
Abstract
With the increasing demand for ride comfort, safety, and performance in modern vehicles, semiactive suspension systems based on magnetorheological dampers (MRDs) have attracted significant attention because of their fast responses, low energy consumption levels, and controllable damping forces. However, the traditional control strategies often rely on precise mathematical models, making it difficult to handle the inherent nonlinearities and parametric uncertainties of such systems. To address this challenge, a reinforcement learning-based semiactive control framework using proximal policy optimization (PPO) is proposed in this study; the framework enables autonomous control policy optimization through continuous interactions with the environment. First, an MRD model is established based on a phenomenological model with an intelligent optimization algorithm. This model is integrated into a PPO control framework, allowing the agent to generate control currents through environmental interactions, thereby adjusting the output damping force of the damper. The proposed method does not require an explicit system model during training and acquires the optimal control policy through trial and error. The simulation results obtained under stochastic road excitations demonstrate that the designed PPO controller significantly outperforms both the passive and Skyhook controllers in terms of vibration reduction. Moreover, even under 20% parametric uncertainty, the retrained controller maintains good stability and control performance, indicating that the randomized training enhances the generalization ability and adaptability of the learned policy to system parameter variations, thereby providing the potential to develop a truly robust control strategy in future work. This study highlights the potential of reinforcement learning (RL) for use in semiactive suspension control tasks with MRDs and offers a scalable control strategy for complex nonlinear systems.
Keywords
Introduction
With the continuous development of the automotive industry, increasing demands have been placed on the performance, safety, and ride comfort of vehicles, imposing stricter standards on the dynamic performance of suspension systems. Semiactive control technology, which was first introduced by Crosby and Karnopp (1973), effectively bridges the gap between passive and active suspension systems by offering an adjustable damping method with a low energy consumption level (Caponetto et al., 2003). This topic has become a significant research focus in the field of vehicle suspension control. As some of the most representative actuators in semiactive systems, magnetorheological dampers (MRDs) are widely used because of their rapid responses and broad dynamic ranges. However, MRDs inherently exhibit strong nonlinearities and hysteresis behaviors, making it essential to develop accurate models that can capture their dynamic characteristics as a foundation for achieving high-performance suspension control (McLaughlin et al., 2014). In addition, the design of control strategies based on MRDs represents a key approach for improving the performance of suspension systems.
To accurately describe the nonlinear and hysteretic behaviors of MRDs, researchers have commonly adopted parameterized modeling approaches, constructing mathematical models by combining spring–damper elements with hysteresis operators (Saufi et al., 2025). Yan et al. (2021) utilized the Dahl model to characterize hysteresis behaviors, whereas Hu et al. (2022) developed an MRD model on the basis of the Bouc–Wen model. Jiang et al. (2023) proposed a phenomenological model that accounts for insufficient fluid flows, demonstrating superior accuracy to that of the prior methods in terms of capturing dynamic characteristics. The establishment of MRD models provides essential support for designing control strategies; however, the overall performance of suspension systems depends more critically on the effectiveness of the utilized control methods. A variety of semiactive control strategies, including skyhook control, the linear quadratic regulator (LQR), H∞/H2 control, and fuzzy radial basis function-based sliding mode control (FRBF-SMC) (Ding et al., 2022; Han et al., 2024; Li et al., 2024; Liu et al., 2019; Margolis et al., 1975; Savaresi and Spelta, 2007), have been proposed. Nevertheless, the classic control strategies lack precision and adaptability in complex dynamic environments, whereas modern control strategies, although more capable of performing optimization, depend heavily on accurate models and remain limited in terms of robustness.
In recent years, reinforcement learning (RL) has been increasingly applied to semiactive suspension control owing to its independence from precise system models and its capability for autonomous policy learning (Li et al., 2019; Wang et al., 2019; Zhao et al., 2019). Beyond these early studies, more recent works have evaluated RL-based suspension controllers under more realistic settings. For example, Lee et al. (2022) modeled the MR damper actuator as a first-order system, thereby partially accounting for actuator dynamics, and demonstrated that their RL controller outperformed the conventional SH–ADD method in terms of ride comfort. Yong et al. (2023) proposed a switching SAC-based control framework and validated its effectiveness under real-road conditions, further confirming the practical feasibility of RL in automotive applications. Ultsch et al. (2024) incorporated actuator dynamics and conducted systematic real-vehicle experiments, providing more direct evidence of the applicability of RL methods to vertical vehicle dynamics control. In addition, DDPG-based approaches (Liu et al., 2020; Tan et al., 2023) and PPO-based strategies (Han and Liang, 2022; Kim et al., 2023) have also been explored for quarter-vehicle suspension vibration control.
Despite the progress achieved by these studies, most existing RL-based suspension controllers are trained exclusively on nominal-parameter models and fail to adequately account for the parameter uncertainties inherently present in real vehicles, which may degrade policy performance under varying operating conditions. Moreover, the nonlinear current–force characteristics of MRDs are seldom explicitly incorporated into the training environment, potentially limiting the deploy ability of the learned policy on real actuators.
To address these limitations, this study develops a physically consistent RL training framework in which a nonlinear MRD model—constructed through experimental data and parameter identification—is integrated into the RL environment, ensuring that the agent’s output current corresponds to a realizable damping force. During the training stage, random perturbations are applied to key suspension parameters, including sprung mass, suspension stiffness, and tire stiffness, thereby constructing a training environment that reflects system parameter variations and enables the learned policy to achieve better generalization ability and potential robustness under different physical operating conditions. As a representative on-policy deep RL method, PPO offers desirable training stability and implementation simplicity through its clipped surrogate objective and relatively stable policy update mechanism (Han and Liang, 2022; Schulman et al., 2017), making it well suited for the semiactive suspension control scenario considered in this study. Accordingly, PPO is adopted as the learning framework in this work, and two agents are developed: Agent A, trained under nominal parameters, and Agent B, trained under parameter-randomized conditions. Simulation results show that, compared with passive control and Skyhook control, the proposed method significantly enhances vibration-reduction performance, and Agent B maintains stable control behavior under parameter variations, demonstrating stronger policy generalization ability and adaptability to system parameter changes, thereby exhibiting greater potential robustness under real operating conditions.
