
Abstract
Clear explanations about automated vehicle (AV) decisions are critical for enhancing user understanding and reducing uncertainty. However, how users perceive different AV explanations and how they would improve them remains underexplored. Through qualitative interviews, this study explored user responses to four types of AV explanations: no explanation, action explanations (“what”), reasoning explanations (“why”), and combined action and reasoning (“what and why”). Participants highlighted evident differences: the absence of explanations caused anxiety and confusion, while explanations offering reasons or actions alone had strengths and weaknesses. Combined explanations generally provided the best balance by enhancing predictability and transparency, though they occasionally risked information overload. Participants also suggested practical improvements for AV explanations, emphasizing the inclusion of visual cues, clear descriptions of consequences, and delivery through natural conversational speech. These insights underscore the importance of adaptable explanation designs tailored to diverse user preferences and contexts. This research provides user-driven recommendations for designing effective AV explanations, enhancing transparency, and strengthening public trust in automated driving technologies.
Keywords
Introduction
Automated vehicles (AVs) have the potential to significantly transform transportation systems by improving safety, reducing congestion, and lowering fuel consumption and emissions (Du et al., 2019; Robert, 2019; Taeihagh & Lim, 2019). Despite these anticipated benefits, public acceptance of AVs remains limited (Choi & Ji, 2015). One barrier to broader adoption is users’ difficulty understanding how AVs operate, particularly when vehicles behave in unpredictable or opaque ways. This challenge highlights the need to design AV systems that support user comprehension, confidence, and engagement. Explaining the AV’s decisions and actions has emerged as a promising strategy to enhance understanding and improve user experience. Explanations can help users understand what the vehicle is doing and why, making its behavior more transparent and predictable (Shen et al., 2020; Zhang et al., 2021). When effectively designed, explanations can improve mental models, driving performance, and acceptance of automation (Du et al., 2019; Koo et al., 2015). They may also influence user trust, which supports adoption by shaping how people evaluate and respond to AV behavior (Ha et al., 2020; Lee & Lee, 2022).
Previous research has examined how the timing and content of AV explanations affect user responses, with particular attention to the specific information included. Studies commonly classify explanation content into three types: what-only, why-only, and what + why. What-only explanations describe the AV’s actions without context (e.g., “Rerouting”) and are often linked to lower user acceptance and reduced performance (Koo et al., 2015). Why-only explanations present reasoning without specifying the action (e.g., “Traffic reported ahead”) and have been shown to improve understanding, increase acceptance, and reduce anxiety (Koo et al., 2015, 2016; Wiegand et al., 2019). What + why explanations combine both elements (e.g., “Rerouting—traffic reported ahead”) and generally support more accurate mental models and, leading to better performance (Forster et al., 2017; Naujoks et al., 2017). However, they may also increase cognitive effort or annoyance under certain conditions (Ha et al., 2020; Hatfield, 2018).
While prior work has demonstrated that explanation content influences user outcomes, less is known about why these effects occur. In particular, few studies have examined how users interpret and evaluate AV explanations or how they would prefer such explanations to be designed. To address this gap, the present study adopts a qualitative approach using semi-structured interviews to explore user perspectives on explanation content. The goal is to understand better how users experience different types of explanations and what they consider helpful or problematic across driving scenarios. Two research questions guide this study:
How do users perceive different types of AV explanation content, and why do they find particular types more effective than others?
How would users design AV explanations to improve understanding, interaction quality, and system acceptance?
Method
This study adopted a qualitative approach to explore how drivers perceive and evaluate different types of AV explanation content. The research used semi-structured interviews to uncover users’ experiences, preferences, and expectations regarding AV explanations in driving scenarios.
