
Abstract
Autonomous Collaborative Platforms, such as Collaborative Combat Aircraft (CCA) will increase in use in United States Air Force (USAF) operations. Research focused on CCA management will be met with participant recruitment challenges. Military contexts are highly complex environments where the availability of well-trained operators for research participation is limited due to competing operational mission priorities and small populations. To overcome this challenge, we highlight the benefits of a Bayesian statistical approach, which can leverage prior experimental data to mitigate statistical power concerns. We applied this approach to examine the relationship between self-reported mental workload and asset similarity in CCA missions, drawing on prior experimental data from a related study. Using a high-fidelity manned-unmanned teaming simulator, pilots completed two missions, during which they supervised a team of four CCAs, while flying their own next-generation fighter aircraft. Results suggested no differences in self-reported mental workload as a function of CCA asset similarity. Advantages of the approach are discussed along with future research opportunities.
Introduction
It remains a challenge to recruit a sufficient number of participants in task domains where there are few experts with requisite experience to adequately evaluate human factors issues with new process designs, human-machine interfaces (HMI), communication modes, etc., within the full complexity of the tasks in the domain of interest. Often, investigators are required to simplify and repeat the task(s) of interest to acquire enough statistical power to gain confidence in the results of an experiment or evaluation. Unfortunately, simplifying tasks under investigation can contribute to missing or neglecting effects of interest, such as detrimental performance resulting from task complexity (e.g., multi-tasking, time pressure, catastrophic failures, etc.) or producing learning effects that occur in the simplified environment that do not actually occur in the domain of interest. Military contexts serve as an example of a high complexity domain containing sparse populations to sample from for research participants. This paper advocates for the use of Bayesian approaches to address this challenge.
Background
Military operations require soldiers, sailors, and airmen to make complex decisions under various physiological, psychological, and cognitive stressors. The tempo of these decisions and the intensity of stressors is further exacerbated in cockpit environments. Before long, operators will be responsible for overseeing autonomous collaborative platforms (such as CCAs) across a number of Department of Defense (DoD) tasks and domains. For example, the USAF is looking to leverage CCAs as a force multiplier, with pilots overseeing multiple CCAs (Gunzinger et al., 2024; Lyons et al., 2024). These uncrewed systems will offer specialized capabilities, but their use will impose unique human performance challenges to include the risk of operator overload. The situation is further complicated by the possibility of heterogeneous capabilities across CCAs, leading to additional cognitive costs related to information maintenance. The ability to make accurate and critical decisions under time pressure about CCAs while executing missions will require sufficient cognitive resources to adequately evaluate options. With enough cognitive resources, individuals may use an optimal decision strategy (e.g., weighted additive strategy). However, as cognitive resources decline, individuals may shift from a normative strategy to a heuristic-based decision strategy (Gigerenzer & Gaissmaier, 2011). Thus, this introduces the dilemma: do investigators evaluate a limited number of experts in a highly complex environment and risk insufficient power and greater behavioral variability, or do they develop a simplified version of the task enabling a greater number of participants while potentially introducing learning effects and the inability to transfer what is learned to the domain of interest?
To address the dilemma, it is reformed into a specific question: can investigators leverage data from previous experiments within the same domain and using the same dependent variables (i.e., discrete, continuous, scales, etc.) to improve power and reduce variability in a new experiment? A Bayesian statistical approach mitigating statistical power concerns inherent in limited participant pools is presented as a solution by incorporating past experimental data within a prior distribution (Gelman & Hill, 2014). In this article, we use the same high-fidelity manned-unmanned teaming simulator as in Lyons et al. (2024), treating a subset of the data collected in that study (n = 13) as a prior distribution.
Approach
Seven 4th and 5th generation fighter pilots completed the study. Data collection will continue until 16 participants successfully complete the study. The study was approved by the Air Force Research Laboratory Institutional Review Board. Participants provided informed consent, reported their flight experience, then received a brief overview of electroencephalogram (EEG) use in research and the cap fitting procedure. Finally, participants completed familiarization training in the simulation environment and received a pre-mission brief outlining mission details. Before starting the experiment, participants were fitted with an EEG cap. Although EEG measures were collected, this article focuses solely on the self-report mental workload data collected using the NASA-TLX instrument (Hart & Staveland, 1988).
