibility, and robustness.
The foraging task is a commonly studied scenario in SRSs as a model for real-world applications. In the foraging task, a specific area is designated as the nest and food items are scattered in the environment. The objective of the swarm is to discover the food items and then transport them to the nest. In addition, task allocation refers to the ability of each agent to dynamically change its task in a distributed manner (Hayakawa et al., 2020; Schmickl & Karsai, 2014). The challenge of SRS in the foraging task is to achieve task allocation such that the swarm of robots completes foraging quickly and energy efficiently.
Social insects allocate tasks for the foraging in a distributed manner, which inspired the solution for task allocation in SRSs. Wilson found that individual ants have a threshold they use to determine their response to a task (Wilson, 1984). Low-threshold resting ants become engaged in a task at a lower level of task-associated stimulus than high-threshold resting ants. In this way, the balance between the number of working and resting ants is dynamically adjusted in response to the environmental change. Based on this observation, the corresponding mathematical model, which is called the response threshold model, was constructed (Bonabeau et al., 1998).
The response threshold model has been used in foraging tasks for a swarm of robots. Task switching from resting to searching is represented using either probabilistic methods or threshold-based methods (Bayindir, 2016). In the following, we introduce both methods in solitary foraging scenarios in which each robot can transport a food item by itself. In probabilistic methods, each robot has a task switching probability, by which each robot switches its current task. Yang et al. give all robots an identical threshold value in the response threshold model (Yang et al., 2009). When food quantity inside the nest decreases, the task-associated stimulus increases. In that case, according to the response threshold model, some resting robots start searching for food items. In this way, food quantity inside the nest can be stabilized to a specific level. Castello et al. improved the response threshold model proposed by Yang et al. (2009) in such a way that each robot dynamically adjusts its personal threshold in response to the current stimulus (Castello et al., 2013). In a robot experiment, it was verified that the stability of the food quantity inside the nest was improved (Castello et al., 2016). Meanwhile, Labella et al. proposed another method to adjust the task switching probability (Labella et al., 2006). In this method, the probability increases in response to successful food retrieval, whereas the probability decreases when food retrieval fails. It was verified that this adaptation scheme contributes to energy-efficient foraging.
Meanwhile in threshold-based methods, each robot has a threshold value, and when a certain quantity reaches the corresponding threshold value, the robot always switches its task. Krieger and Billeter gave each robot a heterogeneous threshold value (Krieger & Billeter, 2000). When the energy level inside the nest is lower than the threshold of a resting robot, then the corresponding robot starts searching for food items. In this way, the food quantity inside the nest was stabilized to a specified level. Liu et al. dynamically changed the maximum resting and searching period of each robot in response to inter-robot collision, its own food retrieval result, and the food retrieval results of other robots (Liu et al., 2007). In detail, when each robot performs a resting (searching) behavior for the corresponding maximum resting (searching) period, then the robot switches its task. The adaptation of these periods improves the energy efficiency of foraging. Additionally, parameters related to the adaptation were optimized using genetic algorithms to maximize the net energy (Liu & Winfield, 2010).
Task allocation also has been studied for a foraging task consisting of sequentially dependent subtasks. A cache area, where the food items can be stored temporarily, is prepared between the food-searching area and the nest. Food items can be transferred from harvesting robots that search for food items to storing robots that transport the food items to the nest at the cache area indirectly. Following studies focus on task allocation between harvesting and storing to collect food items as much as possible. Pini et al. proposed the adaptive method for individual robots to decide whether to transport food items via the cache area by allocating the tasks or other long route (Pini et al., 2011, 2013). Brutschy et al. proposed the task switching rule based on the delay that the robots wait at the cache area (Brutschy et al., 2014). Lee et al. proposed the task switching rule such that adaptive task allocation is achieved under the mathematical guarantee (Lee et al., 2020). Ferrante et al. used an evolutionary algorithm to generate desirable task allocation of robots entirely from scratch (Ferrante et al., 2015).
The above studies assume solitary foraging scenarios. By contrast, group foraging is a foraging scenario in which the food item is so heavy that the cooperation of multiple robots is required to transport the food item. One application of group foraging in real life is human transportation in rescue missions (Gross et al., 2006). Group foraging is composed of a stage to gather a sufficient number of robots at the location of the food item and a stage to achieve cooperative transport. In the case of cooperative transport, robot controllers to achieve the desired velocity of the food item have been constructed (Farivarnejad et al., 2016; Wang & Schwager, 2016). Moreover, cooperative transport of ants has been analyzed (Berman et al., 2011; Feinerman et al., 2018) and emulated by swarm robotic systems (Wilson et al., 2018).
In the following, we summarize the robot controllers used in a swarm to perform the group foraging task including gathering of robots and cooperative transport. Fujisawa et al. constructed a state-transition model of robots by imitating ants, which lay pheromone trails (Fujisawa et al., 2014). In the state-transition model, all robots search for a food item without taking a rest. When one of the robots discovers a food item, it pushes the food item. If the food item cannot be transported due to a lack of power, then the robot lays a pheromone trail between the food item and the nest. When other searching robots perceive the trail, they travel toward the location of the food item along the trail. The above process is repeated until a sufficient number of robots have gathered at the location of the food item; thus, after a while, the robots can successfully transport the food item to the nest. Ijspeert et al. constructed a state-transition model for a stick pulling task which require cooperation of two robots (Ijspeert et al., 2001). In this study, heterogeneous gripping time parameter and inter-robot communication enhanced the number of successful stick pulling. Nouyan et al. constructed a state-transition model by which each robot serves as a landmark between the food item and the nest (Nouyan et al., 2009). By following the chain of the landmarks toward the food item, a sufficient number of robots have gathered at the location of the food item. Then, the robots can successfully transport the food item to the nest by following the chain toward the nest. On the other hand, when the robot serves as a landmark in the wrong place, it returns to the nest. The objective of the returning behavior is not resting but dissolving the wrong chain. Chen et al. focused on group foraging that the food item can occlude the robots’ perception of the goal location (Chen et al., 2015). When a robot performing a random walk has reached a food item, it moves such that the goal cannot be seen from the position. Then, it pushes the food item perpendicularly toward the food item’s surface in front of it. Based on this simple behavior, it was mathematically proved that the food item ultimately coincides with the goal. Jurt et al. constructed another state-transition model such that all robots search for an object without taking a rest (Jurt et al., 2022). When a sufficient number of robots are located at the object, then the robots agree on the timing of transportation. Alternatively, some robot behaviors for group foraging have been autonomously obtained using evolutionary computation (Yu et al., 2013) and deep reinforcement learning (Jin et al., 2020). Through learning, the robots acquire a behavior that causes them to gather together at the location of the food item without taking a rest. Then, they cooperatively transport the heavy food item. One limitation of computational learning methods based on neural networks is that neural networks are black-box systems, and therefore it is often very difficult to understand the behavior of these robots (Brambilla et al., 2013). As noted above (Chen et al., 2015; Fujisawa et al., 2014; Ijspeert et al., 2001; Jin et al., 2020; Jurt et al., 2022; Nouyan et al., 2009; Yu et al., 2013), several robot controllers have been proposed for group foraging. In those studies, energy efficiency was not evaluated, only task execution speed; thus, those controllers did not include a resting state.
However, in addition to saving energy, it is known that the resting behavior has the function of creating a potential labor pool. It can be beneficial to have a pool of resting workers available to take on larger tasks when they become available (Charbonneau & Dornhaus, 2015; Charbonneau et al., 2017) or to respond to a change in task demand (Radeva et al., 2017). Examples are as follows. In some ant species, when an ant discovers a food item outside the nest, it returns to the nest and actively recruits other ants inside the nest through antenna contact (Davidson et al., 2016). Those resting ants then start working and help retrieve the food item (Daly-Schveitzer et al., 2007; McCreery & Breed, 2014). In this way, these resting ants are exploited as a labor pool. Hayakawa et al. constructed a mathematical model of the life cycle of ants that allocates several tasks (Hayakawa et al., 2020). In the model, resting agents switch their task to another task that requires labor. Through simulation, it was verified that the task switching of the resting state improves the disturbance resistance of the colony. Hasegawa et al. used simulation to investigate the potential labor pool function of resting agents from the viewpoint of the sustainability of a colony (Hasegawa et al., 2016). The resting agents start working when the current workers become fatigued; thus, the resting agents perform the critical function of replacing workers. In this way, the agents process the task continuously as a swarm, and therefore the swarm obtains long-term sustainability.
As demonstrated in the above studies (Daly-Schveitzer et al., 2007; Hasegawa et al., 2016; Hayakawa et al., 2020; McCreery & Breed, 2014), the function of resting workers as a potential labor pool has been investigated in several ways. In group foraging, the resting behavior does not contribute to searching for food items, although it does function as a potential labor pool. However, state-transition models focusing on this function as a potential labor pool has not been constructed in terms of group foraging. Because of this, it is not fully understood when and how the resting behavior is effective in group foraging. In this study, we propose a robot state-transition model that includes the resting behavior. Using the state-transition model and multi-agent simulation, we investigate the situations in which the resting behavior functions as a potential labor pool and dominates performance.
The rest of this article is consisted as follows: Section 2 describes the problem setting, and Section 3 presents the proposed robot state-transition model. Section 4 presents the simulation setting, and Section 5 reports the simulation results. Section 6 concludes this article.
2. Problem setting
2.1. Environment
A field consists of a nest with a radius of rN and a search area that are located concentrically on a two-dimensional plane (Figure 1(a)). The radius of the whole area is rS. Global coordinate system is denoted by ∑
G
≡ (O − x y), whose origin O is set to the center of the nest and global axes x and y are fixed as shown in Figure 1(a). Initially, there are NR robots, each with a radius of rR, inside the nest and NF food items, each with a radius of rF, scattered in the search area. The purpose of the swarm of robots is to transport the food items to the nest quickly and energy efficiently. For each food item j, the weight is m, the angle from x-axis is denoted by ϕ
j
, and distance from the center of the nest is denoted by d
j
. Setting of the field and robot. (a) Field. (b) Side view of the robot. (c) Top view of the robot.
2.2. Robot specifications
In this study, the hardware and controllers of all robots are identical. There is no central integrator that comprehensively controls the robots; every robot autonomously determines its own behavior based on local information in a distributed manner. Each robot is equipped with the mobility such that the movement in any direction and the rotation on a two-dimensional plane are possible, for example, using three omnidirectional wheels (Yoshimoto et al., 2018) as shown in Figure 1(b).
Additionally, each robot is equipped with the following inexpensive and limited capabilities (Figure 1(b) and (c)): • The robot can physically connect with another robot. For example, the robot is equipped with a passive ring around the body and an active gripper. The robot can grab the ring of another robot using the gripper so that they physically connect (Mondada et al., 2005). • The robot can indicate the robot’s current state in the state-transition model, for example, using multi-color LEDs around the body (Mondada et al., 2005). The state-transition model includes at most nine states (see Section 3.3 in detail); thus, the difference between states can be indicated by changing the color. • The robot can sense the position and state of neighboring robots and the position of neighboring food items, for example, using an omnidirectional camera with sensing distance lC (Mondada et al., 2005). When a part of a food item or robot is inside the sensing area, then it can be sensed. • The robot can measure the robot’s current position with respect to ∑
G
, for example, using a light sensor and a compass. By indicating the nest position (i.e., the origin of ∑
G
) using a light source, the robot can measure the nest position with respect to the robot coordinate using the light sensor (Fujisawa et al., 2014). Additionally, x and y directions can be measured by the compass (Zahugi et al., 2012).