Modeling
Modeling of a magnetorheological damper
In this study, a laboratory-developed MRD is used as the primary research object. As shown in Figure 1, mechanical characteristic tests are conducted to obtain damping force data under various displacement excitations and input currents. Photograph of the magnetorheological damper.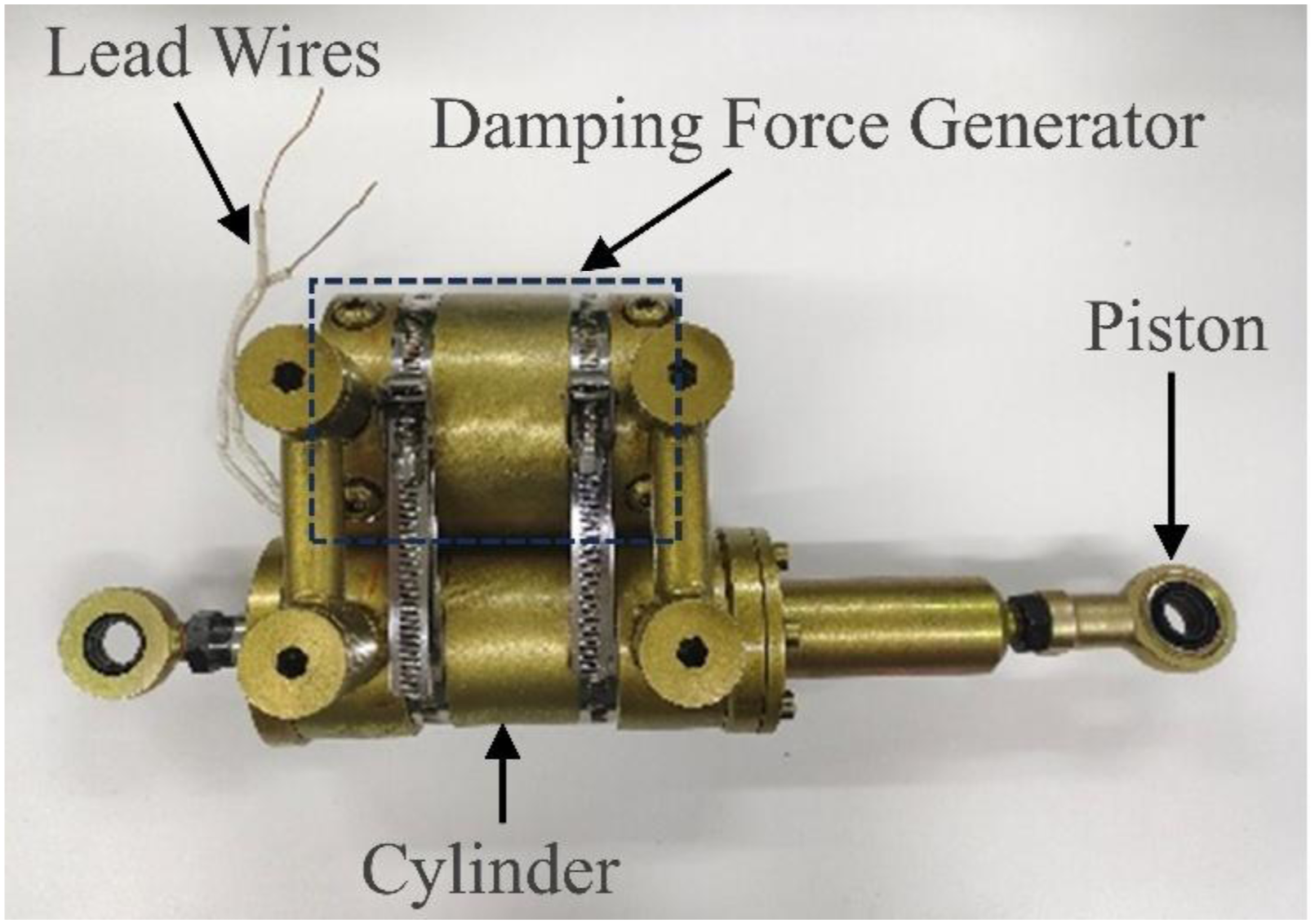
The phenomenological model, derived from the Bouc–Wen model, is improved by incorporating serially connected damping and stiffness components (Gao et al., 2023). In the context of suspension vibration reduction, the primary focus is on the operating conditions that are characterized by low-frequency and large-displacement excitations, under which the influence of the stiffness term becomes negligible. To simplify the subsequent model training process, building upon the work of Bai et al. (2015), the original phenomenological model is refined in this study by omitting the stiffness component to simplify the dynamic representation, resulting in a structure that is more suitable for control design. The modified model structure is illustrated in Figure 2. Modified phenomenological model.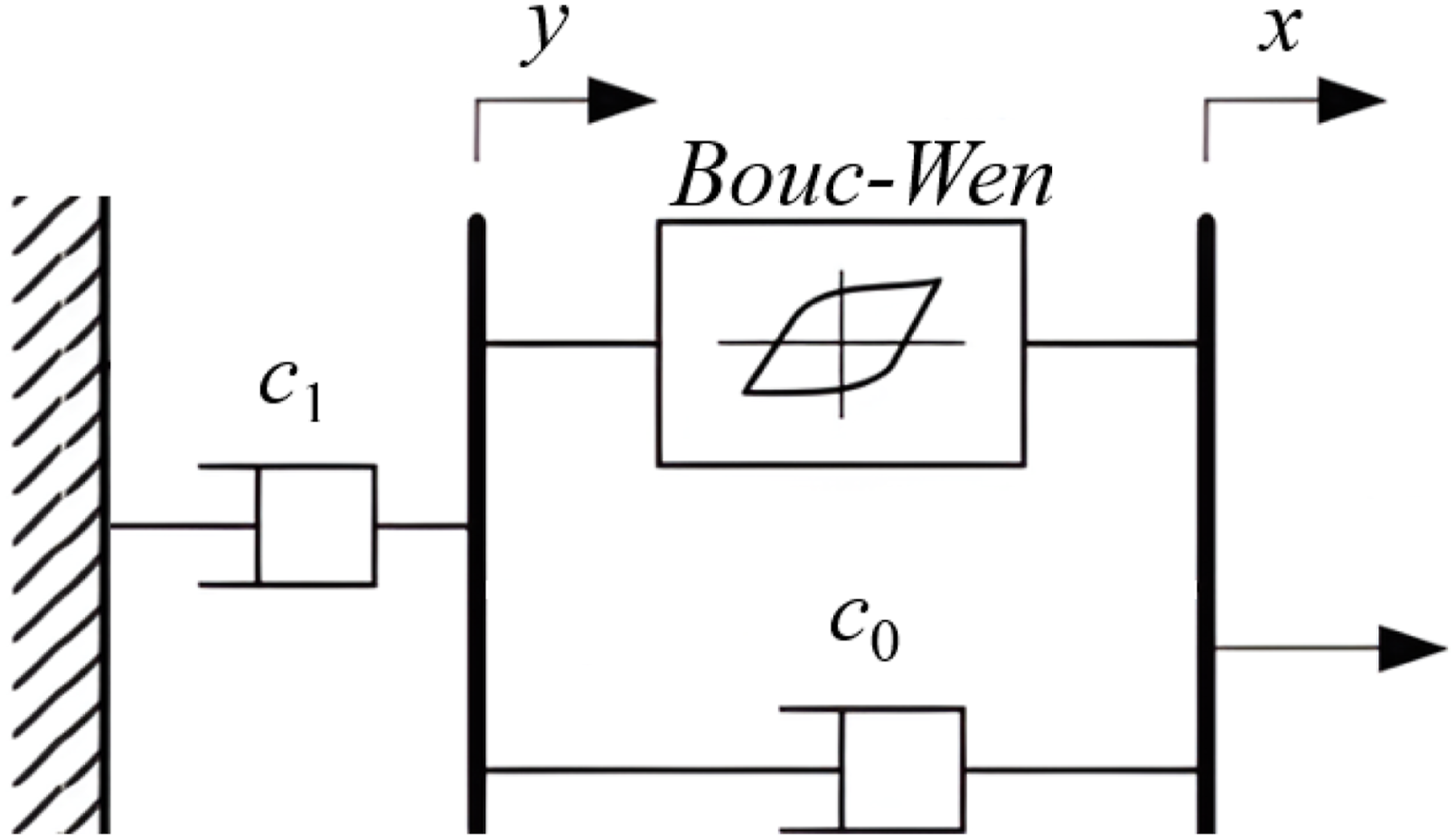
Accordingly, the expression for the damping force is given by equation (1), where the identifiable model parameters are simplified to [
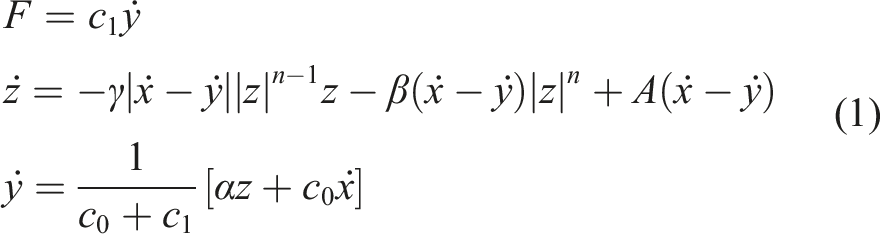
To identify the unknown parameters in the modified phenomenological model, the Manta ray foraging optimization (MRFO) algorithm is employed in this study to fit the model-calculated damping force to the experimental data (Omotoso et al., 2022). The MRFO algorithm simulates three typical foraging behaviors exhibited by manta rays: chain foraging, spiral foraging, and somersault foraging. It demonstrates strong global search capabilities and effective local convergence performance (Abdullahi et al., 2023).
