
Abstract
Malingering is relatively common in criminal forensic evaluations as base rates of malingering have ranged from 20% to 30%. Given that the most prevalent criminal forensic evaluation is the assessment of competency to stand trial, the assessment of feigning during competency evaluations is necessary for accurate findings. Most of the response style literature focuses on feigning mental health symptoms, but in competency evaluations, individuals may attempt to feign legal knowledge deficits in order to be found incompetent to stand trial. The current investigation includes two studies: 195 students instructed to simulate feigned mental illness or incompetence to stand trial and one using a sample of 130 state psychiatric hospital residents who had been adjudicated incompetent to stand trial. The purpose of the study was to evaluate the Inventory of Legal Knowledge’s (ILK; Musick & Otto, 2010) ability to detect individuals who are feigning legal knowledge deficits. Classification utility statistics, including sensitivity, specificity, positive predictive power, and negative predictive power are provided for each cut-score on the ILK beginning with a cut-score of 24 (which is the lower end of the range of chance) are provided. The current cut-score of 47 provided in the professional manual of the ILK was shown to create a large number of false positives and suggests that modifications to this cut-score are required.
Of the various “competency” paradigms relevant to legal consideration, competency to stand trial (CST) is the most frequently adjudicated issue in the United States with approximately 60,000 occurring annually (Melton, Petrila, Poythress, & Slobogin, 2007; Roesch, Zapf, Golding, & Skeem, 1999; Soliman & Resnick, 2010). The contemporary legal standard for CST evaluations was defined in Dusky v. United States (1960) Supreme Court ruling as, the test must be whether he [the defendant] has sufficient present ability to consult with his lawyer with a reasonable degree of rational understanding—and whether he has a rational as well as factual understanding of the proceedings against him.
Considering the base rate of malingering and feigning, professionals who evaluate CST are strongly advised to rule out the possibility that the defendant is feigning or exaggerating psychiatric symptoms, as well as consider the validity of deficits in knowledge concerning understanding of the legal proceedings against him or her. The importance of valid and reliable assessment of potentially exaggerated or feigned deficits in a criminal defendant’s factual understanding of legal issues is the focus of the present study.
Feigning Symptoms in CST Evaluations
Extensive research has been conducted on internal and external factors that influence an individual’s tendency to engage in deceptive practices when undergoing psychological evaluation (see Rogers, 2008, for review). Whether attempting to present as impaired or well-adjusted, the manner in which one attempts to engage in deception during the assessment process is referred to as a response style. The most common feigned response style encountered in CST evaluations is attempting to deceive through presentation of fabricated or exaggerated symptoms of mental illness or cognitive impairment. Malingering is defined as the “intentional production of false or grossly exaggerated physical or psychological symptoms, motivated by external incentives” (American Psychiatric Association, 2013, p. 727). While the base rate of malingering during criminal forensic evaluations has been shown to be between 20% and 30% (Frederick, 2000; Miller, 2001; Mittenberg, Patton, Canyock, & Condit, 2002; Rogers, 1997), the term malingering can be problematic because motivation is a necessary element for diagnosing malingering. Standardized measures of response styles have not been validated for assessment of an individual’s motivations for intentionally fabricating or exaggerating symptoms (Rogers, 2008). Thus, the term feigning is preferred when discussing deliberate or intentional fabrication or exaggeration of symptoms (Rogers, 2008).
Feigning during a CST evaluation can include attempting to fabricate or exaggerate psychiatric symptoms, cognitive problems, and/or knowledge deficits. Although there are a variety of ways to assess the feigning of psychiatric symptoms, research on feigning legal or factual knowledge deficits has been limited. Due to the unique nature of CST evaluations, assessing only for feigned psychiatric symptoms is not sufficient for evaluating feigning during these evaluations, as another feigning strategy includes feigning legal knowledge deficits (Gothard, Viglione, Meloy, & Sherman, 1995; Rubenzer, 2011). As was specified in the Dusky standard, legal knowledge deficits directly affect competency because they interfere with a defendant’s factual and rational understanding of his or her case. As such, it is important to assess for feigned legal knowledge deficits during a CST evaluation.
Screening for Feigning of Nonpsychiatric Symptoms in CST Evaluations
The majority of previously published symptom validity instruments evaluate for the presence of feigned or exaggerated psychiatric symptoms (see Duffy, 2011; Rogers, 1997, 2008; Vitacco, Rogers, Gabel, & Munizza, 2007, for a review of these instruments). This is potentially problematic during CST evaluations as the presence of psychiatric symptoms may not have a direct impact on a criminal defendant’s factual and rational understanding of the proceedings against him or her, and none of these instruments assess for feigned knowledge deficits. Even if a defendant is experiencing severe psychiatric symptoms, she or he can still be adjudicated competent if she or he demonstrates a rational and factual understanding of the proceedings against him or her.
Feigning Factual/Legal Knowledge Deficits
Until recently, the development of assessment instruments designed to specifically detect feigned legal knowledge deficits has been largely overlooked in forensic research. One commercially available measure specifically designed to assess feigned legal knowledge deficits, is the Inventory of Legal Knowledge (ILK; Musick & Otto, 2010). The ILK is a 61-question, forced-choice test [true/false format], and has demonstrated utility in identifying defendants undergoing CST evaluations who may be feigning legal knowledge deficits (Guenther & Otto, 2010; Otto, Musick, & Sherrod, 2010). The ILK assesses the defendant’s response style during an evaluation and is not a measure of true legal knowledge or competency (Otto et al., 2010). However, low scores on the ILK can reveal a criminal defendant employing a response style suggestive of exaggerated or feigned legal knowledge deficits. Additionally, the ILK has evidenced convergent validity with other validated tests of feigning, including the Test of Memory Malingering, the Reliable Digit Span test, and the Rey 15-item test (Otto, Musick, & Sherrod, 2011).
