
Abstract
There is an urgent need for human factors methods which can match the pace and scale of AI development. In this study, we compared two data collection mechanisms to probe nurses’ understanding of an AI-infused patient data display. We collected responses to equivalent questions in two alternative formats: (1) unstructured free text responses and (2) structured multi-select responses. We found nurses were significantly more likely to report 11 of 15 response categories with the multi-select questions. Additionally, we found nurses exhibited significantly different behaviors interacting with the display; however, we found little evidence of differences in task performance. Our findings emphasize that structuring data collection mechanisms to support quick data processing can induce different responses and behaviors that are not directly comparable to unstructured responses.
Keywords
Introduction
Human factors evaluation methods will need to adapt to keep pace with the rapid development of artificial intelligence (AI). For example, the growing popularity of red teaming to evaluate AI-infused technologies underscores the need for methods which can quickly collect, process, and analyze large volumes of human feedback. This favors quantitative research paradigms which utilize highly structured responses for quick data processing. However, concerns remain about structured responses inducing different cognitive processes and behaviors than those which would naturally occur, like questions which trigger recognition processes compared to those which trigger recall processes (Mee et al., 2024). Alternatively, qualitative research paradigms often utilize unstructured observations which more closely approximate realistic conditions. However, the time-intensive costs of qualitative analysis have greatly limited suitability for large-scale research.
Ideally, large-scale human-AI evaluations would collect structured data which closely approximated unstructured responses; however, research comparing structured and unstructured responses has produced mixed results. In education, studies have found different question formats can lead to different responses which are not strongly correlated (Kuechler & Simkin, 2010). Other studies have found strong correlations if unstructured responses are strictly graded with an “all-or-nothing” approach (Kastner & Stangla, 2011). Therefore, the degree to which structured questions can be substituted for unstructured questions in large-scale human-AI research remains unclear.
In this study, we directly compared the impacts of structured and unstructured responses on participants’ reports, behaviors, and performance when using an AI-infused display. Some participants responded using a free text question format which was qualitatively coded by researchers. Other participants responded using a multi-select question format designed to approximate researcher-coded analysis. We compared reporting rates, display interactions, and task performance between the two sets of questions to assess whether they elicited similar responses and behaviors. From these results, we discuss implications for scalable research.
Methods
Experimental Design
Interface
We developed an AI-infused patient data display to assist nurses in the early detection of patient deterioration. The display included the patient’s medical history, laboratory results (Labs), medications (Meds), pulse oxygenation (SpO2), blood pressure (BP), respiratory rate (Resp), heart rate (HR), and clinical alarms which nurses use to recognize deterioration (Horwood et al., 2018). The display also presented predictions and explanations from an AI algorithm trained to predict emergency events. Further details about the algorithm (Morey et al., 2024), interface (Rayo et al., 2022), and explanations (Morey & Rayo, 2024) are published elsewhere.
Participants
Over 2 years, 755 prelicensure nursing students and 18 licensed nurses were recruited for this study. Undergraduates included 173 second-year, 149 third-year, and 216 fourth-year nursing students. Graduates included 148 first-year and 69 second-year nursing students. Licensed nurses included 14 Registered Nurses (RN) and 4 Licensed Practical Nurses (LPN). All participants were trained to recognize patient deterioration but were not familiar with the AI algorithm.
Protocol
Participants were asked to utilize the AI-infused patient data display to assess a randomized sequence of 10 historical patient cases with 4 experimental conditions. Cases included 5 emergency and 5 non-emergency patients, where an emergency was defined as the mobilization of a rapid response team within the next 5 min. Experimental conditions included displays without AI assistance (A), with AI predictions only (B), with both AI predictions and explanations (C), and with AI explanations only (D). Before the study, participants watched a training video and used a practice case to familiarize themselves with the display. During the study, participants were encouraged to spend no more than 5 min analyzing each patient case. Participants received no feedback at any point.
