
Abstract
Game-like personality assessment was developed to be a quick and engaging method of measuring personality in a way that may minimize careless responding and impression management (faking). Thus far developments in game-like personality assessment have focused on iterative improvements in validity. This study is the first test of differences in both careless responding and faking between game-like and traditional personality assessment. Across two experiments participants completed both types of personality assessments; initially and again 1 to 4 weeks later with instructions to make themselves appear as desirable as possible (experiment 1), and with careless responding identification items in each measure (experiment 2). Results support the hypothesis that game-like assessment reduces both careless responding and faking compared to traditional Likert type personality assessment.
Introduction
Personality is a popular tool in personnel selection because it is typically a cost-effective measurement that has shown consistent relationships with performance (Barrick & Mount, 1991; Hurtz & Donovan, 2000). Despite this popularity, there are a number of criticisms of traditional personality measures common to many likert type self-report measures (Piedmont et al., 2000). Two common criticisms is that traditional self-report Likert type personality inventories are amenable to responding in socially desirable ways or faking (Ellingson et al., 1999; Mueller-Hanson et al., 2003) and careless responding (Bowling et al., 2016; Meade & Bartholomew, 2012). One recently proposed solution to these issues is measuring personality in a game-like setting that is context rich and not reliant on self-report statement endorsements. Game-like personality measures (GPM; McCord et al., 2019) were developed as short and engaging text-based games that can measure personality in terms of the big five factors (BFF; Costa & McCrae, 1988) while also being resistant to faking and careless responding. Thus far, tests of GPMs have consisted of iterative tests and improvements in validity and stability (Harman & Brown, 2022; Harman & Purl, 2022). This study represents the first test of whether GPMs are less amenable to impression management efforts (faking, Experiment 1) as well as careless responding (experiment 2). Experiment 1 is a within subjects design where undergraduates played the GPM and filled out a traditional Big five inventory and 1 to 4 weeks later did the same thing with instructions to present themselves as desirably as possible for a potential employer. In experiment 2 participants completed versions of the GPM and IPIP-50 that included careless responding identification items embedded in each measure. Results from both experiments are consistent with the hypothesis that GPMs are less amenable to faking than traditional personality inventories.
Gamification and Personality Assessment
Gamification is the addition of elements commonly associated with games (e.g., narrative, graphics, internal scoring systems, and levels) to a task or activity in order to make the process more engaging. It is typically theorized that incorporating game elements into a survey-like task improves participant engagement by increasing the intrinsic interest and enjoyment of the activity. For these reasons, McCord et al. (2019) developed text-based adventure games where choices made by a player within the game were used to assess the big five factors of personality.
The games created by McCord et al. were motivated by the theory of implicit trait policies: the internal beliefs about the effectiveness of certain behaviors based on the personality trait the behavior expresses (Motowidlo & Beier, 2010; Motowidlo et al., 2006). According to that theory, when we are given options that differ in their expression of personality characteristics, the option that we choose tends to coincide with our own personality characteristics. Based on this idea, a text-based fantasy game was created where participants read through an adventure, making choices about what action to take at given points. Choices were designed to reflect actions consistent with differences in personality expression (with many options created to mirror existing personality scale items). The narrative of the game begins with the character waking up in an underground cave with no memory of who they are or how they got there. Mysterious writing on the wall eventually comes into focus and becomes legible. The writing informs the player that the character has been cast down deep within the earth and that the goal is to reach the surface through a labyrinth of tunnels. As the character moves through various tunnels, several creatures and scenarios are encountered that require a choice between three courses of action (30 choices in total, six per factor). McCord et al. (2019) created two versions of the GPM, an ipsative version (GPM-I) where each option reflected a different personality factor and a non-ipsative version (GPM-nI) where each option represented a different level (high, medium, low) of the same factor. As an example item from the non-ipsative version, at one point in the game, having just awoke from resting in a cave, the character hears someone in the tunnels outside yelling “Ruger! Ruger! Where are you Ruger!?” and has to choose between the following three items designed to measure openness to experience: “You realize that whoever is out there is desperately looking for someone or something, so you gather your things and run toward the tunnel to help” (O-high), “You decide to stick to what you know and wait in the cave and see if the stranger passes by” (O-low), or “You grab your things and wait at the cave entrance because you want to see what you’re up against before committing to some new adventure” (O-medium).
Initially, McCord et al. ran three studies where participants played the game and also filled out a traditional, well-validated, 50 item personality inventory (IPIP-50; Goldberg et al., 2006). Despite the differences in scale, measurement, and context, McCord et al. found consistent significant correlations between Big five measures from the game and the IPIP-50. Harman and Purl (2022) revised some items in the ipsative version of the game and showed stronger and consistent correlations with the IPIP-50 as well as evidence for adequate, construct, convergent, and discriminant validity. Harman and Brown (2022) replicated these strong and consistent correlations, adding illustrations to the GPM which did not affect their relationship to scores from the traditional Big five inventory.
