
Abstract
The emergence of Artificial Intelligence (AI) tools offers new possibilities for simplifying complex information and supporting decision-making. This study investigates how AI-simplified language and framing effects influence decision-making in scenarios involving novel military operations. Using a two (positive vs. negative framing) × two (jargon vs. AI-simplified language) between-subjects design, participants will be presented with one of two military scenarios—one involving a high-value target (HVT) and the other addressing improvised explosive device (IED) deactivation. Outcome measures include perceived desirability of the scenario, compliance, trust in AI, and cognitive workload (NASA-TLX). Drawing from prior framing studies (e.g., Tversky & Kahneman, 1981; Levin et al., 1988), we hypothesize that positively framed, AI-translated scenarios will result in higher desirability ratings, increased compliance, and lower cognitive workload compared to negatively framed or jargon-heavy versions. This research aims to inform the design of AI tools that support clear communication and user-centered decision-making aids. It highlights the importance of considering human cognition and its possible use in the design of new technologies.
Introduction
Artificial Intelligence (AI) tools (also known as large language models or LLMs) can simplify complex concepts, facilitate interactions, and personalize information across areas to improve decision-making (Jayaweera, 2023). However, the way an AI presents information may influence decision-making. We examined the interplay between information framing and AI text simplification in military contexts, specifically how positive and negative framing, presented in jargon or AI-simplified formats, affected choices in novel, ambiguous military operations.
Tversky and Kahneman (1981) showed that framing affects decision outcomes based on how options are described and the decision maker's context. Attribute framing, where positive or negative attributes are emphasized, can strongly influence decisions (Levin et al., 1988). Because decision-makers are often unaware of framing valence, it can become a potentially dangerous, uncontrolled factor in AI tool outputs.
Advances in AI tools have opened new opportunities for simplifying complex language. While engines like ChatGPT show promise (Chen et al., 2018), balancing simplification with accuracy and completeness remains challenging (Abou-Abdallah et al., 2024). This trade-off highlights the need for research on how AI can bridge technical language and user-friendly communication without compromising decision-making outcomes.
Method
Two hundred and seventy-four undergraduate students at a large university in the southern United States were recruited via the university’s online research participation system. Sample size was determined using G*Power to achieve a power of 0.8. Participants received class credit for their participation in the study.
Two scenarios involving potential civilian casualties were created: one focused on neutralizing a high-value target (“Phantom”), and the other on neutralizing explosives in a village (“Mines”). For example, the jargon-filled description of the Phantom was as follows:
AO: Dense urban terrain within a Tier-1 conflict zone, Gorgos geographic region. Local time: 1900. Task Force Viper is conducting sustained kinetic operations against an HVT codenamed Phantom, the apex node of an asymmetric threat network. The HVT is linked to 100 civilian KIA via high-casualty IED events in the AO annually. INTSUM: ISR platforms (Predator MQ-9, supplemented by HUMINT and SIGINT) have PID of the HVI occupying a multi-story residential complex. The structure is classified as a dual-use facility with civilian co-location in a cluttered urban environment. Mission Directive: The JOC requires a COA decision within 30 km to maintain temporal relevance. Targeting criteria fall under ROE guidelines, but operational discretion lies with the Task Force Commander. Commander’s Decision Briefing: The TF Commander convenes a CUB with operations staff, S2, and JTAC. Key considerations include: ROE adherence and proportionality of force.
Scenarios were adapted from prior framing and decision-making studies (Levin et al., 1988; Wilson et al., 1987). Participants viewed one scenario, with half reading (jargon-filled or AI-simplified). Each was followed by an assessment of effectiveness (Table 1). Scenarios were framed positively or negatively as a 50% likelihood of success/failure (Table 1).
Manipulated attribute framing that followed each scenario, presented as jargon or simplified using AI.

Materials were presented remotely using Qualtrics. Outcome measures included a measure of strike desirability that were adapted from the desirability questions in framing research (Levin et al., 1988; Wilson et al., 1987), a test of scenario comprehension (lab-developed), subjective workload (NASA TLX; Hart & Staveland, 1988), and choice to take military action (measured as ‘yes’ or ‘no’). Desirability and comprehension were calculated as the mean of multiple items, creating continuous composite scores.
Results
A two (Scenario: “Phantom” vs. “Mines”) × two (Valence: Positive vs. Negative Framing) × two (Text Type: Jargon vs. AI-simplified) between-subjects analysis was run on each dependent measure.