Participants
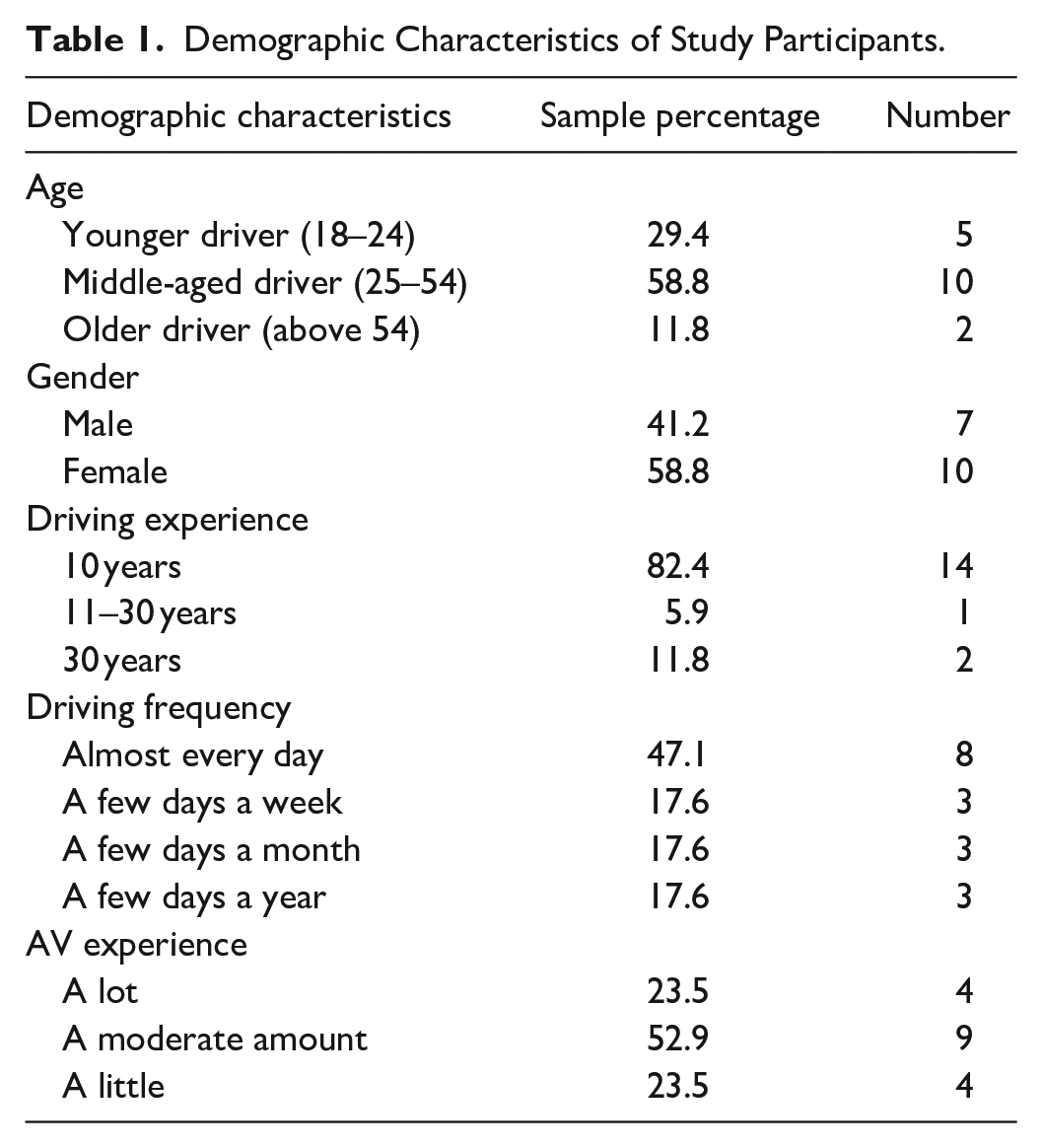
Seventeen licensed drivers in the United States participated in the study. Qualitative research, particularly when using in-depth interviews, often achieves thematic saturation with relatively small samples; prior work suggests saturation usually occurs within the first 12 interviews, with basic themes present as early as six interviews (Guest et al., 2006). Data collection was concluded after 17 interviews, once no new themes emerged. Inclusion criteria required participants to hold a valid driver’s license and report no visual or hearing impairments. Participant demographics are summarized in Table 1. Each participant received $15 in compensation. All procedures were reviewed and granted exemption by the Institutional Review Board at University of Michigan, and informed consent was obtained from each participant.
