
Abstract
Signal decomposition is a meaningful and effective methodology which is widely used for fault diagnosis. Mode/feature selection is an inevitable topic for fault diagnosis of rolling bearing due to over-decomposition. In practical application, the selection of sensitive modes is a challenging task, so many valuable works have been performed to cope with it. However, the published works lack an effective approach to acquire few meaningful modes by avoiding the complicated mode selection procedures, prior to feature extraction. Moreover, selection of the modes of interest fails to take the residual part into account, which makes the diagnosis result sensitive to the number of modes/features retained. This paper proposes a complementary approach to extract fault features and avoid the selection of single mode of interest, which employs canonical variate analysis to convert the original variable into two complementary spaces; canonical variate space; and residual space. Then the complementary statistical indicators Hotelling T2 statistic and Q statistic are used to provide important information about the conditions of the rolling bearing. Subsequently, a new feature index, complementary short-time energy extracted from the two statistics are used as fault features which are given as an input to a classifier such as a support vector machine. Two data sets collected from different test rigs are used for demonstration of the proposed work. The experimental result shows that the troublesome feature/mode selection issue is avoided, and the diagnosis result is not sensitive to the number of canonical variate retained. Besides, the proposed approach can identify various working conditions of rolling bearing accurately, which is simple and effective for fault diagnosis of rolling bearing, compared with the existing methods.
Keywords
1. Introduction
Time–frequency analysis is a potential method used for decomposition of original signal to achieve embedded modes. The outcome of perfect signal decomposition is of great importance for fault diagnosis of rolling bearing. Generally speaking, fault diagnosis of rolling bearing includes three phases, namely, feature extraction, mode/feature selection and pattern recognition (Van and Kang, 2015). In addition to the components of interest, the collected vibration signal also comprises environmental noises. In order to acquire useful information from the collected signal to separate fault patterns, the original signal is first decomposed into a number of modes, which are then used to select the good information about various operating conditions. Although the commonly employed signal decomposition methods, like the empirical mode decomposition (EMD) (Van and Kang, 2015), local mean deposition (Sun et al., 2016), wavelet packet decomposition (Tao et al., 2013), and singular value decomposition (Muruganatham et al., 2013), are suitable for fault diagnosis of rolling bearing, mode/feature selection is a challenging task in many practical applications. To remove redundancy and noises so as to obtain a minimal number of relevant modes, an automatic method combined mode functions (Grasso et al., 2016) which denotes a sum of adjacent intrinsic mode functions (IMF) is proposed to enhance the feature of the original signal. In some cases, intelligent algorithms are adopted to select the optimal subset from the decomposed components, such as particle swarm optimization (Van and Kang, 2015) and attribute clustering (Cerrada et al., 2016a), support vector machine recursive feature elimination ((Yan and Zhang, 2015) and genetic algorithm (Cerrada et al., 2016b). Other presented criterioa for the selection of the most appropriate modes include: Kullback–Leibler divergence based adaptive selection method (Sun et al., 2015); and kurtosis based method (Georgoulas et al., 2013). Indeed, these techniques are effective for bearing fault diagnosis and the results obtained are satisfactory. But, we can clearly observe from these techniques that a common manner is adopted for mode selection. That is, a feature index of rolling bearing is extracted from the modes of interest depending on mode selection criteria but the residual components are ignored. Evidently, only the modes of interest are considered for feature extraction, the rest cannot be accepted for further estimation, so that these techniques are sensitive to the number of components retained. Moreover, this manner fails to estimate the original data comprehensively so as to cause information loss readily. It is worth pointing out here that the important information regarding bearing fault may exist in the removed components. As mentioned above, mode selection is a challenging task, thus the introduction of the extra approaches (e.g., optimization algorithms) for mode selection makes fault diagnosis of rolling bearing computationally intensive. Last but not least, mode/feature selection approaches usually rely on an expert’s knowledge, and they are difficult to implement in an optimal manner which is expected to simplify or avoid the selection of modes of interest. Thus, further study towards presenting an automatic approach for avoiding mode selection is required.
In fact, the aim of mode selection is to choose the important components from a series of modes for feature extraction as well as dimension reduction purposes. An alternative for mode selection is feature selection: many meaningful works based on feature selection approaches have been presented for fault diagnosis of rolling bearing, like the principal component analysis (PCA) (Xu and Chen, 2013), kernel principal component analysis (Liu et al., 2016), distance estimation (DE) technique (Liu et al., 2013), etc. Though the effective features can be retained depending on the selection criteria such as cumulative percent variation and eigenvalue, the diagnosis results are sensitive to the number of features retained. Canonical variate analysis (CVA) is a state space-based dynamic tool, which was first introduced by Hotelling, and then developed by Akaike, Larimore, and Odiowei (Odiowei and Cao, 2010). Moreover, CVA based on correlation statistic has been used for fault detection in many applications such as chemicals and polymers processes (Gajjar and Palazoglu, 2016; Yin et al., 2015). It requires a group of data sets recorded under normal condition to train a reference model so that the resulting model can remember the healthy condition. Furthermore, statistical indicators such as Hotelling T2 and Q statistic (Squared Prediction Error) are adopted to provide useful information about the operating conditions, which are designed to measure the variability in retained space and residual space, respectively. Here, an interesting phenomenon is that the two metrics Hotelling T2 and Q statistic are complementary (Odiowei and Cao, 2010). The ignored components in state space will be considered by the residual space, and vice versa. As a result, the detection result is insensitive to the number of components retained if the two spaces are taken into account at the same time. This complementary property has the potential to avoid the mode/feature selection issue. To solve the classification problem with a simple and effective method, a new feature extraction method for fault diagnosis of rolling bearing based on statistical indicators is proposed to avoid the selection of appropriate modes.
This paper hereafter is organized as follows: Section 2 briefly reviews the theoretical background of CVA and describes the proposed feature extraction method. Section 3 demonstrates the effectiveness of the proposed approach in practical application, and comparison of the proposed approach with the published works is done. Eventually, the conclusion is drawn in section 4.
2. Canonical variate analysis and the scheme for avoiding feature selection
Canonical variate analysis is a state-space based dimension reduction tool, which attempts to provide a linear combination which maximizes the correlation statistic between pairs of variables. Suppose the nonlinear dynamic system is expressed as follows (Odiowei and Cao, 2010):


Where


Where
In order to consider time correlations, the measured vector


Then those variables are scaled to zero mean and unit variance to generate normalized vectors:


Where
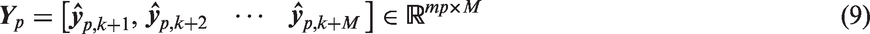
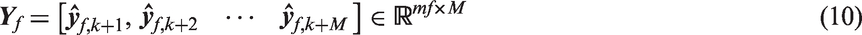
Where M+p+f−1 = N, N and M are the numbers of observations and dimensions, respectively.
Hence, covariance and cross-covariance matrices of



In order to extract an underlying relationship between variables, a singular value decomposition is done on the Hankel matrix
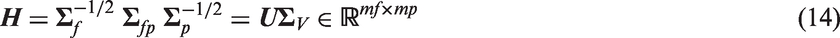
Where
The projection matrices


Subsequently, projection matrices


Hence the states of the system are determined. The system matrices


Where
Consequently, CVA transforms the variable space into canonical variate space and residual space, and the statistics T2 and Q are the measures of all fault information in these spaces, respectively. So, bearing fault can be detected by either the one statistic or both the Q statistic and
Short-time energy feature (STE) is an effective feature index that is widely used for classification scheme (Kang and Kim, 2013). This paper proposes a normalized STE combining the two complementary subspaces to develop a complementary short-time energy (CSTE) feature for overcoming mode/feature selection issue. Two features are respectively extracted from the complementary spaces, retained space and residual space, so as to avoid the procedures of mode/feature selection. Let

Where
Different from the traditional approaches used for feature extraction, the proposed work requires a group of vibration data collected from healthy working condition to construct a reference model. The state information of an unknown variable relative to the reference model can be estimated through Equation (19) and Equation (20). According to Equation (21), the proposed feature indexes are extracted from the two complementary spaces by replacing
From a view of complementation, in this paper, an increment which results from r (the number of canonical variates retained) in the state space will cause a decrement in the residual space, and vice versa. Hence, we take advantage of this thought to achieve that diagnosis results are insensitive to r.
