
Abstract
In Human-Robot Collaboration (HRC) environments, people are often required to perform multiple tasks under time pressure while monitoring or interacting with robotic systems. Time pressure may make people decide faster, but with lower accuracy and confidence, showing Speed-Accuracy Tradeoff (SAT) and Speed-Confidence Tradeoff (SCT). Understanding how humans make decisions under multitasking conditions with time pressure is important for enhancing safety and productivity. To investigate these effects, we conducted experiments in which participants viewed video clips of a robot arm reaching for one of two possible objects and predicted the robot’s final target with four levels of time pressure. In the multitasking condition, participants also performed a concurrent tracking task to simulate a continuous robot control task. Experimental results revealed clear evidence of SAT and SCT, along with significant negative effects of multitasking on prediction accuracy, confidence, and response time. To explain and account for these effects, we developed a computational model, by using the departure processes of the Queuing Network–Model Human Processor (QN-MHP) as a diffusion decision model. The model accurately replicated experimental results, highlighting its potential for predicting human behavior in multitasking human-robot collaboration scenarios.
Keywords
Introduction
In Human-Robot Collaboration (HRC), humans and robots share the same workspace and complement each other’s strengths (Lasota & Shah, 2015). This often creates
In this paper, we use experimental methods and computational Queuing Network (QN) modeling to investigate SAT and SCT in a multitasking HRC environment. Overall, the research seeks to answer: 1) Do humans experience SAT and SCT when predicting robot intentions in multitask conditions? 2) How does multitasking impact SAT and SCT in HRC? 3) Can QN modeling effectively simulate the SAT and SCT in human prediction activities?
Background
Multitasking in HRC
Researchers have explored multitasking to further enhance efficiency in HRC (Chacón et al. 2021). However, multitasking within HRC environments also demands that humans divide their attention across multiple tasks, increasing cognitive load and impacting overall system performance. Effective HRC depends on a careful balance between human cognitive resources and task demands to optimize performance. Previous studies have investigated the effects of multitasking on human task performance and workload in HRC contexts. Some studies suggest that humans can manage multiple tasks effectively. For example, Chacón et al. (2021) found no performance loss when participants performed the Tower of Hanoi alongside a low-demand robotic assembly task. However, other research has shown the limitations of multitasking. Eesee et al. (2024) found that engaging in a secondary task during a wire harnessing task with a collaborative robot led to increased attentional depletion, higher error rates, and prolonged cycle times.
Given these mixed outcomes, a deeper understanding of the performance trade-offs inherent in multitasking HRC becomes necessary. This research addresses this gap by investigating two critical trade-offs: the Speed-Accuracy Tradeoff (SAT) and Speed-Confidence Tradeoff (SCT), particularly concerning predictions of robotic intentions under limited information. SAT examines the relationship between task execution speed and accuracy, highlighting how accelerated decision might compromise prediction precision. SCT explores the trade-off between decision speed and the self-perceived confidence level of the decisions.
Effective HRC requires humans and robots to predict or anticipate each other’s intentions. While robotic inference of human intentions has been widely studied (e.g., Hawkins et al., 2013; Liu & Wang, 2017), few studies focus on improving or modeling human prediction of robot intentions (Dragan et al. 2015; Stulp et al. 2015). Furthermore, these studies primarily focus on single-task scenarios where humans predict robot intentions without managing competing tasks.
QN Modeling
To address complex human behavior in multitasking environments, Queueing Network-Model Human Processor (QN-MHP) has been developed (Liu et al. 2006). This network consists of servers that correspond to different functional units within the human brain. Information is represented as entities and processed by the servers in three subnetworks: the perceptual subnetwork, the cognitive subnetwork, and the motor subnetwork. Entities from different tasks can be processed by one or multiple servers simultaneously, depending on their functions (Wu & Liu, 2008). QN-MHP has proven successful in simulating human performance in a wide range of human factors tasks such as visual search (Lim & Liu, 2004), driver performance (Feng et al., 2017; Wu & Liu, 2007), brain-controlled driving (Lu et al. 2024), etc.
Since QN-MHP allows multiple streams of information to flow through the network, it is well-suited for modeling multitask performance and workload. For example, Liu et al. (2006) used QN-MHP to simulate real-time driver steering performance and in-vehicle map reading task performance.
