
Abstract
Large language models (LLMs) are increasingly used to support psychological assessment, but standards for evaluating their scoring accuracy remain limited. This article introduces a clear, reproducible validation framework to evaluate LLM-based scoring systems. The framework separates pre-validation steps (e.g., balancing base rates, refining prompts, and comparing models) from a standardized validation phase focused on reliability and validity benchmarks. We demonstrate its application with a case study of Morbid Content (MOR) scoring in the Rorschach task, using a two-agent LLM workflow. In an independent dataset (n = 84; 2,176 responses) with natural MOR base rates, the final LLM coder showed good response level agreement (kappa = .72–.74) and excellent protocol level agreement (ICC = 0.94–0.95) with assessors, near-perfect consistency with itself (ICC = 0.97–0.99), and replicated external validity (r = .59–.71) that matched human coders (r = .54–.65). This article offers a practical guide for evaluating automated coders in psychological testing and discusses practical decisions and ethical considerations.
Keywords
Introduction
Early automated-scoring efforts in psychological assessment were largely purpose-built using machine learning, natural-language processing (NLP), or computer-vision pipelines trained for specific instruments or behaviors. These systems often approached human-range reliability and reproduced expected criterion relations across diverse applications. Examples include open-ended story comprehension in children (Devine et al., 2023), psychotherapy session coding (Ewbank et al., 2021; Tanana et al., 2016), episodic-memory narratives (Shen et al., 2023), and image-based scoring in neuropsychological tests (Park et al., 2023).
Building on this technical foundation, language-based assessment researchers have increasingly leveraged advances in NLP. Whereas classical NLP relied on training models for a specific task, contemporary transformer models use pre-trained systems (Qiu et al., 2020). In particular, large language models (LLMs) can be instructed to perform classification tasks (i.e., using prompts), rather than training a new model from scratch (Brown et al., 2020; Liu et al., 2023). A prompt is a set of instructions, guidelines, decision rules, and illustrative examples that a pre-trained model uses as its primary input to predict the most likely outcome and generate a natural-language response. The LLMs can be operationalized as simply as a chatbot like ChatGPT or Gemini, or as more technical, such as using an Application Programming Interface (API) to access a specific model (e.g., GPT 4.1, GPT 4.1-mini, or Gemini 2.0 Flash).
There are various strategies for creating a prompt, such as providing a few examples of what qualifies or not (zero- or few-shot prompting; Brown et al., 2020) and instructing the model to provide intermediate reasoning before the final judgment (chain-of-thought; Wei et al., 2022). Prompts can be iteratively improved using error analysis, in which developers systematically review disagreements or problematic outputs to identify recurring failures and refine decision rules, exclusions, and examples. For a more thorough reading on prompting methods in NLP, see Liu et al. (2023), and for a shorter review applied to mental health, see Priyadarshana et al. (2024). For the current paper, we use the terminology LLM-based coder (or LLM coder for brevity) to describe a prompt-guided LLM performing a classification task, where developers specify a scoring rubric, decision rules, or examples directly in the prompt.
A growing set of studies demonstrates that LLM coders can function as raters with promising psychometric properties. Examples include ratings with the Social Cognition and Object Relations scales – Global Rating Method (Dauphin & Siefert, 2025), divergent-thinking scoring on the Alternate Uses Task (Organisciak et al., 2023; Saretzki et al., 2025), and “LLM rating scales” applied to therapy transcripts (Eberhardt et al., 2025). Preprints further suggest that LLM coders can reasonably score open-ended Theory-of-Mind responses (Wang et al., 2025) and support risk ratings in social media (Jeon et al., 2024). Overall, the conclusion is that LLMs and prompt engineering unlock new possibilities for language-based assessment.
In this emerging landscape, some argue that LLMs can supplement the field’s dominant reliance on self-report (Brickman et al., 2025), whereas others argue that natural-language assessments could eventually replace self-reports and shift the direction of the field (Kjell et al., 2024). Despite these differences, both viewpoints acknowledge the importance of developing LLM coders and evaluating their psychometric quality.
Developing LLM coders and introducing them as a new procedure in psychological assessment workflows is fundamentally a measurement change. It changes how observations are transformed into variables. Consequently, the existing evidence of validity for a measurement using human coders, which forms the foundation for interpretations (American Educational Research Association [AERA] et al., 2014), may not apply to LLM coders. Guo et al. (2024) reviewed the use of LLM in mental health applications and expressed serious concerns regarding the accuracy and reliability of LLM-generated output, as well as the lack of benchmarked frameworks. As a result, similar to other researchers (e.g., Kjell et al., 2024), we argue that LLM coders must be evaluated with the same rigor as any scoring algorithm or rater system, with a focus on reliability and validity.
From a psychometric perspective, supplementing human coders with LLM coders shifts the measurement process. This shift raises at least three questions. First, consistency in the LLM coders: Do independent sessions of the same LLM coder agree with each other as much as independent human raters? Second, LLM-human agreement: To what extent do LLM coders agree with independent human coders? Third, validity of LLM scores: Do the LLM-generated scores relate to external variables in the same direction and magnitude as human-coded scores? The first question targets the reliability of the LLM coder, and the last two address validity issues, with the third being an extension of the second. We address these questions by proposing a practical validation framework for LLM-based coders in psychological assessment. We view an LLM coder as a rating system whose evidence must be compared to the existing gold standard (most often, human coders). We separate our framework into two stages: (a) a pre-validation stage for project- and data-dependent tasks such as prompt design, dataset organization, and model selection, and (b) a validation stage, which would encompass real-world datasets, performance metrics, agreement indices benchmarked to human reliability, consistency checks across replications, and construct-relevant external relations.
We illustrate this framework with a case study using Morbid Content (MOR) coding in the Rorschach task, a thematic code with a long-standing empirical literature (Mihura et al., 2013) and clear coding rules (Meyer et al., 2011). MOR is coded when a Rorschach response contains some damage (e.g., “a butterfly with a broken wing”) or dysphoria (e.g., “a sad dog”). MOR has a relatively low base rate (about 5% of responses) and clinical interpretive value (good meta-analytic support, Mihura et al., 2013), making it a useful case to create and test an LLM coder.
For the case study, we developed a workflow with two different LLM-based coders that operate in series (one after the other), each of them responsible for a different part of the Rorschach coding: (a) clean and prepare the data, and (b) classify MOR subcomponents. We named the LLM-based MOR Coder, or LLM Coder for brevity, as we only use one code.
We do not advocate for a single “best” model or prompt, nor claim that LLM coders should replace trained assessors. Rather, our goals are to: (a) present clear and reproducible steps for evaluating LLM coders for psychological tests that any team can implement, (b) provide a guide for researchers and clinicians working with LLMs in psychological testing, and (c) demonstrate the framework through a case study. In the long run, such standards will facilitate cumulative science by making results comparable across settings and enabling better collaboration among assessment, AI, and LLM researchers.
Method for the Case Study
Datasets
We used two separate datasets. The first one was used to develop and refine the prompts with error analysis and to evaluate the performance of various models under the same constraints. The second dataset was used to assess reliability and validity.
Norms Dataset: Used for the Pre-Validation Stage
This dataset comprises a subset of protocols from the current Rorschach Performance Assessment System (R-PAS; Meyer et al., 2011) norms. We selected only cases with complete English transcripts for both the response and clarification phases, N = 145 protocols. Those cases are used for protocols that were administered following Comprehensive System (CS) procedures (Exner, 2003). Protocols contained on average 23.31 responses (SD = 7.94, range = 14–53). Together, these protocols had 3380 responses. From these, we semi-randomly 1 selected 30 positive and 30 negative classifications of the targeted Rorschach code (i.e., MOR). Because these data contribute to the current R-PAS norms, their existing codes, assigned and reviewed by trained assessors through standard R-PAS procedures, were treated as the gold standard (criterion). We used this subset of 60 responses to evaluate the LLM coder against the assessor’s coding to improve prompts through error analysis, with the expectation that the LLM coder would agree as much as possible with the assessor’s decision.
Chicago Dataset: Used for the Validation Stage
This is an archival dataset previously reported by Meyer (1997, 1999) and colleagues (Meyer et al., 2000), which originates from a University of Chicago hospital-based psychological assessment service. This broader archive includes 661 clinical protocols. Of these, 443 completed the Rorschach, and 362 completed both the Rorschach and the MMPI-2. Cross-method correlations between Rorschach variables and self-reports are typically low (r ~.08; Mihura et al., 2013) when response style is not considered. However, Meyer (1997) showed that when response styles are similar across these tests and reflect spontaneous engagement with the task, correlations increase, such that the Rorschach Depression Index (DEPI) correlates strongly with MMPI-2 affect-distress scales (r range: .42–.66). Although the original articles (Meyer, 1997, 1999) did not examine the correlations of MOR with the MMPI-2, MOR is a component of DEPI and has shown stronger validity with external criteria than the DEPI overall (MOR r = .29 vs. DEPI r = .19; Mihura et al., 2013). Also, in a more recent re-analysis of these data, MOR demonstrated stronger correlations with the relevant MMPI-2 scales (Pimentel & Meyer, 2025).
From the complete dataset, Meyer (1997) identified 87 patients who exhibited a similar engagement style on both the Rorschach and MMPI-2. We obtained access to the complete responses for 84 of them, totaling 2,176 responses. In this style-matched subsample, we know in advance (Pimentel & Meyer, 2025) that assessor-assigned MOR 2 codes correlate strongly with five MMPI-2 scales: Scale 2 (r = .54), Scale 7 (r = .65), Depression Content Scale (DEP; r = .63), Anxiety Content Scale (ANX; r = .59), and Personality Psychopathology Five Negative Emotionality/Neuroticism (PSY-5-Neg; r = .62). Hence, we used these MMPI-2 scales as external validity criteria for our applied (“real-world”) analyses to demonstrate that when LLM-generated MOR scores have good agreement with assessor-coded MOR scores, the LLM coded scores show comparable associations with external criteria.
