
Abstract
To weaken the effects of the outliers or noise in classification, a fuzzy support vector machine (FSVM) based on environmental fuzzy membership is proposed. The environmental fuzzy membership considers not only the number of the similar samples nearby but also the distribution of the samples nearby. As more information of the samples is considered, the reliability and robustness of the FSVM is further enhanced, which can improve the classification performance, especially for overlapping samples. The classification performance of the proposed method is validated by numerical case studies, an experimental study for a breast cancer dataset, and an application to motor fault classification. Compared with the FSVM based on the k-nearest neighbor algorithm, the proposed method obtains more robust and accurate classification rates in all case studies.
Keywords
1. Introduction
With their great performance in terms of reliability, low-cost robustness, and ease of control, motors are widely used in industry (Arabaci and Bilgin, 2009). Thus it is of obvious significance for condition monitoring and fault diagnosis to improve the operational conditions of motors. Furthermore, it has been proved that advanced diagnosis and prognostics of motor faults can reduce the cost of maintenance and probability of unexpected failure (Ayaz et al., 2006). However, due to the complicated mechanism and aliasing characteristic frequencies of motor faults, it is still challenging to classify motor faults to obtain an accurate fault diagnosis.
As a result of the development of data mining techniques, the classification of motor faults has attracted considerable attention in recent years. Many signal processing techniques have been used in this field, such as fast Fourier transform (FFT; Kabla and Mokrani, 2011; Akar, 2013), short time Fourier transform (STFT; Nandi et al., 2011; Cabal-Yepez et al., 2013; Wang et al., 2013a), wavelet transform (Yaqub et al., 2012; Gritli et al., 2013), blind source separation (Cheng et al., 2011, 2012a, 2012b, 2014), Hilbert transform (HT; Pineda-Sanchez et al., 2009; Xu et al., 2013), and empirical mode decomposition (Antonino-Daviu et al., 2012). Intelligent methods also have been considered and widely used, such as artificial neural networks (Arabaci and Bilgin, 2010; Bingol and Pacaci, 2012) and support vector machines (SVMs; Ebrahimi and Faiz, 2010; Banerjee and Das, 2012; Yaqub et al., 2013). All of these methods make great contributions to the classification of motor faults. Torkaman et al. (2011) applied FFT to classify bearing failures based on the characteristic frequencies of faults. Vulli et al. (2009) applied STFT to isolate the occurrence of a particular fault in the time domain. Zhang et al. (2012) applied wavelets to the classification of motor faults, especially for broken bars. To overcome the disadvantages of FFT for the induction motors at low slip, Xu et al. (2013) proposed an improved Hilbert method by combining the HT and estimation of signal parameters via rotational invariance technique (ESPRIT). However, the mechanism of motor faults is complicated, and fault features are difficult to extract, which makes it still a challenging problem for motor fault classification, especially multiple classification. Furthermore, most of these methods are applied to diagnose specific faults rather than multiple faults. Therefore, this paper proposes a novel classification method based on the fuzzy support vector machine (FSVM) to overcome such problems for motor fault classification.
An SVM is a powerful tool for classification problems, and many SVM-based classification methods have been proposed and applied to real applications (Sabzekar et al., 2011; Keskes et al., 2013; Liu et al., 2013; Wang et al., 2013b). However, they are all sensitive to outliers or noise. To overcome such a problem, Lin and Wang (2002) proposed the FSVM, which has been widely studied and applied to engineering applications in recent years. However, the definition of fuzzy membership is a major issue of the FSVM and a general criterion is still lacking. The most challenging problem is that the noise or outliers influence the definition of fuzzy memberships. Lin and Wang (2002) defined a fuzzy membership based on the distances between the samples and their center. Zhang et al. (2006) define a fuzzy membership by combining an affinity with the distances between the samples and their center. Heo et al. (2010) used k-nearest neighbor (KNN) to define the fuzzy membership. Wei and Wu (2012) used a Gaussian kernel-based definition to calculate the fuzzy membership.
However, all these proposed methods still cannot provide an effective way to overcome the effects of the outliers or noise. Therefore, we propose a novel definition of fuzzy membership entitled environmental fuzzy membership, which focuses on the local distribution so that the noise or outliers cannot influence the global fuzzy membership of samples. Our definition contains two factors: average distance and the ratio of similar samples and heterogeneous samples in a local area. Based on these two factors, we classify all the samples into three clusters, and the fuzzy membership is calculated by different methods in each cluster. The performance of our method is validated by numerical case studies, an experimental study for a breast cancer dataset, and an application to motor fault classification. The results show that our method can effectively weaken the effects of the outliers or noise, and adaptively classify all the samples into the right cluster with a high correct rate (near 100%), while the performance of the traditional FSVM based on KNN is influenced by the parameter k and the classification correct rates of some samples are very low (even 19.03%). Therefore, the proposed FSVM with environmental fuzzy membership can effectively solve the problems caused by the outliers or noise.
The rest of this paper is organized as follows. In Section 2, the theory of FSVM is introduced. In Section 3, the disadvantages of the fuzzy membership are described, and the environmental fuzzy membership is also proposed and introduced. In Sections 4 and 5, numerical case studies, an experimental study on a breast cancer dataset, and an application to motor fault classification are presented, and the performances of the FSVM based on KNN and our method are comparatively studied and discussed. In Section 6, we present our conclusions.
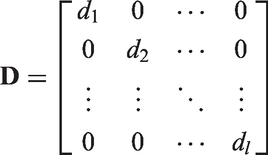
2. Fuzzy support vector machine
The FSVM, which is a modification of the SVM proposed by Lin and Wang (2002), defines a fuzzy membership to each sample of the SVM. With different fuzzy memberships, the samples can make different contributions to the classification. Therefore, we can weaken the effects of the noise or outliers by means of the fuzzy membership.
