
Abstract
Sound is an invisible but powerful force that is central to everyday life. Studies in the neurobiology of everyday communication seek to elucidate the neural mechanisms underlying sound processing, their stability, their plasticity, and their links to language abilities and disabilities. This sound processing lies at the nexus of cognitive, sensorimotor, and reward networks. Music provides a powerful experimental model to understand these biological foundations of communication, especially with regard to auditory learning. We review studies of music training that employ a biological approach to reveal the integrity of sound processing in the brain, the bearing these mechanisms have on everyday communication, and how these processes are shaped by experience. Together, these experiments illustrate that music works in synergistic partnerships with language skills and the ability to make sense of speech in complex, everyday listening environments. The active, repeated engagement with sound demanded by music making augments the neural processing of speech, eventually cascading to listening and language. This generalization from music to everyday communications illustrates both that these auditory brain mechanisms have a profound potential for plasticity and that sound processing is biologically intertwined with listening and language skills. A new wave of studies has pushed neuroscience beyond the traditional laboratory by revealing the effects of community music training in underserved populations. These community-based studies reinforce laboratory work highlight how the auditory system achieves a remarkable balance between stability and flexibility in processing speech. Moreover, these community studies have the potential to inform health care, education, and social policy by lending a neurobiological perspective to their efficacy.
Keywords
Introduction
Music plays a privileged role in human culture and communication. Imagine the ease with which you can hum a familiar tune, the joy of listening to the same album again and again, and the profound sense of loss when a musical icon dies. The intricacies of these deep connections make music a powerful experimental model that addresses fundamental questions in the neurobiology of everyday communication, including the organization of sound processing in the brain (Zatorre and others 2002), the contingency between perception and action (Repp 2005), the cognitive factors that shape perception (Besson and others 2011), the structure and function of the limbic system (Salimpoor and others 2013), the neural basis of creativity (Limb and Braun 2008), and the effects of experience on the nervous system (Patel 2011).
Experience in sound tunes the auditory brain through the integration of sensorimotor, cognitive, and reward circuitry (Kraus and White-Schwoch 2015); this trifecta makes music training particularly appropriate for the study of long-term plasticity engendered by experience in and with sound. Our laboratory has studied how music shapes the nervous system for nearly a decade through a series of cross-sectional and longitudinal studies. This has been a part of an international research effort that identifies a “musician advantage” for thinking and perceiving that is engrained in the fundamental response properties of the nervous system, from cochlea to cortex (Herholz and Zatorre 2012; Patel 2011).
From a theoretical standpoint, this research program elucidates principles of auditory learning, and neuroplasticity in general. From a pragmatic standpoint, this research program motivates strategies such as auditory training to improve human communication, and music in particular as a potential route for auditory enrichment in children. These two lessons are encapsulated by recent work that pushes neuroscience beyond the traditional laboratory to investigate the brain and behavioral impacts of participation in community and school music programs.
Our Approach to Evaluating Auditory Processing in Humans