Note that we used this dataset because it provides a response-style-matched subgroup in which MOR has already shown meaningful relations with selected MMPI-2 scales. We do not intend to treat self-report as a general validator of the Rorschach or to argue that LLM coding should strengthen Rorschach-MMPI correspondence. Rather, given strong LLM-human agreement, we asked whether LLM-generated MOR scores reproduced the same established pattern of criterion relations observed with human-coded MOR in this dataset.
The Rorschach Task
The Rorschach task consists of presenting the respondent with 10 semi-ambiguous inkblots, one at a time, and asking, “What might this be?” Given that the instructions to the task do not specify what an ideal response would look like, the respondent is left to behave according to their preferences, coming up with their own solution. Later, the assessor applies many codes to classify the respondent’s behavior, language, and imagery. Respondents provide a few responses per card, and when summing across cards, they average about 24 responses per protocol (Meyer et al., 2011). Codes are assigned at the response level and then summed at the protocol level. Thus, the task offers two levels of data: (a) response level, which indicates whether a specific code applies to a particular response, and (b) protocol level, which includes the totals (and composites) calculated across all responses within a protocol.
Morbid Content (MOR)
We chose to use MOR as our case study variable, a thematic code with relatively straightforward decision rules. This code is applied in two circumstances: (a) damaged objects, e.g., “spoiled lettuce,” “a bug smashed on a windshield;” or (b) perceptions or attributions of distress, dysphoria, or depression given to response objects, e.g., “a very sad face,” “red eyes, he’s crying” (Meyer et al., 2011, pp. 140–141).
LLM Coder Workflow
We developed this workflow as part of a broader project to build multiple LLM coders. The development followed an iterative, trial-and-error process grounded in the R-PAS manual guidelines, extra guidelines for the second edition of R-PAS, and discussion among expert coders. For design, we used a few-shot prompt (Brown et al., 2020) where, besides instructions on how to classify a response, we also included a few positive and negative examples of expected input and what the output should look like. In addition, we implemented a chain-of-thought design (Wei et al., 2022), adding instructions to provide a rationale before making a final classification decision. Our prompt specifies the agent’s name, goal, expected inputs and outputs, and a step-by-step decision process. For guidance on creating prompts, see Demszky et al. (2023). Our workflow uses two independent LLM agents that process the input in sequence. Below is an explanation of each. All agents had the temperature 3 set to the lowest option:
Data Preparation and API Processing
We organized responses in a long format with columns for card number, response number, Response Phase, and Clarification Phase. Each response (i.e., row) was turned into a JSON object and sent sequentially to the LLM coder workflow: (a) standardization and (b) MOR classification. We deployed all APIs using Copilot Builder (https://copilotbuilder.ai/).
Each response submission to the API starts a new session, so the LLM coder has no memory of previous responses. Given that sessions are independent, potential errors in the rationale or LLM hallucinations 4 in one response do not impact decisions made in other sessions. Essentially, each session works like a Rorschach expert who processes one response, then passes it to another equally trained expert for the next.
Output Consolidation and Analysis Dataset
All API calls and data processing were done using R 5 (R Core Team, 2025). We received the final output in JSON, then we converted it to tabular data, separating LLM-generated MOR decisions from the LLM coder’s rationale. The final file includes card number, response number, Response and Clarification Phase, JSON input and output, and the LLM-generated MOR code for each response. We then added the original assessor-assigned MOR code, organizing two data files for analysis: one at the response level and the other at the protocol level.
Metrics
We treated the assessor’s coding as the gold standard (i.e., “true” cases) and considered the LLM-generated outputs as the predicted cases. We compared them with confusion matrices in which columns are the true classes and rows are the LLM coder’s predictions by calculating True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). From this matrix, we computed: (a) Accuracy: Proportion correct across all cases (N), (TP+TN)/N, answers the question “How often is the LLM coder correct overall?”; (b) Cohen’s kappa: Agreement between LLM coder and assessor beyond chance that answers the question “How much do they agree once chance agreement is removed?”; (c) Positive Predictive Value (PPV): TP/(TP+FP), that answers the question “When the LLM coder says ‘positive,’ how often is it truly positive?”; (d) Negative Predictive Value (NPV): TN/(TN+FN) that answers the question “When the LLM coder says ‘negative,’ how often is it truly negative?”; (e) Sensitivity (Recall or True Positive Rate): TP/(TP+FN) that answers the question “Of all actual positives, how many did the LLM coder find?”; (f) Specificity (True Negative Rate): TN/(TN+FP) that answers “Of all actual negatives, how many did the LLM coder correctly reject?”
Two-Stage Evaluation
Stage 1: Pre-Validation Screening and Prompt Development (Balanced Samples)
To test the performance of models and refine prompts based on error analysis, we artificially balanced the data to approximate a 50/50 split between present and absent codes. Then, we compared across different LLMs and prompts. This artificial balance might not be necessary if researchers are using data that are common occurrences. It is helpful, however, for low or high base rates. This stage is flexible and varies depending on the specific project. It can take many forms depending on the test and variable and may include iterative prompt engineering, rule refinement, or model comparisons. Its purpose is to prepare the final prompt for formal evaluation by stabilizing its performance and selecting the most suitable model. 6
Error Analysis
To refine the prompt, we used the Norms dataset and interactively updated the prompts by conducting error analysis, a structured review of cases in which an LLM output diverges from a reference standard to identify systematic failure and guide revisions. These revisions involved clarifying decision rules, adding counterexamples, strengthening exclusions, and adjusting the standardization of inputs and outputs.
Stage 2: Validation on Natural Data (Low Base Rate)
The validation phase is where we apply our proposed framework. We encourage both psychological test developers and automated-scoring developers to treat this stage as a standard for demonstrating that an automated system works reliably and preserves validity.
For our case study (MOR), we emphasize kappa (chance-corrected agreement), PPV (credibility of positive calls), and Sensitivity (ability to detect positives). These metrics remain most informative when positives are rare. Given the relatively low base rate of MOR, we prioritize not missing positives (i.e., adequate Sensitivity) while ensuring that predicted positives are trustworthy (i.e., adequate PPV), accepting that this balance may allow some FP. For protocol level reliability, we used the Intraclass Coefficient Class (ICC) and followed Cicchetti’s (1994) general interpretation: <.40 poor, .40–.59 fair, .60–.74 good, and ≥.75 excellent.
Framework – Pre-Validation
In the next section, we outline each pre-validation step with (a) the rationale, (b) how to implement it, and (c) an illustration using the MOR variable.
Step A (Pre-Validation): Building the Dataset
Rationale
Many variables in psychological tests occur infrequently, leading researchers to often deal with imbalanced datasets in which target behaviors and traits have low frequency. When evaluating an automated system on a dataset that mirrors a natural imbalance, the system can appear accurate simply by predicting the most common outcome (e.g., “absent”). For instance, with a 5% positive base rate, a trivial LLM coder that always outputs “negative” achieves 95% accuracy but misses all positive cases. NPV and Specificity can also seem inflated at low base rates because most cases are negative. Hence, one problem with imbalanced data is that several performance metrics become useless (He & Garcia, 2009). This leads to inflated accuracy scores that hide weaknesses in detecting the less frequent, yet often clinically significant, cases. A way to overcome this problem and provide informative development data is to use Random Oversampling and Undersampling (He & Garcia, 2009). In practice, this is done by selecting a similar number of cases from each class, in our case, positive and negative. A dataset with roughly equal positive and negative cases allows us to detect weaknesses and make fair comparisons across models, and ensure that metrics like Overall Accuracy and Sensitivity are meaningful.
How to Do It
Identify the variable to be evaluated (e.g., a scoring code or classification category).
From the gold-standard dataset (human-coded), select a fixed number of positive cases.
Randomly select an equal number of negative cases.
Use this balanced dataset only for early-stage development and model selection. It does not replace testing with real base rates.
Example With MOR
We processed 60 responses (30 positive and 30 negative) across nine LLMs. During this pre-validation pass, three models did not meet our prompt, formatting, or reliability requirements and were excluded from further testing: (a) Meta-Llama-3.1-8B: Produced inadequate and underspecified outputs; prompts required substantially more constraints and detail to approach the requested format; (b) Phi-4: Returned outputs inconsistent with the prompt specification (e.g., generated free text instead of JSON-only); (c) DeepSeek-R1: Markedly slower runtime and verbose outputs that did not follow the JSON-only requirement. It generated many more null results (rather than clear true and false decisions).
These issues reflected our specific settings and prompts. These models may behave differently with alternative setups and prompts. For this project, they were not reliable enough to advance. Other models, multiple versions of OpenAI GPTs, and Google Gemini, returned outputs close to the requested specification and were retained for the next step.
Step B (Pre-Validation) – Comparing Multiple LLMs and Prompt Development
Rationale
Given that OpenAI’s and Google’s models are built using different data, different numbers of parameters, and different architectural designs, they differ in how they follow instructions, handle ambiguous cases, or maintain output consistency. Hence, an early comparison across multiple candidate models ensures that a researcher can focus their refinement efforts on a model that is already well-suited to the task and the type of prompt they are working on, rather than trying to compensate for poor baseline performance later.
How to Do It
Choose several candidate models that could be used for the target LLM coder.
Send the responses separately to each model, with the same prompt and temperature.
Compare the LLM-generated outputs to the human-coded gold standard using agreement metrics such as Accuracy, Kappa, Sensitivity, Specificity, PPV, and NPV.
Decide which model to retain for further development and testing.
Conduct error analysis to refine the final prompt.
Example With MOR
After excluding three models during pre-validation, we compared six remaining models on the balanced set (see Table 1 and Figure 1). Each version of the LLM coder used a different model (but the same prompt) and was evaluated against the assessor’s coding. Among the tested models, GPT-4.1 achieved the highest chance-corrected agreement (kappa = .72), and its PPV = 0.92 and Specificity = 0.93 were also among the highest, so positive MOR calls closely matched assessor decisions and non-MOR responses were rarely misclassified as MOR. Gemini 2.0 Flash and GPT-4.1 Mini followed with similar performance across metrics, and GPT-4o showed a solid balance between Sensitivity and Specificity. By contrast, GPT-4.1 Nano showed the weakest overall performance (kappa = .42), driven primarily by lower Sensitivity = 0.50, meaning it missed more MOR-positive cases than other models.