Measures
For each case, participants were asked to report their concern for the patient on a continuous scale from 0 to 10. Participants were also asked two questions to explain why they were concerned about the patient (Q1) and what they thought contributed to the AI prediction (Q2). Additionally, the data sources participants viewed and the time they spent analyzing each patient case were recorded from display interactions.
Manipulations
Two data collection techniques were used to elicit participants’ explanations (see Table 1). In the tradition of qualitative research, one set of questions was unstructured, recall-based, and allowed participants to enter a free text response. These responses can support a broader and richer scope of analyses but required time-intensive manual review. In the tradition of quantitative research, the other set of questions was structured, recognition-based, and allowed participants to multi-select any combination of the data sources presented on the patient display. This latter set of questions also included a series of statements about the patient (e.g., “This patient’s condition is currently stable.”) for which participants indicated agreement on a 5-point Likert scale. The set of multi-select questions were intended to approximate the qualitative analyses that would be conducted for the free text responses without the need for manual review. In total, 6,803 responses from 713 participants and 580 responses from 60 participants were collected in the free text and multi-select formats, respectively.
Question Sets From Two Data Collection Techniques.
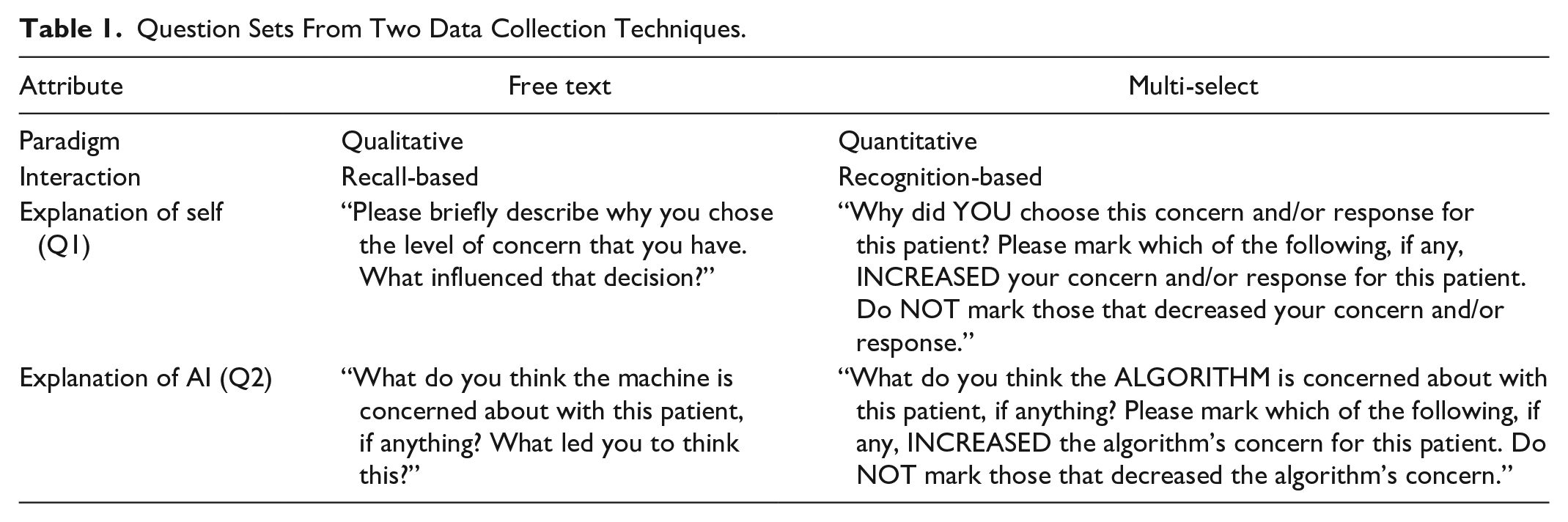
Qualitative Coding
Coding Scheme
Four of the authors coded all free text responses. For each of the data sources available on the patient data display, responses were first coded by whether participants mentioned the data source in their explanation. If present, responses were further categorized by whether participants were concerned, neutral, or unconcerned about the data source. Similarly, we also coded whether participants mentioned the AI algorithm in explanations of their own concern. For comparison to the multi-select responses, we collapsed these four categories of codes into a binary categorization. Only responses which increased participants’ concern were coded as 1. All other responses were coded as 0. This binary categorization directly corresponded to the intent of the multi-select questions. We additionally coded participants’ explanations of the AI algorithm for whether they mentioned the presence or absence of red elements on the display (Red), which was the visual encoding of the algorithm. We collapsed these codes into a binary categorization based on positive mentions only.