The ILK manual suggests using the binomial probability estimate of scoring below chance or the recommended cut-score of 47 to identify those who may be feigning (Otto et al., 2010). The range of chance performance (guessing) on the ILK is reported to be between 24 and 36, with individuals scoring below 24 exceeding the 95% confidence interval for chance performance, thus being suspected of feigning (Otto et al., 2010). This conservative method may cause a proportion of individuals who are feigning to go undetected. Alternatively, users of the ILK may use the recommended cut-score of 47 to make determinations about feigning. However, a cut-score of 47 may be problematic given that individuals in normative and pilot samples who were genuinely incompetent and not suspected of malingering obtained a mean score on the ILK suggesting they were feigning legal knowledge deficits (Rubenzer, 2011). Specifically, according to the ILK manual, out of the 110 individuals in the adult competency examinee reference sample, 17 of those individuals who were incompetent and not suspected of malingering obtained a mean ILK score of 40.59 (SD = 8.53). Furthermore, 82% of this group scored below the recommended cut-score, which indicates an increased risk of false positives (Otto et al., 2010). Indeed, the range of scores for this group was 29 to 55; some of this sample scored below chance (Otto et al., 2010). Although this is concerning, these statistics were based on a very small sized sample and may not be sufficient to draw strong conclusions regarding an optimal cut-score.
An additional source of concern was related to the method and samples used for the validation study that resulted in the recommended cut-score. For the classification utility analysis of the ILK, the authors used a simulation design which Rogers and Cruise (1998) noted excels at internal validity. However, simulation designs have limited external validity (Rogers & Cruise, 1998) and the groups used for this analysis raise concerns regarding their representativeness of the “real world” ILK target population. The study samples used for the ILK classification utility analysis were college student controls, community psychiatric inpatients, and insanity acquittees. Although the use of community psychiatric inpatients and insanity acquittees allows for classification analysis of the ILK with clinical samples, neither sample is truly representative of the target population for ILK use. Community inpatients were not involved in the adjudicative process and insanity acquittees have already had their case adjudicated and were purportedly competent to proceed to trial. It can be reasoned that insanity acquittees are familiar with the adjudicative process and appropriate to serve as a representative analogue for individuals involved in the competency evaluation process; however, the issue of external validity remains. For these reasons, the present study sought to evaluate the classification accuracy of the ILK with both a college student control sample, as well as an inpatient hospital sample of individuals adjudicated as incompetent to stand trial (IST) and involved in the competency restoration process.
The current study sought to address concerns regarding the classification validity of the ILK. Specifically, the current study represents an independent examination of the ILK and provides classification utility statistics for two separate groups of participants, one of which is more representative of the target population for the ILK. Receiver operating characteristics (ROC) analyses were utilized to examine the recommended ILK cut-score of 47 and evaluate utility estimates to determine the effectiveness of the ILK to detect feigning in a representative clinical sample.
Study 1
Study 1 sought to examine the classification utility of the ILK using a simulation sample of undergraduate students. Specifically, two simulated conditions (feigned mental illness and feigned IST) were examined in relation to a group of undergraduate students instructed to respond to the measures honestly. Classification utility statistics, including sensitivity, specificity, positive predictive power (PPP), and negative predictive power (NPP) are provided for each cut-score on the ILK beginning with a cut-score of 24 (which is the lower end of the range of chance).
Method
Participants
This sample consisted of 195 undergraduate students recruited from a large, southeastern university. Participants had a mean age of 19.51 (SD = 2.23), were primarily (73.8%) female, and had almost 14 years of education (M = 14.08, SD = 1.13). With regard to race, 17.4% identified as African American, 77.4% identified as Caucasian, and 5.2% identified as another race. Participants were assigned to three groups/conditions. Group 1 (n = 65) included 21 male and 44 female undergraduate students who were asked to complete the measures honestly. Group 2 (n = 65) included 17 male and 48 female undergraduate students who were asked to simulate symptoms of a mental illness. Group 3 (n = 65) included 13 male and 52 female undergraduate students who were asked to simulate IST.
Measures
Table 1 includes the descriptive statistics for each measure by group.
Descriptive Statistics (Means, Standard Deviations, Ranges) for the Measures by Group.