Pre-Validation Performance Metrics for Each LLM Version.
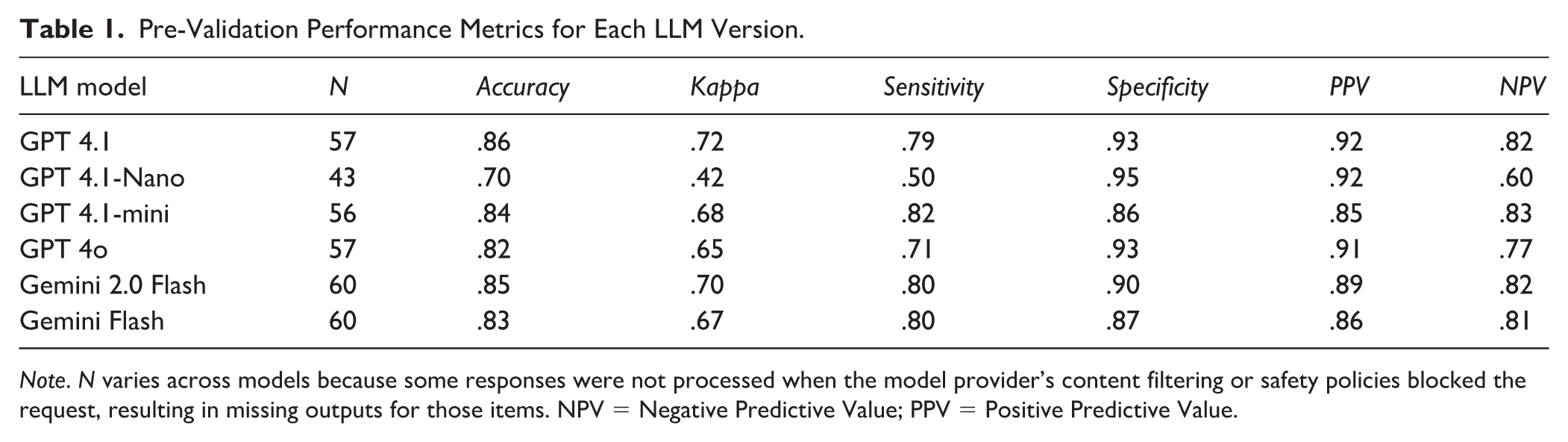
Note. N varies across models because some responses were not processed when the model provider’s content filtering or safety policies blocked the request, resulting in missing outputs for those items. NPV = Negative Predictive Value; PPV = Positive Predictive Value.
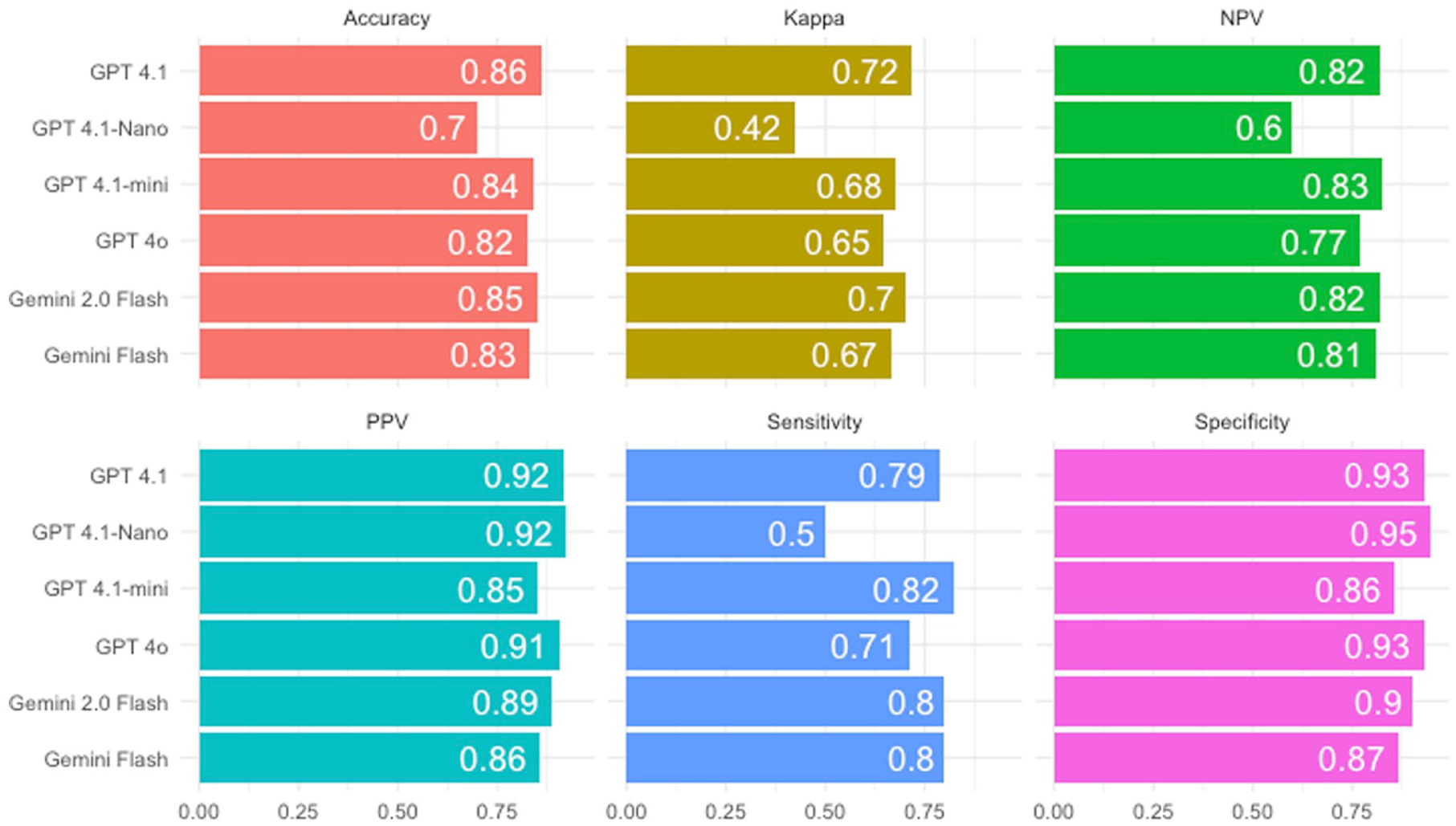
Performance metrics by LLM for morbid contents.
Although GPT-4.1 was optimal, we prioritized performance and scalability for other Rorschach codes we are working on. Considering the relative price, with 4.1 Mini being 80% cheaper than 4.1, and practical performance across tasks, we selected GPT-4.1 Mini for the next stage. It delivered acceptable, stable results with our current prompt while offering a more favorable cost-performance profile for use with other coding agents under development.
Error Analysis and Prompt Refinement
We manually inspected disagreements between GPT-4.1 Mini and the assessors’ scores across several runs to identify recurring errors and revise instructions. Revisions focused on (a) clarifying definitional boundaries, (b) adding targeted inclusion and exclusion rules for recurrent edge cases, and (c) creating a standard output for atypical inputs. For example, early iterations over-classified MOR for fire or explosions alone, even when no object was described as damaged. The prompt was revised to require an explicitly damaged or destroyed object when “fire,” “explosion,” or similar content is mentioned. Additional refinements included: clarifying that intact skeletal percepts are not coded as Damaged Objects unless the percept indicates remains or damage; expanding examples for under-identified morbid representations (e.g., tombstones, cemeteries, plague masks) while adding negative thresholds for superficially related but non-morbid items (e.g., COVID-19 masks); constraining blood to cases implying injury (rather than the word “blood” alone); and distinguishing affect attributed to the object from the respondent’s reaction.
We also enforced the output structure with no follow-up questions and include a fallback template when essential inputs are empty. Finally, because the examples were sometimes applied too literally, we reframed them as illustrative examples rather than exhaustive lists and created a “minimum information needed” for each subcategory. This development continued until remaining discrepancies primarily involved ambiguous or threshold cases where reasonable human disagreement was expected (all FP and FN were reviewed by both authors). The final prompt was then frozen and evaluated in the next stage in an independent Chicago dataset.
Framework – Validation Process
After data preparation and model selection, researchers will formally evaluate the psychometric performance of the LLM coder. The goal is to test whether the LLM coder is reliable, both (a) stable across repeated runs (intrarater reliability) and (b) consistent with human coding (interrater reliability) and valid, meaning its scores relate to external criteria in theoretically coherent ways.
Agreement between the LLM coder and assessors can be interpreted in two ways: (a) as interrater reliability, because both coders apply the same scoring rules to the same responses, or (b) as criterion-related validity, because the LLM score is compared with a reference standard (Grove et al., 1981). In this framework, we emphasize the former because human codes are not error-free, so the assessor’s code is an imperfect gold standard, although aggregated reference scoring can reduce idiosyncratic error (McGraw & Wong, 1996; Shrout & Fleiss, 1979). Conceptually, LLM-assessor agreement indicates whether the LLM can reproduce human scoring, whereas validity against independent external criteria tests whether LLM-generated scores preserve the expected relations between the construct and external measures. If the LLM-assessor agreement produced identical scores, then validity analyses using external criteria would yield the same results for both coders. In this case, the validity evidence concerns the score and the construct it represents, rather than differences between coders. This also means that, under the same conditions, the LLM score could be a substitute for a human score.
Step 1: Intrarater and Interrater Reliability
Rationale
Reliability testing addresses a fundamental psychometric question: “If two raters score the same material, do they agree?” For LLM coders, this first means verifying that they are consistent across different sessions. Then, checking whether the LLM-generated scores align with those of trained assessors, both for individual responses and for aggregated protocol scores. Without sufficient reliability, specifically across sessions, validity is compromised because the coding process is unstable (Furr, 2022; Schmidt & Hunter, 2015).