The calculating framework of FSVM is similar to SVM. Given a set of labeled training samples

Each training sample

Thus the classification problem can be treated as a quadratic programming problem as
A Lagrangian function is applied to solve such a problem

Thus the quadratic programming problem in equation (3) can be transformed as
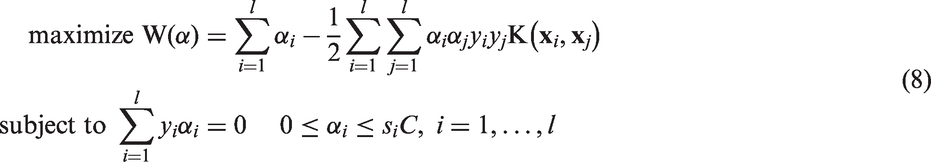
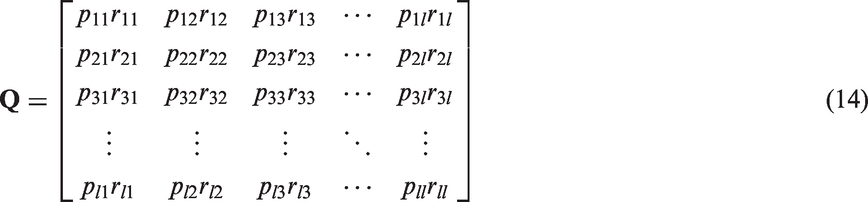
3. Fuzzy membership
3.1. The disadvantages of the existing fuzzy membership
The most challenging problem of FSVM is how to define the fuzzy membership. In past decades, many criteria have been proposed (Zhang et al., 2006; Heo et al., 2010; Wei and Wu, 2012). However, until now there is still lack of a general criterion for the fuzzy membership. All the current FSVMs can be classified into two kinds: one is defined based on the global distribution, and the most representative FSVM in this kind defines the fuzzy membership as the distance between the sample and the cluster center; the other one is based on the local distribution.
For the fuzzy membership of FSVM defined as the distance between the sample and the cluster center, the first step is to calculate the cluster center
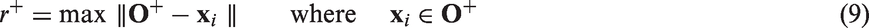
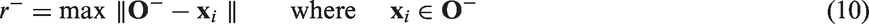
The fuzzy membership si is defined as
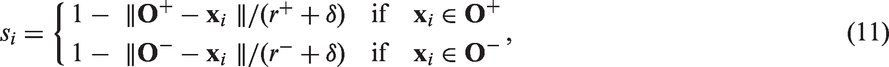
Figures 1 and 2 present two different kinds of distributions. Comparing Figure 1 with Figure 2, it can be seen that these two kinds of samples have the same distribution besides one sample. As an additional sample is added into the second samples, the position of the cluster center is changed, and the radius is also changed. Therefore, the fuzzy memberships of all the samples are changed because of one additional sample, which is the reason that the classification performance of FSVM considering the global distribution normally is influenced by the outliers or noises.
A distribution without outliers. A distribution with one outlier.

Zhang et al. (2006) defined an affinity to improve the performances of the fuzzy memberships. They classify all the samples into two clusters: the fuzzy membership of the samples near the cluster center is more than 0.4, while the fuzzy membership of the samples far from the cluster center is less than 0.4. However, for their method, the additional sample in Figure 2 still influences the fuzzy memberships of some samples, which are very important samples for classification. Furthermore, this method may define some normal samples far from the cluster center as the outliers or noises, which may decrease the correct rate of the classification. Besides, there are several other methods based on the global distribution, but all of them still cannot effectively weaken the effects of the outliers or noises.
The fuzzy memberships based on the local distribution are proposed to complement the insufficiency of the fuzzy membership based on the global distribution, and the well-known one is the KNN: to find k nearest neighbors (k is an operator determined before classification), and calculate the fuzzy membership based on the ratio of similar samples and the k samples. The outliers or noise only influences the nearest k samples, which can improve the correct rate of the classification for the normal samples far from the cluster center. However, the KNN may cause problems as it only considers the number of the similar samples but their distributions.
Figure 3 presents a special distribution in that the red sample is an outlier, whose fuzzy membership becomes bigger if we use KNN, because the close samples are similar samples even the distances between this outlier and the close samples are very big. Therefore, the classification of outliers influences the accuracy rate of FSVM significantly. As the distances between some samples (far from the cluster center) and the nearest samples become bigger, the distributions of these samples tend to the global one rather than the local one. Therefore, some useful information of the distribution is not considered sufficiently as the KNN only considers the number of the nearest samples in the same cluster.