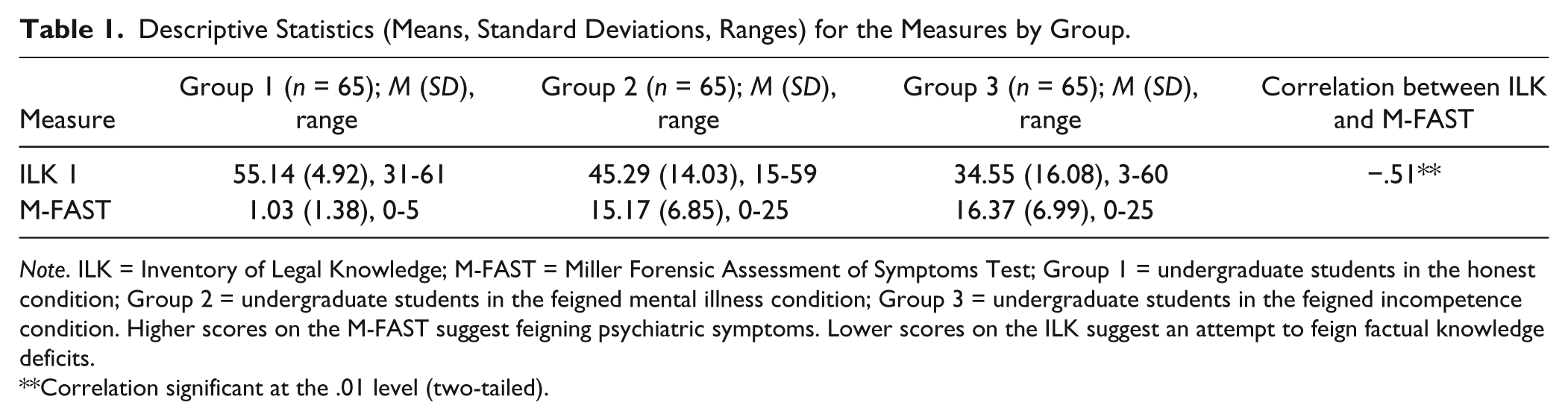
Note. ILK = Inventory of Legal Knowledge; M-FAST = Miller Forensic Assessment of Symptoms Test; Group 1 = undergraduate students in the honest condition; Group 2 = undergraduate students in the feigned mental illness condition; Group 3 = undergraduate students in the feigned incompetence condition. Higher scores on the M-FAST suggest feigning psychiatric symptoms. Lower scores on the ILK suggest an attempt to feign factual knowledge deficits.
Correlation significant at the .01 level (two-tailed).
The Inventory of Legal Knowledge
The ILK (Musick & Otto, 2010) is a 61-question, true/false, measure that assesses a defendant’s response style during a CST evaluation (Otto et al., 2010). Although it contains questions about legal knowledge, the ILK is not designed as a measure of the defendant’s true legal knowledge or of their level of competency. Instead, it is designed to evaluate defendants for feigning factual legal knowledge deficits. During an ILK administration, the clinician reads the items to the examinee who is directed to answer either “true” or “false.” The clinician then provides immediate feedback to the examinee regarding whether she or he answered correctly or incorrectly. In the current study, the ILK demonstrated excellent internal consistency (α = .97).
The ILK has been shown to demonstrate adequate internal consistency (α = .88) and test–retest reliability (r = .76; Otto et al., 2010). A pilot study was conducted to determine the effectiveness of the ILK total score in discriminating between feigned and honest response styles (Otto et al., 2010). Included in the normative sample for the ILK were 100 community psychiatric inpatients and 99 insanity acquittee (NGRI) forensic hospital residents. Both groups were instructed to either fake bad or answer honestly.
The ILK manual suggests using the binomial probability estimate of scoring below chance or the recommended cut-score of 47 (i.e., 47 or lower) to identify those who may be feigning (Otto et al., 2010). The range of chance performance (guessing) on the ILK is reported to be between 24 and 36. Scores below 24 exceed the 95% confidence interval for chance performance. Thus, based on statistical probability, scores below 24 provide evidence of feigning legal knowledge deficits (Otto et al., 2010). Alternatively, users of the ILK may consider the recommended cut-score of 47 (47 and lower) to make determinations about feigning factual legal knowledge deficits.
The Miller Forensic Assessment of Symptoms Test
The Miller Forensic Assessment of Symptoms Test (M-FAST; Miller, 2001) is 25-item screening instrument, developed to provide an estimate of the probability an individual is feigning psychiatric symptoms. The M-FAST has been shown to demonstrate good levels of internal consistency in psychiatric samples (α = .93) and good test–retest reliability (r = .92; Miller, 2001). The M-FAST is highly correlated with the Structured Interview of Reported Symptoms (Rogers, Bagby, & Dickens, 1992) demonstrating convergent validity (Miller, 2001). The M-FAST has good predictive power in both male and female clinical samples (Miller, 2001) and has also been shown to have good validity in a sample of criminal defendants that were currently adjudicated IST (Miller, 2004). The M-FAST was designed to be a brief screening instrument to detect feigned mental illness and has been shown to perform exceptionally well in a known-groups design with the Structured Interview of Reported Symptoms used as the criterion variable (sensitivity = 1.00, NPP = 1.00; Vitacco et al., 2007). In the current study, the M-FAST demonstrated excellent internal consistency (α = .97).
The M-FAST was administered to all study participants as a means of assessing how the simulated groups performed on this measure after being provided with simulation scenarios. The professional manual suggests that at a cut-score of 6 or greater, the M-FAST has NPP of .97, PPP of .68, specificity of .83, and sensitivity of .93 for clinical samples (Miller, 2001).
Procedure
The university’s institutional review board’s Human Subjects Committee approved the study protocol. All participants were treated in accordance with the committee recommendations. Participants were recruited from the research pool of general psychology students to participate in a study titled, “Mental illness and legal knowledge,” and received one credit in exchange for their participation. All participants signed a consent form agreeing to the use of their deidentified responses in this project. Undergraduate participants were randomly assigned to one of the following groups:
Group 1 (honest responders)
Group 1 participants were provided with the standard assessment instrument instructions. These participants were asked to complete the measures honestly and were given no further instructions.
Group 2 (simulated feigned mental illness)
Group 2 participants were read the following scenario, which written for this study and based off of scenarios provided in Gothard et al. (1995) and Tombaugh (1996).
I want you to imagine that you have been arrested and charged with a felony charge of Battery against a Law Enforcement Officer. Your public defender informs you that if you had symptoms of a mental illness and these symptoms were obvious while you were in jail or while being evaluated, it is likely that your charges could be dropped and you would be released from jail. Please answer the following questions in such a way that the evaluator will know that you are mentally ill and your charges will be dropped.