Cohen’s kappa and ICC are typical metrics used when assessing reliability in performance-based tests such as the Rorschach task (McGrath et al., 2005; Meyer et al., 2011). Kappa values, although standardized, vary in magnitude depending on the base rates (Grove et al., 1981). Less frequent codes, by definition, have fewer positive cases, so the same amount of random error has a larger impact on reliability estimates than it would for more frequent codes (Viglione et al., 2012). When looking at dimensional variables, in the case of Rorschach protocol level information, Viglione and Meyer (2008) explain that ICC is preferable, while kappa would be recommended for nominal or categorical variables, as we see in the response level data.
Benchmarks and Thresholds
Although we can simply calculate kappa and ICCs and report the typical interpretation levels, we can go one step further by contextualizing the results and benchmarking them. The challenge is creating such benchmarks as they depend “on the availability of keystone datasets and requires a consensus on how to define and operationalize psychological constructs” (Demszky et al., 2023, p. 698). Until such field-wide resources and consensus emerge, we recommend pragmatic human-centered benchmarks. For example, for reliability, the LLM-LLM agreement would need to meet or exceed the assessor-assessor agreement for the same metric and level. Also, to keep validity at the same human coding level, we would like to see LLM-assessor agreement comparable to assessor-assessor agreement. On the contrary, if reliability is low, we would need to assess validity and require the LLM’s coder-criterion effect sizes to match or approximate the human-criterion effect sizes reported under comparable conditions. Because benchmarks are often construct- and dataset-specific, we illustrate how to select and interpret pragmatic reliability benchmarks in the MOR example, rather than treating any single numeric threshold as universally applicable.
How to Do It
Response level reliability: Compare the LLM-based coding to a gold-standard code (i.e., human coding) on each individual observation (e.g., test item, behavioral response).
Protocol level reliability: Aggregate scores to the protocol or person level. Aggregation can reduce the impact of isolated disagreements and test whether the LLM coders reproduce similar interpretation scores. Because interpretations are made at this level, protocol-level reliability is ultimately the most consequential. Enhancing response level reliability typically boosts overall protocol level agreement (Meyer et al., 2002).
For both response level and protocol level reliability, obtain human–human agreement for the same variable, either from the same dataset, from comparable datasets, or a meta-analytic summary to benchmark reliability against typical human performance.
Metrics to use:
a. For response level data: Because each response is a dichotomous decision, it could be treated as nominal or categorical data, and kappa would be used to evaluate reliability. Also consider transforming multilevel codes into separate prompts, each coding an independent level as a dichotomy. For less frequent variables, especially rare ones (<5%), any disagreement has a greater impact. Although we suggest evaluating all metrics, focus on kappa, PPV, and Sensitivity.
b. For protocol level data: Here we are dealing with the sum of positive cases of a score; now the scores could vary from 0 to as many responses as are in a protocol (e.g., 0–24). Data are now dimensional; hence, ICC would be more appropriate for assessing agreement on continuous scores. Use an absolute-agreement form, a two-way random effects model for a single measure (McGraw & Wong, 1996).
Example with MOR
Response Level
The LLM coder was evaluated against assessor coding using the Chicago dataset with natural base rates for MOR. This step assessed both agreement and the LLM coder’s ability to identify MOR cases in realistic conditions correctly. We ran all responses (N = 2,176) three times (T1, T2, and T3) in independent sessions to assess the consistency of the model responses. After turning off an initial provider-side moderation issue (which had blocked several dozen responses as inappropriate content), only a handful remained unprocessed. In two runs, five responses were not returned (analyzable N = 2,171; 0.23% missing). In the third run, four were not returned (analyzable N = 2,172; 0.18% missing) because the model correctly processed one previously rejected “abstract” response as a real response. Of the items never processed, three contained extreme content (sexuality, harassment, prejudice, or violence) or were interpreted as having some personally identifying information that continued to trigger provider content filtering. 7 The remaining item was correctly not considered a response by the LLM. In this instance, the response was “Colors” with a clarification that simply mentioned several colors, which is not a genuine response, even though the original assessor coded it. To avoid post hoc bias, we did not edit the dataset or the prompt to process the non-coded responses (i.e., we did not conduct error analysis on this dataset). We treat these as genuine LLM-assessor disagreements and retain these responses as missing on the LLM side.
Table 2 summarizes the response level results. Across runs (i.e., T1, T2, and T3), performance of the agent relative to the assessor was virtually identical: kappa = .72–.74 (good chance-corrected agreement), Sensitivity = .79–.81, PPV = .69–.73, Specificity = .96–.97, NPV = ~.98, and Accuracy = ~.95. In practical terms, the agent detected roughly 80% of assessor-identified MOR responses (Sensitivity), and 70% of its positive calls matched assessor codes (PPV). High Specificity and NPV indicate few FP and more reliable negatives. Accuracy remained around 0.95 across runs, but should be interpreted with caution given the low base rate. The near-identical metrics across T1–T3 also support the LLM coder consistency under the same prompt and model settings. For illustration, Figure 2 presents the confusion matrices for T1–T3. Consistent with the metrics, the agent was highly effective at identifying non-MOR responses (high Specificity and NPV) and performed well at detecting MOR, with some FP.
Performance Metrics for the AI-Based Agent for Coding MOR Across Responses (N = 2,176).

Note. NPV = Negative Predictive Value; PPV = Positive Predictive Value. T1–T3 = LLM coder Time 1–3.
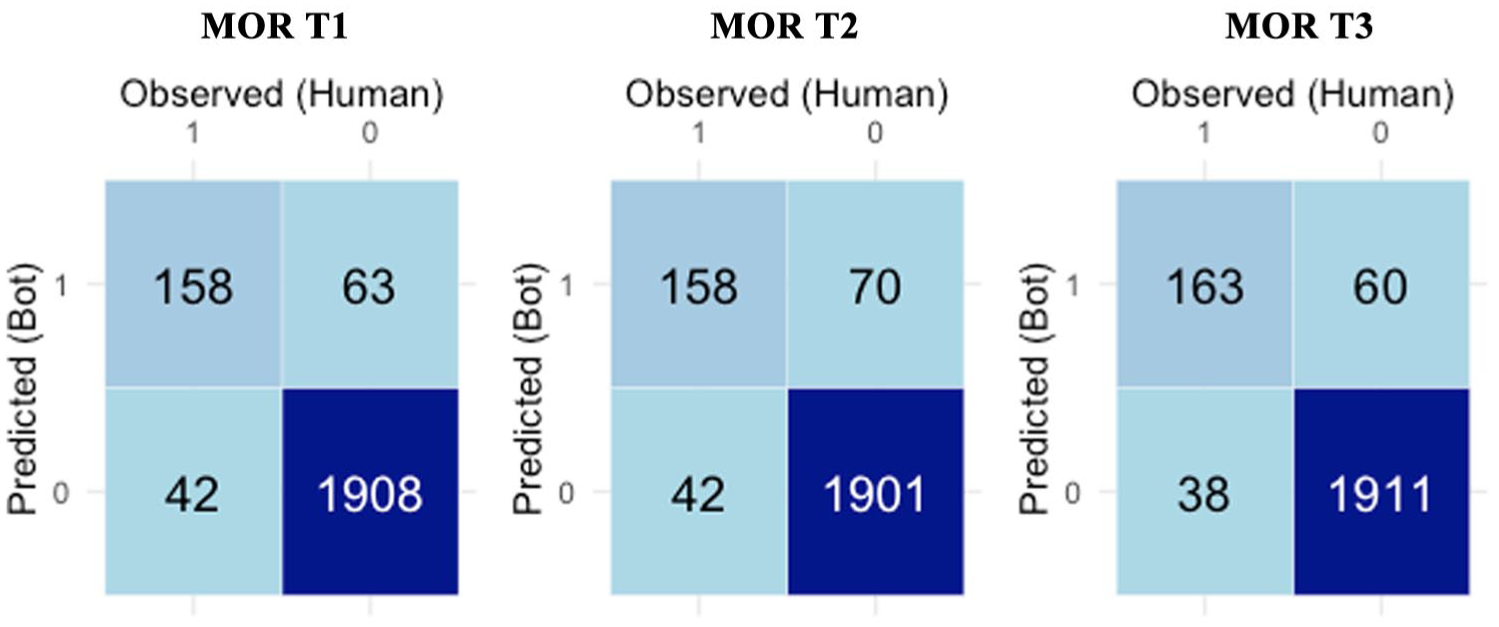
Confusion matrix for morbid content between agent (rows) and human codes (columns) across time 1 (T1), time 2 (T2), and time 3 (T3).
Overall, these findings highlight a good to excellent agreement with human coding, particularly in detecting TN and minimizing FN. The somewhat lower PPV shows that some LLM MOR-positive calls were not coded as MOR by the assessor. Whether these represent overcoding by the LLM coder or borderline and ambiguous cases requires further analysis.
Protocol Level
Because interpretations are ultimately made at the protocol level, we aggregated MOR totals per protocol and evaluated agreement across these 84 protocols. Table 3 shows that protocols had, on average, 25.90 responses (SD = 11.82). Assessor-coded MOR averaged 2.40 (SD = 2.96) per protocol. The LLM coder runs were overall similar to the assessor’s score, although slightly higher: T1 M = 2.63 (SD = 3.13), T2 M = 2.71 (SD = 3.25), and T3 M = 2.65 (SD = 3.21). Given MOR codes were relatively skewed (i.e., around or exceeding|1.8|; Table 3), we square-root-transformed these variables, reducing skew values to below|0.41|, which makes the scores more normally distributed (Table 3). Figure 3 illustrates these transformed distributions with violins and boxplots and no statistically significant differences across groups; the omnibus test was F(2.07, 171.97) = 2.78, p = .06. Also, post hoc Holm-adjusted pairwise effects were small (Hedges’ g: −0.25 to 0.08) and not statistically significant. Practically, if handed a random protocol, the MOR count alone would not reveal whether it was coded by an assessor or by the LLM coder. However, to a small extent, the LLM coder tended to overcode MOR compared to human assessors, assigning 10.2 codes per 100 responses versus 9.3 codes per 100 responses.
Descriptive Statistics of Morbid Coders by Protocol Level (N = 84).