The scheme of the proposed work is summarized in Figure 1.
The flowchart of the proposed complementary scheme.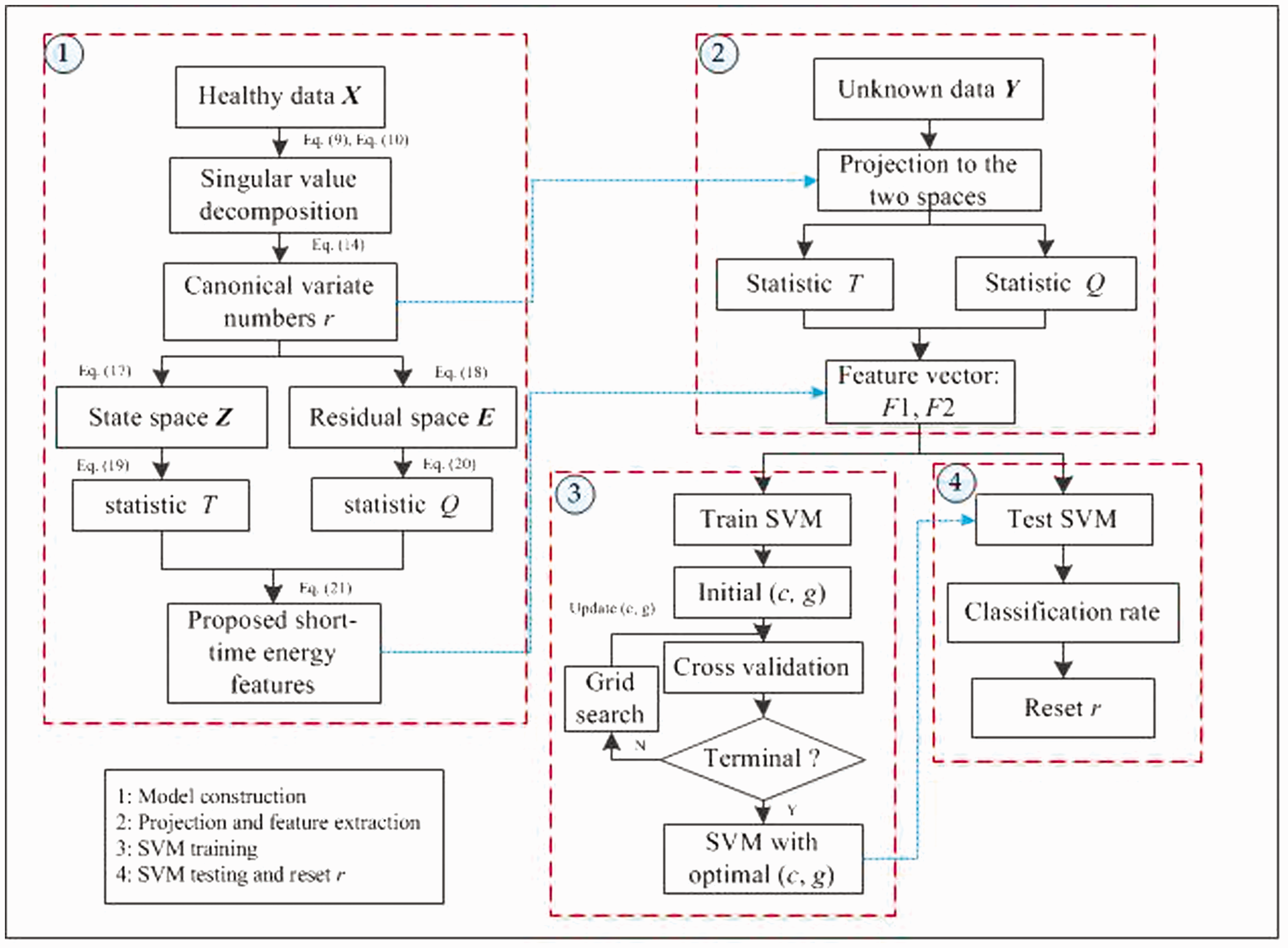
3. Experiment and result
As mentioned earlier, this paper proposes a CSTE feature for bearing fault diagnosis to avoid mode/feature selection. In this section, experiments on validation of the proposed work are implemented.
3.1. Case 1
3.1.1. Experimental setup
The proposed method is evaluated using a data set acquired from the Case Western Reserve University bearing test rig (Yang et al., 2014). Figure 2 shows the bearing test rig. Three bearing faults, inner race fault, outer race fault and ball fault are introduced to rolling bearings. For each state, the vibration signals are collected under various loads and speeds with sampling rate of 12 kHz. The corresponding data sets are listed in Table 1. Further details concerning the bearing test rig can be founded in Smith and Randall (2015).
Case Western Reserve University bearing test rig. Dataset under different operating conditions.

As for the aforementioned strategy, two data sets 97.mat and 98.mat obtained under healthy conditions are selected to train the CVA model as a reference. Then the CVA model is employed to detect various operating conditions such as normal, ball fault, inner race fault and outer race fault. Figure 3 uses the CVA based approach to show the resulting statistics corresponding to the vibration signals under healthy and faulty conditions. As shown in Figure 3, the data sampled under each condition are transformed into two metrics for the purpose of feature extraction.
Output of canonical variate analysis based approach: (a) metrics for state space of normal condition; (b) metrics for residual space of normal condition; (c) metrics for state space of ball fault; and (d) metrics for residual space of ball fault.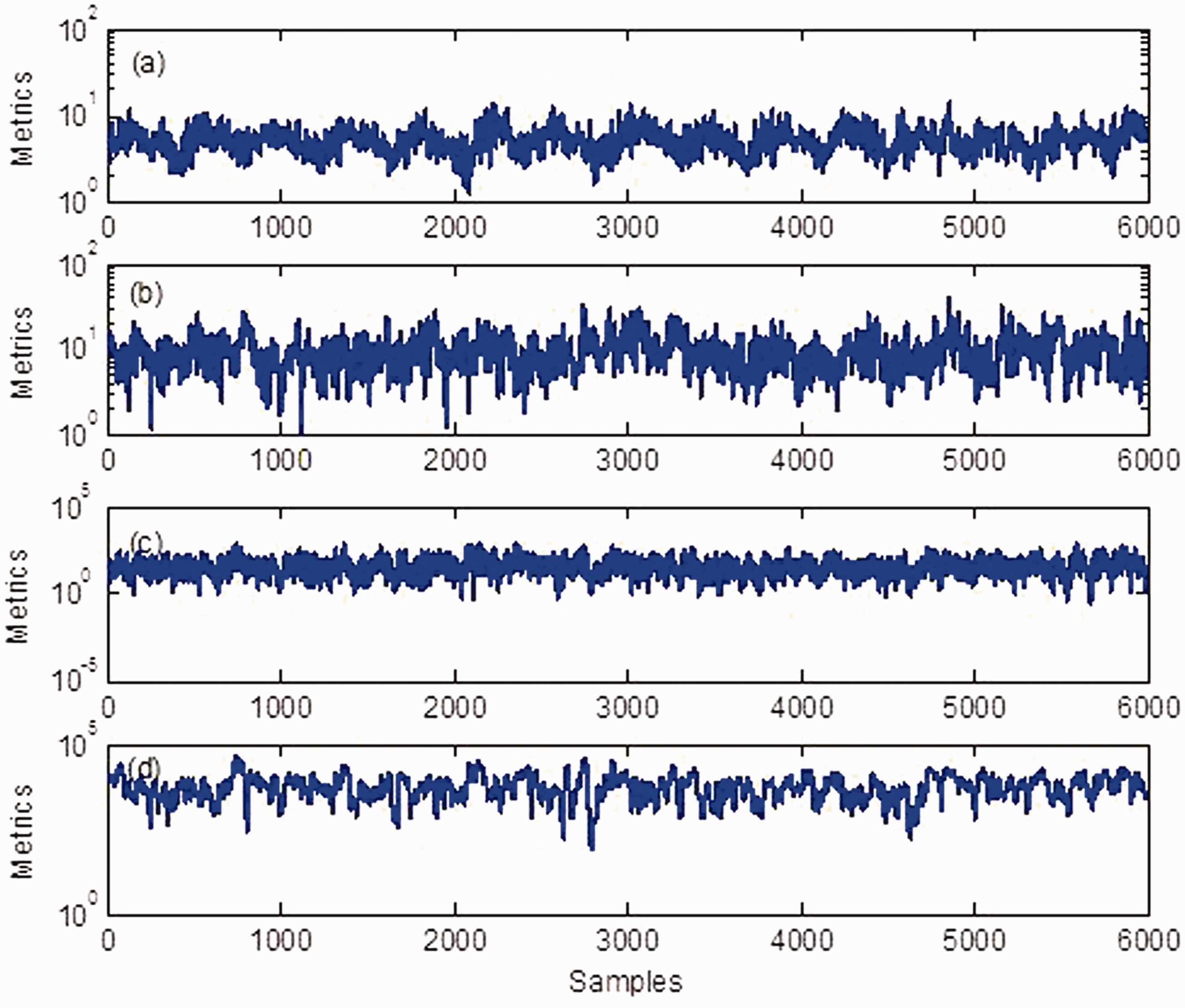
3.1.2. Result and discussion
Features obtained from testing set (for r=4).