2.3. Simulation model
In this study, to achieve the fast simulation under a large number of robots, we construct a custom-built multi-agent simulator. In the simulation, the position of the robot is determined based on the velocity input.
The dynamics of the food transportation is modeled as follows: When m or more robots push a food item in the same direction, then the corresponding food item is moved along with those robots.
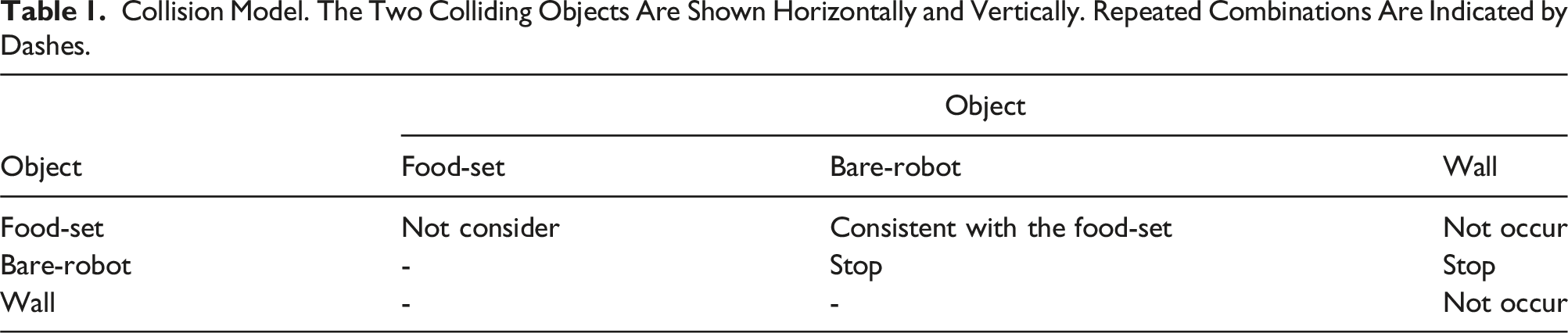
Collision Model. The Two Colliding Objects Are Shown Horizontally and Vertically. Repeated Combinations Are Indicated by Dashes.
3. Robot controller
We propose a robot controller for group foraging that includes the resting behavior. For the controller, we combine a conventional state-transition model of SRSs for solitary foraging (Liu et al., 2007) and an ant recruiting behavior for group foraging (Daly-Schveitzer et al., 2007).
3.1. Conventional state-transition model for solitary foraging
First, we introduce a state-transition model of the SRS that includes the resting behavior for solitary foraging. Figure 2 shows the state-transition model, which simplifies the threshold-based robot controller in Liu et al. (2007). State-transition model for solitary foraging, which is a simplified version of the model proposed by Liu et al. (2007). The upper part in each box shows the state and lower part shows the behavior.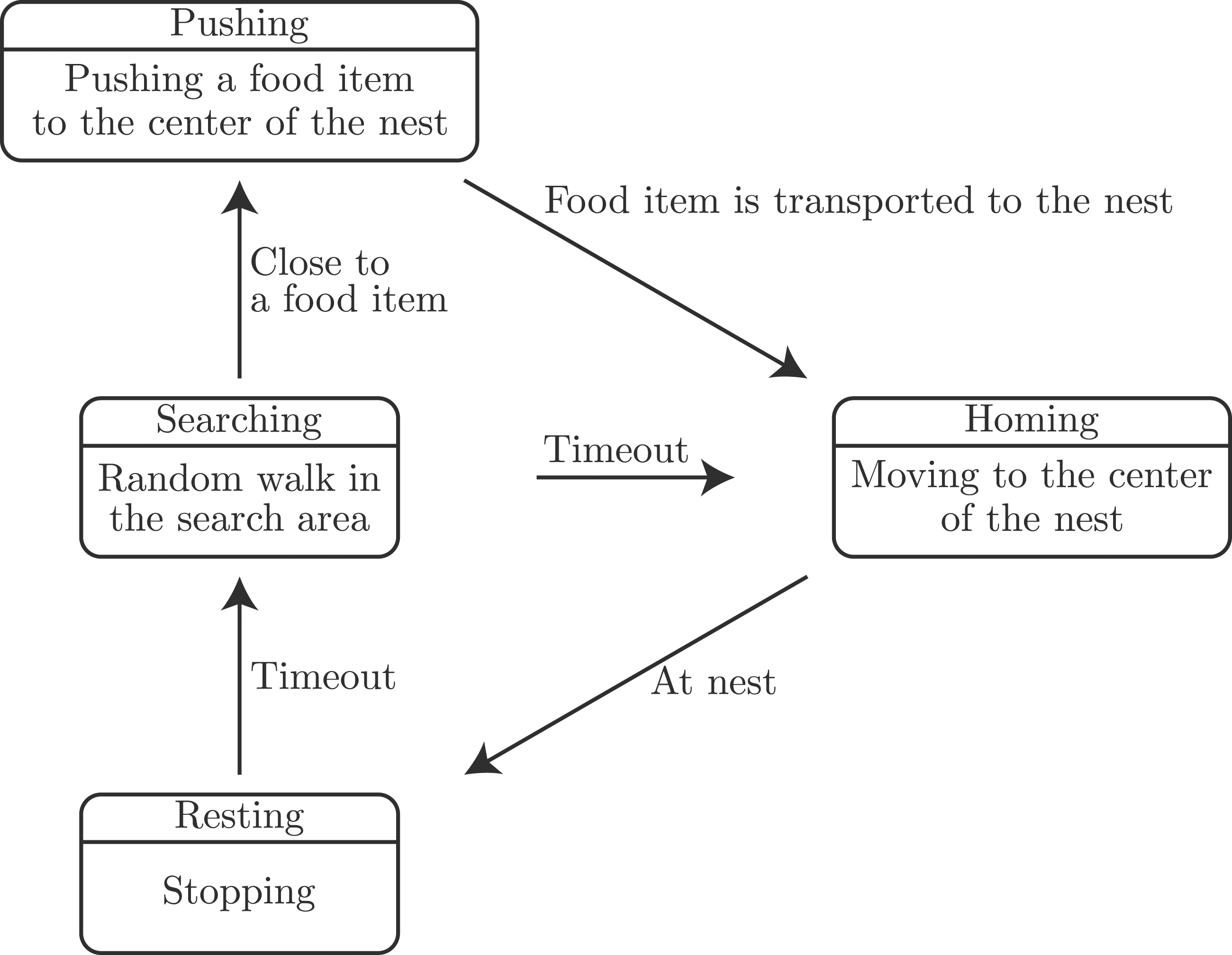
Next, we describe in detail the state-transition model.
In the above transition flow, robots in the Searching and Resting states exist simultaneously. By optimizing the timeout parameters, energy-efficient foraging can be achieved under several food density and population conditions (Liu et al., 2007).
3.2. Ant recruiting behavior for group foraging
Next, we introduce the recruiting behavior of the ant species Gnamptogenys sulcata (Daly-Schveitzer et al., 2007). When an ant discovers a food item (we call this ant the “finder”), the finder tries to transport the food item by itself. If the food item is light enough for the finder to transport, the finder transports the food item by itself. In this case, the foraging is equivalent to solitary foraging. By contrast, if the food item is so heavy that the finder cannot transport it, the finder returns to the nest while laying a chemical trail. After alerting its nestmates, the finder remarks the chemical trail back to the location of the food item. Because of this recruitment, a certain number of nestmates in the nest start to work and move toward the location of the food item by following the chemical trail that the finder has laid. Then, the following ants cooperatively try to transport the food item. If they still cannot transport the food item, the finder returns to the nest and recruits nestmates again. This process is repeated until the total number of ants located at the food item becomes sufficient; thus, the ants finally transport the food item.
3.3. Proposed state-transition model for group foraging
We extend the state-transition model for solitary foraging including the resting behavior (see Section 3.1) to a model for group foraging by adding the ant recruiting behavior (see Section 3.2). Figure 3 shows the proposed state-transition model for group foraging. When the food item is light enough for one robot to transport, then the robot behavior in Figure 3 (black and green states and transitions) is consistent with that for solitary foraging in Figure 2. Proposed state-transition model for group foraging. The upper part in each box shows the state and lower part shows the behavior. The green state represents the initial state of robots. Red states and transitions are newly added to the state-transition model for solitary foraging shown in Figure 2.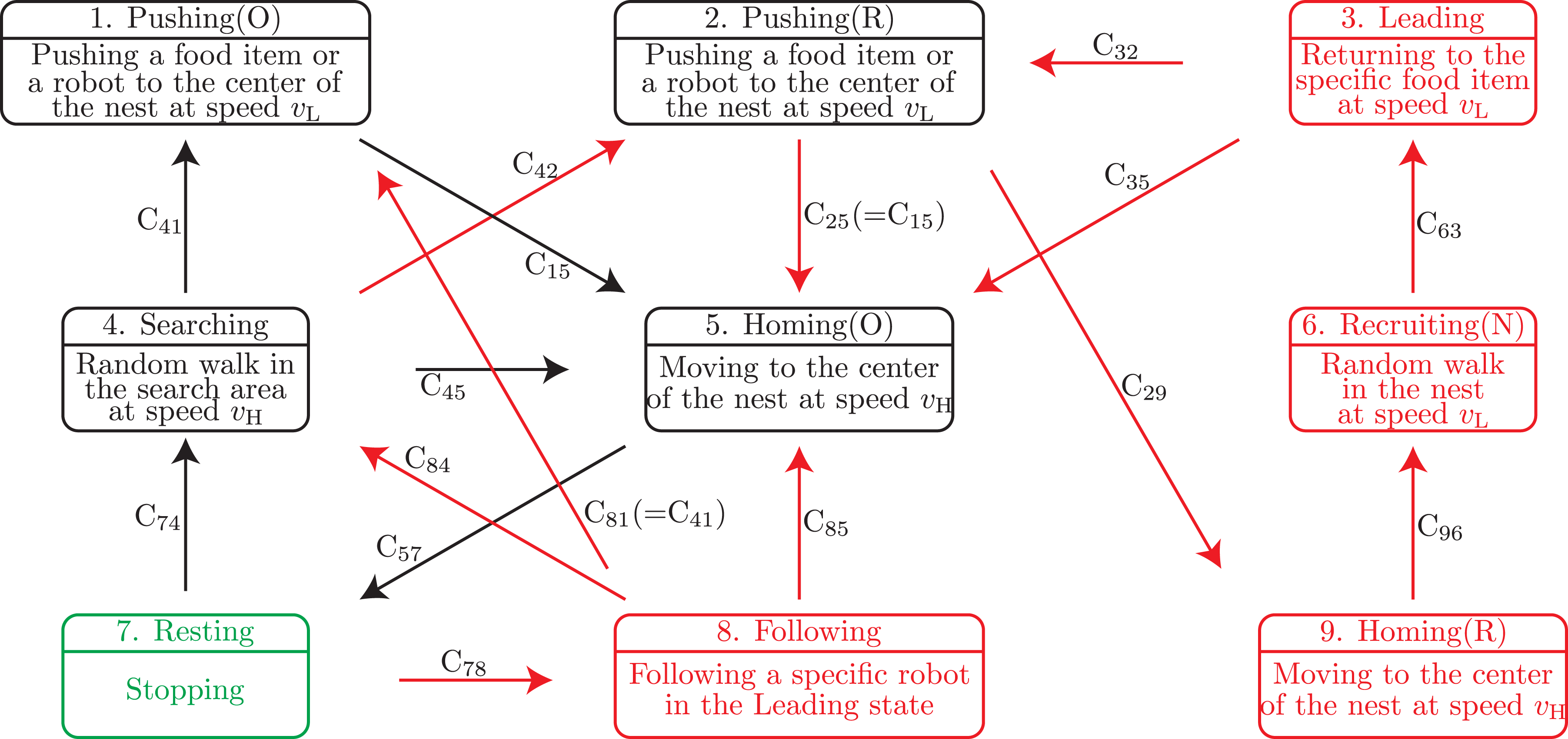
In the following, we explain the behavior and transition model of each state. All symbols representing a position are seen from ∑
G
and symbols representing a direction are seen from x-axis. Let To clarify the behavior of the robot, we define the following conditions (2)–(4). (2) means that there is a food item within the camera’s field of view under the condition that the food item is not being transported. (3) means that a collision occurs in the previous time step. When (3) holds, then the robot changes its moving direction randomly. (4) means that the robot moves a sufficient distance continuously toward a specific direction, where lW(t) corresponds to the mean free path of the random walk at time t. After a robot moves lW(t), the robot changes its moving direction. When the robot searches for food items, lW(t) is set to a large distance lH. However, when the robot approaches the found food item, the robot aims at moving toward a specific place (i.e., the found food item); thus, lW(t) is set to a small distance lL only for resolving inter-robot collision. v