An ANOVA revealed significant main effects of text type, F(1, 263) = 13.31, p < .001, η² = .048; valence, F(1, 263) = 5.08, p = .02, η² = .019; and scenario, F(1, 263) = 8.05, p = .005, η² = .030, on desirability. Military action was rated as more desirable for AI-translated text (M = 6.48, SD = 1.81) than for jargon text (M = 5.74, SD = 1.64), in positively framed text (M = 6.43, SD = 1.63) compared to negatively framed text (M = 5.88, SD = 1.87), and in the Mines scenario (M = 6.40, SD = 1.56) compared to the Phantom scenario (M = 5.82, SD = 1.92). There were no effects on the choice to take military action (all p > .05). There was a main effect of scenario, F(1, 263) = 9.18, p = .003, η² = .033, on comprehension, where participants had higher understanding of the Phantom scenario (M = .83, SD = .33) compared to the Mines scenario (M = .77, SD = .26). Last, there were main effects of scenario, F(1, 261) = 4.33, p = .038, η² = .12, and text type, F(1, 261) = 33.25, p < .001, η² = .88, on perceived workload. Perceived workload was higher in the Phantom scenario (M = 5.07, SD = 1.49) than in the Mines scenario (M = 4.73, SD = 1.38), and higher for AI-translated text (M = 6.49, SD = 1.81) than for Jargon text (M = 5.74, SD = 1.64). This difference may stem from participants in the AI condition reading both the jargon and AI-translated texts, while participants in the jargon condition read only one text. Additionally, a significant interaction was found between Scenario and Valence, F(1, 261) = 4.46, p = .036, η² = .01. Workload was affected by Valence for the Phantom scenario (p = .05) but not for the Mines scenario (p = .79) (Figure 1).
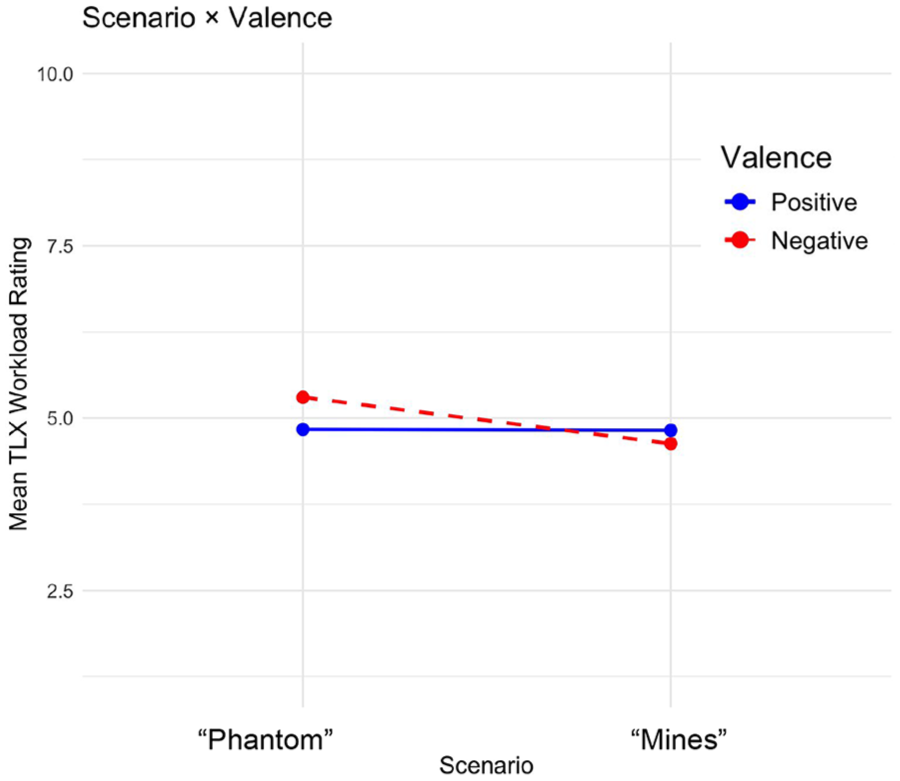
Significant interaction of scenario type and framing valence on overall perception of workload.
Discussion
AI-translated text was rated as more desirable and had a lower workload than jargon-heavy text, aligning with proper work on the benefits of text simplification in enhancing user experience and decision-making (Rochford et al., 2016; Ivchenko & Grabar, 2022). Positive framing increased desirability but did not affect willingness to take military action. The Mines scenario was seen as more desirable but less comprehensible than the Phantom scenario, highlighting a potential trade-off between desirability and understanding. Our results are consistent with those of Wilson et al. (1987) and Levin et al. (1988), who demonstrated that how information is framed can significantly influence decision-making. Similar to their work, our study found that framing affected participants' perceptions and choices, even within unfamiliar or hypothetical contexts.
Limitations
Our study used hypothetical military scenarios unfamiliar to our undergraduate participants. Without a strong affective connection, framing effects may differ from real-life decisions (Poor & Isaac, 2023).
Conclusion
This work has implications for designing AI systems with effective governance and user-centered guardrails. The findings suggest that AI translations can minimize cognitive effort and bias while improving comprehension. These outcomes support the development of responsible AI tools that align with governance frameworks promoting safe and transparent use (Poti & Stanton, 2024). Future research includes applying AI translation to other fields, such as medicine, and examining how AI translation accuracy impacts trust in automation.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.