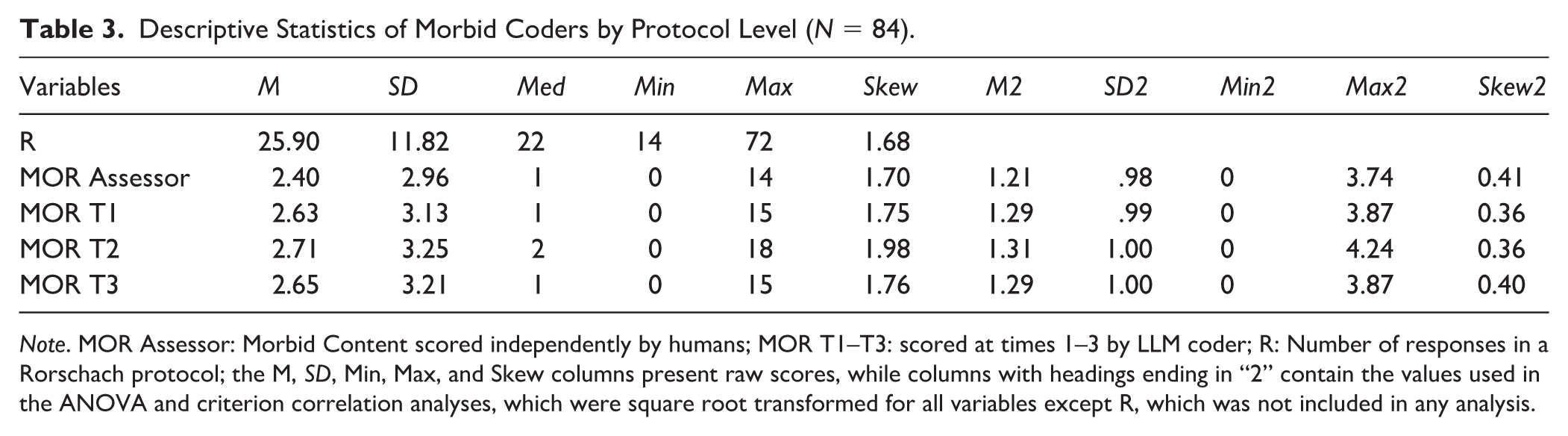
Note. MOR Assessor: Morbid Content scored independently by humans; MOR T1–T3: scored at times 1–3 by LLM coder; R: Number of responses in a Rorschach protocol; the M, SD, Min, Max, and Skew columns present raw scores, while columns with headings ending in “2” contain the values used in the ANOVA and criterion correlation analyses, which were square root transformed for all variables except R, which was not included in any analysis.
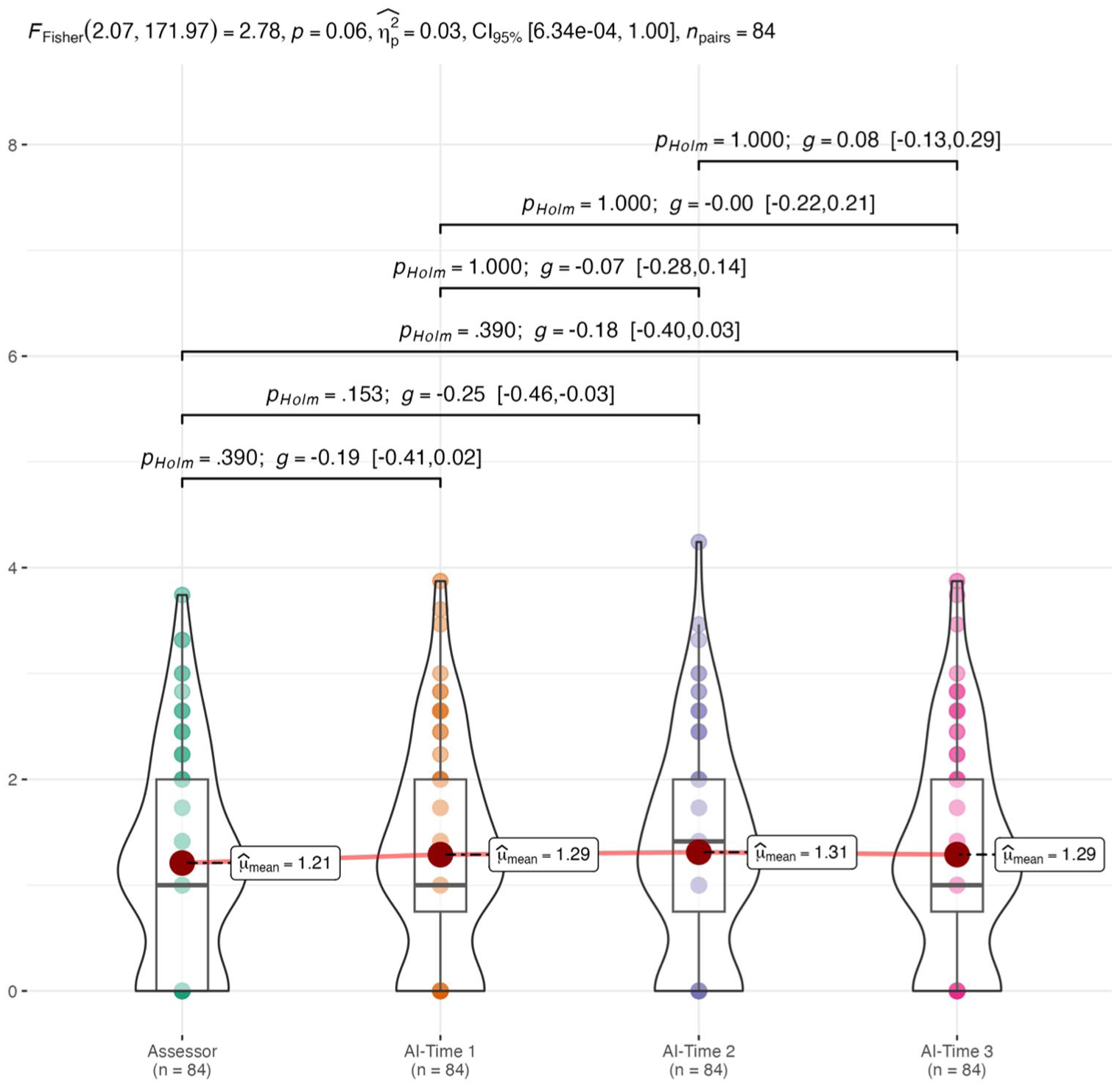
Comparison of MOR across assessor coder and LLM-based agent coder.
Protocol-level agreements were excellent using untransformed raw scores (Table 4). Assessor-LLM ICCs were 0.95, 0.94, and 0.95 for T1–T3, all p < .001. LLM-LLM agreements were higher: 0.98, 0.99, and 0.97, all ps < .001. Notably, the 95% confidence intervals for Assessor-LLM and LLM-LLM barely touch: the strongest Assessor-LLM upper bound is 0.97, which barely exceeds the lowest LLM-LLM lower bound (0.96). This visual separation indicates that the LLM reliably agrees with itself more often than it agrees with a human (Cumming & Finch, 2005).
ICC Summary Protocol Level Agreement (N = 84).
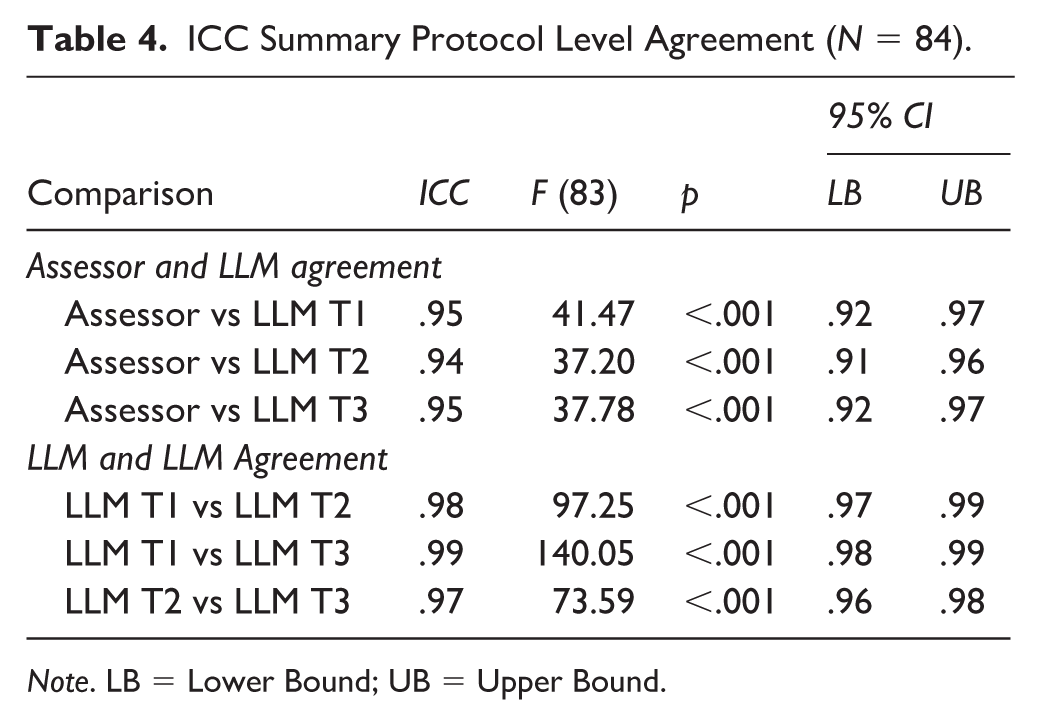
Note. LB = Lower Bound; UB = Upper Bound.
Benchmark Comparisons
At the response level, the LLM coder shows good chance-corrected agreement with the assessor (kappa ≈ .72–.74). To contextualize these findings, we would like to see what an expected kappa level is in practice among assessors. Meyer et al. (2002) examined the interrater reliability for scoring the Rorschach in several datasets and reported a kappa of .90 for experienced coders, a kappa of .81 for students, and .72 for a dataset with 30% random error. Thus, although the LLM coder kappa is good, it is slightly below the student kappa and far below that of experienced raters. It is closest to the 30% error condition. This shows room for response level refinement while still reflecting good agreement under natural base rates. In other words, this is a solid first milestone rather than an endpoint.
