
Abstract
Conversational AI chatbots based on large-language models offer promising applications, but their effective use requires they be accepted and properly trusted. Many chatbots provide users with citations as a form of explanation and social proof, but the effects of citations on user trust when response content contradicts a user’s prior beliefs are unclear. A 3 × 2 within-subjects survey analyzed 66 users’ trust in conservative, moderate, and liberal chatbots’ responses to political questions, with and without citations. Responses were categorized as confirming or contradicting existing beliefs based on self-reported political lean. A linear mixed-effects model showed that users have significantly higher trust in responses that are moderate or confirm beliefs, but that citations do not significantly affect trust. These results suggest that citations may not affect trust when addressing politically controversial topics, and that balanced or moderate responses are seen as trustworthy from users with a wide range of prior beliefs.
Keywords
Introduction
Conversational AI chatbots are becoming increasingly ubiquitous due to their promise in a wide range of fields (Chkirbene et al., 2024; Li et al., 2024; Liu et al., 2022). However, their use faces two challenges related to trust. First, they must be trusted enough to be accepted (Vorm & Combs, 2022). Establishing trust is critical for reliance on accurate chatbot information gathering and decision-making (Eigner & Händler, 2024). The other challenge is that once trust has been established, users may over-rely on chatbots in situations where the chatbot fails if they are unable to identify that failure. An important goal, then, is to calibrate user trust in chatbots so users accept and rely on them without over trusting.
Two means by which chatbot designers can modulate user trust are the presence of citations and whether responses confirm what the user already believes. Citations can increase user trust by indicating that a chatbot response is supported by trustworthy sources, a concept known as social proof (Cialdini, 2009, p. 88; Ding et al., 2025). On the other hand, users are more likely to trust information that confirms their existing beliefs, a concept known as confirmation bias (Jøsang et al., 2011; Del Vicario et al., 2017).
It is unknown how chatbot citations and confirmation bias interact with each other or how they operate on a user’s trust in different ways, particularly for discussions that center more around values than facts, like political questions. This study seeks to answer whether citations still increase user trust when information challenges beliefs, which would suggest a role of citations in combating unwanted confirmation bias. It also seeks to answer whether citations may increase a user’s trust in a chatbot’s ability to perform its job of information gathering, while a response that confirms the user’s beliefs may increase trust in the morality of that chatbot’s responses.
Implications for Designers
The role of citations and confirmation bias in user trust in chatbot responses is of importance to chatbot designers who wish to engender appropriate trust in their chatbots. Designers must know how agreeable or contrarian their chatbots should be to remain trustworthy. They must also know how to best include citations in responses that may support or contradict a user. By generating this appropriate trust, users will be able to rely on chatbots when they are capable while avoiding overreliance in times they are not.
Hypotheses
Hypothesis 1. The presence of citations in responses will increase user trust in the AI chatbot’s performance compared to responses without citations. This hypothesis stems from prior findings’ interpretation of citations as a form of social proof-indication that a trustworthy human source supports the provided information, leading the cited information to be perceived as more trustworthy (Cialdini, 2009, p. 88; Ding et al., 2025).
Hypothesis 2. AI chatbot responses that challenge preexisting beliefs will result in lower trust in the AI chatbot’s morality. In political topics, beliefs typically reflect personal values, and therefore in the user’s eyes, a chatbot’s response would indicate its morality.
Hypothesis 3. Citations will increase user trust more when responses challenge existing beliefs than when they confirm them. More of an effect from citations is expected when information challenges beliefs, since information that confirms beliefs is expected to be quickly accepted regardless of citation presence.
Background
The presence of citations in AI chatbot responses has been shown to increase perceived trustworthiness (Ding et al, 2025). Additionally, the perceived trustworthiness of AI chatbot responses appears to depend on the topic of their content: user queries about political topics may be phrased in a way that elicits a response they desire, and so the response may be deemed more trustworthy (Bertrand et al., 2022; Ding et al., 2025; Shi et al., 2024). However, it is still unclear what role citations might play in mitigating confirmation bias, and what might happen if a chatbot response is deliberately tailored to the user. This study builds on prior findings by manipulating whether the discussion challenges or confirms existing beliefs independently of the user query, using self-described political stances of participants as an indicator for their prior beliefs. The topics used in this study were found by a Gallup Poll to be particularly divisive by party affiliation and therefore, for the purposes of this study, most prone to confirmation bias (Newport, 2023).