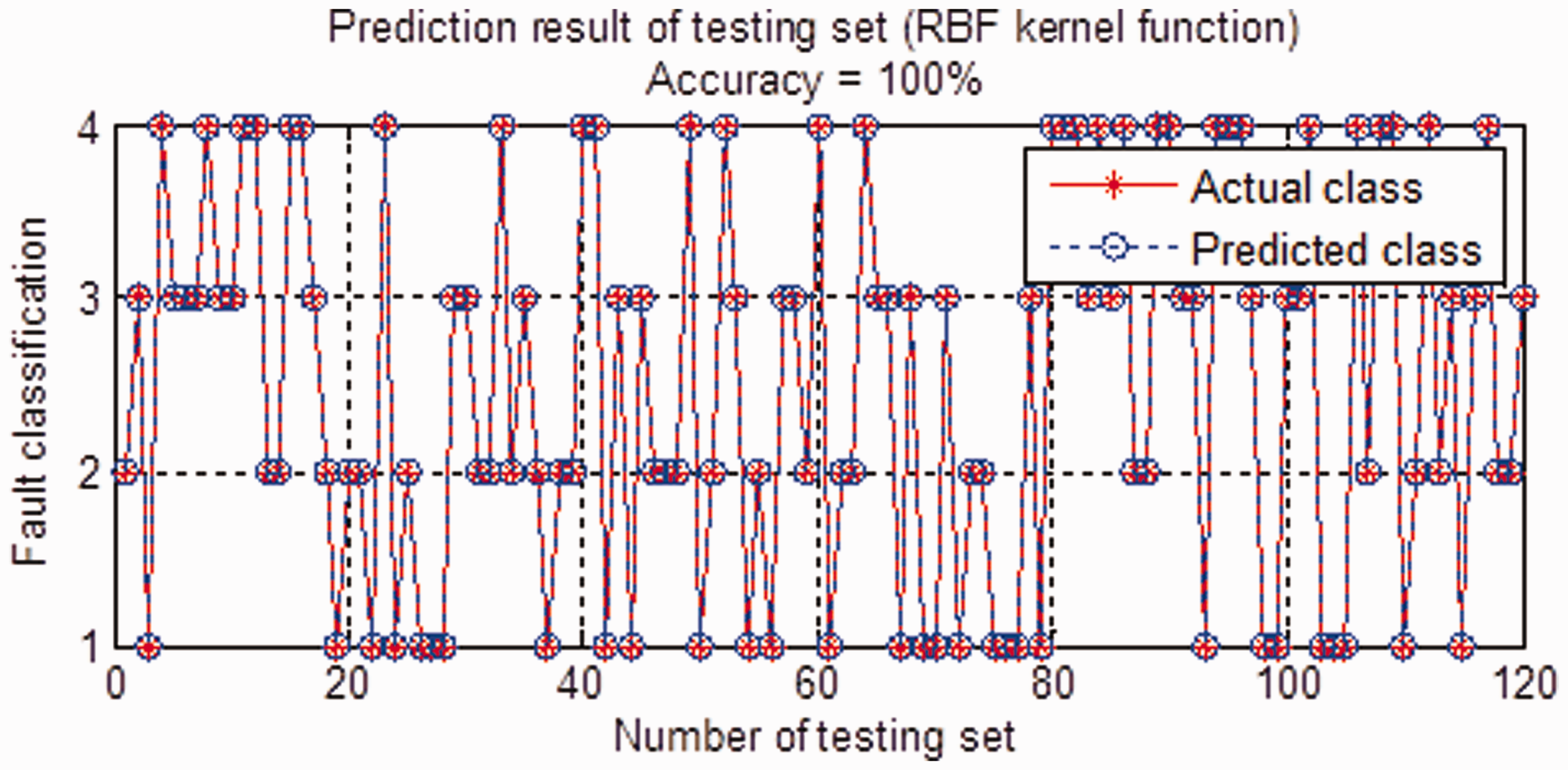
Prediction result for r=4, optimal parameter c=1.0718, and g=8.0556.
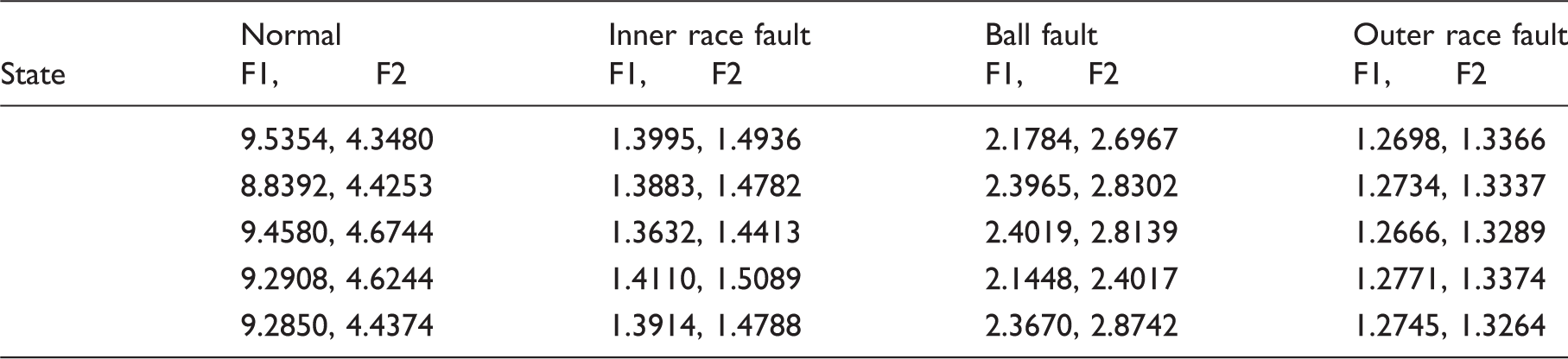
Feature set obtained using present work (for r=2).

Feature set obtained using present work (for r=7).
Feature set obtained using present work (for r=10).
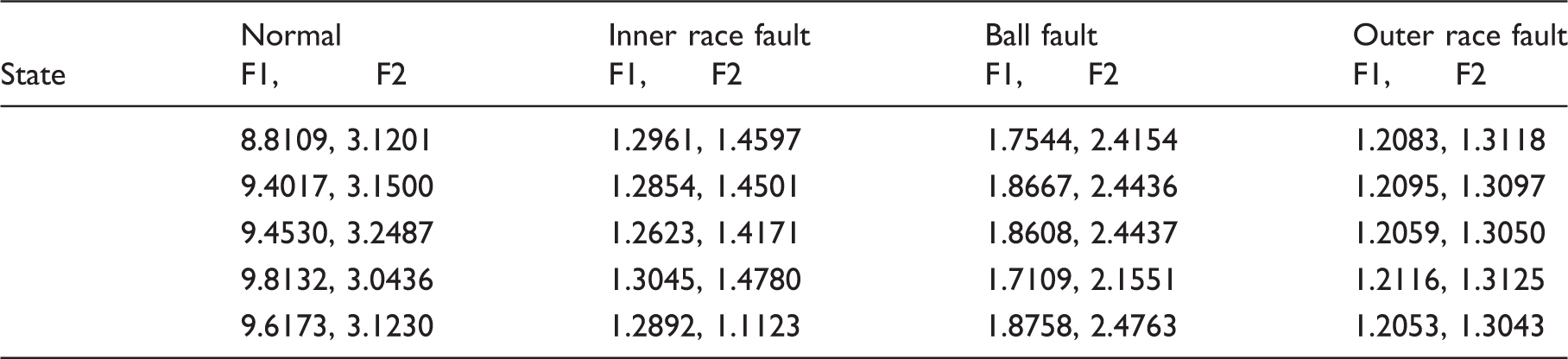
As displayed in Tables 3–5, for each working condition, the CSTE features extracted from the retained space tend to increase along increase of r, while the corresponding features from error space are decreased gradually. Moreover, for each r, the features of the four conditions clearly indicate a separable pattern and similar to two complementary metrics, the features respectively extracted from the two metrics show an obvious complementary property, which makes the features obtained insensitive to r. Similarly, r=2, 7, 10 are then employed to investigate the influence of r on diagnosis result. For each r, the total samples, the samples for SVM training and testing are the same as the case for r=4. The identification rates for the four bearing conditions are depicted in Figure 5. Obviously, for the r considered in this study, the identification accuracies for the four bearing conditions reach 100%. This phenomenon illustrates that the proposed complementary feature also makes the diagnosis results insensitive to r.