Neurophysiological responses to speech sounds offer fine-grained detail into biological sound processing that is meaningful in individuals. An emerging framework to understand these responses distinguishes acoustic and intrinsic aspects of sound processing. Acoustic response features reflect how effectively sound details are processed (such as the timing, pitch, or harmonics of a stimulus) and reveal the fine-tuning of the hearing brain. Intrinsic factors reflect the infrastructure of sensory processing mechanisms (such as the ongoing neural noise and the stability of neural processing) and reveal the overall health of the auditory system. Together, a single response presents a biological mosaic of insight into an individual’s strengths and weaknesses in auditory processing.
We have innovated a noninvasive electrophysiological approach that provides a biological snapshot of auditory processing in humans; we position auditory processing at the nexus of cognitive, sensorimotor, and reward networks in the brain (for review, see Kraus and White-Schwoch 2015). We call this biological approach the FFR (frequency-following response) or cABR (auditory brainstem response to complex sounds). An unusual advantage of this approach is that a single response to speech offers a rich tapestry of information about different biological aspects of sound processing (Fig. 1).
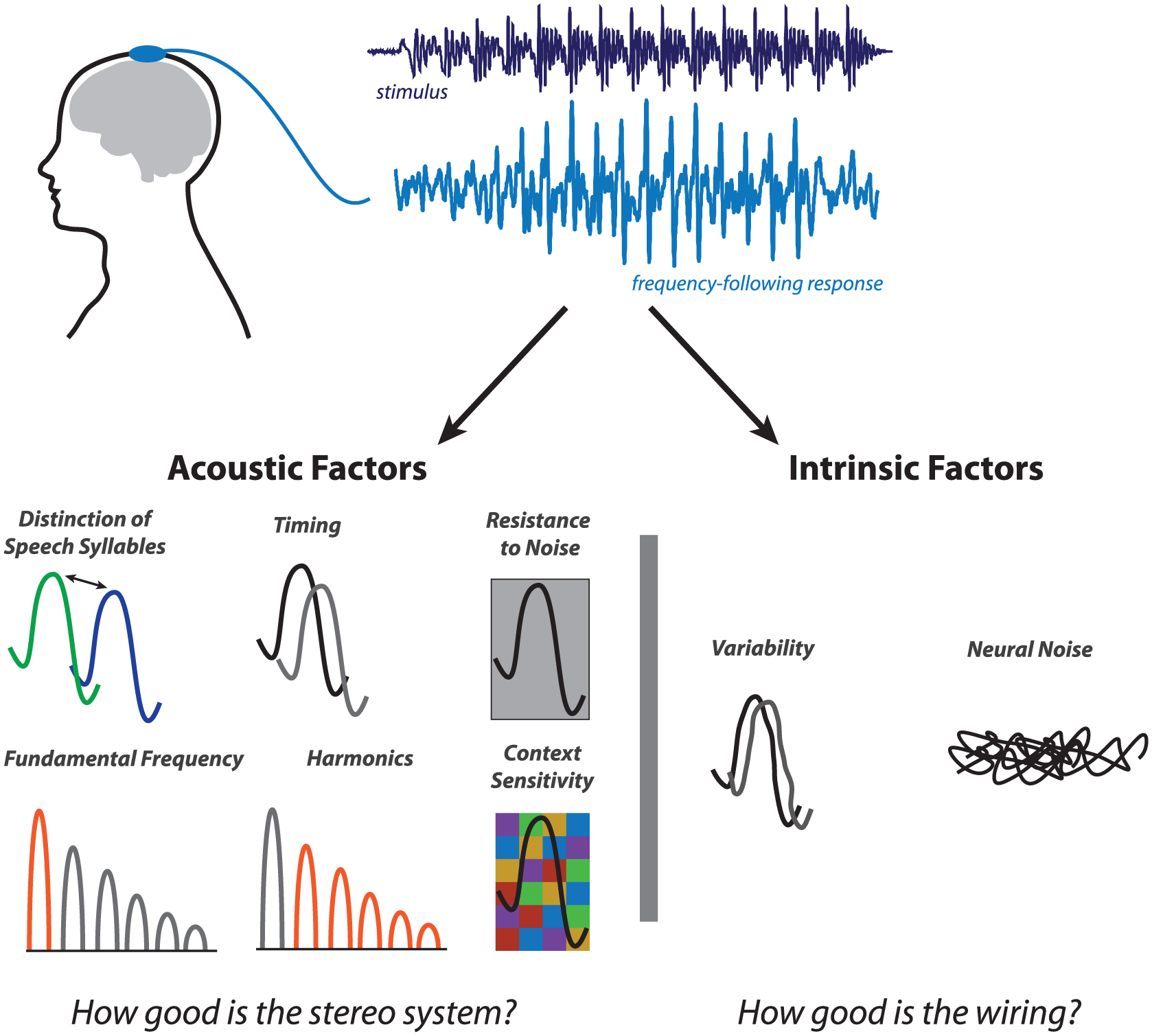
The FFR (frequency-following response) is an objective, biological measure of the integrity of sound processing in the brain. An unusual advantage of the FFR is that it recreates many acoustic features of the stimulus. These can be broadly grouped into acoustic factors (reflecting how effectively the brain codes sound) that are complemented by sound-invariant intrinsic factors (reflecting the health of the brain’s sound processing infrastructure). By analogy to a stereo, these discrete components of an FFR can reflect how good a speaker’s fidelity is and how well wired the system is as a whole, respectively.
The Musician’s Brain Is Primed for Sound
Converging evidence documents a series of enhancements to sound processing and cognition conferred by music training (for reviews, see Herholz and Zatorre 2012; Kraus and Chandrasekaran 2010). Although debates persist with respect to the causal role music training plays (i.e. whether musician vs. non-musician differences are a function of training or if individual differences motivate certain individuals to seek music training), longitudinal evidence now suggests that at least some of the so-called musician advantage is attributable to training (Chobert and others 2012; Fujioka and others 2006; Zhao and Kuhl 2016). Even individuals with music training in the past exhibit stronger brain responses to speech than their peers (Skoe and Kraus 2012; White-Schwoch and others 2013).
With respect to the FFR, comparisons of musicians and non-musicians across the lifespan reveal a signature set of biological enhancements to sound processing (reviewed by Strait and Kraus 2014). These enhancements are not an overall increase to sound processing; rather, specific features of sound that are relevant are enhanced in musicians (Strait and others 2009). This fine-tuning is a principle of auditory learning (Recanzone and others 1993), lending credence to the musician model of neuroplasticity. What matters, though, is that the features of sound that are important to musicians are not restricted to music (Patel 2010; Patel and others 1998; Zatorre and others 2002). For example, pitch is a key cue in music and language, and musicians have stronger processing of pitch cues both in music and language (Musacchia and others 2007; Schön and others 2004).
One of the ways this fine-tuning manifests is through acoustic and intrinsic enhancements patterning distinctly in musicians. Acoustic aspects of speech processing are enhanced in musicians across the lifespan—even in healthy young adults. In general, musicians have faster brain responses to speech, especially to perceptually challenging speech cues such as consonant-vowel transitions. Musicians exhibit stronger neural encoding of speech harmonics, which convey “timbral” features in speech and contribute to identification of phonemes (e.g., was it /b/ or /p/?). Consequently, they also have more precise neurophysiological distinctions between contrastive speech sounds. In addition, musicians’ brain responses tend to correspond more accurately to the evoking stimulus and with more nuance and exhibit stronger sensitivity to stimulus context. Finally, musicians’ neural coding of speech is more resilient to background noise (Fig. 2).