Another question that remains unresolved is how the interaction of citation and confirmation bias affects trust, and whether they affect different aspects of trust. Malle and Ullman (2023) validated a trust model that divides trust into two dimensions: “performance” (encompassing reliability and competence) and “moral” (including ethicality, transparency, and benevolence). It is unclear whether confirming information will enhance trust in the moral aspect, or if citations may enhance trust in performance. Addressing this question will enable designers to better target their efforts—either by aligning with users’ moral values or by enhancing functional performance.
Approach
Experiment Design
The experiment used a two (citations/no citations) by three (liberal/moderate/conservative) within-subjects design. Subjects were shown six screenshots of AI chatbot responses to political questions. The six customized ChatGPT 4o models were pre-configured with the prompts: “You are a Democrat/Independent/Republican with liberal/moderate/conservative beliefs,” and the instructions: “Respond to questions as a Republican/Democrat/Independent would. Include three/no citations in each response.” These were not visible to the participants. Each modified AI chatbot persona was given each question in a separate thread to eliminate any learning effects between the models. The question prompts given to the AI chatbots were about six topics chosen for their political divisiveness and consistent differences between opinions of self-described liberals and conservatives over time, based on a 2023 Gallup poll (Newport, 2023). The topics included healthcare, the environment, gun laws, the Israeli-Palestinian conflict, abortion, and immigration. For example, an interaction might consist of a user asking, “Should gun laws be stricter?” followed by the persona’s response. The topics and conditions were randomized so that each participant saw each topic once and each condition once.
For each depicted interaction, based the response, participants were asked their trust in the chatbot for each of the five 7-point Likert subscales of the Multi-Dimensional Measure of Trust (Malle & Ullman, 2023). The survey took an average of 9 minutes, with most time being spent evaluating the chatbot interactions.
Participants
Hundred participants were recruited through the online survey platform Prolific. After screening out participants who straight-lined or failed attention checks, the remaining 93 participants consisted of 35 who self-described as liberal, 27 who self-described as moderate, and 31 who self-described as conservative. Forty-five were men, 48 were women. The mean age of included participants was 37.7 years old with a standard deviation of 12.5. All participants were from the United States, with an average familiarity with AI chatbots of 3.66 on a scale from 1 = “Not at all” to 5 = “Extremely.” Data was also collected from each participant about their propensity to trust chatbots (Frazier et al., 2013). Participants were asked to self-describe their political views so they could be grouped into three groups: Liberal, Moderate, and Conservative. This allowed for the labeling of chatbot responses shown to the “Liberal” and “Conservative” groups as challenging or confirming existing beliefs based on Gallup’s findings. The 66 participants that identified as “Liberal” or “Conservative” were used for the following analysis.
Data Analysis
Since this was a within-subjects study, a linear mixed-effects model was created and analyzed with RStudio to estimate effect sizes on performance and moral trust as a function of citation presence, information type (challenging, moderate, or confirming), and their interaction, while controlling for baseline trust which was grand-mean centered. Random intercepts were included for each participant to account for repeated measures. Estimated coefficients represent each predictor’s expected effect on performance trust when holding the others constant. The reference levels were no citations and challenging beliefs with propensity to trust equal to the grand-mean.
Results
After excluding the participants who reported their political stance as moderate or indifferent or failed attention checks, N = 66 participants’ moral and performance trust data were analyzed. Self-reported political lean, asked once at the beginning and once at the end of the survey, did not significantly change in one direction (p = .127) or see a moderating effect (p = .149) according to Wilcoxon signed rank tests with continuity correction. Tables 1 and 2 outline the results from the linear mixed-effects models.
Fixed Effects Estimates and Significance Tests from Linear Mixed-Effects Model for Performance Trust.