The participants then completed the study measures, with the standard directions for each test. Participants were reminded of their scenario before the administration of each measure.
Group 3 (simulated feigned incompetence)
Group 3 participants were read the following scenario, which written for this study and based off of scenarios provided in Gothard et al. (1995) and Tombaugh (1996).
I want you to imagine that you have been arrested and charged with a felony charge of Battery against a Law Enforcement Officer. Your public defender informs you that if you are INCOMPETENT to stand trial it is likely that your charges could be dropped and you would be released from jail. If a person is INCOMPETENT to stand trial, this means that for some reason they have been judged to not have the ability to understand what is going on or to cooperate with their attorney. If a person is COMPETENT to stand trial, this means they can go to court, understand what is going on, and cooperate with their attorney. You should pretend to be INCOMPETENT on all of the questions you are being asked here today. Please answer the following questions in such a way that the evaluator will know that you are Incompetent and your charges will be dropped.
The participants then completed the study measures, with the standard directions for each test. Participants were reminded of their scenario before the administration of each measure. Each participant in the student sample completed a demographic questionnaire, the M-FAST, two administrations of the ILK and the Shipley-2 Vocabulary Screener. Data from the second administration of the ILK and the Shipley-2 are not included in the current study. A subset of the data has been previously published in a study examining the relationship between intelligence and performance on the ILK (Gottfried & Carbonell, 2014).
Identification of groups
Through the use of a random number table, undergraduate students were randomly assigned to the honest group, the simulated malingering group, or the simulated incompetent group. The honest group (Group 1) consisted of the undergraduate students directed to answer the measures honestly. The first simulation group (Group 2) was asked to simulate feigned mental illness group (Group 2). The second simulation (Group 3) group was given the scenario and asked to simulate incompetence to proceed to trial.
Data analytic strategy
ROC analyses were used to examine the cut-score recommended in the ILK manual in an attempt to evaluate and improve the classification utility of the instrument to detect feigning. ROC analysis is the best method to determine the ideal cut-point when a continuous scale must be dichotomized (Gönen, 2006; Streiner & Cairney, 2007). The area under the curve (AUC) statistic gives the classification utility of a test (Otto et al., 2010; Streiner & Cairney, 2007). An AUC can range from 0 to 1; with AUCs between .50 and .70 having low classification accuracy, those between .70 and .90 having moderate classification accuracy, and high classification accuracy for those over .90 (Fischer, Bachmann, & Jaeschke, 2003; Streiner & Cairney, 2007). Sensitivity is the ability of the test to accurately classify malingerers as malingering and specificity is accurately classifying those answering honestly as not malingering (Streiner & Cairney, 2007). For example, according to the ILK manual (Otto et al., 2010), the AUC value reflects the probability that anyone feigning deficits in legal knowledge will obtain an ILK total score lower than anyone who is not feigning deficits, sensitivity is the percentage of those instructed to fake bad and being correctly identified as feigning, specificity is the percentage of participants answering honestly and being correctly identified as answering honestly, the PPP is the percentage of persons identified as feigning who are feigning, and the NPP is the percentage of persons identified as not feigning who are not feigning.
Results and Discussion
ROC analyses were performed separately for the honest and feigned mental illness groups and the honest and simulated incompetence groups.
Simulated Feigned Mental Illness
The ILK yielded an ROC-AUC value of .75 (moderate classification accuracy) when tested using the known groups of honest and simulated malingering. At the recommended cut-score of 47, the PPP is .92, indicating that 92% of this sample was correctly classified as feigning, while 60% were correctly classified as not feigning (NPP = .60). The sensitivity and specificity at a cut-score of 47 were .35 and .97, respectively. In other words, at the cut-score of 47, the ILK correctly classified 35% of the sample as feigning that were assigned to the simulated feigning group while appropriately identifying 97% of the sample that was not assigned to the feigning group, whereas 3% of those assigned to the honest group were identified as malingering on the ILK (false positives).
Table 2 reflects the diagnostic efficacy statistics across all possible cut-scores on the ILK, beginning with the lower end of the range of chance, 24. Examining the positive predictive value suggests that 40 may be a more ideal cut-score in this sample. At a cut-score of 40, PPP at is .95, indicating that 95% of this sample was correctly classified as feigning, while 58% were correctly classified as not feigning (NPP = .58). At a cut-score of 40, the sensitivity and specificity of the ILK in detecting feigning were .28 and .99, respectively. In other words, at the cut-score of 40, the ILK correctly classified 28% of the sample as feigning that were assigned to the simulated feigning group while appropriately identifying 99% of the sample that was not assigned to the feigning group. However, this also means that 72% of the students in the simulated feigning group were not identified by the ILK (false negatives), whereas 1% of those in the honest group were identified as feigning on the ILK (false positives).
Performance of the ILK in the Student Simulation Samples.
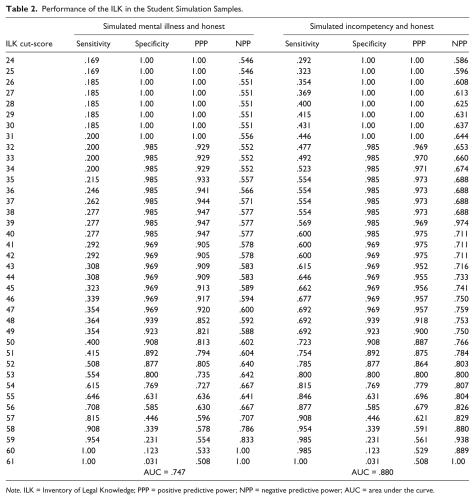
Note. ILK = Inventory of Legal Knowledge; PPP = positive predictive power; NPP = negative predictive power; AUC = area under the curve.