i
(t) and θ
i
(t) are determined in accordance with Algorithm 1, where in the initial state, θ
i
(t) is set to a random value. In Algorithm 1, the behavior of the robots that do not enter the nest is omitted to simplify Algorithm 1. The value atan2(y, x) ∈ [0 2π) is atan(y/x) with its quadrant using two parameters x and y.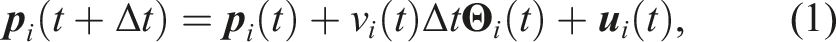

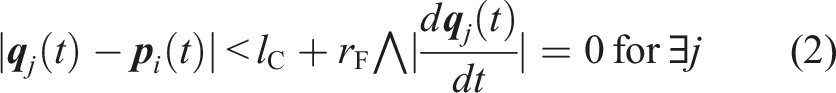

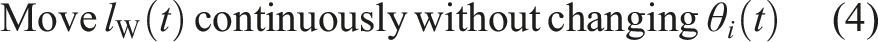



Let C
kl
be a state-transition condition in the proposed model from state k to state l, as shown in Figure 3. Let τ
i
(t) be the duration robot i has been operating in its current state at time t. Duration τ
i
(t) increases as time goes by and is reset to 0 when robot i changes its state to another state. Let TR, TS, TP, and TW be the maximum durations of resting, searching, pushing, and recruiting, respectively. In the initial state, all robots are located randomly within the nest and set to the Resting state such that the τ
i
(0) for each robot i is set randomly within the range [0 TR]. The state-transition model of each state is summarized as follows: C15: The center of the transporting food item enters the nest area, that is, | C29: τ
i
(t) > TP holds under the condition that the food item is not being transported, that is, C32: The robot is close to a food item that is not being transported. Alternatively, the robot is close to another robot in the Pushing(O) state under the condition that a food item that is not being transported is within the camera’s field of view. Here, Pushing(R) state is excluded because the robot in the Pushing(R) state moves away from the food item in a short time for recruitment. Let I
s
(t) be an index set of robots whose state is s at time t. To clarify the state-transition condition, we define the following conditions (5) and (6). (5) means that there is a food item which is contacting to the robot under the condition that the food item is not being transported. (6) means that there is a robot in the Pushing(O) state that is contacting to the robot. C32 is equivalent to the condition of (5) ∨ (6).
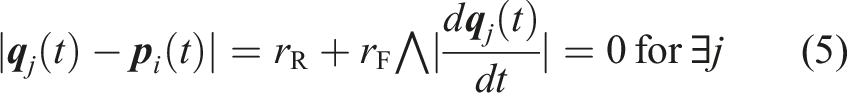
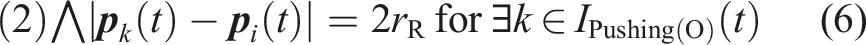
C35: There is no food item that is not being transported within the camera’s field of view under the condition that the robot has returned to the position of the found food item, which is stored in its memory. In other words, (2) does not hold under the condition that |
C41: The robot is close to a food item that is not being transported under the condition that another pushing(R) or Pushing(O) robot is within the camera’s field of view. Alternatively, the robot is close to another robot in the Pushing(O) state under the condition that a food item that is not being transported is within the camera’s field of view. To clarify the state-transition condition, we define the following condition (7). (7) means that there is a robot in the Pushing(R) or Pushing(O) state within the camera’s field of view. C41 is equivalent to the condition of ((5)∧(7))∨(6).
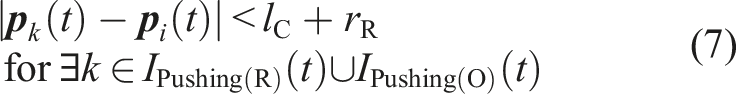
C42: The robot is close to a food item that is not being transported under the condition that no other robot in the Pushing(R) or Pushing(O) state is within the camera’s field of view. In other words, (5) holds under the condition that (7) does not hold. C45: τ
i
(t) > TS holds. C57: The robot collides with another robot under the condition that the center of the robot has entered the nest area. Alternatively, the center of the robot reaches the center of the nest. In other words, (| C63: τ
i
(t) > TW holds. C74: τ
i
(t) > TR holds. C78: Another robot in the Recruiting(N) state is within the camera’s field of view. C78 is equivalent to the following condition (8). C84: The robot that is being followed is within the camera’s field of view and transits its state to Pushing(R). C84 is equivalent to the following condition (9). C85: The robot that is being followed is within the camera’s field of view and transits its state to Homing(O). Alternatively, the robot that is being followed is outside the camera’s field of view. To clarify the state-transition condition, we define the following conditions (10) and (11). C96: The center of the robot enters the nest area, that is, |
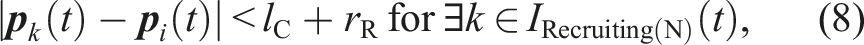
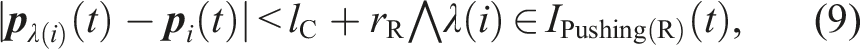
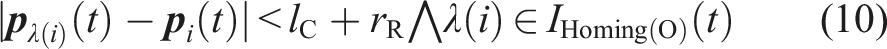
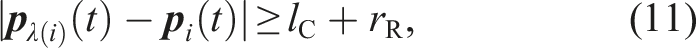
Mathematical Descriptions of All State-Transition Conditions.

As shown in Section 3.2, a finder ant first returns to the nest, then performs recruiting for a certain period, and then returns to the food item. This single cycle of the recruiting behavior corresponds to the following flow: Searching