Despite the extensive applications of QN-MHP, two key gaps remain. First, QN-MHP is still underutilized in human-robot collaboration (HRC). While Li et al. (2020) applied a QN-MHP-based operator decision model to simulate human behavior in brain-actuated robot steering, further research is needed to explore its applications in broader HRC and multitasking HRC scenarios. Second, previous QN research has primarily focused on entity arrival and service processes to model human performance. However, Liu (2007) mathematically demonstrated that entity departure processes in QN can account for speed-accuracy tradeoff. This research investigates whether these findings extend to more complex HRC multitasking conditions and SCT modeling.
Approach
Experiment
Experimental Design and Procedure
We conducted a multi-tasking HRC experiment, which includes a single-task baseline and a dual-task condition simulating real-world multitasking in HRC. Participants watched video segments of a Rethink Robotics Sawyer robot reaching for one of two objects among a total of nine objects in a 3 × 3 grid (Soratana et al., 2021). After viewing a partial trajectory, they predicted the robot’s reach destination from the two options. In the dual-task condition, participants simultaneously performed a horizontal tracking task shown on the same screen with the videos, imitating human operators controlling a continuously moving device, while predicting the Robot’s reach intention. The experiments were organized into blocks, each associated with a pair of objects within a specific difficulty level. Each block contained eight trials, covering four different video durations for each object in the pair. Participants first completed a training block before beginning the main experiment (Wang et al., 2024). In the single-task experiment, participants only performed one task: after watching each video, predicting the robot’s selection using A/D keys (left hand) and reported confidence. The dual-task experiment alternated between tracking-only and dual-task blocks, in which participants performed the same prediction task while simultaneously tracking a target that shifted left or right every 0.5 s with arrow keys (right hand). Before each dual-task block, participants were instructed that the prediction task was the primary task and the tracking task was secondary.
Independent and Dependent Variables
In the single-task experiment, the independent variables are video duration and task difficulty. Video duration has four levels (20%, 40%, 60%, and 80% of the robot’s reach trajectory), with longer segments offering more information for prediction. Task difficulty has three levels (easy, medium, and hard), based on the distance between the two potential target objects. In easier/medium/hard task conditions, the two targets are positioned farther apart or medium distance or closest to each other, respectively (Wang et al., 2024).
The dependent variables in the single-task experiment are prediction accuracy, confidence, and response time. Accuracy is recorded as 1 for a correct prediction and 0 for an incorrect prediction. Confidence is rated by participants on a scale from 1 to 9. Response time is measured from the moment the video stops to when the participant makes their prediction.
In the dual-task experiment, the independent and dependent variables for the target prediction task remain the same as in the single-task experiment. In addition, a new dependent variable is introduced: tracking performance, measured by the distance between the target point and the participant’s tracking point, recorded every half second throughout the task. This variable evaluates participants’ performance in maintaining tracking accuracy while predicting the robot’s target.
Participants
Forty students participated in the experiment: 20 in the single-task experiment (9 females, 11 males, age = 24.3 ± 4.0) and 20 in the dual-task experiment (8 females, 12 males, age = 23.3 ± 3.1), all right-handed. Participants were randomly assigned to single-task or dual-task scenario. Each participant completed all the levels in their assigned condition (4 durations × 3 difficulty levels × 4 target objects per difficulty level × 3 repetitions).
QN Model
Entities
Three distinct entities, denoted as A, B, and C, representing the Targets, Non-targets and Tracking entities, are generated and enter the QN-MHP network. Target entities represent visual cues in the videos that guide participants to correctly predict the robot’s final target object. Non-target entities represent visual cues that mislead participants into incorrectly predicting that the robot will reach the non-target object. Tracking entities correspond to the moving target point in the tracking task, which shifts randomly during the trial. The number of A and B entities leaving the network is used to measure how much information the human brain accumulates. Meanwhile, the presence of C entities introduces delays in the queueing network, representing multitasking situations. Previous research established a mapping between each server in the QN-MHP model and specific brain region functions (Liu et al, 2006; Wu and Liu, 2008). Building on this foundation, entity routes are determined by the demands of the target task in the perceptual, cognitive and motor subnetworks. Servers whose functions align with the target task are included in an entity’s route.
