
Abstract
This paper studies forest fires from the perspective of dynamical systems. Burnt area, precipitation and atmospheric temperatures are interpreted as state variables of a complex system and the correlations between them are investigated by means of different mathematical tools. First, we use mutual information to reveal potential relationships in the data. Second, we adopt the state space portrait to characterize the system’s behavior. Third, we compare the annual state space curves and we apply clustering and visualization tools to unveil long-range patterns. We use forest fire data for Portugal, covering the years 1980–2003. The territory is divided into two regions (North and South), characterized by different climates and vegetation. The adopted methodology represents a new viewpoint in the context of forest fires, shedding light on a complex phenomenon that needs to be better understood in order to mitigate its devastating consequences, at both economical and environmental levels.
Keywords
1. Introduction
Forest fires (FFs) have a great impact on the environment and the economy (Logan et al., 2003; Rittmaster et al., 2006). Burnt areas correspond directly to flora and fauna losses, ecosystem damage and soil degradation (Smith et al., 2000; Certini, 2005). Long-term consequences are the modification of the water cycle, replacement of autochthonous vegetation by invasive species (Brooks et al., 2004), increase in carbon dioxide emissions (Page et al., 2002) and climate change (Flannigan et al., 2000) (e.g. global warming and extreme weather events). In fact, wildfires can be regarded as positive feedback loops acting on the climate complex system (CS), simultaneously potentiating and being potentiated by climate changes (Dale et al., 2001; Kirilenko and Sedjo, 2007).
FF propagation depends on many factors, such as weather conditions, terrain orography and type of vegetation. Moreover, the effectiveness of detection and suppression measures is fundamental in order to mitigate fire impact (Chandler et al., 1983). Fire size patterns and spatiotemporal distributions provide valuable information for deciding about preventive measures, helping in identifying possible hazards, and in planning strategies for prevention, detection and suppression (Tenreiro Machado and Lopes, 2014).
Standard statistical methods have proved to be inadequate for analyzing extreme fire events (Holmes et al., 2008) as they are not capable of capturing all characteristics underneath fire dynamics (Alvarado et al., 1998). FFs exhibit complex spatiotemporal correlations, characterized by long-range memory and absence of a characteristic length-scale (Malamud et al., 1998; Ricotta et al., 1999; Reed and McKelvey, 2002; Telesca et al., 2005; Song et al., 2006). Those features are explained by the self-organized critical (SOC) (Bak, 1990) and highly optimized tolerance (HOT) models, proposed to explain fire behavior (Grassberger and Kantz, 1991; Drossel and Schwabl, 1992; Carlson and Doyle, 1999; Moritz et al., 2005).
Ricotta et al. (1999) analyzed FF data for the region of Liguria (Italy), covering the years 1986–1993. They concluded that there is a power-law (PL) relationship between the frequency of occurrence of the event and the burnt area (size). Malamud et al. (1998) analyzed FFs in the USA and Australia and showed that FFs exhibit a PL dependence frequency versus size, over many orders of magnitude. A simple fire model was proposed and it was concluded that actual FFs can be directly associated with the model. Deviations from PL behavior, observed in certain cases, were explained by Song et al. (2006). They examined the SOC and fractal characteristics of FFs in China and hinted at actual FF protection. Reed and McKelvey (2002) proposed empirical frequency–size distributions, derived from real data in six regions in North America, concluding that a simple PL distribution of sizes may be too simple to describe the distributions over their full range. They developed a stochastic model for the spread and extinguishment of FFs to examine the necessary conditions for PL behavior. FF time-scaling was addressed by Telesca et al. (2005), who characterized the temporal distribution of fires occurring in Gargano (Italy), known for its high density of fires. They concluded that the point process of fire events is a fractal process with a high degree of time-clusterization. Time-scales are of the order of a few days and the fire process tends to be less time-clustered with an increase in the burnt area. The time-scaling properties of yearly FF sequences occurring in the Reggio Calabria (Italy) region were studied by Lasaponara et al. (2005). Their results show that FFs exhibit a strong degree of time-clusterization.
The HOT conceptual framework, as an alternate to SOC, was used to explain the formation of scale-invariant patterns in CSs (Carlson and Doyle, 1999). It emphasizes that PL behavior results from optimization of tradeoffs between system yield and tolerance to risk, which drives the system to a specific spatial configuration. Moritz et al. (2005) studied historical fire catalogs and proposed a detailed fire simulation model. They concluded that both are in agreement with the HOT concept. Boer et al. (2008) showed that FF size distributions are closely related to distributions of weather events. Zheng et al. (2008) investigated the PL scaling behavior of FFs and weather parameters by means of a detrended fluctuation analysis method. They verified that temperature, relative humidity and precipitation data reveal characteristics similar to FFs. Their reported findings were shown to be useful for quantifying the underlying dynamics of FF and weather parameters, and for understanding the relationship between them.
In this paper we study FFs from the perspective of dynamical systems. Burnt area and weather variables, such as precipitation and atmospheric temperatures, are interpreted as state variables of a CS and the correlations between them are investigated on an annual basis using different mathematical tools. First, we propose the mutual information concept to unveil potential relationships in the data. Second, we adopt the state space portrait to characterize the system behavior. Third, we compare the state space curves and use clustering and visualization tools, namely hierarchical clustering and multidimensional scaling. Several long-range patterns emerge in FF time-lines. Our study focuses on data for Portugal (excluding Azores and Madeira), covering the time period from 1980–2003. We divide the Portuguese territory into two regions (North and South), as they present different climates and vegetation. The adopted methodology and tools represent a new viewpoint in the context of FF analysis, shedding light on a complex phenomenon that needs to be better understood in order to mitigate its severe consequences. The paper reveals the difficulties in forecasting future events based on a limited set of variables. However, it is clear that the emergence of clusters corresponds to complex dynamical effects. In fact, the emerging patterns resemble those of chaotic systems, leading to poor predictability. On the other hand, the study demonstrates that the results point towards measuring a richer set of environmental variables and the recording of longer time-series in order to establish a solid basis for computer data analysis systems.
Bearing these ideas in mind, this paper is organized as follows. Section 2 introduces some fundamental mathematical concepts. Section 3 describes the experimental dataset and characterizes the data using simple statistics. Section 4 analyzes the data by means of state space portrait and compares the state space curves using clustering and visualization tools. Finally, Section 5 presents the main conclusions.
2. Mathematical background
This section presents the mathematical tools used to process the data, namely mutual information (MI), state space portrait (SSP), hierarchical clustering (HC) and multidimensional scaling (MDS).
2.1. Mutual information
The MI statistical concept originated from the area of information theory. MI measures the statistical dependence between two random variables and can be interpreted as the amount of information that one variable ‘contains’ about the other (Shannon, 2001). Recently, MI has been used as an approach to analyze different CSs (Fraser and Swinney, 1986; Matsuda, 2000; Tenreiro Machado and Lopes, 2013). Mathematically, for two discrete random variables (X,Y), the MI, I(X,Y) is given by
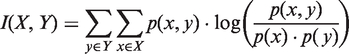
2.2. State space portrait
A n-dimensional dynamical system can be represented by a set of first-order differential equations governing n state variables,
2.3. Hierarchical clustering
Clustering analysis organizes data into groups (clusters) such that there is a high/low intra/inter-cluster similarity between objects. Clustering exposes the internal structures of the data, underlying rules and patterns. It has been adopted in data mining, machine learning, pattern recognition, image analysis and bioinformatics, among others (Hartigan, 1975).