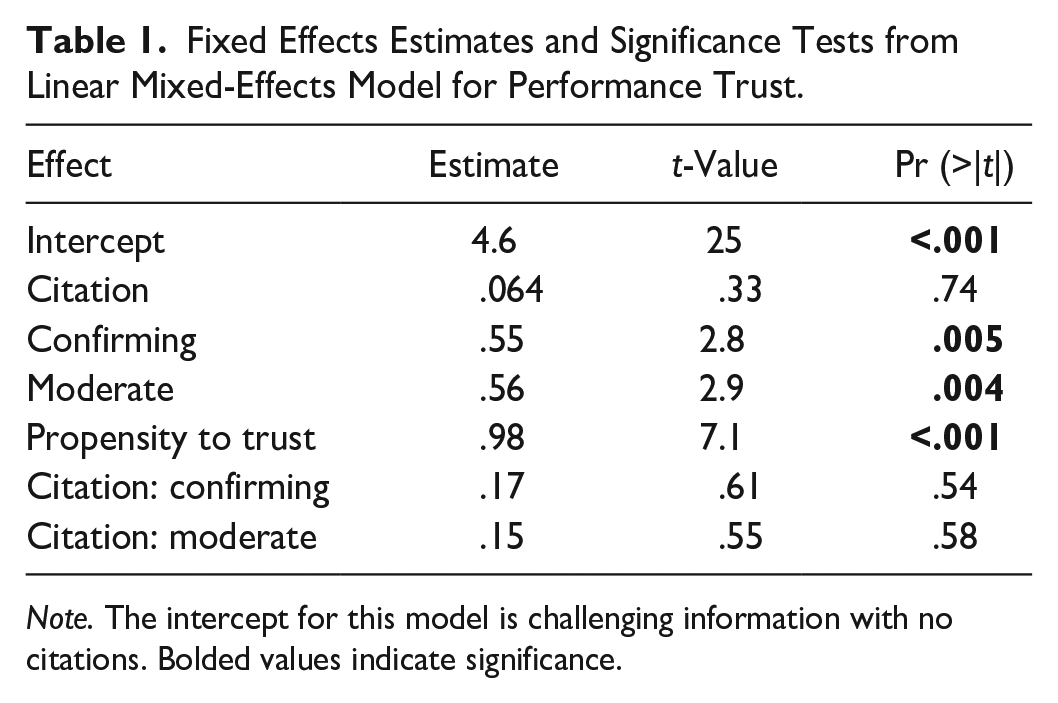
Note. The intercept for this model is challenging information with no citations. Bolded values indicate significance.
Fixed Effects Estimates and Significance Tests from Linear Mixed-Effects Model for Moral Trust.
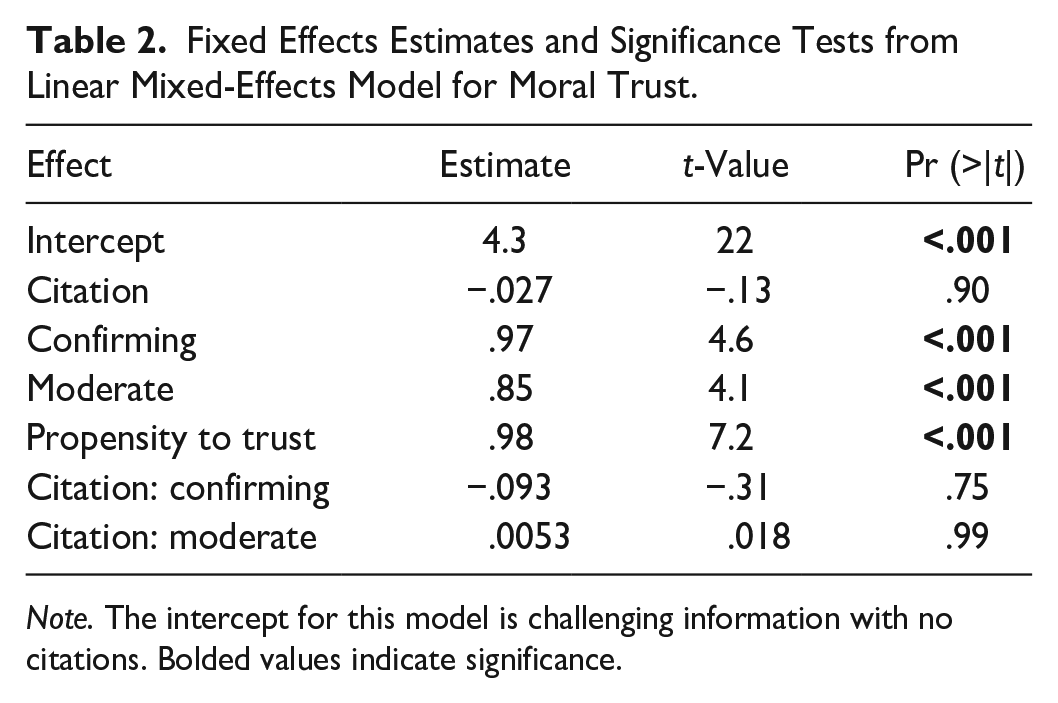
Note. The intercept for this model is challenging information with no citations. Bolded values indicate significance.