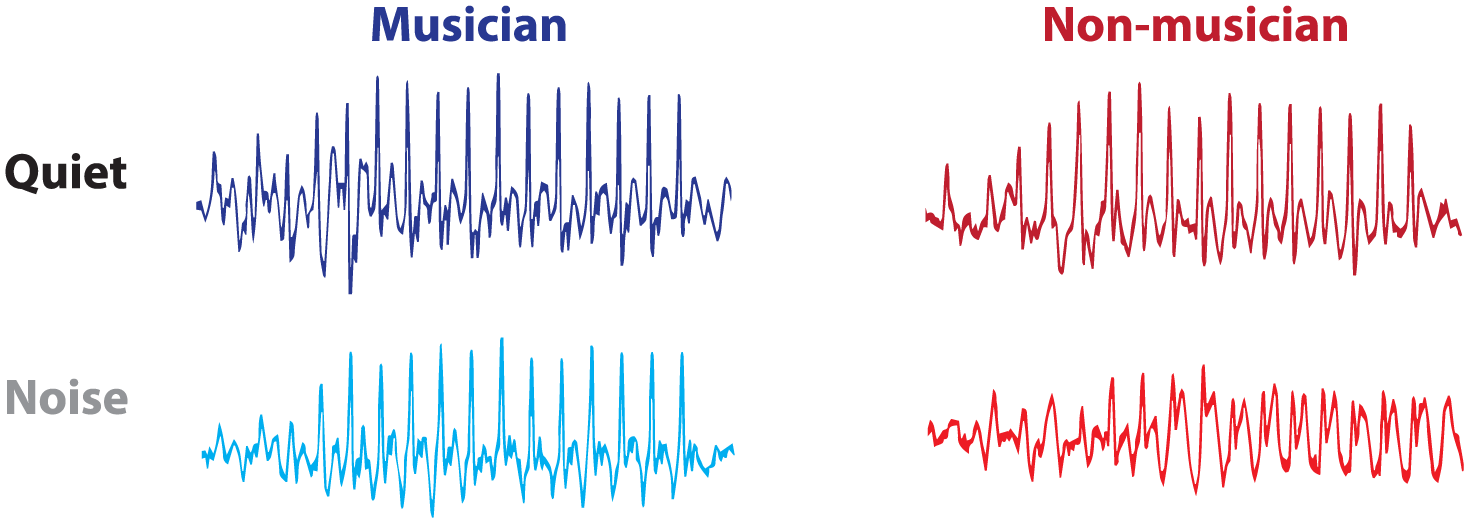
A hallmark of musicians’ sound processing is a resiliency to background noise. Noise taxes listening for everybody, but musicians have stronger neural responses, and superior perception, of speech in noise. Illustrated are speech-evoked FFRs (frequency-following responses) in quiet (top) and background noise (bottom) elicited in an individual musician (left) and non-musician (right). As may be seen, the musician’s response in noise resembles the response in quiet to a much greater degree than the non-musician’s, indicating it is more resilient to the background noise.
It would appear that intrinsic aspects of sound processing are only enhanced in populations that otherwise exhibit difficulties in auditory processing. This is exemplified by older adults with music experience, who, compared to their peers, exhibit more stable neural responses to speech in addition to the aforementioned enhancements to acoustic factors of the response (Parbery-Clark and others 2012). Likewise, it appears that the maturation of intrinsic sound processing may be speeded up by music training during early development (Skoe and Kraus 2013).
These biological enhancements are not mere parlor tricks: they cascade to gains in listening skills and cognitive functions. These include improvements in executive function, auditory attention, auditory-temporal processing, literacy skills, and auditory working memory (reviewed by Tierney and Kraus 2014). In addition, musicians tend to exhibit superior perception of speech in noise (Parbery-Clark and others 2009b; Swaminathan and others 2015; Zendel and Alain 2012; but see Ruggles and others 2014), a key skill to support classroom learning and the development of academic skills such as reading (Bradlow and others 2003; White-Schwoch and others 2015).
It is thought that the communication advantages musicians enjoy are intimately tied to enhanced auditory-neurophysiological processing. Patel (2011) proposes the “OPERA” hypothesis, which outlines the conditions under which music training generalizes to the neural coding of speech. He points out that there is anatomical overlap in the brain networks involved in speech and music, that music places stringent demands on the precision of these overlapping networks, that music-related activities spark activity in emotion networks (known to catalyze neuroplasticity), that the inherent repetition in musical activities strengthens the circuit and facilitates learning of sound nuances on which a musician focuses attention. This framework proposes that when these conditions are met, neural plasticity in these networks drives them to function with higher precision than would be demanded by everyday speech communication.
Patel’s framework dovetails with more general frameworks for auditory learning that emphasize overlap between brain networks (Kraus and White-Schwoch 2015) and the idea that training drives neural networks to optimize the default state of sound processing (Kilgard 2012). It should be emphasized that the brain networks involved in speech and music are similar but not identical—there are specialized areas both for coding speech and music (Norman-Haignere and others 2015; Zatorre and others 2002)—but the overlap in the activity patterns they elicit is nevertheless remarkable (Abrams and others 2011) and is emphasized in studies of music training.
Weiss and Bidelman (2015) elegantly tested the hypothesis that superior neurophysiological representation of speech, viewed through the FFR, augments speech perception. They measured musician’s and non-musician’s FFRs to a continuum of vowel-like sounds ranging from /a/ to /u/. Then, exploiting the morphological similarity between the FFR and the evoking stimulus, they “sonified” the FFRs—that is, tricked a computer into thinking that the FFRs were audio files—and used these as the stimuli in a classic categorical perception task. Listeners could perform a better fine-grained classification of musicians’ FFRs than of non-musicians’. Although correlational, this provides evidence that musicians’ heightened neural processing of sound contributes to better speech perception.
Music and Everyday Listening Skills Coincide
Everyday listening rarely occurs in pristine acoustic conditions. Many factors compromise the intelligibility of speech, such as competing talkers, reverberation, and accents. One of the most insidious sources of adversity in speech perception is background noise. The ear is an open door to sound, and indiscriminately transmits speech and noise as a single stream to the brain, which must pick out the message from the din. It has been argued that understanding speech in noise is one of the most computationally demanding tasks the brain has to perform (Kraus and White-Schwoch 2015), and it may be a uniquely biological feat—despite decades of attempts, computer algorithms still cannot disentangle speech from noise. This ability relies on a constellation of factors, including the integrity with which sound is coded in the brain, accurate localization of sound sources, and cognitive abilities such as attention and working memory (Anderson and others 2013). Importantly, these factors are intertwined in an interactive networking (e.g., Carlile and Corkhill 2015), motivating a hypothesis that enhancements or diminutions to any node in this listening circuit cascade to its other components and shape the ability to understand speech in noise (Fig. 3).
