
Abstract
Intelligent fault diagnosis (IFD) based on deep learning methods has shown excellent performance, however, the fact that their implementation requires massive amount of data and lack of sufficient labeled data, limits their real-world application. In this paper, we propose a two-step technique to extract fault discriminative features using unlabeled and a limited number of labeled samples for classification. To this end, we first train an Autoencoder (AE) using unlabeled samples to extract a set of potentially useful features for classification purpose and consecutively, a Contrastive Learning-based post-training is applied to make use of limited available labeled samples to improve the feature set discriminability. Our Experiments—on SEU bearing dataset—show that unsupervised feature learning using AEs improves classification performance. In addition, we demonstrate the effectiveness of the employment of contrastive learning to perform the post-training process; this strategy outperforms Cross-Entropy based post-training in limited labeled information cases.
Keywords
Introduction
It is almost impossible to prevent the generation of faults in rotating machinery, primarily due to their long operations hours and complex operational environment Zhao et al. (2020). On the other hand, the vital role these equipment have in modern industry raises the need to keep them in operational condition as much as possible. Thus, during recent decades, fault diagnosis of rotating machinery has gained special attention Liu et al. (2018b). The promising performance of artificial intelligence methods in solving pattern recognition problems, alongside the hard to provide solid understanding of the machines’ dynamical behavior and extensive experience required to diagnose complex machines, resulted in the creation of a new terminology known as Intelligent Fault Diagnosis (IFD). Accordingly, IFD is defined as taking advantage of intelligent methods to diagnose machine health states Lei et al. (2020).
Rolling element bearings are among the most important pieces in rotating machinery Cheng et al. (2021). Therefore, the application of intelligent methods toward the diagnosis of them is widely investigated Han et al. (2021), Xu et al. (2020) and Pei et al. (2021).
In the context of machinery fault diagnosis, Deep Learning methods are well known, mainly due to the fact that, unlike classical machine learning approaches, they do not require human supervision for feature extraction and feature selection; as they are able to learn features from the given inputs, independently Lei et al. (2020).
The training of deep networks needs enormous amounts of information as training data since it involves the optimization of huge numbers of variables as model parameters. In contrast, in most cases of machinery fault diagnosis, sufficient amounts of information are not available as running industrial machines and pieces of equipment in faulty mode have severe consequences Wang et al. (2020). Therefore, insufficient labeled training data are a challenge for the application of deep learning methods in real-world applications.
Due to its simpler collection process and affordability, unlabeled information can be considered a potential candidate to decrease the amount of labeled information required. Autoencoders, as neural networks employing unsupervised learning strategies, are a great choice to mine unlabeled information.
In order to improve the extracted feature set by the AE, for classification purposes, different supervised strategies are likely to be employed. The simplest approach to take is to place a softmax layer at the end of the feature extractor and retrain it again. However, this method is not able to perform well in extremely low-labeled information scenarios.
In cases where the available labeled information is extremely low, Few-Shot Learning is potentially capable of making better classification performances available, compared with the conventional methods Zhang et al. (2019). Few-Shot Learning (FSL) approaches are a set of methods and techniques with a great potential to decrease the dependency of deep learning models on the availability of training data Jadon (2020). Although they are mostly famous for their great performance in computer vision, their application in other fields, including intelligent fault diagnosis, is growing rapidly.
In this paper, we introduce a hybrid classification approach consisting of unsupervised feature learning alongside contrastive representation learning-based post-training. This goal is achieved by the application of Siamese networks as a Few-Shot Learning strategy, to optimize the feature space created by the Encoder section of an Autoencoder network. To our very knowledge, we are the pioneers of utilizing both these methods, as complementaries of each other. Additionally, the applicability of the proposed method in cases involving limited labeled data scenarios is demonstrated by comparing its performance with conventional baselines. Based on the results of this case study, we succeeded in achieving plus 90% classification accuracy using only 5 labeled observations from each class and an advantage over the conventional classification approaches as high as almost 9%. Furthermore, the potential use of trainable parameter reduction to improve the classification accuracy achievable by post-training steps is investigated.