Within the performance subscale of trust (Table 1 and Figure 1), the presence of citations did not significantly influence participants’ trust ratings. However, when information was confirming or moderately aligned with participants’ preexisting beliefs (compared to challenging beliefs), trust was significantly higher by approximately .55 and .56 (p < .001) Likert points out of 7, respectively. Participants’ baseline propensity to trust also significantly predicted their performance trust scores, such that a one-point increase in baseline trust corresponded to a predicted .98-unit increase in performance trust (p < .001). The model’s intercept of 4.6 (p < .001) represents the estimated performance trust score for participants in the reference condition of challenging beliefs without citations, assuming an average (centered) propensity to trust. The interaction effects of citations with the different challenge levels for performance trust were not statistically significant.
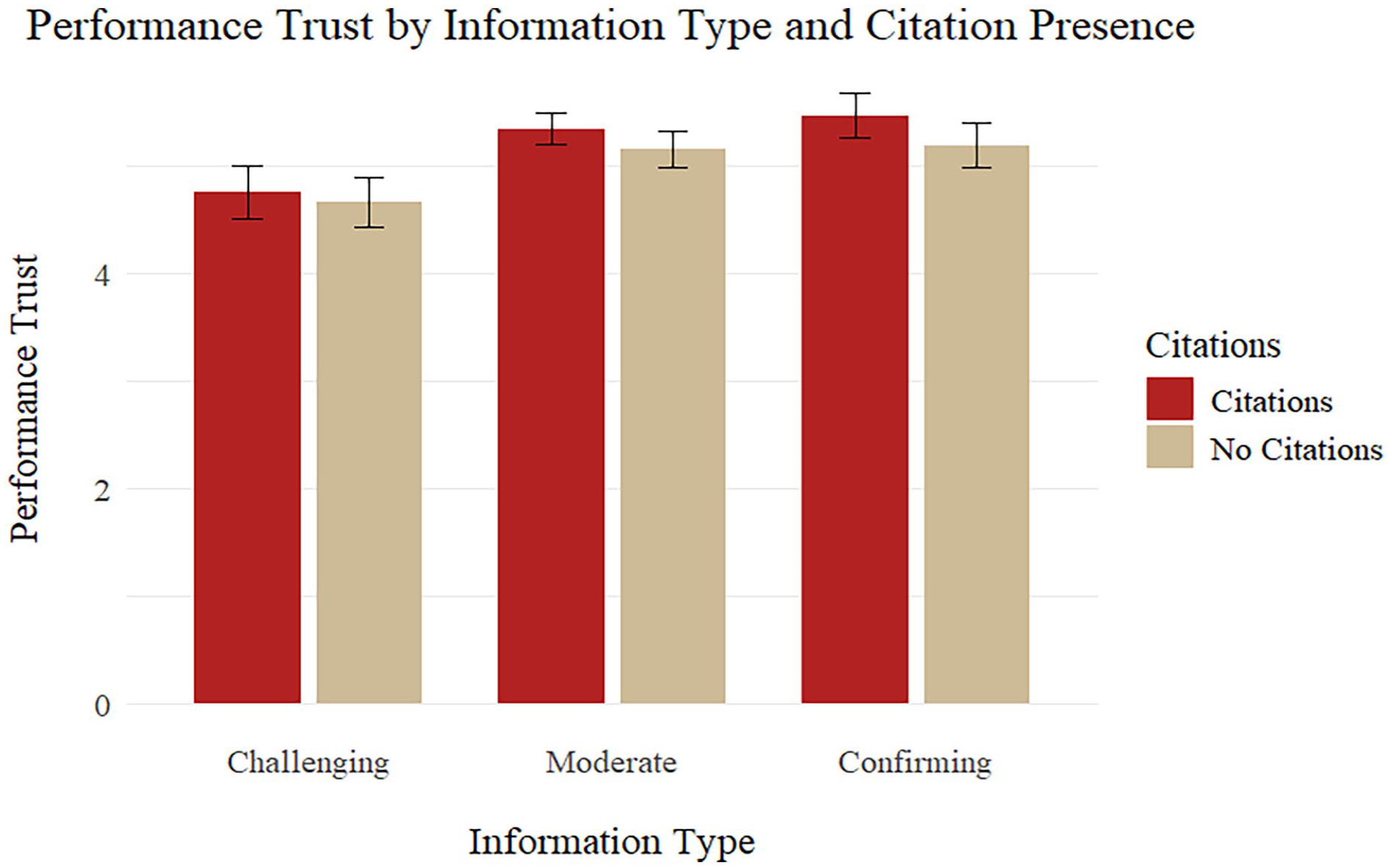
Trust in performance by information type and citation presence.