Demographic Characteristics of Study Participants.
Interview Procedure
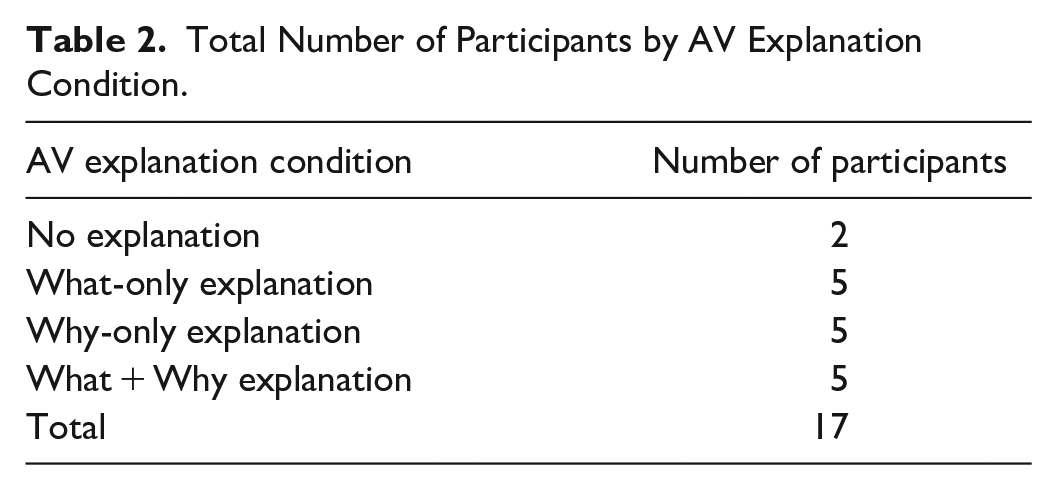
Data were collected through in-person interviews conducted by the same trained researcher. Before the interview began, participants were informed about the study’s purpose and signed a consent form. They were then randomly assigned to one of four explanation content conditions—what-only, why-only, what + why, or no explanation—and watched three short AV driving videos from a first-person perspective. In the what-only condition, the AV stated its immediate action (e.g., “Rerouting”) without offering a reason. In the why-only condition, it explained the rationale for its action (e.g., “Severe accident ahead”) without stating what it would do. In what + why condition, the AV provided both the reason and the action (e.g., “Severe accident ahead. Rerouting”). Those in the no-explanation condition viewed the same videos without hearing any verbal explanation. Each video included different driving scenarios, such as navigating urban, highway, and rural environments. The number of participants assigned to each condition is shown in Table 2.
Total Number of Participants by AV Explanation Condition.
Following the video, a semi-structured interview was conducted using a flexible guide that included open-ended and follow-up questions. The interview asked about participants’ prior experience with automated technologies, including in-vehicle systems and AVs. Participants were then asked to reflect on the AV’s behavior and how they experienced the explanations in the videos. Specific questions probed their understanding, perceived usefulness, emotional reactions, and perceived trustworthiness of the AV. Follow-up prompts were used to clarify and expand on responses. Interviews lasted approximately 40 to 50 min, with the main discussion averaging 23 min. All sessions were audio-recorded and later transcribed for analysis.
Data Analysis
Interview transcripts were generated using Otter.ai and manually reviewed for accuracy. NVivo software was used to support data management, coding, and analysis. A thematic analysis was conducted following the procedures outlined by Creswell and Creswell (2003), which included the following steps: (1) organizing and familiarizing with the data, (2) generating initial codes using inductive and in vivo techniques, (3) grouping codes into broader categories, (4) identifying recurring themes, and (5) interpreting themes in relation to the research questions.