Experimental results: (a) identification result for r = 2, optimal parameters c = 1.0718, g = 1.0070; (b) identification result for r = 7, optimal parameters c = 1.0718, g = 4.0278; and (c) identification result for r = 10, optimal parameters c = 4.2871, g = 16.1113.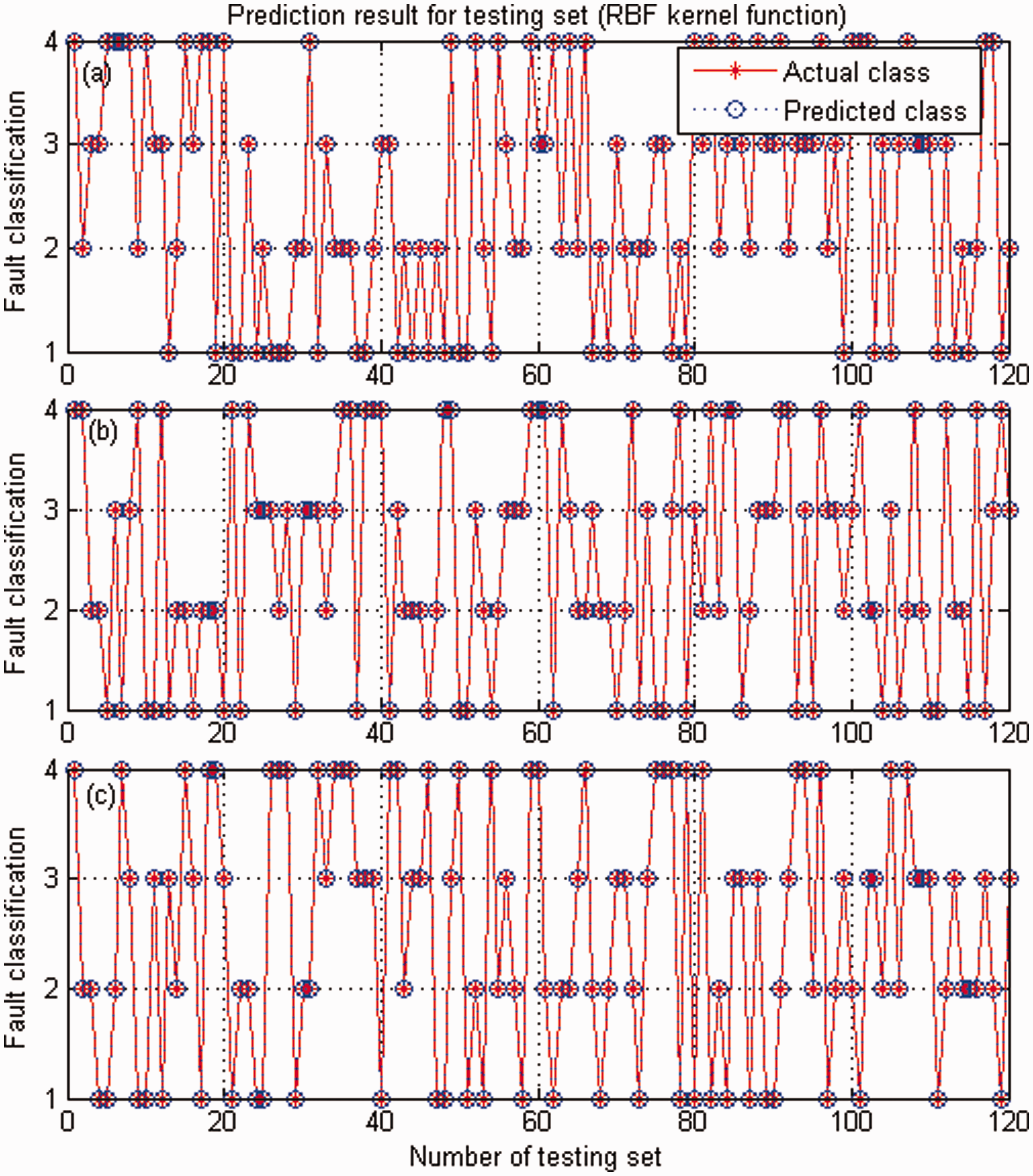
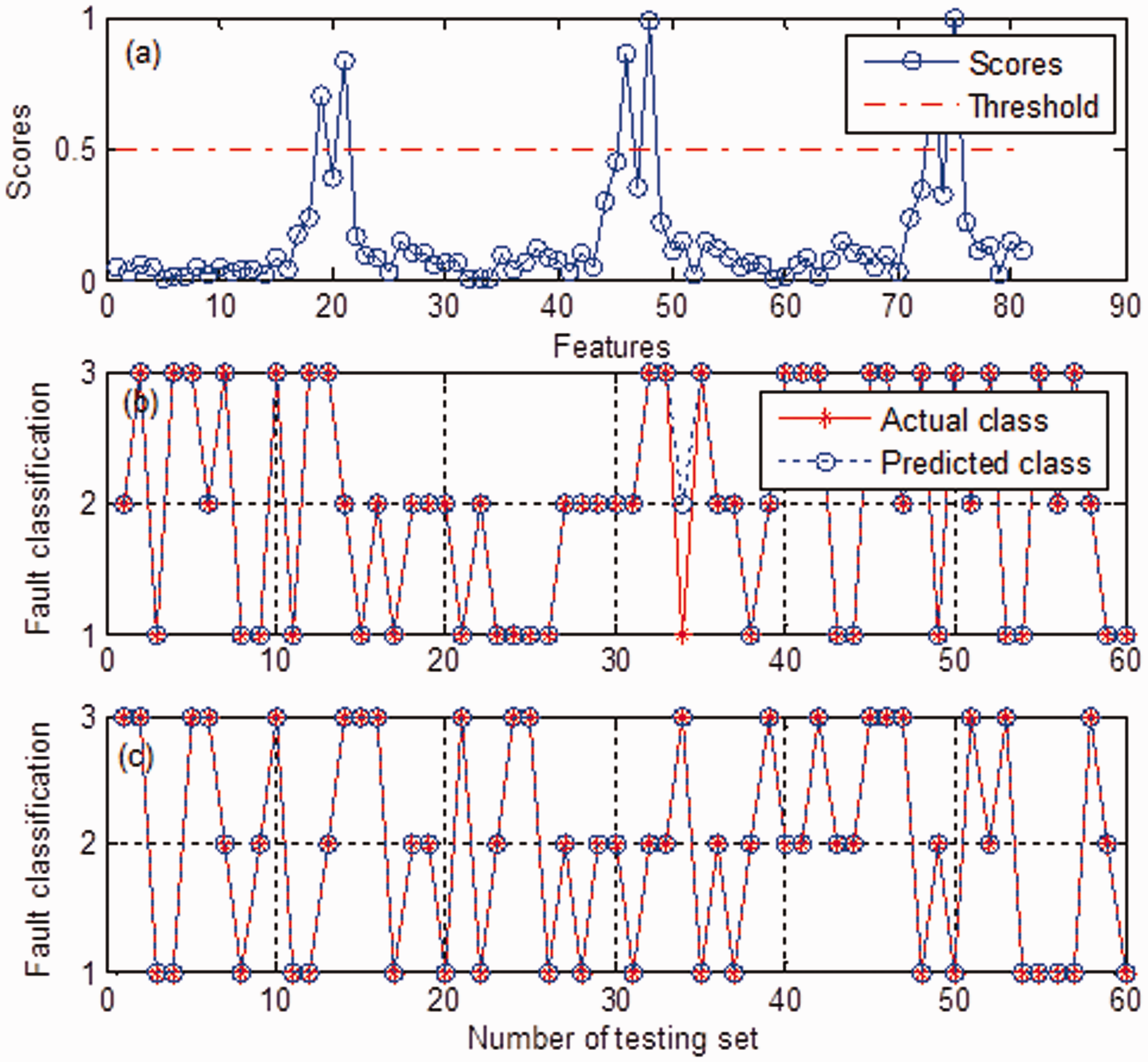
Then comparison of the proposed work with the published methods is done. In this study, two representative approaches for feature/mode selection are employed for comparison. To make a fair comparison, the techniques compared are tested under the same conditions. As shown in Table 6, derived from Xu and Chen (2013), to collect energy features, the authors first decomposed the vibration signal into a number of IMFs using EMD. Then the first six modes were selected using PCA to generate energy feature indexes for bearing fault diagnosis purposes. According to the procedures for extraction of the features, the energy feature indexes are extracted from the data used above as an input of the SVM. PCA is applied on the features obtained to retain the most effective components. In this study, accumulation contribution rate of 85% is chosen to retain the first 6 modes. Finally, we get 6 features and 320 samples. The other is based on feature selection criteria, for example, the DE technique. Liu et al. (2013) used 27 feature parameters (14 time-domain features and 13 frequency-domain features) to characterize bearing faults. Then the DE technique was applied to remove redundant features and retain the most important features for bearing fault diagnosis. In their study, the first 3 modes are selected from the IMFs adaptively decomposed by EMD. As a result, a total of 3×27=81 features were obtained. Subsequently, the important features are chosen from the feature set using a defined threshold. We repeat the feature extraction steps to obtain the 81 feature parameters. It is well known that the redundant features may have significant impact on performance of a classifier. Therefore, 4 important features and 320 samples are selected from the feature set with the help of the DE technique. For the techniques compared, the samples obtained are separated into two sets, training set (200 samples) and testing set (120 samples), which are then fed to SVM optimized by grid search using 10-fold cross-validation for further analysis. The details on comparison are presented in Table 6. Here, the accuracy is an average of five identification rates. As an example, Figure 6 depicts the results obtained for the two techniques.