There are two types of clustering: partitional and hierarchical. In partitional clustering, different partitions are created and then evaluated by means of some criterion (e.g. k-means (Jain, 2010)). In HC a hierarchy of object clusters is built. This is typically done by means of heuristic algorithms. In agglomerative clustering the algorithm starts with each object in its own cluster and, at each step, it finds the best (most similar) pair of clusters to merge into a new cluster. It iterates until all clusters are merged together. In divisive clustering the algorithm starts with all items in a single cluster, at each step, it chooses the best way to split the cluster into two and, recursively, operates on both new-formed clusters. The iterations stop when each object is in its own cluster.
Both in agglomerative and divisive clustering, the clusters are generated by evaluating the inter-cluster dissimilarity. A metric (i.e. a measure of the distance between pairs of objects) and a linkage criterion (i.e. the definition of the dissimilarity between clusters as a function of the pairwise distances between objects) are adopted to quantify the inter-cluster dissimilarity. Mathematically, for two clusters, U and V, a metric is used to measure the distance between objects,
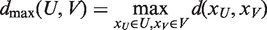
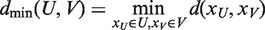
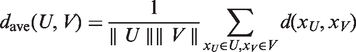
The results of HC are usually presented in a dendrogram, where the similarity between two objects is represented by the height of their lowest common internal node.
2.4. Multidimensional scaling
MDS is a set of techniques for visualizing similarities/dissimilarities between objects in a dataset (Cox and Cox, 2000). MDS generates maps describing the objects’ locus in the perspective that, if they are perceived to be similar/dissimilar to each other, then they are placed on the map close/distant to/from each other. MDS provides an intuitive and useful visual representation of complex relationships present among objects. In metric MDS the input is an n × n symmetric matrix,
3. Brief description of the dataset
This section describes the dataset used in this study (i.e. FFs, precipitation and temperature) and complements the presentation with simple statistics.
We consider the Portuguese continental territory divided into the North (N) and South (S) regions as shown in Figure 1. These regions correspond to different climate, vegetation and orography conditions, which influence fire behavior. The time period of analysis is limited to years 1980–2003, which is imposed by the data available.
Location of the two Portuguese regions studied.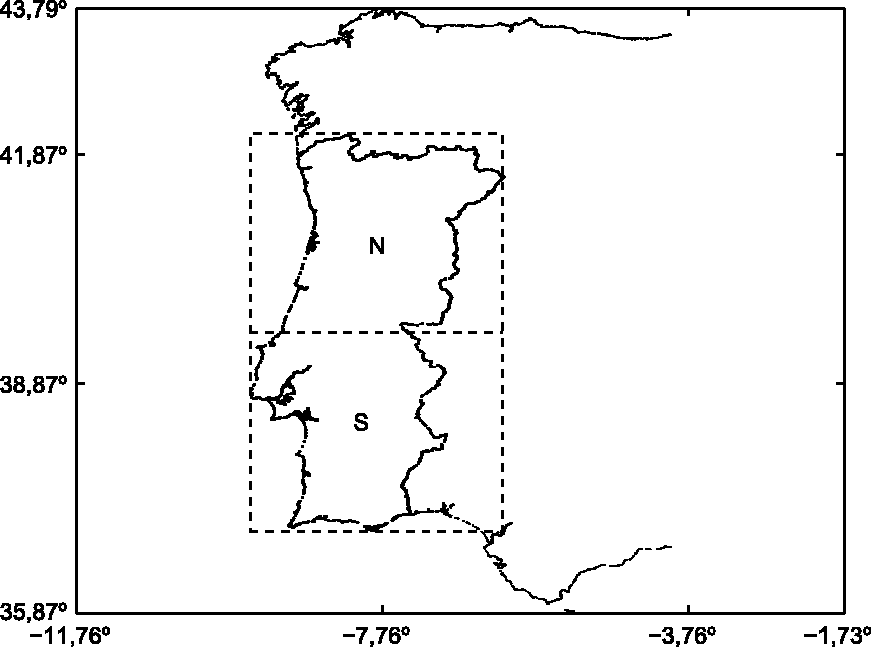
A catalog of FFs is compiled by the Portuguese Instituto da Conservação da Natureza e das Florestas (INCF), and is available online at http://www.icnf.pt/portal/florestas/dfci/inc/estatisticas. Each data record contains information about the date of the event, time (with one-minute resolution), geographic location (expressed in latitude and longitude coordinates) and size (quantified by the burnt area, expressed in hectares). All occurrences are included, independently of their cause, namely natural factors, human negligence and human intent.
The data is pre-processed by calculating the daily burnt area in each region. Figure 2 shows the burnt area for regions N and S. We adopt a circular time-scale to represent the time evolution of fire within the period 1980–2003. The circular time evolves along an Archimedean spiral with its origin at the center of the circumferences defined by
Time evolution of the daily burnt area, during the period 1980–2003: (a) region N; (b) region S.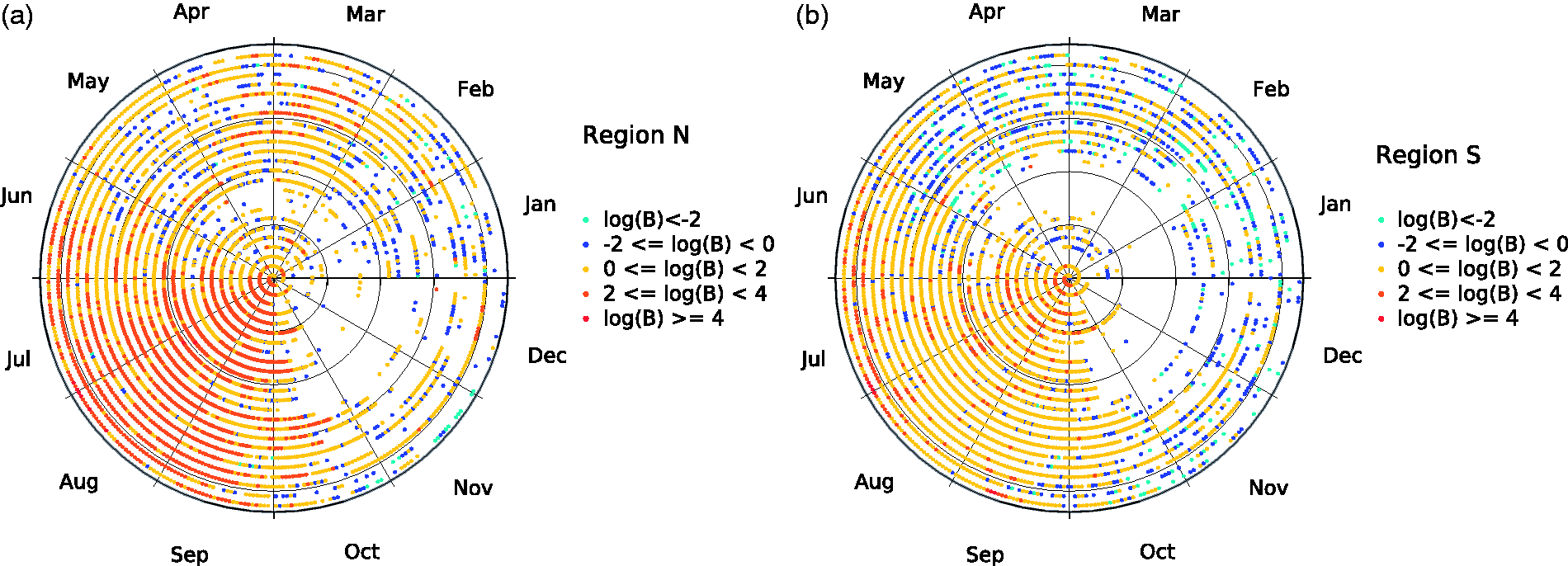
Data on precipitation was collected at the Instituto Português do Mar e da Atmosfera (IPMA) https://www.ipma.pt/en/. The database contains information of daily precipitation for Portugal, in a regular grid with 0.2° × 0.2° resolution, for the period 1950–2003. The gridded data was obtained based on records from 806 meteorological stations, interpolating the original data using the Kriging method (Belo-Pereira et al., 2011).
