
Abstract
This paper focuses on exploring the use cases and practical applicability of deep learning in Industry 4.0 by studying on a water pump time series dataset with 5 models namely LSTM, CNN-LSTM, GAF-CNN, BiLSTM and Time-Series Transformer. The unplanned downtime due to sudden equipment failure costs the industry huge losses every year. The proposed methodology based on deep learning architectures uses sensor readings and leads to meaningful predictions for cost-cutting and time saving. The study evaluates and compares these models in terms of fine-grained architecture-level components and prediction accuracy. The results demonstrated that the transformer based time series hybrid model is more accurate in prediction with balanced performance and strong interpretability than other models.
Introduction
Mechanical asset failure can lead to downtime, costly repairs, and potential safety hazards in industries. Traditionally, maintenance strategies were based on scheduled approaches that are often inefficient in unexpected breakdowns (Hakami, 2024). As industries continue to embrace the principles of Industry 4.0, there is growing demand for intelligent automated solutions that can anticipate failures and optimize the maintenance process driven by the economic necessity to mitigate unplanned downtime (Achouch et al., 2022).
According to the Aberdeen Group (2016), global manufacturing incurs approximately US $1 trillion in annual losses due to such failures. In the specific context of industrial pumping systems, the Hydraulic Institute and Europump estimate that maintenance and downtime account for roughly 25% of the total lifecycle expenditure—significantly higher than the initial purchase cost 10% (Hydraulic Institute and Europump, 2001). Therefore, the deep learning models analyzed in this study are not merely classifiers but critical enablers of the Industry 4.0 ‘Smart Factory'. By predicting failures before they occur, these architectures directly address the 25% cost burden, facilitating the shift from reactive repairs to autonomous, predictive lifecycle management (Lee et al.,, 2013).
Deep learning has shown promise in this domain due to its ability to extract temporal and spatial features from large, multivariate datasets. Among various deep learning architectures, Long Short-Term memory (LSTM) networks, BiLSTM, Convolutional Neural network combined with LSTM (CNN-LSTM), Gramian Angular Field - Convolutional Neural Networks (GAF-CNN), Transformer based networks have gained considerable attention. LSTM networks are effective in modeling sequential dependencies and capturing temporal patterns in time - series data (Hochreiter and Schmidhuber, 1997). BiLSTM network works in both forward and backward direction to capture recent and past data for accurate prediction (Schuster and Paliwal, 1997). CNN-LSTM hybrid model combines strengths of CNNs local feature extraction with LSTMs capability to model long term temporal dependencies making it well suited for complex degradation processes (Ordonez and Roggen, 2016). GAF-CNN approaches transform time-series data into two dimensional images using Gramian Angular Fields, allowing CNN to learn discriminative spatial features from encoded time-series pattern (Zhang, 2025). Transformer based time series model is beneficial with ample amount of data for prediction.
Despite of their promising performance, these architectures also present challenges related to data requirements and pre-processing, interpretability, model complexity and deployment in real time applications. Specifically, the existing approaches present the following challenges which must be addressed. LSTM model is effective in identifying temporal dependencies, often struggles with very long sequential data it can be computationally intensive. BiLSTM model improves these by spanning in both the directions simultaneously but leads to high computational cost and memory requirements which becomes unsuitable for real time applications. CNN-LSTM combines sequential modeling and local feature extraction, but if there persists flaw in designing convolutional layer, then performance of model may degrade. These trade-offs underscores importance of comparing different data models to identify the most suitable model for time series data.
Our contributions
Besides comparing deep learning models for accuracy, this work is distinguished by evaluating its operational and practical feasibility of the architecture for edge computing and industrial digital twin. (1) Baseline for Edge Deployment: Assessing the trade-offs in storage and computational cost to identify models suitable for embedded devices. This facilitates on-spot processing, eliminating the need to export sensitive sensor data to the cloud and thereby preserving industrial data using embedded systems. (2) Enablement of Digital Twin: Analyzing model interpretability and latency to enable ’policy twins’— digital counterparts that allow operators to answer ’what-if’ maintenance questions (e.g., simulating deferred maintenance scenarios) before implementation. (3) Trade-off Analysis: Systematically categorize the strengths and weaknesses of LSTM, CNN-LSTM, GAF-CNN, and Transformers to guide the selection of architectures that balance fault detection with the resource constraints of IoT infrastructure.
Paper organization
The remainder of this paper is organized as follows: • • • • Finally,
Related works
Deep learning models have become the cornerstone of modern predictive maintenance with powerful tools for learning spatial patterns, temporal dependencies and image encoded time-series in context of Industry 4.0. In particular LSTM, BiLSTM, CNN-LSTM, GAF-CNN, Transformer based architectures are leading frameworks to predict Remaining Useful Life (RUL) and fault detection. Various recent approaches have been proposed to enhance predictive maintenance capabilities, each comes with specific limitations regarding data requirements, scalability and interpretability.
Ho et al. (2025) employed reinforcement learning for planning dynamic path of automated guided vehicles in smart logistics and operations, improving efficiency in automated manufacturing system. Drakaki et al. (2022) provided a comprehensive survey on deep learning and machine learning methods towards Industry 4.0 for predictive maintenance in induction motors highlighting techniques that improves operational efficiency and reduce downtime. Kotsiopoulos et al. (2021) explored the integration of machine learning and deep learning in smart manufacturing systems to optimize production process and resource management. Integration of Remaining Useful life (RUL) of machinery into decision making becomes a critical task in predictive maintenance. Wang et al., (2025a) demonstrated how predictive maintenance strategy can be optimized by combining RUL predictions. Similarly, Wang et al., (2025b) proposed novel formulation and metaheuristic algorithm mainly for aircraft engines illustrating RUL-driven optimization in high-stake engineering contexts.
Liu and Xu (2021) introduced LSTM, to predict RUL of roller bearings by capturing vibration signals. They demonstrate superior performance over LSTM based datasets. The methodology used here is pure sequenced LSTM, they often struggle with noisy and multivariate data sets. Yang and Peng (2022) proposed the LSTM framework with Monte Carlo Dropout and nonparametric kernel density and estimation of both RUL and prediction uncertainty and lacks built-in data interpretability. Hochreiter and Schmidhuber (1997) introduced LSTM networks providing base for handling sequential data effectively. Their work limelights the capability of LSTM to capture long term dependencies, crucial for time-series applications.
Schuster and Paliwal (1997); Isnain et al. (2020) presented bidirectional Recurrent Neural Networks spanning in both the direction simultaneously for fault prediction based on past and future states. This approach is better then simple RNN model but less suitable for real-time systems due to high computational cost then other models.
Khorram et al. (2021) presented a Convolutional Recurrent Neural Network (CRNN) that intakes raw accelerometer signals, applies 1D convolutions to extract local temporal features and feeds to LSTM layers for fault detection. This method outperforms hand-crafted feature methods on two benchmark vibration datasets without any preprocessing. Kiangala and Wang (2020) used CNN with time series imaging for predictive maintenance of conveyor motors, identifying research gap in LSTM sequential data processing.
Methodology
We analyze five deep learning models, i.e., LSTM model, BiLSTM model, CNN-LSTM hybrid model, GAF-CNN model and Transformer based model one after another to come up with efficient suitable technique for predictive maintenance of mechanical assets.