Using a high-fidelity manned-unmanned teaming simulator, participants completed a total of two missions, each between 60 and 90 min in duration. In each mission, participants supervised a team of four CCAs, while flying their own fighter aircraft. They were directed to select the most appropriate CCA to neutralize a series of ground targets. Participants needed to complete these objectives and egress before the arrival of an incoming air interceptor.
Consistent with the experimental design in Lyons et al. (2024), we used a repeated-measures design to understand the impact of CCA similarity (heterogeneous vs. homogenous platforms) on cognitive workload. In the heterogeneous mission, the CCAs had limited fuel, and were specialized for particular tasks. We represented task specialization by manipulating available CCA armament (e.g., CCAs only equipped with guns/missiles or bombs). To further reinforce differences among the platforms, the four CCAs contained a mixture of platform types—this was communicated to pilots on the CCA control interface via the platform names (e.g., SNAKE-2, ADDER-3, VIPER-4, and COBRA-5; pilot ownship SNAKE-1). In the homogeneous mission, the CCAs had maximum fuel and weapons loads at mission start, and the CCAs were not specialized for particular tasks (e.g., all CCAs equipped with gun, missiles, and bombs). To reinforce the similarities amongst the platforms, the naming across the four CCAs in this condition remained consistent (e.g., all SNAKE 2-5; pilot ownship SNAKE-1). Participants completed the missions in a randomized, counterbalanced order.
Following each mission, participants completed a Decision Making Debrief and the NASA-TLX (Hart & Staveland, 1988). For the NASA-TLX, participants reported their workload for all six dimensions (e.g., mental demand: how mentally demanding was the task?) and responded using a 5-point Likert-type scale. After finishing all missions, participants completed the Mini-IPIP questionnaire (Donnellan et al., 2006) and the SIR inventory (Zaleskiewicz, 2001). All measures with the exception of the NASA-TLX mental workload dimension data were excluded from the present analysis. Using both the NASA-TLX mental workload data reported in Lyons et al. (2024), which similarly manipulated CCA similarity, and the preliminary data from the present study, we addressed the following research question: how does CCA asset similarity impact self-reported mental workload?
Outcome
Data cleaning and analysis were conducted using R (R Core Team, 2025). Due to a data entry error, participants were only presented a 1 to 5 scale (very low to very high) for all six dimensions of the NASA-TLX instrument, which led to a misalignment with the NASA-TLX mental workload values reported in Lyons et al. (2024). In Lyons et al. (2024), participants reported mental workload on a 1 to 7 scale (very low to very high). To correct for this, we rescaled the values in the present study, which ensured alignment with the values in Lyons et al. (2024).
A Bayesian regression using the brms package (Bürkner, 2017) was performed to evaluate the relationship between CCA similarity and mental workload. The model included the main effect of similarity, a two-level categorical predictor (heterogenous, homogenous).
Bayesian analyses can incorporate the results from past studies into a prior distribution to produce a posterior distribution representing the possible range of model parameters, given what was previously observed (Gelman & Hill, 2014; Young, 2019). Here, priors (i.e., model parameter estimates) were derived using the NASA-TLX mental workload data (n = 13) from Lyons et al. (2024). By integrating these priors from a study performed under similar circumstances (i.e., high-fidelity manned-unmanned teaming simulator), with a similar population of participants (i.e., 4th and 5th-generation fighter pilots), one can ascertain whether the new data increases the level of certainty in previously observed effects. Instead of p-values and confidence intervals, Bayesian regressions output 95% credible intervals (CIs) for each model parameter. When new data falls within the prior’s CI, the interval narrows, reflecting greater confidence in the estimate. Data falling outside the CI causes the interval to shift. CIs that do not include zero suggest the presence of a statistically significant effect (Gelman & Hill, 2007).