We pre-processed the gridded database, calculating the total daily precipitation for regions N and S in the period 1980–2003.
The source of temperature data was the National Aeronautics and Space Administration (NASA) website (http://data.giss.nasa.gov/gistemp/station_data/). Each data series consists of the average temperatures per month, expressed in Celsius degrees, of several worldwide meteorological stations. We use temperature time-series of Porto and Lisbon to represent the N and S regions of Portugal, respectively. This option is justifiable by the existence of accurate data for both cities and because Portugal is a small country, making the inclusion of other centers unnecessary. Thus, using data from one place to characterize each region is a good approximation. We pre-processed the data, filling occasional gaps of one month (represented on the original dataset by the value 999.9) by temperature values calculated using linear interpolation between the two adjacent points. The distinct number of days of each month and the leap years were taken into account. The data was then interpolated linearly in order to get daily mean temperatures (Tenreiro Machado and Lopes, 2012; Lopes and Tenreiro Machado, 2014).
In Figure 3 we represent the evolution of the annual total burnt area, mean temperature and precipitation, for regions N and S, over the time period 1980–2003. It can be seen that there is a correlation between burnt area and both mean temperature and precipitation.
Evolution of the annual burnt area, mean temperature and precipitation, over the time period 1980–2003: (a) region N; (b) region S.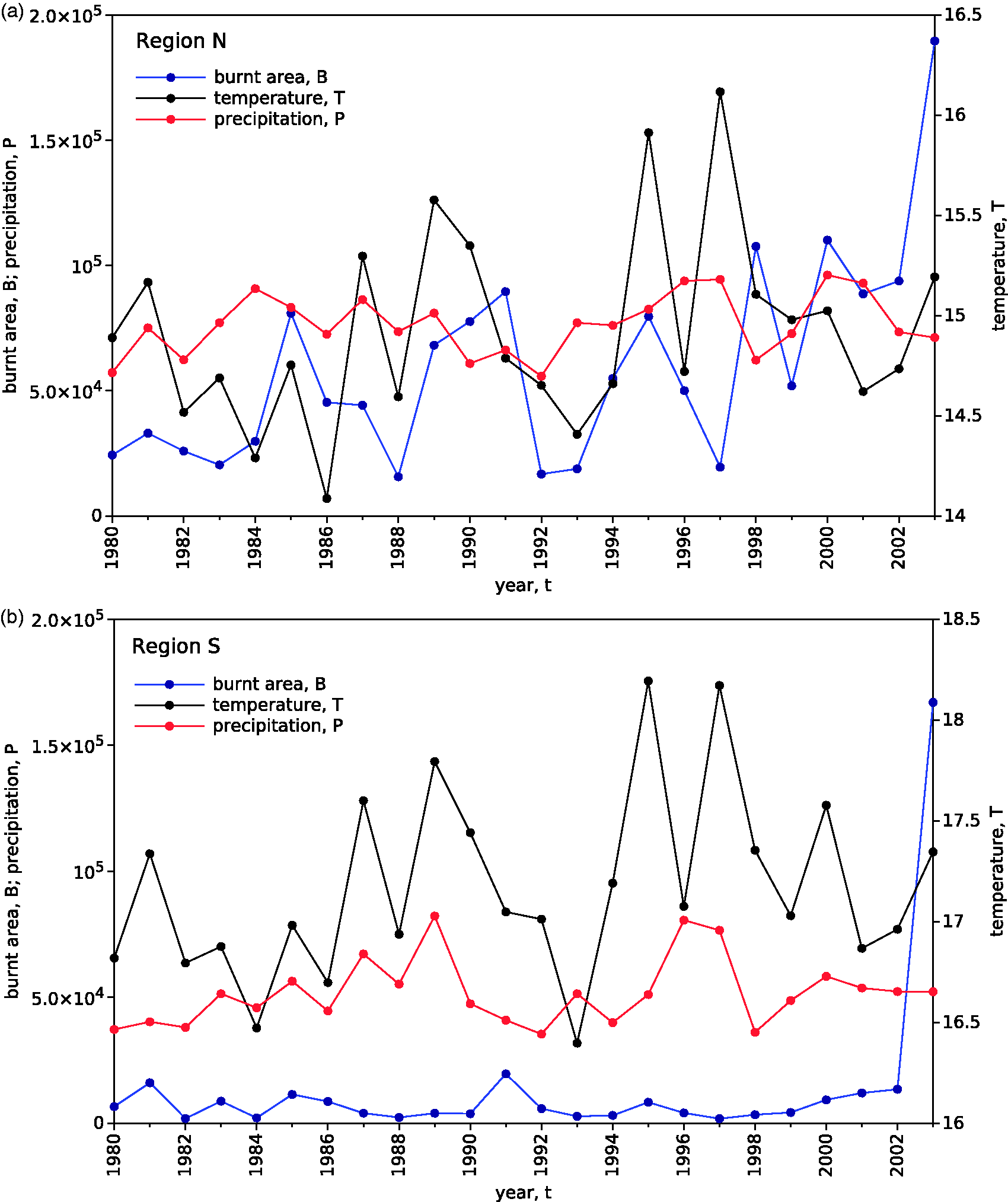
We verify that the previous simple statistics do not capture all the hidden relationships in the data. Therefore, in the next section, several complementary mathematical tools are adopted.
4. Data analysis and results
In this section, data comprising burnt area, precipitation and atmospheric temperatures are interpreted as state variables of a CS and correlations between the variables are investigated on an annual basis. In subsection 4.1, we use MI to analyze the relationships in the data. In Section 4.2, we adopt the SSP to characterize the system’s behavior. Finally, in Section 4.3 we compare the state space curves by means of HC and MDS.
4.1. Mutual information analysis
To calculate the MI, we first generate the annual time-series of daily values
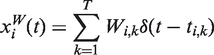
The annual MI between burnt area and precipitation, I(B,P) and between burnt area and mean atmospheric temperature I(B,T) were calculated, estimating the probabilities by means of the histograms of relative frequencies. For constructing the histograms, we adopt N = 200 bins.
