
Abstract
Numerous studies leverage item response theory (IRT) methods to examine measurement characteristics of alcohol use disorder (AUD) diagnostic criteria. Less work has examined the consistency of AUD IRT parameter estimates, an essential step for establishing measurement invariance, making statements about symptom diagnosticity, and validating the theoretical construct. A Bayesian meta-analysis of IRT discrimination values for AUD criteria across 33 independent samples (Total N = 321,998) revealed that overall consistency of AUD criteria discriminations was low (generalized intraclass correlation range = .105-.249). However, specific study characteristics accounted for substantial variability, suggesting that the unreliability is partially systematic. We replicated evidence of differential item functioning (DIF) via established factors (e.g., age, gender), but the magnitudes were small compared with DIF associated with assessment instrument. These results offer practical recommendations regarding which instruments to use when specific AUD criteria are of interest and which criteria are most sensitive when comparing demographic groups.
Keywords
The diagnosis and conceptualization of alcohol use disorder (AUD) has gone through substantial revision since the syndrome was first included among the personality disorders in earlier versions of the Diagnostic and Statistical Manual of Mental Disorders (i.e., DSM-I and DSM-II; American Psychiatric Association [APA], 1942, 1952). 1 In the current iteration of the DSM–Fifth edition (DSM-5; APA, 2013), AUD is diagnosed based on the presence of 2 or more of 11 different criteria that assess cognitive, behavioral, and physiological symptoms with severity being determined by the number of criteria endorsed. As statistical tools have become more advanced in recent decades, researchers have leveraged these advancements to further refine the field’s understanding of AUD. One such advancement has been the application of item response theory (IRT) to studying the AUD criteria.
Numerous IRT studies have been conducted on the AUD criteria set as instantiated in the 4th and 5th editions of the DSM (APA, 1994, 2013). The most common IRT model used in AUD research is the two-parameter logistic (2PL) model. The 2PL model estimates two parameters for each criterion based on a logistic model of (usually) binary endorsement: a threshold and discrimination parameter. Thresholds relate to how difficult it is to endorse a particular criterion. Consequently, many clinical measures are designed to include items/criteria that fall along a continuum of difficulty to ensure that the measure provides information about individuals who fall along various points of the latent spectrum (Reise & Waller, 2009). Within AUD research, studies have shown that certain AUD criteria like tolerance (having to drink a greater amount to achieve similar effects) tend to be relatively easy to endorse, while others such as withdrawal (insomnia/sweating/tremors/nausea within a few hours or days after stopping drinking) are more difficult (e.g., Martin et al., 2006).
In comparison, discrimination parameters relate to a criterion’s ability to distinguish between persons given their standing on the latent AUD spectrum. Higher discrimination values indicate that an item or criterion is better able to differentiate between persons at similar levels of the latent spectrum while lower values suggest that a criterion provides less information about individuals across varying levels of the latent spectrum. That is, a highly discriminating criterion is associated with a high probability of identifying individuals who will, versus will not, endorse the criterion within a narrow range along the latent spectrum. In contrast to criteria thresholds, past research suggests that both tolerance and withdrawal provide comparatively less information about latent AUD precision whereas interpersonal problems and giving up activities due to drinking have high discriminations (e.g., Martin et al., 2006; Saha et al., 2006). It is important to note that while thresholds often receive preferential attention given their association with symptom severity (Balsis et al., 2007; Cooper & Balsis, 2009; Langenbucher et al., 2004; Uebelacker et al., 2009), focused attention on any criterion given its relative severity is (arguably) only warranted to the extent that the corresponding discrimination is also high.
IRT studies of AUD criteria have addressed a range of research questions. For example, IRT-based results have shown that the AUD criteria set assesses a single latent dimension (e.g., Harford et al., 2009; Hasin et al., 2013), with some indication that it is most effective at identifying severe cases along the AUD continuum (Saha et al., 2006). Other studies suggest that AUD criteria are most informative for individuals along the moderate portion of the AUD latent spectrum (e.g., Borges et al., 2010). Despite the relatively large number of IRT studies on AUD criteria, less work has examined the overall consistency of the observed threshold and discrimination estimates across studies. In their recent meta-analysis of IRT threshold estimates, Lane et al. (2016) found notably low reliability in AUD criteria thresholds, and also found important sources of systematic variability in threshold values (e.g., measurement instruments and age group). The present study extends similar analyses to examine the between-study consistency of IRT-derived discrimination parameters, and examine competing hypotheses regarding the perceived consistency of AUD criteria discrimination values. Such analyses are critical for arguments asserting the generalizability of AUD phenomenology and diagnosis across demographic subpopulations.
IRT Analyses of AUD Criteria
An important topic within IRT analyses of the AUD criteria is the presence (or lack thereof) of differential item functioning (DIF). DIF analyses have tended to focus on whether the discrimination and/or threshold values for AUD criteria show variability across relevant sample characteristics (e.g., gender, age group, ethnicity, etc.). The presence of DIF for discrimination estimates may indicate that an AUD criterion’s ability to distinguish between individuals that fall along different points of the underlying AUD spectrum is dependent on factors that may differ across samples.
Important instances of DIF have been noted in the AUD IRT literature. For example, when examining the discriminations of AUD criteria in a sample of adolescents, the quit/cut down criterion showed relatively poor discrimination (Martin et al., 2006), consistent with other work that has found that adolescents with more severe alcohol abuse problems tend to not endorse trying to cut down while other adolescents with less severe problems do report attempts to limit their use (Chung & Martin, 2002).
In their analysis of nationally representative data from the National Epidemiological Survey of Alcohol and Related Conditions, Saha et al. (2006) found DIF across men and women, age groups, and ethnicity. With regard to discrimination values, the 24- to 44-year-old age group showed lower discrimination values compared with the ≥45 years old and 18- to 24-year-old age groups for the tolerance and hazardous use criteria. When considering ethnicity, African American participants showed lower discriminations for the tolerance, quit/cut down, and hazardous use criteria compared with White participants. By contrast, using another representative data set from the National Survey on Drug Use and Health across gender, age, and ethnicity, Harford et al. (2009) reported patterns not wholly consistent with the criteria identified by Saha et al. (2006; i.e., tolerance and hazardous use) while also reporting DIF across gender and age groups not identified by the those authors (e.g., giving up activities, role interference). When focusing on the specific AUD symptom of dependence across four studies, Witkiewitz et al. (2016) found that certain assessment items tied to alcohol dependence showed differential functioning across relevant sample characteristics. For example, the authors found that items related to physiological dependence and delirium tremens were less useful in assessing the degree of dependence severity in younger individuals and females, respectively.
Given that numerous studies have examined DIF with regard to discrimination estimates within studies, the consistency of DIF at a more global level can help inform future efforts in establishing whether AUD criteria discriminations from any given study are generalizable, and if not, what sources may be limiting the generalizability of the estimates.
The Current Study
Though IRT has been utilized to explore differences in threshold and/or discrimination values within the AUD criteria set, less work has examined the between-study consistency of the AUD criteria discriminations. Discrepancies in discrimination estimates across studies can provide important insights into diagnoses of AUD. Most important, in cases where the criteria discriminations are not comparable across different types of groups (e.g., gender, ethnicity, etc.), it suggests that the underlying composition of the latent AUD trait may differ. The implications of such findings would suggest that not only can the presentation of AUD look different across groups even when similar symptoms are endorsed, but that the underlying etiology may also differ.