Dataset description
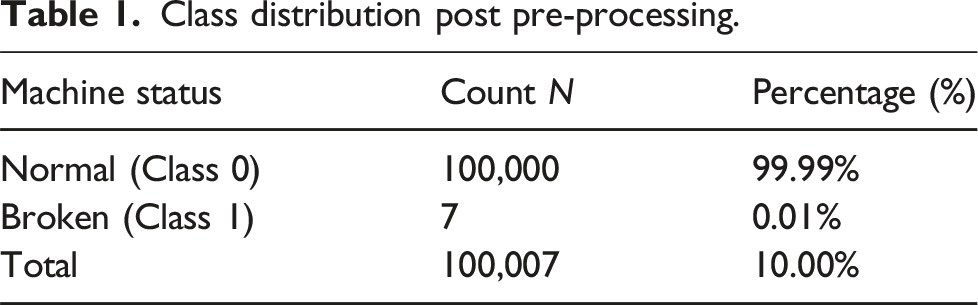
Class distribution post pre-processing.
It is utilized to model the relationship between multivariate sensor trends and machine failure events. The predictive goal is to classify machine status at any given timestamp and forecast potential breakdowns before they occur, enabling timely maintenance intervention and reduced operational downtime and costs associated with it. The dataset contains 220320 time-stamped observations recorded at one-minute intervals. Each row corresponds to: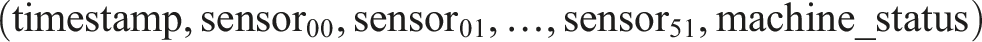
Data preprocessing and class distribution
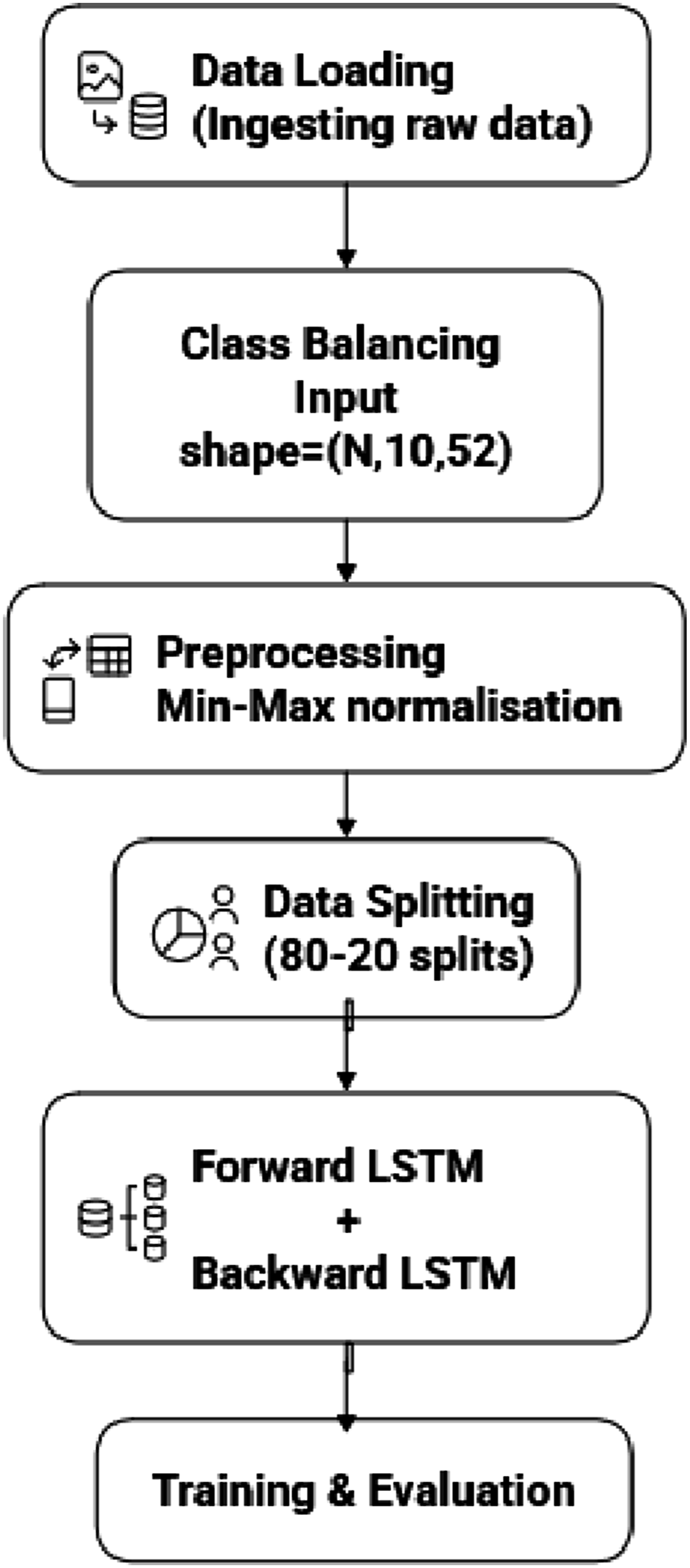
The dataset comprises of sensor readings recorded at one-minute interval across 52 sensor channels. Raw data passes through several preprocessing stages including label refining, handling missing values, class balancing and feature preservation to ensure suitability for predictive modeling. Firstly, the data sets which are not suitable for binary classification are labeled as RECOVERING state. Data from sensors which are under RECOVERING state, nil or undefined are dropped to preserve integrity of time series pattern. Nearly 100,000 records are downsampled to reduce computational complexity, making them model-suitable. Following pre processing stages the class distribution of dataset is given in Table 1.
Model architecture and workflow
LSTM (Long short term memory)
LSTM model learns sequential data and avoids vanishing gradient issues using gates. The architecture of LSTM can be visualized as a series of repeating blocks. It includes: • Input Layer: This layer ingests current input at each timestamp in sequence. • LSTM Layers: The model comprises two stacked LSTM layers each containing hidden units. To reduce risk, dropout layers with dropout rate of 0.2 are inserted after each LSTM layer to prevent overfitting of data. • Dense layers: Fully connected layer with sigmoid activation function to produce binary prediction.
As shown in Figure 1 the workflow of LSTM model begins with ingesting the raw data and performing initial cleansing i.e to drop corrupt entries. Cleaned data is then segmented into fixed length sequence and labeled after 10 consecutive spans, resulting into an input array of required format. LSTM Data flow.