Accuracy Model (Diffusion Model)
The two-choice situation can be modeled as a diffusion process: two types of evidence accumulate from an initial starting point: “correct” evidence moves the accumulator positively, while “incorrect” evidence moves it negatively. This diffusion process continues until crossing either the positive or negative boundary, which determines the final decision outcome (Ratcliff & Rouder, 1998). Liu (2007) demonstrated that the departure process of a single-server queueing system exactly matches this diffusion model.
The prediction task in our study is a two-choice problem, as participants must predict which of the two possible targets will be selected. In our prediction task model, entities of type A (target) and B (non-target) arrive with probabilities
This accumulation process terminates once
The diffusion model begins at a starting point of 0, with ±T as the positive and negative boundaries. The drift rate representing the expected incremental change per step derives from the difference in arrival rates of the two entity types (
Speed-Accuracy Tradeoff (SAT) can be modeled by adjusting the threshold in the diffusion model. Emphasizing speed places the threshold closer to the starting point (small
In our study, the prediction decision threshold is determined by the video duration. Longer videos correspond to larger values of
Estimating prediction accuracy analytically with this diffusion model becomes extremely difficult due to the complexity of the multitasking QN-MHP network. Therefore, in the following section, we perform a simulation-based approach to evaluate the model in comparison with experimental data.
Simulation
The QN model is implemented in Python 3.9 using SimPy. Simulations were run for 2,880 trials to match the total experimental trials with 20 participants in the dual-task condition. Entity arrival probabilities and departure thresholds were iteratively explored for their effects on fitting the experimental data.
Confidence Model
To model participants’ confidence after each trial in the prediction task, we transformed the performance based “correct ratio,” defined as the number of target entity departure divided by the total number of entity departure, into a bounded confidence score using a logistic function. This mapping also captures the effect of task difficulty and time duration.
The model tracks the number of target entities (
This ratio, constrained between 0 and 1, serves as the primary measure of performance input into the confidence model. The correct ratio is transformed into a confidence score via a logistic function:
Where

Where
Result and Discussion
Experimental Results
Experimental results revealed that (1) SAT is evident in both single-task and dual-task conditions for easy levels (Figure 1): increasing video clip duration improves accuracy. Logistic regression was used to compare mean accuracy differences between single and dual-task conditions. In easy tasks, prediction accuracy steadily improves as time duration improves for both conditions, with no significant difference, indicating that multitasking does not hinder information accumulation. In medium tasks, multitasking initially impairs accuracy, as shown by a significant difference at 40% duration, where single-task performance is superior. However, as more trajectory information becomes available, accuracy in the dual-task condition catches up by 60% and 80% duration, suggesting that while multitasking delays information processing, it does not prevent it. Hard tasks show a negative impact of multitasking, with a significant difference at 60% duration, where single-task accuracy remains notably higher, suggesting that multitasking imposes lasting cognitive constraints when task complexity is high.
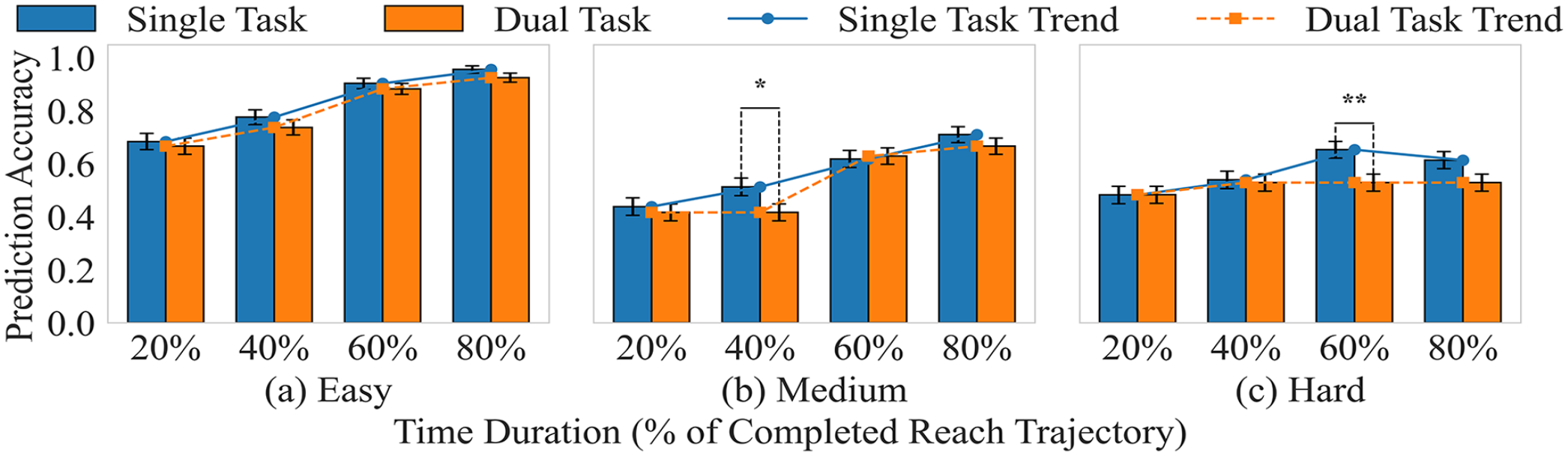
Mean comparison of the prediction accuracy between single and dual tasks. **p < .01, *p < .05.