Simulated Incompetence
The ILK yielded an ROC-AUC value of .88 (moderate classification accuracy) when tested using the known groups of honest and simulated incompetence. At the recommended cut-score of 47, PPP is .96, indicating that 96% of this sample was correctly classified as feigning, while 76% were correctly classified as not feigning (NPP = .76). Sensitivity and specificity of the ILK in detecting feigning were .69 and .97, respectively. In other words, at the cut-score of 47, the ILK correctly classified 69% of the sample as feigning that were assigned to the simulated incompetence groups while appropriately identifying 97% of the sample that was not assigned to the feigning group. However, this also implies that 31% of the students that were assigned to the incompetent group were not identified by the ILK (false negatives), whereas 3% of those assigned to the honest group were identified as feigning on the ILK (false positives). A review of the positive predictive value indicates that 42 to be a better cut-score. At a cut-score of 42, PPP is .98, indicating that 98% of this sample was correctly classified as feigning, while 71% were correctly classified as not feigning (NPP = .71). Sensitivity and specificity of the ILK in detecting feigning were .60 and .97, respectively. In other words, at the cut-score of 42, the ILK correctly classified 60% of the sample as feigning that were assigned to the stimulated incompetent group while appropriately identifying 97% of the sample that was not assigned to the incompetent group. However, this also implies that 40% of the students assigned to the incompetent group were not identified by the ILK (false negatives), whereas 3% of those who were in the honest group were identified as feigning on the ILK (false positives).
Study 2
Study 2 sought to examine the classification utility of the ILK using a naturalistic sample of forensic state hospital residents who had been adjudicated IST and were receiving competency restoration treatment. This sample represents the first attempt to evaluate the classification utility of the ILK with what is considered the target population for this assessment instrument. Classification utility statistics, including sensitivity, specificity, PPP, and NPP are provided for each cut-score on the ILK beginning with a cut-score of 24 (which is the lower end of the range of chance). The base rate of feigning, as defined by obtaining an M-FAST score of 6 or greater, was 50% in this sample and there was an overselection of individuals who were feigning.
Method
Participants
The participants for Study 2 were recruited from a state psychiatric hospital which houses residents who have been adjudicated IST. Demographic data are displayed in Table 3. The “honest” group (n = 65) included 59 male and 6 female psychiatric state hospital residents who had been adjudicated IST and were not suspected of feigning symptoms based on the results of a screening test (M-FAST). The “suspected of feigning” group (n = 65) included 61 male and 4 female psychiatric state hospital residents who had been adjudicated IST and were suspected of feigning symptoms based on an M-FAST score of 6 or greater.
Demographic Data for Study 2 (N = 130).
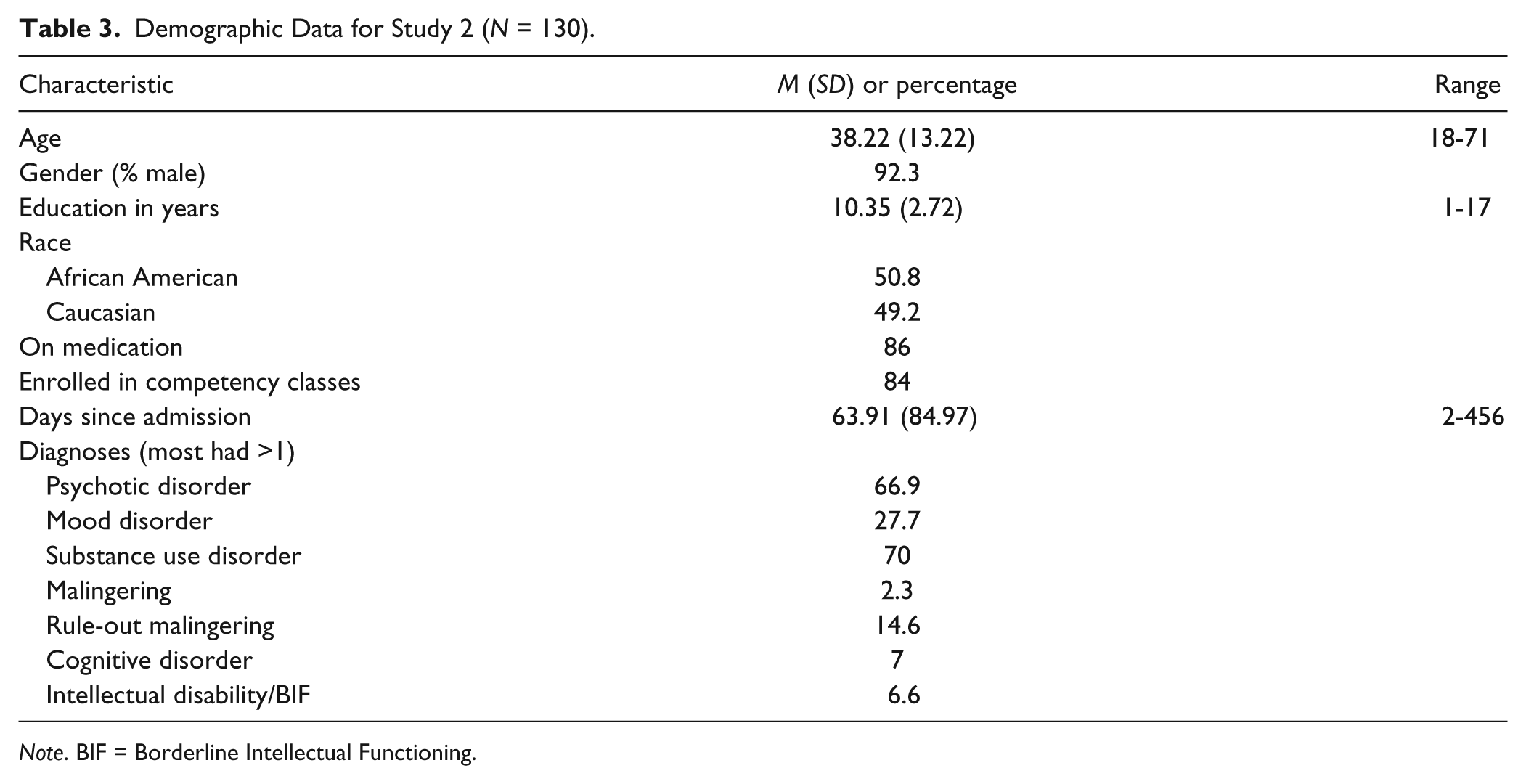
Note. BIF = Borderline Intellectual Functioning.