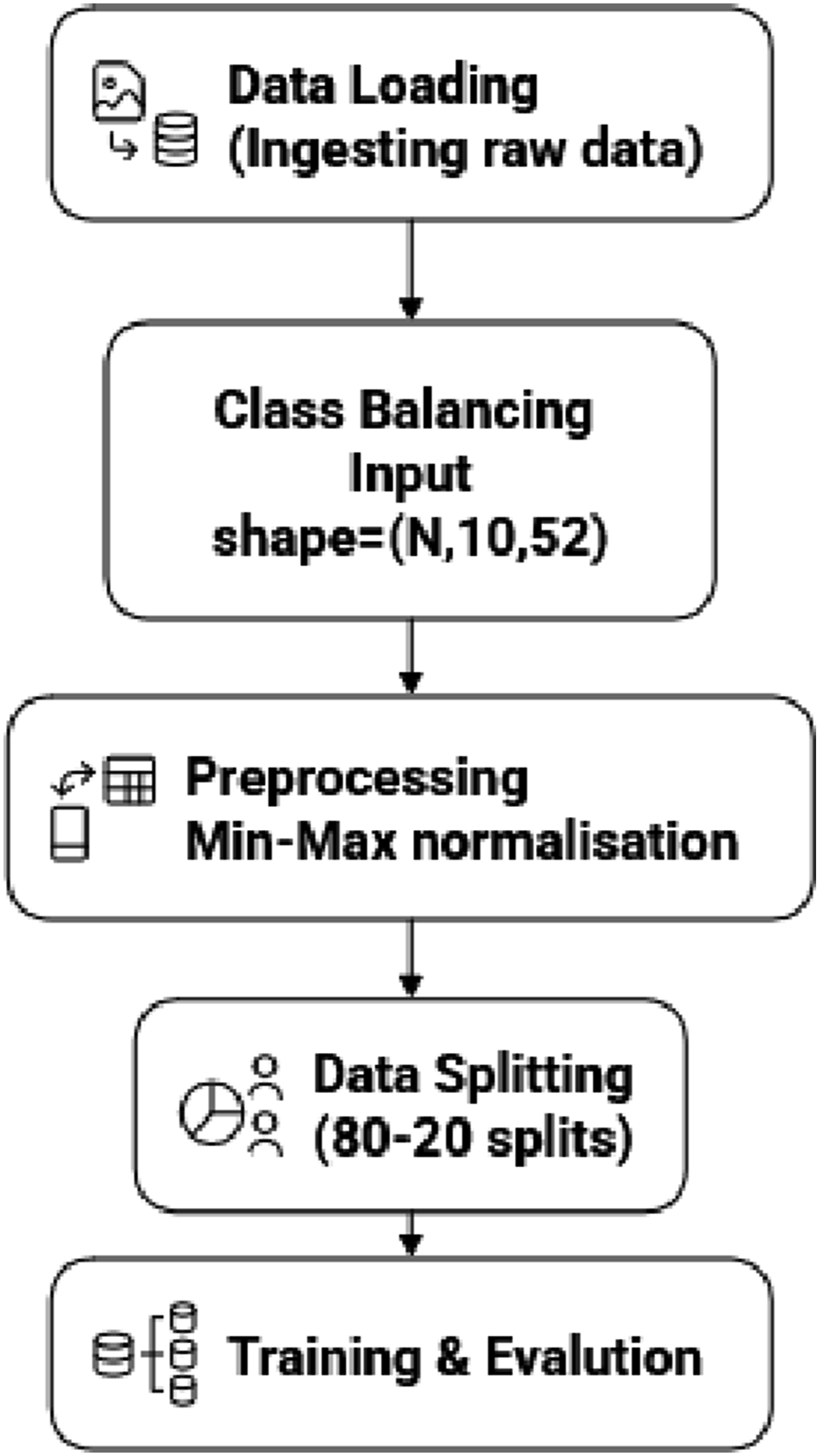
Data is then pre-processed using MinMax normalisation, readings are scaled to the range [0, 1]. Followed by preprocessing data is chronologically splited (Time based) into 80–20 splits to preserve temporal sequence of data and to prevent data leakage. 20% data from data split is fed for validation to enable early stopping and overfitting of data. 80% data from split is sent future for evaluation.
BiLSTM (Bidirectional long short term memory)
BiLSTM model is extended version of LSTM network, it processes data simultaneously in both forward and backward direction to avail data from past and future for accurate predictions. As shown in Figure 2 it includes two different forward and backward layer running in parallel connected to same output layer. • Forward LSTM Layer: This layer processes the input sequence from beginning to end. At each time stamp it computes a hidden state having past information. • Backward LSTM Layer: This layer processes the forward layers inputs sequence in reverse direction. At each time stamp it computes a hidden state having access to future information. • Output Layer: Hidden state of both forward and backward layer is concatenated to produce final output in terms of past and future data. BiLSTM model.
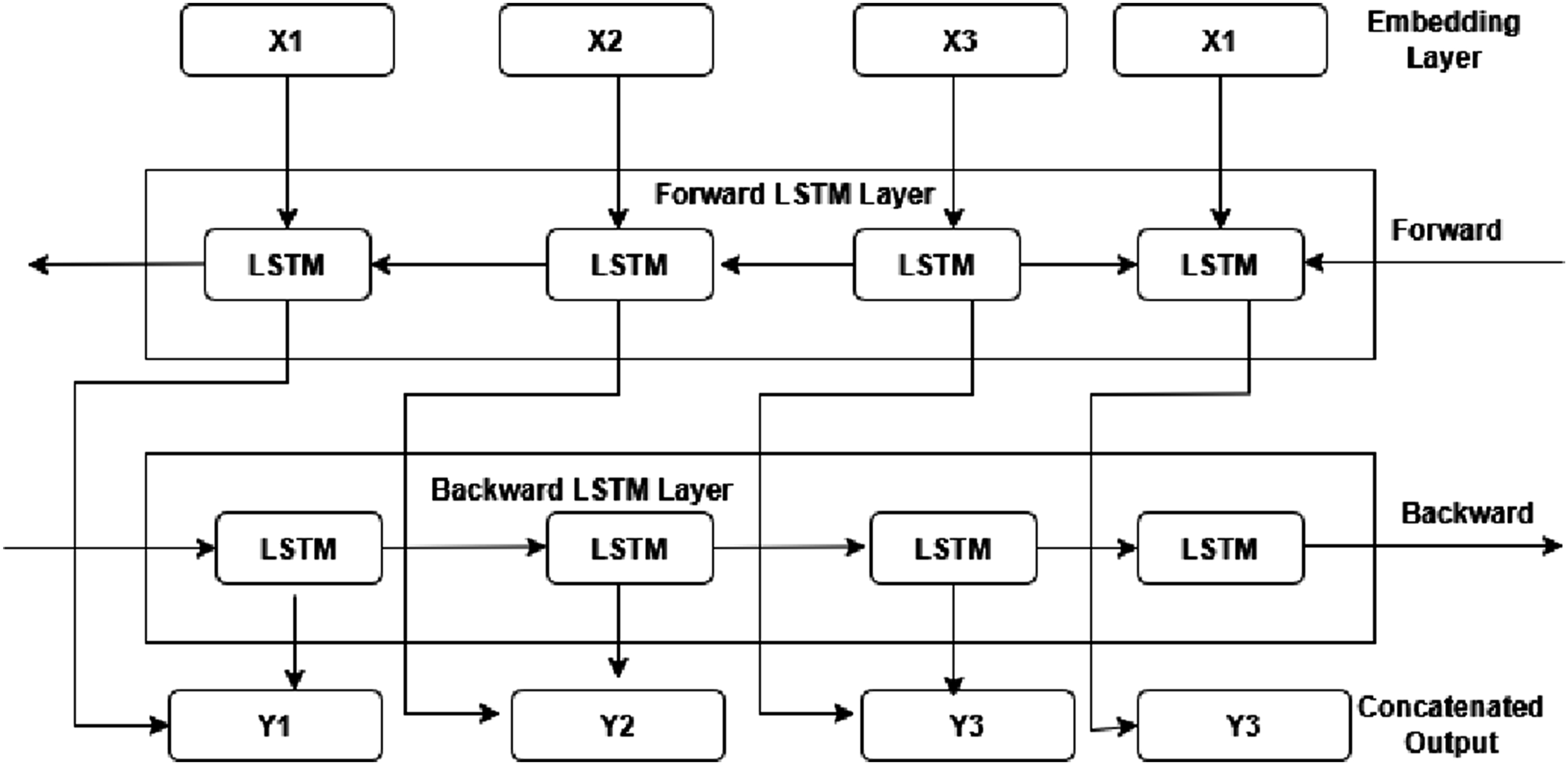
As shown in Figure 3 the workflow of BiLSTM model begins with ingesting the raw data and performimg initial cleansing i.e to drop corrupt entries. Cleaned data is then segmented into fixed length sequence and labeled after 10 consecutive spans, resulting into an input array of required format. BiLSTM model data flow.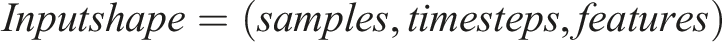
Data is then pre-processed using MinMax normalisation, readings ae scaled to the range [0, 1]. Followed by preprocessing data is chronologically splited (Time based) into 80–20 splits to preserve temporal sequence of data and to prevent data leakage. 20% data from data split is fed for validation to enable early stopping and overfitting of data. 80% split is sent to forward and backward LSTM layers which runs simultaneously. The output from both the layers is concatenated in the output layer and sent for evaluation.