Multiple strategies were used to strengthen validity and reliability. Triangulation was applied by comparing interview responses with researcher notes and participant demographic information. Peer debriefing sessions were held with two faculty experts in AV research and qualitative methods to confirm the robustness and relevance of emerging themes. NVivo supported the consistent application of codes and transparent documentation of the analytic process.
Results
When asked to describe their impressions of the AVs featured in the videos, participants in each explanation condition identified both positive and negative aspects of the information provided. They also suggested ways to improve explanation design to enhance driver-AV interaction.
No Explanation
Although the AV functioned correctly in the no-explanation condition, two participants in this condition expressed largely negative reactions. Three recurring themes emerged.
Difficulty Understanding AV Actions
Without any verbal feedback, both participants struggled to interpret the AV’s decisions. One participant commented, “I did not understand some of its actions,” referring to confusion about why the vehicle exited the highway without any indication. Another said, “I don’t know if this car is doing the right thing,” highlighting uncertainty without context.
Concerns About AV Capability
The absence of explanations made both participants question the vehicle’s reliability and environmental awareness. One participant noted a need for information to assess whether the AV met their expectations for safe driving. Another recalled hearing an ambulance and panicking when the AV continued moving, unsure if its sensors were working properly.
Negative Emotional Reactions
Both participants described feeling anxious, fearful, or even unsafe. One participant likened the experience to being kidnapped, expressing terror at not knowing what the AV was doing or where it was going.
What-Only Explanation
Participants in the what-only explanation condition (n = 5) identified several benefits of receiving action-based information but raised significant concerns about the lack of context. Benefits included improved predictability, transparency, and ease of understanding.
Predictable AV Actions
Two out of five participants mentioned that the what-only explanation helped reduce surprise and made AV behavior more predictable. One participant mentioned that accurate descriptions increased their confidence, while another emphasized the value of knowing what the system would do.
Increased Transparency
This explanation helped participants understand the driving process and develop mental models. A participant reflected that they wanted more than just getting from point A to point B; they tried to understand the steps involved in that journey.
Clarity and Simplicity
Two participants appreciated the explanation’s brevity and clarity. One noted that it was “very short and clear,” and required minimal attention. Another added that matching what the AV says it will do with the actual action helped them evaluate safety.
Despite these perceived benefits, participants also reported limitations, including increased cognitive effort, a lack of understanding about intent, and emotional discomfort.
Increased Cognitive Load and Confusion
Four participants reported that the lack of reasoning required them to exert more mental effort to interpret the AV’s behavior. One participant found themselves second guessing why the vehicle was turning. Another described feeling confused when they could not see what was ahead, making the AV’s behavior harder to interpret. Others found it unclear whether the information was meant to signal user control or AV autonomy.
Lack of Intention Behind Actions
Participants wanted more than just the action; they wanted to understand the reasoning. One person emphasized the importance of understanding the environment to understand the AV’s decisions. Another expressed discomfort with the lack of empathy in machine decision-making, explaining their desire to be involved in or at least understand those decisions. Some participants (n = 3) felt uneasy or anxious without understanding the AV’s intent. Concerns ranged from discomfort with complete machine control to worries about unexpected actions and their safety implications.
Why-Only Explanation
Participants in the why-only explanation condition (n = 5) recognized both the advantages and challenges of receiving reasoning without a corresponding description of the AV’s actions. The benefits centered primarily on improved environmental awareness, predictability, and confidence in the system.
Improved Understanding of the Environment
All five participants appreciated that the AV shared its reasoning, which helped them make sense of unfamiliar or dynamic driving situations. Several noted that the AV appeared to anticipate things they had not noticed, such as emergency vehicles or sudden changes in road conditions. This enhanced their awareness of the surrounding environment and made the AV seem more perceptive.
Predictable Intentions
Two participants reported that reasoning-based explanations helped them infer the AV’s underlying intent. One participant remarked that receiving the same information as the AV created a shared understanding. Another explained that even if the AV did not state its specific action, they could mentally connect the reason with a likely outcome, allowing them to follow the AV’s decision-making logic.