Meanwhile, a resting ant follows a finder ant, reaches the food item, and then pushes the food item as part of the additional labor pool. The following behavior corresponds to the following flow: Resting
In this way, by repeating the recruiting behavior, the total number of robots that are located at the found food item increases.
4. Simulation setting
We verified the efficacy of the proposed state-transition model for group foraging through multi-agent simulation. In the simulation, the foraging performance of the proposed state-transition model with the resting behavior and another conventional model without the resting behavior was compared.
4.1. Conventional state-transition model without resting for comparison
As explained in Section 1, the conventional robot controllers for group foraging do not include a resting state (Chen et al., 2015; Fujisawa et al., 2014; Ijspeert et al., 2001; Jin et al., 2020; Jurt et al., 2022; Nouyan et al., 2009; Yu et al., 2013). In accordance with those previous studies, we newly constructed a state-transition model without resting and homing states, as shown in Figure 4 for comparison. In the following, we call the state-transition model in Figure 3 the proposed model, whereas the state-transition model in Figure 4 is called the conventional model. State-transition model for group foraging without a resting state. The upper part in each box shows the state and lower part shows the behavior. The green state represents the initial state of robots. Red state and transitions correspond to the modified parts of the proposed model in Figure 3. C
kl
is common to Figure 3.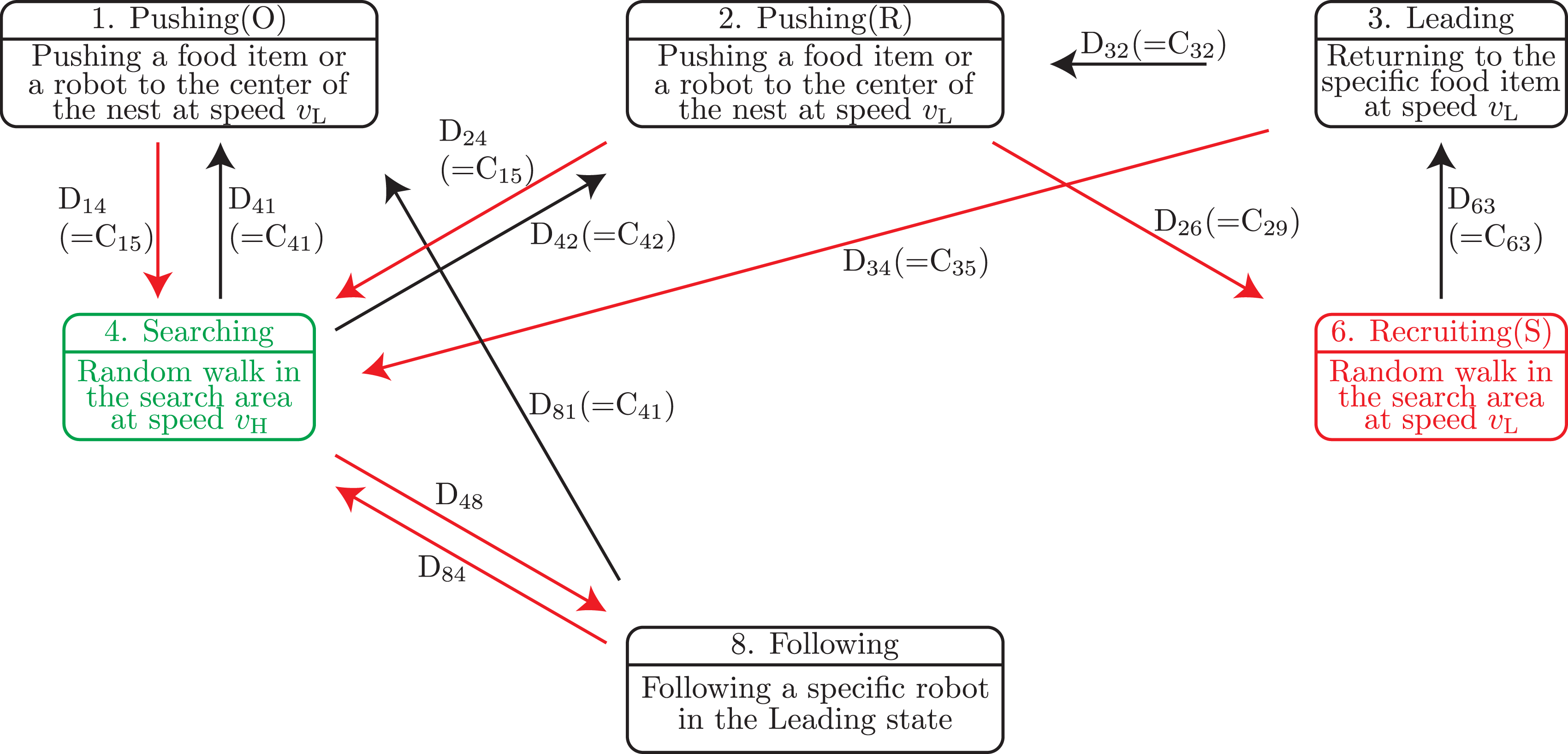
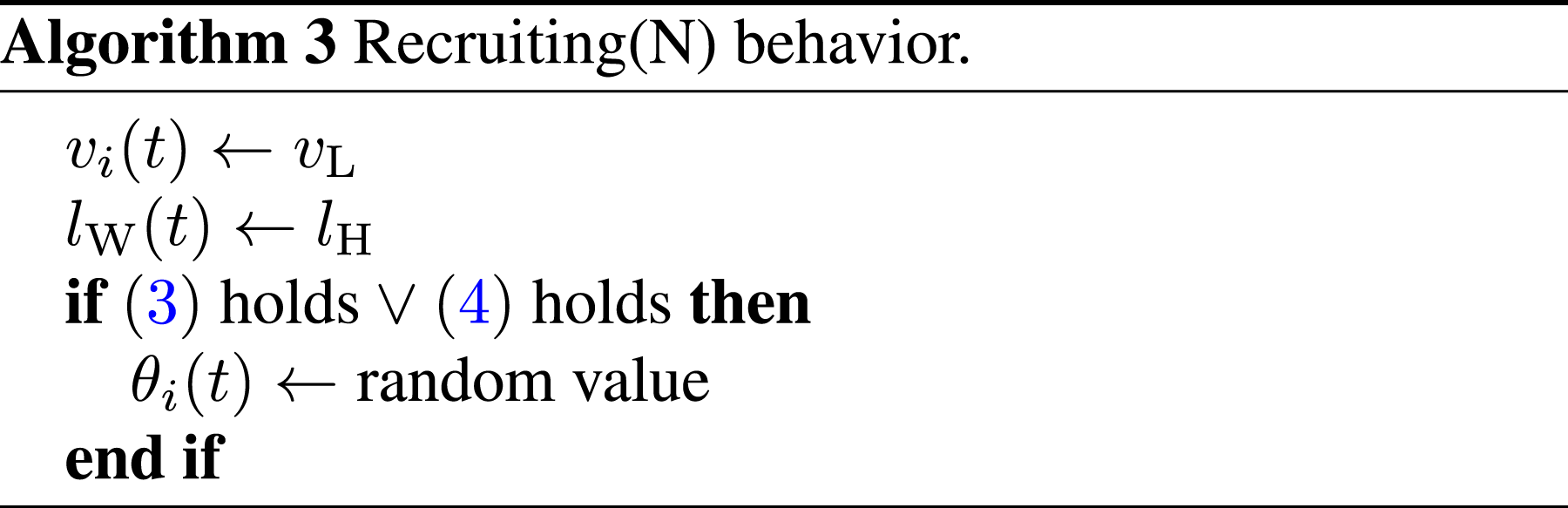
In the initial state, all robots are located randomly within the nest and set to the Searching state. Because the conventional model has no resting behavior, a finder robot recruits other robots in the Searching state, which are located in the search area. Additionally, because the resting behavior has been eliminated, the Recruiting(S) state is newly defined. Each robot in the Recruiting(S) state performs a random walk as shown in Algorithm 3 in the search area instead of the nest area.
Let D
kl
be a state-transition condition in the conventional model from state k to state l, as shown in Figure 4. The state-transition conditions are as follows: D48: Another robot in the Recruiting(S) state is within the camera’s field of view. D48 is equivalent to the following condition (12). D84: The robot that is being followed is within the camera’s field of view and transits its state to Pushing(R) or Searching. Alternatively, the robot that is being followed is outside the camera’s field of view. To clarify the state-transition condition, we define the following condition (13).
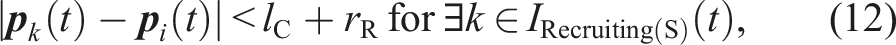
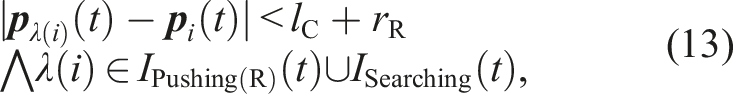
4.2. Initial state of the food items
Let the total weight of all food items scattered in the field be mtotal. The weight of each food item m is set to mtotal/NF in such a way that the weight of the food items decreases as the number of food items increases; thus, the total number of robots required to transport all NF food items simultaneously is constant. As a result, there are a few heavy food items when NF is small, whereas there are many light food items when NF is large. A figure showing the influence of changing mtotal is uploaded as a supplemental material. Additionally, the ϕ j for each food item j is randomly determined.
Next, we set the distance between each food item j and center of the nest, that is, d
j
. When d
j
is large, it is difficult to discover food item j and it takes much time to transport this food item to the nest. We determined d
j
such that the difficulty of transporting all food items is constant regardless of NF as follows: d
j
is given randomly within search area [rN + rF rS − rF] such that
4.3. Evaluation method of foraging performance
We evaluated the performance of a swarm based on the food transport rate and energy efficiency. Let NT be the total number of food items that are located inside the nest at the end of the simulation. The food transport rate of the swarm of robots is defined by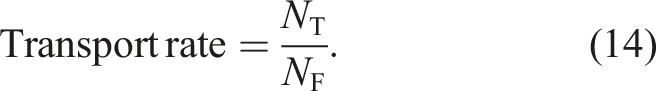
Next, we define energy efficiency. Regarding energy consumption, a robot in the Resting state does not consume energy because it does not move, whereas a robot in all other states consumes energy at one unit per time step because it is always moving or pushing a food item. The total consumed energy of robot i in the simulation is denoted by e
i
and regarded as the cost. The total weight of the transported food items is regarded as the reward. From Labella et al. (2006), the energy efficiency of a swarm of robots is defined as the ratio of reward to cost as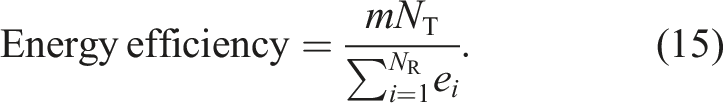
4.4. Other settings
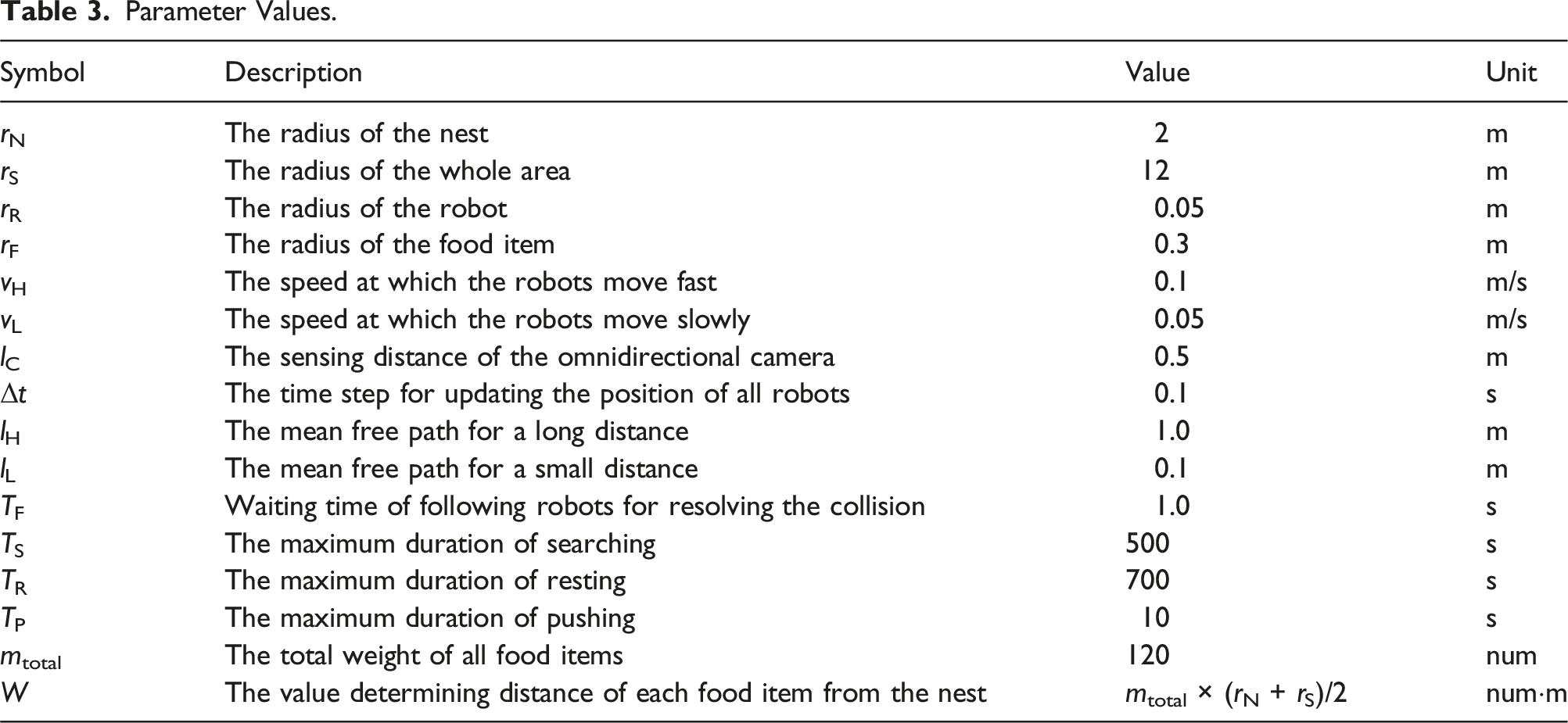
Parameter Values.