By contrast, at the protocol level, where interpretation occurs, we can see the big picture. Assessor-LLM ICCs of 0.94–0.95 match expert-assessor results reported by Meyer et al. (protocol level ICC = 0.95, 2002) and are at or above typical assessor-assessor agreement reported in Schneider et al. (2022), who reviewed ICC for R-PAS variables across four datasets. The ICCs across four samples for MOR were 0.93, 0.94, 0.78, 0.93 (unweighted mean 0.90, weighted mean 0.87). This pattern of higher protocol level reliability than response level reliability is expected and has already been explained and described by Meyer et al. (2002). However, the specific findings going from good reliability at the response level and excellent reliability at the protocol level in this case, may also imply that, although the LLM coder does not fully capture response level reliability at expert standards, it nevertheless yields protocol totals that are comparable to expert coders, likely because some LLM-flagged, assessor-negative responses (e.g., borderline cases) aggregate to a stable overall MOR count.
Finally, the observed LLM-LLM consistency (0.97–0.99) is numerically higher than assessor-assessor reliability (e.g., Meyer et al., 2002; Schneider et al., 2022). In practice, the protocol level agreement (the level used for clinical and research interpretation) meets established human benchmarks even as response level refinement remains open to improvement. Together, these results show that the LLM coder closely reproduces assessor totals with minimal bias and near-perfect stability across independent runs.
Step 3: Validity Against Independent Criterion
Rationale
In the previous section, we checked the consistency of the LLM coder across independent runs and the agreement with human coders. To demonstrate that the reliability with an already valid coder (assessor) generalizes to its validity, we also show that the LLM coder is measuring the same construct or behavior. Validity testing asks whether LLM-generated scores relate to external variables in the same pattern and with the same magnitude as human-coded scores. This typically means reproducing established associations with a relevant criterion. In a typical validity study, behavioral and clinically consequential outputs provide the strongest evidence and can be considered the “gold standard” when available. However, when the goal is to test whether an LLM coder preserves the meaning of an established human-coded score, it could be more practical to begin by replicating prior human-coded findings using the same criterion measures that have already demonstrated validity. For this part, we recommend starting by choosing a criterion with prior theoretical support and demonstrated validity. For instance, one used in earlier studies or available in an existing dataset. Then, replicate those associations with the LLM-generated scores independent of human scores. Pre-specify the expected direction and magnitude of effects and compare effect sizes with past findings.
How to Do It
Identify external measures that have well-documented associations with the variable being coded (e.g., prior studies or datasets).
Note predicted direction and magnitude.
Calculate associations between the LLM-generated scores and these external measures and compare them with correlations from human-coded scores.
Focus on whether the LLM preserves the direction, magnitude, and statistical significance of these associations.
Example with MOR
To evaluate validity against external criteria, we correlated protocol-level √MOR totals with MMPI indices that should relate to dysphoria and negative affect (Scale 2, Scale 7, DEP, ANX, PSY-5-Neg; Table 5 and Figure 4) in patients with matching response styles on both tests. All correlations were statistically significant (n = 84, df = 82, ps < .001). The pattern was consistent across LLM coders: associations ranged from .59 to .71, with Scale 7 the strongest and Scale 2 the lowest. Relative to human coding, the LLM coders produced numerically higher correlations on every scale (e.g., Assessor vs. LLM ranges: Scale 2 = .54 vs .59–.63; Scale 7 = .65 vs .70–.71; DEP = .62 vs .68–.69; ANX = .59 vs .65–.66; PSY-5-Neg = .62 vs .65–.68). Average correlations were .61 for the assessor and .66 across the three LLM coder T1–T3, indicating small, consistent gains while preserving the same substantive profile. The bar plot (Figure 4) illustrates these parallel patterns across coders. Hence, the LLM coder maintains the expected external relations and does so reproducibly across independent runs.
Pearson’s Correlations Between MOR and the MMPI Scale by Coder (n = 84, df = 82, ps < .001).
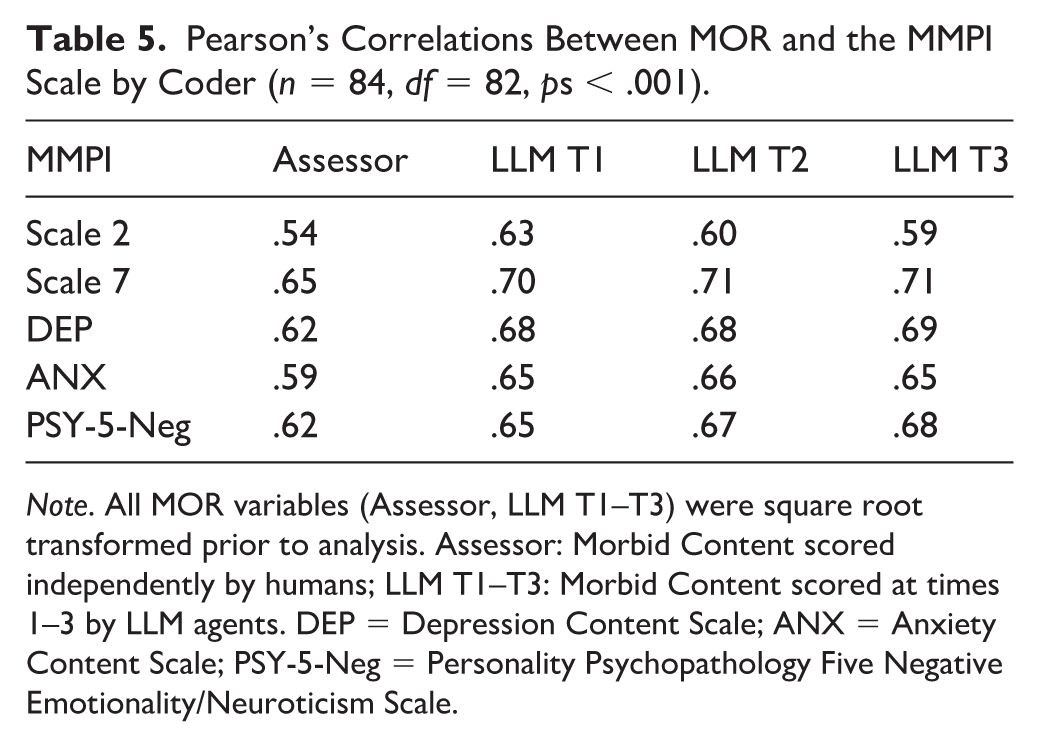
Note. All MOR variables (Assessor, LLM T1–T3) were square root transformed prior to analysis. Assessor: Morbid Content scored independently by humans; LLM T1–T3: Morbid Content scored at times 1–3 by LLM agents. DEP = Depression Content Scale; ANX = Anxiety Content Scale; PSY-5-Neg = Personality Psychopathology Five Negative Emotionality/Neuroticism Scale.
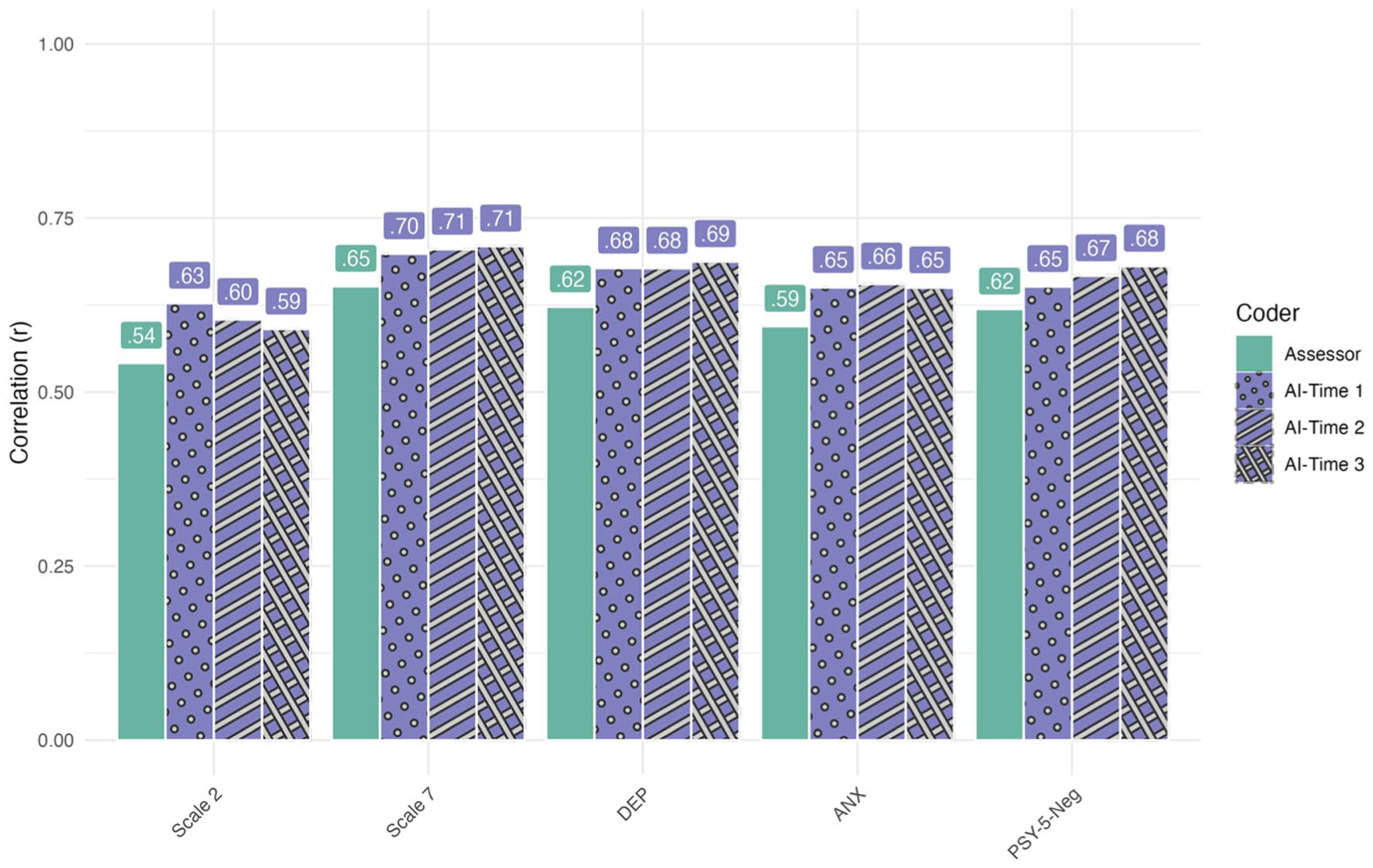
Correlation sizes across LLM-based coders and human coder (N = 84, df = 82, all ps <.001).