The current study looks to more critically examine the overall consistency in AUD criterion discriminations across studies. Previous work has been conducted examining the consistency of threshold estimates (Lane et al., 2016) and the present study looks to apply the same analytical framework to examinations of discriminations. Specifically, we aim to test whether previously reported sources of DIF within samples (e.g., gender, ethnicity, age group) as well as commonly examined meta-analytic moderators (e.g., clinical vs. nonclinical samples, measurement instrument) emerge as systematic sources of discrimination variability. Given previous DIF findings regarding AUD discrimination estimates, we hypothesize that there will be notable sources of systematic variability in discrimination estimates, which will limit the likelihood that the AUD discrimination estimates will be consistent across studies. However, debates remain regarding whether the AUD criteria consistently distinguish between individuals at differing levels of AUD severity, and whether certain criteria are more discriminating than others (e.g., Martin et al., 2011; Martin et al., 2014; Sayette, 2016). The argument that the criteria consistently distinguish between individuals would lead to the prediction that the AUD criteria will be the primary source of variability in discrimination values across studies, especially if criteria differences reported by epidemiological investigations are to be considered generalizable (cf. Harford et al., 2009; Saha et al., 2006).
Method 2
Literature Search
The present literature search incorporated all results returned from the initial publication conducted in May of 2015 (see Lane et al., 2016, for a full review). Briefly, the PubMed, Web of Science, ProQuest (including dissertations), and PsycINFO databases were searched with a time restriction of January 1977 to May 2015. The search terms entered were “item response theory” or “differential item functioning” crossed with “alcohol use disorder,” “alcohol abuse,” or “alcohol dependence.” Inclusion criteria for studies returned by these search terms were that the paper needed to report on discrimination and severity parameter estimates from IRT analyses that assessed DSM-III, DSM-III-R, DSM-IV, DSM-5, ICD-9, or ICD-10 AUD criteria, and that the results were derived from analyses of 2PL. In order to include recent studies that had used IRT analyses since the publication of the original meta-analysis, an updated search was conducted following the exact procedures outlined above with the exception that the search aimed to identify studies published between May of 2015 and May of 2018.
The updated search returned 74 articles for review. After removing duplicate articles (n = 30), a review of the remaining 44 articles identified 3 new articles to be added, resulting in a total of 33 nonoverlapping articles (with 52 samples providing discrimination estimates) included in our quantitative analyses. Though the number of included articles could be considered moderate, the total sample size (N = 321,998) for the present study was extremely large, even by meta-analytic standards. A flow chart of the literature search results is presented in Figure 1, which maps the path of study inclusion over the four phases of our systematic review: identification, screening, eligibility, and inclusion. Studies included in the meta-analysis are marked with an asterisk in the references.
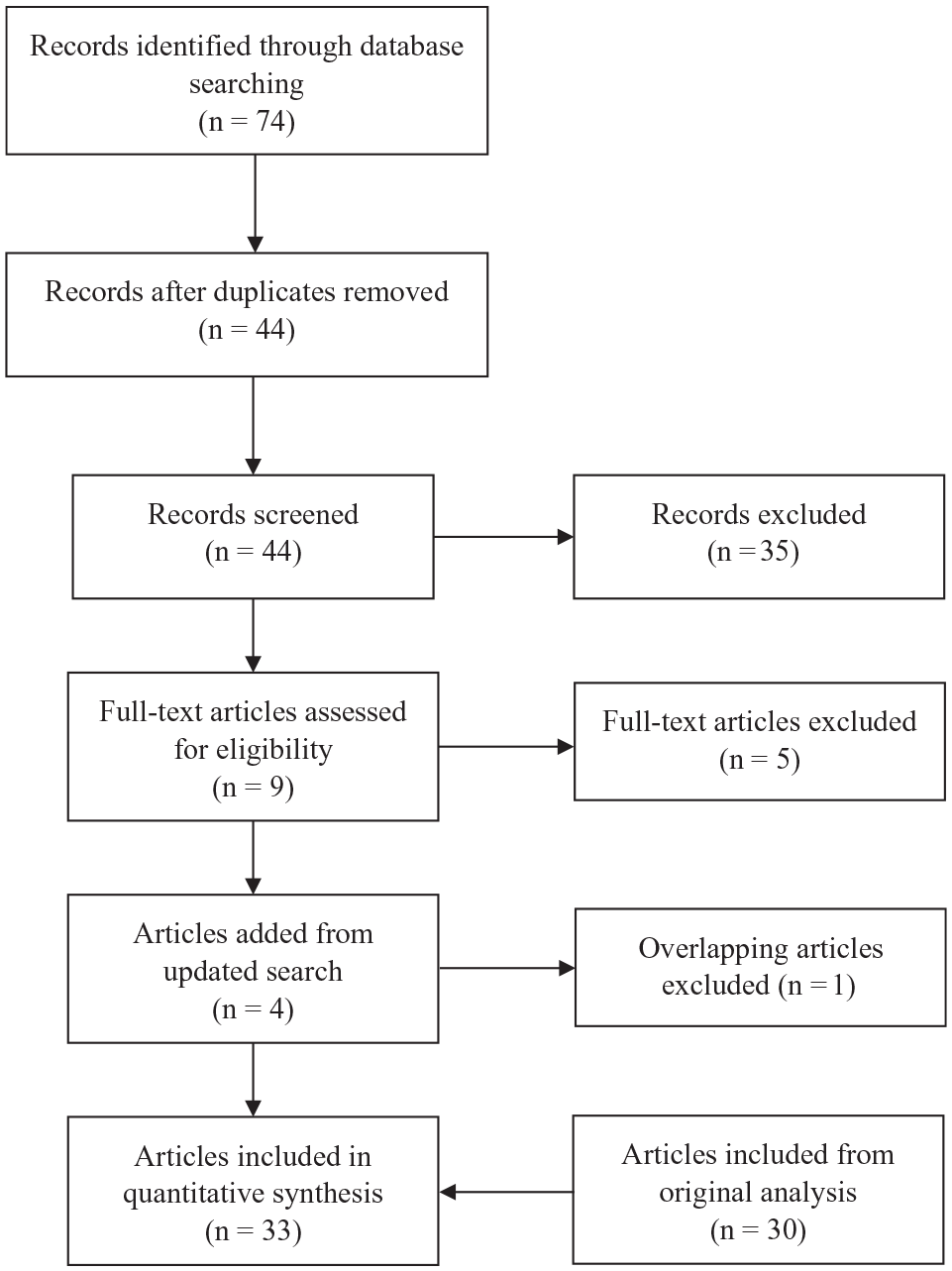
Flow diagram of updated literature search results.
Coded Information
In addition to the AUD criteria discrimination values, the information taken from each article included the study authors, year of publication, sample characteristics (i.e., mean age, clinical vs. population, gender ratio, etc.), sample size, AUD diagnostic instrument, diagnostic time frame, number of criteria assessed, and reporting metric for the discrimination values (unstandardized, standardized, IRT parameterized). 3 The original data were coded by two independent raters and the raters showed near perfect agreement for the discrimination and severity values (intraclass correlations [ICCs] = .98-1.00) and showed good to excellent agreement for descriptive information taken from the studies (κ = .86-1.00). Due to only three unique studies being included from the updated literature search, the first and second author independently coded the three studies and results showed perfect agreement across all coded information.