Theoretical background
Autoencoders
In its simplest formation, an Autoencoder (AE) is a neural network consisting of 3 layers, known as the input, latent space or bottleneck, and output, where input and output layers have an equal number of neurons, and the bottleneck has lower dimensions. During the training process, the AE learns how to reconstruct the given input at the output, with the restriction of extracting a lower dimension representation, at the bottleneck Xia et al. (2017). As illustrated in Figure 1, an AE is made of two main building blocks, known as encoder and decoder. While the encoder is supposed to derive the set of features available at latent space, the decoder is responsible for reconstructing the given input at the output layer Liu et al. (2018a). Similar to every other neural network, the training of an AE requires a loss function. An ideal AE is capable of reconstructing the given input exactly the same at its output layer; therefore, the loss function of an AE is usually a similarity metric. Due to its ease of implementation and reliable performance, Mean Squared Error is the most frequent choice as the loss function to train an AE. Visual demonstration of a simple 3-layered autoencoder network.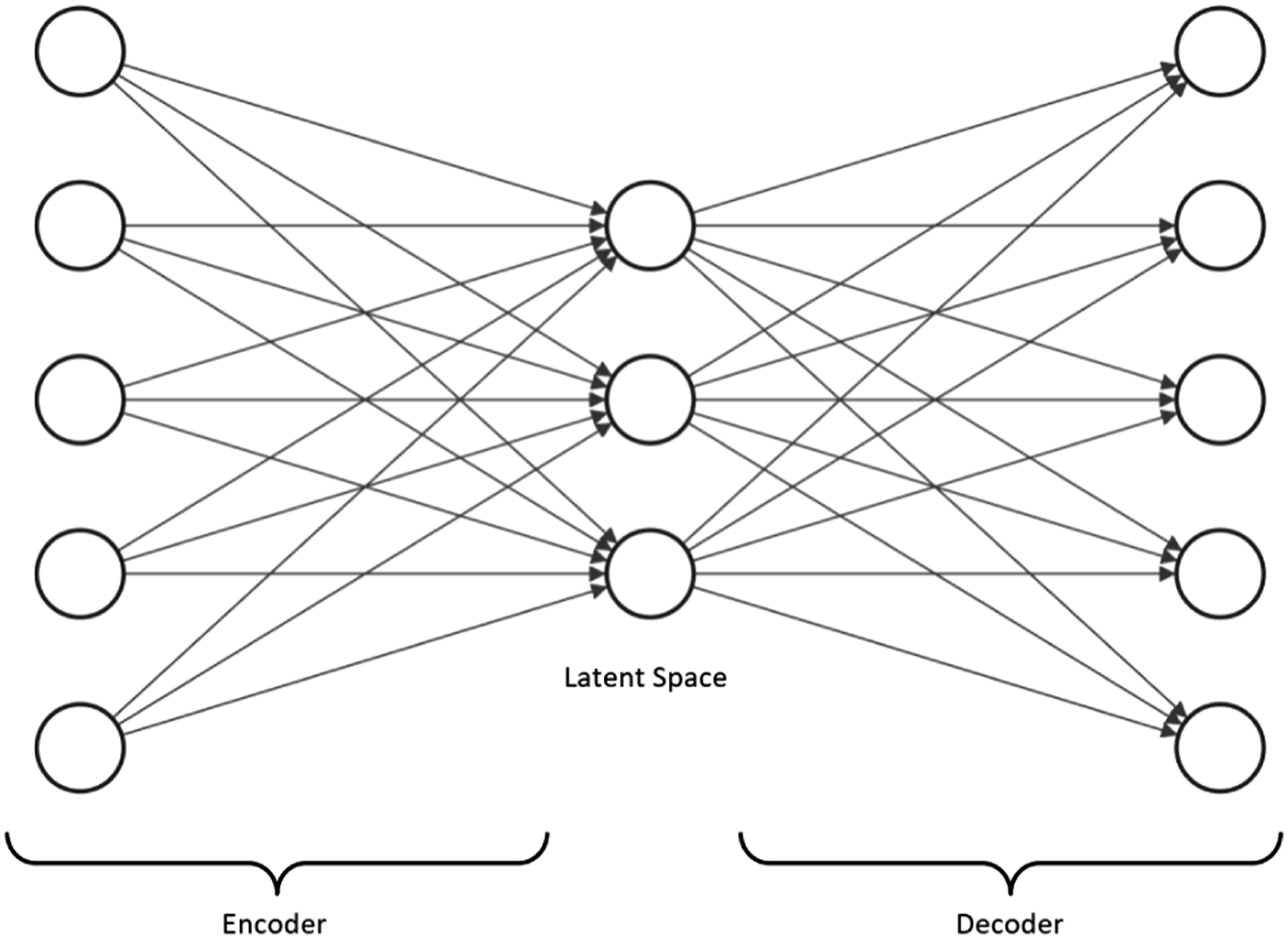
Similar to other neural networks, the deeper an AE is, the more abstract feature set it would extract at its bottleneck. Making use of a deep encoder and decoder is one strategy to implement a deep AE; however, it is not the only approach to take. Alternatively, a series of shallow AEs can be trained, where the embedding provided at the latent space of an AE is used as the input of another one. Having all the AEs trained, encoders existing at each AE are placed consecutively to produce a deep encoder, and similarly, a deep decoder is produced by putting decoders in a row. A deep AE implemented using this technique is known as Stacked Autoencoder (SAE).