Among these parameters,
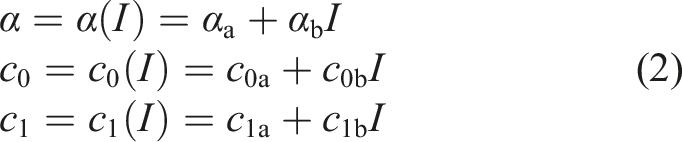
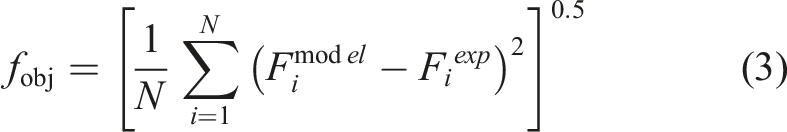
Parameter identification results obtained for the phenomenological model.
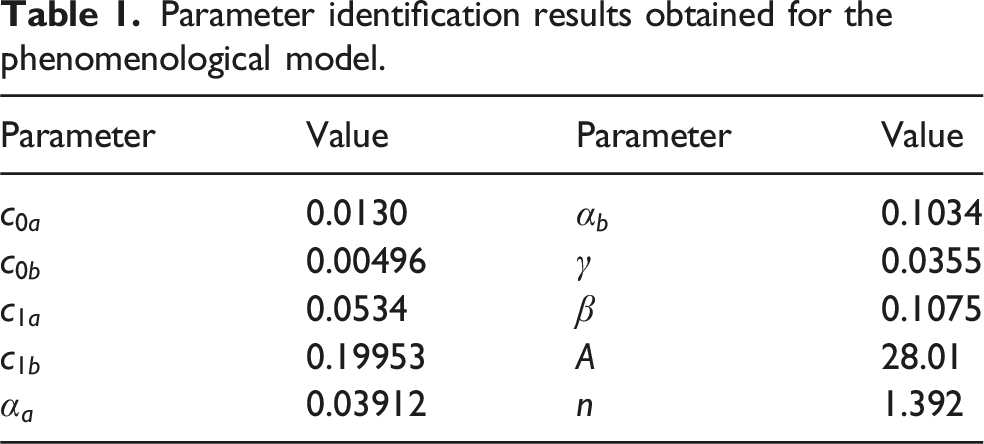
On the basis of the identified parameters, an MRD model is constructed according to the modified phenomenological model. A comparison between the model-predicted damping force and the experimentally measured force is shown in Figure 3. The results indicate that the model can accurately capture the dynamic responses of the damper under varying displacement amplitudes and velocity conditions. The generated hysteresis loops closely match the experimental data, exhibiting good agreement across the entire operating range. The computed fitness function value is 0.241 kN, accounting for approximately 4% of the maximum measured damping force, which confirms the effectiveness and accuracy of the model in terms of representing the mechanical behavior. This validated MRD model serves as a reliable foundation for constructing the training environment of the proposed RL-based control system. Comparison between the model-produced and experimental results.
Quarter-car suspension modeling
In the absence of coupling effects between wheels, the vertical vibration responses induced by road excitation can be analyzed using a quarter-car suspension model. As shown in Figure 4, this model primarily consists of a sprung mass, a suspension spring, a controllable damping element, an unsprung mass, and a tire stiffness element (Verros et al., 2005). Two-degree-of-freedom semiactive suspension model with MRDs.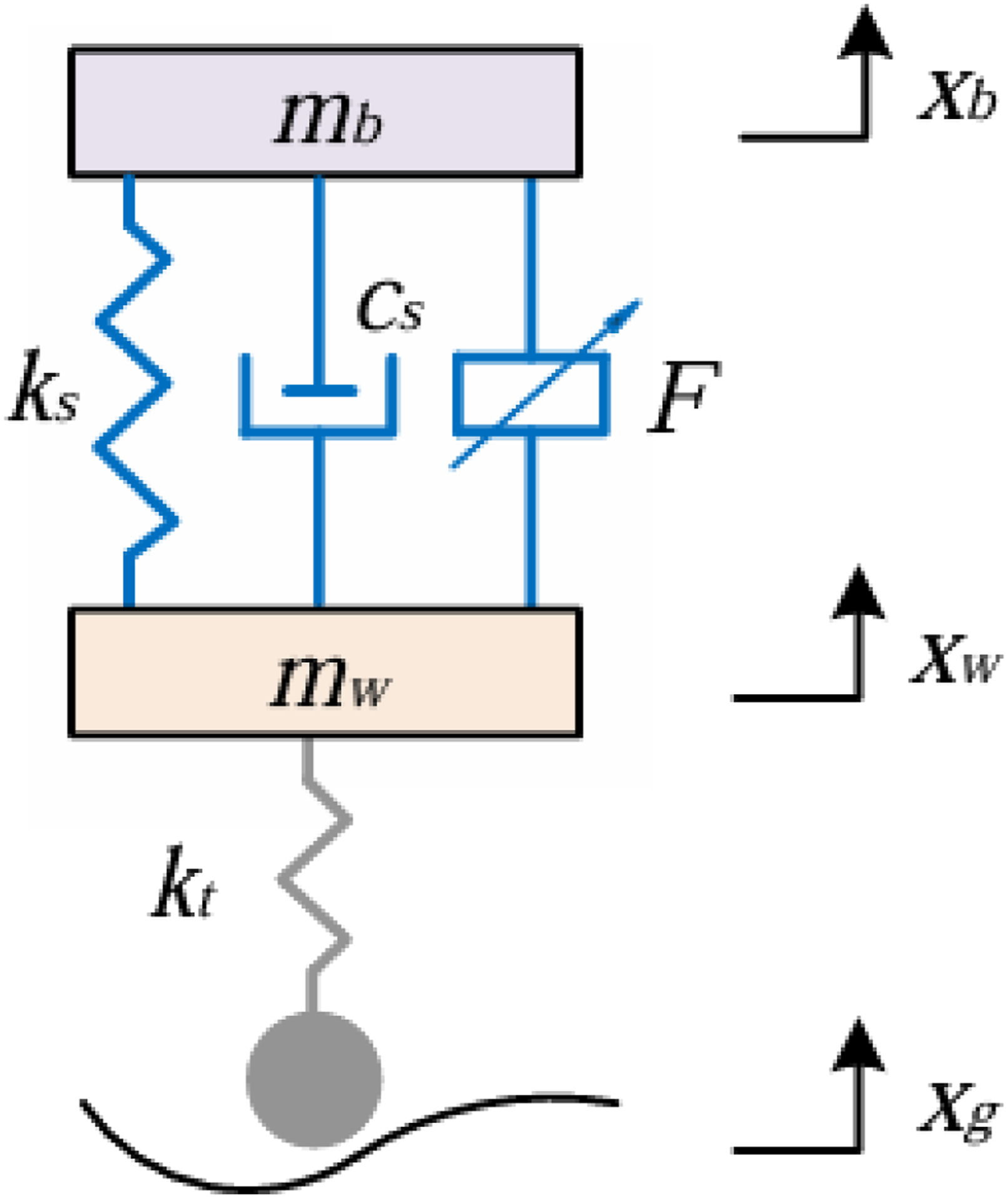
The dynamic equations of the system can be derived from Newton’s second law, as expressed in equation (4).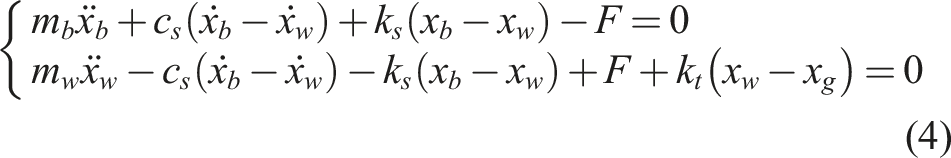
Road excitation modeling
To represent the road excitation term in equation (4), a simple and efficient time-domain modeling method based on filtered Gaussian white noise is adopted in this study. According to ISO 8608 (Múčka, 2018), the statistical properties of road surface roughness can be characterized by a spatial power spectral density (PSD) function, as given in equation (5).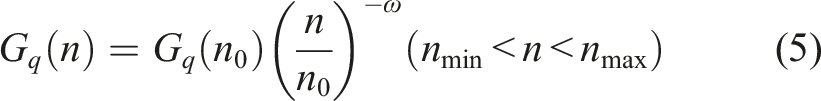
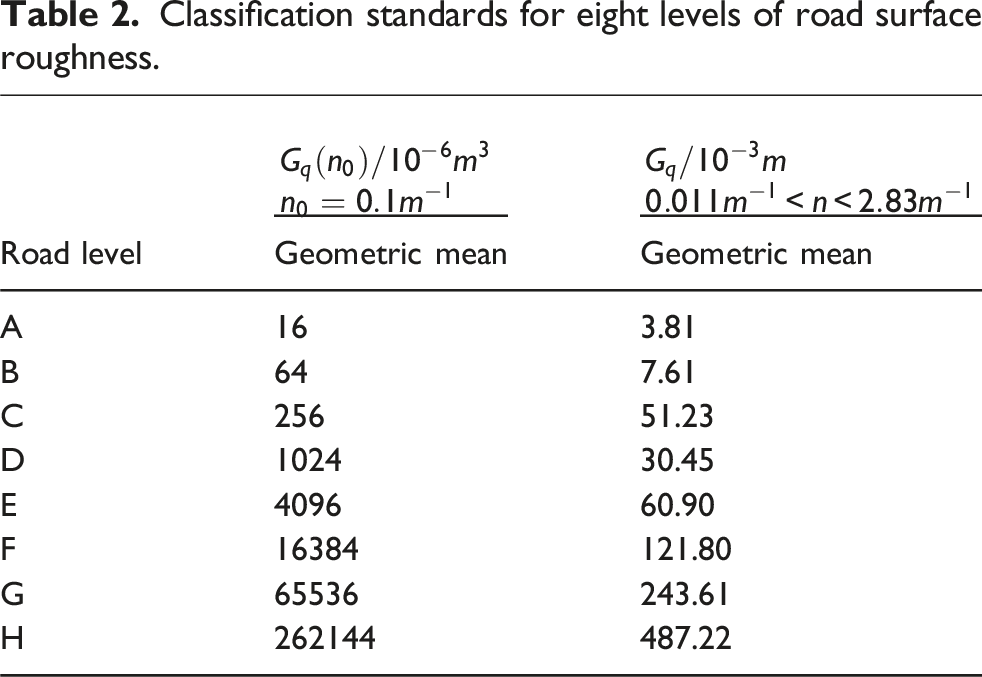
Classification standards for eight levels of road surface roughness.