Measures
Table 4 includes the descriptive statistics for each measure by group.
Descriptive Statistics (Means, Standard Deviations, Ranges) for the Measures by Group.
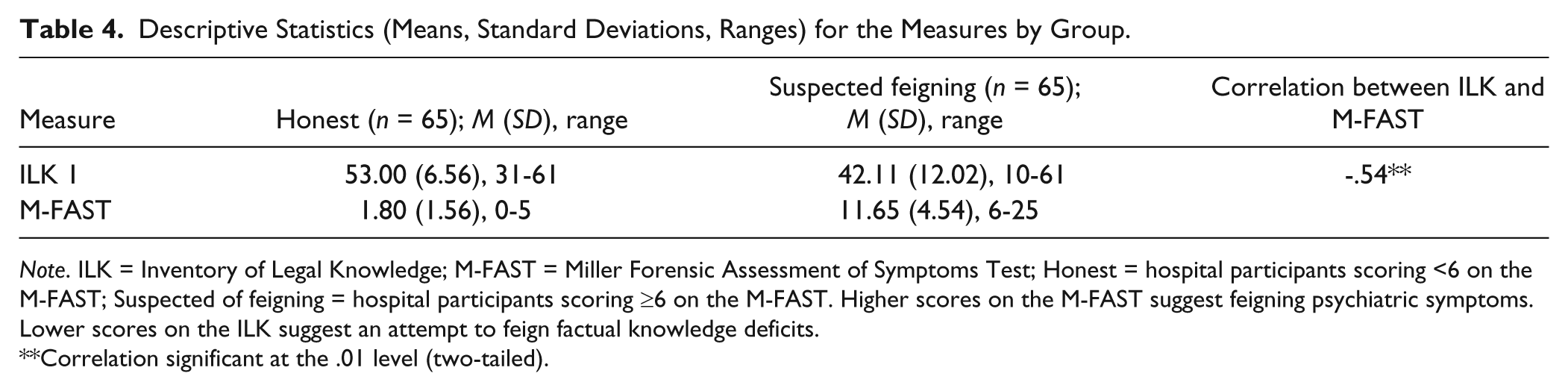
Note. ILK = Inventory of Legal Knowledge; M-FAST = Miller Forensic Assessment of Symptoms Test; Honest = hospital participants scoring <6 on the M-FAST; Suspected of feigning = hospital participants scoring ≥6 on the M-FAST. Higher scores on the M-FAST suggest feigning psychiatric symptoms. Lower scores on the ILK suggest an attempt to feign factual knowledge deficits.
Correlation significant at the .01 level (two-tailed).
The Inventory of Legal Knowledge
Please refer to the measures section in Study 1 for a description of the ILK (Musick & Otto, 2010). In the current sample, the ILK demonstrated excellent internal consistency (α = .94).
The Miller Forensic Assessment of Symptoms Test
Please refer to the measures section in Study 1 for a description of the M-FAST (Miller, 2001). In the current sample, the M-FAST demonstrated excellent internal consistency (α = .91).
Procedure
Both the hospital’s and the university’s institutional review board’s Human Subjects Committees approved the study protocol. All participants were treated in accordance with the committees’ recommendations.
Hospital residents were recruited based on their legal status of IST. 1 The procedures for both groups (honest and suspected of feigning) were identical. As part of their routine hospital psychological examination, residents that had been adjudicated IST were screened with one administration each of the M-FAST and the ILK by the primary investigator. On completion of these measures, the primary investigator introduced herself as a graduate student and asked if the hospital resident would be willing to sign a consent form to have his or her deidentified responses used and complete two additional measures (a second administration of the ILK and the Shipley-2 Vocabulary subtest) for a study examining the relationship between mental illness and legal knowledge. A subset of the data has been previously published in a study examining the relationship between intelligence and performance on the ILK (Gottfried & Carbonell, 2014). The current study was only concerned with the performance on the first administration of the ILK and thus, the results of the second ILK administration or the Shipley-2 are not presented in this article. Those residents who did not consent were not included in the study and a chart review was not completed. Out of 164 residents approached, 34 potential participants declined to consent to the study. Following the assessment, demographic information was obtained via hospital chart review for the 130 residents who agreed to participate.