Few-shot learning
Few-Shot Learning (FSL) can be considered as a set of strategies and techniques to improve the performance of deep learning networks in limited data scenarios. The Idea behind every FSL strategy is to train a neural network with few observations and acceptable generalization to unseen observations Jadon (2020). Contrastive representation learning, using Siamese Networks, is one of the FSL approaches that is effective in low data scenarios. As the name suggests, a Siamese network is made of two identical models (not only sharing the same structure but also sharing the same network parameters), used to extract embeddings, given an arbitrary pair of observations. Pairs passed to the Siamese network either belong to the same classes (positive pairs) or different classes (negative pairs). During the training process, the Siamese networks are trained to maximize the similarity between positive pairs and simultaneously minimize the similarity between negative pairs, resulting in the construction of a contrastive space. The similarity between two arbitrary observations is usually evaluated using a distance metric, such as Euclidean Distance. Euclidean Distance is the widely used option Witten and Frank (2002), mainly due to its geometric intuition and applicability to high-dimensional spaces (Euclidean Distance is the preferred choice when it comes to 1-Dimensional and 2-Dimensional signals, such as vibration, images, and other similar modalities of information). A Siamese network in its simplest form is illustrated in Figure 2. Illustration of a simple Siamese network.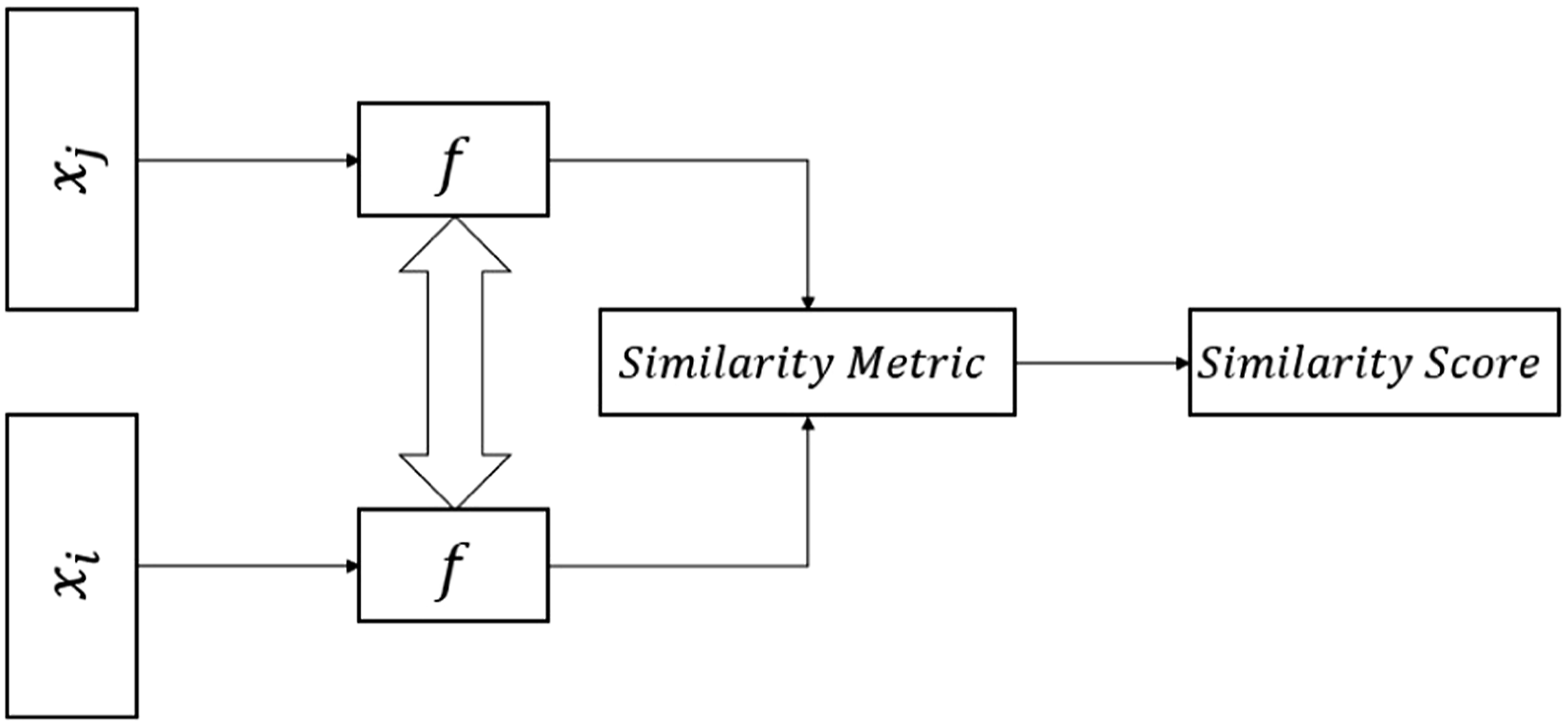
Contrastive loss Jadon (2020) is an option used for contrastive learning. For a pair of inputs, the contrastive loss can be computed as follows • The first term is responsible for minimizing the distance between the embeddings of observations, sharing the same class • The second term, to maximize the dissimilarity of the embeddings belonging to observations of different classes Jadon (2020)
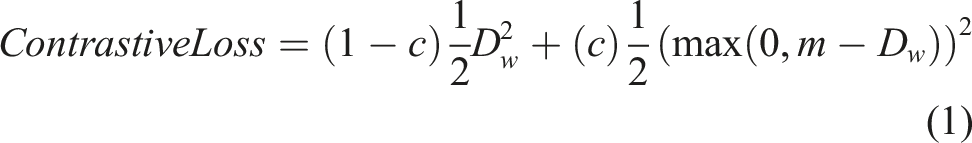
Related works
Some studies are conducted to assess the effectiveness of AEs for unsupervised feature learning for fault diagnosis purposes. For instance in Liu et al. (2018a) a Stacked Autoencoder, is used to train a deep AE for gearbox fault diagnosis. Similarly, in Xia et al. (2017) SAE is employed to diagnose the health state of motor bearing. In their study, the effectiveness of the proposed method is evaluated by the variation of the availability of labeled data. Moreover, Denoising Autoencoders (DAE), a set of AEs capable of reconstructing a noise-free version of an arbitrary noisy observation, are widely used to encounter noise interference in noisy environments. For example, Sun et al. (2016) took advantage of Sparse Denoising Autoencoders, which are the employment of dropout layers in conventional DAEs to assess the efficiency of AE-powered fault diagnosis solutions to diagnose induction motors, in the presence of different noise levels and various levels of labeled data availability. In Li et al. (2017), AE with a series of modifications is used to improve the robustness towards noise presence for