Standard Gaussian white noise is filtered to generate the road excitation model, whose time-domain expression is shown in equation (6).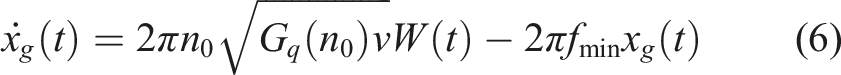
The model is developed in accordance with the ISO 8608 standard and serves as a time-domain road excitation model for control algorithm simulation and analysis.
PPO-based control design
Principle of PPO
PPO introduces a clipped surrogate objective to constrain the update step between the current and previous policies, effectively mitigating the risk of excessively large policy deviations during the optimization scheme. This mechanism enhances the stability and sample efficiency of the training process. As a policy gradient method, PPO seeks to improve the utilized policy by maximizing the expected cumulative return, thereby enabling continuous refinement of action selection behaviors throughout the training cycle. In this study, the standard PPO framework (Schulman et al., 2017) is employed. Its algorithmic architecture is illustrated in Figure 5, and its implementation process is summarized as follows. Overview of the architecture of the PPO algorithm.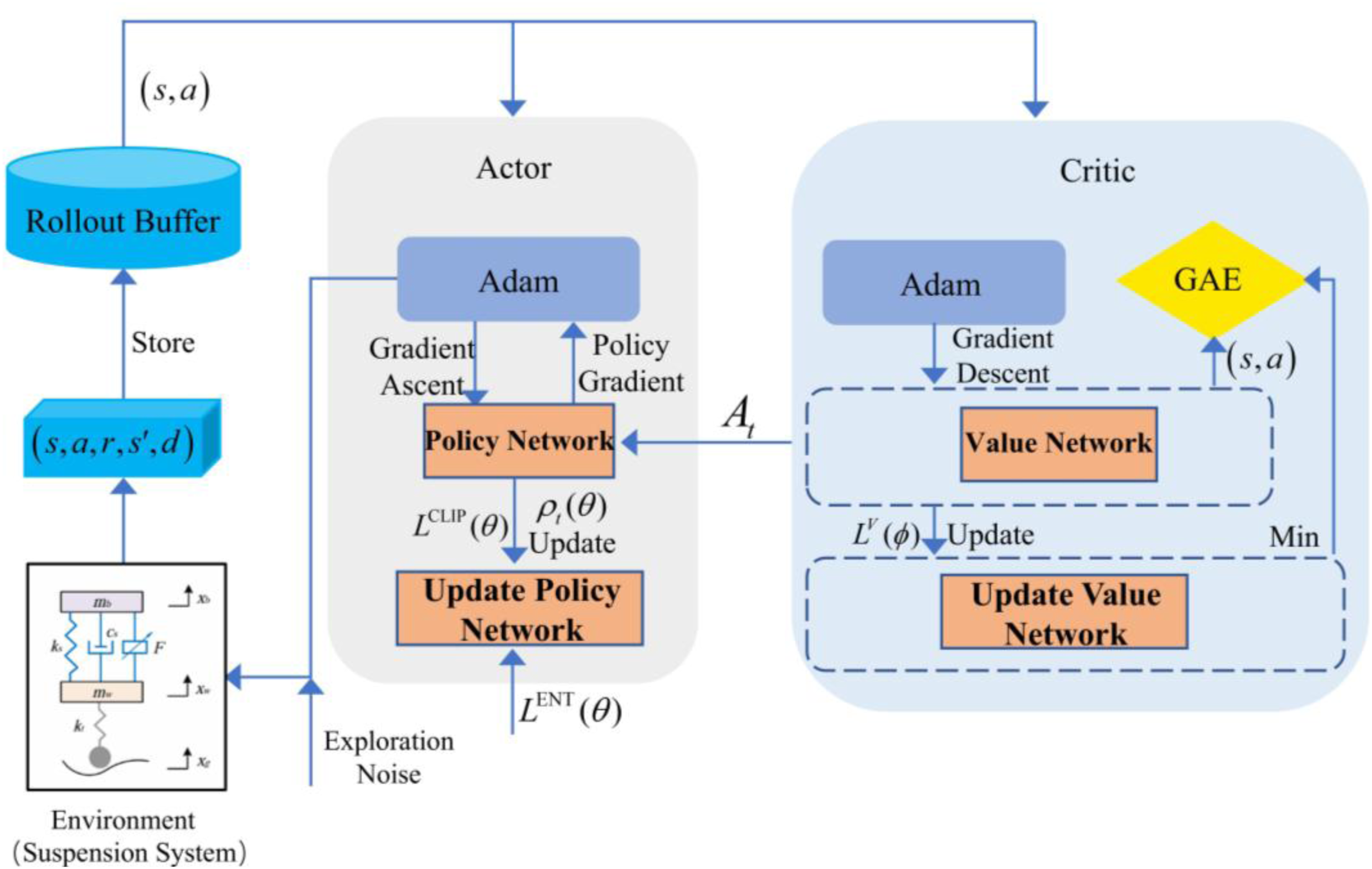
The agent interacts with the environment over multiple episodes under the current policy, collecting trajectories consisting of states 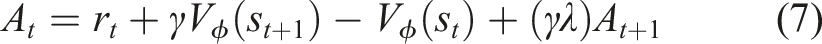
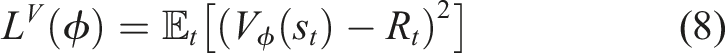
where
In the policy network, to constrain the magnitudes of policy updates, PPO introduces a clipping mechanism for constructing a surrogate objective function, as shown in equation (9). The probability ratio between the new and old policies for taking the same action under the same state is defined in equation (10).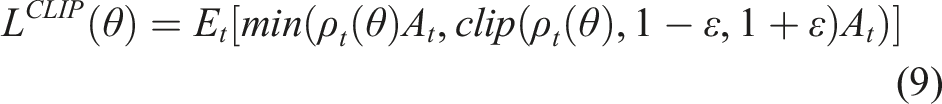
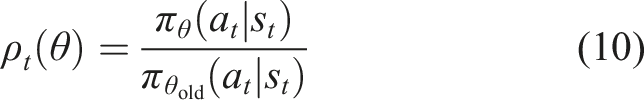
In addition, to encourage exploration and prevent premature convergence, an entropy regularization term is incorporated into the PPO objective function. Its formulation is given in equation (11).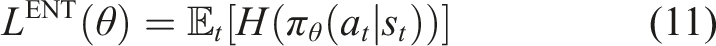
By combining all the components described above, the final objective function is formulated as shown in equation (12). This objective is maximized through iterative optimization, enabling the policy of the agent to gradually converge toward the optimum. As a result, the training process converges with improved long-term cumulative rewards.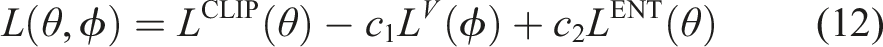