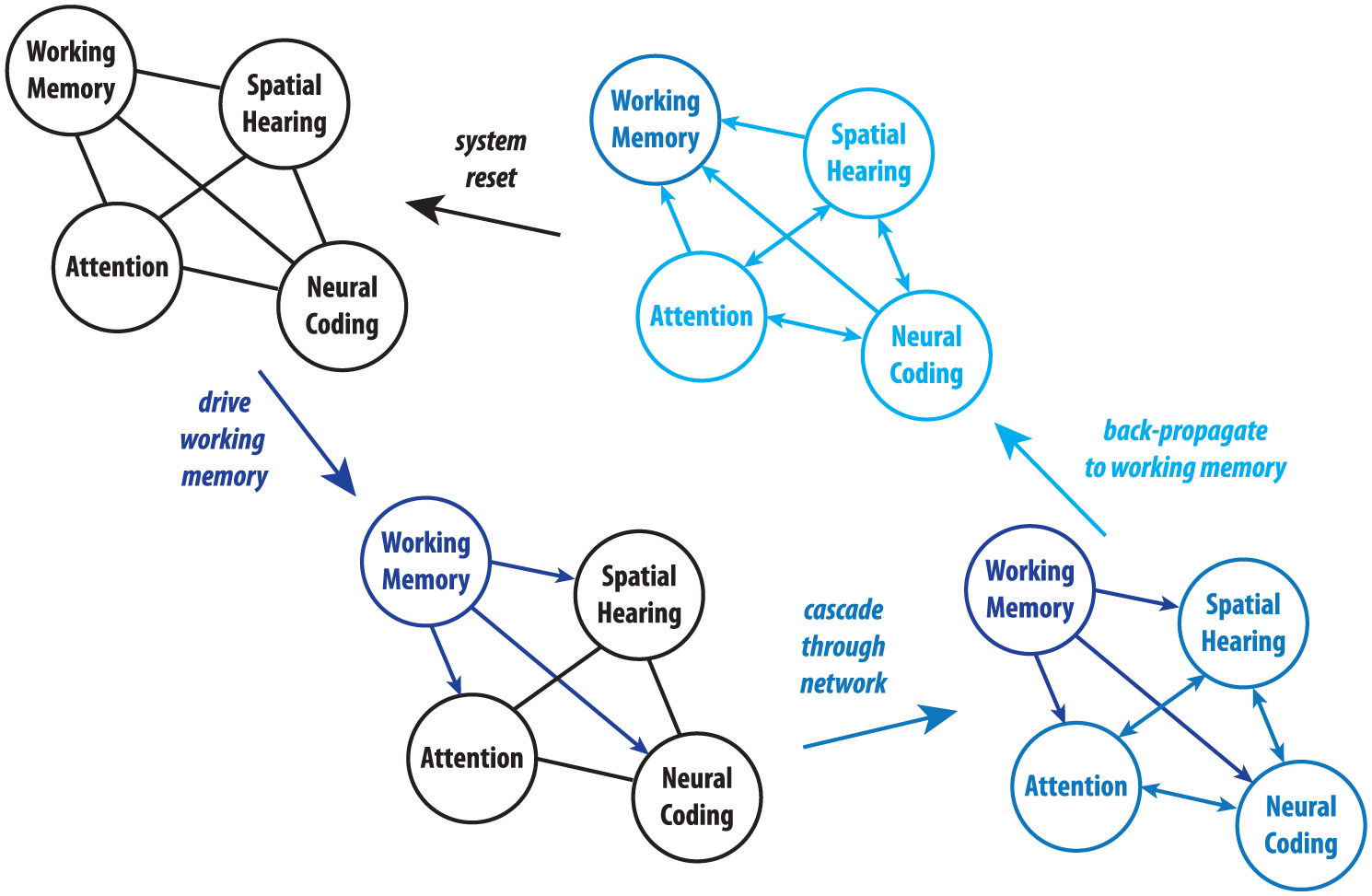
An example of how an active listening network interacts. Working memory, attention, spatial hearing, and neural coding are illustrated, all in a circuit (note that active listening involves much more than these four elements—for the purposes of illustration, only these are shown). A listener might engage working memory systems during complex, real-world listening. Counterclockwise from top right: (1) A drive in working memory interacts with attention, spatial hearing, and neural coding systems. (2) This drive cascades through the network as these systems interact. (3) This drive is then back-propagated to interact again with working memory. (4) Once the task is over, the system resets. Should this be repeated, the acuity of each component of this system could eventually be shaped by long-term, experience-dependent neuroplasticity, thereby making the “default settings” for sound processing inherently more effective. Thus, sound processing and cognition are mutually reinforced in a feedback cycle.
Research on music training and speech-in-noise processing supports this hypothesis. Specifically, FFR neural signatures for music training and hearing in noise partially overlap (Fig. 4). Compared to their peers, musicians have faster responses to speech, responses that more closely resemble the stimulus, stronger neurophysiological distinctions of speech syllables, greater resiliency to the degrading effects of background (Fig. 2) noise, and increased sensitivity to stimulus context (reviewed by Strait and Kraus 2014). These facets of neural processing are tied to the ability to understand speech in noise (reviewed by White-Schwoch and Kraus in press), and in many cases, auditory working memory is thought to drive this overlap. In turn, stronger representations of incoming sounds allow more resources to be dedicated to back cognitive function, such as working memory, which eventually strengthens them once again. This process is thought to be gated by the reward system (Bakin and Weinberger 1996; Kilgard and Merzenich 1998), which is highly activated by music (Blood and Zatorre 2001; Herholz and Zatorre 2012). Thus, sound processing and cognition are mutually reinforced in a feedback cycle.