rolling bearing fault diagnosis purposes. The applied modifications mainly rely on using dropout layers to set the activation value of randomly chosen neurons in both input and the latent space equal to zero. Taking such an approach makes the whole network more strong in dealing with random processes, interfering with the original data. In Shao et al. (2017), a new loss function is designed by taking advantage of Cross-Entropy to train feature learning using AEs. Moreover, the artificial fish swarm algorithm is used to optimize the key parameters of the deep AE used. The efficiency of the proposed method is assessed based on its performance in fault diagnosis of a gearbox test rig and electrical locomotive roller bearing. In Sohaib and Kim (2018), SAE is taken advantage of to train deep AEs for roller bearing fault detection. In this study, sparsity is also employed to prevent overfitting during the training process.
Zhang et al. (2019) employed a Siamese network consisting of a pair of deep convolutional neural networks as feature extractor, to achieve performance superior to conventional approaches, in the diagnosis of rolling bearings in limited data scenarios. This study also considered the tolerance of the proposed training strategy to the presence of various levels of noise, in the form of random Gaussian noise. More recently, in Zhang et al. (2021), FSL is employed to diagnose bearings using model-agnostic meta-learning with an aim to train fault classifiers in scenarios involving low amounts of training data availability. Similarly, in Tao et al. (2022) a novel Few-Shot learning strategy based on model agnostic matching network is proposed. The performance of the introduced method is evaluated based on both identical machines and cross-equipment fault diagnosis scenarios. Their experiments confirm the effectiveness of the proposed approach, in comparison with conventional approaches.
Proposed Method
Any deep neural network (DNN) as to solve a classification task, can be considered to be consisting of two main parts: the feature extractor and the classifier. The feature extractor is supposed to extract a feature set with higher levels of abstraction through the network, while the classifier is responsible for mapping the final set of extracted features by the feature extractor to the labels. Assume x as the input,
While conventional approaches to training DNN-based classification networks are merely dependent on labeled information, as mentioned earlier, the collection of labeled information—in huge amounts—for the cases of machinery fault diagnosis is not only time-consuming and costly but also not always possible as operation of industrial machines in faulty mode affects other machines in relation with it severely. Therefore, a DNN-based fault diagnosis approach capable of using both labeled and unlabeled information, able to perform robustly in cases where labeled data is extremely low, is quite beneficial. The proposed method in this paper is such an approach; by using an AE capable of learning features in an absolutely unsupervised manner, we are able to gain and invaluable preliminary understanding of the data with no labeled information used. Once