PPO-based semiactive control using MRDs
In the RL-based semiactive control scheme of the MRD suspension system, the PPO agent functions as the semiactive controller, whereas its interactive environment is composed of a suspension system integrated with an MRD model. To accurately capture the vertical dynamic characteristics of the vehicle, the vertical acceleration of the body, vertical velocity of the body, vertical velocity of the wheel, and suspension deflection effect are selected as the state inputs. The formulation of the scheme is given in equation (13).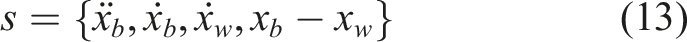
The action space is defined as the control current applied to the MRD, with discrete values ranging from 0 to 3 A. In the PPO algorithm, the agent optimizes the control policy by maximizing the cumulative reward, where the instantaneous reward 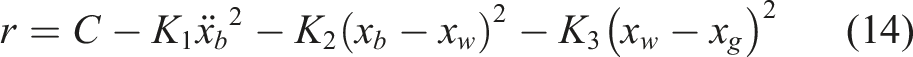
This design comprehensively accounts for ride comfort, suspension safety, and tire–road contact performance (International Organization for Standardization,1997), enabling the PPO agent to achieve balanced control among multiple conflicting objectives.
The PPO-based control framework for the MRD-based semiactive suspension system is illustrated in Figure 6. The agent receives state observations from the suspension system, which, on the basis of the current policy, generates a control current that is applied to the MRD to regulate its output damping force. This force, in turn, acts on the suspension system, updating its dynamic state. The value network evaluates the received reward on the basis of the current state and action, providing feedback for assessing the quality of the chosen action and guiding the continuous policy improvement procedure. Semiactive vibration control framework for an MRD suspension system based on PPO.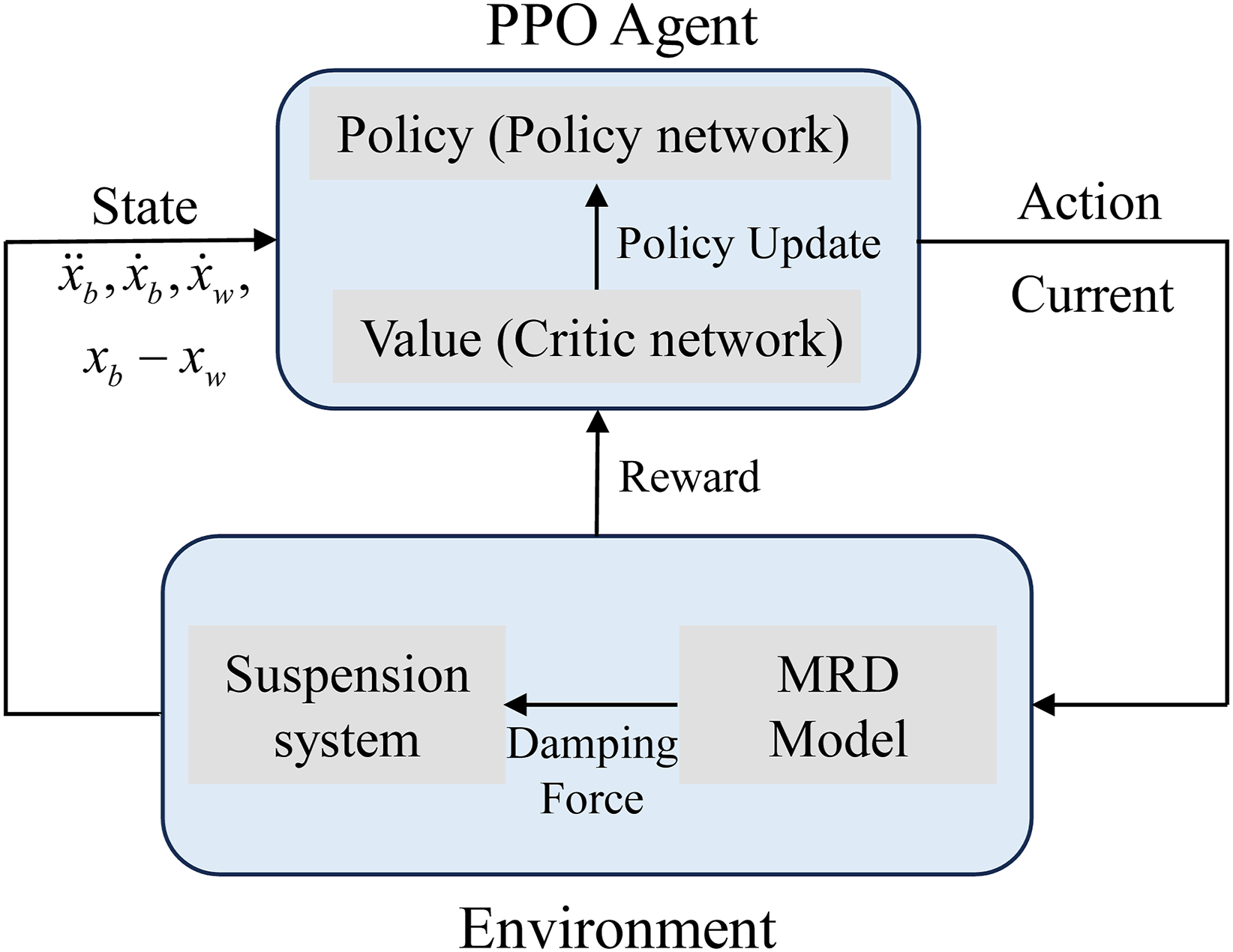
Through repeated interactions with the environment, the agent maximizes the cumulative reward instead of minimizing a single performance metric, thereby autonomously learning to balance multiple performance objectives. This process enables coordinated optimization across competing objectives, and as rewards accumulate, the agent progressively converges toward an optimal control policy, thereby achieving efficient suspension system control.