LSTM-CNN hybrid model
Hybrid CNN-LSTM architecture combines the local feature-learning power of convolution networks with the temporal-dependency modeling recurrent units. As shown in Figure 4 hybrid model consists of: • CNN Layers: Consists of one or two one dimensional convolutional layers and Max pooling layers for detecting recurring patterns and reducing sequence length. • LSTM Layer: Refines data for suitable classification. • Dense Layers: Fully connected layer for classification and regression of data. CNN-LSTM hybrid model.
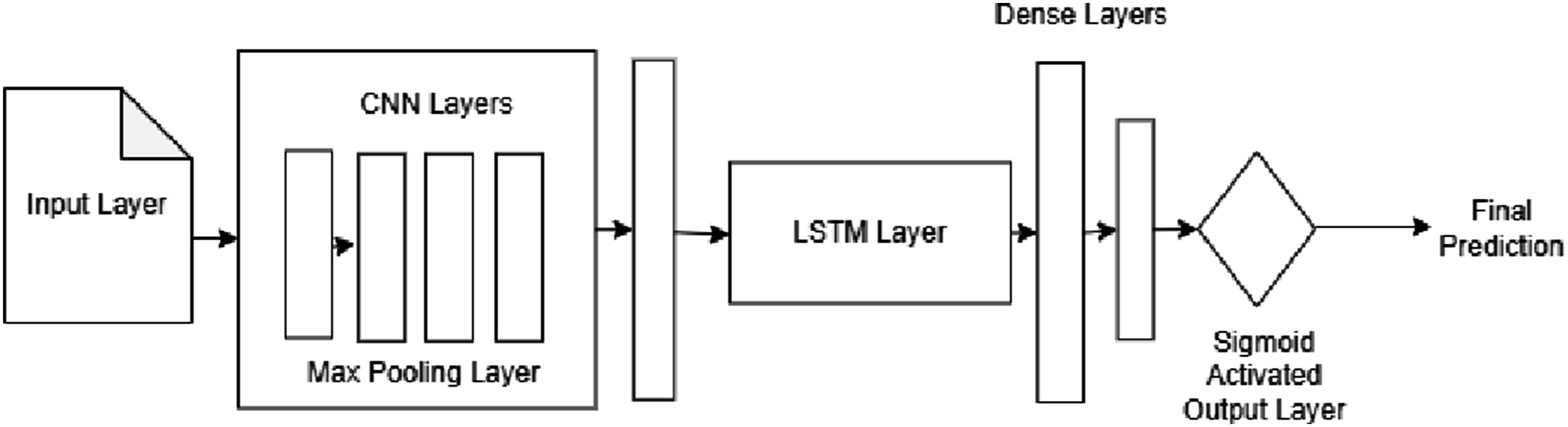
Workflow of CNN-LSTM model begins with ingesting the raw data and performimg initial cleansing i.e to drop corrupt entries. Cleaned data is then segmented into fixed length sequence and labeled after 10 consecutive spans, resulting into an input array of required format.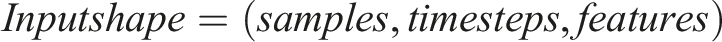
Data is then pre-processed using MinMax normalisation, readings ae scaled to the range [0, 1]. Followed by preprocessing data is chronologically splited (Time based) into 80–20 splits to preserve temporal sequence of data and to prevent data leakage and fed to CNN layers, here they are assembled into pooling blocks followed by stacked LSTM layers, dropout and dense classification head. Now the data set is optimised using Adam optimiser with early stopping based on validation loss. GAF-CNN model.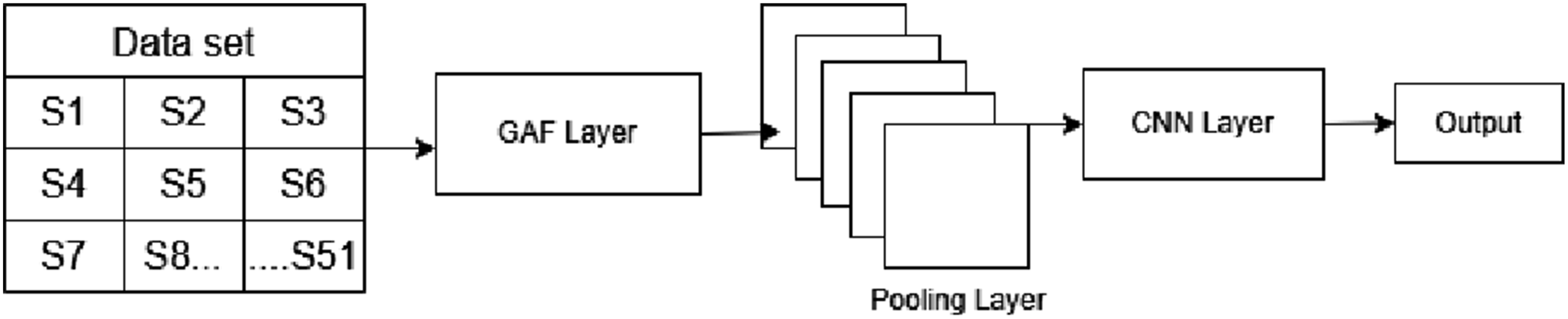
GAF-CNN model
As shown in Figure 5 GAF-CNN model consists of five stages: • GAF Layer: Encodes 1D time series data to 2D matrix (image). • Convolutional Layer: Filters are applied to input image to extract local features, followed by Rectified Linear Unit (ReLU) activation function for non-linearity. • Pooling Layer: Reduces spatial dimensions and flattens data in one dimension undergoing many pooling stages. • Fully Connected Layer: Learns higher-level representation and performs classification or regression task based on extracted features.