the AE absorbs basic characteristics of the data—according to its performance in the reconstruction of unseen data—a post-training process capable of optimizing the feature space provided by the encoder section of the AE is essential. This is due to the fact that the AE is not aware of the orientation of the classes within the feature space and therefore not useful originally for classification purposes. Different post-training procedures are likely to be used, in order to make the feature space of the encoder a useful one for classification purposes. To keep the amount of labeled information during this procedure as low as possible, we take advantage of Siamese networks; a contrastive representation learning approach, adaptable to extremely limited labeled data scenarios. During this post-training, feature space produced by the encoder is modified in a way that observations belonging to the same classes of health state are aggregated to similar region of space while simultaneously the distance between regions representing different health states are oriented sufficiently far from each other. Contrastive learning as an FSL approach is capable of achieving a more separable feature set, in comparison with conventional approaches, and an increase in the separability is equal to higher classification performance. The proposed method is demonstrated in Figure 3. Visual demonstration of the proposed hybrid method.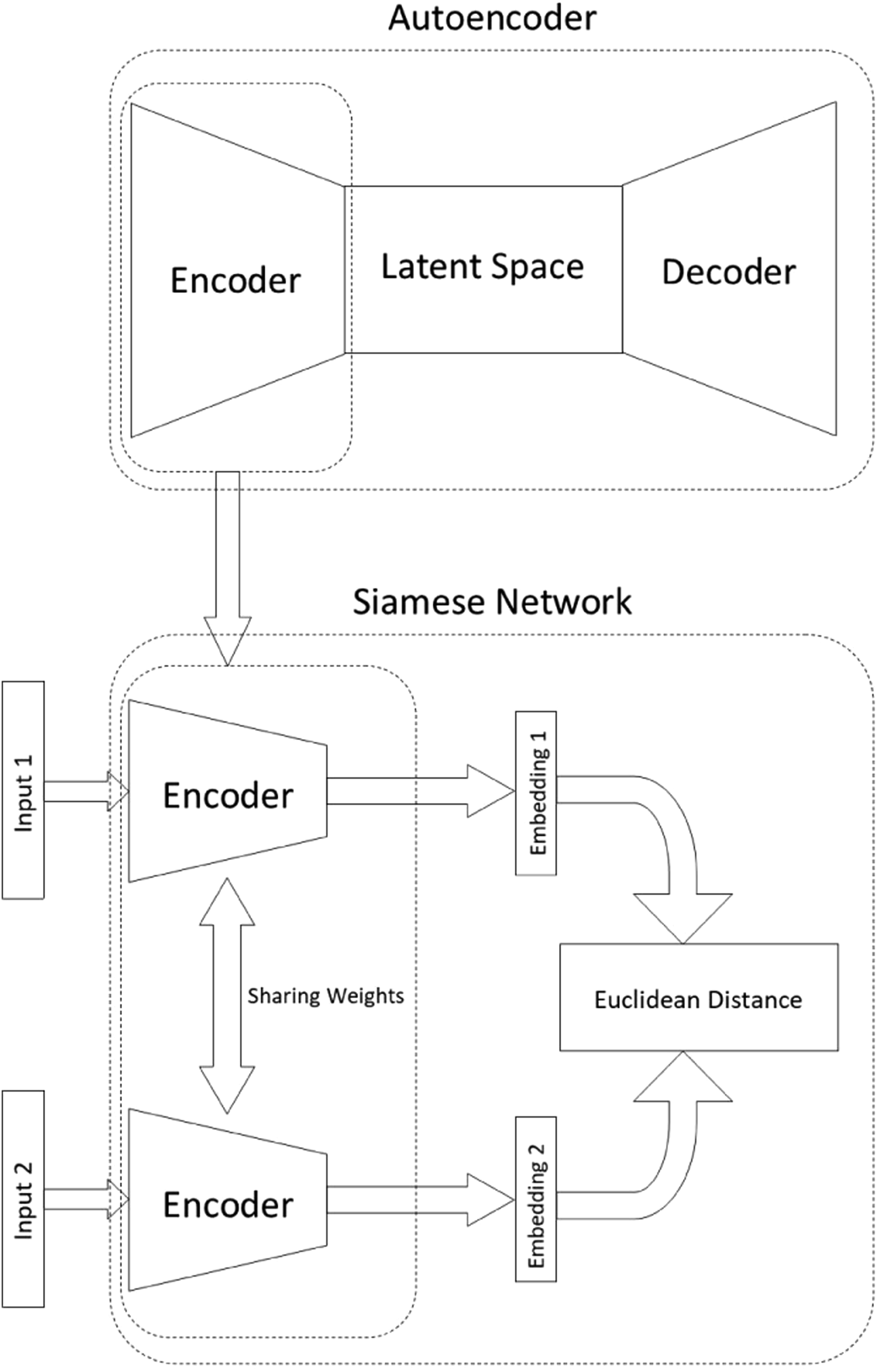
Experiments
Dataset
Rolling bearing plays a crucial role in rotating machinery and their failure is one of the most frequent reasons behind the downtime of these machines. In this study, the multi-fault bearing dataset provided by Southeast University 1 Shao et al. (2018) is used to evaluate the performance of the learning regimes introduced in the previous section. This dataset includes 5 classes as Normal, Inner Ring, Outer Ring, and simultaneous Inner and Outer Ring faults. In addition to those, two rotating speeds are included as 20 and 30 Hz. This dataset provides various channels of accelerations, corresponding to the various measurement locations. In this study, the time signal provided in the second channel is first windowed to a series of signals with a length of 1024, and then Fast Fourier Transform (FFT) is used as a preprocessing method. Application of FFT to transform the time-domain signal to the frequency-domain signal is a fairly accepted course of action Liu et al. (2018a), Li et al. (2017), Meng et al. (2018) in vibration analysis for rotating machinery fault detection; as faults are considerably easier to recognize in the frequency domain. By the application of FFT on time-domain signals, we are likely to obtain 512-point long frequency-domain signals covering 0–1000 Hz frequency range. According to the length of the signal, we have a frequency resolution lower than 2 Hz which we find it adequate. The dataset is split into train, validation, and test datasets with ratios of 0.6, 0.2679, and 0.1321, respectively. Moreover, the MinMax scaler is used to scale the components in the frequency spectrum. The feature scaler is fitted on the training dataset and is used across all the datasets.