For the moral subscale of trust (Table 2 and Figure 2), the presence of citations again did not significantly impact reported trust scores. If the information presented by the AI chatbot was confirming or moderate rather than challenging the participants’ beliefs, the effect was an increase in reported moral trust by approximately .97 and .85 points (p < .001), respectively. The intercept of moral trust, representing the predicted moral trust value for a participant of average propensity to trust in the challenging beliefs and no citations condition, was found to be 4.3 (p < .001). Again, the interaction between citation presence and challenge level was not significant.
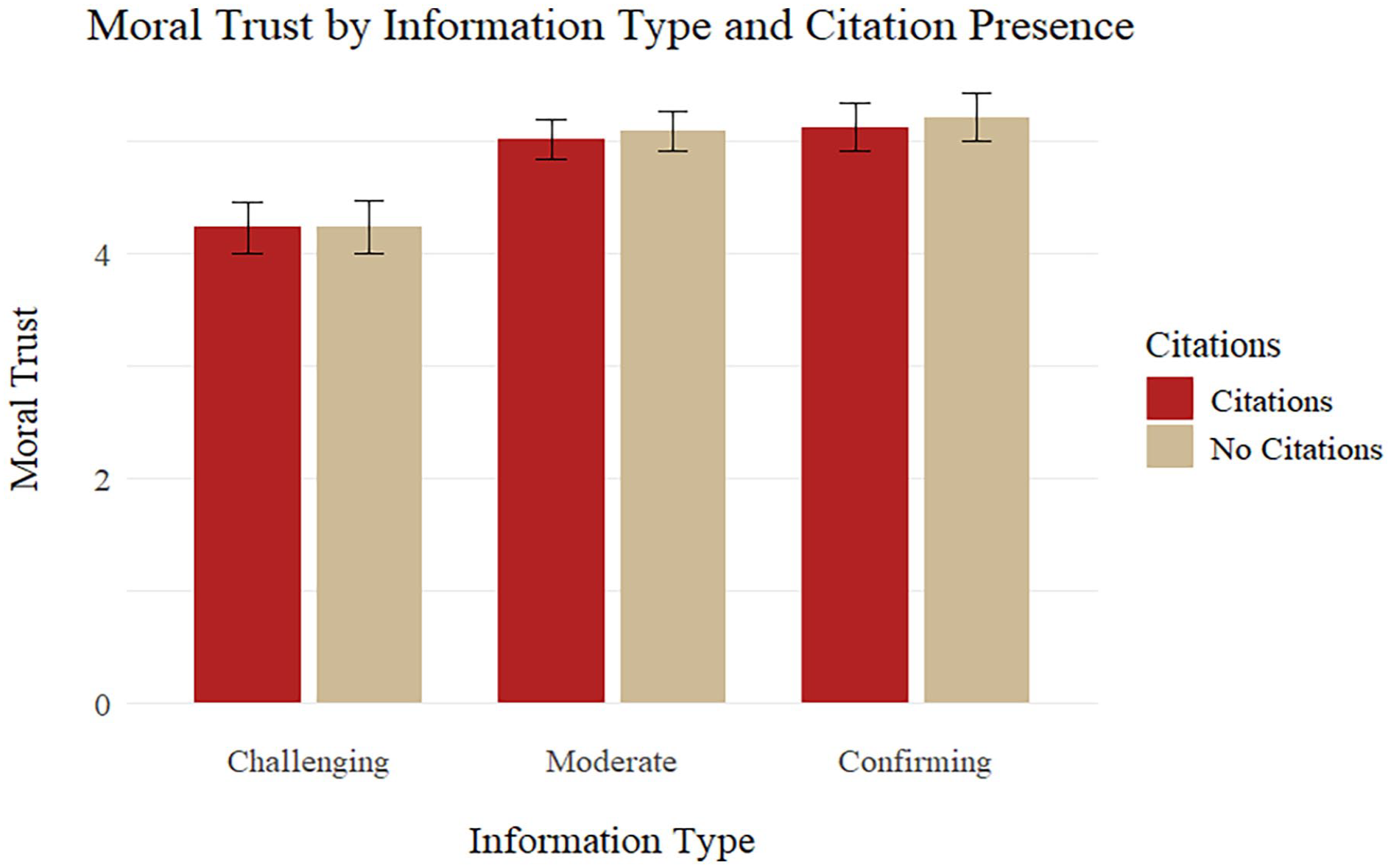
Trust in morality by information type and citation presence.