Inter-Rater Reliability
To assess inter-rater reliability (IRR), 10% of the free text responses were coded by at least two researchers. We calculated Krippendorff’s alpha for both categorical and binary codes to assess agreement among raters (Krippendorff, 1970). We considered α ≥ .80 evidence of good agreement and α ≥ .66 the lowest limit of acceptable agreement (Krippendorff, 2018).
Data Analysis
To evaluate the impacts of each question set on participants’ explanations, display interactions, and concern, we used generalized linear mixed effects models. We included two-way interactions of patient case and experimental condition as fixed effects to separate the effects of the question set from the effects of cases and conditions. We also included trial number as a nominal variable to account for potential effects of learning or fatigue. Additionally, we included random intercepts for each participant to account for repeated measures. To model the binary codes from participants’ explanations and the probability of participants viewing each data source, we used a binomial error distribution. To model the total time participants spent analyzing each case, we used a logarithmic transformation and t distribution. To model participants’ reports of concern on the closed interval from 0 to 10, we normalized concern and used an ordered beta distribution (Kubinec, 2023). Since the appropriateness of participants’ concern depended upon the severity of the patient, we included all interactions with the case and condition for both the question set and trial number. For all models, our null hypothesis was that participant responses would be similar across questions sets.
To evaluate model fit, we used the variance inflation factor (VIF) to assess multicollinearities and a simulation approach to assess residuals for hierarchical models (Hartig, 2022). All VIFs for base model terms were less than 5 and model assumptions were determined not to be violated.
Results
Impacts on Explanations
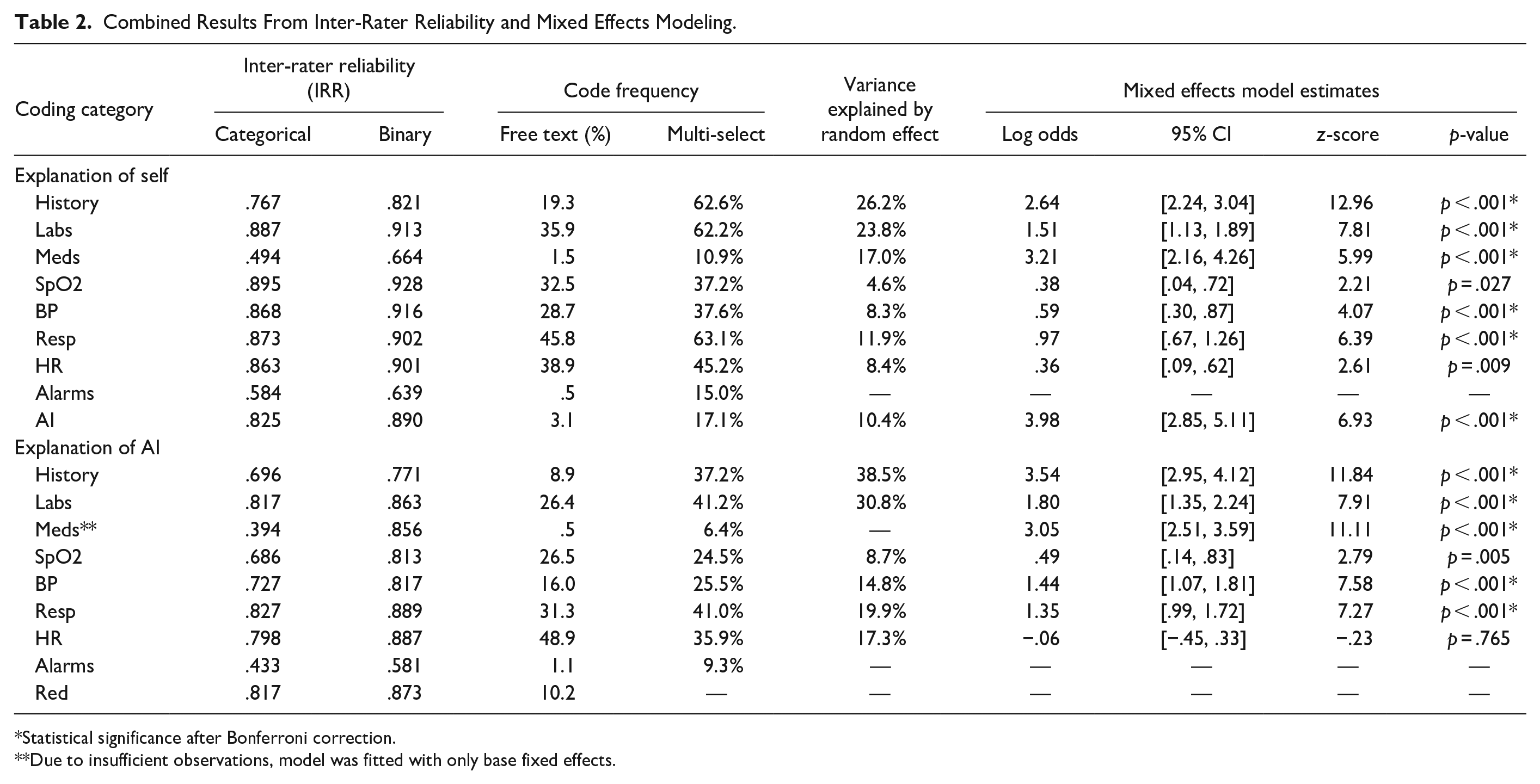