For publications that examined DIF, we included discrimination estimates for each respective group in the analyses. We did not include aggregated estimates if such an analysis was conducted since they would be partially confounded with the individual DIF results. In this way, specific DIF identified in different publications was not explicitly examined, but was included and appropriately weighted to estimate meta-analytic evidence of DIF. We considered whether DIF in general across the criteria set existed, and, if so, for what criteria and factors was it robust across the extant literature.
Analyses
Our primary interest was in the overall reliability of the discrimination estimates for the AUD criteria set across studies. As such, we made use of GT (Brennan, 1992) to estimate generalized ICCs (Shrout & Fleiss, 1979) within a Bayesian framework. Two models were examined. The first model is expressed in Equation 1,
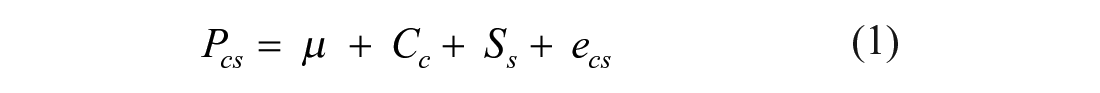
where Pcs represents the discrimination estimate for criterion c from study s. µ represents the grand mean of all criteria discrimination estimates. Cc is the tendency for criterion c to be more or less discriminative across samples while Ss is the tendency for study s to produce higher or lower discriminations across the criteria set on average. The reliability of the estimated discrimination values for a fixed criterion set (i.e., Cc from Equation 1) for any randomly selected study can be examined using Equation 2:

Equation 2 provides a reliability estimate between 0 and 1, with higher values indicating a greater level of reliability for the AUD criteria set. In the present context, reliability refers to the ability of the criteria set to consistently account for variability observed in discrimination values across studies, relative to other sources of variability. In the basic model, the other sources of variability are aggregated into either a study component or error component.
The basic model in Equation 1 was then expanded to estimate additional variance components for diagnostic instrument, diagnosis time frame, sample type, gender, and age along with their interactions with AUD criteria (Equation 3).
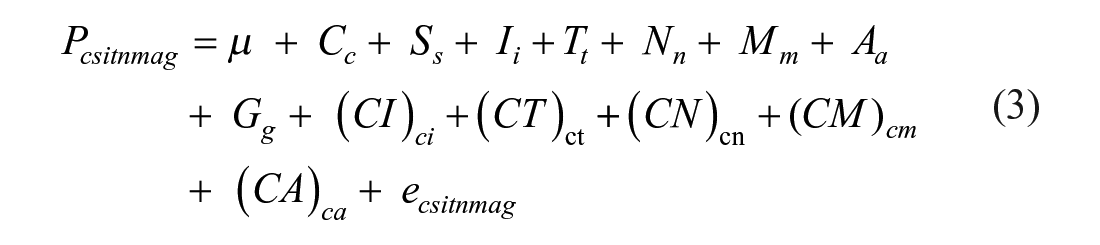
In the expanded model Pcsitnmag represents the discrimination parameter estimate for criterion, c, from study, s, where study was indexed by specific instrument (i; Seven categories: Alcohol Use Disorder and Associated Disabilities Interview Schedule [AUDADIS]; Composite International Diagnostic Interview [CIDI]; Semistructured Assessment for the Genetics of Alcoholism [SSAGA]; Substance Abuse and Mental Health Services Administration [SAMHSA]; Psychiatric Research Interview for Substance and Mental Disorders [PRISM]; Structured Clinical Interview for DSM-IV [SCID]; Other), AUD diagnostic time frame (t; Two categories: current, lifetime), sample composition (n; Four categories: clinical, healthy, mixed, population), gender distribution (m; Five Categories: exclusively men, primarily men, approximately equal men and women, primarily women, exclusively women), age distribution (a; 5 categories: <18 years, primarily 18-30 years, primarily, 30-50 years, >50 years, representative of the population 18 years and older), and being part of a group of studies that used the same or a partially overlapping sample (g). µ, Cc, and Ss are the same as in Equation 1, but now we include effects for instrument (Ii), diagnosis time frame (Tt), sample population (Nn), gender composition (Mm), age group (Aa), and being part of a group of studies that used overlapping samples (Gg). Two-way interaction terms are also included to examine additional sources of systematic variance in reliability. In the expanded model, the consistency of criterion discriminations for any randomly selected study that is not attributable to instrument, time frame, population, gender, or age can be examined using Equation 4.
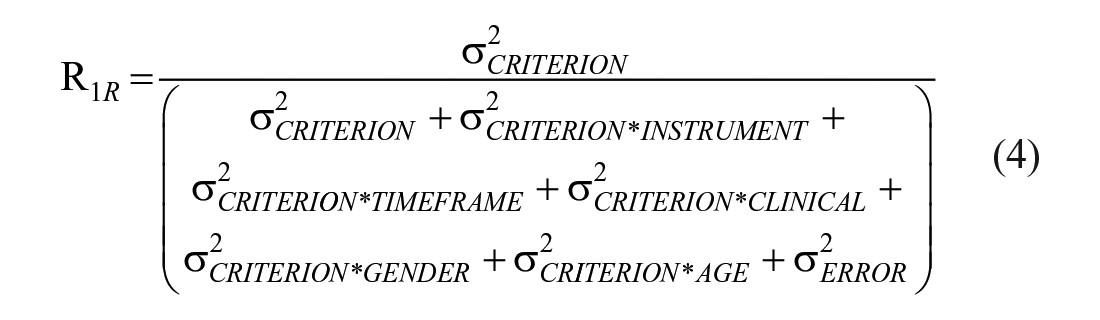
Similar to Equation 2 above, Equation 4 provides a reliability estimate between 0 and 1, with higher values indicating that the criteria set account for the most variability in discrimination estimates across studies, relative to other potential sources of variability (e.g., an interaction between a particular criterion and measurement instrument). The analyses described were all completed using a Bayesian approach. Sample sizes from each included analysis were used to weight sets of criteria discriminations to adjust for differences in precision when calculating met-analytic estimates and confidence intervals (DuMouchel, 1990).
Although the various benefits of Bayesian methods have been emphasized elsewhere (e.g., Kruschke & Liddell, 2018; Wagenmakers et al., 2016), we chose to rely on Bayesian analyses in the present study in order to test different beliefs regarding whether the AUD criteria set would be the primary source of variability in discrimination estimates across studies. 4 We made use of the Savage-Dickey method (Wagenmakers et al., 2010), allowing for approximate Bayes factors (BF) to be computed. The Savage-Dickey method provides an approximate BF by comparing the prior and posterior distribution densities at a specified point estimate (typically zero, the null hypothesis). In turn, the BF describes how much more (or less) likely the point estimate is after having seen the data. Thus, Bayesian analysis allows for direct quantification of evidence for or against particular point hypotheses.
In the context of the present study, BFs were computed to test point hypotheses regarding the amount of variability in discrimination estimates that could be accounted for by the AUD criteria set. Specifically, we examined the influence of two different types of prior specifications for the σ2criterion parameter. 5 First, we used moderately informed priors (σ2criterion ~ N [.60, .035]) that reflect some degree of confidence that the AUD criteria will be the primary source of variability in discrimination estimates before having seen the data. Next, we used strongly informed priors (σ2criterion ~ N [.60, .001]) that reflect very strong beliefs that the AUD criteria set will be the primary source of variability in discrimination estimates. By comparing the likelihoods of σ2criterion parameter estimates under the prior and posterior distributions at the point estimate of .60, BFs can be computed to quantify the degree of evidence in favor of (or against) beliefs that the AUD criteria set will account for a moderate to large degree of variability (i.e., σ2criterion = .60) in discrimination estimates across studies.