Experimental results for the techniques compared: (a) identification result for energy feature, optimal parameters c = 2.1435, g = 8.0556; (b) distance estimation result for threshold = 0.7; (c) identification result for 81 features parameters, optimal parameters c = 2.1435, g = 1.0070; and (d) identification result for 4 features parameters, optimal parameters c = 1.0718, g = 1.0070.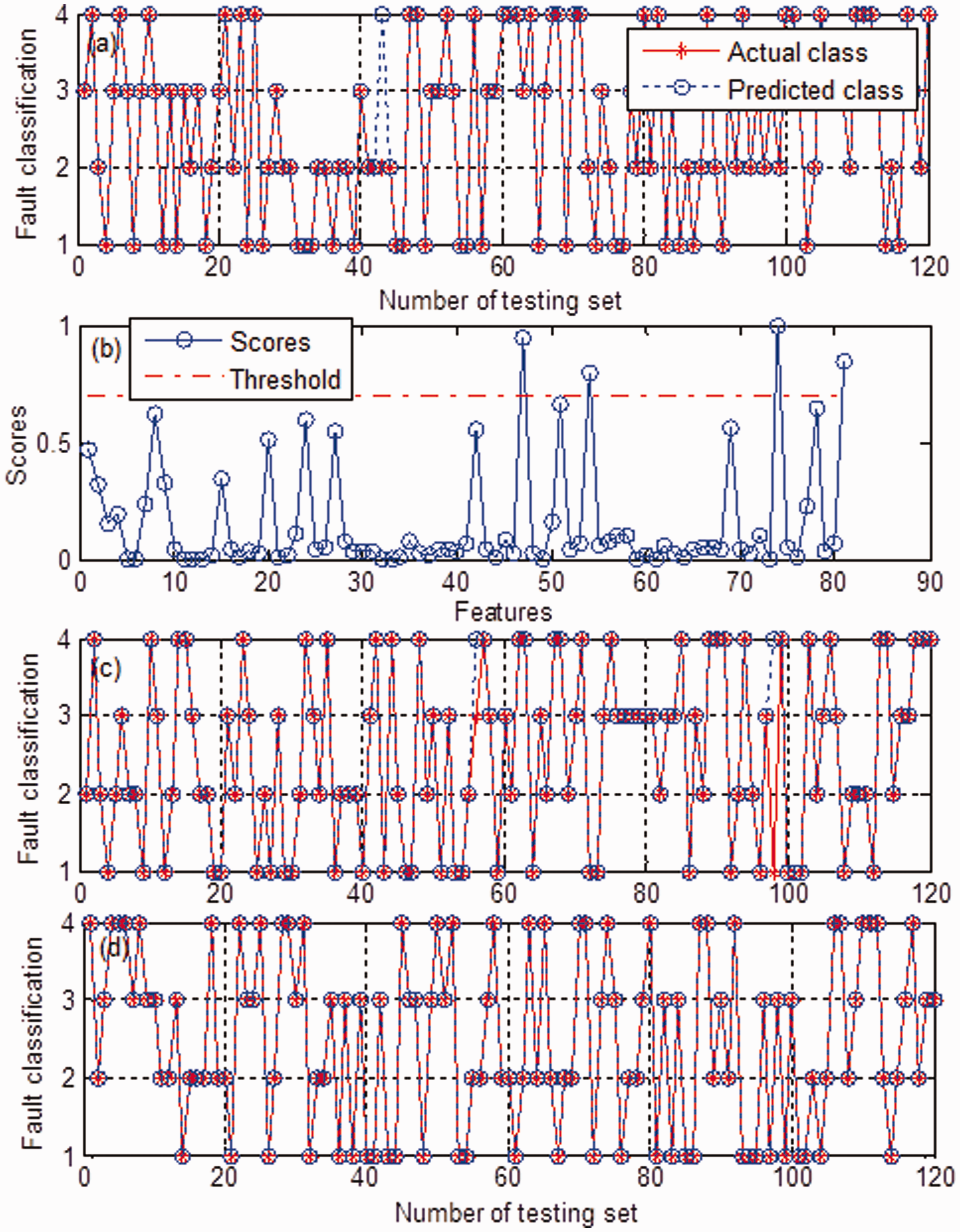
As displayed in Figure 6 (a), the energy features corresponding to four bearing conditions are basically recognized, the identification rate is 99.2%. Figure 6 (b) gives a result of DE for the 81 features, and the features with scores exceeding a threshold are selected as the most important features for SVM training and testing. For comparison, the 81 feature parameters and the reduced features are respectively presented to SVM. As shown in Figure 6 (c), the recognition rate for 81 features is 98.3%, while for the reduced features it reaches 100%. Therefore, feature/mode selection procedure is efficient for bearing fault diagnosis, which can improve the performance of classifier and reduce computational complexity. However, the procedures of feature/mode selection inevitably rely on an expert’s knowledge, which may resist the implementation of these techniques in practical application. Moreover, we can observe that the diagnosis results are sensitive to the feature/mode retained, which has important influence on the robustness of the existing approaches.
As shown in Tables 2–5, clearly, the complementary short-energy features for different r indicate a distinguishable phenomenon. Besides, no matter what value of r is selected from the predefined range, the dimensionality of features is invariable. In other words, the proposed technique transforms the impact of different r into changes in values of features while the resulting features still show a separable pattern. This is why the diagnosis results are not sensitive to r. However, for the published contributions, the common way for feature/mode selection has inevitable influence on the length of feature vector so that the diagnosis results are sensitive to the features. For example, the length of feature vector in technique (Liu et al., 2013) is based on selection of a threshold. In the current paper, the proposed features are derived from the two complementary statistics rather than from the modes of interest. Thus, the feature/mode selection procedures can be avoided. To further investigate the superiority and effectiveness of the proposed work, case 2 is carried out.