(2) SCT is observed across all difficulty levels in both single-task and dual-task conditions (Figure 2), as confidence consistently increases with time duration. Mann–Whitney U test results showed that in easy tasks, significant differences at all time points indicate that confidence remains consistently higher in the single-task condition, suggesting that multitasking reduces confidence even in relatively simple tasks. In medium tasks, multitasking also lowers confidence, with significant differences observed at 60% and 80% durations. In hard tasks, confidence is generally lower compared to easy and medium conditions, but no significant differences emerge between single-task and dual-task conditions, suggesting that when cognitive demands are already high, multitasking does not further suppress confidence.
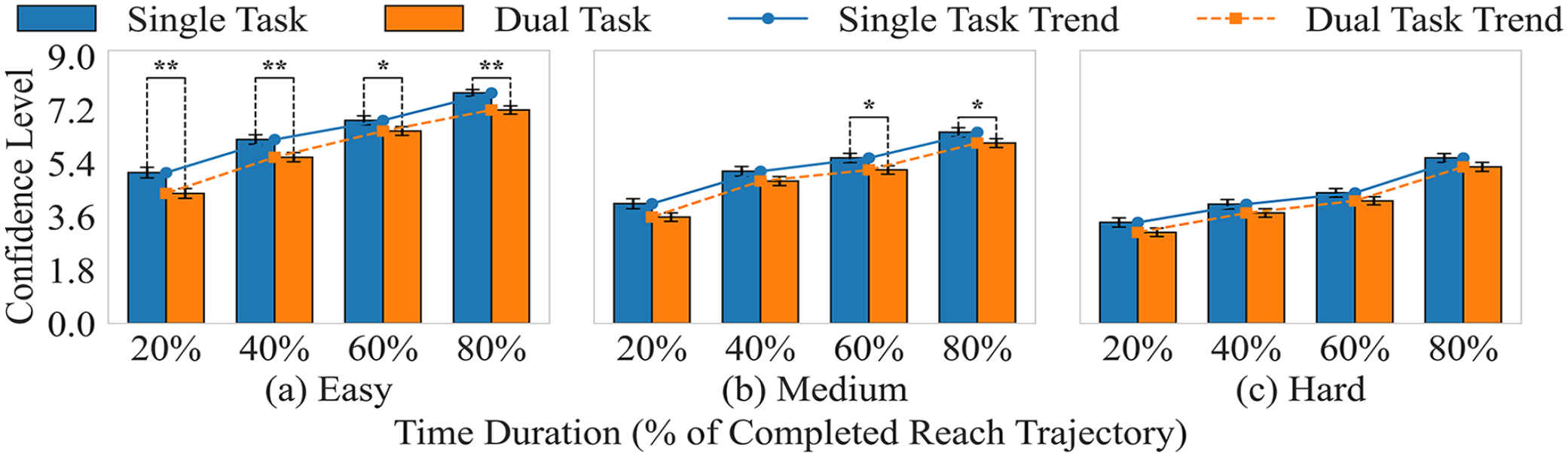
Mean comparison of the prediction confidence between single and dual tasks. **p < .01, *p < .05.
(3) Reaction time decreases as video duration increases in all the conditions (Figure 3), showing faster decisions with more visual information. One-way ANOVA results showed that multitasking significantly delays responses at 80% duration in all conditions, suggesting sustained cognitive load regardless of additional information.