Results
Figure 2 displays the plotted IRT discrimination estimates for raw and standardized values. The criteria are plotted in ascending order according to their median discrimination value across studies (Table 1). Both the raw and standardized discrimination values show notable degrees of systematic unreliability in that, (1) there is marked variability within each criterion category across studies, and (2) there are multiple patterns of opposing change (larger/longer, cut down, role interference, time spent, interpersonal problems) across the different continuous study series. However, the standardized data show an increasing linear trend in discrimination values, suggesting some degree of reliability in the criteria. The differences between the unstandardized and standardized results is a consequence of differing within-study means and variances, which are eliminated when standardized data are used due to all discrimination estimates being placed on the same scale. The choice to use standardized results may be justifiable if the between-study differences in scaling is viewed as nuisance variance as opposed to being indicative of meaningful study-specific variability. Therefore, although we primarily focus on unstandardized values for interpretation, we present results for both unstandardized and standardized discrimination values in Table 2. 6
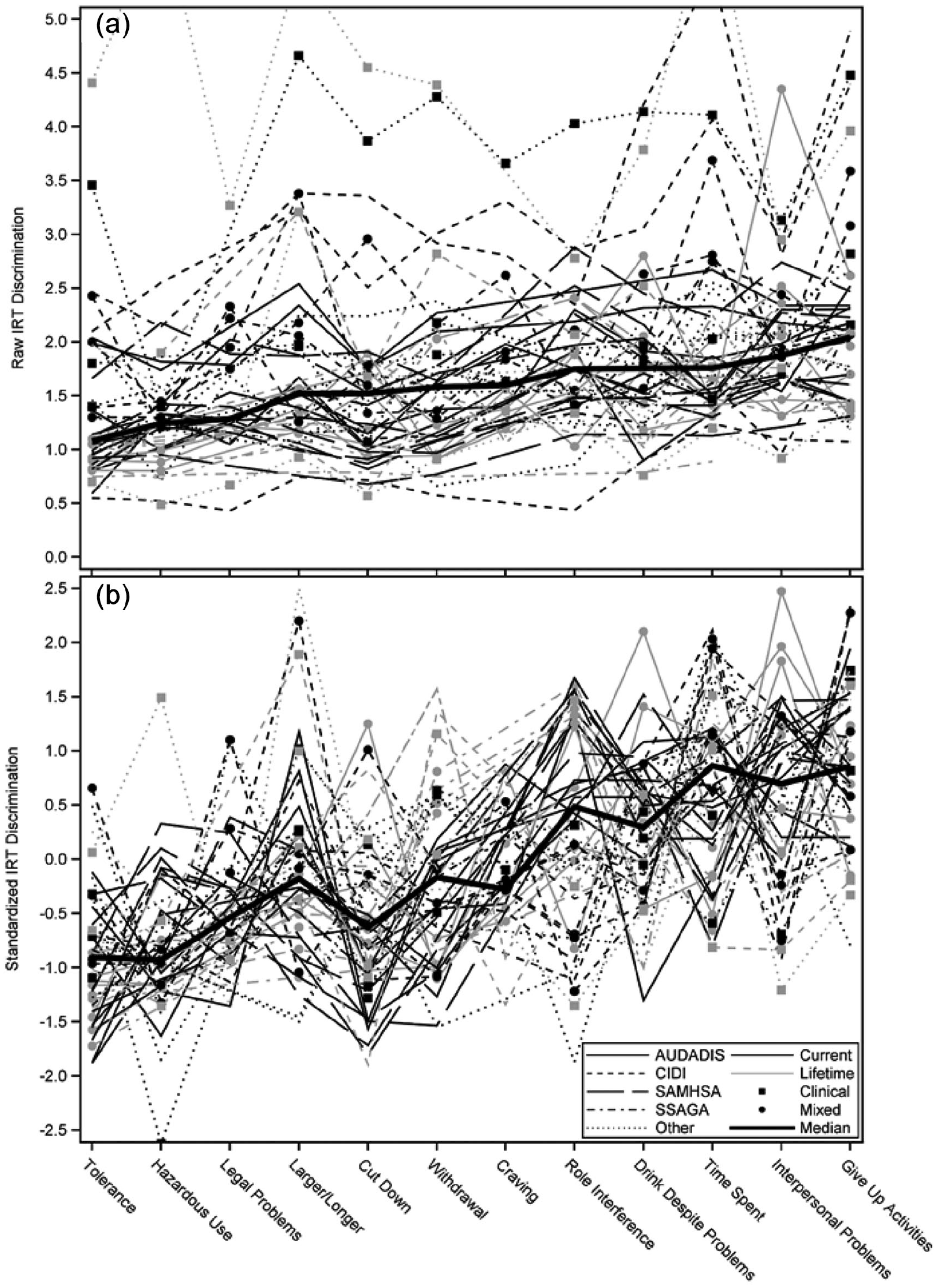
Unstandardized (a) and standardized (b) discrimination estimates for AUD criteria.
Descriptive Information for Included Studies.
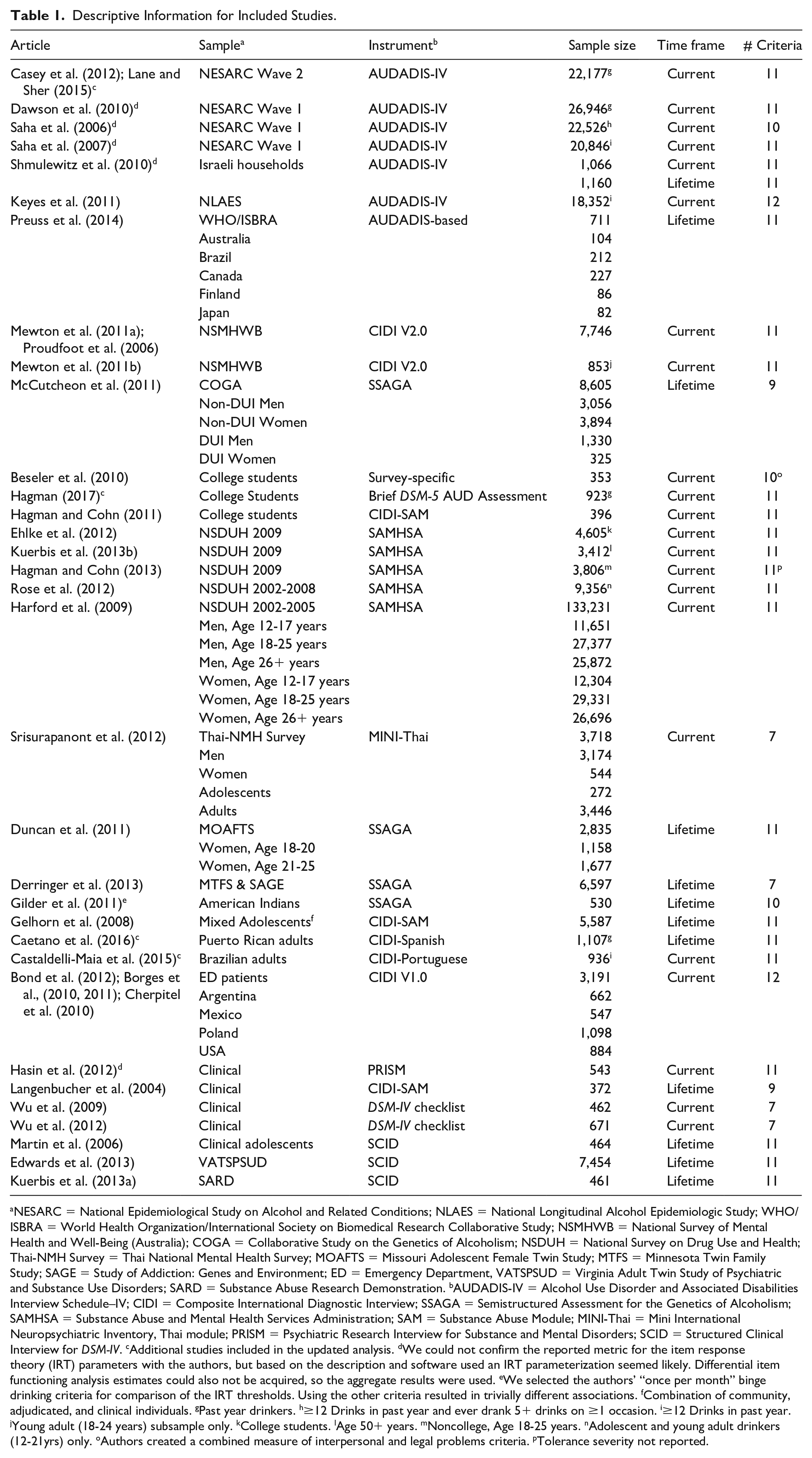
NESARC = National Epidemiological Study on Alcohol and Related Conditions; NLAES = National Longitudinal Alcohol Epidemiologic Study; WHO/ISBRA = World Health Organization/International Society on Biomedical Research Collaborative Study; NSMHWB = National Survey of Mental Health and Well-Being (Australia); COGA = Collaborative Study on the Genetics of Alcoholism; NSDUH = National Survey on Drug Use and Health; Thai-NMH Survey = Thai National Mental Health Survey; MOAFTS = Missouri Adolescent Female Twin Study; MTFS = Minnesota Twin Family Study; SAGE = Study of Addiction: Genes and Environment; ED = Emergency Department, VATSPSUD = Virginia Adult Twin Study of Psychiatric and Substance Use Disorders; SARD = Substance Abuse Research Demonstration. bAUDADIS-IV = Alcohol Use Disorder and Associated Disabilities Interview Schedule–IV; CIDI = Composite International Diagnostic Interview; SSAGA = Semistructured Assessment for the Genetics of Alcoholism; SAMHSA = Substance Abuse and Mental Health Services Administration; SAM = Substance Abuse Module; MINI-Thai = Mini International Neuropsychiatric Inventory, Thai module; PRISM = Psychiatric Research Interview for Substance and Mental Disorders; SCID = Structured Clinical Interview for DSM-IV. cAdditional studies included in the updated analysis. dWe could not confirm the reported metric for the item response theory (IRT) parameters with the authors, but based on the description and software used an IRT parameterization seemed likely. Differential item functioning analysis estimates could also not be acquired, so the aggregate results were used. eWe selected the authors’ “once per month” binge drinking criteria for comparison of the IRT thresholds. Using the other criteria resulted in trivially different associations. fCombination of community, adjudicated, and clinical individuals. gPast year drinkers. h≥12 Drinks in past year and ever drank 5+ drinks on ≥1 occasion. i≥12 Drinks in past year. jYoung adult (18-24 years) subsample only. kCollege students. lAge 50+ years. mNoncollege, Age 18-25 years. nAdolescent and young adult drinkers (12-21yrs) only. oAuthors created a combined measure of interpersonal and legal problems criteria. pTolerance severity not reported.
Bayesian Variance Parameter Estimates for Basic and Expanded Models Using Unstandardized and Standardized Discrimination Values.
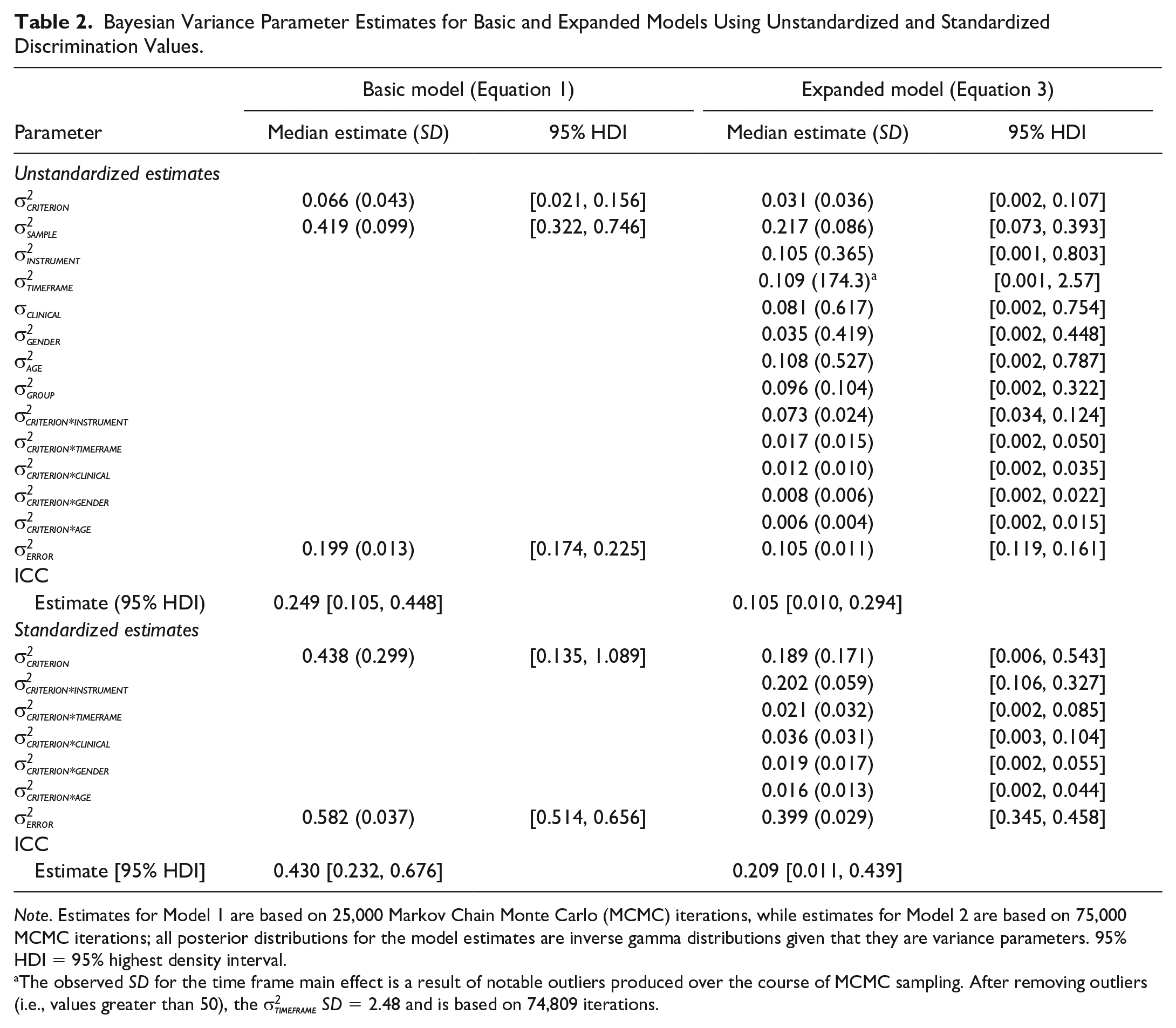
Note. Estimates for Model 1 are based on 25,000 Markov Chain Monte Carlo (MCMC) iterations, while estimates for Model 2 are based on 75,000 MCMC iterations; all posterior distributions for the model estimates are inverse gamma distributions given that they are variance parameters. 95% HDI = 95% highest density interval.