The distributions of two samples with one outlier.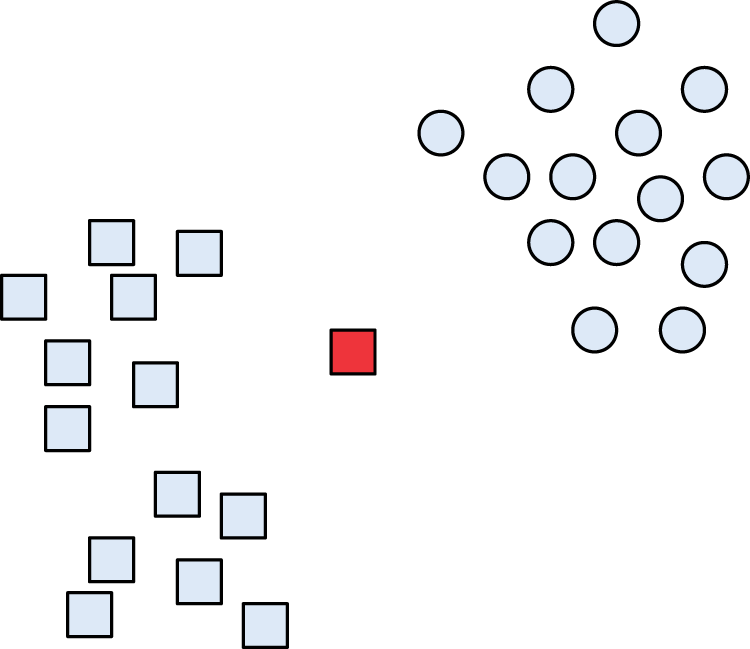
3.2. The environmental fuzzy membership
In this section, we propose a novel definition of the fuzzy membership entitled as environmental fuzzy membership, and we consider both the number of the similar samples nearby and the distribution of the samples nearby. The definition of the environmental fuzzy membership

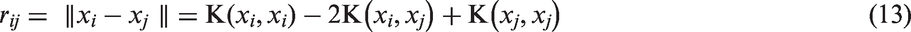
With the distance


The samples located in the range R can be found with the distance matrix Different conditions of the outlier: (a) case 1; (b) case 2; (c) case 3.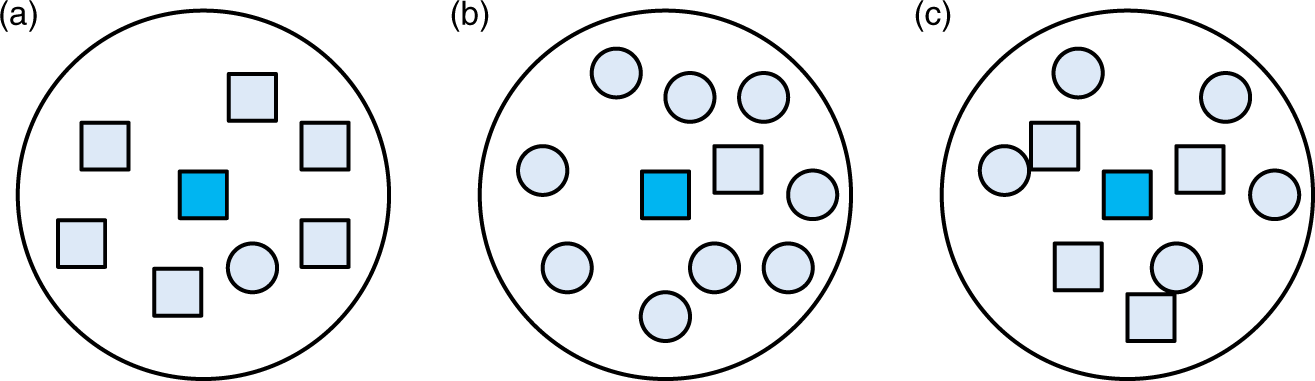
For all the three different conditions of the outlier in Figure 4, the blue sample in the center is the one that we calculate its fuzzy membership. In Figure 4(a), the number of the similar samples nearby is much bigger than the number of the heterogeneous samples nearby. Therefore, we consider this sample as a normal sample with a high probability, and we can give a large fuzzy membership to the sample. However, in Figure 4(b), the number of the similar samples nearby is much smaller than the number of the heterogeneous samples nearby, and we consider it as an outlier or noise with a high probability. Therefore, we give a small fuzzy membership to the sample. For the case in Figure 4(c), the number of the similar samples nearby is similar to the number of the heterogeneous samples nearby, and we consider it as a sample locating near the margin with a high probability. Therefore, we give a suitable fuzzy membership to the sample. According to this principle, we can determine the fuzzy memberships based on the environments of the given samples.
We also consider the mean distances of the similar samples nearby and heterogeneous samples nearby, especially for the case shown in Figure 4(c). The samples are classified into three parts according to the difference between the mean distance of similar samples nearby and the mean distance of the heterogeneous samples nearby. After these processes, we construct
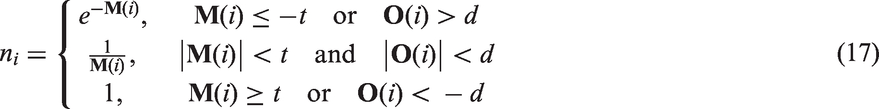
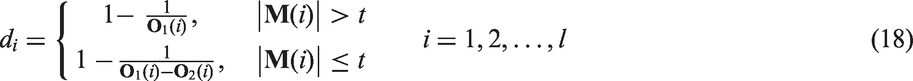
Thus, there are


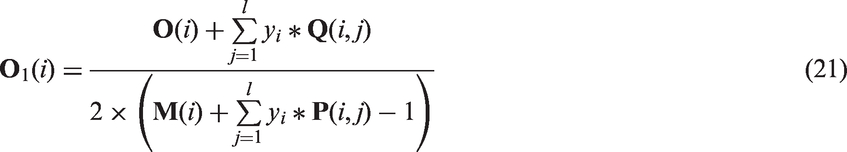
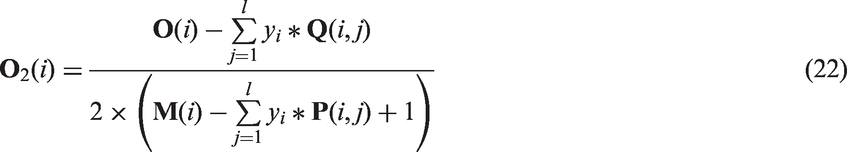
The flowchart of the environmental fuzzy membership is shown in Figure 5: the fuzzy memberships are given suitable values in each cluster as some samples are particularly treated, which can significantly improve the classification performances of the FSVM.