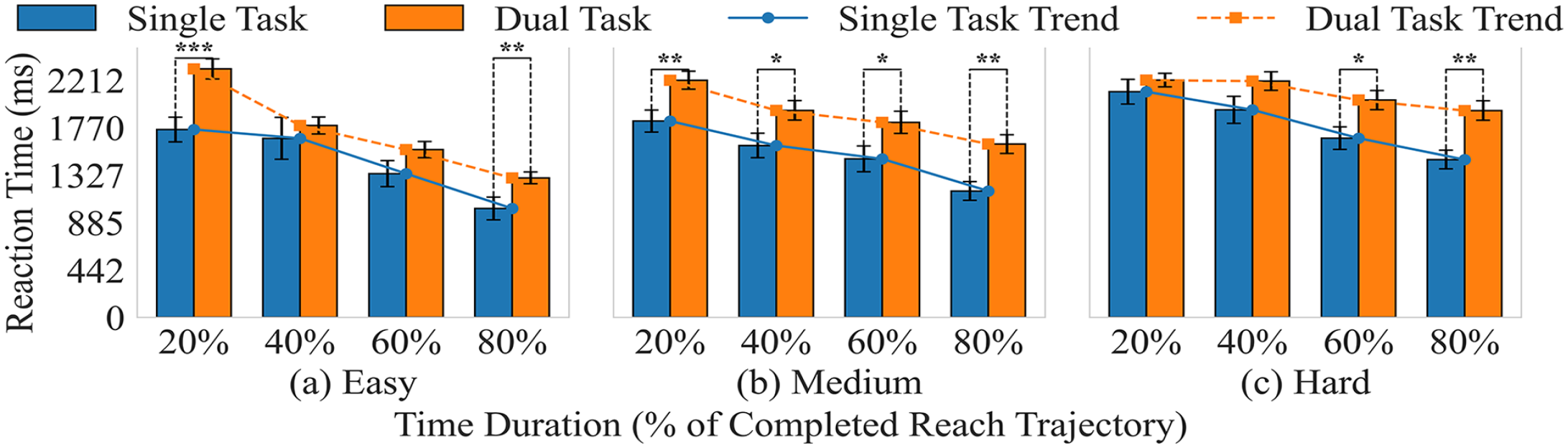
Mean comparison of the reaction time between single and dual tasks. ***p < .001, **p < .01, *p < .05.
Model Results
The QN model for prediction accuracy effectively captures the speed–accuracy tradeoff in most dual-task conditions (Figure 4), closely matching the experimental data in the easy (RMSE = 0.043) and hard (RMSE = 0.023) conditions. However, it diverges in the early time segments (20%–40%) for the medium condition (RMSE = 0.110), where the experimental accuracy is notably lower than the model’s prediction. A likely reason is that, during the first part of the video, the robot arm’s trajectory appears to move toward a non-target object, misleading participants before enough information is available to identify the correct target. Because the model does not account for this effect, it overestimates performance at these time points in the medium condition.
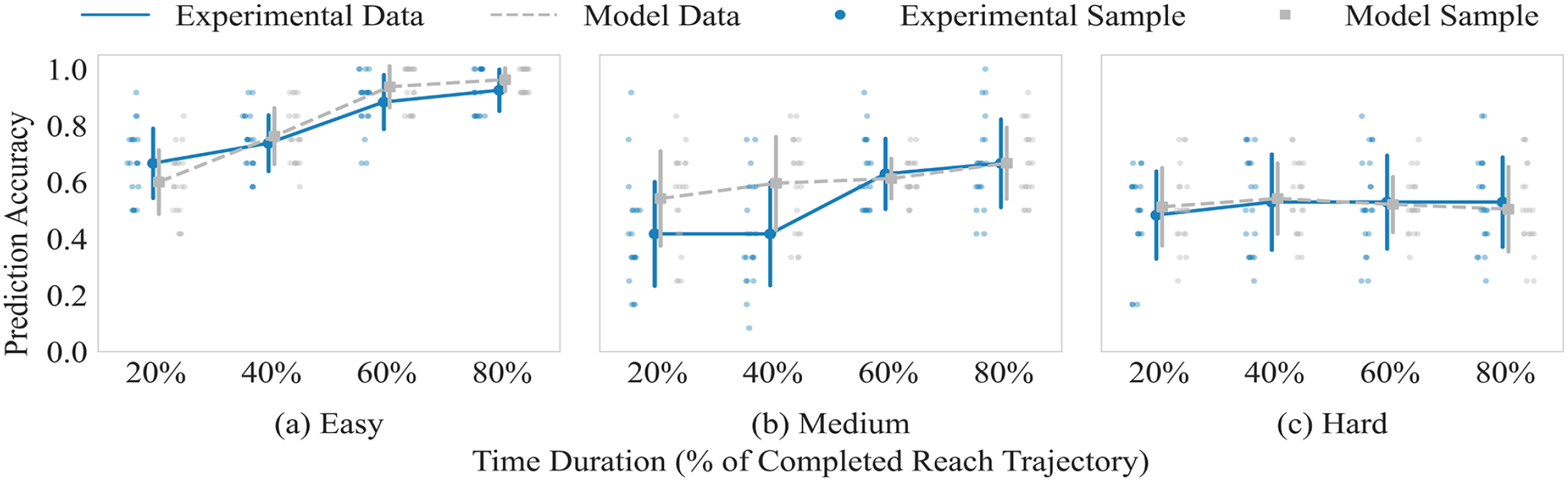
Model result versus experiment result of prediction accuracy.