The observed SD for the time frame main effect is a result of notable outliers produced over the course of MCMC sampling. After removing outliers (i.e., values greater than 50), the
The unstandardized results for the basic model show an estimated ICC of .249 (95% HDI 7 [0.105, 0.448]) when only considering two potential sources of variability in discrimination values: criteria and study-specific variance. The results for the expanded model show even lower reliability (ICC = .105, 95% HDI [0.010, 0.294]). The results for the expanded model show that the primary source of systematic unreliability in discrimination estimates was the criterion × instrument interaction (σ2 = .073, 95% HDI [0.034, 0.124]).
Further exploration of the criterion × instrument parameter showed that the types of measures that contributed significant variability to discrimination estimates (for certain criteria) were the AUDADIS, SSAGA, PRISM, SCID, CIDI, and SAMSHA, with the latter three measures showing significant effects for multiple criteria. Compared with the average discrimination estimate across all studies, studies that used the AUDADIS produced a higher discrimination value for social problems (b = .27, HDI [0.01, 0.55]) 8 while the SSAGA produced a higher discrimination value for role interference (b = .31, HDI [0.04, 0.59]). The PRISM produced a lower discrimination for the hazardous use criterion (b = −.61, HDI [−1.09, −0.21]). The SCID produced higher discrimination values for two criteria: hazardous use (b = .37, HDI [0.05, 0.73]) and larger/longer (b = .40, HDI [0.07, 0.76]). The CIDI produced higher discrimination estimates than the average study for both the give up activities (b = .31, HDI [0.04, 0.59]) and time spent (b = .36, HDI [0.09, 0.63]) criteria, but a lower discrimination estimate for the role interference criterion (b = −.30, HDI [−0.56, −0.04]). The SAMSHA produced higher discrimination estimates for both the role interference (b = .28, HDI [0.004, 0.56]) and social problems (b = .32, HDI [0.04, 0.60]) criteria, but a lower estimate for time spent (b = −.34, HDI [−0.62, −0.07]). Table 3 provides the posterior estimates for all criterion × instrument interactions (also see online supplementary Figure S1).
Posterior Median Discrimination Values for Instrument × Criterion Interactions.
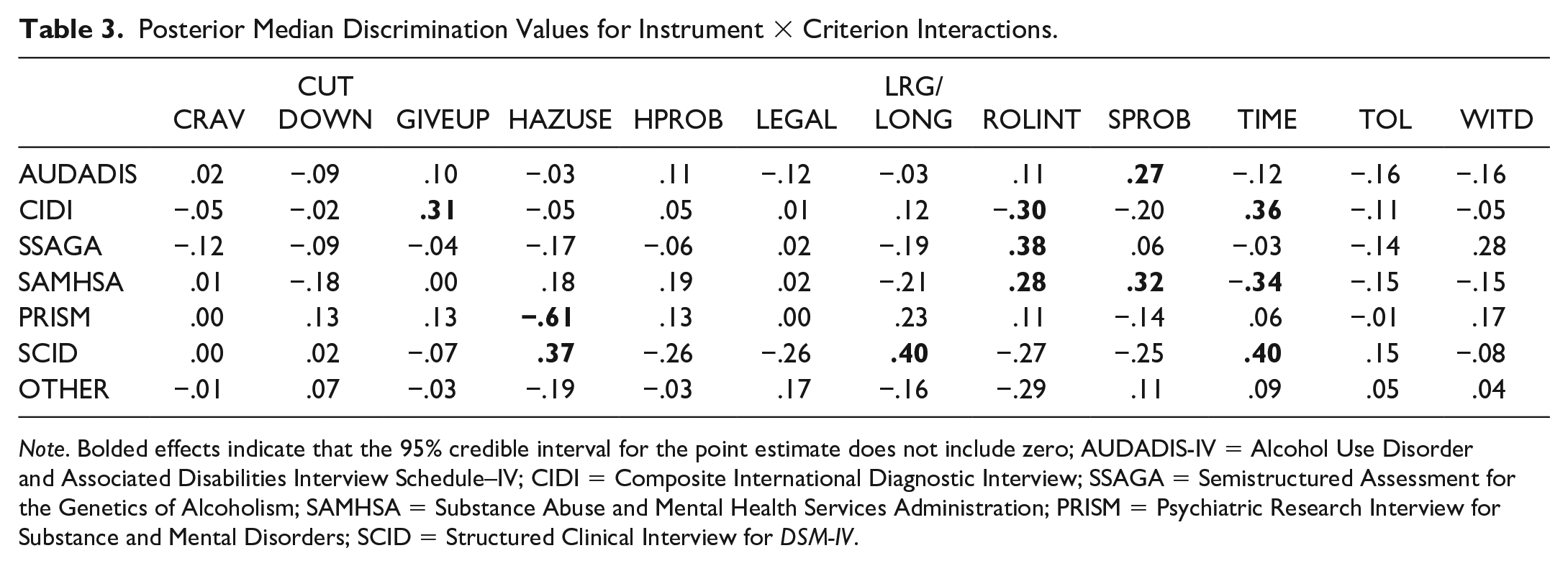
Note. Bolded effects indicate that the 95% credible interval for the point estimate does not include zero; AUDADIS-IV = Alcohol Use Disorder and Associated Disabilities Interview Schedule–IV; CIDI = Composite International Diagnostic Interview; SSAGA = Semistructured Assessment for the Genetics of Alcoholism; SAMHSA = Substance Abuse and Mental Health Services Administration; PRISM = Psychiatric Research Interview for Substance and Mental Disorders; SCID = Structured Clinical Interview for DSM-IV.
Despite expanding the number of variance parameters, there remained a main effect due to study-specific effects (σ2 = .217, 95% HDI [0.073, 0.393]), indicating that there was notable within-study variability in discrimination estimates that was not attributable to the criteria or other sources of variability. It should be noted, however, that for some model parameters there was little variability, which limited the opportunity to examine meaningful differences. For example, many of the included samples were made up of equal parts men and women (n = 26; 50%). With regard to age, only six samples (11.54%) were composed of adolescents and only one sample was made up of elderly adults (1.92%; see online supplementary Figure S1).
Influence of σ2CRITERION Prior Distributions
Figure 3 9 shows the prior and posterior distributions for the basic and expanded models that made use of moderately informed priors on the σ2criterion parameter. In both models, the estimate of .60 for the σ2criterion parameter is less likely after the data are observed. In the basic model, the ratio of densities suggests strong evidence that a value of .60 is unlikely given the data (BF10 ≈ .09). Specifically, a value of .60 is about 11 times less likely after having seen the data (i.e., 1/.09 = 11.11). Similar results were observed for the expanded model. In the expanded model, the ratio of densities also suggests strong evidence that a value of .60 is unlikely given the data (BF10 ≈ .10). Unsurprisingly, the basic and expanded models with moderately informed priors produced higher estimates for both the σ2criterion and ICC median estimates due to the influence of the priors on the σ2criterion parameter (Unstandardized Basic Model: σ2criterion = .15; ICC = .43; Unstandardized Expanded Model: σ2criterion = .14; ICC = .34).