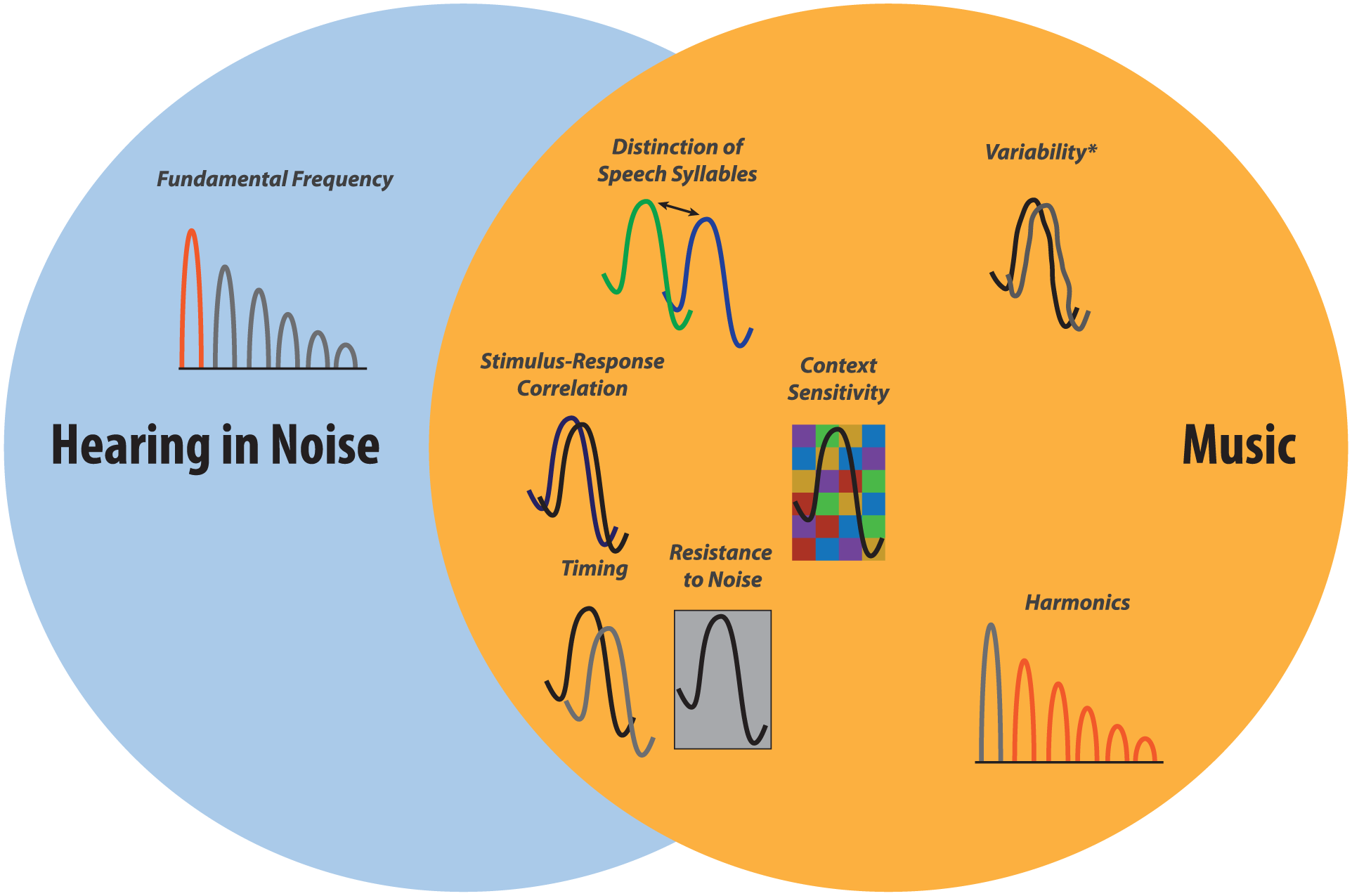
The neural functions enhanced by music training partially overlap those associated with speech-in-noise perception. Hearing in noise pulls on the ability to distinguish speech syllables, to accurately encode sound features, to adapt to stimulus context, to respond quickly to input, and to resist noise degradation. All of these facets of neural processing are enhanced by music training. In contrast, strong coding of the fundamental frequency supports hearing in noise but is not affected by music training. Neither coding speech harmonics nor the variability of neural responses supports hearing in noise, although they are affected by music training. (*Response variability is only affected by music training in vulnerable populations, such as children from low socioeconomic status backgrounds or older adults.).
The music and hearing-in-noise signatures are distinguished, however, when considering the neural processing of distinct spectral cues in speech. Models of speech production and perception distinguish cues generated by the vibrations of the vocal tract (such as the fundamental frequency, F0, that contributes to pitch perception and object grouping) and filter cues generated by the harmonics resonance of the vocal tract (such as the formants that contribute to phonemic identification; Zatorre and others 1992). These orthogonal cues may be analyzed in FFRs (Kraus and Nicol 2005), and the strength of coding the F0 relates to speech-in-noise perception across the lifespan (reviewed by White-Schwoch and Kraus in press). In musicians, however, the coding of the F0 is attenuated in favor of pulling out the harmonics (Fig. 4), which are akin to the timbre of an instrument (Parbery-Clark and others 2009a). This information is extracted from the F0 of a sound, suggesting a more biologically sophisticated sound processing scheme in musicians.
Noteworthy is that only acoustic FFR factors pertain to listening skills in noise. Although intrinsic factors are enhanced by music training in populations that tend to have difficulties in sound processing, even these populations probably rely on acoustic factors to hear in noise (e.g., Parbery-Clark and others 2012).
In summary:
Everyday listening is an active process that is coupled to cognition. Computations must be performed on incoming sounds to extract signal from noise, and when successful, the sensorimotor, cognitive, and reward ingredients of these computations mutually reinforce each other.
Listening and music coincide. Music strengthens listening skills, and many aspects of sound processing strengthened by music training are associated with the ability to understand speech in realistic environments.