Experiment 1: Faking
Self-report personality surveys, particularly when used for selection or diagnosis decisions, have been commonly criticized for being amenable to intentionally distorted responses or faking (Dilchert et al., 2006; Goffin & Christiansen, 2003; Griffith et al., 2007; Ziegler et al., 2011). However, in organizational contexts, this bias can be magnified intentionally by those being surveyed. It is easy to imagine how a person filing out application material is likely to respond to an item that askes them whether the statement “I tend to make a mess of things” (standard personality item) describes them.
This study is the first experimental test of whether GPM actually can reduce faking. To test this proposition, we had undergraduate students play the game and fill out the IPIP-50 at 2 time points. At the 2 time point they were told that we were interested in their ability to fake responses and to “imagine these tasks are part of a job interview that will be used to make hiring decisions and we want you to respond in a way that would make you seem like the best job candidate (e.g., honest, conscientious, thoughtful, and highly motivated).” We hypothesized that participants would be able to fake responses in predictable directions (higher for openness, conscientiousness, extroversion, agreeableness, and lower for neuroticism) but that this change would be moderated by measure type with GPM-nI scores shifting less than IPIP-50 scores. Although we hypothesized that the engaging nature of the game would reduce faking, the fact that the GPM-nI is not readily identifiable as a personality assessment also has the strong potential to reduce faking. In the current design participants are already familiar with the game and aware that the GPM-nI is used as an assessment related to personality. For this reason, the current study represents a very stringent test of the GPM-nI in terms of reducing faking. Additionally, traditional within subjects tests of faking instruct participants to answer honestly or to fake good and counterbalance presentation order (e.g., Stewart et al., 2010). Because the GPM-nI doesn’t have “honest” answers (personality is measured implicitly through participants beliefs that actions consistent with their personality are more effective) we fixed the order of presentation, introducing the fake good instruction only at time 2.
Methods
75 undergraduate students completed both parts of a two part study for course credit. At time 1, participants first filled out a demographic questionnaire and played the GPM-nI and completed the IPIP-50 in random order. After completing every portion of part 1, participants were provided their scores on the IPIP-50 along with information explaining their scores. 1 to 4 weeks after completing part 1, participants were given part 2 of the study which was identical to part 1 with the exception of additional instructions which stated “we want you to imagine these tasks are part of a job interview that will be used to make hiring decisions and we want you to respond in a way that would make you seem like the best job candidate (e.g., honest, conscientious, thoughtful and highly motivated).”
Materials
GPM-nI
The GPM-nI revised is a 31 item text-based game described in the introduction. Throughout the narrative, the participant chooses between different options to continue the adventure (measure available on the first author’s website). 30 of 31 choices are used to measure the big five personality factors (six questions per factor). Response options for each question represent differing levels (high, medium, low) of a personality factor with low-level options being scored 0 and high-level options scored 2. Scores for each factor are the sum of the six questions for each factor.
IPIP-50
The IPIP-50 is a 50-item Big five inventory provided on the IPIP website (www.ipip.org) with high validity and reliability measures. The IPIP-50 provides 10 statements per personality factor using a Likert-type scale ranging from one (very inaccurate) to five (very accurate). For each factor, the highest score a participant can obtain is 50 while the lowest is 10.
Results
Correlations between factor scores from the GPM-nI and the IPIP-50 were significant for each factor and evidence of both convergent and discriminant validity is acceptable. Table 1 shows the mean factor scores for each measure at each time and the standardized differences between time 1 and time 2 for each measure, as well as the mean standardized within participant difference. As expected, when instructed to fake desirable responses participants scored higher in openness, conscientiousness, extroversion, and agreeableness, and scored lower on neuroticism. For the IPIP-50 these differences were significant for all five factors while the differences between GPM-nI scores were significant for four factors but not for conscientiousness. Because both measures are on different scales, we also present Cohen’s d as a standardized measure of differences between time 1 and time 2. With this standardization, the difference between time 1 and time 2 was larger for the IPIP-50 for each factor except extroversion and agreeableness which had similar differences between measures.
Mean Factor Scores and Standardized Differences and Correlations. Mean Factor Scores for Each Measure at Both Time 1 (Baseline) and Time 2 (Faking) Along with the Mean Difference (and Paired Sample t Test Results), Effect Size and Correlation of Each Factor at Both Time Points.