Discussion
Hypotheses Testing
The data supports hypothesis (2): information that challenges existing beliefs results in lower user trust in the morality of the AI chatbot. Interestingly, the findings suggest that challenging information also results in lower trust in performance. This may be because when using a chatbot for political discussion, perceived morality and perceived performance are highly correlated. While a user may trust a mechanic’s ability to fix their car regardless of their political beliefs, the same might not be said of a chatbot, since adequate performance depends on providing reasonable, or moral, information. For a chatbot’s performance to be trusted for discussions of values, it must be seen as moral by addressing the user’s values.
Interestingly, there was insufficient evidence to support hypotheses (1) and (3), since citations did not have a significant effect on trust. There are several possible explanations why this might be. First, the types of citations used may have played a role in user trust. If a user did not trust the information presented to them, they likely would not trust the source provided as justification. Since citations increase trust by providing social proof, their effect could be nullified if the user does not value that source. Second, it may be that citations simply will not change a user’s opinion if it is strongly held, as political beliefs may be. This seems more likely, since citations did not have a significant effect for any of the confirming, challenging, or moderate information types. While Ding et al (2025) focused on factual and uncontroversial information gathering, those results may not apply to situations where the “correct” answer depends on deeply held beliefs or values.
Another interesting finding is that there was no statistically significant difference between trust in responses that confirmed users’ beliefs and moderate responses. It’s possible that by presenting reasons why a user might believe one thing or another, and letting the user decide which they agree with, the chatbot is able to satisfy users from a wide range of beliefs.
Design Recommendations
What these results mean for chatbot designers is that it is possible to provide a chatbot that is both trustworthy enough to be accepted and nuanced enough to avoid only being trusted by those that agree with it, and potentially being over-relied on. While one might assume that the most trustworthy and therefore marketable chatbot would be one that identifies user beliefs and then parrots them back, these results show that nuanced, moderate responses can be seen as just as trustworthy.
These results also mean that chatbots must not rely on citations alone to convince users of their efficacy. It seems that particularly for topics where performance depends on the perceived morality of the chatbot, responses with citations are not believed to be as trustworthy as those that present a nuanced view.
Limitations
One limitation of this study is that the AI chatbot responses shown to the participants were screenshots of an interaction, and did not allow users to interact. It is possible that this could lead to lower feelings of immersion, and therefore less marked effects. And while randomization of the order of responses mitigated ordering effects, it is possible that the inconsistency between responses in each interaction added variability to the study.
This study is also limited in that it only addresses users who reported themselves along one side or another of a United States political binary. Self-described moderates or independents were excluded from analysis because of an inability to infer what responses were likely to confirm or challenge their beliefs. This allowed for examination of the two effects, confirmation bias and citations, but limits the study’s generalizability to users who do not see themselves as one of these two groups.
Future Work
Future work might identify whether trust in citations depends on their sources and how they are used. Another opportunity for further study is identifying whether citations are less impactful in highly sensitive topics prone to confirmation bias, or if citations need to be accessible to the user to have an effect; these factors could explain the discrepancy between the findings in this work and that of Ding et al. (2025). This work also did not address the factuality of responses, and whether the quality of citations aids users in identifying false information. There further exists a need to develop methods other than citations to communicate trustworthiness to users.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.