Discussion
We present a practical, test-agnostic framework that adapts established psychometric practice to LLM-based scoring and aligns with Transparent Reporting of multivariable prediction model for Individual Prognosis Or Diagnosis +AI (TRIPOD+AI; Collins et al., 2024) and with Guidelines for Reporting Reliability and Agreement Studies (GRRAS; Kottner et al., 2011). Our contribution is a step-by-step process with two separate stages: a flexible, project-specific pre-validation phase and a standardized validation phase. Concretely, we recommend (a) balanced screening samples to avoid inflated accuracy, (b) response level agreement emphasizing kappa, PPV, and Sensitivity under low base rate conditions, (c) protocol level agreement via ICC, and (d) validity against independent criteria by replicating established relations, allowing direct comparison of LLM coders to human coders, particularly when reliability between the LLM coder and human coders is modest or weak.
For pre-validation, we emphasize pragmatic decisions whenever possible, such as comparing multiple models on a balanced dataset, iterating on prompts, and addressing formatting and classification issues. Researchers should aim to select the best-performing model for their intended use. “Best” should be defined in advance, as different metrics can favor different tasks. For example, for screening tasks, the priority is often Sensitivity, because missing true cases can be costly (e.g., screening for suicide risk, early psychosis, neurocognitive impairment). In contrast, when FP carries substantial consequences, priorities often shift toward PPV and Specificity (e.g., forensic evaluations of competency, criminal responsibility; classifications that could trigger restrictive interventions; high-stakes occupational clearance). Once priorities are specified, a pragmatic choice is to retain the model that performs best on the primary metric while meeting the predefined minimums on the others. On the contrary, the model with the highest performance may not be the best practical choice, because model selection also depends on external constraints such as cost, privacy, data handling, and provider governance. Researchers should weigh in those factors. Although a researcher may opt for a model that is not the “best” performing because it may be too expensive or does not meet the necessary ethical requirements, the subsequent validation steps remain fixed and are designed to test whether LLM-generated scores preserve the meaning of human-generated scores.
Reliability: Expectations and Evidence
Perfect agreement (e.g., ICC = 1.00 or r = 1.00) is not the standard that humans achieve in psychological or medical literature (Meyer, 2004). Ambiguity in responses, threshold cases, and non-exhaustive guidelines produces genuine assessor disagreements, so an LLM coder that matches high human-level agreement is already performing at a demanding benchmark. In our case study, the LLM coder achieved good response level agreement (kappa = .71–.74) and excellent protocol level agreement (ICCs = .94–.95) with human coders. The LLM coder demonstrated near-perfect consistency across independent runs (LLM-LLM ICC T1–T3 = .97–.99), indicating, to some extent, that the LLM coder agrees with itself more often than with a single human rater. This is not a surprising finding for a model with unchanged prompts and low temperature. Literature benchmarks for MOR (expert ICC = .90, Meyer et al., 2002; weighted mean ICC ≈ .87; Schneider et al., 2022) place the assessor-assessor agreement 8 to 11 points below the LLM-LLM consistency. Also, the LLM-assessor agreement was directly comparable to the assessor-assessor agreement at the protocol level.
A related consideration is the choice of the human reference standard. In our example, we used a single-rater score to parallel prior work, but developers can also use aggregate reference scoring, such as majority vote or adjudicated consensus at the response level and averaged totals at the protocol level, which typically reduces idiosyncratic rater error and increases reliability (McGraw & Wong, 1996; Shrout & Fleiss, 1979). However, aggregate criteria are not automatically “truer” because they can mask poor single-rater performance (Shrout & Fleiss, 1979), obscure genuine boundary uncertainty (AERA et al., 2014), and introduce shared or group-level biases. Ultimately, the most appropriate reference standard depends on the intended use and research question, including whether conclusions will be applied in settings where scoring is typically done by a single coder or by pooled ratings.
Validity: Preserving Construct Meaning
Evaluating validity against an external criterion is a logical extension of high interrater reliability, given that the human rater already demonstrated good validity. If two raters produce highly reliable, interchangeable scores, then each set of scores should correlate similarly with relevant external measures. In our study, we make this point concrete by first showing compelling LLM-assessor reliability and then showing parallel validity with an independent criterion. Practically, when reliability is high with a human coder, additional validity analysis will replicate the validity for humans and the LLM; when reliability is modest or low, criterion analyses become decisive, because the question shifts from “is the LLM as good as humans?” to “which coder is more valid?” In that circumstance, researchers should compare LLM and human coders with theory-relevant external criteria to determine which better preserves the construct.
In our example, we used MMPI indicators of dysphoria and negative affect as independent criteria, in a dataset where we knew those correlations were already high with human coders (see Meyer, 1997; Pimentel & Meyer, 2025). The LLM coder reproduced the expected pattern and showed slightly larger correlations while retaining the same rank ordering across scales. This pattern supports that the LLM-generated codes preserve the construct assessed by MOR rather than introducing noise, and it supports the argument that strong agreement between the LLM coder and the human coder preserves the validity of those scores.
Implications for Practice
We are not anticipating having a fully automated Rorschach coder yet. The Rorschach is time-intensive to learn, administer, and score, so a practical near-term goal is to develop a human-in-the-loop coding assistant that accelerates research and supports clinical workflows. This use of LLMs as assistants is also advocated by Guo et al. (2024), who concluded that professional oversight of LLMs could enhance health care efficiency. In the context of the Rorschach task, if multiple variables can be pre-coded reliably, studies could include larger samples and deploy performance-based tests more routinely. This matters because studies using performance-based measures typically have far fewer participants than studies using self-reports. Our case study demonstrates good to excellent reliability and validity for a single code; many other LLM coders would be required to build a complete LLM-based Rorschach coder.
For MOR, the slight overcoding from the LLM coder (raw score means ≈ 2.63–2.71 vs. assessor 2.40) is operationally useful because assessors can triage by prioritizing positive calls. Instead of scanning ~20 to 30 responses per protocol, an assessor can review ~2 to 4 LLM-flagged positive responses to confirm or reject them. This is preferable to an undercoding system that would force clinicians to hunt for missed positives across many negatives.
This triage workflow also clarifies how performance metrics should be prioritized. Although sensitivity and specificity tradeoffs are well described in the assessment and diagnostic literature (Hajian-Tilaki, 2013; Meehl & Rosen, 1955; Swets, 1988), LLM development enables us to go one step further through targeted error analysis. When some FPs are acceptable, the practical priority is to minimize FN, so clinically relevant content is rarely missed, and then to reduce FP to lower the assessor’s review burden. In practice, this means using error analysis to identify recurring sources of missed cases or false alarms, and updating prompts, with the expectation that refinement will gradually narrow the gap with human coding, likely surpassing it, given the high LLM-LLM stability. The high LLM-LLM stability also benefits longitudinal research as the model applies its decision rules consistently across time, protocols, and administrations, reducing rater-related noise and increasing the ability to detect true change. In those studies, the specific values for a score are not the focus, but rather the change over time. In those circumstances, LLM coding could be highly valuable to speed up processing time.
Future researchers might also consider a multiple-coder workflow, which, conceptually, is similar to ensemble models (Breiman, 2001; Mohammed & Kora, 2023) or crowdsourcing (Shapley & Grofman, 1984; Snow et al., 2008) in which multiple independent processes are combined into a single decision rule. Although our three runs were used to evaluate output stability rather than to aggregate decisions, one could combine them using a majority vote or a more inclusive any-positive rule in which a code is assigned if at least one session endorses it. These aggregation rules would shift error tradeoffs, with the any-positive rule tending to reduce FN at the cost of more FP, and majority vote, the opposite. If an ensemble rule is used, it should be evaluated as a new coder, including repeating the ensemble procedure across multiple runs to test stability. This approach is slower and more costly, but it may be valuable depending on the context (when FP and FN priorities are clear). However, at low temperatures, we anticipate that ensemble workflows will not deviate much from single runs, as outputs will be more stable. Increasing the temperature would, in principle, result in larger differences across runs.
Disagreements as Signals and Future Developments
Beyond assisting with scoring established variables, the use of an LLM coder can also support test development and refinement. During the development of guidelines for clinicians, an LLM coder can serve as a scalable stress test of scoring rules by processing large datasets, surfacing recurring ambiguities and boundary cases where rules or examples are underspecified. Error analysis can then guide revisions to definitions, decision thresholds, and illustrative examples. Also, if an LLM coder shows greater validity against a specific external criterion than humans, disagreements that appear to be errors might be systematic signals rather than noise. These signals are response patterns that humans miss. In such cases, error analysis can help identify candidate additions to manuals and guidelines that would improve human scoring. This type of analysis must be conducted prudently, because apparent gains in validity could also reflect other issues (e.g., overfitting, criterion contamination, or construct drift). Disagreements should be evaluated by experts, documented, and tested in independent validation samples before being incorporated into scoring guidance.