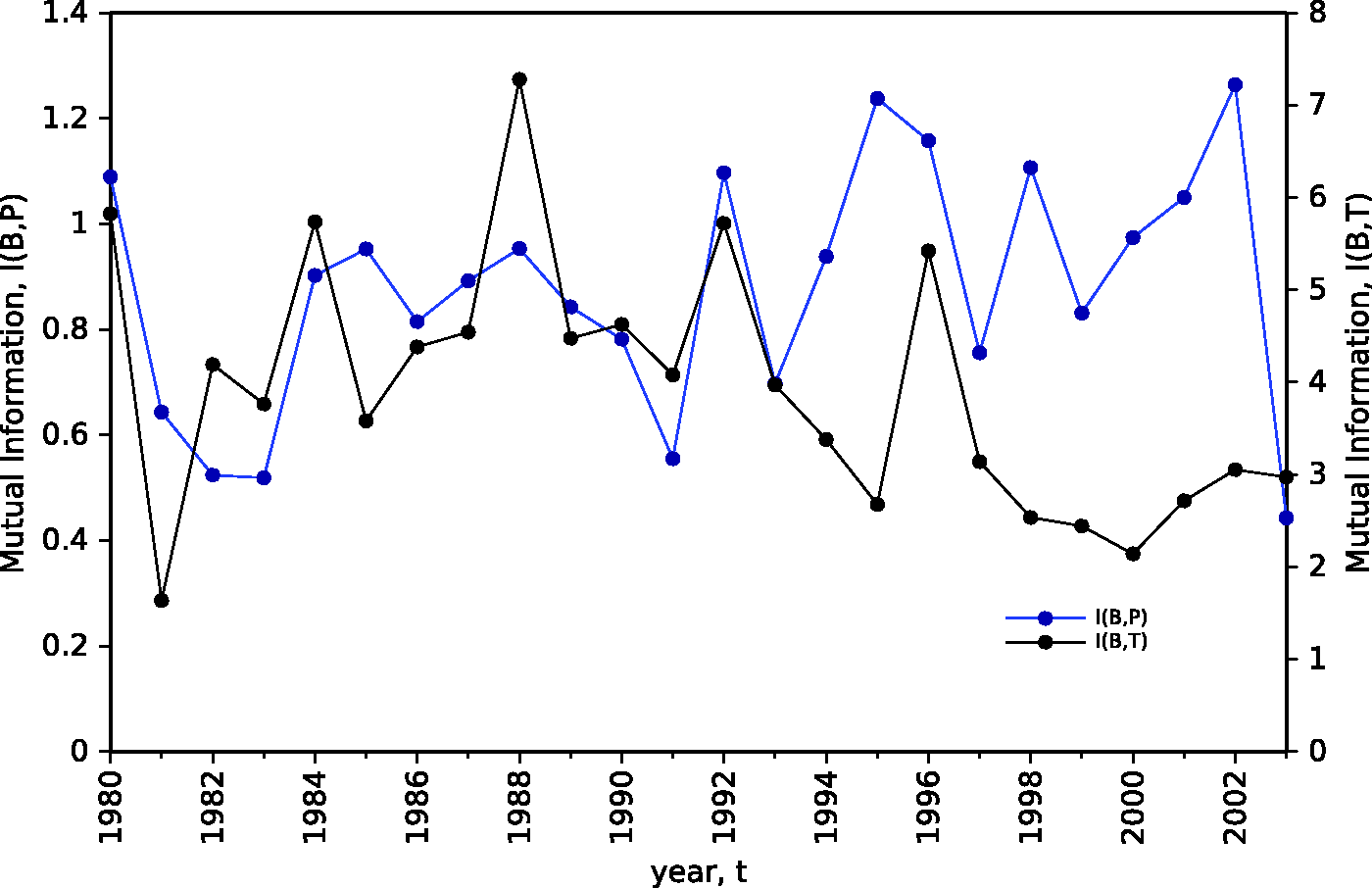
Figures 4 and 5 represent the evolution of the annual MI between burnt area and precipitation, I(B,P), and between burnt area and mean atmospheric temperature I(B,T), for regions N and S, respectively. We can see that, for the two regions, I(B,P) is lower than I(B,T). For region N, I(B,P) is somewhat ‘noisy’, but it stays almost constant over the period 1980–2003, with exception of the years {1990, 2003} and {1997}, where minimum and maximum values of MI are registered, respectively. With respect to I(B,T), in the early years it is almost constant. In year {1988} it reaches a maximum value and, for