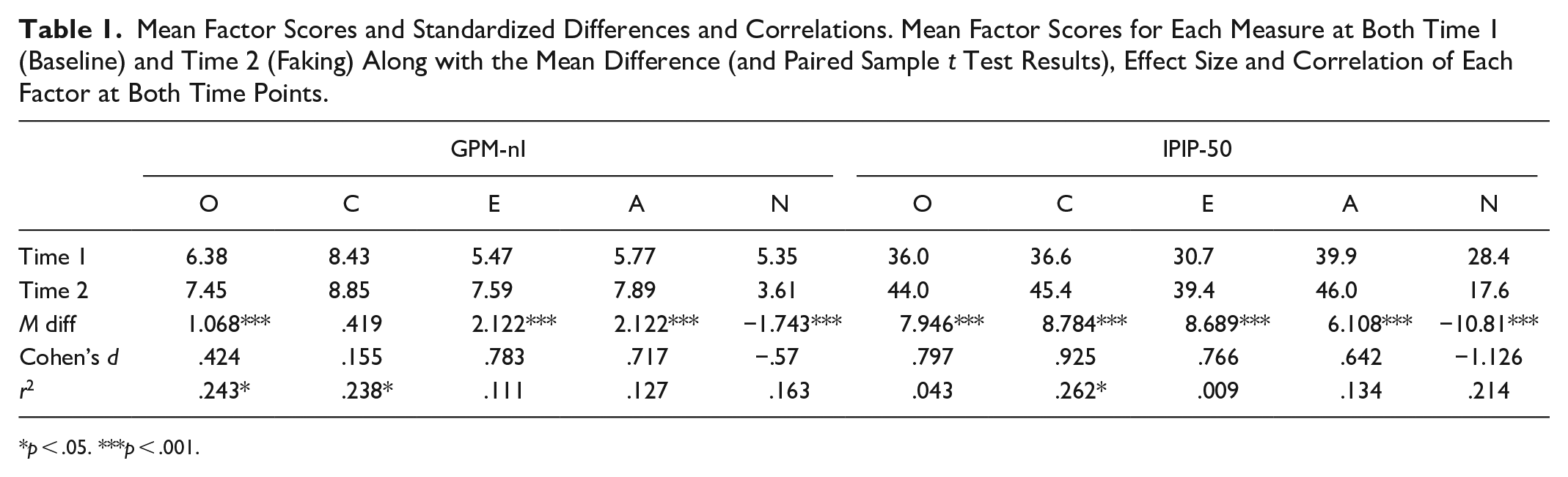
p < .05. ***p < .001.
Experiment 2: Careless Responding
Another common issue with survey methodology that affects personality testing is careless responding, defined as the lack of effort in responding to survey items. Particularly with online surveys, careless responding, sometimes referred to as insufficient effort responding, is a major threat to data quality. Researchers believe a major source of careless responding is lack of interest in or motivation for the task and is often characterized by random responding or responding with consecutive identical responses (straightlining) (DeSimone et al., 2018; Huang et al., 2015). Ward and Meade (2018) developed and tested strategies to prevent careless responding that were aimed to increase participant motivation to respond carefully. They found that facets of careless responding can be influenced by survey design. The authors go on to suggest that future research should investigate different practices in survey design with respect to preventing careless responding. Gamification represents an avenue to accomplish this goal. Following the methodology of previous studies (i.e., Bowling et al., 2016) we added careless responding indentification items to each pesonality measure (e.g., “click blue on this item”), which would be answered correctly by any individual with sufficient attention and effort and report the mean number of incorrect responses on these items.
Methods
Participants and Procedure
204 students participated in the study for course credit. Participant were instructed that the study aimed to see how performance in a text-based game was related to personality. After providing informed consent participants completed the GPM and IPIP-50 in random order and filled out a demographic questionnaire.
GPM-nI and IPIP-50
Participants complete the same measures as in experiment 1 with the addition of careless responding items. Four target items were added to each measure with minor differences to match the given measure (e.g., “click blue on this item” for the GPM and “click strongly agree on this item” for the IPIP-50).
Results
Correlation between the GPM-nI and the IPIP-50 in experiment 2 were significant for each factor and evidence of both convergent and discriminant validity is acceptable. Sure careless responding, incorrect answers to the four questions were summed for each measure, resulting in a 0 to 4 score on each inventory per participant. A majority of participants scored 0 in each inventory with more scoring 0 in the GPM (n = 186) compared to the IPIP-50 (n = 158). Means and standard deviations are shown in Figure 1. A Wilcoxon rank sign test confirms that careless responding scores were significantly lower for the GPM compared to the IPIP-50 (w = 1,104, p < .001, d = .286) (Paired sample t(203) = 4.08).