In our example, the LLM-criterion correlations were slightly higher than assessor-criterion correlations while preserving the same profile. As such, some LLM-flagged responses that disagree with the assessor’s coding may be relevant for improving coding relative to this specific criterion. However, if we change the prompts based on mistakes we see in the validation dataset, we risk making a prompt that works well only for that dataset. Hence, we did not review the LLM-assessor disagreements in the Chicago validation dataset (i.e., we did not conduct error analysis). We kept this dataset untouched so it can remain a clean test of performance and be reused later to check stability over time. Instead, we used a separate dataset (i.e., Norms) to refine the prompts with error analysis. This separation helps reduce overfitting and makes it more likely that any improvements will generalize to new data.
Our results show a small, consistent numerical edge for LLM-criterion correlations relative to assessor-criterion correlations on MMPI-2 negative affect markers. If one were to treat these MMPI-2 scales as the defining criterion for MOR, the implication would be straightforward: MOR guidelines should be updated to code more like the LLM coder because the LLM coder is both more consistent (LLM-LLM ICC ≈ 0.98) and slightly more predictive of that criterion than individual human coders. However, MMPI negative affect is not the construct definition of MOR; it is only a plausible external criterion with established, historical utility (e.g., Meyer, 1997) that we deliberately used to check whether the LLM coder preserves known relations. Consequently, stronger LLM-MMPI correlations are evidence of preserved validity with respect to that criterion, not a mandate to revise MOR guidelines only because of that. An alternative path is to treat LLM-assessor disagreements as potential room for revisiting and updating guidelines rather than a mandate for guideline changes.
Although responding to structured self-report items likely engages different psychological processes than producing unstructured descriptions (Bornstein, 2011; Meyer, 1997; Mihura, 2012), some researchers argue that LLMs will change mental health assessment by replacing self-reports with natural-language communication (Kjell et al., 2024). In the context of performance-based tasks, we believe they will not be replaced, but rather complemented and enhanced, making screening and coding less time-consuming and enabling busy clinicians and researchers to use these tasks more often and effectively.
Another advantage of using LLMs for coding is that they can process information in several languages (e.g., Rathje et al., 2024; Rosoł et al., 2023). Although we did not test it systematically, we had initial optimistic results testing this LLM coder in Portuguese, Spanish, and Italian. A future study should focus on testing these languages on datasets with strong criteria for each language. In this study, we presented results for the LLM MOR coder; however, we are currently working on many other LLM coders. We plan to make these available on the R-PAS website for assessors when ready.
High-Stakes Use, Ethics, Standards, and Governance
The use of LLMs in psychological assessment raises ethical and governance issues that extend beyond reliability and validity (Fareed et al., 2025; Putica et al., 2025) and brings additional technical and ethical responsibilities as society tends to tolerate human error more than machine error, and often shows aversion to automated decisions (Bigman & Gray, 2018; Dietvorst et al., 2015; Mayer et al., 2023). Hence, developers should strive to meet or exceed human benchmarks. Our framework operationalizes this by comparing model-model and model-human agreement to assessor-assessor benchmarks and providing evidence of validity against independent criteria also used with human scores.
Test standards prioritize governance and transparency with clear documentation of the theoretical and procedural basis of automated logic for expert evaluation (AERA et al., 2014; International Test Commission [ITC] & Association of Test Publishers [ATP], 2025). Because LLM processes are often opaque (also called black-box), developers should prioritize transparency in how outputs are generated and reviewed (Zhui et al., 2024). Our example supports this by providing outputs with a fixed structure and requiring brief, evidence-based explanations that point to the words or phrases that trigger each decision. Although it does not open the black-box, it makes outputs easier to inspect, debug, and evaluate systematically. In addition, responsible use requires ongoing monitoring rather than one-time validation (AERA et al., 2014; ITC & ATP, 2025), so we recommend periodic calibration checks, including repeated runs and intrarater and interrater comparisons against human-scored samples, to detect drift and verify that the models have not changed their outcomes.
Bias and fairness are also an ethical concern because LLMs may reflect training data biases and may misclassify culturally specific content (Fareed et al., 2025; Putica et al., 2025; Zhui et al., 2024). Although developers cannot control proprietary training data, emerging work suggests that prompt structure, constraints, and multi-step procedures can reduce biased outputs (Li et al., 2025; Morales & Raman, 2025). In our example, we added inclusion and exclusion rules to reduce false positives when cultural, artistic, or normative contexts were present.
Safety and clinical risk also require attention because LLMs can produce confident errors and overgeneralize from salient cue words (Fareed et al., 2025; Zhui et al., 2024). Testing standards emphasize governance for boundary cases, quality control, and human review, particularly when responses are unusual or ambiguous (AERA et al., 2014; ITC & ATP, 2025). Accordingly, in our MOR example, we used error analysis to identify failure patterns to add minimum thresholds and constraints (e.g., prompt changes for “fire” and “blood”).
Also, privacy and accountability are essential (Fareed et al., 2025; Zhui et al., 2024), as psychological tests can contain sensitive personal information. LLM-based scoring should follow institutional governance and applicable privacy standards (e.g., AERA et al., 2014; ITC & ATP, 2025), including data minimization, restricted access, and secure processing (Fareed et al., 2025; Zhui et al., 2024). In our example, we minimized risk by sending only the Response and Clarification Phase text without the respondent’s identifiers. Also, we note that provider safeguards can still assist by blocking content that contains personal identification. In our example, one response was automatically blocked because the respondent mentioned a person’s name, and OpenAI’s safeguards were triggered.
Limitations and Strengths
This study has limitations that should guide interpretation and inform future work. First, findings are limited to a single Rorschach variable (MOR) and are not generalized to other codes with different coding rules. Second, validation was conducted with a single external dataset, which is clinically focused. Broader replication across sites, languages, and populations will be valuable. Third, external validity analyses were restricted to MMPI-2 negative affect scales. Although correlations were in the expected range, additional validity evidence from known-groups, discriminant measures, and real-world outcomes would be informative. Fourth, although the framework addresses low-base-rate coding, the rarity of the MOR code led to just moderate positive predictive values (~.69–.71), meaning that about 30% of the LLM-flagged positives did not match the assessor codes. This underscores the importance of human review, especially for FP, and suggests opportunities for prompt refinement (e.g., using error analysis). Finally, the workflow treated each response independently, which maximizes psychometric clarity but may underuse cross-response contextual cues that human coders sometimes rely on.
This article also offers several strengths. First, it presents a clear two-stage framework that distinguishes flexible pre-validation from fixed psychometric evaluation procedures, aligning with reporting standards such as TRIPOD+AI, AERA, and ITC. Second, it emphasizes reliability and validity metrics suited to low-base-rate variables, improving comparability and transparency in evaluation. Third, validation was performed on an independent dataset with natural base rates. Fourth, the model demonstrated good to excellent performance relative to the human coders, with good response level agreement (κ ≈ .72), excellent protocol level ICCs (.94–.95), and near-perfect stability across independent runs (.97–.99). Fifth, construct-relevant external validity was preserved and slightly enhanced. Sixth, the manuscript explicitly highlights the pitfalls of accuracy and specificity in rare-event contexts and centers evaluation on kappa, PPV, and Sensitivity, providing a methodological contribution to the field. Seventh, operationally, the LLM coder’s slight overcoding at the protocol level favors clinical triage by reducing the likelihood of missed positives. Eighth, the study also compared multiple LLMs, documented prompt design decisions, and manually reviewed disagreements (i.e., error analysis) to target ambiguous thresholds. Finally, the analytic pipeline was deliberately structured for reproducibility so that other researchers can mirror and extend the approach.
Conclusion
We provided a replicable framework for evaluating LLM-based coders in psychological assessment, with a focus on evaluating psychometric rigor. The steps outlined can be generalized to other coding and classification tasks and other domains. This framework supports the responsible integration of LLM tools into clinical and research settings, empowering psychologists to assess and adopt these emerging technologies critically. The MOR case demonstrates that such LLM coders can achieve excellent protocol-level agreement, near-perfect stability, and external validity relations, supporting their suitability for research and careful clinical use.
Supplemental Material
sj-docx-1-asm-10.1177_10731911261455137 – Supplemental material for Evaluating LLM-Based Coders in Psychological Assessment: A Validation Framework With Application to the Rorschach Morbid Content Variable
Supplemental material, sj-docx-1-asm-10.1177_10731911261455137 for Evaluating LLM-Based Coders in Psychological Assessment: A Validation Framework With Application to the Rorschach Morbid Content Variable by Ruam P. F. A. Pimentel and Gregory J Meyer in Assessment
Supplemental Material
sj-docx-2-asm-10.1177_10731911261455137 – Supplemental material for Evaluating LLM-Based Coders in Psychological Assessment: A Validation Framework With Application to the Rorschach Morbid Content Variable
Supplemental material, sj-docx-2-asm-10.1177_10731911261455137 for Evaluating LLM-Based Coders in Psychological Assessment: A Validation Framework With Application to the Rorschach Morbid Content Variable by Ruam P. F. A. Pimentel and Gregory J Meyer in Assessment
Footnotes
Ethical Considerations
Ethical approval was not required for this article.
Consent to Participate
There are no human participants in this article, and informed consent is not required.
Consent for Publication
Not applicable.
Author Contributions
Ruam Pimentel, conceptualization, data curation, formal analysis, investigation, methodology, project administration, resources, software, visualization, writing – original draft, writing – review & editing; Gregory Meyer, conceptualization, methodology, resources, supervision, validation, writing – review & editing.
All authors approved the final version of the article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The first author is a postdoctoral fellow at the Rorschach Performance Assessment System® (R-PAS®). The second author is a member of the company that sells the manual for R-PAS® and associated products.
Data Availability Statement
The data are not publicly available but can be obtained by request.
AI Assistance
AI tools were used to enhance language, clarity, and conciseness. Specifically, we used Grammarly as the primary grammar checker and its AI writing assistance tool, which operates GPT models in the background. We also used Copilot, available in Microsoft Word, in other instances. Finally, we used Apple Intelligence in a few cases. All AI usage focused on improving language; it was not used to generate new content, to define concepts, or for other improper uses of AI in research. Most uses of AI did not require prompts; instead, we checked the AI tool’s automatic suggestions. The authors reviewed and edited all final outputs to maintain the original intent. The authors generated all content in this article, and none was generated by AI.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.