As shown in Figure 6 workflow of GAF-CNN model begins with ingesting the raw data and performing initial cleansing i.e to drop corrupt entries. Cleaned data is then reduced dimensionally using principal component analysis (PCA) to collapse 52- channel sensor data into a single time-series per sample GAF- CNN model data flow.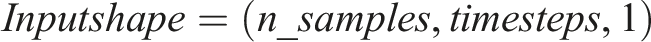
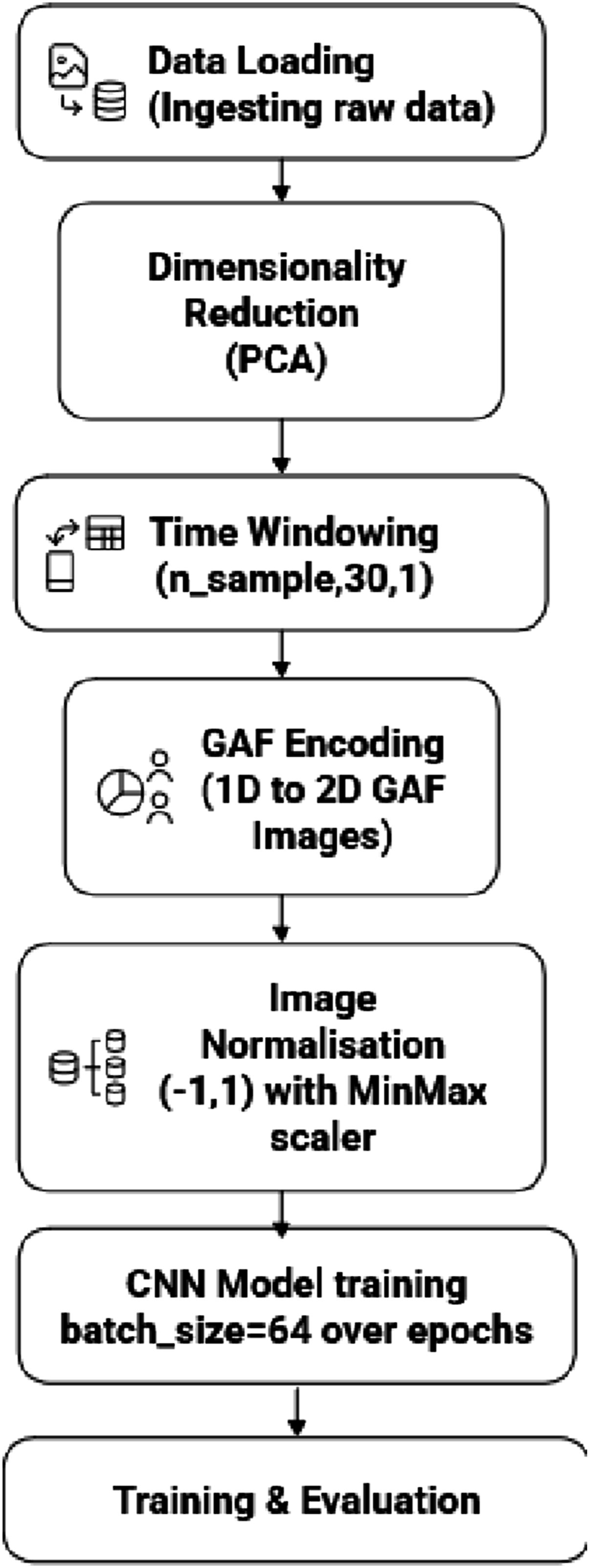
Overlapping window of length 30 is slid over each time series. Each 1D window is transformed into 2D GAF images using summation method. The images are normalized to [−1, 1] with MinMax scaler to stabilize CNN training. Data is then flatten in CNN layers and trained in batch size of 64 over several epochs and evaluated.
Time Series Transformer model
The Time Series Transformer model employs a self-attention mechanism to learn temporal dependencies directly from multivariate sensor data, without relying on recurrent computations. Unlike LSTM-based models that process inputs sequentially, the Transformer attends to all time steps in parallel, allowing it to effectively capture both short- and long-range temporal relationships.
The model is composed of two stacked Transformer blocks as shown in Figure 7. (1) Encoder: takes length of time series value data as input (past values). • Input Embedding: Encoder receives text and transform them into vectors adding information X = {x1, x2, ….x
n
}. Position encoding is added to preserve time order. We employ fixed sinusoidal function to encode relative position: Time series Transformer Model Data flow.
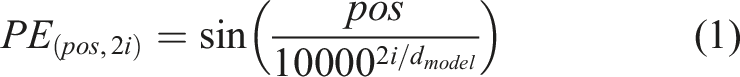
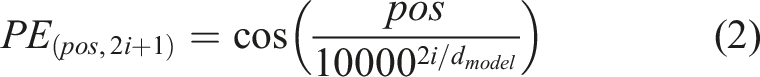
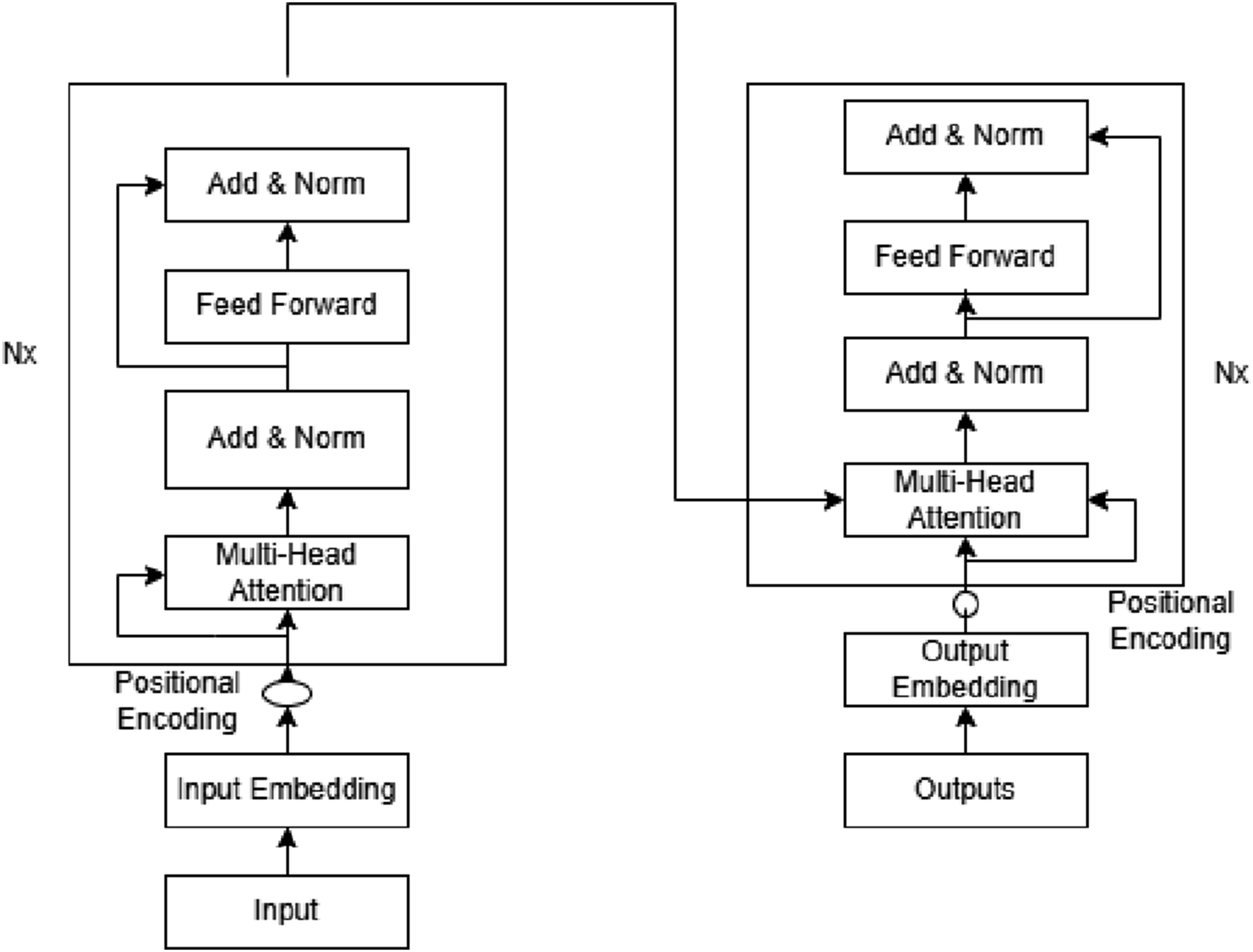
• Self Attention layer: This layer allows encoder to learn from past data that what part are important for forecasting (4 heads, head size = 128).