Confidence in AV Functionality
Four participants noted that hearing why the AV made decisions reassured them about the system’s ability to navigate various road scenarios. For many, the reasoning offered a glimpse into the AV’s logic, making them feel the system was more capable and trustworthy, especially in unfamiliar or high-stakes situations.
Despite these advantages, participants also identified several drawbacks, primarily related to the absence of clear action information and the cognitive demands of interpretation.
Lack of Observable Action
Two participants felt that reasoning alone was insufficient to assess or anticipate what the AV would do. They pointed out that the same reason could justify different actions depending on the context, making it difficult to predict the AV’s behavior confidently.
Increased Cognitive Effort
Interpreting reasoning without an explicit description of the action required more mental effort. Several participants (n = 3) noted that they had to spend additional time and attention figuring out what was happening. One remarked that this additional cognitive load made them feel less in control and more uncertain about the AV’s next move.
What + Why Explanation
All participants in the what + why explanation condition (n = 5) described their experience positively, emphasizing the value of receiving both the AV’s reasoning and its corresponding action. Key benefits emerged around contextual awareness, cognitive ease, and increased confidence.
Transparency in Environment and Vehicle Behavior
All participants consistently noted that receiving both the action and the reason helped them understand the AV’s behavior in context. The explanation made it easier to grasp what the system detected and how it planned to respond. Several participants mentioned that the AV picked up on environmental cues they might have missed, and that having both elements made them more aware of state changes. The additional context was particularly appreciated in unfamiliar environments, where it helped participants feel more informed and secure.
Reduced Cognitive Load
Two participants reported that receiving complete explanations reduced their mental strain and helped them stay relaxed and engaged. They described feeling more at ease throughout the ride, as they were not left wondering what the AV was doing or why. The transparency of the system’s decision-making allowed participants to focus on the ride rather than filling in gaps in understanding.
Increased Confidence in AV
Three participants felt more confident in AV actions and future performance. They appreciated having detailed feedback, especially during their first AV experience, and said it helped them feel aligned with the vehicle’s reasoning. Some indicated that as their familiarity with AVs increased, they might prefer less explanation over time.
Despite the overwhelmingly positive feedback, participants did mention one limitation.
Information Overload
Some participants (n = 3) reported that the combination of visual and auditory inputs could feel overwhelming in high-demand environments, such as dense urban areas. One participant described the experience as stressful when too much information was delivered simultaneously. Others suggested that as users become more comfortable with AVs, the system could offer more concise or optional explanations to avoid cognitive fatigue.
Improving AV Explanations
Participants across all conditions (n = 17) offered concrete suggestions to improve the clarity, usefulness, and user-friendliness of AV explanations. Their suggestions focused on three main areas: explanation content, modality, and voice.
Explanation Content
Beyond stating what the AV is doing and why, five participants expressed a desire for additional contextual details. Some wanted information about potential consequences, such as how a reroute might affect travel time or arrival location. Others requested greater spatial specificity, for instance, knowing whether the vehicle intended to stop on the left or right side of the road. A few also wanted to understand the AV’s decision priorities, such as whether the system was optimizing for safety, efficiency, or passenger comfort. These added layers of explanation were seen as valuable for improving predictability and supporting users’ mental models.
Explanation Modality
Four participants emphasized combining audio with visual elements to improve clarity and reduce cognitive load. While spoken explanations were generally appreciated, some found them potentially annoying or disruptive when used alone. Participants suggested that visual feedback, such as maps, directional arrows, or contextual overlays, could complement verbal information and enhance situational awareness. The combination of modalities was especially useful in fast-changing or complex driving environments.