Bayesian analyses use Markov Chain Monte Carlo (MCMC) methods to determine the stability of model estimates. Within this framework, chains are used to simulate a sequence of sampled parameter values. Using multiple chains allows for independent simulations from different starting points. Estimating posterior distributions by sampling over multiple chains reduces concerns of poor model convergence (Vehtari et al., 2021). We estimated the posterior distribution by drawing 4,000 samples over four chains. The first 1,000 samples served as a burn-in and were discarded. All R-hat values (i.e., fit indices) for each model parameter equaled one, indicating model convergence (Gelman & Hill, 2014). Planned comparisons did not suggest significant differences across similarity conditions (Bdiff = .07, 95% CI [−.09, .21]), see Figure 1.
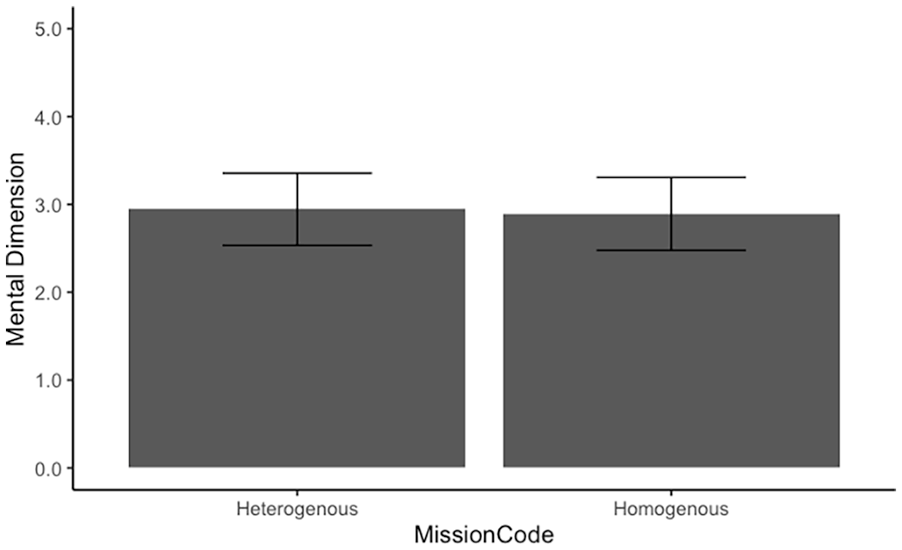
Self-reported mental workload did not significantly differ as a function of similarity condition; error bars represent 95% CI.
Discussion
Our preliminary results (based on our seven participants collected thus far) indicated that CCA similarity did not significantly impact self-reported measures of mental workload as assessed by the NASA-TLX. These findings are reassuring considering future contexts where military operators can reasonably be expected to supervise and task heterogeneous teams of CCAs. Results from a 2023 war gaming exercise revealed a preference for experienced operators to employ mixes of CCA variants with regards to capabilities, price points (e.g., low cost, expendable CCAs vs. moderate cost, more capable CCAs), and differing use cases (Gunzinger et al., 2024).
It is possible that, although the homogeneous and heterogeneous conditions initially differed in CCA starting fuel and weapons load, the homogeneous CCAs may have transitioned during the mission to resemble the composition of heterogeneous assets (i.e., reduced fuel and weapons load). This would explain why pilots across the heterogenous and homogenous conditions reported similar values (on average) of mental workload post-mission.
Conclusion
One of the challenges of conducting research studies with highly experienced personnel performing tasks in high fidelity domains is recruitment. This work demonstrates the value of applying Bayesian statistical approaches to address power limitations in small sample sizes and is broadly applicable in other domains (e.g., maritime environments, satellite command, and control). We recommend that future research further explore the application of Bayesian methodologies within emerging and underexplored applied domains. Finally, our work underscores the importance of well-structured research programs and experiments, as these provide the ideal conditions for applying Bayesian approaches.
Footnotes
Acknowledgements
Distribution A. Approved for public release: distribution is unlimited. AFRL-2025-3465; cleared 17 July 2025. The views expressed are those of the authors and do not reflect the official guidance or position of the United States Government, the Department of Defense or of the United States Air Force.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Air Force Research Laboratory; FA8650-22-F-2611.