Proposed method Vs. Comparable methods
To evaluate the effectiveness of the proposed method in fault diagnosis of rolling bearings, its performance is compared with the following methods.
Softmax feature extractor
The implementation of this learning regime involves a fully supervised process of training, where the classification network consists of a feature extractor and a simple softmax layer, as the classification network.
Few-shot feature extractor
A Few-Shot feature extractor is a feature extractor whose training procedure is done in an absolutely supervised manner.
Softmax optimization of encoder
The implementation of such learning regimes is a hybrid process, from the supervised or unsupervised learning point of view. Firstly, an Autoencoder is trained on the dataset in an unsupervised manner and using only unlabeled information. Afterward, by adding a softmax layer to the encoder, the whole network is post-trained using the labeled information to achieve improved classification capabilities of the encoder.
Procedure of experiments
The whole training dataset referenced in the previous section is used to train the AE. We employed a symmetrical structure with the formation of 512-256-128-256-512 as the number of neurons per layer, to construct the AE used in this study. Moreover, we used Adam optimizer to train the AE with the learning rate set to 0.001 and 100 epochs provided satisfactory training process. It is worth mentioning that the choice of activation function for all the layers of the AE is the hyperbolic tangent, due to its highly discriminative feature set. It is also noteworthy that the AE used in this paper is a conventional deep one, as the employment of stacking technique was not essential. Finally yet importantly, Mean Squared Error(MSE) is used not only as the loss function during the training of the AE but also as its performance evaluation criterion; according to our previous experience we considered a MSE value—on unseen data—lower than 0.0075 sufficient. The AE trained with the previously referenced architecture and set of parameters achieved a MSE equal to 0.0064 on the unseen test set.
As this study focuses on the robustness of the learning regimes to restricted labeled data scenarios, various amount of labeled information is provided to the aforementioned methods as follows: • 2 Samples of each machine health class (Total of 10 Labeled Samples) • 3 Samples of each machine health class (Total of 15 Labeled Samples) • 4 Samples of each machine health class (Total of 20 Labeled Samples) • 5 Samples of each machine health class (Total of 25 Labeled Samples) • 1% of Training Data (Total of 49 Labeled Samples) • 5% of Training Data (Total of 245 Labeled Samples) • 10% of Training Data (Total of 490 Labeled Samples)
In each of the above cases, labeled samples are randomly selected from the training dataset.
In cases in which the post-training is implemented using FSL, Adam optimizer with the learning rate of 0.00001 is used and 1500 epochs guaranteed appropriate training process. On the other hand, in scenarios where the addition of softmax layer to the feature extractor and using Cross-Entropy loss function to perform the post-training, Adam optimizer with 0.001 as the learning rate and 100 epochs were used.
To keep the comparison between the methods fair, the efficiency of the feature extractors for classification purposes is evaluated by training a K-nearest neighbor classifier on the embedding provided by each feature extractor. The classification performance of the KNN classifier is evaluated on the testing dataset. The number of neighbors used by the KNN classifier varies according to the number of labeled samples provided. In the cases where less than five samples of each health state are provided, the number of neighbors is the same as the number of samples of each health state. For cases with more or equal to five samples of each health state, the number of neighbors is set to five.
In the implementation of learning regimes involving Few-Shot Learning, it is not always computationally affordable to use all the available pairs. Therefore, in the experiments where 5% and 10% of the whole training dataset is used as the available labeled information, respectively, 12 and 6 pairs are randomly sampled out of all available pairs. In these two cases, sampling out of pairs is done in a way that the number of positive and negative pairs is equal. Moreover, to exclude the effect of randomness in the training of the networks, experiments are done with ten repetitions.
Results and discussion
Mean classification accuracy and standard deviation, by Methods and Amount of Labeled Information.