On the basis of the above principles, the soft-code implementation of the PPO-based semiactive control algorithm for the MRD suspension system is summarized as follows.

Training procedure
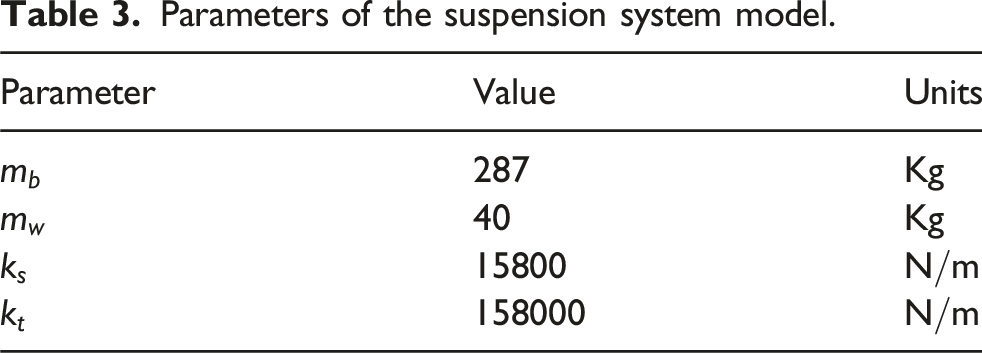
Parameters of the suspension system model.
The PPO agent consists of two neural network structures, namely, a policy network and a value network (Schulman et al., 2017). The policy network receives a 4-dimensional state vector from the environment as input. It comprises three fully connected layers (ActorFC1, ActorFC2, and ActorFC3), each consisting of 64 neurons activated by the ReLU function. The final output layer (ActorFC4) adopts a Softmax activation to generate the probability distribution over discrete actions. The critic network shares a similar architecture: its input layer also processes a 4-dimensional state vector, followed by three fully connected layers (CriticFC1, CriticFC2, and CriticFC3) with 64 ReLU-activated neurons each. The output layer provides the estimated state value for the current state.
The training parameters are configured as follows: the learning rates for both the value network and the policy network are set to 0.0005, and the adaptive moment estimation (Adam) optimizer is used for both networks. The gradient clipping threshold is set to 1. In the reward function, the parameters are configured as follows: the constant term C = 5, and the weighting coefficients are K1 = 1, K2 = 0.5, and K3 = 0.5. In the PPO algorithm, the clipping factor is set to 0.2, the discount factor is set to 0.99, and the GAE parameter is set to 0.95. The minibatch size per training epoch is set to 256, and the maximum number of training episodes is 5000.
The PPO agent is trained using the framework described above, and the resulting training curve is shown in Figure 7. As illustrated in the figure, the agent begins to converge after approximately 1000 episodes, indicating that it has effectively learned a stable control policy. Convergence curve produced by the PPO agent during training.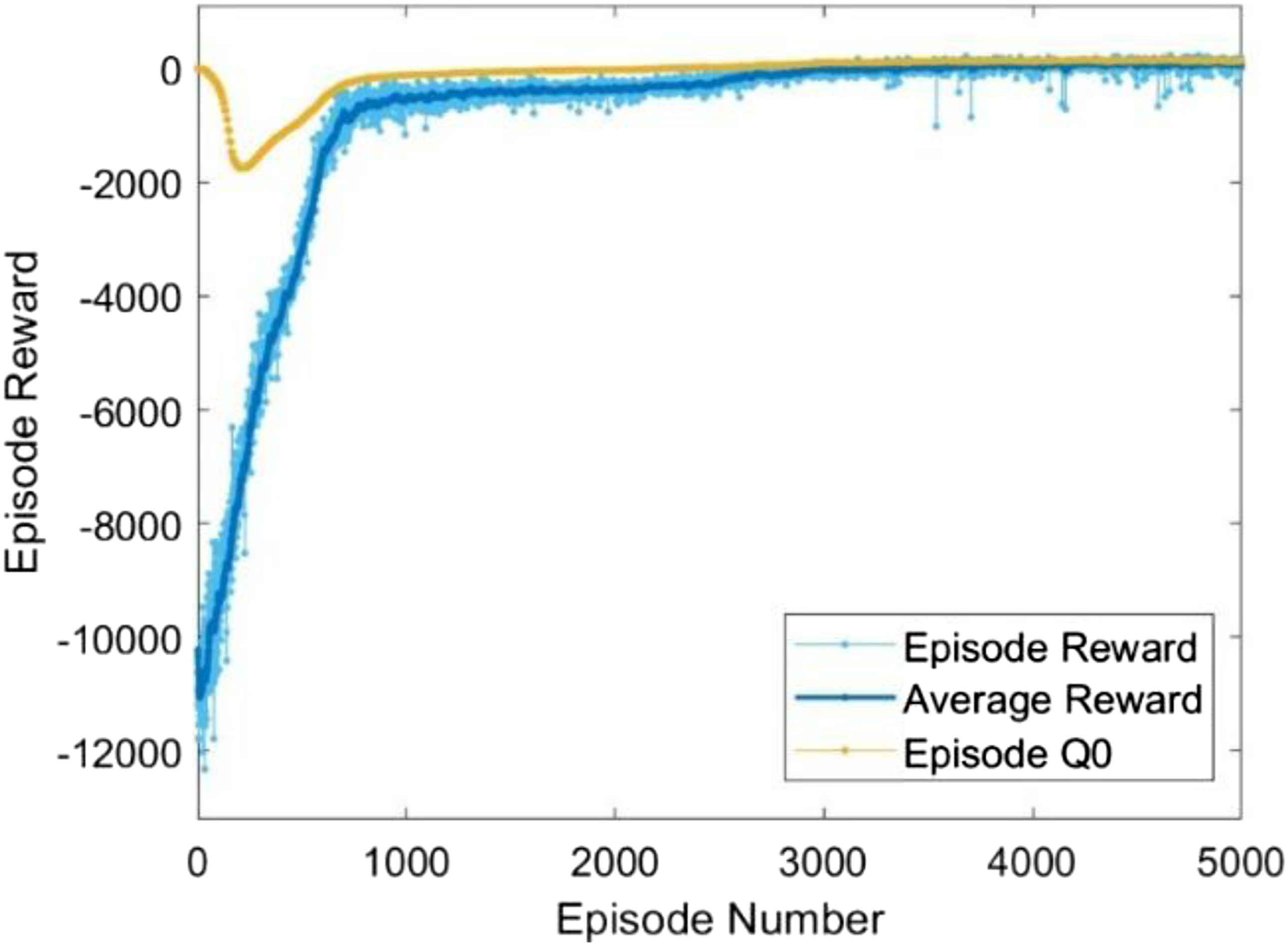
Simulations
Simulation implemented under random road excitations
To verify the effectiveness of the proposed PPO-based control strategy, simulations were conducted using the trained agent under different road conditions, and the results were compared with those of passive control and Skyhook control. The damping coefficient of the passive suspension is set to 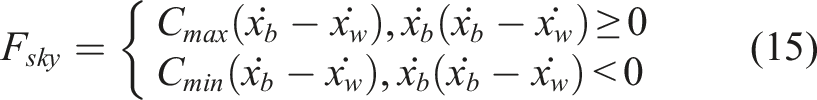
Based on the MRD model developed in this study, the maximum and minimum damping coefficients are set to
RMS values of three performance metrics produced under different road roughness levels.

Performance improvements (%) achieved by the Skyhook and PPO controllers over passive control.

The results demonstrate that the PPO-based control strategy consistently outperforms both the passive and Skyhook control schemes in terms of vibration attenuation under various road conditions.