In addition to refining sound processing in the brain, music training may change listening strategies—non-musicians seem to rely on pitch-bearing cues to track sounds in noise whereas musicians seem to rely on harmonic cues.
Music and Language Skills Coincide
Another sphere of crossover between music and everyday communication pertains to language skills such as reading (see Box 1). This work is motivated by recognition of evolutionary and neurobiological connections between music and language (Patel 2010, 2014). It should be mentioned that hearing in noise and language skills themselves overlap (Bradlow and others 2003), and this may be one of the avenues by which music strengthens language skills. The neural signature for literacy encompasses all aspects of that for music (Fig. 5) and, like music, excludes neural coding of the F0 (Kraus and others 2014a; Strait and others 2013; reviewed by Tierney and Kraus 2014; White-Schwoch and Kraus in press).
Box 1. What Does Hearing Have To Do With Reading?
Converging evidence supports the hypothesis that auditory function is a chief factor in reading development. For example, many children and adults with dyslexia have abnormal perception of sound, particularly acoustic events that convey phonemic cues in speech (Goswami 2011; Tallal 2004). If a child is forced to learn with a “blurry” representation of incoming signals, this will create an imprecise phonemic inventory that, in turn, causes problems when these sounds need to be associated with written letters. From a theoretical standpoint, then, we are inspired by theories that impute poor phonological processing as one of the core deficits that predisposes a child to reading impairment (Ramus and others 2003), and thus a necessary foundation of reading.
Research on music training and the brain emphasizes the distributed, but integrated, nature of auditory processing. Making music is about connecting sounds to meaning, and connecting meaning to sound. Thus, the auditory enrichment music offers may catalyze these developmental processes and provide a stronger, automatic infrastructure for processing sounds and connecting those sounds with their written forms (Tallal and Gaab 2006). In contrast, blurry neural coding likely results from interactions between imprecise bottom-up neural coding and a failure of top-down mechanisms to refine those biological processes (Kraus and White-Schwoch 2015). This disrupts the ability to connect sounds and meaning. A child has to listen to speech and connect those speech sounds to meaning to develop a robust linguistic repertoire (Benasich and others 2014; Kuhl 2004). This repertoire comes to bear when it is time to associate those sounds with letters and learn to read, and fuzzy representations of those sounds will impede literacy development.
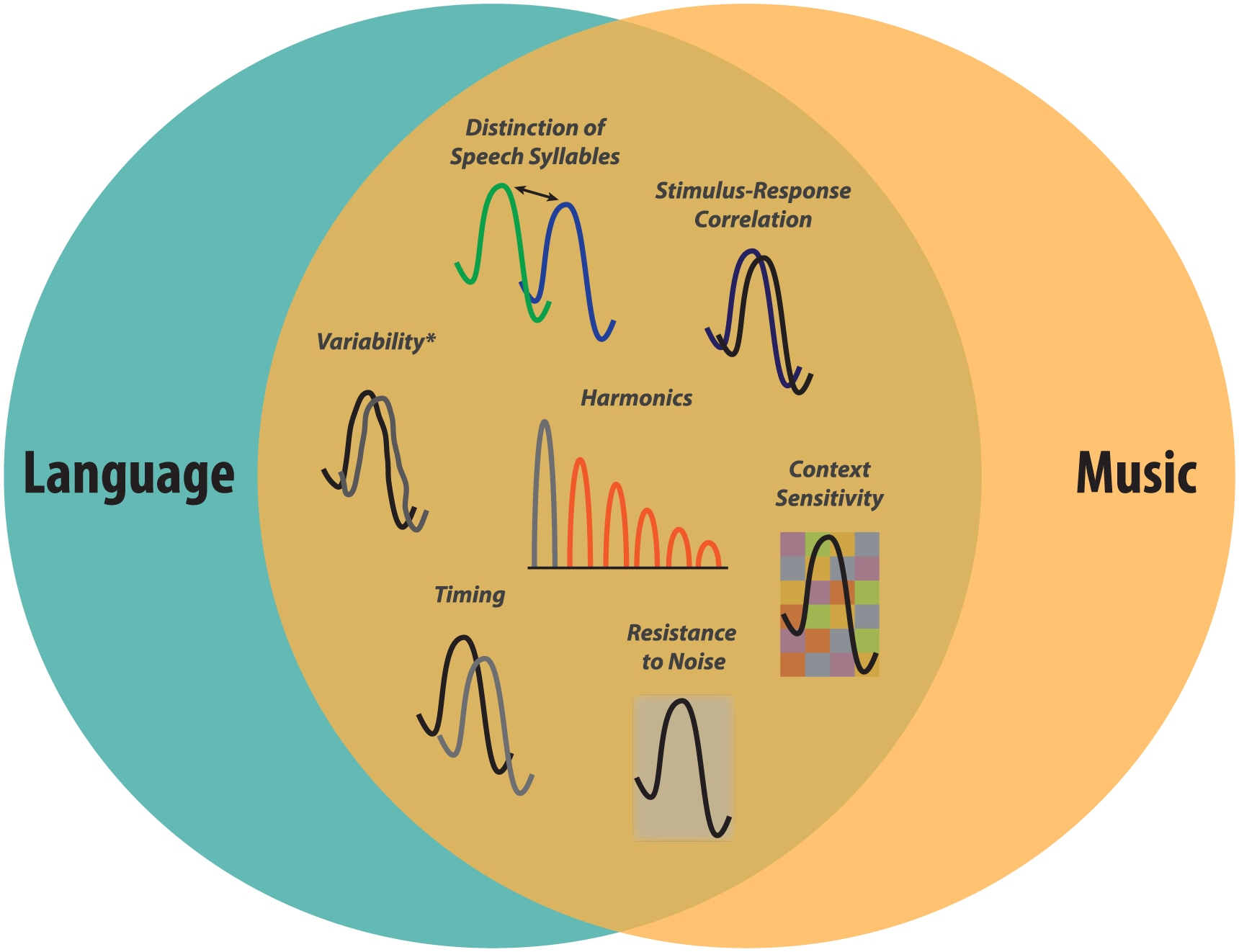
The neural functions enhanced by music training overlap those associated with literacy. Learning to read requires a child to build a robust knowledge of the sound structure of language that can eventually be mapped to letters. Reliable fine-grained auditory processing is critical to develop this phonemic inventory. Specifically, literacy pulls on the ability to distinguish speech syllables, to accurately encode sound features, to adapt to stimulus context, to respond quickly to input, to resist noise degradation, and to process speech harmonics robustly. All of these facets of neural processing are enhanced by music training. Interestingly, representation of the F0 is not enhanced by music training (if anything, it is attenuated) nor is it associated with literacy, in contrast to the neural signature for hearing in noise (Fig. 4). (*Response variability is only affected by music training in vulnerable populations, such as children from low socioeconomic status backgrounds or older adults.).