Explanation Voice
Ten participants discussed how the qualities of the AV’s voice—such as tone, pitch, speed, gender, and accent—shaped their comfort and trust. Participants consistently preferred a voice that sounded natural and conversational rather than robotic. Many associated a human-like voice with greater trust and familiarity. Some mentioned a preference for female voices, finding them more soothing and emotionally engaging. Others highlighted the role of accent in shaping the tone of the interaction, with a few noting that British or Australian accents made the experience feel more enjoyable or personable.
Discussion
This study examined user experiences with various types of AV explanation content and identified design preferences through in-depth interviews. The findings underscore that explanation content is not merely informative but deeply shapes how users think and feel during automated driving. Rather than just reiterating user preferences in prior research, our results point to underlying cognitive and emotional needs that explanations either fulfill or leave unmet.
Participants in the no-explanation condition reported confusion, discomfort, and even fear. In the context of driving, where users are accustomed to being active agents, the absence of feedback from the AV leaves them disoriented and anxious. The what-only explanations were valued for their clarity and simplicity, which helped participants anticipate AV actions and improved transparency. However, they also created uncertainty about intent. The resulting uncertainty may lead users to over-interpret or second-guess the AV’s behavior, especially when environmental cues are unclear. Why-only explanations were praised for offering insight into the AV’s environmental awareness and decision-making logic. Yet, the lack of stated actions required users to mentally fill in gaps and increased cognitive effort. This suggests that understanding why an AV acts is meaningful only when users can also clearly map that reason to a specific action. The added cognitive burden may reduce users’ confidence and preference, especially under time pressure or in unfamiliar settings.
What + why explanation emerged as the most effective and satisfying format. By presenting both the AV’s action and its underlying reasoning, this explanation type supported users’ sense of predictability and offered clear justification for the vehicle’s behavior. This completeness appeared to reduce anxiety not simply by providing more information, but by addressing users’ desire for both situational clarity and control. When participants understood not only what the AV was doing but also why, they felt more confident in the system and less uncertain about potential outcomes. This reduced perceived unpredictability and strengthened feelings of safety and trust. However, several participants noted that receiving too much information could become overwhelming.
Participants also provided actionable suggestions for improving AV explanation design. In addition to conveying what and why, they wanted explanations to include consequences (e.g., changes to travel time), spatial specificity (e.g., direction of action), and system priorities (e.g., safety vs. efficiency). Participants also emphasized the value of multimodal delivery, suggesting that combining audio and visual information could reduce mental effort and enhance situational awareness. Finally, the qualities of the explanation, voice, tone, naturalness, accent, and gender, shaped how participants interpreted and emotionally connected with the AV.
Taken together, these findings suggest that explanation content is not one-size-fits-all. Effective AV explanations must be informative and context-sensitive, designed to address users’ emotional and cognitive needs. Listening to users’ design perspectives can further support tailoring explanations to match individual preferences and expectations better. Future AV systems should incorporate flexible explanation strategies that adapt over time and across contexts, striking a balance between clarity and cognitive load to foster long-term user trust, comfort, and engagement.
This study has several limitations. First, although the total sample size aligns with qualitative research standards, the number of participants assigned to each explanation condition was uneven (i.e., no-explanation condition). This imbalance may have limited the richness and diversity of insights within specific groups. Second, participants were exposed to short, simulated AV scenarios in an online setting rather than real-world or longitudinal use, which may not fully capture trust dynamics that evolve over time or in high-stakes contexts. Third, the sample was limited to U.S. drivers, which may not reflect broader cultural, regional, or demographic differences in how AV explanations are perceived or evaluated.
Conclusion
This study highlights the critical role of explanatory content in shaping how users understand, evaluate, and emotionally respond to AV behavior. Through qualitative interviews, participants revealed that different types of explanations, what-only, why-only, and what + why, each offer unique benefits and drawbacks. Participants also shared valuable redesign suggestions, emphasizing the need for adaptive, multimodal explanations, and aligned with user expectations. These insights point toward the importance of user-centered explanation strategies that improve comprehension and support emotional comfort and trust in AV technology.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received financial support from M-City under the University of Michigan Office of Research for the research, authorship, and/or publication of this article.