Table 2 shows the combined inter-rater reliability (IRR) scores, frequency, and modeling estimates for all codes derived from participants’ explanations. The free text code for mentions of red had no analogous multi-select question.
Combined Results From Inter-Rater Reliability and Mixed Effects Modeling.
Statistical significance after Bonferroni correction.
Due to insufficient observations, model was fitted with only base fixed effects.
Binary IRR
IRR scores for binary codes indicated general agreement among raters, especially for frequently appearing codes. Of the 18 coding categories, 14 showed evidence of good agreement, 2 showed evidence of acceptable agreement, and 2 showed evidence of unacceptable agreement. All codes with at least 10% frequency showed evidence of good agreement among raters. Clinical alarms were the only binary codes with unacceptable agreement. Unlike other coding categories which were visually separated on the display, clinical alarms were integrated with the corresponding patient vitals visualizations. The lack of dedicated space and dispersion of alarms across the display may have increased the ambiguity of alarms in participants’ explanations and contributed to the poor IRR scores. Only binary codes with acceptable IRR were considered suitable for comparison to multi-select responses. Therefore, alarms were omitted from modeling and further analysis.
Categorical IRR
IRR scores for categorical codes indicated mostly acceptable agreement among raters. Of the 16 coding categories which showed at least acceptable agreement among binary codes, 9 showed evidence of good agreement, 5 showed evidence of acceptable agreement, and 2 showed evidence of unacceptable agreement among categorical codes. Medications were the only additional categorical codes with unacceptable agreement. Participants were often less precise in their explanations of data sources that did not increase their concern, which increased the ambiguity of whether data sources were neutral, unconcerned, or unmentioned. This may have disproportionately impacted medications, which were among the least frequently coded.