• Feed Forward Network: After self attention layer is updated the feedback their representation is passed to two layered feed forward network. FFN (x) = ReLU (xW1 + b1) W2 + b2
• Residual Connection and Normalization: Each layers are wrapped with residual connection and normalization layer stabilizes the data with dropout (0.5).
(2) Decoder: Predicts the time series values into future values.
• Input: Previously predicted values are embedded into positional encoding to form sequence of required shape = (n_samples, timesteps,1).
• Cross Attention: It connects past encoded values and current values for future prediction values. This is termed as Encoder-Decoder Attention.
• Multi-Head Attention: It improves self attention mechanism by using multiple attention heads that learns on various representation of data simultaneuosly.
The model is optimized using Adam optimizer with binary cross-entropy loss. Early stopping (patience = 20) based on validation loss prevents overfitting. Training and validation accuracy and loss curves are monitored to verify stable convergence.
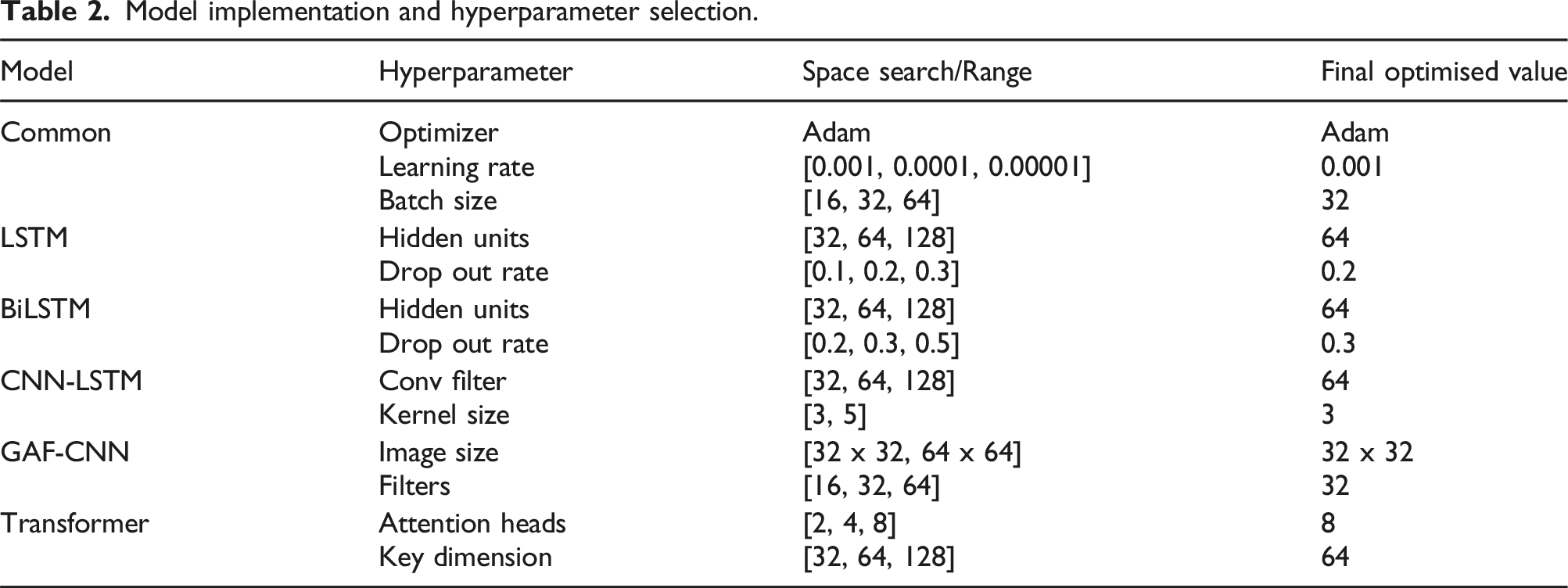
Model implementation and hyperparameter selection
Model implementation and hyperparameter selection.
Evaluation metrics
To quantitatively evaluate the performance of the proposed deep learning models, we utilized four standard metrics: Accuracy, Precision, Recall, and F1-score. These metrics are derived from the confusion matrix components: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN).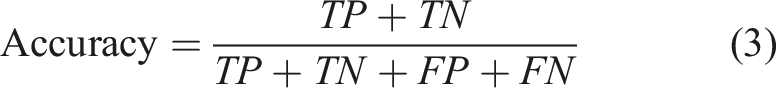
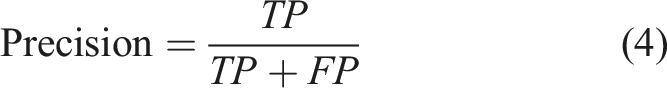


Experimental result and analysis
We employed five deep learning models: LSTM, BiLSTM, CNN-LSTM hybrid model, GAF-CNN model and Time Series Transformer model to distinguish between normal and faulty assets by evaluating accuracy, precision, recall and F1 score of the dataset.
Experimental environment
The experiments were executed on the Google Colab (Free Tier) platform. The computing environment consisted of: • RAM: 12.7 GB System RAM • Storage: 78 GB Available Disk Space • Language: Python 3
Results achieved by LSTM model
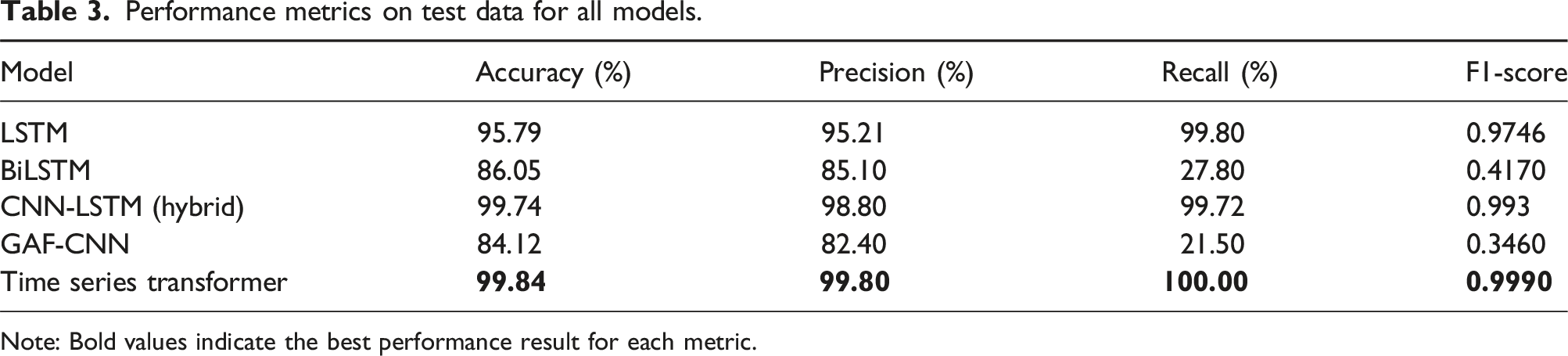
LSTM model achieved accuracy of 95.79%, precision of 95.21% and recall of 98.80% resulting in F1 score of 0.9746. LSTM model learns sequential temporal patterns effectively but shows overfitting when trained for longer epochs.