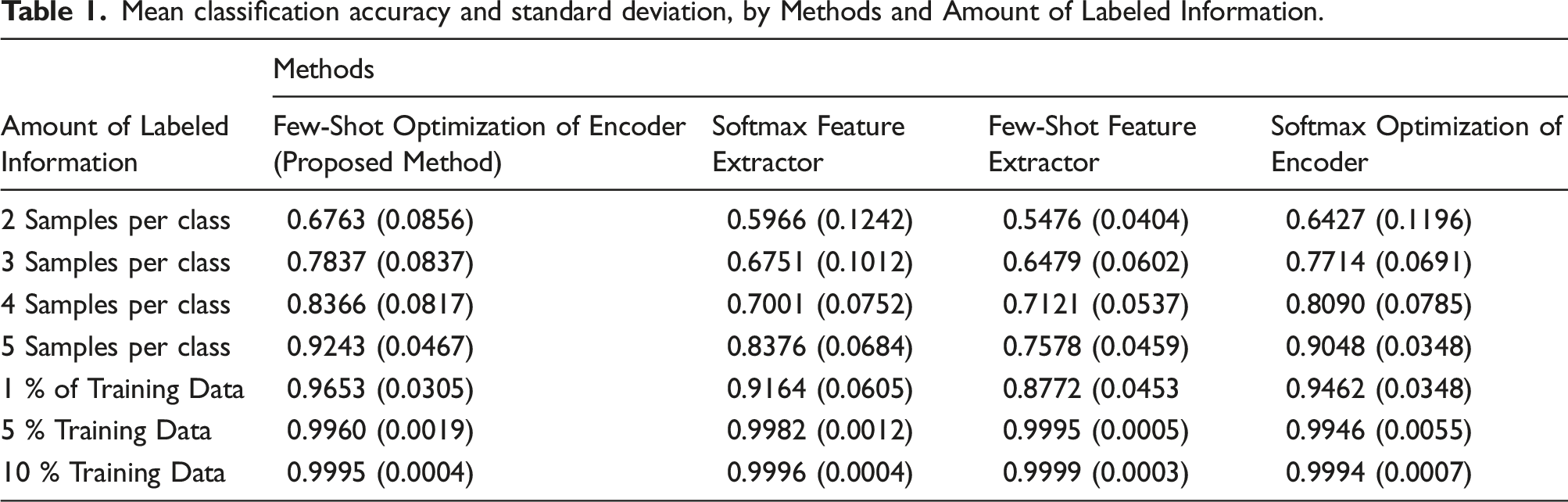
It can be easily understood that learning regimes utilizing unlabeled information by unsupervised feature learning, have outperformed methods depending on supervised-only training strategies for a wide range of labeled information availability. The effectiveness of unsupervised feature learning in the improvement of classification accuracy is as significant as that higher levels of classification accuracy are available in extremely lower amounts of labeled information. For example, methods capable of unsupervised feature learning unlock 90% and higher classification accuracy with just 25 samples, while Softmax Feature Extractor requires at least 49 samples (1% of the whole training data available) and Few-Shot Feature Extractor is not capable of achieving such performance until it is provided with 245 samples (5% of the whole training data available).
Excluding Few-Shot Feature Extractor learning regime due to its poor classification accuracy, generally lower SD shows that methods with unsupervised feature learning are likely to perform better according to classification accuracy robustness.
The significant difference between the classification performance provided by Softmax Feature Extractor and Softmax Optimization of Encoder can be explained by the fact that Softmax Feature Extractor as a fully supervised learning regime, is not able to take advantage of unlabeled information. Moreover, the performance of this learning regime is highly dependent on the amount of labeled information.
Similar to Softmax Feature Extractor, Few-Shot Feature Extractor is also incapable of making use of unlabeled information.
In addition to those, FSL post-tuning of the encoder turned out to be more effective, rather than the Softmax Optimization from an average classification accuracy point of view.
In the Figure 4(a), the separability of health states on raw data is demonstrated using the T-distributed Stochastic Neighbor Embedding visualization tool. The existence of two clusters from each health state is the result of the presence of two loading conditions in the dataset. Although these clusters look easily separable, severe over-fitting is inevitable in limited labeled information cases. In the Figure 4(b), the separablity of health states on the embedding provided by the encoder post-trained with FSL is demonstrated. Five labeled observations per class (25 observations in total) are used to conduct the post-training process. Except for the clusters identical to healthy operation of the bearing and Inner-Outer ring combinatory fault state which seem to have a neat