The definition of the environmental fuzzy membership.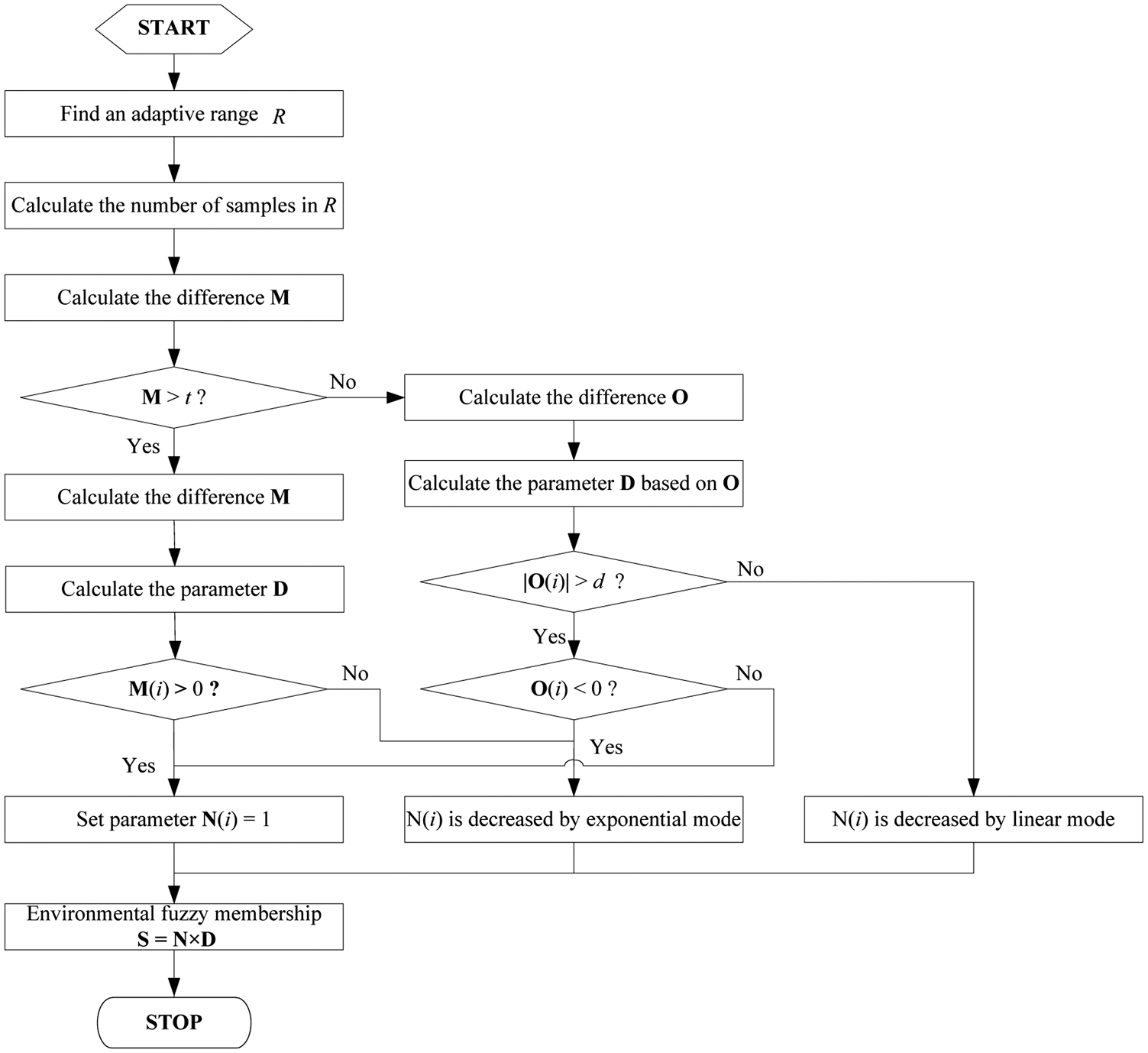
4. Experimental studies
In this section, we validate our method according to two numerical case studies and a breast cancer dataset from UCI machine learning database. For these cases, all the samples are classified by both FSVM based on KNN (KNNFSVM) and FSVM based on the environmental fuzzy membership (EFSVM), and the classification performances of the two methods are comparatively studied and discussed.
4.1. Numerical case studies
To reveal the classification performances of EFSVM on weakening the effects of the outliers or noises, we randomly generate two kinds of samples with some outliers, and there is no overlapping between these two kinds of samples. In the dataset, there are in total 600 samples: 80 of 600 samples are used to train the FSVM algorithm, and the other 520 samples are used to test the classification performances. For the 80 samples, they contain two different kinds of samples, and each kind of samples has three outliers. In the training process, we apply a particle swarm optimization (PSO) algorithm to optimize the parameter c, d, t, and R.
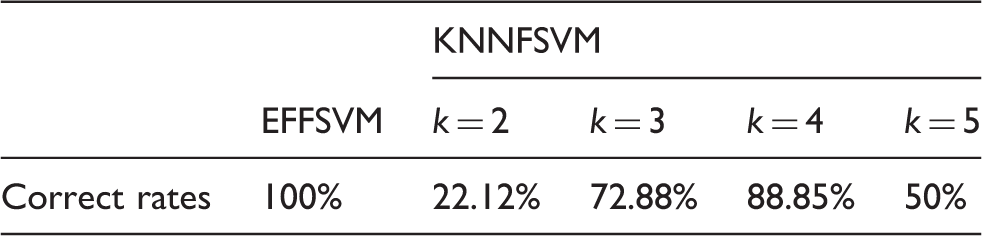
Correct rates of EFSVM and KNNFSVM for numerical case 1.