Mixed Effects Models
Adjusting for the effects of each case, each condition, learning or fatigue, and individual differences between participants, results of the mixed effects model suggested substantial differences in the frequency of codes between the two question sets. After applying a Bonferroni correction to adjust the level of significance for multiple comparisons, 11 of 15 coding categories were significantly different. Across all significant differences, participants were more likely to report each coding category in the multi-select condition. Patient history, labs, and medications showed the largest differences (in log odds) across both types of explanations. Mentions of the AI algorithm in explanations of participants’ concern also substantially increased in the multi-select condition. Heart rate and SpO2 were the only coding categories which did not show significant differences between free text and multi-select responses.
Impacts on Behaviors
Figure 1 shows the impacts of each question set on participant behaviors recorded from interactions with the display. Separate mixed effects models were used to adjust for the effects of each case, each condition, learning or fatigue, and individual differences on the total time participants spent analyzing each case and the probability of viewing each data source. The estimated marginal means from the model are shown with 95% confidence intervals. Differences between free text and multi-select conditions with p < .05 are annotated. Since patient history and heart rate were shown to all participants by default, these data sources are omitted.
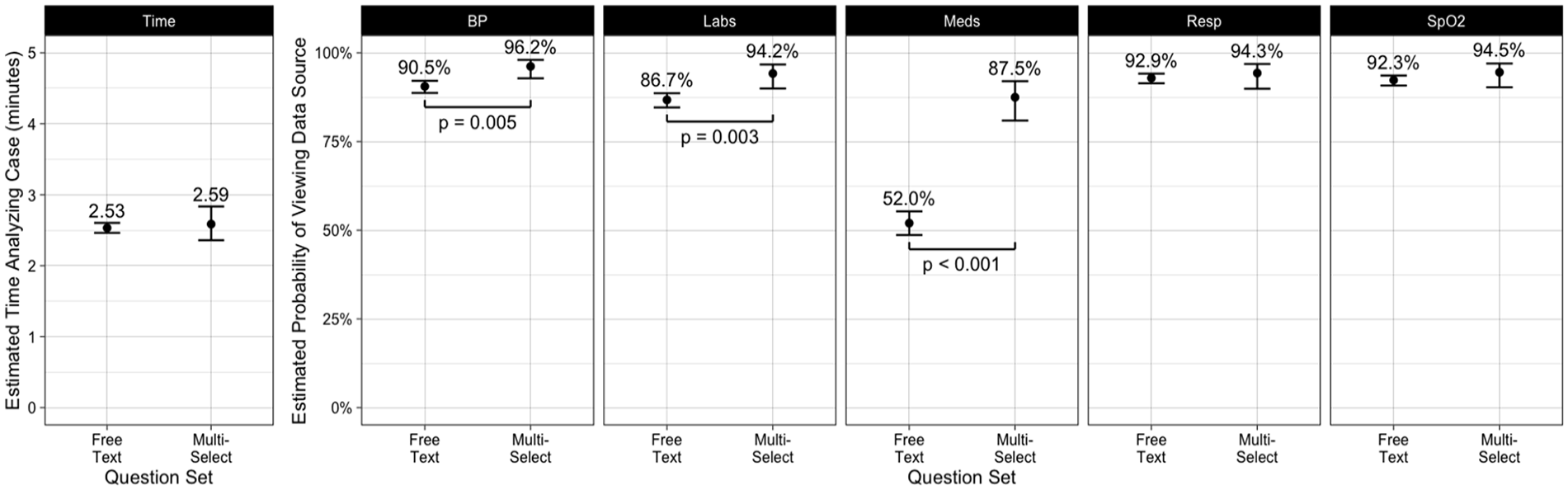
Participant behaviors with free text and multi-select question sets.
Half of participant behaviors showed significant differences between question sets. Participants were significantly more likely to view blood pressure, labs, and medications when using the multi-select condition. These significant differences corresponded to the three data sources which were least frequently viewed in the free text condition. In particular, the rate at which participants viewed medications was substantially increased in the multi-select condition (52.0% vs. 87.5%, log odds = 1.86, 95% CI: [1.35, 2.38], z = 7.07, p < .001). We did not find significant differences in the rates participants viewed respiratory rate and SpO2 or the time participants spent analyzing each case.