Unlike the music-listening overlap, the music-language overlap spans acoustic and intrinsic factors (Fig. 5). Specifically, preschoolers and older adults engaged in music lessons tend to have more stable neural responses than their peers (Skoe and Kraus 2013). We think that variable responses represent a neurophysiological vulnerability endemic to populations with emerging and compromised communication. Variable neural processing is associated with poor literacy skills in prereaders (White-Schwoch and others 2015) and school-aged children (Hornickel and Kraus 2013). Additionally, a rat model of dyslexia exhibits variable responses to speech in auditory cortex (Centanni and others 2014). Early music instruction may stabilize neurophysiological processing, supporting better language development (Fig. 5). At the other end of the lifespan, aging is associated with an increase in response variability that is attenuated in older adults with lifelong music training (Parbery-Clark and others 2012).
Beyond this effect on auditory processing stability, converging evidence supports the idea that music training directly benefits language and literacy skills. For example, a clinical trial involving 7 months of active music training improved reading skills in children with dyslexia (Flaugnacco and others 2015; see also Bonacina and others 2015). There are also systematic relations between musical aptitude and reading skills (Moritz and others 2013; for review, see Tierney and Kraus 2014), and, in adolescents, music training strengthens sound processing mechanisms important for literacy along with key literacy skills (Tierney and others 2015). Although it remains to be seen what particular aspects of music training generalize to reading, rhythm is a strong candidate mechanism (Box 2). Moreover, while many studies emphasize the phonological acuity strengthened by music training, it is noteworthy that other aspects of language, including syllabic, semantic, and syntactic processing, are likely strengthened by music experience as well (François and others 2013; Marie and others 2011).
Box 2. Unpacking the role of rhythm in listening and language
Rhythm appears to be a key channel by which music crosses over to listening and language skills. Early evidence in young adults suggests that rhythmic awareness also strengthens the ability to understand sentences in noise (Slater and Kraus 2015), reinforcing the idea that the brain systems involved in music, language, and listening comprise a highly interactive and self-reinforcing network (Fig. 3). This work ties into with rhythmic theories of attention (Large and Jones 1999), which suggest temporal organization of ongoing brain rhythms allows a listener to organize auditory streams, allowing directed attention to one stream and attenuation of others. These brain rhythms are thought to play an important role in listening, especially when understanding speech in noise (Thompson and others 2016).
With respect to language and literacy, there is also a systematic relation between the ability to maintain a steady beat and reading skills (Thomson and Goswami 2008), and both abilities share a common neural substrate of synchronous neural responses to speech (Tierney and Kraus 2013; Woodruff Carr and others 2016). Additionally, prereaders with more precocious rhythm skills outperform their peers on tests of reading readiness, have stronger neural coding of amplitude modulations in speech, and have more consistent responses to speech (Woodruff Carr and others 2014). Music and rhythm training emphasizes auditory-temporal awareness, and it is hypothesized that this generalizes to timing cues in speech, which figure prominently in several influential theories of language impairment (Goswami 2011; Tallal 2004).
In summary:
With rare exception, language and literacy development are contingent on auditory processing. Several theories of language impairment and reading disorders identify a bottleneck making sense of sound.
Language and music coincide. Music aptitude is associated with literacy aptitude, and several studies show that music training boosts reading skills. Additionally, the neural signatures of music training and language overlap—the same facets of sound processing that are weaker in children with reading disorders are strengthened by music training.
Music strengthens language skill by facilitating sound-to-meaning connections. These generalize to speech, and strengthen knowledge of what acoustic cues in sound convey meaning in language. Both rhythm and hearing in noise are candidate channels by which this sound-to-meaning mapping is strengthened.
Neuroscience beyond the Laboratory: Longitudinal Studies of Music Training
Despite the robust nature of the musician’s signature across cross-sectional studies, questions remain about its causal nature and consequences for everyday communication. A recent push takes neuroscience out of the laboratory and into the real world. Music training provides an excellent opportunity for this transition, encapsulated by several studies of community music programs. Perhaps the biggest surprise in this work was that there were no surprises: the neural signature of music training already gleaned from cross-sectional comparisons of musicians and non-musicians emerges longitudinally in these experiments (Chobert and others 2012; Fujioka and others 2006; Hyde and others 2009; Putkinen and others 2014).
Two large-scale studies, each with its own strengths and weaknesses, employed the FFR as an outcome measure in underserved children receiving music lessons. Both studies are motivated, in part, by evidence that disparities in socioeconomic status (SES; measured by maternal education; Hoff and others 2012) shape brain and cognitive function (Noble and others 2015). With respect to the FFR, adolescents from low-SES families have responses that are noisier, less consistent across trials, and represent harmonic cues less robustly (Skoe and others 2013). This signature partially overlaps the signatures for language and music training (Fig. 5), motivating the use of auditory and linguistic enrichment as an intervention (Neville and others 2013), including music training.