3.2. Case 2
3.2.1. Experimental setup
In this study, inner and outer race faults are introduced to NICE® bearings to collect vibration data for further validation of the proposed work. Figure 7 shows the schematic diagrams of bearing component faults. The bearings are tested at various loads. The data considered are recorded at a load of 150 lbs, with sampling rate of 48828 sps. The speed of the input shaft is 1500 rpm. The baseline data are regarded as data collected from healthy conditions. In total, three working conditions, like normal state, inner race fault and outer race fault, are considered for validation.
Bearing faults: (a) inner race fault; and (b) outer race fault.
Comparison of the proposed method with the existing works.
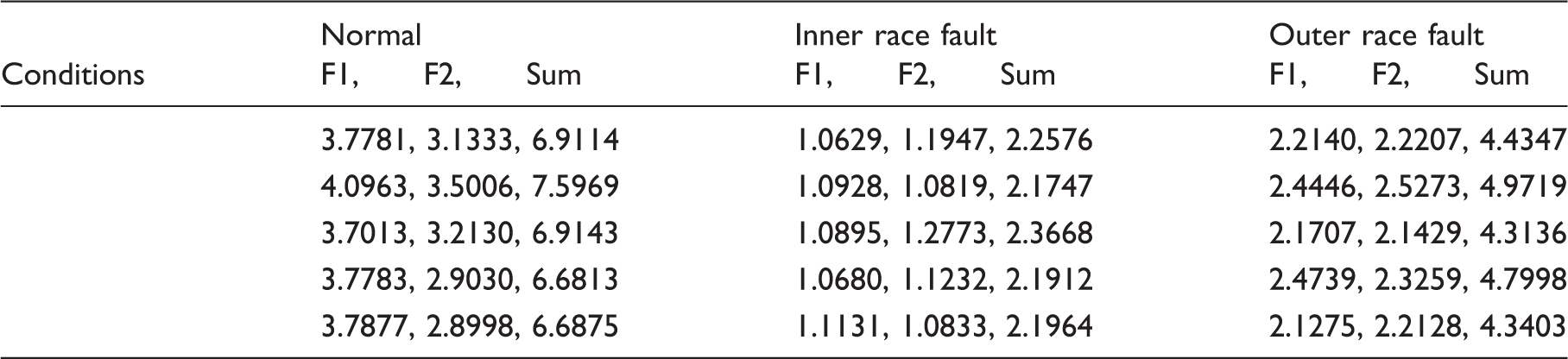
Features obtained for r=3.
3.2.2. Result and discussion
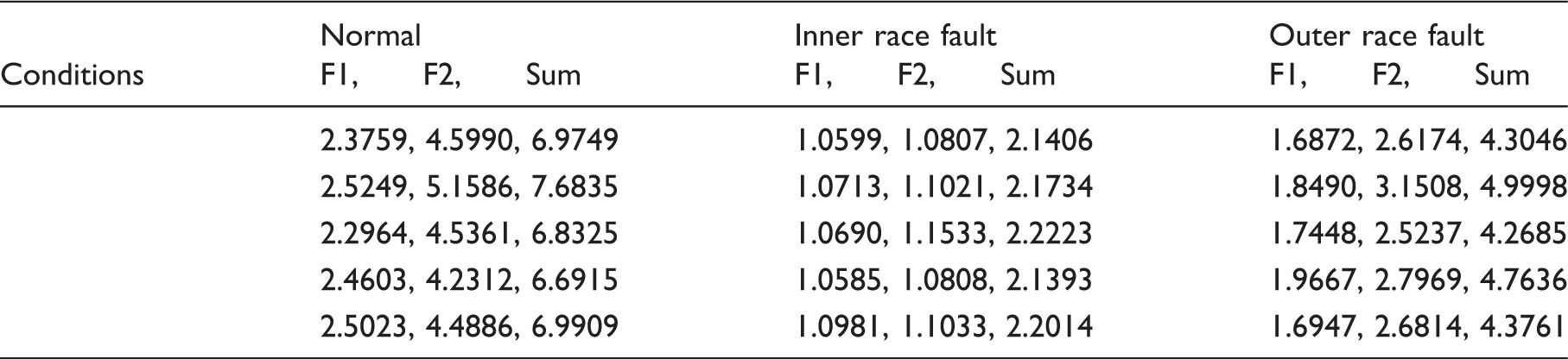
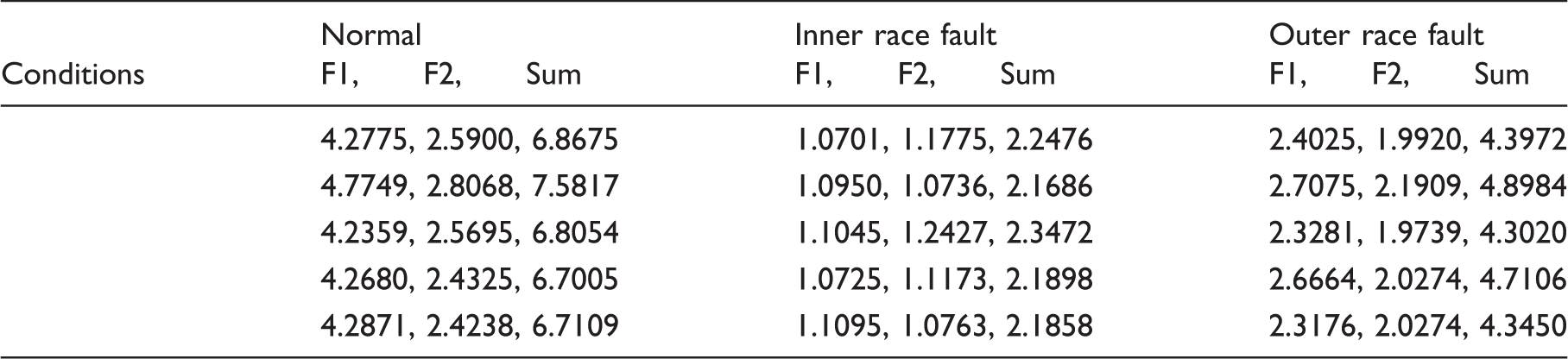
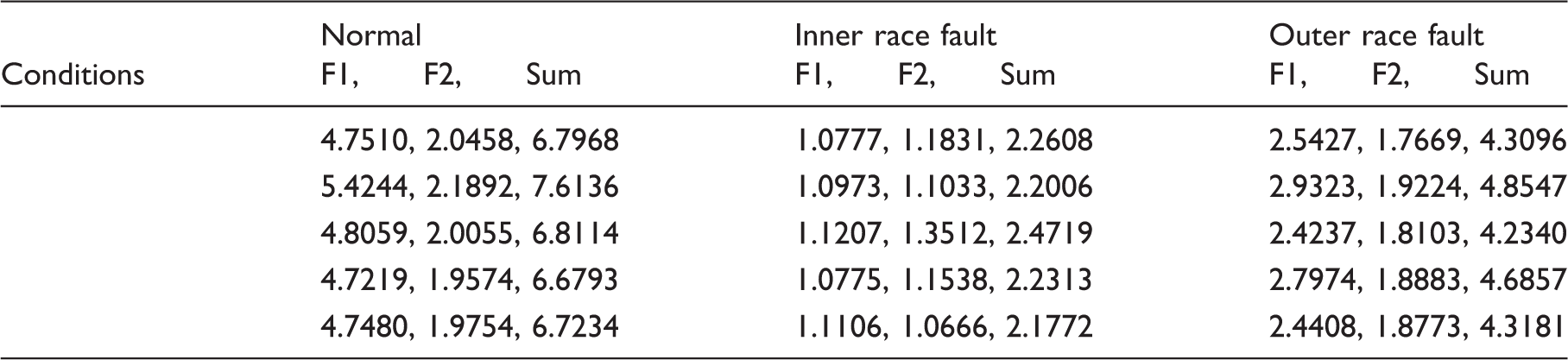
As described in Tables 7–11, for normal condition, the features (F1) extracted from state space tend to grow as r is changed from 3 to 8. In contrast to this, the features (F2) obtained from the residual space tend to decrease. Moreover, the sums of the two features are relatively stable. The root cause for this phenomenon lies in the fact that the subspaces are complementary. For inner race fault, with increasing the values of r, variation of the CSTE features are not obvious, which shows that the features are not sensitive to r, as demonstrated by case 1. For the outer race fault, the features (F1) collected from the retained space tend to increase gradually along growth in the values of r, while F2 is opposite. These phenomena agree well with the conclusion that an increment triggered by r in retained space will cause a decrement in error space. Evidently, the proposed CSTE feature indicates a complementary property. In addition, for different r, Tables 7–11 show that the features collected from the three working conditions are separable. Then the feature vectors are considered as an input of a classifier for the purpose of validation. Here, taking SVM as an example to illustrate the effectiveness of the proposed work, penalty weight c and kernel width g are optimized by grid search using 10-fold cross-validation.