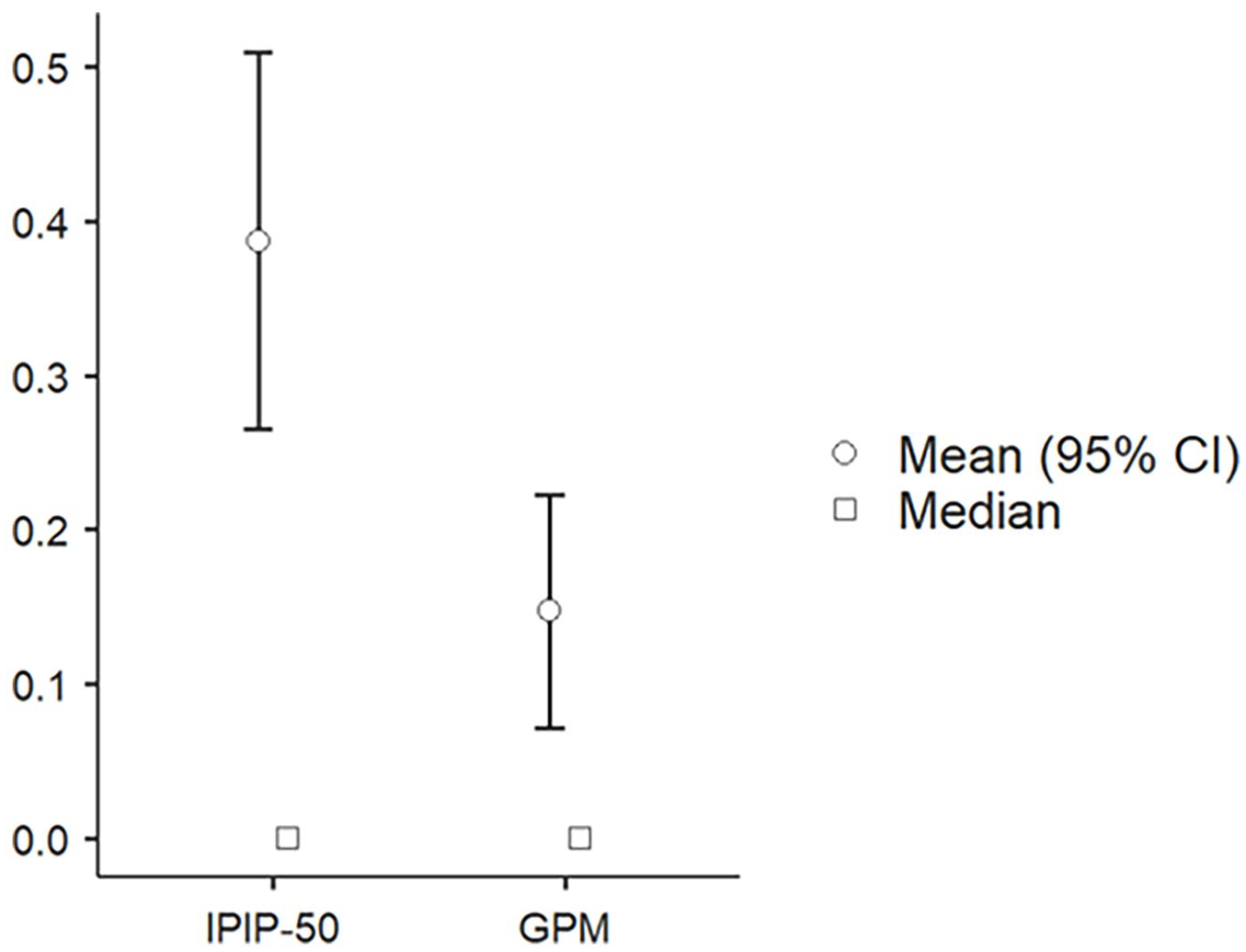
Careless responding scores (mean, median, and 95% CI) for each personality inventory in experiment 2.
Discussion
This brief study is the first test of GPMs hypothesized resilience to faking and careless responding. On average when instructed to make their scores more desirable, participants were able to do so in both the GPM-nI and the IPIP-50. The magnitude of these effects however were consistently smaller in the GPM-nI in line with the idea that game-like personality assessment is more resilient to impression management efforts. Though scores for the GPM-nI did change in the expected direction, the smaller effect along with the other advantageous attributes of the GPM-nI make it a promising tool for assessment moving forward. In terms of careless responding, experiment 2 showed initial evidence in support of the hypothesis that a game based measure of personality may reduce careless responding. There is still however much work to be done including criterion validity studies exploring whether the GPM-nI predicts outcomes (such as job performance) comparably with traditional personality inventories. Beyond personality, the framework created in the GPM-nI and gamification in general represents one possible way forward for assessment measures where faking and careless responding are concerns.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.