The Harmony Project: Youth Community Music Training in Los Angeles
The first study was a collaboration with Harmony Project (www.harmony-project.org), a Los Angeles–based music and mentorship program that has provided free music instruction to over 1000 children from gang-reduction zones. Children (ages 6–9 years) were randomly assigned to either receive music instruction or to a waitlist, with guaranteed admission to music training the following year. A strength of this study was the use of random assignment; however, the cohort of families was highly motivated to receive music instruction, and there was no active control group.
Children received a pretraining assessment including FFRs, speech-in-noise perception, and language skills, followed by two annual follow-ups. After the first year of training, the group engaged in music lessons had better perception of sentences in noise (Slater and others 2015). Additionally, they maintained their literacy skills relative to their peers on the waitlist, who fell behind with respect to expected literacy milestones (Slater and others 2014).
After the second year of training neurophysiological changes began to emerge. Specifically, children engaged in 2 years of music making had stronger neurophysiological distinctions of contrastive speech sounds (Kraus and others 2014b). A follow-up study directly compared children engaged in active music making to those in music appreciation classes (Kraus and others 2014a). This study emphasized that making music matters: the children engaged in instrumental lessons had faster and more robust responses to spectral features in speech. Finally, the second year of music training further strengthened children’s speech-in-noise perception (Slater and others 2015).
Noteworthy is that all of these enhancements evoke the aforementioned musician’s signature discovered through cross-sectional studies (Figs. 4 and 5). These experiments also illustrate two important lessons in auditory learning. For one, the nervous system does maintain a resiliency to change that is likely adaptive. Auditory training, including music, must be repeated for a prolonged period of time to reshape automatic response properties. For two, these studies highlight the importance of active engagement during auditory learning in order to spark neuroplasticity, as supported by the OPERA hypothesis (Patel 2011).
In summary:
Community music programs have the potential to spark neuroplasticity in underserved children. The resulting neural signature aligns with evidence from cross-sectional comparisons of musicians and non-musicians (Figs. 4 and 5).
It takes time to change the brain. One year of community music training was not enough to engender auditory plasticity, but after 2 years biological sound processing—and everyday listening skills—were strengthened.
Making music matters. Neuroplasticity was only observed in children actively engaged in making music, showing the importance active sound-to-meaning mapping in eliciting learning. This also suggests that simple music appreciation classes may not be an effective intervention.
High School Music: Adolescent Music Training in Chicago
The second study involved adolescents in the Chicago Public School system who first had the opportunity for music training when they entered high school (starting age ~14 years). Adolescents engaged in either music training (band or choir) or paramilitary training (group drills and marching). Thus, although there was not random assignment, this study provides an active control that compares children within the same schools matched for cocurricular engagement.
Once again it took time for music to spark biological changes in sound processing. After 2 years, however, adolescents engaged in music training had FFRs that were more resilient to background noise (Tierney and others 2013), again consistent with the aforementioned musician’s neural signature (Fig. 2). After an additional year, their FFRs were less variable across trials (Tierney and others 2015). This is noteworthy because this was in a predominantly low-SES population, thus partially countervailing the signature of auditory deprivation associated with low SES. These children also showed stronger phonological processing, evocative of links between the stability of neural coding and language skills. Moreover, after 3 years of training adolescents had more mature cortical responses to speech, suggesting that music training interacts with neurophysiological processes under development. This finding was later replicated in a younger group of children engaged in music training (Habibi and others 2016).
In summary:
Music training initiated at least as late as high school still has the potential to improve sound processing in the brain. This study reinforces cross-sectional studies by showing a consistent neural signature of music training (Figs. 3 and 4) and previous longitudinal studies, by showing that it takes time to change the brain.
Experience piggybacks on neural processes that are undergoing maturation. This suggests that auditory enrichment such as music could serve as an intervention strategy to strengthen auditory processing in children who lag behind their peers developmentally.
Music training can counteract parts of other neural signatures. Specifically, the neural signature of low-SES backgrounds is partially erased by high school music training, further supporting music as a community-based intervention to enrich sound processing and everyday communication.
Conclusion
Our life in sound imparts an enduring biological legacy on the brain, and music provides new and applicable insights into this neurobiology of everyday communication. Studies of music training highlight the plasticity and stability of sound processing in the brain and show the consequences of this plasticity for everyday communication skills, including listening in noise and literacy. This sound processing lies at the interface of cognitive, sensorimotor, and reward networks. New work takes neuroscience into the community by investigating the biological impact of real-world music programs, in children and adolescents. This work both reinforces cross-sectional comparisons of musicians and non-musicians and paves new ground by showing that the musician’s brain is not restricted to individuals with formal, lifelong music training. Importantly, this work has the potential to teach basic lessons about the biology of learning, including that it takes time to change the brain and that active engagement during learning is crucial. This approach also provides a framework to unravel individual differences in learning and plasticity and map out the interactions between predispositions and specific experiences. Community enrichment programs initiated at least as late as adolescence may eventually refine sound processing in the brain. Objective biological measures, such as the FFR, document these changes and show their relation to communication impairments. Thus, this approach could serve as an outcome measure in evaluating community interventions to influence health care, education, and social policy.
Footnotes
Acknowledgements
We thank Silvia Bonacina and Sebastian Otto-Meyer for their input on this work and members of the Auditory Neuroscience Laboratory, past and present, for their many contributions.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: NK is chief scientific officer of Synaural, a company working to develop a user-friendly measure of auditory processing.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Supported by the National Association of Music Merchants, NSF (BCS 092127, BCS 1057556, and BCS 1329440), the Dana Foundation, and the Knowles Hearing Center.