Impacts on Concern
Figure 2 shows the impacts of each question set on participants’ concern for each patient and experimental condition. The estimated marginal means from the mixed effects model are shown with 95% confidence intervals after adjusting for effects of learning or fatigue and individual differences. Differences between free text and multi-select conditions with p < .05 are annotated.
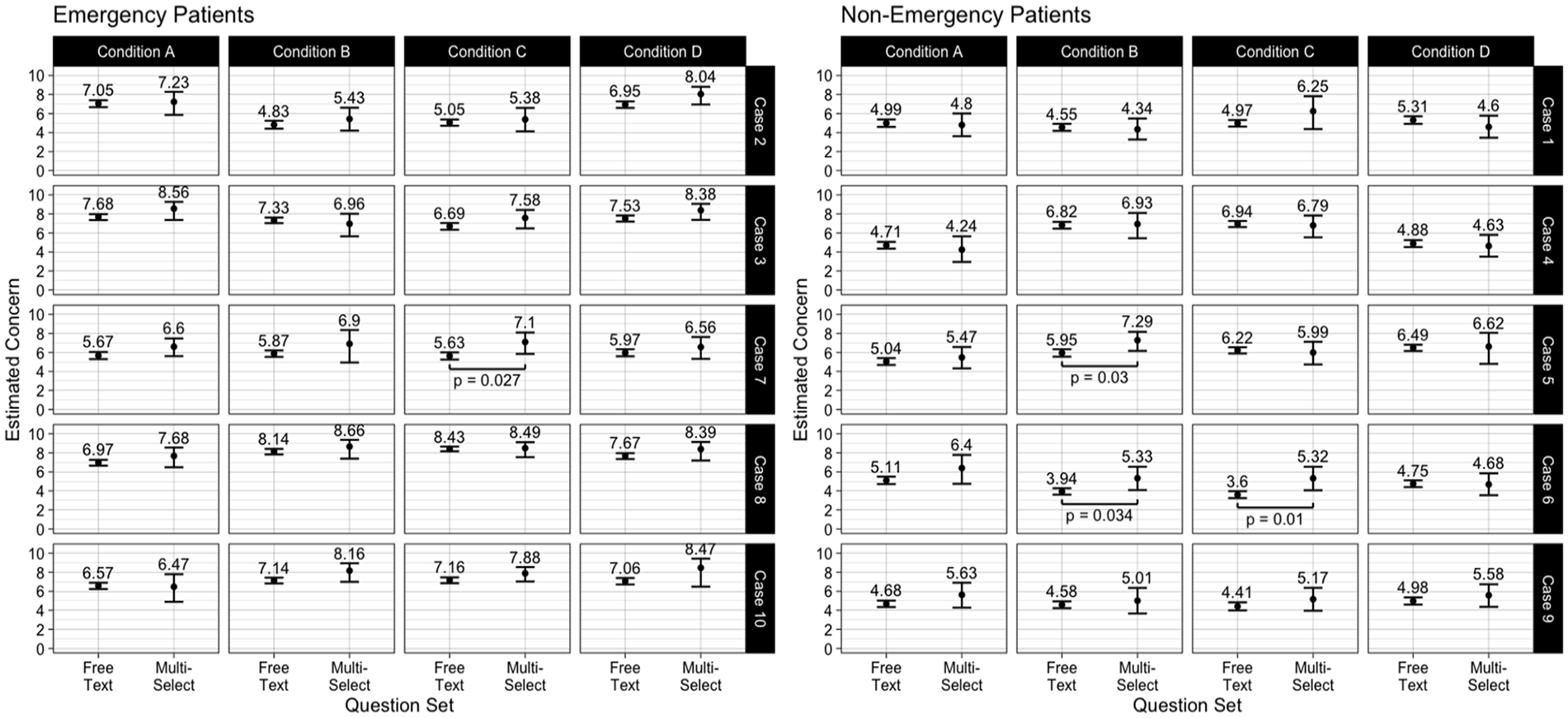
Nurses’ concern for each patient case, experimental condition, and question set.