5. Simulation result and discussion
5.1. Visualization of the robot behaviors in both models
First, we visualize the robot behaviors in both models in one of the simulations. Figure 5 visualizes the multi-agent simulation for the case of (NR, NF, TW) = (100, 6, 100) in the proposed model. When a robot in the Searching state discovers a food item (Figure 5(b)), the robot pushes the food item toward the center of the nest. Because the robot fails to transport it because of a lack of power, the finder robot starts to return to the nest (Figure 5(c)). After the finder robot has arrived at the nest, the finder robot transits to the Recruiting(N) state and recruits other resting robots in the nest (Figure 5(d)). Some robots in the Resting state find the recruiting robot and then transit to the Following state (Figure 5(e)). After a sufficient time has passed while recruiting, the finder robot transits to the Leading state and leads the following robots to the location of the food item (Figure 5(f)). After the finder robot has reached the location of the food item, the robots that followed the finder start to push or search for the corresponding food item (Figure 5(g)). Some of the searching robots successfully discover the corresponding food item and transit to the Pushing(O) state (Figure 5(h)). Thus, the total number of robots in Pushing state at the location of the food item increases. This recruiting process is repeated by finder robots as long as the corresponding food item is not being transported. Finally, a sufficient number of robots in the Pushing state are located at the position of the corresponding food item, and then the food item is transported by those robots (Figure 5(i)). Visualization of the multi-agent simulation for the case of (NR, NF, TW) = (100, 6, 100) in the proposed model. Red characters represent the behavior of the recruiting robots, whereas blue characters represent the behavior of the following robots. (a) t = 0 s. Initial state. (b) t = 87 s. A robot discovers a food item. (c) t = 97 s. The finder starts to return to the nest because of the shortage of pushing robots. (d) t = 121 s. The finder starts to recruit other robots inside the nest. (e) t = 130 s. Some resting robots start to follow the finder. (f) t = 221 s. The finder starts to lead the following robots to the location of the corresponding food item. (g) t = 274 s. The finder reaches the location of the corresponding food item. The robots that followed the finder start to search for the corresponding food item or push it. (h) t = 289 s. The robots that followed the finder successfully found the corresponding food item and start to push the food item. On the other hand, the finder robot started to return to the nest again because of the shortage of pushing robots. (i) t = 439 s. Finally, the corresponding food item is transported.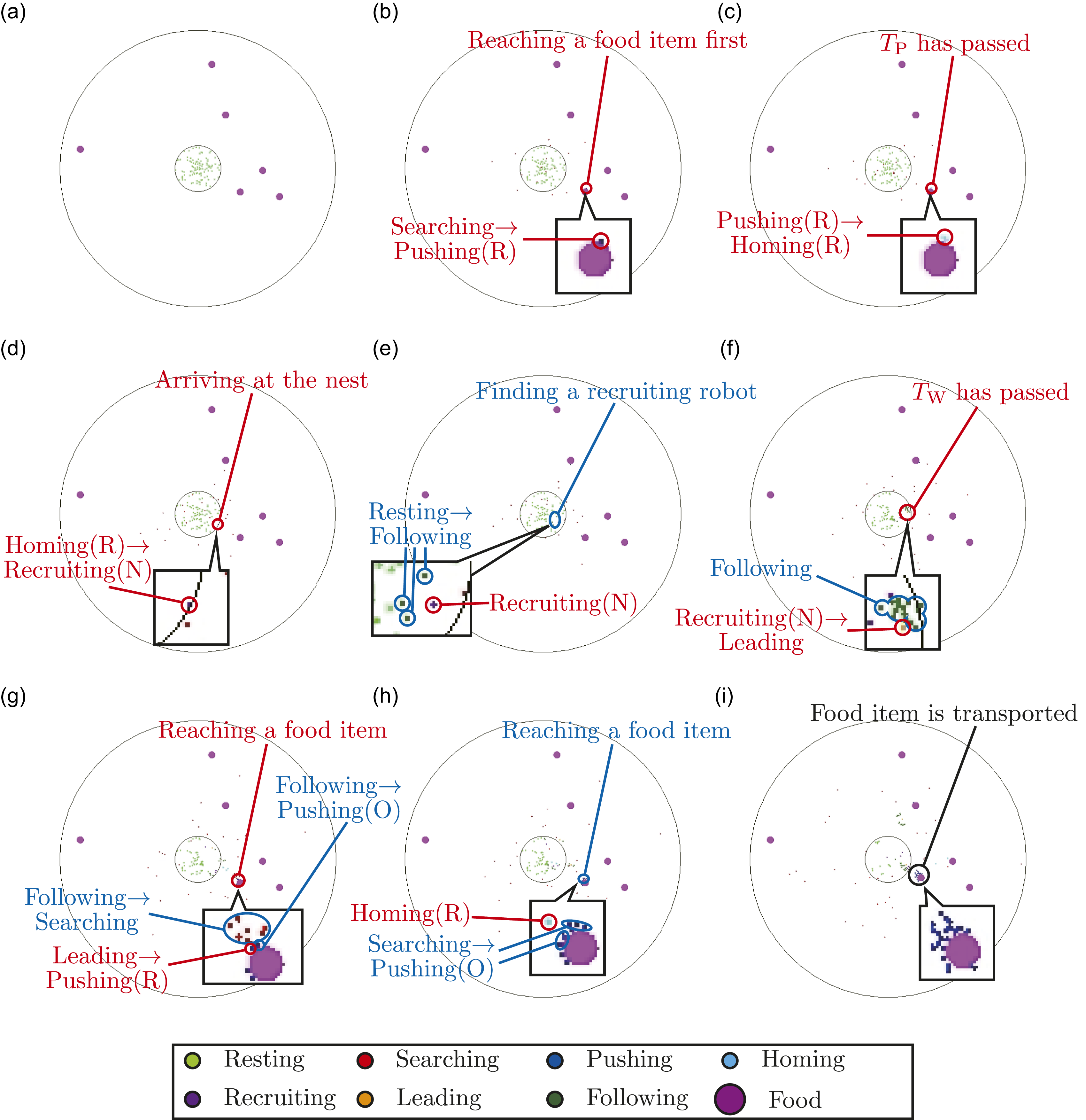
Meanwhile, Figure 6 visualizes the multi-agent simulation for the case of (NR, NF, TW) = (100, 6, 100) in the conventional model. In the conventional model, all robots search for food items, so it takes less time to discover a food item than in the proposed model (Figure 6(b)). Because the robot fails to transport it because of a lack of power, the finder robot starts to recruit other searching robots in the search area (Figure 6(c)). Some robots in the Searching state find the recruiting robot and then transit to the Following state (Figure 6(d)). After a sufficient time has passed while recruiting, the finder robot transits to the Leading state and leads the following robots to the location of the food item (Figure 6(e)). After the finder robot has reached the location of the food item, the robots that followed the finder start to push or search for the corresponding food item (Figure 6(f)). Because the number of robots that followed the finder is small, the total number of robots which start pushing is fewer than in the proposed case (Figure 6(g)). This recruiting process is repeated by finder robots as long as the corresponding food item is not being transported. Finally, a sufficient number of robots in the Pushing state are located at the corresponding food item’s position, but it takes more time to gather the pushing robots at the location of the food item than in the proposed model (Figure 6(h)). Two videos showing whole simulation about Figures 5 and 6 are uploaded as supplemental materials. Visualization of multi-agent simulation for (NR, NF, TW) = (100, 6, 100) in the conventional model. Red characters represent the behavior of the recruiting robots, whereas blue characters represent the behavior of the following robots. (a) t = 0 s. Initial state. (b) t = 25 s. A robot discovers a food item. (c) t = 35 s. The finder starts to recruit other robots in the search area because of the shortage of pushing robots. (d) t = 63 s. Some searching robots start to follow the finder. (e) t = 135 s. The finder starts to lead the following robots to the location of the corresponding food item. (f) t = 177 s. The finder reaches the location of the corresponding food item. The robots that followed the finder start to search for the corresponding food item or push it. (g) t = 187 s. The finder robot starts to recruit other robots again because of the shortage of pushing robots. On the other hand, one of the robots that followed the finder still searches for the corresponding food item. (h) t = 1047 s. Finally, the corresponding food item is transported.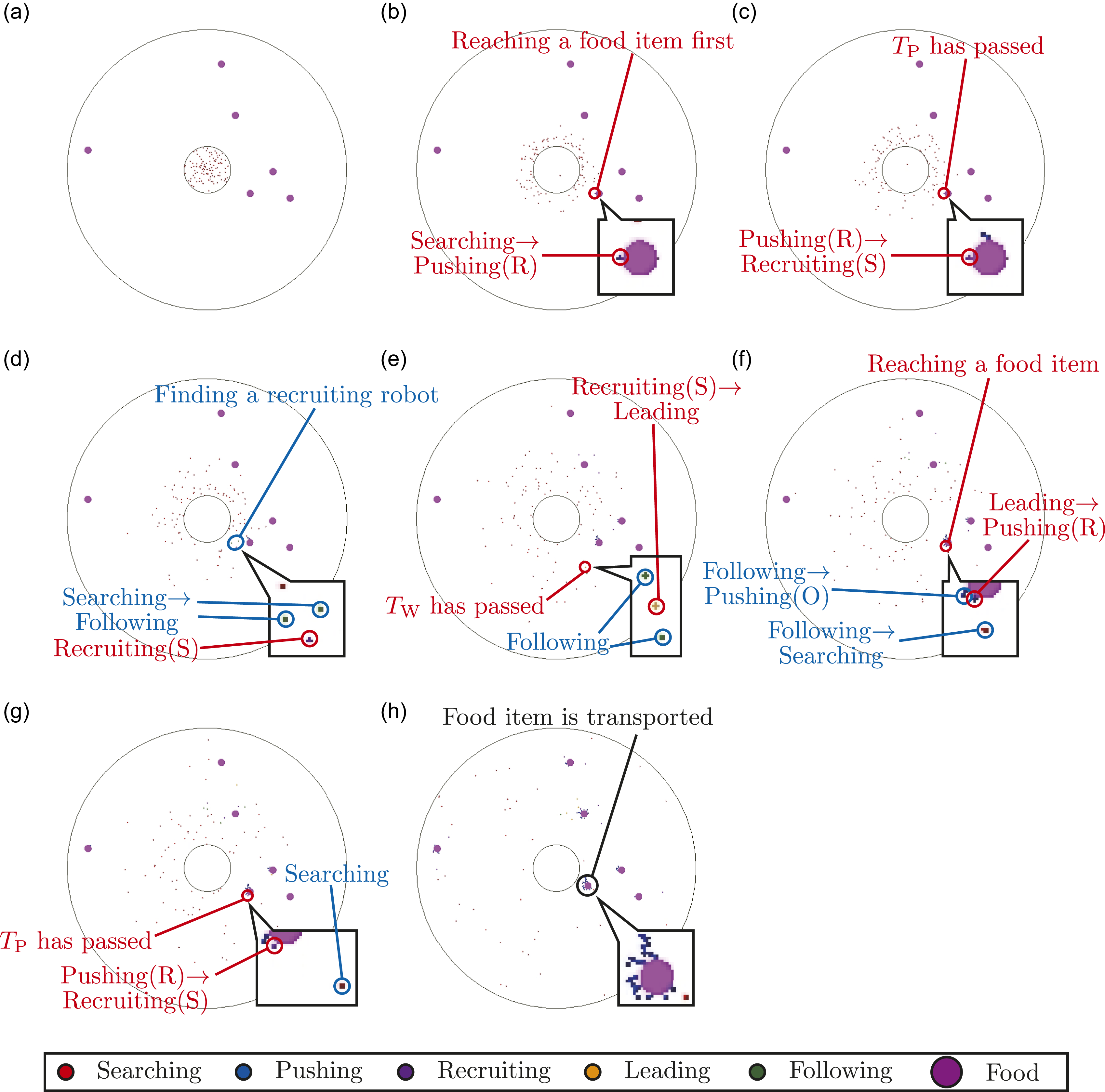
5.2. Comparison of the models with respect to the number of food items
Next, we evaluate the performance of the proposed and conventional models in various environments. We prepared four scenarios such that NR was set to 100 and NF was set to 6, 8, 10, 12.