Correct rates of EFSVM and KNNFSVM for numerical case 2.
4.2. Experimental studies on a breast cancer dataset
In this section, the classification performances of the EFSVM and KNNFSVM are comparatively studied with a breast cancer dataset from the UCI machine learning database. The dataset was obtained from the University of Wisconsin Hospital at Madison by Kristin and Mangasarian (2002), and it contains 699 samples which have nine attributes. Among the 699 samples, 458 samples belong to the data of normal people, and 241 samples belong to the data of the patients. We choose 80 samples as the training samples (two kinds, each kind contains 40 samples), and the remaining 619 samples are used as the test samples.
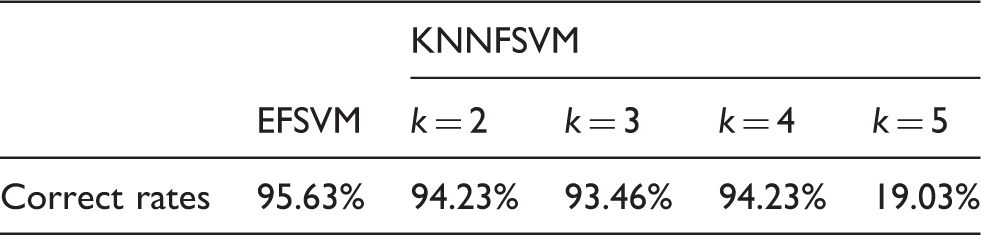
Correct rates of EFSVM and KNNFSVM for the breast cancer dataset.
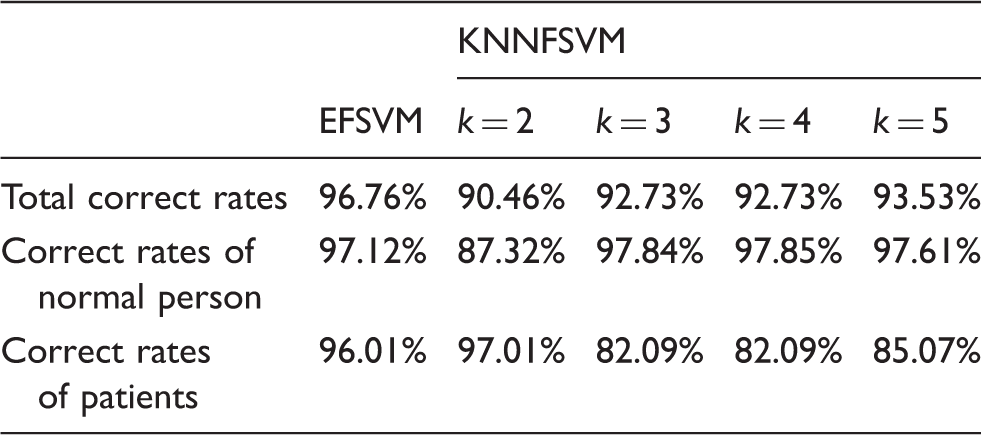
According to these three case studies, it can be concluded that the outliers or noise influence the classification significantly. The fuzzy membership of KNN only considers the number of the nearest samples with the same kind, while the environment fuzzy membership considers both the number of all the samples and the distribution of the samples nearby. Therefore, the correct rates of the EFSVM are higher than that of the KNNFSVM for all the three case studies, which validate that the EFSVM is more robust and reliable than the KNNFSVM in weakening the effects of the outliers or noises.
5. Application to motor fault classification
5.1. Introduction of the motor test bed
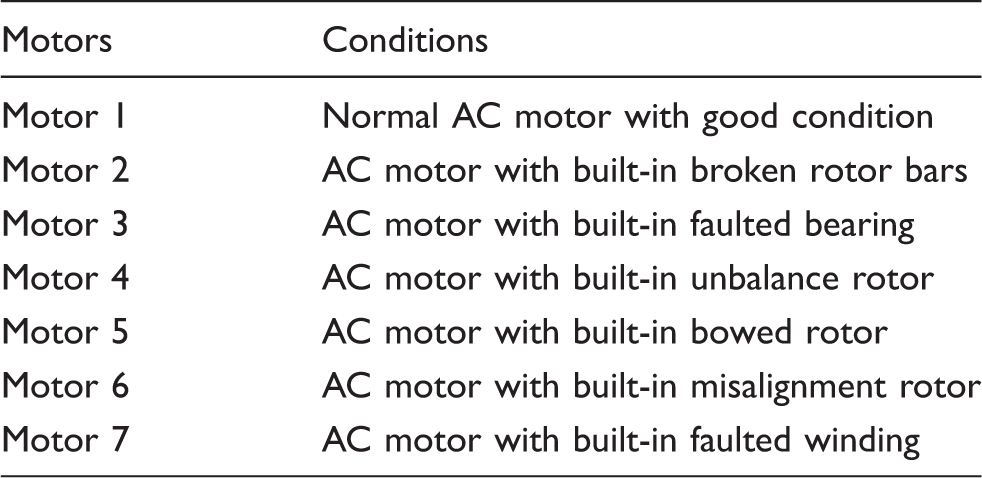
In this section, the proposed method is applied to a motor test bed which contains three parts: the transmission system with a shaft, a coupling, two pairs of rolling bearings, four rotors, a pulley, and a gear box; the horsepower variable frequency AC driver with multi-featured front panel programmable controller that can control the motor rotational speed; seven motors with a normal condition and six faults. A photo of the test bed is shown in Figure 6, and the detailed information of the motors is shown in Table 4.