overlap and a few outliers, the health state clusters are properly separable. In addition to that, this training procedure succeeded in the aggregation of observations belonging to similar health states over different loading conditions. Demonstration of Health Separability by Dimensions Derived using t-SNE. (a) 2D t-SNE Visualization of Raw Data. (b) 2D t-SNE Visualization of the Embedding Derived by Few-Shot Optimization of Encoder (utilizing 5 labeled observation per class). H: healthy, B: ball fault, I: inner race fault, O: outer race fault and I-O: combination of inner race and outer race faults.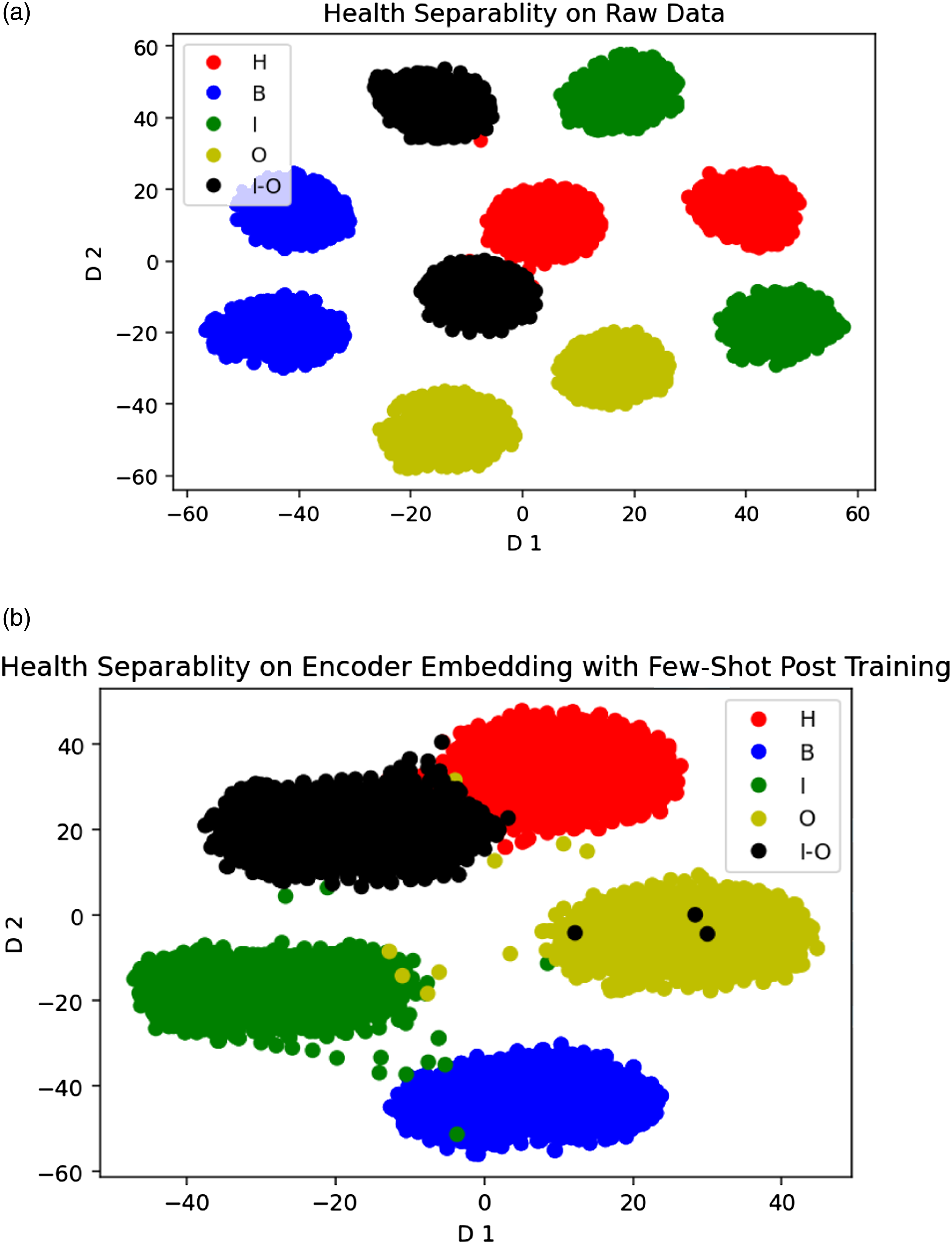
Ablation study—improving post-training process by reduction of trainable parameters
Effect of freezing the initial layer of encoder on the mean and standard deviation of classification accuracy.

Mean and standard deviation of classification accuracy achieved by secondary feature extractors on encoder embedding.

Conclusion
In this study, a hybrid learning approach from the supervised or unsupervised learning point of view is presented to take advantage of both labeled and unlabeled information available. The proposed method has the potential to decrease the required amount of information to achieve baseline accuracy metrics, compared with most frequent conventional methods.
The performance of the proposed method is evaluated using the SEU Bearings Datasets, known to be amongst the best available rotating machinery benchmark datasets. This dataset includes time-domain acceleration signals, collected from bearings for various loads and different health states. In addition to the presented method, the performance of other methods is also evaluated to provide a performance comparison across classification approaches.
The conducted experiments show the benefits of using AEs to take advantage of unlabeled information. This approach not only improves the mean of accuracy but also provides a lower SD. Besides that, FSL turns out to be a better choice to post-train the embedding provided by encoders in limited labeled information scenarios.
The proposed method in this study can be regarded as a solution to low-labeled data availability cases. Its performance in fault diagnosis of other types of rotating machinery can be evaluated by taking advantage of similar datasets such as SEU Gear Datasets. Besides that, as in real-world fault diagnosis applications, the available machinery data are highly unbalanced, the performance of the proposed method needs to be assessed where unlabeled data suffers unbalancing.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.