Identification of groups
Hospital residents were sorted into their respective groups after all data were collected. The honest group was operationally defined as individuals scoring below 6 on the M-FAST, while the suspected of feigning symptoms group was operationally defined as participants scoring 6 or higher on the M-FAST.
Results and Discussion
The ILK yielded a ROC-AUC value of .79 (moderate classification accuracy) when tested against the M-FAST total score of 6 and greater being classified as feigning. At the recommended cut-score of 47, PPP is .80, indicating that 80% of this sample was correctly classified as feigning, while 67% was correctly classified as not feigning (NPP = .67). Sensitivity and specificity of the ILK in detecting feigning were .57 and .86, respectively. In other words, at the cut-score of 47, the ILK correctly classified 57% of the sample as feigning as ascertained by the M-FAST while appropriately identifying 86% of the sample that was not classified as feigning on the M-FAST. However, this also implies that 43% of the residents that were shown to be feigning on the M-FAST were not identified by the ILK (false negatives), whereas 14% of those who were not shown to be feigning on the M-FAST were identified as feigning on the ILK (false positives).
Table 5 reflects the efficacy statistics across all possible cut-scores on the ILK. An examination of the positive predictive values indicates that 35 would be a better cut-score in this population. At a cut-score of 35, the PPP is .94, indicating that 94% of this sample was correctly classified as feigning, while 57% was correctly classified as not feigning (NPP = .57). Sensitivity and specificity of the ILK in detecting feigning were .25 and .99, respectively. In other words, at the cut-score of 35, the ILK correctly classified 25% of the sample as feigning as ascertained by the M-FAST while appropriately identifying 99% of the sample that was not classified as feigning on the M-FAST. However, this also implies that 75% of the residents that were shown to be feigning on the M-FAST were not identified by the ILK (false negatives), whereas 1% of those who were not shown to be feigning on the M-FAST were identified as feigning on the ILK (false positives).
Performance of the ILK in the Hospital Sample ILK Predicting M-FAST Feigning.
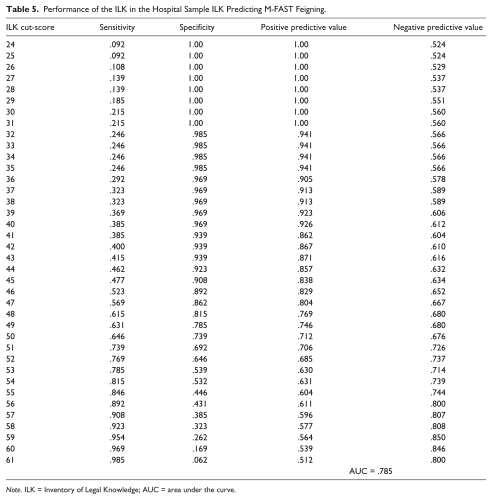
Note. ILK = Inventory of Legal Knowledge; AUC = area under the curve.
General Discussion
The present study was the first cross-validation study investigating the validity of the ILK by a researcher other than the authors of the instrument. Overall, the findings revealed a moderate relationship between the ILK and the M-FAST in the target population, suggesting that suspected feigning, as expected, affected both the ILK and M-FAST results. This finding replicates the research reporting convergent validity of the ILK in a clinical sample (Otto et al., 2010).
The primary aim of the present investigation sought to address the classification validity concerns regarding the ILK’s ability to identify individuals motivated to feign factual legal knowledge deficits. To this end, two separate studies were conducted, the first with a college sample employing a simulation design and the second with a sample of hospitalized inpatients who had been adjudicated IST. The latter sample is the first to be evaluated with the ILK to assess the classification utility of the ILK with a sample of individuals for whom this instrument was intended.
It has been noted that at a cut-score of 47, the ILK produces a large number of false positives (Rubenzer, 2011). Indeed, data from the current study are consistent with those results by finding a false positive rate of approximately 14% in the hospital sample when the recommended cut-score of 47 was employed. This finding is troubling given the implications of a defendant being incorrectly classified as feigning incompetence (Kulbarsh, 2009; LoPiccolo, Goodkin, & Baldewicz, 1999; Singh, Avasthi, & Grover, 2007).
In order to address the critique regarding the unacceptable rate of false positives, ROC analyses were conducted to reexamine the recommended cut-score of 47 by testing a range of scores. Depending on the nature of the sample, a range of cut-scores between 35 (target population) and 42 (simulation design group) were identified. This range is closer to the mean of 40.59 reported in the ILK professional manual regarding the sample group of 17 defendants who were adjudicated IST and were not suspected of feigning (Otto et al., 2010). Moreover, the differences noted in the cut-scores for the simulated sample and the hospitalized IST sample exemplifies Rogers’s and Cruise’s (1998) assertion that while simulation designs excel at internal validity, the external validity of this type of research design is limited.
In Study 1, a cut-score of 47 resulted in a much higher false positive rate than more conservative cut-scores. Cut-scores of 40 and 42 were identified as having much better predictive validity for the simulated feigning mental illness and simulated incompetent groups, respectively. This range of cut-scores was relatively close to one another considering it was comparing groups instructed to feign mental illness with those instructed to feign adjudicative incompetence. However, these scores were lower than the ILK recommended cut-score. What was also apparent in these findings was the difference in the AUC statistic. The ILK manual reported an AUC of .97 for the College Control Sample. The present study also used a College Control Sample of individuals simulating incompetence and found an AUC of .88. While the ILK simulation design group AUC fell in the high classification accuracy category (Fischer et al., 2003; Streiner & Cairney, 2007), the present findings fell on the cusp of the moderate and high classification categories. Thus, the present findings were not quite as robust in terms of overall classification accuracy as those reported by the authors for the simulation groups.