The photo of the motor test bed. Details of the motors.
The locations of the sensors are shown in Figure 7: two sensors are located on the top and left sides of the motor casing to measure the vertical and horizontal vibrations, and another sensor is located at the shaft to measure the vibration in axial direction. The Sony EX series data acquisition and analysis system is applied to collect the vibration data, and the parameters of the measuring system are shown in Table 5.
The locations of the sensors. Parameters of the data acquisition system.

5.2. Motor fault classification
In the experiments, the rotational speeds of the motors are set to 25 Hz, and three data labeled data 1, data 2, and data 3 with a sampling length of 1 min are collected on the top of the motor casing: the first 20 s of the data 1 are used as the training samples, and the first 20 s of the data 2 are used as the testing samples to optimize the parameters of the FSVM, and then the first 40 s of the data 3 for all seven motors are classified by both the EFSVM and the KNNFSVM. The waveforms of the vibration data for each motor are shown in Figure 8.
The waveforms of the vibration data for each motor.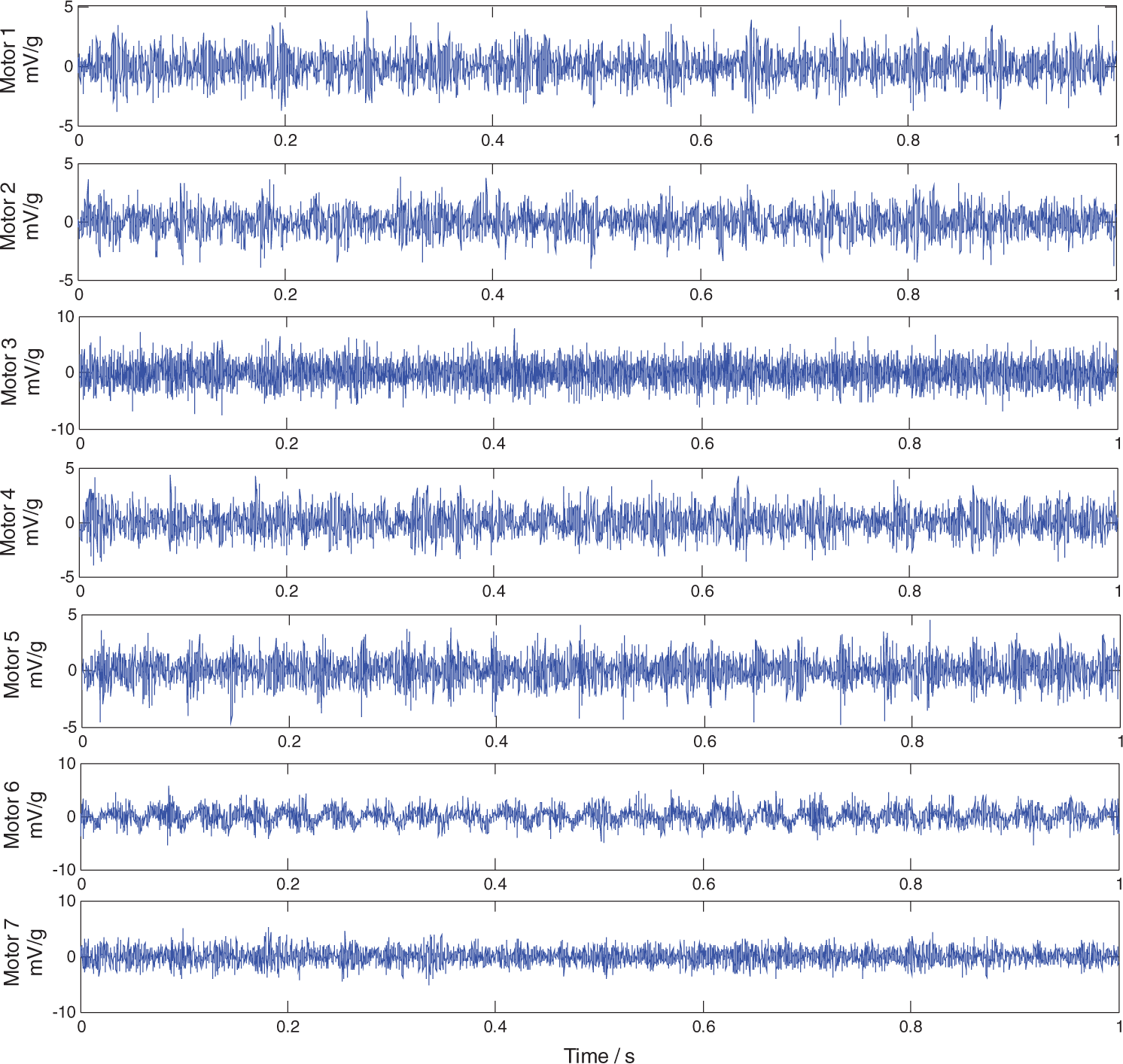
The time and frequency features.