The LSTM model shows overfitting as validation loss increases after 20 epochs. Figure 8 shows a clear trend of decreasing training loss and increasing accuracy. Result of LSTM model.
Results achieved by BiLSTM model
BiLSTM model achieved accuracy of 86.05%, precision of 85.10% and recall of 27.80% resulting in F1 score of 0.4170. BiLSTM model processes sequences in both forward and backward direction, but performance remains limited due to class imbalance as shown in Figure 9. Result of BiLSTM model.
Results achieved by CNN-LSTM hybrid model
CNN-LSTM model achieved accuracy of 99.74%, precision of 98.80% and recall of 99.72% resulting in F1 score of 0.993. CNN-LSTM model combines CNN feature extraction for local pattern learning with LSTM temporal modeling, enabling superior classification performance.
Figure 10 shows training and validation loss curves, indicating good convergence and minimal overfitting. Result of CNN-LSTM hybrid model.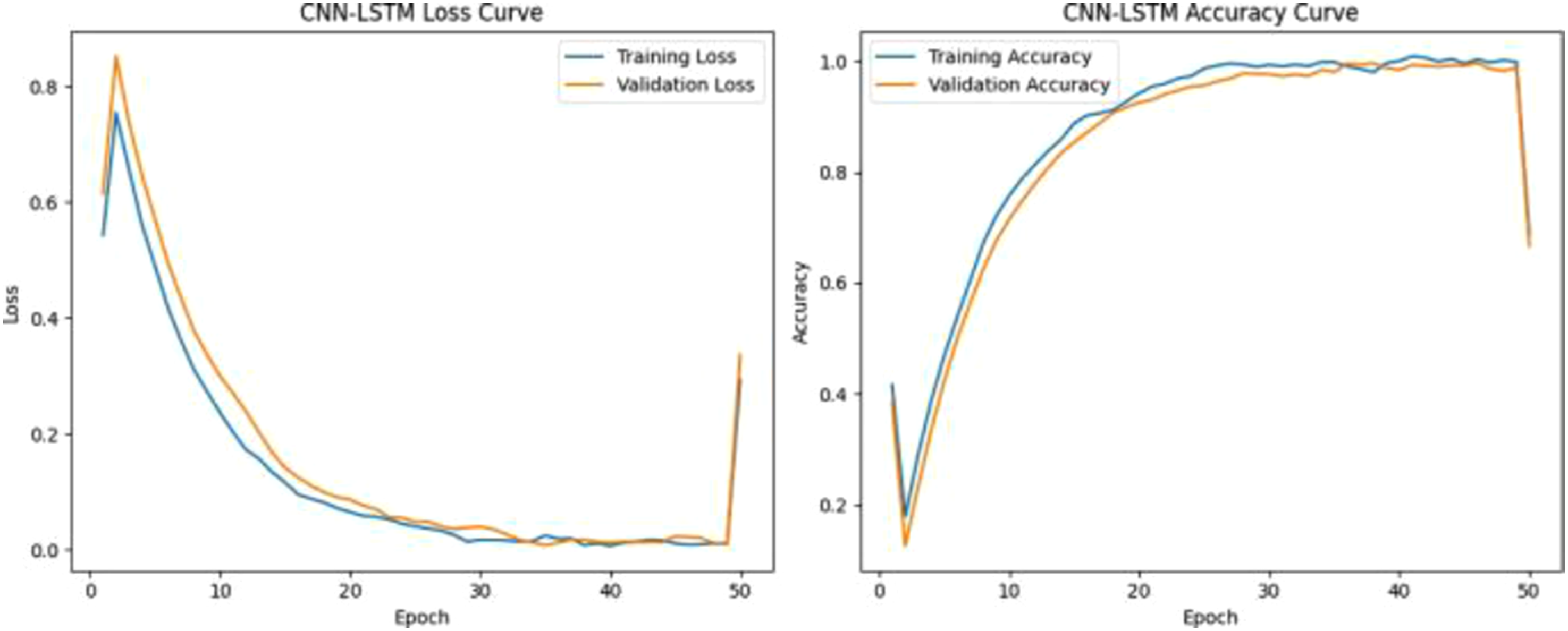
Results achieved by GAF-CNN model
GAF-CNN model achieved accuracy of 84.12%, precision of 82.40% and recall of 21.50% resulting in F1 score of 0.3460. Converts time-series data into GAF images to learn spatial correlations, but loses direct temporal continuity leading to poor minority class detection.
This model struggles significantly with minority class recall due to class imbalance and the loss of temporal representation in image encoding. Figure 11 shows training and validation loss curves of GAF-CNN model. Result of GAF-CNN model.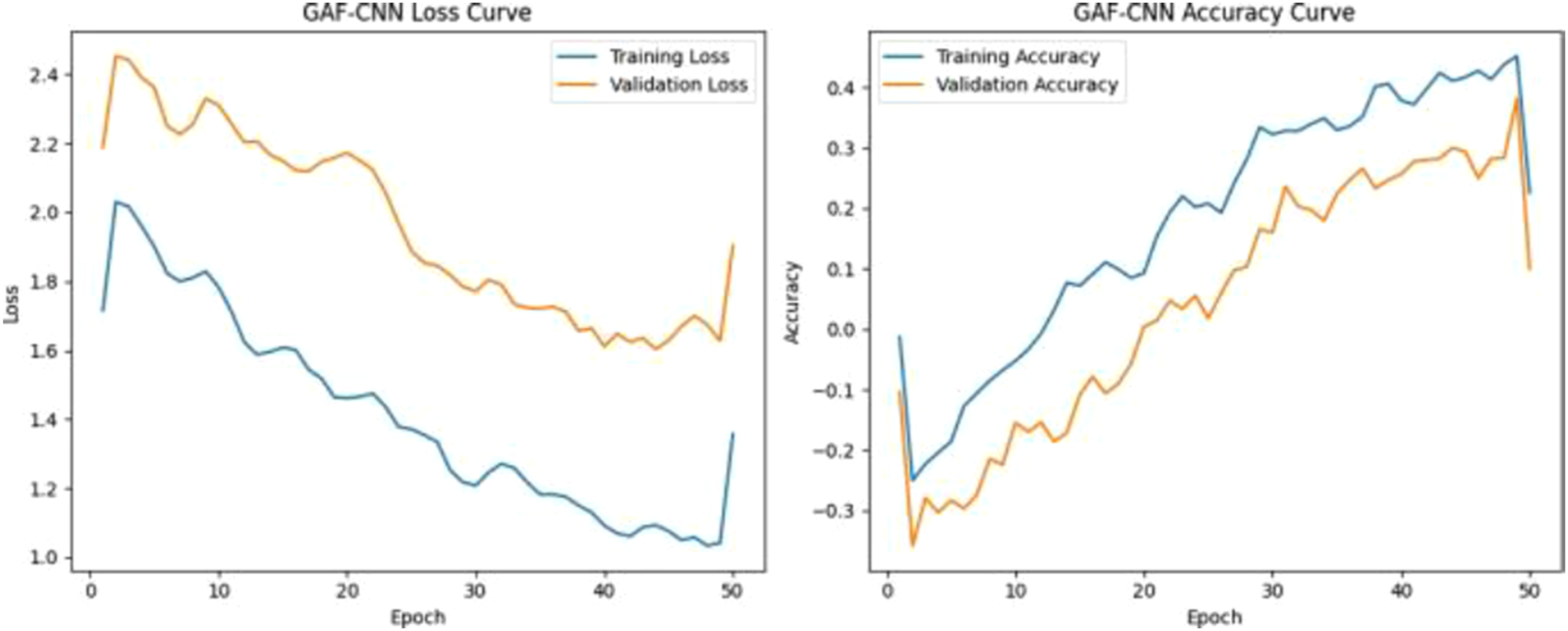
Results achieved by time series transformer model
Time Series Transformer model achieved accuracy of 99.84%, precision of 99.80% and recall of 100% resulting in F1 score of 0.9990. Time series transformer model uses self-attention to capture long-range dependencies but requires larger dataset size and stronger regularization to outperform recurrent models. Figure 12 shows training and validation loss curves of Time Series Transformer model. Result of time series transformer model. Performance metrics on test data for all models. Note: Bold values indicate the best performance result for each metric.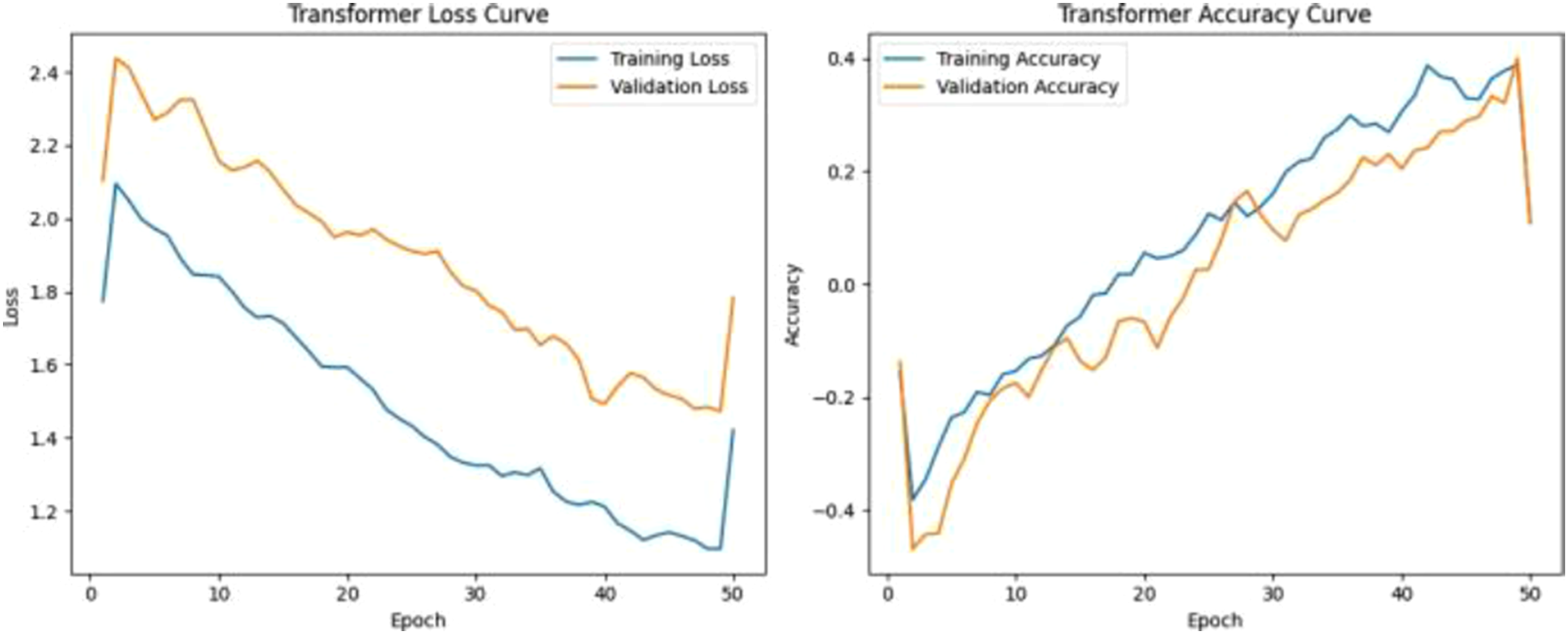
Comparison of results of different models
Baseline comparision and model justification.

Discussion
The primary objective of this study was to compare five different deep learning models on time series sensor data. In Predictive maintenance framework, the performance metrics like Acuuracy, Precision, Recall and F1-score translates directly into operational costs and reliability. The LSTM model showed accuracy 95.79%, and near perfect recall 99.8%. It remains a strong candidate for application where detecting rare failure events is paramount. BiLSTM model outperforms LSTM model due to bidirectional computation but