The body acceleration, suspension deflection, and dynamic tire load comparison results of produced under C-class road excitations are shown in Figure 8. The PPO controller outperformed both the passive and Skyhook control schemes in terms of all performance metrics, demonstrating significantly enhanced vibration attenuation. Comparison among the body acceleration, suspension deflection, and dynamic tire load results produced under C-class road excitations.
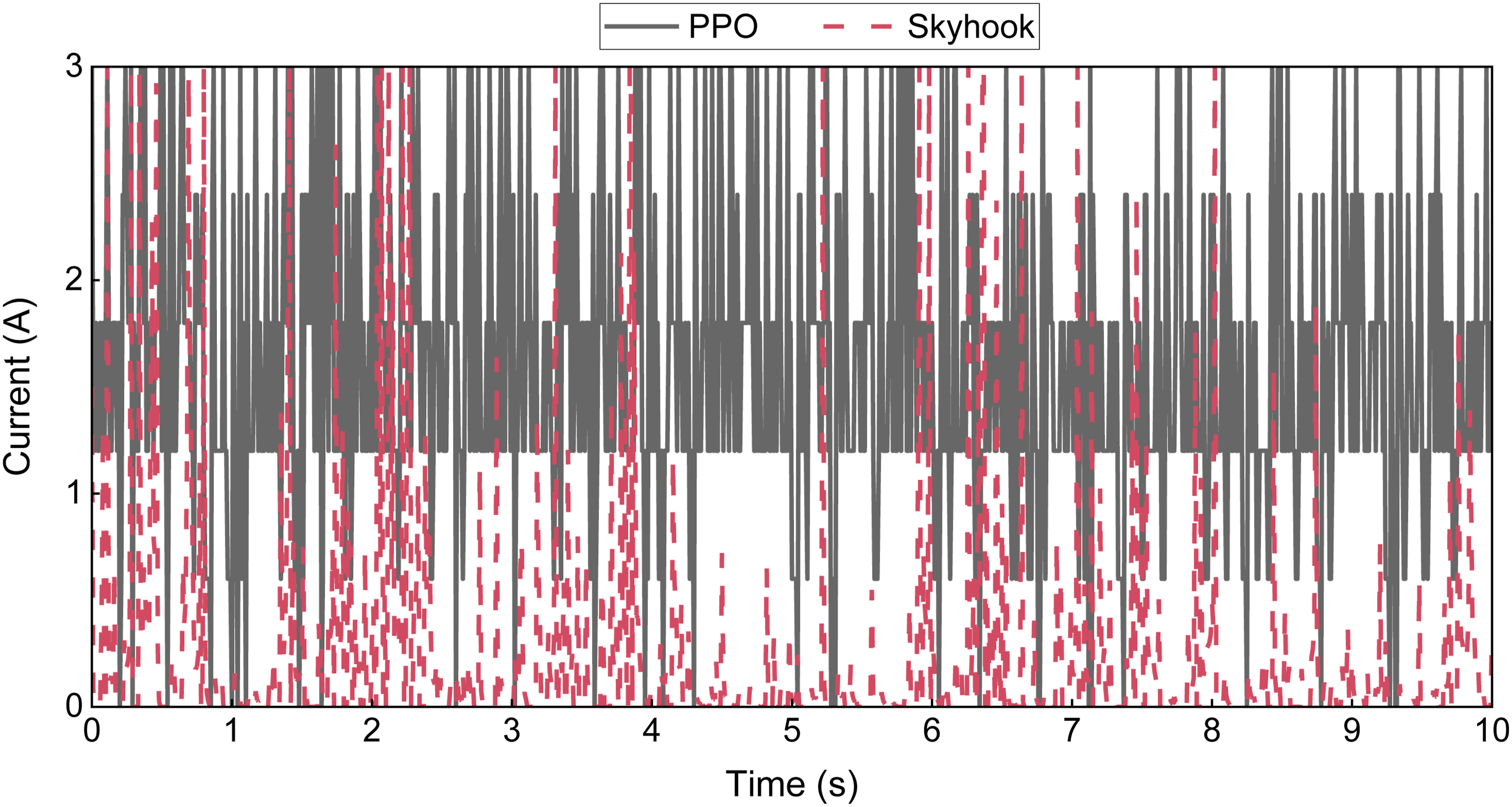
In addition, Figure 9 compares the control forces of the passive, Skyhook, and PPO control strategies under C-class road excitations, while Figure 10 depicts the variations in control current outputs of the Skyhook and PPO controllers under the same conditions. Comparison of control forces for the three control strategies under C-class road excitations. Comparison of control current responses between the Skyhook and PPO control strategies.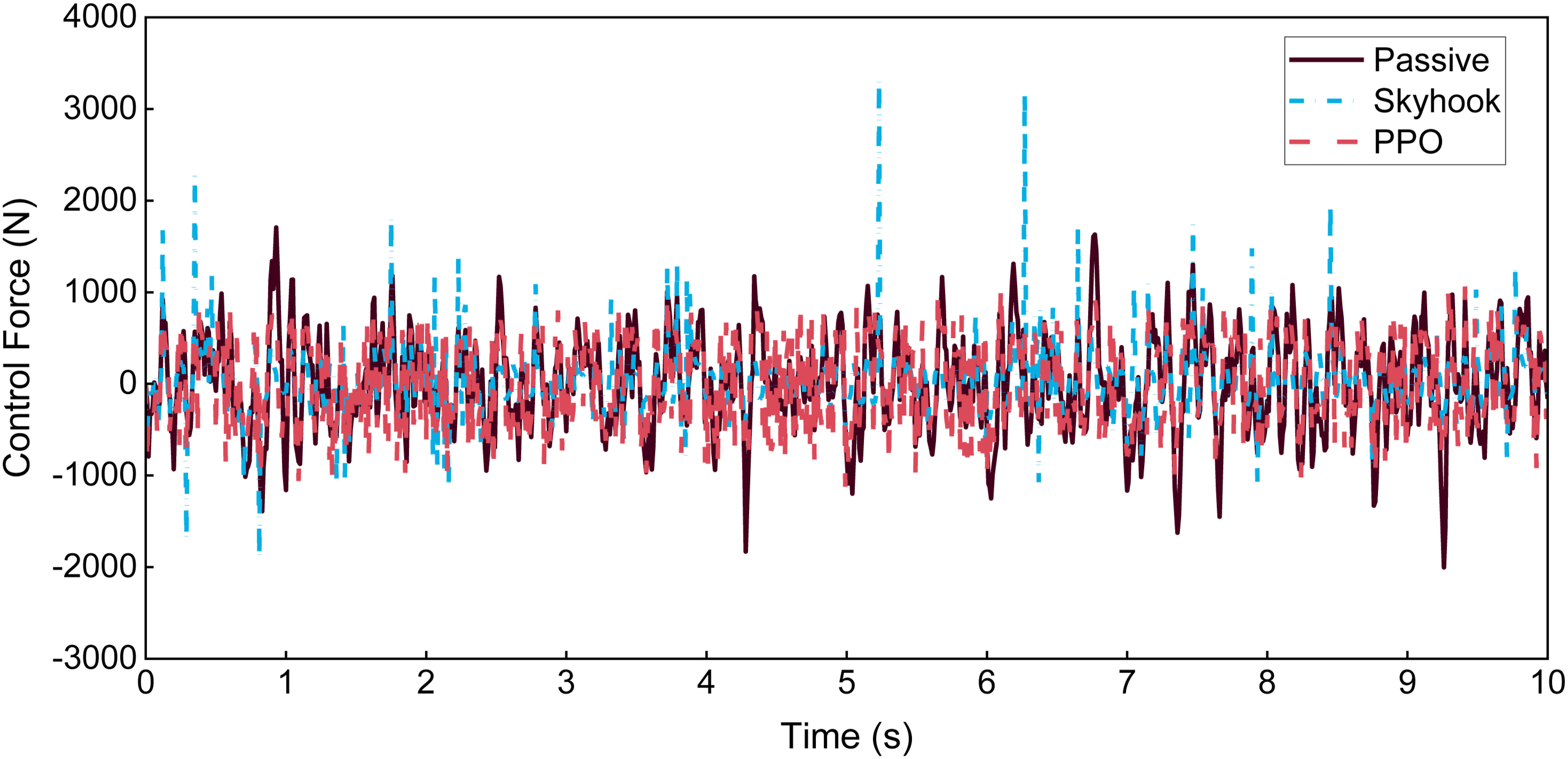
Simulation implemented under system uncertainty
To simulate real-world system parameter variations while ensuring the feasibility of training across a wide range of operating conditions, a 20% parameter uncertainty rate was introduced during the training process. Specifically, in each training episode, key suspension parameters—including sprung mass, unsprung mass, suspension stiffness, and tire stiffness—were randomly perturbed within ± 20% of their nominal values, resulting in the training of PPOAgentB. This agent is compared with PPOAgentA, which was trained under nominal parameters.