Figure 8 indicates that the features corresponding to three operating conditions are identified perfectly by SVM (optimal parameters c=1.0718, g=1.0070). Experimental results show the diagnosis results are insensitive to the number of components retained r (1<r<10). The diagnosis result for r=7 is not presented in Figure 6 due to space limitation. It is worth noting that this paper proposes an approach for fault diagnosis of rolling bearing for avoiding mode/feature selection derived from signal decomposition techniques, rather than only presents a feature extraction method.
Identification results for the features corresponding to different r: (a) for r = 3; (b) for r = 4; (c) for r = 6; and (d) for r = 8.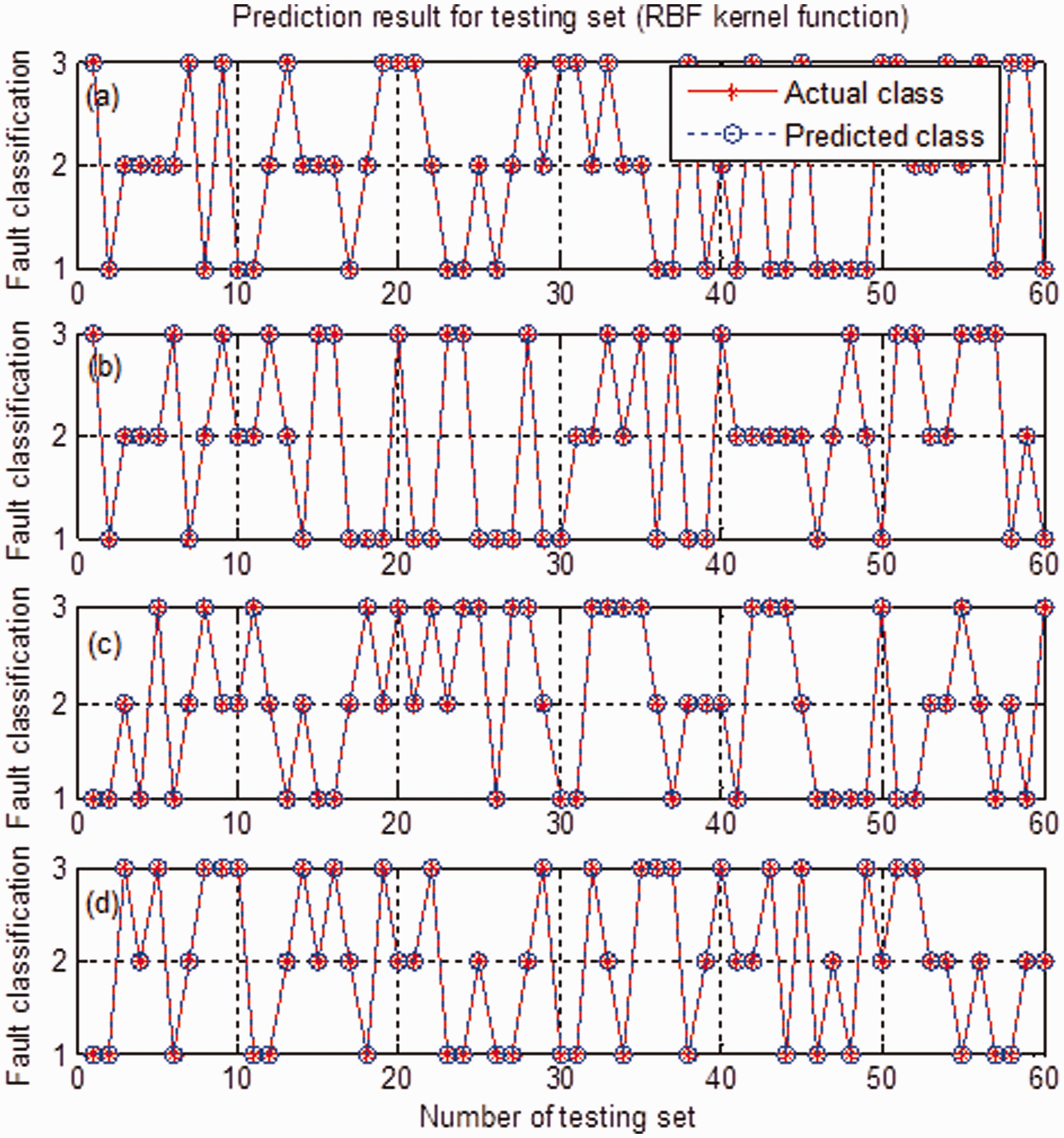
To further validate the effectiveness of the proposed work, two representative techniques for fault diagnosis of rolling bearing are performed for comparison. To make a fair and valid comparison, the techniques compared are tested under the same conditions, like the number of samples used for SVM training and testing. The energy feature proposed in Xu and Chen (2013) is extracted from the data used in this study according to the original procedures (the details have been presented in case 1).
Cumulative percent variation of 95% is chosen to retain the first l=7 modes for further analysis. Moreover, l=5, 6 are also examined for comparison. For each l, the obtained feature set comprises 120 samples covering the three working conditions. Then these samples are divided into 60 training and 60 testing samples for classifier (SVM) training and testing, respectively. In addition, the 27 feature parameters consisting of 14 time-domain features and 13 frequency-domain features, employed in Liu et al. (2013) are also extracted from the first three modes derived from EMD. So, a feature set including 120 samples and 3× 27=81 features are obtained. The DE technique is utilized to select the most important features for the aim of dimensionality reduction. Finally, the selected 6 features and 120 samples (60 training samples and 60 testing samples) are presented to SVM classifier optimized by grid search using 10-fold cross-validation. Considering that the identification result may be sensitive to initial condition, we run the SVM classifier five times and obtain an average accuracy. Figures 9 and 10 show an example of experimental results for the three bearing conditions. The details on comparison are listed in Table 12.