We found few differences in participants’ reports of concern between free text and multi-select conditions. Only 4 of 40 combinations of patient case and experimental condition (1 emergency and 3 non-emergency) showed significant differences between question sets. However, none of these results were significant after applying a Bonferroni correction to adjust for multiple comparisons. In each of these marginally significant cases, participants reported higher concern in the multi-select condition compared to the free text condition. Notably, we considered higher concern to be appropriate for emergency patients but inappropriate for non-emergency patients. Therefore, participants did not consistently perform better with either question set.
Discussion
Our results clearly suggest that utilizing recall-based and recognition-based data collection mechanisms changed participants’ responses. For most data sources, participants were significantly more likely to report when using the multi-select questions. However, the magnitude of impact varied across data sources. Participants were especially more likely to report data sources regarding a patient’s background (patient history and labs) and data sources that were sparsely reported in free text responses (medications and AI algorithm). Conversely, some of the most frequently reported data sources in free text responses (heart rate and SpO2) were reported in similar rates with multi-select responses. These mixed results are consistent with the expected benefits of recognition-based designs over recall-based designs. The disproportionate impacts on data sources that were either rarely or pervasively applicable correspond to the expected reduction of memory burden and ease of task execution for recognition-based designs, respectively (Nielsen, 1994). Because response rates across the two question sets were neither equivalent nor proportionally related, they do not appear to be directly comparable.
Additionally, our results suggest recognition-based and recall-based data collection mechanisms can change not only participants’ reports but also their behaviors. When presented with the multi-select questions, participants were significantly more likely to view each of the three data sources that were least commonly viewed with the free text questions. For example, medications were viewed by approximately half of participants in the free text condition but most participants in the multi-select condition. This suggests the persistence of each data source in the recognition-based multi-select questions either reminded or encouraged participants to view each data source before reporting. These results affirm that perceptual characteristics of displays can induce different cognitive processes (Smith, 2018) and further emphasize that data collection mechanisms can inadvertently act as cognitive aids.
Despite differences in reports and behaviors, we found no evidence that either recognition-based or recall-based data collection mechanisms impacted task performance. Differences in participants’ concern were neither strongly significant nor consistently better for either free text or multi-select questions. Though differences in behaviors and cognitive processes could certainly produce differences in performance (e.g., Smith, 2018), the behaviors which were impacted by our question sets did not appear to impact performance. These results reiterate that measuring participant reports and behaviors alone is not a reliable substitute for measuring human-AI performance.
Our findings underscore the urgent need for novel approaches which can combine the rich insights of qualitative research paradigms at the scale that is facilitated by quantitative research paradigms. The trade-offs and complementarity of qualitative and quantitative research are well-documented (Creswell & Plano Clark, 2018). However, our findings highlight an underappreciated drawback of quantitative data collection at scale: structuring responses to support quick data processing can induce behaviors that would not naturally occur. Our results reiterate that research should not expect to collect similar data for a fraction of the processing costs by replacing unstructured with structured collection mechanisms. Future research should explore the use of computational technologies to support unstructured qualitative insights at scale.
This study had two notable limitations. First, the two question formats were designed as a between-subjects study, so we could not directly assess impacts on individuals’ responses. However, we included random intercepts in our models to account for different base reporting rates among individuals. Second, the two sets of questions did not use identical language. This was in part a necessity for changing question formats. However, different interpretations of the question sets could have impacted results.
Footnotes
Acknowledgements
We would like to thank our collaborators at The Ohio State University College of Nursing for their support of this study, especially Mike Ackerman, Wendy Bowles, and Amy Jauch. We also thank Ryan Gifford, Morgan Reynolds, and Miriam Balkin, their support in developing the display and experiment.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the American Nurses Foundation (ANF) Reimagining Nursing Initiative. Any opinions, findings, conclusions, or recommendations expressed in this work are those of the authors and do not necessarily reflect the views of ANF.