more recent years, its trend is for decreasing. For region S, I(B,P) is also ‘noisy’, but its trend reflects some increasing over time, except for years {1980, 2003}. The evolution of I(B,T) shows a trend to increase during the first half and to decrease for the second half of the period of analysis.
Evolution of the annual MI between burnt area and precipitation, I(B,P), and between burnt area and mean atmospheric temperature I(B,T), for region N, during the time period 1980–2003. Evolution of the annual MI between burnt area and precipitation, I(B,P), and between burnt area and mean atmospheric temperature I(B,T), for region S, during the time period 1980–2003.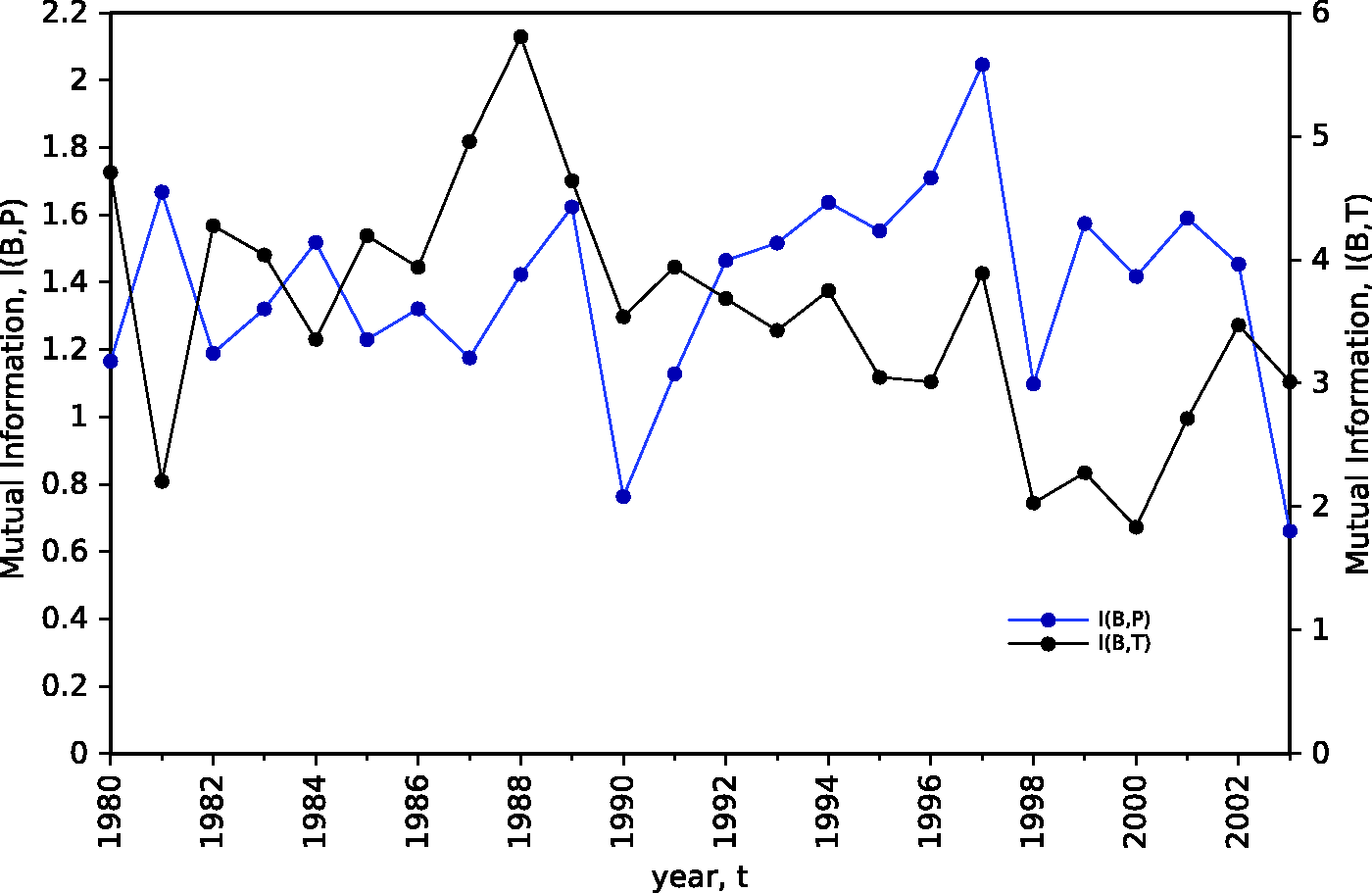