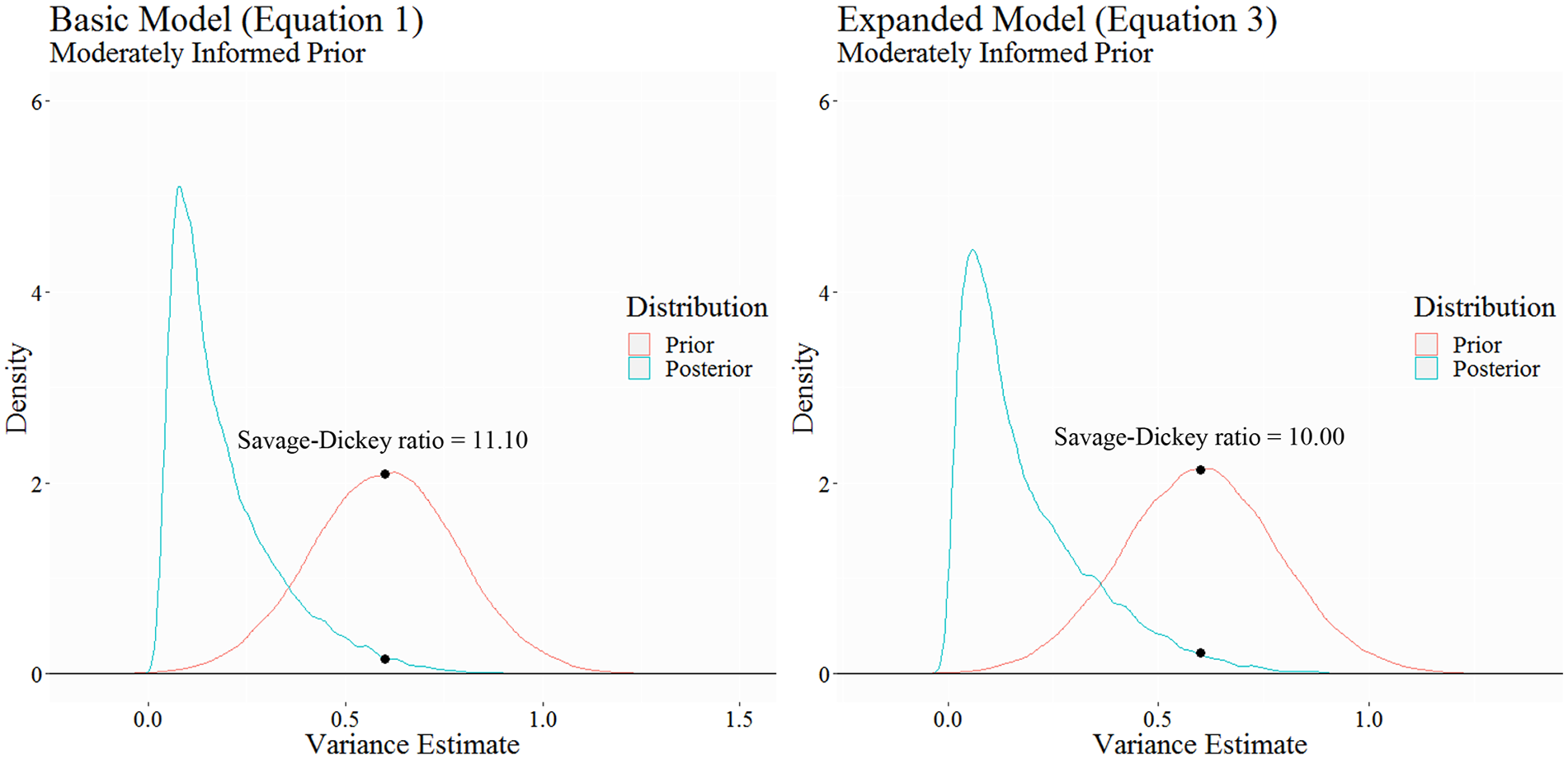
Effects of
The results for the strongly informed priors for the basic and expanded models yielded much different results. The BFs for the basic and expanded models were BF10 ≈ .97 and BF10 ≈ .90, respectively. Both BFs which indicate that a hypothesis of σ2criterion = .60 is just as likely after having seen the data as it was before having seen the data. 10 Thus, the posterior distributions for both models were effectively uninfluenced by any observed data and instead determined almost entirely by the strong priors on σ2criterion.
Discussion
The present results show that for any randomly selected study, the reliability of AUD criteria discrimination estimates is low, though not trivial, ranging from .11 to .43 depending on the model and scaling. The results also show that diagnostic instrument was the largest source of systematic unreliability in the average discrimination estimates. Other, more commonly investigated factors, such as gender, age, diagnostic status, and diagnostic timeframe were estimated to contribute to some degree to DIF across criteria discriminations, but these effects were less than 10% to 25% the magnitude of the instrument effect.
The lack of consistency in discrimination estimates is not inherently problematic in cases where all criteria discriminations are high, which was the case in general (see Figure 2a). Yet, there remained significant variability in discrimination estimates across criteria that was attributable to study-specific effects in the expanded model, indicating that criteria, and consequently diagnostic, precision can still be improved. If such factors are acknowledged in advance then they could reasonably be argued as true signal to be counted toward reliability (Lane et al., 2016); in which the reported estimates could be altered for the expanded models and the corresponding range indicating fair consistency (ICC range = .578-.603). In addition, if we consider the entirety of the AUD IRT literature as a whole, averaging across them (k = 52) as in the classic ICC(3, k) case (Shrout & Fleiss, 1979), we estimate a range of .865 to .941, indicating substantial reliability. These are hypothetical estimates that indicate stability in the AUD criteria on average; but caution should be taken before interpreting them too optimistically, as most researchers can only conduct a single study at a time and do not have the luxury of pooling results across 52 samples. Indeed, the BFs derived from comparing the likelihood of specific point estimates of σ2criterion showed that the present data are inconsistent with a belief that the AUD criteria would be a reliable source of discrimination variability for any given study. When contrasting the results of the moderately informed priors with the strongly informed priors, one can see just how strongly one must believe in AUD criteria reliability to maintain that belief. Specifically, the belief must be strong enough so as to ignore all the present data. Though the results from the basic and expanded models with strong priors are not incorrect per se, the models necessitate a position that appears untenable—one must ignore the data made available in the present study.
Practically speaking, the present findings for discrimination estimates suggest that which AUD criteria are better or worse at differentiating between individuals given their standing on the latent AUD spectrum are unlikely to be consistent from study to study. When considering the generally low reliability of discrimination estimates alongside the similarly low reliability observed for threshold estimates (Lane et al., 2016), the current results underscore the fact that discrimination/threshold estimates based on AUD criteria from a given study are unlikely to generalize to a separate IRT study of AUD criteria. These results have important implications for conceptualizations of AUD as a clinical construct. They also likely extend to other latent variable models of psychopathology to the extent to which consistency of factor structure is overlooked and otherwise judged by factor numeracy and/or item/factor specificity (Watts et al., 2020).