5.2.1. Quantitative evaluation of the model performances
First, we compared the food transport rate. Figure 7 shows the average transport rate and energy efficiency for the two models in several environments. We call the TW value that maximizes the transport rate the optimal TW. The value of TW can be arbitrary selected; thus, it is reasonable to evaluate the performance when TW is the optimal value. Figure 7 shows that the proposed strategy induces the highest transport rate around TW = 100 for all NF. By contrast, the conventional strategy achieves almost the same transport rate regardless of TW for all NF. As NF increases, the food transport rate of the proposed model remains almost constant, whereas that of the conventional model increases. When each food item is heavy, for instance, NF = 6 and 8, the maximum transport rate of the proposed model is higher than that of the conventional model (Figure 7). As a result, we found that the small NF environment is a situation in which the resting behavior dominates. In these situations, the advantage of the potential labor pool created by the resting behavior exceeds the disadvantage of doing nothing. Average transport rates and energy efficiencies with different TW over 10 runs under various NF and NR = 100. Shaded areas indicate the standard deviation. The average differences under the optimal TW were examined using a two-sided independent sample t test. Here, ∗ indicates a significance level of 0.01 for the two optimal values of TW.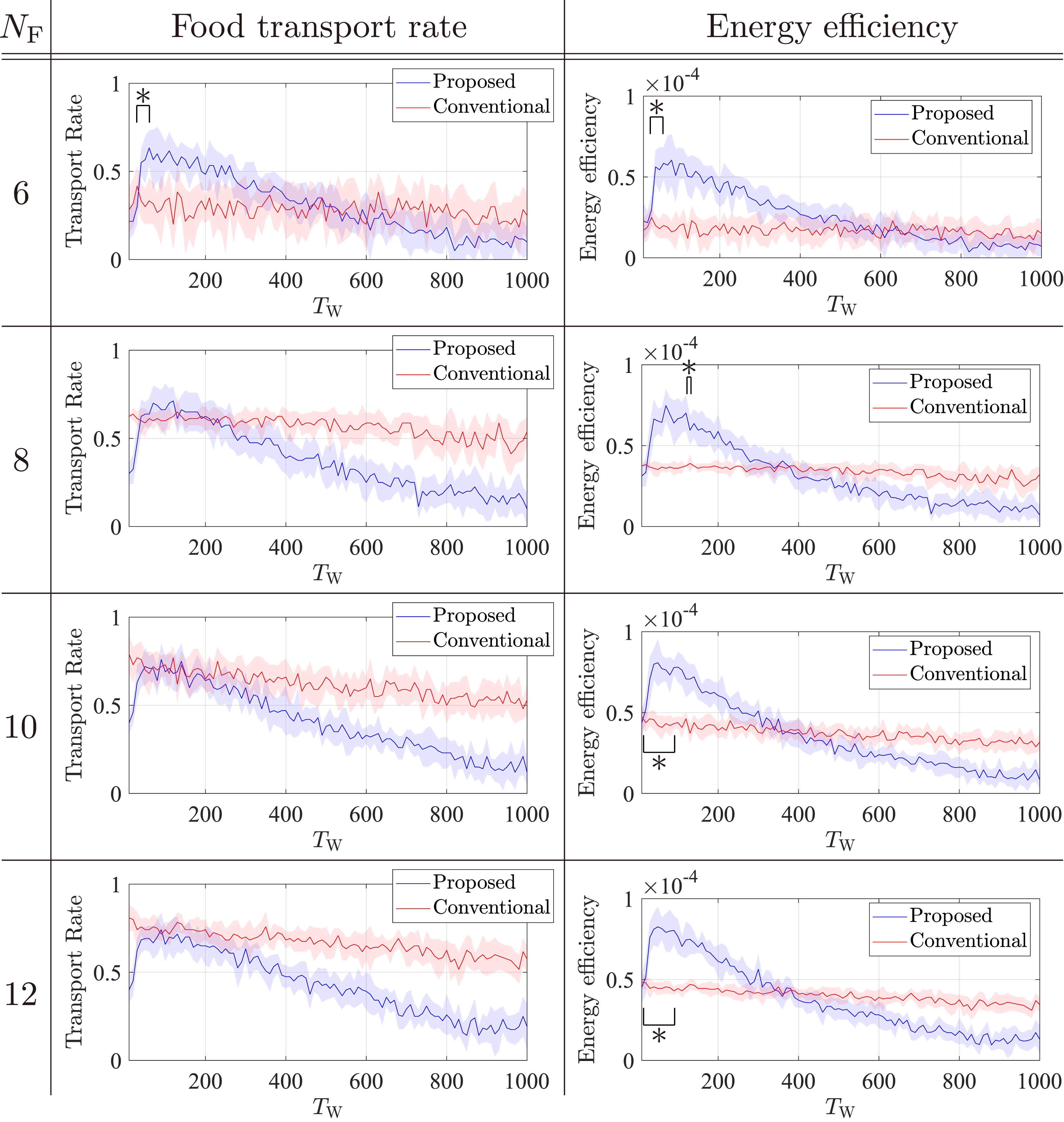
Next, we compared the energy efficiency. As shown in Figure 7, the values of TW that maximizes the transport rate and energy efficiency are almost the same. Therefore, the maximum energy efficiency can also be evaluated when the optimal value of TW is used. Figure 7 reveals that the proposed model outperforms the conventional model in maximum energy efficiency for all environments. This is because the resting robots help foraging only if needed; thus, they generally save energy.
5.2.2. Reasons for the performance differences
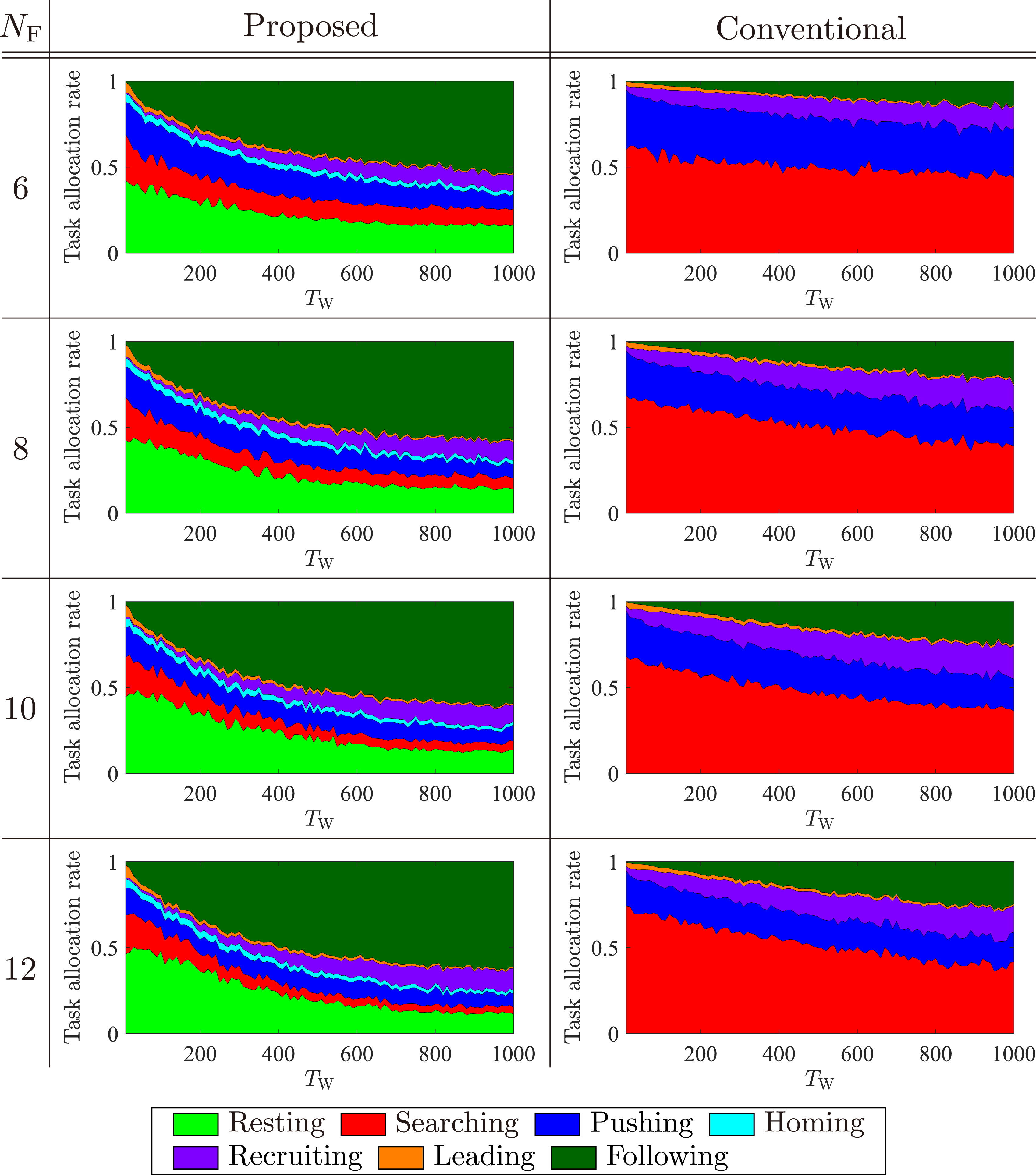
Next, we discuss the reasons for the performance differences in various environments. To investigate these reasons, we focused on the task allocation rate. Let N
k
(t) be the number of robots whose state is k at time t. Furthermore, let total period of each simulation be Tsim. We denote the average task allocation rate for each task k in one simulation by A
k
, which is represented as Average task allocation rates for the proposed and conventional models with different TW over 10 runs under various NF and NR = 100.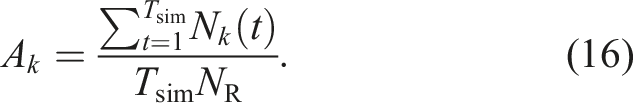
Let Ttot be the duration from the start of the simulation to the moment at which sufficient number of robots has been gathered for a food item. Let Tsearch be the duration of searching for the food item and Trecruit be the duration of recruiting a sufficient number of robots. Ttot is the sum of Tsearch and Trecruit as follows: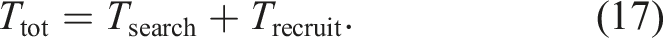
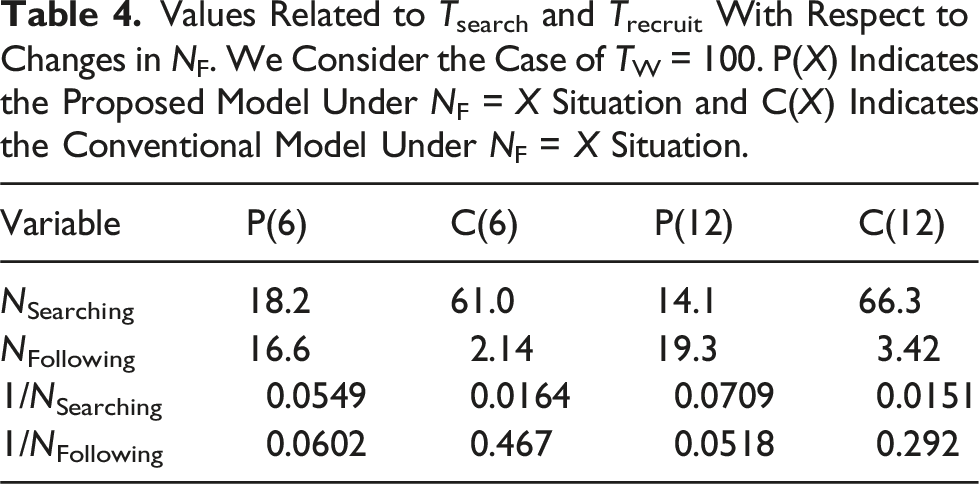
Additionally, Trecruit is equivalent to the duration needed to gather m or more robots at the food item. When the robots in the Following state are spatially distributed to each food item, the number of following robots for a specific food item is in proportion to NFollowing/NF. Therefore, Trecruit ∝ mNF/NFollowing. Furthermore, considering that mNF is constant, Trecruit ∝ 1/NFollowing.