4.2. State space analysis
To generate the SSP we first compute the annual time-series of accumulated burnt area,
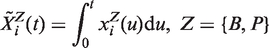
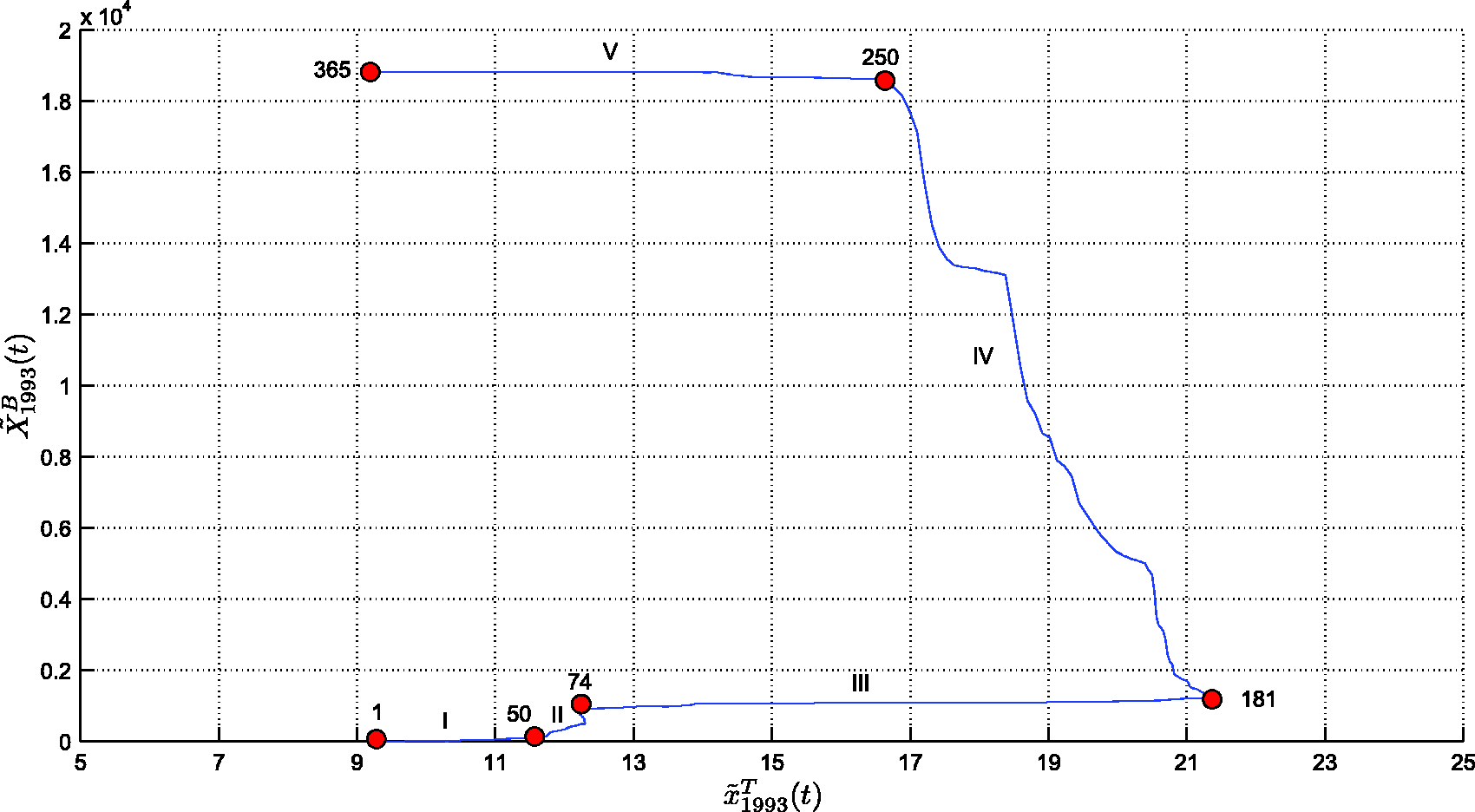
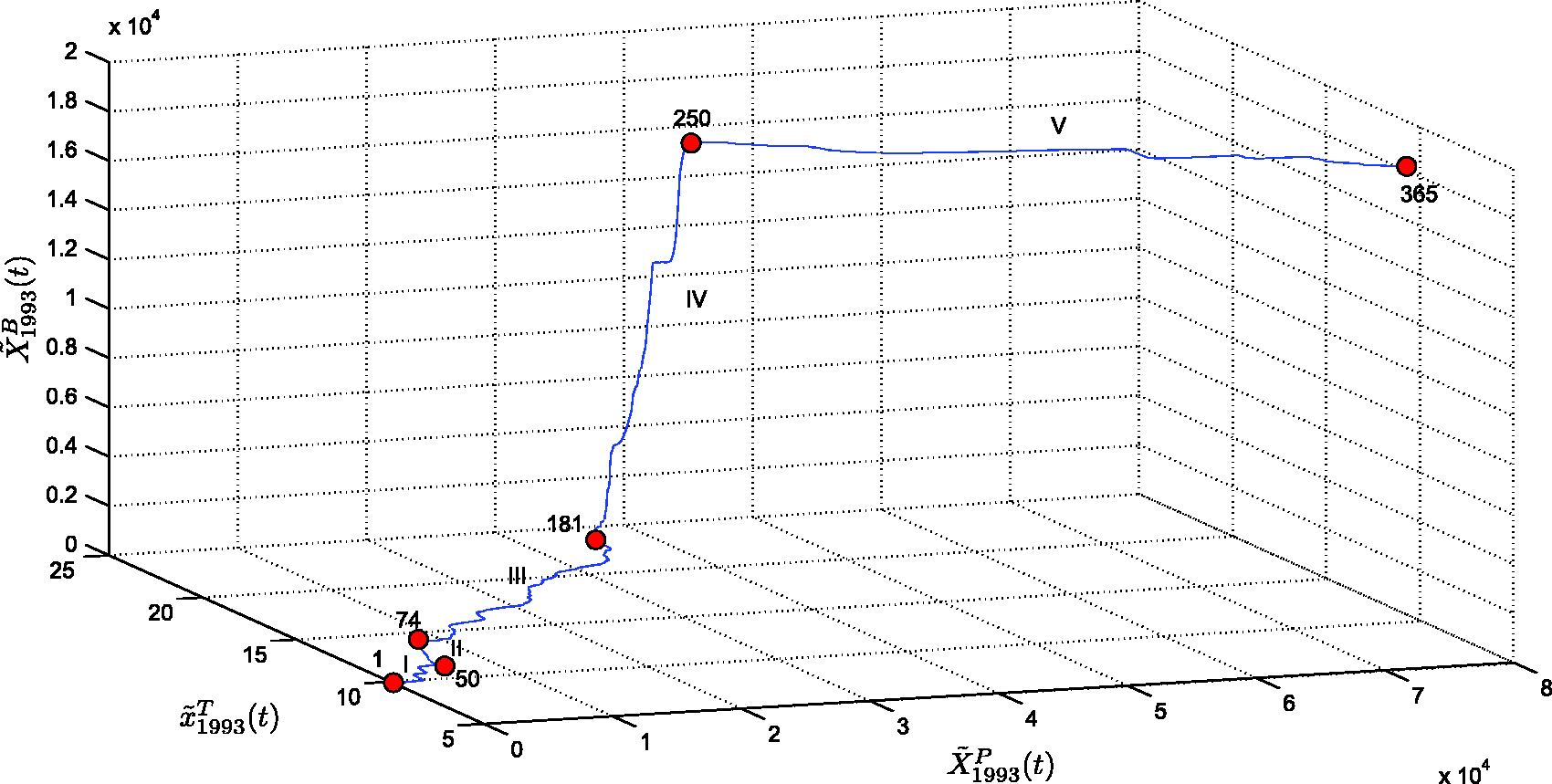
Second, we analyze the annual SSP generated by the three ‘state’ variables: accumulated burnt area,
In this second analysis, to illustrate the methodology, we present the results for year 1993, in region N. Figure 6 depicts the time evolution of the variables, where we can see that the accumulated burnt area, Time evolution of the variables 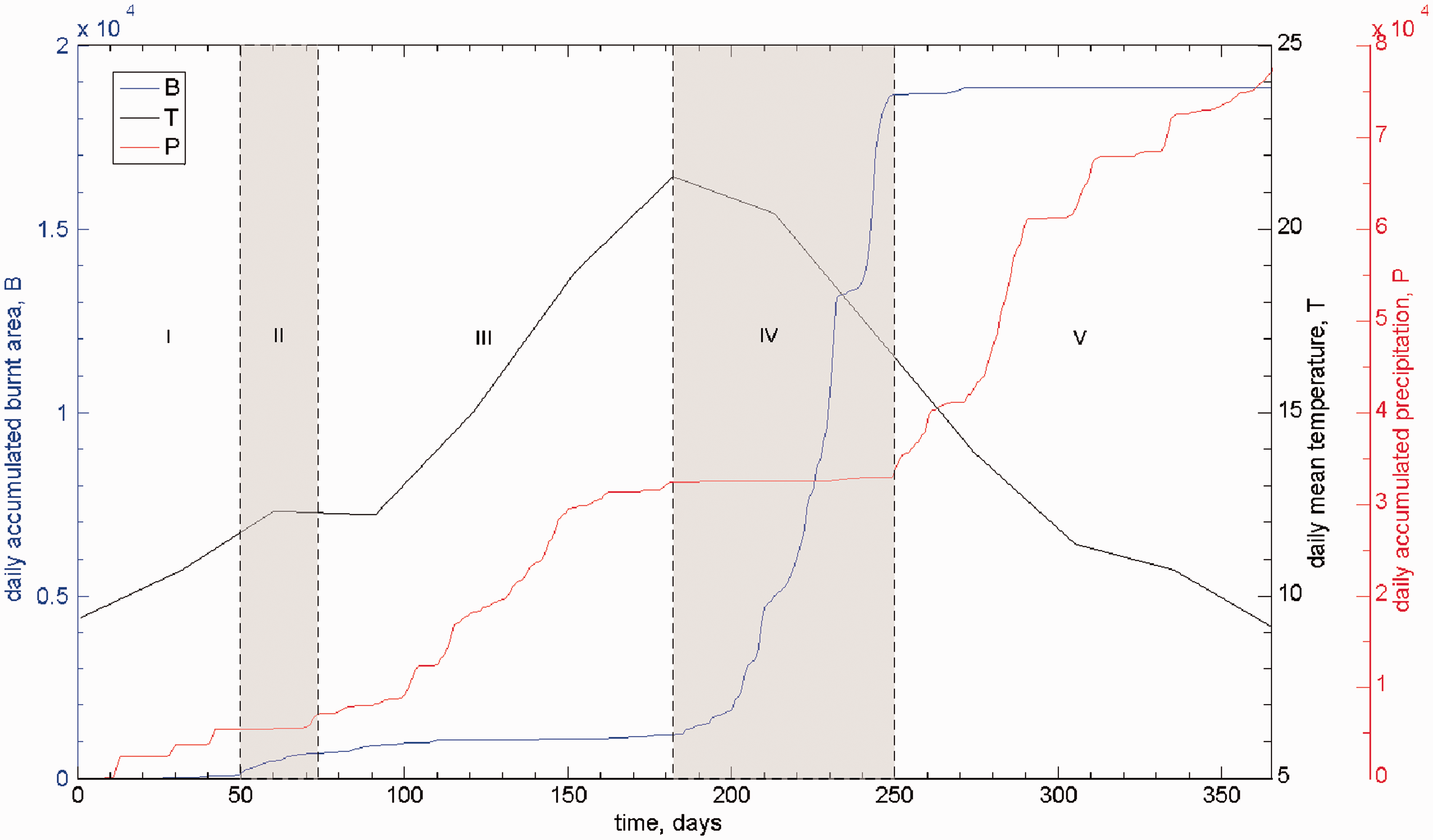