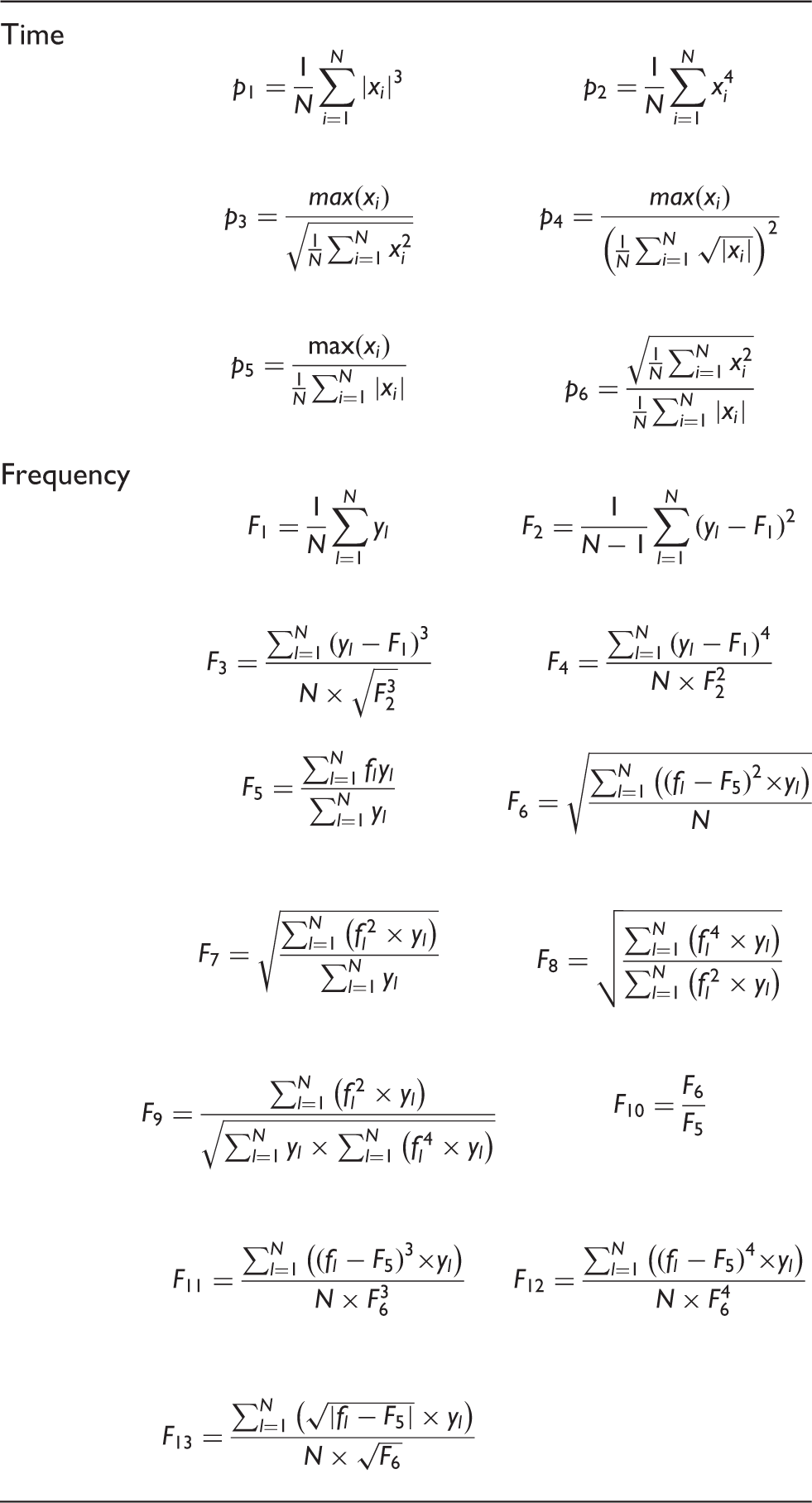
SVM is a two-category classifier, but our case is a multi-category classification problem. Based on the distributions of the samples for all seven motors: the distributions of the samples for motor 1, motor 2, motor 4, and motor 6 overlap, while the distributions of the samples for motor 3, motor 5, and motor 7 are far from each other. Therefore, we use a classification strategy of binary tree for the motor 1, motor 2, motor 4, and motor 6, and use a classification strategy of the directed acyclic graph (DAG) for the motor 3, motor 5 and motor 7. For the first case, the distance between the distributions of the motor 2 and that of motor 4 are much close, and the distance between the distributions of motor 1 and that of the motor 6 are much close. Therefore, we consider motor 2 and motor 4, motor 1 and motor 6 as two kinds, respectively. Our classification strategy is shown in Figure 9.
The multi-classification strategy of the motor faults.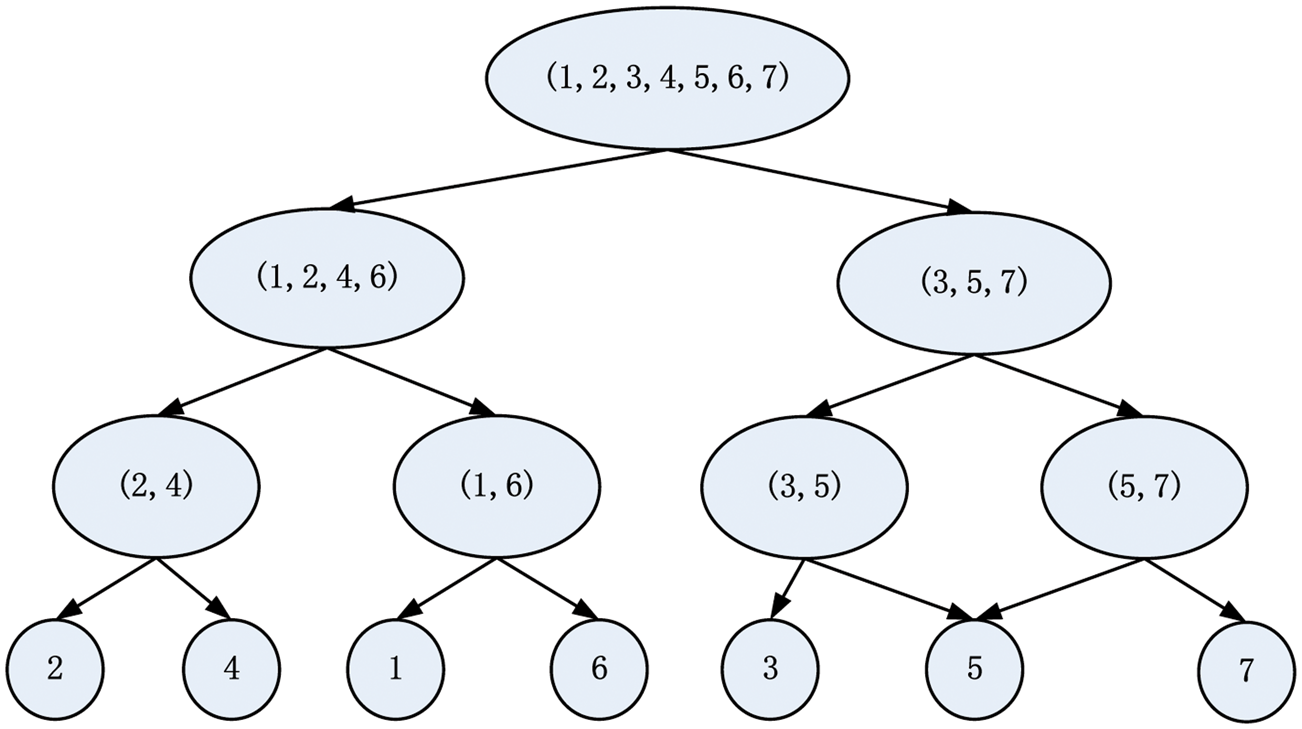
The classification correct rates of the EFSVM.