Implications for Clinical Assessment of AUD
One of the more important implications of the present study is that the choice of AUD assessment instrument may lead to substantively different conclusions regarding AUD diagnoses. For example, the SAMSHA and SSAGA instruments produced higher discrimination estimates for the role interference criterion compared with other measures. In turn, these measures assign greater weight to role interference as an indicator of the underlying AUD spectrum than do other measures. On the other hand, the CIDI produced a lower discrimination estimate for the role interference criterion. Ultimately, the results suggest that what may seem like an inconsequential decision (i.e., which assessment to choose for AUD) can result in important consequences for any given study’s understanding of the underlying disorder. The results displayed in Table 3 also offer information to clinicians and researchers about the strengths and/or limitations of particular AUD instruments in relation to their abilities to discriminate between individuals at various levels of the AUD latent spectrum. The data do not indicate that one particular measure is particularly better or worse than other measures. Instead, the results show that depending on what researchers or clinicians may be most interested in, some measures may be better suited for their interests compared with others.
For example, if a researcher is interested in ensuring that the criteria of tolerance and withdrawal reliably discriminate between individuals at differing levels of the AUD spectrum, the present results show that there are no meaningful differences across measures in assessing the discriminatory ability of tolerance and withdrawal criteria. Thus, the researcher can be relatively confident that the assessment instrument they choose will not result in systemic bias with regard to those particular criteria. However, in cases where a researcher is interested in reliably assessing role interference as a means to discriminate between individuals, the data have clear suggestions. The SSAGA and SAMSHA both provide relatively higher discrimination estimates for the role interference criterion, while the CIDI provides relatively lower estimates.
Last, the present results provide important information that can inform both past and future IRT studies on AUD, as well as other disorders. As previously noted, there have been inconsistent findings regarding which AUD criteria have displayed DIF when examining discrimination estimates (e.g., Saha et al., 2006; Harford et al., 2009). Our results suggest that systematic sources of variability (e.g., measurement) may help explain why discrimination values from a given study do not generalize to another study. This point is particularly important given the influence IRT studies have had on refining the conceptualization and diagnosis of AUD. For example, IRT studies provided strong evidence that the AUD criteria assessed a single latent continuum, leading to the distinction between abuse and dependence criteria being eliminated in the DSM-5 (Hasin et al., 2013). Furthermore, IRT studies are frequently cited as reasons for eliminating the “legal trouble” criterion from the AUD criteria set, after such studies showed that the “legal trouble” criterion showed to be uninformative regarding an individual’s standing on the latent AUD spectrum relative to the other AUD criteria (Saha et al., 2006). Thus, though the utility of IRT analyses is clear, our results highlight that more work can be done to more broadly examine the generalizability of IRT findings from a given study. One important step to take would be to directly model the factors that may influence estimation variability to potentially increase knowledge about the generalizability of the findings.
Implications for Clinical Assessment More Broadly
Though we have focused on AUD criteria in the present article, we believe that the analytical framework we utilized can also be extended to other clinical constructs to examine important clinical assessment questions. For example, researchers have argued that emotion dysregulation ought to be considered the core feature of borderline personality disorder (BPD; Glenn & Klonsky, 2009). As such, clinicians and researchers are likely to want to ensure that BPD assessment instruments contain emotion dysregulation items/criteria that reliably distinguish between individuals at varying levels of the BPD spectrum. Leveraging the current methods to explore these empirical questions may provide important information for clinicians and researchers seeking to use instruments that reliably assess core features of various disorders. Furthermore, the current methods may be useful to future IRT work on diagnostic criteria given that interest in replicability issues within clinical psychology research continues to grow (Tackett et al., 2017; Tackett et al., 2019).
It is also worthwhile to contrast the present results with previous analyses examining AUD criteria threshold estimates (Lane et al., 2016). Though both the discrimination and threshold analyses found 12 and 13 random effects, respectively, (out of 84; 12 criteria × 7 instruments) that were noteworthy when examining the criteria × instrument interaction, there was only one overlapping effect. For example, in the original meta-analysis of threshold estimates, 5 of the 13 significant effects were found for the AUDADIS while only one was found for the AUDADIS with regard to discrimination estimates, and for a separate criterion. The only overlap observed was for the SAMHSA and the time spent criterion—both threshold and discrimination estimates were lower than in the average study. Taken together, the combined meta-analytic results suggest that both threshold and discrimination estimates are in part a function of the AUD diagnostic instrument used, and the effects of diagnostic instruments span a diverse range of AUD criteria.
Limitations
There are some important limitations in the present study. First, there are other potential sources of variability in discrimination estimates that were not explored. For example, ethnicity has been examined as a source of DIF, with previous work finding evidence of DIF across different ethnic groups (e.g., Saha et al., 2006). However, there was little variability in ethnic makeup in the included samples and other options (e.g., a dichotomous comparison of White vs. non-White samples) would likely mask important differences across ethnic groups (Sue, 2001). An additional source of variability not explicitly accounted for is study quality. Our analyses included individual study sample as a random factor, which spans large-scale epidemiological studies through more idiosyncratic investigations of smaller clinical groups. The analyses also included research group as a random factor, which would capture whether some groups may produce higher quality, or “more significant,” results than others, or in higher impact journals. We did not code factors of study quality, and the variables we coded were not meant to be indicators as such. The present results should be considered with these caveats in mind.
Second, of the parameters included in the expanded models, some showed little variability (e.g., gender and age). Thus, despite their inclusion, the estimates for these parameters should be interpreted with caution. Though our results are generally consistent with DIF across gender and age as reported in previous investigations (e.g., larger/longer, withdrawal; see online supplementary Figure S2), as more data become available, it may be possible to more fully and precisely explore the influence of such factors on discrimination estimates.
Conclusion
There is generally low, but nontrivial consistency in AUD criteria discriminations within individual studies. This may underlie why DIF for various factors across individual criteria has been inconsistent. Nevertheless, averaging across all available data, there appears to be consistent structure in the discriminations of the set of AUD criteria. In other words, when one averages across studies, the AUD criteria do produce a consistent structure with respect to the overall variability observed in discrimination estimates, suggesting consistent rank-order stability in discriminations among the criteria. Thus, at the average level, the criteria are consistent in their abilities to differentiate between persons at varying levels along the AUD spectrum. This represents a silver lining in that an identifiable core structure is recoverable; but our primary analyses illustrate that such results cannot be expected in individual studies. It also ignores the considerable heterogeneity that exists in the latent AUD construct (Lane et al., 2016). We still found evidence of DIF as a function of established factors (e.g., age, gender), providing meta-analytic support on average, but the magnitudes were small in comparison with the effect of instrument. Thus, consideration of the assessment instrument, in addition to more common factors, remains a critical open issue regarding the inferred comparability of AUD diagnosis and severity across individuals and contexts.
Supplemental Material
sj-pdf-1-asm-10.1177_1073191120986613 – Supplemental material for Reliability of Differential Item Functioning in Alcohol Use Disorder: Bayesian Meta-Analysis of Criteria Discrimination Estimates
Supplemental material, sj-pdf-1-asm-10.1177_1073191120986613 for Reliability of Differential Item Functioning in Alcohol Use Disorder: Bayesian Meta-Analysis of Criteria Discrimination Estimates by Colin E. Vize and Sean P. Lane in Assessment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received the following financial support for the research, authorship, and/or publication of this article: Sean Lane was supported through funding provided by the National Institues of Health (Grant R01AA027264).
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.