The QN model for prediction confidence effectively captures the speed–confidence tradeoff across difficulty levels in dual-task conditions (Figure 5). It achieves a root mean square error (RMSE) of 0.11, 0.06, and 0.11 for the easy, medium, and difficult conditions, respectively. However, the current model may require further refinement to accurately reflect the variability (i.e., standard deviation) observed in human confidence judgments. Future studies should consider individual differences to better account for this variability in the model.
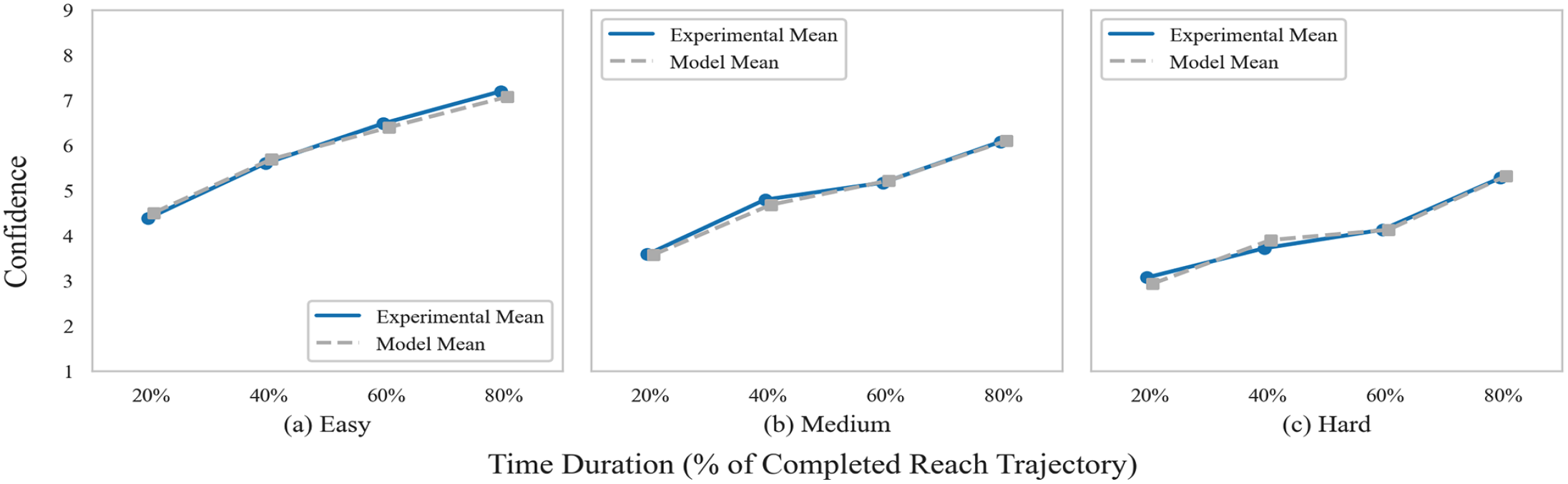
Model result versus experiment result of prediction confidence.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.