The relationships between The SSP The SSP The SSP Visualization tree generated by the HC algorithm, representing similarities between SSP annual curves, for region N. Visualization tree generated by the HC algorithm, representing similarities between SSP annual curves, for region S.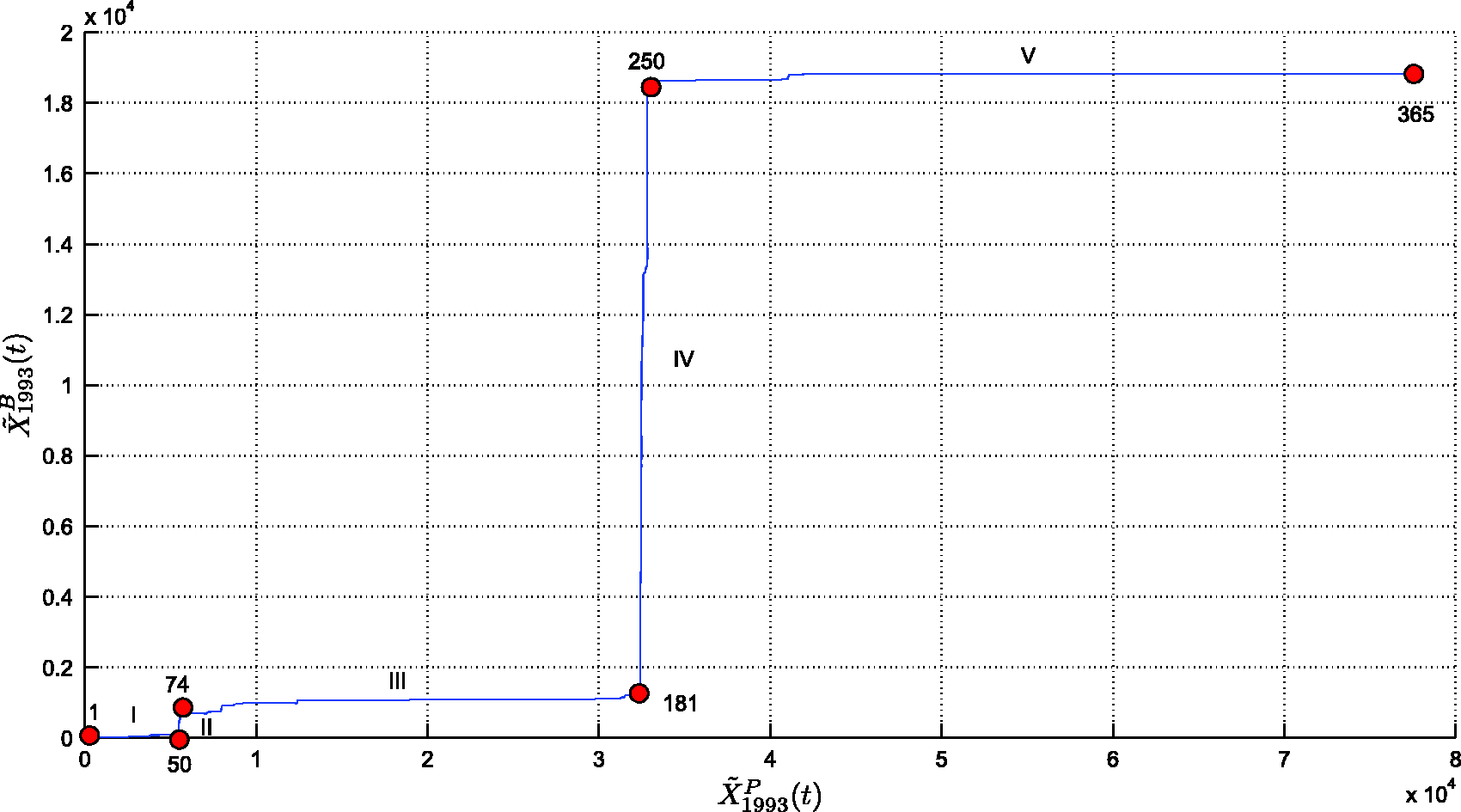
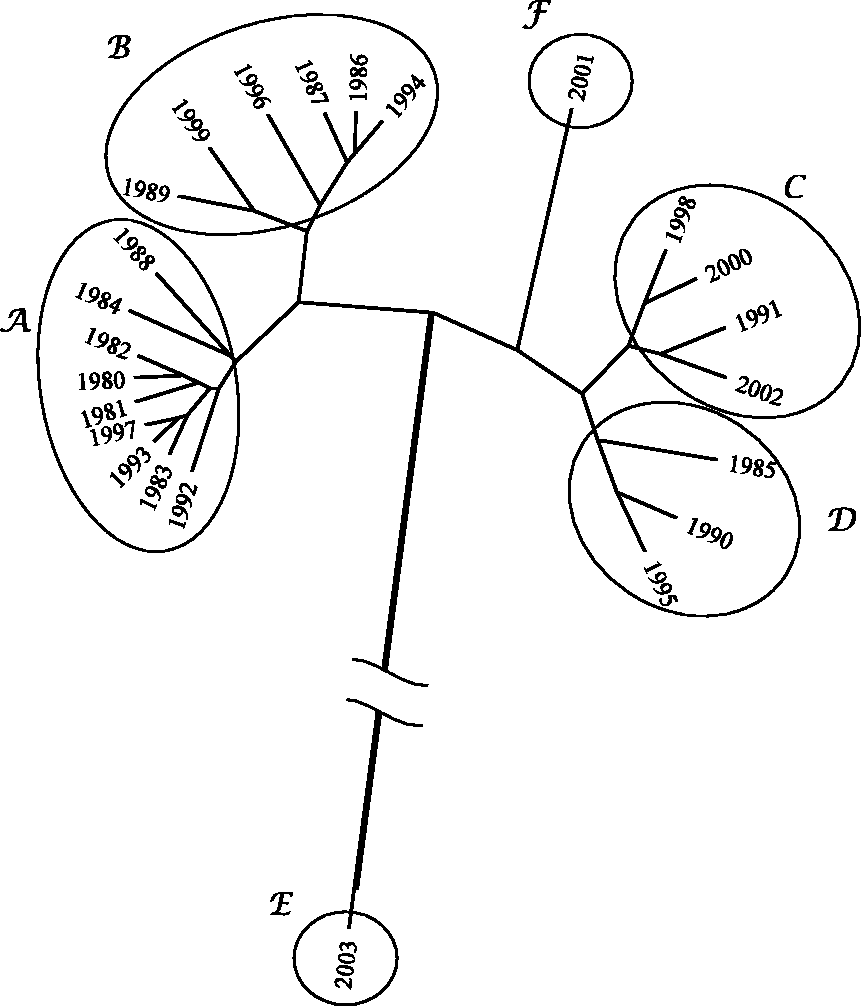
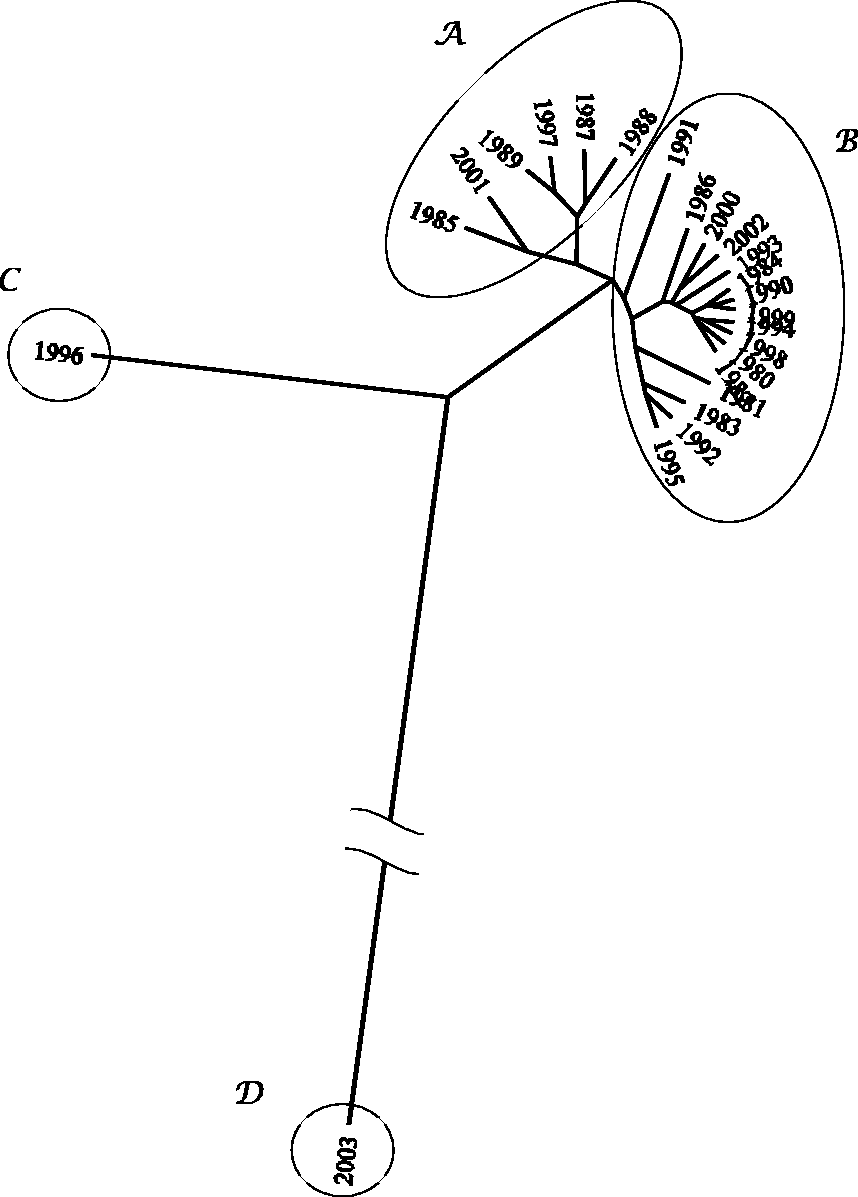
4.3. Clustering analysis and visualization
In this subsection clustering and visualization algorithm are adopted to compare the annual SSP curves and to unveil relationships in the data.