Experimental results for different conditions using the technique in Xu and Chen (2013): (a) for l=5, c=1.0718, g=1.0070; (b) for l=6, c=1.0718, g=1.0070; and (c) for l=7, c=1.0718, g=1.0070. Experimental results for different conditions using technique in Liu et al. (2013): (a) distance evaluation for all features (threshold=0.5); (b) identification result for the 81 features, optimal parameters c=1.0718, g=1.0070; and (c) identification result for the selected 6 features, optimal parameters c=1.0718, g=1.0070. Features obtained for r=4. Features obtained for r=6. Features obtained for r=7. Features obtained for r=8. Comparison of the proposed work with the reported techniques.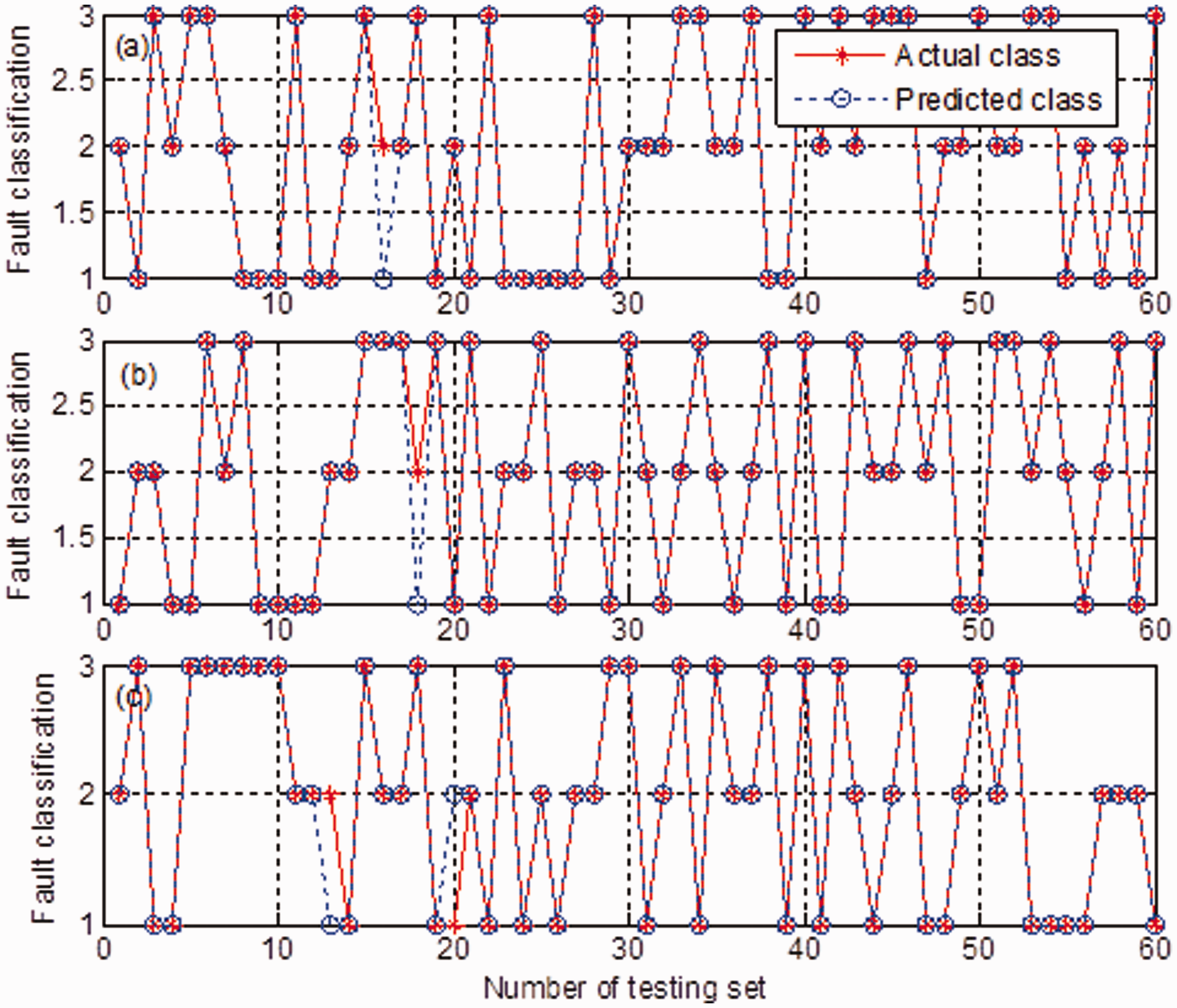
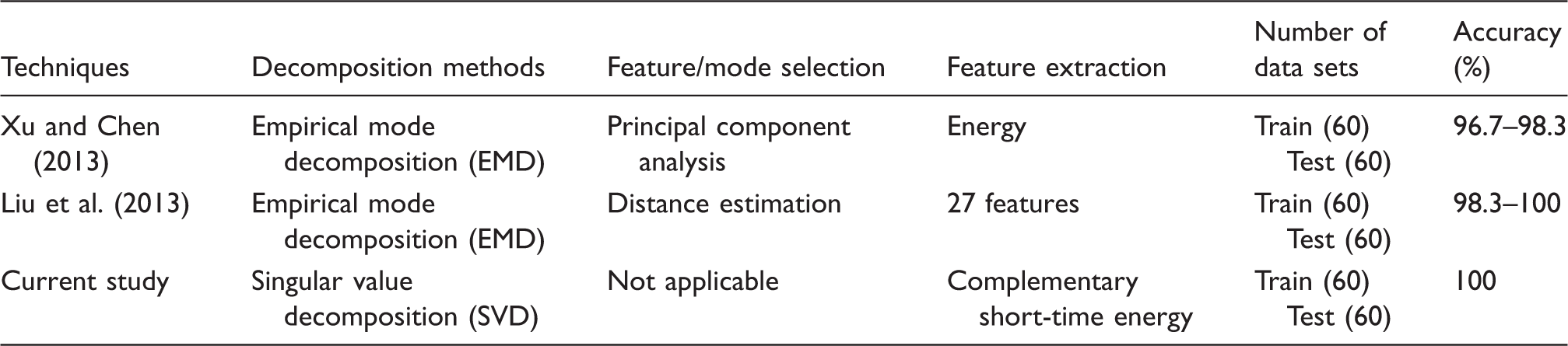
As shown in Figure 9, for l=7, the classification accuracy for the three bearing conditions is 96.7%. For l=6, the classification accuracy is 98.3%. Moreover, for l=5, identification rate of 98.3% is achieved. Obviously, the diagnosis result is sensitive to the number of components retained l. For the energy features, too large l will add more redundancy into the modes of interest, while small l causes information loss readily. So, selection of useful features may weaken reliability of fault diagnosis of rolling bearing. As displayed in Figure 10 (b), first, the original 81 features are employed as an input of SVM classifier, and the resulting classification rate is 98.3%. However, redundant features may significantly influence the performance of classifier such as SVM. Figure 10 (a) suggests that the features with scores exceeding the predefined threshold should be selected as an input of SVM. The diagnosis result obtained for the reduced feature set is shown in Figure 10 (c). After feature selection, the identification accuracy is increased to 100%. Indeed, feature selection technique is effective to improve recognition rate of bearing faults. Nevertheless, the diagnosis results are sensitive to the number of selected components. Besides, the selection of feature usually relies on an expert’s knowledge, which is hard for implementation of an automatic fault diagnosis. Different from the existing approaches, to avoid feature selection the proposed work takes advantage of two complementary metrics to transform the original signal into two parts for extraction of fault features. This approach has three merits. On the one hand, the length of feature vector is constant with changes in the values of r. On the other hand, the features collected from the complementary metrics are of complementary property. For the two subspaces, the impact of r is transformed into an increment/decrement in the values of the features. Last but not least, the diagnosis results are not sensitive to the number of canonical variate retained r. Table 12 indicates that the proposed technique is simple and robust for bearing fault diagnosis, and the result obtained is satisfactory.
4. Conclusions
This paper proposes an effective approach to avoid the mode/feature selection issue. The advantages of the proposed work over the published works are discussed. The experimental results indicate that the novel feature extraction method is suitable for application of bearing fault diagnosis. In this paper, the diagnosis result is insensitive to the number of retained components, and mode/feature selection procedure can be removed by applying the proposed work. Identification accuracy of proposed method is satisfactory. To sum up, the following conclusions can be obtained:
This paper proposes a simple and effective scheme to avoid the complex feature/mode selection procedure. Two complementary subspaces are considered at the same time without considering selection of modes of interest. A CSTE feature is proposed to distinguish various working conditions of bearing. In this paper, for different r, the features obtained still retain a separable pattern. Different from the reported works, the length of proposed feature vector is constant. Viz. two features, one is extracted from retained space and the other is from residual space. It is worth pointing out that the objective of feature/mode selection is to retain the most useful components for feature extraction. So, how to achieve small number of features is essential for improving accuracy of bearing fault diagnosis. The diagnosis results are not sensitive to the number of canonical variates retained. And the results obtained are satisfactory. Two representative techniques are estimated for comparison. Experimental results show that the proposed work is simple and effective for fault diagnosis of rolling bearing.
In this paper, CVA is used as a data-driven technique, which requires vibration data collected from healthy operating condition to construct a reference model. For detecting a single operating condition, only one healthy vibration datum is sufficient for model training. For detecting varying operating conditions, it is necessary to ensure that the training set covers different normal working conditions in order to obtain a comprehensive and robust reference model. To achieve this, in case 1, normal data sets 97.mat and 98.mat collected from different working conditions are used to train a CVA model through calculating the past and future matrices of each data set according to Equation (9) and Equation (10), and then the matrices obtained are combined to produce a new matrix covering different normal conditions. Similarly, in case 2, the baseline conditions are joined for model construction to avoid loss of information and enhance the robustness of a reference model. Indeed, we should pay more attention to the effects of averaging on reference model construction in normal condition.
Footnotes
Acknowledgements
The research is supported by the National Natural Science Foundation of China (Grant: 51675491 and 51175480). The authors would like to express their most sincere appreciation to the Society for Machinery Failure Prevention Technology for providing the experimental data.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.