Figure 11 compares the body acceleration, suspension deflection, and dynamic tire load responses of the two agents under C-class random road excitations. The RMS values of these three performance indices under different road classes are summarized in Table 6. It should be noted that all results in Figure 11 and Table 6 are obtained using the nominal-parameter plant model to ensure consistent testing conditions across the control strategies. Although PPOAgentB was trained with ± 20% parameter randomization, its performance under nominal conditions remains very close to that of PPOAgentA. This suggests that the randomized training prevents the learned policy from becoming specialized to a single nominal parameter set and instead improves its generalization and adaptability to parameter variations. While PPOAgentB shows a slight compromise in fine-tuning optimal actions, it exhibits stronger adaptability to system deviations that may arise in real operation, thereby demonstrating improved potential for practical engineering applications. Comparison of body acceleration, suspension deflection, and dynamic tire load under C-class road excitations with parameter uncertainties considered. RMS values of three performance metrics for different control strategies under various road roughness levels.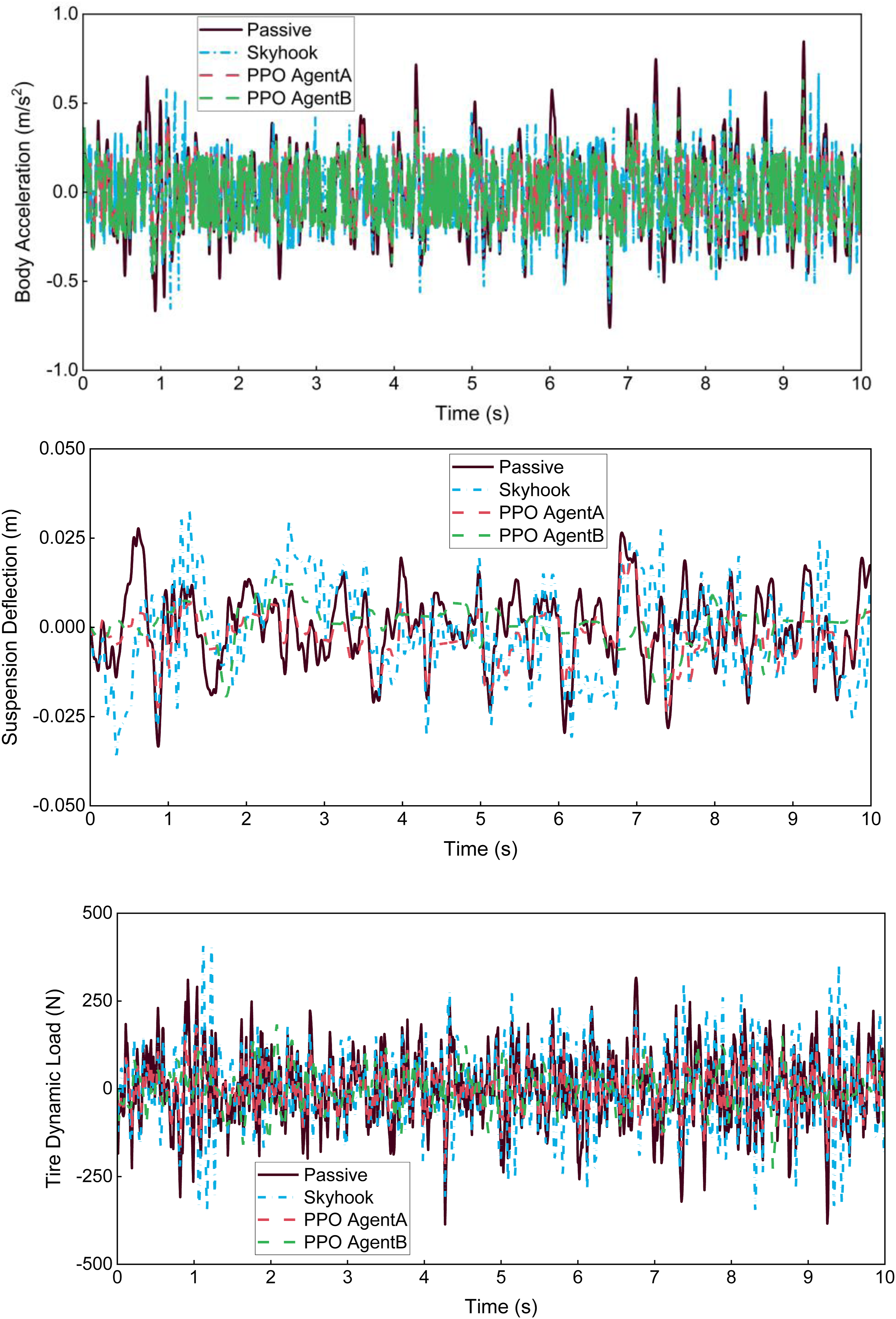

Conclusion
A semiactive suspension control strategy based on the PPO algorithm for MRDs was proposed in this study. An RL training environment was constructed by developing an MRD model and a quarter-car suspension model, within which a PPO control framework composed of policy and value networks was established. During the training process, the control action was defined as a discrete current ranging from 0 to 3 A. The agent selected an appropriate current according to the learned policy, which was then applied to the MRD to adjust its damping force and achieve vibration attenuation. This method avoids the need for an inverse MRD model and instead directly integrates the MRD model into the control system, significantly simplifying the overall structure.
Simulation results under B-, C-, and D-class random road excitations indicate that the proposed PPO controller, compared with passive and Skyhook control strategies under optimal operating conditions, achieves superior performance in body acceleration, suspension deflection, and dynamic tire load. Specifically, under D-class road excitations, the PPO controller reduced the RMS value of body acceleration by 49.8% compared with that of passive control and by 22.4% compared with that of Skyhook control. Furthermore, by introducing 20% system parameter uncertainty during training, the trained agent maintained strong control performance, demonstrating its potential robustness and generalizability.
This study implements the standard PPO algorithm within a physically constrained training environment incorporating an MRD model and parameter uncertainties. The proposed framework enables the agent to learn realistic semiactive suspension control strategies, demonstrating the potential of RL for complex nonlinear suspension systems. Although robust control can effectively handle system uncertainties, its performance relies on accurate modeling, which is difficult to ensure in practical applications. The PPO controller proposed in this study exhibits comparable potential robustness without requiring an explicit model. Future work will integrate robust control concepts with RL and focus on controller compression and hardware deployment to advance the practical implementation of RL-based semiactive suspension control.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by application Research and Industrialization of High-Reliability Vibration Dampers Based on Magnetorheological Fluid Smart Sensing Materials, China (2019JZZY020215HZ).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.