Values Related to Tsearch and Trecruit With Respect to Changes in NF. We Consider the Case of TW = 100. P(X) Indicates the Proposed Model Under NF = X Situation and C(X) Indicates the Conventional Model Under NF = X Situation.
Additionally, we explain the reason why the proposed model has more following robots than the conventional model (Figure 8). In the proposed model, recruiting robots recruit resting robots inside the nest, whereas those in the conventional model recruit searching robots in the search area. The average density of robots that can start following in the proposed model is
5.3. Comparison of the models with respect to population
Next, we compared the performance of the models when number of robots was varied. We prepared four scenarios such that NR was set to 70, 100, 130, 160 and NF was set to 6.
5.3.1 Quantitative evaluation of the model performances
Figure 9 shows the average transport rate and average energy efficiency for the two models in several population sizes. Figure 9 reveals that the proposed strategy induces the highest transport rate around TW = 100 for all NR. By contrast, the conventional strategy induces almost the same transport rate regardless of the value of TW for all NR. This result is consistent with the change in the number of food items described in Section 5.2.1. As NR increases, the food transport rate of the proposed model increases a little, whereas that of the conventional model increases dramatically. When NR is small, that is, NR = 70, 100, and 130, the maximum transport rate of the proposed model is higher than that of the conventional model (Figure 9). As a result, we found that small NR environment is a situation in which the resting behavior dominates. In such situations, the advantage of the potential labor pool function of the resting behavior exceeds the disadvantage of doing nothing. Average transport rates and energy efficiencies with different values of TW over 10 runs under NF = 6 and various NR. Shaded areas indicate the standard deviation. The average differences under the optimal TW were examined using a two-sided independent sample t test. Here, ∗ indicates a significance level of 0.01.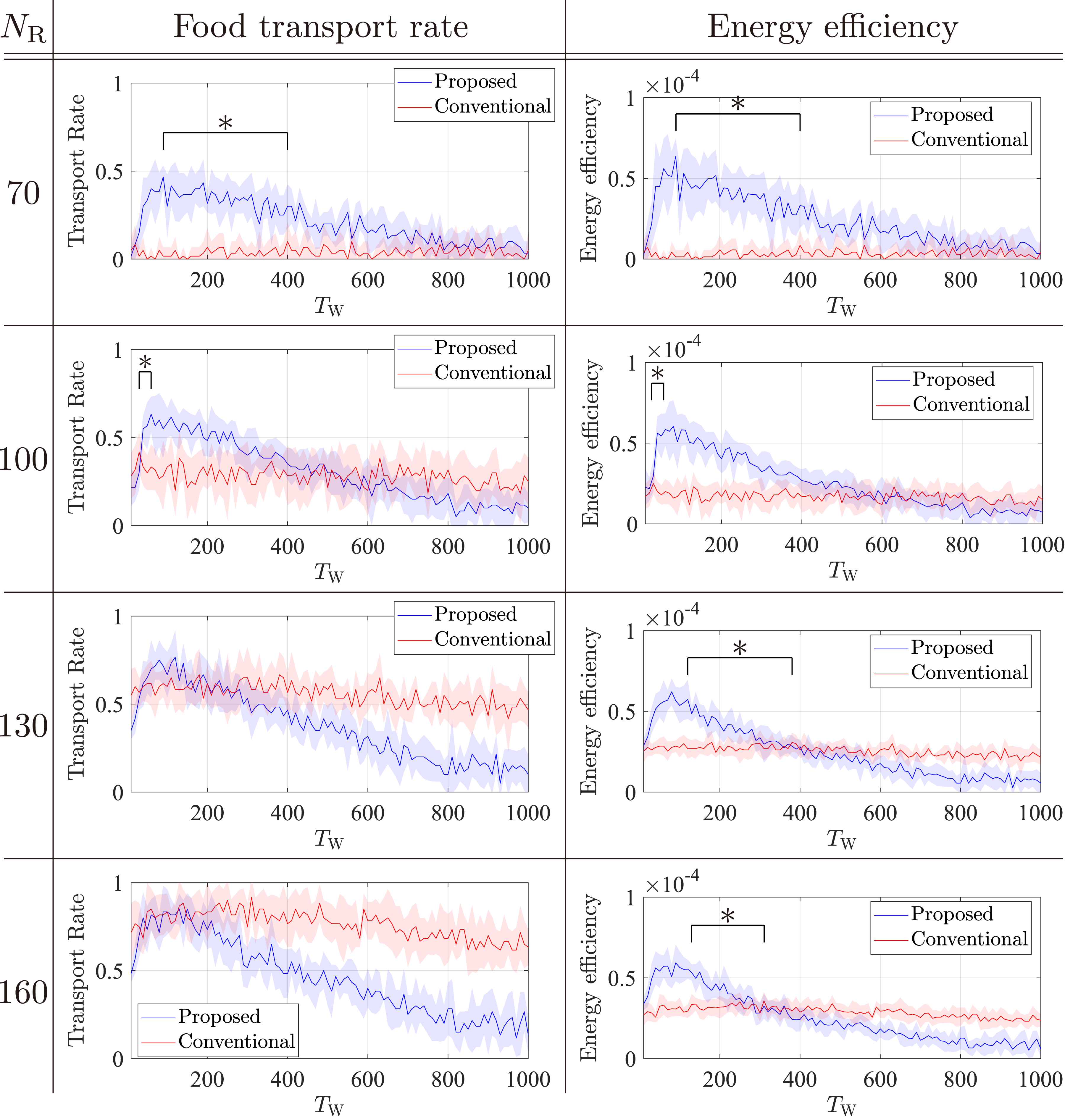
Next, we compared energy efficiency. The proposed model outperforms the conventional model in maximum energy efficiency for all population sizes for the same reasons described in Section 5.2.1.
5.3.2. Reasons for the performance differences
Next, we discuss the reasons for the performance differences caused by various population sizes. Figure 10 shows average task allocation rate for proposed and conventional models. From Figure 10 and discussions in Section 5.2.2, we can infer that the average density of robots that can start following in the proposed model is always larger than that in the conventional model. Average task allocation rates for proposed and conventional models with different TW over 10 runs under NF = 6 and various NR.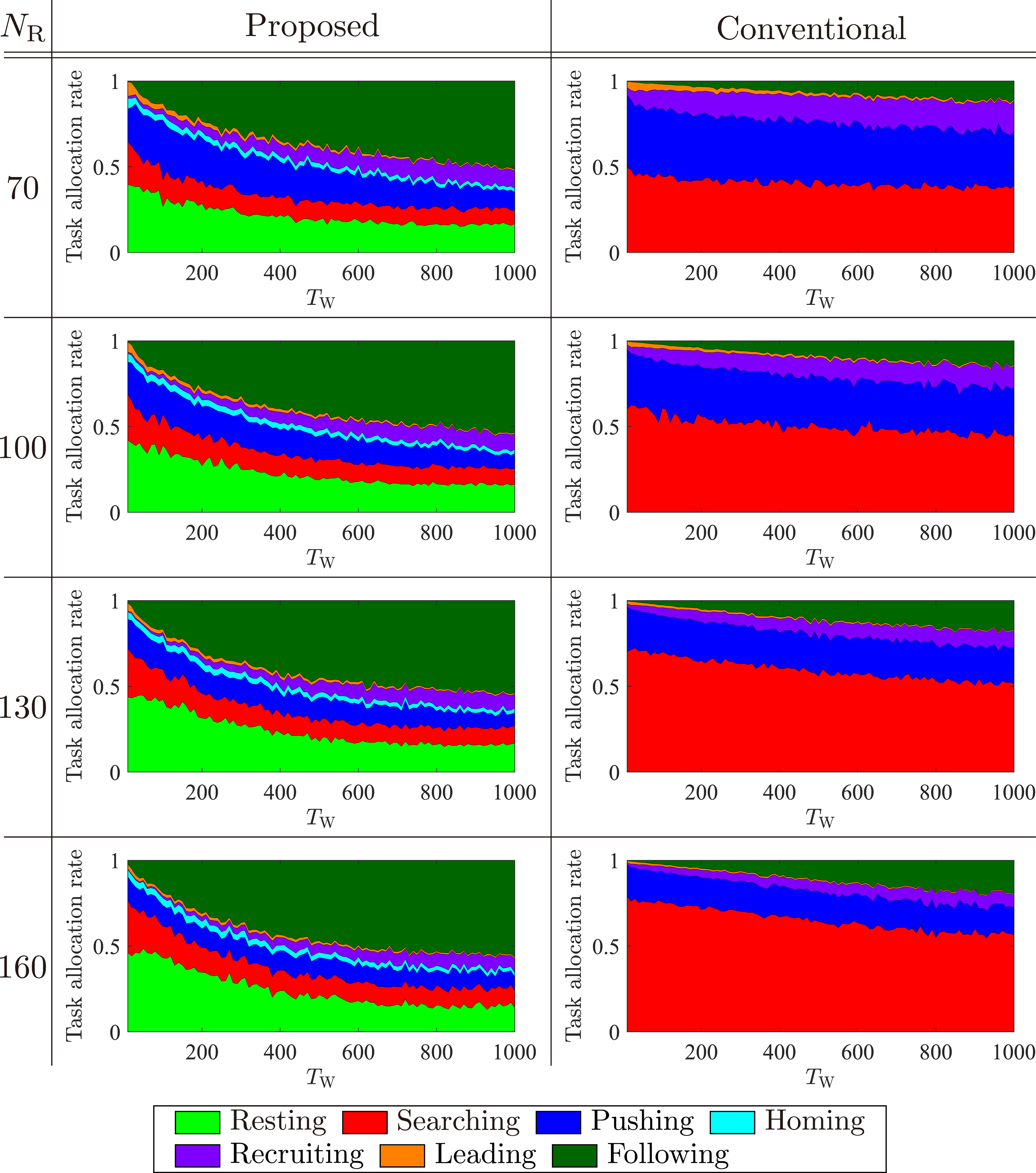
Values Related to Tsearch and Trecruit With Respect to Changes in NR. We Consider the Case of TW = 100. P(X) Indicates the Proposed Model Under NR = X Situation and C(X) Indicates the Conventional Model Under NR = X Situation.