To compare all SSPs we calculate a 24 × 24 dissimilarity matrix
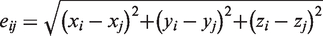
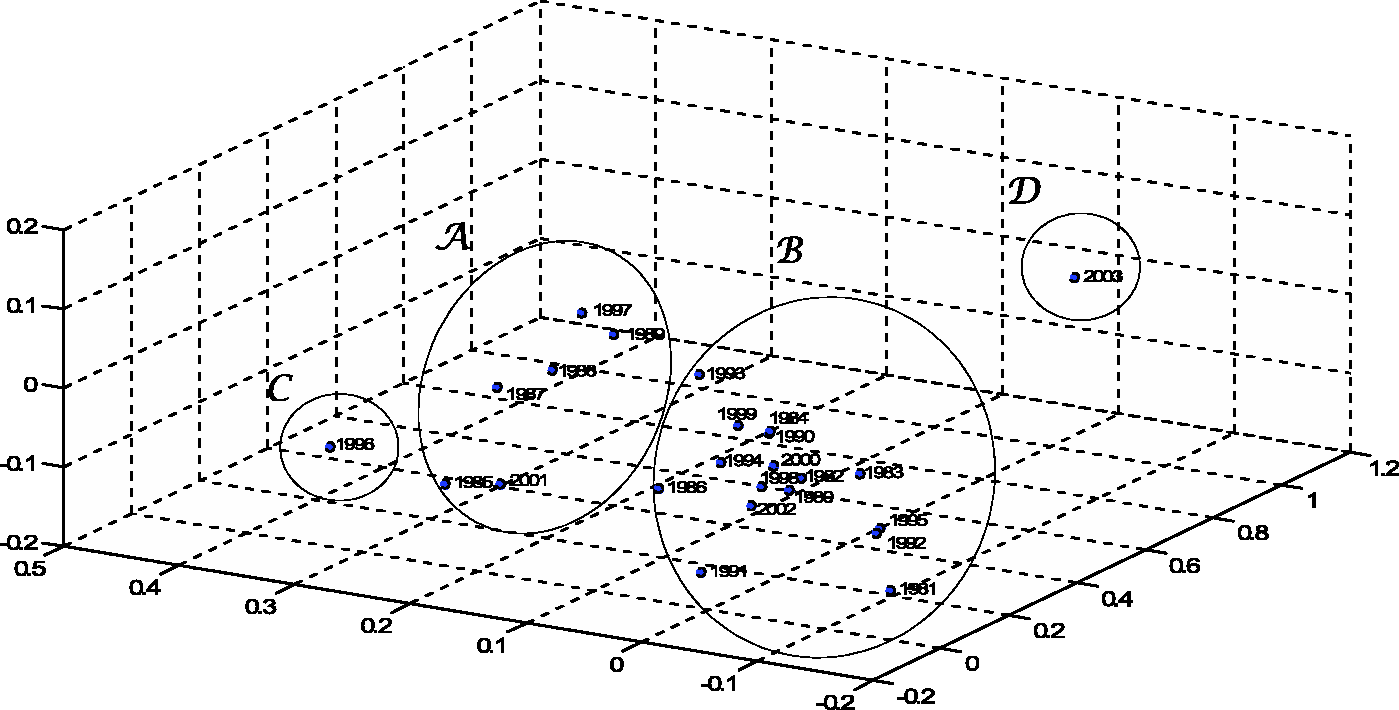
Two visualization trees are generated using HC, corresponding to regions N and S (Figures 10 and 11, respectively). The successive (agglomerative) clustering and average-linkage methods are adopted. The software PHYLIP is used for generating the graphs (http://evolution.genetics.washington.edu/phylip.html). For region N, we can note the emergence of six clusters:
As an alternative to HC and visualization trees we adopt MDS, feeding the algorithm with matrix The MDS map for k = 3, representing similarities between SSP annual curves, for region N. The MDS map for k = 3, representing similarities between SSP annual curves, for region S.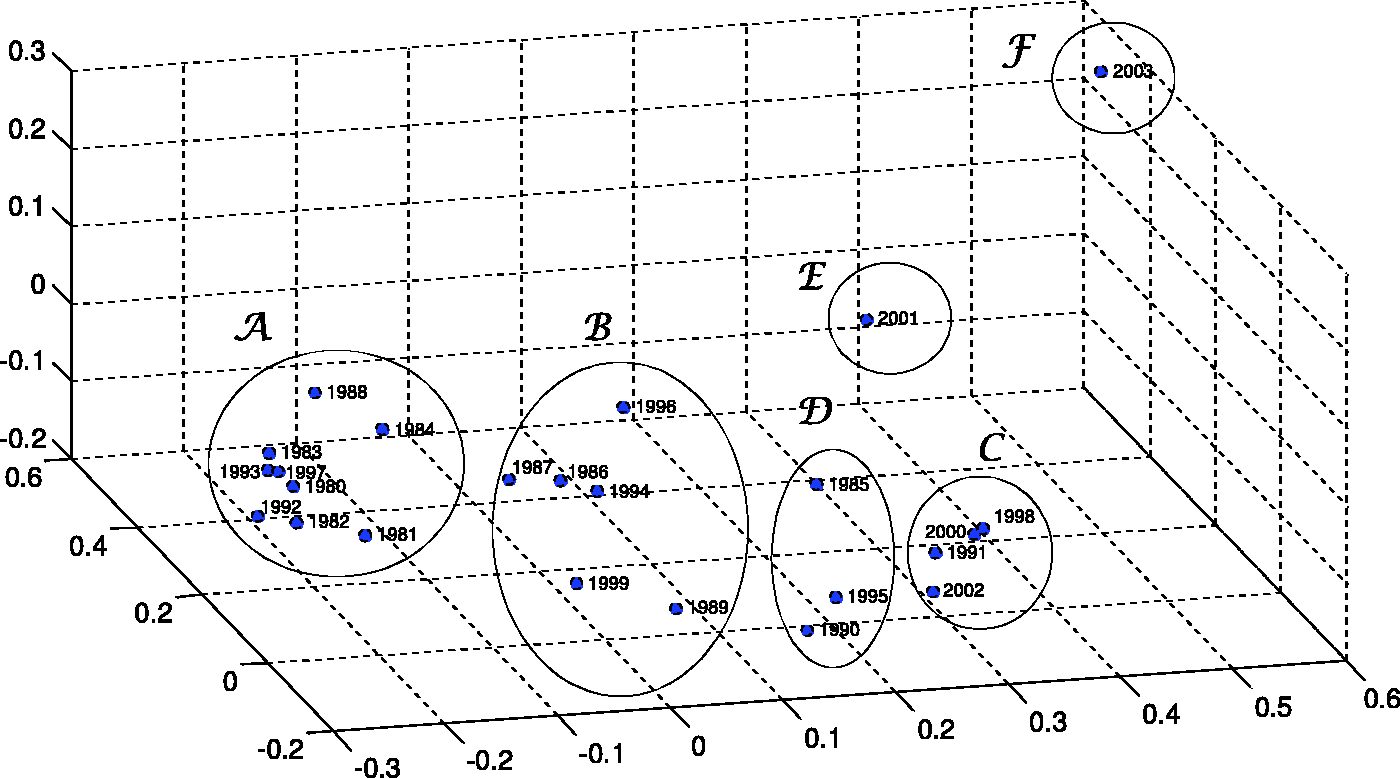
5. Conclusions
In this paper we proposed analyzing FFs from the perspective of dynamical systems. We used daily data for Portugal (excluding the Atlantic islands Azores and Madeira), covering the time period from 1980–2003. In the adopted methodology, burnt area, precipitation and atmospheric temperatures were interpreted as state variables of a CS and the correlations between them were investigated. First, we used the MI concept to unveil potential relationships in the data. Second, we considered the SSP to characterize the system’s behavior. Third, we compared the annual state space curves and adopted HC and MDS techniques to unveil existing patterns. Both tools identified the same clusters and exposed similarities between groups of consecutive years. The proposed analysis and findings can further contribute to better understand FF behavior and reveal hidden features not captured by standard tools.
Footnotes
Acknowledgments
The authors acknowledge the Instituto da Conservação da Natureza e das Florestas (INCF), the Instituto Português do Mar e da Atmosfera (IPMA) and the National Aeronautics and Space Administration (NASA) for the data.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.