leads to high computation cost. BiLSTM and GAF-CNN model showed lower recall leads to risk of catastrophic breakdowm of assests and unplanned downtime compared to other models attributed to high sensitivity to specific hyper parameters. GAF- CNN model is dependent on image resolution of Gramian fields and kernel size of convolutional layers. Grid search was performed (see Table 2), it is possible that model requires more extensive architectural tuning or large training space to fully capture minority class of given dataset. This model achieves high precision 99.00% on majority “NORMAL” class but failed to recall most “BROKEN” class instances 18.33%. Transformer time series based model showed high accuracy 99.84% and precision 99.80% with recall of 100% as it uses self attention mechanism. The model shows highest recall rate which ensures any incipient faults are not missed which may lead to equipment failure. Also F1-score obtained by this model is highest (0.9990) which represents most cost optimal balance for industrial deployment. By accurately finding the machine status using deep learning models, maintenance in assets can shift from proactive to reactive. For instance the models ability to distinguish minor or major failure allows the industry to apply suitable maintenance required. The study acts as a bridge between transforming theoretical deep learning into determining maintenance call if required before breakdown of mechanical assets. Its ability to highlight most relevant time steps not only enhance accuracy but also interpretability which makes it robust choice for real time application.
Conclusion and future directions
In this systematic evaluation study of five deep learning architectures—LSTM, BiLSTM, Hybrid CNN-LSTM, GAF-CNN, and Time Series Transformers—for predictive maintenance using multivariate sensor data, the analysis confirms that the Time Series Transformer explicitly outperforms recurrent and hybrid baselines, achieving a test accuracy of 99.84%, precision of 99.80%, and a perfect recall of 100%.
The Transformer architecture excels in capturing long-range dependencies and is the ideal default for environments where accuracy is important. However, in resource-constrained scenarios where battery life and inference speed are critical, a well-regularized LSTM remains a viable, lightweight alternative. Conversely, our analysis of the GAF-CNN model highlighted a significant limitation: the loss of temporal resolution during image encoding led to poor recall on minority classes, suggesting that image-based approaches require rigorous re-balancing before real-world deployment.
Future scope
The transition from theoretical accuracy to industrial deployment presents three specific challenges that define our future research:
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.