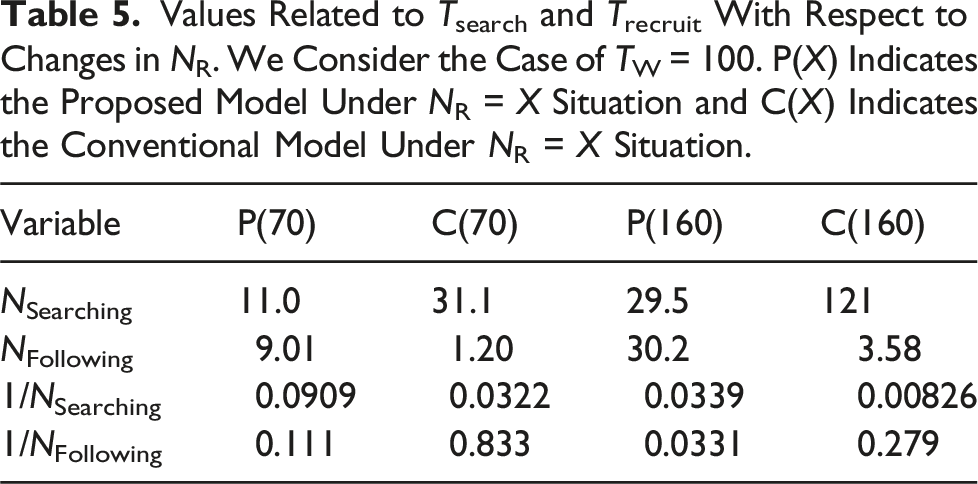
Next, we summarize the population-dependent differences. When the population is small, gathering a sufficient number of robots is difficult. In this scenario, the robots in the proposed model discover fewer food items, but most of these items are successfully transported to the nest owing to the effective recruitment. By contrast, the robots in the conventional model discover more food items, but only a few of them are transported to the nest because of the ineffective recruitment. Therefore, the time needed to gather a sufficient number of robots affects food transportation the most; thus, the proposed model outperforms the conventional model in food transport rate.
When the population is large, gathering a sufficient number of robots is easy. In this scenario, the robots in the proposed model discover fewer food items, which are successfully transported. By contrast, the robots in the conventional model also discover more food items, which are again successfully transported. Therefore, the time to discover a food item affects food transportation the most; thus, the conventional model outperforms the proposed model in food transport rate.
5.4. Summary of the performance of both models
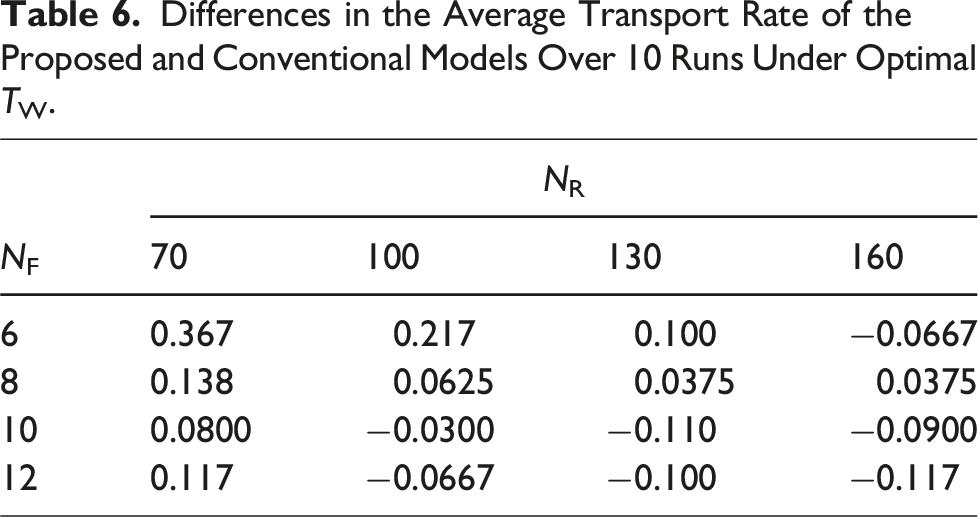
We summarize relationship between NR, NF, and foraging performance. NR was set to 70, 100, 130, 160, and for each NR, NF was set to 6, 8, 10, 12.
Differences in the Average Transport Rate of the Proposed and Conventional Models Over 10 Runs Under Optimal TW.
Differences in the Average Energy Efficiency of the Proposed and Conventional Models Over 10 Runs Under Optimal TW.
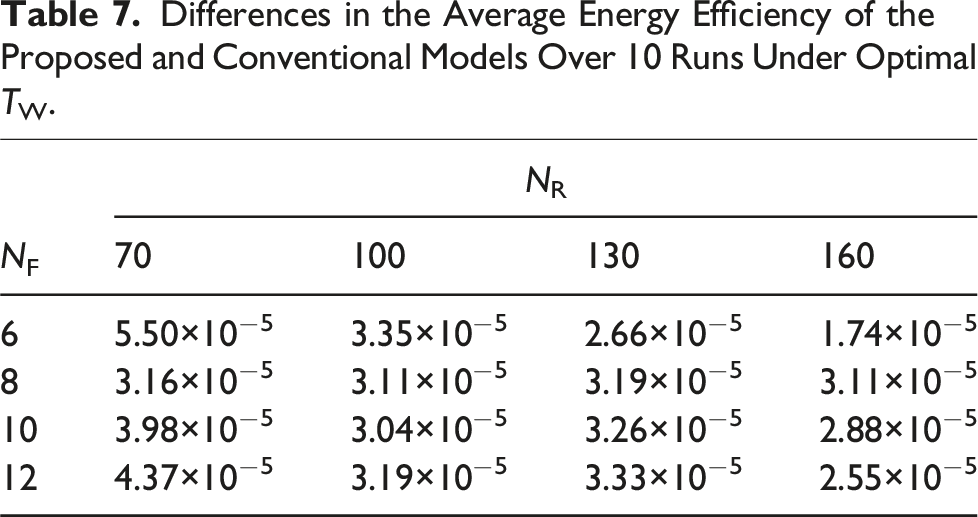
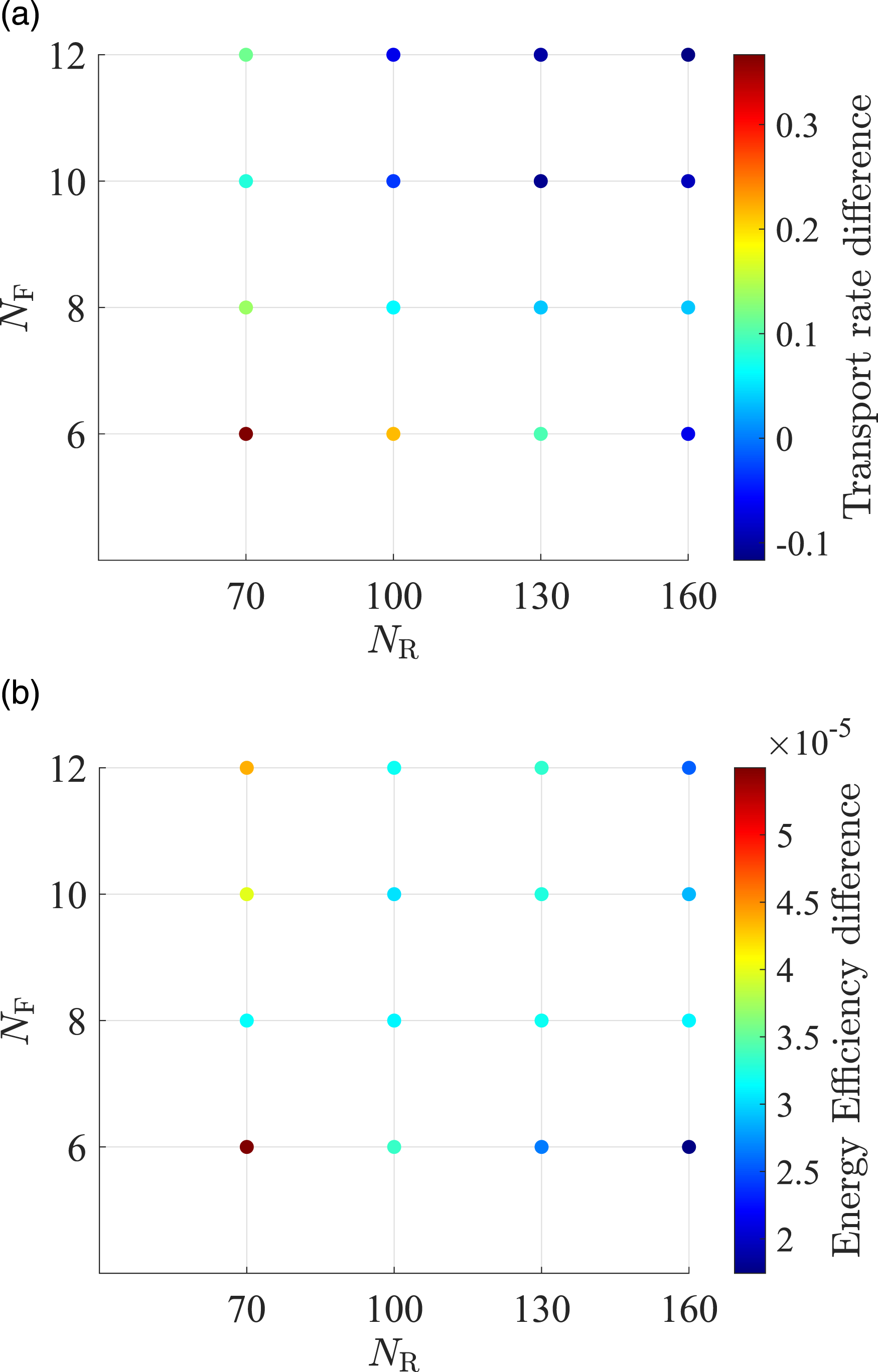
Differences in the average (a) transport rate and (b) energy efficiency of the proposed and conventional models over 10 runs under optimal TW.
6. Conclusion and future extensions
In this study, we constructed a state-transition model for a swarm of robots for group foraging. In the proposed model, a state-transition model for solitary foraging including the resting behavior (Liu et al., 2007) and ant recruiting behavior for group foraging are combined.
Because of its resting behavior, the proposed model leads to more resting robots and fewer searching robots than the conventional state-transition model without the resting behavior. Moreover, the maximum search duration is limited, so exploration at distant sites is not sufficient. Therefore, the proposed model underperforms the conventional model in food item discovery. By contrast, because of the resting behavior, the nest functions as a gathering spot and therefore the robot density inside the nest is high. Therefore, recruiting robots can recruit many robots quickly inside the nest. In this way, the resting robots function as a potential labor pool. As a result, the proposed model outperforms the conventional model in gathering sufficient number of robots.
Regarding the evaluation of the transport rate, when each food item in the environment is light or there are many robots in the swarm, the proposed model underperforms the conventional model. This is because the time required to discover a food item is important in those situations. However, the proposed model, which includes the resting behavior, is dominant in environments where heavy food items are scattered and population in the swarm is small. This is because the time required to gather a sufficient number of robots is important in such situations. Regarding the evaluation of energy efficiency, the proposed model always outperforms the conventional model. This is because resting robots save energy when they are not needed; they are recruited and consume energy only when they are needed.
The well-known central-place foraging approach is defined as a set of foraging behaviors, that is, departure from a place, searching for food items at distant sites, and returning to the same place (Olsson et al., 2008). In central-place foraging, a return trip is necessary, and hence the search range is constrained. However, a central place provides benefits exceeding the constraint, for example, a safe resting place and frequent interaction between agents (Davidson et al., 2016). In this study, recruitment through frequent interaction between robots increased the speed of foraging, and hence it is consistent with the characteristics of central-place foraging.
For future extensions, we would like to introduce adaptive versions of the parameters TR, TS, TP, and TW that change in response to changes in NR and NF. Additionally, a real robot experiment will be a primary challenge.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material - Investigating dominant situation of resting behavior as a potential labor pool in robotic swarm for group foraging
Supplemental Material for Investigating dominant situation of resting behavior as a potential labor pool in robotic swarm for group foraging by Tomohiro Hayakawa, Toshiyuki Yasuda, and Fumitoshi Matsuno in Adaptive Behavior
Footnotes
Authors’ note
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
About the Authors
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.