For the hospitalized target group sample used in the present study, the AUC was .79. Although this finding represents moderate range classification accuracy, the present hospitalized sample AUC was also below the clinical simulation sample AUC statistics reported by the ILK authors (.90 and .86). Again, although the ILK demonstrated moderate range classification utility, the present findings were not as robust as those reported by the authors for the ILK classification utility analysis. As will be discussed below, the use of the M-FAST to classify individuals as feigning may have accounted for a portion of the variance in the reduced AUC statistic; however, the same cannot be said of the aforementioned college student simulation design samples.
Thus, the overall findings revealed an overall moderate range classification accuracy of the ILK with both simulation and target population samples, but the findings were not quite as robust as those reported by the ILK authors. Given this finding, the discussion returns to focusing on the recommended cut-scores.
Interestingly, the present simulation design findings resulted in a lower recommended cut-score (40) for a group of individuals instructed to feign mental illness and for those simulating feigned incompetence (42). Moreover, the NPP and PPP for the scores of 40, 41, and 42 remained the same for the Simulated Incompetent Group (.98 and .71, respectively), while the sensitivity (.60) did not vary between the scores and the specificity varied only slightly (.97 to .99). If the present study were to focus solely on a cut-score generated from a Simulation Design Study, it would be prudent to offer a recommended cut-score of 42; however, as noted above, simulation studies have limited external validity and the present study has the advantage of a target group sample for ILK classification utility analysis.
For the present target group sample, a cut-score of 35 is recommended; however, it was found that the sensitivity (.25), specificity (.99), PPP (.94), and NPP (.57) were identical for ILK scores ranging from 32 to 35. Scores below 32 resulted in specificity and PPPs of 1.00. This finding is not surprising, as all these scores fall in the upper limits of the range of scores identified as chance responding. In sum, the present findings revealed that the use of an ILK cut-score above that of a score that falls within the range of chance responding is not optimal when evaluating a hospitalized patient adjudicated IST.
Limitations and Future Directions
Several potential problems were noted in the present study. For the hospital sample, female subjects were limited. This was primarily due to far fewer females being available for participation in the study based on the census of IST individuals available for study participation. In comparison, females made up the majority of experimental participants in the university sample. Similar gender disparity was noted in the ILK validation samples (Otto et al., 2010). In fact, the ILK authors noted that 90% of criminal defendants were male (Minton & Sabol, 2009) and opted to use masculine instead of masculine and feminine pronouns for the relevant ILK items. Despite the disparity between male and female criminal defendant population sizes, additional research is warranted regarding potential differences between men and women on ILK performance in both simulated and real-world settings.
Additionally, the present study used a feigning screening measure for psychopathology, the M-FAST, to differentiate between those who were suspected of feigning and those who were not. Use of this instrument assumes that individuals who exaggerate psychiatric symptoms are also feigning factual legal knowledge deficits. Based on the present findings, it appears that this assumption is not always correct. This contention is further supported by the classification accuracy finding for the hospital sample in the present study, which revealed that the NPP remained at .800 for those individuals who responded accurately to all 61 ILK questions. The present findings from the hospitalized IST sample suggest that individuals are more likely to exaggerate psychiatric symptoms than to feign factual knowledge deficits; however, as noted by Rubenzer (2011) through anecdotal observation, some individuals feign factual legal knowledge deficits without feigning mental illness. Future research could employ a cognitive feigning test, such as the Test of Memory Malingering (Tombaugh, 1996) or the Rey 15-item test as an adjunct classification measure. Additionally, other measures of feigned factual knowledge deficits, such as the Test of Malingered Incompetence (Colwell, Colwell, Perry, Wasieleski, & Billings, 2008) or the Test of Competency Evaluation Effort (Belfi, Klaver, Tussey, & Green, 2012), could be used to identify those in the suspected of feigning group. These studies could serve to replicate the ILK convergent validity findings, as well as assess the utility of the other competency feigning assessment instruments. Finally, the use of the ILK with individuals with intellectual disability is cautioned. Previous research utilizing the present sample indicated that there is a moderate relationship between IQ score and ILK performance (Gottfried & Carbonell, 2014).
Conclusions
Overall, the present study was limited by a small sample size and a marked disparity between the gender makeup of the experimental and hospitalized [real world] samples. However, the findings strongly suggest that reliance on a cut-score for classification of potential feigning of legal knowledge factual knowledge deficits is not advised for hospitalized individuals adjudicated as IST. Rather, the evaluator should use the ILK findings to evaluate the probability of chance responding. These findings further emphasize the importance of evaluators not relying solely on a single indicator when assessing potential feigning in forensic cases (Otto et al., 2010; Rogers, 2008).
Due to the frequency of CST evaluations and the fact that they affect approximately 60,000 individuals each year in the United States (Soliman & Resnick, 2010), it is of great importance to assess competency accurately. Due to the prevalence of symptom feigning and the costs associated with incorrectly classifying one as feigning or being genuine, it is paramount that response style during these evaluations be accurately assessed (Kulbarsh, 2009; LoPiccolo et al., 1999; Singh et al., 2007). Results of the current study indicated further research is necessary to evaluate and reconfigure the optimal cut-score on the ILK in order to maximize predictive validity. It is clear that the ILK evidences potential in identifying individuals not putting forth their best effort or feigning legal knowledge deficits during a competency assessment.
Footnotes
Acknowledgements
The authors wish to express appreciation to the staff at Florida State Hospital, including Dr. May Tay and Dr. Trina Christner-Renfroe, for their invaluable support and assistance during data collection.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.