The classification correct rates of the KNNFSVM.
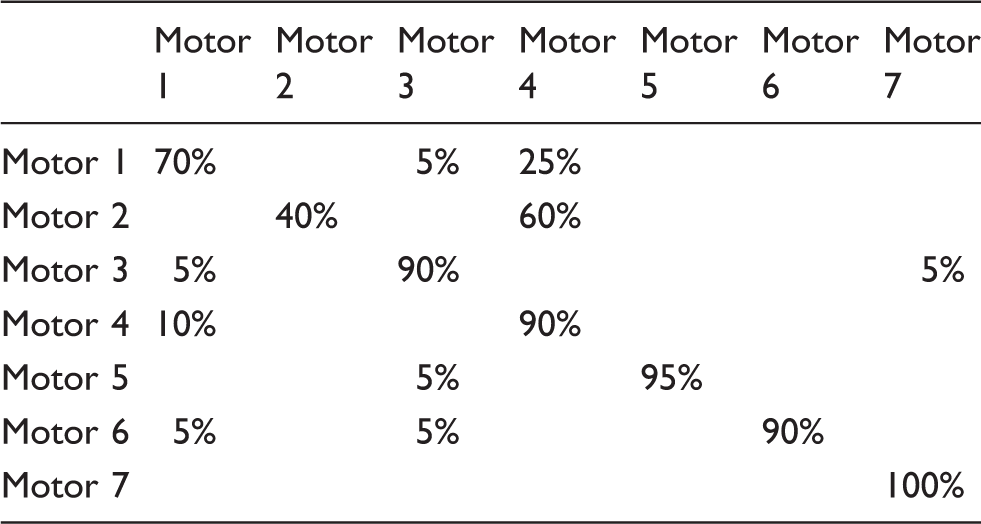
Comparing Table 7 with Table 8, both the EFSVM and the KNNFSVM obtain a good classification performance, and the mean correct rates of the EFSVM and the KNNFSVM are up to 97.86% and 82.14%, respectively. However, the correct rates of EFSVM for motors 1–7 are 100%, 85%, 100%, 100%, 100%, 100%, 100%, while the correct rates of KNNFSVM for motors 1–7 are 70%, 40%, 90%, 90%, 95%, 90%, and 100%. Obviously, EFSVM obtains a better classification performance for all the motors (especially motor 2) than KNNFSVM. The reason is that the distributions of the samples for motor 1, motor 2, motor 4, and motor 6 are close to each other, and some samples close to the classification boundary known as the outliers cause KNNFSVM low classification correct rates, because KNNFSVM is sensitive to the outliers or noises; while EFSVM obtains more higher correct rates as it has better performances on weakening the effects of the outliers or noise.
6. Conclusions
In this paper, a FSVM based on environmental fuzzy membership is proposed to weaken the effects of the outliers or noises in classification. The environmental fuzzy membership considers not only the number of the similar samples nearby but also the distribution of the samples nearby. Different from the KNN, the number of the considered samples is not a constant but a variable determined by a local area. By means of this definition, the effects of the outliers or noises on classification problem are obviously weakened, and thus the reliability and robustness of FSVM are enhanced.
In the numerical case studies, the correct rates of EFSVM are 100% and 95.63% while the correct rates of KNNFSVM are 22.12% for k = 2 and 19.03% for k = 5, which indicate that the classification performances of KNNFSVM are influenced by the parameter k while our method is adaptive and robust for all two cases. For the breast cancer data set, the boundary of KNNFSVM is obviously influenced by the outliers or noise, which causes some samples to be classified into wrong clusters with high probability; while our method can overcome such a difficulty and obtain higher classification correct rates. The application to motor fault classification also indicates that the EFSVM has a better classification performance for all seven kinds of motors, while the KNNFSVM cannot classify some faults into correct clusters as the correct rate is only 40%. Therefore, the EFSVM has more robust and reliable classification performances as it can effectively weaken the effects of the outliers or noises.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (grant numbers 51775407 and 51475356), Natural Science in Shaanxi Province (grant number 2015JQ5183), and the Fundamental Research Funds for the Central Universities.